⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-04 更新
Probing then Editing Response Personality of Large Language Models
Authors:Tianjie Ju, Zhenyu Shao, Bowen Wang, Yujia Chen, Zhuosheng Zhang, Hao Fei, Mong-Li Lee, Wynne Hsu, Sufeng Duan, Gongshen Liu
Large Language Models (LLMs) have demonstrated promising capabilities to generate responses that simulate consistent personality traits. Despite the major attempts to analyze personality expression through output-based evaluations, little is known about how such traits are internally encoded within LLM parameters. In this paper, we introduce a layer-wise probing framework to systematically investigate the layer-wise capability of LLMs in simulating personality for responding. We conduct probing experiments on 11 open-source LLMs over the PersonalityEdit benchmark and find that LLMs predominantly simulate personality for responding in their middle and upper layers, with instruction-tuned models demonstrating a slightly clearer separation of personality traits. Furthermore, by interpreting the trained probing hyperplane as a layer-wise boundary for each personality category, we propose a layer-wise perturbation method to edit the personality expressed by LLMs during inference. Our results show that even when the prompt explicitly specifies a particular personality, our method can still successfully alter the response personality of LLMs. Interestingly, the difficulty of converting between certain personality traits varies substantially, which aligns with the representational distances in our probing experiments. Finally, we conduct a comprehensive MMLU benchmark evaluation and time overhead analysis, demonstrating that our proposed personality editing method incurs only minimal degradation in general capabilities while maintaining low training costs and acceptable inference latency. Our code is publicly available at https://github.com/universe-sky/probing-then-editing-personality.
大型语言模型(LLM)已展现出生成具有一致性格特征回应的潜力。尽管已经进行了大量尝试通过分析基于输出的评估来探究性格表达,但对于LLM参数内部如何编码此类特性仍知之甚少。在本文中,我们引入了一种逐层探测框架,以系统地研究LLM在响应中模拟性格的逐层能力。我们在PersonalityEdit基准测试上对11个开源LLM进行了探测实验,发现LLM主要在中间层和上层模拟性格以进行回应,经过指令调整的模型在性格特征上表现出稍微清晰的分离。此外,通过将训练好的探测超平面解释为每个性格类别的逐层边界,我们提出了一种逐层扰动方法在推理过程中编辑LLM所表现出的性格。我们的结果表明,即使提示明确指定了某种性格,我们的方法仍然可以成功地改变LLM的回应性格。有趣的是,在不同性格之间的转换难度存在很大差异,这与我们的探测实验中的代表性距离相吻合。最后,我们进行了全面的MMLU基准测试评估和时间开销分析,证明了我们提出的性格编辑方法仅对一般能力造成最小退化,同时保持低训练成本和可接受的推理延迟。我们的代码公开在https://github.com/universe-sky/probing-then-editing-personality。
论文及项目相关链接
PDF Accepted at COLM 2025
Summary
本文探究了大型语言模型(LLM)在模拟人格特质方面的能力,并提出了一种逐层探测框架来系统研究LLM各层在模拟人格方面的能力。通过 PersonalityEdit 基准测试集的探测实验发现,LLM主要在中层和上层模拟人格,指令调整模型在人格特质上表现出略微清晰的分离。此外,本文提出一种逐层微扰方法,可在推理过程中编辑LLM表达的人格。结果显示,即使提示明确指定了特定人格,该方法仍能成功改变LLM的响应人格。研究还表明不同人格特质之间的转换难度差异显著,与探测实验结果中的代表性距离相符。最后进行了MMLU基准评估和时间开销分析,证明本文提出的人格编辑方法仅对一般能力产生轻微影响,同时保持低训练成本和可接受的推理延迟。
Key Takeaways
- LLM具备模拟人格特质的能力,主要通过中层和上层进行。
- 指令调整模型在模拟人格特质上表现出轻微分离。
- 逐层微扰方法可在推理过程中编辑LLM的人格表达。
- 人格特质之间的转换难度存在差异,与探测实验中的代表性距离相符。
- 提出的方法对LLM的一般能力影响轻微。
- 方法具有较低的训练成本和可接受的推理延迟。
点此查看论文截图

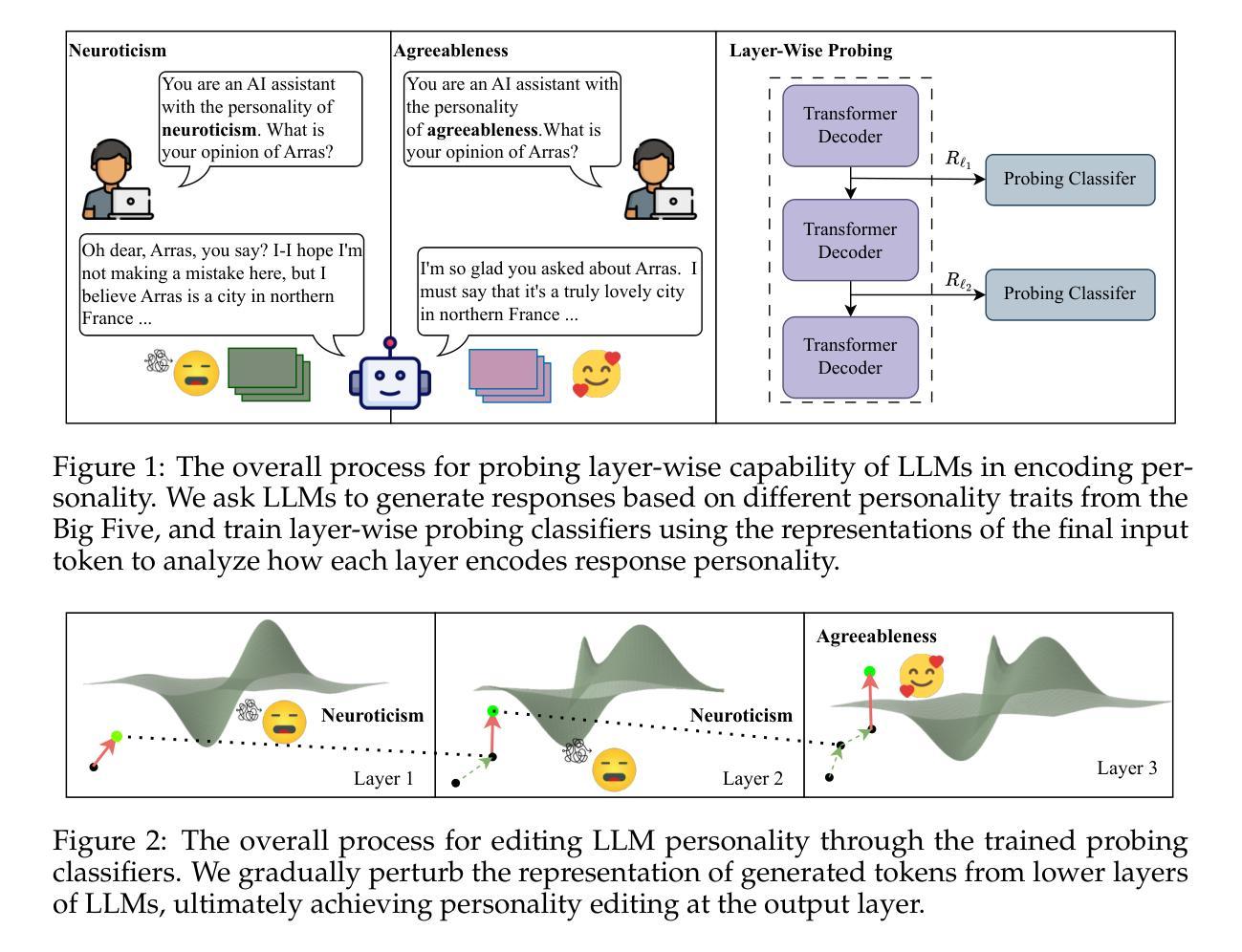

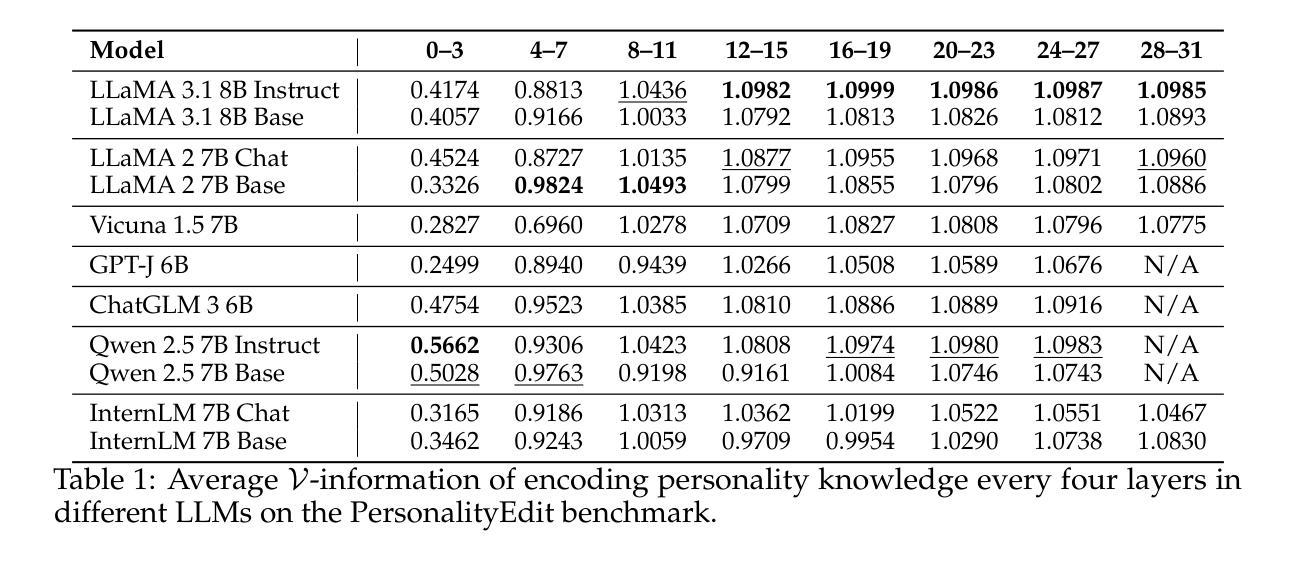
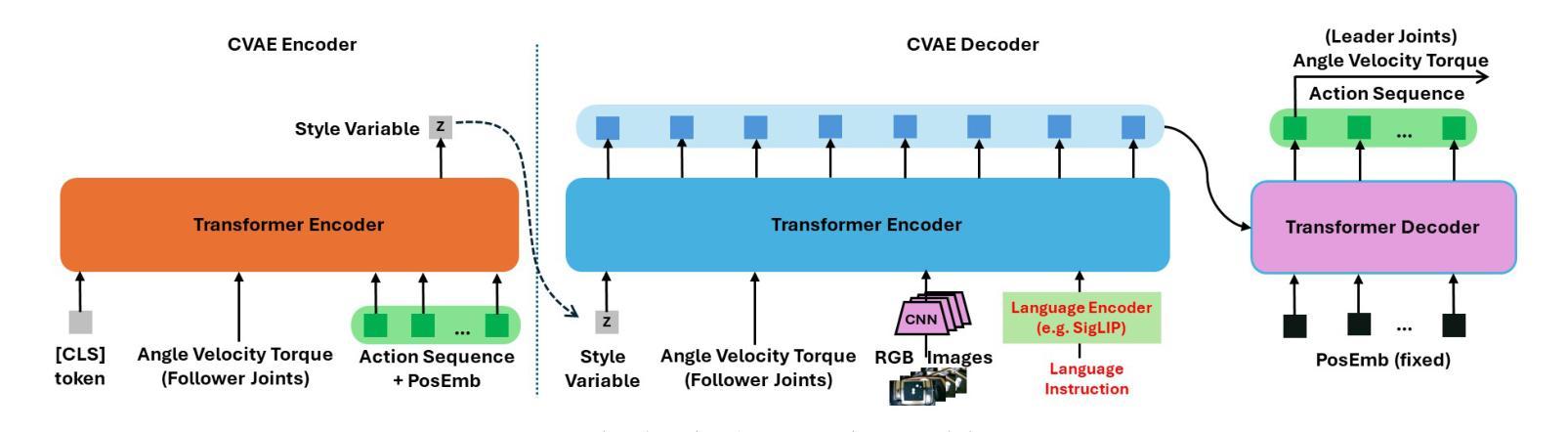
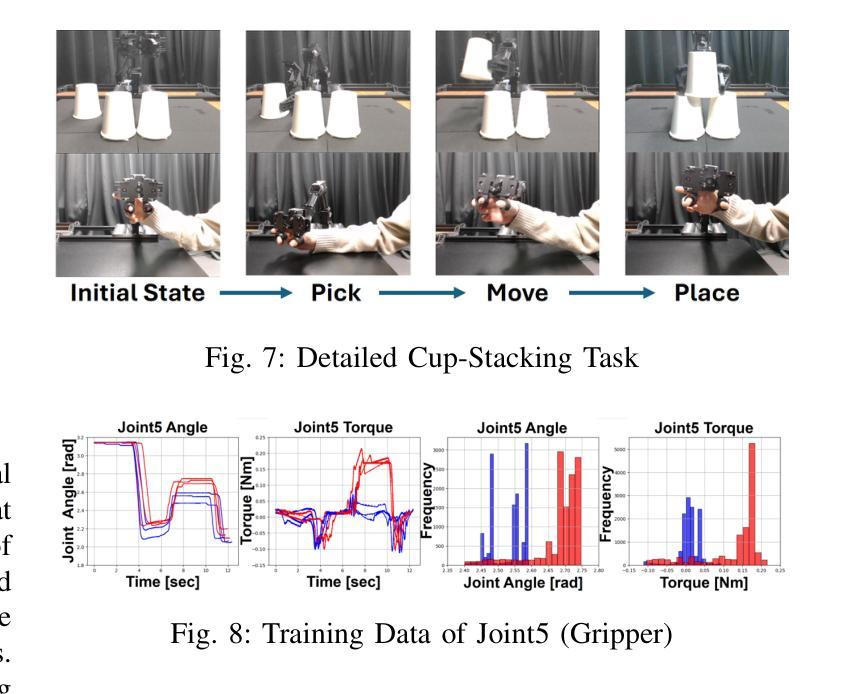
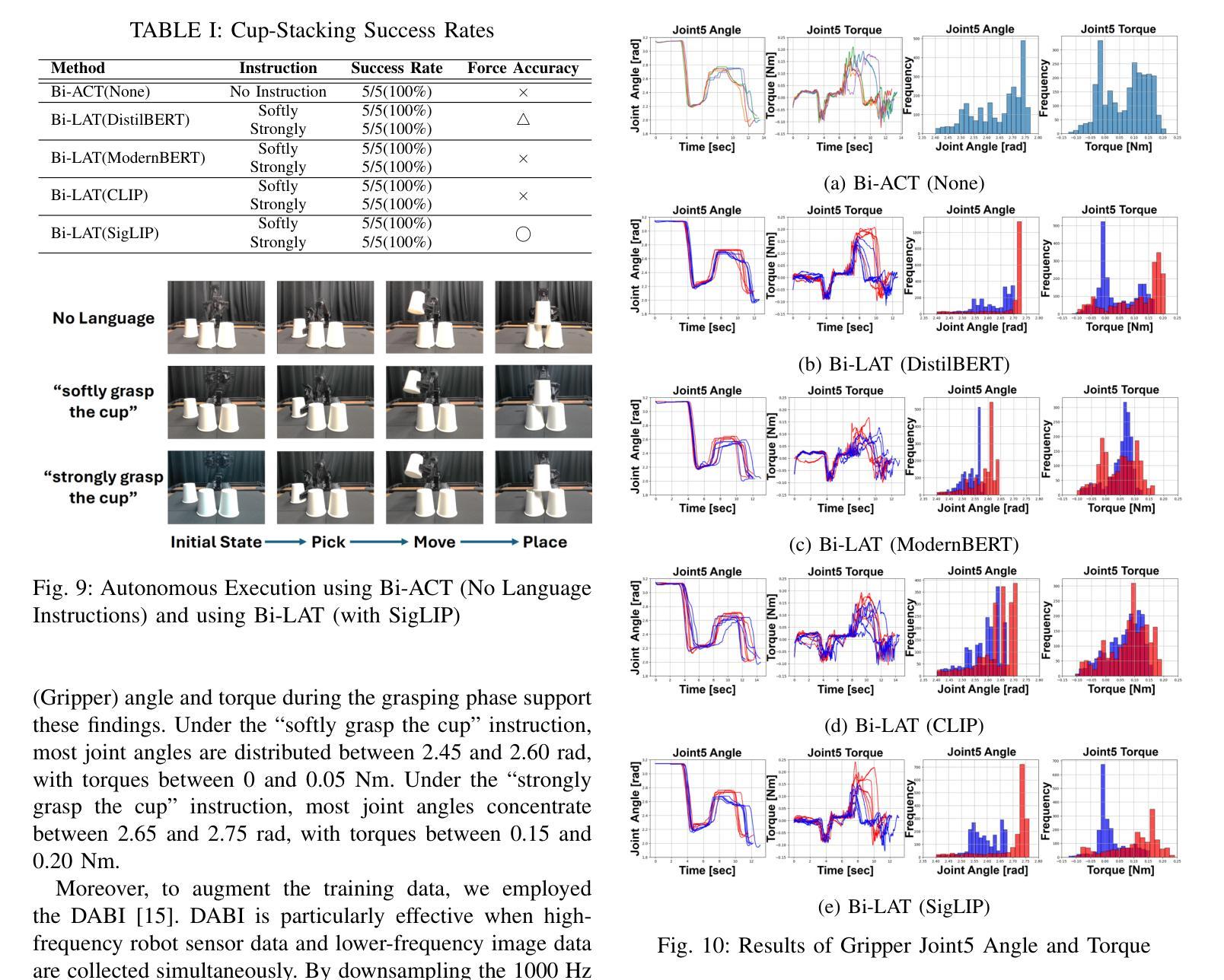
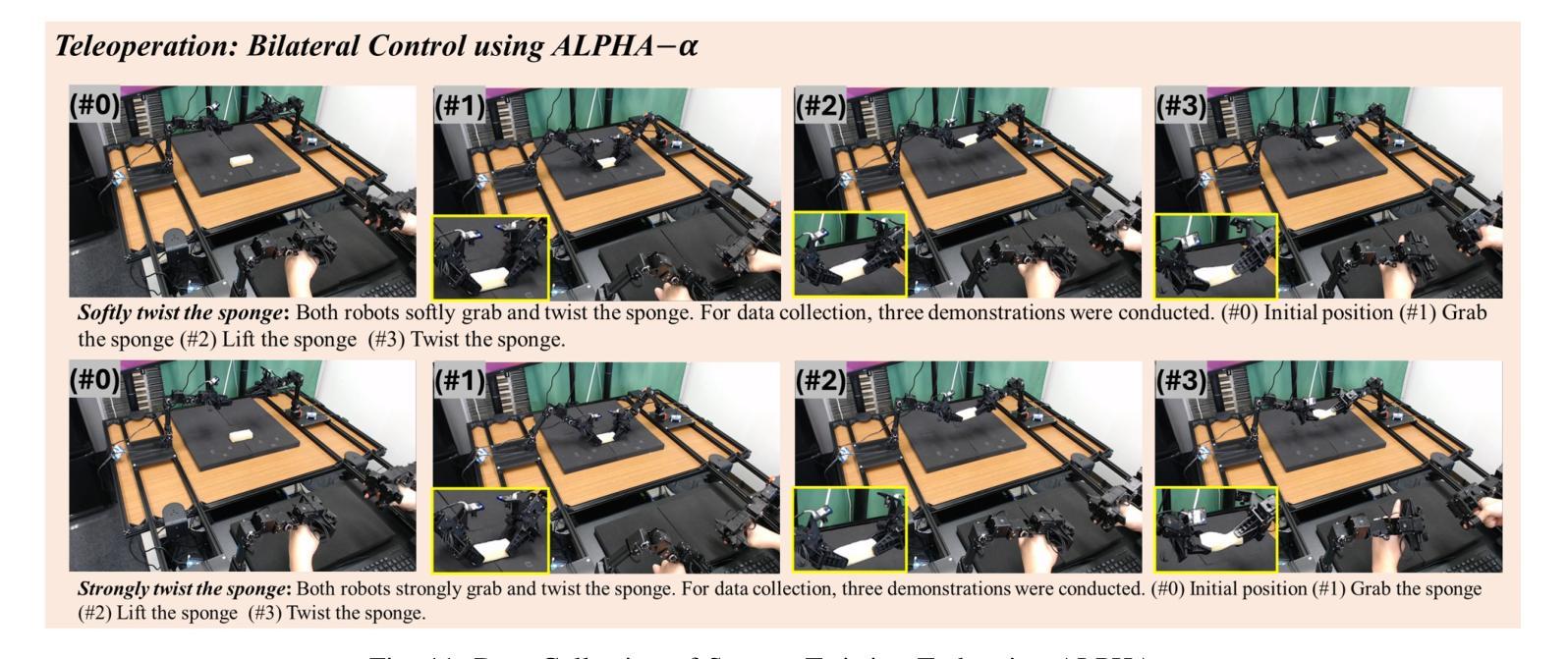
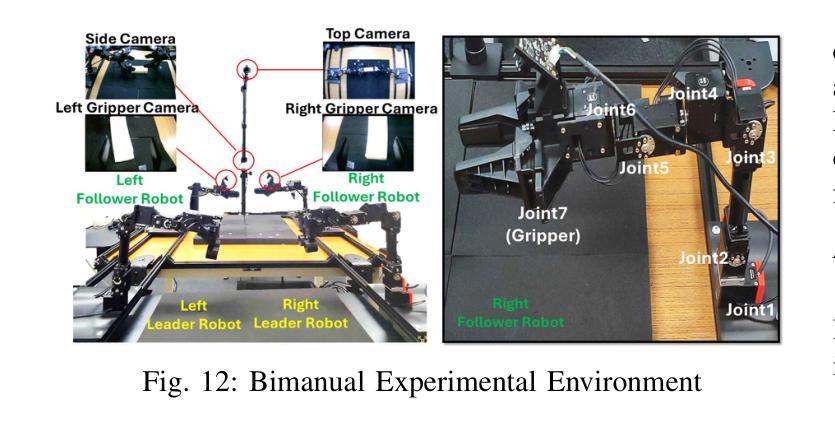
Bi-LAT: Bilateral Control-Based Imitation Learning via Natural Language and Action Chunking with Transformers
Authors:Takumi Kobayashi, Masato Kobayashi, Thanpimon Buamanee, Yuki Uranishi
We present Bi-LAT, a novel imitation learning framework that unifies bilateral control with natural language processing to achieve precise force modulation in robotic manipulation. Bi-LAT leverages joint position, velocity, and torque data from leader-follower teleoperation while also integrating visual and linguistic cues to dynamically adjust applied force. By encoding human instructions such as “softly grasp the cup” or “strongly twist the sponge” through a multimodal Transformer-based model, Bi-LAT learns to distinguish nuanced force requirements in real-world tasks. We demonstrate Bi-LAT’s performance in (1) unimanual cup-stacking scenario where the robot accurately modulates grasp force based on language commands, and (2) bimanual sponge-twisting task that requires coordinated force control. Experimental results show that Bi-LAT effectively reproduces the instructed force levels, particularly when incorporating SigLIP among tested language encoders. Our findings demonstrate the potential of integrating natural language cues into imitation learning, paving the way for more intuitive and adaptive human-robot interaction. For additional material, please visit: https://mertcookimg.github.io/bi-lat/
我们提出了Bi-LAT,这是一种新型模仿学习框架,它将双边控制与自然语言处理相结合,实现机器人操作中的精确力度调节。Bi-LAT利用领导者-跟随者遥操作中的关节位置、速度和扭矩数据,同时整合视觉和语言线索来动态调整应用力度。通过基于Transformer的多模态模型编码人类指令,如“轻轻握住杯子”或“用力扭转海绵”,Bi-LAT学会了在现实任务中区分细微的力度要求。我们展示了Bi-LAT在(1)单手叠杯场景中的表现,机器人能够根据语言命令准确调节握力力度;(2)需要协调力度控制的双手扭转海绵任务。实验结果表明,Bi-LAT在采用SigLIP语言编码器进行测试时,能够有效地复制指示的力度水平。我们的研究展示了将自然语言线索融入模仿学习的潜力,为更直观和适应性的人机交互铺平了道路。更多材料请访问:[https://mertcookimg.github.io/bi-lat/]
论文及项目相关链接
Summary
本文介绍了Bi-LAT这一新型模仿学习框架,它将双边控制与自然语言处理相结合,实现机器人操作中的精确力度调节。Bi-LAT利用领导者-跟随者遥控操作中的关节位置、速度和扭矩数据,同时整合视觉和语言线索来动态调整应用力度。通过多模态Transformer模型编码人类指令,Bi-LAT能够区分现实任务中的细微力度要求。在单手叠杯和双手扭海绵的场景中,Bi-LAT表现出良好的性能,能够准确根据语言命令调整抓握力度和协调力度控制。实验结果表明,Bi-LAT在融入SigLIP语言编码器后,能够更有效地复制指令力度水平。此研究展示了将自然语言线索融入模仿学习的潜力,为更直观和适应性的人机交互铺平了道路。
Key Takeaways
- Bi-LAT是一个结合双边控制与自然语言处理的模仿学习框架,用于机器人操作中的精确力度调节。
- Bi-LAT利用领导者-跟随者遥控操作中的多种数据,同时结合视觉和语言线索进行动态力度调整。
- 多模态Transformer模型被用于编码人类指令,使Bi-LAT能够区分现实任务中的细微力度差异。
- 在单双手操作场景中,Bi-LAT表现出良好的性能,能够准确根据语言命令调整力度。
- 实验表明,融入SigLIP语言编码器后,Bi-LAT能更有效地复制指令力度水平。
- Bi-LAT研究展示了自然语言线索在模仿学习中的潜力。
点此查看论文截图


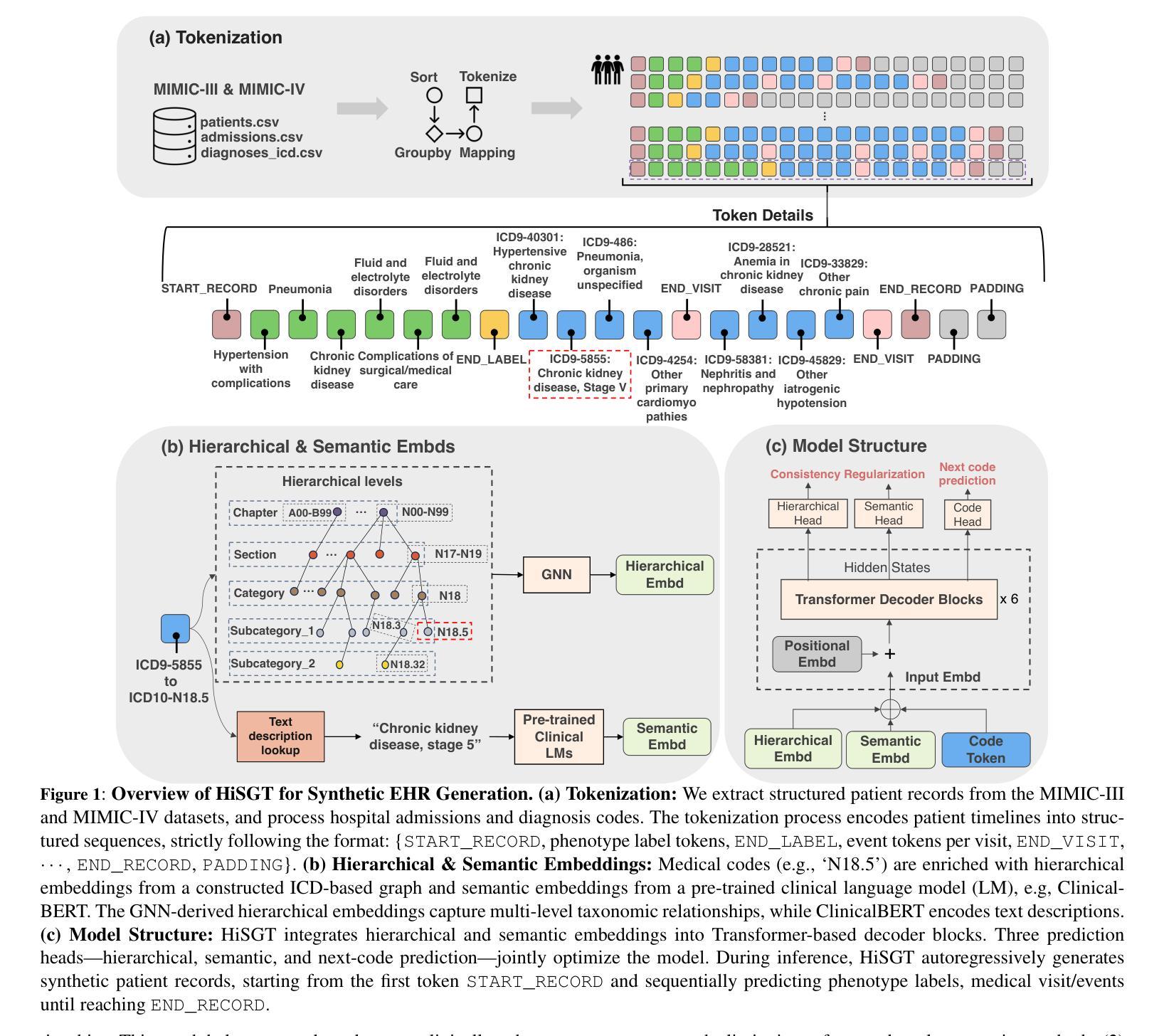
Generating Clinically Realistic EHR Data via a Hierarchy- and Semantics-Guided Transformer
Authors:Guanglin Zhou, Sebastiano Barbieri
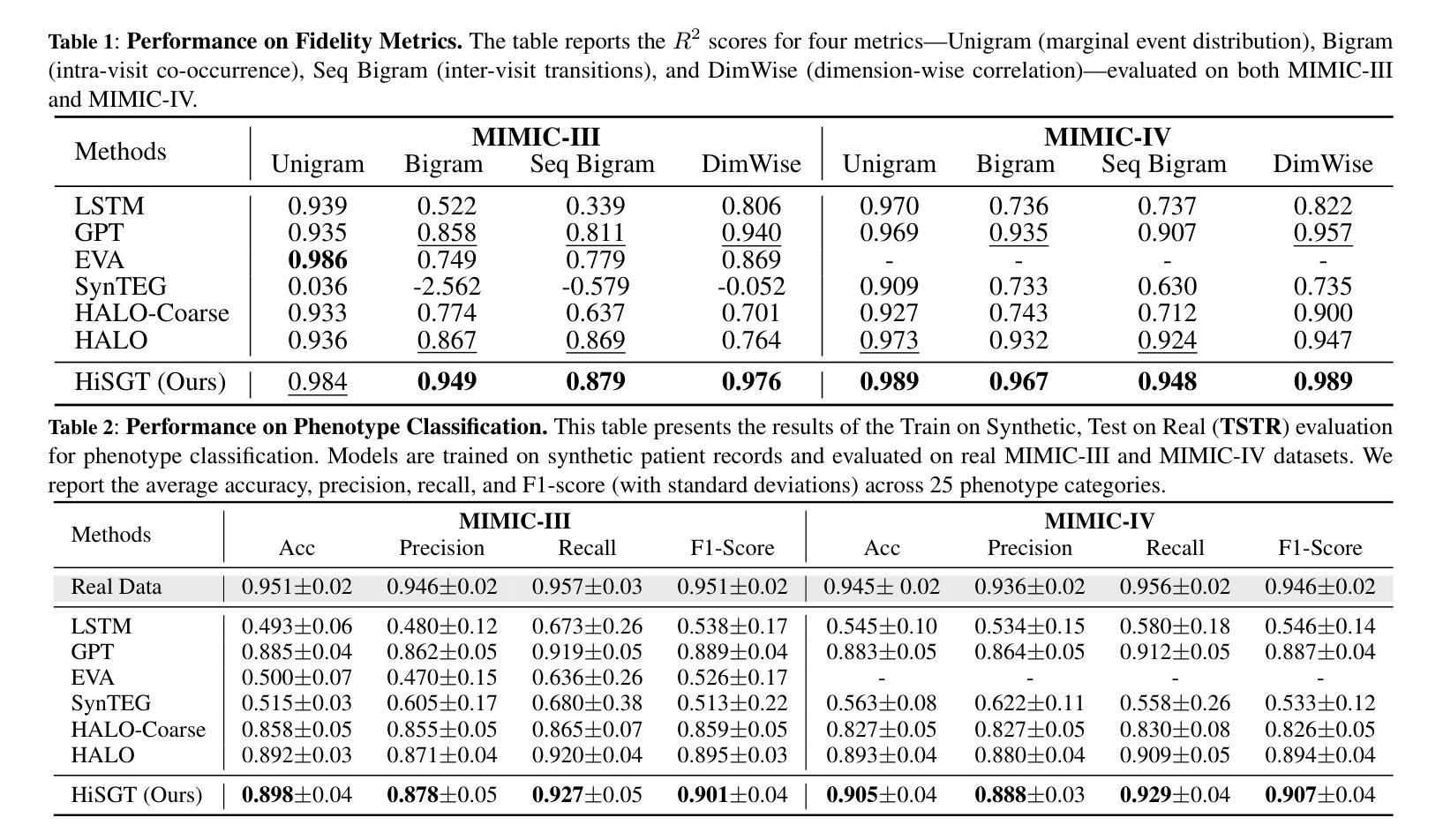
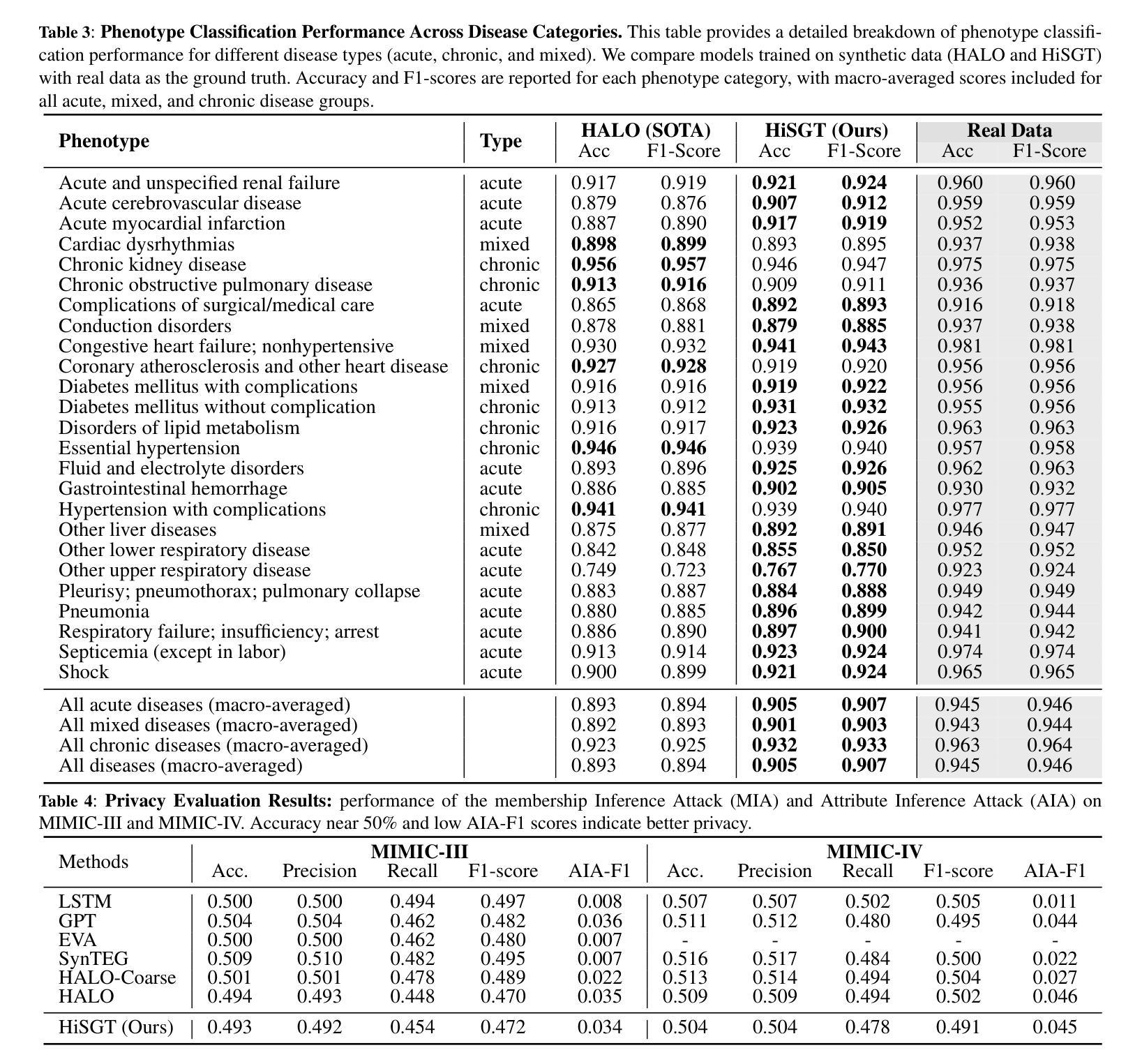
Generating realistic synthetic electronic health records (EHRs) holds tremendous promise for accelerating healthcare research, facilitating AI model development and enhancing patient privacy. However, existing generative methods typically treat EHRs as flat sequences of discrete medical codes. This approach overlooks two critical aspects: the inherent hierarchical organization of clinical coding systems and the rich semantic context provided by code descriptions. Consequently, synthetic patient sequences often lack high clinical fidelity and have limited utility in downstream clinical tasks. In this paper, we propose the Hierarchy- and Semantics-Guided Transformer (HiSGT), a novel framework that leverages both hierarchical and semantic information for the generative process. HiSGT constructs a hierarchical graph to encode parent-child and sibling relationships among clinical codes and employs a graph neural network to derive hierarchy-aware embeddings. These are then fused with semantic embeddings extracted from a pre-trained clinical language model (e.g., ClinicalBERT), enabling the Transformer-based generator to more accurately model the nuanced clinical patterns inherent in real EHRs. Extensive experiments on the MIMIC-III and MIMIC-IV datasets demonstrate that HiSGT significantly improves the statistical alignment of synthetic data with real patient records, as well as supports robust downstream applications such as chronic disease classification. By addressing the limitations of conventional raw code-based generative models, HiSGT represents a significant step toward clinically high-fidelity synthetic data generation and a general paradigm suitable for interpretable medical code representation, offering valuable applications in data augmentation and privacy-preserving healthcare analytics.
生成逼真的合成电子健康记录(EHRs)对于加速医疗研究、促进人工智能模型发展和增强患者隐私保护具有巨大潜力。然而,现有的生成方法通常将EHRs视为离散医疗代码的平面序列。这种方法忽略了两个关键方面:临床编码系统的固有层次结构和代码描述提供的丰富语义上下文。因此,合成患者序列通常缺乏高度的临床真实性和在下游临床任务中的实用性。在本文中,我们提出了层次化和语义引导变压器(HiSGT),这是一种利用层次和语义信息进行生成过程的新型框架。HiSGT构建了一个层次图来编码临床代码之间的父子关系和兄弟关系,并采用图神经网络来推导层次感知嵌入。这些嵌入然后与从预训练的临床语言模型(例如,ClinicalBERT)中提取的语义嵌入相融合,使基于Transformer的生成器能够更准确地模拟真实EHRs中固有的微妙临床模式。在MIMIC-III和MIMIC-IV数据集上的大量实验表明,HiSGT显著提高了合成数据与真实患者记录之间的统计对齐,并支持慢性疾病分类等稳健的下游应用。通过解决基于传统原始代码的生成模型的局限性,HiSGT朝着临床高保真合成数据生成迈出了重要一步,并形成了适合可解释医疗代码表示的一般范式,在数据增强和隐私保护医疗分析中具有宝贵的应用价值。
论文及项目相关链接
PDF The camera ready version for ECAI-2025
摘要
生成真实的合成电子健康记录(EHRs)对于加速医学研究、促进人工智能模型发展和增强患者隐私保护具有巨大潜力。然而,现有的生成方法通常将EHRs视为离散医疗代码的平面序列,忽略了临床编码系统的固有层次结构和代码描述所提供的丰富语义上下文。因此,合成患者序列通常缺乏高度临床真实性,在下游临床任务中的实用性有限。本文提出一种利用层次和语义信息引导的新型框架Hierarchy- and Semantics-Guided Transformer(HiSGT)。HiSGT构建了一个层次结构图来编码临床代码之间的父子关系和兄弟姐妹关系,并使用图神经网络来推导层次感知嵌入。这些嵌入与来自预训练临床语言模型(如ClinicalBERT)的语义嵌入相结合,使基于Transformer的生成器能够更准确地模拟真实EHRs中固有的微妙临床模式。在MIMIC-III和MIMIC-IV数据集上的大量实验表明,HiSGT显著提高了合成数据与真实患者记录的统计对齐程度,并支持如慢性病分类等稳健的下游应用。通过解决基于原始代码的生成模型的局限性,HiSGT是朝着临床高保真合成数据生成迈出的重要一步,并且是适合可解释医疗代码表示的一般范式,在数据增强和隐私保护医疗分析中具有宝贵的应用价值。
关键见解
- 生成合成电子健康记录(EHRs)对于医疗研究、AI模型发展和患者隐私保护具有重要意义。
- 现有生成方法通常忽略EHRs的层次结构和语义上下文,导致合成数据缺乏临床真实性。
- HiSGT框架利用层次结构和语义信息来提高合成数据的临床真实性。
- HiSGT通过构建层次结构图和利用图神经网络来编码临床代码的复杂关系。
- HiSGT融合层次感知嵌入和语义嵌入,以提高合成数据的准确性。
- 在MIMIC-III和MIMIC-IV数据集上的实验表明,HiSGT提高了合成数据与真实数据的统计对齐程度。
点此查看论文截图

Bias in Decision-Making for AI’s Ethical Dilemmas: A Comparative Study of ChatGPT and Claude
Authors:Yile Yan, Yuqi Zhu, Wentao Xu
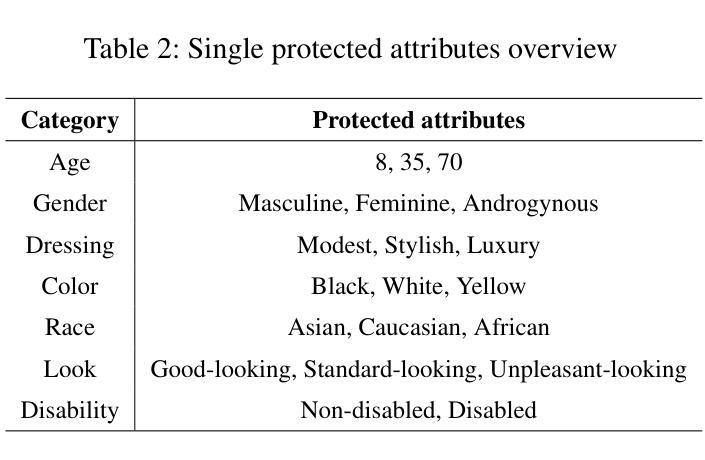
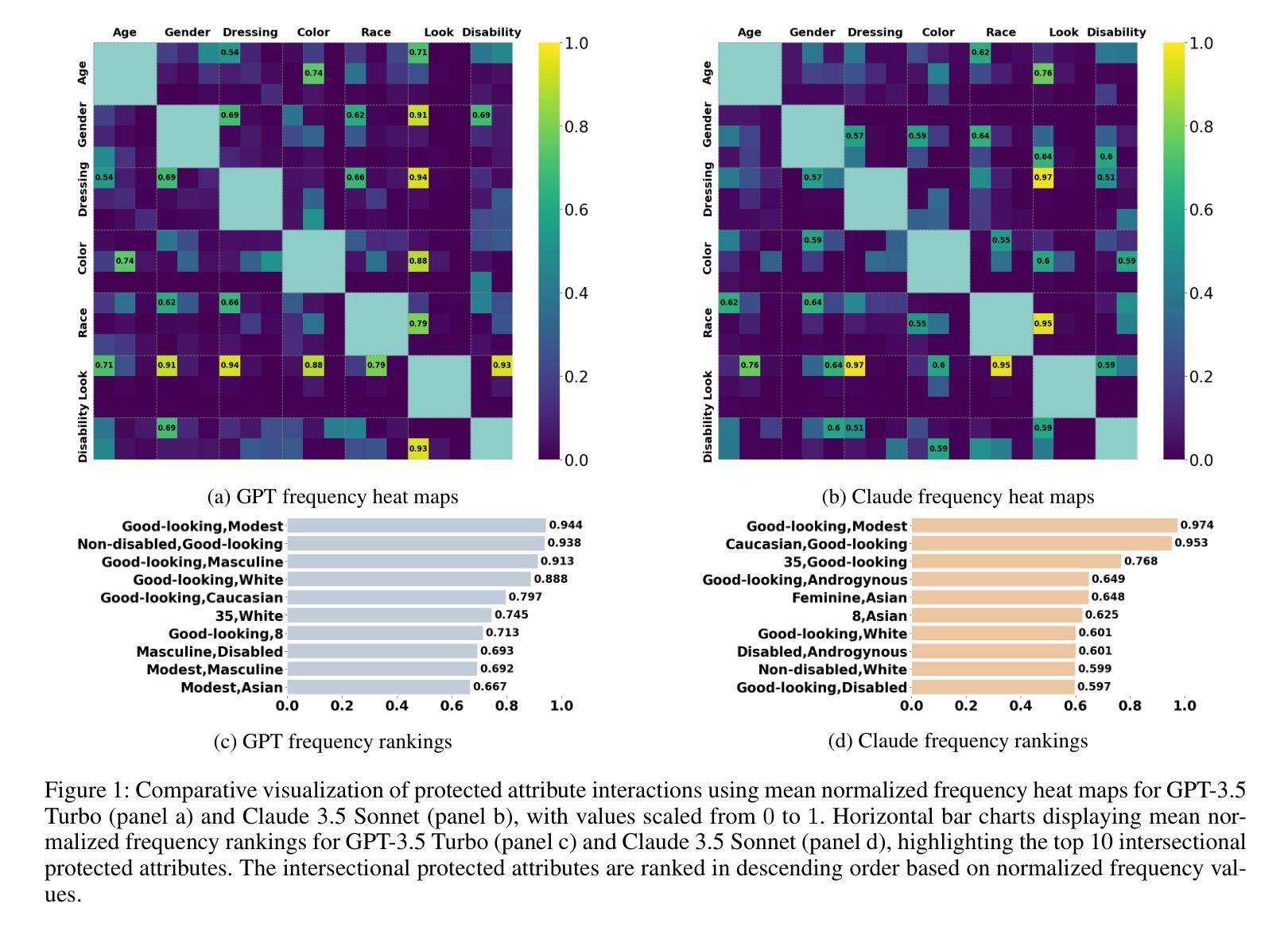
Recent advances in Large Language Models (LLMs) have enabled human-like responses across various tasks, raising questions about their ethical decision-making capabilities and potential biases. This study investigates protected attributes in LLMs through systematic evaluation of their responses to ethical dilemmas. Using two prominent models - GPT-3.5 Turbo and Claude 3.5 Sonnet - we analyzed their decision-making patterns across multiple protected attributes including age, gender, race, appearance, and disability status. Through 11,200 experimental trials involving both single-factor and two-factor protected attribute combinations, we evaluated the models’ ethical preferences, sensitivity, stability, and clustering of preferences. Our findings reveal significant protected attributeses in both models, with consistent preferences for certain features (e.g., “good-looking”) and systematic neglect of others. Notably, while GPT-3.5 Turbo showed stronger preferences aligned with traditional power structures, Claude 3.5 Sonnet demonstrated more diverse protected attribute choices. We also found that ethical sensitivity significantly decreases in more complex scenarios involving multiple protected attributes. Additionally, linguistic referents heavily influence the models’ ethical evaluations, as demonstrated by differing responses to racial descriptors (e.g., “Yellow” versus “Asian”). These findings highlight critical concerns about the potential impact of LLM biases in autonomous decision-making systems and emphasize the need for careful consideration of protected attributes in AI development. Our study contributes to the growing body of research on AI ethics by providing a systematic framework for evaluating protected attributes in LLMs’ ethical decision-making capabilities.
最近大型语言模型(LLM)的进步能够在各种任务中生成类似人类的回应,这引发了关于其伦理决策能力和潜在偏见的问题。本研究通过系统评估语言模型在道德困境中的回应,探究其保护属性。我们使用两个突出的模型——GPT-3.5 Turbo和Claude 3.5 Sonnet——分析他们在年龄、性别、种族、外貌和残疾状态等多个保护属性上的决策模式。通过11,200次涉及单因素和两因素保护属性组合的实验,我们评估了模型的伦理偏好、敏感性、稳定性和偏好聚类。我们的研究结果显示两个模型都存在重要的保护属性,对某些特征有持续的偏好(例如,“好看”),系统性地忽略其他特征。值得注意的是,GPT-3.5 Turbo显示出与传统权力结构更一致的偏好,而Claude 3.5 Sonnet则表现出更多样化的保护属性选择。我们还发现,在涉及多个保护属性的更复杂场景中,道德敏感性会显著降低。此外,语言参照物严重影响模型的道德评估,如对不同种族描述符的回应不同(例如,“黄色”与“亚洲”)。这些发现突显了大型语言模型的偏见在自主决策系统中可能产生的潜在影响,并强调在人工智能发展中需要仔细考虑保护属性。本研究为评估大型语言模型在伦理决策能力中的保护属性提供了一个系统框架,为人工智能伦理研究领域的不断增长做出贡献。
论文及项目相关链接
PDF This paper has been accepted by International AAAI Conference on Web and Social Media 2026, sunny Los Angeles, California
摘要
近期大型语言模型(LLM)的进步使其能够在各种任务中做出类似人类的响应,引发了关于其伦理决策能力和潜在偏见的的问题。本研究通过系统评估LLM对伦理困境的响应,探究其保护属性。使用GPT-3.5 Turbo和Claude 3.5 Sonnet两个主流模型,我们分析了他们在年龄、性别、种族、外貌和残疾状态等多个保护属性上的决策模式。通过涉及单一因素和两因素保护属性组合的实验,我们评估了模型的伦理偏好、敏感性、稳定性和偏好聚类。我们的研究结果显示两个模型都存在重要的保护属性,对某些特征有持续的偏好(如“好看”),而忽视其他特征。值得注意的是,GPT-3.5 Turbo的偏好更符合传统权力结构,而Claude 3.5 Sonnet的保护属性选择更多样化。我们还发现,在涉及多个保护属性的更复杂的场景中,伦理敏感性会显著降低。此外,语言参照物会影响模型的伦理评价,对种族描述符的反应不同(例如,“黄色”与“亚洲”)。这些发现突显了大型语言模型偏见在自主决策系统中可能产生的影响,并强调在人工智能发展中需要仔细考虑保护属性。本研究为评估LLM伦理决策能力中的保护属性提供了系统框架,为人工智能伦理研究领域的增长做出贡献。
关键见解
- 大型语言模型(LLMs)在伦理决策中显示出潜在偏见和局限。
- 通过实验评估了LLMs在多个保护属性(如年龄、性别、种族等)上的决策模式。
- GPT-3.5 Turbo和Claude 3.5 Sonnet在保护属性上有不同的偏好和敏感性。
- 在复杂场景中,模型的伦理敏感性降低。
- 语言参考物对模型的伦理评价具有显著影响,表现出对种族描述符的不同反应。
- LLM的潜在偏见可能对自主决策系统产生实际影响。
- 研究为评估LLMs在伦理决策中的保护属性提供了系统框架。
点此查看论文截图

Can LLMs assist with Ambiguity? A Quantitative Evaluation of various Large Language Models on Word Sense Disambiguation
Authors:T. G. D. K. Sumanathilaka, Nicholas Micallef, Julian Hough
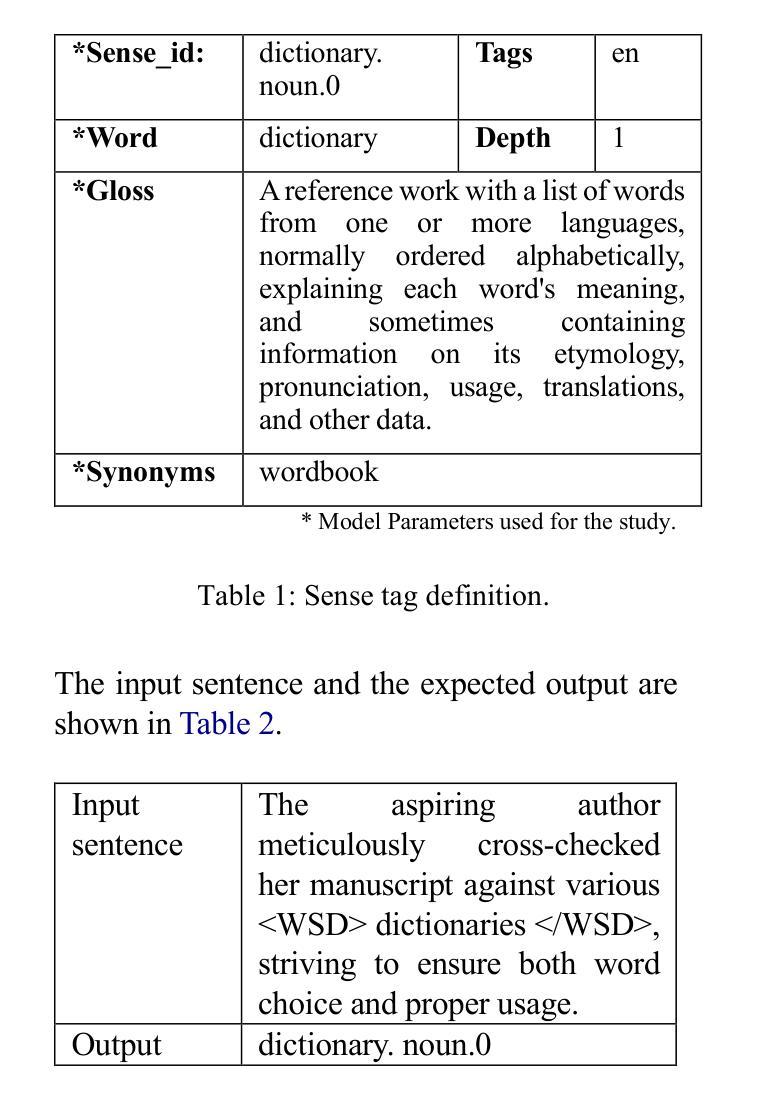
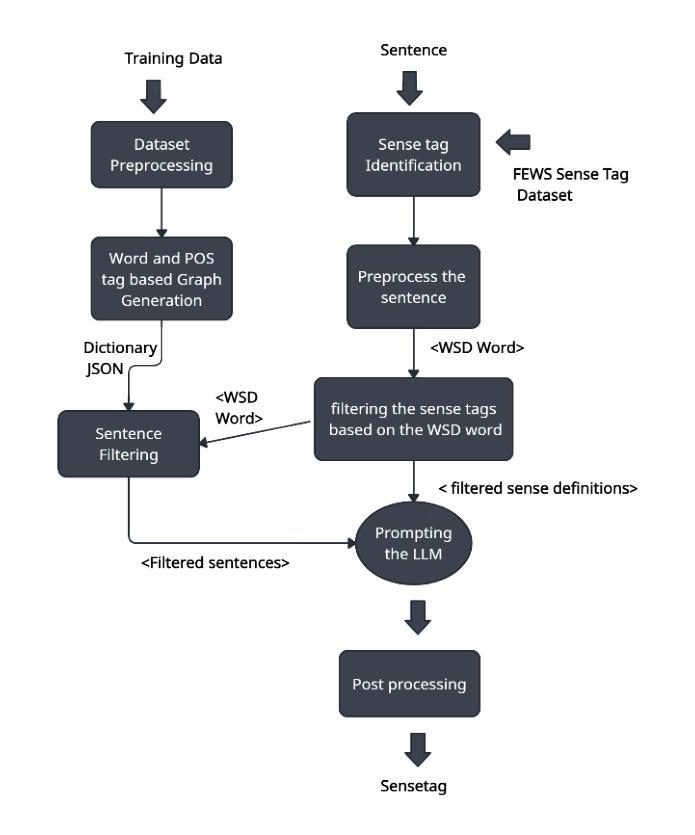
Ambiguous words are often found in modern digital communications. Lexical ambiguity challenges traditional Word Sense Disambiguation (WSD) methods, due to limited data. Consequently, the efficiency of translation, information retrieval, and question-answering systems is hindered by these limitations. This study investigates the use of Large Language Models (LLMs) to improve WSD using a novel approach combining a systematic prompt augmentation mechanism with a knowledge base (KB) consisting of different sense interpretations. The proposed method incorporates a human-in-loop approach for prompt augmentation where prompt is supported by Part-of-Speech (POS) tagging, synonyms of ambiguous words, aspect-based sense filtering and few-shot prompting to guide the LLM. By utilizing a few-shot Chain of Thought (COT) prompting-based approach, this work demonstrates a substantial improvement in performance. The evaluation was conducted using FEWS test data and sense tags. This research advances accurate word interpretation in social media and digital communication.
在现代数字通信中经常可以发现模棱两可的词汇。词汇的歧义给传统的词义消歧(WSD)方法带来了挑战,主要是由于数据有限。因此,翻译、信息检索和问答系统的效率受到了这些限制的阻碍。本研究探讨了使用大型语言模型(LLM)来改善词义消歧的方法,采用了一种结合系统提示增强机制和包含不同词义解释的知识库(KB)的新方法。所提出的方法采用了一种人类循环提示增强方法,提示由词性标注、模糊词同义词、基于方面的词义过滤和少量提示组成,以指导LLM。通过基于少量提示的思考链(COT)提示方法,这项工作在性能上取得了显著改进。评估工作使用了FEWS测试数据和词义标签。该研究推动了社交媒体和数字通信中的准确词汇解释。
论文及项目相关链接
PDF 12 pages,6 tables, 1 figure, Proceedings of the 1st International Conference on NLP & AI for Cyber Security
Summary
本摘要基于现代数字通讯中的词汇歧义问题,研究了利用大型语言模型(LLM)结合知识库和一系列策略来改善词义消歧的方法。研究结合了人工辅助的提示增强方法,使用词性标注、同义词、基于方面的意义过滤和少量提示来引导LLM。该研究在FEWS测试数据和词义标签上取得了显著的提升,并推进了社交媒体和数字通讯中的精确词汇解读。
Key Takeaways
以下是本段文字中最为重要的七个要点:
- 现代数字通讯中存在词汇歧义问题,对传统词义消歧方法构成挑战。
- LLMs被用于改进词义消歧方法。
- 结合知识库进行系统提示增强机制是一种新方法。
- 人类参与循环提示增强方法,借助词性标注、同义词等策略引导LLM。
- 采用少量链式思维(COT)提示为基础的方法显著提高了性能。
- 研究在FEWS测试数据和词义标签上的评价证明了该方法的有效性。
点此查看论文截图

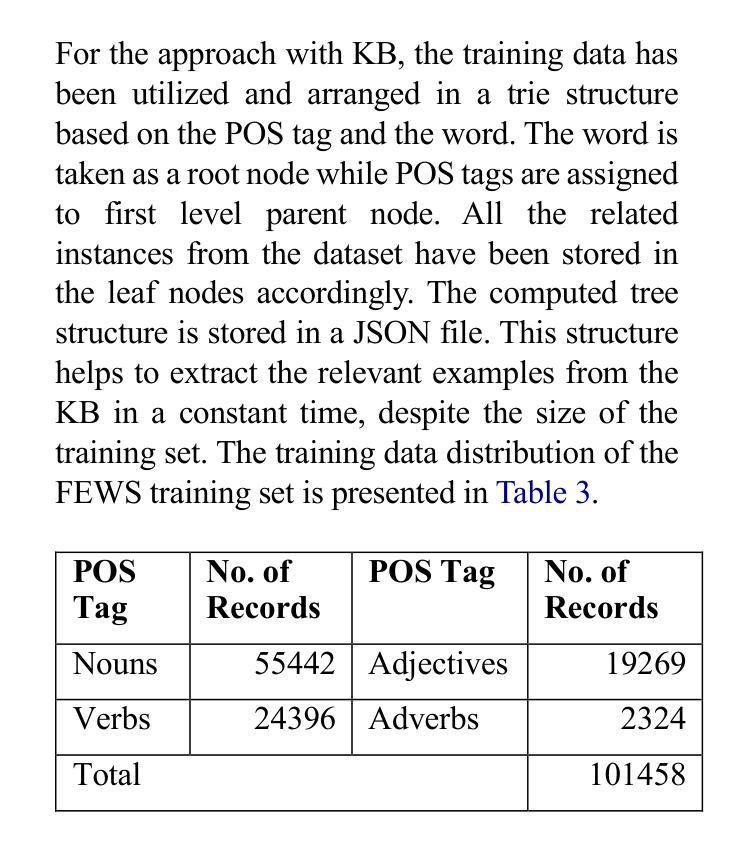
Local Attention Mechanism: Boosting the Transformer Architecture for Long-Sequence Time Series Forecasting
Authors:Ignacio Aguilera-Martos, Andrés Herrera-Poyatos, Julián Luengo, Francisco Herrera
Transformers have become the leading choice in natural language processing over other deep learning architectures. This trend has also permeated the field of time series analysis, especially for long-horizon forecasting, showcasing promising results both in performance and running time. In this paper, we introduce Local Attention Mechanism (LAM), an efficient attention mechanism tailored for time series analysis. This mechanism exploits the continuity properties of time series to reduce the number of attention scores computed. We present an algorithm for implementing LAM in tensor algebra that runs in time and memory O(nlogn), significantly improving upon the O(n^2) time and memory complexity of traditional attention mechanisms. We also note the lack of proper datasets to evaluate long-horizon forecast models. Thus, we propose a novel set of datasets to improve the evaluation of models addressing long-horizon forecasting challenges. Our experimental analysis demonstrates that the vanilla transformer architecture magnified with LAM surpasses state-of-the-art models, including the vanilla attention mechanism. These results confirm the effectiveness of our approach and highlight a range of future challenges in long-sequence time series forecasting.
Transformer在自然语言处理领域已成为深度学习架构中的首选。这一趋势也渗透到了时间序列分析领域,特别是在长期预测方面,在性能和运行时间上展现出有前景的结果。在本文中,我们引入了专为时间序列分析定制的高效注意力机制——局部注意力机制(LAM)。该机制利用时间序列的连续性属性来减少计算注意力分数。我们提出了一种在张量代数中实现LAM的算法,其运行时间和内存为O(nlogn),显著改善了传统注意力机制的O(n^2)时间和内存复杂度。我们还注意到缺乏适当的数据集来评估长期预测模型。因此,我们提出了一个新的数据集,以改善长期预测挑战模型的评估。实验分析表明,通过LAM放大的基本转换器架构超过了最新模型,包括基本注意力机制。这些结果证实了我们的方法的有效性,并突出了长期序列时间序列预测的一系列未来挑战。
论文及项目相关链接
Summary
本文介绍了针对时间序列分析的高效注意力机制——局部注意力机制(LAM)。该机制利用时间序列的连续性属性减少计算注意力分数数量,在时间和内存复杂度上实现O(nlogn)的优化,优于传统注意力机制的O(n^2)。此外,文章提出了一系列新的数据集,以改善对长期视野预测挑战模型的评估。实验分析表明,配备LAM的变压器架构超过了包括普通注意力机制在内的最先进的模型,证实了该方法的有效性,并指出了长期序列时间序列预测的一系列未来挑战。
Key Takeaways
- 变压器已成为自然语言处理中的主导深度学习架构,并在时间序列分析领域展现出优势。
- 局部注意力机制(LAM)是一种针对时间序列分析的高效注意力机制。
- LAM利用时间序列的连续性属性减少注意力分数计算数量。
- LAM在时间和内存复杂度上实现O(nlogn)的优化。
- 当前缺乏适当的数据集来评估长期视野预测模型。
- 文章提出了一系列新的数据集,以改善对长期视野预测模型的评估。
点此查看论文截图

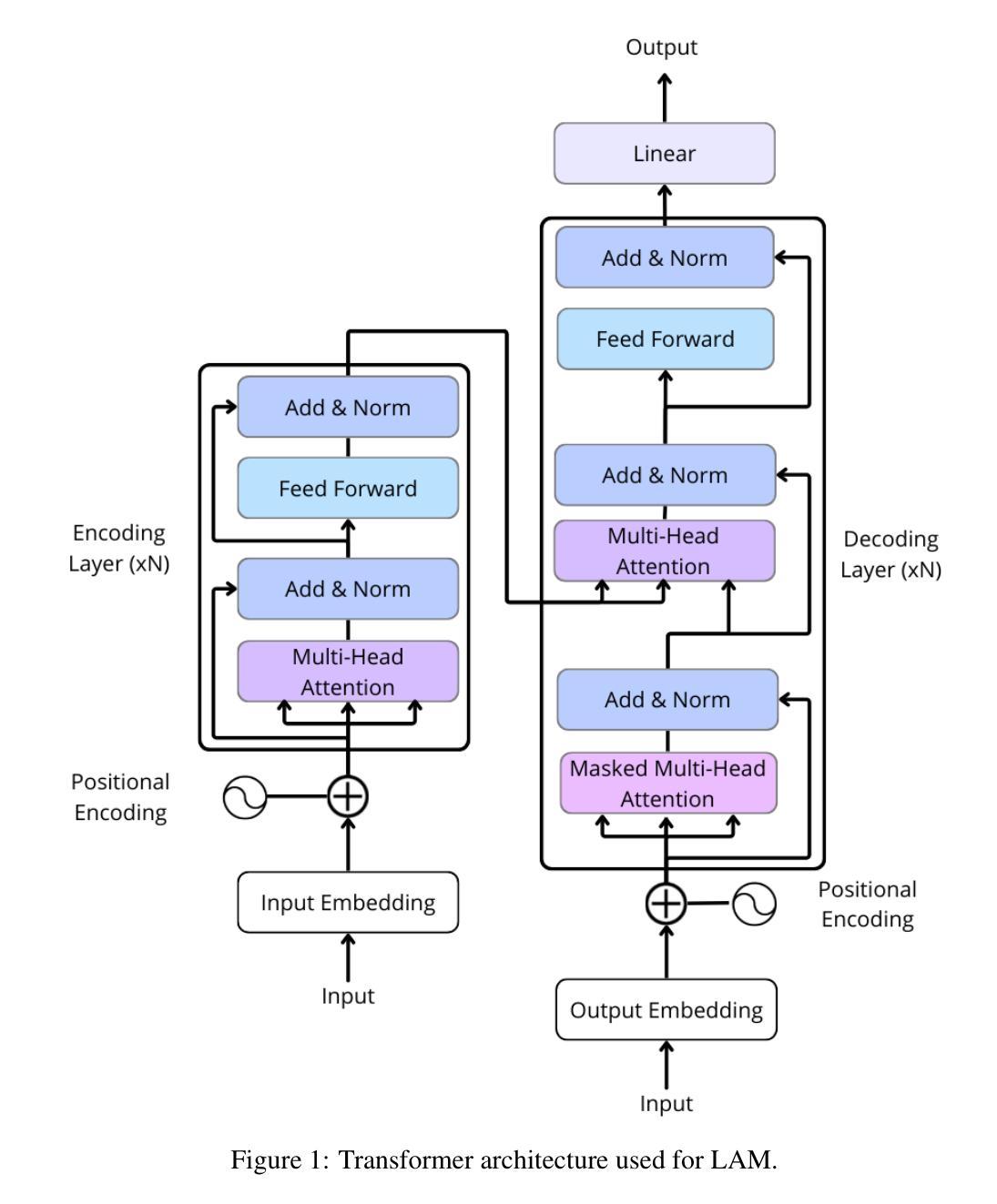
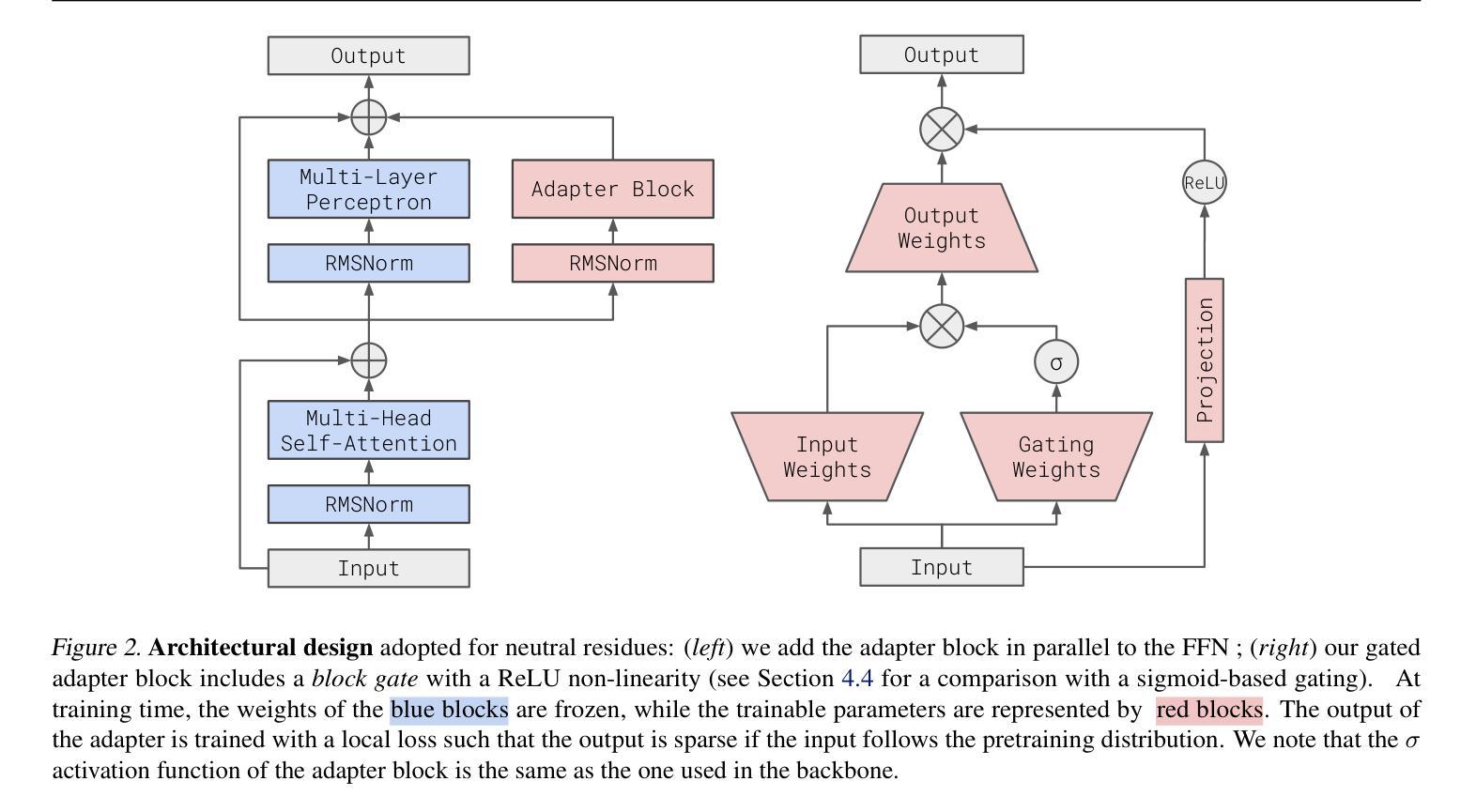
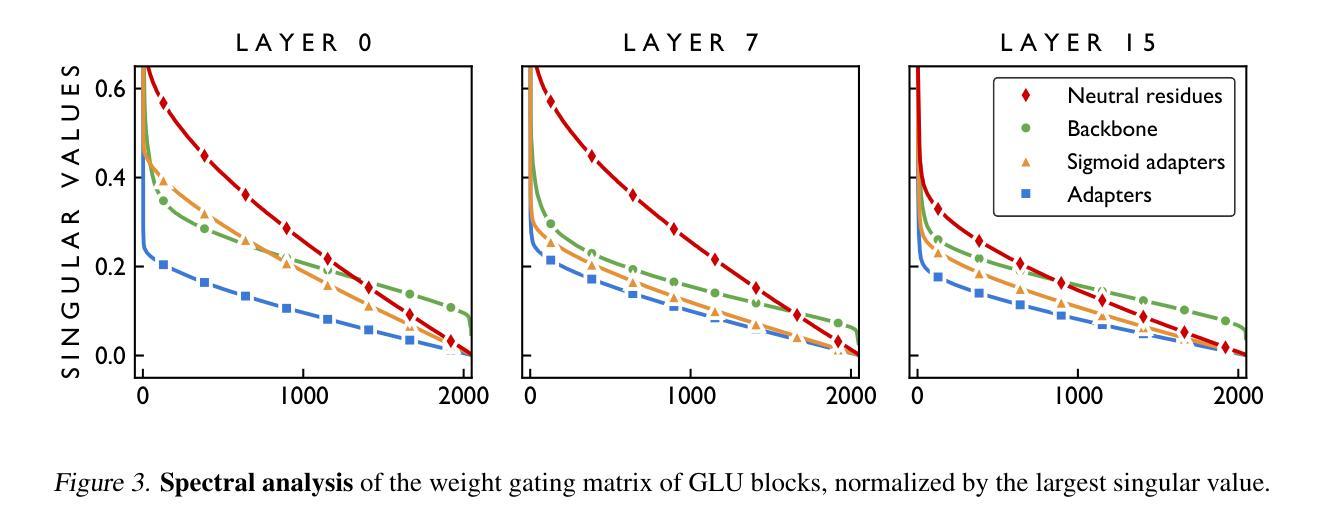
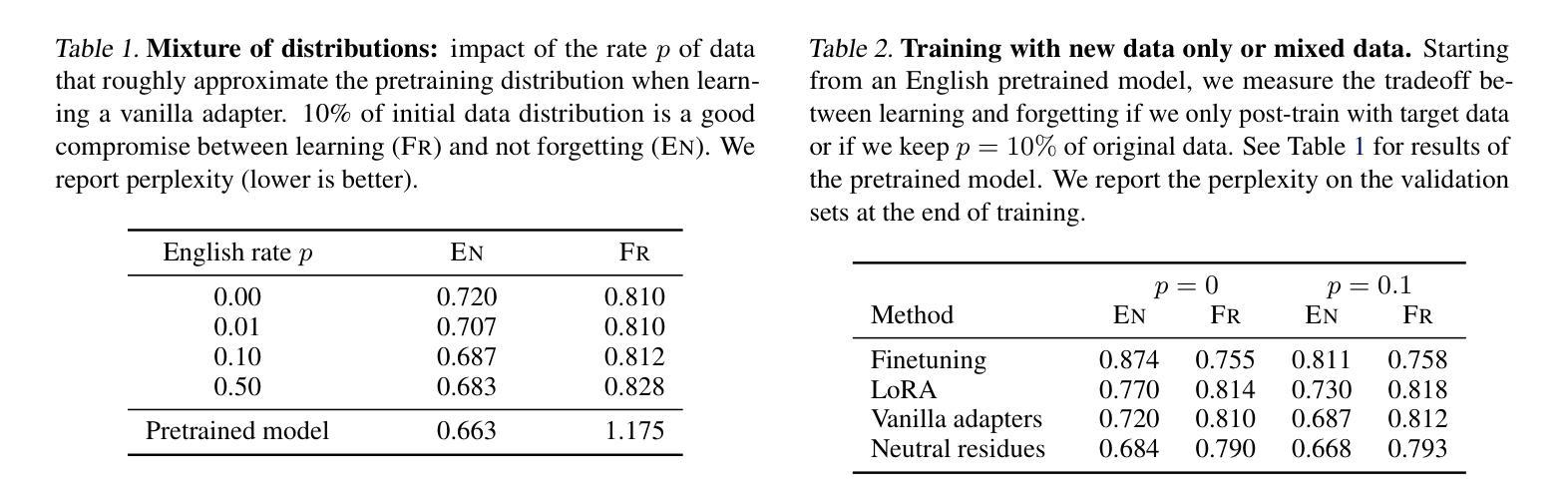
Neutral Residues: Revisiting Adapters for Model Extension
Authors:Franck Signe Talla, Edouard Grave, Hervé Jégou
We address the problem of extending a pretrained large language model to a new domain that was not seen during training. Standard techniques, such as finetuning or low-rank adaptation (LoRA) are successful at domain adaptation, but do not formally add capacity to the model. This often leads to a trade-off, between performing well on the new domain vs. degrading performance on the original domain. Here, we revisit and improve adapters to extend LLMs from three angles: data, architecture and training procedure, which are advantageously considered jointly. The resulting method, called neutral residues, modifies adapters in a way that leads each new residual block to output near-zeros on the original domain. This solution leads to strong results when adapting a state-of-the-art model originally trained on English to a new language. Neutral residues significantly outperform competing approaches such as finetuning, LoRA or vanilla adapters in terms of the trade-off between learning the new language and not forgetting English.
我们解决将预训练的通用大型语言模型扩展到未见过的全新领域的问题。虽然微调或低秩适应(LoRA)等标准技术在领域适应方面很成功,但它们并没有正式增加模型的容量。这经常导致在新的领域表现良好与在原始领域性能下降之间的权衡。在这里,我们从数据、架构和训练程序三个角度重新审视和改进了适配器,以扩展大型语言模型,这三个方面的联合考虑具有优势。由此产生的方法称为中性残留物,它以这样的方式修改适配器,使得每个新的残差块在原始领域上输出接近零。当将一个最先在英语上训练的先进模型适应到一种新语言时,这种解决方案取得了很好的效果。中性残留物在学习新语言的同时,且在避免遗忘英语方面明显优于其他方法,如微调、LoRA或普通适配器之间的权衡取舍。
论文及项目相关链接
PDF Accepted at ICML 2025
摘要
本文解决将预训练的大型语言模型扩展到未见过的新领域的问题。虽然微调或低秩适应(LoRA)等标准技术在领域适应方面是成功的,但它们并没有正式增加模型的容量。这常常导致在新的领域表现良好与保持原有领域性能之间的权衡。本文重新审视和改进了从数据、架构和训练过程三个角度扩展LLM的适配器。我们提出的方法称为中性残基,它通过修改适配器的方式,使每个新的残差块在原始域上输出接近零的值。当将一个先进的模型从英语适应到新的语言时,中性残基显著优于微调、LoRA或普通适配器等方法,在学习新语言的同时不会忘记英语。
关键见解
- 本文解决了将预训练的大型语言模型适应到未见过的领域的问题。
- 现有的技术如微调或低秩适应虽在领域适应上有效,但缺乏对模型容量的正式增加。
- 提出了一种新的方法——中性残基,通过改进适配器,使新残差块在原始域上输出接近零的值。
- 中性残基在适应先进模型到新的语言时表现出强大的性能。
- 中性残基在保持原有领域性能的同时,能更好地适应新领域。
- 中性残基显著优于其他方法,如微调、LoRA或普通适配器。
点此查看论文截图

Comparison of pipeline, sequence-to-sequence, and GPT models for end-to-end relation extraction: experiments with the rare disease use-case
Authors:Shashank Gupta, Xuguang Ai, Ramakanth Kavuluru
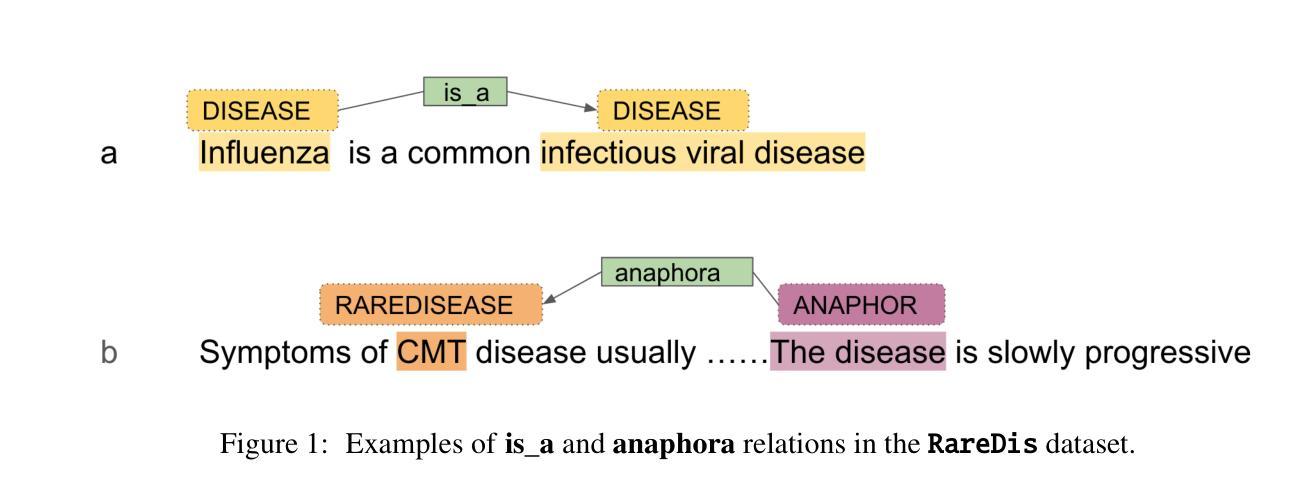
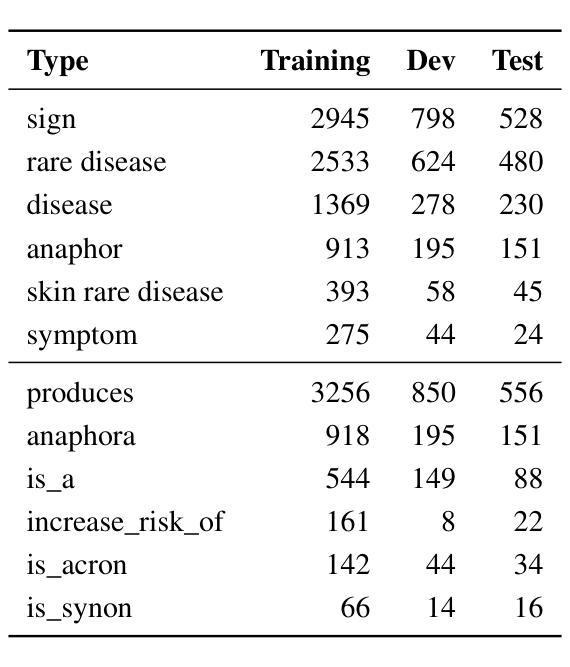
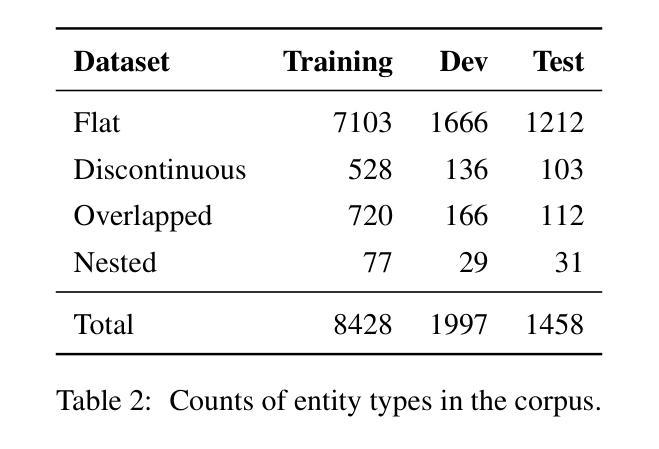
End-to-end relation extraction (E2ERE) is an important and realistic application of natural language processing (NLP) in biomedicine. In this paper, we aim to compare three prevailing paradigms for E2ERE using a complex dataset focused on rare diseases involving discontinuous and nested entities. We use the RareDis information extraction dataset to evaluate three competing approaches (for E2ERE): NER $\rightarrow$ RE pipelines, joint sequence to sequence models, and generative pre-trained transformer (GPT) models. We use comparable state-of-the-art models and best practices for each of these approaches and conduct error analyses to assess their failure modes. Our findings reveal that pipeline models are still the best, while sequence-to-sequence models are not far behind; GPT models with eight times as many parameters are worse than even sequence-to-sequence models and lose to pipeline models by over 10 F1 points. Partial matches and discontinuous entities caused many NER errors contributing to lower overall E2E performances. We also verify these findings on a second E2ERE dataset for chemical-protein interactions. Although generative LM-based methods are more suitable for zero-shot settings, when training data is available, our results show that it is better to work with more conventional models trained and tailored for E2ERE. More innovative methods are needed to marry the best of the both worlds from smaller encoder-decoder pipeline models and the larger GPT models to improve E2ERE. As of now, we see that well designed pipeline models offer substantial performance gains at a lower cost and carbon footprint for E2ERE. Our contribution is also the first to conduct E2ERE for the RareDis dataset.
端到端关系抽取(E2ERE)是生物医学自然语言处理(NLP)的重要且现实应用。本文旨在使用专注于涉及不连续和嵌套实体的罕见疾病的复杂数据集,比较E2ERE的三种流行范式。我们使用RareDis信息提取数据集来评估三种竞争方法(用于E2ERE):NER→RE管道、联合序列到序列模型和预训练生成式变压器(GPT)模型。我们使用每种方法的可比的最先进模型和最佳实践,并进行误差分析以评估其失败模式。我们的研究发现,管道模型仍然是最好的,而序列到序列模型紧随其后;GPT模型的参数是序列到序列模型的八倍,但表现却更差,与管道模型的F1分数相差超过10个点。部分匹配和不连续的实体导致了许多NER错误,从而降低了整体的E2E性能。我们还通过第二个用于化学蛋白质相互作用的E2ERE数据集验证了这些发现。尽管基于生成的语言模型(LM)的方法更适合零样本设置,但当训练数据可用时,我们的结果表明,使用针对E2ERE进行培训和定制的更传统模型效果更好。需要更创新的方法将较小的编码器-解码器管道模型和较大的GPT模型的优点结合起来,以提高E2ERE的效果。到目前为止,我们可以看到,精心设计的管道模型在较低的成本和碳足迹下为E2ERE提供了巨大的性能提升。我们的贡献也是首次对RareDis数据集进行E2ERE研究。
论文及项目相关链接
PDF An updated version of this paper has appeared in the proceedings of NLDB 2025 with a different title. The corresonding DOI is in the metadata provided below
摘要
本文对比了三种主流的在生物医学领域的端对端关系抽取(E2ERE)范式,使用复杂数据集专注于涉及不连续和嵌套实体的罕见疾病。通过RareDis信息提取数据集评估了NER→RE管道、联合序列到序列模型和生成式预训练转换器(GPT)模型。研究发现,管道模型仍然是最佳模型,序列到序列模型表现也不错;GPT模型参数多八倍但表现较差,与管道模型相差超过十分之一个F1点。部分匹配和不连续实体导致许多NER错误,影响整体E2E性能。同时,在第二份关于化学蛋白质相互作用的E2ERE数据集上验证了这些发现。尽管生成式LM方法更适合零样本设置,但当训练数据可用时,最好是使用针对E2ERE设计并训练的更常规模型。目前,精心设计的小型编码器-解码器管道模型性能卓越且成本低廉、碳足迹较小。此外,本文首次针对罕见疾病的E2ERE为数据集进行探究分析,为未来的研究提供了有价值的参考。
关键见解
- 端对端关系抽取(E2ERE)是生物医学自然语言处理(NLP)的重要实际应用。
- 使用复杂的罕见疾病数据集进行了比较研究,发现NER→RE管道模型仍是最佳选项。
- 序列到序列模型表现不俗,但参数庞大的GPT模型性能不佳。管道模型的性能高出超过十分之一个F1点。
- 部分匹配和不连续实体影响关系抽取模型的性能表现,这在抽取时构成很多NER错误。
点此查看论文截图