⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-02 更新
Multi-Modal Motion Retrieval by Learning a Fine-Grained Joint Embedding Space
Authors:Shiyao Yu, Zi-An Wang, Kangning Yin, Zheng Tian, Mingyuan Zhang, Weixin Si, Shihao Zou
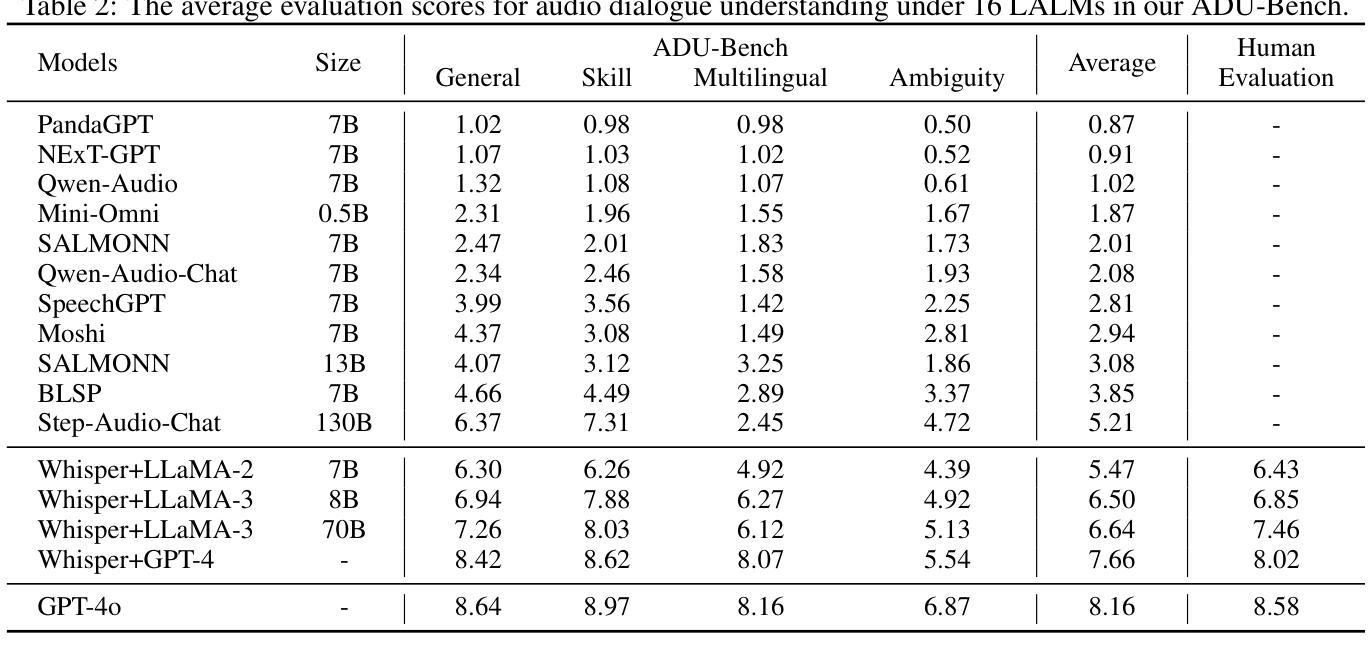
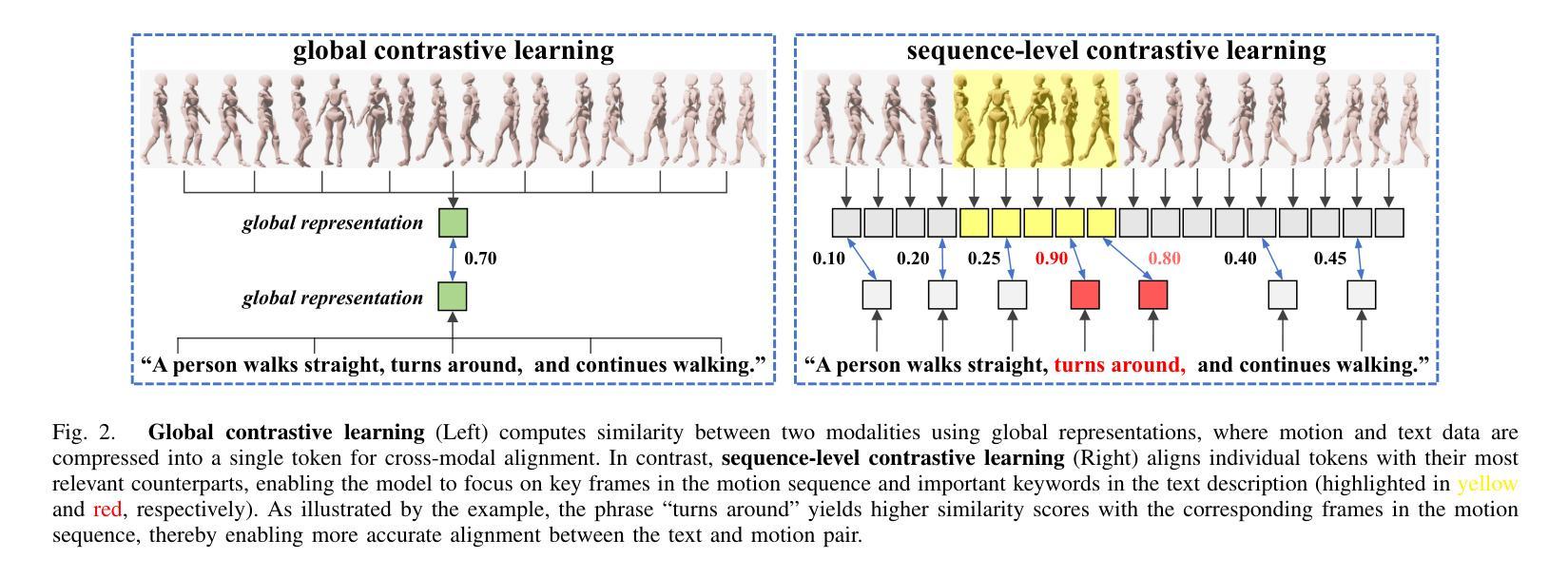
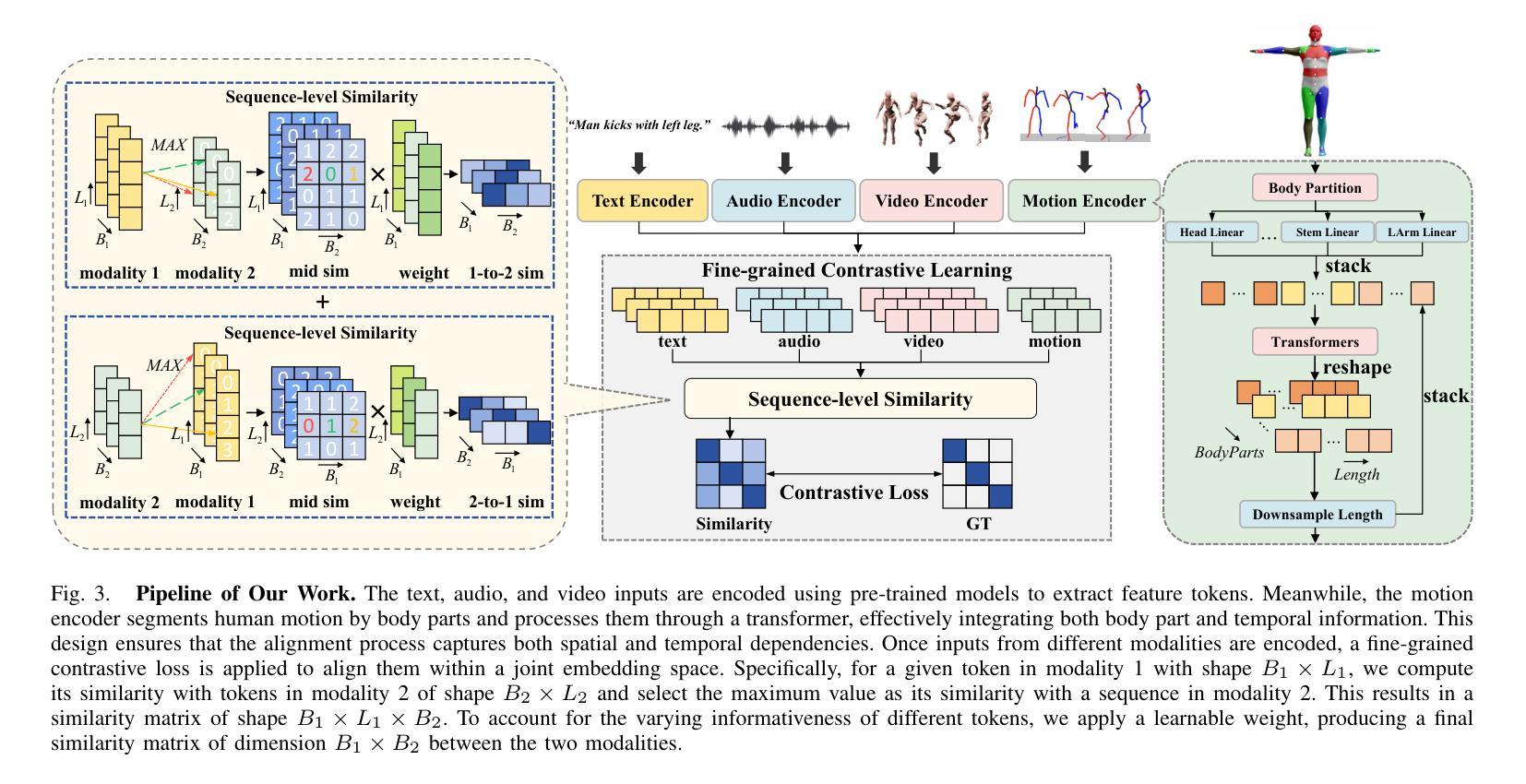
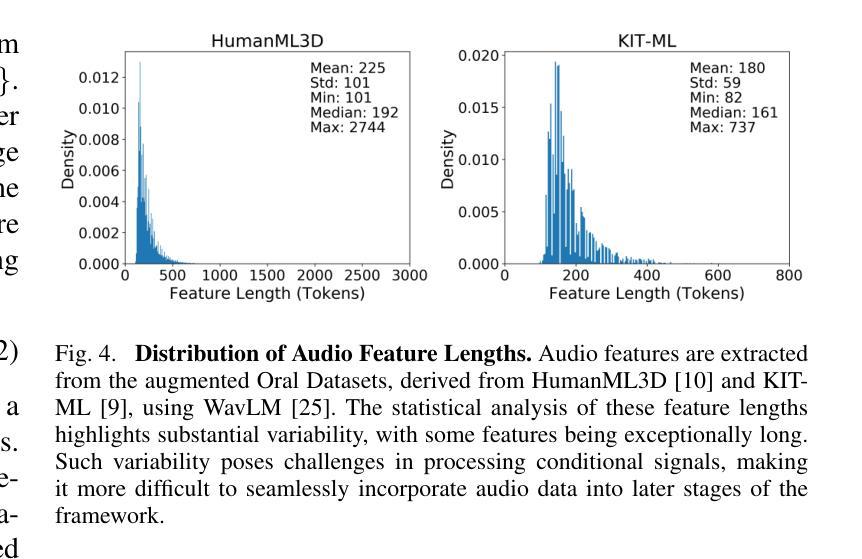
Motion retrieval is crucial for motion acquisition, offering superior precision, realism, controllability, and editability compared to motion generation. Existing approaches leverage contrastive learning to construct a unified embedding space for motion retrieval from text or visual modality. However, these methods lack a more intuitive and user-friendly interaction mode and often overlook the sequential representation of most modalities for improved retrieval performance. To address these limitations, we propose a framework that aligns four modalities – text, audio, video, and motion – within a fine-grained joint embedding space, incorporating audio for the first time in motion retrieval to enhance user immersion and convenience. This fine-grained space is achieved through a sequence-level contrastive learning approach, which captures critical details across modalities for better alignment. To evaluate our framework, we augment existing text-motion datasets with synthetic but diverse audio recordings, creating two multi-modal motion retrieval datasets. Experimental results demonstrate superior performance over state-of-the-art methods across multiple sub-tasks, including an 10.16% improvement in R@10 for text-to-motion retrieval and a 25.43% improvement in R@1 for video-to-motion retrieval on the HumanML3D dataset. Furthermore, our results show that our 4-modal framework significantly outperforms its 3-modal counterpart, underscoring the potential of multi-modal motion retrieval for advancing motion acquisition.
运动检索对于运动采集至关重要,与运动生成相比,它提供了更高的精度、真实感、可控性和可编辑性。现有方法利用对比学习来构建用于从文本或视觉模式进行运动检索的统一嵌入空间。然而,这些方法缺乏更直观和用户友好的交互模式,并且经常忽视大多数模式的序列表示以提高检索性能。为了解决这些局限性,我们提出了一个框架,在一个精细的联合嵌入空间内对齐四种模式:文本、音频、视频和运动,首次将音频纳入运动检索中,以增强用户沉浸感和便利性。这种精细的空间是通过序列级对比学习方法实现的,该方法捕获跨模式的关键细节,以实现更好的对齐。为了评估我们的框架,我们增强了现有的文本-运动数据集,加入了合成但多样的音频记录,创建了两个多模式运动检索数据集。实验结果表明,我们的方法在多个子任务上的性能优于最先进的方法,包括在HumanML3D数据集上文本到运动的检索R@10提高了10.16%,视频到运动的检索R@1提高了25.43%。此外,我们的结果表明,我们的四模态框架显著优于其三模态对应物,这突显了多模态运动检索在推动运动采集方面的潜力。
论文及项目相关链接
PDF Accepted by IEEE TMM 2025
Summary
本文提出一种多模态运动检索框架,融合文本、音频、视频和运动四种模态,在精细联合嵌入空间内对齐。采用序列级别对比学习方法,捕获多模态关键细节,实现更好对齐。创建两个多模态运动检索数据集,并在多个子任务上实现优于现有技术的方法,如文本到运动的检索R@10提升10.16%,视频到运动的检索在HumanML3D数据集上R@1提升25.43%。同时验证了四模态框架显著优于三模态框架,展现了多模态运动检索的巨大潜力。
Key Takeaways
- 运动检索对于运动获取至关重要,相比运动生成提供更优越的精度、现实感、可控性和可编辑性。
- 现有方法利用对比学习构建统一嵌入空间,实现文本或视觉模态的运动检索。
- 提出一种多模态运动检索框架,融合文本、音频、视频和运动四种模态,在精细联合嵌入空间内对齐,首次将音频纳入运动检索中。
- 采用序列级别对比学习方法,捕获各模态的关键细节,实现更好的对齐效果。
- 创建两个多模态运动检索数据集,通过合成多样的音频记录增强现有文本-运动数据集。
- 实验结果表明,该框架在多个子任务上优于现有技术,如文本到运动的检索和视频到运动的检索。
点此查看论文截图

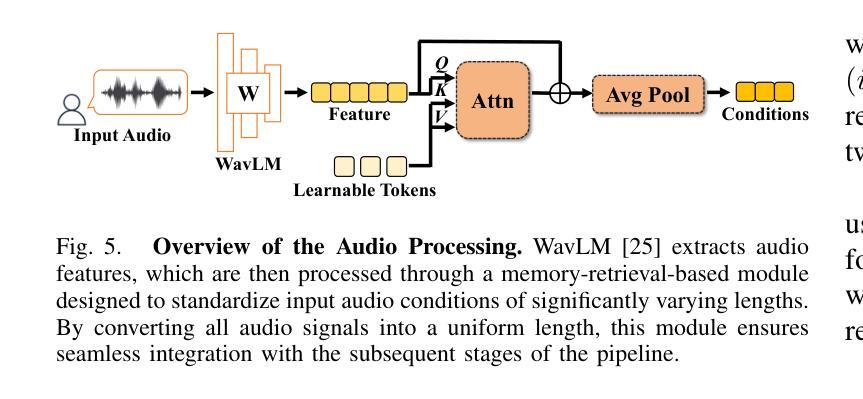
Towards Robust and Controllable Text-to-Motion via Masked Autoregressive Diffusion
Authors:Zongye Zhang, Bohan Kong, Qingjie Liu, Yunhong Wang
Generating 3D human motion from text descriptions remains challenging due to the diverse and complex nature of human motion. While existing methods excel within the training distribution, they often struggle with out-of-distribution motions, limiting their applicability in real-world scenarios. Existing VQVAE-based methods often fail to represent novel motions faithfully using discrete tokens, which hampers their ability to generalize beyond seen data. Meanwhile, diffusion-based methods operating on continuous representations often lack fine-grained control over individual frames. To address these challenges, we propose a robust motion generation framework MoMADiff, which combines masked modeling with diffusion processes to generate motion using frame-level continuous representations. Our model supports flexible user-provided keyframe specification, enabling precise control over both spatial and temporal aspects of motion synthesis. MoMADiff demonstrates strong generalization capability on novel text-to-motion datasets with sparse keyframes as motion prompts. Extensive experiments on two held-out datasets and two standard benchmarks show that our method consistently outperforms state-of-the-art models in motion quality, instruction fidelity, and keyframe adherence. The code is available at: https://github.com/zzysteve/MoMADiff
从文本描述生成3D人体运动仍然是一个挑战,这主要是由于人体运动的多样性和复杂性。尽管现有方法在训练分布内表现优异,但它们在处理超出训练分布的运动时常常遇到困难,从而限制了它们在现实世界场景中的应用。基于VQVAE的方法通常无法用离散符号忠实表示新动作,这阻碍了它们对未见数据的泛化能力。同时,基于连续表示的操作的扩散方法通常缺乏对单个帧的精细控制。为了应对这些挑战,我们提出了一个稳健的运动生成框架MoMADiff,它将掩模建模与扩散过程相结合,使用帧级连续表示生成运动。我们的模型支持用户提供的灵活关键帧规范,实现对运动合成的空间和时间方面的精确控制。MoMADiff在具有稀疏关键帧的新文本到运动数据集上展示了强大的泛化能力。在两个独立数据集和两个标准基准测试上的大量实验表明,我们的方法在动作质量、指令保真度和关键帧遵循方面始终优于最新模型。代码可在以下网址找到:https://github.com/zzysteve/MoMADiff。
论文及项目相关链接
PDF Accepted by ACM MM 2025
Summary
本文介绍了从文本描述生成3D人体运动的技术挑战,并提出了一个新的运动生成框架MoMADiff。该框架结合了掩模建模与扩散过程,支持用户提供的关键帧指定,能够实现精细的运动合成控制。MoMADiff在不同文本到运动的数据集上展示了强大的泛化能力,并且在运动质量、指令保真度和关键帧遵循方面优于其他最先进模型。
Key Takeaways
- 文本到3D人体运动的生成具有多样性和复杂性,现有方法在新分布的运动上表现有限。
- MoMADiff是一个结合了掩模建模和扩散过程的运动生成框架,能够生成基于连续表示的关键帧级别的运动。
- MoMADiff支持用户指定的关键帧,实现对运动合成的精确控制。
- MoMADiff在新型文本到运动数据集上展示了强大的泛化能力,即使关键帧稀疏也能良好工作。
- MoMADiff在运动质量、指令保真度和关键帧遵循方面超越现有最先进模型。
- 该方法的代码已公开可用。
点此查看论文截图

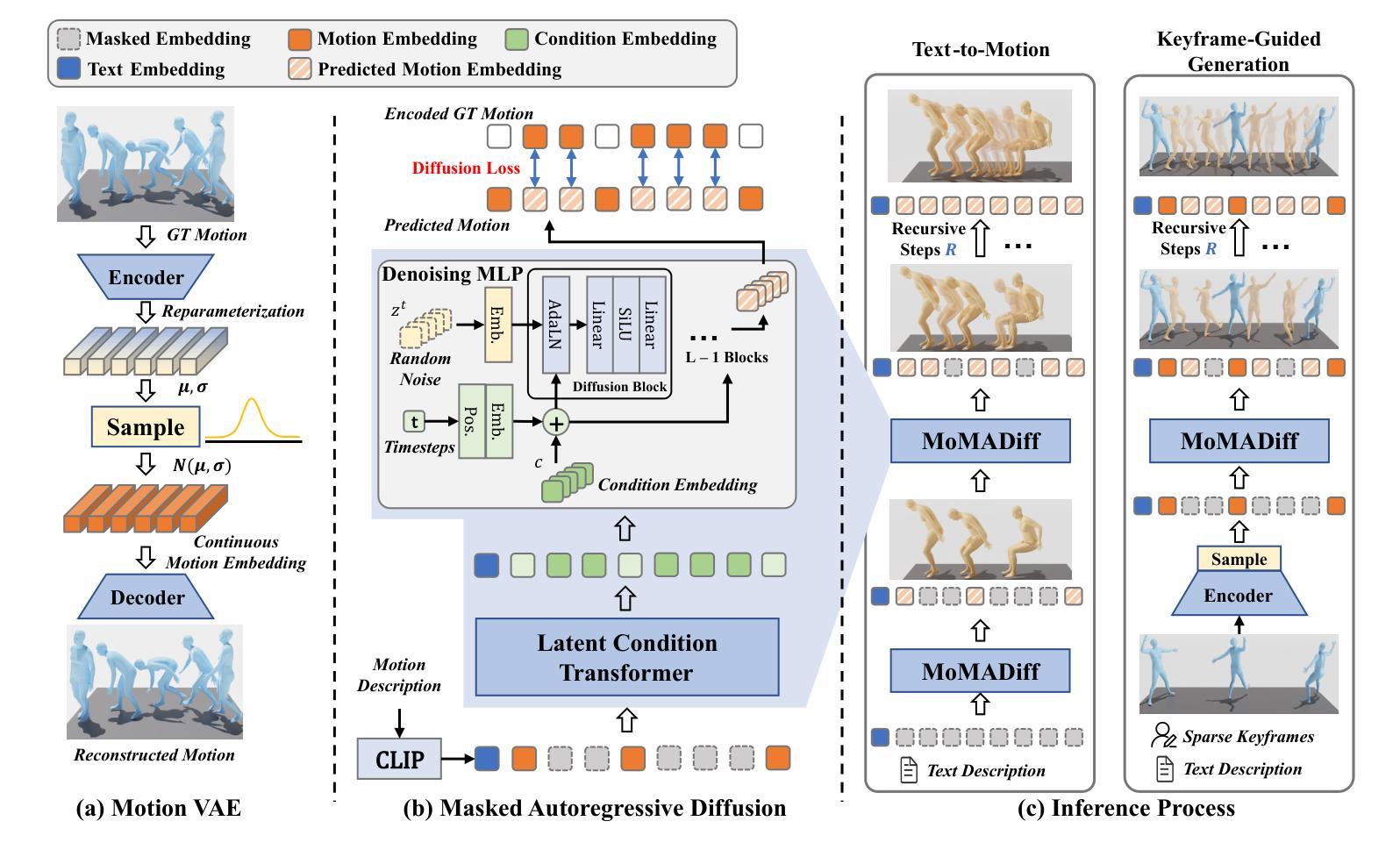
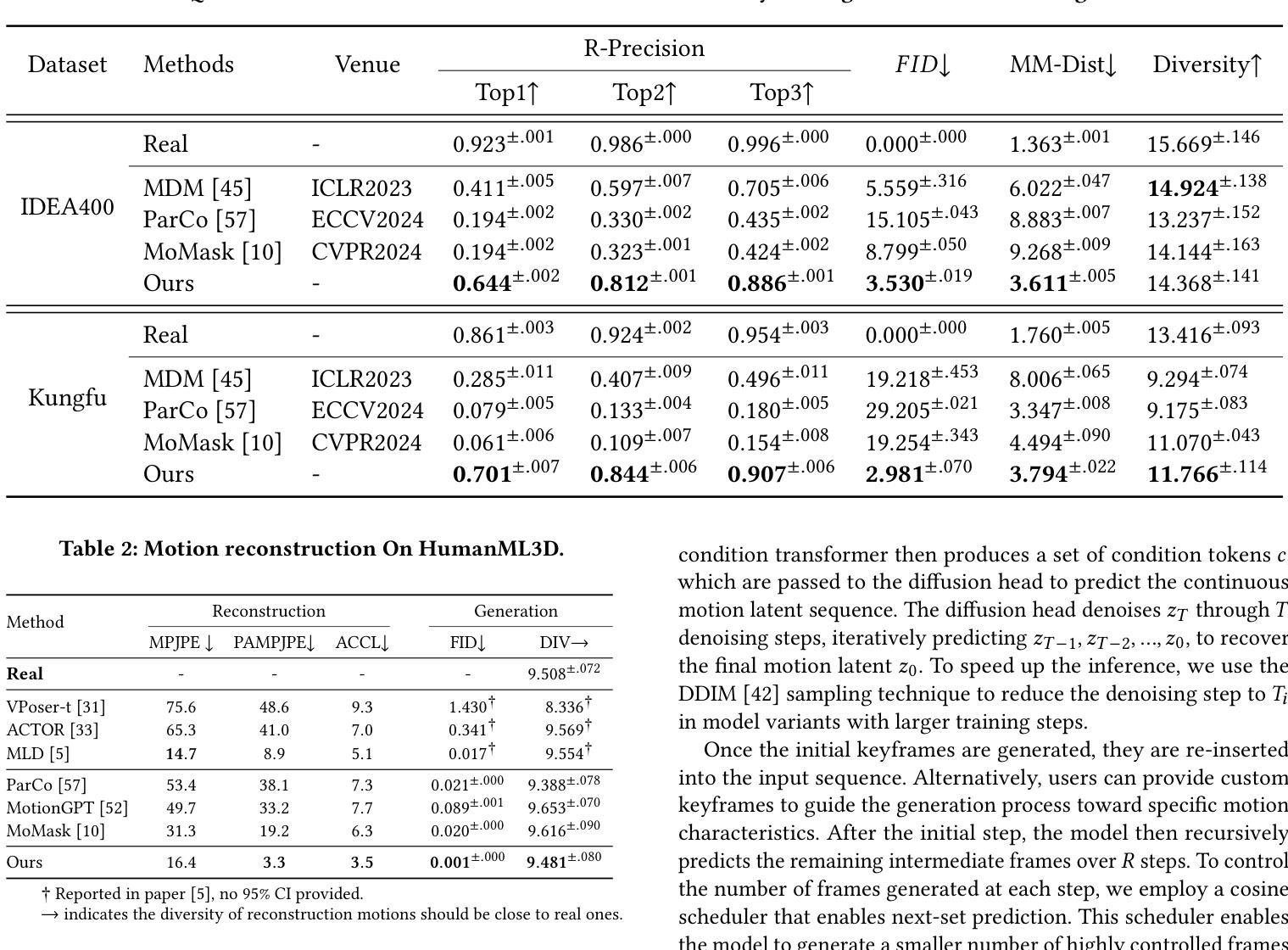

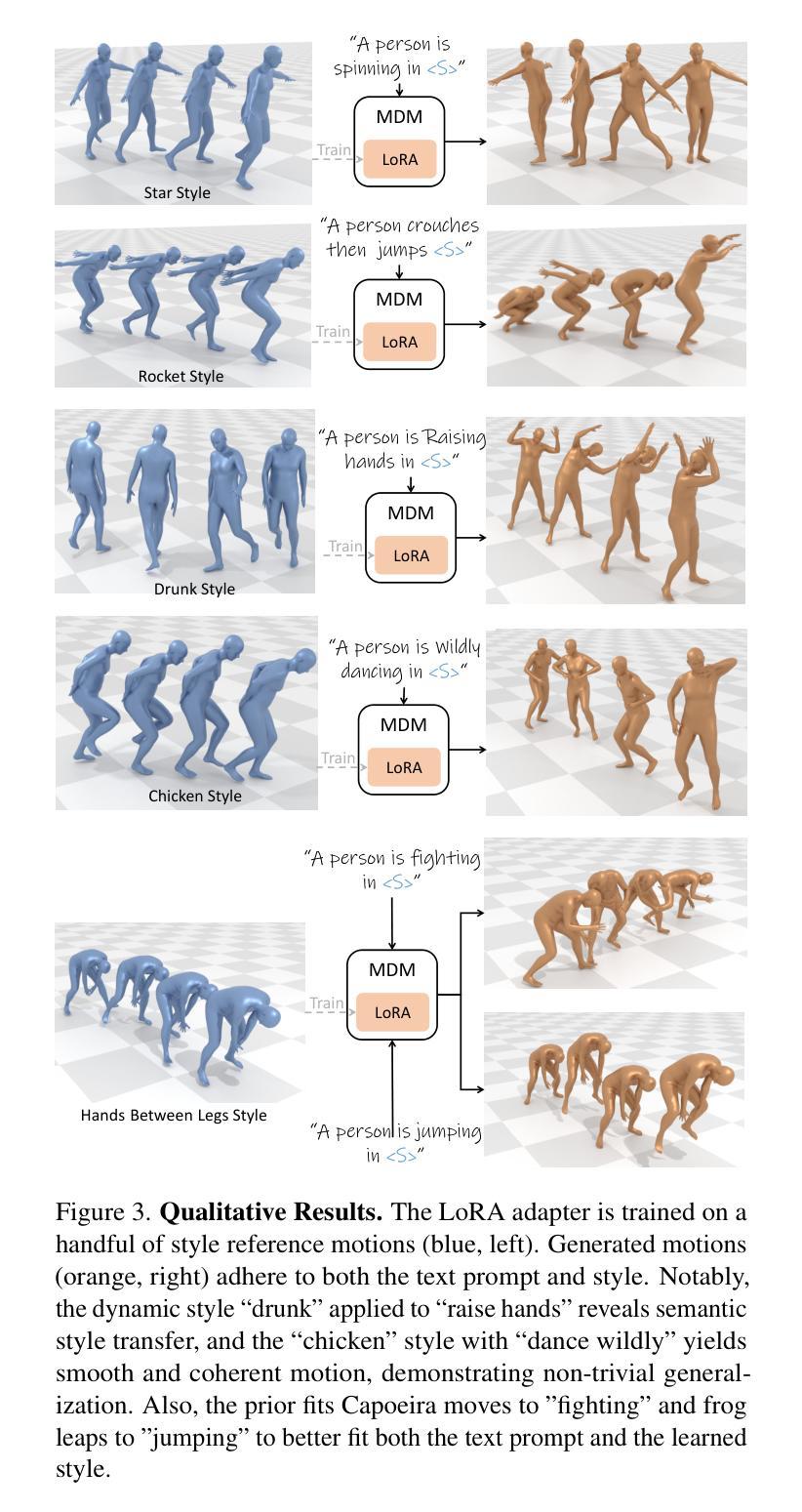
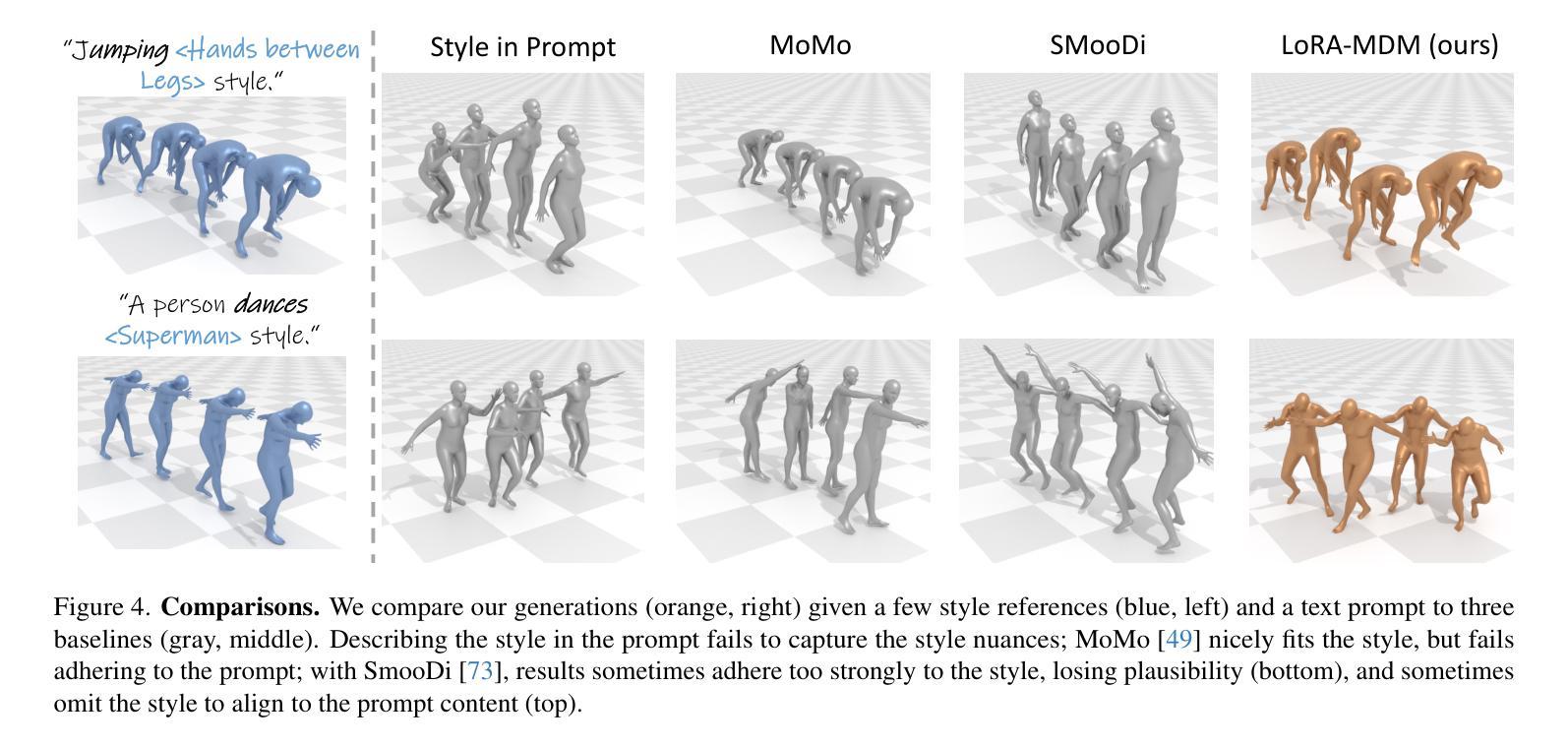
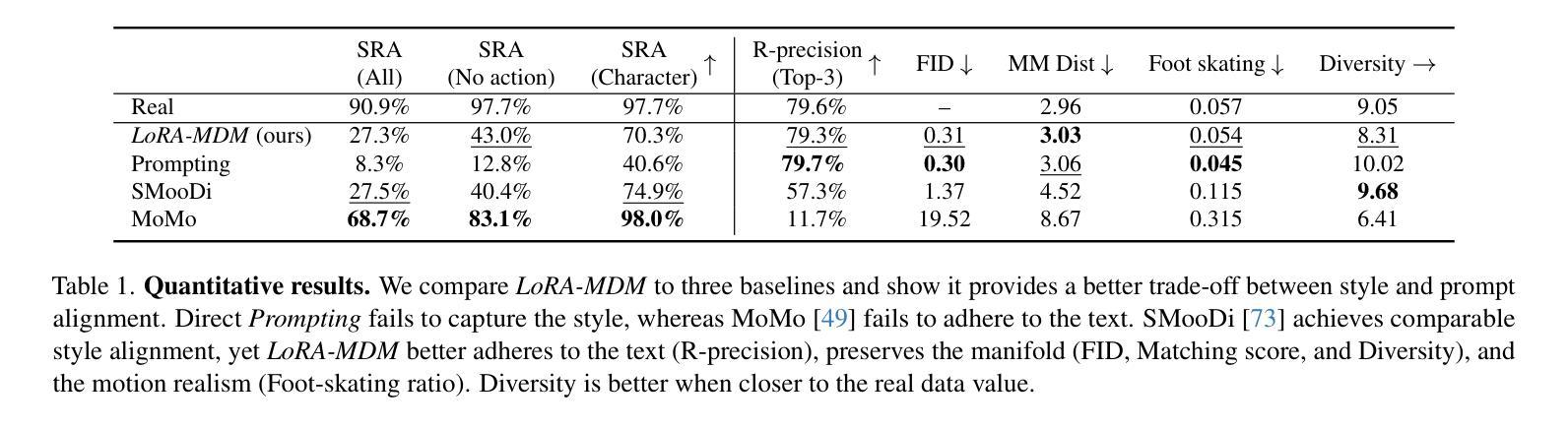
Dance Like a Chicken: Low-Rank Stylization for Human Motion Diffusion
Authors:Haim Sawdayee, Chuan Guo, Guy Tevet, Bing Zhou, Jian Wang, Amit H. Bermano
Text-to-motion generative models span a wide range of 3D human actions but struggle with nuanced stylistic attributes such as a “Chicken” style. Due to the scarcity of style-specific data, existing approaches pull the generative prior towards a reference style, which often results in out-of-distribution low quality generations. In this work, we introduce LoRA-MDM, a lightweight framework for motion stylization that generalizes to complex actions while maintaining editability. Our key insight is that adapting the generative prior to include the style, while preserving its overall distribution, is more effective than modifying each individual motion during generation. Building on this idea, LoRA-MDM learns to adapt the prior to include the reference style using only a few samples. The style can then be used in the context of different textual prompts for generation. The low-rank adaptation shifts the motion manifold in a semantically meaningful way, enabling realistic style infusion even for actions not present in the reference samples. Moreover, preserving the distribution structure enables advanced operations such as style blending and motion editing. We compare LoRA-MDM to state-of-the-art stylized motion generation methods and demonstrate a favorable balance between text fidelity and style consistency.
文本到动作的生成模型涵盖了多种3D人类动作,但在处理微妙的风格属性(如“小鸡”风格)方面遇到了困难。由于特定风格数据的稀缺性,现有方法常常将生成优先参考某一风格,这通常会导致生成的分布范围外的低质量动作。在这项工作中,我们引入了LoRA-MDM,这是一个轻量级的动作风格化框架,能够概括复杂动作并保持可编辑性。我们的关键见解是,在生成过程中适应风格并保留其整体分布比修改每个单独的动作更有效。基于此想法,LoRA-MDM学会了适应包含参考风格的先验知识,并且仅使用少数样本即可完成这一任务。然后可以在不同的文本提示中使用此风格进行生成。低秩适应将动作流形以语义上有意义的方式移动,即使在参考样本中不存在的动作中也能实现逼真的风格融合。此外,保留分布结构使得能够进行高级操作,如风格混合和运动编辑。我们将LoRA-MDM与最先进的风格化运动生成方法进行了比较,并证明了其在文本忠诚度和风格一致性之间的平衡性。
论文及项目相关链接
PDF Project page at https://haimsaw.github.io/LoRA-MDM/
Summary
文本到动作生成模型涵盖多种3D人类动作,但在微妙的风格特征(如“鸡步”风格)方面存在挑战。由于风格特定数据的稀缺性,现有方法往往将生成先验拉向参考风格,这通常导致生成结果分布外且质量低下。本研究引入LoRA-MDM,一个轻量级的动作风格化框架,能够推广到复杂动作并保持可编辑性。我们的关键见解是,适应生成先验以包含风格,同时保持其整体分布,比在生成过程中修改每个单独的动作更有效。基于此想法,LoRA-MDM学习适应先验以包含参考风格,仅使用少量样本。然后,可以在不同的文本提示的上下文中使用该风格进行生成。低秩适应以语义上有意义的方式移动动作流形,即使在参考样本中不存在的动作中也能实现逼真的风格融合。此外,保持分布结构可实现高级操作,如风格混合和运动编辑。我们将LoRA-MDM与最新的风格化动作生成方法进行比较,并证明了其在文本忠实度和风格一致性之间的有利平衡。
Key Takeaways
- 文本到动作生成模型面临特定风格数据稀缺的问题。
- 现有方法倾向于将生成先验拉向参考风格,导致生成结果质量不高且分布外。
- LoRA-MDM框架通过适应生成先验来包含参考风格,同时保持其整体分布,实现复杂动作的推广并保持可编辑性。
- LoRA-MDM使用少量样本学习适应先验,并能在不同的文本提示中使用该风格进行生成。
- 低秩适应能够语义上有意义地移动动作流形,实现逼真的风格融合,即使对于参考样本中不存在的动作也是如此。
- 保持动作分布结构可实现高级操作,如风格混合和运动编辑。
点此查看论文截图

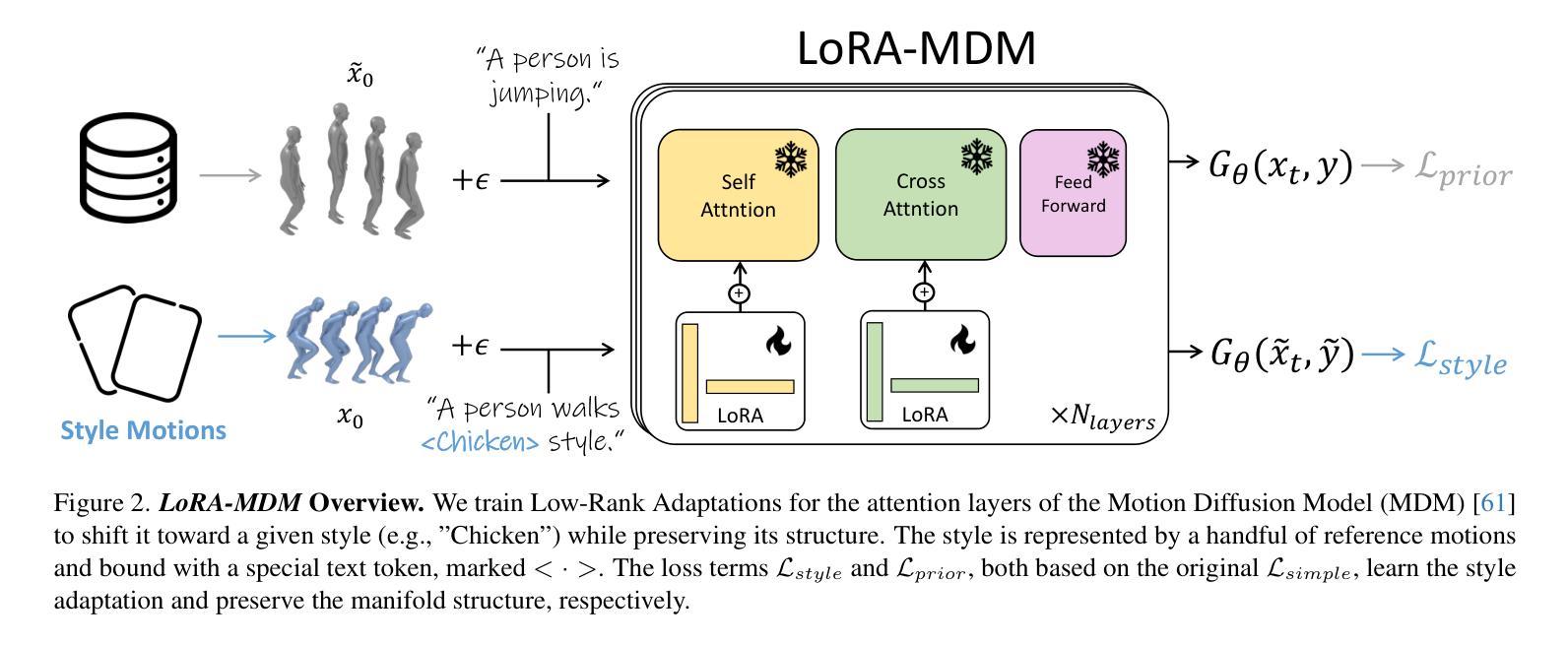

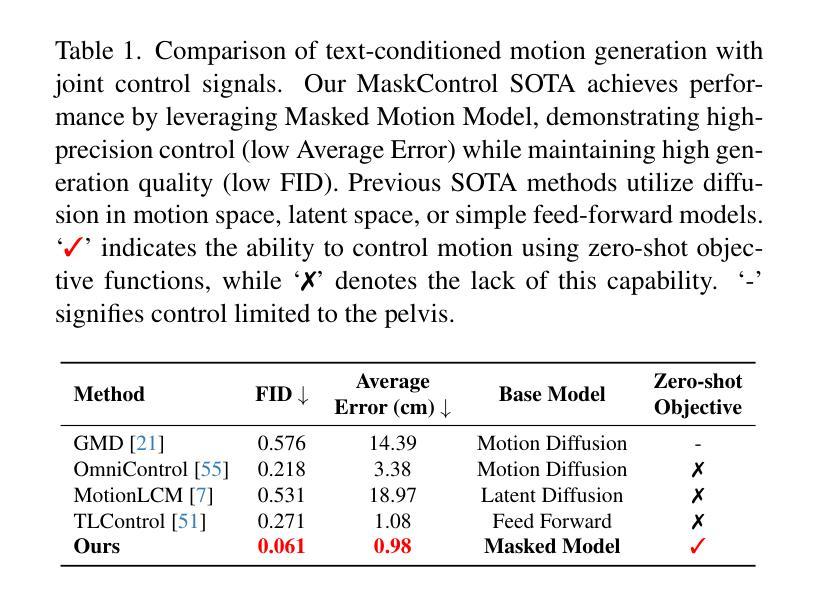
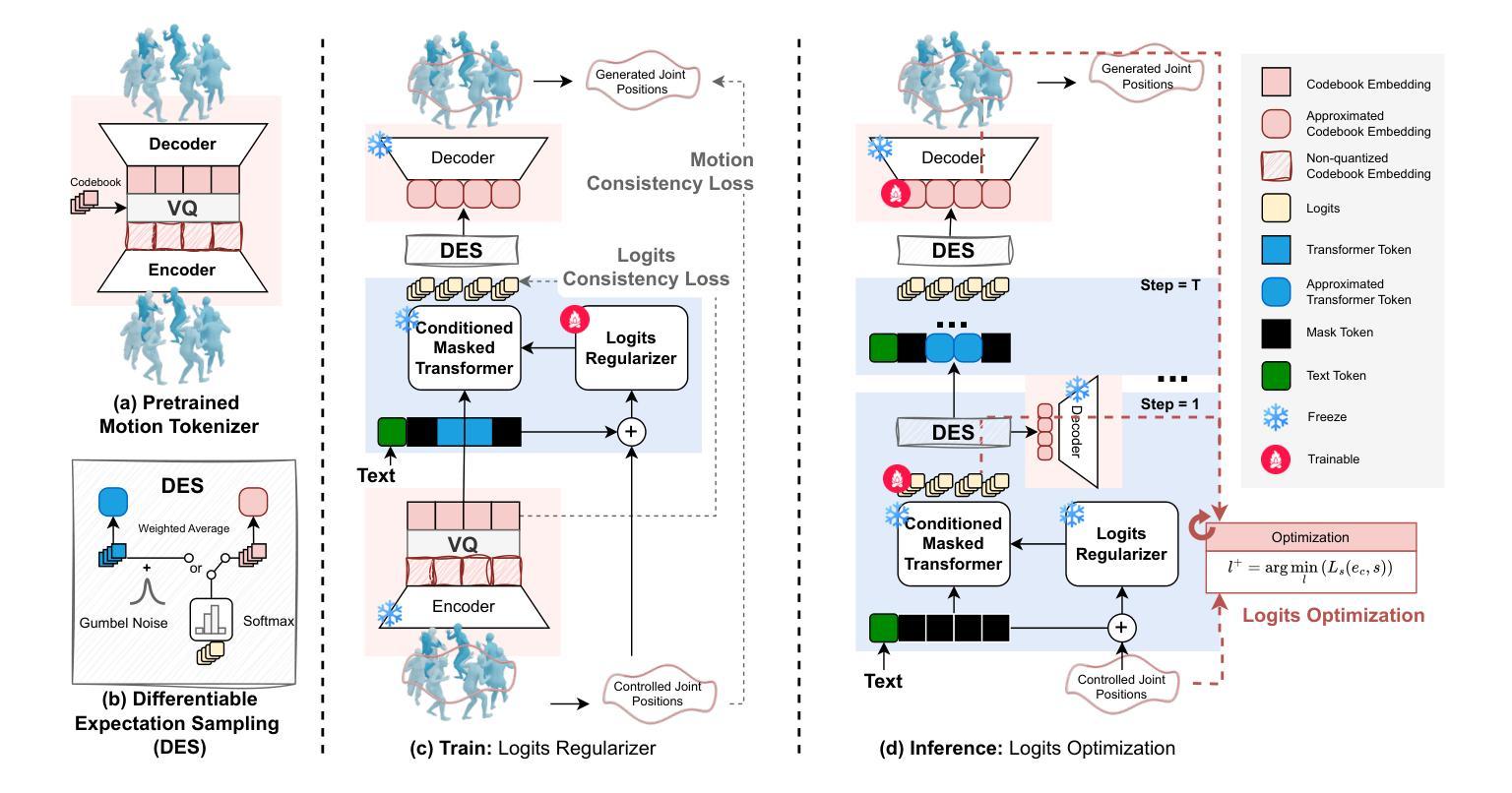
MaskControl: Spatio-Temporal Control for Masked Motion Synthesis
Authors:Ekkasit Pinyoanuntapong, Muhammad Usama Saleem, Korrawe Karunratanakul, Pu Wang, Hongfei Xue, Chen Chen, Chuan Guo, Junli Cao, Jian Ren, Sergey Tulyakov
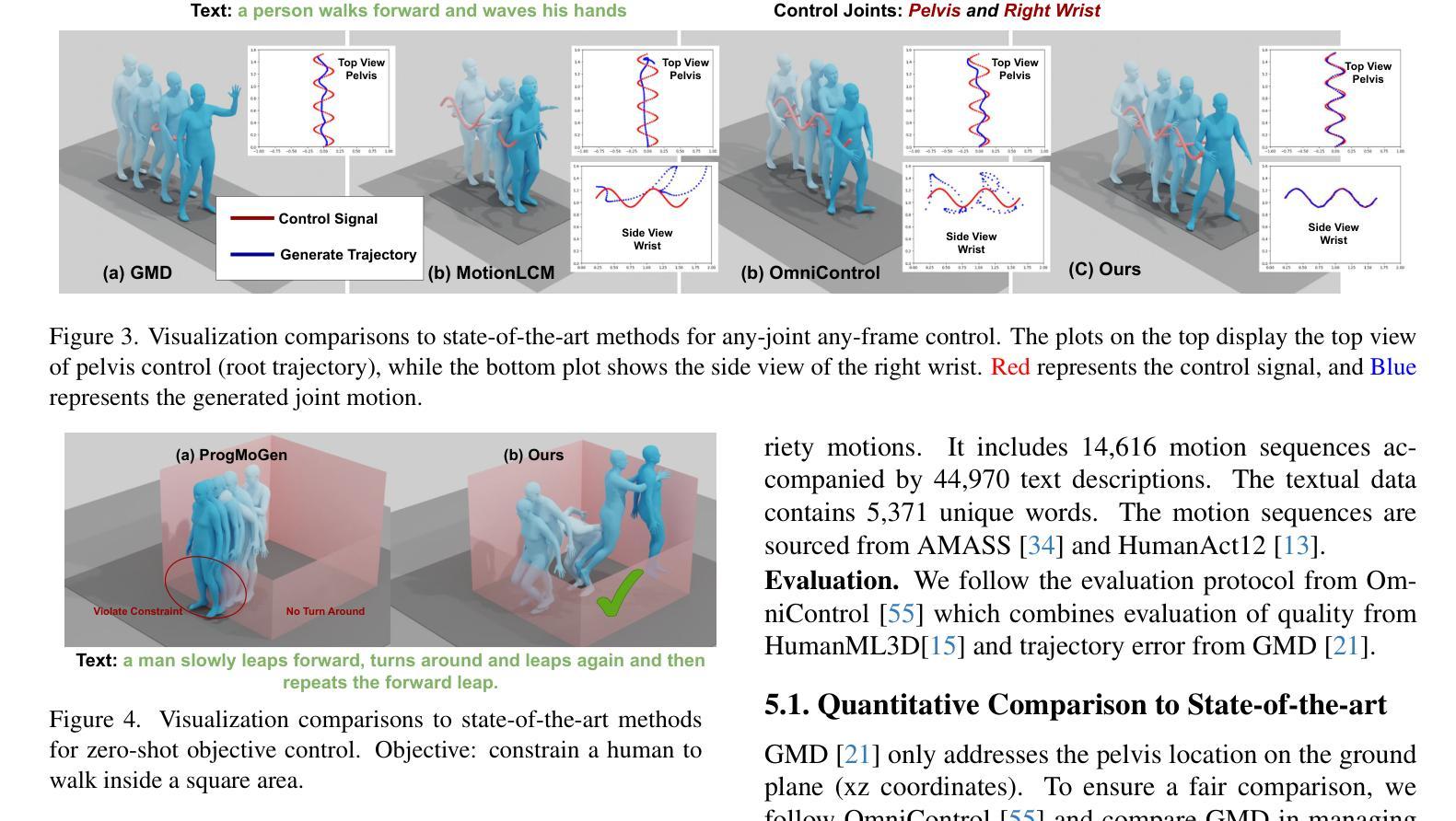
Recent advances in motion diffusion models have enabled spatially controllable text-to-motion generation. However, these models struggle to achieve high-precision control while maintaining high-quality motion generation. To address these challenges, we propose MaskControl, the first approach to introduce controllability to the generative masked motion model. Our approach introduces two key innovations. First, \textit{Logits Regularizer} implicitly perturbs logits at training time to align the distribution of motion tokens with the controlled joint positions, while regularizing the categorical token prediction to ensure high-fidelity generation. Second, \textit{Logit Optimization} explicitly optimizes the predicted logits during inference time, directly reshaping the token distribution that forces the generated motion to accurately align with the controlled joint positions. Moreover, we introduce \textit{Differentiable Expectation Sampling (DES)} to combat the non-differential distribution sampling process encountered by logits regularizer and optimization. Extensive experiments demonstrate that MaskControl outperforms state-of-the-art methods, achieving superior motion quality (FID decreases by ~77%) and higher control precision (average error 0.91 vs. 1.08). Additionally, MaskControl enables diverse applications, including any-joint-any-frame control, body-part timeline control, and zero-shot objective control. Video visualization can be found at https://www.ekkasit.com/ControlMM-page/
最近,动作扩散模型的进步已经实现了空间可控的文本到动作生成。然而,这些模型在保持高质量动作生成的同时,很难实现高精度的控制。为了应对这些挑战,我们提出了MaskControl,这是首个在生成式掩膜运动模型中引入可控性的方法。我们的方法引入了两个关键的创新点。首先,\textit{Logits Regularizer}在训练时隐式地扰动逻辑值,使运动标记的分布与受控关节位置对齐,同时正则化类别标记预测,以确保高保真生成。其次,\textit{Logit Optimization}在推理时显式优化预测的逻辑值,直接重塑标记分布,迫使生成的动作准确与受控关节位置对齐。此外,我们引入了\textit{Differentiable Expectation Sampling (DES)}来应对逻辑值正则器和优化所遇到的非微分分布采样过程。大量实验表明,MaskControl优于现有方法,实现了卓越的动作质量(FID降低约77%),以及更高的控制精度(平均误差0.91 vs. 1.08)。此外,MaskControl支持多样化的应用,包括任意关节任意帧控制、身体部位时间线控制和零目标控制。视频可视化请访问:[https://www.ekkasit.com/ControlMM-page/]
论文及项目相关链接
PDF Camera Ready Version. ICCV2025 (Oral). Change name from ControlMM to MaskControl. project page https://exitudio.github.io/ControlMM-page
Summary
本文介绍了针对运动扩散模型的新技术MaskControl,它首次实现了生成式掩膜运动模型的操控性。此技术包含两大创新点:Logits Regularizer和Logit Optimization。Logits Regularizer在训练过程中隐式扰动逻辑值,使运动标记的分布与控制的关节位置对齐;而Logit Optimization则在推理时间显式优化预测逻辑值,重塑标记分布以精准控制生成的关节运动。此外,还引入了Differentiable Expectation Sampling (DES)技术来解决非微分分布采样过程中遇到的问题。实验证明,MaskControl在动作质量和控制精度上均优于现有技术,并实现了多种应用,如任意关节任意帧控制、身体部位时间线控制和零目标控制等。相关视频可视化链接:链接地址。
Key Takeaways
- MaskControl是首个将操控性引入生成式掩膜运动模型的方案。
- MaskControl包含两大创新点:Logits Regularizer和Logit Optimization,分别用于隐式和显式控制逻辑值的优化。
- DES技术解决了非微分分布采样问题。
- MaskControl在动作质量和控制精度上优于现有技术,实现了高质量的运动生成和高精度的控制。
- MaskControl具有多种应用,包括任意关节任意帧控制、身体部位时间线控制等。
- 视频可视化链接提供了直观了解MaskControl功能的方式。
点此查看论文截图