⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-03 更新
EPSilon: Efficient Point Sampling for Lightening of Hybrid-based 3D Avatar Generation
Authors:Seungjun Moon, Sangjoon Yu, Gyeong-Moon Park
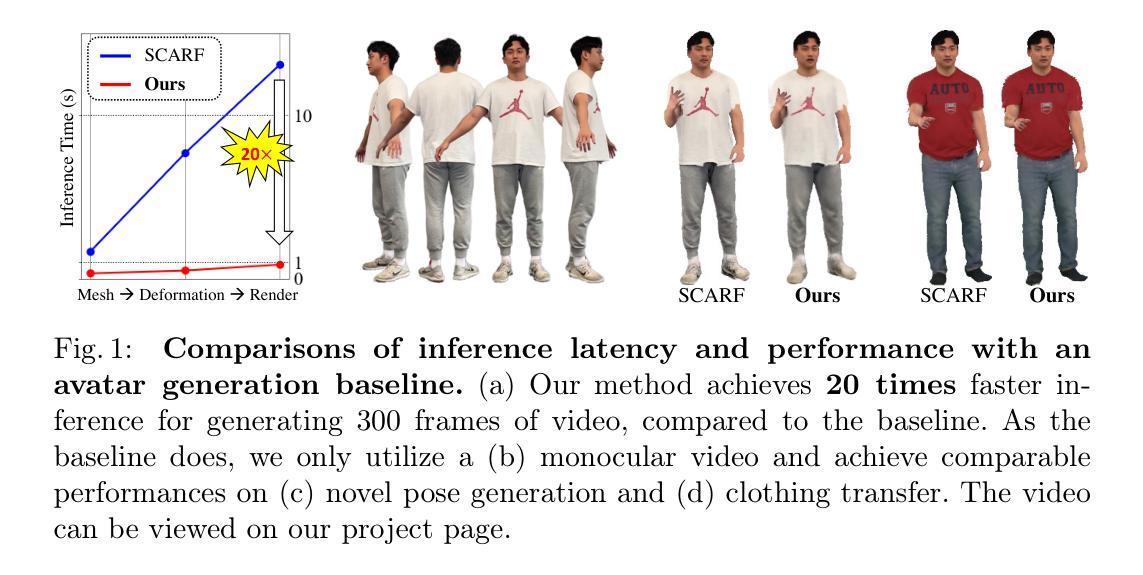
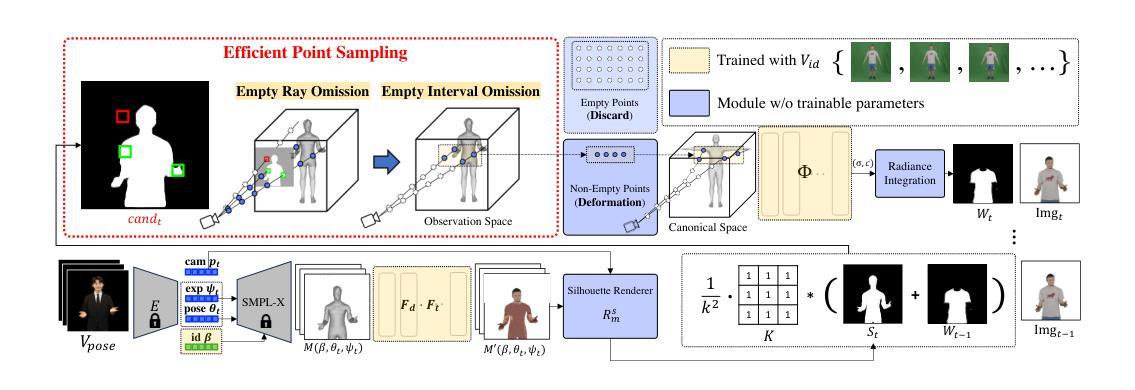
The rapid advancement of neural radiance fields (NeRF) has paved the way to generate animatable human avatars from a monocular video. However, the sole usage of NeRF suffers from a lack of details, which results in the emergence of hybrid representation that utilizes SMPL-based mesh together with NeRF representation. While hybrid-based models show photo-realistic human avatar generation qualities, they suffer from extremely slow inference due to their deformation scheme: to be aligned with the mesh, hybrid-based models use the deformation based on SMPL skinning weights, which needs high computational costs on each sampled point. We observe that since most of the sampled points are located in empty space, they do not affect the generation quality but result in inference latency with deformation. In light of this observation, we propose EPSilon, a hybrid-based 3D avatar generation scheme with novel efficient point sampling strategies that boost both training and inference. In EPSilon, we propose two methods to omit empty points at rendering; empty ray omission (ERO) and empty interval omission (EIO). In ERO, we wipe out rays that progress through the empty space. Then, EIO narrows down the sampling interval on the ray, which wipes out the region not occupied by either clothes or mesh. The delicate sampling scheme of EPSilon enables not only great computational cost reduction during deformation but also the designation of the important regions to be sampled, which enables a single-stage NeRF structure without hierarchical sampling. Compared to existing methods, EPSilon maintains the generation quality while using only 3.9% of sampled points and achieves around 20 times faster inference, together with 4 times faster training convergence. We provide video results on https://github.com/seungjun-moon/epsilon.
神经辐射场(NeRF)的快速发展为从单目视频中生成可动画的人形化身铺平了道路。然而,仅仅使用NeRF存在细节不足的问题,这导致了利用SMPL基础网格与NeRF表示相结合的混合表示的兴起。虽然混合模型表现出逼真的人类化身生成质量,但由于其变形方案,它们遭受了极慢的推理时间:为了与网格对齐,混合模型使用基于SMPL蒙皮权重的变形,这在每个采样点上都需要很高的计算成本。我们观察到,由于大多数采样点位于空空间中,它们并不影响生成质量,但会导致推理延迟。鉴于此观察,我们提出EPSilon,这是一种基于混合的3D化身生成方案,具有新颖的高效点采样策略,可提升训练和推理。在EPSilon中,我们提出了两种方法在渲染时省略空点:空射线剔除(ERO)和空区间剔除(EIO)。ERO中,我们消除了穿过空空间的射线。然后,EIO缩小了射线上的采样间隔,从而消除了未被衣物或网格占据的区域。EPSilon的精细采样方案不仅大大降低了变形过程中的计算成本,还能指定要采样的重要区域,从而实现无需分层采样的单阶段NeRF结构。与现有方法相比,EPSilon在仅使用3.9%的采样点的同时,保持生成质量,并实现约20倍的快速推理,以及4倍的训练收敛速度。有关视频结果,请访问:https://github.com/seungjun-moon/epsilon。
论文及项目相关链接
Summary
神经网络辐射场(NeRF)的快速发展为从单目视频中生成可动画化的人类角色奠定了基础。然而,单纯使用NeRF会导致细节不足,因此出现了结合SMPL网格和NeRF表示的混合模型。虽然混合模型能够生成逼真的角色形象,但它们因基于SMPL蒙皮权重的变形方案而推理过程缓慢。本文提出EPSILON方案,采用高效的点采样策略提升训练和推理速度,同时保持高质量的生成效果。通过剔除空射线(ERO)和缩小采样间隔(EIO)等方法减少不必要的计算消耗,使模型更高效。相比现有方法,EPSILON仅用3.9%的点样本便实现相似质量,推理速度提升约20倍,训练收敛速度也提高了四倍。具体视频效果可见相关GitHub链接。
Key Takeaways
- NeRF技术为生成可动画化的人类角色提供了基础。
- 单纯使用NeRF生成的细节不足,因此出现了混合模型结合SMPL网格和NeRF表示。
- 混合模型能生成逼真的角色形象但推理过程慢,主要由于基于SMPL蒙皮权重的变形方案计算成本高。
- EPSILON方案采用高效的点采样策略提升训练和推理效率。
- EPSILON通过剔除空射线和缩小采样间隔减少计算消耗。
点此查看论文截图

Public Evaluation on Potential Social Impacts of Fully Autonomous Cybernetic Avatars for Physical Support in Daily-Life Environments: Large-Scale Demonstration and Survey at Avatar Land
Authors:Lotfi El Hafi, Kazuma Onishi, Shoichi Hasegawa, Akira Oyama, Tomochika Ishikawa, Masashi Osada, Carl Tornberg, Ryoma Kado, Kento Murata, Saki Hashimoto, Sebastian Carrera Villalobos, Akira Taniguchi, Gustavo Alfonso Garcia Ricardez, Yoshinobu Hagiwara, Tatsuya Aoki, Kensuke Iwata, Takato Horii, Yukiko Horikawa, Takahiro Miyashita, Tadahiro Taniguchi, Hiroshi Ishiguro
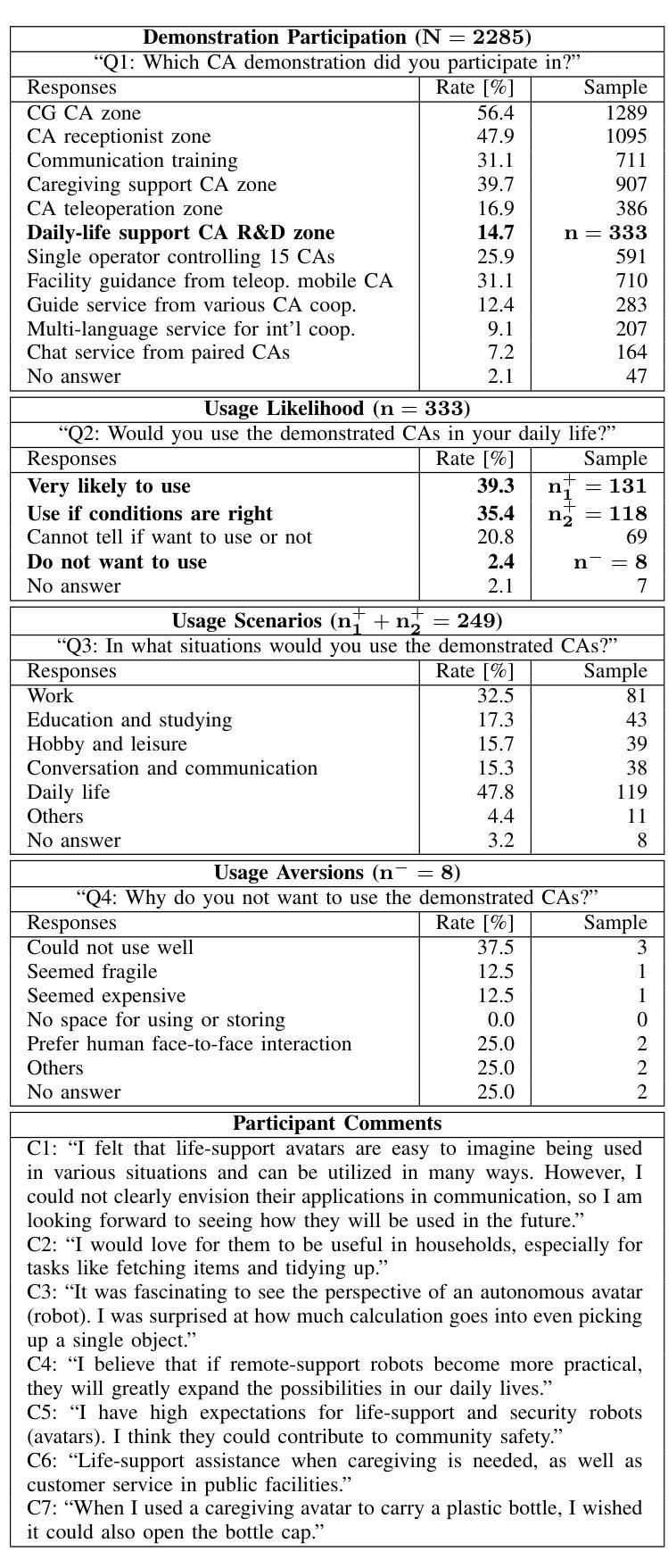
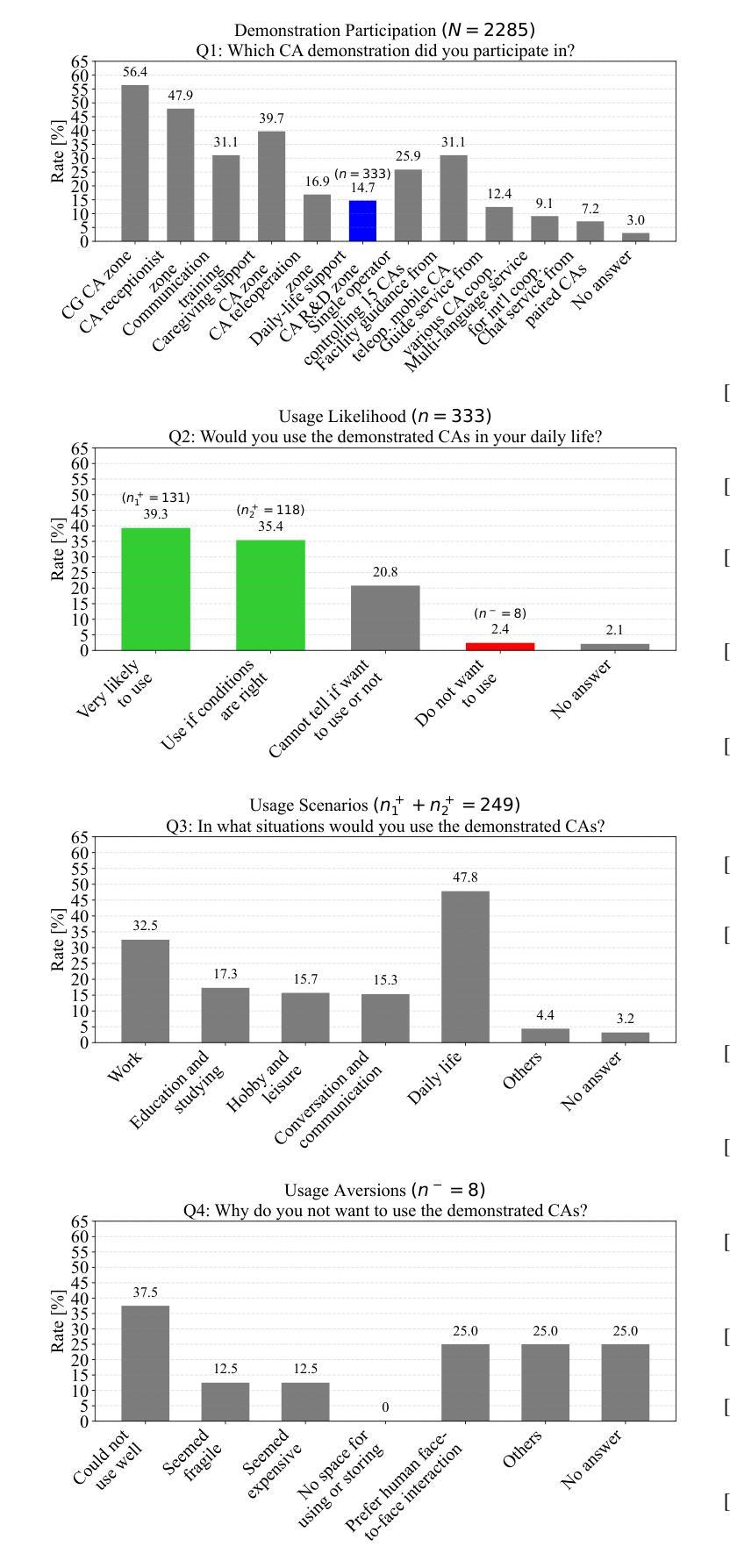
Cybernetic avatars (CAs) are key components of an avatar-symbiotic society, enabling individuals to overcome physical limitations through virtual agents and robotic assistants. While semi-autonomous CAs intermittently require human teleoperation and supervision, the deployment of fully autonomous CAs remains a challenge. This study evaluates public perception and potential social impacts of fully autonomous CAs for physical support in daily life. To this end, we conducted a large-scale demonstration and survey during Avatar Land, a 19-day public event in Osaka, Japan, where fully autonomous robotic CAs, alongside semi-autonomous CAs, performed daily object retrieval tasks. Specifically, we analyzed responses from 2,285 visitors who engaged with various CAs, including a subset of 333 participants who interacted with fully autonomous CAs and shared their perceptions and concerns through a survey questionnaire. The survey results indicate interest in CAs for physical support in daily life and at work. However, concerns were raised regarding task execution reliability. In contrast, cost and human-like interaction were not dominant concerns. Project page: https://lotfielhafi.github.io/FACA-Survey/.
赛博化身(Cybernetic Avatars,简称CAs)是化身共生社会的重要组成部分,通过虚拟代理和机器人助手使个人能够克服身体局限。虽然半自主CAs需要间歇性的遥操作和监控,但完全自主的CAs部署仍然是一个挑战。本研究旨在评估公众对日常生活中用于物理支持的完全自主CAs的看法和潜在社会影响。为此,我们在日本大阪举行的为期19天的公共活动“化身之地”(Avatar Land)进行了大规模演示和调查。在此期间,完全自主的机器人CAs与半自主CAs一起执行日常物品检索任务。具体来说,我们分析了与各种CAs互动的2285名访客的反应,其中包括与完全自主CAs互动的333名参与者。他们通过调查问卷分享了他们的看法和担忧。调查结果表明,人们在工作和日常生活中对使用CAs进行物理支持感兴趣。然而,人们对任务执行的可靠性提出了担忧。相比之下,成本和人类般的互动并不是主要的担忧点。项目页面:https://lotfielhafi.github.io/FACA-Survey/。
论文及项目相关链接
PDF Accepted for presentation at the 2025 IEEE International Conference on Advanced Robotics and its Social Impacts (ARSO), Osaka, Japan
Summary
本研究探讨了全自动智能机器人(Cybernetic avatars,简称CAs)在日常生活中的物理支持应用,以及公众对其的感知和社会影响。在大阪举办的为期十九天的公共活动Avatar Land中进行了大规模展示和调查,对与全自动机器人交互的公众进行了调研,探讨了他们对全自动机器人的态度和感知。研究结果表明,人们普遍对CAs在日常生活和工作中提供物理支持表示感兴趣,但任务执行可靠性问题引发关注,而成本和类似人类的交互不是主要的担忧点。
Key Takeaways
一、全自动智能机器人(CAs)可在日常物体检索任务中提供物理支持。
二、公众对CAs在日常生活和工作中提供物理支持表示感兴趣。
三、任务执行可靠性是公众对全自动CAs的主要关注点。
四、成本问题和类似人类的交互不是公众的主要担忧点。
五、全自动CAs在公开场合的展示为公众参与体验和技术反馈提供了机会。
六、此类技术展示了为老龄化社会提供物理支持和解决劳动力短缺问题的潜力。
点此查看论文截图

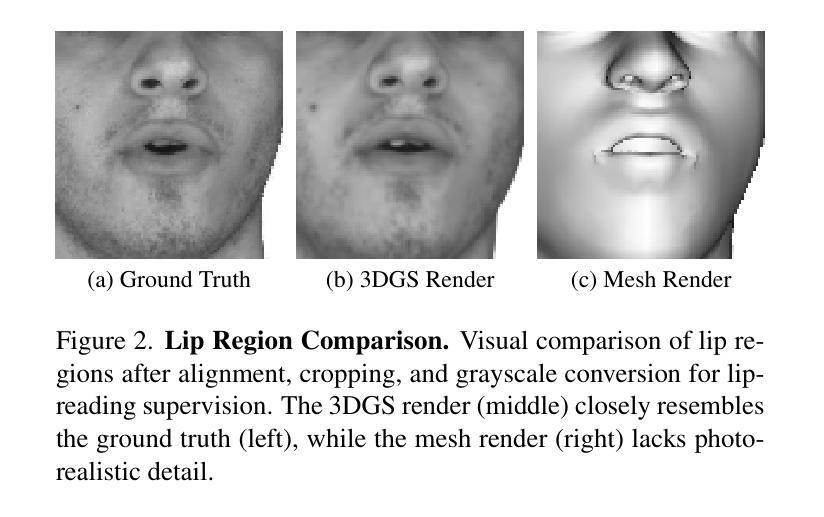
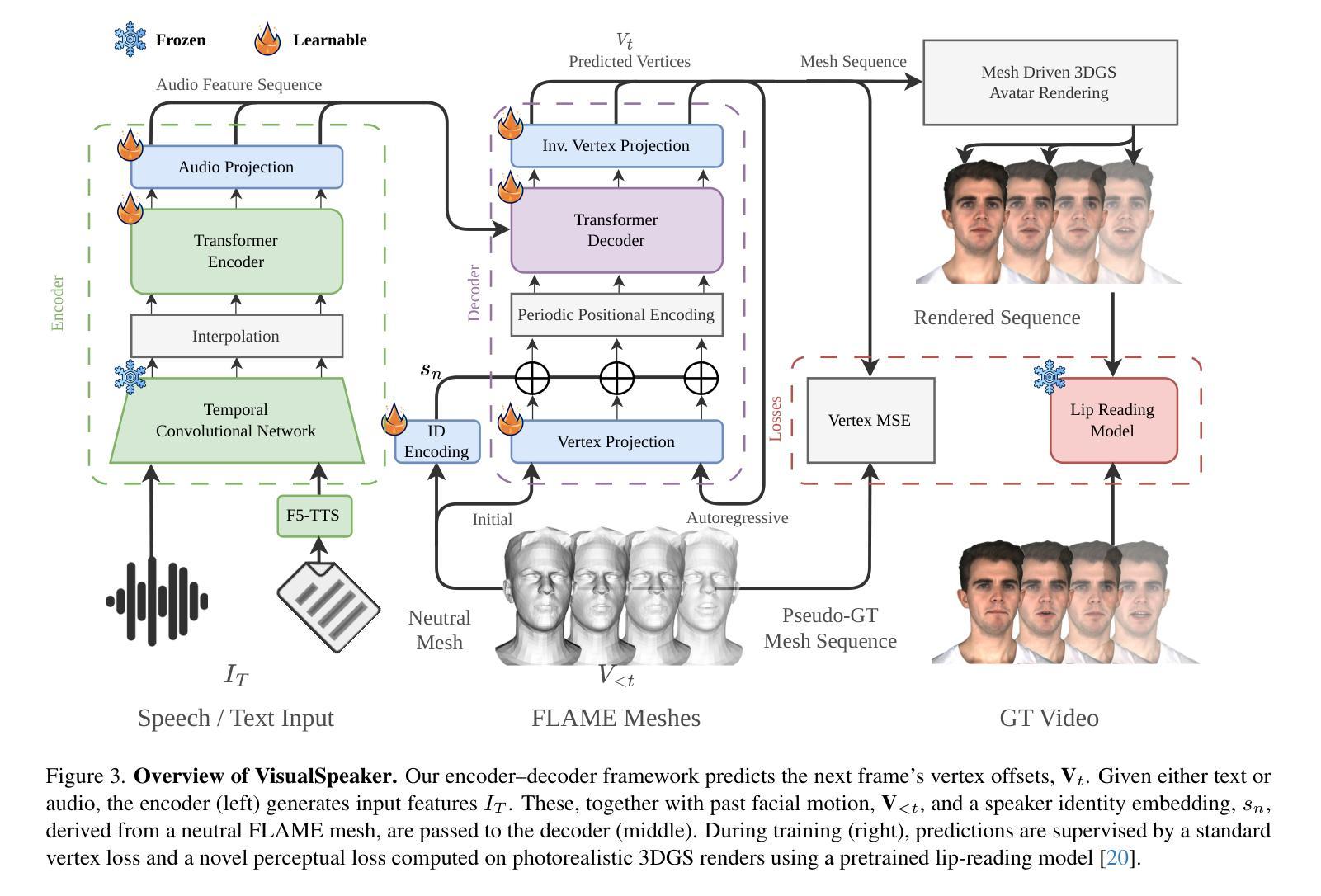
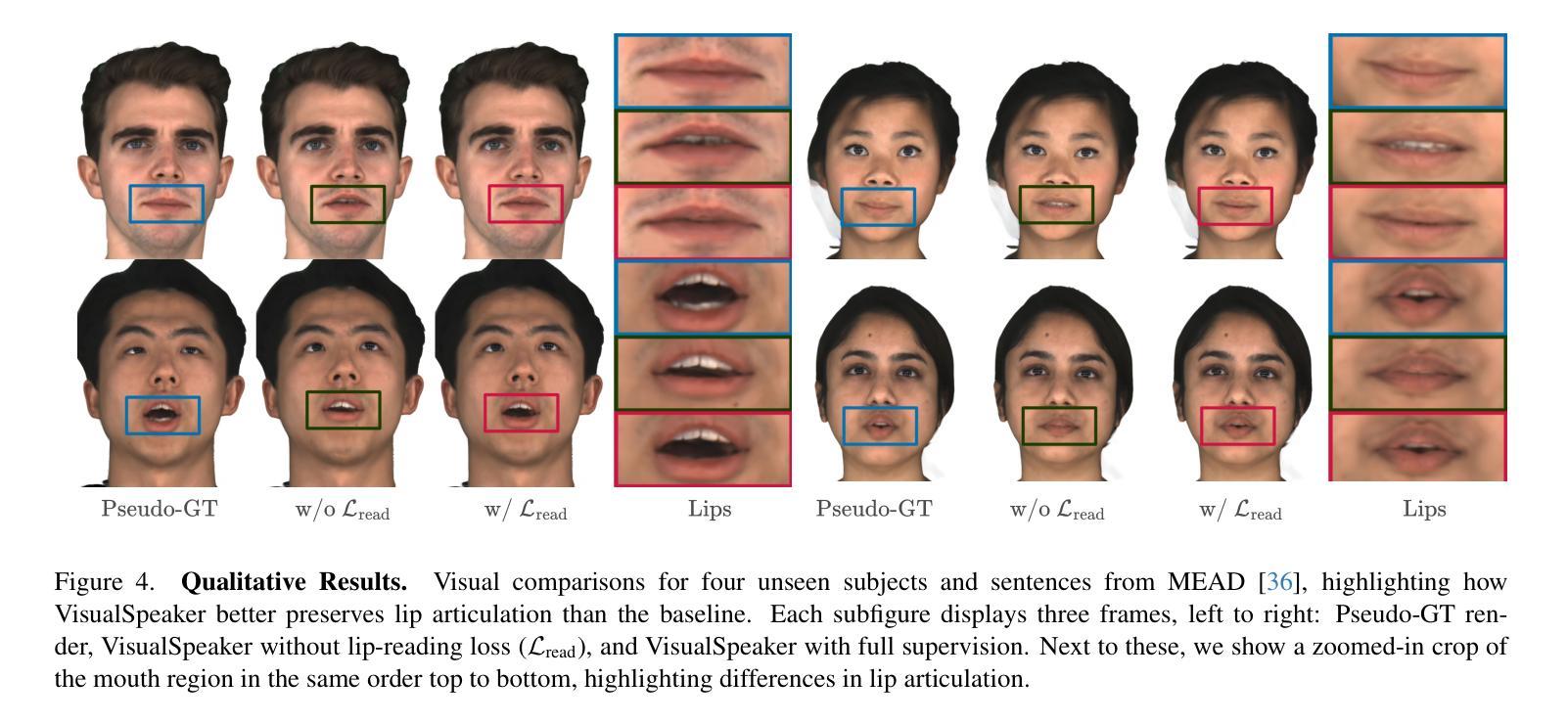
VisualSpeaker: Visually-Guided 3D Avatar Lip Synthesis
Authors:Alexandre Symeonidis-Herzig, Özge Mercanoğlu Sincan, Richard Bowden
Realistic, high-fidelity 3D facial animations are crucial for expressive avatar systems in human-computer interaction and accessibility. Although prior methods show promising quality, their reliance on the mesh domain limits their ability to fully leverage the rapid visual innovations seen in 2D computer vision and graphics. We propose VisualSpeaker, a novel method that bridges this gap using photorealistic differentiable rendering, supervised by visual speech recognition, for improved 3D facial animation. Our contribution is a perceptual lip-reading loss, derived by passing photorealistic 3D Gaussian Splatting avatar renders through a pre-trained Visual Automatic Speech Recognition model during training. Evaluation on the MEAD dataset demonstrates that VisualSpeaker improves both the standard Lip Vertex Error metric by 56.1% and the perceptual quality of the generated animations, while retaining the controllability of mesh-driven animation. This perceptual focus naturally supports accurate mouthings, essential cues that disambiguate similar manual signs in sign language avatars.
真实、高保真的3D面部动画对于人机交互和可访问性中的表情符号系统至关重要。尽管先前的方法显示出有希望的品质,但它们对网格域的依赖限制了它们充分利用2D计算机视觉和图形中快速视觉创新的能力。我们提出了VisualSpeaker,这是一种新颖的方法,它通过基于真实感的可微分渲染来弥合这一鸿沟,并由视觉语音识别进行监督,以改进3D面部动画。我们的贡献在于感知唇读损失,这是在训练过程中,通过将逼真的3D高斯模糊肖像渲染通过预训练的视觉自动语音识别模型而获得。在MEAD数据集上的评估表明,VisualSpeaker不仅将标准的唇顶点误差度量指标提高了56.1%,而且提高了生成动画的感知质量,同时保持了网格驱动动画的控制性。这种感知重点自然支持准确的嘴巴动作,这是重要线索,可以区分手语表情符号中的相似手势。
论文及项目相关链接
PDF Accepted in International Conference on Computer Vision (ICCV) Workshops
Summary
本文提出一种名为VisualSpeaker的新型方法,利用逼真可微渲染技术,结合视觉语音识别技术,改进了3D面部动画。该方法通过预训练的视觉自动语音识别模型对逼真的三维高斯投影(Gaussian Splatting)角色渲染进行监督,以计算感知唇部阅读损失(lip-reading loss)。在MEAD数据集上的评估显示,VisualSpeaker在唇顶点误差指标上提高了56.1%,同时提高了动画的感知质量,并保持了网格驱动的动画的可控性。此方法对于准确呈现嘴部动作至关重要,对于区分类似的手语符号在聋哑人手语角色中尤为重要。
Key Takeaways
- VisualSpeaker方法结合了逼真可微渲染技术和视觉语音识别技术,提高了3D面部动画的质量。
- 该方法通过使用预训练的视觉自动语音识别模型计算感知唇部阅读损失,以提升动画的真实感和识别准确性。
- 在MEAD数据集上的评估显示,VisualSpeaker在唇顶点误差指标上显著提高,这意味着动画的嘴部动作更加准确。
- VisualSpeaker提高了动画的感知质量,这包括动画的自然度和流畅度等方面的改进。
- 该方法保持了网格驱动动画的可控性,使得动画制作更加灵活和方便。
- VisualSpeaker对于制作手语角色特别重要,因为它能够准确呈现嘴部动作,从而区分类似的手语符号。
点此查看论文截图