⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-03 更新
Pathology Foundation Models are Scanner Sensitive: Benchmark and Mitigation with Contrastive ScanGen Loss
Authors:Gianluca Carloni, Biagio Brattoli, Seongho Keum, Jongchan Park, Taebum Lee, Chang Ho Ahn, Sergio Pereira
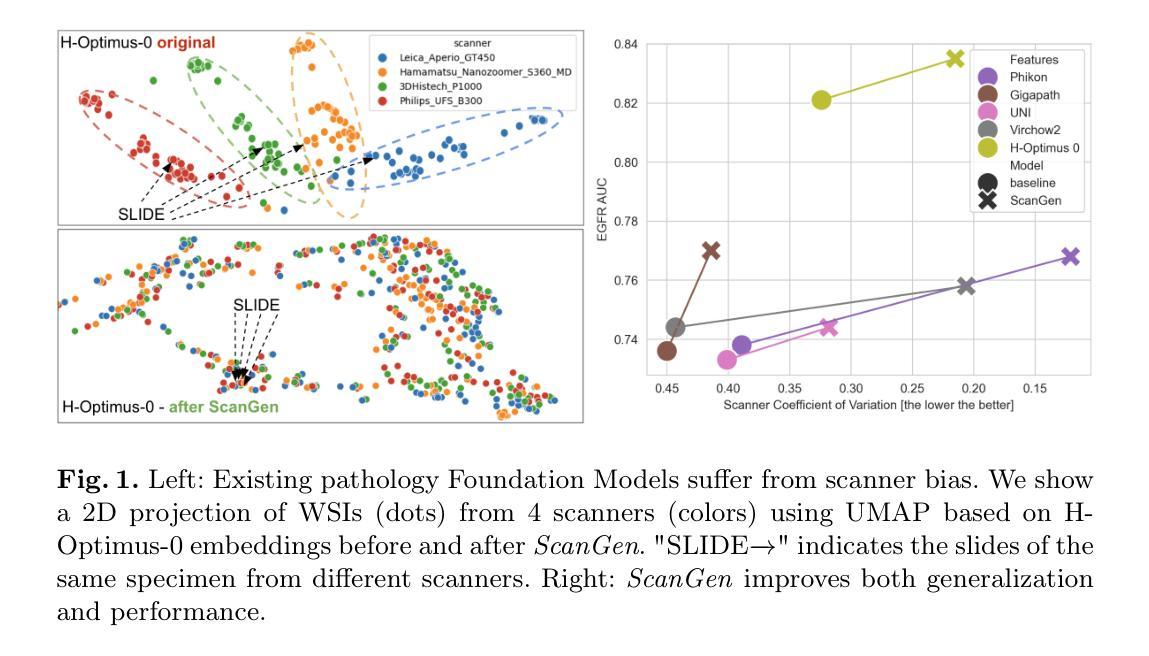
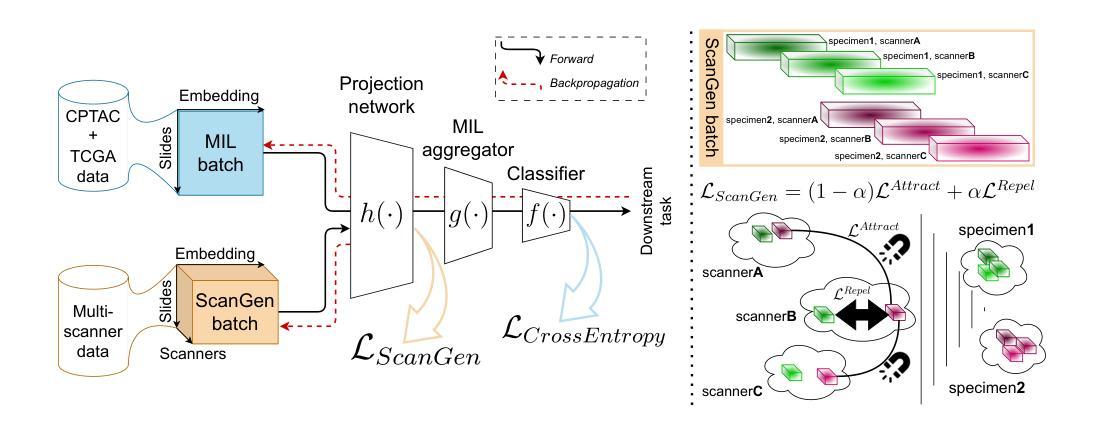
Computational pathology (CPath) has shown great potential in mining actionable insights from Whole Slide Images (WSIs). Deep Learning (DL) has been at the center of modern CPath, and while it delivers unprecedented performance, it is also known that DL may be affected by irrelevant details, such as those introduced during scanning by different commercially available scanners. This may lead to scanner bias, where the model outputs for the same tissue acquired by different scanners may vary. In turn, it hinders the trust of clinicians in CPath-based tools and their deployment in real-world clinical practices. Recent pathology Foundation Models (FMs) promise to provide better domain generalization capabilities. In this paper, we benchmark FMs using a multi-scanner dataset and show that FMs still suffer from scanner bias. Following this observation, we propose ScanGen, a contrastive loss function applied during task-specific fine-tuning that mitigates scanner bias, thereby enhancing the models’ robustness to scanner variations. Our approach is applied to the Multiple Instance Learning task of Epidermal Growth Factor Receptor (EGFR) mutation prediction from H&E-stained WSIs in lung cancer. We observe that ScanGen notably enhances the ability to generalize across scanners, while retaining or improving the performance of EGFR mutation prediction.
计算病理学(CPath)在从全切片图像(WSIs)中提取可操作洞察力方面显示出巨大潜力。深度学习(DL)是现代CPath的核心,虽然它提供了前所未有的性能,但众所周知,DL可能会受到无关细节的影响,如不同商业扫描仪在扫描过程中引入的细节。这可能导致扫描仪偏见,对于由不同扫描仪获取的相同组织,模型的输出可能会有所不同。这种情况阻碍了临床医生对基于CPath的工具的信任及其在现实世界临床实践中的部署。最近的病理学基础模型(FMs)承诺提供更好的领域泛化能力。在本文中,我们使用多扫描仪数据集对FMs进行基准测试,并表明FMs仍受到扫描仪偏见的影响。基于这一观察,我们提出ScanGen,这是一种在特定任务微调期间应用的对比损失函数,可以缓解扫描仪偏见,从而提高模型对扫描仪变化的稳健性。我们的方法应用于肺癌中表皮生长因子受体(EGFR)突变的预测的多实例学习任务。我们发现ScanGen显著提高了跨扫描仪的泛化能力,同时保持或提高了EGFR突变预测的性能。
论文及项目相关链接
PDF Accepted (Oral) in MedAGI 2025 International Workshop at MICCAI Conference
摘要
本文探讨了计算病理学(CPath)在全幻灯片图像(WSI)中挖掘可操作的见解的巨大潜力。深度学习(DL)是现代CPath的核心,虽然它提供了前所未有的性能,但DL可能受到无关细节的影响,如不同商业扫描仪在扫描过程中引入的细节。这可能导致扫描仪偏见,使得同一组织通过不同扫描仪获得的模型输出可能有所不同。进而阻碍临床医生对基于CPath的工具的信任及其在现实世界临床实践中的部署。最近的病理学基础模型(FMs)承诺提供更好的领域泛化能力。在本文中,我们对FMs进行了多扫描仪数据集基准测试,发现FMs仍存在扫描仪偏见。基于这一观察,我们提出了ScanGen,一种在特定任务微调期间应用对比损失函数,以减轻扫描仪偏见,从而提高模型对扫描仪变化的稳健性。我们的方法应用于肺癌中表皮生长因子受体(EGFR)突变的预测的多实例学习任务。我们发现ScanGen在跨扫描仪泛化方面表现出显著的提升,同时保持或提高了EGFR突变预测的性能。
关键见解
- 计算病理学(CPath)能够从全幻灯片图像(WSI)中挖掘出可操作的见解,具有巨大潜力。
- 深度学习可能会受到不同扫描仪引入的无关细节的影响,导致扫描仪偏见。
- 现有的病理学基础模型(FMs)虽然提供了更好的领域泛化能力,但仍存在扫描仪偏见问题。
- 提出的ScanGen方法通过应用对比损失函数,在特定任务微调时减轻扫描仪偏见,提高模型的稳健性。
- ScanGen在跨扫描仪泛化方面表现出显著的提升。
- ScanGen在EGFR突变预测任务中保持或提高了性能。
点此查看论文截图

Contrast-Prior Enhanced Duality for Mask-Free Shadow Removal
Authors:Jiyu Wu, Yifan Liu, Jiancheng Huang, Mingfu Yan, Shifeng Chen
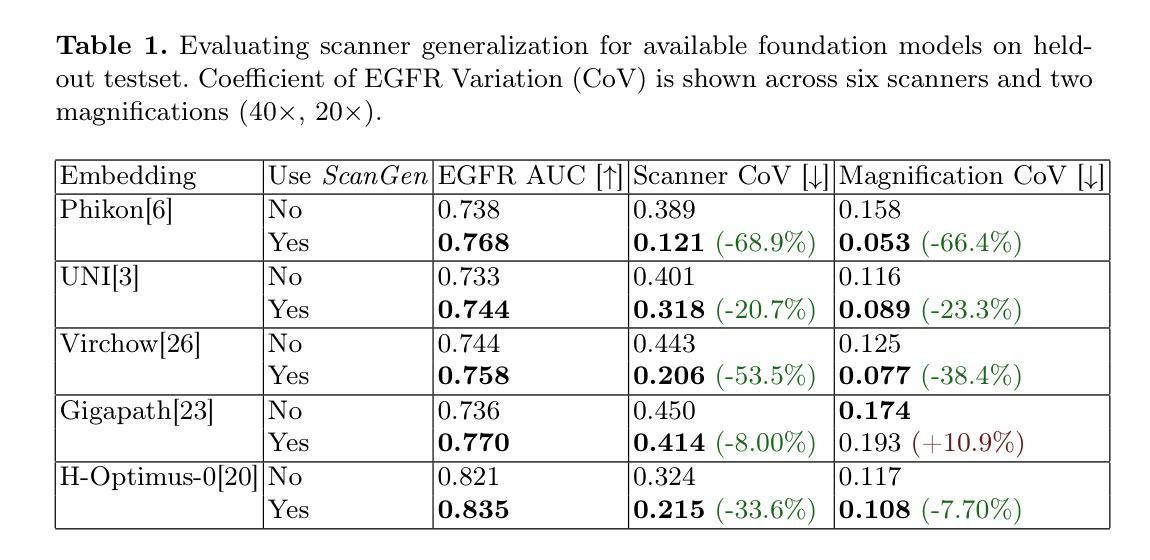
Existing shadow removal methods often rely on shadow masks, which are challenging to acquire in real-world scenarios. Exploring intrinsic image cues, such as local contrast information, presents a potential alternative for guiding shadow removal in the absence of explicit masks. However, the cue’s inherent ambiguity becomes a critical limitation in complex scenes, where it can fail to distinguish true shadows from low-reflectance objects and intricate background textures. To address this motivation, we propose the Adaptive Gated Dual-Branch Attention (AGBA) mechanism. AGBA dynamically filters and re-weighs the contrast prior to effectively disentangle shadow features from confounding visual elements. Furthermore, to tackle the persistent challenge of restoring soft shadow boundaries and fine-grained details, we introduce a diffusion-based Frequency-Contrast Fusion Network (FCFN) that leverages high-frequency and contrast cues to guide the generative process. Extensive experiments demonstrate that our method achieves state-of-the-art results among mask-free approaches while maintaining competitive performance relative to mask-based methods.
现有阴影去除方法通常依赖于阴影掩膜,但在真实场景中获取阴影掩膜具有挑战性。探索内在的图像线索,如局部对比度信息,为在没有明确掩膜的情况下指导阴影去除提供了潜在的可能性。然而,线索本身的模糊性在复杂场景中成为关键限制,因为它可能无法区分真实阴影与低反射物体和复杂背景纹理。为了解决这一动机,我们提出了自适应门控双分支注意力(AGBA)机制。AGBA动态过滤并重新加权对比度,以有效地从混淆的视觉元素中分离阴影特征。此外,为了解决恢复软阴影边界和细节精细的持续挑战,我们引入了一个基于扩散的频率对比融合网络(FCFN),该网络利用高频和对比度线索来指导生成过程。大量实验表明,我们的方法在无需掩膜的方法中达到最新水平的结果,同时在基于掩膜的方法中保持竞争力。
论文及项目相关链接
Summary
本文提出一种无需阴影掩膜的自适应门控双分支注意力(AGBA)机制,通过动态筛选和重新加权对比信息,有效区分阴影特征和其他视觉元素。为解决软阴影边界和细节恢复难题,引入基于扩散的频率对比融合网络(FCFN),利用高频和对比线索引导生成过程。实验证明,该方法在无掩膜方法中达到最佳效果,与基于掩膜的方法相比也表现出竞争力。
Key Takeaways
- 现有阴影去除方法常依赖阴影掩膜,但在真实场景中获取掩膜具有挑战性。
- 局部对比信息可作为内在图像线索,在无明确掩膜的情况下指导阴影去除。
- 对比信息在复杂场景中可能存在内在模糊性,难以区分真实阴影、低反射物体和复杂背景纹理。
- 提出自适应门控双分支注意力(AGBA)机制,动态筛选和重新加权对比信息,以有效区分阴影特征。
- 为解决软阴影边界和细节恢复难题,引入扩散基础上的频率对比融合网络(FCFN)。
- FCFN利用高频和对比线索来指导生成过程。
点此查看论文截图


UNICE: Training A Universal Image Contrast Enhancer
Authors:Ruodai Cui, Lei Zhang
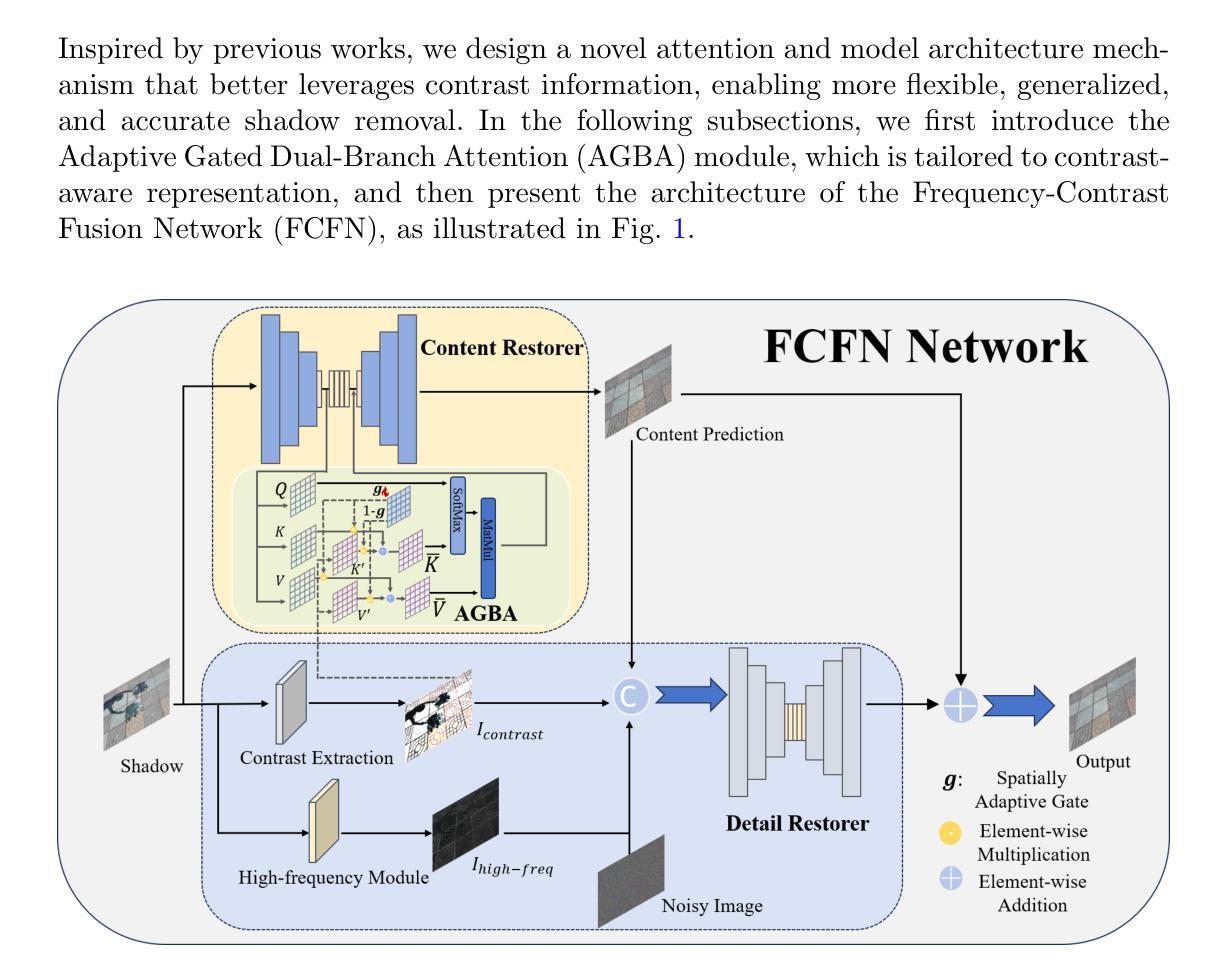
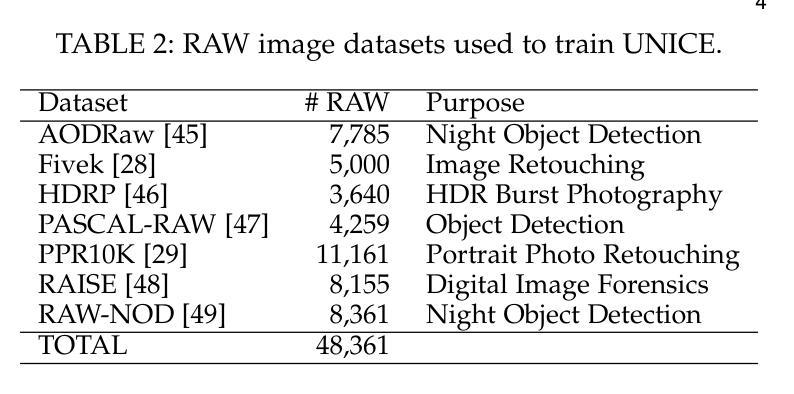
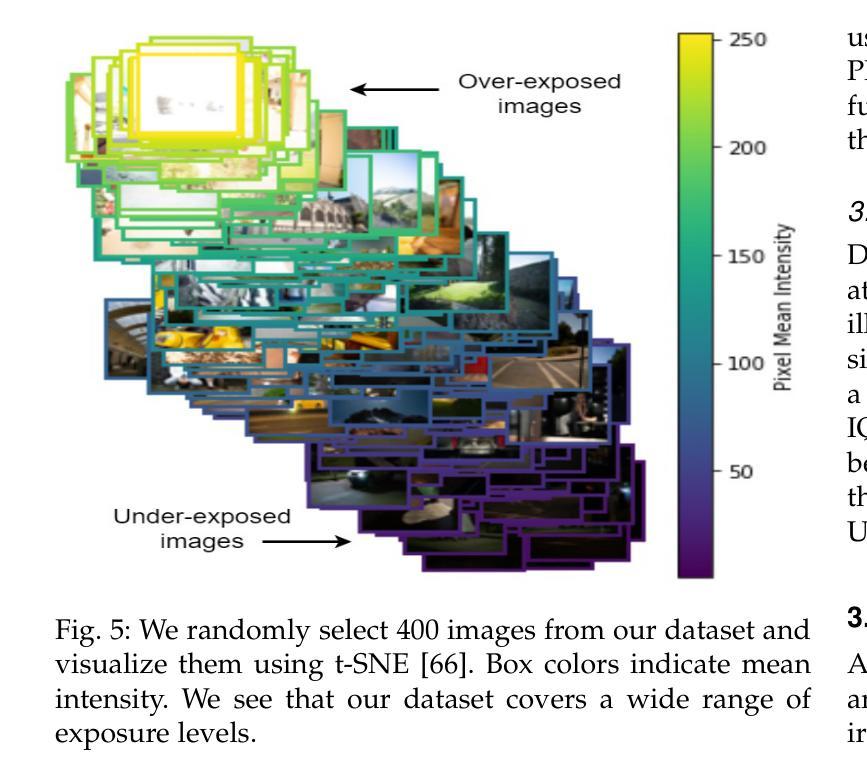
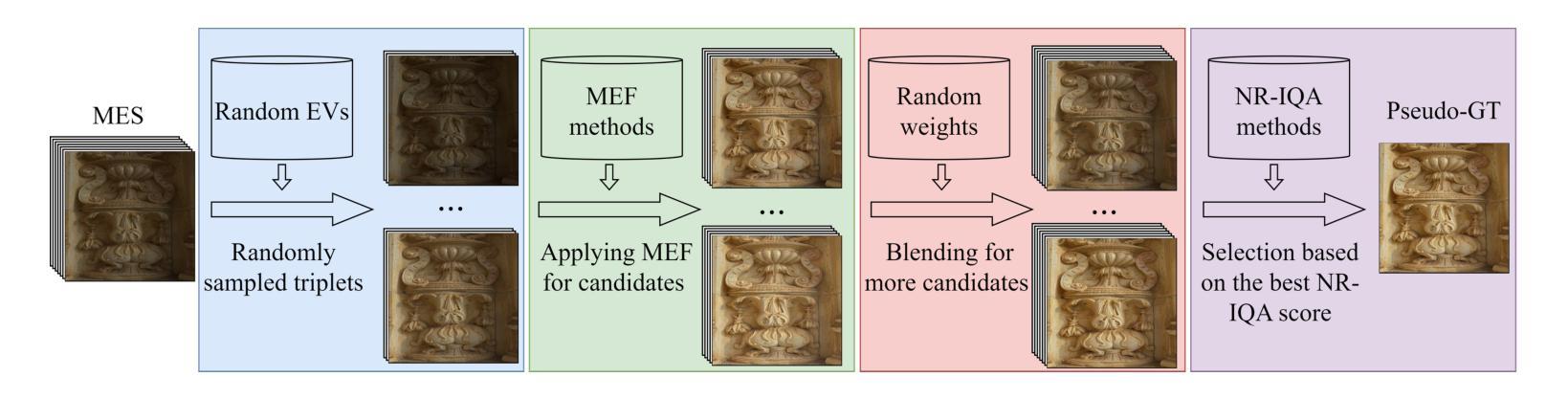
Existing image contrast enhancement methods are typically designed for specific tasks such as under-/over-exposure correction, low-light and backlit image enhancement, etc. The learned models, however, exhibit poor generalization performance across different tasks, even across different datasets of a specific task. It is important to explore whether we can learn a universal and generalized model for various contrast enhancement tasks. In this work, we observe that the common key factor of these tasks lies in the need of exposure and contrast adjustment, which can be well-addressed if high-dynamic range (HDR) inputs are available. We hence collect 46,928 HDR raw images from public sources, and render 328,496 sRGB images to build multi-exposure sequences (MES) and the corresponding pseudo sRGB ground-truths via multi-exposure fusion. Consequently, we train a network to generate an MES from a single sRGB image, followed by training another network to fuse the generated MES into an enhanced image. Our proposed method, namely UNiversal Image Contrast Enhancer (UNICE), is free of costly human labeling. However, it demonstrates significantly stronger generalization performance than existing image contrast enhancement methods across and within different tasks, even outperforming manually created ground-truths in multiple no-reference image quality metrics. The dataset, code and model are available at https://github.com/BeyondHeaven/UNICE.
现有的图像对比度增强方法通常针对特定任务设计,如欠曝光/过曝光校正、低光和低背光图像增强等。然而,学到的模型在不同任务甚至特定任务的不同数据集上表现出较差的泛化性能。探索是否可以学习用于各种对比度增强任务的通用和泛化模型非常重要。在这项工作中,我们观察到这些任务的共同关键因素在于曝光和对比度调整的需求,如果高动态范围(HDR)输入可用,则可以很好地解决这一问题。因此,我们从公共源收集了46928张HDR原始图像,渲染了328496张sRGB图像,通过多曝光融合构建多曝光序列(MES)和相应的伪sRGB真实标签。接着,我们训练了一个网络来生成单一sRGB图像的多曝光序列,然后训练另一个网络将生成的多曝光序列融合成增强图像。我们提出的方法称为通用图像对比度增强器(UNICE),无需昂贵的人工标注。然而,它在不同任务之间甚至任务内部都表现出显著强于现有图像对比度增强方法的泛化性能,甚至在多个无参考图像质量指标上超越了手动创建的真实标签。数据集、代码和模型可在https://github.com/BeyondHeaven/UNICE找到。
论文及项目相关链接
Summary
该研究旨在探索一种通用的图像对比度增强模型,以适应不同的对比度增强任务。通过收集HDR原始图像并渲染成sRGB图像,构建多曝光序列(MES)和相应的伪sRGB地面真实值。训练网络生成MES,并通过融合生成的网络图像增强对比。所提出的方法称为UNICE,无需昂贵的人力标注,且在跨任务和内部任务中的泛化性能明显优于现有的图像对比度增强方法,并在多种无参考图像质量指标上优于手动创建的地面真实值。数据集、代码和模型均可用在指定网站下载。
Key Takeaways
- 研究旨在开发一种通用的图像对比度增强模型,适用于多种任务。
- HDR原始图像被用于构建多曝光序列(MES)和相应的伪sRGB地面真实值。
- 通过训练网络生成MES,并通过融合增强对比。
- 所提出的UNICE方法无需昂贵的人力标注。
- UNICE在跨任务和内部任务的泛化性能上优于现有方法。
- 在多种无参考图像质量指标上,UNICE的表现优于手动创建的地面真实值。
点此查看论文截图




Equivariant Goal Conditioned Contrastive Reinforcement Learning
Authors:Arsh Tangri, Nichols Crawford Taylor, Haojie Huang, Robert Platt
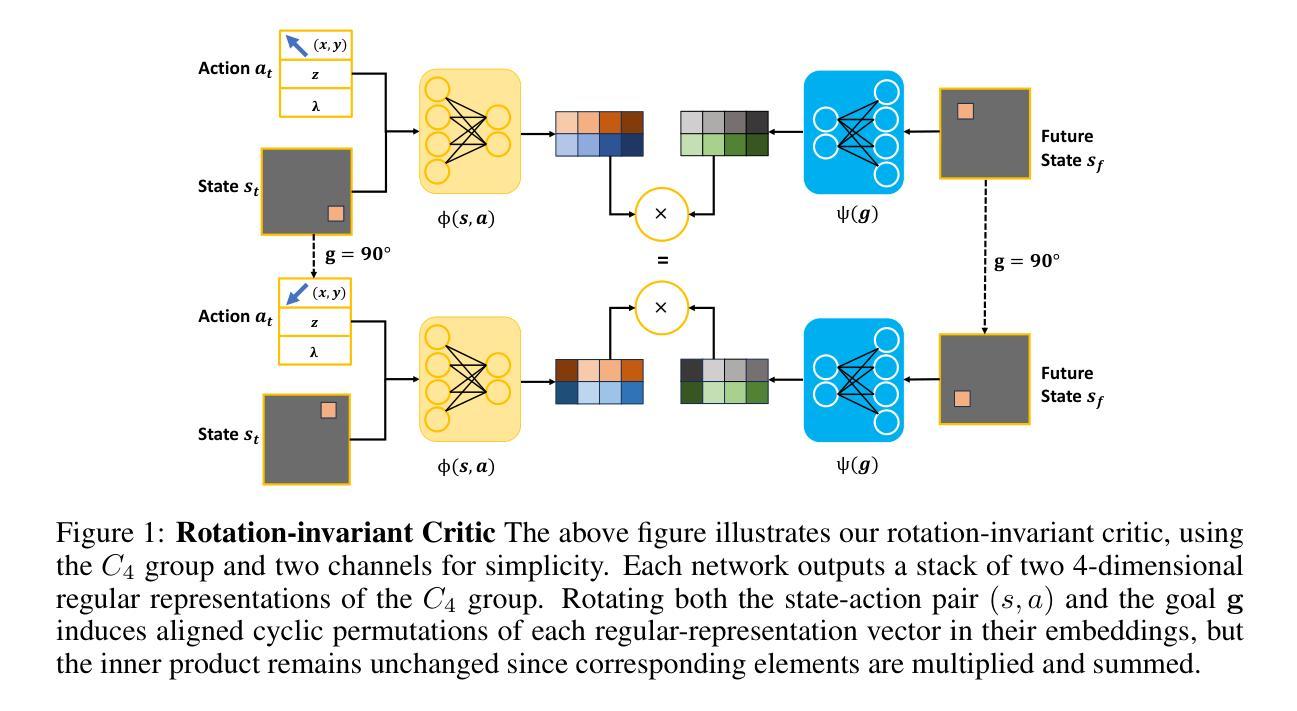
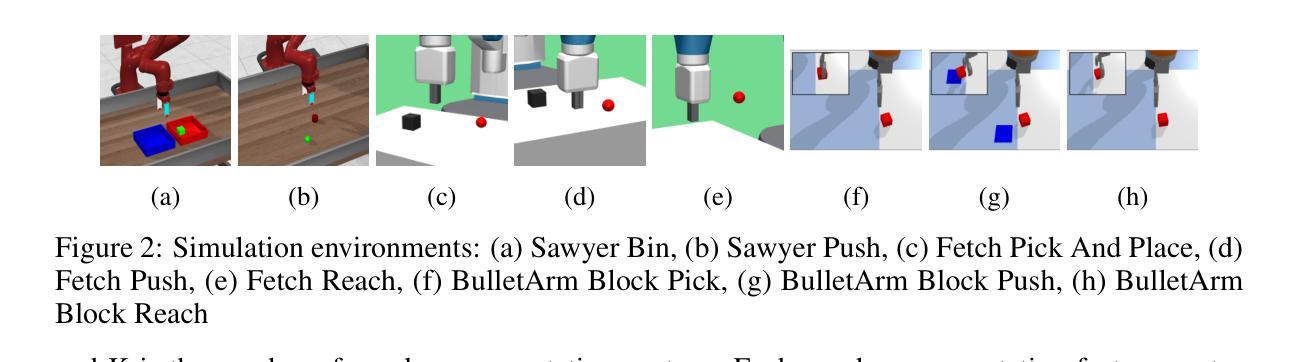
Contrastive Reinforcement Learning (CRL) provides a promising framework for extracting useful structured representations from unlabeled interactions. By pulling together state-action pairs and their corresponding future states, while pushing apart negative pairs, CRL enables learning nontrivial policies without manually designed rewards. In this work, we propose Equivariant CRL (ECRL), which further structures the latent space using equivariant constraints. By leveraging inherent symmetries in goal-conditioned manipulation tasks, our method improves both sample efficiency and spatial generalization. Specifically, we formally define Goal-Conditioned Group-Invariant MDPs to characterize rotation-symmetric robotic manipulation tasks, and build on this by introducing a novel rotation-invariant critic representation paired with a rotation-equivariant actor for Contrastive RL. Our approach consistently outperforms strong baselines across a range of simulated tasks in both state-based and image-based settings. Finally, we extend our method to the offline RL setting, demonstrating its effectiveness across multiple tasks.
对比强化学习(CRL)提供了一个很有前景的框架,可以从无标签的互动中提取有用的结构化表示。它通过把状态-行动对及其相应的未来状态拉到一起,同时推开负面对,使CRL能够在没有手动设计奖励的情况下学习非平凡的策略。在这项工作中,我们提出了等价CRL(ECRL),它通过使用等价约束进一步结构化潜在空间。通过利用目标条件下的操作任务中的固有对称性,我们的方法提高了样本效率和空间泛化能力。具体来说,我们正式定义了目标条件下的群不变MDP,以描述旋转对称的机器人操作任务,并在此基础上引入了一种新型的旋转不变批评家表示,与对比强化学习的旋转等价演员配对。我们的方法在一系列基于状态和基于图像的模拟任务中始终优于强大的基线。最后,我们将方法扩展到离线RL设置,证明了其在多任务中的有效性。
论文及项目相关链接
Summary
对比强化学习(CRL)能够从无标签的交互中提取有用的结构化表示,通过结合状态-动作对及其相应的未来状态,同时分离负面配对,实现无需手动设计奖励即可学习非平凡策略。在此基础上,我们提出了等价CRL(ECRL),它通过利用目标条件下的操作任务的内在对称性,进一步结构化潜在空间,提高了样本效率和空间泛化能力。本研究定义了目标条件下的组不变性MDP,以描述旋转对称的机器人操作任务,并基于此引入了一种新型的旋转不变评论家表示法,与旋转等价的动作演员一起用于对比强化学习。我们的方法在一系列模拟任务中始终优于强大的基准线,并在状态和图像基础设置中都得到了验证。最后,我们将该方法扩展到离线RL设置,展示了其在多任务中的有效性。
Key Takeaways
- 对比强化学习(CRL)能够从无标签的交互中学习非平凡策略。
- 等价CRL(ECRL)通过利用目标条件下的操作任务的内在对称性,进一步提高学习效果。
- ECRL通过引入旋转不变评论家表示法和旋转等价的动作演员,构建了新的学习框架。
- ECRL在模拟任务中的表现优于其他方法,适用于状态和图像基础设置。
- ECRL方法能够提高样本效率和空间泛化能力。
- ECRL成功扩展到离线RL设置,展示了其在多任务中的有效性。
点此查看论文截图

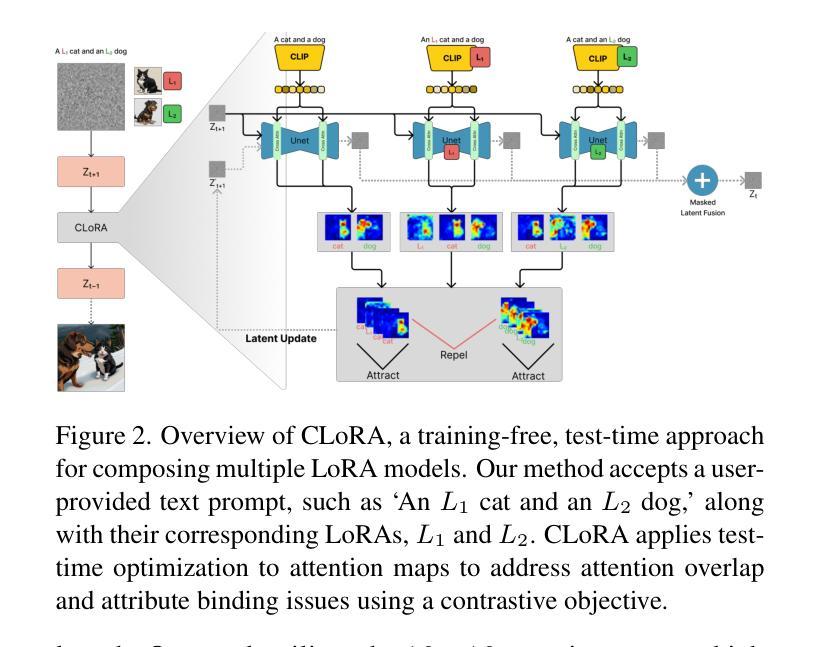
Contrastive Test-Time Composition of Multiple LoRA Models for Image Generation
Authors:Tuna Han Salih Meral, Enis Simsar, Federico Tombari, Pinar Yanardag
Low-Rank Adaptation (LoRA) has emerged as a powerful and popular technique for personalization, enabling efficient adaptation of pre-trained image generation models for specific tasks without comprehensive retraining. While employing individual pre-trained LoRA models excels at representing single concepts, such as those representing a specific dog or a cat, utilizing multiple LoRA models to capture a variety of concepts in a single image still poses a significant challenge. Existing methods often fall short, primarily because the attention mechanisms within different LoRA models overlap, leading to scenarios where one concept may be completely ignored (e.g., omitting the dog) or where concepts are incorrectly combined (e.g., producing an image of two cats instead of one cat and one dog). We introduce CLoRA, a training-free approach that addresses these limitations by updating the attention maps of multiple LoRA models at test-time, and leveraging the attention maps to create semantic masks for fusing latent representations. This enables the generation of composite images that accurately reflect the characteristics of each LoRA. Our comprehensive qualitative and quantitative evaluations demonstrate that CLoRA significantly outperforms existing methods in multi-concept image generation using LoRAs.
低秩适配(LoRA)作为一种强大且受欢迎的个人化技术应运而生,它能够在无需全面重新训练的情况下,有效地使预训练图像生成模型适应特定任务。虽然使用单个预训练的LoRA模型擅长表示单一概念,如代表特定的狗或猫,但利用多个LoRA模型来捕捉单张图像中的多种概念仍然是一个重大挑战。现有方法往往达不到预期效果,主要是因为不同LoRA模型内的注意力机制会重叠,导致出现完全忽略某一概念(例如忽略狗)或错误组合概念(例如生成两张猫的图片而不是一张猫和一张狗)的情况。我们引入了CLoRA,这是一种无需训练的方法,通过测试时更新多个LoRA模型的注意力图,并利用注意力图创建语义掩膜来融合潜在表示,从而解决这些限制。这能够使生成的组合图像准确反映每个LoRA的特性。我们全面的定性和定量评估表明,在使用LoRA进行多概念图像生成方面,CLoRA显著优于现有方法。
论文及项目相关链接
Summary
本文介绍了LoRA模型在个性化图像生成任务中的强大和流行,并指出其在特定任务中的高效适应性。然而,当需要在单一图像中捕捉多种概念时,使用多个LoRA模型仍然存在挑战。本文提出的CLoRA方法通过测试时更新多个LoRA模型的注意力图,并利用注意力图创建语义掩膜来融合潜在表示,解决了这一问题,从而实现了多概念图像生成的显著性能提升。
Key Takeaways
- LoRA已成为个性化图像生成的有力工具,可实现高效的任务适应性,无需全面重新训练。
- 在单一图像中捕捉多种概念是使用多个LoRA模型时的主要挑战。
- 现有方法经常失效,因为不同LoRA模型内的注意力机制会重叠,导致忽略某些概念或错误地组合概念。
- CLoRA是一种训练外方法,通过测试时更新多个LoRA模型的注意力图来解决这些问题。
- CLoRA利用注意力图创建语义掩膜,用于融合潜在表示,提高了多概念图像生成的质量。
- 综合定性和定量评估表明,CLoRA在利用LoRA进行多概念图像生成方面显著优于现有方法。
点此查看论文截图