⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-03 更新
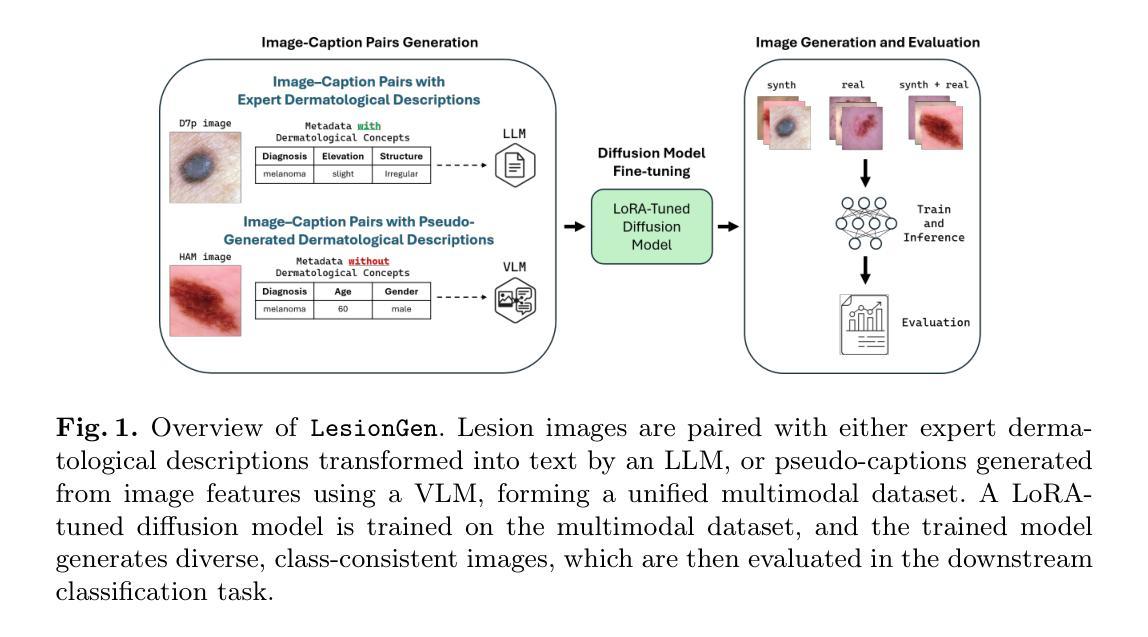
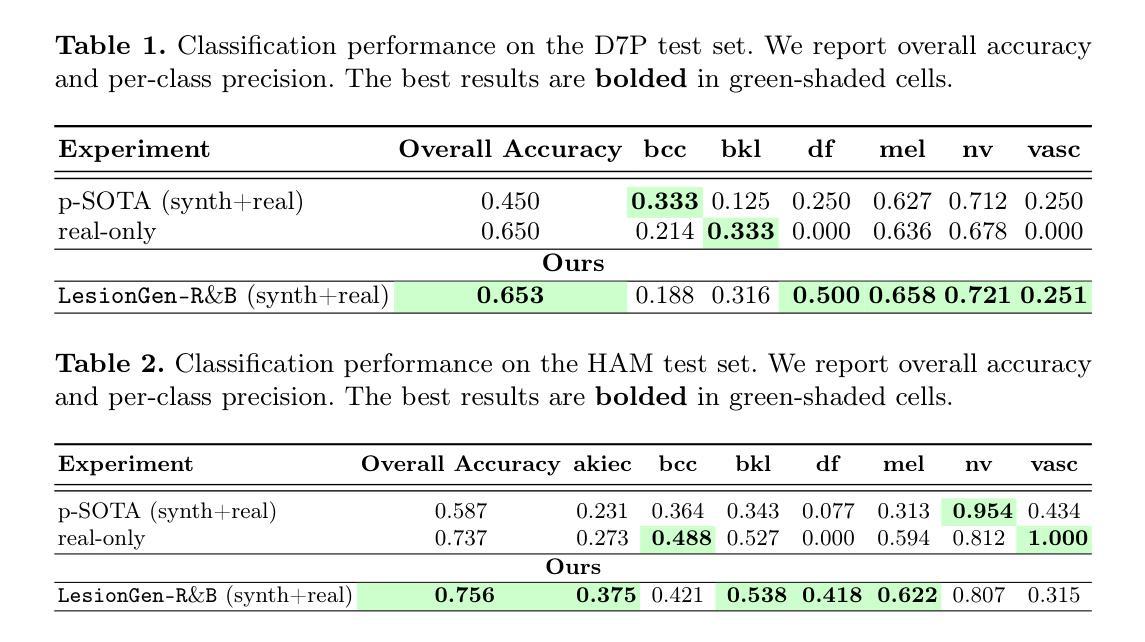
LesionGen: A Concept-Guided Diffusion Model for Dermatology Image Synthesis
Authors:Jamil Fayyad, Nourhan Bayasi, Ziyang Yu, Homayoun Najjaran
Deep learning models for skin disease classification require large, diverse, and well-annotated datasets. However, such resources are often limited due to privacy concerns, high annotation costs, and insufficient demographic representation. While text-to-image diffusion probabilistic models (T2I-DPMs) offer promise for medical data synthesis, their use in dermatology remains underexplored, largely due to the scarcity of rich textual descriptions in existing skin image datasets. In this work, we introduce LesionGen, a clinically informed T2I-DPM framework for dermatology image synthesis. Unlike prior methods that rely on simplistic disease labels, LesionGen is trained on structured, concept-rich dermatological captions derived from expert annotations and pseudo-generated, concept-guided reports. By fine-tuning a pretrained diffusion model on these high-quality image-caption pairs, we enable the generation of realistic and diverse skin lesion images conditioned on meaningful dermatological descriptions. Our results demonstrate that models trained solely on our synthetic dataset achieve classification accuracy comparable to those trained on real images, with notable gains in worst-case subgroup performance. Code and data are available here.
深度学习模型在皮肤疾病分类方面需要大规模、多样化和标注良好的数据集。然而,由于隐私担忧、标注成本高昂以及人口代表性不足等问题,此类资源往往有限。虽然文本到图像扩散概率模型(T2I-DPMs)在医学数据合成方面显示出潜力,但它们在皮肤科的应用仍被较少探索,这主要是因为现有皮肤图像数据集中缺乏丰富的文本描述。在这项工作中,我们引入了LesionGen,这是一个基于临床信息的皮肤科图像合成T2I-DPM框架。不同于依赖简单疾病标签的先前方法,LesionGen以专家标注生成的丰富概念的皮肤科标题以及伪造的基于概念的报告进行训练。通过对这些高质量图像与标题配对进行微调扩散模型,我们能够根据具有意义的皮肤科描述生成逼真且多样化的皮肤病变图像。我们的结果显示,仅在我们合成数据集上训练的模型达到了与真实图像训练相当的分类精度,并且在最差情况下的小组表现中取得了显著的提升。代码和数据集可在此处获取。
论文及项目相关链接
PDF Accepted at the MICCAI 2025 ISIC Workshop
Summary
基于深度学习模型的皮肤疾病分类需要大规模、多样化和标注良好的数据集。然而,由于隐私担忧、高标注成本和人口代表性不足,此类资源往往有限。文本到图像扩散概率模型(T2I-DPMs)在医学数据合成方面显示出潜力,但在皮肤科的应用仍然探索不足,这主要是由于现有皮肤图像数据集中丰富的文本描述稀缺。在此研究中,我们引入了LesionGen,这是一个基于临床信息的皮肤科图像合成T2I-DPM框架。不同于依赖简单疾病标签的先前方法,LesionGen的训练数据是结构化的、概念丰富的皮肤科注释以及伪生成的、概念引导的报告。通过在这些高质量图像-字幕对上对预训练的扩散模型进行微调,我们能够根据有意义的皮肤科描述生成真实且多样的皮肤病变图像。实验结果表明,仅在我们的合成数据集上训练的模型,其分类准确率可与在真实图像上训练的模型相媲美,并且在最不利的情况下取得了明显的性能提升。相关代码和数据可在XX获得。
Key Takeaways
- 深度学习模型在皮肤疾病分类中受限于大规模、多样化和标注良好的数据集缺乏的问题。
- 文本到图像扩散概率模型(T2I-DPMs)在医学数据合成中有潜力,但在皮肤科应用尚未得到充分探索。
- LesionGen是一个基于临床信息的皮肤科图像合成框架,使用结构化的皮肤科注释和概念引导的报告进行训练。
- LesionGen通过高质量图像-字幕对预训练的扩散模型进行微调,生成真实且多样的皮肤病变图像。
- 仅使用合成数据集训练的模型可以达到与真实图像训练的模型相当的分类准确率。
- 在最不利的情况下,模型性能有所提升。
点此查看论文截图


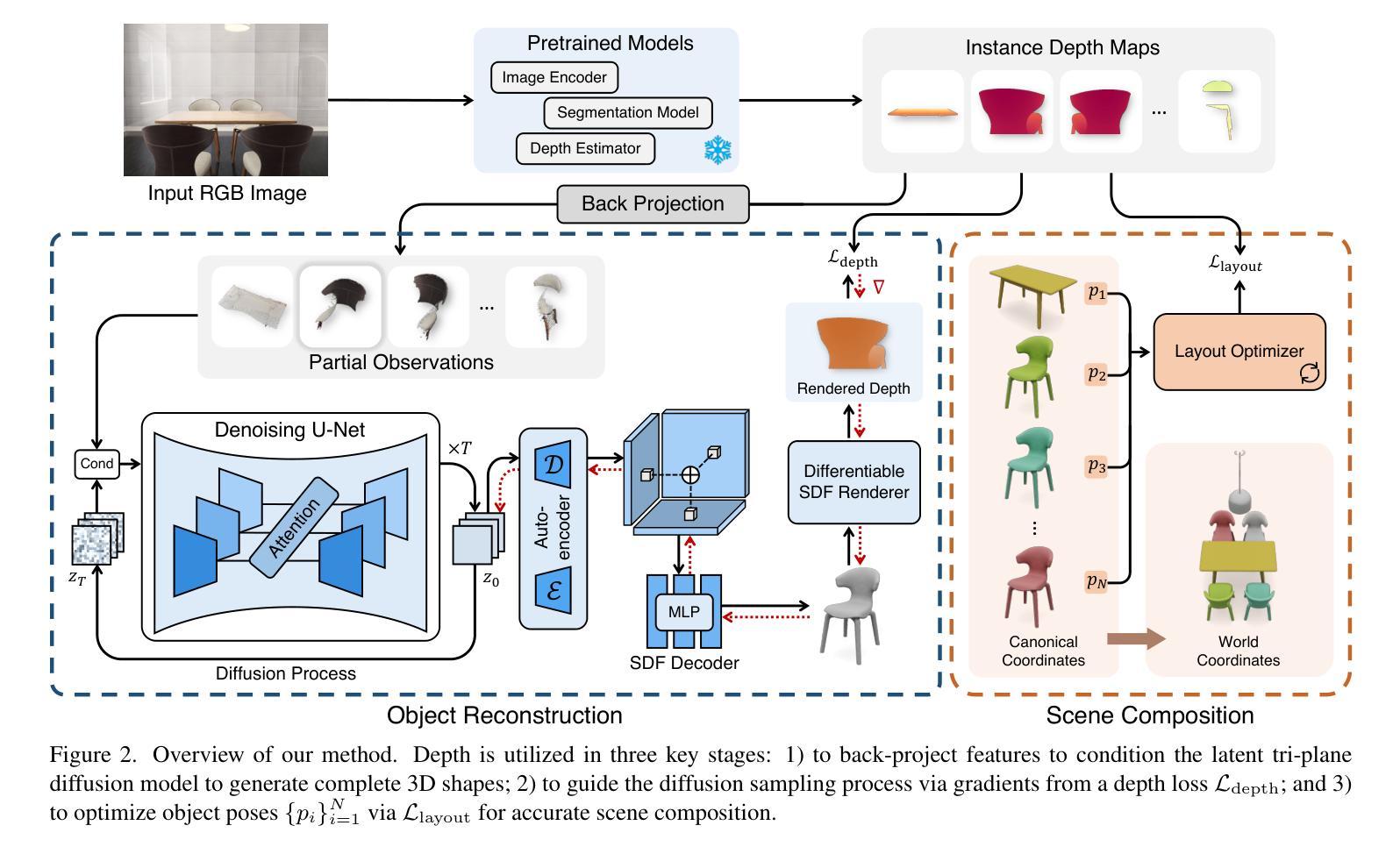
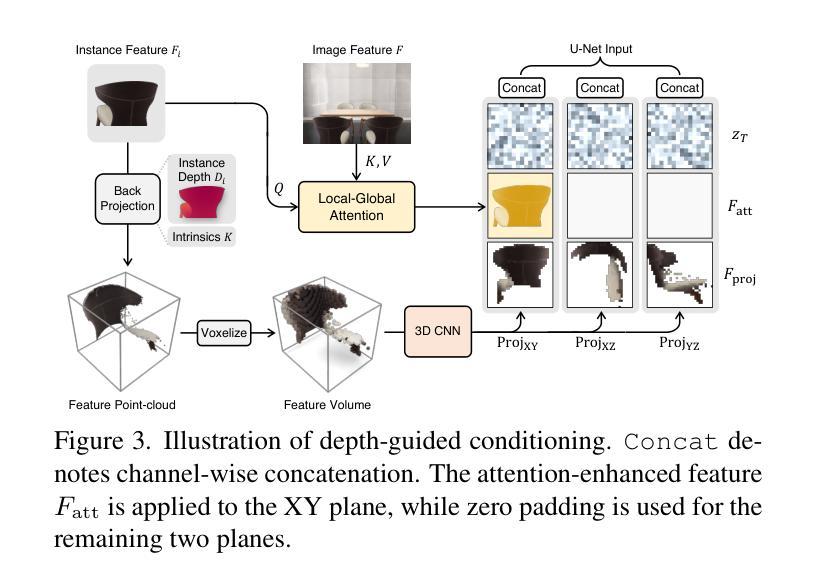
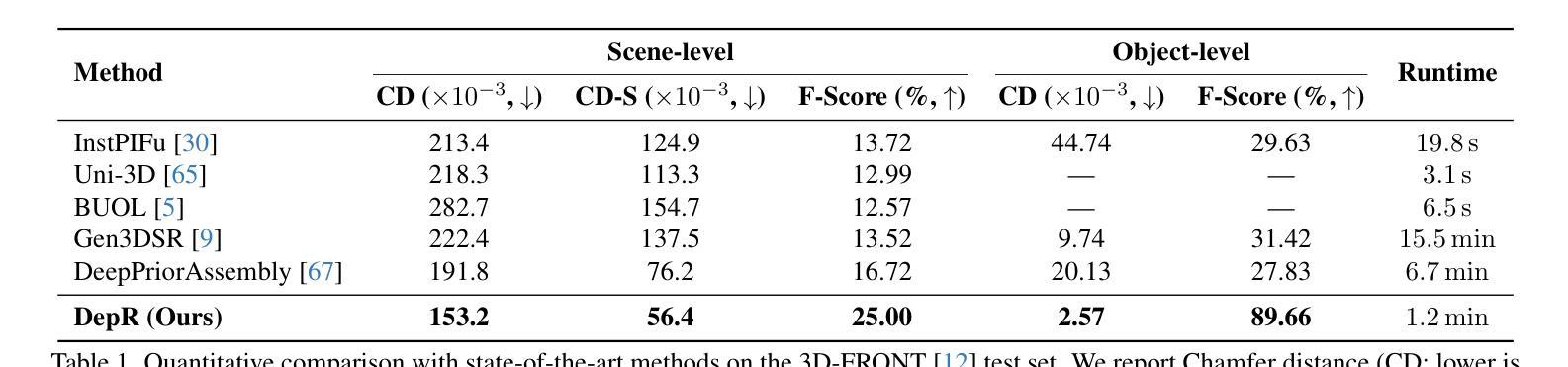
DepR: Depth Guided Single-view Scene Reconstruction with Instance-level Diffusion
Authors:Qingcheng Zhao, Xiang Zhang, Haiyang Xu, Zeyuan Chen, Jianwen Xie, Yuan Gao, Zhuowen Tu
We propose DepR, a depth-guided single-view scene reconstruction framework that integrates instance-level diffusion within a compositional paradigm. Instead of reconstructing the entire scene holistically, DepR generates individual objects and subsequently composes them into a coherent 3D layout. Unlike previous methods that use depth solely for object layout estimation during inference and therefore fail to fully exploit its rich geometric information, DepR leverages depth throughout both training and inference. Specifically, we introduce depth-guided conditioning to effectively encode shape priors into diffusion models. During inference, depth further guides DDIM sampling and layout optimization, enhancing alignment between the reconstruction and the input image. Despite being trained on limited synthetic data, DepR achieves state-of-the-art performance and demonstrates strong generalization in single-view scene reconstruction, as shown through evaluations on both synthetic and real-world datasets.
我们提出了DepR,这是一个深度引导的单视图场景重建框架,它在一个组合范式中集成了实例级别的扩散。DepR不同于整体重建整个场景的方法,而是生成单个物体,然后将其组合成一个连贯的3D布局。与之前的方法不同,这些方法仅在推理过程中使用深度进行对象布局估计,因此未能充分利用其丰富的几何信息,DepR在训练和推理过程中都利用了深度信息。具体来说,我们引入了深度引导条件,以有效地将形状先验知识编码到扩散模型中。在推理过程中,深度进一步引导DDIM采样和布局优化,提高了重建与输入图像之间的对齐性。尽管DepR是在有限的合成数据上训练的,但在单视图场景重建方面取得了最先进的性能,并在合成和真实世界数据集上的评估中展示了强大的泛化能力。
论文及项目相关链接
PDF ICCV 2025
Summary
本文提出了DepR框架,这是一个深度引导的单视图场景重建框架,它在一组成分的模式中集成了实例级别的扩散。DepR不同于整体重建整个场景的方法,而是生成单个物体,然后将其组合成一个连贯的3D布局。不同于之前仅在推理阶段使用深度进行物体布局估计的方法,未能充分利用深度的丰富几何信息,DepR在训练和推理阶段都使用深度信息。具体来说,我们引入了深度引导条件,以有效地将形状先验知识编码到扩散模型中。在推理阶段,深度进一步引导DDIM采样和布局优化,提高了重建与输入图像的契合度。即使在有限的合成数据上进行训练,DepR仍取得了最先进的性能,并在单视图场景重建中展示了强大的泛化能力,通过合成和真实世界数据集的评价得到了验证。
Key Takeaways
- DepR是一个深度引导的单视图场景重建框架,采用成分式方法生成并组合个体物体。
- 不同于整体重建方法,DepR生成单个物体并组合成连贯的3D布局。
- DepR在训练和推理阶段都利用深度信息,而之前的方法主要只在推理阶段使用深度进行物体布局估计。
- 引入深度引导条件,有效编码形状先验知识到扩散模型中。
- 深度信息在推理阶段指导DDIM采样和布局优化,提高重建与输入图像的契合度。
- DepR在有限的合成数据上训练,但取得了先进的性能。
点此查看论文截图

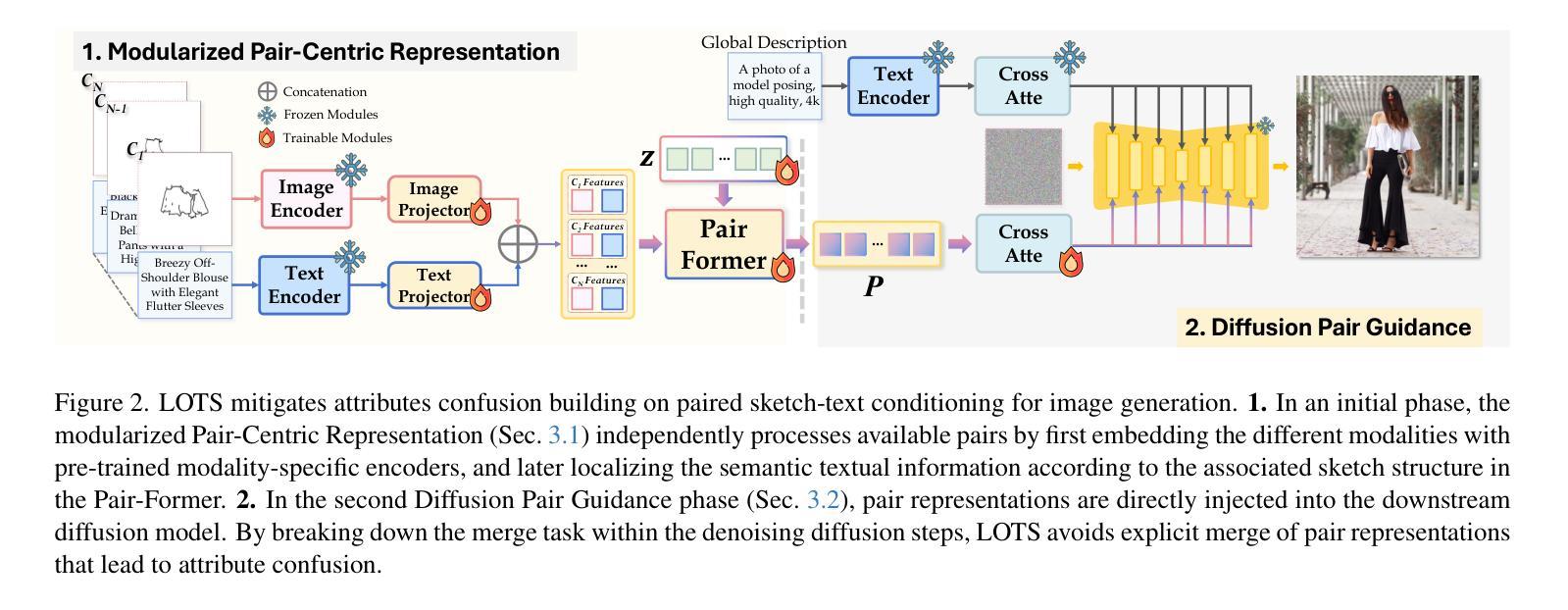
LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing
Authors:Federico Girella, Davide Talon, Ziyue Liu, Zanxi Ruan, Yiming Wang, Marco Cristani
Fashion design is a complex creative process that blends visual and textual expressions. Designers convey ideas through sketches, which define spatial structure and design elements, and textual descriptions, capturing material, texture, and stylistic details. In this paper, we present LOcalized Text and Sketch for fashion image generation (LOTS), an approach for compositional sketch-text based generation of complete fashion outlooks. LOTS leverages a global description with paired localized sketch + text information for conditioning and introduces a novel step-based merging strategy for diffusion adaptation. First, a Modularized Pair-Centric representation encodes sketches and text into a shared latent space while preserving independent localized features; then, a Diffusion Pair Guidance phase integrates both local and global conditioning via attention-based guidance within the diffusion model’s multi-step denoising process. To validate our method, we build on Fashionpedia to release Sketchy, the first fashion dataset where multiple text-sketch pairs are provided per image. Quantitative results show LOTS achieves state-of-the-art image generation performance on both global and localized metrics, while qualitative examples and a human evaluation study highlight its unprecedented level of design customization.
服装设计是一个复杂的创意过程,融合了视觉和文本表达。设计师通过草图传达想法,这些草图定义了空间结构和设计元素,以及文本描述,捕捉材料、纹理和风格细节。在本文中,我们介绍了用于服装图像生成的局部文本和草图(LOTS),这是一种基于组合草图文本生成完整时尚外观的方法。LOTS利用全局描述与配对局部草图+文本信息进行条件设置,并引入了一种基于步骤的合并策略来进行扩散适应。首先,模块化配对中心表示法将草图和文本编码到共享潜在空间中,同时保留独立的局部特征;然后,扩散对指导阶段通过扩散模型的多步去噪过程中的注意力导向整合了局部和全局条件。为了验证我们的方法,我们在Fashionpedia的基础上构建了Sketchy数据集,这是第一个每张图像都提供多个文本草图对的数据集。定量结果表明,LOTS在全球和局部指标上都达到了最先进的图像生成性能,而定性示例和人类评估研究则突出了其前所未有的设计定制水平。
论文及项目相关链接
PDF Accepted at ICCV25 (Oral). Project page: https://intelligolabs.github.io/lots/
Summary
本文提出一种基于组合草图与文本信息的时尚图像生成方法——LOTS。该方法通过利用全局描述与配对局部草图及文本信息来适应扩散模型,引入了一种新型的基于步骤的合并策略。首先,采用模块化配对中心表示法将草图和文本编码到共享潜在空间中,同时保留独立的局部特征;接着,在扩散模型的去噪过程中的多步骤中,通过注意力导向机制整合局部和全局条件,形成扩散配对导向阶段。为验证方法的有效性,研究团队在Fashionpedia的基础上构建了Sketchy数据集,该数据集为每个图像提供了多个文本草图对。定量结果表明,LOTS在全局和局部指标上均实现了图像生成性能的最佳状态,而定性示例和人为评估研究突出了其前所未有的设计定制水平。
Key Takeaways
- 时尚设计是一个复杂的创意过程,结合视觉和文本表达。
- LOTS方法利用全局描述与配对局部草图及文本信息,为适应扩散模型提供条件。
- 提出了一种新颖的基于步骤的合并策略,整合局部和全局条件。
- 通过模块化配对中心表示法,将草图和文本编码到共享潜在空间并保留独立局部特征。
- 扩散配对导向阶段通过注意力机制实现局部和全局信息的结合。
- 为验证方法的有效性,建立了Sketchy数据集,每个图像包含多个文本草图对。
点此查看论文截图

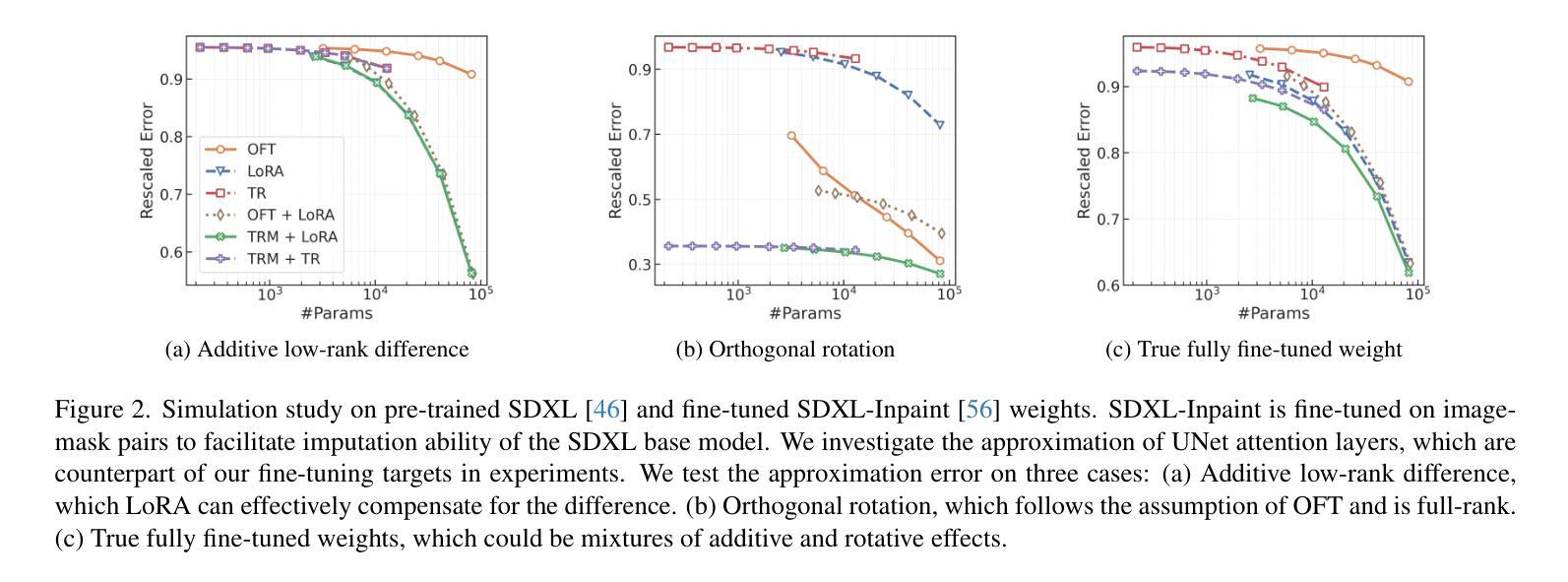
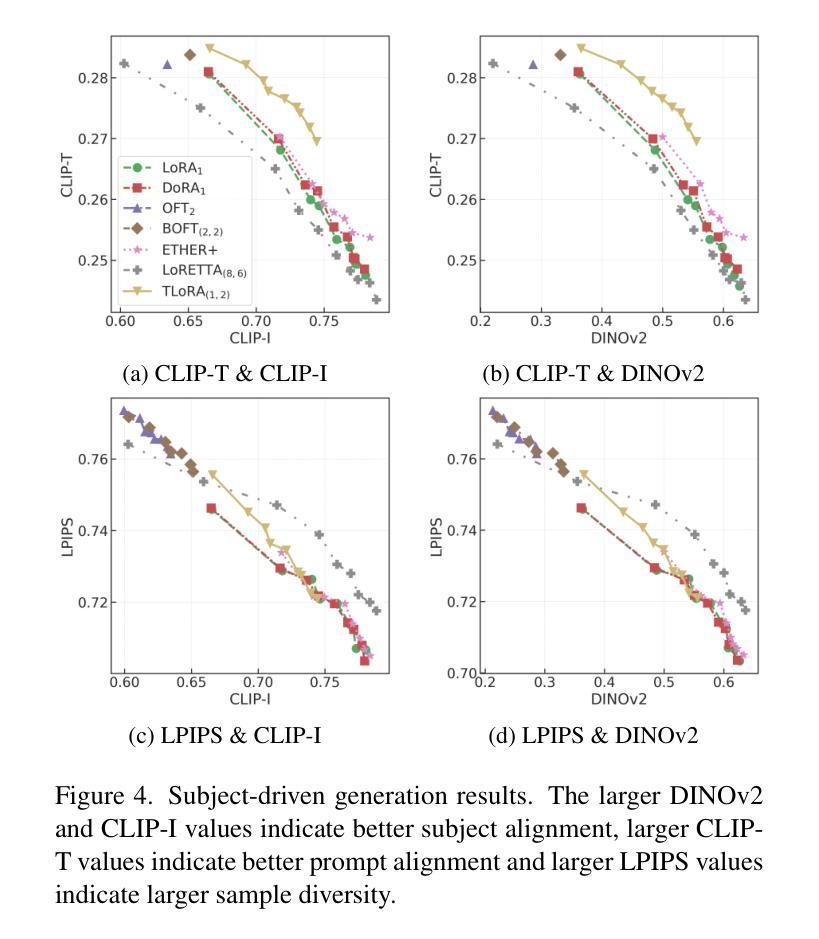
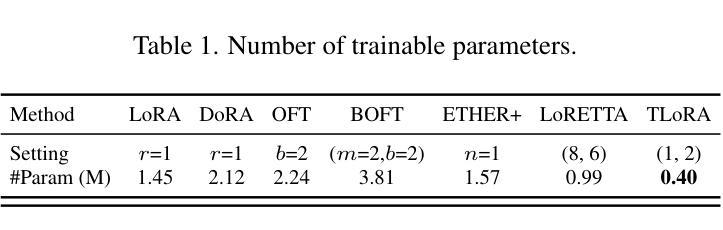
Transformed Low-rank Adaptation via Tensor Decomposition and Its Applications to Text-to-image Models
Authors:Zerui Tao, Yuhta Takida, Naoki Murata, Qibin Zhao, Yuki Mitsufuji
Parameter-Efficient Fine-Tuning (PEFT) of text-to-image models has become an increasingly popular technique with many applications. Among the various PEFT methods, Low-Rank Adaptation (LoRA) and its variants have gained significant attention due to their effectiveness, enabling users to fine-tune models with limited computational resources. However, the approximation gap between the low-rank assumption and desired fine-tuning weights prevents the simultaneous acquisition of ultra-parameter-efficiency and better performance. To reduce this gap and further improve the power of LoRA, we propose a new PEFT method that combines two classes of adaptations, namely, transform and residual adaptations. In specific, we first apply a full-rank and dense transform to the pre-trained weight. This learnable transform is expected to align the pre-trained weight as closely as possible to the desired weight, thereby reducing the rank of the residual weight. Then, the residual part can be effectively approximated by more compact and parameter-efficient structures, with a smaller approximation error. To achieve ultra-parameter-efficiency in practice, we design highly flexible and effective tensor decompositions for both the transform and residual adaptations. Additionally, popular PEFT methods such as DoRA can be summarized under this transform plus residual adaptation scheme. Experiments are conducted on fine-tuning Stable Diffusion models in subject-driven and controllable generation. The results manifest that our method can achieve better performances and parameter efficiency compared to LoRA and several baselines.
文本到图像模型的参数高效微调(PEFT)技术越来越受到欢迎,并有许多应用。在各种PEFT方法中,低秩适应(LoRA)及其变体因其有效性而备受关注,使用户能够在有限的计算资源下微调模型。然而,低秩假设与所需的微调权重之间的近似差距阻碍了超参数效率和性能的同时提升。为了减少这个差距并进一步提升LoRA的威力,我们提出了一种新的PEFT方法,该方法结合了两种适应类别,即变换适应和残差适应。具体来说,我们首先应用全秩和密集变换到预训练权重上。这个可学习的变换期望尽可能紧密地对齐预训练权重到所需权重,从而减少残差权重的秩。然后,残差部分可以通过更紧凑和参数高效的结构进行有效的近似,以减小近似误差。为了实现实践中的超参数效率,我们为变换和残差适应都设计了高度灵活和有效的张量分解。此外,流行的PEFT方法如DoRA可以归纳在这种变换加残差适应方案下。实验在微调Stable Diffusion模型的主题驱动和可控生成上进行了实施。结果表明,我们的方法相较于LoRA和一些基线方法,在性能和参数效率方面都能取得更好的表现。
论文及项目相关链接
PDF ICCV 2025
Summary
本文介绍了一种新的参数高效微调(PEFT)方法,结合了转换和残差适应两类适应方式,用于优化文本到图像模型的微调。该方法首先应用全秩密集转换来尽可能地接近预训练权重和目标权重,然后通过更紧凑和参数高效的结构有效地近似剩余部分,以减小近似误差。实验表明,该方法在主题驱动和可控生成方面对Stable Diffusion模型的微调具有更好的性能和参数效率。
Key Takeaways
- PEFT方法结合了转换和残差适应,旨在缩小低秩假设与所需微调权重之间的近似差距。
- 通过全秩密集转换来接近预训练权重和目标权重,减少剩余权重的秩。
- 剩余部分通过更紧凑和参数高效的结构进行有效近似,减小近似误差。
- 提出高度灵活和有效的张量分解来实现实际中的超参数效率。
- 现有的PEFT方法如DoRA可归纳为此转换加残差适应方案。
- 实验结果表明,该方法在主题驱动和可控生成方面对Stable Diffusion模型的微调具有更好的性能。
点此查看论文截图

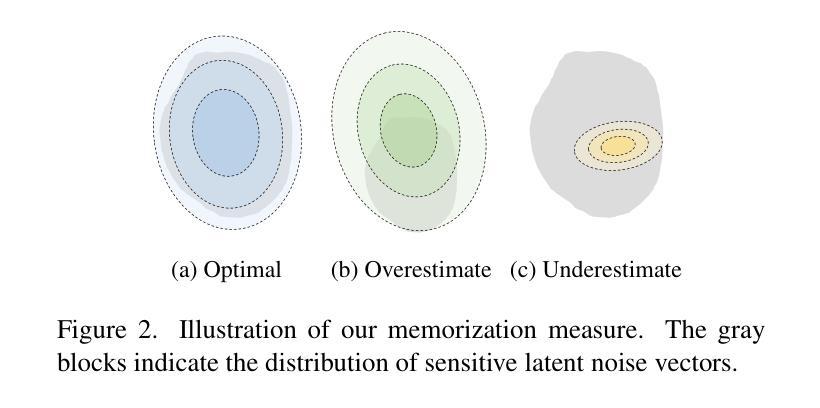
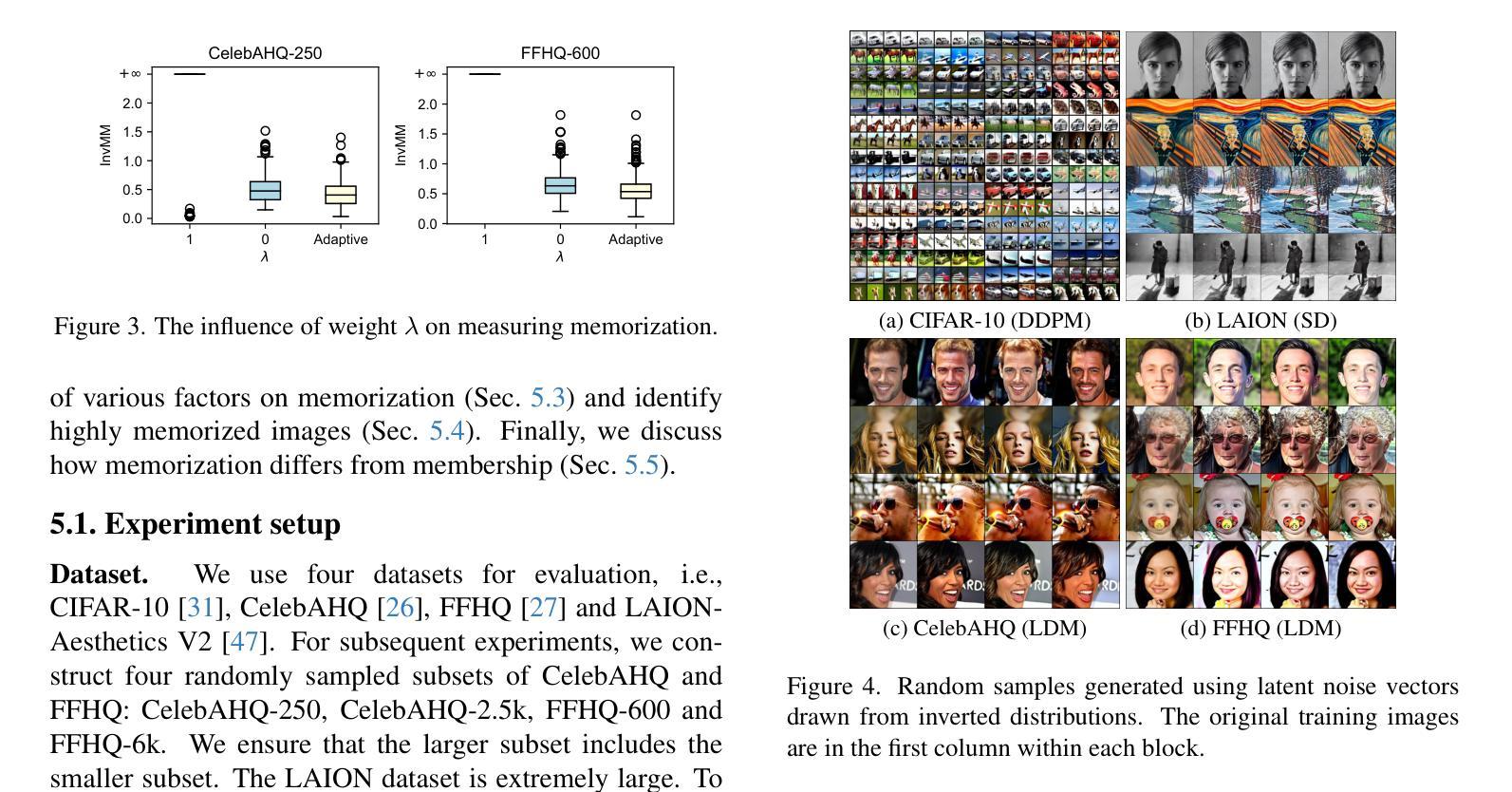
An Inversion-based Measure of Memorization for Diffusion Models
Authors:Zhe Ma, Qingming Li, Xuhong Zhang, Tianyu Du, Ruixiao Lin, Zonghui Wang, Shouling Ji, Wenzhi Chen
The past few years have witnessed substantial advances in image generation powered by diffusion models. However, it was shown that diffusion models are susceptible to training data memorization, raising significant concerns regarding copyright infringement and privacy invasion. This study delves into a rigorous analysis of memorization in diffusion models. We introduce InvMM, an inversion-based measure of memorization, which is based on inverting a sensitive latent noise distribution accounting for the replication of an image. For accurate estimation of the measure, we propose an adaptive algorithm that balances the normality and sensitivity of the noise distribution. Comprehensive experiments across four datasets, conducted on both unconditional and text-guided diffusion models, demonstrate that InvMM provides a reliable and complete quantification of memorization. Notably, InvMM is commensurable between samples, reveals the true extent of memorization from an adversarial standpoint and implies how memorization differs from membership. In practice, it serves as an auditing tool for developers to reliably assess the risk of memorization, thereby contributing to the enhancement of trustworthiness and privacy-preserving capabilities of diffusion models.
过去几年,扩散模型在图像生成领域取得了重大进展。然而,研究表明扩散模型容易记忆训练数据,这引发了关于版权侵犯和隐私侵犯的担忧。本研究深入分析了扩散模型中的记忆问题。我们介绍了InvMM,这是一种基于反演的记忆度量方法,它基于敏感潜在噪声分布的反演来计量图像的复制程度。为了准确估计该度量标准,我们提出了一种平衡噪声分布的正常性和敏感性的自适应算法。在无条件扩散模型和文本引导扩散模型上进行的四个数据集的综合实验表明,InvMM提供了可靠的记忆量化方法。值得注意的是,InvMM在样本之间具有可比较性,从对抗角度揭示了记忆的真实程度,并显示了记忆与成员资格之间的差异。在实践中,它作为开发人员可靠的评估记忆风险的审计工具,有助于提高扩散模型的可靠性和隐私保护能力。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
扩散模型在图像生成领域取得了显著进展,但其易受到训练数据记忆能力的影响,引发版权和隐私侵权问题。本研究深入探讨了扩散模型的记忆能力问题,提出了基于反演的测量手段InvMM,能有效评估图像复制中的敏感潜在噪声分布。通过自适应算法准确估计测量值,并在四个数据集上进行了实验验证。InvMM可靠且全面地量化记忆能力,与样本之间具有可比性,揭示了记忆能力的真实程度,并强调了其与成员身份的区别。它可作为开发人员评估记忆风险的可信工具,有助于提高扩散模型的可靠性和隐私保护能力。
Key Takeaways
- 扩散模型在图像生成领域取得显著进展,但存在训练数据记忆能力问题。
- 训练数据记忆能力问题可能引发版权和隐私侵权问题。
- 提出了基于反演的测量手段InvMM来评估图像复制中的敏感潜在噪声分布。
- 通过自适应算法准确估计测量值,进行实验研究验证。
- InvMM可靠且全面地量化记忆能力,具有样本间可比性。
- InvMM能揭示记忆能力的真实程度,与成员身份有所区别。
点此查看论文截图


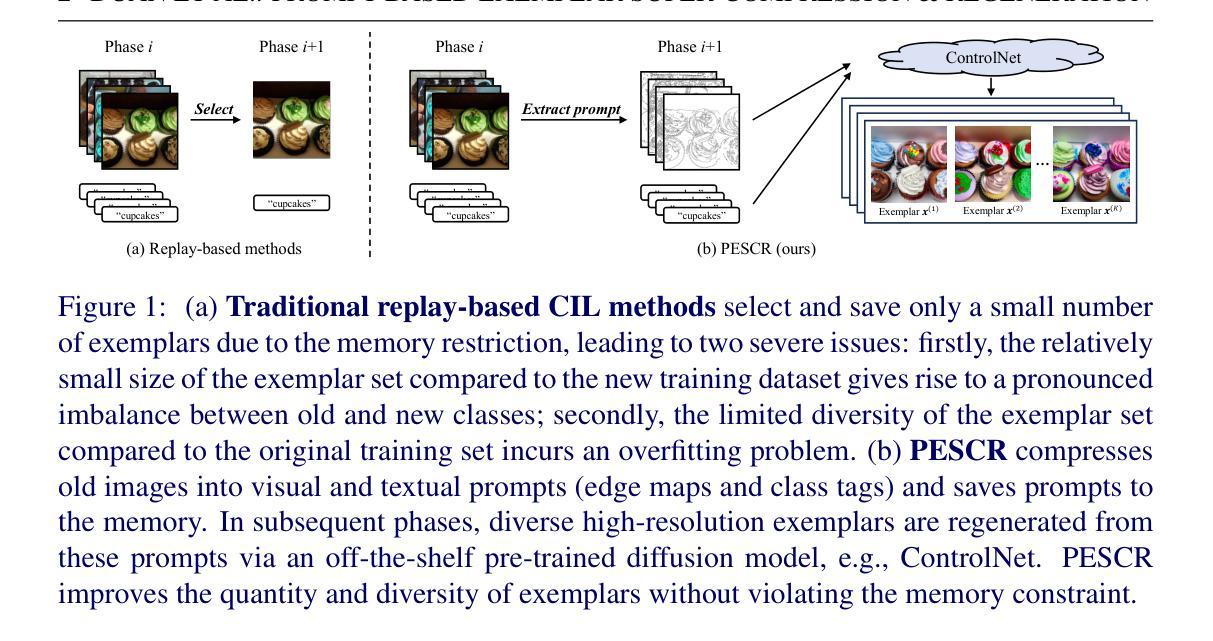
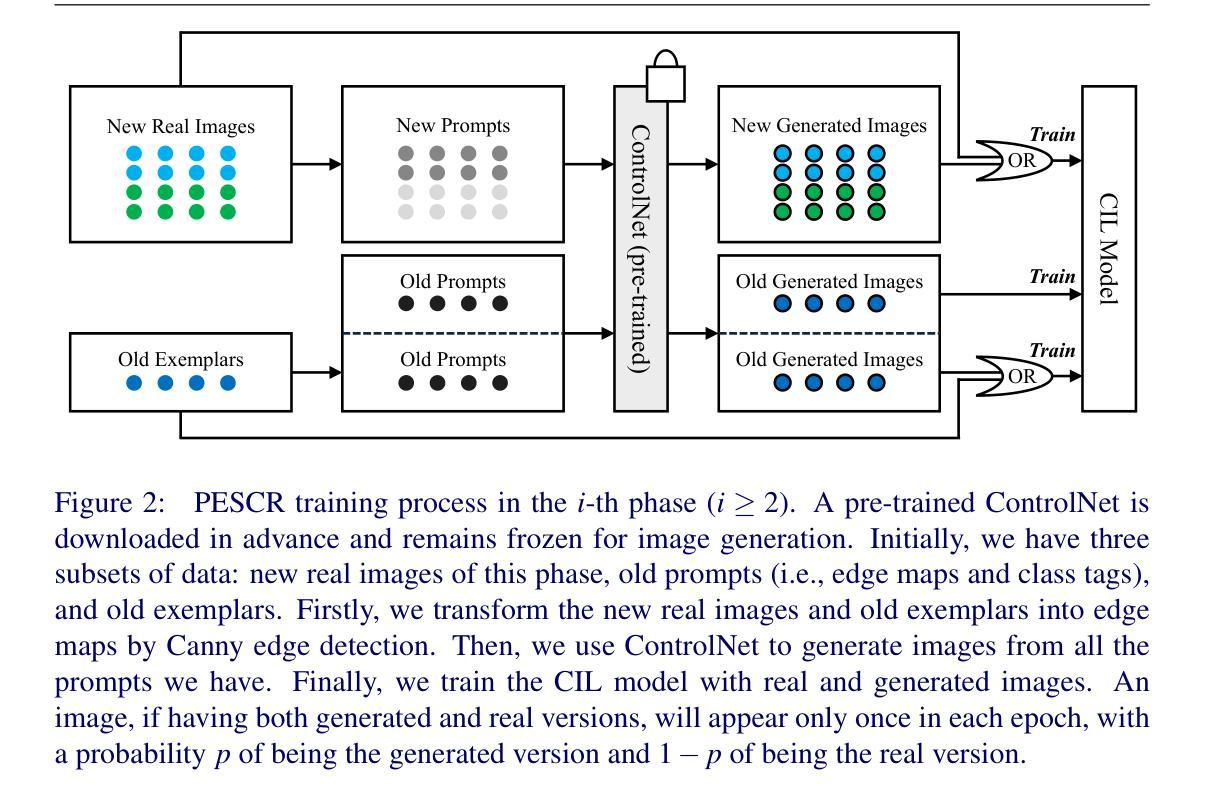
Prompt-Based Exemplar Super-Compression and Regeneration for Class-Incremental Learning
Authors:Ruxiao Duan, Jieneng Chen, Adam Kortylewski, Alan Yuille, Yaoyao Liu
Replay-based methods in class-incremental learning (CIL) have attained remarkable success. Despite their effectiveness, the inherent memory restriction results in saving a limited number of exemplars with poor diversity. In this paper, we introduce PESCR, a novel approach that substantially increases the quantity and enhances the diversity of exemplars based on a pre-trained general-purpose diffusion model, without fine-tuning it on target datasets or storing it in the memory buffer. Images are compressed into visual and textual prompts, which are saved instead of the original images, decreasing memory consumption by a factor of 24. In subsequent phases, diverse exemplars are regenerated by the diffusion model. We further propose partial compression and diffusion-based data augmentation to minimize the domain gap between generated exemplars and real images. PESCR significantly improves CIL performance across multiple benchmarks, e.g., 3.2% above the previous state-of-the-art on ImageNet-100.
在类增量学习(CIL)中,基于重放的方法已经取得了显著的成果。尽管它们有效,但固有的内存限制导致保存的样本数量有限且多样性较差。在本文中,我们介绍了PESCR,这是一种基于预训练的通用扩散模型的新方法,可以在不微调目标数据集或将其存储在内存缓冲区中的情况下,大幅增加样本数量并提高样本的多样性。图像被压缩成视觉和文本提示,代替原始图像进行保存,使内存消耗减少了24倍。在后续阶段,扩散模型会重新生成多样化的样本。我们还提出了部分压缩和基于扩散的数据增强,以最小化生成样本和真实图像之间的域差距。PESCR在多个基准测试上显著提高了CIL的性能,例如在ImageNet-100上的性能超过了之前的最先进水平3.2%。
论文及项目相关链接
PDF BMVC 2025. Code: https://github.com/KerryDRX/PESCR
摘要
回放方法在班级增量学习(CIL)中取得了显著的成功。然而,由于内存限制,这些方法只能保存有限数量的样本,且多样性较差。本文介绍了一种新方法PESCR,它基于预训练的通用扩散模型,在不对目标数据集进行微调或占用内存缓冲区的情况下,大幅增加样本数量并提高样本多样性。图像被压缩成视觉和文本提示,替代原始图像进行保存,降低了24倍的内存消耗。随后,扩散模型再生各种样本。为进一步缩小生成样本与真实图像之间的域差距,我们还提出了部分压缩和基于扩散的数据增强方法。PESCR在多个基准测试上显著提高了CIL性能,例如在ImageNet-100上的表现优于最新技术状态3.2%。
关键见解
- 回放方法在班级增量学习中表现优秀,但受内存限制影响,保存样本数量有限且多样性不足。
- PESCR方法基于预训练的通用扩散模型,能提高样本数量和多样性。
- 图像被压缩成视觉和文本提示来保存,大幅度降低了内存消耗。
- 扩散模型在后续阶段再生各种样本。
- 部分压缩技术用于缩小生成样本和真实图像之间的域差距。
- PESCR在多个基准测试上显著提高了班级增量学习的性能。
- 在ImageNet-100上,PESCR的表现优于其他方法,表现出较大的潜力。
点此查看论文截图