⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-03 更新
VideoMind: An Omni-Modal Video Dataset with Intent Grounding for Deep-Cognitive Video Understanding
Authors:Baoyao Yang, Wanyun Li, Dixin Chen, Junxiang Chen, Wenbin Yao, Haifeng Lin
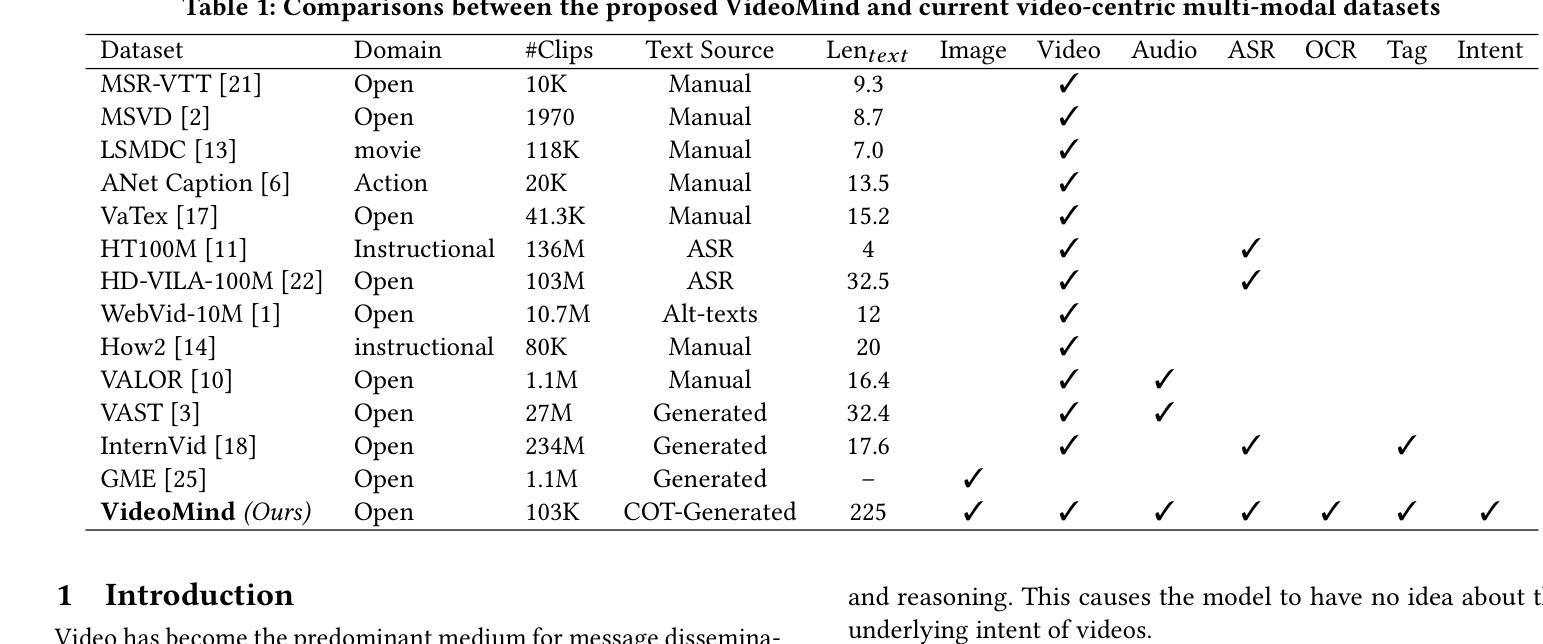
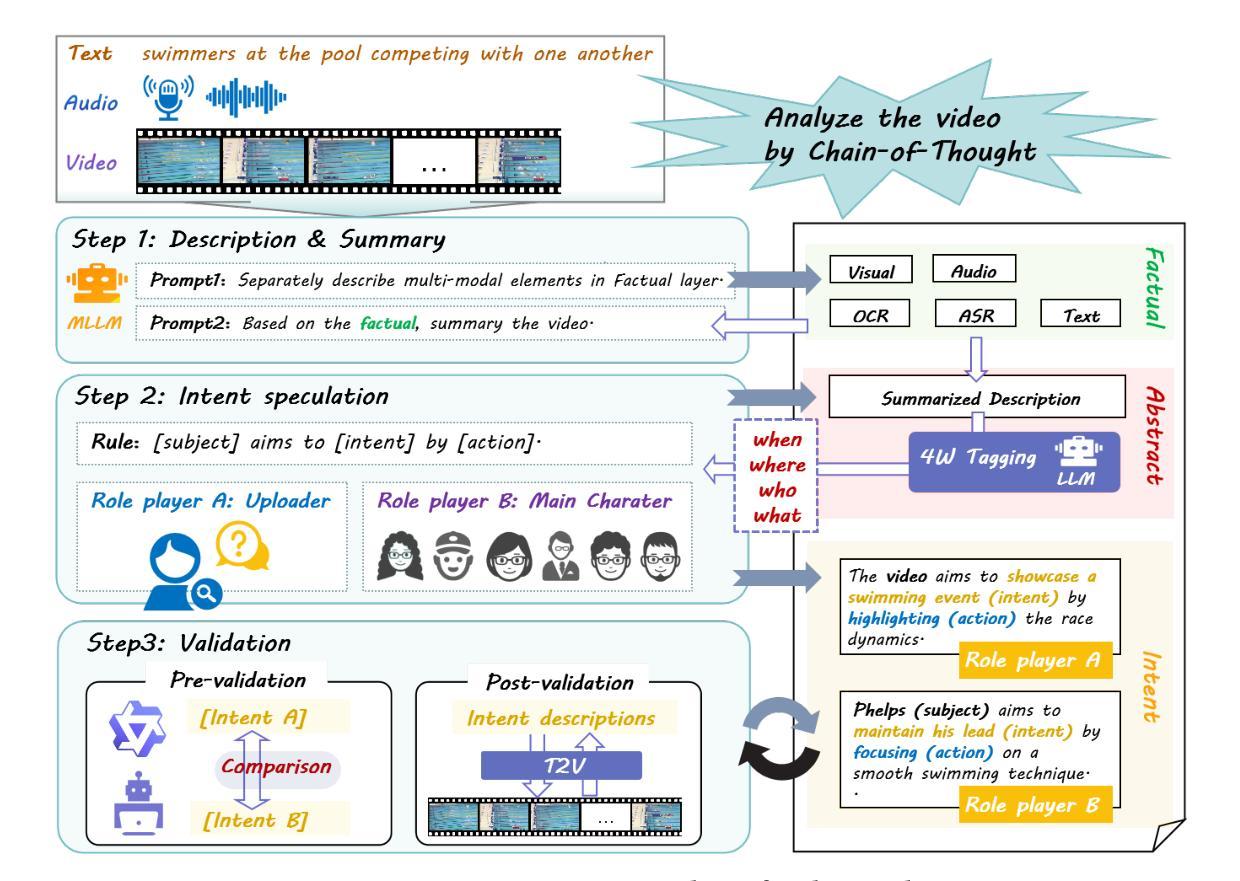
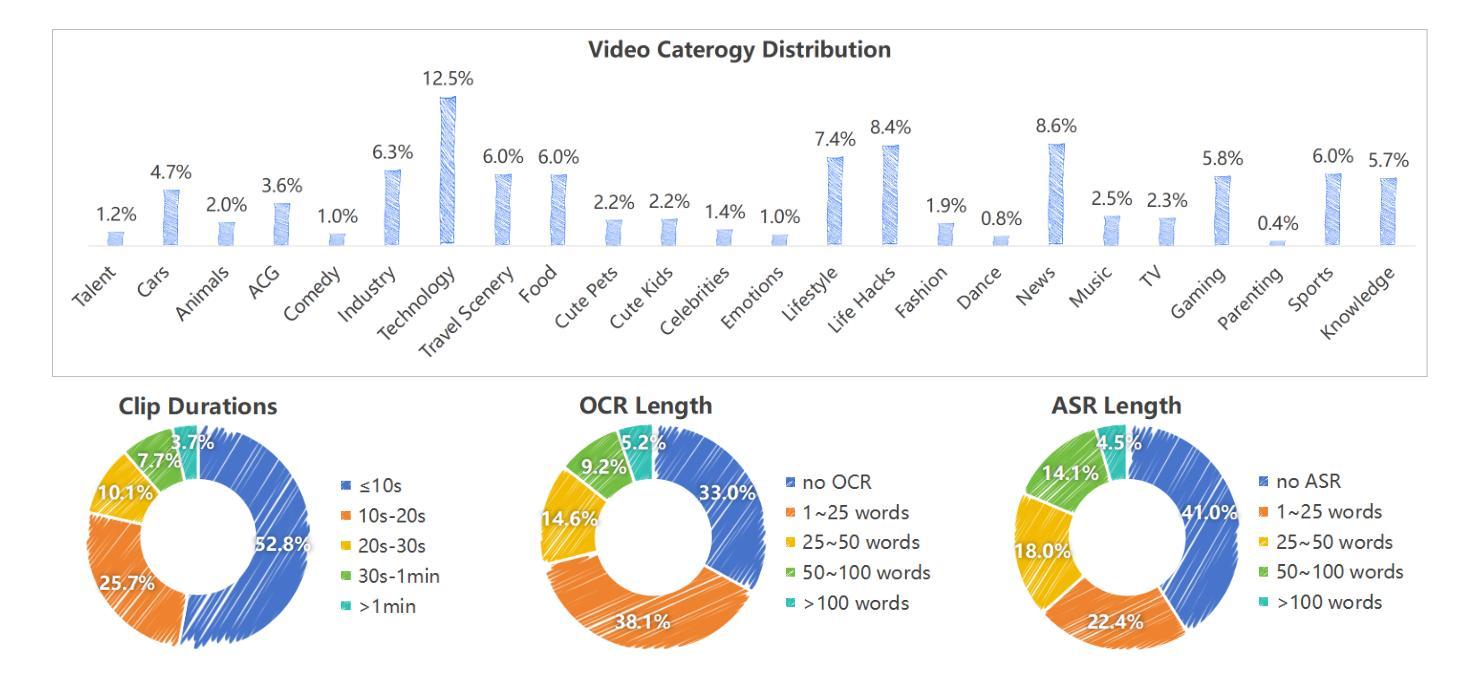
This paper introduces VideoMind, a video-centric omni-modal dataset designed for deep video content cognition and enhanced multi-modal feature representation. The dataset comprises 103K video samples (3K reserved for testing), each paired with audio and systematically detailed textual descriptions. Specifically, every video and its audio is described across three hierarchical layers (factual, abstract, and intent), progressing from surface to depth. It contains over 22 million words, averaging ~225 words per sample. VideoMind’s key distinction from existing datasets is its provision of intent expressions, which require contextual integration across the entire video and are not directly observable. These deep-cognitive expressions are generated using a Chain-of-Thought (COT) approach, prompting the mLLM through step-by-step reasoning. Each description includes annotations for subject, place, time, event, action, and intent, supporting downstream recognition tasks. Crucially, we establish a gold-standard benchmark with 3,000 manually validated samples for evaluating deep-cognitive video understanding. We design hybrid-cognitive retrieval experiments, scored by multi-level retrieval metrics, to appropriately assess deep video comprehension. Evaluation results for models (e.g., InternVideo, VAST, UMT-L) are released. VideoMind serves as a powerful benchmark for fine-grained cross-modal alignment and advances fields requiring in-depth video understanding, such as emotion and intent recognition. The data is publicly available on GitHub, HuggingFace, and OpenDataLab, https://github.com/cdx-cindy/VideoMind.
本文介绍了VideoMind,这是一个以视频为中心的跨模态数据集,旨在用于深度视频内容认知和增强的多模态特征表示。该数据集包含103K个视频样本(其中3K用于测试),每个样本都配备了音频和系统的详细文本描述。具体来说,每个视频及其音频都在三个层次(事实、抽象和意图)上进行描述,从表面到深度逐步深入。它包含超过2200万个单词,每个样本平均约225个单词。VideoMind与现有数据集的主要区别在于它提供了意图表达,这需要整合整个视频的上下文,并且无法直接观察到。这些深度认知表达是通过“思维链”(COT)方法生成的,通过逐步推理来提示大型语言模型。每个描述都包括主题、地点、时间、事件、行为和意图的注释,支持下游识别任务。重要的是,我们建立了3000个手动验证样本的金标准基准,用于评估深度认知视频理解。我们设计了混合认知检索实验,通过多级检索指标进行评分,以适当评估深度视频理解。已发布了对模型(如InternVideo、VAST、UMT-L)的评估结果。VideoMind是细粒度跨模态对齐的强大基准,并推动了需要深度视频理解(如情感和意图识别)的领域的发展。数据已在GitHub、HuggingFace和OpenDataLab上公开可用,https://github.com/cdx-cindy/VideoMind。
论文及项目相关链接
PDF 7 pages; 14 figures
Summary
本文介绍了VideoMind视频主导的多模态数据集,该数据集旨在用于深度视频内容认知和增强多模态特征表示。数据集包含103K视频样本(其中3K用于测试),每个样本都配有音频和详细的文本描述。每个视频及其音频的描述分为三个层次结构(事实、抽象和意图),从表面到深度逐步深入。VideoMind的关键区别在于它提供了意图表达,这需要整合整个视频中的上下文,不能直接观察到。通过Chain-of-Thought方法生成深度认知表达,为下游识别任务提供支持。数据集已在GitHub、HuggingFace和OpenDataLab上公开发布。
Key Takeaways
- VideoMind是一个视频为中心的多模态数据集,旨在用于深度视频内容认知。
- 数据集包含超过10万个视频样本,每个样本都带有音频和详细的文本描述。
- VideoMind引入了意图表达的概念,这需要整合整个视频的上下文信息。
- 数据集采用Chain-of-Thought方法生成深度认知表达。
- VideoMind为下游识别任务提供支持,如情绪识别和意图识别。
- VideoMind已建立了一个黄金标准基准,包括用于评估深度视频理解的3000个手动验证样本。
点此查看论文截图


EgoExoBench: A Benchmark for First- and Third-person View Video Understanding in MLLMs
Authors:Yuping He, Yifei Huang, Guo Chen, Baoqi Pei, Jilan Xu, Tong Lu, Jiangmiao Pang
Transferring and integrating knowledge across first-person (egocentric) and third-person (exocentric) viewpoints is intrinsic to human intelligence, enabling humans to learn from others and convey insights from their own experiences. Despite rapid progress in multimodal large language models (MLLMs), their ability to perform such cross-view reasoning remains unexplored. To address this, we introduce EgoExoBench, the first benchmark for egocentric-exocentric video understanding and reasoning. Built from publicly available datasets, EgoExoBench comprises over 7,300 question-answer pairs spanning eleven sub-tasks organized into three core challenges: semantic alignment, viewpoint association, and temporal reasoning. We evaluate 13 state-of-the-art MLLMs and find that while these models excel on single-view tasks, they struggle to align semantics across perspectives, accurately associate views, and infer temporal dynamics in the ego-exo context. We hope EgoExoBench can serve as a valuable resource for research on embodied agents and intelligent assistants seeking human-like cross-view intelligence.
将第一人称(以自我为中心)和第三人称(以外部为中心)观点之间的知识转移和整合是人类智慧的核心部分,使人类能够学习他人的知识并传达自己的经验见解。尽管多模态大型语言模型(MLLMs)发展迅速,但它们执行这种跨视角推理的能力仍然未被探索。为了解决这一问题,我们推出了EgoExoBench,这是首个针对以自我为中心和以外部为中心的视频理解和推理的基准测试。EgoExoBench由公开可用的数据集构建而成,包含超过7300个问答对,涵盖11个子任务,分为三大挑战:语义对齐、视角关联和时序推理。我们评估了13种最先进的多模态大型语言模型,发现这些模型在单视角任务上表现优异,但在跨视角的语义对齐、准确关联视角以及在以自我为中心和以外部为中心的上下文中的时间动态推理方面遇到困难。我们希望EgoExoBench能成为研究智能主体和智能助手等寻求人类式跨视角智能的宝贵资源。
论文及项目相关链接
Summary
本文介绍了人类智能中跨第一人称(以自我为中心)和第三人称(以外部为中心)观点的知识转移和整合的重要性。尽管多模态大型语言模型(MLLMs)发展迅速,但它们在这种跨视角推理方面的能力尚未被探索。为解决这一问题,本文引入了EgoExoBench,这是一个用于以自我为中心和以外部为中心的视频理解和推理的基准测试。EgoExoBench包含超过7300个问答对,涵盖11个子任务,分为三大核心挑战:语义对齐、视角关联和时序推理。对13种最新MLLMs的评估发现,这些模型在单视角任务上表现优异,但在跨视角语义对齐、准确关联视角以及在以自我为中心和以外部为中心的上下文中推断时间动态方面存在困难。期望EgoExoBench能成为研究具有人类智能特征的跨视角智能的宝贵资源。
Key Takeaways
- 人类智能涉及跨第一人称和第三人称观点的知识转移和整合。
- 多模态大型语言模型(MLLMs)在跨视角推理方面的能力尚未得到充分探索。
- EgoExoBench是首个针对以自我为中心和以外部为中心的视频理解和推理的基准测试。
- EgoExoBench包含7300多个问答对,涵盖语义对齐、视角关联和时序推理三大核心挑战。
- 最新MLLMs在单视角任务上表现良好,但在跨视角任务方面存在困难。
- MLLMs在语义对齐、准确关联视角以及推断时间动态方面需要改进。
点此查看论文截图


SV3.3B: A Sports Video Understanding Model for Action Recognition
Authors:Sai Varun Kodathala, Yashwanth Reddy Vutukoori, Rakesh Vunnam
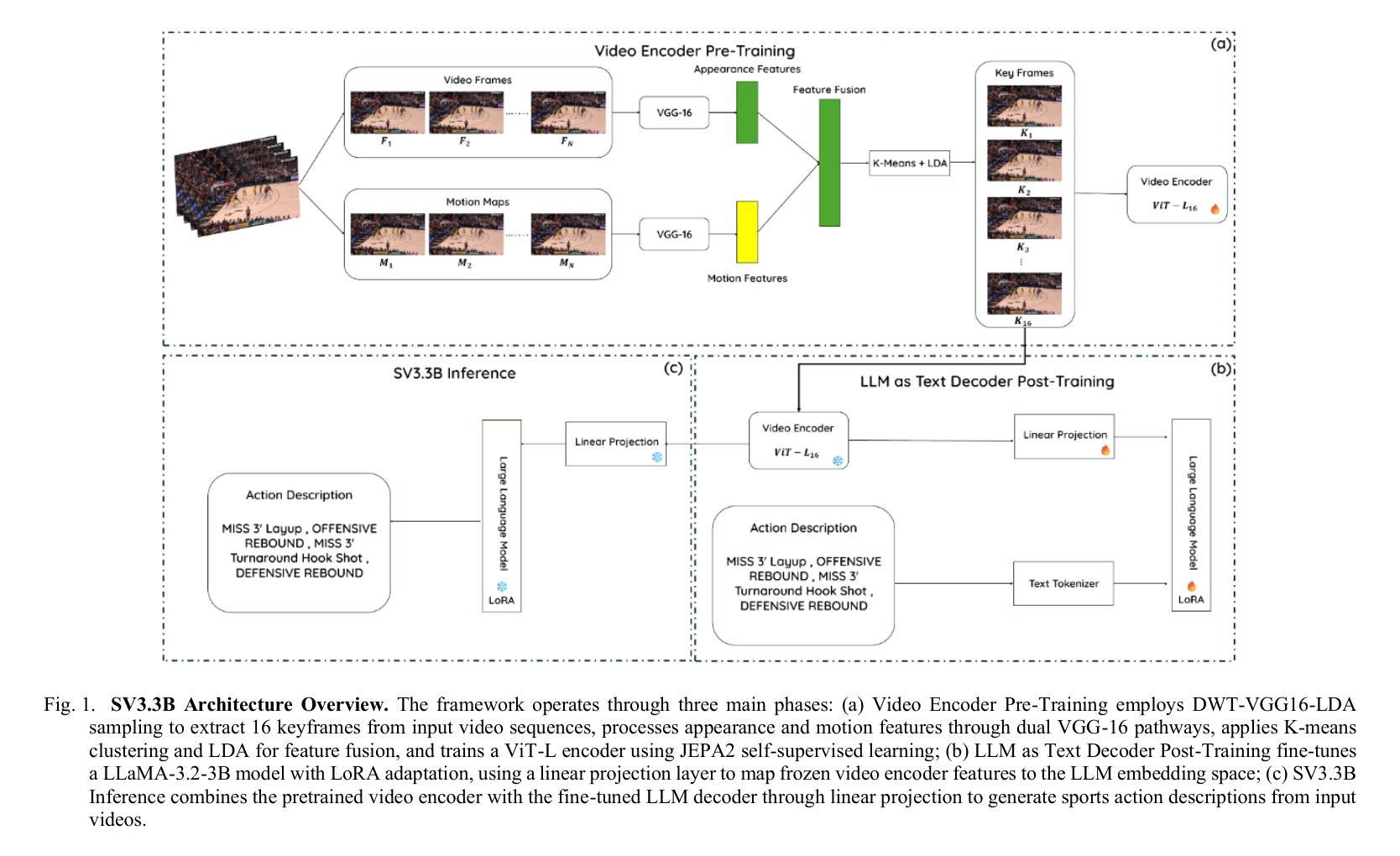
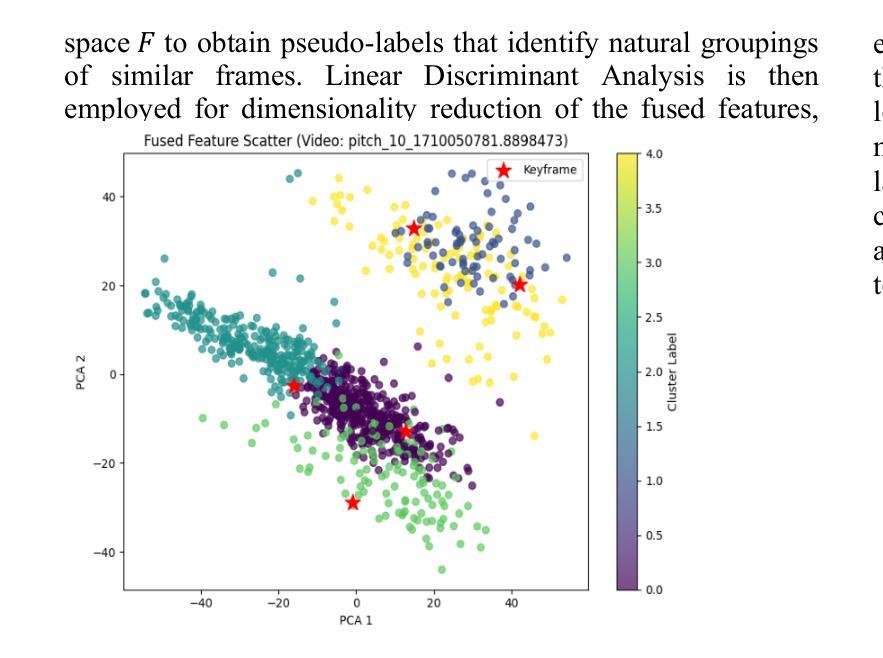
This paper addresses the challenge of automated sports video analysis, which has traditionally been limited by computationally intensive models requiring server-side processing and lacking fine-grained understanding of athletic movements. Current approaches struggle to capture the nuanced biomechanical transitions essential for meaningful sports analysis, often missing critical phases like preparation, execution, and follow-through that occur within seconds. To address these limitations, we introduce SV3.3B, a lightweight 3.3B parameter video understanding model that combines novel temporal motion difference sampling with self-supervised learning for efficient on-device deployment. Our approach employs a DWT-VGG16-LDA based keyframe extraction mechanism that intelligently identifies the 16 most representative frames from sports sequences, followed by a V-DWT-JEPA2 encoder pretrained through mask-denoising objectives and an LLM decoder fine-tuned for sports action description generation. Evaluated on a subset of the NSVA basketball dataset, SV3.3B achieves superior performance across both traditional text generation metrics and sports-specific evaluation criteria, outperforming larger closed-source models including GPT-4o variants while maintaining significantly lower computational requirements. Our model demonstrates exceptional capability in generating technically detailed and analytically rich sports descriptions, achieving 29.2% improvement over GPT-4o in ground truth validation metrics, with substantial improvements in information density, action complexity, and measurement precision metrics essential for comprehensive athletic analysis. Model Available at https://huggingface.co/sportsvision/SV3.3B.
本文旨在应对自动运动视频分析的挑战。传统的视频分析模型因计算量大、需要服务器端处理且对运动动作缺乏精细理解而受到限制。现有方法难以捕捉运动分析中必不可少的关键生物力学转变细节,这些转变通常会在几秒内发生,如准备阶段、执行阶段和后续阶段。为了克服这些局限性,我们推出了SV3.3B,这是一款轻量级的3.3B参数视频理解模型。它结合了新型时间运动差分采样和自监督学习,可实现高效的设备端部署。我们的方法采用基于DWT-VGG16-LDA的关键帧提取机制,智能地从运动序列中识别出最具有代表性的16个帧,然后通过掩码去噪目标的V-DWT-JEPA2编码器进行预处理,并使用微调的大型语言模型(LLM)解码器进行运动动作描述生成。在NSVA篮球数据集的一个子集上进行评估,SV3.3B在传统的文本生成指标和运动特定评估标准上均表现出卓越性能,优于包括GPT-4o变体在内的更大闭源模型,同时大大减少了计算需求。我们的模型在生成技术详细、分析丰富的运动描述方面表现出卓越能力,在真实验证指标上实现了对GPT-4o的29.2%的提升,在信息密度、动作复杂度和测量精度等关键指标上都有显著改进,对于全面的运动分析至关重要。模型可通过https://huggingface.co/sportsvision/SV3.3B 访问。
论文及项目相关链接
PDF 8 pages, 6 figures, 4 tables. Submitted to AIxSET 2025
Summary
本文提出了一种针对自动运动视频分析的新方法SV3.3B。传统方法受限于计算密集型模型,需要在服务器端处理,且对运动员动作的精细理解不足。SV3.3B模型结合了新颖的时间运动差异采样与自我监督学习,实现了高效的设备端部署。通过DWT-VGG16-LDA的帧提取机制,智能识别运动序列中最具代表性的16帧。采用预训练的V-DWT-JEPA2编码器与LLM解码器进行微调,用于生成运动动作描述。在NSVA篮球数据集的一个子集上评估,SV3.3B模型在文本生成指标和运动专项评估标准上均表现出卓越性能,相较于GPT-4o等大型闭源模型有明显优势,同时计算需求更低。模型公开于huggingface.co/sportsvision/SV3.3B。
Key Takeaways
- SV3.3B模型解决了自动运动视频分析中的挑战,包括计算密集型模型和缺乏精细动作理解的问题。
- SV3.3B结合了时间运动差异采样和自我监督学习,实现高效设备部署。
- 采用DWT-VGG16-LDA的帧提取机制智能识别最具代表性的帧。
- V-DWT-JEPA2编码器与LLM解码器用于生成详细且富有分析性的运动描述。
- SV3.3B在NSVA篮球数据集上表现优越,相较于GPT-4o等大型模型有显著提升。
点此查看论文截图



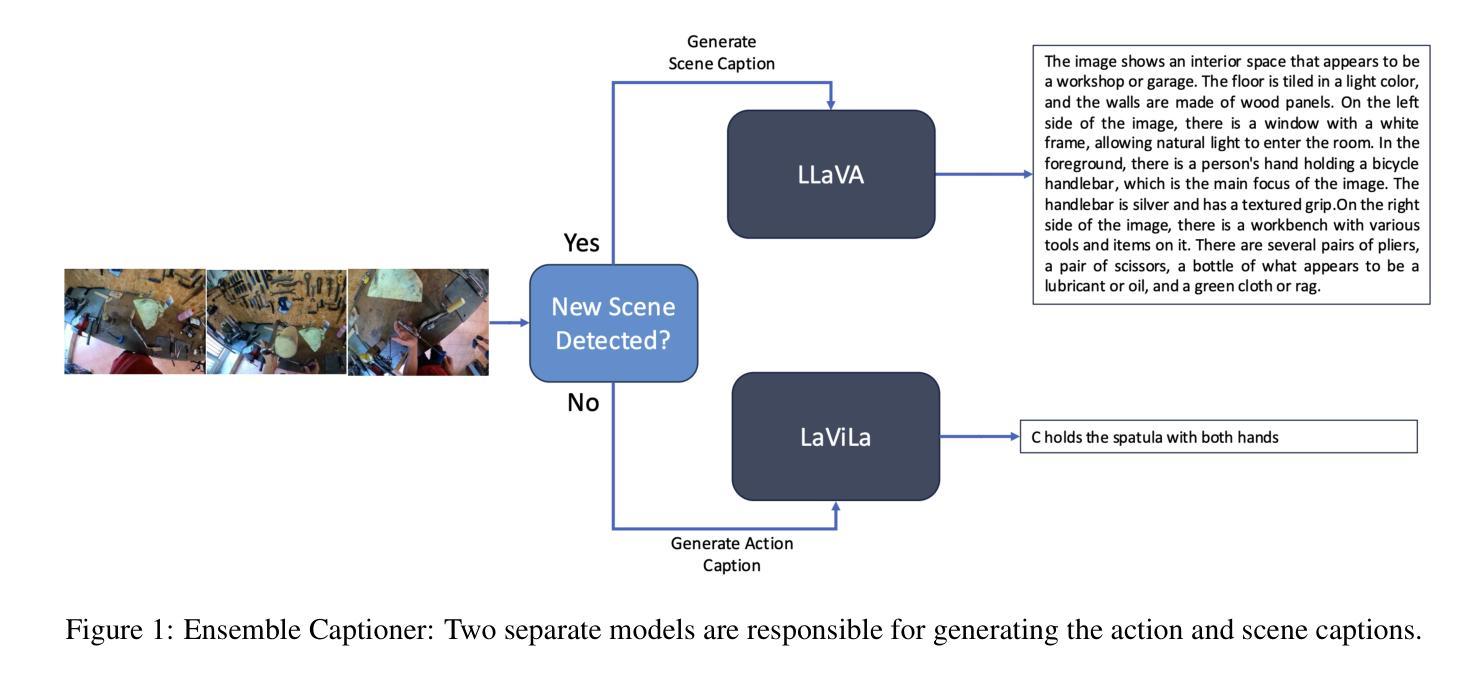
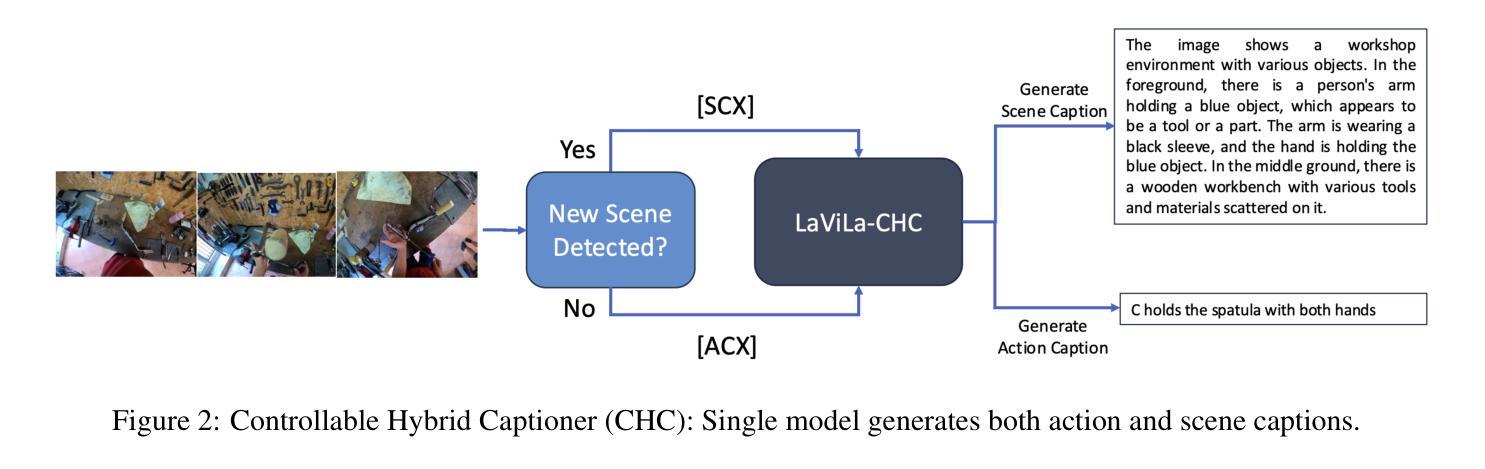
Controllable Hybrid Captioner for Improved Long-form Video Understanding
Authors:Kuleen Sasse, Efsun Sarioglu Kayi, Arun Reddy
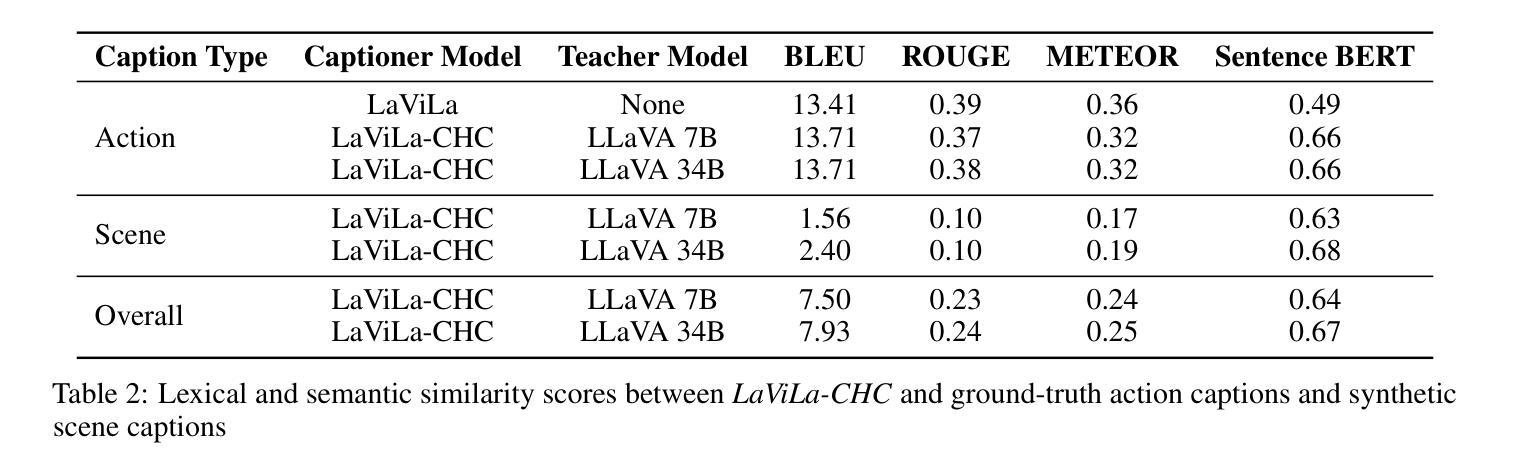
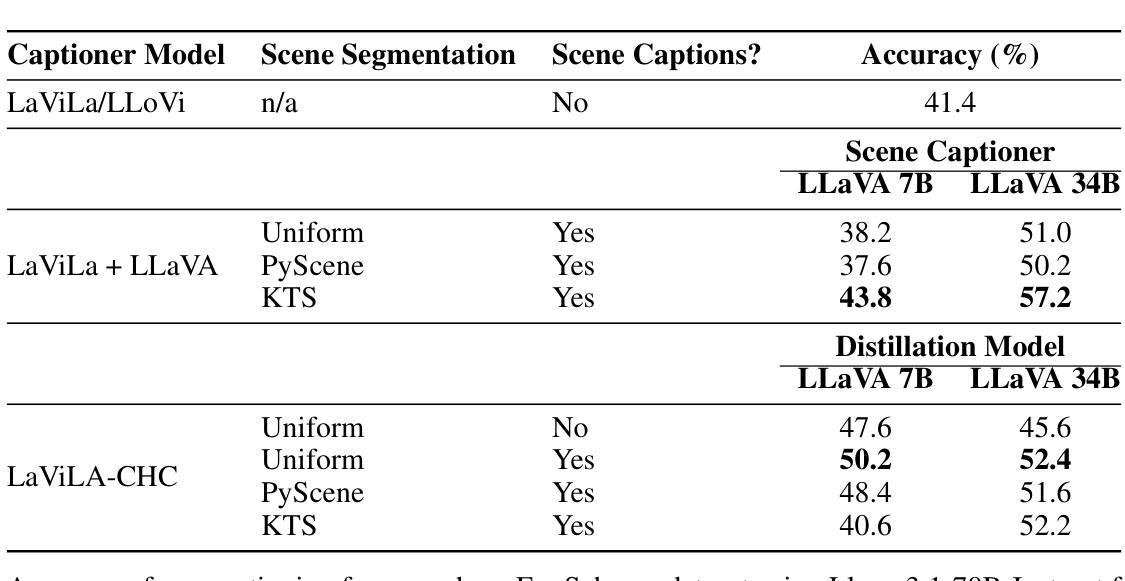
Video data, especially long-form video, is extremely dense and high-dimensional. Text-based summaries of video content offer a way to represent query-relevant content in a much more compact manner than raw video. In addition, textual representations are easily ingested by state-of-the-art large language models (LLMs), which enable reasoning over video content to answer complex natural language queries. To solve this issue, we rely on the progressive construction of a text-based memory by a video captioner operating on shorter chunks of the video, where spatio-temporal modeling is computationally feasible. We explore ways to improve the quality of the activity log comprised solely of short video captions. Because the video captions tend to be focused on human actions, and questions may pertain to other information in the scene, we seek to enrich the memory with static scene descriptions using Vision Language Models (VLMs). Our video understanding system relies on the LaViLa video captioner in combination with a LLM to answer questions about videos. We first explored different ways of partitioning the video into meaningful segments such that the textual descriptions more accurately reflect the structure of the video content. Furthermore, we incorporated static scene descriptions into the captioning pipeline using LLaVA VLM, resulting in a more detailed and complete caption log and expanding the space of questions that are answerable from the textual memory. Finally, we have successfully fine-tuned the LaViLa video captioner to produce both action and scene captions, significantly improving the efficiency of the captioning pipeline compared to using separate captioning models for the two tasks. Our model, controllable hybrid captioner, can alternate between different types of captions according to special input tokens that signals scene changes detected in the video.
视频数据,特别是长视频,极为密集且高维。基于文本的视频内容摘要提供了一种比原始视频更紧凑地表示查询相关内容的方式。此外,文本表示很容易被最新的大型语言模型(LLM)所接纳,这使得能够推理视频内容以回答复杂的自然语言查询。为解决此问题,我们依赖于由操作视频较短片段的视频字幕器逐步构建的基于文本的存储器,其中时空建模是计算可行的。我们探索了提高仅由短视频字幕构成的活动日志质量的方法。由于视频字幕往往侧重于人类行为,而问题可能与场景中的其他信息有关,我们寻求使用视觉语言模型(VLM)丰富存储器中的静态场景描述。我们的视频理解系统依赖于LaViLa视频字幕器结合LLM来回答有关视频的问题。我们首先探索了将视频划分为有意义的片段的不同方式,以使文本描述更准确地反映视频内容的结构。此外,我们利用LLaVA VLM将静态场景描述纳入字幕管道,从而得到更详细和完整的字幕日志,并扩大了可从文本记忆中提问的空间。最后,我们已经成功地对LaViLa视频字幕器进行了微调,以产生动作和场景字幕,与为这两个任务使用单独的字幕模型相比,这大大提高了字幕管道的效率。我们的模型——可控混合字幕器,可以根据视频中的场景变化等特殊输入令牌交替生成不同类型的字幕。
论文及项目相关链接
摘要
视频数据,特别是长视频,极为密集且高维。文本对视频内容的摘要提供了一种比原始视频更紧凑的方式来表示查询相关内容。此外,文本表示很容易被当前最先进的自然语言大型模型(LLM)所摄取,能够推理视频内容以回答复杂的自然语言查询。为解决此问题,我们依靠视频描述者基于较短的视频片段逐步构建文本基础记忆来解决时空建模的计算可行性。我们探索了提高仅由短视频字幕构成的活动日志质量的方法。由于视频字幕往往侧重于人类行为,而问题可能涉及场景中的其他信息,我们寻求使用视觉语言模型(VLM)丰富记忆,加入静态场景描述。我们的视频理解系统依赖于LaViLa视频描述器与大型语言模型结合回答视频问题。我们探索了将视频划分为有意义片段的不同方式,以使文本描述更准确地反映视频内容结构。此外,我们借助LLaVA VLM将静态场景描述纳入描述管道,得到更详细和完整的字幕日志,扩大了可从文本记忆中回答问题空间。最后,我们已经成功微调了LaViLa视频描述器以产生动作和场景字幕,与使用两个任务的单独描述模型相比大大提高了描述管道的效率。我们的模型可控混合描述器可以根据检测到视频中的场景变化特殊输入令牌交替不同类型字幕。
关键见解
- 视频数据具有高密度和高维度特性,文本摘要为查询相关内容提供了更紧凑的表示方式。
- 大型语言模型(LLM)能够摄取文本表示并进行视频内容的推理,以回答复杂的自然语言查询。
- 通过将视频划分为有意义片段来构建文本基础记忆,以实现时空建模的计算可行性。
- 结合短视频字幕和静态场景描述提高活动日志质量。
- 使用视觉语言模型(VLM)加入静态场景描述丰富记忆内容。
- LaViLa视频描述器与大型语言模型结合形成强大的视频理解系统。
点此查看论文截图

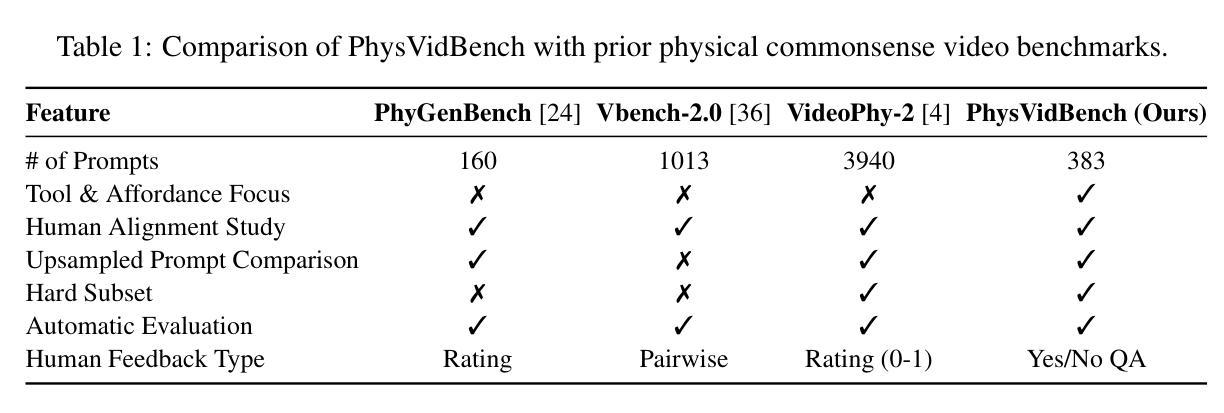
Can Your Model Separate Yolks with a Water Bottle? Benchmarking Physical Commonsense Understanding in Video Generation Models
Authors:Enes Sanli, Baris Sarper Tezcan, Aykut Erdem, Erkut Erdem
Recent progress in text-to-video (T2V) generation has enabled the synthesis of visually compelling and temporally coherent videos from natural language. However, these models often fall short in basic physical commonsense, producing outputs that violate intuitive expectations around causality, object behavior, and tool use. Addressing this gap, we present PhysVidBench, a benchmark designed to evaluate the physical reasoning capabilities of T2V systems. The benchmark includes 383 carefully curated prompts, emphasizing tool use, material properties, and procedural interactions, and domains where physical plausibility is crucial. For each prompt, we generate videos using diverse state-of-the-art models and adopt a three-stage evaluation pipeline: (1) formulate grounded physics questions from the prompt, (2) caption the generated video with a vision-language model, and (3) task a language model to answer several physics-involved questions using only the caption. This indirect strategy circumvents common hallucination issues in direct video-based evaluation. By highlighting affordances and tool-mediated actions, areas overlooked in current T2V evaluations, PhysVidBench provides a structured, interpretable framework for assessing physical commonsense in generative video models.
近期文本到视频(T2V)生成的进展已经能够合成具有视觉吸引力和时间连贯性的视频来自自然语言。然而,这些模型通常在基本物理常识方面表现不足,产生的输出违反了因果、物体行为和工具使用的直观预期。为了解决这个问题,我们提出了PhysVidBench,这是一个旨在评估T2V系统物理推理能力的基准测试。该基准测试包括383个精心策划的提示,强调工具使用、材料属性和程序交互,以及在物理可行性至关重要的领域。对于每个提示,我们使用各种最先进模型生成视频,并采用三阶段评估流程:(1)根据提示制定基于物理的问题,(2)使用视觉语言模型为生成的视频添加标题,(3)任务语言模型仅使用标题回答涉及物理的若干问题。这种间接策略避免了直接基于视频的评估中常见的幻觉问题。通过突出优势和工具介导的行动,以及当前T2V评估中被忽视的领域,PhysVidBench为评估生成视频模型中的物理常识提供了一个结构化、可解释的框架。
论文及项目相关链接
Summary
文本至视频生成(T2V)技术在生成具有视觉吸引力和时间连贯性的视频方面取得了进展,但在基本物理常识方面存在缺陷,产生的输出违反了因果、物体行为和工具使用等方面的直观预期。为解决这一问题,本文提出PhysVidBench基准测试,旨在评估T2V系统的物理推理能力。该基准测试包含383个精心策划的提示,强调工具使用、材料属性和程序性交互,以及在物理可信度至关重要的领域。采用三阶段评估流程对生成的视频进行评价,包括从提示中制定基于物理的问题、使用视觉语言模型为生成的视频添加字幕,以及仅使用字幕回答涉及物理的多个问题。这种间接策略避免了在直接视频评估中的常见幻觉问题。PhysVidBench通过强调便利性和工具介导的行动,提供了评估生成视频模型中的物理常识的结构化、可解释框架,弥补了当前T2V评估中被忽视的领域。
Key Takeaways
- 文本至视频生成(T2V)技术在生成视觉上吸引人的视频方面取得进展,但缺乏基本物理常识。
- PhysVidBench基准测试旨在评估T2V系统在物理推理方面的能力。
- 该基准测试包含383个精心策划的提示,涵盖工具使用、材料属性和程序性交互等领域。
- 采用三阶段评估流程,包括制定基于物理的问题、为生成视频添加字幕以及回答涉及物理的问题。
- 间接评估策略有助于避免直接视频评估中的幻觉问题。
- PhysVidBench提供了一个结构化、可解释的框架,用于评估生成视频模型中的物理常识。
点此查看论文截图




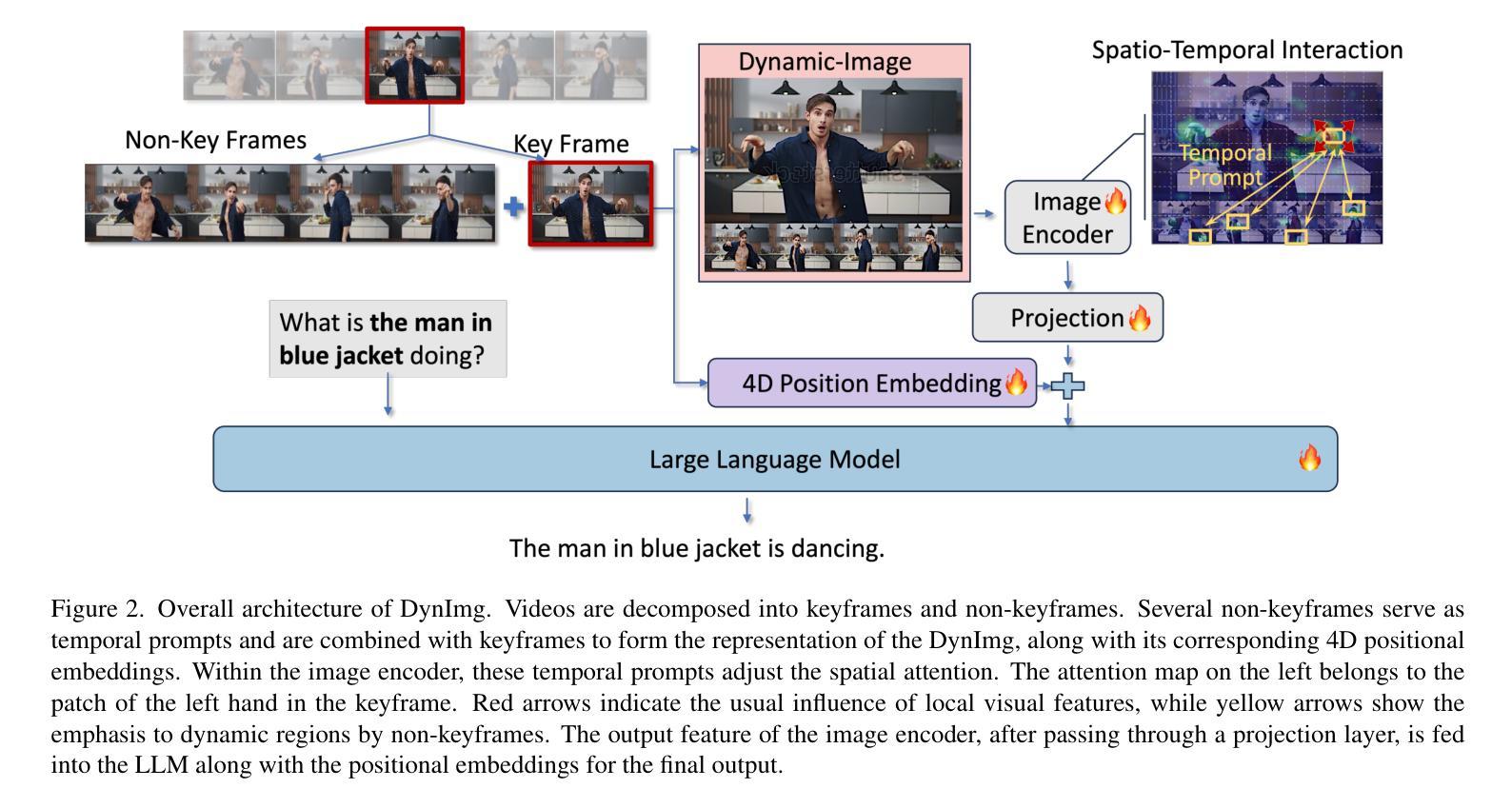
DynImg: Key Frames with Visual Prompts are Good Representation for Multi-Modal Video Understanding
Authors:Xiaoyi Bao, Chenwei Xie, Hao Tang, Tingyu Weng, Xiaofeng Wang, Yun Zheng, Xingang Wang
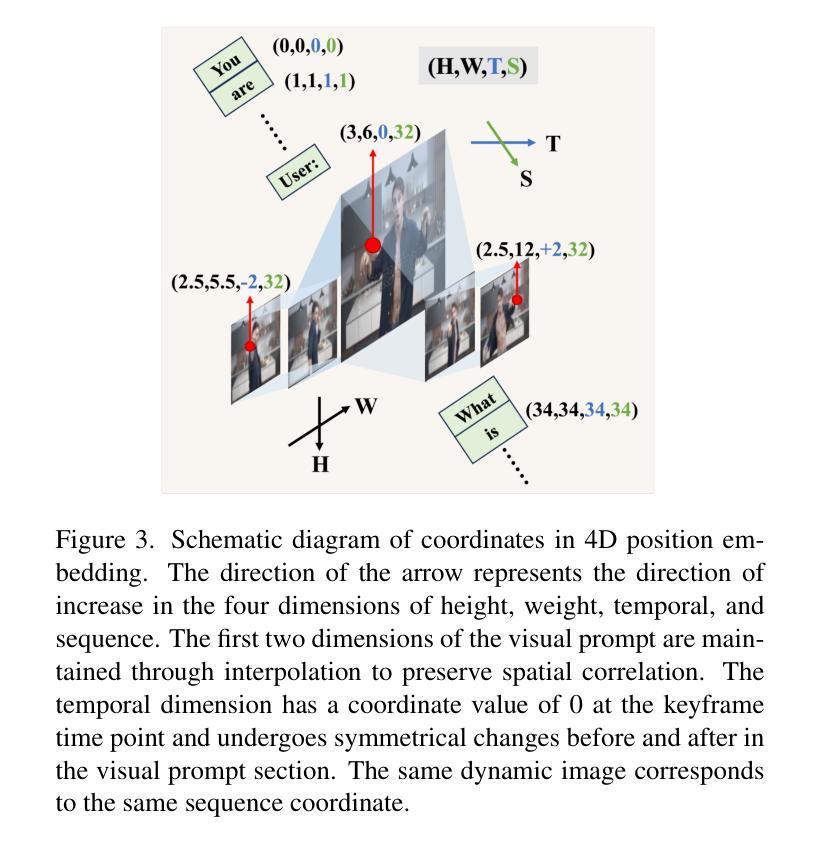
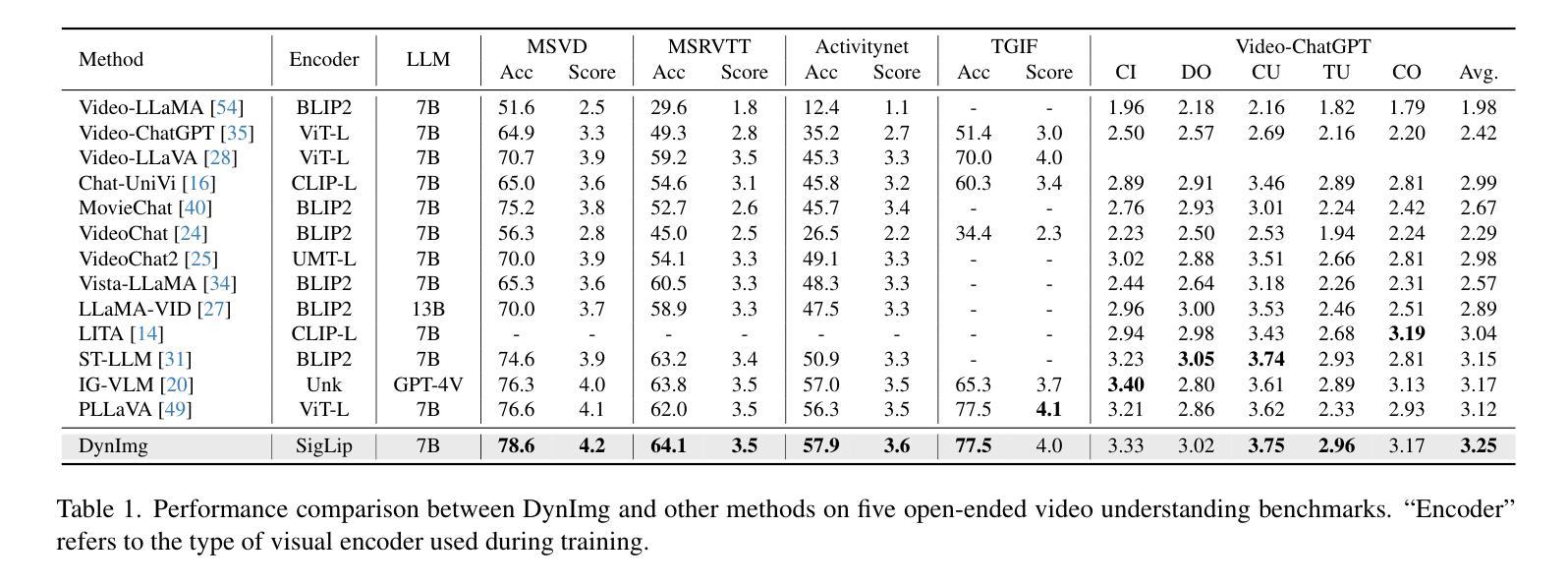
In recent years, the introduction of Multi-modal Large Language Models (MLLMs) into video understanding tasks has become increasingly prevalent. However, how to effectively integrate temporal information remains a critical research focus. Traditional approaches treat spatial and temporal information separately. Due to issues like motion blur, it is challenging to accurately represent the spatial information of rapidly moving objects. This can lead to temporally important regions being underemphasized during spatial feature extraction, which in turn hinders accurate spatio-temporal interaction and video understanding. To address this limitation, we propose an innovative video representation method called Dynamic-Image (DynImg). Specifically, we introduce a set of non-key frames as temporal prompts to highlight the spatial areas containing fast-moving objects. During the process of visual feature extraction, these prompts guide the model to pay additional attention to the fine-grained spatial features corresponding to these regions. Moreover, to maintain the correct sequence for DynImg, we employ a corresponding 4D video Rotary Position Embedding. This retains both the temporal and spatial adjacency of DynImg, helping MLLM understand the spatio-temporal order within this combined format. Experimental evaluations reveal that DynImg surpasses the state-of-the-art methods by approximately 2% across multiple video understanding benchmarks, proving the effectiveness of our temporal prompts in enhancing video comprehension.
近年来,多模态大型语言模型(MLLMs)在视频理解任务中的引入越来越普遍。然而,如何有效地整合时间信息仍然是关键的研究重点。传统的方法分别处理空间和时间信息。由于运动模糊等问题,准确表示快速移动物体的空间信息具有挑战性。这可能导致在提取空间特征时忽视了时间上重要的区域,从而妨碍准确的时空交互和视频理解。为了解决这一局限性,我们提出了一种创新的视频表示方法,称为动态图像(DynImg)。具体来说,我们引入了一系列非关键帧作为时间提示,以突出包含快速移动物体的空间区域。在提取视觉特征的过程中,这些提示引导模型额外关注这些区域对应的精细空间特征。此外,为了保持DynImg的正确序列,我们采用相应的4D视频旋转位置嵌入。这保留了DynImg的时间和空间邻接性,帮助MLLM理解这种组合格式内的时空顺序。实验评估表明,DynImg在多个视频理解基准测试上超越了最先进的方法,提高了大约2%,证明了我们的时间提示在提高视频理解能力方面的有效性。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
近年来,多模态大型语言模型(MLLMs)在视频理解任务中的应用越来越普遍。然而,如何有效地整合时间信息仍然是一个关键的研究重点。传统方法分别处理空间和时间信息,由于运动模糊等问题,准确表示快速移动物体的空间信息具有挑战性。为此,我们提出了一种创新的视频表示方法——动态图像(DynImg)。我们通过引入一系列非关键帧作为时间提示来突出包含快速移动物体的空间区域。这些提示在视觉特征提取过程中引导模型额外关注这些区域的精细空间特征。同时,为了保持DynImg的正确序列,我们采用了相应的4D视频旋转位置嵌入,这保留了DynImg的时间和空间邻接性,帮助MLLM理解这种组合格式中的时空顺序。实验评估表明,DynImg在多个视频理解基准测试中比最新技术领先约2%,证明了我们的时间提示在提高视频理解能力方面的有效性。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视频理解中的应用越来越重要。
- 整合时间信息是视频理解的关键,传统方法处理空间和时间信息存在挑战。
- 引入非关键帧作为时间提示可以突出快速移动物体的空间区域。
- 动态图像(DynImg)方法通过引导模型关注精细空间特征来提高视频理解。
- 4D视频旋转位置嵌入技术用于保持DynImg的正确序列和时空邻接性。
- DynImg在多个视频理解基准测试中表现优异,证明其有效性。
点此查看论文截图