⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-03 更新
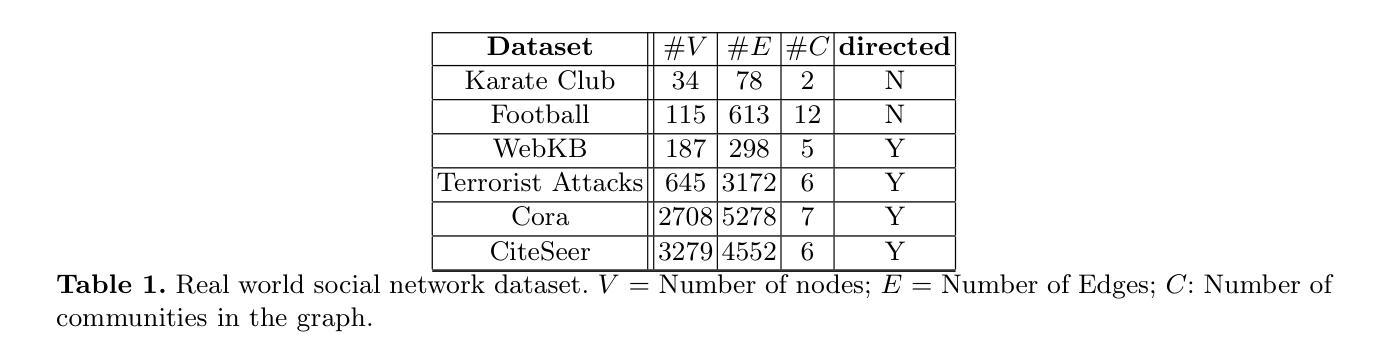
LLMs Between the Nodes: Community Discovery Beyond Vectors
Authors:Ekta Gujral, Apurva Sinha
Community detection in social network graphs plays a vital role in uncovering group dynamics, influence pathways, and the spread of information. Traditional methods focus primarily on graph structural properties, but recent advancements in Large Language Models (LLMs) open up new avenues for integrating semantic and contextual information into this task. In this paper, we present a detailed investigation into how various LLM-based approaches perform in identifying communities within social graphs. We introduce a two-step framework called CommLLM, which leverages the GPT-4o model along with prompt-based reasoning to fuse language model outputs with graph structure. Evaluations are conducted on six real-world social network datasets, measuring performance using key metrics such as Normalized Mutual Information (NMI), Adjusted Rand Index (ARI), Variation of Information (VOI), and cluster purity. Our findings reveal that LLMs, particularly when guided by graph-aware strategies, can be successfully applied to community detection tasks in small to medium-sized graphs. We observe that the integration of instruction-tuned models and carefully engineered prompts significantly improves the accuracy and coherence of detected communities. These insights not only highlight the potential of LLMs in graph-based research but also underscore the importance of tailoring model interactions to the specific structure of graph data.
社交网络图中的社区检测在揭示群体动态、影响路径和信息传播方面起着至关重要的作用。传统的方法主要关注图的结构属性,但大型语言模型(LLM)的最新进展为将此任务与语义和上下文信息集成提供了新的途径。在本文中,我们对基于LLM的不同方法在识别社交网络图中社区的表现进行了详细调查。我们介绍了一个两步框架CommLLM,它利用GPT-4o模型以及基于提示的推理,将语言模型输出与图结构相融合。我们在六个真实世界的社交网络数据集上进行了评估,使用归一化互信息(NMI)、调整兰德指数(ARI)、信息变异(VOI)和集群纯度等关键指标来衡量性能。我们发现,特别是当受到图感知策略引导时,LLM可以成功应用于小到中型图的社区检测任务。我们发现指令调整模型的集成和精心设计的提示显著提高了检测到的社区的准确性和连贯性。这些见解不仅突出了LLM在图基研究中的潜力,而且强调了根据图形数据的特定结构定制模型交互的重要性。
论文及项目相关链接
Summary
社区检测在社会网络图中发挥着揭示群体动态、信息传播路径的重要作用。传统方法主要关注图的结构属性,但大型语言模型(LLM)的最新进展为集成语义和上下文信息提供了新的途径。本文详细调查了基于LLM的方法在识别社会图内社区时的表现。我们提出了一种名为CommLLM的两步框架,它利用GPT-4o模型和基于提示的推理来融合语言模型输出和图结构。在六个真实世界的社会网络数据集上进行了评估,使用归一化互信息(NMI)、调整兰德指数(ARI)、变异信息(VOI)和集群纯度等关键指标来衡量性能。研究发现,大型语言模型在小型至中型图中的社区检测任务中表现良好,特别是在图形感知策略的引导下,准确率有所提高。这些发现不仅突显了大型语言模型在图研究中的潜力,也强调了针对图形数据特定结构定制模型交互的重要性。
Key Takeaways
以下是关于文本的关键见解:
- 社区检测在社会网络图中具有重要意义,有助于揭示群体动态和信息传播路径。
- 传统社区检测方法主要关注图的结构属性。
- 大型语言模型(LLM)的进展为社区检测提供了新的方法,能够集成语义和上下文信息。
- 提出的CommLLM框架结合了语言模型和图结构,通过两步实现社区检测。
- 在多个真实世界数据集上的评估表明,LLM在小型至中型图的社区检测中表现良好。
- 图形感知策略和指令微调模型的结合提高了社区检测的准确性和连贯性。
点此查看论文截图

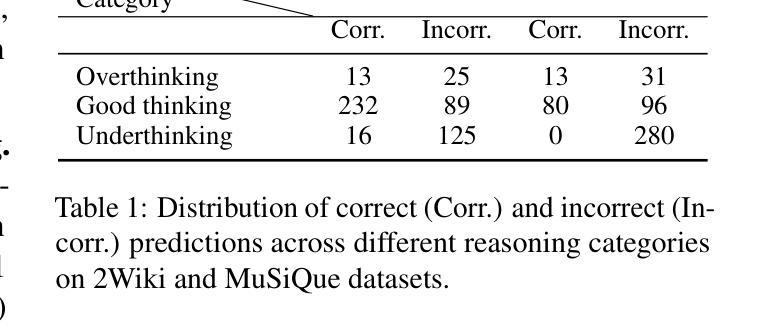
From Sufficiency to Reflection: Reinforcement-Guided Thinking Quality in Retrieval-Augmented Reasoning for LLMs
Authors:Jie He, Victor Gutierrez Basulto, Jeff Z. Pan
Reinforcement learning-based retrieval-augmented generation (RAG) methods enhance the reasoning abilities of large language models (LLMs). However, most rely only on final-answer rewards, overlooking intermediate reasoning quality. This paper analyzes existing RAG reasoning models and identifies three main failure patterns: (1) information insufficiency, meaning the model fails to retrieve adequate support; (2) faulty reasoning, where logical or content-level flaws appear despite sufficient information; and (3) answer-reasoning inconsistency, where a valid reasoning chain leads to a mismatched final answer. We propose TIRESRAG-R1, a novel framework using a think-retrieve-reflect process and a multi-dimensional reward system to improve reasoning and stability. TIRESRAG-R1 introduces: (1) a sufficiency reward to encourage thorough retrieval; (2) a reasoning quality reward to assess the rationality and accuracy of the reasoning chain; and (3) a reflection reward to detect and revise errors. It also employs a difficulty-aware reweighting strategy and training sample filtering to boost performance on complex tasks. Experiments on four multi-hop QA datasets show that TIRESRAG-R1 outperforms prior RAG methods and generalizes well to single-hop tasks. The code and data are available at: https://github.com/probe2/TIRESRAG-R1.
基于强化学习的检索增强生成(RAG)方法提高了大型语言模型(LLM)的推理能力。然而,大多数方法仅依赖于最终答案的奖励,忽视了中间推理质量。本文分析了现有的RAG推理模型,并识别出了三种主要的失败模式:(1)信息不足,即模型未能检索到足够的支持信息;(2)推理错误,即使信息充足,逻辑或内容层面仍然会出现缺陷;(3)答案与推理不一致,有效的推理链导致最终的答案不匹配。我们提出了TIRESRAG-R1,这是一个使用思考-检索-反思过程和多维奖励系统的新型框架,以提高推理和稳定性。TIRESRAG-R1引入了:(1)充足性奖励,以鼓励全面检索;(2)推理质量奖励,以评估推理链的合理性和准确性;(3)反思奖励,以检测和修正错误。它还采用了难度感知的重新加权策略和训练样本过滤,以提高在复杂任务上的性能。在四个多跳问答数据集上的实验表明,TIRESRAG-R1优于先前的RAG方法,并能很好地推广到单跳任务。代码和数据集可在https://github.com/probe2/TIRESRAG-R1获得。
论文及项目相关链接
Summary:
强化学习增强的检索辅助生成(RAG)方法能够提升大语言模型的推理能力,但多数方法仅依赖最终答案奖励,忽视了推理过程的品质。本文分析了现有RAG推理模型,并指出了三种主要失败模式。为改进此状况,提出TIRESRAG-R1框架,采用思考-检索-反思过程和多种奖励系统来提升推理能力和稳定性。实验证明,TIRESRAG-R1在多个多跳问答数据集上的表现优于先前的RAG方法,并能很好地泛化到单跳任务。
Key Takeaways:
- 强化学习增强的检索辅助生成(RAG)方法能提升大语言模型的推理能力。
- 现有RAG方法主要依赖最终答案奖励,忽视中间推理品质。
- 现有RAG推理模型存在三大失败模式:信息不足、推理错误和答案与推理不一致。
- TIRESRAG-R1框架通过思考-检索-反思过程和多种奖励系统改进了RAG的推理能力。
- TIRESRAG-R1引入充分性奖励来鼓励全面检索。
- TIRESRAG-R1通过难度感知重权策略和训练样本过滤来提升复杂任务性能。
点此查看论文截图


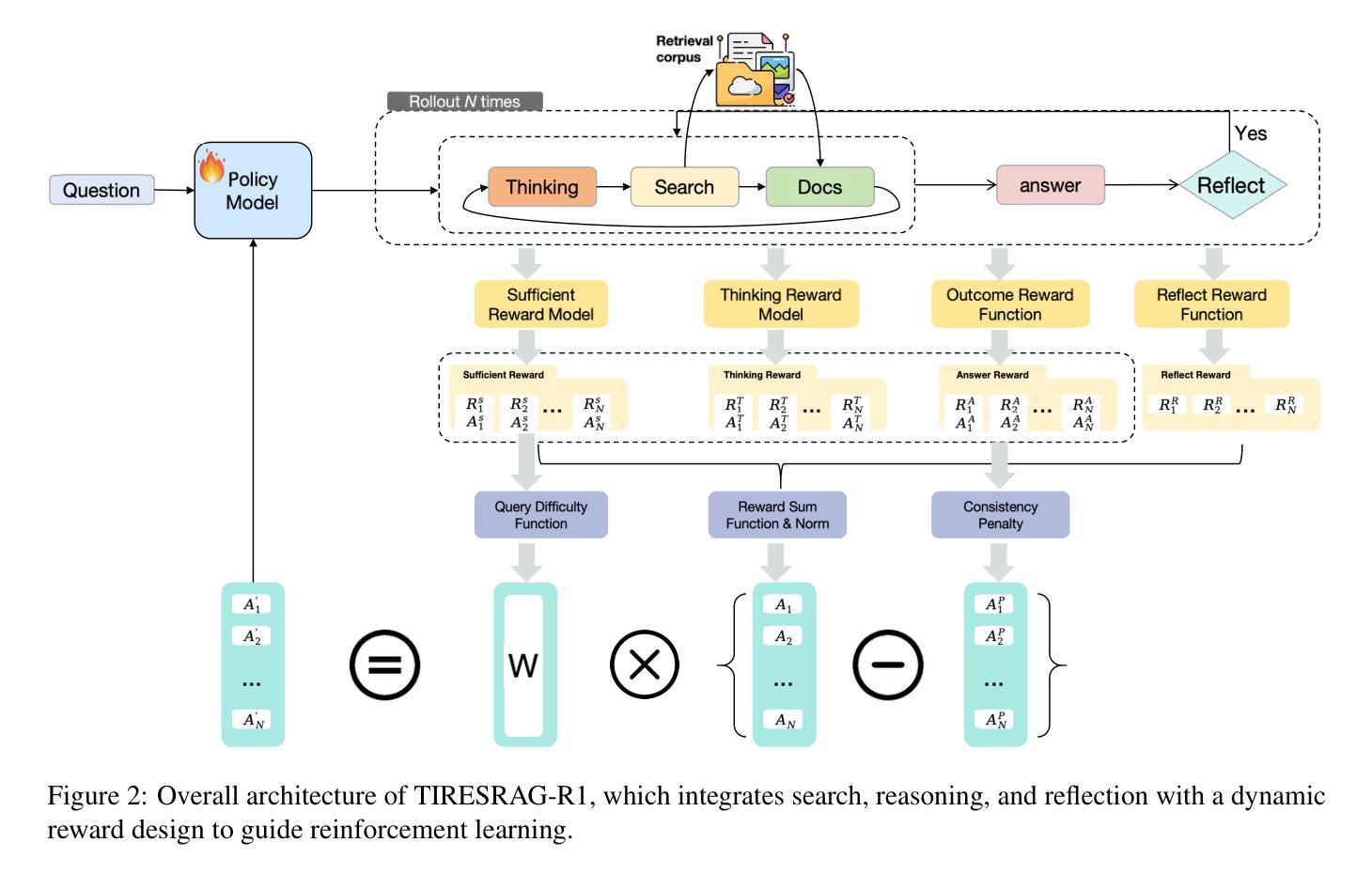
RePaCA: Leveraging Reasoning Large Language Models for Static Automated Patch Correctness Assessment
Authors:Marcos Fuster-Pena, David de-Fitero-Dominguez, Antonio Garcia-Cabot, Eva Garcia-Lopez
Automated Program Repair (APR) seeks to automatically correct software bugs without requiring human intervention. However, existing tools tend to generate patches that satisfy test cases without fixing the underlying bug, those are known as overfitting patches. To address this issue, Automated Patch Correctness Assessment (APCA) attempts to identify overfitting patches generated by APR tools. It can be solved as a static approach, meaning that no additional information is needed beyond the original and fixed code snippets. Current static techniques often struggle with reliability, flexibility and transparency. To address these issues, we introduce RePaCA, a novel static APCA technique that leverages Large Language Models (LLMs) specialized in thinking tasks. Our model is prompted with both buggy and fixed code snippets and guided to generate a Chain of Thought that analyses code differences, reasons about how the patch addresses the root cause, and ultimately provides a binary classification: correct or overfitting. To enhance these reasoning capabilities for the APCA task specifically, the LLM is finetuned using Reinforcement Learning with the Group Relative Policy Optimization algorithm. When evaluated on a standard Defects4J-derived test, our approach achieves state-of-the-art performance, with 83.1% accuracy and an 84.8% F1-score. Furthermore, our model demonstrates superior generalization capabilities when trained on different datasets, outperforming the leading technique. This reasoning capability also provides enhanced explainability for the patch assessment. These findings underscore the considerable promise of finetuned, reasoning LLMs to advance static APCA by enhancing accuracy, generalization, and explainability.
自动化程序修复(APR)旨在无需人工干预即可自动修复软件中的漏洞。然而,现有工具往往生成满足测试用例的补丁,而没有修复底层漏洞,这些被称为过度拟合补丁。为了解决这一问题,自动化补丁正确性评估(APCA)试图识别APR工具生成的过度拟合补丁。它可以作为一种静态方法来解决,这意味着除了原始和固定的代码片段之外,不需要额外的信息。当前的静态技术在可靠性、灵活性和透明度方面经常面临挑战。为了解决这些问题,我们引入了RePaCA,这是一种新的静态APCA技术,它利用专门用于思考任务的大型语言模型(LLM)。我们的模型以带有错误和固定代码片段的提示进行引导,生成分析代码差异的思考链,推理补丁如何解决根本原因,并最终提供二元分类:正确或过度拟合。为了提高这些专门针对APCA任务的推理能力,我们使用强化学习Group Relative Policy Optimization算法对LLM进行微调。在基于Defects4J的标准测试上评估时,我们的方法达到了最先进的性能,准确率83.1%,F1分数84.8%。此外,我们的模型在训练不同的数据集时表现出卓越的综合能力,超过了领先的技术。这种推理能力还为补丁评估提供了增强的可解释性。这些发现凸显了微调后的推理LLM在增强准确性、通用性和可解释性方面对推进静态APCA的巨大潜力。
论文及项目相关链接
Summary:
自动化程序修复(APR)旨在无需人工干预即可自动修复软件中的漏洞。然而,现有工具产生的补丁常常仅满足测试用例的要求而并未真正修复原有漏洞,这被称为过拟合补丁。为了解决这一问题,自动化补丁正确性评估(APCA)尝试识别APR工具产生的过拟合补丁。针对该问题,我们提出了一种新型的静态APCA技术——RePaCA,该技术利用大型语言模型(LLM)进行思维任务分析。RePaCA模型接收有缺陷的代码片段和修复后的代码片段作为输入,通过生成分析代码差异的思考链,理解补丁如何从根本上解决问题,并给出是否为正确补丁或过度拟合的二元分类结果。通过强化学习对模型进行微调,采用相对策略优化算法,以提高模型在APCA任务中的推理能力。在基于Defects4J的标准测试集上评估,RePaCA达到了业界领先水平,准确率达到了83.1%,F1分数为84.8%,并且在不同数据集上的训练表现出卓越泛化能力。这些发现凸显了微调后的推理型大型语言模型在提升静态APCA的准确性、泛化能力和解释性方面的巨大潜力。
Key Takeaways:
- 自动化程序修复(APR)能自动修复软件漏洞但存在生成过拟合补丁的问题。
- 自动化补丁正确性评估(APCA)用于识别APR工具产生的过拟合补丁。
- RePaCA是一种新型的静态APCA技术,利用大型语言模型(LLM)进行思维任务分析。
- RePaCA通过强化学习微调,采用相对策略优化算法提高在APCA任务中的推理能力。
- RePaCA在标准测试集上表现优异,准确率和F1分数高。
- RePaCA在不同数据集上展现出良好的泛化能力。
点此查看论文截图

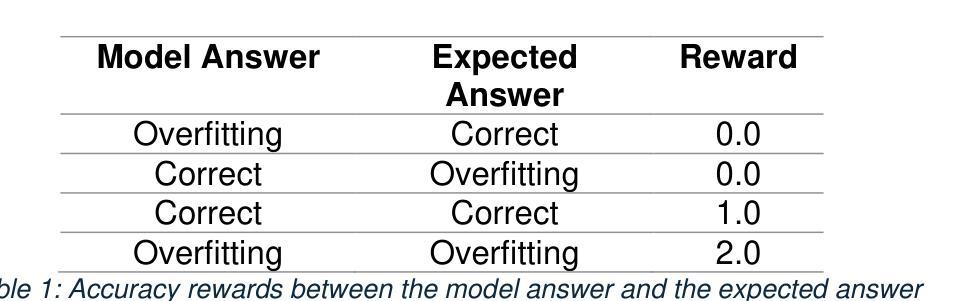
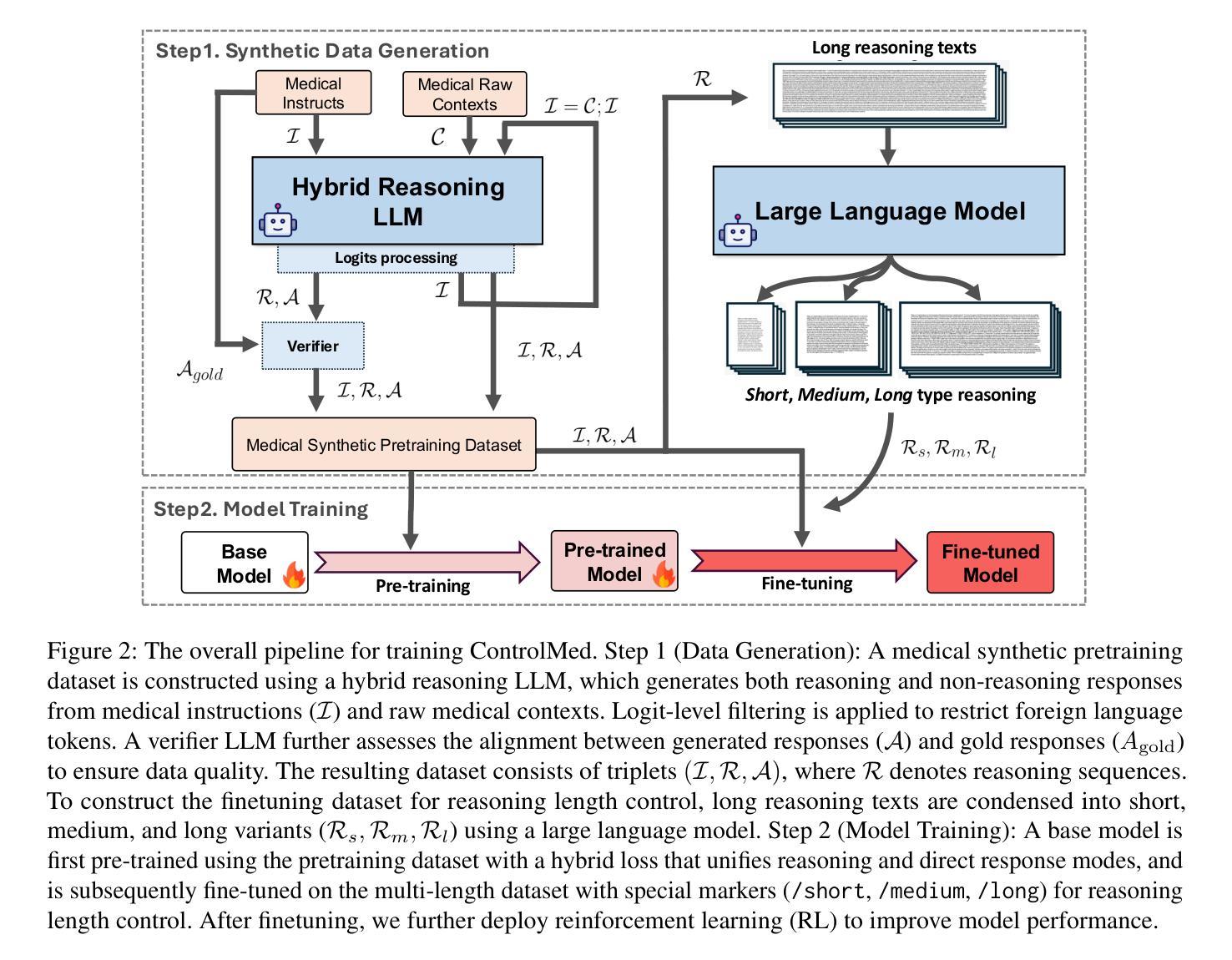
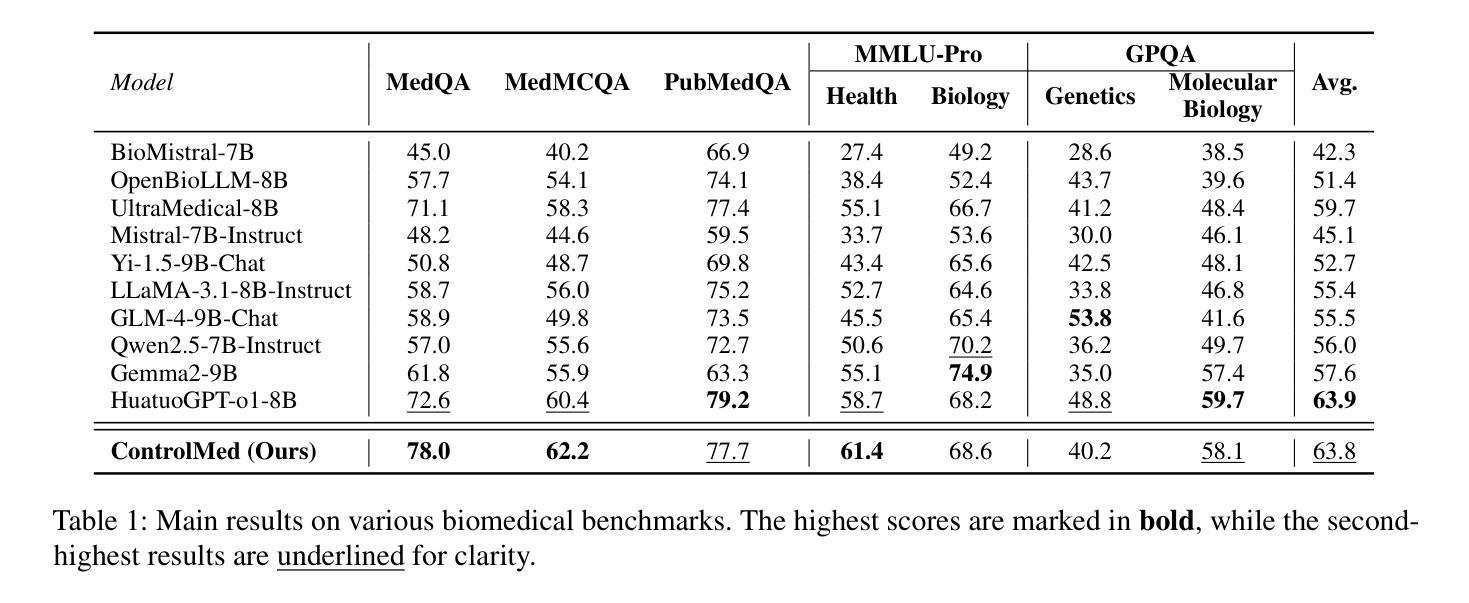
ControlMed: Adding Reasoning Control to Medical Language Model
Authors:Sung-Min Lee, Siyoon Lee, Juyeon Kim, Kyungmin Roh
Reasoning Large Language Models (LLMs) with enhanced accuracy and explainability are increasingly being adopted in the medical domain, as the life-critical nature of clinical decision-making demands reliable support. Despite these advancements, existing reasoning LLMs often generate unnecessarily lengthy reasoning processes, leading to significant computational overhead and response latency. These limitations hinder their practical deployment in real-world clinical environments. To address these challenges, we introduce \textbf{ControlMed}, a medical language model that enables users to actively control the length of the reasoning process at inference time through fine-grained control markers. ControlMed is trained through a three-stage pipeline: 1) pre-training on a large-scale synthetic medical instruction dataset covering both \textit{direct} and \textit{reasoning responses}; 2) supervised fine-tuning with multi-length reasoning data and explicit length-control markers; and 3) reinforcement learning with model-based reward signals to enhance factual accuracy and response quality. Experimental results on a variety of English and Korean medical benchmarks demonstrate that our model achieves similar or better performance compared to state-of-the-art models. Furthermore, users can flexibly balance reasoning accuracy and computational efficiency by controlling the reasoning length as needed. These findings demonstrate that ControlMed is a practical and adaptable solution for clinical question answering and medical information analysis.
随着临床决策的生命关键性质对可靠支持的需求不断增长,具有增强准确性和可解释性的推理大型语言模型(LLMs)在医疗领域的应用也越来越广泛。尽管有这些进展,现有的推理LLMs常常产生不必要的冗长推理过程,导致巨大的计算负担和响应延迟。这些限制阻碍了它们在实际临床环境中的实际应用。为了解决这些挑战,我们引入了ControlMed医疗语言模型,它允许用户在推理时间通过精细的粒度控制标记来主动控制推理过程的长度。ControlMed通过三阶段管道进行训练:1)在大规模合成医疗指令数据集上进行预训练,涵盖直接和推理响应;2)使用多长度推理数据和明确的长度控制标记进行有监督的微调;3)使用基于模型的奖励信号进行强化学习,以提高事实准确性和响应质量。在多种英语和韩语医疗基准测试上的实验结果表明,我们的模型与最先进模型的性能相当或更好。此外,用户可以根据需要控制推理长度,灵活地平衡推理准确性和计算效率。这些发现表明,ControlMed是临床问答和医疗信息分析的实用且可适应的解决方案。
论文及项目相关链接
PDF 13 pages
Summary
在医疗领域,大型语言模型(LLMs)的推理应用日益普及,因为它们具备更高的准确性和可解释性,能为临床决策提供可靠支持。然而,现有推理LLMs常常生成冗长的推理过程,导致计算资源消耗过大和响应延迟。针对这些问题,我们推出ControlMed医学语言模型,用户可通过精细的控制标记在推理时主动控制推理长度。ControlMed通过三阶段训练管道实现:1)在大规模合成医学指令数据集上进行预训练,涵盖直接和推理响应;2)使用多长度推理数据和明确的长度控制标记进行有监督微调;3)使用模型基础奖励信号进行强化学习,提高事实准确性和响应质量。实验结果表明,我们的模型在英语和韩语医疗基准测试上的表现与最新模型相当或更好。此外,用户可根据需要灵活平衡推理准确性和计算效率,控制推理长度。
Key Takeaways
- 大型语言模型(LLMs)在医疗领域的应用逐渐普及,因其高准确性和可解释性为临床决策提供支持。
- 现有LLMs存在冗长推理问题,导致计算资源消耗大及响应延迟。
- ControlMed医学语言模型通过精细控制标记实现推理长度的主动控制。
- ControlMed采用三阶段训练管道,包括预训练、有监督微调和强化学习。
- ControlMed在英语和韩语医疗基准测试中表现优异。
- 用户可灵活调整推理长度以平衡推理准确性和计算效率。
点此查看论文截图

A Benchmark Dataset and Evaluation Framework for Vietnamese Large Language Models in Customer Support
Authors:Long S. T. Nguyen, Truong P. Hua, Thanh M. Nguyen, Toan Q. Pham, Nam K. Ngo, An X. Nguyen, Nghi D. M. Pham, Nghia H. Nguyen, Tho T. Quan
With the rapid growth of Artificial Intelligence, Large Language Models (LLMs) have become essential for Question Answering (QA) systems, improving efficiency and reducing human workload in customer service. The emergence of Vietnamese LLMs (ViLLMs) highlights lightweight open-source models as a practical choice for their accuracy, efficiency, and privacy benefits. However, domain-specific evaluations remain limited, and the absence of benchmark datasets reflecting real customer interactions makes it difficult for enterprises to select suitable models for support applications. To address this gap, we introduce the Customer Support Conversations Dataset (CSConDa), a curated benchmark of over 9,000 QA pairs drawn from real interactions with human advisors at a large Vietnamese software company. Covering diverse topics such as pricing, product availability, and technical troubleshooting, CSConDa provides a representative basis for evaluating ViLLMs in practical scenarios. We further present a comprehensive evaluation framework, benchmarking 11 lightweight open-source ViLLMs on CSConDa with both automatic metrics and syntactic analysis to reveal model strengths, weaknesses, and linguistic patterns. This study offers insights into model behavior, explains performance differences, and identifies key areas for improvement, supporting the development of next-generation ViLLMs. By establishing a robust benchmark and systematic evaluation, our work enables informed model selection for customer service QA and advances research on Vietnamese LLMs. The dataset is publicly available at https://huggingface.co/datasets/ura-hcmut/Vietnamese-Customer-Support-QA.
随着人工智能的飞速发展,大型语言模型(LLM)对于问答(QA)系统来说已经变得至关重要,提高了效率,并减少了客户服务中的人力工作量。越南大型语言模型(ViLLM)的出现,凸显出轻量化开源模型具有准确度高、效率高和隐私优势的特点,是一个实际可行的选择。然而,针对特定领域的评估仍然有限,缺乏反映真实客户互动的基准数据集,使得企业在选择支持应用程序的合适模型时面临困难。为了弥补这一空白,我们引入了客户支持对话数据集(CSConDa),这是一组经过筛选的基准测试数据,包含超过9000对问答对,这些数据来自一家大型越南软件公司中人类顾问的真实互动。CSConDa涵盖了定价、产品可用性、技术故障排除等多样化主题,为评估ViLLM在实际场景中的表现提供了代表性的基础。我们还提供了一个全面的评估框架,在CSConDa上对11个轻量化开源ViLLM进行基准测试,采用自动指标和句法分析来揭示模型的优势、劣势和语言模式。本研究深入了解了模型的行为,解释了性能差异,并指出了关键改进领域,有助于下一代ViLLM的发展。通过建立稳健的基准测试和系统的评估,我们的工作可以为客户服务QA提供知情的模型选择,并推动越南LLM的研究。该数据集可在https://huggingface.co/datasets/ura-hcmut/Vietnamese-Customer-Support-QA公开访问。
论文及项目相关链接
PDF Under review at ICCCI 2025
Summary:随着人工智能的快速发展,大型语言模型(LLM)在问答系统中扮演着越来越重要的角色,提高了效率并减轻了客服工作的负担。越南语LLM(ViLLM)的出现凸显了轻量级开源模型在准确性、效率和隐私方面的优势。然而,针对特定领域的评估仍然有限,缺乏反映真实客户互动的基准数据集,使得企业难以选择适合的支持应用程序的模型。为解决这一空白,我们推出了客户支持对话数据集(CSConDa),这是一组包含超过9000个问答对的基准测试,取自越南一家大型软件公司真实的人机互动场景。我们对11个轻量级开源ViLLM进行了全面的评估框架,使用自动指标和句法分析在CSConDa上对其进行了评估,揭示了模型的优势、劣势和语言模式。此研究为模型行为提供了见解,解释了性能差异并确定了关键改进领域,支持下一代ViLLM的开发。我们的工作通过建立稳健的基准测试和系统的评估,为客服问答的模型选择提供了依据,并推动了越南语LLM的研究进展。数据集可在链接公开访问。
Key Takeaways:
- 大型语言模型(LLM)在问答系统中的重要性日益凸显,特别是在提高效率和减少客服工作量方面。
- 越南语LLM(ViLLM)因其准确性、效率和隐私优势而受到关注。
- 针对特定领域的模型评估仍然有限,缺乏反映真实客户互动的基准数据集,给企业选择适合的模型带来困难。
- 引入客户支持对话数据集(CSConDa),包含真实人机互动场景中的问答对,为评估ViLLM提供实际基础。
- 对轻量级开源ViLLM进行全面评估,揭示其优势、劣势和语言模式。
- 研究为模型的行为和性能差异提供了有价值的见解,并指出了关键改进领域。
点此查看论文截图

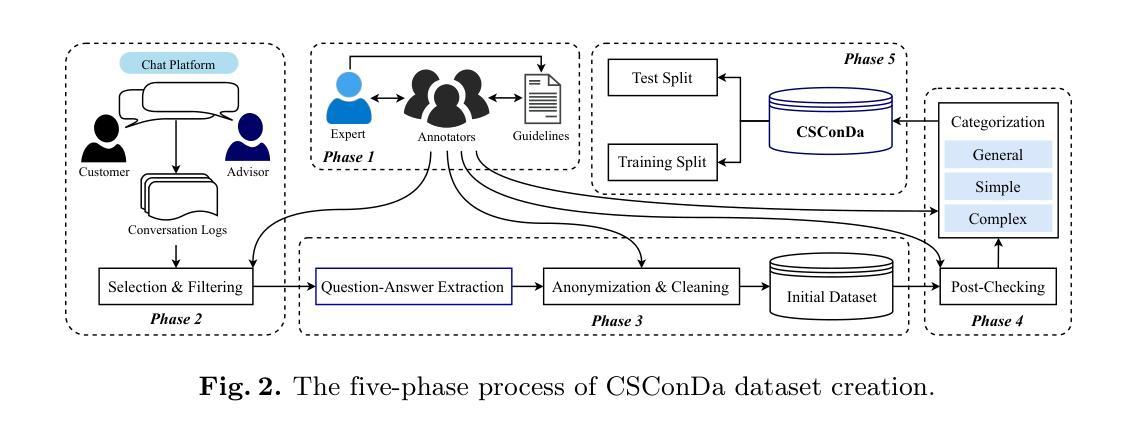
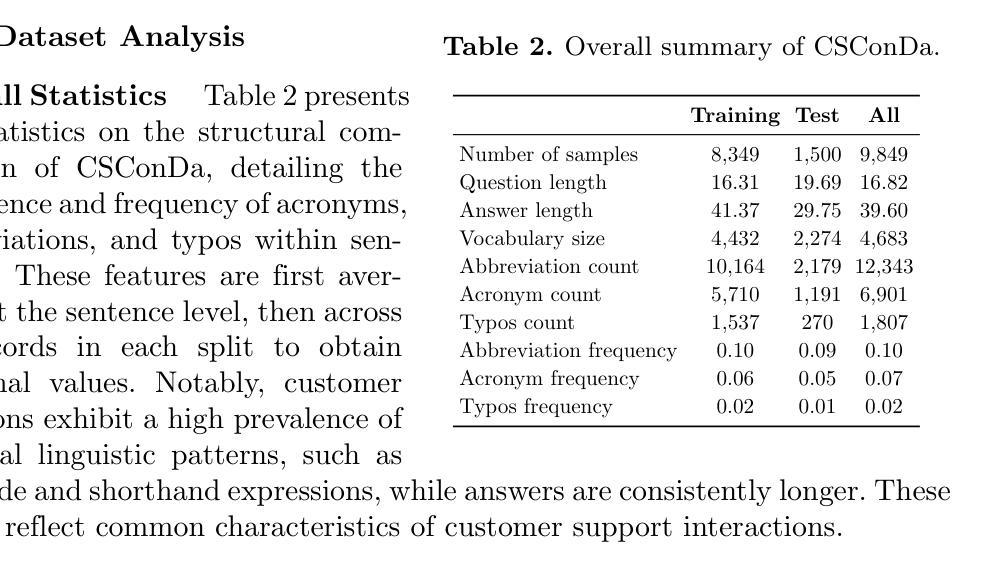
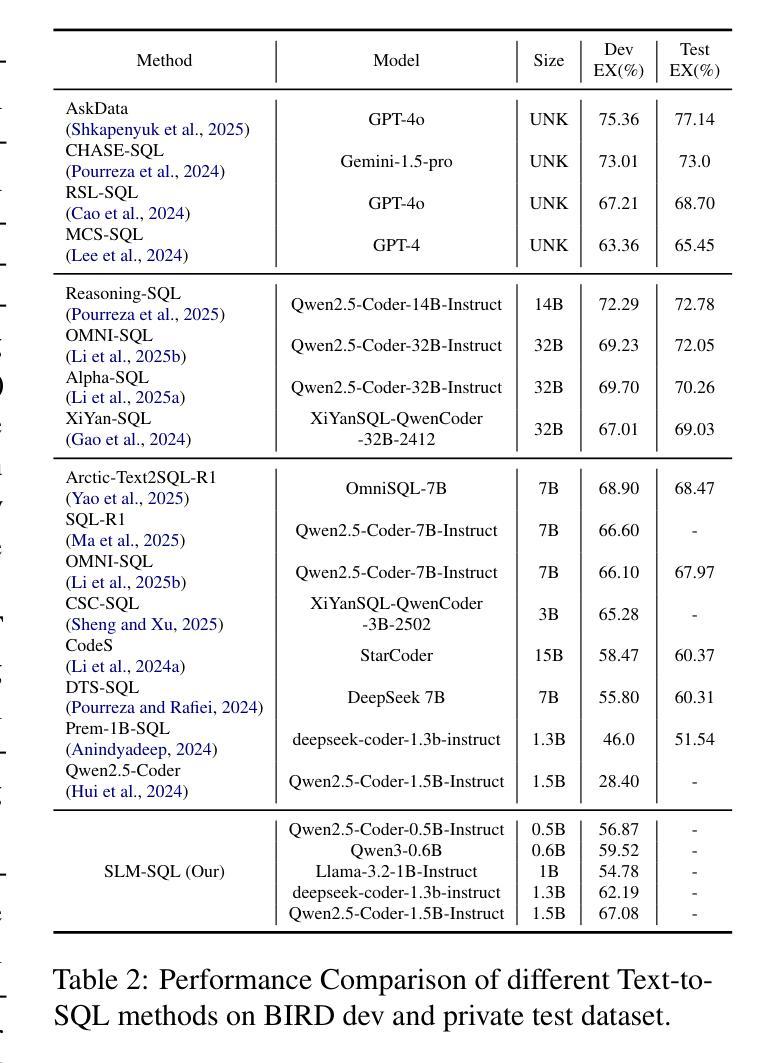
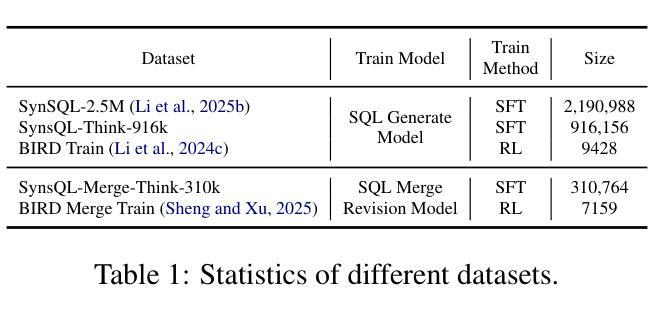
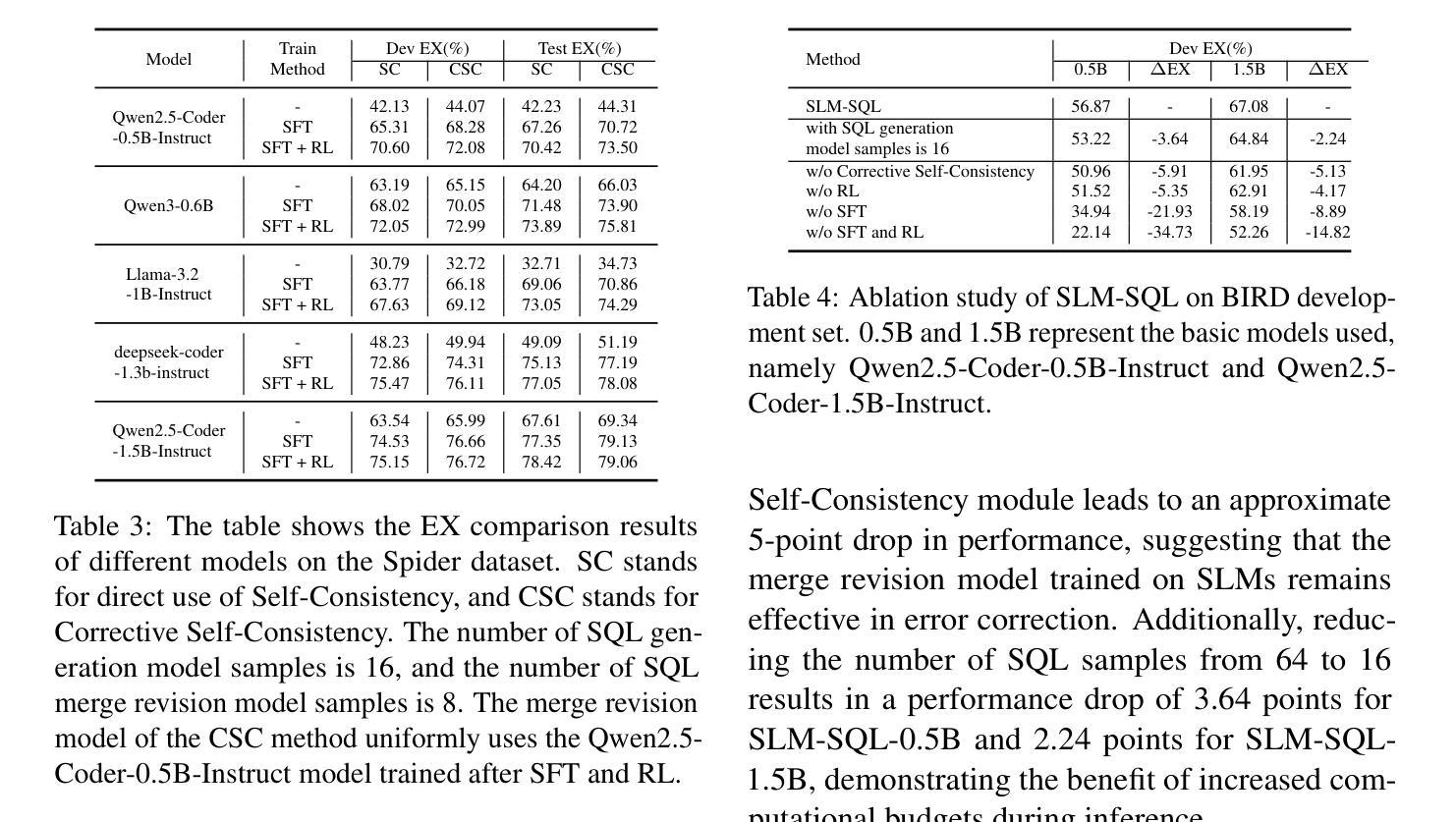
SLM-SQL: An Exploration of Small Language Models for Text-to-SQL
Authors:Lei Sheng, Shuai-Shuai Xu
Large language models (LLMs) have demonstrated strong performance in translating natural language questions into SQL queries (Text-to-SQL). In contrast, small language models (SLMs) ranging from 0.5B to 1.5B parameters currently underperform on Text-to-SQL tasks due to their limited logical reasoning capabilities. However, SLMs offer inherent advantages in inference speed and suitability for edge deployment. To explore their potential in Text-to-SQL applications, we leverage recent advancements in post-training techniques. Specifically, we used the open-source SynSQL-2.5M dataset to construct two derived datasets: SynSQL-Think-916K for SQL generation and SynSQL-Merge-Think-310K for SQL merge revision. We then applied supervised fine-tuning and reinforcement learning-based post-training to the SLM, followed by inference using a corrective self-consistency approach. Experimental results validate the effectiveness and generalizability of our method, SLM-SQL. On the BIRD development set, the five evaluated models achieved an average improvement of 31.4 points. Notably, the 0.5B model reached 56.87% execution accuracy (EX), while the 1.5B model achieved 67.08% EX. We will release our dataset, model, and code to github: https://github.com/CycloneBoy/slm_sql.
大型语言模型(LLM)在将自然语言问题翻译成SQL查询(文本到SQL)方面表现出强大的性能。相比之下,小型语言模型(SLM)的参数范围在0.5B到1.5B之间,目前在文本到SQL任务上的表现较差,主要是由于其逻辑推理能力有限。然而,SLM在推理速度和适用于边缘部署方面有着固有优势。为了探索其在文本到SQL应用中的潜力,我们利用最近的后训练技术进展。具体来说,我们使用开源的SynSQL-2.5M数据集构建了两个派生数据集:用于SQL生成的SynSQL-Think-916K和用于SQL合并修订的SynSQL-Merge-Think-310K。然后我们对SLM应用了基于监督微调和强化学习的后训练,随后使用纠正自我一致性方法进行推理。实验结果验证了我们方法SLM-SQL的有效性和通用性。在BIRD开发集上,五个评估模型的平均改进了31.4个点。值得注意的是,0.5B模型的执行准确率(EX)达到56.87%,而1.5B模型的EX达到67.08%。我们将在GitHub上发布我们的数据集、模型和代码:https://github.com/CycloneBoy/slm_sql。
简化版翻译
论文及项目相关链接
PDF 16 pages, 2 figures, work in progress
Summary
大型语言模型(LLMs)在文本转SQL(Text-to-SQL)任务上表现优异,而小型语言模型(SLMs)因逻辑推理能力有限,在此类任务上表现较差。然而,SLMs在推理速度和边缘部署方面具有优势。本研究利用最新的后训练技术,构建了两个衍生数据集,并通过监督微调与强化学习进行后训练。实验结果显示,所提方法SLM-SQL效果显著,平均提升31.4个百分点。相关模型将在GitHub上发布。
Key Takeaways
- 大型语言模型在文本转SQL任务上表现良好。
- 小型语言模型因逻辑推理能力有限,在此类任务上表现较差。
- 小型语言模型在推理速度和边缘部署方面具有优势。
- 研究者构建了两个用于文本转SQL任务的衍生数据集。
- 采用监督微调与强化学习进行后训练,提升小型语言模型在文本转SQL任务上的性能。
- 所提方法SLM-SQL在实验中表现出显著效果,平均提升31.4个百分点。
点此查看论文截图
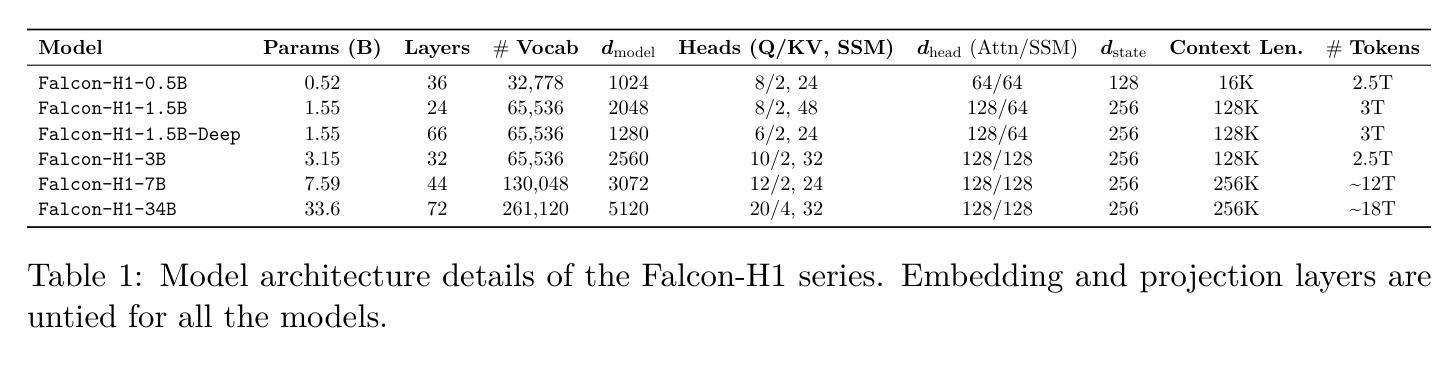
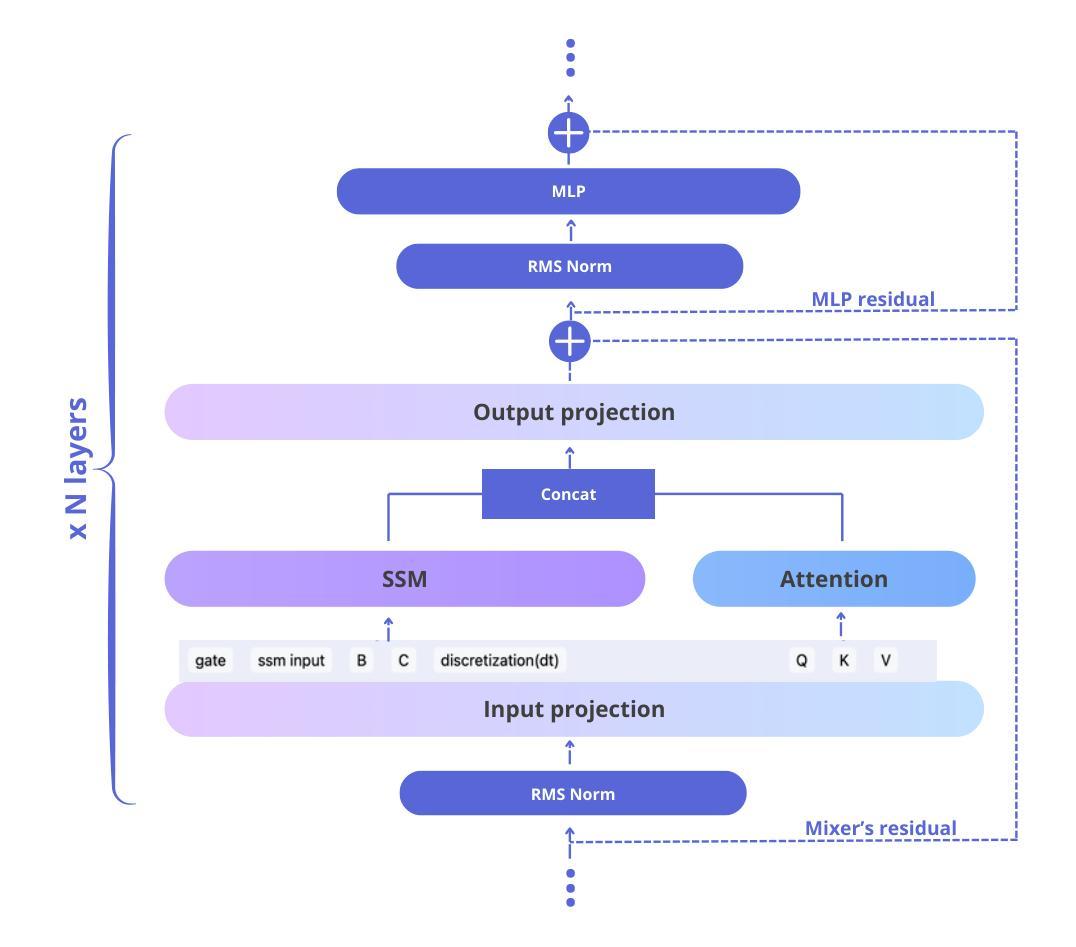
Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
Authors:Jingwei Zuo, Maksim Velikanov, Ilyas Chahed, Younes Belkada, Dhia Eddine Rhayem, Guillaume Kunsch, Hakim Hacid, Hamza Yous, Brahim Farhat, Ibrahim Khadraoui, Mugariya Farooq, Giulia Campesan, Ruxandra Cojocaru, Yasser Djilali, Shi Hu, Iheb Chaabane, Puneesh Khanna, Mohamed El Amine Seddik, Ngoc Dung Huynh, Phuc Le Khac, Leen AlQadi, Billel Mokeddem, Mohamed Chami, Abdalgader Abubaker, Mikhail Lubinets, Kacper Piskorski, Slim Frikha
In this report, we introduce Falcon-H1, a new series of large language models (LLMs) featuring hybrid architecture designs optimized for both high performance and efficiency across diverse use cases. Unlike earlier Falcon models built solely on Transformer or Mamba architectures, Falcon-H1 adopts a parallel hybrid approach that combines Transformer-based attention with State Space Models (SSMs), known for superior long-context memory and computational efficiency. We systematically revisited model design, data strategy, and training dynamics, challenging conventional practices in the field. Falcon-H1 is released in multiple configurations, including base and instruction-tuned variants at 0.5B, 1.5B, 1.5B-deep, 3B, 7B, and 34B parameters. Quantized instruction-tuned models are also available, totaling over 30 checkpoints on Hugging Face Hub. Falcon-H1 models demonstrate state-of-the-art performance and exceptional parameter and training efficiency. The flagship Falcon-H1-34B matches or outperforms models up to 70B scale, such as Qwen3-32B, Qwen2.5-72B, and Llama3.3-70B, while using fewer parameters and less data. Smaller models show similar trends: the Falcon-H1-1.5B-Deep rivals current leading 7B-10B models, and Falcon-H1-0.5B performs comparably to typical 7B models from 2024. These models excel across reasoning, mathematics, multilingual tasks, instruction following, and scientific knowledge. With support for up to 256K context tokens and 18 languages, Falcon-H1 is suitable for a wide range of applications. All models are released under a permissive open-source license, underscoring our commitment to accessible and impactful AI research.
在此报告中,我们介绍了Falcon-H1,这是一个新的大型语言模型(LLM)系列,具有混合架构设计,针对各种用例进行了高性能和效率的优化。不同于早期仅基于Transformer或Mamba架构的Falcon模型,Falcon-H1采用了并行混合方法,将基于Transformer的注意力与以状态空间模型(SSM)相结合,后者以出色的长上下文记忆和计算效率而闻名。我们系统地回顾了模型设计、数据策略和训练动态,挑战了该领域的传统实践。Falcon-H1以多种配置发布,包括基础型和指令调优型,参数从0.5B、1.5B、1.5B-deep、3B、7B到34B。还提供量化指令调优模型,总计超过30个检查点在Hugging Face Hub上提供。Falcon-H1模型展现了最先进的性能和出色的参数和训练效率。旗舰产品Falcon-H1-34B在参数更少和数据更少的情况下,与Qwen3-32B、Qwen2.5-72B和Llama3.3-70B等模型相匹敌或表现更好。较小的模型也显示出类似趋势:Falcon-H1-1.5B-Deep与当前领先的7B-10B模型相匹敌,而Falcon-H1-0.5B的表现与2024年的典型7B模型相当。这些模型在推理、数学、多语种任务、指令遵循和科学知识等方面表现出色。支持高达256K个上下文标记和18种语言,Falcon-H1适用于广泛的应用。所有模型都在许可的开源许可证下发布,这凸显了我们致力于可访问和有影响力的AI研究的承诺。
论文及项目相关链接
PDF Technical report of Falcon-H1 model series
Summary
本报告介绍了新型的大型语言模型系列——Falcon-H1。它采用混合架构设计,结合了Transformer的注意力机制和状态空间模型(SSM)的优势,实现了高性能和效率。Falcon-H1模型系列具有多种配置,包括基础型和指令调优型,参数从0.5B到34B不等。这些模型在参数和训练效率方面表现出卓越的性能,其中旗舰版Falcon-H1-34B在参数更少、数据更少的情况下,与更大规模的模型如Qwen3-32B等相媲美。此外,Falcon-H1还支持多达256K个上下文标记和18种语言,适用于广泛的应用。
Key Takeaways
- Falcon-H1是结合Transformer和SSM的新型大型语言模型系列。
- 它采用了混合架构设计以实现高性能和效率。
- Falcon-H1模型系列具有多种配置,包括不同参数大小的基础型和指令调优型模型。
- 旗舰版Falcon-H1-34B在参数和数据使用方面表现出卓越的性能,与更大规模的模型相媲美。
- Falcon-H1模型在推理、数学、多语言任务、指令遵循和科学知识等方面表现出色。
- Falcon-H1支持多达256K个上下文标记和18种语言,适用于广泛的应用。
点此查看论文截图

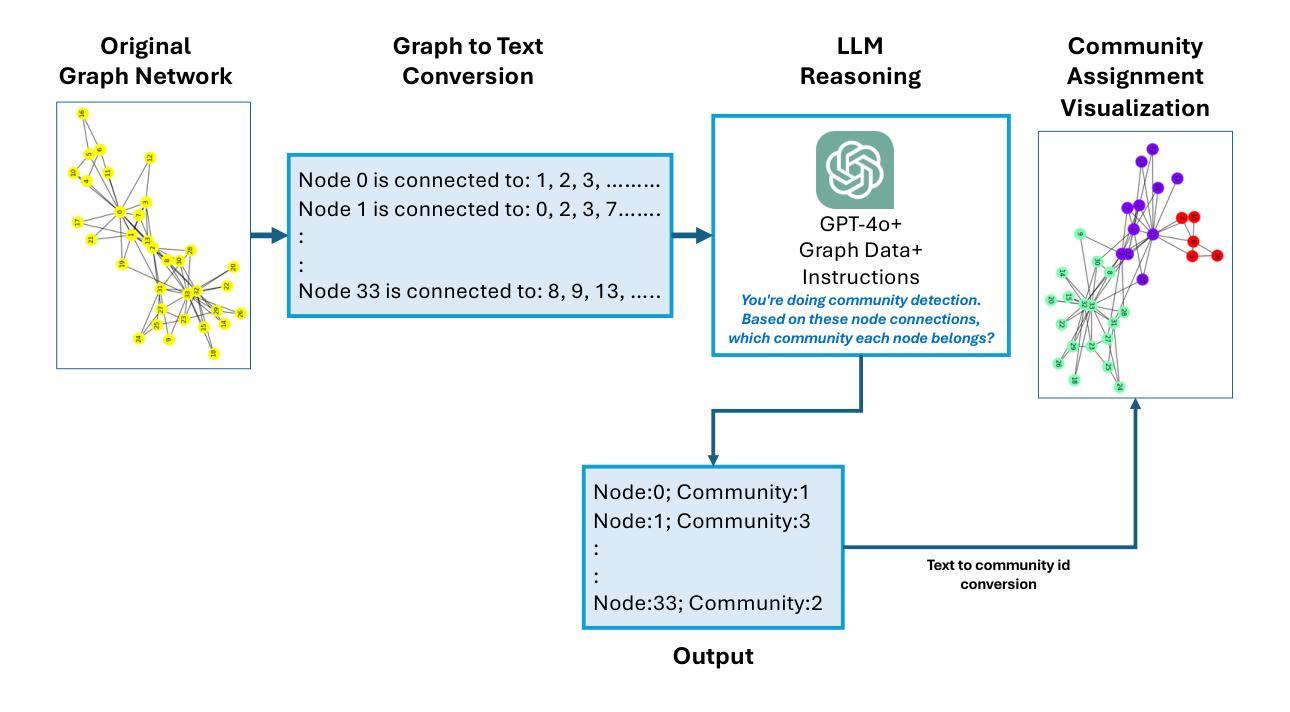
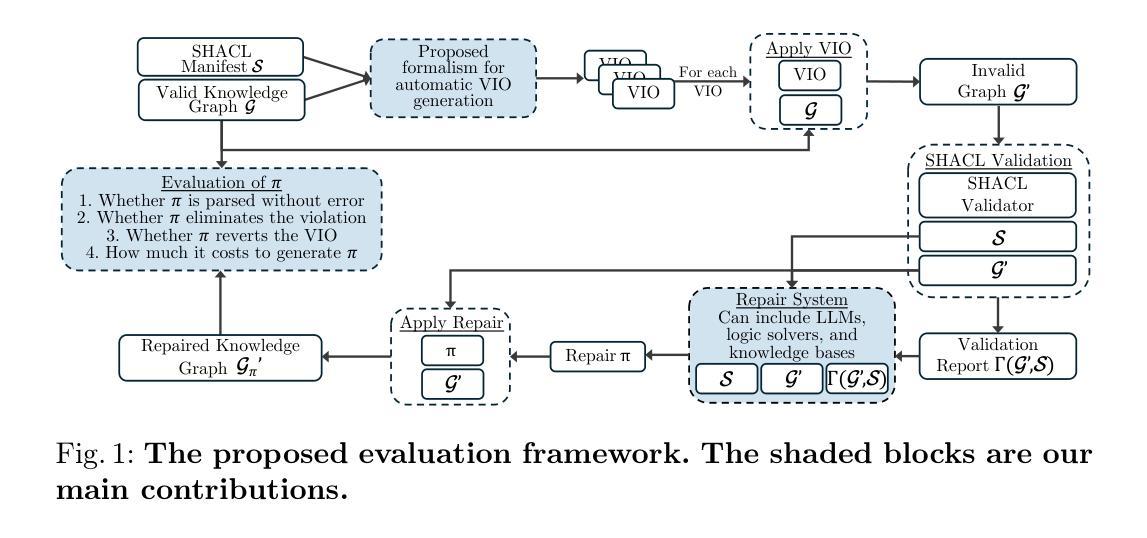
Systematic Evaluation of Knowledge Graph Repair with Large Language Models
Authors:Tung-Wei Lin, Gabe Fierro, Han Li, Tianzhen Hong, Pierluigi Nuzzo, Alberto Sangiovanni-Vinentelli
We present a systematic approach for evaluating the quality of knowledge graph repairs with respect to constraint violations defined in shapes constraint language (SHACL). Current evaluation methods rely on \emph{ad hoc} datasets, which limits the rigorous analysis of repair systems in more general settings. Our method addresses this gap by systematically generating violations using a novel mechanism, termed violation-inducing operations (VIOs). We use the proposed evaluation framework to assess a range of repair systems which we build using large language models. We analyze the performance of these systems across different prompting strategies. Results indicate that concise prompts containing both the relevant violated SHACL constraints and key contextual information from the knowledge graph yield the best performance.
我们提出了一种系统的评估知识图谱修复质量的方法,该方法针对形状约束语言(SHACL)中定义的约束违规情况。当前的评估方法依赖于特定的数据集,这在更一般的环境中限制了修复系统的严格分析。我们的方法通过一种新型机制——违规诱导操作(VIOs)来系统地生成违规情况,以解决这一差距。我们使用提出的评估框架来评估使用大型语言模型构建的多种修复系统。我们分析了这些系统在不同提示策略下的性能。结果表明,包含相关违反的SHACL约束和来自知识图谱的关键上下文信息的简洁提示会产生最佳性能。
论文及项目相关链接
Summary
:本文提出了一种基于SHACL约束语言的知识图谱修复质量评估方法。当前评估方法依赖于特定数据集,限制了修复系统在更广泛环境中的严谨分析。本文方法通过引入一种新型机制——违规诱导操作(VIOs)来系统化生成违规,以评估修复系统。同时,本文利用大型语言模型构建了一系列修复系统,并分析了不同提示策略下的系统性能。结果显示,包含相关违反的SHACL约束和关键上下文信息的简洁提示能带来最佳性能。
Key Takeaways
- 提出了一种新的评估知识图谱修复质量的方法,基于SHACL约束语言。
- 当前评估方法受限于特定数据集,新的方法通过违规诱导操作(VIOs)系统化生成违规。
- 利用大型语言模型构建了一系列修复系统。
- 分析发现,包含相关违反的SHACL约束和关键上下文信息的简洁提示能提高系统性能。
- 评估结果显示,修复系统在处理特定类型的约束违规时表现最佳。
- 这种方法为知识图谱修复领域的未来研究提供了新的方向。
点此查看论文截图


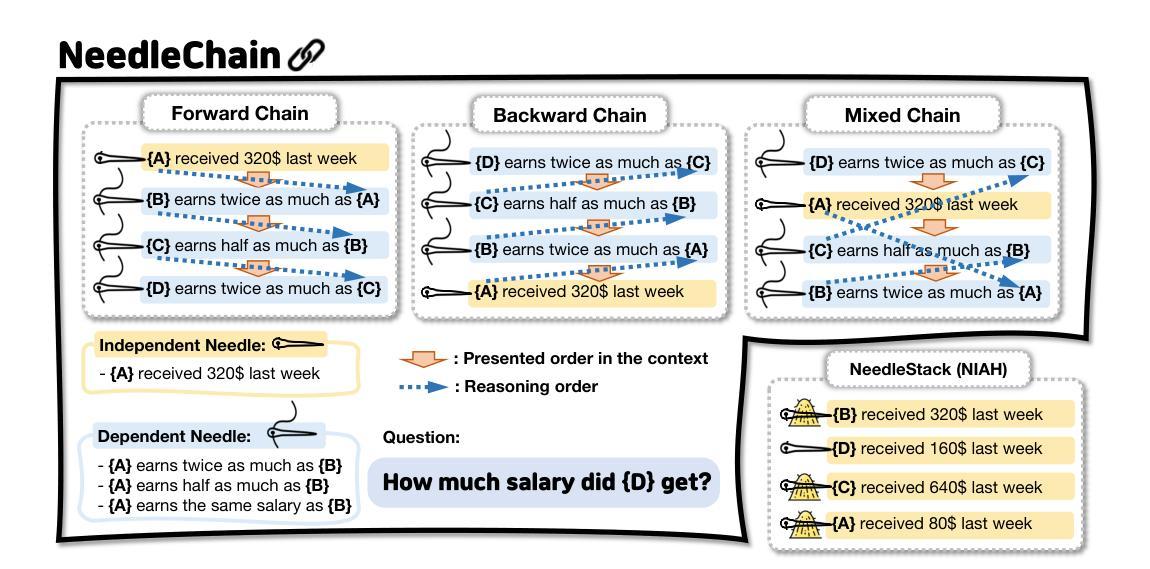
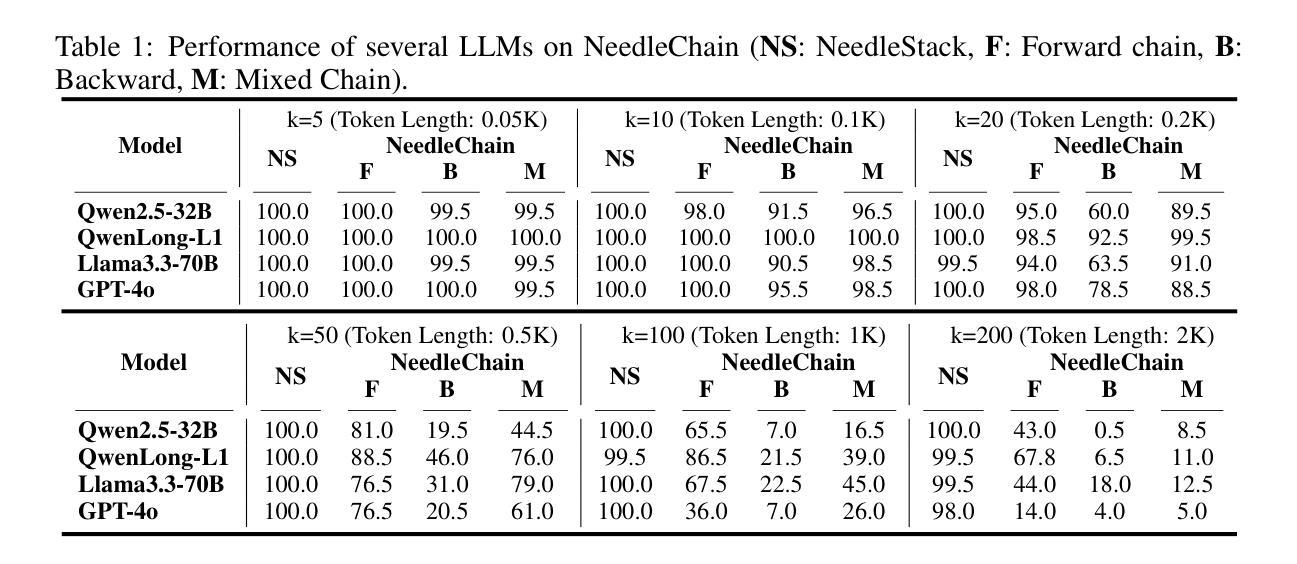
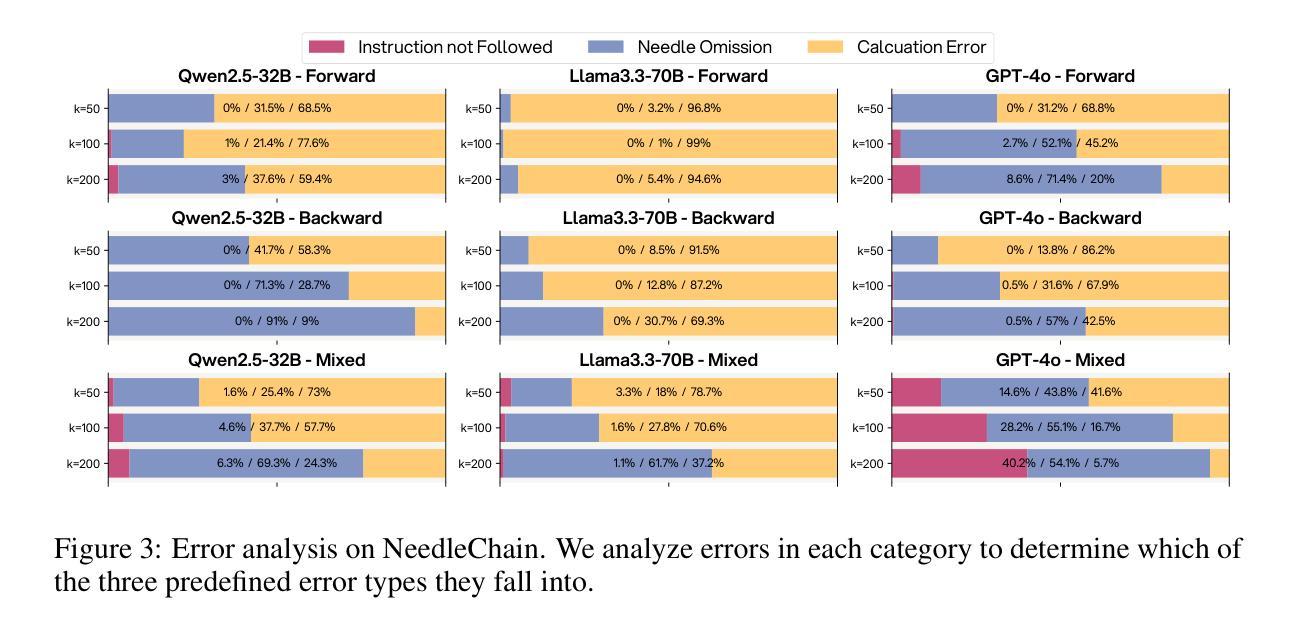
NeedleChain: Measuring Intact Long-Context Reasoning Capability of Large Language Models
Authors:Hyeonseok Moon, Heuiseok Lim
The Needle-in-a-Haystack (NIAH) benchmark is widely used to evaluate Large Language Models’ (LLMs) ability to understand long contexts (LC). It evaluates the capability to identify query-relevant context within extensive query-irrelevant passages. Although this method serves as a widely accepted standard for evaluating long-context understanding, our findings suggest it may overestimate the true LC capability of LLMs. We demonstrate that even state-of-the-art models such as GPT-4o struggle to intactly incorporate given contexts made up of solely query-relevant ten sentences. In response, we introduce a novel benchmark, \textbf{NeedleChain}, where the context consists entirely of query-relevant information, requiring the LLM to fully grasp the input to answer correctly. Our benchmark allows for flexible context length and reasoning order, offering a more comprehensive analysis of LLM performance. Additionally, we propose an extremely simple yet compelling strategy to improve LC understanding capability of LLM: ROPE Contraction. Our experiments with various advanced LLMs reveal a notable disparity between their ability to process large contexts and their capacity to fully understand them. Source code and datasets are available at https://github.com/hyeonseokk/NeedleChain
“针尖在稻草堆中的查找”(Needle-in-a-Haystack,NIAH)基准测试被广泛用于评估大型语言模型(LLM)对长文本上下文(LC)的理解能力。它评价的是在一个大量无关语句中识别出与查询相关的上下文的能力。尽管此方法被广泛接受为评估长文本理解的标准,但我们的研究结果表明,它可能会高估LLM的真正长文本理解能力。我们证明,即使是最先进的模型,如GPT-4o,在完全融入仅由与查询相关的十个句子组成的给定上下文时也面临困难。作为回应,我们引入了一种新的基准测试,“针链”(NeedleChain),其中的上下文完全由与查询相关的信息组成,要求LLM完全理解输入才能正确回答问题。我们的基准测试允许灵活的上下文长度和推理顺序,为LLM的性能提供了更全面的分析。此外,我们提出了一种简单而引人注目的策略来提高LLM对长文本的理解能力:ROPE收缩法。我们对各种先进的LLM进行的实验揭示了它们在处理大量上下文和完全理解上下文之间的显著差异。相关源代码和数据集可在 https://github.com/hyeonseokk/NeedleChain 上找到。
论文及项目相关链接
PDF 13 pages
Summary
大型语言模型(LLM)理解长文本的能力常用Haystack中的针(NIAH)基准测试来评估。该测试评估模型在大量无关文本中识别查询相关上下文的能力。然而,研究发现NIAH可能高估了LLM的真实长文本理解能力。我们展示了最先进的模型如GPT-4o在仅包含查询相关的十句上下文中也难以完全融入。因此,我们引入了新的基准测试——NeedleChain,其中上下文完全由查询相关信息组成,要求LLM完全理解输入才能正确回答。我们的基准测试允许灵活的上下文长度和推理顺序,为评估LLM性能提供了更全面的分析。此外,我们还提出了一种简单而有效的策略——ROPE Contraction,以提高LLM对长文本的理解能力。实验表明,各种先进的LLM在处理大量文本和完全理解它们之间存在明显的差异。
Key Takeaways
- NIAH基准测试被广泛用于评估LLM理解长文本的能力,但可能高估了LLM的真实性能。
- 引入NeedleChain基准测试,完全由查询相关信息组成上下文,更全面地评估LLM的性能。
- NeedleChain允许灵活的上下文长度和推理顺序。
- 提出了提高LLM长文本理解能力的简单而有效的策略——ROPE Contraction。
- 实验结果显示,先进LLM在处理大量文本和完全理解它们之间存在差异。
- NeedleChain基准测试和数据集可在https://github.com/hyeonseokk/NeedleChain找到。
点此查看论文截图


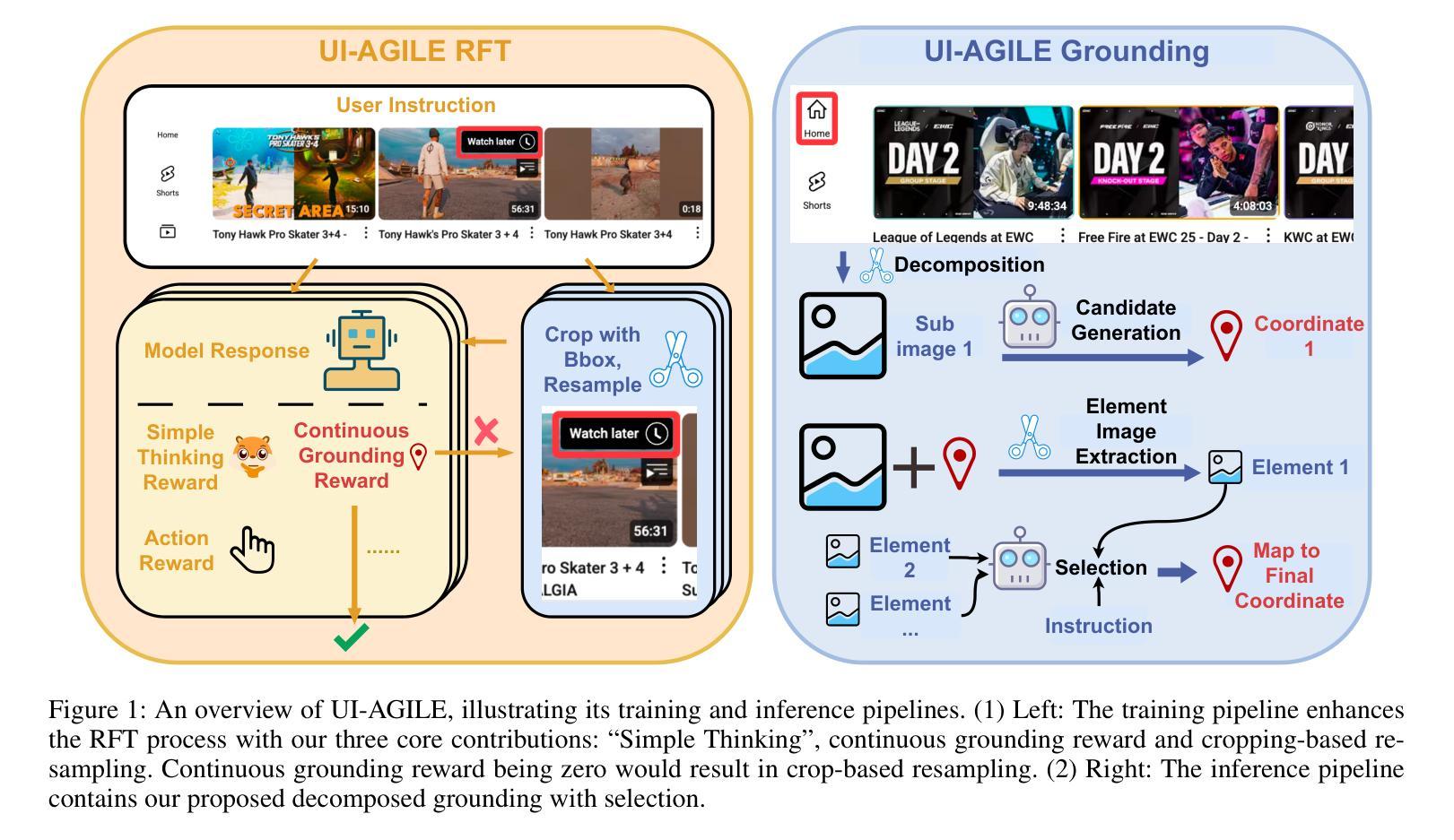
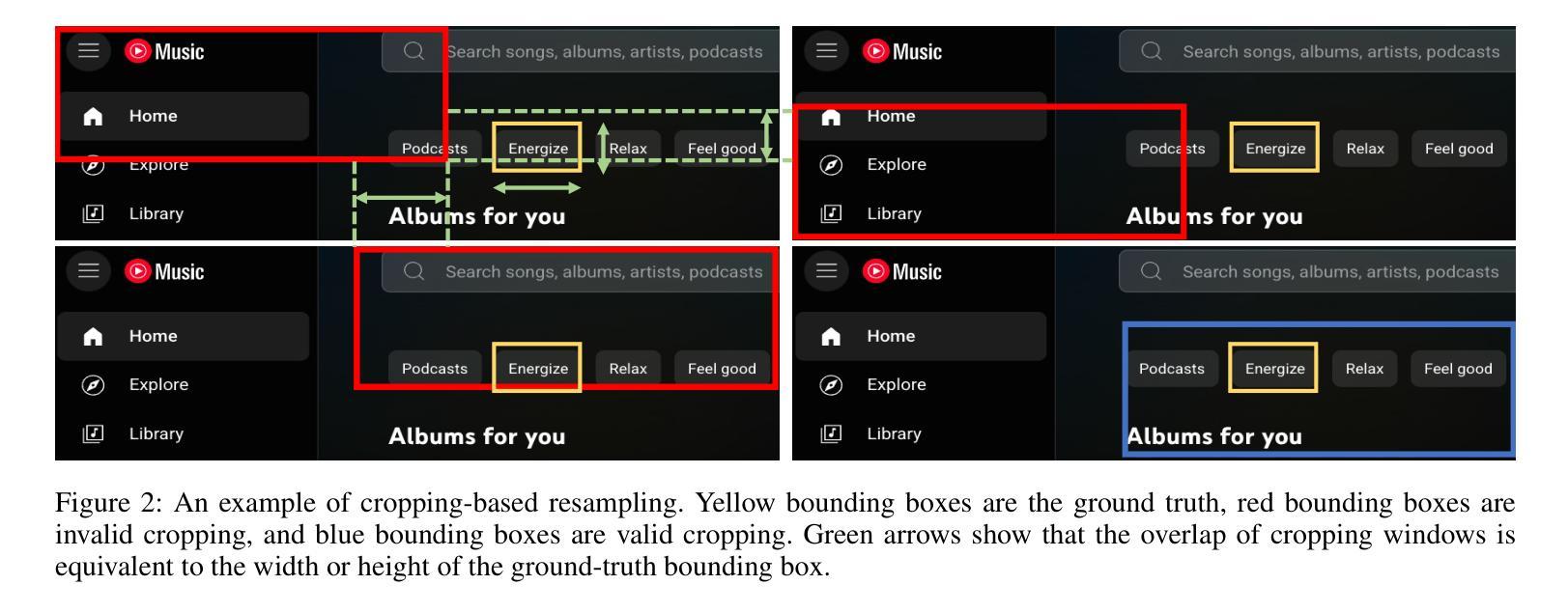
UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
Authors:Shuquan Lian, Yuhang Wu, Jia Ma, Zihan Song, Bingqi Chen, Xiawu Zheng, Hui Li
The emergence of Multimodal Large Language Models (MLLMs) has driven significant advances in Graphical User Interface (GUI) agent capabilities. Nevertheless, existing GUI agent training and inference techniques still suffer from a dilemma for reasoning designs, ineffective reward, and visual noise. To address these issues, we introduce UI-AGILE, a comprehensive framework enhancing GUI agents at both the training and inference stages. For training, we propose a suite of improvements to the Supervised Fine-Tuning (SFT) process: 1) a Continuous Reward function to incentivize high-precision grounding; 2) a “Simple Thinking” reward to balance planning with speed and grounding accuracy; and 3) a Cropping-based Resampling strategy to mitigate the sparse reward problem and improve learning on complex tasks. For inference, we present Decomposed Grounding with Selection, a novel method that dramatically improves grounding accuracy on high-resolution displays by breaking the image into smaller, manageable parts. Experiments show that UI-AGILE achieves the state-of-the-art performance on two benchmarks ScreenSpot-Pro and ScreenSpot-v2. For instance, using both our proposed training and inference enhancement methods brings 23% grounding accuracy improvement over the best baseline on ScreenSpot-Pro.
多模态大型语言模型(MLLMs)的出现推动了图形用户界面(GUI)代理能力的显著进步。然而,现有的GUI代理训练和推理技术仍然面临着推理设计、奖励无效和视觉噪声的困境。为了解决这些问题,我们引入了UI-AGILE,这是一个在训练和推理阶段增强GUI代理的综合框架。在训练方面,我们对有监督微调(SFT)过程提出了一系列改进:1)连续奖励功能,以激励高精度接地;2)“简单思考”奖励,以平衡规划与速度和接地准确性;3)基于裁剪的重新采样策略,以缓解稀疏奖励问题并提高复杂任务上的学习效果。对于推理,我们提出了分解接地与选择法,通过将图像分割成更小、更易管理的部分,显著提高了在高分辨率显示器上的接地准确性。实验表明,UI-AGILE在ScreenSpot-Pro和ScreenSpot-v2两个基准测试上达到了最新性能水平。例如,使用我们提出的训练和推理增强方法,在ScreenSpot-Pro上的最佳基线基础上提高了23%的接地准确性。
论文及项目相关链接
Summary
本文主要介绍了多模态大型语言模型(MLLMs)的兴起对图形用户界面(GUI)智能体能力的推动作用。针对现有GUI智能体的训练和推理技术存在的问题,如推理设计困境、奖励机制无效和视觉噪声等,本文提出了UI-AGILE框架,在训练和推理阶段提升GUI智能体的性能。训练方面,作者对监督微调(SFT)过程进行了一系列改进,包括连续奖励函数、“简单思考”奖励和基于裁剪的重新采样策略。推理方面,提出了一种名为分解接地与选择的新方法,通过将图像分割成较小的部分来提高在高分辨率显示器上的接地精度。实验表明,UI-AGILE在ScreenSpot-Pro和ScreenSpot-v2两个基准测试上取得了最新性能。例如,使用本文提出的训练和推理增强方法,在ScreenSpot-Pro上的接地精度比最佳基线提高了23%。
Key Takeaways
- 多模态大型语言模型(MLLMs)推动了GUI智能体能力的显著进步。
- 现有GUI智能体的训练和推理技术面临困境,如推理设计、奖励机制无效和视觉噪声等问题。
- UI-AGILE框架旨在解决这些问题,提升GUI智能体的训练和推理性能。
- 训练阶段的改进包括连续奖励函数、“简单思考”奖励和基于裁剪的重新采样策略。
- 推理阶段提出了一种新的分解接地与选择方法,提高了在高分辨率显示器上的接地精度。
- UI-AGILE在ScreenSpot-Pro和ScreenSpot-v2两个基准测试上实现了最佳性能。
点此查看论文截图


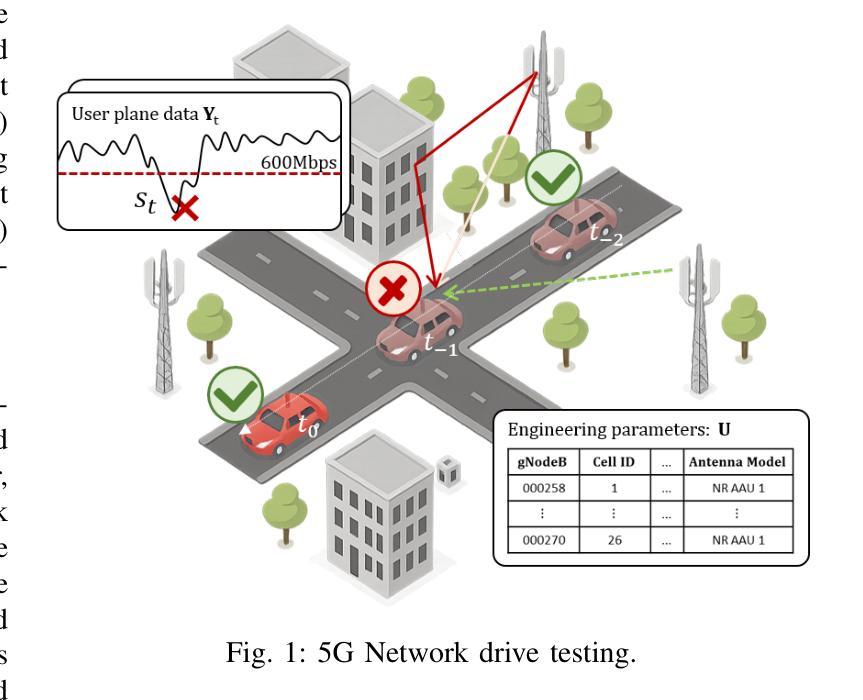
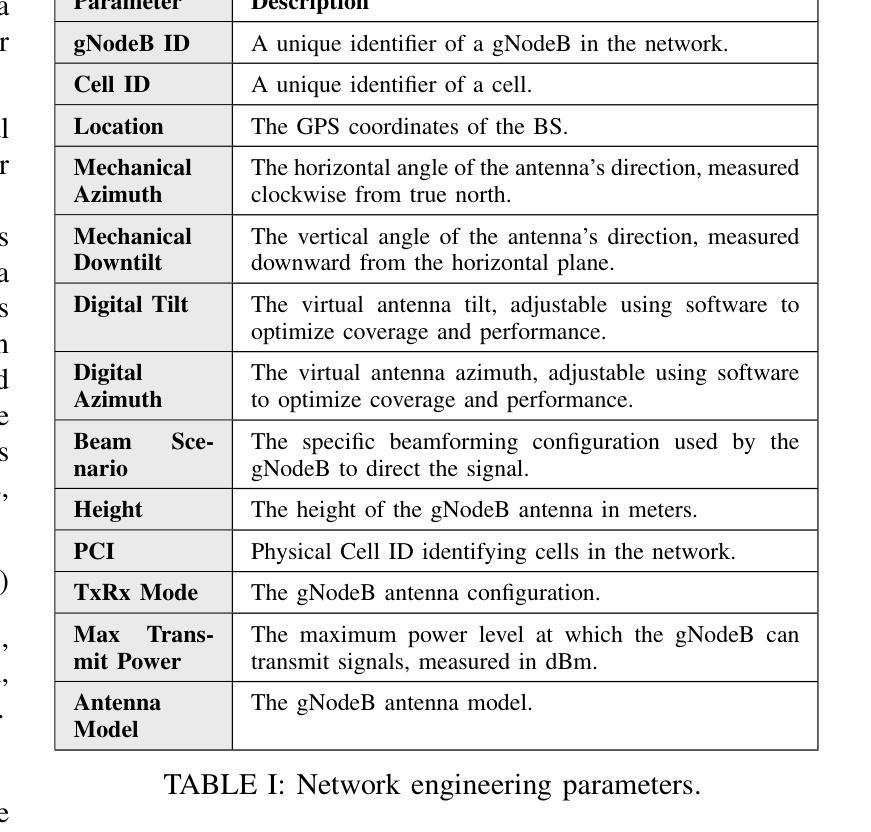
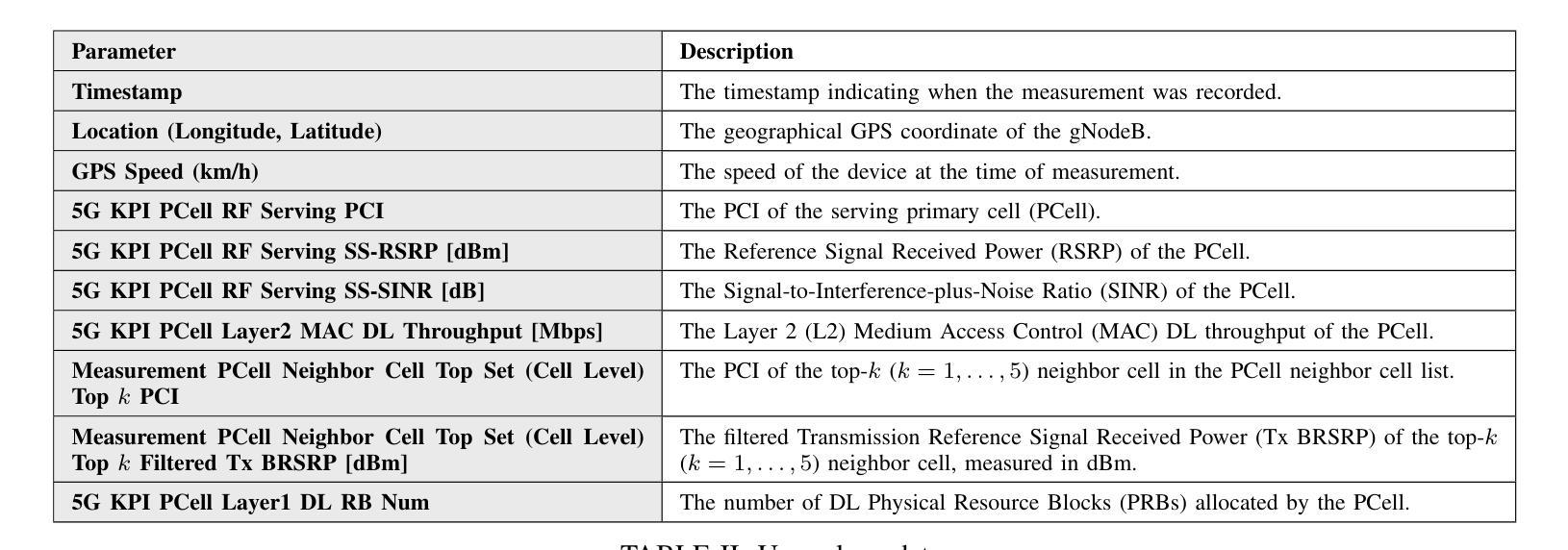
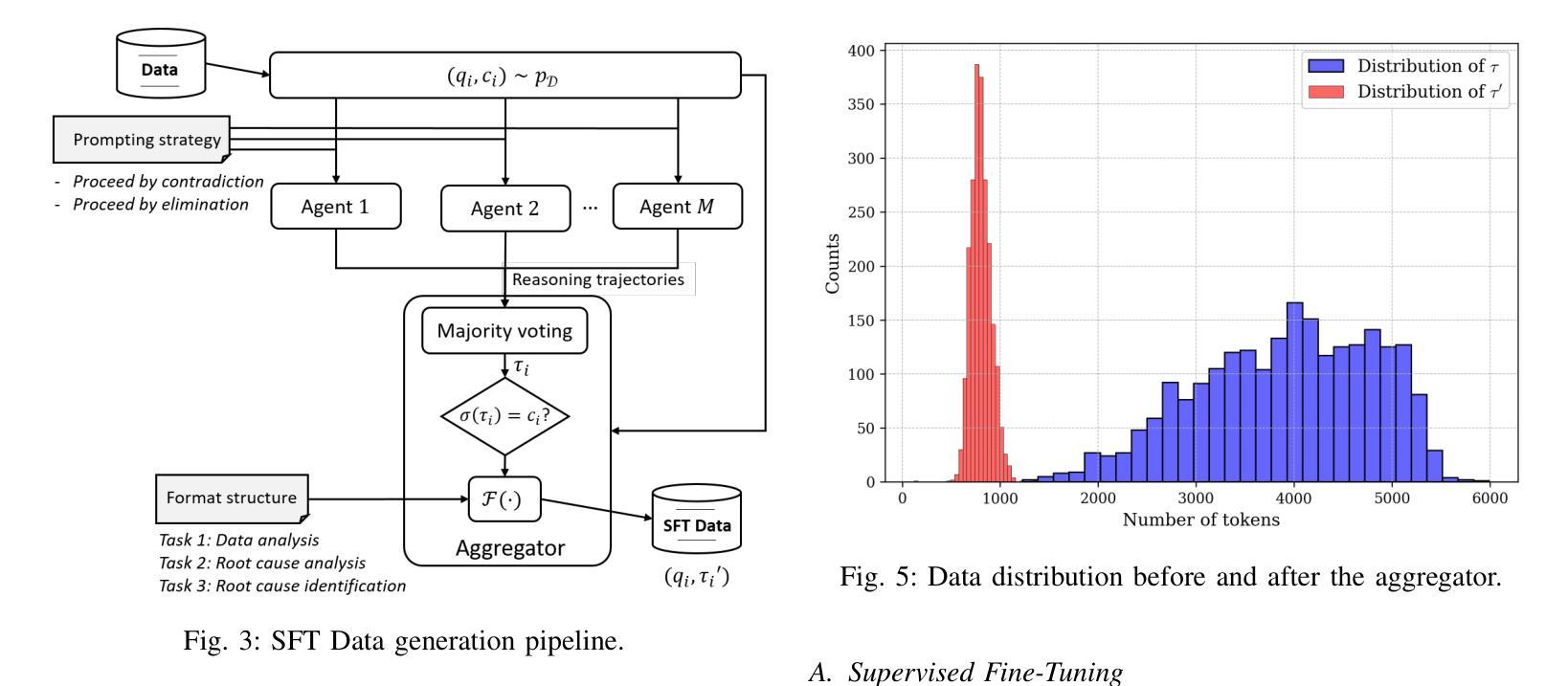
Reasoning Language Models for Root Cause Analysis in 5G Wireless Networks
Authors:Mohamed Sana, Nicola Piovesan, Antonio De Domenico, Yibin Kang, Haozhe Zhang, Merouane Debbah, Fadhel Ayed
Root Cause Analysis (RCA) in mobile networks remains a challenging task due to the need for interpretability, domain expertise, and causal reasoning. In this work, we propose a lightweight framework that leverages Large Language Models (LLMs) for RCA. To do so, we introduce TeleLogs, a curated dataset of annotated troubleshooting problems designed to benchmark RCA capabilities. Our evaluation reveals that existing open-source reasoning LLMs struggle with these problems, underscoring the need for domain-specific adaptation. To address this issue, we propose a two-stage training methodology that combines supervised fine-tuning with reinforcement learning to improve the accuracy and reasoning quality of LLMs. The proposed approach fine-tunes a series of RCA models to integrate domain knowledge and generate structured, multi-step diagnostic explanations, improving both interpretability and effectiveness. Extensive experiments across multiple LLM sizes show significant performance gains over state-of-the-art reasoning and non-reasoning models, including strong generalization to randomized test variants. These results demonstrate the promise of domain-adapted, reasoning-enhanced LLMs for practical and explainable RCA in network operation and management.
移动网络中的根本原因分析(RCA)由于需要可解释性、领域专业知识和因果推理,仍然是一项具有挑战性的任务。在这项工作中,我们提出了一个利用大型语言模型(LLM)进行RCA的轻量级框架。为此,我们引入了TeleLogs,这是一个经过注释的故障排除问题数据集,旨在评估RCA能力。我们的评估表明,现有的开源推理LLM在处理这些问题时遇到困难,这突显了领域特定适应性的需求。为了解决这一问题,我们提出了一种两阶段训练方法,将监督微调与强化学习相结合,以提高LLM的准确性和推理质量。所提出的方法对一系列RCA模型进行微调,以整合领域知识并生成结构化、多步骤的诊断解释,提高可解释性和有效性。跨多个LLM大小的广泛实验表明,与最新推理和非推理模型相比,所提出的方法在性能上有显著的提升,包括对随机测试变量的强大泛化能力。这些结果展示了领域适应、增强推理的LLM在网络操作和管理中的实际和可解释RCA的潜力。
论文及项目相关链接
Summary
在本研究中,针对移动网络中的根本原因分析(RCA)挑战,提出一种利用大型语言模型(LLM)的轻量级框架。通过引入TeleLogs数据集,评估现有推理LLM在故障排除问题上的表现,发现需要针对特定领域进行适应。为解决这一问题,研究提出了一种两阶段训练法,结合监督微调与强化学习,提高LLM的准确性和推理质量。该方法可微调一系列RCA模型,整合领域知识,生成结构化、多步骤的诊断解释,提高解释性和有效性。实验表明,该方法在多个LLM尺寸上均表现出卓越性能,相较于最新推理和非推理模型有显著优势,并在随机测试变体上展现出强大的泛化能力。这证明了领域适应的推理增强LLM在网络操作和管理中的实际和可解释RCA方面的潜力。
Key Takeaways
- 移动网络中的根本原因分析(RCA)是一项具有挑战性的任务,需要可解释性、领域专业知识和因果推理。
- 提出一种利用大型语言模型(LLM)的轻量级框架进行RCA。
- 引入TeleLogs数据集,用于评估推理LLM在故障排除问题上的性能。
- 现有开放源码推理LLM在这些问题上表现挣扎,需要领域特定适应。
- 提出一种两阶段训练法,结合监督微调与强化学习,提高LLM的准确性和推理质量。
- 方法可生成结构化、多步骤的诊断解释,提高解释性和有效性。
点此查看论文截图


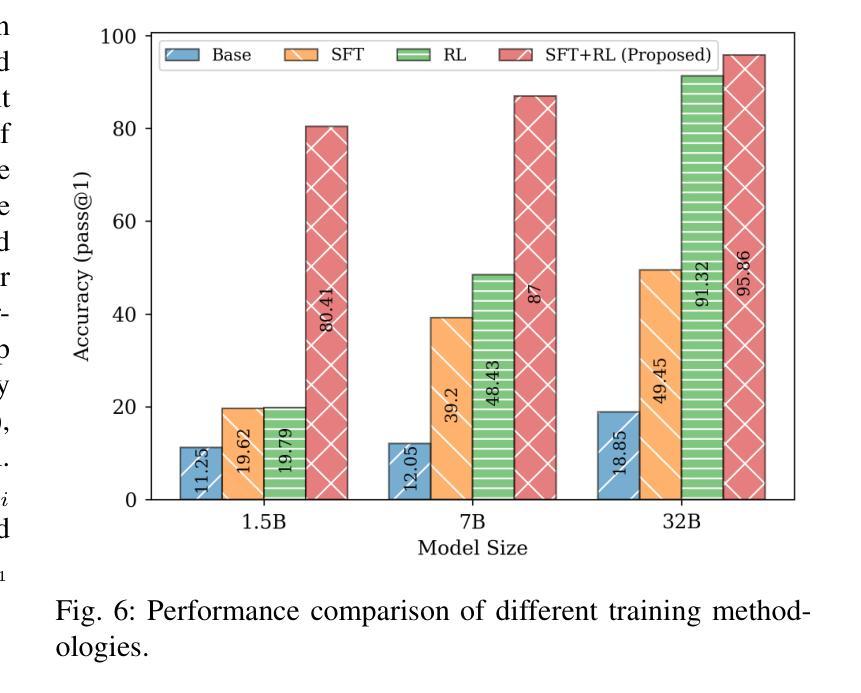
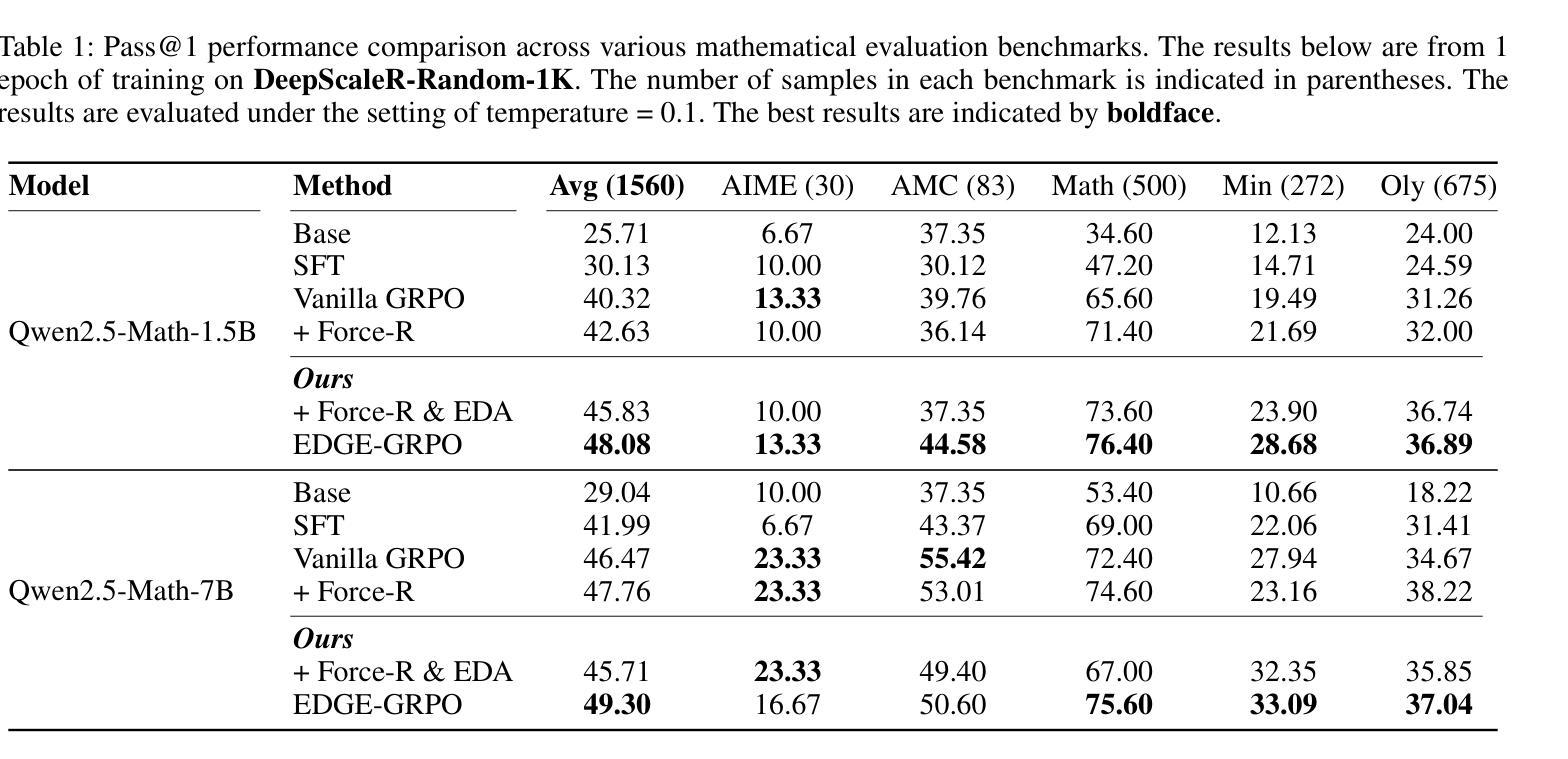
EDGE-GRPO: Entropy-Driven GRPO with Guided Error Correction for Advantage Diversity
Authors:Xingjian Zhang, Siwei Wen, Wenjun Wu, Lei Huang
Large Language Models (LLMs) have made remarkable progress in enhancing step-by-step reasoning through reinforcement learning. However, the Group Relative Policy Optimization (GRPO) algorithm, which relies on sparse reward rules, often encounters the issue of identical rewards within groups, leading to the advantage collapse problem. Existing works typically address this challenge from two perspectives: enforcing model reflection to enhance response diversity, and introducing internal feedback to augment the training signal (advantage). In this work, we begin by analyzing the limitations of model reflection and investigating the policy entropy of responses at the fine-grained sample level. Based on our experimental findings, we propose the EDGE-GRPO algorithm, which adopts \textbf{E}ntropy-\textbf{D}riven Advantage and \textbf{G}uided \textbf{E}rror Correction to effectively mitigate the problem of advantage collapse. Extensive experiments on several main reasoning benchmarks demonstrate the effectiveness and superiority of our approach. It is available at https://github.com/ZhangXJ199/EDGE-GRPO.
大型语言模型(LLMs)通过强化学习在逐步推理方面取得了显著进步。然而,依赖稀疏奖励规则的组相对策略优化(GRPO)算法经常遇到组内相同奖励的问题,导致优势崩溃问题。现有工作通常从两个角度来解决这一挑战:通过强制模型反射来增强响应多样性,以及引入内部反馈来增强训练信号(优势)。在这项工作中,我们首先分析模型反射的局限性,并研究细粒度样本级别响应的策略熵。基于我们的实验发现,我们提出了EDGE-GRPO算法,该算法采用熵驱动优势和导向误差校正,有效地缓解了优势崩溃问题。在几个主要的推理基准测试上的广泛实验证明了我们方法的有效性和优越性。可通过https://github.com/ZhangXJ199/EDGE-GRPO获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在通过强化学习提升逐步推理能力方面取得了显著进展。然而,依赖稀疏奖励规则的Group Relative Policy Optimization(GRPO)算法常遇到组内相同奖励的问题,导致优势崩溃。现有工作主要从两个角度解决这一问题:强制模型反思以增强响应多样性,以及引入内部反馈以增加训练信号(优势)。本研究首先分析了模型反思的局限性,并调查了响应策略熵的精细样本水平。基于实验发现,我们提出了EDGE-GRPO算法,采用熵驱动优势和引导错误修正,有效解决优势崩溃问题。在多个主要推理基准测试上的广泛实验证明了该方法的有效性和优越性。
Key Takeaways
- 大型语言模型(LLMs)在强化学习下逐步增强推理能力。
- Group Relative Policy Optimization (GRPO) 算法面临组内相同奖励的问题,即优势崩溃。
- 现有解决方案包括强制模型反思和引入内部反馈。
- 本研究分析了模型反思的局限性,并调查了响应策略熵的精细样本水平。
- 提出了EDGE-GRPO算法,通过熵驱动优势和引导错误修正解决优势崩溃问题。
- 在多个基准测试上,EDGE-GRPO算法展现出优越效果。
点此查看论文截图

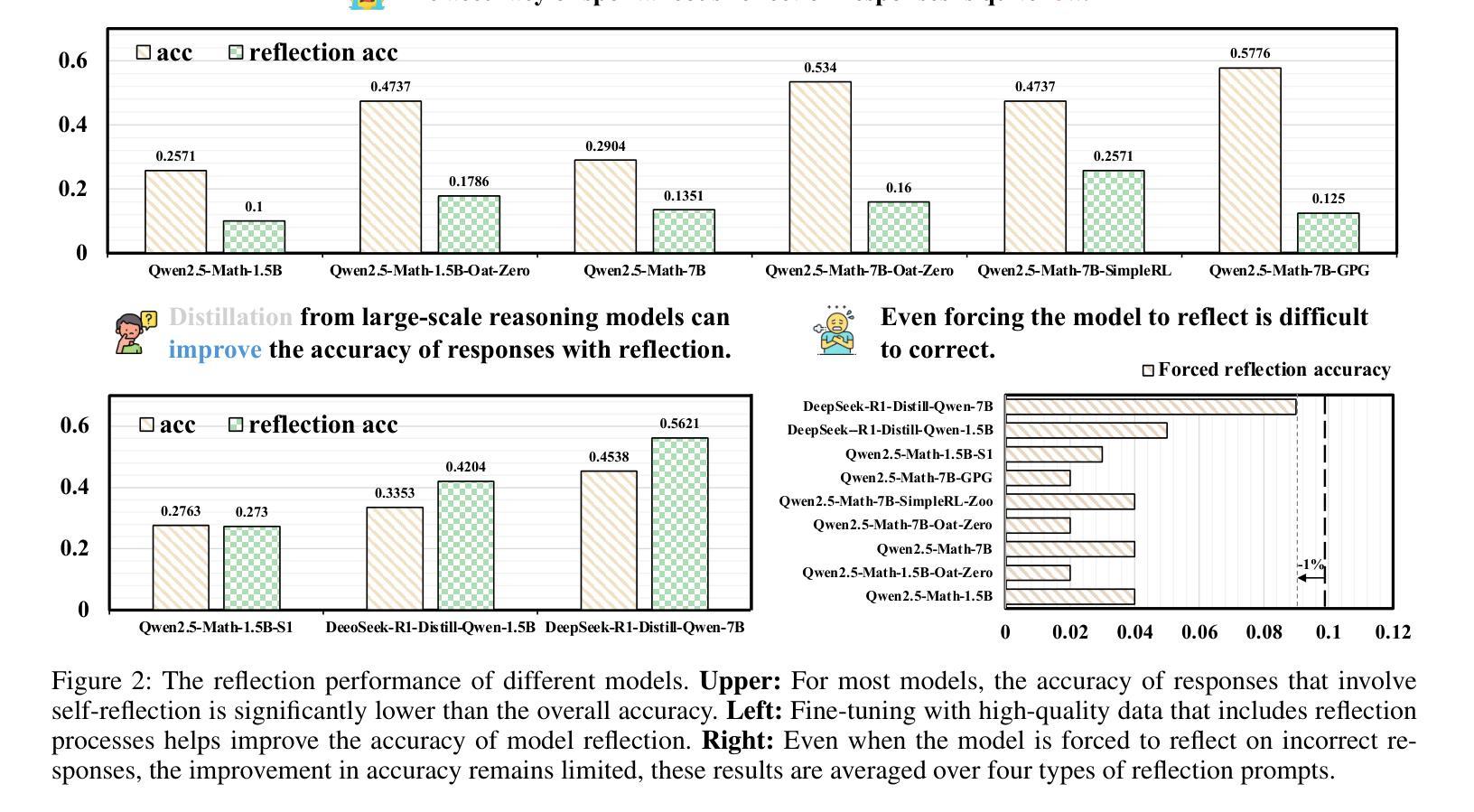
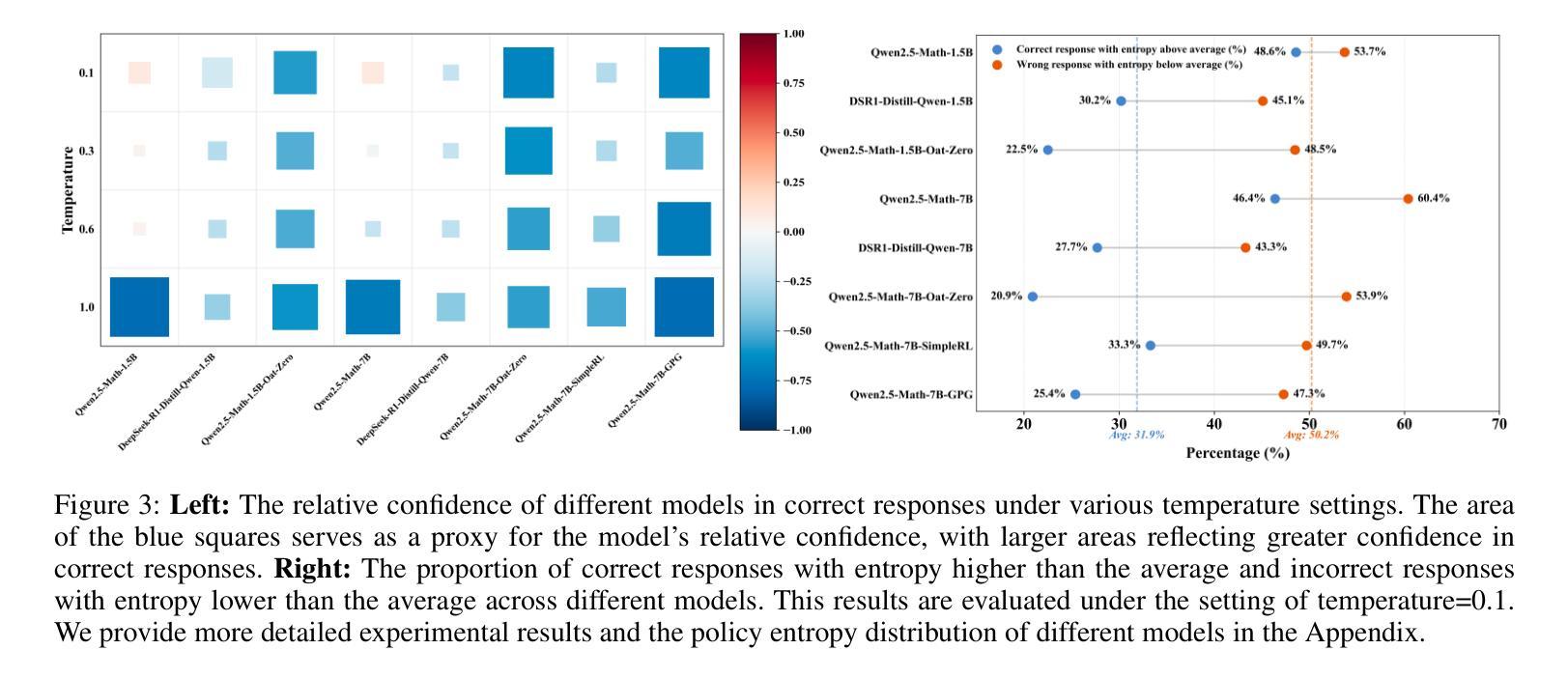
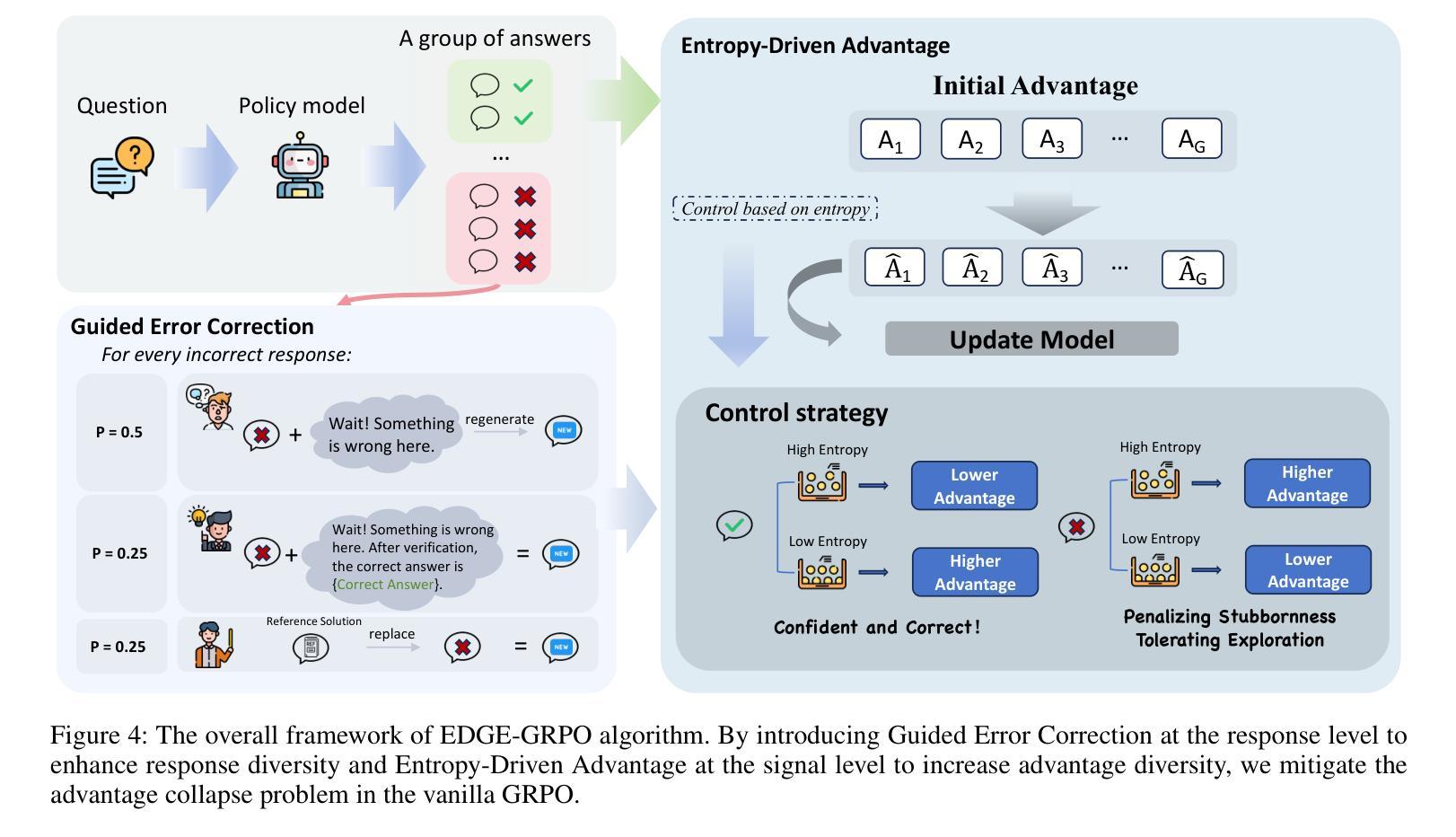
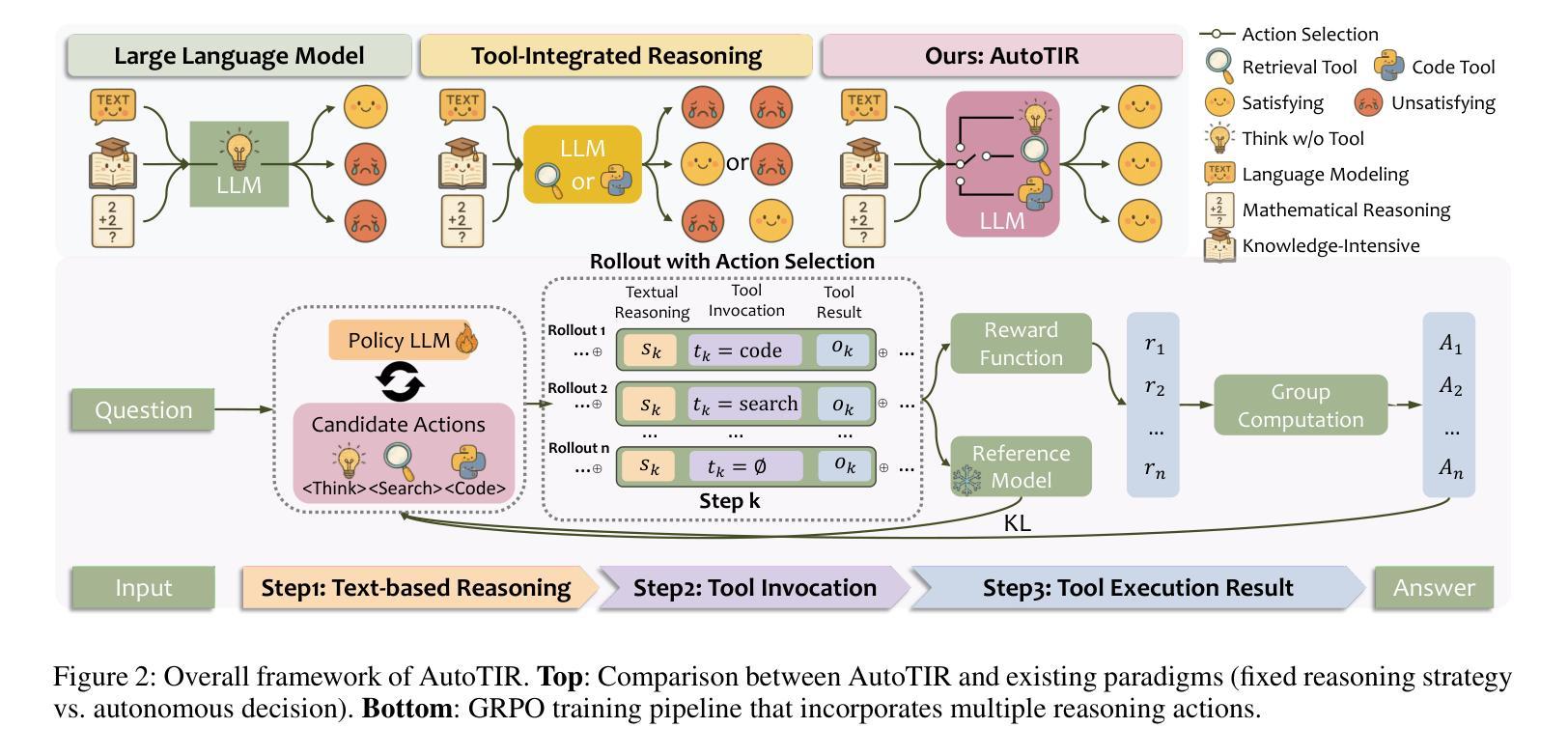
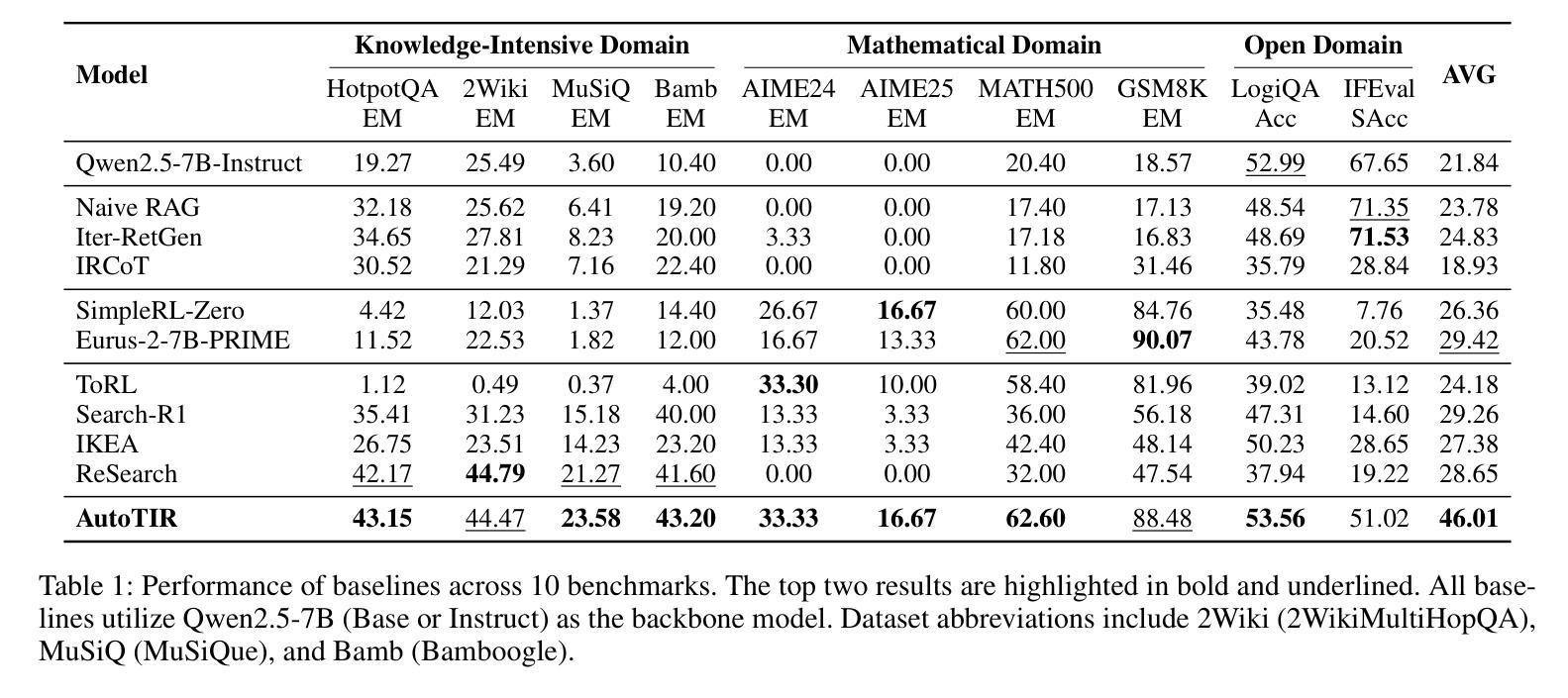
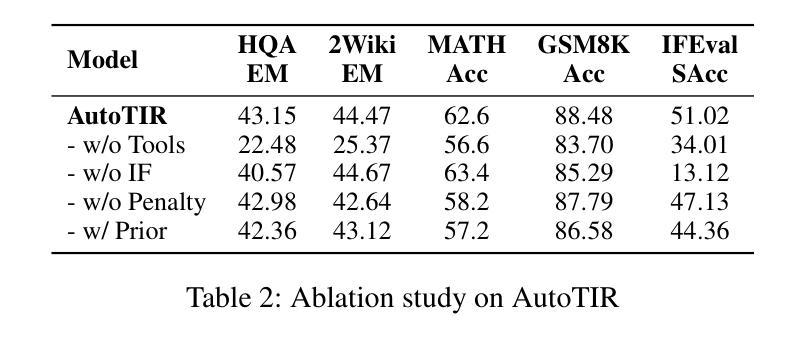
AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning
Authors:Yifan Wei, Xiaoyan Yu, Yixuan Weng, Tengfei Pan, Angsheng Li, Li Du
Large Language Models (LLMs), when enhanced through reasoning-oriented post-training, evolve into powerful Large Reasoning Models (LRMs). Tool-Integrated Reasoning (TIR) further extends their capabilities by incorporating external tools, but existing methods often rely on rigid, predefined tool-use patterns that risk degrading core language competence. Inspired by the human ability to adaptively select tools, we introduce AutoTIR, a reinforcement learning framework that enables LLMs to autonomously decide whether and which tool to invoke during the reasoning process, rather than following static tool-use strategies. AutoTIR leverages a hybrid reward mechanism that jointly optimizes for task-specific answer correctness, structured output adherence, and penalization of incorrect tool usage, thereby encouraging both precise reasoning and efficient tool integration. Extensive evaluations across diverse knowledge-intensive, mathematical, and general language modeling tasks demonstrate that AutoTIR achieves superior overall performance, significantly outperforming baselines and exhibits superior generalization in tool-use behavior. These results highlight the promise of reinforcement learning in building truly generalizable and scalable TIR capabilities in LLMs. The code and data are available at https://github.com/weiyifan1023/AutoTIR.
大型语言模型(LLM)通过面向推理的后训练增强,进化为强大的大型推理模型(LRM)。工具集成推理(TIR)通过融入外部工具进一步扩展了它们的能力,但现有方法往往依赖于僵化的预定义工具使用模式,这可能会削弱核心语言技能。受人类自适应选择工具能力的启发,我们引入了AutoTIR,这是一个强化学习框架,它使LLM能够自主决定是否在推理过程中调用工具以及调用哪个工具,而不是遵循静态的工具使用策略。AutoTIR利用混合奖励机制,联合优化针对特定任务的答案正确性、结构输出遵循和错误工具使用的惩罚,从而鼓励精确推理和有效的工具集成。在多样化知识密集型、数学和一般语言建模任务上的广泛评估表明,AutoTIR实现了卓越的整体性能,显著优于基准测试,并在工具使用行为中表现出优异的泛化能力。这些结果突显了强化学习在LLM中构建真正通用和可扩展的TIR能力的潜力。代码和数据可在https://github.com/weiyifan1023/AutoTIR找到。
论文及项目相关链接
Summary
大型语言模型通过推理导向的后期训练进化为强大的大型推理模型。工具集成推理技术进一步扩展了其功能,但现有方法通常依赖于预设的工具使用模式,可能会削弱其核心语言竞争力。本文提出一种基于强化学习的AutoTIR框架,使语言模型能够自适应选择是否调用外部工具,进行推理决策。AutoTIR使用混合奖励机制优化任务特定答案的正确性、结构化输出的遵循性以及对不正确工具使用的惩罚,从而实现精确推理和高效工具集成。评估表明,AutoTIR在多种知识密集型、数学和一般语言建模任务上的总体性能优于基准测试,展现出良好的工具使用行为泛化能力。该代码和数据在GitHub上可用。
Key Takeaways
- 大型语言模型通过推理导向的后期训练可进化为大型推理模型。
- 工具集成推理技术扩展了语言模型的功能,但现有方法存在依赖预设工具使用模式的局限性。
- AutoTIR框架采用强化学习,使语言模型能自主决定是否使用外部工具进行推理。
- AutoTIR使用混合奖励机制优化任务性能,包括答案的正确性、结构化输出的遵循性和对不正确工具使用的惩罚。
- AutoTIR在多种任务上表现出优越的性能,优于基准测试,具有良好的工具使用行为泛化能力。
点此查看论文截图

MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Authors:Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, Zhao Zhong
Although GRPO substantially enhances flow matching models in human preference alignment of image generation, methods such as FlowGRPO still exhibit inefficiency due to the necessity of sampling and optimizing over all denoising steps specified by the Markov Decision Process (MDP). In this paper, we propose $\textbf{MixGRPO}$, a novel framework that leverages the flexibility of mixed sampling strategies through the integration of stochastic differential equations (SDE) and ordinary differential equations (ODE). This streamlines the optimization process within the MDP to improve efficiency and boost performance. Specifically, MixGRPO introduces a sliding window mechanism, using SDE sampling and GRPO-guided optimization only within the window, while applying ODE sampling outside. This design confines sampling randomness to the time-steps within the window, thereby reducing the optimization overhead, and allowing for more focused gradient updates to accelerate convergence. Additionally, as time-steps beyond the sliding window are not involved in optimization, higher-order solvers are supported for sampling. So we present a faster variant, termed $\textbf{MixGRPO-Flash}$, which further improves training efficiency while achieving comparable performance. MixGRPO exhibits substantial gains across multiple dimensions of human preference alignment, outperforming DanceGRPO in both effectiveness and efficiency, with nearly 50% lower training time. Notably, MixGRPO-Flash further reduces training time by 71%. Codes and models are available at $\href{https://github.com/Tencent-Hunyuan/MixGRPO}{MixGRPO}$.
尽管GRPO在很大程度上增强了图像生成中人类偏好对齐的流量匹配模型,但FlowGRPO等方法仍表现出由于马尔可夫决策过程(MDP)指定的所有去噪步骤都需要采样和优化而导致的不高效。在本文中,我们提出了$\textbf{MixGRPO}$,这是一个新的框架,它通过混合微分方程(SDE)和常微分方程(ODE)的集成,利用混合采样策略的灵活性。这简化了MDP中的优化过程,提高了效率并提升了性能。具体来说,MixGRPO引入了一个滑动窗口机制,仅在窗口内使用SDE采样和GRPO指导的优化,而在窗口外应用ODE采样。这种设计将采样随机性限制在窗口的时间步内,从而减少了优化开销,并允许更集中的梯度更新以加速收敛。此外,由于滑动窗口之外的时间步不参与优化,因此支持更高阶的求解器进行采样。因此,我们提出了一种更快的变体,称为$\textbf{MixGRPO-Flash}$,它进一步提高了训练效率,同时实现了相当的性能。MixGRPO在人类偏好对齐的多个维度上都取得了实质性的收益,在有效性和效率方面都超越了DanceGRPO,训练时间降低了近50%。值得注意的是,MixGRPO-Flash进一步将训练时间减少了71%。代码和模型可在$\href{https://github.com/Tencent-Hunyuan/MixGRPO}{MixGRPO}$获取。
论文及项目相关链接
Summary
文本提出了一个新的框架MixGRPO,它通过混合采样策略,利用随机微分方程和普通微分方程来优化Markov决策过程中的优化过程,以提高效率和性能。MixGRPO引入滑动窗口机制,只在窗口内使用SDE采样和GRPO引导的优化,窗口外应用ODE采样。该方法降低了优化开销,并支持更高阶的采样求解器,进一步提高训练效率。其中,MixGRPO-Flash作为更高效变种,训练时间缩短了约71%。此新方法在人类偏好对齐的多个维度上都取得了显著的提升。
Key Takeaways
- MixGRPO是一个新的框架,用于改进图像生成中人类偏好对齐的流匹配模型。
- 它结合了随机微分方程和普通微分方程来优化Markov决策过程。
- MixGRPO引入了滑动窗口机制,只在特定窗口内进行采样和优化,提高了效率。
- 该方法支持更高阶的采样求解器,进一步提升了训练效率。
- MixGRPO-Flash作为MixGRPO的变种,训练时间缩短了约71%。
- MixGRPO在人类偏好对齐的多个维度上实现了显著的性能提升。
点此查看论文截图


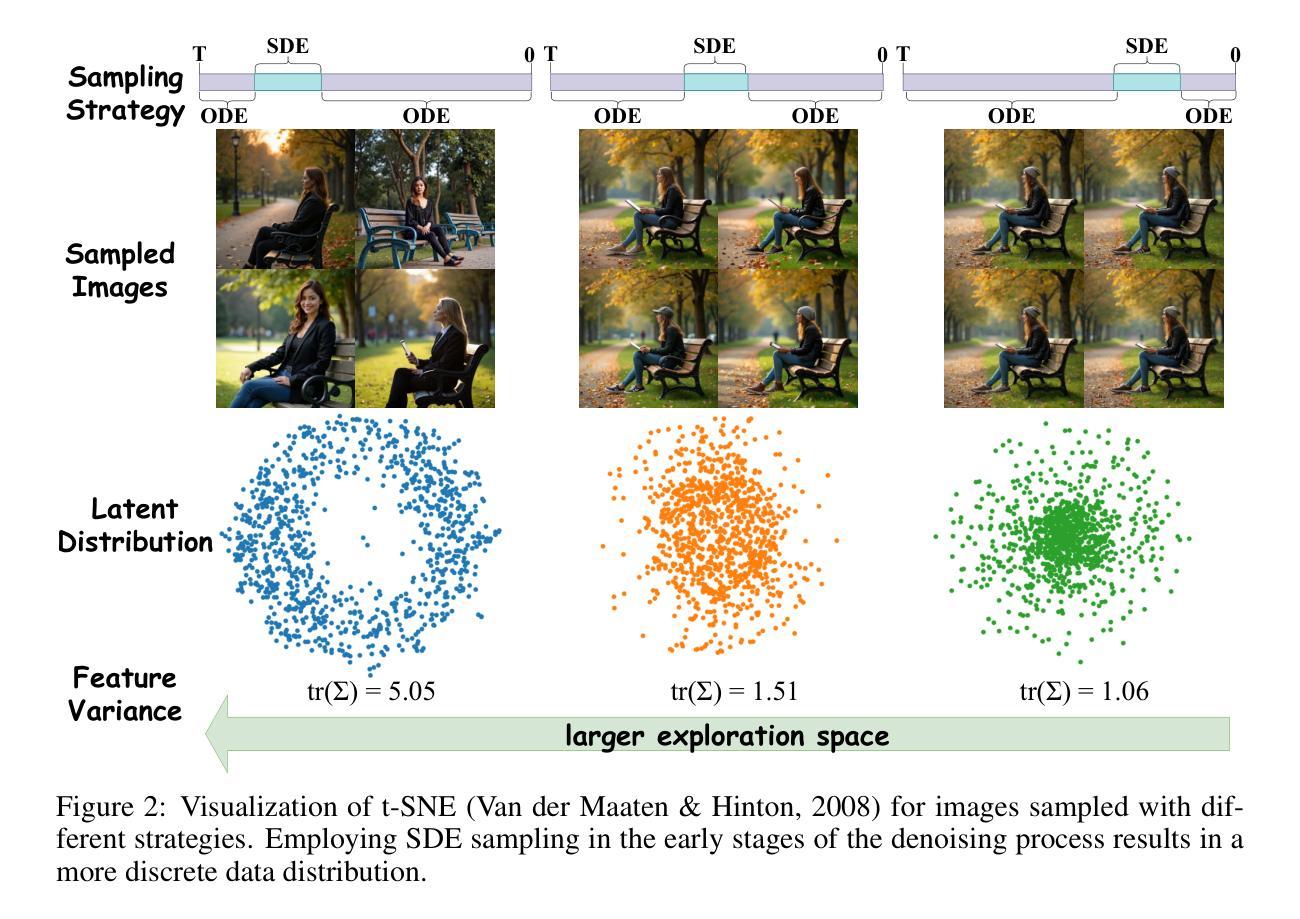

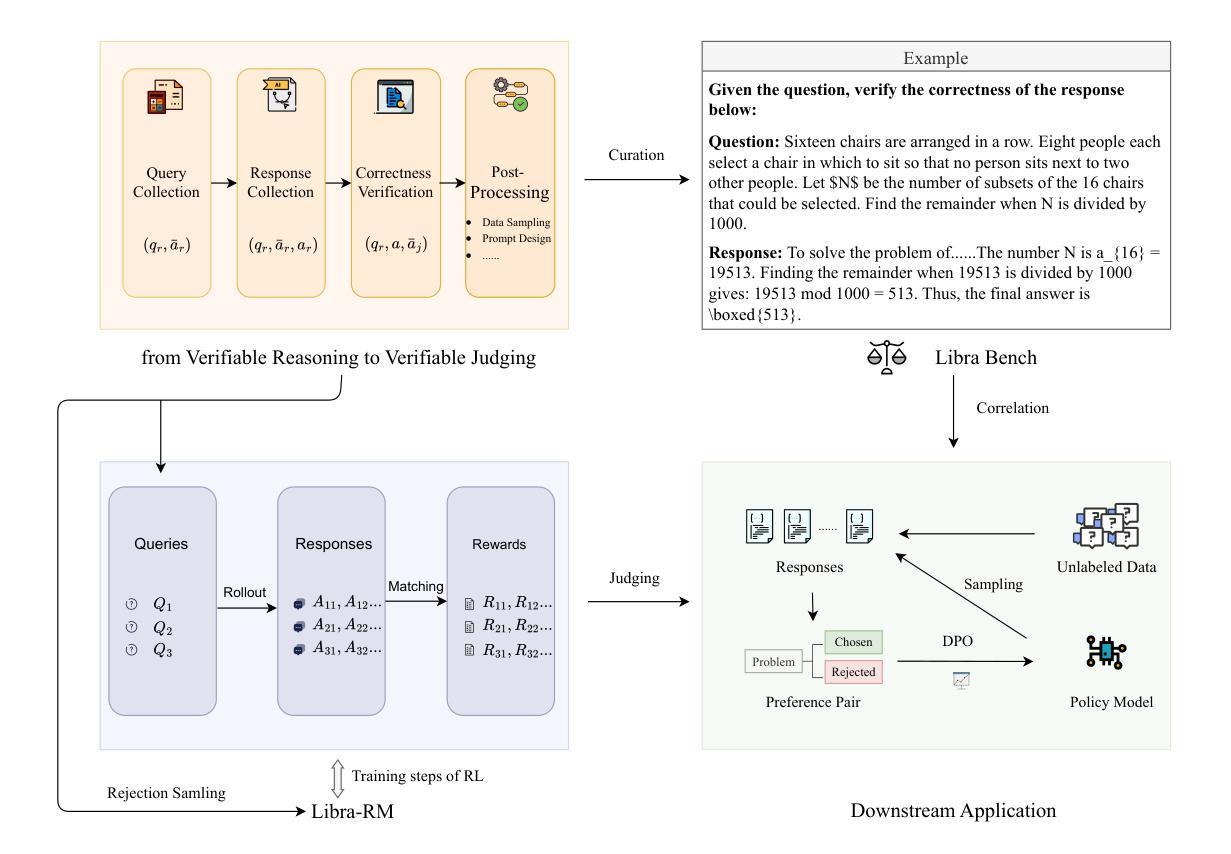
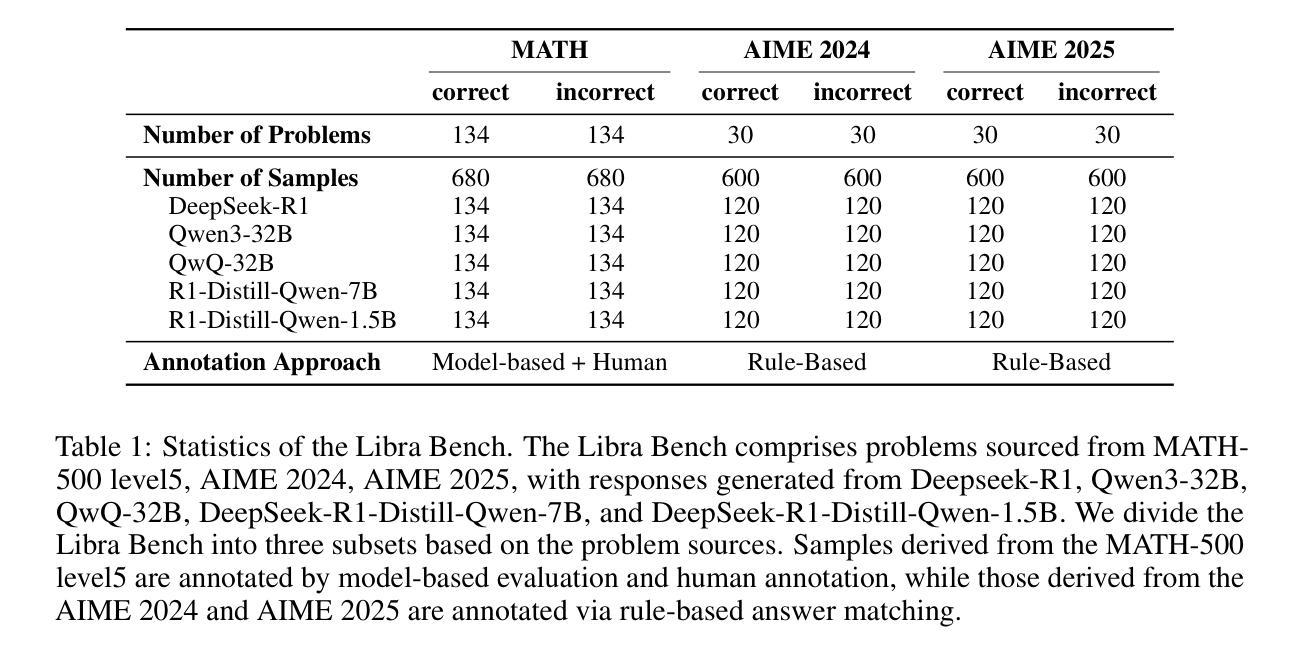
Libra: Assessing and Improving Reward Model by Learning to Think
Authors:Meng Zhou, Bei Li, Jiahao Liu, Xiaowen Shi, Yang Bai, Rongxiang Weng, Jingang Wang, Xunliang Cai
Reinforcement learning (RL) has significantly improved the reasoning ability of large language models. However, current reward models underperform in challenging reasoning scenarios and predominant RL training paradigms rely on rule-based or reference-based rewards, which impose two critical limitations: 1) the dependence on finely annotated reference answer to attain rewards; and 2) the requirement for constrained output format. These limitations fundamentally hinder further RL data scaling and sustained enhancement of model reasoning performance. To address these limitations, we propose a comprehensive framework for evaluating and improving the performance of reward models in complex reasoning scenarios. We first present a reasoning-oriented benchmark (Libra Bench), systematically constructed from a diverse collection of challenging mathematical problems and advanced reasoning models, to address the limitations of existing reward model benchmarks in reasoning scenarios. We further introduce a novel approach for improving the generative reward model via learning-to-think methodologies. Based on the proposed approach, we develop Libra-RM series, a collection of generative reward models with reasoning capabilities that achieve state-of-the-art results on various benchmarks. Comprehensive downstream experiments are conducted and the experimental results demonstrate the correlation between our Libra Bench and downstream application, and the potential of Libra-RM to further improve reasoning models with unlabeled data.
强化学习(RL)显著提高了大型语言模型的推理能力。然而,当前的奖励模型在具有挑战性的推理场景中表现不佳,主流的强化学习训练范式依赖于基于规则或基于参考的奖励,这带来了两个关键的局限性:1)需要精细标注的参考答案才能获得奖励;2)需要约束的输出格式。这些局限性从根本上阻碍了强化学习数据的进一步扩展和模型推理性能的持续提升。为了解决这些局限性,我们提出了一个全面评估和改进奖励模型在复杂推理场景中性能的框架。我们首先提出了一个面向推理的基准测试(Libra Bench),该系统是从各种具有挑战性的数学问题和高阶推理模型中收集构建的,以解决现有奖励模型在推理场景中的基准测试局限性。我们还介绍了一种通过“学习思考”方法来改进生成奖励模型的新方法。基于该方法,我们开发了Libra-RM系列,这是一系列具有推理能力的生成奖励模型,在各种基准测试中达到了最先进的成果。进行了全面的下游实验,实验结果表明了我们的Libra Bench与下游应用的相关性,以及Libra-RM在无需标签数据的情况下进一步改进推理模型的潜力。
论文及项目相关链接
PDF Work In Progress
Summary:强化学习显著提高了大型语言模型的推理能力,但当前奖励模型在复杂推理场景中表现不佳,存在依赖精细标注的参考答案和输出格式受限等局限性。为解决这些问题,提出了一个综合框架,包括构建Libra Bench基准测试集和改进生成奖励模型的方法。Libra Bench涵盖各种具有挑战性的数学问题和高级推理模型,旨在解决现有奖励模型在推理场景中的局限性。新方法通过采用学习思考的方法改进生成奖励模型,并开发出具有推理能力的Libra-RM系列奖励模型,在各种基准测试中达到最佳效果。实验结果表明Libra Bench与下游应用的相关性,以及Libra-RM在进一步提高推理模型的潜力。
Key Takeaways:
- 强化学习增强了语言模型的推理能力。
- 当前奖励模型在复杂推理场景中存在局限性,如依赖精细标注的参考答案和输出格式受限。
- Libra Bench的构建旨在解决现有奖励模型在推理场景中的局限性,包括各种挑战性的数学问题。
- 通过学习思考的方法改进生成奖励模型。
- Libra-RM系列奖励模型具有推理能力,在各种基准测试中表现优异。
- 实验结果证明了Libra Bench与下游应用的相关性。
点此查看论文截图

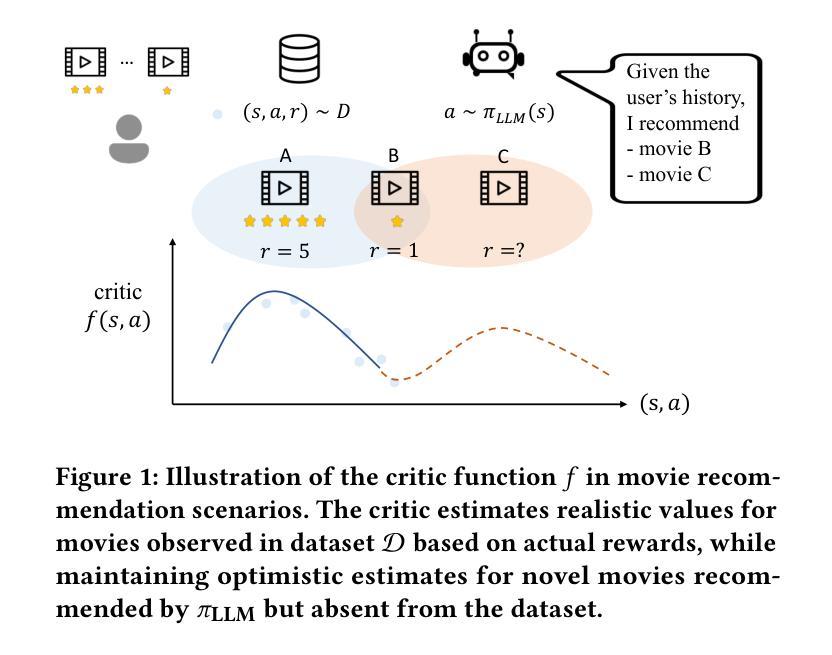
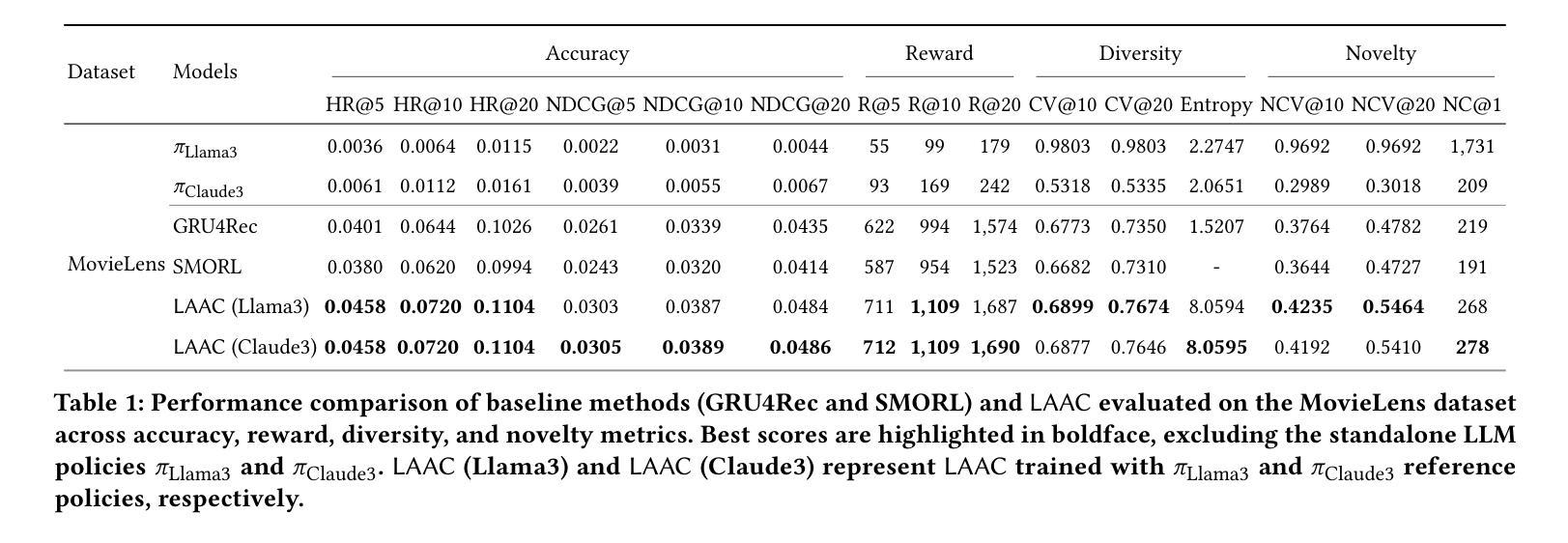
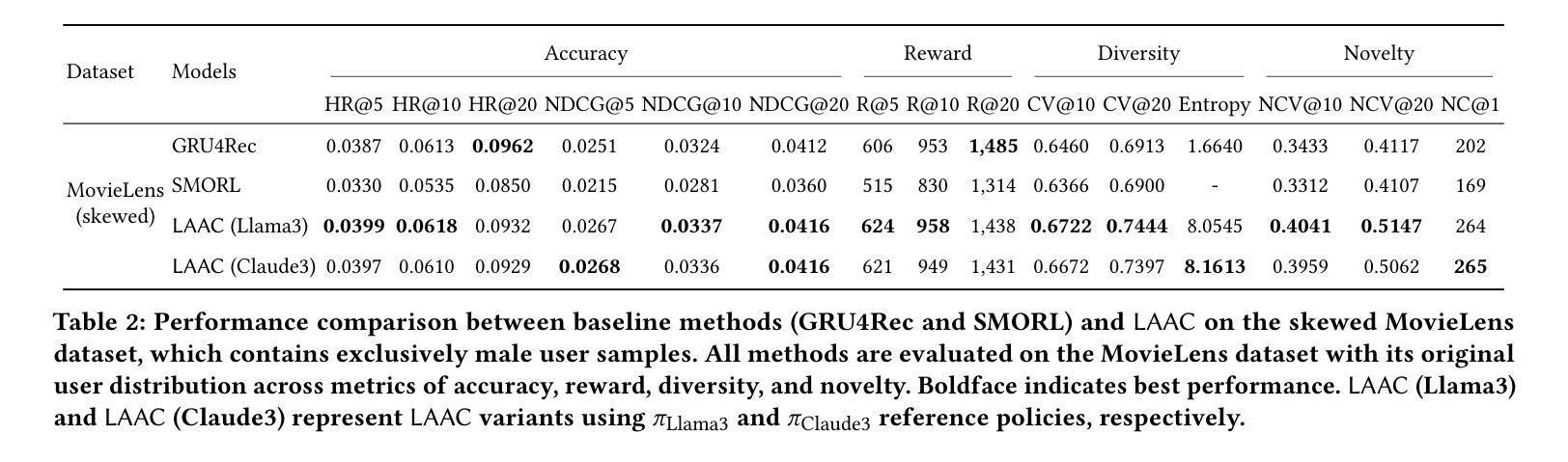
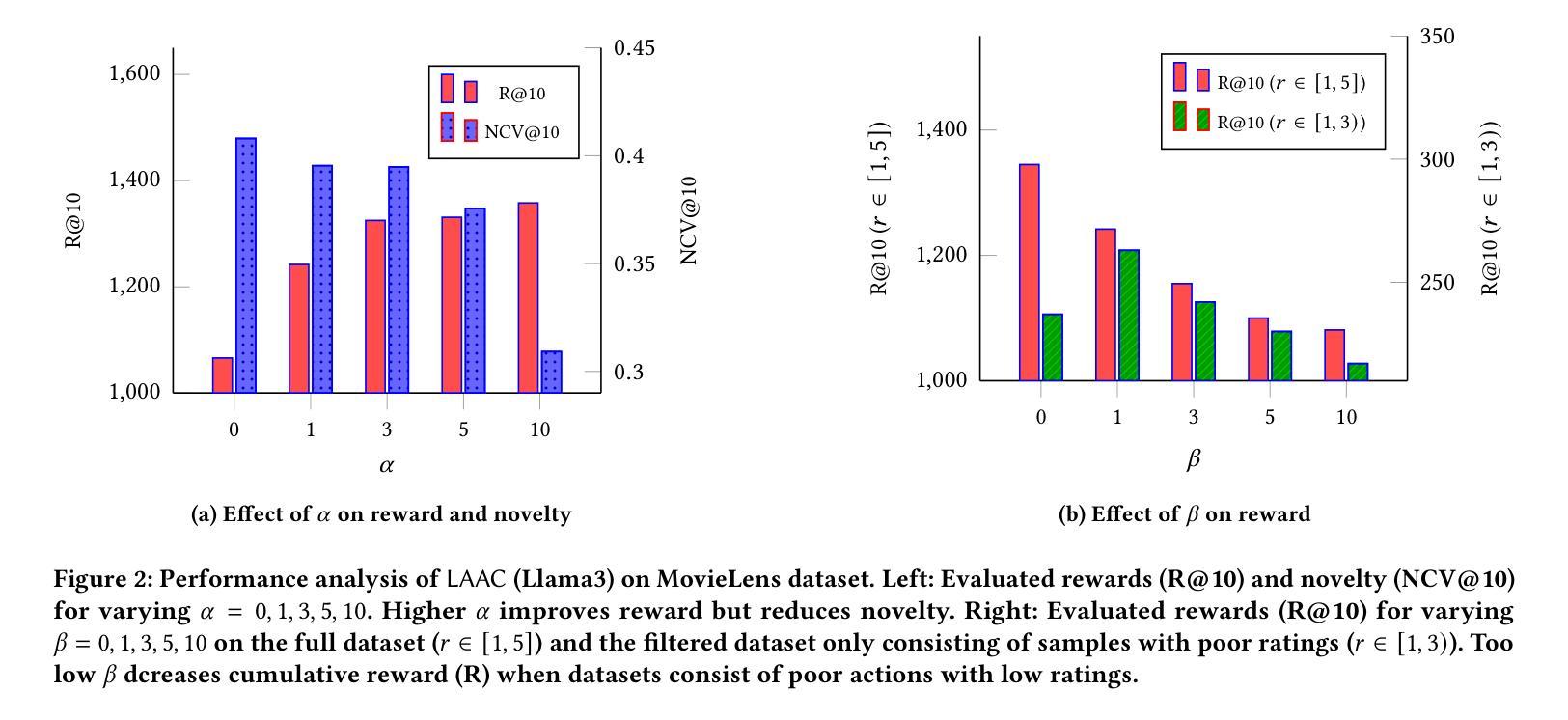
Large Language Model-Enhanced Reinforcement Learning for Diverse and Novel Recommendations
Authors:Jiin Woo, Alireza Bagheri Garakani, Tianchen Zhou, Zhishen Huang, Yan Gao
In recommendation systems, diversity and novelty are essential for capturing varied user preferences and encouraging exploration, yet many systems prioritize click relevance. While reinforcement learning (RL) has been explored to improve diversity, it often depends on random exploration that may not align with user interests. We propose LAAC (LLM-guided Adversarial Actor Critic), a novel method that leverages large language models (LLMs) as reference policies to suggest novel items, while training a lightweight policy to refine these suggestions using system-specific data. The method formulates training as a bilevel optimization between actor and critic networks, enabling the critic to selectively favor promising novel actions and the actor to improve its policy beyond LLM recommendations. To mitigate overestimation of unreliable LLM suggestions, we apply regularization that anchors critic values for unexplored items close to well-estimated dataset actions. Experiments on real-world datasets show that LAAC outperforms existing baselines in diversity, novelty, and accuracy, while remaining robust on imbalanced data, effectively integrating LLM knowledge without expensive fine-tuning.
在推荐系统中,多样性和新颖性对于捕捉各种用户偏好和鼓励探索至关重要,然而许多系统更优先点击相关性。虽然强化学习(RL)已被探索用于提高多样性,但它通常依赖于随机探索,可能与用户兴趣不符。我们提出了LAAC(LLM引导的对抗性演员评论家,LLM-guided Adversarial Actor Critic),这是一种利用大型语言模型(LLM)作为参考策略来建议新颖项目的新方法,同时训练一个轻量级策略,使用系统特定数据来完善这些建议。该方法将训练制定为演员和评论家网络之间的双级优化,使评论家能够有选择地支持有前途的新颖行动,并使演员能够超越LLM建议改进其策略。为了减轻对不可靠的LLM建议的过度估计,我们应用了将未探索项目的评论家价值锚定到估算良好的数据集行动附近的正则化。在真实数据集上的实验表明,LAAC在多样性、新颖性和准确性方面优于现有基线,同时在不平衡数据上保持稳健,有效地整合了LLM知识,无需昂贵的微调。
论文及项目相关链接
Summary
本文提出一种名为LAAC的新型推荐系统方法,该方法利用大型语言模型(LLM)作为参考策略来推荐新颖项目,同时训练轻量级策略使用系统特定数据来完善这些建议。LAAC通过演员和评论家网络之间的二层优化进行训练,使评论家能够有选择地支持有前景的新行动,而演员则能在超越LLM建议的基础上改进其策略。为缓解对不可靠LLM建议的过度估计,本文采用正则化方法,将未经探索项目的评论家值锚定到估算良好的数据集操作上。实验表明,LAAC在多样性、新颖性和准确性方面优于现有基准测试,同时在处理不平衡数据时保持稳健,有效地融合了LLM知识,无需昂贵的微调。
Key Takeaways
- 推荐系统中多样性和新颖性对于捕捉用户偏好和鼓励探索至关重要。
- 当前许多推荐系统过于注重点击相关性,忽视了多样性和新颖性。
- LAAC方法利用大型语言模型(LLM)作为参考策略来推荐新项目。
- LAAC通过演员和评论家网络的二层优化进行训练,以提高策略质量和推荐多样性。
- LAAC采用正则化来缓解对不可靠LLM建议的过度估计。
- 实验表明,LAAC在多样性、新颖性和准确性方面优于现有方法。
点此查看论文截图

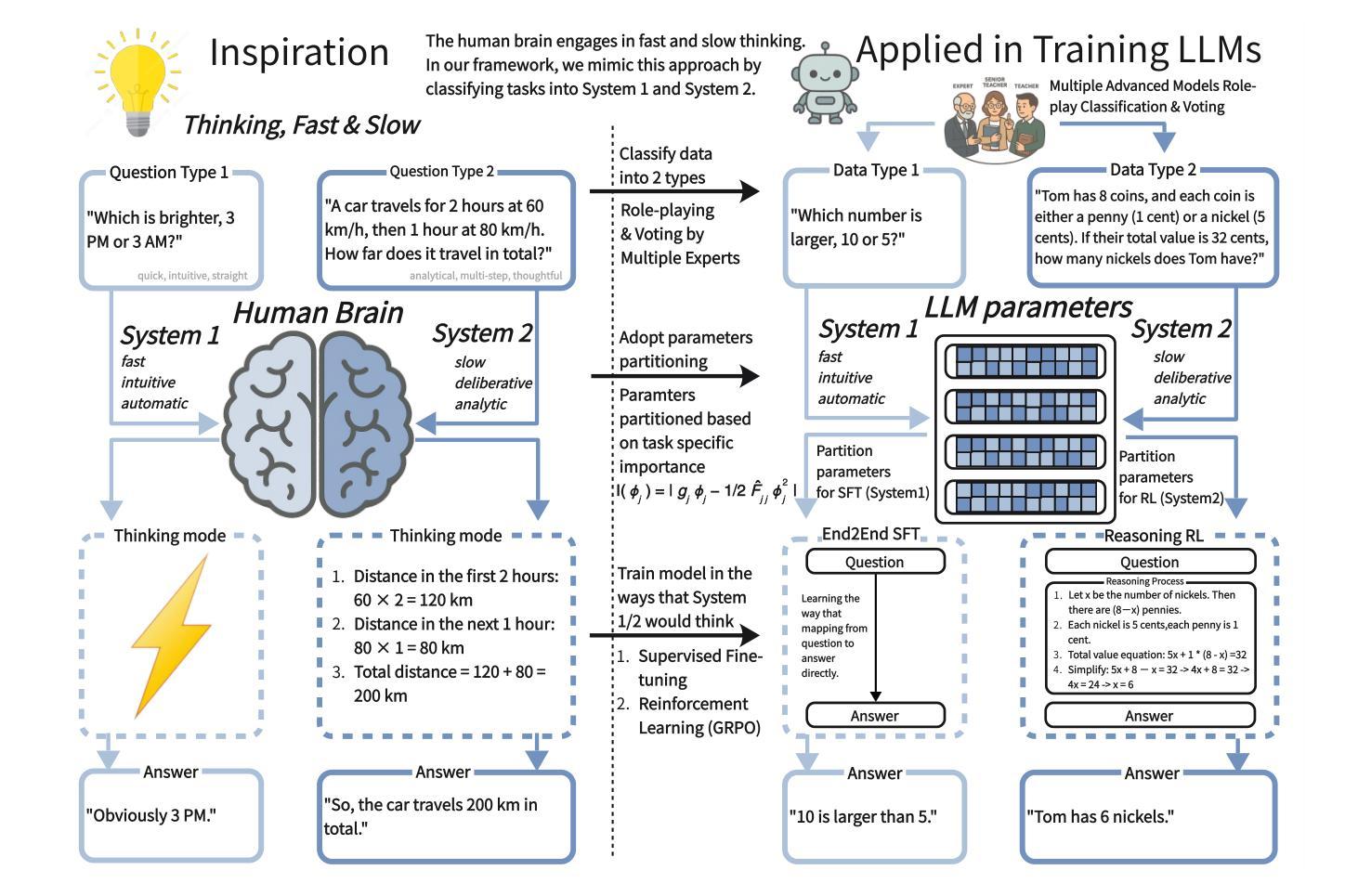
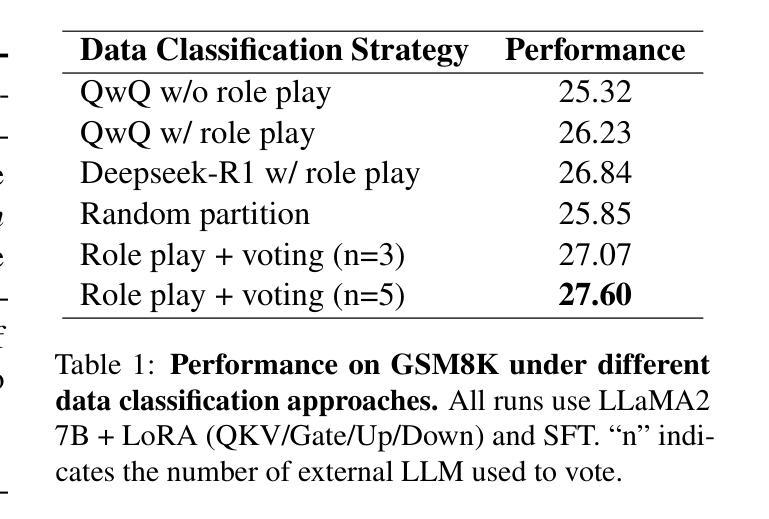
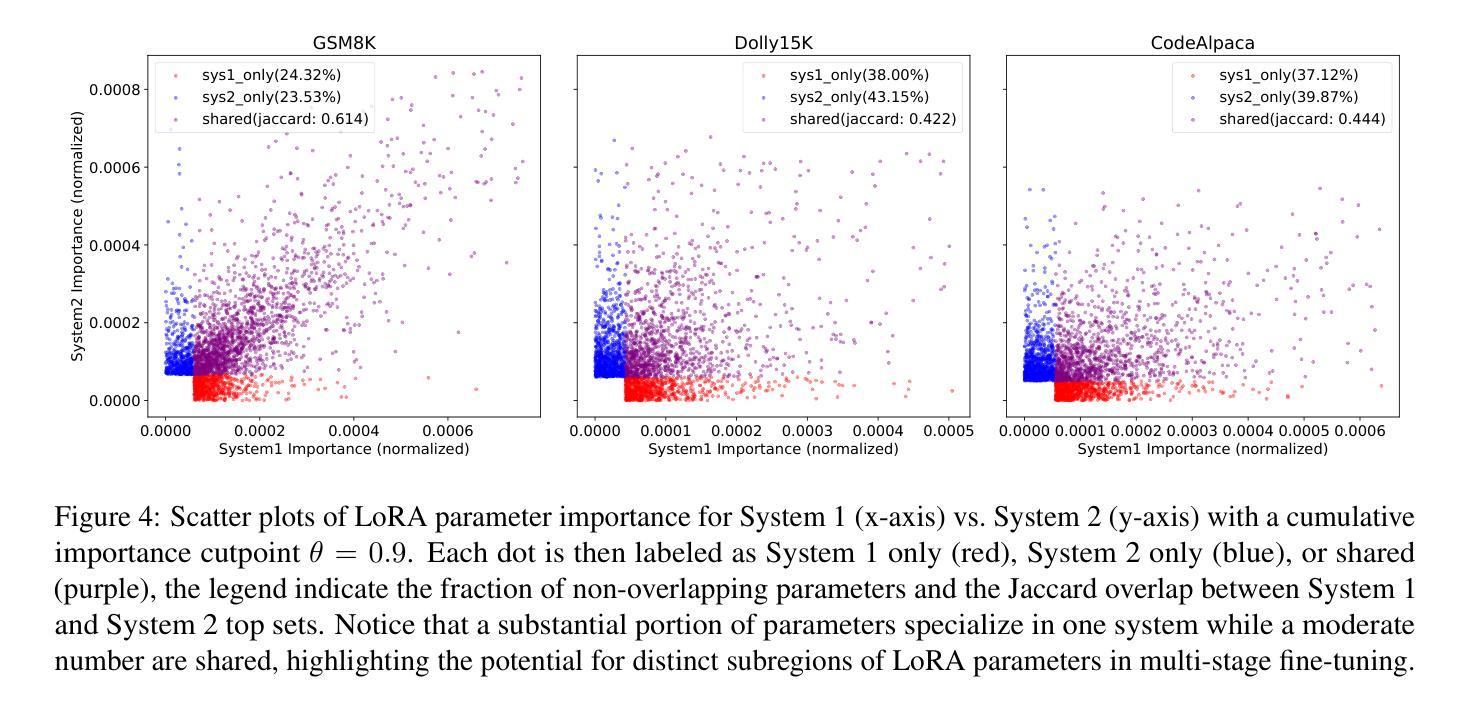
LoRA-PAR: A Flexible Dual-System LoRA Partitioning Approach to Efficient LLM Fine-Tuning
Authors:Yining Huang, Bin Li, Keke Tang, Meilian Chen
Large-scale generative models like DeepSeek-R1 and OpenAI-O1 benefit substantially from chain-of-thought (CoT) reasoning, yet pushing their performance typically requires vast data, large model sizes, and full-parameter fine-tuning. While parameter-efficient fine-tuning (PEFT) helps reduce cost, most existing approaches primarily address domain adaptation or layer-wise allocation rather than explicitly tailoring data and parameters to different response demands. Inspired by “Thinking, Fast and Slow,” which characterizes two distinct modes of thought-System 1 (fast, intuitive, often automatic) and System 2 (slower, more deliberative and analytic)-we draw an analogy that different “subregions” of an LLM’s parameters might similarly specialize for tasks that demand quick, intuitive responses versus those requiring multi-step logical reasoning. Therefore, we propose LoRA-PAR, a dual-system LoRA framework that partitions both data and parameters by System 1 or System 2 demands, using fewer yet more focused parameters for each task. Specifically, we classify task data via multi-model role-playing and voting, and partition parameters based on importance scoring, then adopt a two-stage fine-tuning strategy of training System 1 tasks with supervised fine-tuning (SFT) to enhance knowledge and intuition and refine System 2 tasks with reinforcement learning (RL) to reinforce deeper logical deliberation next. Extensive experiments show that the two-stage fine-tuning strategy, SFT and RL, lowers active parameter usage while matching or surpassing SOTA PEFT baselines.
大规模生成模型,如DeepSeek-R1和OpenAI-O1,在很大程度上受益于思维链(CoT)推理。然而,提升它们的性能通常需要大量数据、大型模型以及精细调整所有参数。虽然参数效率高的微调(PEFT)有助于降低成本,但大多数现有方法主要解决领域适应或逐层分配问题,而不是显式地针对数据和参数进行不同的响应需求调整。受《思考,快与慢》的启发,该书描述了两种截然不同的思维方式——系统1(快速、直观、通常自动)和系统2(较慢、更加审慎和分析性)——我们类比推断,大型语言模型(LLM)参数的“不同子区域”可能同样专长于快速直观反应的任务与需要多步骤逻辑推理的任务。因此,我们提出了LoRA-PAR双系统LoRA框架,它根据系统1或系统2的需求来划分数据和参数。具体来说,我们通过多模型角色扮演和投票对任务数据进行分类,根据重要性评分对参数进行划分,然后采用两阶段微调策略,用监督微调(SFT)训练系统1任务以增强知识和直觉,用强化学习(RL)精炼系统2任务以加强更深层次的逻辑思考。大量实验表明,两阶段微调策略,即SFT和RL,降低了活动参数的使用量,同时达到或超越了最新的PEFT基准测试。
论文及项目相关链接
PDF 10 pages
Summary
大型生成模型如DeepSeek-R1和OpenAI-O1受益于链式思维(CoT)推理,但要提升其性能通常需要大量数据、大型模型及全参数微调。虽然参数效率微调(PEFT)有助于降低成本,但现有方法主要关注领域适应或逐层分配,并未明确针对数据参数适应不同响应需求。受“快速与慢速思考”启发,将大型语言模型(LLM)的参数子区域划分为适应快速直觉反应与需要多步骤逻辑推理的任务。因此,提出LoRA-PAR双系统框架,按系统1或系统2需求划分数据与参数,为每个任务使用更少但更集中的参数。通过多任务角色扮演和投票进行分类,基于重要性评分对参数进行划分,并采用两阶段微调策略:用监督微调(SFT)训练系统1任务增强知识和直觉,用强化学习(RL)完善系统2任务以强化深度逻辑思考。实验表明,两阶段微调策略在降低活动参数使用的同时,达到或超越了最新PEFT基准线。
Key Takeaways
- 大型生成模型受益于链式思维(CoT)推理。
- 参数效率微调(PEFT)有助于降低成本,但现有方法主要关注领域适应和逐层分配。
- 受“快速与慢速思考”启发,提出LLM参数子区域划分以适应不同任务需求。
- 提出LoRA-PAR双系统框架,按系统1和系统2需求划分数据和参数。
- 采用多任务角色扮演和投票分类任务数据,基于重要性评分对参数进行划分。
- 采用两阶段微调策略:监督微调(SFT)强化知识和直觉,强化学习(RL)强化深度逻辑思考。
点此查看论文截图


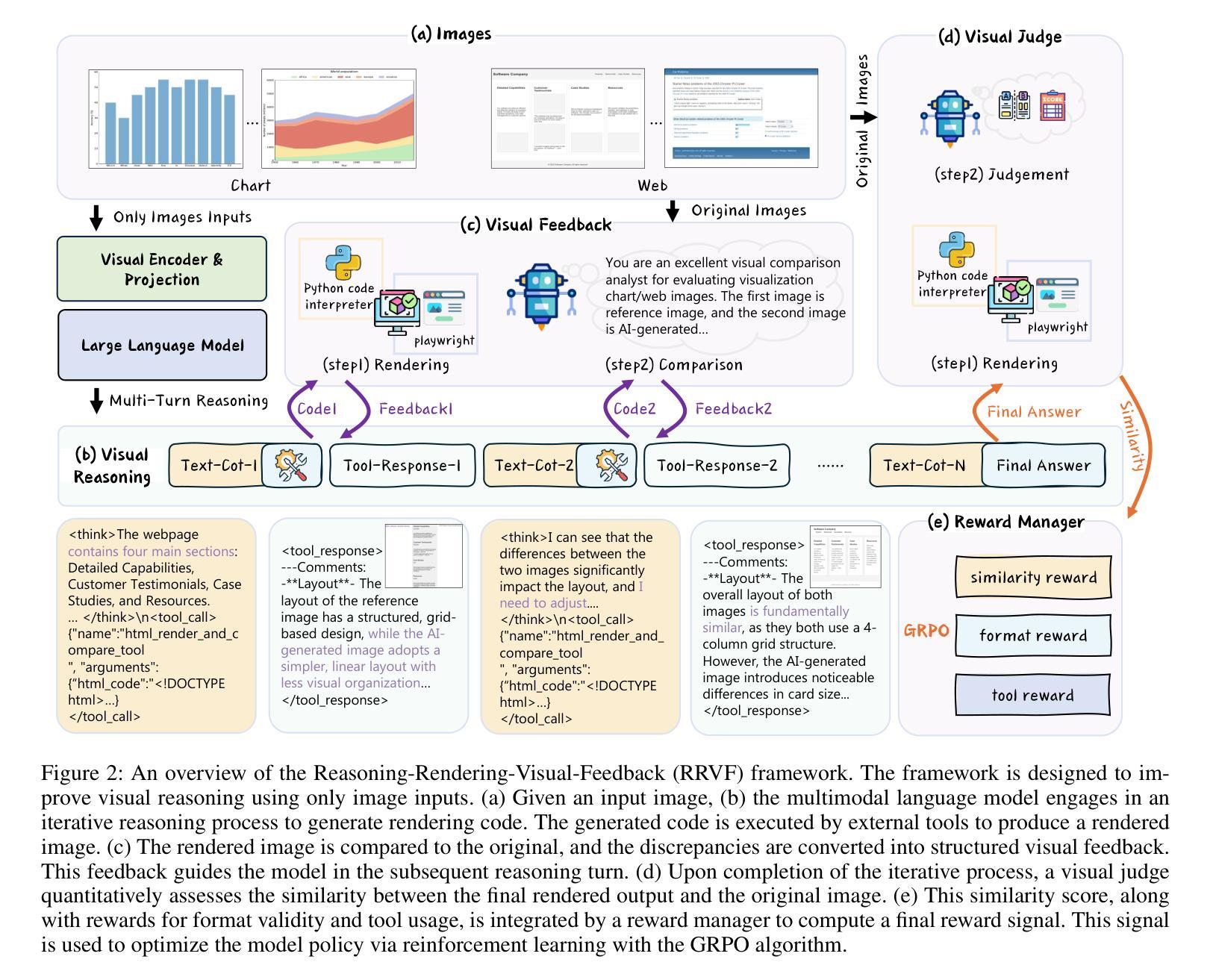
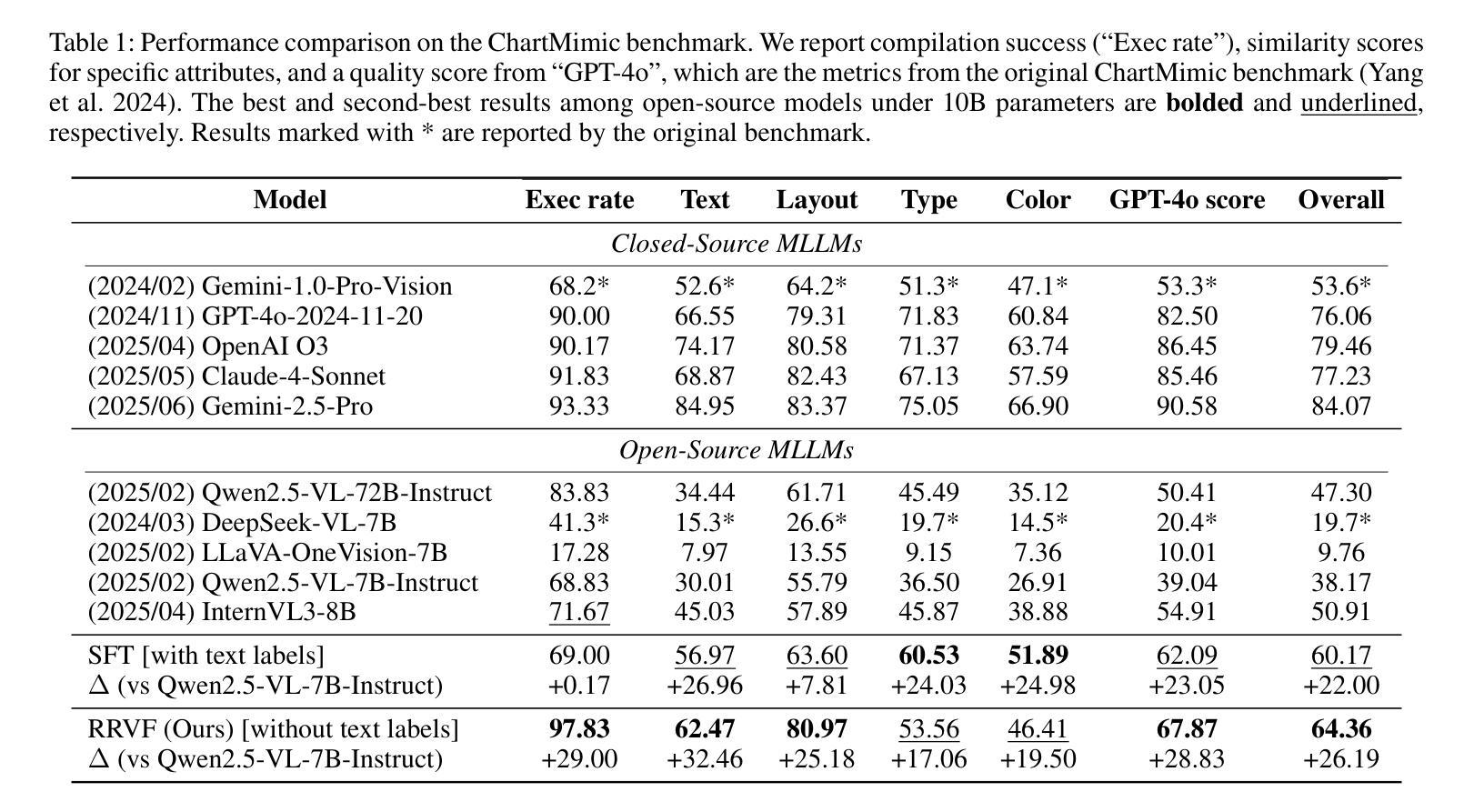
Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Authors:Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, Yu Qiao
Multimodal Large Language Models (MLLMs) exhibit impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the Asymmetry of Verification’’ principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions, while this pipeline can be optimized end-to-end by the GRPO algorithm. Extensive evaluations are conducted on image-to-code generation across two diverse domains: data charts and web interfaces. The RRVF-trained model not only outperforms existing open-source MLLMs and supervised fine-tuning baselines but also exhibits superior generalization to unseen datasets. Critically, the model’s performance surpasses that of the more advanced MLLM used to provide the feedback signal during training. This work establishes a self-improvement paradigm that offers a viable path to robust, generalizable models without reliance on explicit supervision. Code will be available at https://github.com/L-O-I/RRVF.
多模态大型语言模型(MLLMs)在各种视觉任务中表现出令人印象深刻的效果。后续关于提高其视觉推理能力的研究极大地扩大了其性能范围。然而,在推动MLLMs实现深度视觉推理方面存在一个关键瓶颈,即它们严重依赖于精选的图像文本监督。为了解决这个问题,我们引入了一个名为“推理渲染视觉反馈”(RRVF)的新型框架,该框架使MLLMs能够从原始图像中学习复杂的视觉推理。该框架建立在“验证不对称性”原则的基础上来训练MLLMs,即验证渲染输出与源图像相比更容易生成。我们证明这种相对容易性为通过强化学习(RL)训练优化提供了理想的奖励信号,减少了图像文本监督的依赖。在以上原则的引导下,RRVF实现了一个闭环迭代过程,包括推理、渲染和视觉反馈组件,使模型能够通过多轮交互进行自我校正,同时这个流程可以通过GRPO算法进行端到端的优化。在数据图表和网页界面两个不同领域进行了图像到代码生成的大量评估。通过RRVF训练的模型不仅优于现有的开源MLLMs和监督微调基线,而且在进行未见数据集的推理时表现出卓越泛化能力。关键的是,该模型的性能超过了训练过程中用于提供反馈信号的更先进的MLLM。这项工作建立了一种自我改进的模式,为构建不依赖显式监督的稳健、通用模型提供了可行的路径。代码将在https://github.com/L-O-I/RRVF上提供。
论文及项目相关链接
Summary
大型多模态语言模型(MLLMs)在各种视觉任务中表现出强大的性能,但其对高质量图文标注数据的依赖限制了其在深度视觉推理领域的进一步发展。为解决此瓶颈,引入了一种名为“Reasoning-Rendering-Visual-Feedback”(RRVF)的新型框架,使MLLMs仅通过原始图像学习复杂的视觉推理。该框架基于“验证不对称性”原理进行训练,通过强化学习(RL)优化,减少对图文标注数据的依赖。RRVF框架在图像到代码生成任务(数据图表和网页界面)上的表现优异,超越了现有开源MLLMs和监督微调基线,且对新数据集具有良好的泛化能力。此工作为无明确监督的稳健、泛化模型提供了可行的自我改进范式。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉任务中表现出强大的性能。
- MLLMs在深度视觉推理方面存在对高质量图文标注数据的依赖问题。
- 引入名为RRVF的新型框架,使MLLMs仅通过原始图像学习复杂的视觉推理。
- RRVF框架基于“验证不对称性”原理,利用强化学习(RL)进行优化。
- RRVF框架在图像到代码生成任务上的表现显著,超越了现有模型。
- RRVF训练的模型具有良好的泛化能力,能在新数据集上表现优异。
点此查看论文截图


Geometric-Mean Policy Optimization
Authors:Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, Fang Wan, Furu Wei
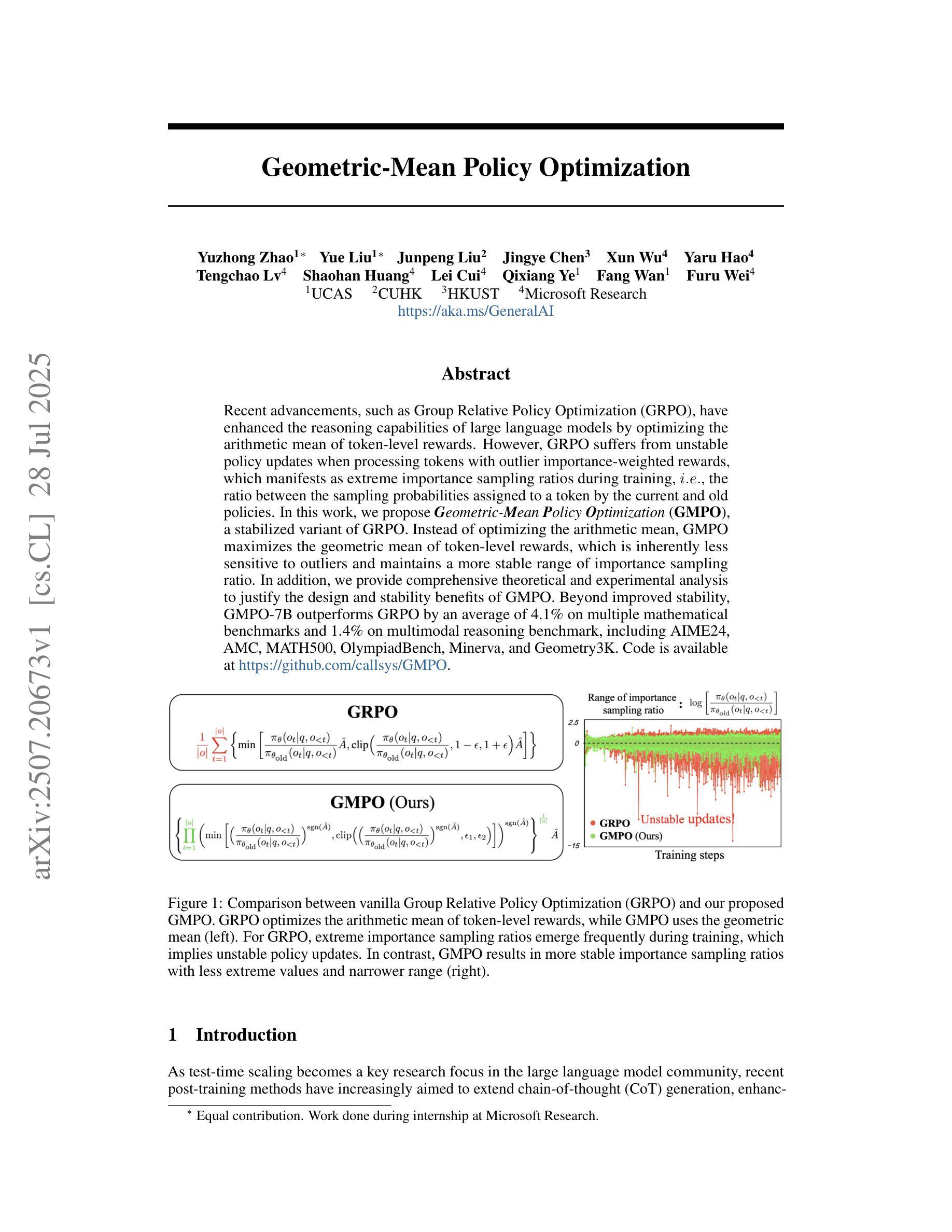
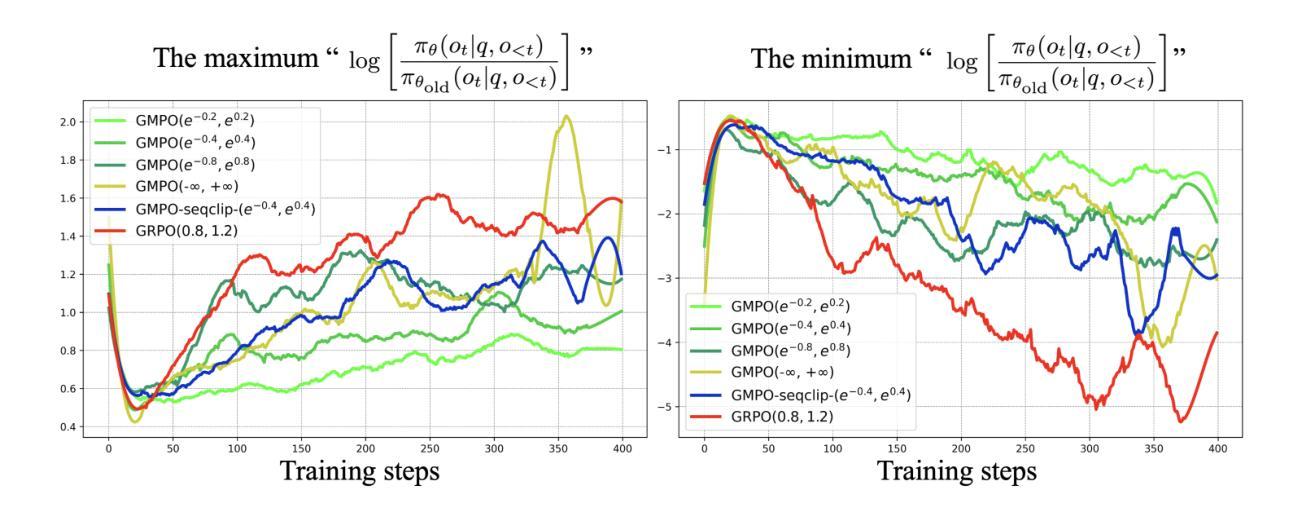
Recent advancements, such as Group Relative Policy Optimization (GRPO), have enhanced the reasoning capabilities of large language models by optimizing the arithmetic mean of token-level rewards. However, GRPO suffers from unstable policy updates when processing tokens with outlier importance-weighted rewards, which manifests as extreme importance sampling ratios during training, i.e., the ratio between the sampling probabilities assigned to a token by the current and old policies. In this work, we propose Geometric-Mean Policy Optimization (GMPO), a stabilized variant of GRPO. Instead of optimizing the arithmetic mean, GMPO maximizes the geometric mean of token-level rewards, which is inherently less sensitive to outliers and maintains a more stable range of importance sampling ratio. In addition, we provide comprehensive theoretical and experimental analysis to justify the design and stability benefits of GMPO. Beyond improved stability, GMPO-7B outperforms GRPO by an average of 4.1% on multiple mathematical benchmarks and 1.4% on multimodal reasoning benchmark, including AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K. Code is available at https://github.com/callsys/GMPO.
最近的进展,如组相对策略优化(GRPO),通过优化令牌级别奖励的算术平均值,增强了大型语言模型的推理能力。然而,GRPO在处理具有异常重要性加权奖励的令牌时会出现策略更新不稳定的问题,这表现为训练过程中重要性采样比率的极端化,即当前策略和旧策略分配给令牌采样概率之间的比率。在这项工作中,我们提出了几何均值策略优化(GMPO),它是GRPO的一种稳定变体。GMPO不同于优化算术均值,而是最大化令牌级别奖励的几何均值,这从本质上讲对异常值不那么敏感,并保持了重要性采样比率更稳定的范围。此外,我们还提供了全面的理论和实验分析,以证明GMPO的设计和稳定性优势。除了提高稳定性外,GMPO-7B在多数学术数学基准测试和多模态推理基准测试上的表现优于GRPO,平均高出4.1%(包括AIME24、AMC、MATH500、OlympiadBench、Minerva和Geometry3K)代码可在https://github.com/callsys/GMPO中找到。
论文及项目相关链接
PDF Code is available at https://github.com/callsys/GMPO
Summary
大型语言模型的推理能力最近通过Group Relative Policy Optimization (GRPO)等技术的提升得到了增强,但GRPO在处理具有异常重要性加权奖励的令牌时会出现政策更新不稳定的问题。本研究提出一种稳定的变体——Geometric-Mean Policy Optimization (GMPO),它通过最大化令牌级别奖励的几何平均值来优化策略,对异常值具有较低的敏感性,并能维持更稳定的重要性采样比率。GMPO不仅提高了稳定性,还在多个数学基准测试和多模式推理基准测试上表现出优于GRPO的性能。
Key Takeaways
- GRPO通过优化令牌级别奖励的算术平均值增强了大型语言模型的推理能力。
- GRPO在处理具有异常重要性加权奖励的令牌时会出现政策更新不稳定的问题。
- GMPO是GRPO的一种稳定变体,通过最大化令牌级别奖励的几何平均值来优化策略。
- GMPO对异常值具有较低的敏感性,并能维持更稳定的重要性采样比率。
- GMPO在提高稳定性的同时,还在多个数学基准测试上平均优于GRPO 4.1%。
- GMPO在多模式推理基准测试上相比GRPO有1.4%的性能提升。
点此查看论文截图
Kimi K2: Open Agentic Intelligence
Authors: Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Hao Hu, Xiaoru Hao, Tianhong He, Weiran He, Wenyang He, Chao Hong, Yangyang Hu, Zhenxing Hu, Weixiao Huang, Zhiqi Huang, Zihao Huang, Tao Jiang, Zhejun Jiang, Xinyi Jin, Yongsheng Kang, Guokun Lai, Cheng Li, Fang Li, Haoyang Li, Ming Li, Wentao Li, Yanhao Li, Yiwei Li, Zhaowei Li, Zheming Li, Hongzhan Lin, Xiaohan Lin, Zongyu Lin, Chengyin Liu, Chenyu Liu, Hongzhang Liu, Jingyuan Liu, Junqi Liu, Liang Liu, Shaowei Liu, T. Y. Liu, Tianwei Liu, Weizhou Liu, Yangyang Liu, Yibo Liu, Yiping Liu, Yue Liu, Zhengying Liu, Enzhe Lu, Lijun Lu, Shengling Ma, Xinyu Ma, Yingwei Ma, Shaoguang Mao, Jie Mei, Xin Men, Yibo Miao, Siyuan Pan, Yebo Peng, Ruoyu Qin, Bowen Qu, Zeyu Shang, Lidong Shi, Shengyuan Shi, Feifan Song, Jianlin Su, Zhengyuan Su, Xinjie Sun, Flood Sung, Heyi Tang, Jiawen Tao, Qifeng Teng, Chensi Wang, Dinglu Wang, Feng Wang, Haiming Wang, Jianzhou Wang, Jiaxing Wang, Jinhong Wang, Shengjie Wang, Shuyi Wang, Yao Wang, Yejie Wang, Yiqin Wang, Yuxin Wang, Yuzhi Wang, Zhaoji Wang, Zhengtao Wang, Zhexu Wang, Chu Wei, Qianqian Wei, Wenhao Wu, Xingzhe Wu, Yuxin Wu, Chenjun Xiao, Xiaotong Xie, Weimin Xiong, Boyu Xu, Jing Xu, Jinjing Xu, L. H. Xu, Lin Xu, Suting Xu, Weixin Xu, Xinran Xu, Yangchuan Xu, Ziyao Xu, Junjie Yan, Yuzi Yan, Xiaofei Yang, Ying Yang, Zhen Yang, Zhilin Yang, Zonghan Yang, Haotian Yao, Xingcheng Yao, Wenjie Ye, Zhuorui Ye, Bohong Yin, Longhui Yu, Enming Yuan, Hongbang Yuan, Mengjie Yuan, Haobing Zhan, Dehao Zhang, Hao Zhang, Wanlu Zhang, Xiaobin Zhang, Yangkun Zhang, Yizhi Zhang, Yongting Zhang, Yu Zhang, Yutao Zhang, Yutong Zhang, Zheng Zhang, Haotian Zhao, Yikai Zhao, Huabin Zheng, Shaojie Zheng, Jianren Zhou, Xinyu Zhou, Zaida Zhou, Zhen Zhu, Weiyu Zhuang, Xinxing Zu
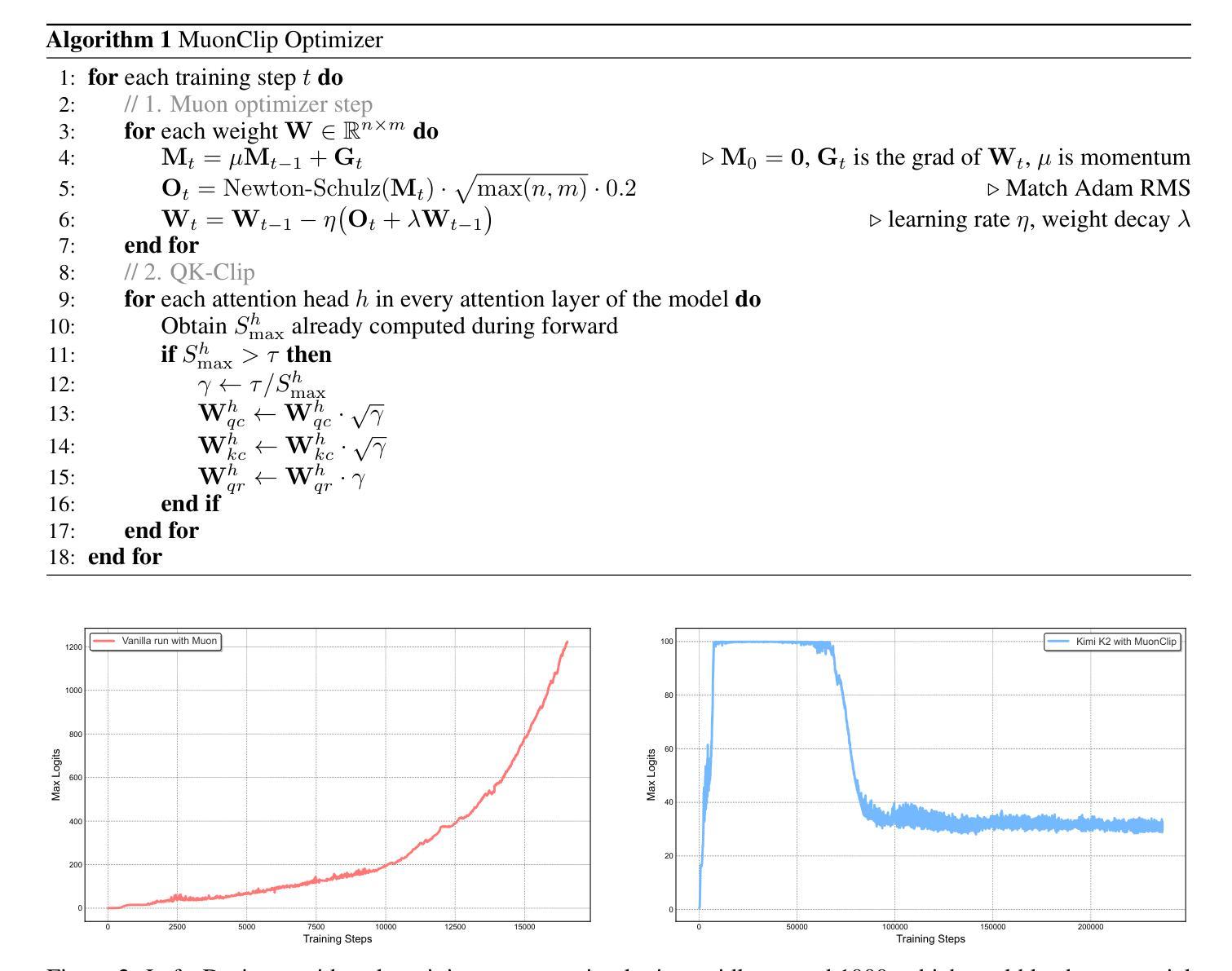
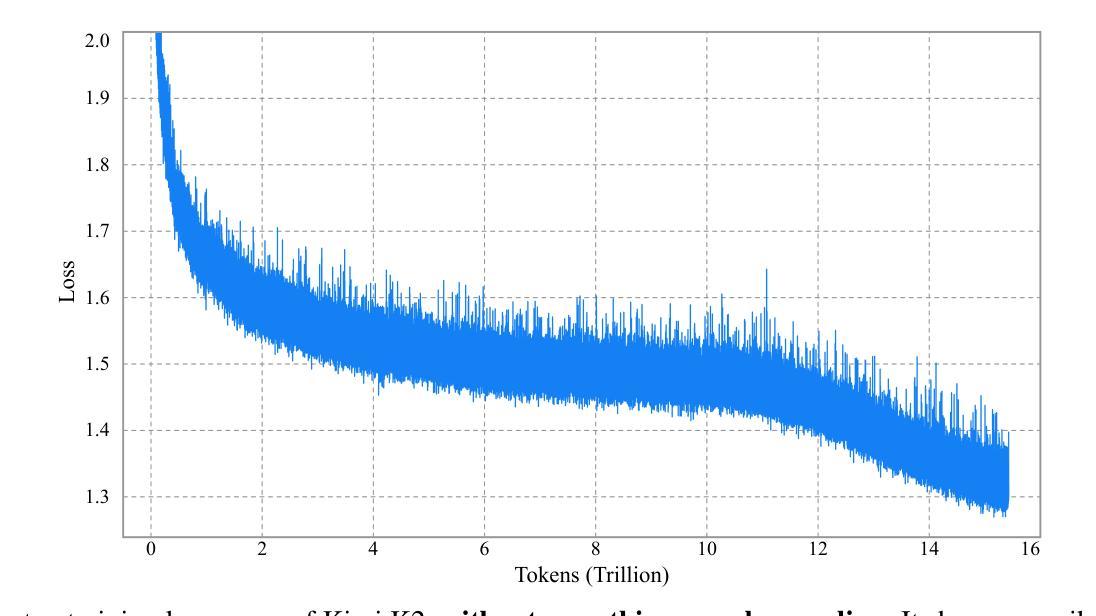
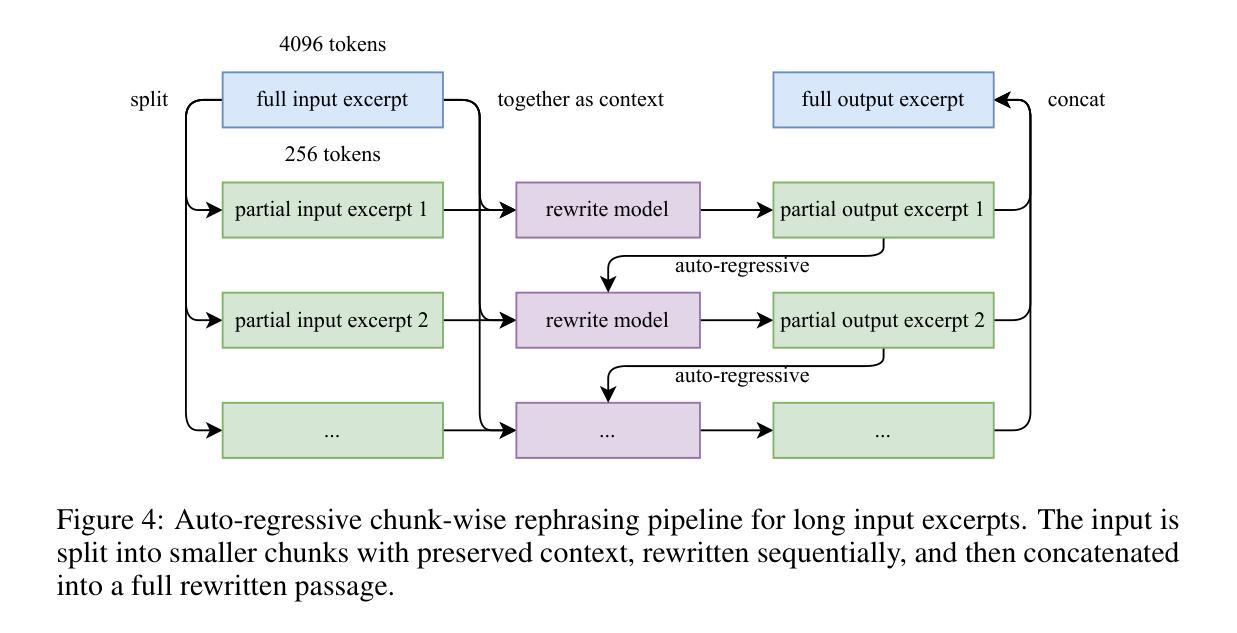
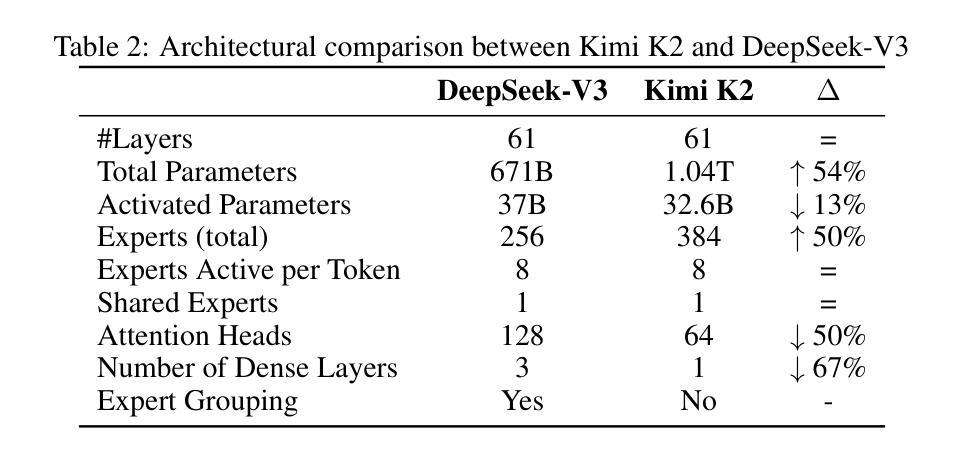
We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual – surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
我们介绍了Kimi K2,这是一个拥有32亿激活参数和1万亿总参数的混合专家(MoE)大型语言模型。我们提出了MuonClip优化器,它在Muon的基础上采用新颖的QK-clip技术,解决了训练不稳定的问题,同时享受Muon的高级令牌效率。基于MuonClip,K2在15.5万亿个令牌上进行预训练,没有损失峰值。在训练后,K2经历了多阶段训练后处理过程,以大规模代理数据合成管道和联合强化学习(RL)阶段为特色,模型通过与现实和合成环境的互动提高其能力。Kimi K2在开源非思考模型中实现了最先进的性能,尤其在智能能力方面表现出色。值得注意的是,K2在Tau2-Bench上获得66.1分,在ACEBench(英语)上获得76.5分,在SWE-Bench经过验证的情况下获得65.8分,在SWE-Bench多语言情况下获得47.3分,在非思考设置中超越了大多数开放和封闭源代码的基准测试。它还在编码、数学和推理任务中表现出强大的能力,在LiveCodeBench v6上获得53.7分,在AIME 2025上获得49.5分,在GPQA-Diamond上获得75.1分,在OJBench上获得27.1分,所有这些成绩都没有经过深入思考。这些结果将Kimi K2定位为迄今为止最强大的开源大型语言模型之一,特别是在软件工程和智能任务方面。我们发布了基础和训练后的模型检查点,以促进未来对智能的研究和应用。
论文及项目相关链接
PDF tech report of Kimi K2
Summary
这篇文章介绍了名为Kimi K2的大型语言模型,具有强大的能力与优异的表现。该模型引入混合专家技术(MoE),具备高度灵活性与精准度。通过采用创新的MuonClip优化器,K2在训练过程中保持稳定,并提升了令牌效率。经过预训练与多阶段后训练,K2在智能数据合成管道与强化学习联合阶段中不断提升自身能力。在多个基准测试中,Kimi K2均展现出卓越性能,特别是在软件工程与智能任务方面表现突出。本文最后公布了基础与后训练模型检查点,以便未来研究与应用智能体智能。
Key Takeaways
- Kimi K2是一个采用混合专家技术的大型语言模型,具备强大的能力与优异的表现。
- MuonClip优化器的引入提高了模型的训练稳定性与令牌效率。
- Kimi K2经历了预训练与多阶段后训练,包括智能数据合成管道与强化学习联合阶段。
- Kimi K2在多个基准测试中表现卓越,特别是在软件工程与智能任务方面。
- Kimi K2在非思考模式下实现了先进性能,展现出强大的编码、数学与推理能力。
- Kimi K2的发布旨在促进未来对智能体智能的研究与应用。
点此查看论文截图