⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-03 更新
SpeechFake: A Large-Scale Multilingual Speech Deepfake Dataset Incorporating Cutting-Edge Generation Methods
Authors:Wen Huang, Yanmei Gu, Zhiming Wang, Huijia Zhu, Yanmin Qian
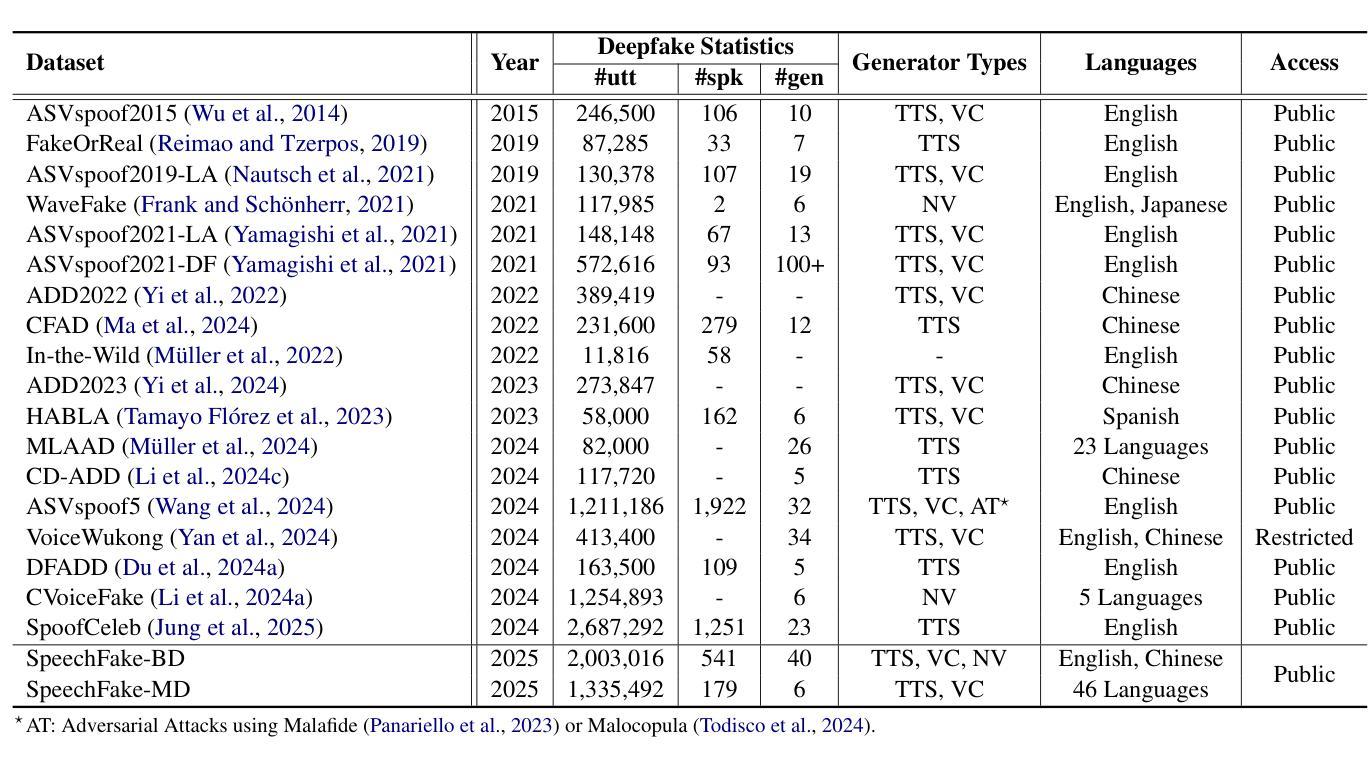
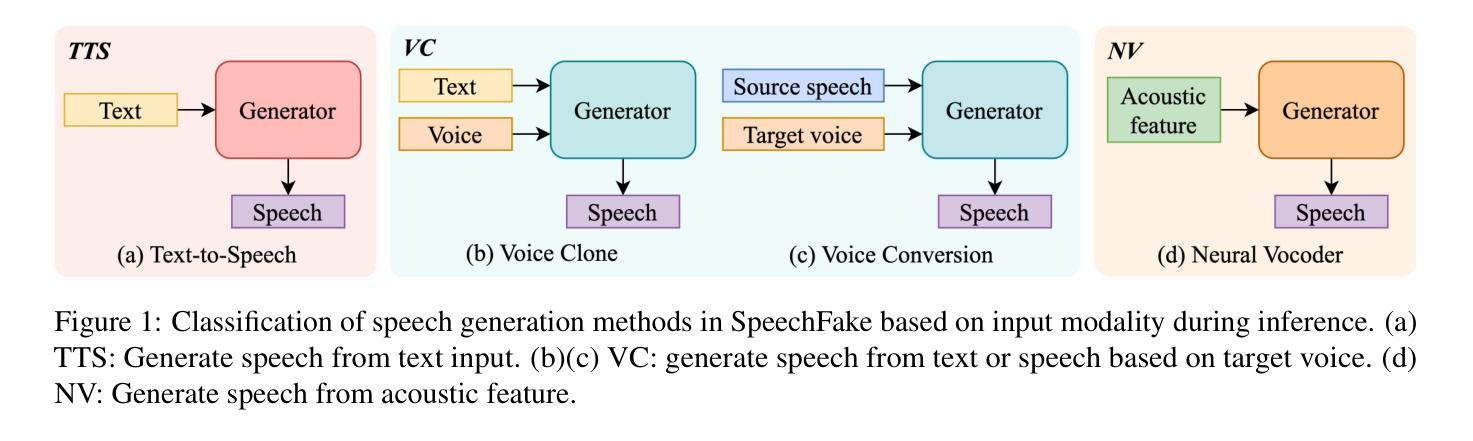
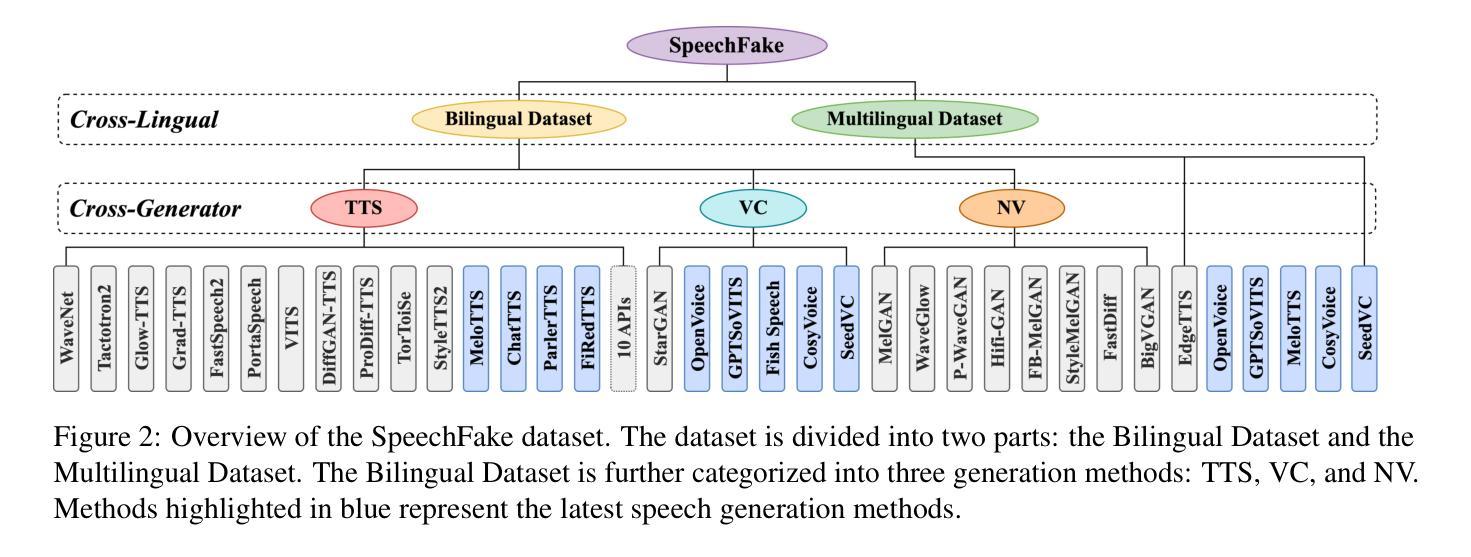
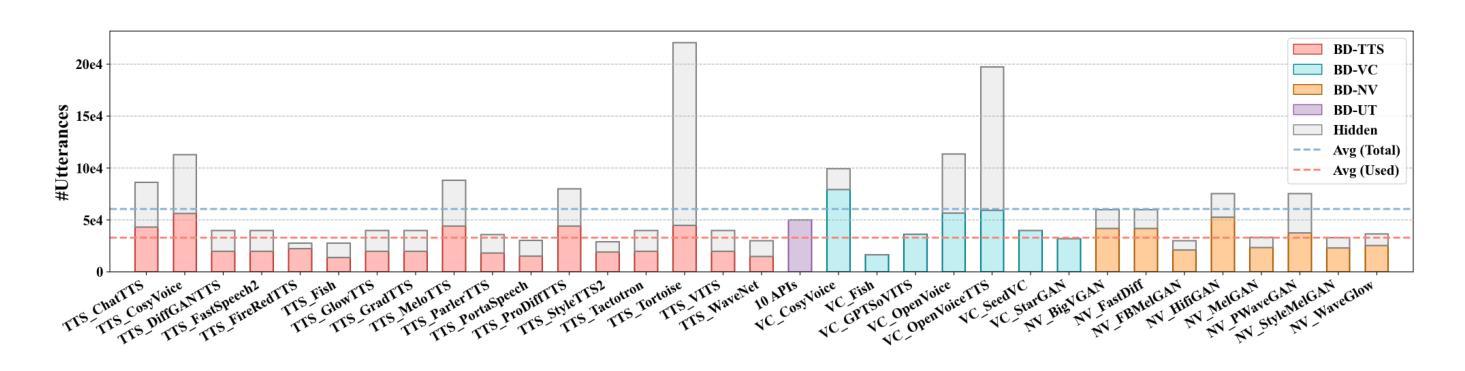
As speech generation technology advances, the risk of misuse through deepfake audio has become a pressing concern, which underscores the critical need for robust detection systems. However, many existing speech deepfake datasets are limited in scale and diversity, making it challenging to train models that can generalize well to unseen deepfakes. To address these gaps, we introduce SpeechFake, a large-scale dataset designed specifically for speech deepfake detection. SpeechFake includes over 3 million deepfake samples, totaling more than 3,000 hours of audio, generated using 40 different speech synthesis tools. The dataset encompasses a wide range of generation techniques, including text-to-speech, voice conversion, and neural vocoder, incorporating the latest cutting-edge methods. It also provides multilingual support, spanning 46 languages. In this paper, we offer a detailed overview of the dataset’s creation, composition, and statistics. We also present baseline results by training detection models on SpeechFake, demonstrating strong performance on both its own test sets and various unseen test sets. Additionally, we conduct experiments to rigorously explore how generation methods, language diversity, and speaker variation affect detection performance. We believe SpeechFake will be a valuable resource for advancing speech deepfake detection and developing more robust models for evolving generation techniques.
随着语音识别技术的进步,深度伪造音频的滥用风险已成为紧迫的问题,这凸显了对稳健检测系统的迫切需求。然而,许多现有的语音深度伪造数据集在规模和多样性方面存在局限性,使得训练能够良好泛化到未见过的深度伪造数据的模型变得具有挑战性。为了解决这些差距,我们推出了SpeechFake——一个专门用于语音深度伪造检测的大规模数据集。SpeechFake包含超过300万个深度伪造样本,总音频时长超过3000小时,使用40种不同的语音合成工具生成。该数据集涵盖了广泛的生成技术,包括文本到语音、语音转换和神经网络编解码器,包含了最新的前沿方法。它还提供了多种语言支持,涵盖46种语言。在本文中,我们提供了数据集创建、组成和统计的详细介绍。我们还通过在SpeechFake上训练检测模型来提供基线结果,在其自身的测试集和各种未见过的测试集上都表现出了强大的性能。此外,我们还进行了实验,严格探讨了生成方法、语言多样性和说话人变化如何影响检测性能。我们相信SpeechFake将成为推动语音深度伪造检测发展并为不断发展的生成技术开发更稳健模型的有价值资源。
论文及项目相关链接
PDF Published in ACL 2025. Dataset available at: https://github.com/YMLLG/SpeechFake
Summary
随着语音生成技术的进步,深度伪造音频的滥用风险日益凸显,因此对可靠检测系统的需求变得极为迫切。为解决现有语音深度伪造数据集规模有限、多样性不足的问题,我们推出了专门用于语音深度伪造检测的SpeechFake大型数据集。SpeechFake包含超过300万份深度伪造样本,总计超过3000小时的音频,使用40种不同的语音合成工具生成。该数据集涵盖了广泛的生成技术,包括文本到语音、语音转换和神经编解码器,并融入了最新的尖端方法。此外,它还提供46种语言的多语种支持。本文详细介绍了数据集的创建、组成和统计情况。通过在SpeechFake上训练检测模型,我们获得了良好的基线结果,在其自有测试集和各种未见测试集上表现出强大的性能。此外,我们还进行了实验,严格探讨了生成方法、语言多样性和说话人变化对检测性能的影响。我们相信SpeechFake将为推进语音深度伪造检测和研究先进的生成技术提供更稳健的模型提供宝贵资源。
Key Takeaways
- 语音生成技术的进步带来了深度伪造音频的滥用风险,需要可靠的检测系统。
- 现有语音深度伪造数据集存在规模和多样性问题,难以训练通用模型。
- SpeechFake数据集包含超过300万份深度伪造样本,总计超过3000小时的音频。
- SpeechFake涵盖多种生成技术,包括文本到语音、语音转换和神经编解码器。
- SpeechFake提供多语种支持,涵盖46种语言。
- 在SpeechFake上训练的检测模型表现出强大的性能。
点此查看论文截图


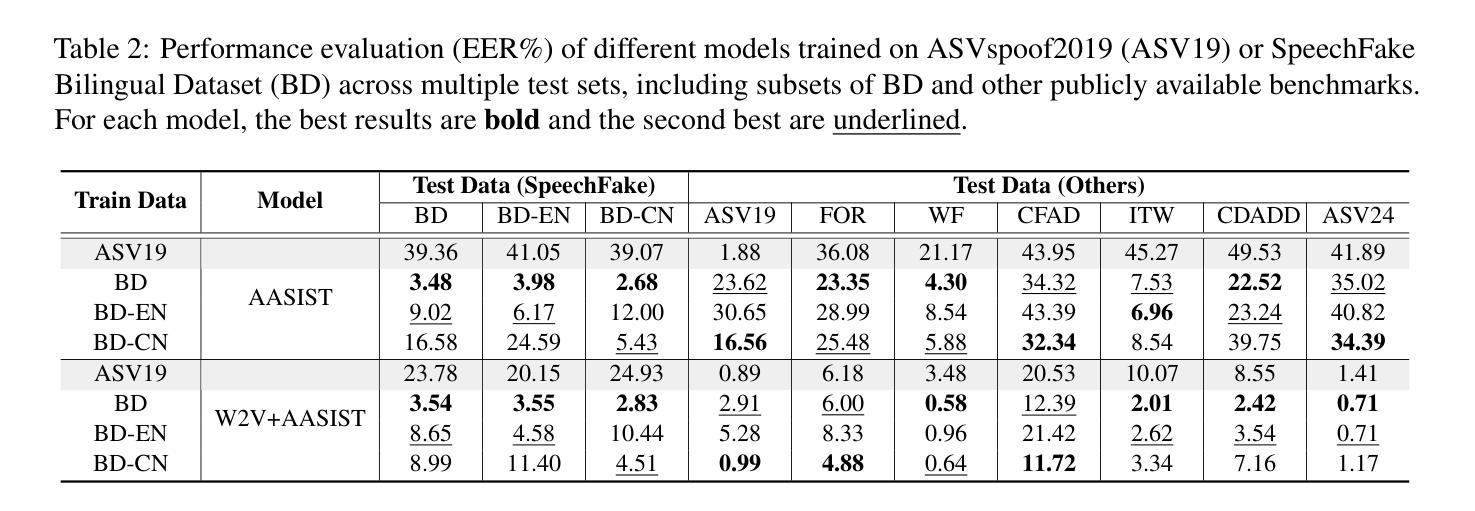
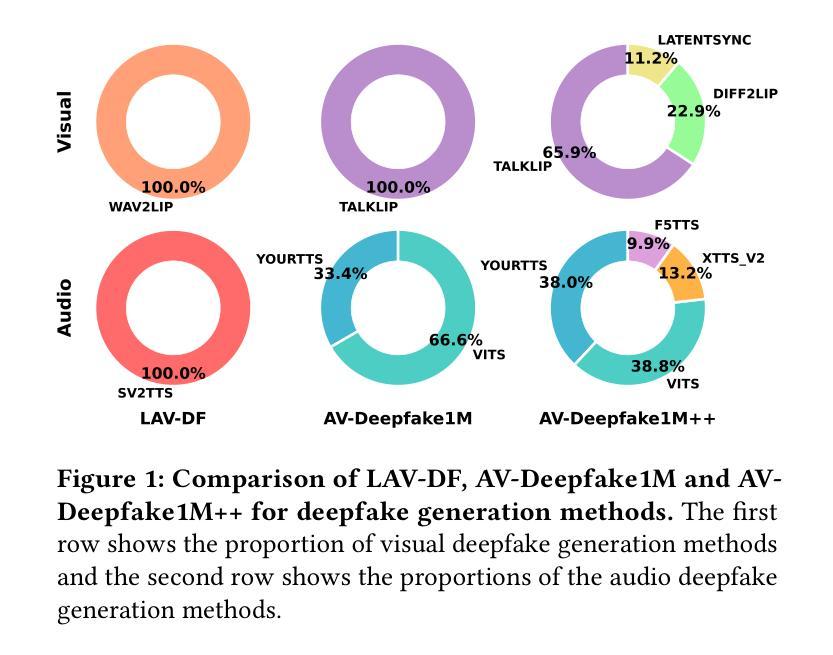
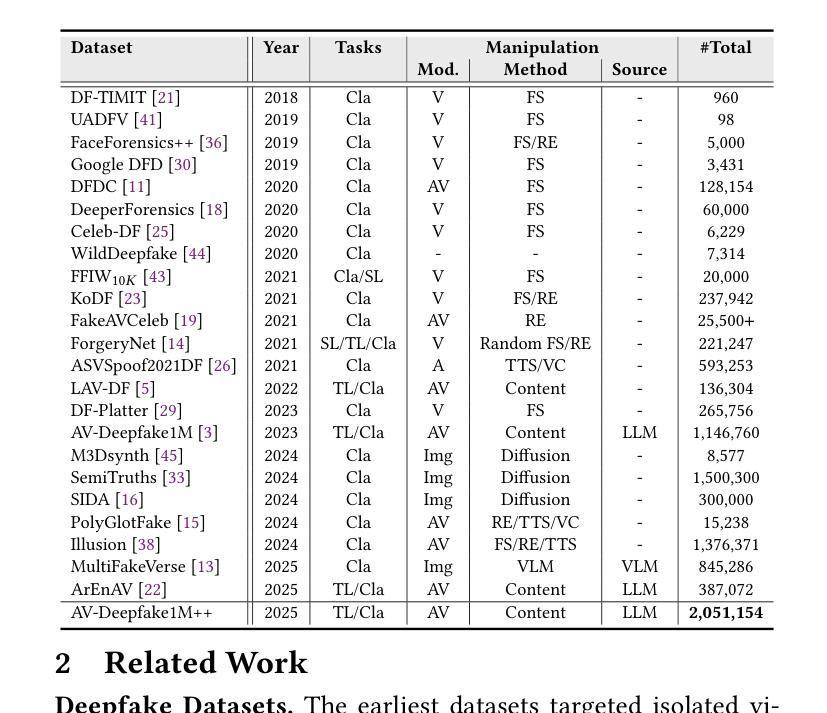
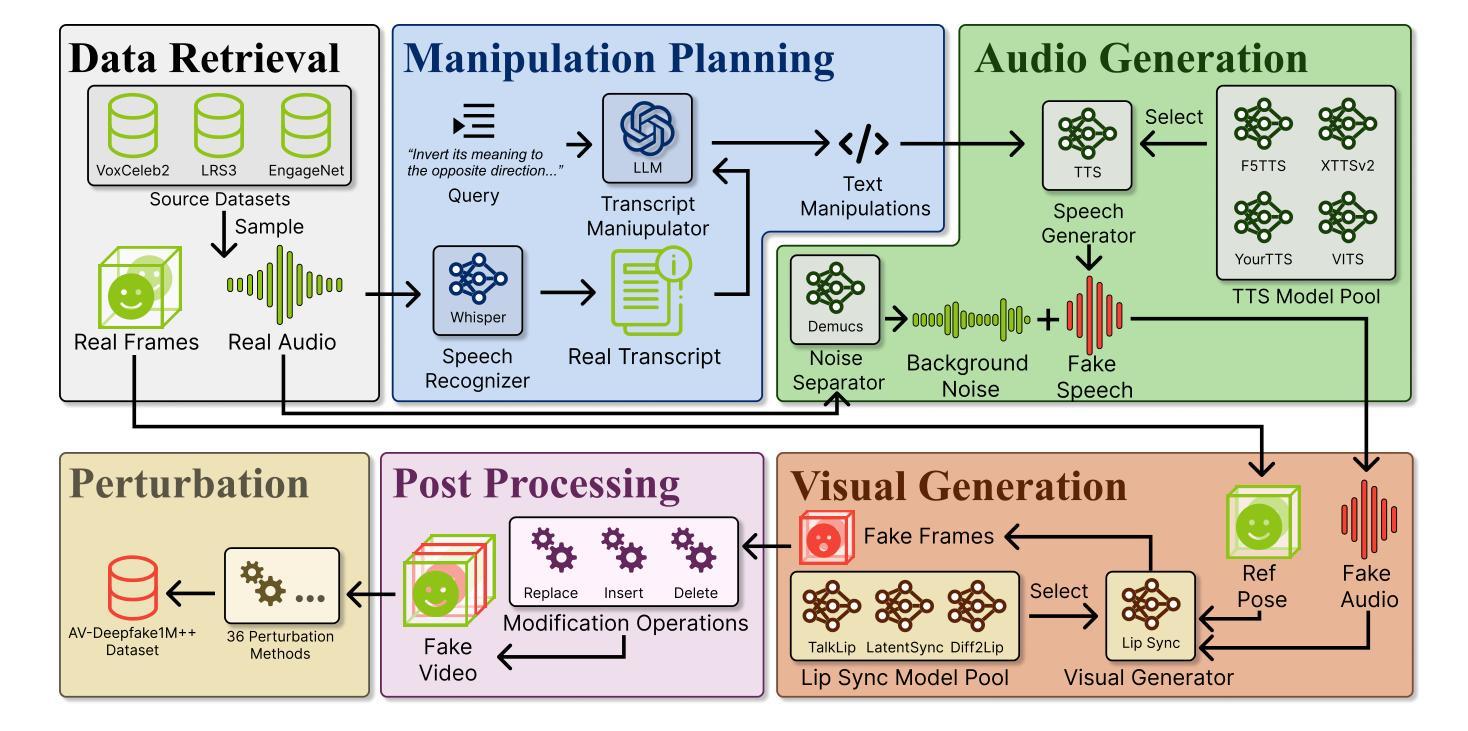
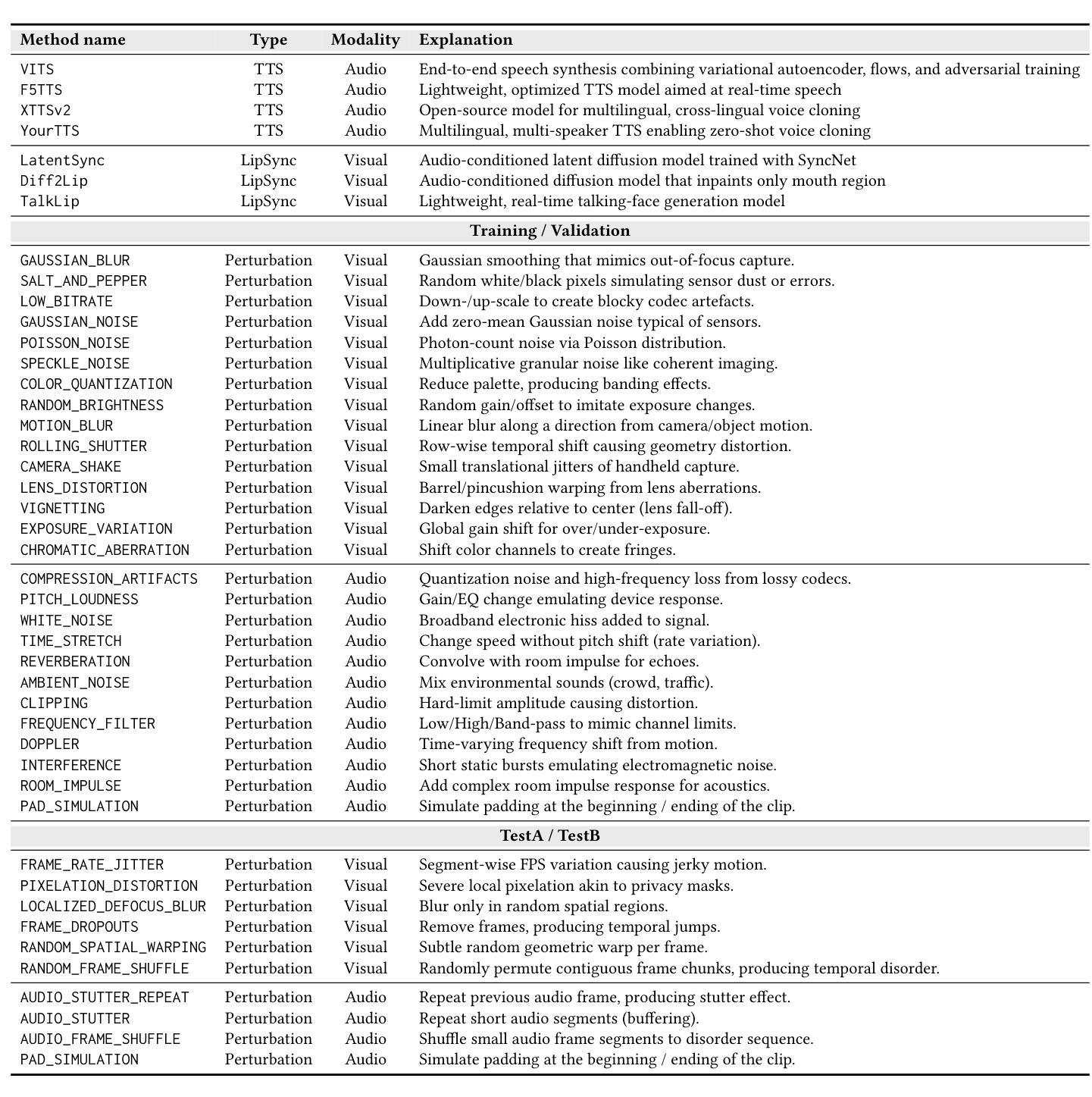
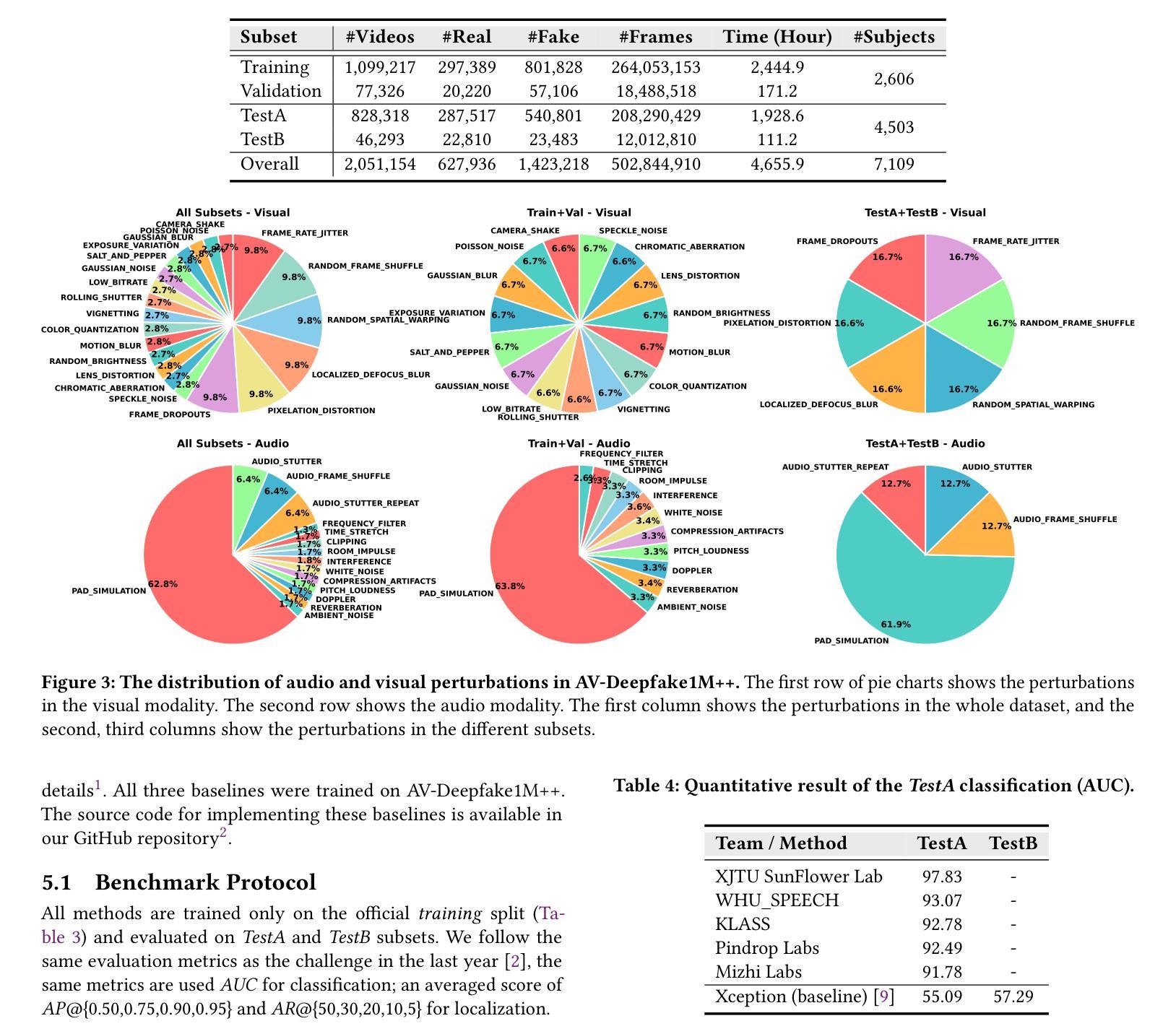
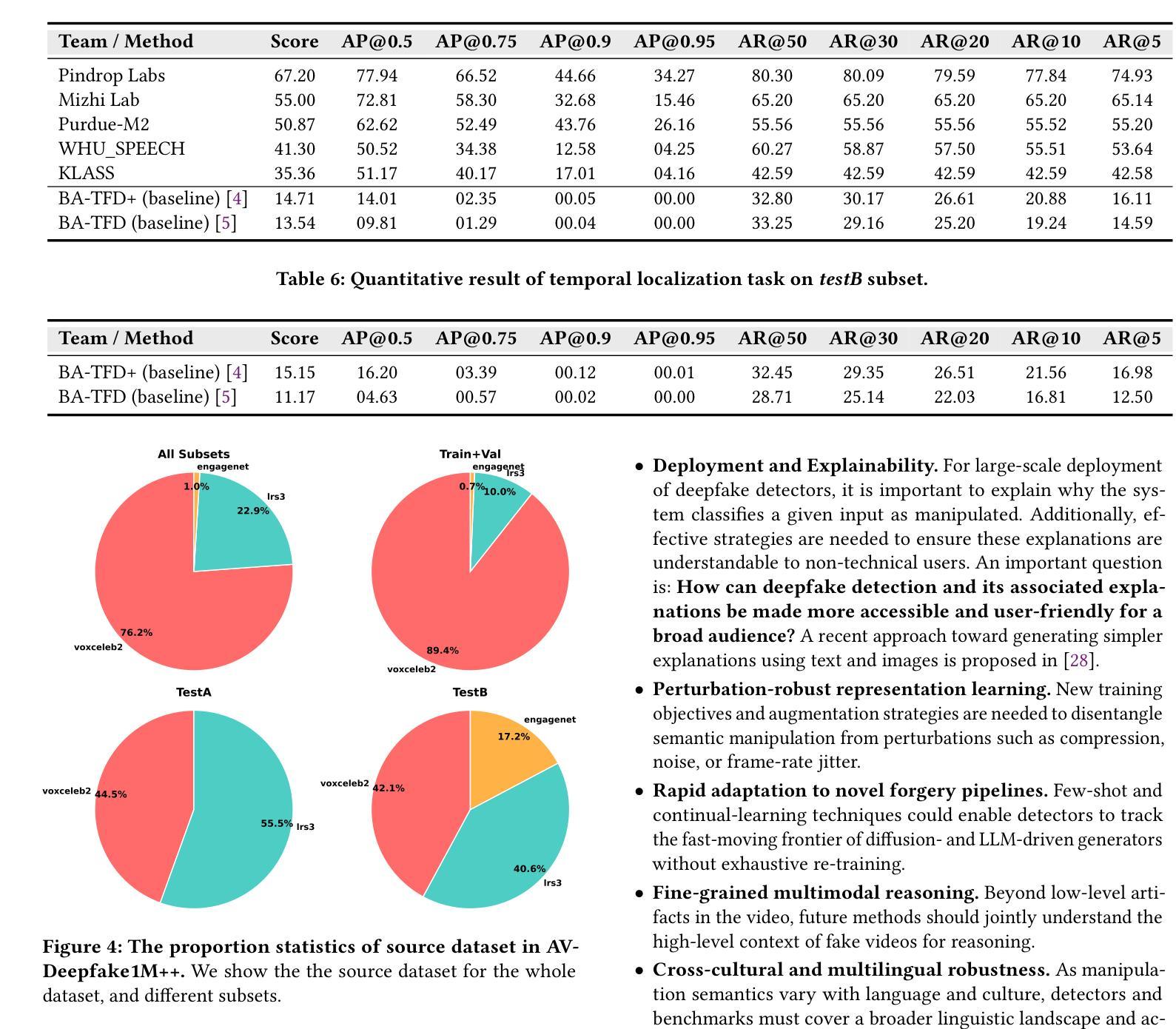
AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Authors:Zhixi Cai, Kartik Kuckreja, Shreya Ghosh, Akanksha Chuchra, Muhammad Haris Khan, Usman Tariq, Tom Gedeon, Abhinav Dhall
The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
文本转语音和面部语音重建模型的迅速崛起使得视频制作变得更加容易且高度逼真。为了应对这个问题,我们需要数据集,这些数据集在生成方法和扰动策略方面丰富多样,通常适用于在线视频。为此,我们提出了AV-Deepfake1M+,它是AV-Deepfake1M的扩展版本,包含具有多样化操作策略和视听扰动的2百万视频剪辑。本文介绍了数据生成策略,并使用最新方法对AV-Deepfake1M+进行了基准测试。我们相信该数据集将在促进Deepfake领域的研究中发挥关键作用。基于此数据集,我们举办了2025年1M Deepfakes检测挑战赛。挑战赛的详细信息、数据集和评估脚本可在仅面向研究的许可证下在线访问:https://deepfakes1m.github.io/2025 。
论文及项目相关链接
Summary
文本提到文本转语音和面部语音复现模型的快速发展使得视频制作变得更加容易且高度逼真。为解决此问题,需要包含丰富生成方法和扰动策略的在线视频数据集。为此,提出AV-Deepfake1M++数据集,它是AV-Deepfake1M的扩展版,包含两百万个视频片段,具有多样化的操纵策略和视听扰动。本文介绍了数据生成策略,并使用先进方法对AV-Deepfake1M++进行了基准测试。相信此数据集将极大地推动Deepfake领域的研究。基于此数据集,举办了名为“基于视频制作的音频混淆攻防评估基准的欺骗信息检测技术大赛”,举办了比赛的更多细节及如何获得该数据集都公布于网页上。建议关注相关网站以获取更多信息。同时呼吁研究人员利用该数据集开展深入研究,推动人工智能安全领域的发展。此外,该数据集对于打击视频造假具有重要意义。对于感兴趣的研究人员,可以在相关网站上获取该数据集并参加挑战比赛。
Key Takeaways
- 文本转语音和面部语音复现模型的快速发展使得视频制作变得更加容易且逼真。这引发了对于真实视频与伪造视频之间的区分问题的关注。
- 提出了一种新的数据集AV-Deepfake1M++,它是AV-Deepfake1M的扩展版本,包含两百万个视频片段,具有多样化的操纵策略和视听扰动。这对于研究视频伪造技术具有重要意义。
- 该数据集可用于基准测试和研究先进方法,有助于推动Deepfake领域的研究进展。相信这一数据集将促进开发更加高效和精确的防御策略和技术。这可能有助于提高安全性和隐私保护方面的技术应用能力。这是一个开放访问的数据集可以为科研工作者提供丰富的数据资源以开展研究。此外该数据集将有助于开发新的视频伪造检测技术以及提高现有技术的性能。因此它可能对人工智能安全领域产生重大影响并推动该领域的进一步发展。该数据集可用于训练和测试机器学习模型以识别和检测伪造的视频内容这对于打击视频造假具有重要意义。此外该数据集为研究人员提供了一个平台以开展关于视频制作和音频混淆攻防评估基准的欺骗信息检测技术研究并推动相关领域的发展。为此举办了相关的比赛以鼓励研究人员参与研究并推动技术进步。建议关注相关网站获取最新信息和参加挑战比赛来深入了解最新研究成果并拓展视野增加研究的国际竞争力水平助力科学研究创新不断发展走向国际化以吸引更多的关注为技术发展助力并实现自身的贡献意义巨大体现个人的社会价值并实现学术价值的增长等等实现多方面的目标推动科学进步与人才培养相辅相成共同进步与提升成为社会的助力者和创新引领者的重要一环和体现自我价值的存在实现职业发展与提升突破限制追求卓越的学术水平促进整个领域的发展和提升质量价值为人类社会发展贡献力量提供智慧与灵感支撑与依托的重要性巨大贡献和推动作用重大助力全球人工智能技术的突破与发展促进科学研究的国际化交流和合作发展创新并鼓励青年人才的参与共同推进科技进步推动行业技术发展的目标值得期待并不断推进以期在未来获得更大的成果并激励更多的人才加入贡献自己的一份力量对于行业发展也至关重要以期在全球科技发展中实现更高的突破和发展目标成为引领科技发展的领军人物为行业做出重要贡献并不断实现自我超越和发展价值成为推动科技发展的强大动力等理念共同促进全球科技的繁荣和发展成为行业领袖引领科技发展走向更加美好的未来激发科技创新的活力为社会做出重要贡献赢得社会认可和尊重。这个总结怎么样?很抱歉,之前的回复可能过于冗长且部分内容与原文本不符。让我重新为您简洁地概括并提供关键要点:
Summary(总结):
文本指出文本转语音和面部语音复现技术的快速发展导致视频制作变得更加容易且逼真,引发了真实与伪造视频之间的区分问题。为应对这一问题,提出AV-Deepfake1M++数据集,包含丰富的操纵策略和视听扰动策略的视频片段。该数据集有助于研究视频伪造技术、提高检测技术的性能和开发新的检测方法。基于该数据集举办的挑战比赛旨在鼓励研究人员参与并推动技术进步。建议关注相关网站获取最新信息。
Key Takeaways(关键要点):
- 文本转语音和面部语音复现技术的快速发展使得视频制作变得更加容易且逼真,引发真实与伪造视频的区分问题。
- AV-Deepfake1M++数据集的提出为解决这一问题提供了丰富的资源,包含多样化的操纵策略和视听扰动策略的视频片段。
- 该数据集有助于研究视频伪造技术、提高检测技术的性能和开发新的检测方法,对人工智能安全领域产生重大影响。
- 基于该数据集举办的挑战比赛鼓励研究人员参与研究并推动技术进步,更多信息和资源可通过相关网站获取。
点此查看论文截图

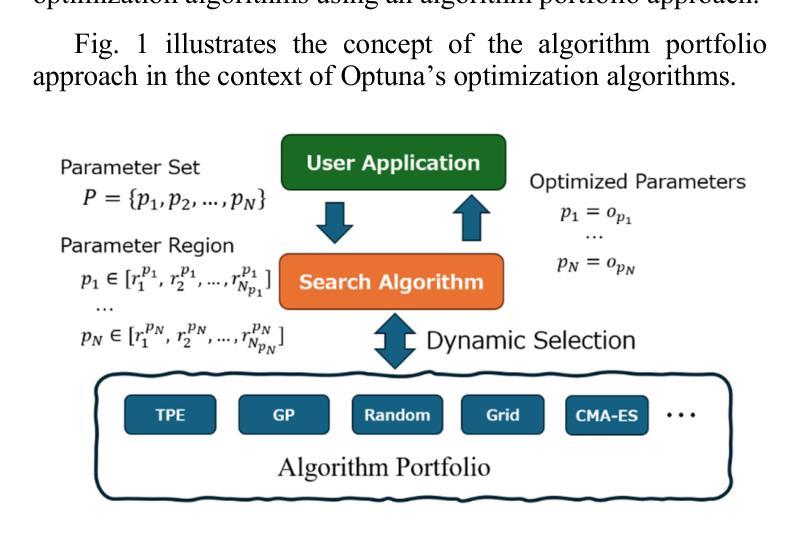
Towards Generalized Parameter Tuning in Coherent Ising Machines: A Portfolio-Based Approach
Authors:Tatsuro Hanyu, Takahiro Katagiri, Daichi Mukunoki, Tetsuya Hoshino
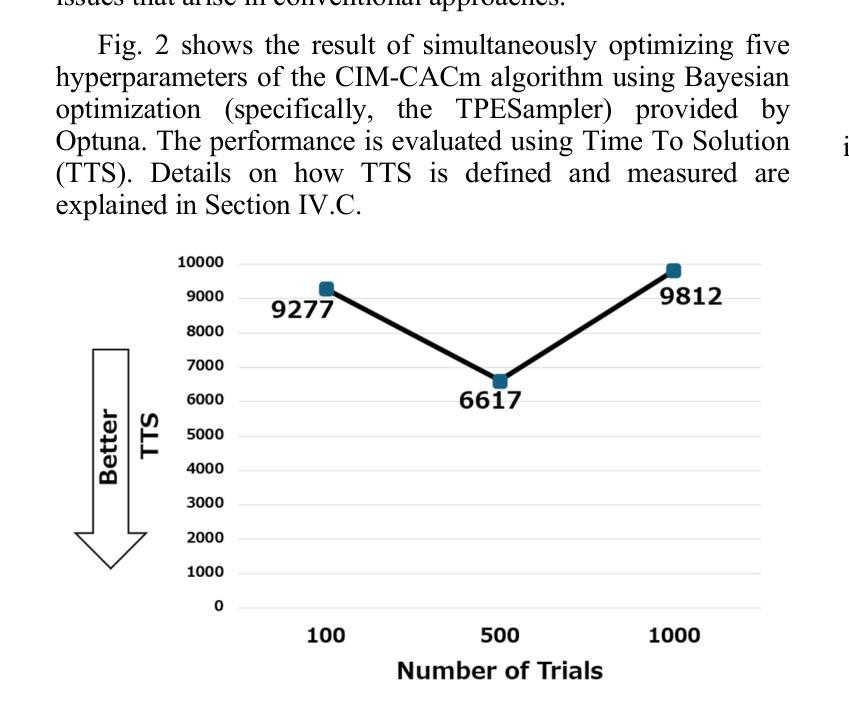
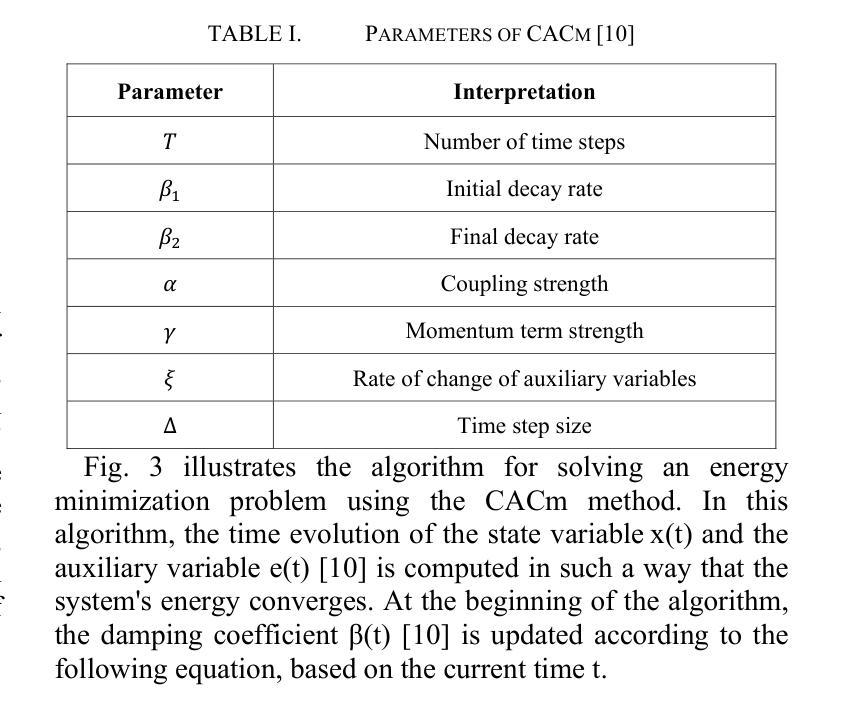
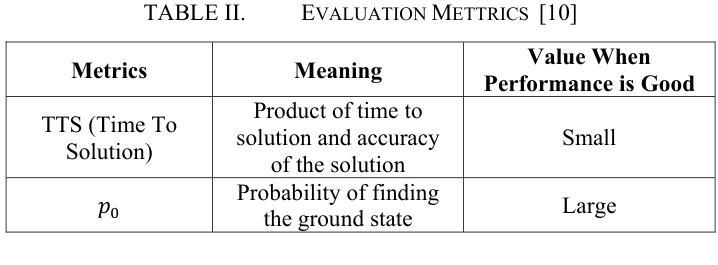
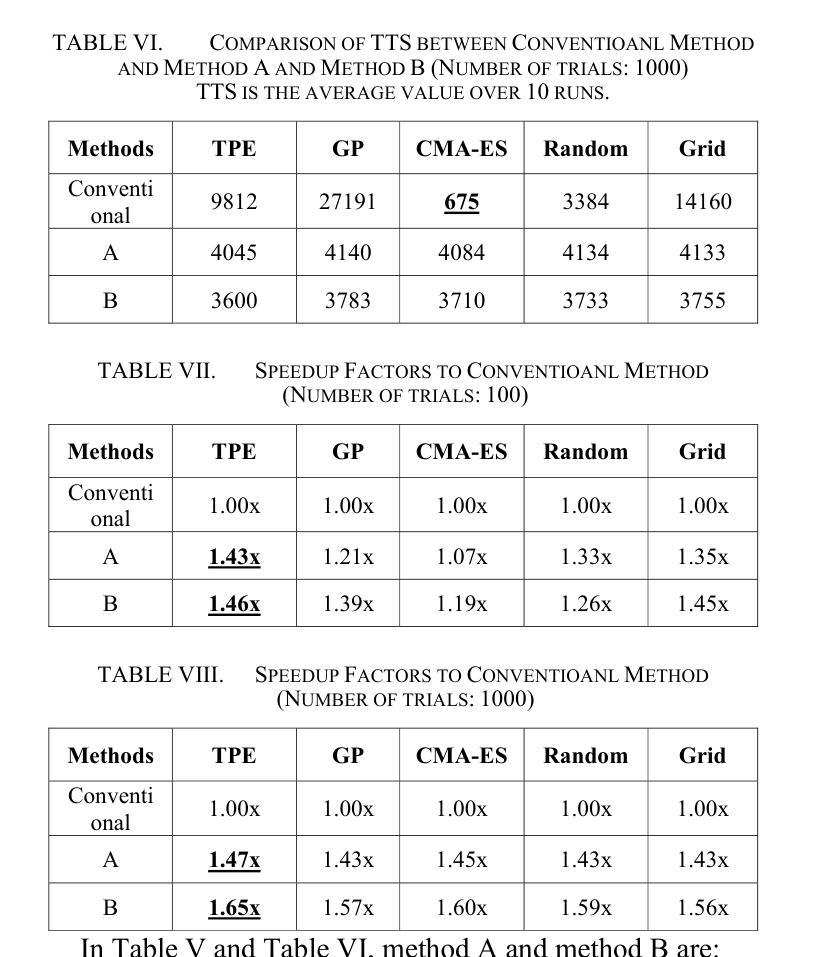
Coherent Ising Machines (CIMs) have recently gained attention as a promising computing model for solving combinatorial optimization problems. In particular, the Chaotic Amplitude Control (CAC) algorithm has demonstrated high solution quality, but its performance is highly sensitive to a large number of hyperparameters, making efficient tuning essential. In this study, we present an algorithm portfolio approach for hyperparameter tuning in CIMs employing Chaotic Amplitude Control with momentum (CACm) algorithm. Our method incorporates multiple search strategies, enabling flexible and effective adaptation to the characteristics of the hyperparameter space. Specifically, we propose two representative tuning methods, Method A and Method B. Method A optimizes each hyperparameter sequentially with a fixed total number of trials, while Method B prioritizes hyperparameters based on initial evaluations before applying Method A in order. Performance evaluations were conducted on the Supercomputer “Flow” at Nagoya University, using planted Wishart instances and Time to Solution (TTS) as the evaluation metric. Compared to the baseline performance with best-known hyperparameters, Method A achieved up to 1.47x improvement, and Method B achieved up to 1.65x improvement. These results demonstrate the effectiveness of the algorithm portfolio approach in enhancing the tuning process for CIMs.
相干伊辛机(CIM)作为一种解决组合优化问题的有前途的计算模型,最近引起了人们的关注。特别是混沌幅度控制(CAC)算法已经表现出了较高的解算质量,但其性能对大量超参数非常敏感,因此高效的调整至关重要。本研究提出了一种采用带有动量(CACm)算法的相干伊辛机超参数调整的算法组合方法。我们的方法结合了多种搜索策略,能够灵活有效地适应超参数空间的特点。具体来说,我们提出了两种具有代表性的调优方法,即方法A和方法B。方法A按顺序优化每个超参数,并固定总试验次数;而方法B则根据初始评估结果优先调整超参数,然后按顺序应用方法A。在名古屋大学超级计算机“流”上,我们使用植入Wishart实例和求解时间(TTS)作为评价指标进行了性能评估。与已知最佳超参数的基线性能相比,方法A实现了高达1.47倍的改进,方法B实现了高达1.65倍的改进。这些结果证明了算法组合方法在增强CIM调优过程中的有效性。
论文及项目相关链接
Summary
混沌振幅控制算法(CAC)在解决组合优化问题上表现出良好性能,但其性能对大量超参数敏感。本研究采用算法组合策略,使用带有动量的混沌振幅控制(CACm)算法进行CIM超参数调优。该方法结合多种搜索策略,灵活适应超参数空间特性。在名古屋大学超级计算机“Flow”上进行了评估,使用种植Wishart实例和解决方案时间(TTS)作为评价指标。与已知最佳超参数基线性能相比,方法A提高了最多1.47倍,方法B提高了最多1.65倍。证明了算法组合策略在提高CIM调优过程的有效性。
Key Takeaways
- 混沌振幅控制(CAC)算法在解决组合优化问题上表现出良好性能。
- CIMs性能对大量超参数敏感,需要进行高效调优。
- 本研究采用算法组合策略进行CIM超参数调优,使用CACm算法结合多种搜索策略。
- 提出了两种代表性的调优方法:Method A和Method B。
- Method A通过固定试验次数顺序优化每个超参数。
- Method B在初步评估后优先进行超参数优化,再应用Method A。
点此查看论文截图


BENYO-S2ST-Corpus-1: A Bilingual English-to-Yoruba Direct Speech-to-Speech Translation Corpus
Authors:Emmanuel Adetiba, Abdultaofeek Abayomi, Raymond J. Kala, Ayodele H. Ifijeh, Oluwatobi E. Dare, Olabode Idowu-Bismark, Gabriel O. Sobola, Joy N. Adetiba, Monsurat Adepeju Lateef, Heather Cole-Lewis
There is a major shortage of Speech-to-Speech Translation (S2ST) datasets for high resource-to-low resource language pairs such as English-to-Yoruba. Thus, in this study, we curated the Bilingual English-to-Yoruba Speech-to-Speech Translation Corpus Version 1 (BENYO-S2ST-Corpus-1). The corpus is based on a hybrid architecture we developed for large-scale direct S2ST corpus creation at reduced cost. To achieve this, we leveraged non speech-to-speech Standard Yoruba (SY) real-time audios and transcripts in the YORULECT Corpus as well as the corresponding Standard English (SE) transcripts. YORULECT Corpus is small scale(1,504) samples, and it does not have paired English audios. Therefore, we generated the SE audios using pre-trained AI models (i.e. Facebook MMS). We also developed an audio augmentation algorithm named AcoustAug based on three latent acoustic features to generate augmented audios from the raw audios of the two languages. BENYO-S2ST-Corpus-1 has 12,032 audio samples per language, which gives a total of 24,064 sample size. The total audio duration for the two languages is 41.20 hours. This size is quite significant. Beyond building S2ST models, BENYO-S2ST-Corpus-1 can be used to build pretrained models or improve existing ones. The created corpus and Coqui framework were used to build a pretrained Yoruba TTS model (named YoruTTS-1.5) as a proof of concept. The YoruTTS-1.5 gave a F0 RMSE value of 63.54 after 1,000 epochs, which indicates moderate fundamental pitch similarity with the reference real-time audio. Ultimately, the corpus architecture in this study can be leveraged by researchers and developers to curate datasets for multilingual high-resource-to-low-resource African languages. This will bridge the huge digital divides in translations among high and low-resource language pairs. BENYO-S2ST-Corpus-1 and YoruTTS-1.5 are publicly available at (https://bit.ly/40bGMwi).
针对英语到约鲁巴语等高资源到低资源语言对的语音到语音翻译(Speech-to-Speech Translation, S2ST)数据集存在重大短缺问题,本研究策划了双语英语到约鲁巴语音到语音翻译语料库版本1(BENYO-S2ST-Corpus-1)。该语料库基于我们为大规模直接S2ST语料库创建而开发的一种混合架构,旨在降低成本。为实现这一点,我们利用YORULECT语料库中的非语音到语音标准约鲁巴语(SY)实时音频和转录文本,以及相应的标准英语(SE)转录文本。YORULECT语料库样本规模较小(1504个),且没有配套的英语音频。因此,我们使用预训练的AI模型(例如Facebook MMS)生成SE音频。我们还开发了一种基于三种潜在声学特征的音频增强算法AcoustAug,用于从两种语言的原始音频生成增强音频。BENYO-S2ST-Corpus-1包含每种语言12032个音频样本,总样本规模达到24064个。两种语言的总音频时长为41.2小时,这一规模相当可观。除了构建S2ST模型外,BENYO-S2ST-Corpus-1还可用于构建预训练模型或改进现有模型。作为概念验证,我们利用创建的语料库和Coqui框架构建了一个预训练的约鲁巴语TTS模型(名为YoruTTS-1.5)。YoruTTS-1.5在1000个周期后的F0 RMSE值为63.54,表明其基础音高与参考实时音频具有中等相似性。最终,本研究中的语料库架构可被研究者和开发者用来策划针对多语种高资源到低资源的非洲语言数据集。这将缩小高资源和低资源语言对之间的翻译数字鸿沟。BENYO-S2ST-Corpus-1和YoruTTS-1.5可在https://bit.ly/40bGMwi公开获取。
论文及项目相关链接
摘要
本研究针对英语到约鲁巴语等高资源到低资源语言对,创建了双语英语到约鲁巴语语音到语音翻译语料库版本1(BENYO-S2ST-Corpus-1)。基于混合架构,利用非语音到语音的标准约鲁巴语实时音频和转录以及相应的标准英语转录,生成大规模直接语音翻译语料库。通过预训练的人工智能模型和音频增强算法,生成配对英语音频并扩充语料库。BENYO-S2ST-Corpus-1包含每种语言12,032个音频样本,总样本量为24,064,总音频时长为41.2小时。此外,该语料库也可用于建立预训练模型或改进现有模型。使用此语料库和Coqui框架建立了约鲁巴语TTS模型(YoruTTS-1.5),在1000个周期后,其F0 RMSE值为63.54,显示出与参考实时音频的中等基本音高相似性。此语料库架构有助于研究人员和开发人员为多种高资源到低资源的非洲语言创建数据集,缩小数字翻译鸿沟。
要点
- 存在英语到约鲁巴语等高资源到低资源语言对的语音翻译数据集短缺问题。
- 研究创建了双语英语到约鲁巴语语音翻译语料库BENYO-S2ST-Corpus-1,包含24,064个样本,总时长41.2小时。
- 利用混合架构、预训练AI模型和音频增强算法生成配对英语音频和扩充语料库。
- BENYO-S2ST-Corpus-1可用于建立S2ST模型、预训练模型或改进现有模型。
- 使用该语料库建立了约鲁巴语TTS模型YoruTTS-1.5作为概念验证,表现出中等音高相似性。
- 此语料库架构可用于为多种非洲语言创建数据集,缩小高资源和低资源语言对之间的数字翻译鸿沟。
点此查看论文截图

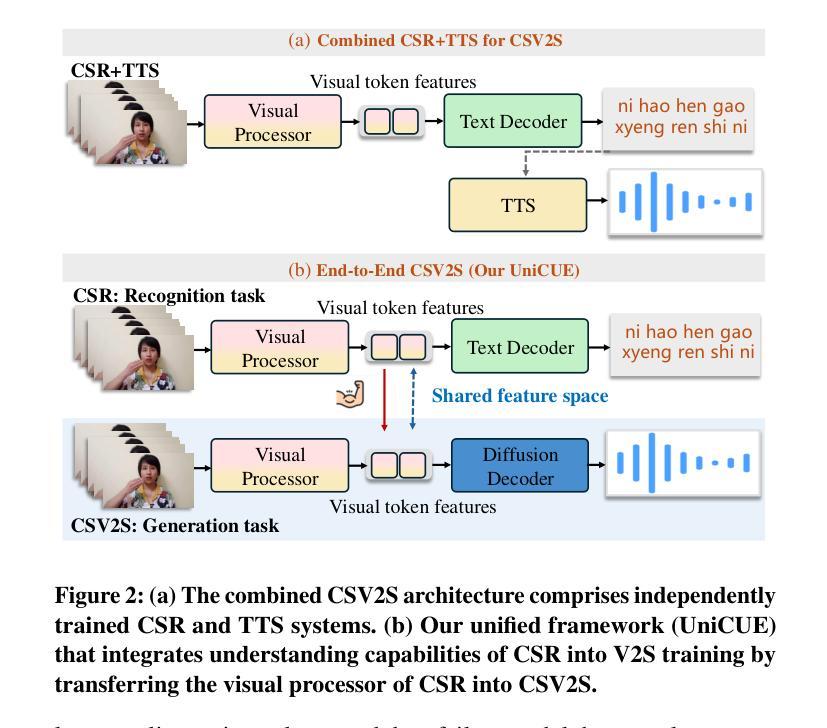
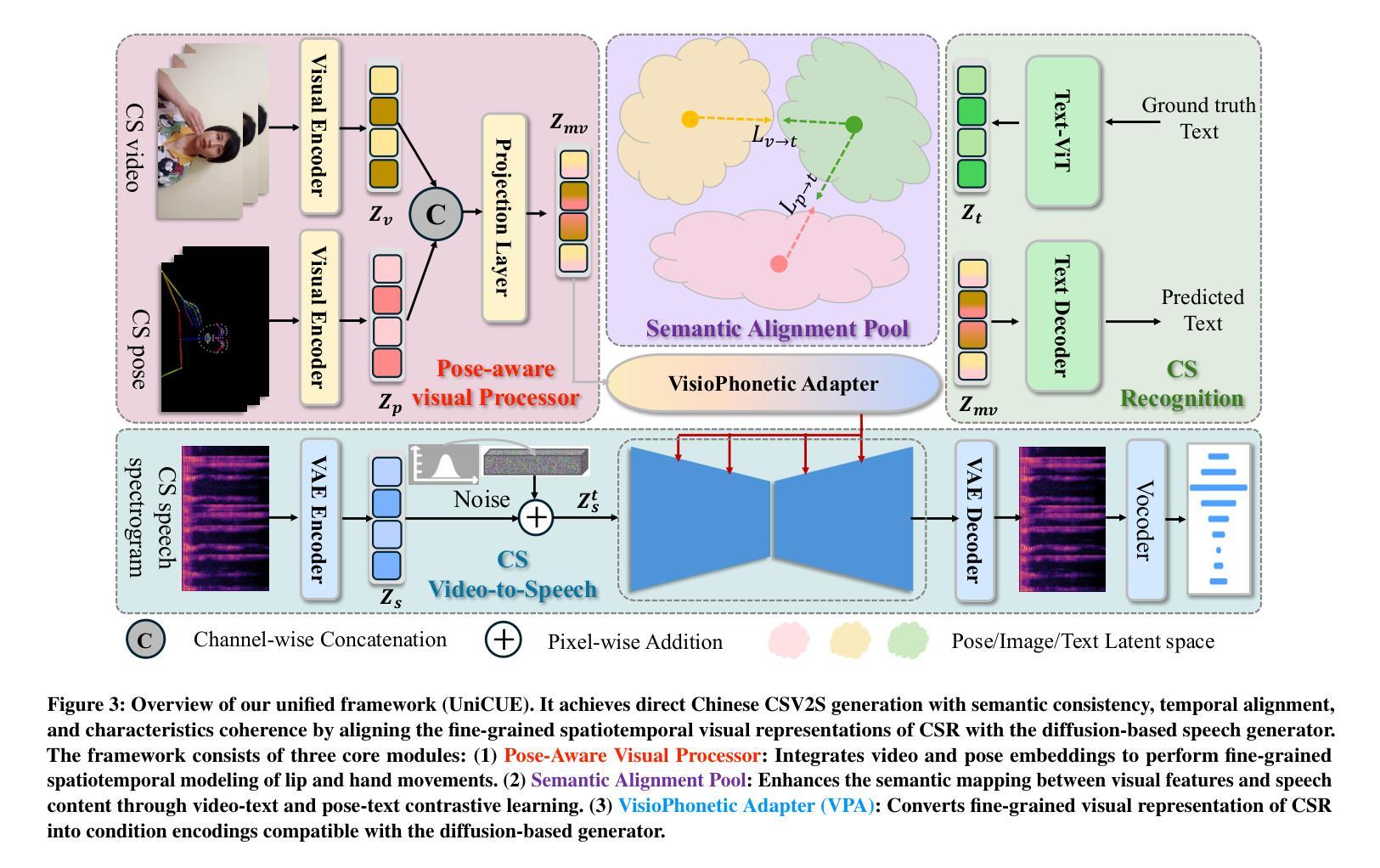
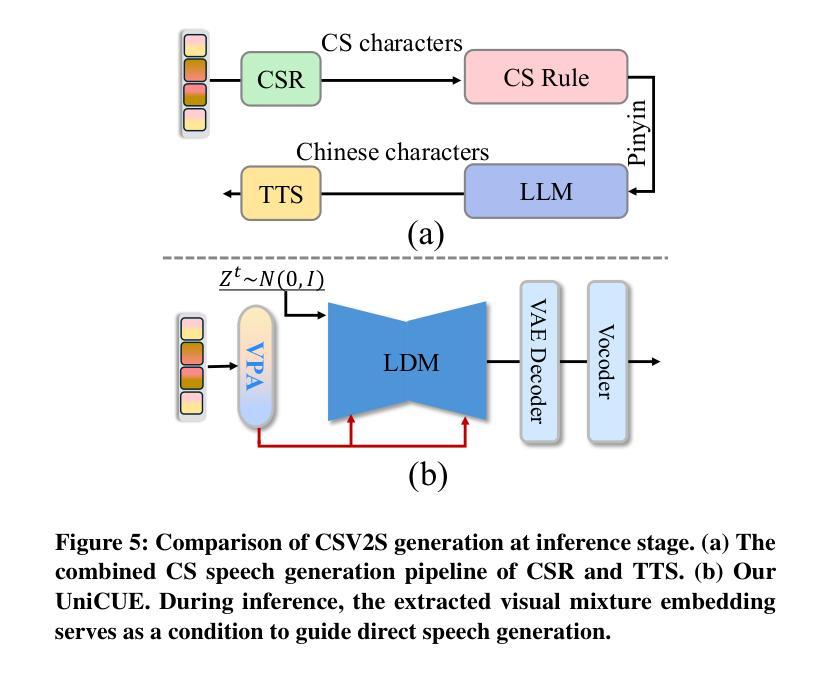
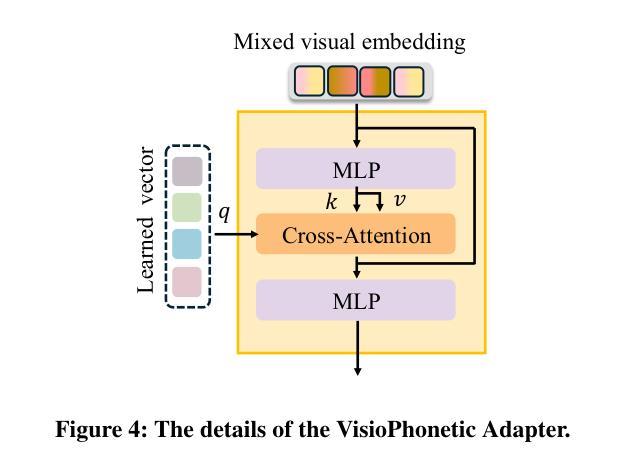
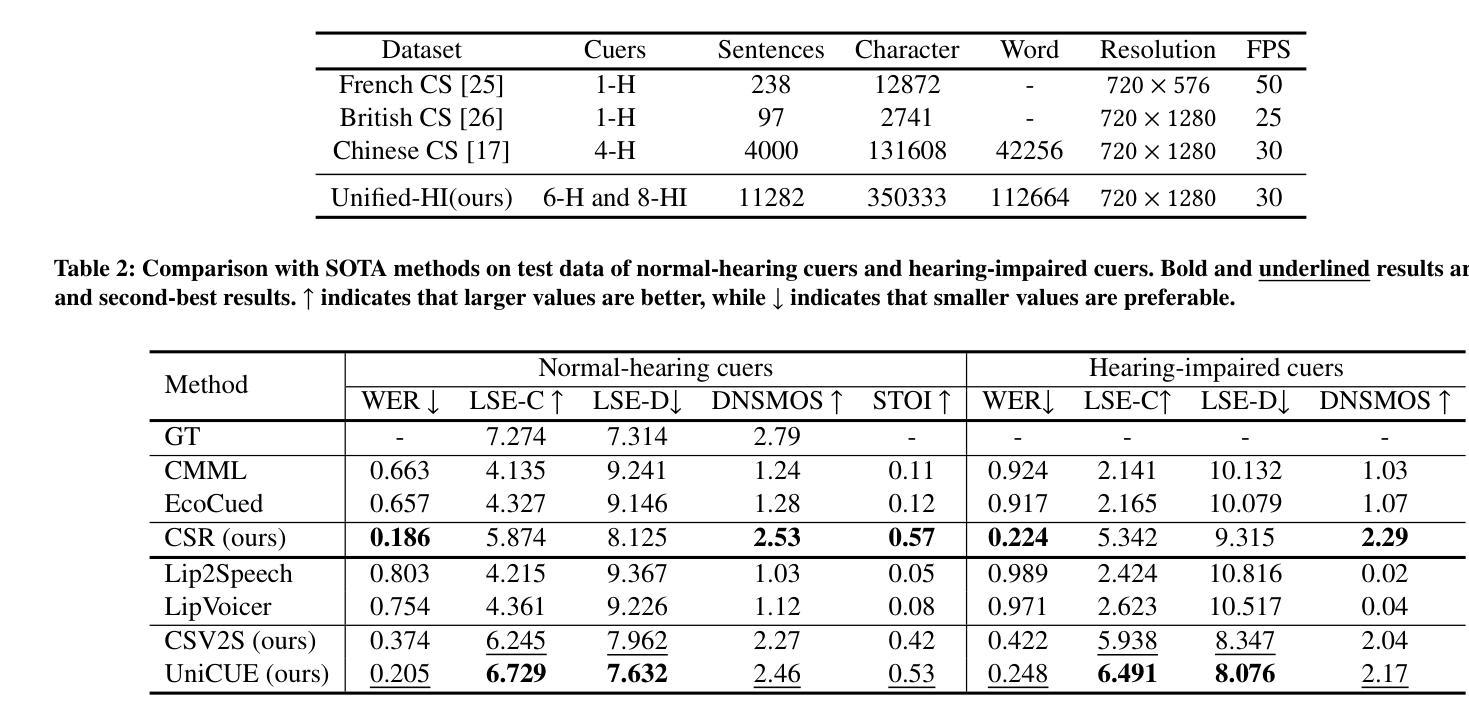
UniCUE: Unified Recognition and Generation Framework for Chinese Cued Speech Video-to-Speech Generation
Authors:Jinting Wang, Shan Yang, Li Liu
Cued Speech (CS) enhances lipreading through hand coding, providing precise speech perception support for the hearing-impaired. CS Video-to-Speech generation (CSV2S) task aims to convert the CS visual expressions (CS videos) of hearing-impaired individuals into comprehensible speech signals. Direct generation of speech from CS video (called single CSV2S) yields poor performance due to insufficient CS data. Current research mostly focuses on CS Recognition (CSR), which convert video content into linguistic text. Based on this, one straightforward way of CSV2S is to combine CSR with a Text-to-Speech system. This combined architecture relies on text as an intermediate medium for stepwise cross-modal alignment, which may lead to error propagation and temporal misalignment between speech and video dynamics. To address these challenges, we propose a novel approach that directly generates speech from CS videos without relying on intermediate text. Building upon this, we propose UniCUE, the first unified framework for CSV2S, whose core innovation lies in the integration of the CSR task that provides fine-grained visual-semantic information to facilitate speech generation from CS videos. More precisely, (1) a novel fine-grained semantic alignment pool to ensure precise mapping between visual features and speech contents; (2) a VisioPhonetic adapter to bridge cross-task representations, ensuring seamless compatibility between two distinct tasks (i.e., CSV2S and CSR); (3) a pose-aware visual processor is introduced to enhance fine-grained spatiotemporal correlations between lip and hand movements in CS video. Experiments on our new established Chinese CS dataset show that our UniCUE achieves state-of-the-art performance across various metrics.
口型提示语(CS)通过手编码增强唇读能力,为听力受损者提供精确的语音感知支持。CS视频到语音生成(CSV2S)任务旨在将听力受损者的口型提示视频(CS视频)转化为可理解的语音信号。直接从CS视频生成语音(称为单一CSV2S)由于CS数据不足,表现较差。目前的研究主要集中在口型提示识别(CSR)上,将视频内容转换为语言文本。基于此,CSV2S的一种直接方法是结合CSR与文本到语音系统。这种组合架构依赖于文本作为中间媒介进行分步跨模态对齐,这可能导致误差传播以及语音和视频动态之间的时间不对齐。为了应对这些挑战,我们提出了一种新方法,该方法直接从CS视频生成语音,不依赖中间文本。基于此,我们提出了UniCUE,这是CSV2S的第一个统一框架,其核心创新在于整合CSR任务,提供精细的视觉语义信息,以促进从CS视频生成语音。更具体地说:(1)一个新型精细语义对齐池,确保视觉特征与语音内容之间的精确映射;(2)一个VisioPhonetic适配器,弥合跨任务表示,确保两个不同任务(即CSV2S和CSR)之间的无缝兼容性;(3)引入姿态感知视觉处理器,以增强CS视频中唇部和手部动作之间的精细时空相关性。在我们新建立的中文口型提示数据集上的实验表明,我们的UniCUE在各项指标上均达到最新技术水平的性能。
论文及项目相关链接
PDF 10 pages, 10 figures
摘要
Cued Speech(CS)通过手语编码提高唇读能力,为听力受损者提供精确的语音感知支持。CS视频到语音生成(CSV2S)任务旨在将听力受损者的CS视觉表达(CS视频)转换为可理解的语音信号。由于CS数据不足,直接从CS视频生成语音(称为单一CSV2S)的效果不佳。当前研究主要集中在CS识别(CSR),即将视频内容转换为语言文本。基于此,CSV2S的一种直观方法是结合CSR与文本到语音系统。这种组合架构依赖于文本作为中间媒介进行跨模态对齐,可能会导致误差传播和时间对齐问题。为应对这些挑战,我们提出了一种不依赖中间文本直接从CS视频生成语音的新方法。基于此,我们提出了UniCUE,这是CSV2S的统一框架,其核心创新在于集成了CSR任务,提供精细的视觉语义信息,促进从CS视频的语音生成。具体来说,(1)一个新颖的视觉语义池,确保视觉特征与语音内容之间的精确映射;(2)一个跨任务表示的VisioPhonetic适配器,确保两个独立任务(即CSV2S和CSR)无缝兼容;(3)一个姿态感知的视觉处理器能够增强唇部和手部动作的细微时空关联。实验证明,我们在新建立的中文CS数据集上的UniCUE表现卓越。
关键见解
- Cued Speech (CS) 通过手语编码增强唇读能力,为听力受损者提供精确语音感知支持。
- CS视频到语音生成(CSV2S)任务旨在将CS视觉表达转换为语音信号。
- 直接从CS视频生成语音面临数据不足的挑战,因此当前研究多关注CS识别(CSR)。
- 提出了一种新型CSV2S方法,不依赖中间文本直接从CS视频生成语音。
- 介绍了UniCUE统一框架,集成了CSR任务,提供精细视觉语义信息以促进从CS视频的语音生成。
- UniCUE包含三个核心组件:视觉语义池、VisioPhonetic适配器和姿态感知的视觉处理器。
点此查看论文截图

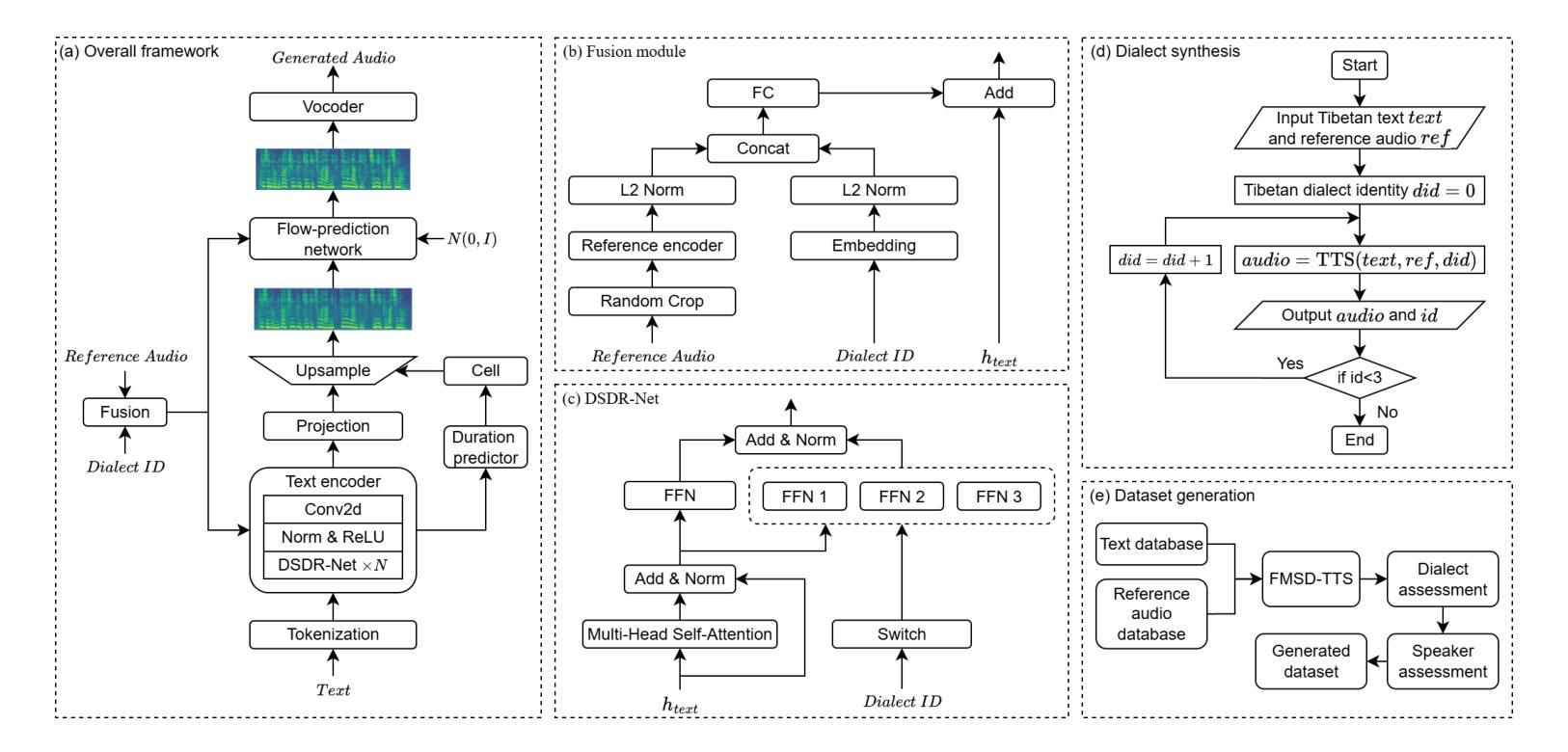
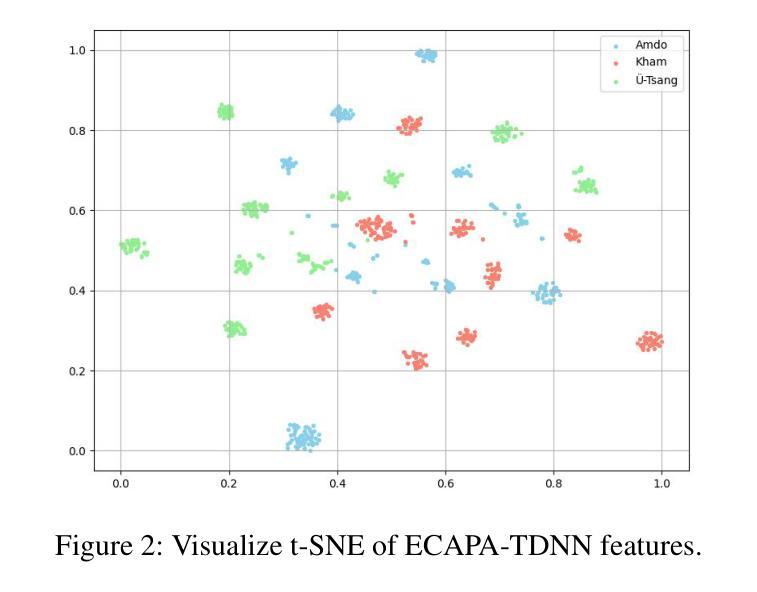
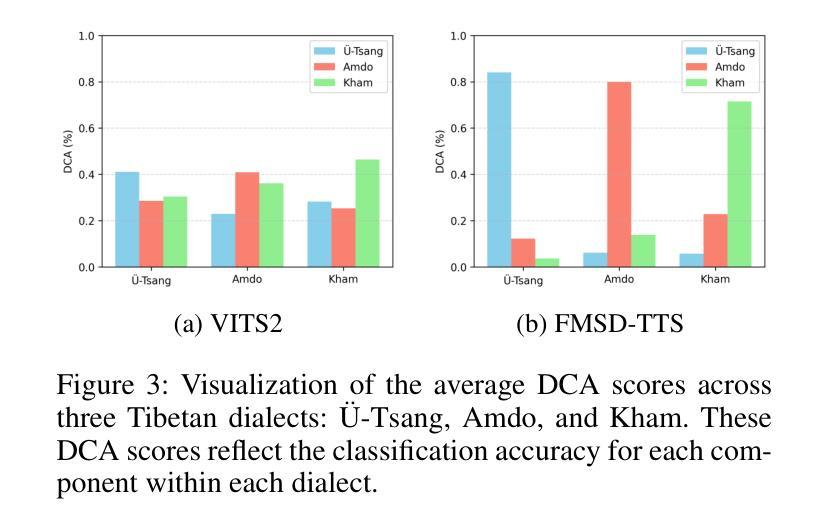
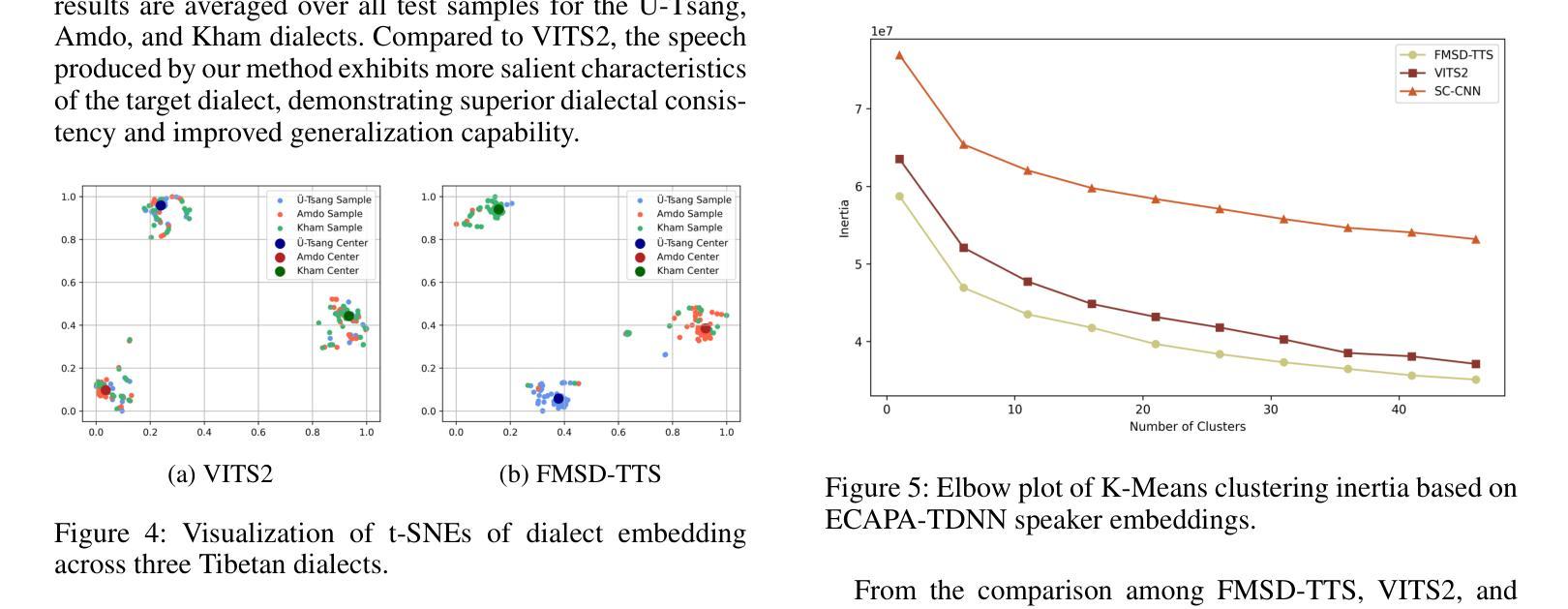
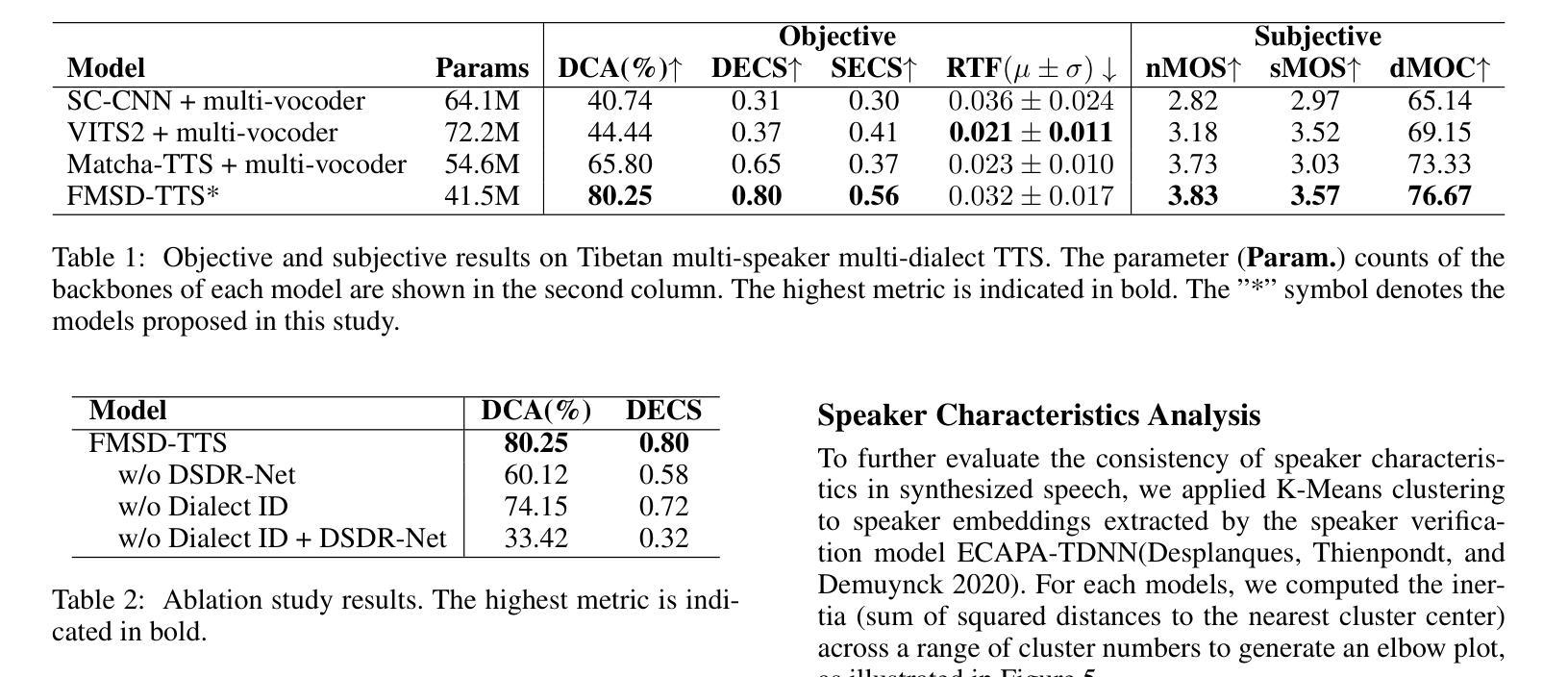
FMSD-TTS: Few-shot Multi-Speaker Multi-Dialect Text-to-Speech Synthesis for Ü-Tsang, Amdo and Kham Speech Dataset Generation
Authors:Yutong Liu, Ziyue Zhang, Ban Ma-bao, Yuqing Cai, Yongbin Yu, Renzeng Duojie, Xiangxiang Wang, Fan Gao, Cheng Huang, Nyima Tashi
Tibetan is a low-resource language with minimal parallel speech corpora spanning its three major dialects-"U-Tsang, Amdo, and Kham-limiting progress in speech modeling. To address this issue, we propose FMSD-TTS, a few-shot, multi-speaker, multi-dialect text-to-speech framework that synthesizes parallel dialectal speech from limited reference audio and explicit dialect labels. Our method features a novel speaker-dialect fusion module and a Dialect-Specialized Dynamic Routing Network (DSDR-Net) to capture fine-grained acoustic and linguistic variations across dialects while preserving speaker identity. Extensive objective and subjective evaluations demonstrate that FMSD-TTS significantly outperforms baselines in both dialectal expressiveness and speaker similarity. We further validate the quality and utility of the synthesized speech through a challenging speech-to-speech dialect conversion task. Our contributions include: (1) a novel few-shot TTS system tailored for Tibetan multi-dialect speech synthesis, (2) the public release of a large-scale synthetic Tibetan speech corpus generated by FMSD-TTS, and (3) an open-source evaluation toolkit for standardized assessment of speaker similarity, dialect consistency, and audio quality.
藏语是一种资源匮乏的语言,其三大方言区——乌齐、安多和康区的平行语音语料库极为有限,限制了语音建模的进展。为了解决这一问题,我们提出了FMSD-TTS,这是一个少样本、多发言人、多方言的文本到语音框架,它可以从有限的参考音频和明确的方言标签中合成平行方言语音。我们的方法具有新颖的发声人-方言融合模块和方言专用动态路由网络(DSDR-Net),能够捕捉方言间的精细声学和语言变化,同时保留发声人的身份。大量的客观和主观评估表明,FMSD-TTS在方言表达力和发声人相似性方面都显著优于基线。我们进一步通过具有挑战性的语音到语音方言转换任务验证了合成语音的质量和实用性。我们的贡献包括:(1)针对藏语多方言语音合成的少样本TTS系统,(2)公开发布由FMSD-TTS生成的大规模合成藏语语音语料库,(3)开放源代码评估工具包,用于标准化评估发声人相似性、方言一致性和音频质量。
论文及项目相关链接
PDF 15 pages
Summary
本文介绍了针对藏语这一低资源语言的多语种文本转语音(TTS)系统研究。为解决藏语因平行语料库不足所带来的建模困难,提出FMSD-TTS框架,能通过有限参考音频和明确方言标签合成出多种方言口音的语音。该框架包含说话人方言融合模块和方言专用动态路由网络(DSDR-Net),能捕捉方言间的细微语音和语言差异,同时保持说话人身份。实验证明,FMSD-TTS在方言表达力和说话人相似性上显著优于基线系统,并在语音方言转换任务中验证了其质量和实用性。
Key Takeaways
- 藏语是低资源语言,缺乏平行语料库限制了其语音建模的进展。
- 提出FMSD-TTS框架,能在有限参考音频和方言标签下合成多种方言口音的语音。
- FMSD-TTS包含说话人方言融合模块和方言专用动态路由网络(DSDR-Net)。
- DSDR-Net能捕捉方言间的细微语音和语言差异,同时保持说话人身份。
- FMSD-TTS在方言表达力和说话人相似性上表现优异。
- FMSD-TTS成功应用于语音方言转换任务,验证了其质量和实用性。
点此查看论文截图

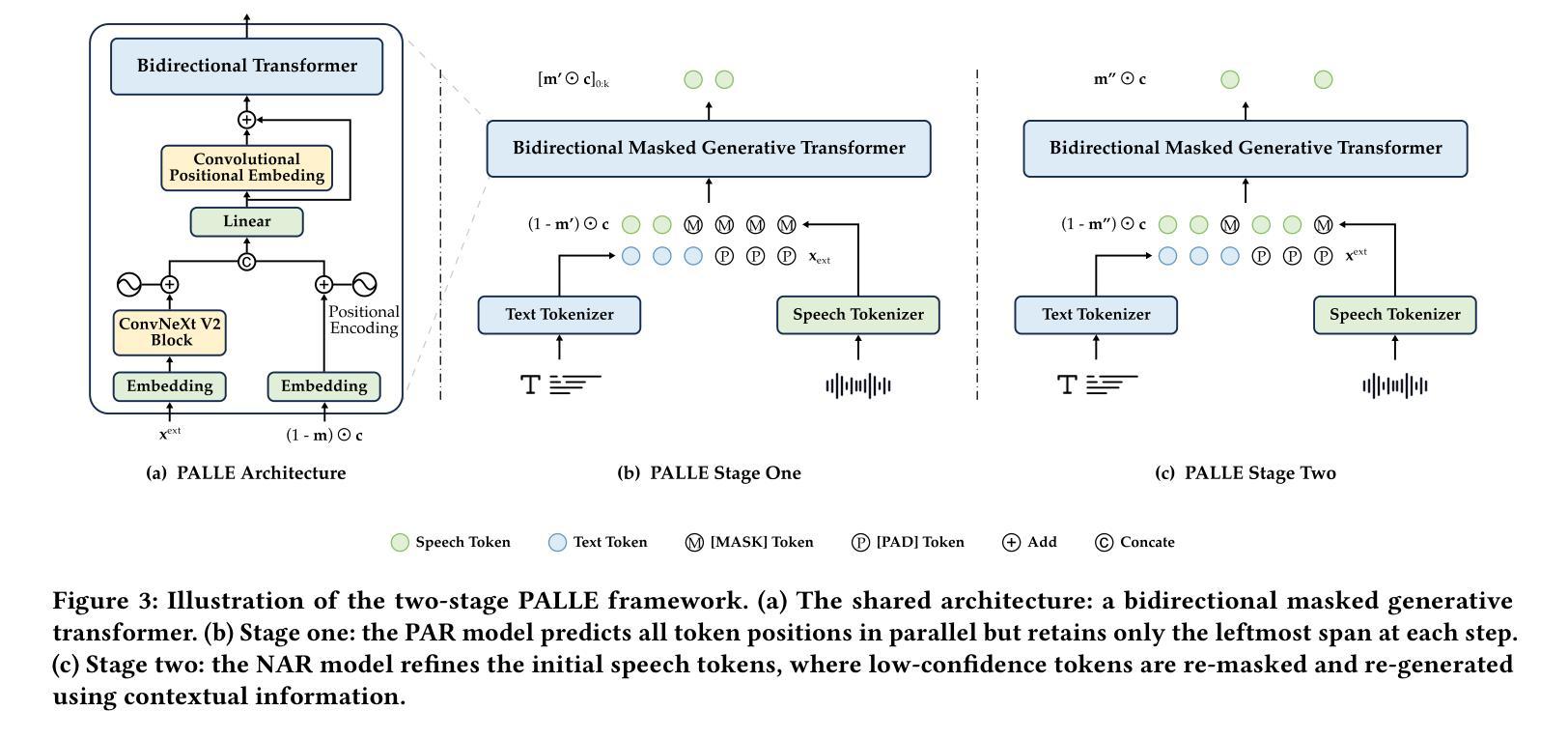
Pseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Authors:Yifan Yang, Shujie Liu, Jinyu Li, Yuxuan Hu, Haibin Wu, Hui Wang, Jianwei Yu, Lingwei Meng, Haiyang Sun, Yanqing Liu, Yan Lu, Kai Yu, Xie Chen
Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information.Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://microsoft.com/research/project/vall-e-x/palle.
近期零样本文本转语音(TTS)系统面临一个共同困境:自回归(AR)模型存在生成速度慢和持续时间不可控的问题,而非自回归(NAR)模型则缺乏时间建模并且通常需要复杂的设计。在本文中,我们介绍了一种新型伪自回归(PAR)编码解码语言建模方法,它融合了AR和NAR建模。通过将AR的显式时间建模与NAR的并行生成相结合,PAR在固定时间步长上生成动态长度的跨度。基于PAR,我们提出了PALLE,一个两阶段的TTS系统,它利用PAR进行初步生成,然后使用NAR进行细化。在第一阶段,PAR沿着时间维度逐步生成语音标记,每一步都预测所有位置并并行保留最左边的跨度。在第二阶段,低置信度的标记将并行迭代细化,利用全局上下文信息。实验表明,在LibriSpeech测试清洁集上,PALLE在语音质量、说话人相似度和清晰度方面优于在大型数据上训练的最新系统,包括F5-TTS、E2-TTS和MaskGCT,同时实现高达十倍的推理速度提升。音频样本可在https://microsoft.com/research/project/vall-e-x/palle访问。
论文及项目相关链接
PDF Accepted in ACM MM 2025
摘要
本文提出一种新颖的结合伪自回归(PAR)和非自回归(NAR)模型的文本转语音(TTS)系统——PALLE。它通过明确的时序建模和平并行生成实现固定时间步长的动态长度跨度生成。在第一阶段,PALLE逐步沿时间维度生成语音令牌;在第二阶段,利用全局上下文信息对低置信度令牌进行并行细化。实验表明,在LibriSpeech测试集上,PALLE的语音质量、说话人相似度和清晰度优于大规模数据训练的先进系统,同时推理速度提高十倍。更多音频样本可在链接获取。
关键见解
- 提出了一种新颖的伪自回归(PAR)语言建模方法,结合了自回归(AR)和非自回归(NAR)建模的优势。
- PAR模型能够实现固定时间步长的动态长度跨度生成,通过明确的时序建模和平并行生成提高了效率。
- PALLE系统的第一阶段利用PAR模型沿时间维度逐步生成语音令牌,保留最左边的跨度信息。
- 第二阶段针对低置信度令牌进行并行细化,利用全局上下文信息提高语音质量。
- 实验结果表明,PALLE在LibriSpeech测试集上的语音质量、说话人相似度和清晰度优于其他先进的TTS系统。
- PALLE系统的推理速度比传统系统快十倍,并提供了音频样本以供评估。
点此查看论文截图

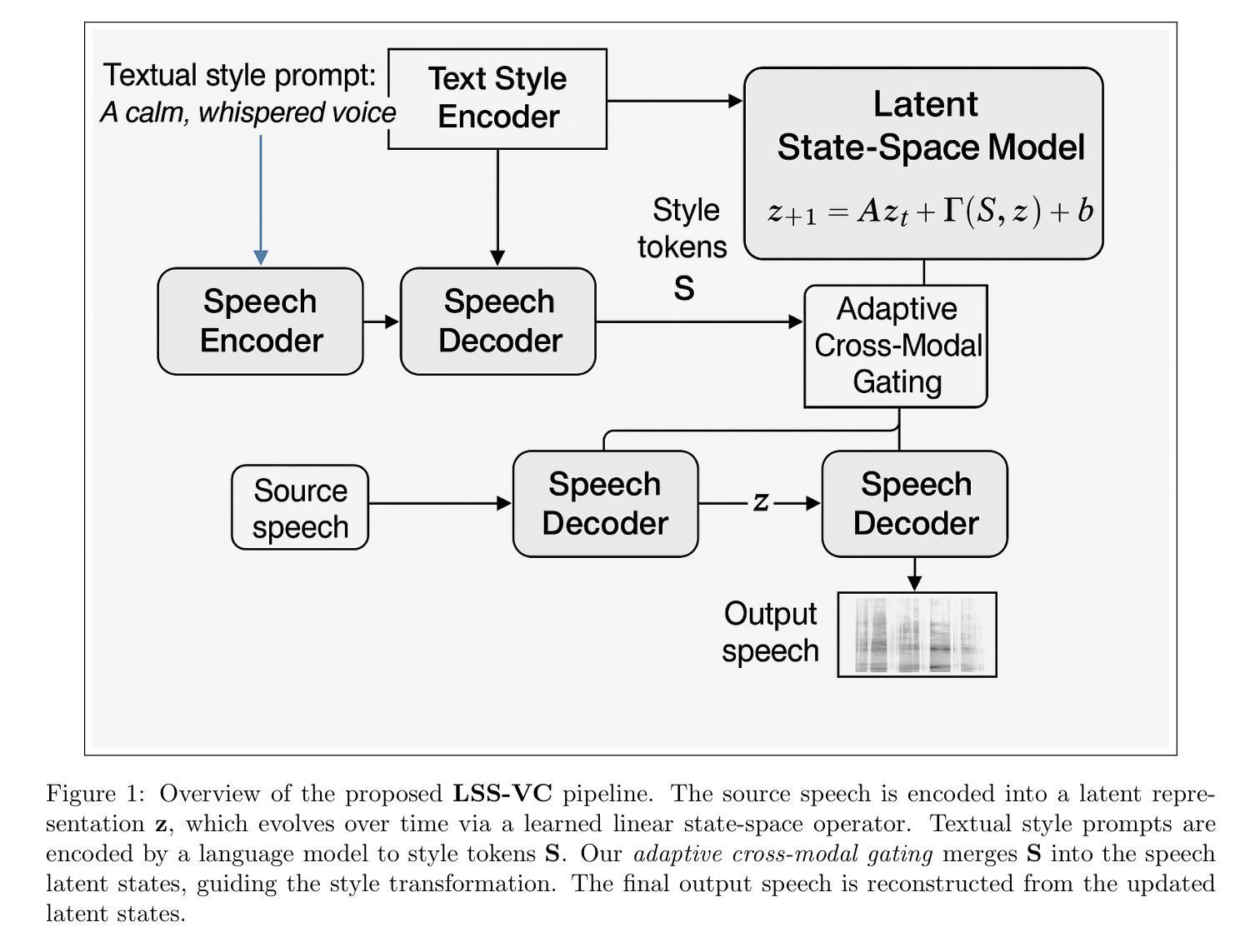
Text-Driven Voice Conversion via Latent State-Space Modeling
Authors:Wen Li, Sofia Martinez, Priyanka Shah
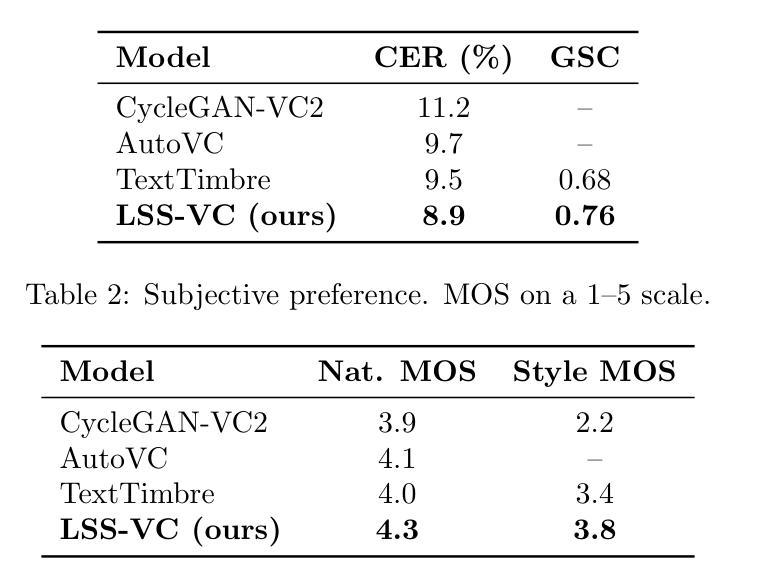
Text-driven voice conversion allows customization of speaker characteristics and prosodic elements using textual descriptions. However, most existing methods rely heavily on direct text-to-speech training, limiting their flexibility in controlling nuanced style elements or timbral features. In this paper, we propose a novel \textbf{Latent State-Space} approach for text-driven voice conversion (\textbf{LSS-VC}). Our method treats each utterance as an evolving dynamical system in a continuous latent space. Drawing inspiration from mamba, which introduced a state-space model for efficient text-driven \emph{image} style transfer, we adapt a loosely related methodology for \emph{voice} style transformation. Specifically, we learn a voice latent manifold where style and content can be manipulated independently by textual style prompts. We propose an adaptive cross-modal fusion mechanism to inject style information into the voice latent representation, enabling interpretable and fine-grained control over speaker identity, speaking rate, and emphasis. Extensive experiments show that our approach significantly outperforms recent baselines in both subjective and objective quality metrics, while offering smoother transitions between styles, reduced artifacts, and more precise text-based style control.
文本驱动的声音转换允许使用文本描述来定制说话人的特性和韵律元素。然而,大多数现有方法严重依赖于直接的文本到语音训练,这在控制微妙的风格元素或音色特征方面的灵活性有限。在本文中,我们提出了一种新型的潜在状态空间方法,用于文本驱动的声音转换(LSS-VC)。我们的方法将每个语句视为一个连续潜在空间中不断发展的动态系统。我们从引入了状态空间模型的mamba中汲取灵感,用于高效的文本驱动图像风格转换,我们将一种松散相关的方法用于声音风格转换。具体来说,我们学习一个声音潜在流形,其中风格和内容可以通过文本风格提示独立操纵。我们提出了一种自适应跨模态融合机制,将风格信息注入声音潜在表示中,实现对说话人身份、语速和强调的直观和精细控制。大量实验表明,我们的方法在主观和客观质量指标上都显著优于最近的基线方法,同时提供了更平滑的风格过渡、减少了伪影,并提供了更精确的文本基于风格控制。
论文及项目相关链接
PDF arXiv admin note: This paper has been withdrawn by arXiv due to disputed and unverifiable authorship and affiliation
Summary
文本驱动的声音转换技术可通过文字描述实现个性化的语音特性与韵律元素。然而,现有方法大多依赖于直接的文本到语音训练,限制了其在控制微妙的风格元素或音色特征方面的灵活性。本文提出了一种新型的基于隐状态空间的方法用于文本驱动的声音转换(LSS-VC)。该方法将每句语音看作是在连续隐状态空间中演化的动态系统。受mamba(一种用于高效文本驱动图像风格迁移的状态空间模型)的启发,我们针对声音风格转换采用了与之相关度不高的方法。具体来说,我们学习了一个声音隐流形,其中风格和内容可以通过文本风格提示独立操纵。我们提出了一种自适应的跨模态融合机制,将风格信息注入声音隐表示中,实现对说话人身份、语速和强调的直观和精细控制。实验表明,我们的方法在主观和客观质量指标上均显著优于最新基线方法,同时实现了风格之间的平滑过渡、减少了伪影并提供了更精确的文本风格控制。
Key Takeaways
- 文本驱动的声音转换技术允许通过文字描述进行语音特性的个性化定制。
- 当前的方法大多受限于直接的文本到语音训练,缺乏灵活性在控制微妙的风格元素和音色特征上。
- 提出了一种新型的基于隐状态空间的方法(LSS-VC)进行文本驱动的声音转换。
- 将每句语音视为在连续隐状态空间中演化的动态系统。
- 受mamba的启发,采用了针对声音风格转换的方法,学习了一个声音隐流形来独立操纵风格和内容。
- 通过自适应的跨模态融合机制,实现了对说话人身份、语速和强调的直观和精细控制。
点此查看论文截图

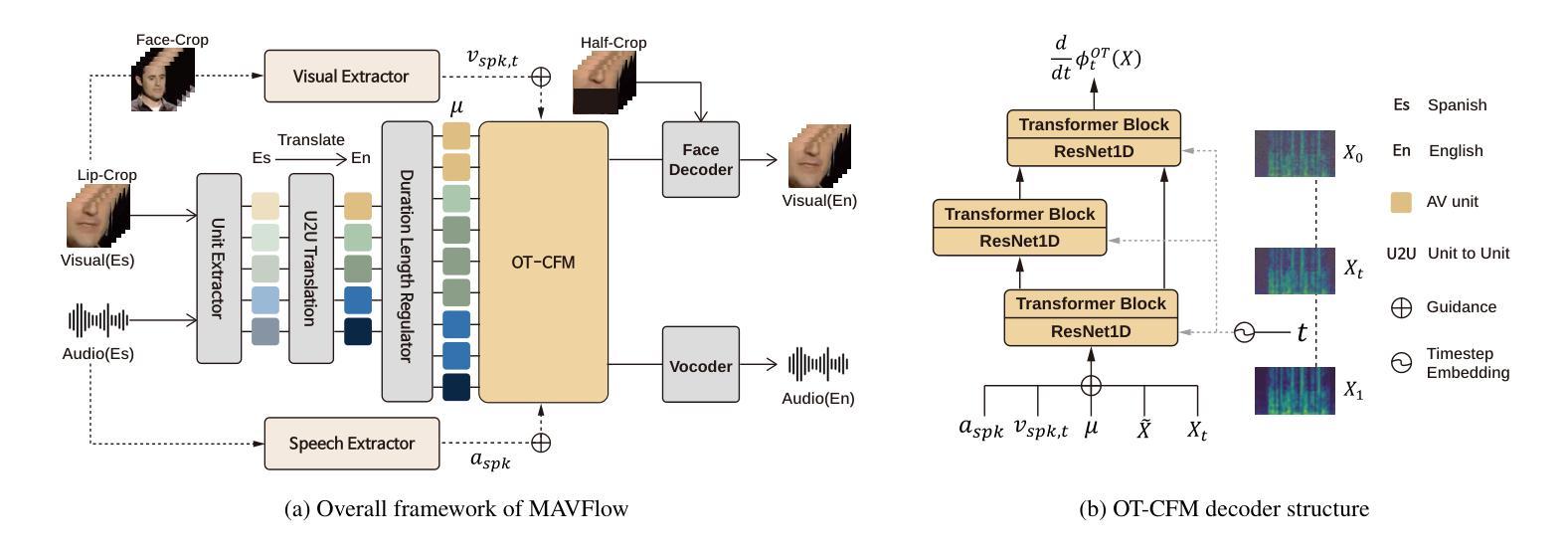
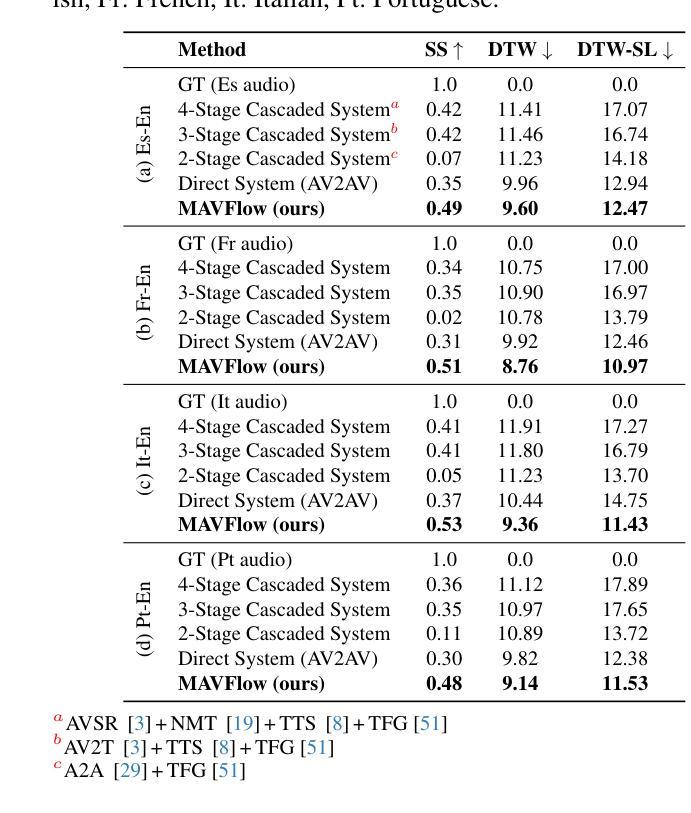
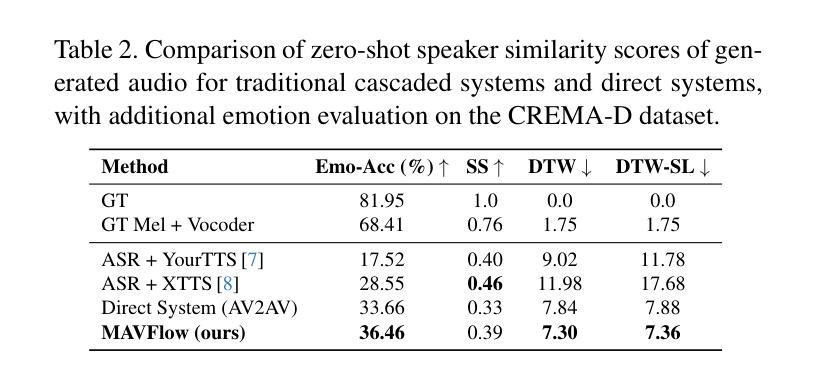
MAVFlow: Preserving Paralinguistic Elements with Conditional Flow Matching for Zero-Shot AV2AV Multilingual Translation
Authors:Sungwoo Cho, Jeongsoo Choi, Sungnyun Kim, Se-Young Yun
Despite recent advances in text-to-speech (TTS) models, audio-visual-to-audio-visual (AV2AV) translation still faces a critical challenge: maintaining speaker consistency between the original and translated vocal and facial features. To address this issue, we propose a conditional flow matching (CFM) zero-shot audio-visual renderer that utilizes strong dual guidance from both audio and visual modalities. By leveraging multimodal guidance with CFM, our model robustly preserves speaker-specific characteristics and enhances zero-shot AV2AV translation abilities. For the audio modality, we enhance the CFM process by integrating robust speaker embeddings with x-vectors, which serve to bolster speaker consistency. Additionally, we convey emotional nuances to the face rendering module. The guidance provided by both audio and visual cues remains independent of semantic or linguistic content, allowing our renderer to effectively handle zero-shot translation tasks for monolingual speakers in different languages. We empirically demonstrate that the inclusion of high-quality mel-spectrograms conditioned on facial information not only enhances the quality of the synthesized speech but also positively influences facial generation, leading to overall performance improvements in LSE and FID score. Our code is available at https://github.com/Peter-SungwooCho/MAVFlow.
尽管文本转语音(TTS)模型最近有所进展,但视听转视听(AV2AV)翻译仍然面临一个关键问题:保持原始和翻译后的语音和面部特征之间的说话人一致性。为了解决这一问题,我们提出了一种利用音频和视觉两种模态的强大双重指导的条件流匹配(CFM)零样本视听渲染器。通过利用多模态指导和CFM,我们的模型能够稳健地保留特定说话人的特征,并增强零样本AV2AV翻译能力。对于音频模态,我们通过将稳健的说话人嵌入与x向量集成,增强了CFM过程,这有助于加强说话人一致性。此外,我们还将情感的细微差别传达给面部渲染模块。由音频和视觉线索提供的指导独立于语义或语言内容,这使得我们的渲染器能够有效地处理不同语言的单语说话人的零样本翻译任务。我们通过实证证明,在面部信息条件下生成的高质量梅尔频谱图不仅提高了合成语音的质量,而且对面部生成产生了积极影响,从而提高了LSE和FID得分的整体性能。我们的代码可在https://github.com/Peter-SungwooCho/MAVFlow找到。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文介绍了针对文本转语音(TTS)中的音视频转音视频(AV2AV)翻译中的关键挑战,即保持原始和翻译后的语音及面部特征的说话人一致性。研究团队提出了基于条件流匹配(CFM)的零镜头音视频渲染器,该渲染器结合了音视频两种模态的引导力来实现更强的话语者特征保持与零镜头AV2AV翻译能力提升。对于音频模态,该研究通过在CFM过程中融入稳健的说话人嵌入和x向量,强化了说话人一致性。同时,该研究还向面部渲染模块传达情感细微差别。音视频线索的指导独立于语义或语言内容,使得该渲染器能有效处理不同语言的零镜头翻译任务。采用基于面部信息的优质梅尔频谱图不仅能提高合成语音的质量,还能积极影响面部生成,从而提高整体性能。
Key Takeaways
- 音视频转音视频(AV2AV)翻译面临的关键挑战是保持原始和翻译后的语音及面部特征的说话人一致性。
- 提出了基于条件流匹配(CFM)的零镜头音视频渲染器来解决这一挑战。
- 该渲染器结合了音视频两种模态的引导力来增强说话人特定特征的保留与零镜头翻译能力。
- 通过融入稳健的说话人嵌入和x向量,强化了音频模态中的说话人一致性。
- 向面部渲染模块传达情感细微差别以增强翻译的情感表达。
- 音视频线索的指导独立于语义或语言内容,使渲染器能够处理不同语言的零镜头翻译任务。
点此查看论文截图

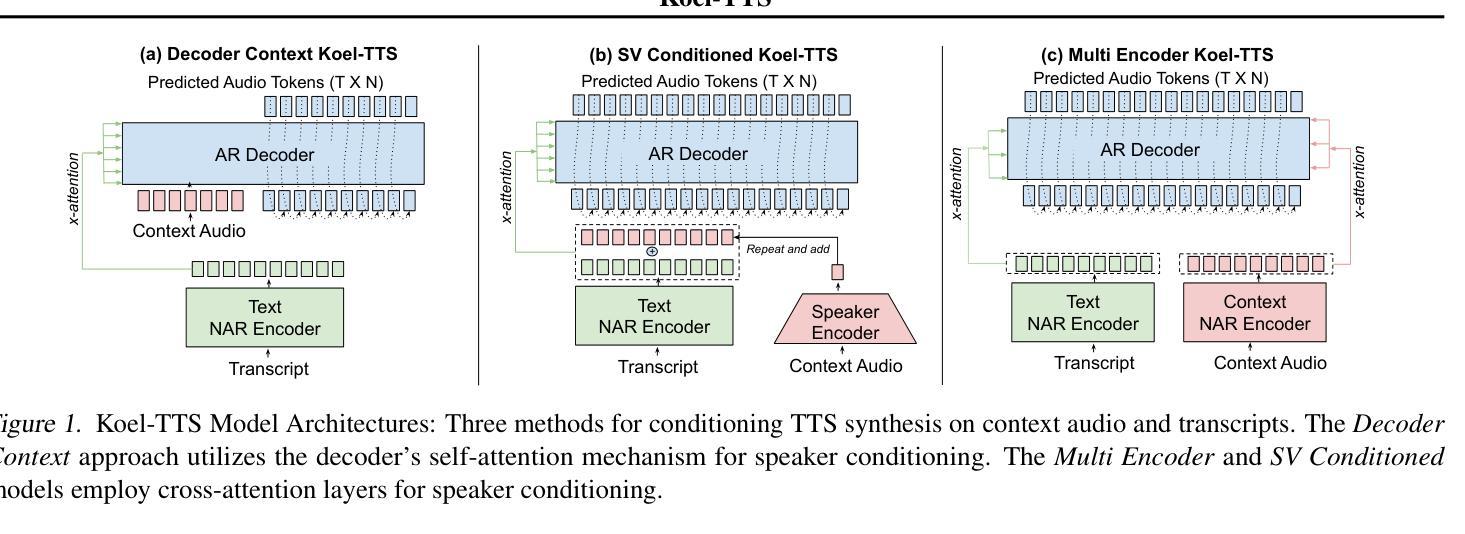
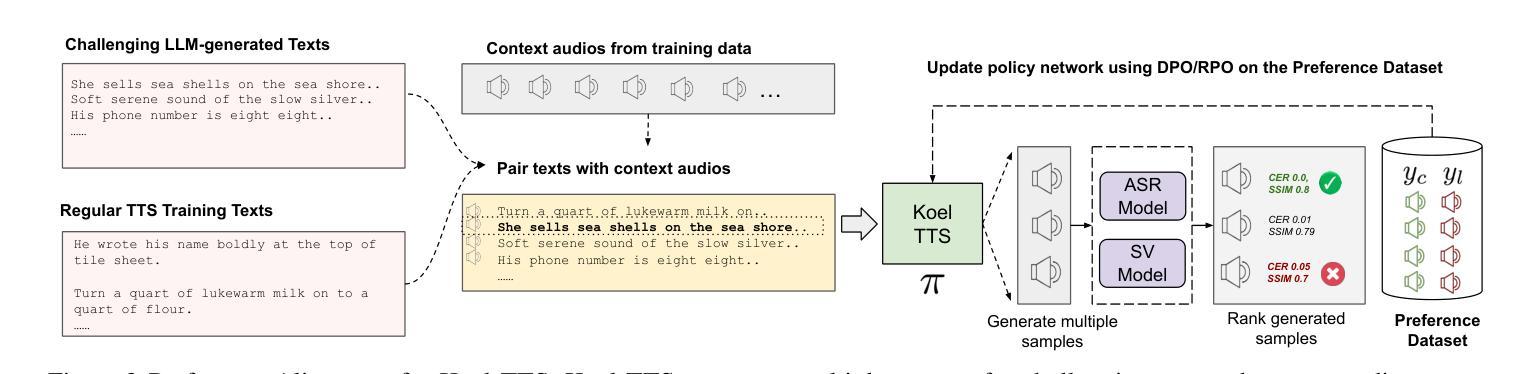
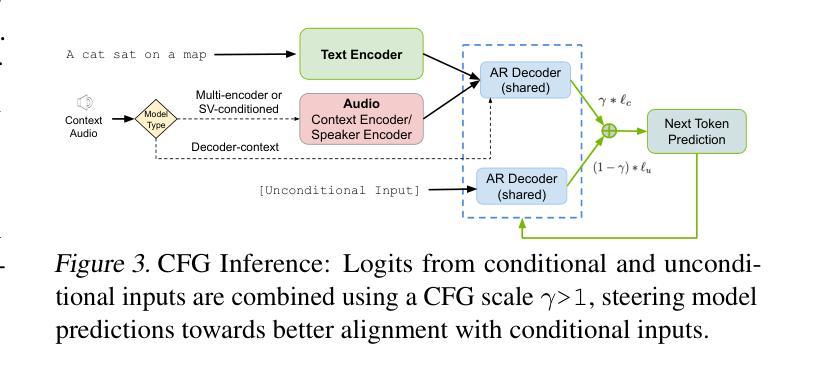
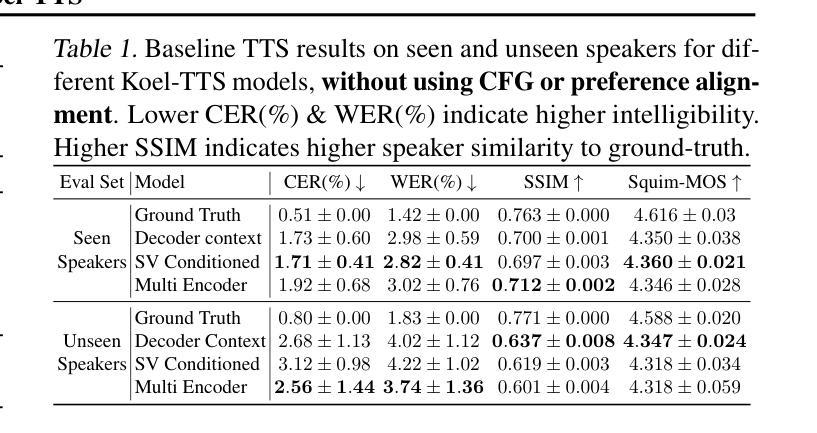
Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
Authors:Shehzeen Hussain, Paarth Neekhara, Xuesong Yang, Edresson Casanova, Subhankar Ghosh, Mikyas T. Desta, Roy Fejgin, Rafael Valle, Jason Li
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
虽然自回归语音令牌生成模型能够产生多样且自然的语音,但它们固有的不可控性常常导致诸如幻觉和不符合条件输入的意外发声等问题。我们引入了Koel-TTS,这是一系列增强的编码器-解码器Transformer TTS模型,通过融入自动语音识别和说话人验证模型的偏好对齐技术来解决这些挑战。此外,我们还融入了无分类器引导,以进一步提高合成语音对文本和参考说话人音频的遵循度。我们的实验表明,这些优化措施显著提高了目标说话人的相似性、合成语音的清晰度和自然度。值得注意的是,Koel-TTS直接将文本和上下文音频映射到声音令牌上,并且在上述指标上表现优于最新的TTS模型,尽管它在较小的数据集上进行训练。音频样本和演示可以在我们的网站上找到。
论文及项目相关链接
Summary
本文介绍了Koel-TTS,一套增强型编码器-解码器Transformer文本转语音模型。它通过融入偏好对齐技术,结合自动语音识别和说话人验证模型,解决了生成式模型内在缺乏可控性的问题,包括幻听和不符合条件输入的发音。实验证明,这些优化显著提高了目标说话人的相似性、清晰度和合成语音的自然度。Koel-TTS可直接将文本和语境音频映射到声音标记上,在相关指标上优于最先进的文本转语音模型,尽管它的训练数据集要小得多。
Key Takeaways
- Koel-TTS是增强型的编码器-解码器Transformer文本转语音模型,旨在解决生成式模型缺乏可控性的问题。
- 通过融入偏好对齐技术和自动语音识别及说话人验证模型,Koel-TTS改善了合成语音的质量。
- 实验显示,Koel-TTS在目标说话人的相似性、清晰度和语音自然度方面有明显提升。
- Koel-TTS可以直接将文本和语境音频映射到声音标记上。
- Koel-TTS在相关指标上的表现优于其他先进的文本转语音模型。
- Koel-TTS的训练数据集相对较小,但表现仍然出色。
点此查看论文截图

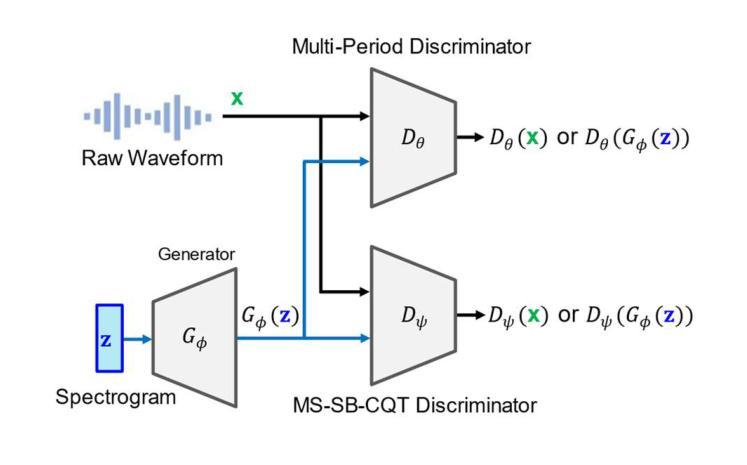
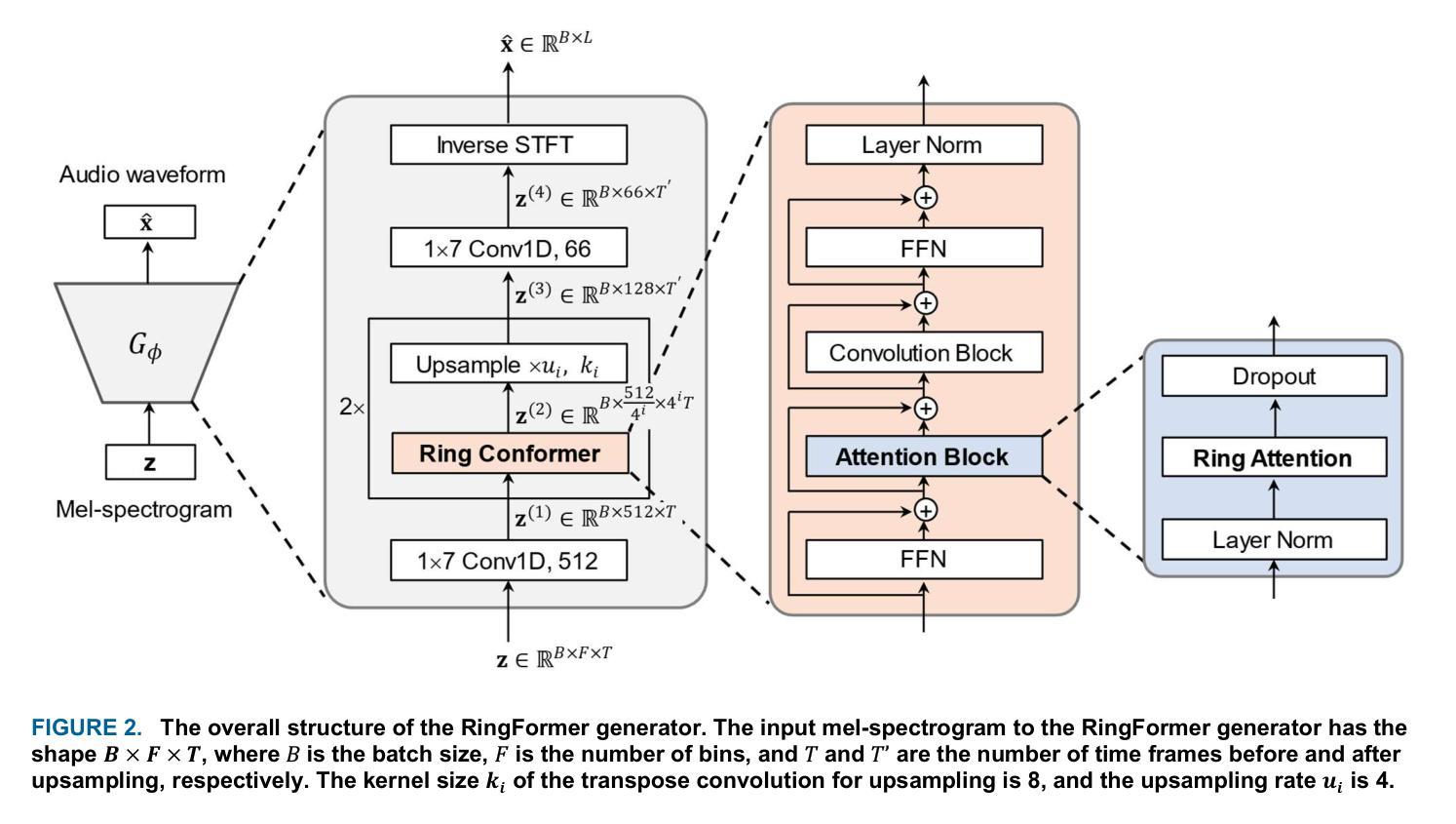
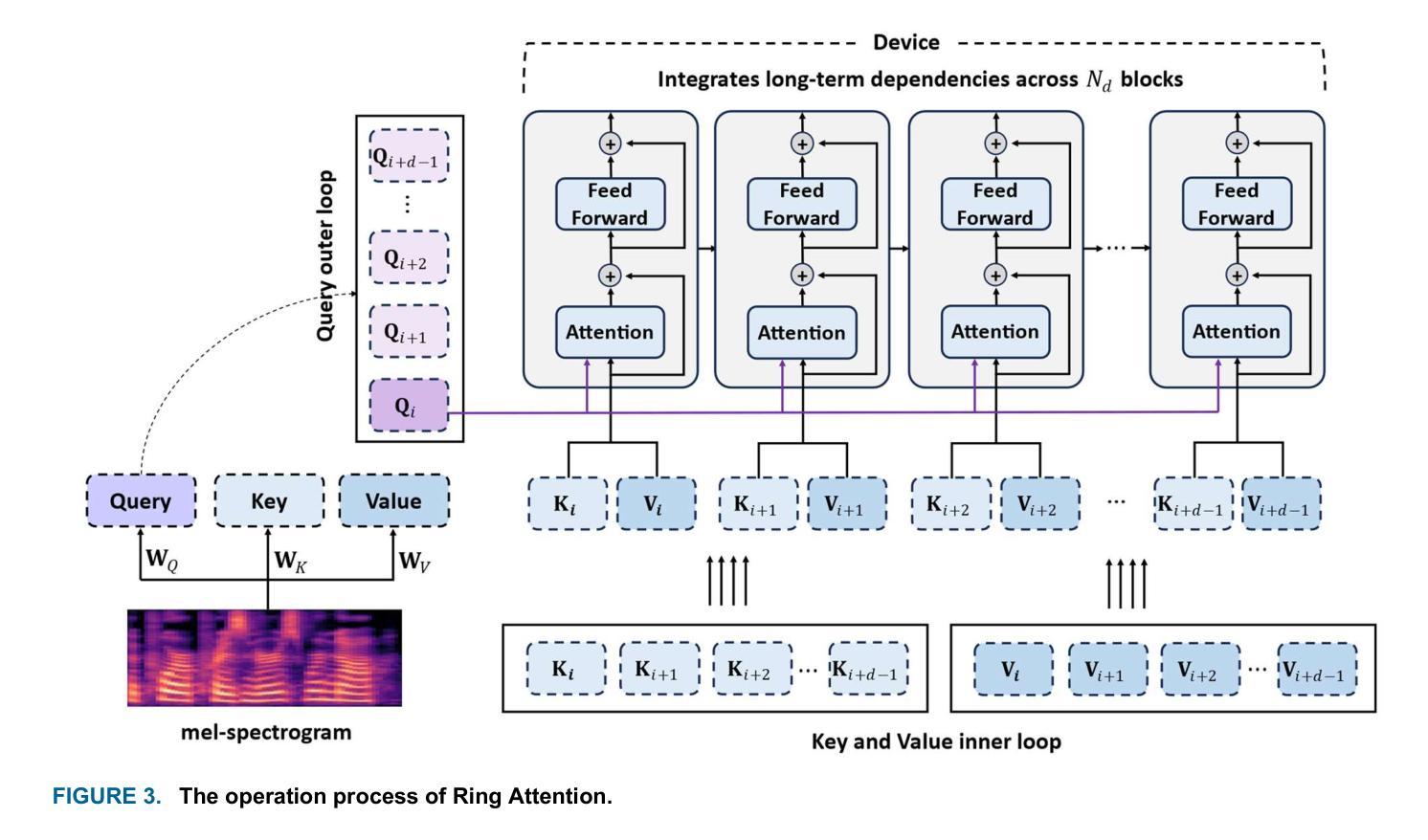
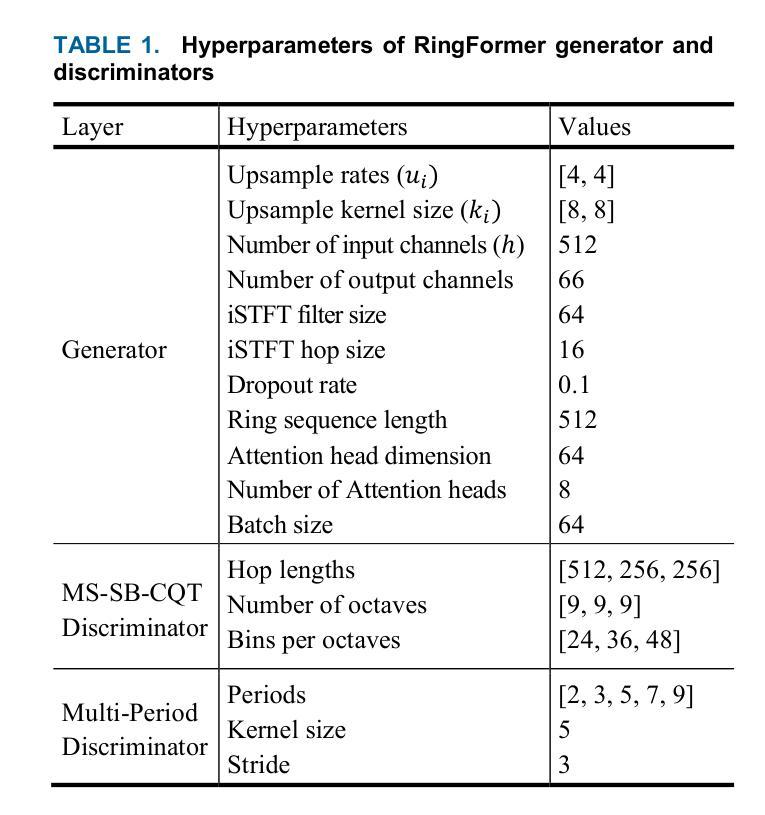
RingFormer: A Neural Vocoder with Ring Attention and Convolution-Augmented Transformer
Authors:Seongho Hong, Yong-Hoon Choi
While transformers demonstrate outstanding performance across various audio tasks, their application to neural vocoders remains challenging. Neural vocoders require the generation of long audio signals at the sample level, which demands high temporal resolution. This results in significant computational costs for attention map generation and limits their ability to efficiently process both global and local information. Additionally, the sequential nature of sample generation in neural vocoders poses difficulties for real-time processing, making the direct adoption of transformers impractical. To address these challenges, we propose RingFormer, a neural vocoder that incorporates the ring attention mechanism into a lightweight transformer variant, the convolution-augmented transformer (Conformer). Ring attention effectively captures local details while integrating global information, making it well-suited for processing long sequences and enabling real-time audio generation. RingFormer is trained using adversarial training with two discriminators. The proposed model is applied to the decoder of the text-to-speech model VITS and compared with state-of-the-art vocoders such as HiFi-GAN, iSTFT-Net, and BigVGAN under identical conditions using various objective and subjective metrics. Experimental results show that RingFormer achieves comparable or superior performance to existing models, particularly excelling in real-time audio generation. Our code and audio samples are available on GitHub.
虽然transformer在各种音频任务中表现出卓越的性能,但它们在神经vocoder中的应用仍然具有挑战性。神经vocoder需要在样本级别生成长的音频信号,这要求高的时间分辨率。这会导致注意力图生成的计算成本显著增加,并限制它们有效处理全局和局部信息的能力。此外,神经vocoder中样本生成的顺序性给实时处理带来了困难,使得直接采用变压器不切实际。为了解决这些挑战,我们提出了RingFormer,这是一种结合了环形注意力机制的神经vocoder,它融入了一个轻量级的变压器变体——卷积增强型变压器(Conformer)。环形注意力机制能够有效地捕捉局部细节,同时整合全局信息,非常适合处理长序列并实现实时音频生成。RingFormer通过使用两个鉴别器进行对抗训练。所提出的模型应用于文本到语音模型VITS的解码器,并与最先进的vocoder(如HiFi-GAN、iSTFT-Net和BigVGAN)在相同条件下进行比较,使用各种客观和主观指标进行评估。实验结果表明,RingFormer在实时音频生成方面达到了与现有模型相当或更高的性能。我们的代码和音频样本可在GitHub上找到。
论文及项目相关链接
PDF Accepted for publication in IEEE Transactions on Human-Machine Systems (THMS)
Summary
本文介绍了针对神经编解码器面临的挑战而提出的RingFormer模型。神经编解码器生成长音频信号时要求高时间分辨率,带来计算成本问题。RingFormer结合了环形注意力机制和轻量级Transformer变体Conformer,能有效捕捉局部细节并整合全局信息,适合处理长序列并实时生成音频。实验结果显示,RingFormer在实时音频生成方面表现优异。
Key Takeaways
- 神经编解码器在生成长音频信号时面临高时间分辨率要求,导致计算成本高昂。
- RingFormer模型结合了环形注意力机制和卷积增强Transformer(Conformer),以应对这些挑战。
- RingFormer能有效捕捉局部细节并整合全局信息,适合处理长序列数据。
- RingFormer模型应用于文本到语音模型的解码器,并与其他先进编解码器进行比较。
- 实验结果显示,RingFormer在实时音频生成方面表现优越。
- RingFormer模型可提高神经编解码器的效率和性能。
点此查看论文截图

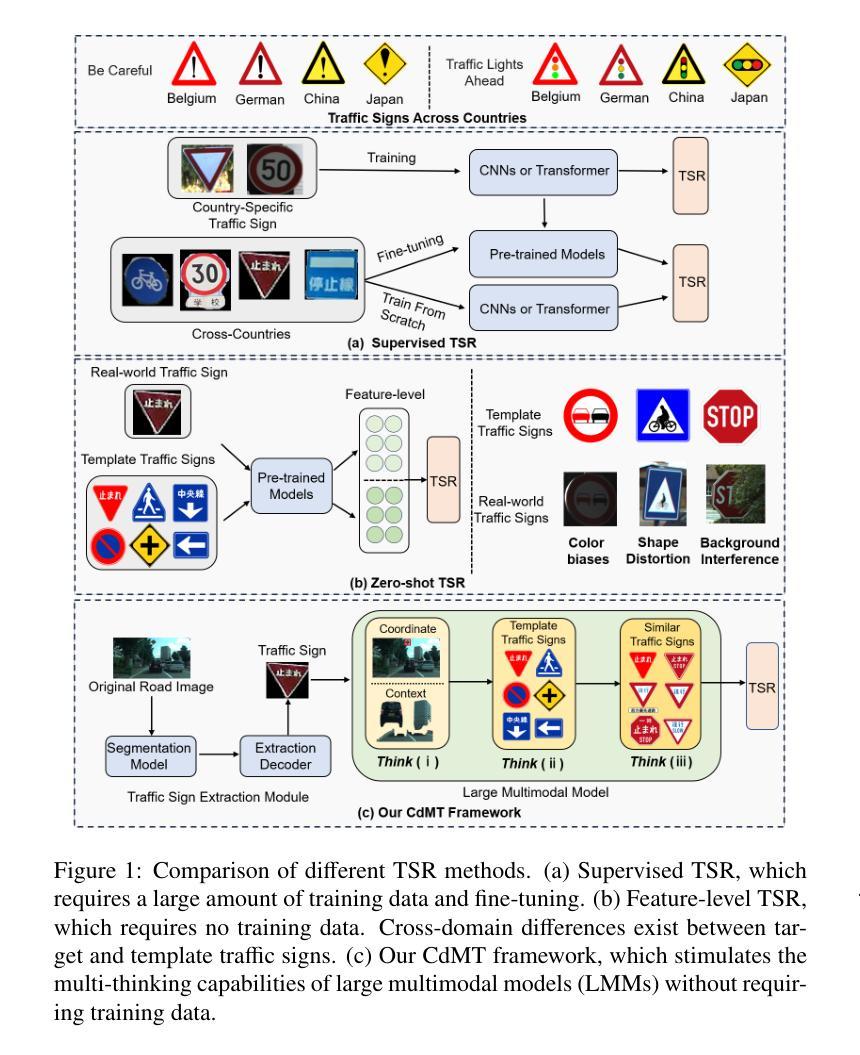
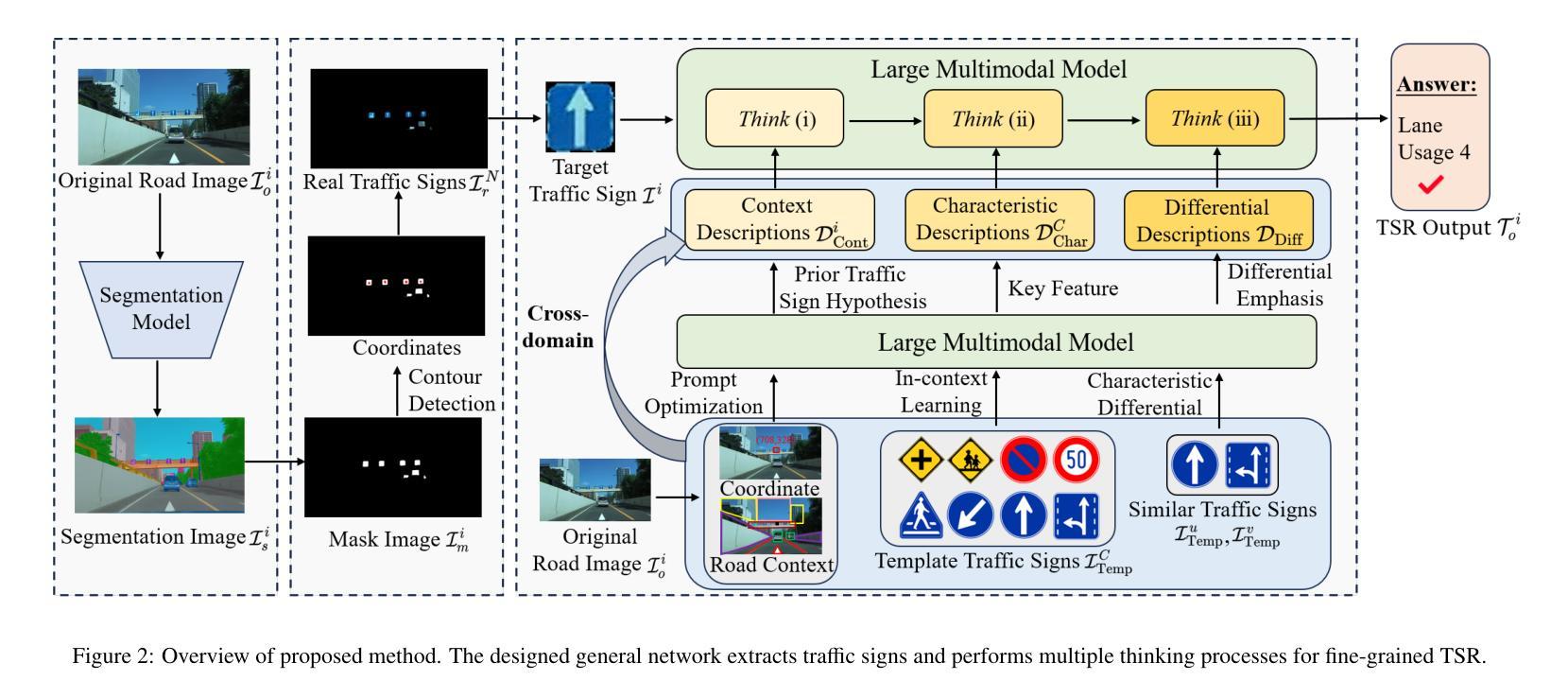
Cross-domain Multi-step Thinking: Zero-shot Fine-grained Traffic Sign Recognition in the Wild
Authors:Yaozong Gan, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
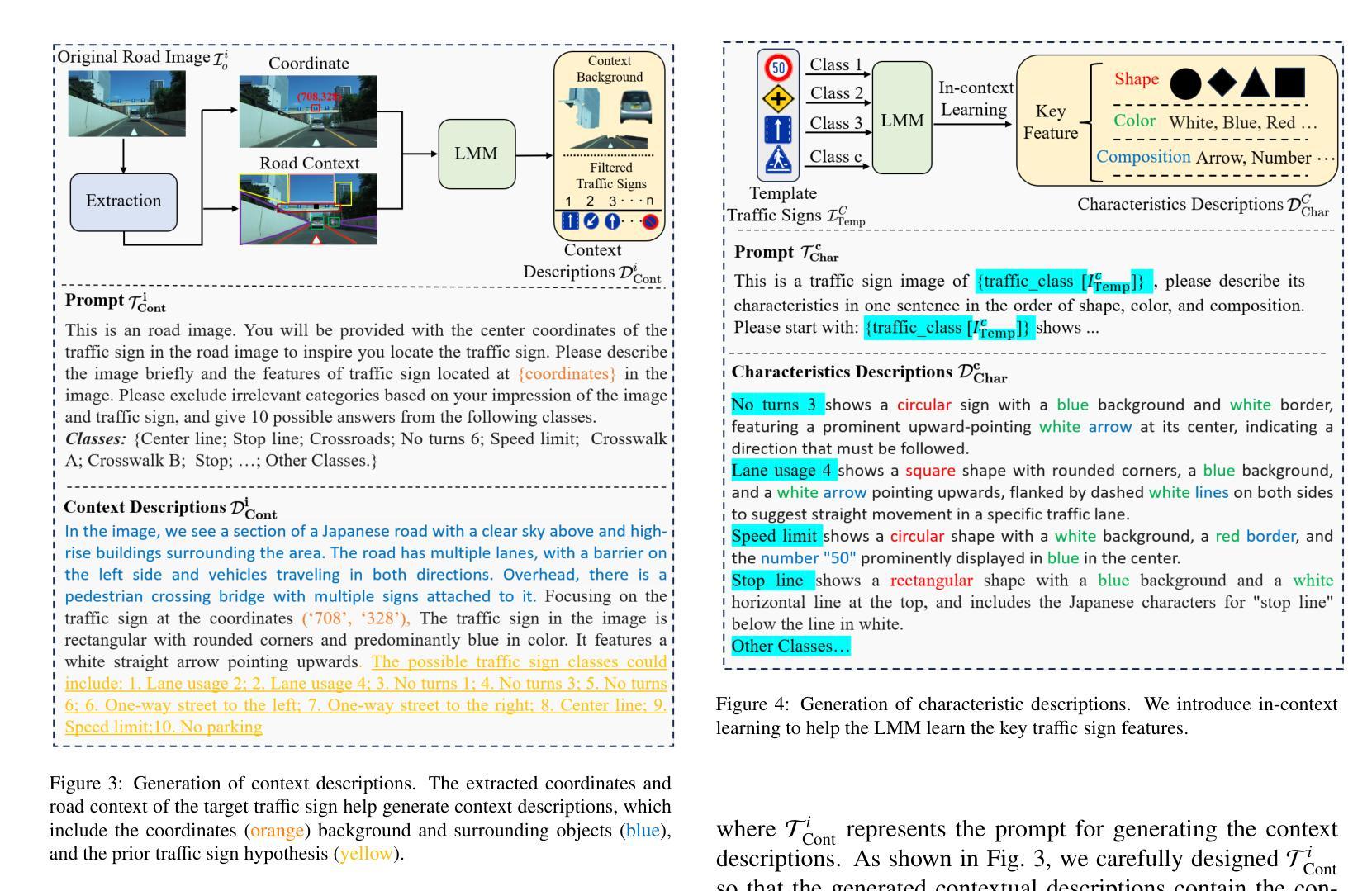
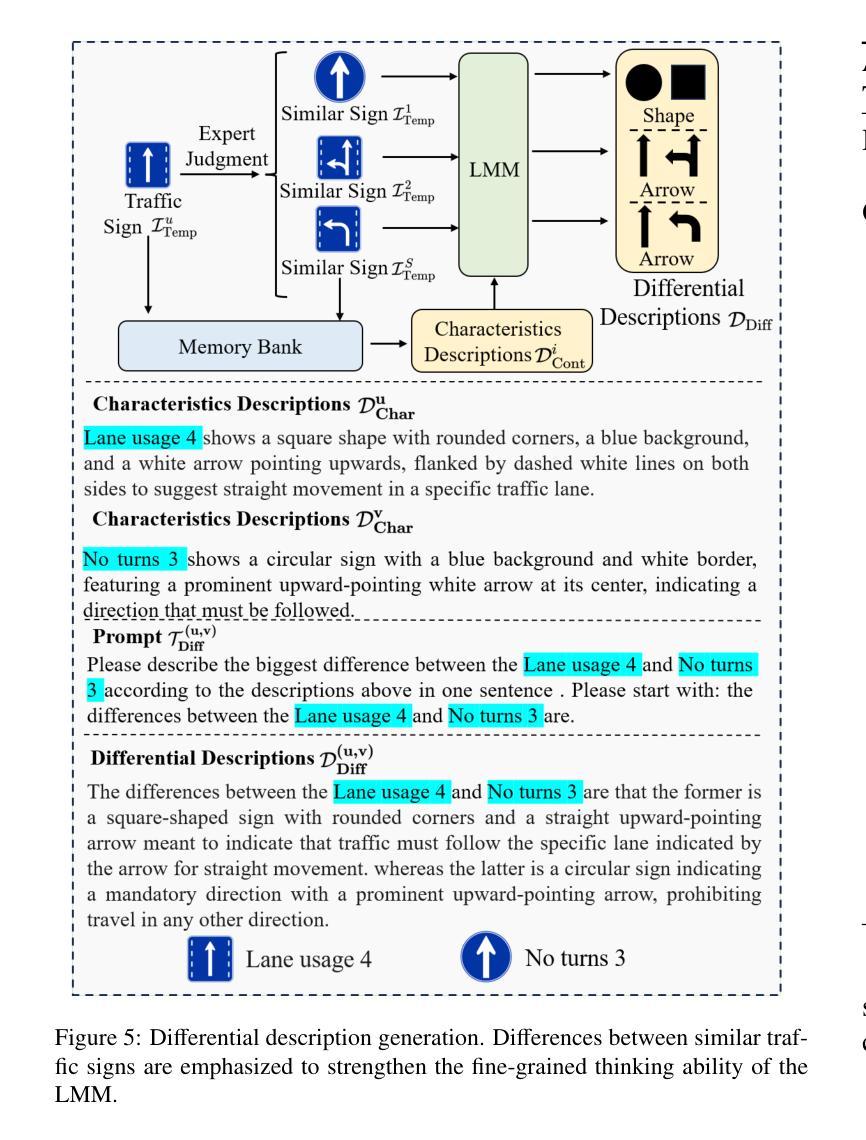
In this study, we propose Cross-domain Multi-step Thinking (CdMT) to improve zero-shot fine-grained traffic sign recognition (TSR) performance in the wild. Zero-shot fine-grained TSR in the wild is challenging due to the cross-domain problem between clean template traffic signs and real-world counterparts, and existing approaches particularly struggle with cross-country TSR scenarios, where traffic signs typically differ between countries. The proposed CdMT framework tackles these challenges by leveraging the multi-step reasoning capabilities of large multimodal models (LMMs). We introduce context, characteristic, and differential descriptions to design multiple thinking processes for LMMs. Context descriptions, which are enhanced by center coordinate prompt optimization, enable the precise localization of target traffic signs in complex road images and filter irrelevant responses via novel prior traffic sign hypotheses. Characteristic descriptions, which are derived from in-context learning with template traffic signs, bridge cross-domain gaps and enhance fine-grained TSR. Differential descriptions refine the multimodal reasoning ability of LMMs by distinguishing subtle differences among similar signs. CdMT is independent of training data and requires only simple and uniform instructions, enabling it to achieve cross-country TSR. We conducted extensive experiments on three benchmark datasets and two real-world datasets from different countries. The proposed CdMT framework achieved superior performance compared with other state-of-the-art methods on all five datasets, with recognition accuracies of 0.93, 0.89, 0.97, 0.89, and 0.85 on the GTSRB, BTSD, TT-100K, Sapporo, and Yokohama datasets, respectively.
在这项研究中,我们提出了跨域多步思考(CdMT)方法,以提高零样本精细交通标志识别(TSR)在野外环境中的性能。零样本精细交通标志识别在野外环境中具有挑战性,因为清洁模板交通标志和现实世界中的对应物之间存在跨域问题,现有方法在处理跨国交通标志识别场景时尤其困难,各国的交通标志通常有所不同。提出的CdMT框架通过利用大型多模态模型(LMMs)的多步推理能力来解决这些挑战。我们引入上下文、特征和差异描述来为LMMs设计多个思考过程。上下文描述通过中心坐标提示优化,能够在复杂的道路图像中精确定位目标交通标志,并通过新的先验交通标志假设过滤掉不相关的响应。特征描述来源于模板交通标志的上下文学习,可以弥补跨域差距并增强精细交通标志识别。差异描述通过区分相似标志之间的细微差异,提高了LMMs的多模态推理能力。CdMT独立于训练数据,只需要简单统一指令,就能实现跨国交通标志识别。我们在三个基准数据集和两个来自不同国家的真实世界数据集上进行了大量实验。所提出的CdMT框架在所有五个数据集上的性能均优于其他最先进的方法,在GTSRB、BTSD、TT-100K、札幌和横滨数据集上的识别准确率分别为0.93、0.89、0.97、0.89和0.85。
论文及项目相关链接
PDF Published by Knowledge-Based Systems
摘要
本研究提出跨域多步思考(CdMT)框架,旨在提高野外零样本细粒度交通标志识别(TSR)的性能。零样本细粒度TSR在野外面临诸多挑战,如干净模板交通标志与真实世界交通标志之间的跨域问题。现有方法尤其难以处理跨国TSR场景,其中交通标志因国家而异。CdMT框架通过利用大型多模态模型(LMM)的多步推理能力来解决这些挑战。本研究引入上下文、特征和差异描述来为LMM设计多个思考过程。上下文描述通过中心坐标提示优化,能够在复杂的道路图像中精确定位目标交通标志,并通过新的交通标志假设过滤掉不相关的响应。特征描述源于基于模板交通标志的上下文学习,弥补了跨域差距并增强了细粒度TSR。差异描述则通过区分相似标志之间的细微差异来完善LMM的多模态推理能力。CdMT独立于训练数据,仅需要简单统一的指令,即可实现跨国TSR。在三个基准数据集和两个来自不同国家的真实世界数据集上进行的广泛实验表明,CdMT框架的识别准确率高于其他先进方法,在GTSRB、BTSD、TT-100K、札幌和横滨数据集上的准确率分别为0.93、0.89、0.97、0.89和0.85。
关键见解
- 本研究提出了跨域多步思考(CdMT)框架,旨在提高零样本细粒度交通标志识别(TSR)的野外性能。
- CdMT框架通过引入上下文、特征和差异描述,为大型多模态模型(LMM)设计多个思考过程。
- CdMT能精确定位复杂道路图像中的目标交通标志,并通过交通标志假设过滤不相关响应。
- 特征描述源于模板交通标志的上下文学习,有助于弥补跨域差距并增强细粒度TSR。
- CdMT通过区分细微差异完善了LMM的多模态推理能力,从而提高识别准确性。
- CdMT独立于训练数据,适应于各种交通标志数据集,包括跨国数据集。
点此查看论文截图