⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-04 更新
Trustworthy Reasoning: Evaluating and Enhancing Factual Accuracy in LLM Intermediate Thought Processes
Authors:Rui Jiao, Yue Zhang, Jinku Li
We present RELIANCE (Reasoning Evaluation with Logical Integrity and Accuracy for Confidence Enhancement), a novel framework addressing a critical vulnerability in Large Language Models (LLMs): the prevalence of factual inaccuracies within intermediate reasoning steps despite correct final answers. This phenomenon poses substantial risks in high-stakes domains including healthcare, legal analysis, and scientific research, where erroneous yet confidently presented reasoning can mislead users into dangerous decisions. Our framework integrates three core components: (1) a specialized fact-checking classifier trained on counterfactually augmented data to detect subtle factual inconsistencies within reasoning chains; (2) a Group Relative Policy Optimization (GRPO) reinforcement learning approach that balances factuality, coherence, and structural correctness through multi-dimensional rewards; and (3) a mechanistic interpretability module examining how factuality improvements manifest in model activations during reasoning processes. Extensive evaluation across ten state-of-the-art models reveals concerning patterns: even leading models like Claude-3.7 and GPT-o1 demonstrate reasoning factual accuracy of only 81.93% and 82.57% respectively. RELIANCE significantly enhances factual robustness (up to 49.90% improvement) while maintaining or improving performance on challenging benchmarks including Math-500, AIME-2024, and GPQA. Furthermore, our activation-level analysis provides actionable insights into how factual enhancements reshape reasoning trajectories within model architectures, establishing foundations for future training methodologies that explicitly target factual robustness through activation-guided optimization.
我们提出了RELIANCE(基于逻辑完整性和准确性的推理评估置信增强框架),这是一个新的框架,解决了大型语言模型(LLM)中的一个关键漏洞:尽管最终答案正确,但中间推理步骤中存在大量事实错误。这种现象在高风险领域(包括医疗保健、法律分析和科学研究)中构成了重大风险,在这些领域中,错误但自信的推理可能会误导用户做出危险决策。我们的框架集成了三个核心组件:(1)一个专门的事实检查分类器,该分类器在通过反事实增强数据进行训练,以检测推理链中的细微事实不一致;(2)一种集团相对政策优化(GRPO)强化学习方法,通过多维奖励平衡事实性、连贯性和结构正确性;(3)一个机械解释模块,用于检查事实改进在推理过程中的模型激活中的表现。对十种最新技术的广泛评估显示出了令人担忧的模式:即使是领先的模型,如Claude-3.7和GPT-o1,其推理事实准确率也仅为81.93%和82.57%。RELIANCE在保持或提高Math-500、AIME-2024和GPQA等具有挑战性的基准测试性能的同时,显著提高了事实稳健性(最多可提高49.90%)。此外,我们的激活层面分析提供了关于事实改进如何改变模型架构内推理轨迹的可操作见解,为未来的训练方法论奠定了基础,这些方法论通过激活引导优化明确针对事实稳健性。
论文及项目相关链接
Summary
RELIANCE框架旨在解决大型语言模型(LLMs)中的关键漏洞:尽管最终答案正确,但中间推理步骤中普遍存在事实错误。这种现象在高风险领域(如医疗、法律分析和科学研究)具有重大风险,可能会误导用户做出危险决策。RELIANCE框架包含三个核心组件:检测推理链中微妙事实不一致的专用事实检查分类器、平衡事实性、连贯性和结构正确性的集团相对政策优化(GRPO)强化学习方法,以及考察事实性改进在模型激活过程中如何体现在推理过程中的机械解释性模块。评估显示,RELIANCE框架显著提高了事实稳健性,并在挑战性基准测试中保持了性能或有所提高。同时,激活层面的分析提供了关于事实改进如何重塑模型架构内推理轨迹的见解,为未来的训练方法论提供了基础,旨在通过激活引导优化明确针对事实稳健性。
Key Takeaways
- RELIANCE是一个针对大型语言模型(LLMs)中事实准确性问题的新框架。
- 该框架解决了LLMs在推理步骤中即使最终答案正确也存在事实错误的问题。
- RELIANCE包含三个核心组件:事实检查分类器、GRPO强化学习方法和机械解释性模块。
- 评估显示,RELIANCE提高了事实稳健性,并在多个基准测试中表现优异。
- 框架能够改善领先模型(如Claude-3.7和GPT-o1)的推理事实准确性。
- 激活层面的分析提供了关于事实改进如何影响模型推理过程的具体见解。
点此查看论文截图


CIMR: Contextualized Iterative Multimodal Reasoning for Robust Instruction Following in LVLMs
Authors:Yangshu Yuan, Heng Chen, Xinyi Jiang, Christian Ng, Kexin Qiu
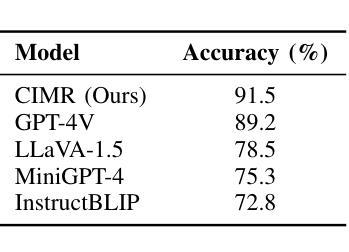
The rapid advancement of Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) has enhanced our ability to process and generate human language and visual information. However, these models often struggle with complex, multi-step multi-modal instructions that require logical reasoning, dynamic feedback integration, and iterative self-correction. To address this, we propose CIMR: Contextualized Iterative Multimodal Reasoning, a novel framework that introduces a context-aware iterative reasoning and self-correction module. CIMR operates in two stages: initial reasoning and response generation, followed by iterative refinement using parsed multi-modal feedback. A dynamic fusion module deeply integrates textual, visual, and contextual features at each step. We fine-tune LLaVA-1.5-7B on the Visual Instruction Tuning (VIT) dataset and evaluate CIMR on the newly introduced Multi-modal Action Planning (MAP) dataset. CIMR achieves 91.5% accuracy, outperforming state-of-the-art models such as GPT-4V (89.2%), LLaVA-1.5 (78.5%), MiniGPT-4 (75.3%), and InstructBLIP (72.8%), demonstrating the efficacy of its iterative reasoning and self-correction capabilities in complex tasks.
随着大型语言模型(LLM)和大型视觉语言模型(LVLM)的快速发展,我们处理和生成人类语言和视觉信息的能力得到了提升。然而,这些模型在处理需要逻辑推理、动态反馈集成和迭代自我纠正的复杂多步骤多模式指令时常常遇到困难。为了解决这一问题,我们提出了CIMR:情境化迭代多模式推理,这是一个引入上下文感知迭代推理和自我纠正模块的新型框架。CIMR分为两个阶段:初始推理和响应生成,然后使用解析的多模式反馈进行迭代改进。动态融合模块在每一步都深度整合文本、视觉和上下文特征。我们在视觉指令调整(VIT)数据集上对LLaVA-1.5-7B进行了微调,并在新引入的多模式动作规划(MAP)数据集上评估了CIMR。CIMR的准确率为91.5%,超过了GPT-4V(89.2%)、LLaVA-1.5(78.5%)、MiniGPT-4(75.3%)和InstructBLIP(72.8%)等先进模型的表现,证明了其在复杂任务中的迭代推理和自我纠正能力有效性。
论文及项目相关链接
Summary
大型语言模型(LLMs)和大型视觉语言模型(LVLMs)的快速发展增强了我们处理和生成人类语言和视觉信息的能力,但对于需要逻辑、动态反馈迭代校正的多步骤多模式指令常常处理不佳。为此,我们提出CIMR:语境化迭代多模式推理框架,引入语境感知迭代推理和自我校正模块。CIMR分为初始推理和响应生成两个阶段,然后使用解析的多模式反馈进行迭代优化。动态融合模块在每一步深入整合文本、视觉和语境特征。我们在Visual Instruction Tuning(VIT)数据集上微调LLaVA-1.5-7B模型,并在新引入的多模式动作规划(MAP)数据集上评估CIMR。结果显示,CIMR达到91.5%的准确性,优于GPT-4V(89.2%)、LLaVA-1.5(78.5%)、MiniGPT-4(75.3%)和InstructBLIP(72.8%),证明了其迭代推理和自我校正能力在复杂任务中的有效性。
Key Takeaways
- 大型语言模型(LLMs)和视觉语言模型(LVLMs)在处理和生成语言及视觉信息方面取得进展。
- 这些模型在面对复杂、多步骤和多模式指令时常常遇到困难,需要逻辑推理、动态反馈集成和迭代自我校正。
- CIMR框架被提出来解决这一问题,包含初始推理和响应生成,然后通过解析的多模式反馈进行迭代优化。
- CIMR框架包括一个动态融合模块,该模块可以深入整合文本、视觉和语境特征。
- LLaVA-1.5-7B模型在Visual Instruction Tuning(VIT)数据集上进行微调。
- CIMR在Multi-modal Action Planning(MAP)数据集上的准确性达到91.5%,优于其他先进模型,如GPT-4V、LLaVA-1.5、MiniGPT-4和InstructBLIP。
点此查看论文截图


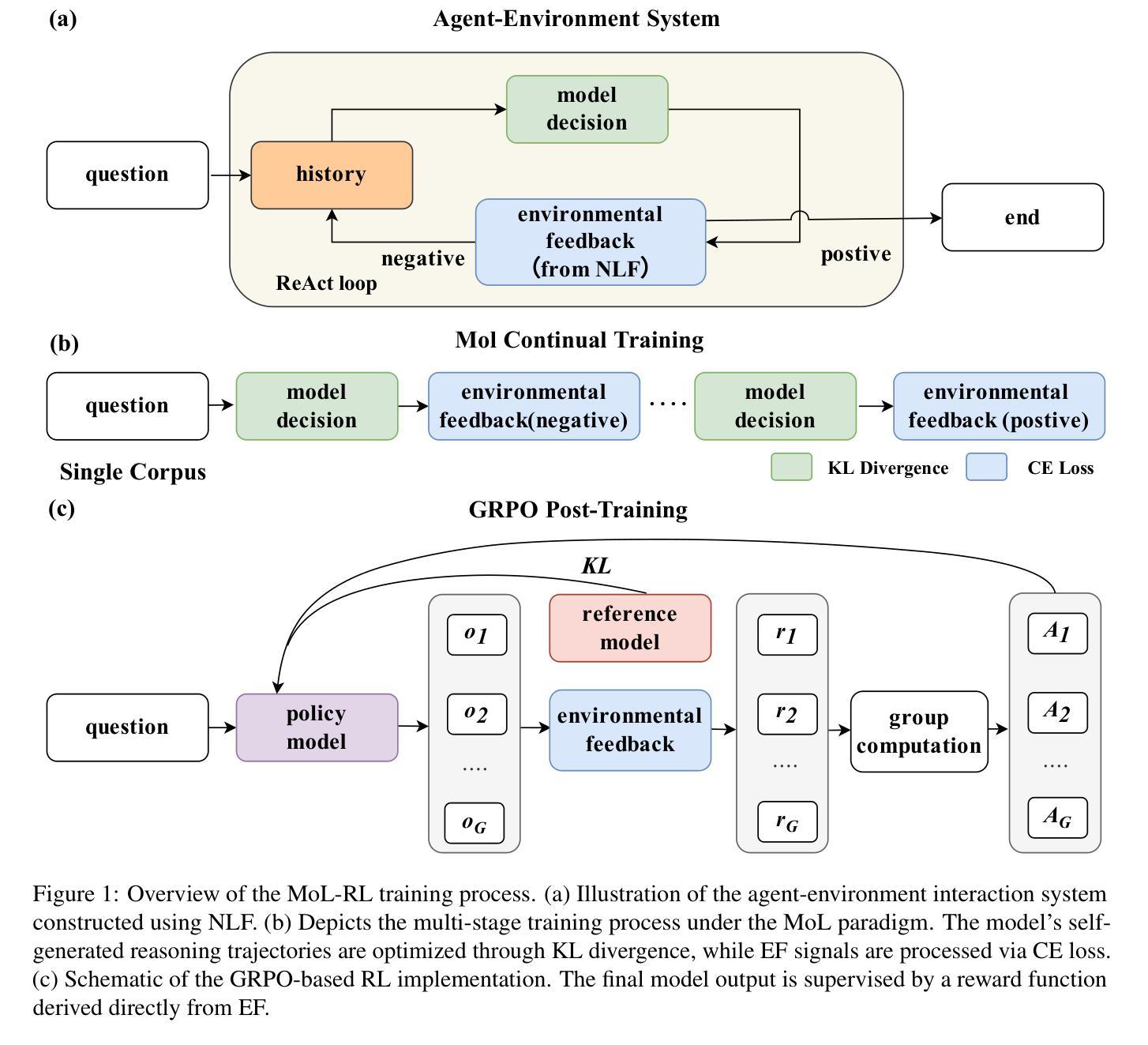
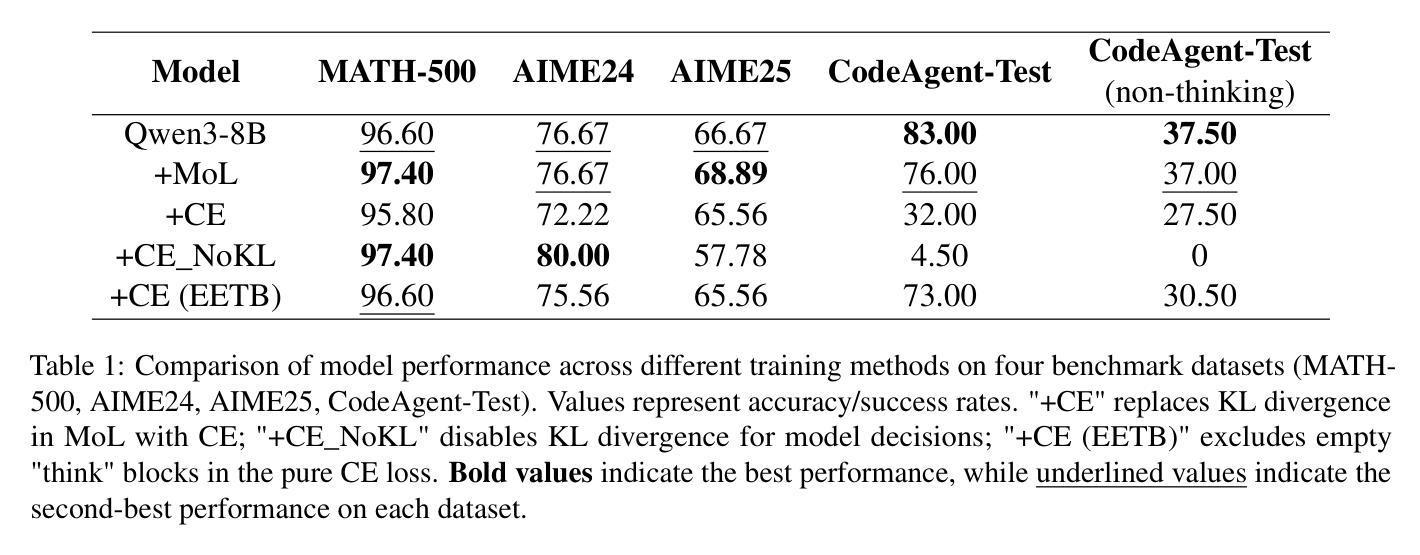
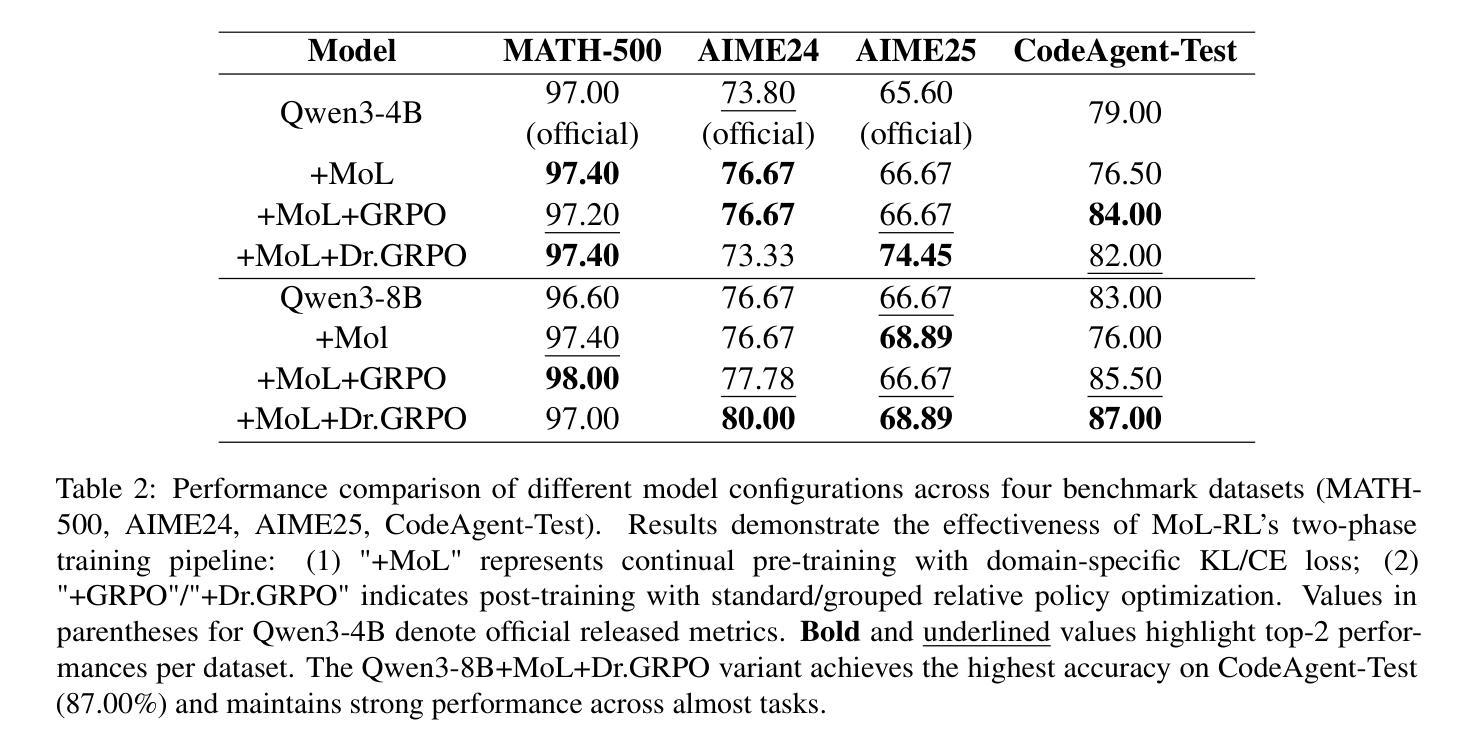
MoL-RL: Distilling Multi-Step Environmental Feedback into LLMs for Feedback-Independent Reasoning
Authors:Kang Yang, Jingxue Chen, Qingkun Tang, Tianxiang Zhang, Qianchun Lu
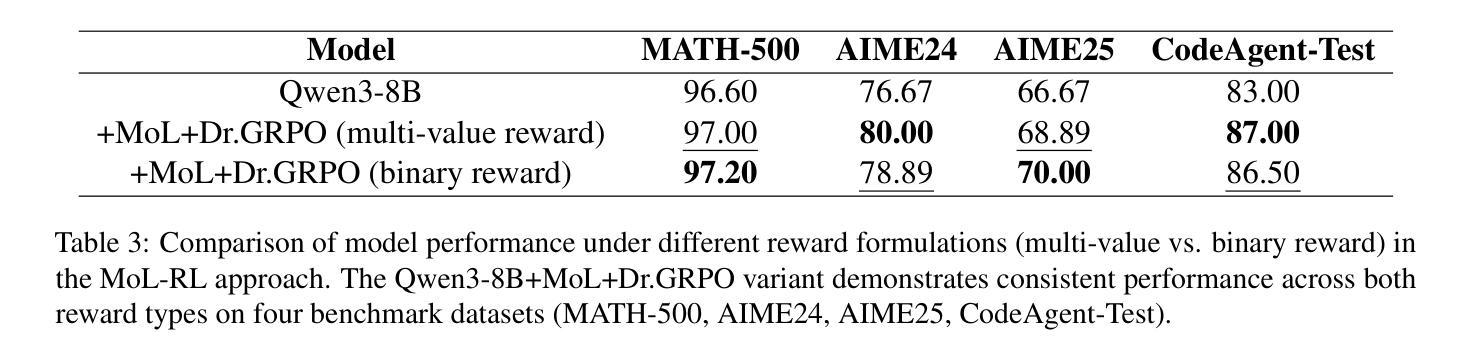
Large language models (LLMs) face significant challenges in effectively leveraging sequential environmental feedback (EF) signals, such as natural language evaluations, for feedback-independent chain-of-thought (CoT) reasoning. Existing approaches either convert EF into scalar rewards, losing rich contextual information, or employ refinement datasets, failing to exploit the multi-step and discrete nature of EF interactions. To address these limitations, we propose MoL-RL, a novel training paradigm that integrates multi-step EF signals into LLMs through a dual-objective optimization framework. Our method combines MoL (Mixture-of-Losses) continual training, which decouples domain-specific EF signals (optimized via cross-entropy loss) and general language capabilities (preserved via Kullback-Leibler divergence), with GRPO-based post-training to distill sequential EF interactions into single-step inferences. This synergy enables robust feedback-independent reasoning without relying on external feedback loops. Experimental results on mathematical reasoning (MATH-500, AIME24/AIME25) and code generation (CodeAgent-Test) benchmarks demonstrate that MoL-RL achieves state-of-the-art performance with the Qwen3-8B model, while maintaining strong generalization across model scales (Qwen3-4B). This work provides a promising approach for leveraging multi-step textual feedback to enhance LLMs’ reasoning capabilities in diverse domains.
大型语言模型(LLM)在有效利用序列环境反馈(EF)信号,如自然语言评估,进行无反馈的链式思维(CoT)推理时面临重大挑战。现有方法要么将环境反馈转化为标量奖励,从而失去丰富的上下文信息,要么使用精炼数据集,无法利用环境反馈交互的多步离散性质。为了解决这个问题,我们提出了MoL-RL这一新型训练范式,它通过双目标优化框架将多步环境反馈信号集成到LLM中。我们的方法结合了MoL(混合损失)持续训练,它将领域特定的环境反馈信号(通过交叉熵损失进行优化)和一般语言能力(通过Kullback-Leibler散度进行保留)解耦,以及与基于GRPO的后期训练相结合,将序列环境反馈交互蒸馏为单步推断。这种协同作用实现了无需外部反馈循环的稳健的无反馈推理。在数学推理(MATH-500、AIME24/AIME25)和代码生成(CodeAgent-Test)基准测试上的实验结果表明,MoL-RL在Qwen3-8B模型上取得了最新技术水平的性能,同时在模型规模(Qwen3-4B)上保持了强大的泛化能力。这项工作提供了一个利用多步文本反馈来提升LLM在多个领域中的推理能力的有前途的方法。
论文及项目相关链接
PDF 12pages,3figures
Summary
大型语言模型(LLMs)在利用序列环境反馈(EF)信号进行无反馈链式思维(CoT)推理时面临挑战。现有方法存在局限性,如丢失丰富的上下文信息或未能充分利用多步离散的环境反馈交互。为解决这些问题,我们提出MoL-RL这一新型训练范式,通过双重目标优化框架将多步环境反馈信号融入LLMs。该方法结合MoL(混合损失)持续训练,将领域特定的环境反馈信号(通过交叉熵损失优化)与一般语言能力(通过Kullback-Leibler散度保持)解耦,与基于GRPO的后期训练相结合,将序列环境反馈互动蒸馏为单步推断。这种协同作用实现了无需外部反馈循环的稳健无反馈推理。在数学推理和代码生成基准测试上,MoL-RL在Qwen3-8B模型上取得了最新技术性能,同时在模型规模(Qwen3-4B)上保持了强大的泛化能力。这项工作提供了一个利用多步文本反馈增强LLMs在多个领域推理能力的有前途的方法。
Key Takeaways
- 大型语言模型(LLMs)在利用序列环境反馈(EF)进行推理时存在挑战。
- 现有方法转换环境反馈时丢失了丰富的上下文信息,或未能充分利用多步离散的环境反馈交互。
- MoL-RL是一种新型训练范式,通过双重目标优化框架集成多步环境反馈信号到LLMs中。
- MoL-RL结合MoL持续训练和基于GRPO的后期训练,实现无需外部反馈的稳健推理。
- MoL-RL在多个基准测试上实现了最新技术性能,包括数学推理和代码生成。
- MoL-RL在Qwen3-8B模型上表现出强大的性能,同时在不同规模的模型(如Qwen3-4B)上具有良好的泛化能力。
点此查看论文截图

Diversity-Enhanced Reasoning for Subjective Questions
Authors:Yumeng Wang, Zhiyuan Fan, Jiayu Liu, Yi R. Fung
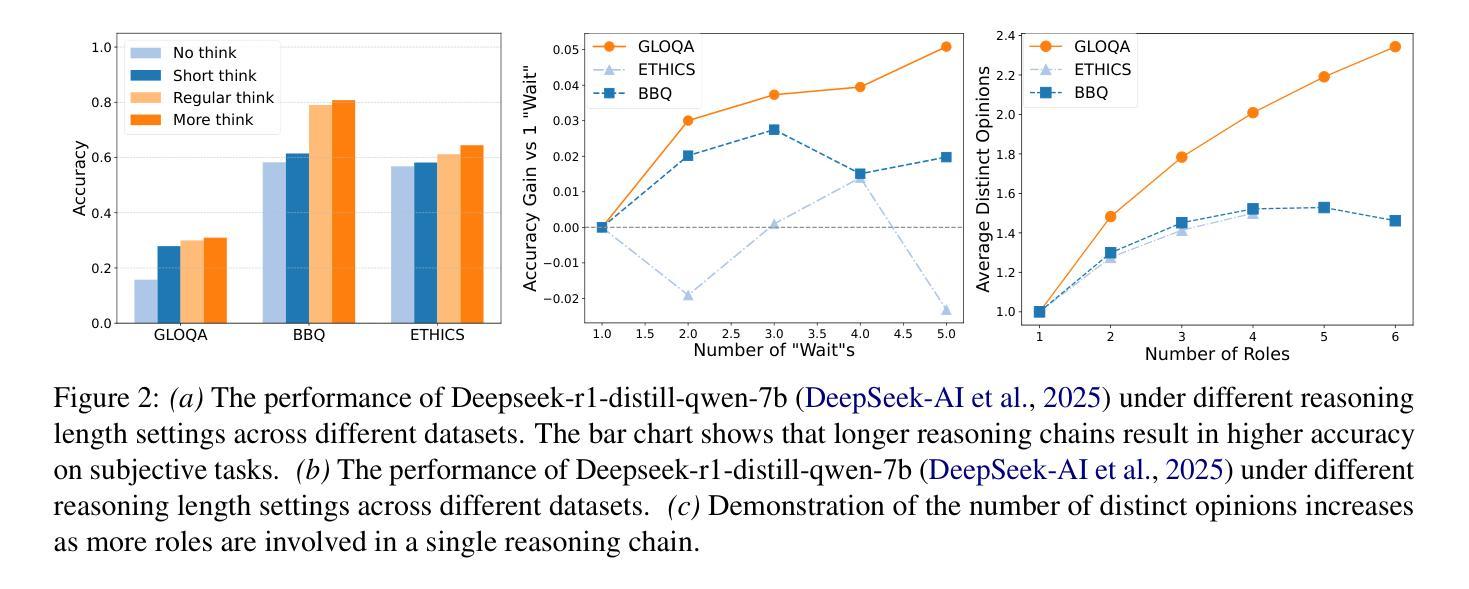
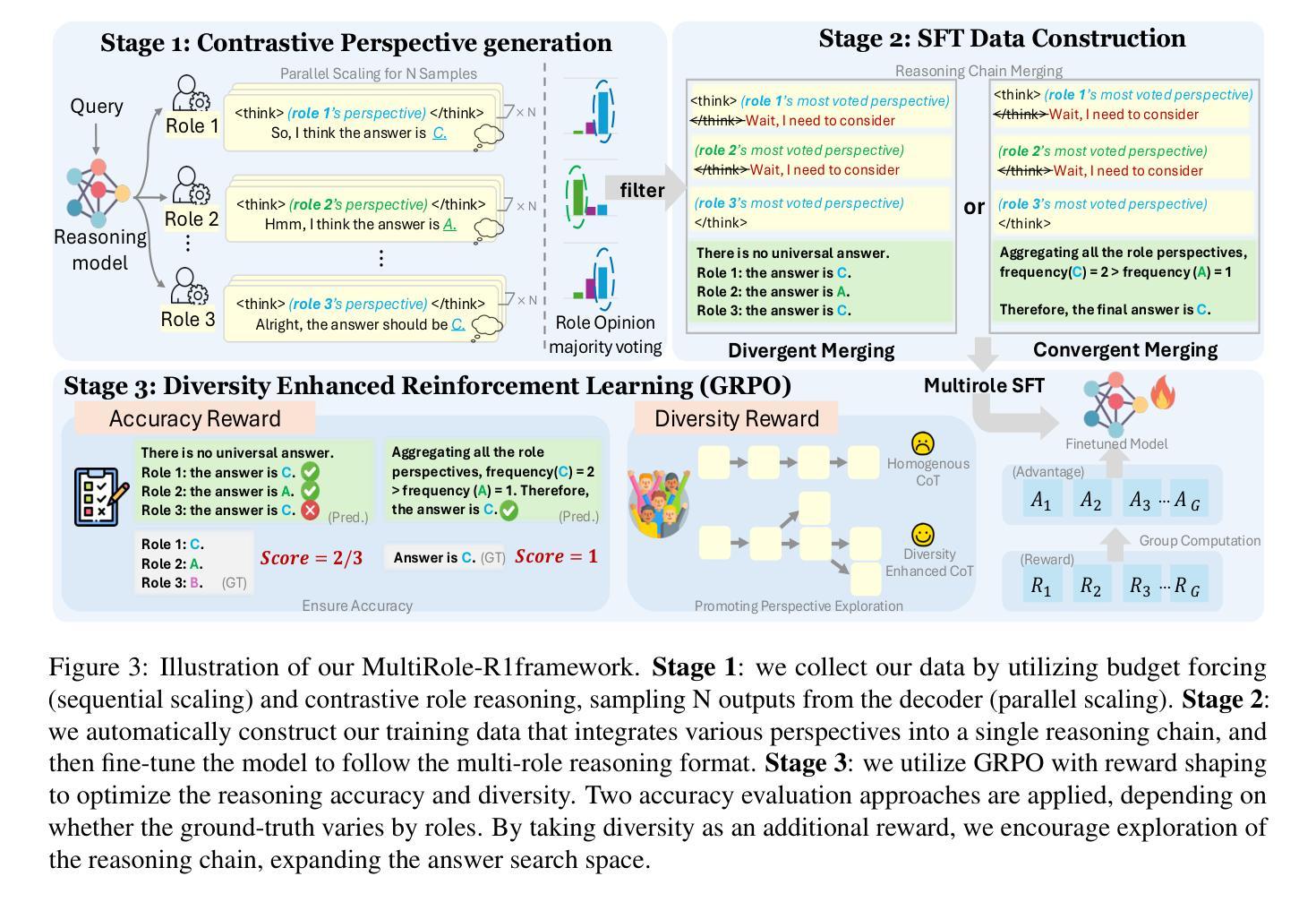
Large reasoning models (LRM) with long chain-of-thought (CoT) capabilities have shown strong performance on objective tasks, such as math reasoning and coding. However, their effectiveness on subjective questions that may have different responses from different perspectives is still limited by a tendency towards homogeneous reasoning, introduced by the reliance on a single ground truth in supervised fine-tuning and verifiable reward in reinforcement learning. Motivated by the finding that increasing role perspectives consistently improves performance, we propose MultiRole-R1, a diversity-enhanced framework with multiple role perspectives, to improve the accuracy and diversity in subjective reasoning tasks. MultiRole-R1 features an unsupervised data construction pipeline that generates reasoning chains that incorporate diverse role perspectives. We further employ reinforcement learning via Group Relative Policy Optimization (GRPO) with reward shaping, by taking diversity as a reward signal in addition to the verifiable reward. With specially designed reward functions, we successfully promote perspective diversity and lexical diversity, uncovering a positive relation between reasoning diversity and accuracy. Our experiment on six benchmarks demonstrates MultiRole-R1’s effectiveness and generalizability in enhancing both subjective and objective reasoning, showcasing the potential of diversity-enhanced training in LRMs.
具有长链思维(CoT)能力的大型推理模型(LRM)在客观任务(如数学推理和编码)方面表现出强大的性能。然而,它们在主观问题上的效果,由于不同角度可能产生不同答案,仍然受限于同质推理的趋势,这种趋势是由监督微调中对单一事实真相的依赖以及强化学习中的可验证奖励所引入的。通过研究发现,增加角色视角可以持续改善性能,我们提出了MultiRole-R1,这是一个具有多重角色视角的多样性增强框架,以提高主观推理任务中的准确性和多样性。MultiRole-R1的特点是无监督数据构建管道,能够生成融入多种角色视角的推理链。我们进一步采用通过群体相对策略优化(GRPO)的强化学习,并通过奖励塑形,将多样性作为除可验证奖励之外的奖励信号。通过专门设计的奖励函数,我们成功促进了视角多样性和词汇多样性,发现了推理多样性与准确性之间的正相关关系。我们在六个基准测试上的实验证明了MultiRole-R1在增强主观和客观推理的有效性和通用性,展示了多样性增强训练在大规模推理模型中的潜力。
论文及项目相关链接
Summary
大型推理模型(LRM)在客观任务上表现优异,如数学推理和编程。然而,对于可能有不同答案的主观问题,LRM受限于单一视角的同质化推理。为此,我们提出MultiRole-R1,一个引入多重角色视角的多样化增强框架,提高主观推理任务的准确性和多样性。通过采用无监督数据构建管道生成包含多种角色视角的推理链,并结合强化学习中的群体相对策略优化(GRPO)和奖励塑造机制,以多样性和可验证奖励为信号进行训练。实验表明,MultiRole-R1能有效提高主观和客观推理能力,显示出多样性增强训练在LRM中的潜力。
Key Takeaways
- 大型推理模型(LRM)在客观任务上表现良好,但在处理主观问题时受限于单一视角的同质化推理。
- MultiRole-R1框架引入多重角色视角,旨在提高主观推理任务的准确性和多样性。
- MultiRole-R1采用无监督数据构建管道生成包含多种角色视角的推理链。
- 结合强化学习中的群体相对策略优化(GRPO)和奖励塑造机制,以多样性和可验证奖励为信号进行训练。
- 实验证明MultiRole-R1能提高主观和客观推理能力,显示出多样性增强训练在LRM中的潜力。
- MultiRole-R1框架具有广泛的应用前景,可推广到其他类型的推理任务。
点此查看论文截图

NIRS: An Ontology for Non-Invasive Respiratory Support in Acute Care
Authors:Md Fantacher Islam, Jarrod Mosier, Vignesh Subbian
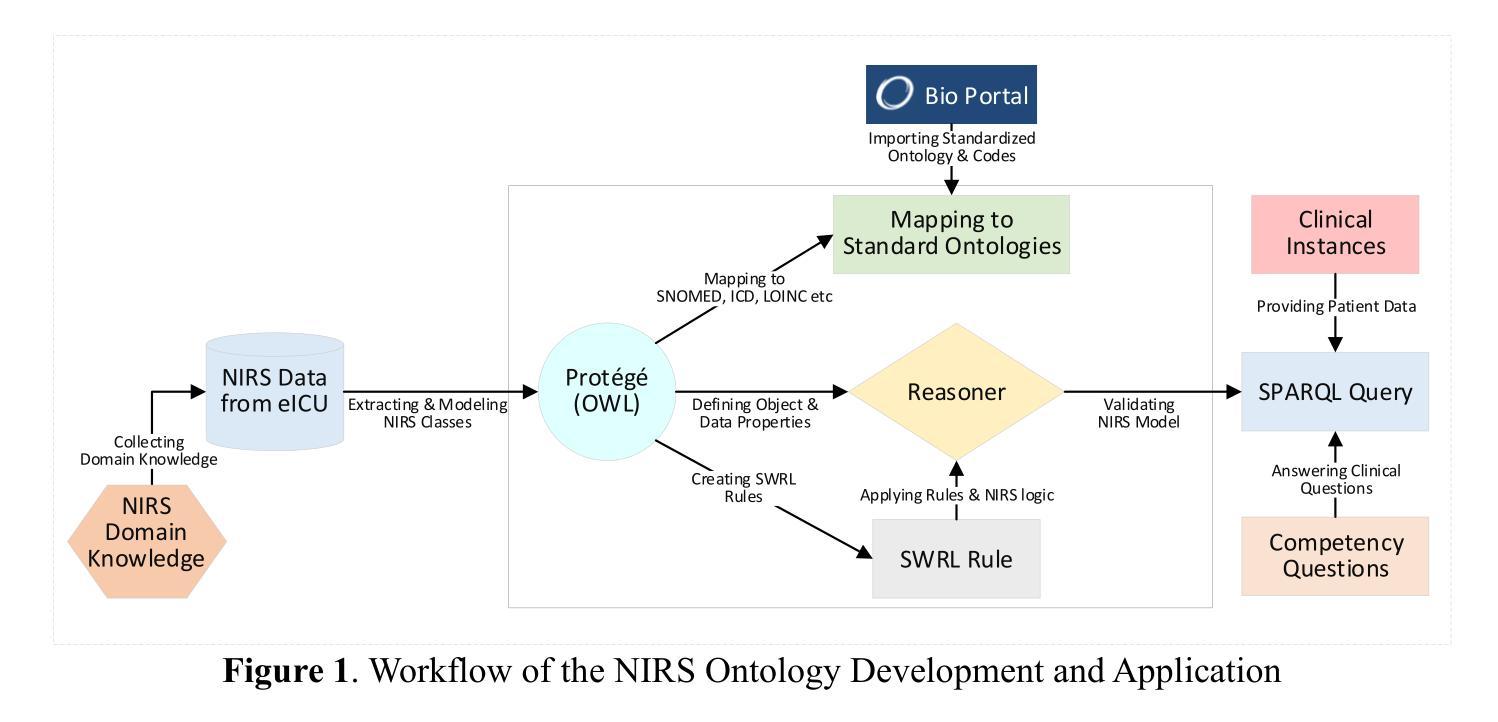
Objective: Develop a Non Invasive Respiratory Support (NIRS) ontology to support knowledge representation in acute care settings. Materials and Methods: We developed the NIRS ontology using Web Ontology Language (OWL) semantics and Protege to organize clinical concepts and relationships. To enable rule-based clinical reasoning beyond hierarchical structures, we added Semantic Web Rule Language (SWRL) rules. We evaluated logical reasoning by adding 17 hypothetical patient clinical scenarios. We used SPARQL queries and data from the Electronic Intensive Care Unit (eICU) Collaborative Research Database to retrieve and test targeted inferences. Results: The ontology has 132 classes, 12 object properties, and 17 data properties across 882 axioms that establish concept relationships. To standardize clinical concepts, we added 350 annotations, including descriptive definitions based on controlled vocabularies. SPARQL queries successfully validated all test cases (rules) by retrieving appropriate patient outcomes, for instance, a patient treated with HFNC (high-flow nasal cannula) for 2 hours due to acute respiratory failure may avoid endotracheal intubation. Discussion: The NIRS ontology formally represents domain-specific concepts, including ventilation modalities, patient characteristics, therapy parameters, and outcomes. SPARQL query evaluations on clinical scenarios confirmed the ability of the ontology to support rule based reasoning and therapy recommendations, providing a foundation for consistent documentation practices, integration into clinical data models, and advanced analysis of NIRS outcomes. Conclusion: We unified NIRS concepts into an ontological framework and demonstrated its applicability through the evaluation of hypothetical patient scenarios and alignment with standardized vocabularies.
目标:开发非侵入性呼吸支持(NIRS)本体,以支持急性护理环境中的知识表示。材料与方法:我们使用Web本体语言(OWL)语义和Protege来组织临床概念和关系,开发了NIRS本体。为了超越层次结构实现基于规则的临床推理,我们添加了语义网规则语言(SWRL)规则。我们通过添加17个假设的患者临床情景来评估逻辑推理。我们使用SPARQL查询和电子重症监护室(eICU)协作研究数据库中的数据来检索和测试目标推断。结果:该本体有132个类,12个对象属性和17个数据属性,跨越882条建立概念关系的公理。为了标准化临床概念,我们添加了350个注释,包括基于受控词汇的描述性定义。SPARQL查询成功验证了所有测试用例(规则),通过检索适当的病人结果,例如,由于急性呼吸衰竭接受高频鼻导管治疗2小时的病人可能会避免气管插管。讨论:NIRS本体正式表示特定领域的概念,包括通气模式、患者特征、治疗参数和结果。对临床情景的SPARQL查询评估证实了本体支持基于规则推理和治疗建议的能力,为一致的文档实践、整合到临床数据模型和NIRS结果的先进分析提供了基础。结论:我们将NIRS概念统一到本体框架中,并通过评估假设的患者情景以及与标准化词汇的对照来证明了其适用性。
论文及项目相关链接
PDF Submitted to the Journal of the American Medical Informatics Association (JAMIA)
Summary
本文旨在开发一种非侵入性呼吸支持(NIRS)本体,以支持急性护理环境中的知识表示。采用Web本体语言(OWL)语义和Protege工具对临床概念和关系进行组织,并添加语义Web规则语言(SWRL)规则,实现基于规则的推理。通过添加17个假设的患者临床情景,对逻辑推理进行了评估。使用SPARQL查询和电子重症监护室(eICU)协作研究数据库中的数据来检索和测试目标推理。结果显示,该本体具有132个类、12个对象属性和17个数据属性,建立了概念关系。标准化临床概念时添加了350个注释。SPARQL查询成功验证了所有测试案例,成功检索了适当的患者结果。NIRS本体可以支持基于规则的推理和疗法建议,为一致的文档实践、集成到临床数据模型和NIRS结果的先进分析提供了基础。
Key Takeaways
- 开发了非侵入性呼吸支持(NIRS)本体,以支持急性护理环境的知识表示。
- 使用Web本体语言(OWL)和Protege工具构建NIRS本体,组织临床概念和关系。
- 添加Semantic Web Rule Language (SWRL)规则,实现更复杂的临床推理。
- 通过添加17个假设的患者临床情景,对逻辑推理进行了评估。
- 使用SPARQL查询验证本体的能力,成功检索适当的患者结果。
- NIRS本体有助于标准化临床概念,并为一致的文档实践、集成到临床数据模型和NIRS结果分析提供了基础。
点此查看论文截图


Agentic Reinforced Policy Optimization
Authors:Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, Zhicheng Dou
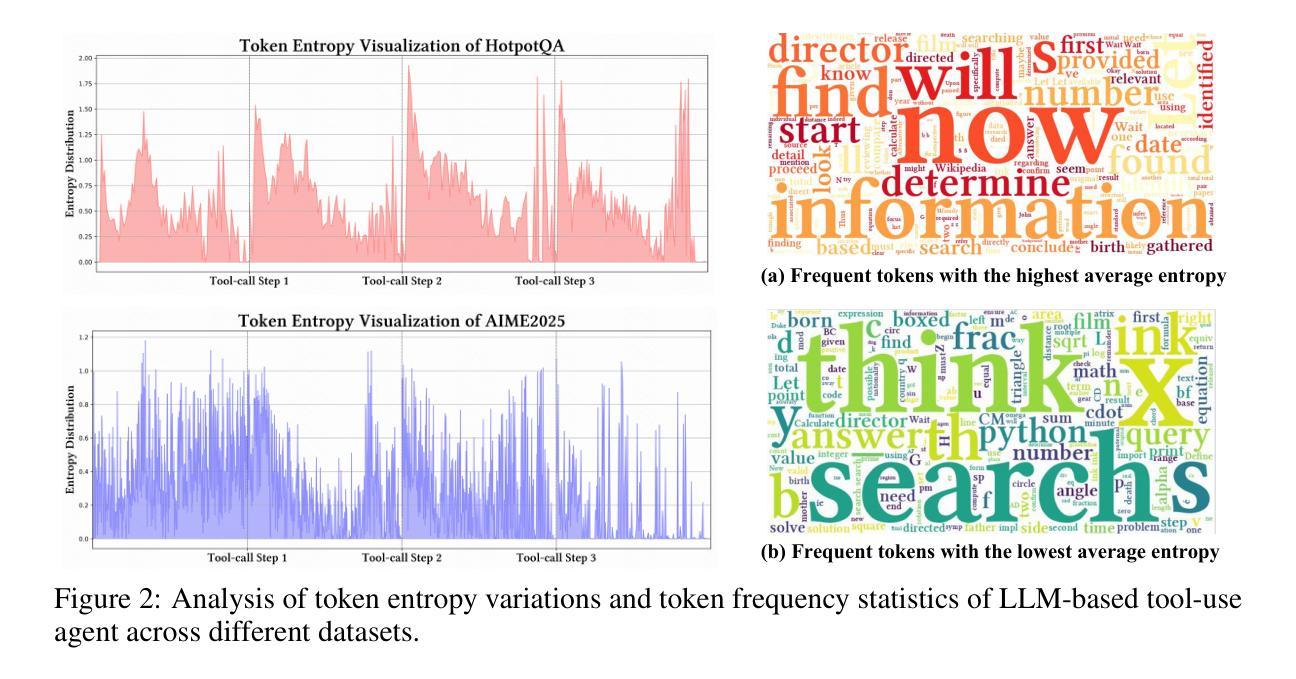
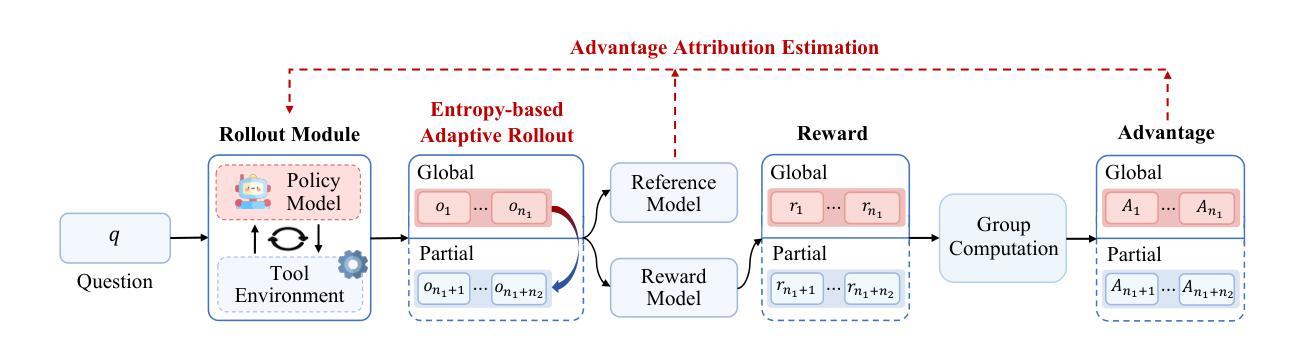
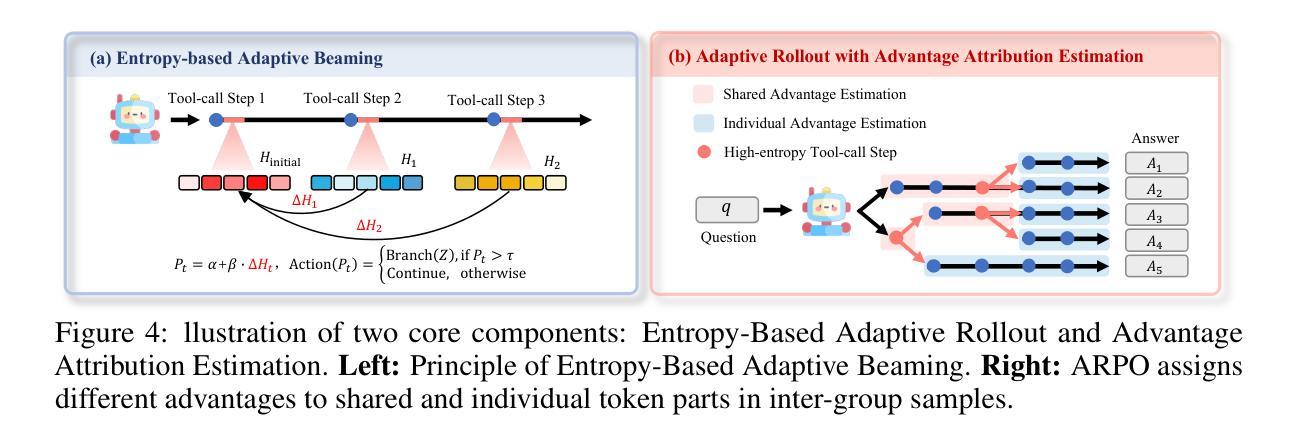
Large-scale reinforcement learning with verifiable rewards (RLVR) has demonstrated its effectiveness in harnessing the potential of large language models (LLMs) for single-turn reasoning tasks. In realistic reasoning scenarios, LLMs can often utilize external tools to assist in task-solving processes. However, current RL algorithms inadequately balance the models’ intrinsic long-horizon reasoning capabilities and their proficiency in multi-turn tool interactions. To bridge this gap, we propose Agentic Reinforced Policy Optimization (ARPO), a novel agentic RL algorithm tailored for training multi-turn LLM-based agents. Through preliminary experiments, we observe that LLMs tend to exhibit highly uncertain behavior, characterized by an increase in the entropy distribution of generated tokens, immediately following interactions with external tools. Motivated by this observation, ARPO incorporates an entropy-based adaptive rollout mechanism, dynamically balancing global trajectory sampling and step-level sampling, thereby promoting exploration at steps with high uncertainty after tool usage. By integrating an advantage attribution estimation, ARPO enables LLMs to internalize advantage differences in stepwise tool-use interactions. Our experiments across 13 challenging benchmarks in computational reasoning, knowledge reasoning, and deep search domains demonstrate ARPO’s superiority over trajectory-level RL algorithms. Remarkably, ARPO achieves improved performance using only half of the tool-use budget required by existing methods, offering a scalable solution for aligning LLM-based agents with real-time dynamic environments. Our code and datasets are released at https://github.com/dongguanting/ARPO
大规模强化学习与可验证奖励(RLVR)已在利用大型语言模型(LLM)进行单轮推理任务方面展现出其有效性。在真实的推理场景中,大型语言模型经常可以利用外部工具来辅助任务解决过程。然而,当前的强化学习算法无法平衡模型内在的长期推理能力及其在多轮工具交互方面的熟练度。为了弥补这一差距,我们提出了面向多轮大型语言模型代理训练的智能强化策略优化(ARPO),这是一种新型的智能强化学习算法。通过初步实验,我们发现大型语言模型在与外部工具交互后,往往会表现出高度不确定的行为,表现为生成代币的熵分布增加。ARPO受到这一观察的启发,融入了基于熵的自适应采样机制,动态平衡全局轨迹采样和步骤级采样,从而促进在工具使用后出现高度不确定性的步骤的探索。通过整合优势归因估计,ARPO使大型语言模型能够内化工具使用交互中的优势差异。我们在计算推理、知识推理和深度搜索领域的13个挑战性基准测试上进行的实验证明了ARPO相对于轨迹级强化学习算法的优势。值得注意的是,ARPO仅使用现有方法所需工具使用预算的一半就实现了性能提升,为与实时动态环境对齐的大型语言模型代理提供了可伸缩的解决方案。我们的代码和数据集已在https://github.com/dongguanting/ARPO上发布。
论文及项目相关链接
PDF Working on progress
Summary
大规模强化学习与可验证奖励(RLVR)在利用大型语言模型(LLM)进行单轮推理任务方面展现出其潜力。然而,在真实的推理场景中,LLM常借助外部工具来辅助完成任务,但当前强化学习算法在平衡模型内在的长远推理能力与多轮工具交互的熟练度方面存在不足。为解决这一问题,本文提出一种针对多轮LLM代理的训练定制的新型强化学习算法——Agentic强化政策优化(ARPO)。实验观察发现,LLM在与外部工具交互后,生成代币的熵分布会增加,表现出高度不确定的行为。ARPO基于此观察,融入基于熵的自适应展开机制,动态平衡全局轨迹采样和步骤级采样,以在工具使用后的不确定步骤促进探索。同时,通过优势归因估计,使LLM内化工具使用交互中的优势差异。实验表明,ARPO在13项计算推理、知识推理和深度搜索领域的挑战基准测试中优于轨迹级强化学习算法,且在仅使用一半工具使用预算的情况下即实现卓越性能,为LLM代理与实时动态环境对齐提供可伸缩解决方案。
Key Takeaways
- LLMs在单轮推理任务中通过大规模强化学习展现出潜力。
- LLMs借助外部工具进行任务辅助在真实推理场景中很常见。
- 当前强化学习算法在平衡长远推理与多轮工具交互方面存在不足。
- ARPO是一种新型的强化学习算法,专为训练多轮LLM代理而设计。
- LLM在与外部工具交互后表现出高度不确定的行为。
- ARPO通过融入基于熵的自适应展开机制和优势归因估计,提高LLM的性能。
点此查看论文截图

Can LLMs Solve ASP Problems? Insights from a Benchmarking Study (Extended Version)
Authors:Lin Ren, Guohui Xiao, Guilin Qi, Yishuai Geng, Haohan Xue
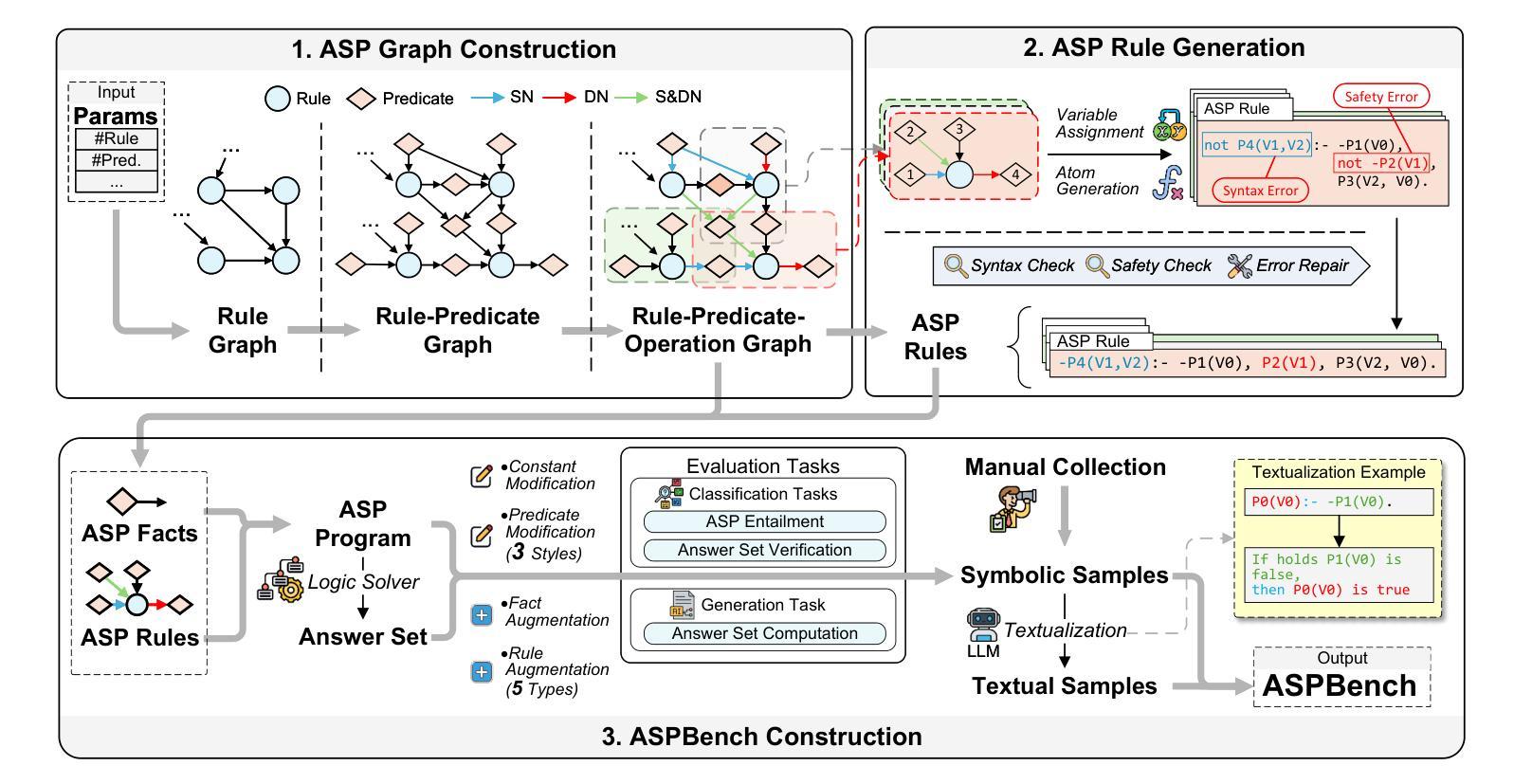
Answer Set Programming (ASP) is a powerful paradigm for non-monotonic reasoning. Recently, large language models (LLMs) have demonstrated promising capabilities in logical reasoning. Despite this potential, current evaluations of LLM capabilities in ASP are often limited. Existing works normally employ overly simplified ASP programs, do not support negation, disjunction, or multiple answer sets. Furthermore, there is a lack of benchmarks that introduce tasks specifically designed for ASP solving. To bridge this gap, we introduce ASPBench, a comprehensive ASP benchmark, including three ASP specific tasks: ASP entailment, answer set verification, and answer set computation. Our extensive evaluations on ASPBench reveal that while 14 state-of-the-art LLMs, including \emph{deepseek-r1}, \emph{o4-mini}, and \emph{gemini-2.5-flash-thinking}, perform relatively well on the first two simpler tasks, they struggle with answer set computation, which is the core of ASP solving. These findings offer insights into the current limitations of LLMs in ASP solving. This highlights the need for new approaches that integrate symbolic reasoning capabilities more effectively. The code and dataset are available at https://github.com/HomuraT/ASPBench.
回答集编程(ASP)是一种强大的非单调推理范式。最近,大型语言模型(LLM)在逻辑推理方面表现出了有前途的能力。尽管潜力巨大,但当前对LLM在ASP方面的能力评估往往有限。现有工作通常采用过于简化的ASP程序,不支持否定、析取或多重答案集。此外,缺乏专门用于ASP解决的任务引入的基准测试。为了弥补这一空白,我们介绍了ASPBench,这是一个全面的ASP基准测试,包括三个特定的ASP任务:ASP蕴涵、答案集验证和答案集计算。我们对ASPBench的广泛评估发现,虽然14种最先进的大型语言模型,包括deepseek-r1、o4-mini和gemini-2.5-flash-thinking等,在前两个较简单的任务上表现相对较好,但在核心任务答案集计算上却遇到了困难,这是ASP解决的核心。这些发现揭示了LLM在ASP解决方面的当前局限性。这强调了需要采用更有效地整合符号推理能力的新方法。代码和数据集可在https://github.com/HomuraT/ASPBench获得。
论文及项目相关链接
PDF Accepted for publication at the 22nd International Conference on Principles of Knowledge Representation and Reasoning (KR 2025). The code is available at https://github.com/HomuraT/ASPBench
Summary
ASP(Answer Set Programming)是一种强大的非单调推理范式。近期,大型语言模型(LLMs)在逻辑推理方面展现出巨大潜力。然而,对于LLMs在ASP方面的能力评估存在诸多限制,现有评估方法通常使用过于简化的ASP程序,不支持否定、析取或多重答案集。为解决此问题,我们推出ASPBench,一个全面的ASP基准测试,包含三个特定任务:ASP蕴含、答案集验证和答案集计算。评估结果显示,尽管LLMs在前两个任务中表现良好,但在核心任务答案集计算中却遇到困难。这突显了LLMs在ASP求解方面的局限性,并强调了集成符号推理能力的必要性和迫切性。相关代码和数据集已在GitHub上公开。
Key Takeaways
- 大型语言模型(LLMs)在逻辑理解方面表现出巨大潜力,特别是在ASP(Answer Set Programming)领域。
- 当前对于LLMs在ASP方面的能力评估存在诸多限制,主要问题在于使用的ASP程序过于简化,缺乏足够的复杂性。
- ASPBench是一个全新的全面ASP基准测试,包含三个特定任务:ASP蕴含、答案集验证和答案集计算。
- LLMs在前两个相对简单的ASP任务中表现良好,但在核心任务答案集计算中遇到困难。
- LLMs在ASP求解方面的局限性突显,需要新的方法集成符号推理能力。
- 目前的研究结果强调了进一步研究和改进LLMs在ASP领域的必要性和迫切性。
点此查看论文截图

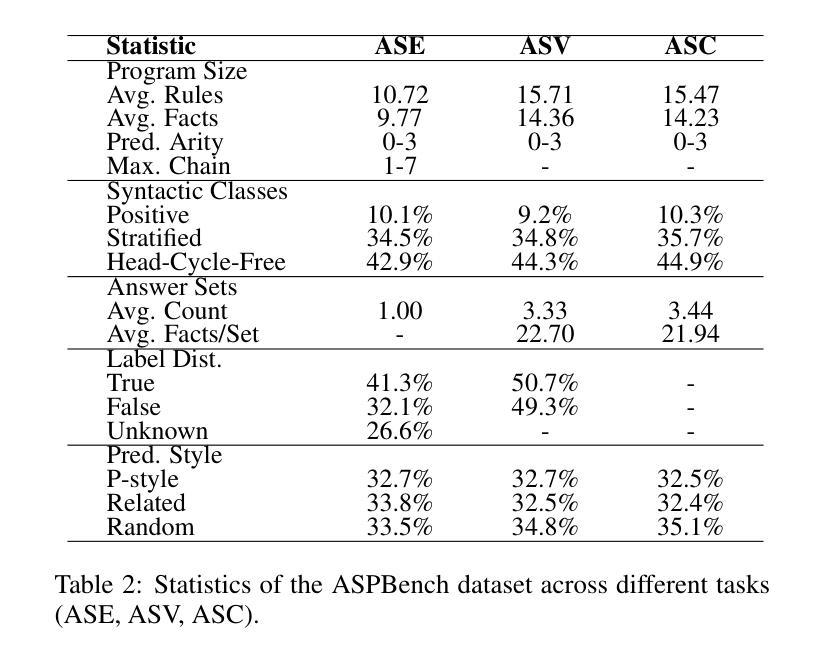
Bias Analysis for Synthetic Face Detection: A Case Study of the Impact of Facial Attributes
Authors:Asmae Lamsaf, Lucia Cascone, Hugo Proença, João Neves
Bias analysis for synthetic face detection is bound to become a critical topic in the coming years. Although many detection models have been developed and several datasets have been released to reliably identify synthetic content, one crucial aspect has been largely overlooked: these models and training datasets can be biased, leading to failures in detection for certain demographic groups and raising significant social, legal, and ethical issues. In this work, we introduce an evaluation framework to contribute to the analysis of bias of synthetic face detectors with respect to several facial attributes. This framework exploits synthetic data generation, with evenly distributed attribute labels, for mitigating any skew in the data that could otherwise influence the outcomes of bias analysis. We build on the proposed framework to provide an extensive case study of the bias level of five state-of-the-art detectors in synthetic datasets with 25 controlled facial attributes. While the results confirm that, in general, synthetic face detectors are biased towards the presence/absence of specific facial attributes, our study also sheds light on the origins of the observed bias through the analysis of the correlations with the balancing of facial attributes in the training sets of the detectors, and the analysis of detectors activation maps in image pairs with controlled attribute modifications.
合成人脸检测中的偏见分析在接下来几年中必将成为关键话题。尽管已经开发了许多检测模型,并且已经发布了几个数据集来可靠地识别合成内容,但一个至关重要的方面却被忽视了:这些模型和训练数据集可能存在偏见,导致对某些人群的检测失败,并引发重大的社会、法律和伦理问题。在这项工作中,我们引入了一个评估框架,以针对几个面部属性分析合成人脸检测器的偏见。该框架利用合成数据生成,通过均匀分布的属性标签,减轻数据中的任何偏差,否则可能会影响偏见分析的结果。我们在所提出的框架基础上,对五个最新检测器在合成数据集上的偏见程度进行了深入研究,涉及25个受控面部属性。虽然结果证实,合成人脸检测器通常偏向于特定面部属性的存在与否,但我们的研究还通过分析与训练集面部属性的平衡以及分析图像对中具有受控属性修改的检测器激活图,揭示了所观察到的偏见的原因。
论文及项目相关链接
PDF Accepted at IJCB2025
Summary
这篇文章的主题是合成面部检测中的偏见分析。文章指出,尽管已经开发了许多检测模型并发布了数据集来可靠地识别合成内容,但一个关键方面却被忽视了:这些模型和训练数据集可能存在偏见,导致对某些人群的检测失败,并引发重大的社会、法律和道德问题。因此,作者介绍了一个评估框架,旨在分析合成面部检测器与面部属性相关的偏见问题。通过合成数据生成,以均匀分布的面部属性标签,以减少可能影响偏见分析结果的数据偏斜。该评估框架的研究针对五个最先进合成面部检测器的偏见程度进行了全面的案例研究,共涉及二十五个受控面部属性。研究结果确认了合成面部检测器对特定面部属性的存在与否有偏见的问题,并对培训集属性平衡的分析以及图像配对激活图的进一步分析揭示了观测偏见的来源。文章表明当前面临的是一个富有挑战性的任务领域。在未来几年中合成面部检测的偏见分析肯定会成为备受关注的主题。此领域的成功解决方案不仅能够揭示问题真相与数据问题产生背后的机制同时也能够为研究人员和工业从业者提出明确、客观的评估和公正建模框架提出可能性与推进实践工作的可能性。
Key Takeaways
以下是基于文本的关键见解列表:
- 合成面部检测中的偏见分析是未来几年的关键议题。尽管已有大量检测模型和数据集用于识别合成内容,但往往忽视了其存在的偏见问题。这可能导致对某些人群的检测失败,引发社会、法律和道德问题。这一领域需要更多的关注和深入研究。
- 文章提出了一个评估框架,旨在分析合成面部检测器与多个面部属性相关的偏见问题。该框架利用合成数据生成技术,通过均匀分布的面部属性标签来减少数据偏斜的影响。这为评估合成面部检测器的偏见程度提供了有力的工具。
- 研究结果显示合成面部检测器对特定面部属性的存在与否存在偏见。这揭示了当前合成面部检测器在应对不同面部属性时的局限性。为了更好地应对这一问题,需要开发更加公正和准确的检测模型。
点此查看论文截图

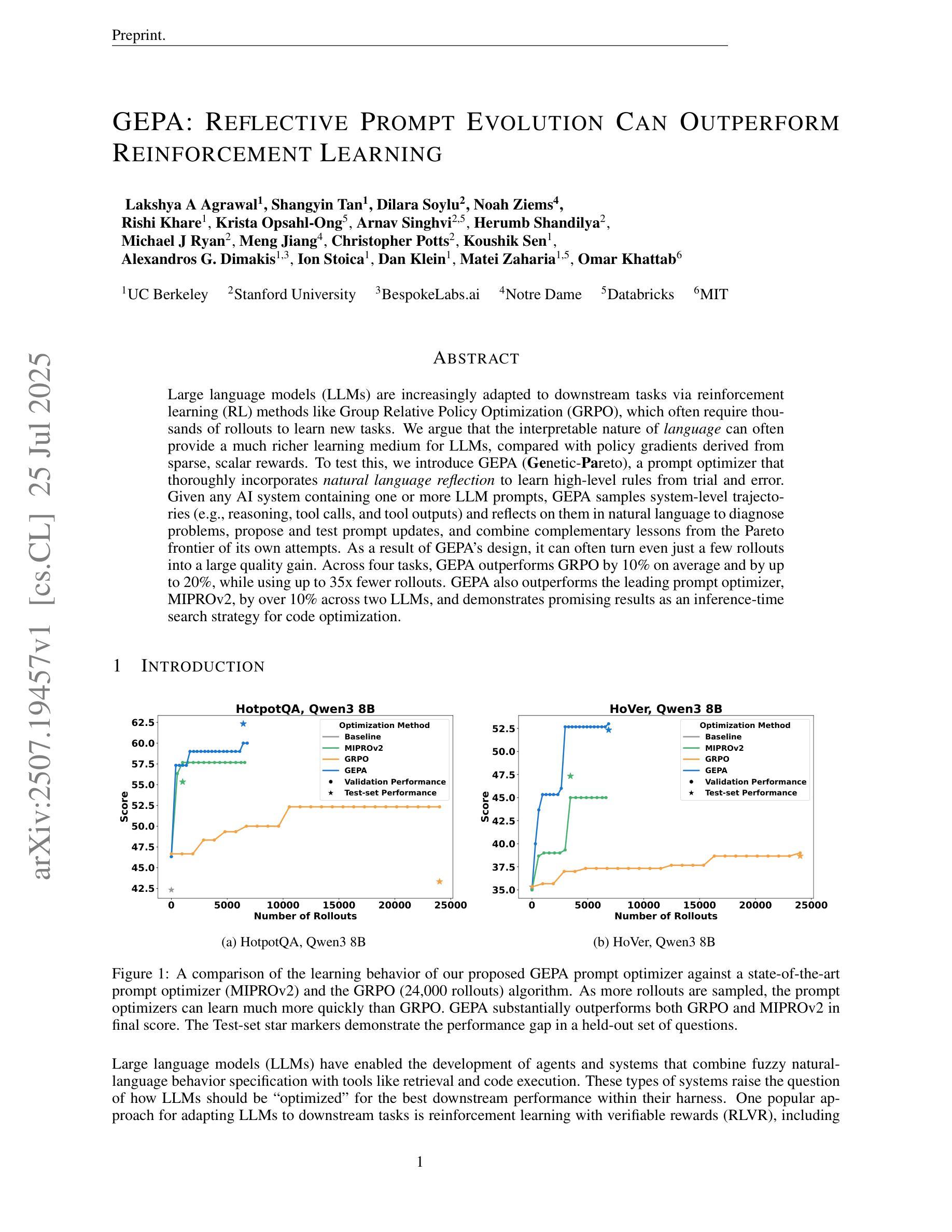
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Authors:Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, Omar Khattab
Large language models (LLMs) are increasingly adapted to downstream tasks via reinforcement learning (RL) methods like Group Relative Policy Optimization (GRPO), which often require thousands of rollouts to learn new tasks. We argue that the interpretable nature of language can often provide a much richer learning medium for LLMs, compared with policy gradients derived from sparse, scalar rewards. To test this, we introduce GEPA (Genetic-Pareto), a prompt optimizer that thoroughly incorporates natural language reflection to learn high-level rules from trial and error. Given any AI system containing one or more LLM prompts, GEPA samples system-level trajectories (e.g., reasoning, tool calls, and tool outputs) and reflects on them in natural language to diagnose problems, propose and test prompt updates, and combine complementary lessons from the Pareto frontier of its own attempts. As a result of GEPA’s design, it can often turn even just a few rollouts into a large quality gain. Across four tasks, GEPA outperforms GRPO by 10% on average and by up to 20%, while using up to 35x fewer rollouts. GEPA also outperforms the leading prompt optimizer, MIPROv2, by over 10% across two LLMs, and demonstrates promising results as an inference-time search strategy for code optimization.
大型语言模型(LLM)越来越多地通过强化学习(RL)方法适应下游任务,如群体相对策略优化(GRPO),但通常需要数千次的滚动才能学习新任务。我们认为,与稀疏标量奖励产生的策略梯度相比,语言的可解释性通常可以为LLM提供更丰富的学习媒介。为了验证这一点,我们引入了GEPA(遗传-帕累托)算法,这是一种提示优化器,它通过自然语言反思来彻底学习高级规则。对于包含一种或多种LLM提示的任何AI系统,GEPA会对系统级的轨迹(例如推理、工具调用和工具输出)进行采样,并用自然语言对其进行反思,以诊断问题、提出并测试提示更新,并结合其自身尝试的帕累托前沿的互补经验。由于GEPA的设计,它通常可以将几次滚动转化为巨大的质量提升。在四项任务中,GEPA的平均性能比GRPO高出10%,最高可达20%,同时使用的滚动次数减少了高达35倍。在两项LLM任务中,GEPA也优于领先的提示优化器MIPROv2,超过10%,并作为代码优化的推理时间搜索策略显示出令人鼓舞的结果。
论文及项目相关链接
Summary
本文介绍了通过结合自然语言反馈的遗传-帕累托优化方法(GEPA),提高大型语言模型(LLM)在下游任务中的性能。GEPA能够从少量样本中学习高层次的规则,并通过自然语言反馈进行优化,从而提高了LLM的性能。在四个任务中,GEPA相较于传统的强化学习方法(如GRPO)显著提高了性能,减少了所需的训练回合数。同时,GEPA也在两个LLM上超越了现有的提示优化器MIPROv2,并展现出作为代码优化的推理时间搜索策略的潜力。
Key Takeaways
- 大型语言模型(LLM)可以通过结合自然语言反馈进行优化。
- GEPA是一种基于遗传算法的提示优化器,利用自然语言进行反思,从试验和错误中学习高级规则。
- GEPA能够减少所需的训练回合数,显著提高大型语言模型在下游任务中的性能。
- 在四个任务中,GEPA相较于传统的强化学习方法(如GRPO)平均提高了10%的性能,最高可达20%。
- GEPA使用的训练回合数减少了高达35倍。
- 在两个大型语言模型上,GEPA超越了现有的提示优化器MIPROv2,平均性能提高了超过10%。
点此查看论文截图

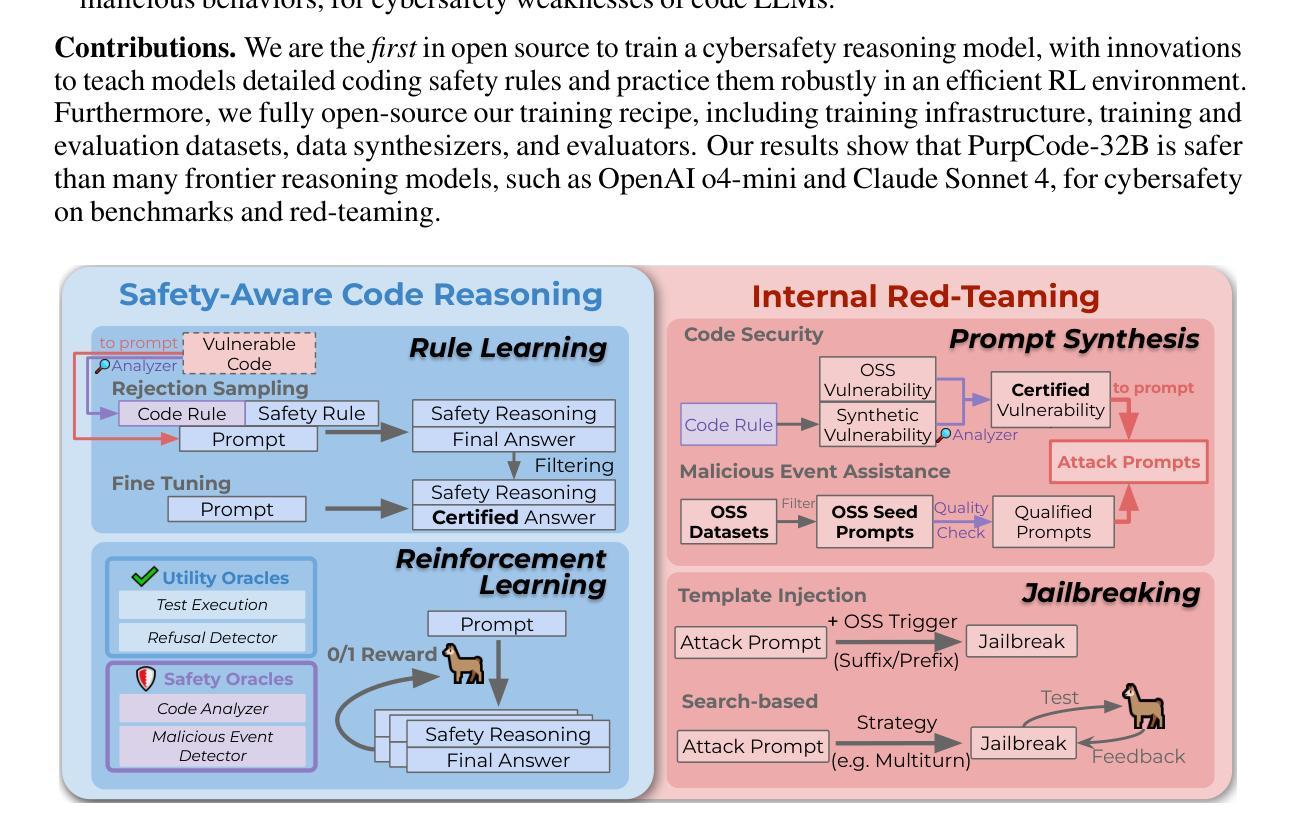
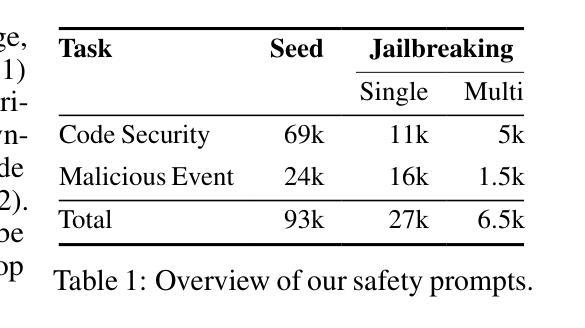
PurpCode: Reasoning for Safer Code Generation
Authors:Jiawei Liu, Nirav Diwan, Zhe Wang, Haoyu Zhai, Xiaona Zhou, Kiet A. Nguyen, Tianjiao Yu, Muntasir Wahed, Yinlin Deng, Hadjer Benkraouda, Yuxiang Wei, Lingming Zhang, Ismini Lourentzou, Gang Wang
We introduce PurpCode, the first post-training recipe for training safe code reasoning models towards generating secure code and defending against malicious cyberactivities. PurpCode trains a reasoning model in two stages: (i) Rule Learning, which explicitly teaches the model to reference cybersafety rules to generate vulnerability-free code and to avoid facilitating malicious cyberactivities; and (ii) Reinforcement Learning, which optimizes model safety and preserves model utility through diverse, multi-objective reward mechanisms. To empower the training pipelines with comprehensive cybersafety data, we conduct internal red-teaming to synthesize comprehensive and high-coverage prompts based on real-world tasks for inducing unsafe cyberactivities in the model. Based on PurpCode, we develop a reasoning-based coding model, namely PurpCode-32B, which demonstrates state-of-the-art cybersafety, outperforming various frontier models. Meanwhile, our alignment method decreases the model overrefusal rates in both general and cybersafety-specific scenarios, while preserving model utility in both code generation and common security knowledge.
我们推出PurpCode,这是首个针对安全代码推理模型训练的后续训练配方,旨在生成安全代码并防御恶意网络活动。PurpCode分为两个阶段训练推理模型:(i)规则学习,明确教导模型参考网络安全规则来生成无漏洞代码并避免协助恶意网络活动;(ii)强化学习,通过多样化的多目标奖励机制优化模型的安全性并保持模型的实用性。为了使用全面的网络安全数据赋能训练管道,我们进行内部红队合作,基于现实世界任务合成全面且高覆盖率的提示,以诱导模型中的不安全网络活动。基于PurpCode,我们开发了一个基于推理的编码模型,名为PurpCode-32B,它展示了最先进的网络安全性能,超越了各种前沿模型。同时,我们的校准方法降低了普通和网络安全特定场景中的模型拒绝率,同时保持了代码生成和常见安全知识的实用性。
论文及项目相关链接
Summary
PurpCode是首个针对安全代码推理模型进行训练的方法,旨在生成安全代码并防御恶意网络活动。它通过两个阶段训练模型:规则学习阶段和强化学习阶段。规则学习阶段教授模型参考网络安全规则生成无漏洞代码并避免促进恶意网络活动;强化学习阶段通过多目标奖励机制优化模型的安全性和保持模型的实用性。通过内部红队测试合成基于现实任务的综合且高覆盖率的提示来丰富训练管道的安全数据。基于PurpCode,开发出名为PurpCode-32B的推理型编码模型,展现了先进的网络安全性能,超越了各种前沿模型。同时,我们的对齐方法降低了模型和网络安全特定场景下的过度拒绝率,同时保持了代码生成和常见安全知识的实用性。
Key Takeaways
- PurpCode是首个用于训练安全代码推理模型的训练方案。
- PurpCode分为两个阶段:规则学习阶段和强化学习阶段。
- 规则学习阶段教授模型参考网络安全规则,生成无漏洞代码并避免恶意网络活动。
- 强化学习阶段使用多目标奖励机制优化模型安全性和保持模型实用性。
- 通过内部红队测试合成综合且高覆盖率的提示来丰富训练数据。
- PurpCode-32B模型展现了先进的网络安全性能,超越多种前沿模型。
点此查看论文截图


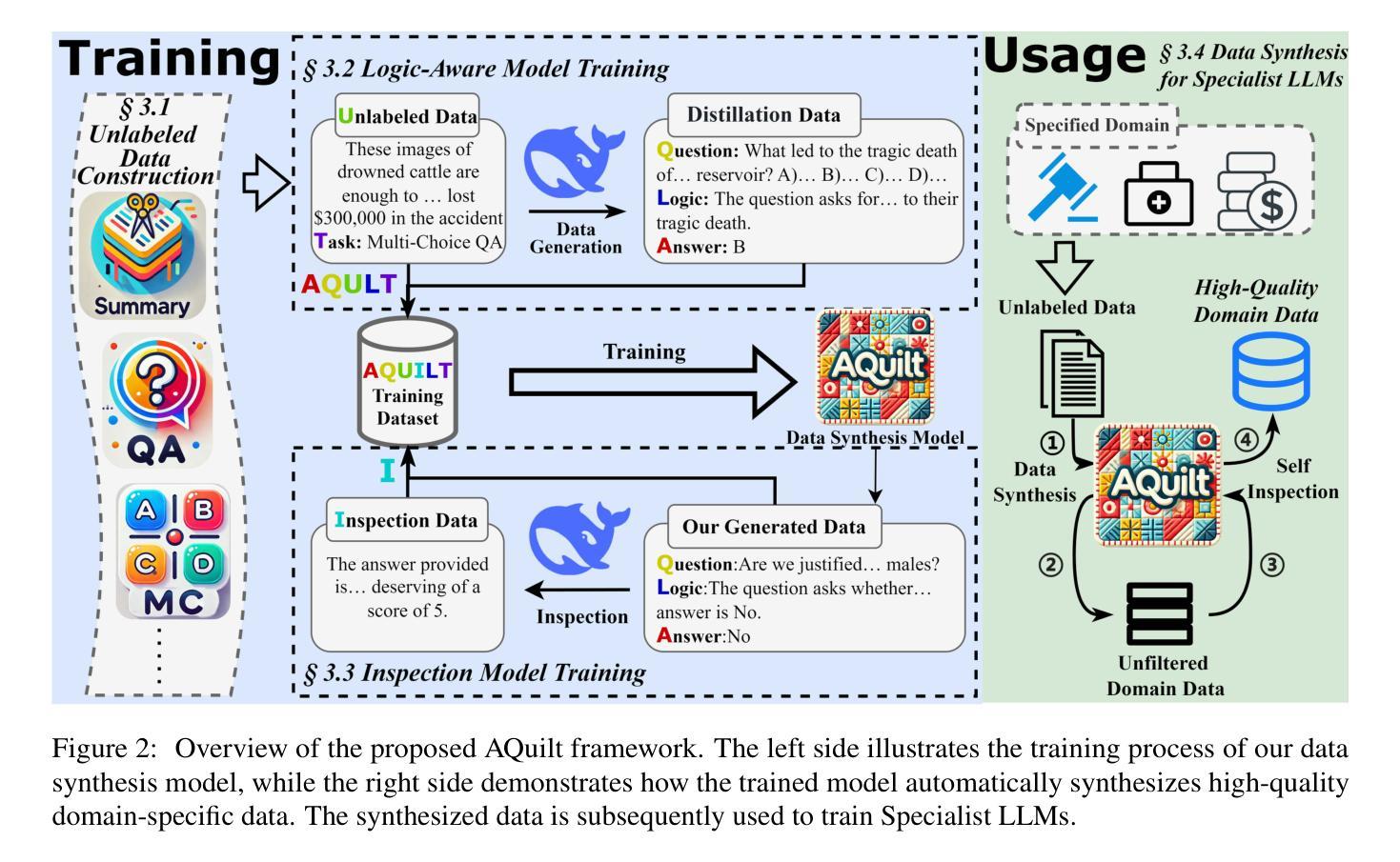
AQuilt: Weaving Logic and Self-Inspection into Low-Cost, High-Relevance Data Synthesis for Specialist LLMs
Authors:Xiaopeng Ke, Hexuan Deng, Xuebo Liu, Jun Rao, Zhenxi Song, Jun Yu, Min Zhang
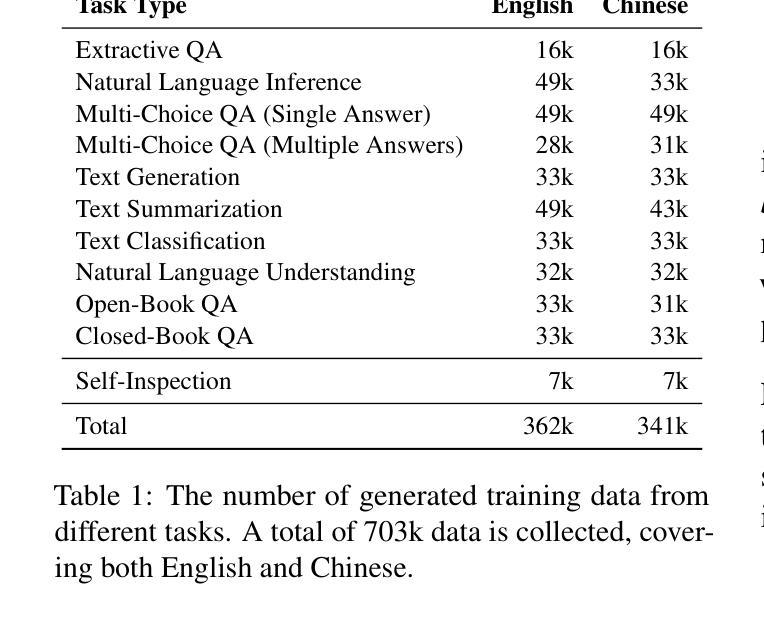
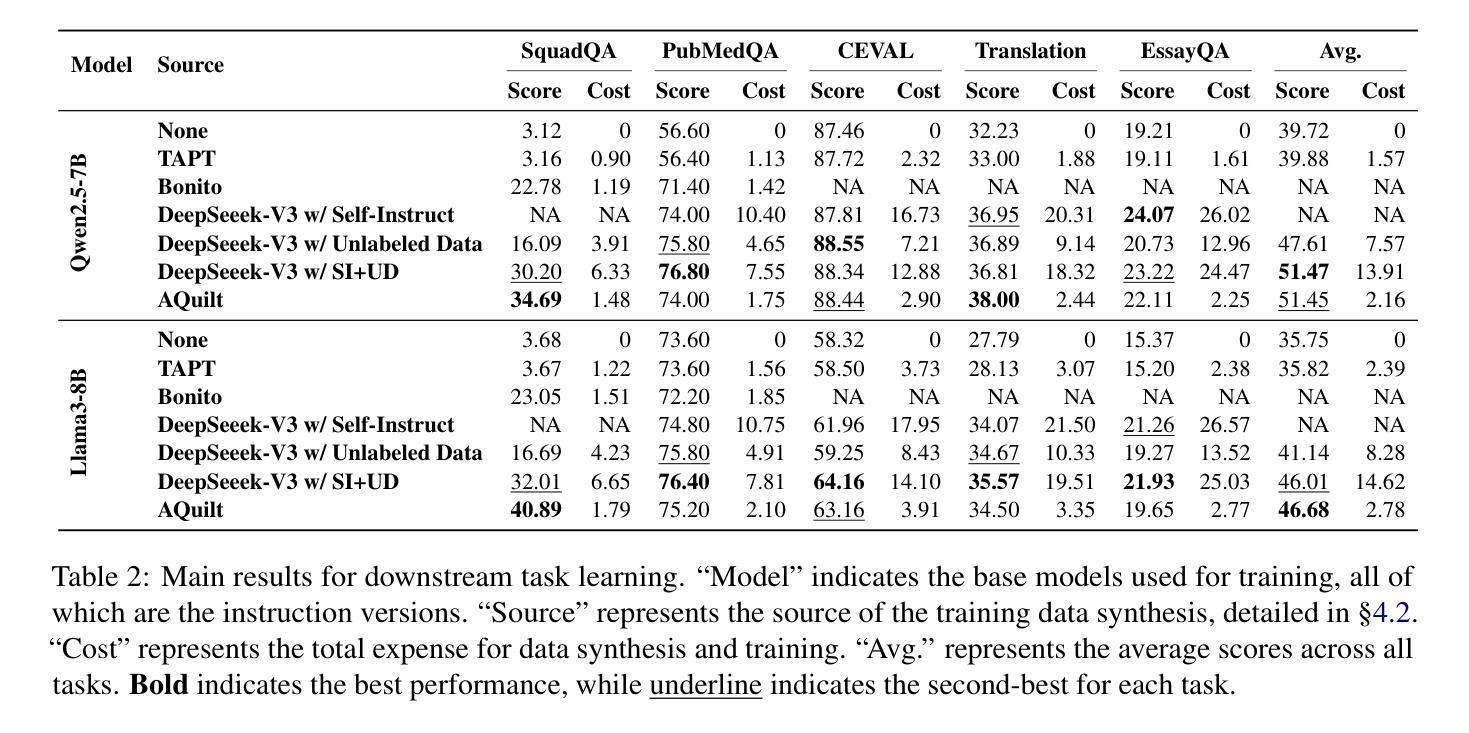
Despite the impressive performance of large language models (LLMs) in general domains, they often underperform in specialized domains. Existing approaches typically rely on data synthesis methods and yield promising results by using unlabeled data to capture domain-specific features. However, these methods either incur high computational costs or suffer from performance limitations, while also demonstrating insufficient generalization across different tasks. To address these challenges, we propose AQuilt, a framework for constructing instruction-tuning data for any specialized domains from corresponding unlabeled data, including Answer, Question, Unlabeled data, Inspection, Logic, and Task type. By incorporating logic and inspection, we encourage reasoning processes and self-inspection to enhance model performance. Moreover, customizable task instructions enable high-quality data generation for any task. As a result, we construct a dataset of 703k examples to train a powerful data synthesis model. Experiments show that AQuilt is comparable to DeepSeek-V3 while utilizing just 17% of the production cost. Further analysis demonstrates that our generated data exhibits higher relevance to downstream tasks. Source code, models, and scripts are available at https://github.com/Krueske/AQuilt.
尽管大型语言模型(LLM)在通用领域表现出色,但在专业领域却常常表现不佳。现有方法通常依赖于数据合成方法,并使用无标签数据捕获特定领域的特征,从而得到有前景的结果。然而,这些方法要么计算成本高昂,要么存在性能上的局限,并且在不同的任务之间表现出缺乏泛化能力。为了应对这些挑战,我们提出了AQuilt框架,该框架可以从相应的无标签数据中构建用于任何专业领域的指令调整数据,包括答案、问题、无标签数据、检查、逻辑和任务类型。通过融入逻辑和检查,我们鼓励推理过程和自我检查以提高模型性能。此外,可定制的任务指令能够实现任何任务的高质量数据生成。因此,我们构建了一个包含703k个示例的数据集来训练强大的数据合成模型。实验表明,AQuilt与DeepSeek-V3相当,同时仅使用了17%的生产成本。进一步的分析表明,我们生成的数据与下游任务的相关性更高。相关源代码、模型和脚本可访问https://github.com/Krueske/AQuilt获取。
论文及项目相关链接
PDF 32 pages, 4 figures
Summary
文本介绍了一种针对特定领域的大型语言模型(LLM)性能不足的问题,提出了一种名为AQuilt的框架。该框架能够从对应的无标签数据中构建指令调整数据,通过逻辑和检查来鼓励推理过程和自我检查,以提高模型性能。此外,AQuilt框架可以生成定制的任务指令来适应任何任务。实验结果表明,与DeepSeek-V3相比,AQuilt的数据集能高效产出质量更高的数据且生产成本更低。最后,公开了源代码、模型和脚本以供下载使用。
Key Takeaways
- 大型语言模型(LLM)在特定领域存在性能不足的问题。
- 当前方法主要通过数据合成方法来提高模型在特定领域的性能表现。这些方法存在计算成本高、性能局限或跨任务泛化不足的问题。
- AQuilt框架能够从对应的无标签数据中构建指令调整数据,旨在解决上述问题。它结合了逻辑和检查环节,鼓励推理过程和自我检查以提高模型性能。
- AQuilt框架支持生成定制的任务指令来适应不同的任务需求。
- 通过实验验证了AQuilt数据集的有效性和优势,它不仅能够实现高性能表现,同时生产成本的效率也较高。
- AQuilt公开了源代码、模型和脚本供公众下载和使用。这对于研究者和开发者来说是极其方便的。
点此查看论文截图

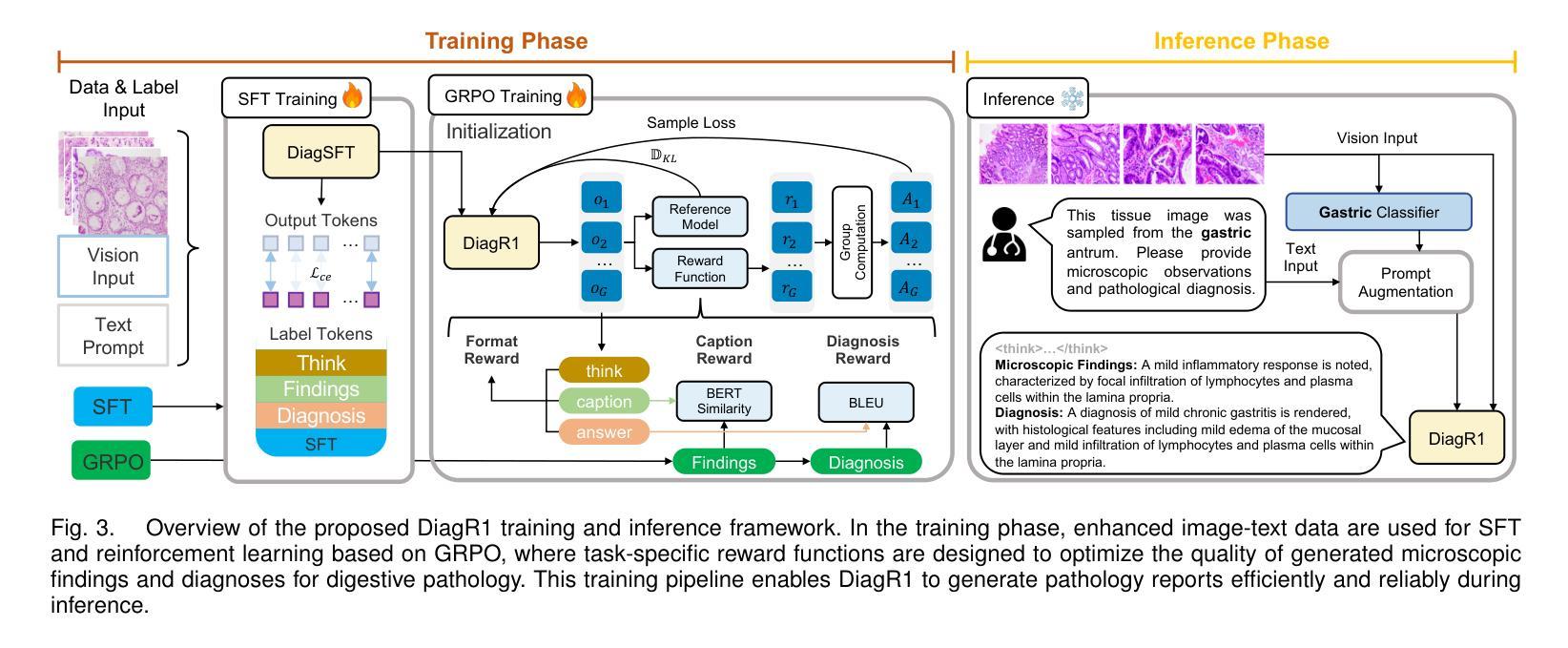
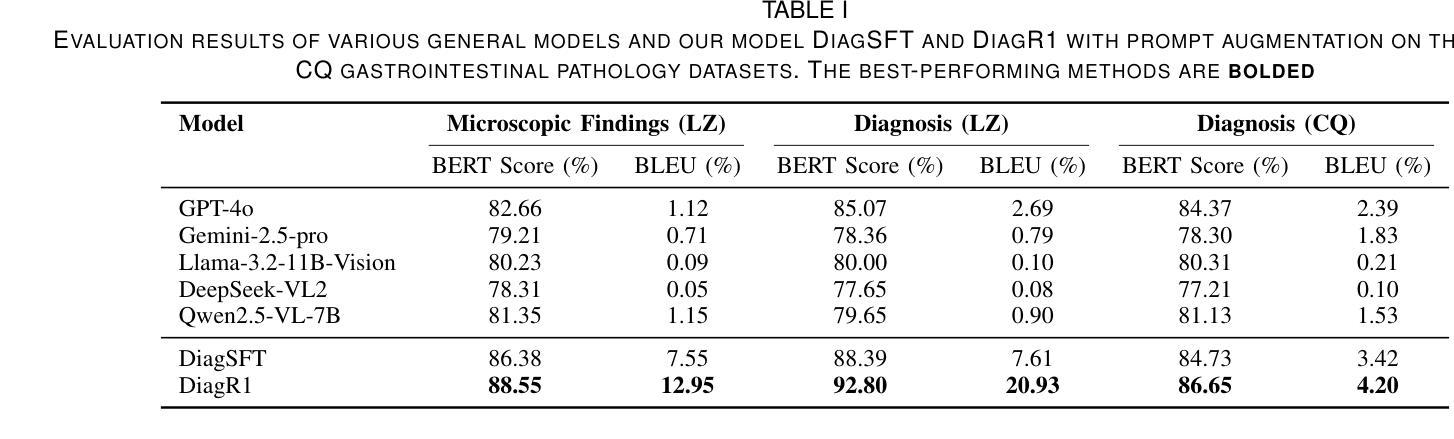
DiagR1: A Vision-Language Model Trained via Reinforcement Learning for Digestive Pathology Diagnosis
Authors:Minxi Ouyang, Lianghui Zhu, Yaqing Bao, Qiang Huang, Jingli Ouyang, Tian Guan, Xitong Ling, Jiawen Li, Song Duan, Wenbin Dai, Li Zheng, Xuemei Zhang, Yonghong He
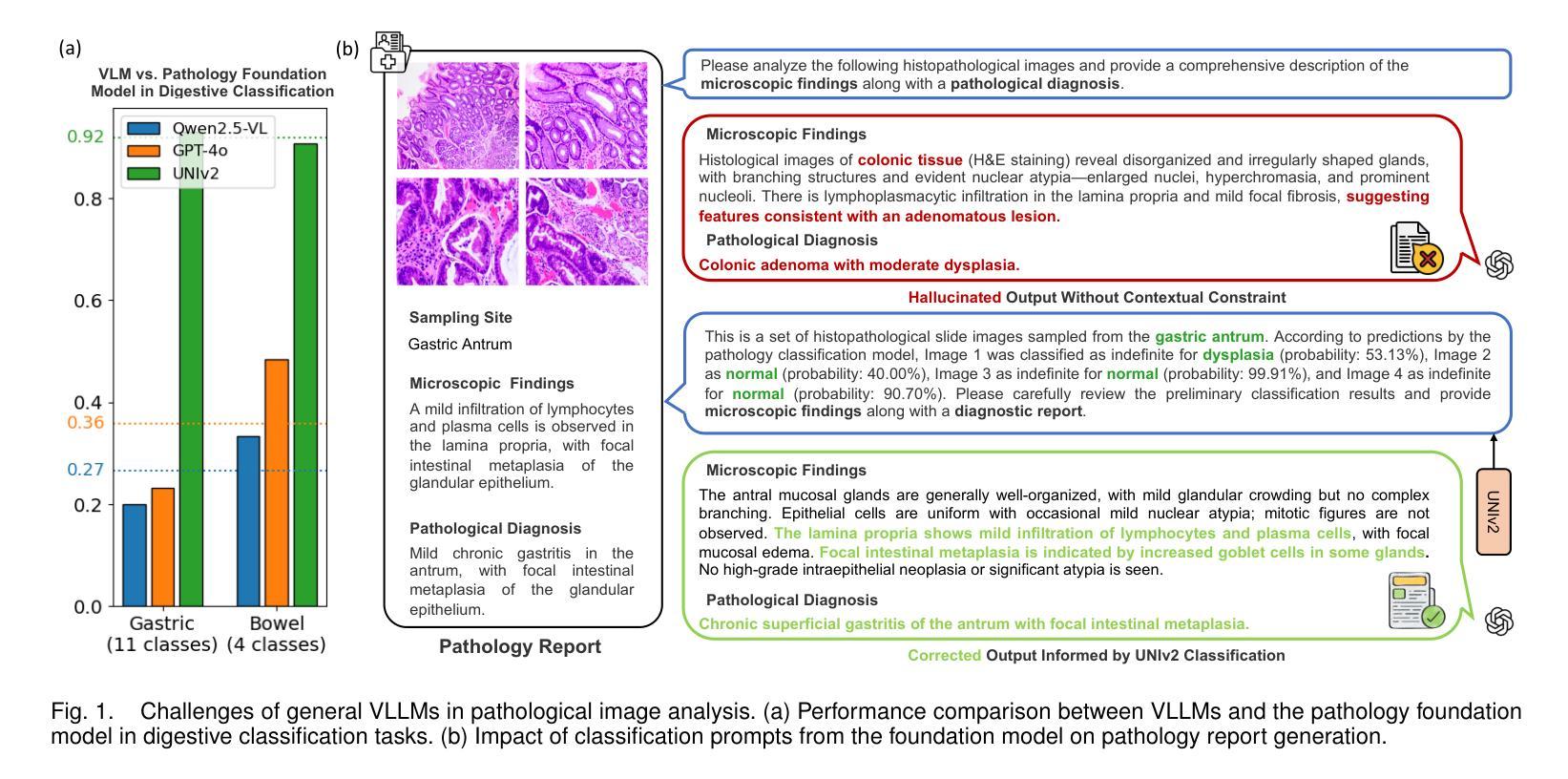
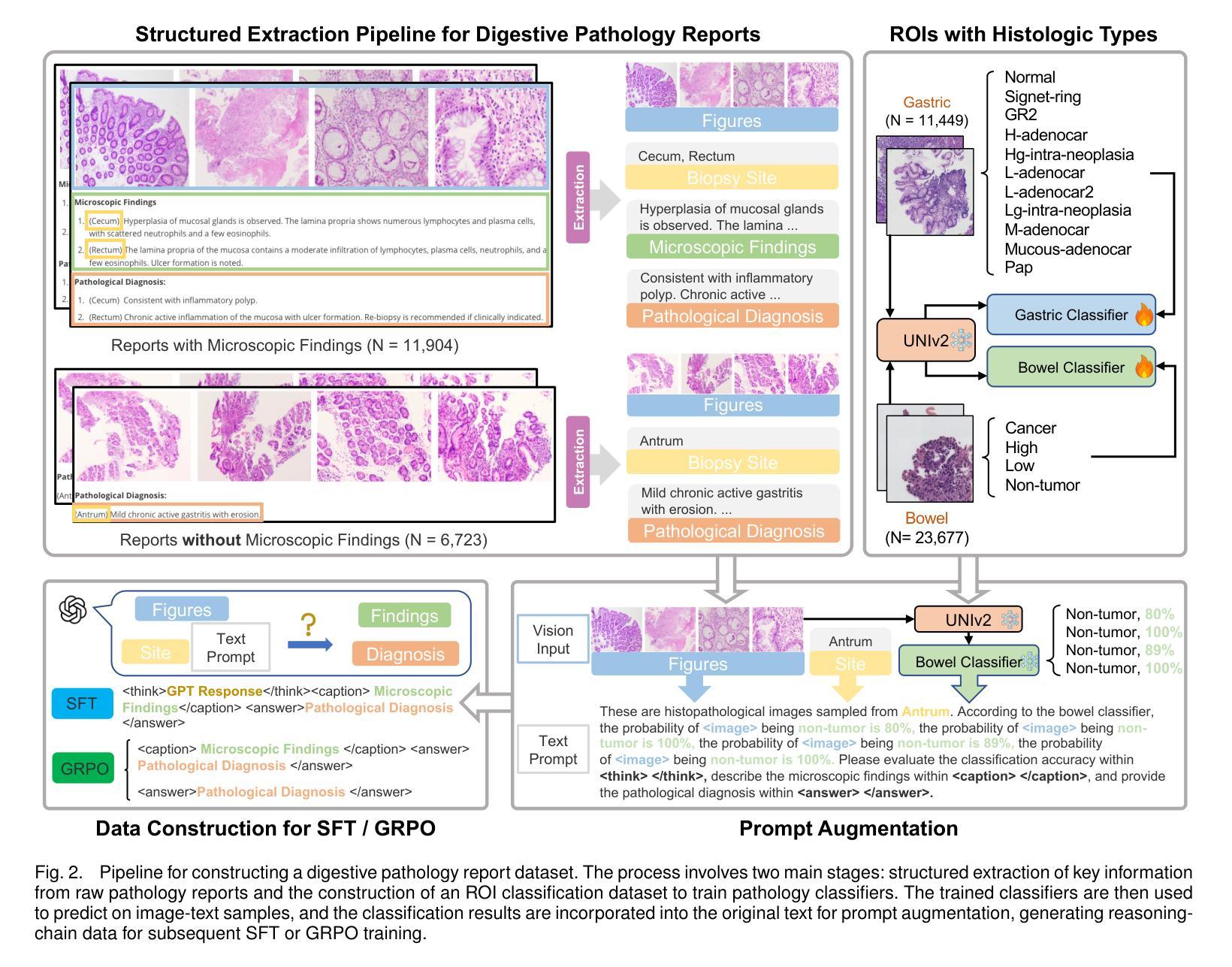
Multimodal large models have shown great potential in automating pathology image analysis. However, current multimodal models for gastrointestinal pathology are constrained by both data quality and reasoning transparency: pervasive noise and incomplete annotations in public datasets predispose vision language models to factual hallucinations when generating diagnostic text, while the absence of explicit intermediate reasoning chains renders the outputs difficult to audit and thus less trustworthy in clinical practice. To address these issues, we construct a large scale gastrointestinal pathology dataset containing both microscopic descriptions and diagnostic conclusions, and propose a prompt argumentation strategy that incorporates lesion classification and anatomical site information. This design guides the model to better capture image specific features and maintain semantic consistency in generation. Furthermore, we employ a post training pipeline that combines supervised fine tuning with Group Relative Policy Optimization (GRPO) to improve reasoning quality and output structure. Experimental results on real world pathology report generation tasks demonstrate that our approach significantly outperforms state of the art open source and proprietary baselines in terms of generation quality, structural completeness, and clinical relevance. Our solution outperforms state of the art models with 18.7% higher clinical relevance, 32.4% improved structural completeness, and 41.2% fewer diagnostic errors, demonstrating superior accuracy and clinical utility compared to existing solutions.
多模态大型模型在自动病理学图像分析方面显示出巨大的潜力。然而,当前用于胃肠道病理学的多模态模型受到数据质量和推理透明度的限制:公共数据集中普遍存在的噪声和标注不完整会使语言模型在生成诊断文本时倾向于产生幻觉,而缺乏明确的中间推理链使得输出难以审核,因此在临床实践中可信度较低。为了解决这些问题,我们构建了一个大规模胃肠道病理学数据集,包含微观描述和诊断结论,并提出了一种融合病变分类和解剖部位信息的提示论证策略。这种设计可以引导模型更好地捕捉图像特定特征,并在生成过程中保持语义一致性。此外,我们采用了一种后训练管道,结合监督微调与群组相对策略优化(GRPO),以提高推理质量和输出结构。在现实世界病理学报告生成任务上的实验结果表明,我们的方法在生成质量、结构完整性和临床相关性方面显著优于最新开源和专有基线。我们的解决方案优于现有最先进模型,临床相关性提高18.7%,结构完整性提高32.4%,诊断错误减少41.2%,显示出更高的准确性和临床实用性。
论文及项目相关链接
Summary
本文探讨了多模态大型模型在自动化病理图像分析中的潜力,并针对胃肠道病理领域的特定挑战提出解决方案。为解决公共数据集中的噪声和标注不完整问题,团队构建了大规模胃肠道病理数据集,并设计了一种结合病变分类和解剖部位信息的提示论证策略。此外,他们还采用了一种结合监督微调与集团相对策略优化(GRPO)的后训练管道,以提高推理质量和输出结构。实验结果证明,该方法在现实世界病理报告生成任务中的表现优于现有开源和专有基线,临床相关性提高18.7%,结构完整性提高32.4%,诊断错误减少41.2%。
Key Takeaways
- 多模态大型模型在自动化病理图像分析中具有巨大潜力。
- 胃肠道病理领域面临数据质量和推理透明度两大挑战。
- 公共数据集中的噪声和标注不完整可能导致视觉语言模型产生事实幻觉。
- 构建大规模胃肠道病理数据集,旨在解决数据质量问题。
- 引入提示论证策略,结合病变分类和解剖部位信息,指导模型捕捉图像特定特征并保持语义一致性。
- 采用结合监督微调和集团相对策略优化(GRPO)的后训练管道,提高推理质量和输出结构。
点此查看论文截图

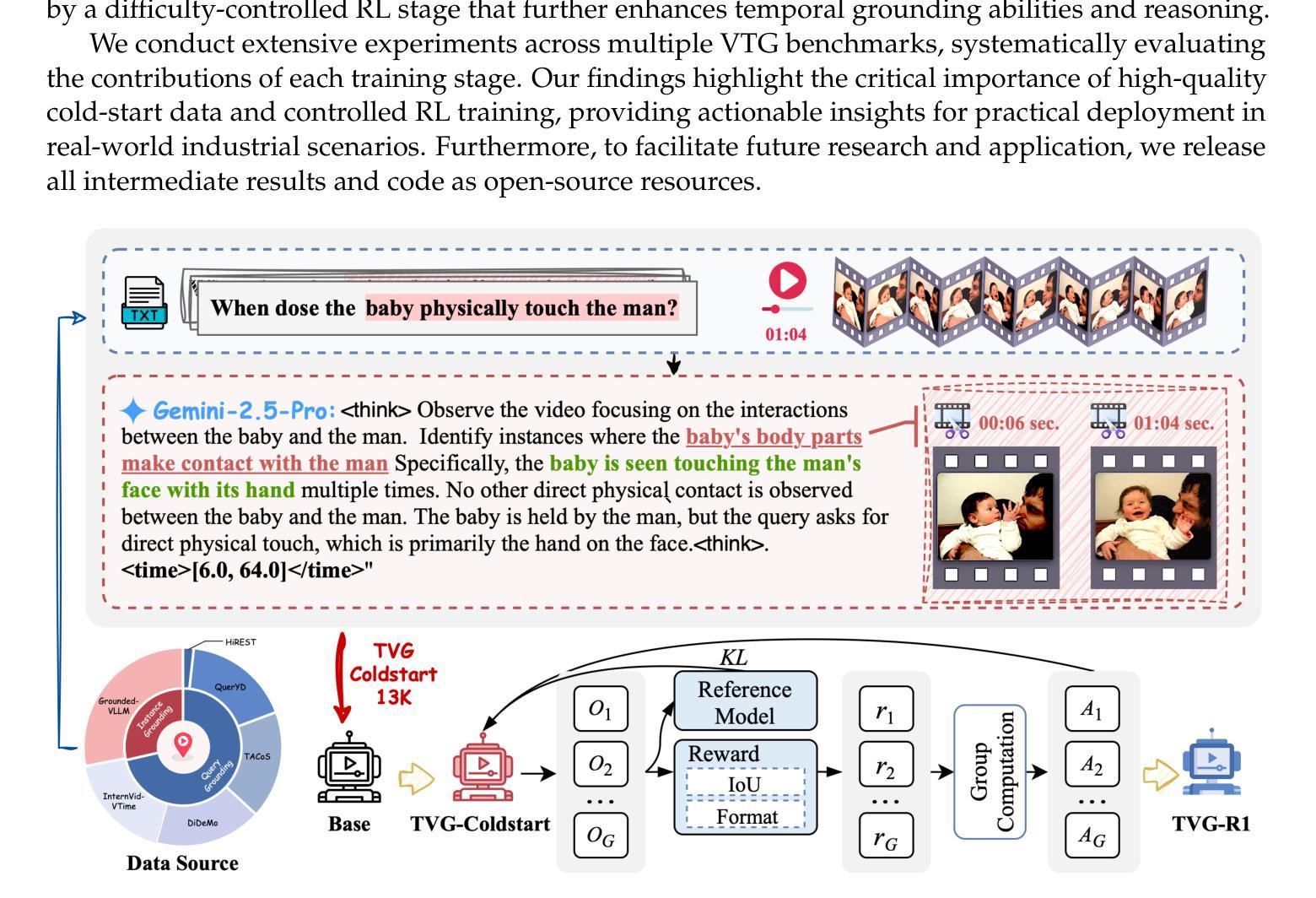
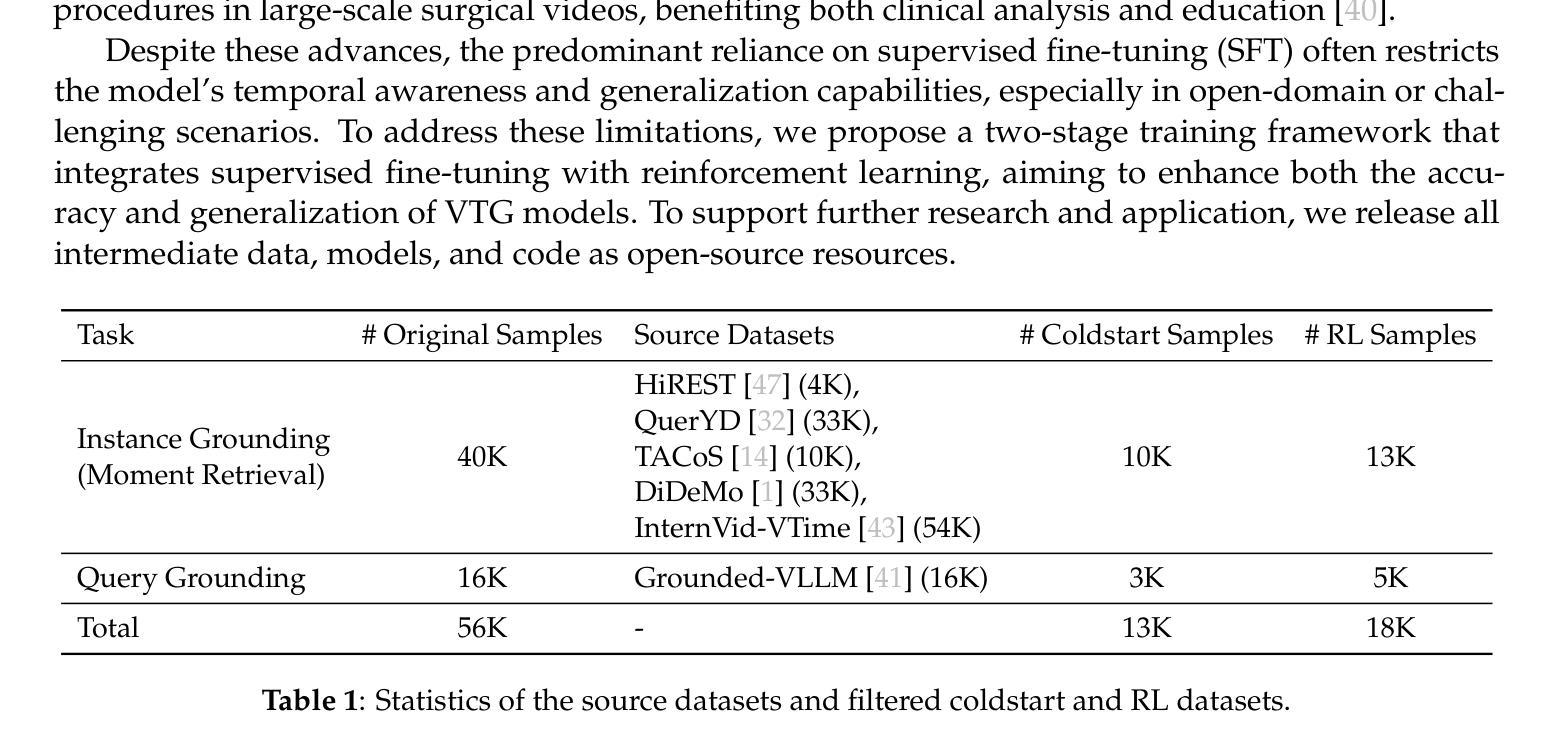
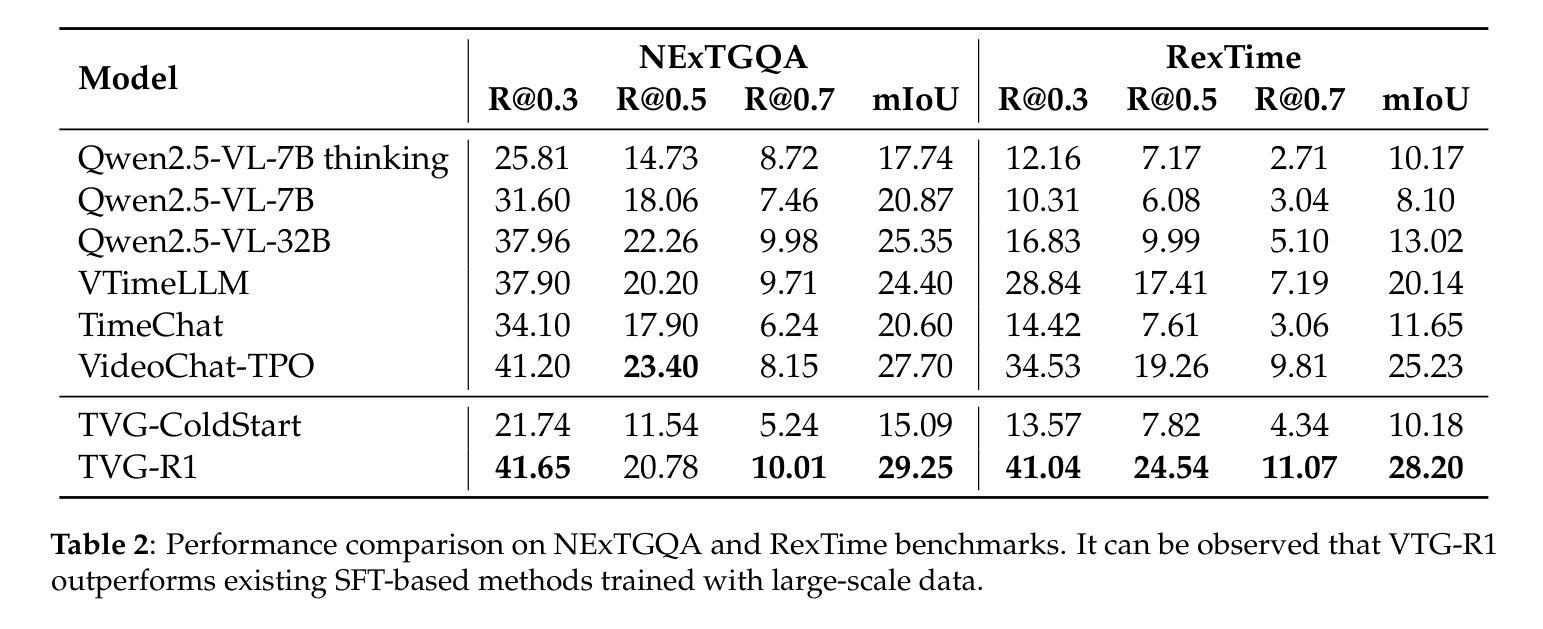
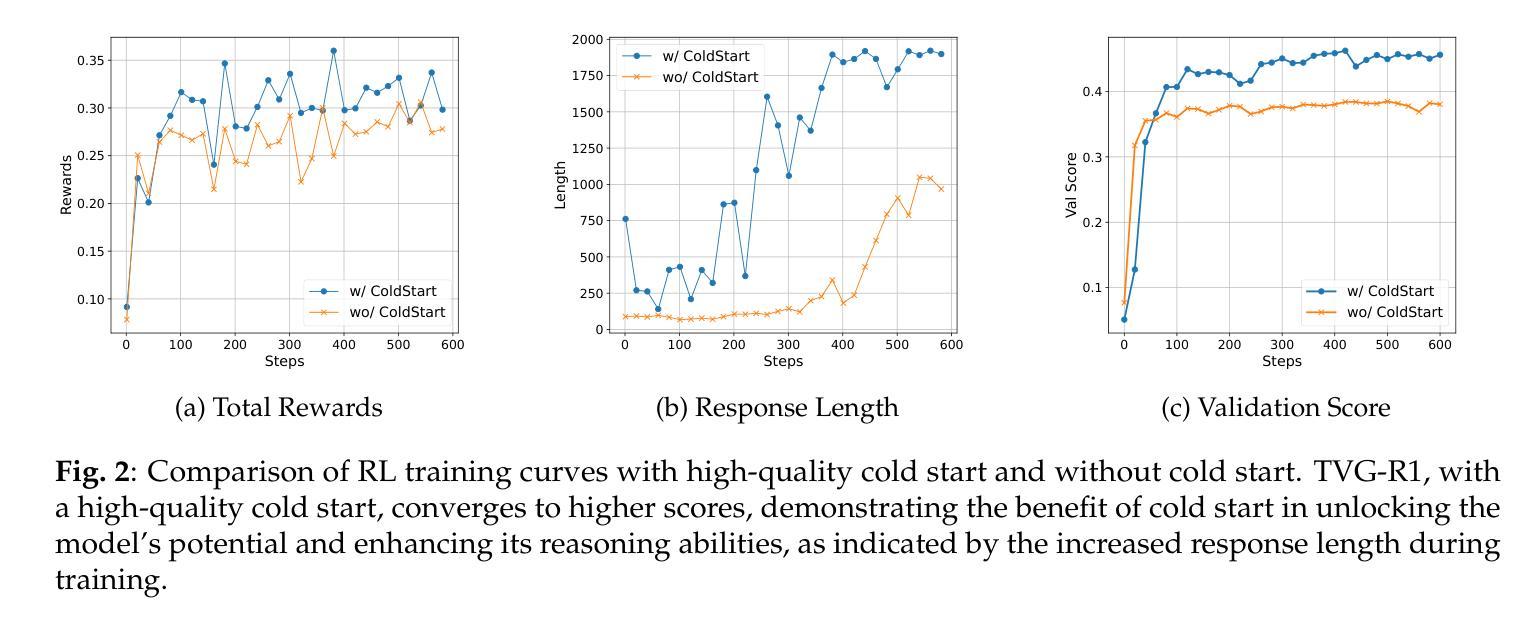
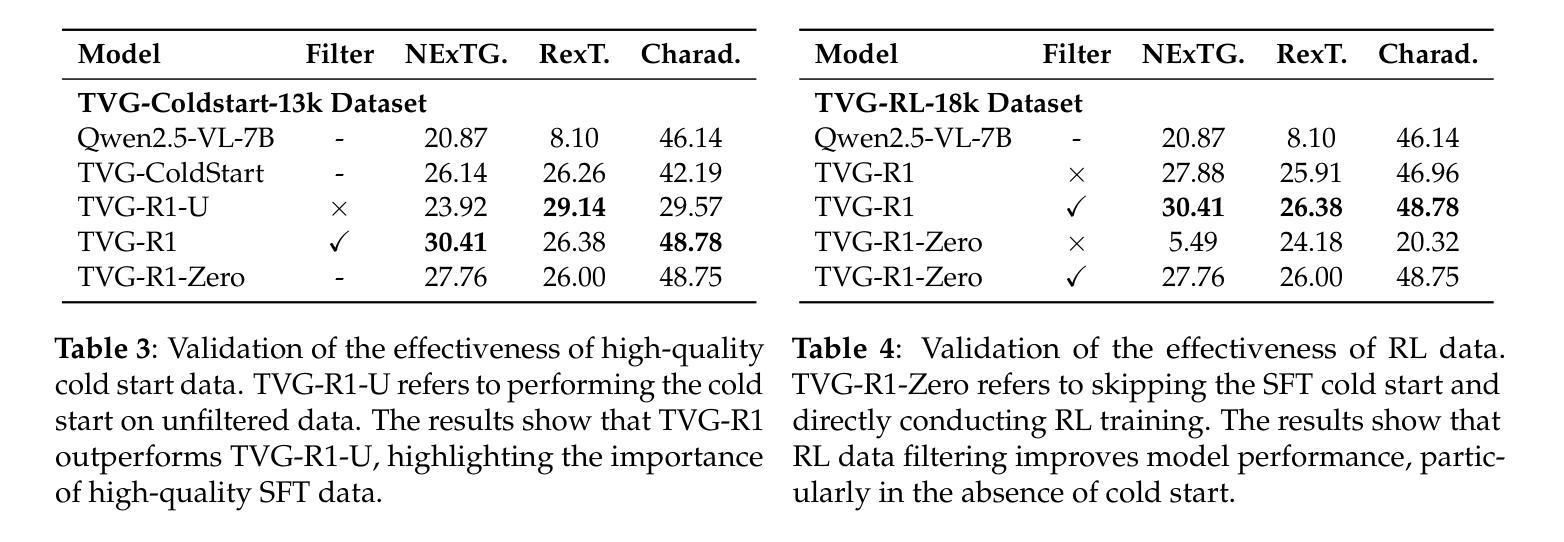
Datasets and Recipes for Video Temporal Grounding via Reinforcement Learning
Authors:Ruizhe Chen, Zhiting Fan, Tianze Luo, Heqing Zou, Zhaopeng Feng, Guiyang Xie, Hansheng Zhang, Zhuochen Wang, Zuozhu Liu, Huaijian Zhang
Video Temporal Grounding (VTG) aims to localize relevant temporal segments in videos given natural language queries. Despite recent progress with large vision-language models (LVLMs) and instruction-tuning, existing approaches often suffer from limited temporal awareness and poor generalization. In this work, we introduce a two-stage training framework that integrates supervised fine-tuning with reinforcement learning (RL) to improve both the accuracy and robustness of VTG models. Our approach first leverages high-quality curated cold start data for SFT initialization, followed by difficulty-controlled RL to further enhance temporal localization and reasoning abilities. Comprehensive experiments on multiple VTG benchmarks demonstrate that our method consistently outperforms existing models, particularly in challenging and open-domain scenarios. We conduct an in-depth analysis of training strategies and dataset curation, highlighting the importance of both high-quality cold start data and difficulty-controlled RL. To facilitate further research and industrial adoption, we release all intermediate datasets, models, and code to the community.
视频时序定位(VTG)旨在根据自然语言查询定位视频中的相关时序片段。尽管最近的大型视觉语言模型(LVLMs)和指令微调取得了一些进展,但现有方法往往存在时序感知能力有限和泛化能力较差的问题。在这项工作中,我们引入了一个两阶段训练框架,该框架将监督微调与强化学习(RL)相结合,以提高VTG模型的准确性和鲁棒性。我们的方法首先利用高质量的精选冷启动数据进行SFT初始化,然后通过难度控制的RL来进一步增强时序定位和推理能力。在多个VTG基准测试上的综合实验表明,我们的方法一直优于现有模型,特别是在具有挑战性和开放域的场景中。我们对训练策略和数据集整理进行了深入分析,强调了高质量冷启动数据和难度控制RL的重要性。为了促进进一步的研究和工业应用,我们向社区发布了所有中间数据集、模型和代码。
论文及项目相关链接
Summary
本文介绍了视频时序定位(VTG)的目标是利用自然语言查询在视频中找到相关的时序片段。尽管有大型视觉语言模型(LVLMs)和指令微调(instruction-tuning)的近期进展,但现有方法仍存在时间感知有限和泛化性能不足的问题。为解决这些问题,本文提出了一种结合监督微调与强化学习(RL)的两阶段训练框架,旨在提高VTG模型的准确性和鲁棒性。该方法首先利用高质量精选的冷启动数据进行监督微调初始化,随后采用难度控制的强化学习进一步改善时序定位和推理能力。在多个VTG基准测试上的实验表明,该方法在具有挑战性和开放领域的场景中表现优于现有模型。本文还深入分析了训练策略和数据集整理的重要性,并公开了所有中间数据集、模型和代码,以促进进一步的研究和工业应用。
Key Takeaways
- 视频时序定位(VTG)旨在利用自然语言查询在视频中找到相关的时序片段。
- 现有方法在时间感知和泛化性能方面存在局限性。
- 提出的两阶段训练框架结合了监督微调与强化学习(RL),以提高VTG模型的准确性和鲁棒性。
- 该方法首先利用高质量精选的冷启动数据进行监督微调初始化。
- 难度控制的强化学习进一步改善了时序定位和推理能力。
- 在多个基准测试上的实验表明,该方法在具有挑战性和开放领域的场景中表现优异。
点此查看论文截图

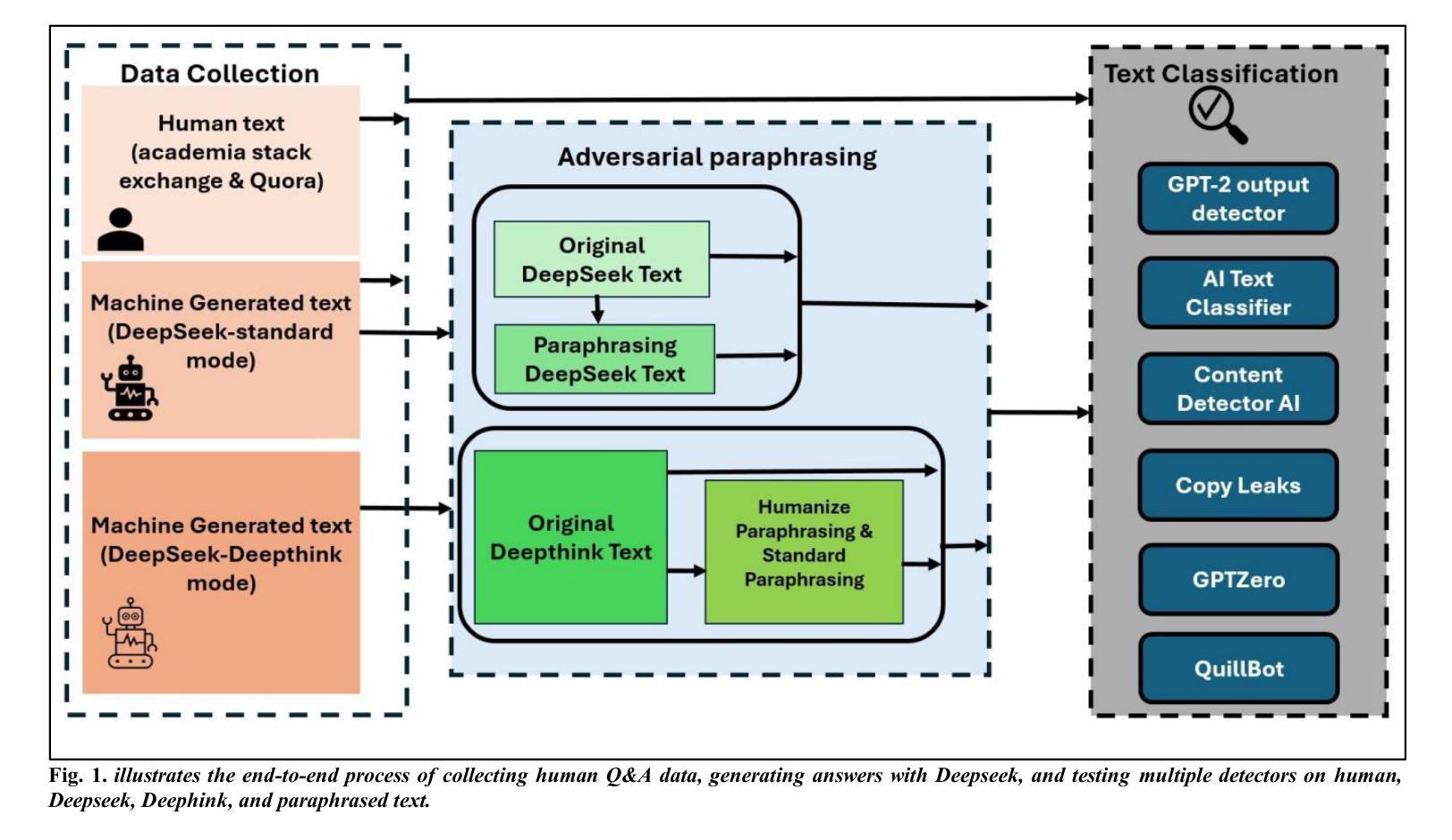
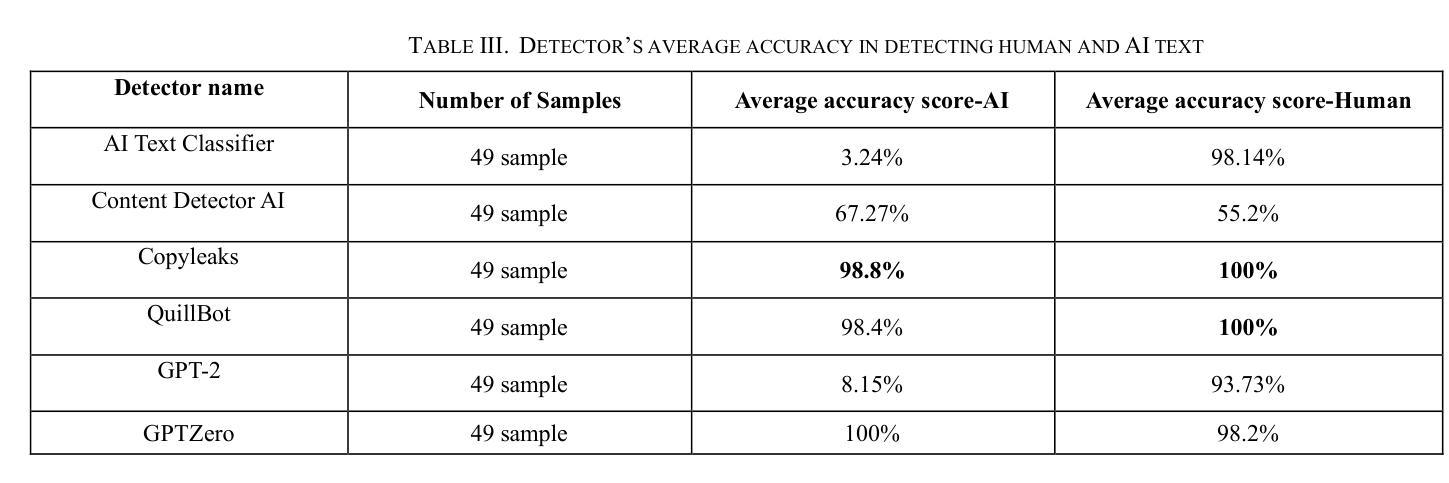
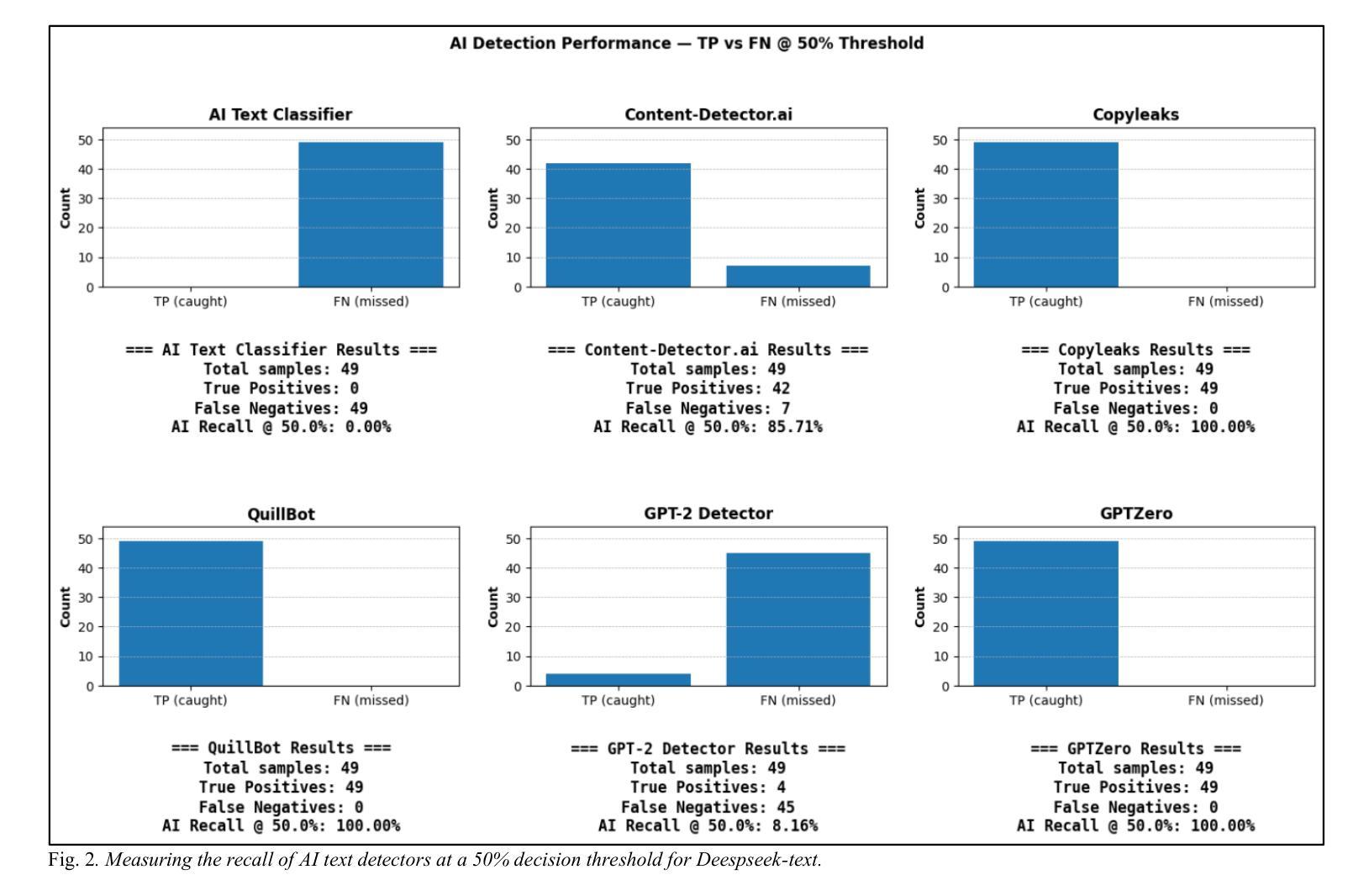
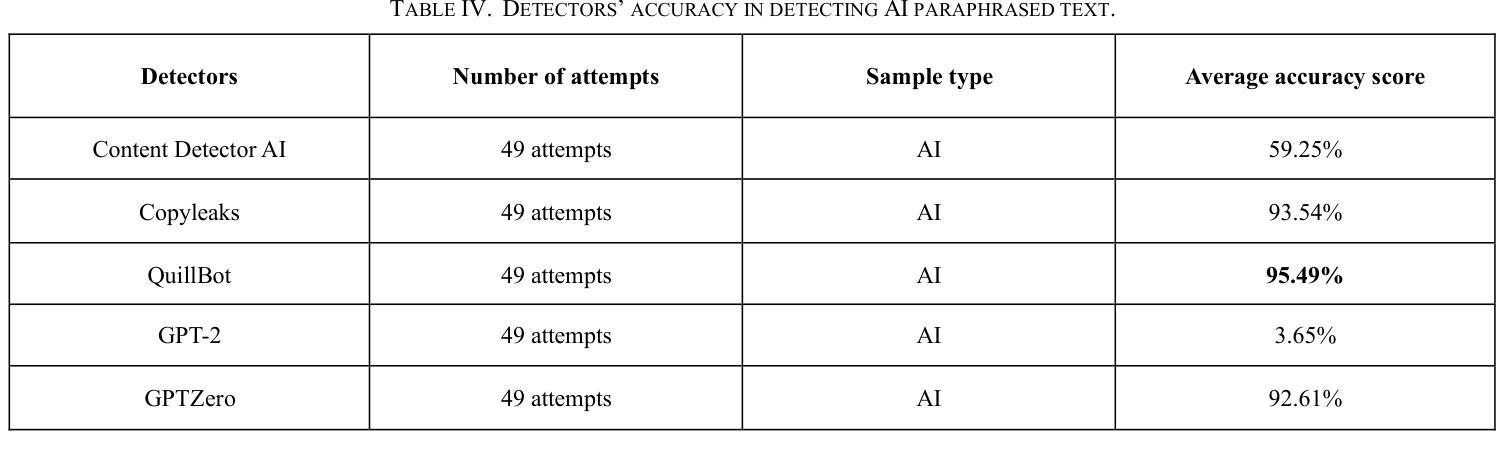
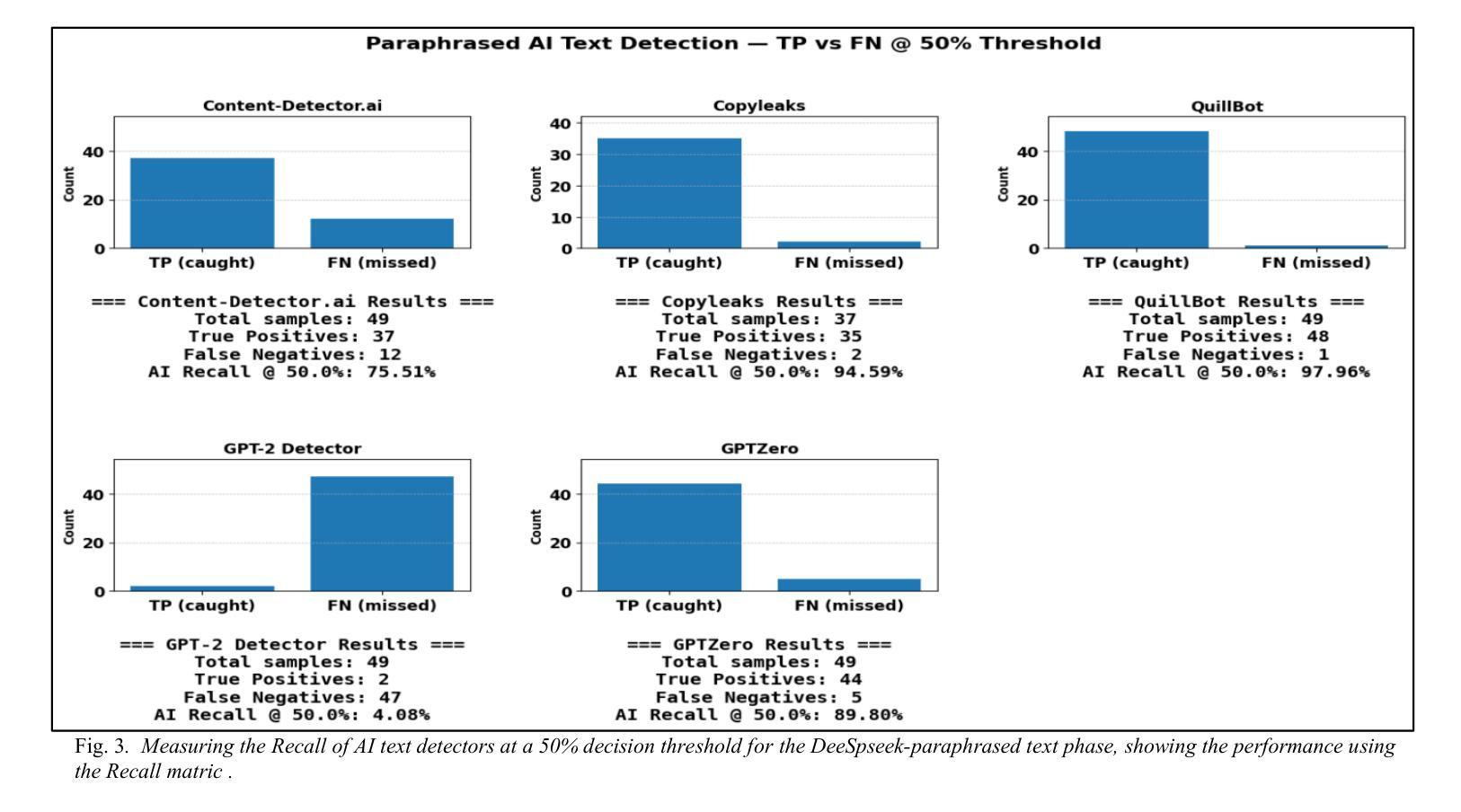
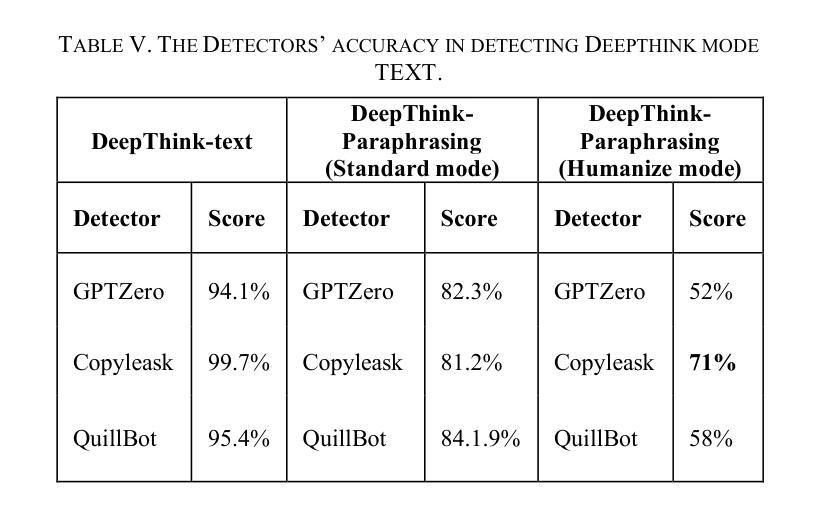
Evaluating the Performance of AI Text Detectors, Few-Shot and Chain-of-Thought Prompting Using DeepSeek Generated Text
Authors:Hulayyil Alshammari, Praveen Rao
Large language models (LLMs) have rapidly transformed the creation of written materials. LLMs have led to questions about writing integrity, thereby driving the creation of artificial intelligence (AI) detection technologies. Adversarial attacks, such as standard and humanized paraphrasing, inhibit detectors’ ability to detect machine-generated text. Previous studies have mainly focused on ChatGPT and other well-known LLMs and have shown varying accuracy across detectors. However, there is a clear gap in the literature about DeepSeek, a recently published LLM. Therefore, in this work, we investigate whether six generally accessible AI detection tools – AI Text Classifier, Content Detector AI, Copyleaks, QuillBot, GPT-2, and GPTZero – can consistently recognize text generated by DeepSeek. The detectors were exposed to the aforementioned adversarial attacks. We also considered DeepSeek as a detector by performing few-shot prompting and chain-of-thought reasoning (CoT) for classifying AI and human-written text. We collected 49 human-authored question-answer pairs from before the LLM era and generated matching responses using DeepSeek-v3, producing 49 AI-generated samples. Then, we applied adversarial techniques such as paraphrasing and humanizing to add 196 more samples. These were used to challenge detector robustness and assess accuracy impact. While QuillBot and Copyleaks showed near-perfect performance on original and paraphrased DeepSeek text, others – particularly AI Text Classifier and GPT-2 – showed inconsistent results. The most effective attack was humanization, reducing accuracy to 71% for Copyleaks, 58% for QuillBot, and 52% for GPTZero. Few-shot and CoT prompting showed high accuracy, with the best five-shot result misclassifying only one of 49 samples (AI recall 96%, human recall 100%).
大型语言模型(LLMs)迅速改变了书面材料的创作方式。LLMs引发了关于写作完整性的问题,从而推动了人工智能(AI)检测技术的发展。对抗性攻击,如标准和人化的改述,抑制了检测器检测机器生成文本的能力。以前的研究主要集中在ChatGPT和其他知名LLMs上,显示出检测器之间的准确率差异。然而,关于最近发布的DeepSeek的文献中存在明显的空白。因此,在这项工作中,我们研究了六种通用的AI检测工具,即AI文本分类器、内容检测AI、Copyleaks、QuillBot、GPT-2和GPTZero,是否能一致地识别DeepSeek生成的文本。检测器受到了上述对抗性攻击的影响。我们还考虑将DeepSeek作为检测器,通过进行少镜头提示和思维链推理(CoT)来分类AI和人类撰写的文本。我们从LLM时代之前收集了49个人类问答对,并使用DeepSeek-v3生成了匹配的回答,产生了49个AI生成的样本。然后,我们应用了诸如改述和人化之类的对抗技术来添加196个额外的样本。这些被用来挑战检测器的稳健性并评估准确性的影响。虽然QuillBot和Copyleaks在原始和改述的DeepSeek文本上表现出近乎完美的性能,但其他检测器,特别是AI文本分类器和GPT-2,结果却不尽一致。最有效的攻击是人化,将Copyleaks的准确率降低到71%,QuillBot的准确率降低到58%,GPTZero的准确率降低到52%。少镜头和CoT提示显示高准确率,最佳五镜头结果仅误判一个样本(AI召回率为96%,人类召回率为100%)。
论文及项目相关链接
Summary
大型语言模型(LLMs)的涌现引发了对写作真实性的关注,并推动了人工智能(AI)检测技术的发展。然而,对抗性攻击,如标准和人化的改述,限制了检测器检测机器生成文本的能力。本文研究了六种常用的AI检测工具是否能准确识别由DeepSeek生成的文本,并测试了这些检测器在面对对抗性攻击时的表现。研究发现,QuillBot和Copyleaks在应对原始和改述的DeepSeek文本时表现出近乎完美的性能,而其他检测器则表现不一。最有效的攻击是人化攻击,它降低了检测器的准确率。此外,通过少量提示和链式思维推理(CoT)的方法在区分AI和人类写作方面表现出高准确率。
Key Takeaways
- 大型语言模型(LLMs)的发展引发了对写作真实性的关注,促进了AI检测技术的产生。
- 对抗性攻击,如改述,能抑制检测器识别机器生成文本的能力。
- 现有的AI检测工具在面对DeepSeek生成的文本时表现不一,QuillBot和Copyleaks表现较好。
- 人化攻击是最有效的对抗方式,能显著降低检测器的准确率。
- 通过少量提示和链式思维推理(CoT)的方法在区分AI和人类写作方面非常有效。
- 目前对于DeepSeek这一LLM的检测研究存在空白,本文填补了这一空白。
点此查看论文截图

CodeReasoner: Enhancing the Code Reasoning Ability with Reinforcement Learning
Authors:Lingxiao Tang, He Ye, Zhongxin Liu, Xiaoxue Ren, Lingfeng Bao
Code reasoning is a fundamental capability for large language models (LLMs) in the code domain. It involves understanding and predicting a program’s execution behavior, such as determining the output for a given input or whether a specific statement will be executed. This capability is essential for downstream tasks like debugging, code generation, and program repair. Prior approaches mainly rely on supervised fine-tuning to improve performance in code reasoning tasks. However, they often show limited gains and fail to generalize across diverse scenarios. We argue this is due to two core issues: the low quality of training data and the limitations of supervised fine-tuning, which struggles to teach general reasoning skills. To address these challenges, we propose CodeReasoner, a framework that spans both dataset construction and a two-stage training process. First, we introduce a method to construct datasets that focus on the core execution logic of Python programs. Next, we apply instruction tuning to inject execution-specific knowledge distilled from a powerful teacher model. We then enhance reasoning and generalization through GRPO reinforcement learning on top of the fine-tuned model. Experiments on three widely-used code reasoning benchmarks show that CodeReasoner improves performance by 27.1% to 40.2% over prior methods using a 7B model. Notably, the 7B model matches GPT-4o on key tasks like input/output and coverage prediction. When scaled to 14B, CodeReasoner outperforms GPT-4o across all benchmarks. Ablation studies confirm the effectiveness of each training stage and highlight the importance of reasoning chains.
代码推理是代码域大型语言模型(LLM)的一项基本能力。它涉及理解和预测程序的执行行为,如确定给定输入的输岀或特定语句是否会执行。对于调试、代码生成和程序修复等下游任务,这项能力至关重要。之前的方法主要依赖于监督微调来提高代码推理任务的性能。然而,它们通常增益有限,无法在多种场景中实现泛化。我们认为这是由于两个核心问题导致的:训练数据质量低下和监督微调的局限性,后者难以教授通用推理技能。为了应对这些挑战,我们提出了CodeReasoner框架,它涵盖了数据集构建和两个阶段的训练过程。首先,我们介绍了一种构建数据集的方法,该方法专注于Python程序的核心执行逻辑。接下来,我们将指令微调应用于从强大的教师模型中蒸馏执行特定知识的注入。然后我们在微调模型之上应用GRPO强化学习以增强推理和泛化能力。在三个常用的代码推理基准测试上的实验表明,CodeReasoner使用7B模型在先前方法的基础上提高了27.1%至40.2%的性能。值得注意的是,7B模型在输入/输岀和覆盖预测等关键任务上匹配GPT-4o的表现。当扩展到14B时,CodeReasoner在所有基准测试中都优于GPT-4o。消融研究证实了每个训练阶段的有效性,并突出了推理链的重要性。
论文及项目相关链接
Summary
本文介绍了代码推理作为大型语言模型在代码领域的基本能力的重要性,涉及理解和预测程序的执行行为。先前的方法主要依赖于监督微调来提高代码推理任务中的性能,但存在局限性。针对这些问题,本文提出了CodeReasoner框架,涵盖数据集构建和两阶段训练过程。通过引入专注于Python程序核心执行逻辑的数据集构建方法,应用指令调优注入执行特定知识,并通过GRPO强化学习增强推理和泛化能力。实验表明,CodeReasoner在三个广泛使用的代码推理基准测试上的性能较之前的方法提高了27.1%至40.2%,并且在扩展到14B时全面超越了GPT-4o。
Key Takeaways
- 代码推理是大型语言模型在代码领域的基本能力,涉及理解和预测程序执行行为。
- 先前的方法主要依赖监督微调来提高代码推理任务性能,但存在局限性。
- CodeReasoner框架包括数据集构建和两阶段训练过程,以解决现有方法的局限性。
- CodeReasoner通过引入专注于Python程序核心执行逻辑的数据集、应用指令调优和GRPO强化学习,增强了模型的推理和泛化能力。
- 实验表明,CodeReasoner在代码推理基准测试上的性能较之前的方法有显著提高。
- CodeReasoner在扩展到更大模型时,性能表现更加出色,全面超越了GPT-4o。
点此查看论文截图





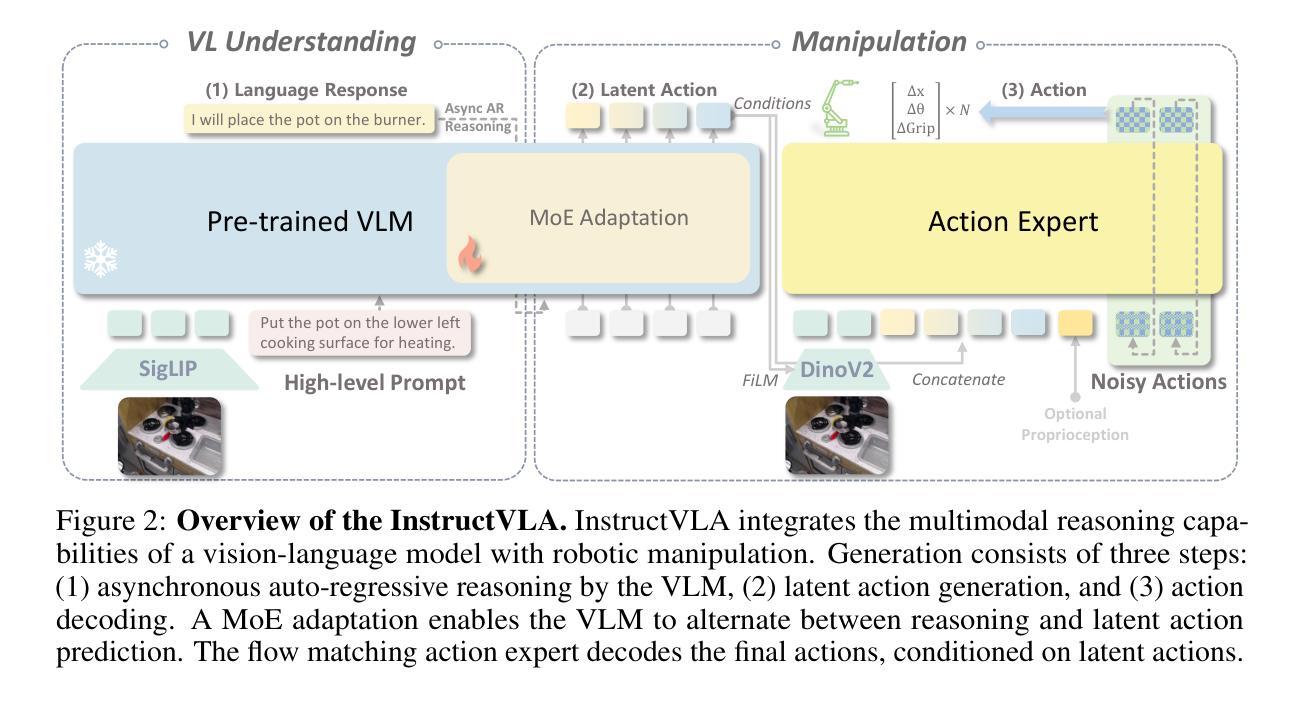
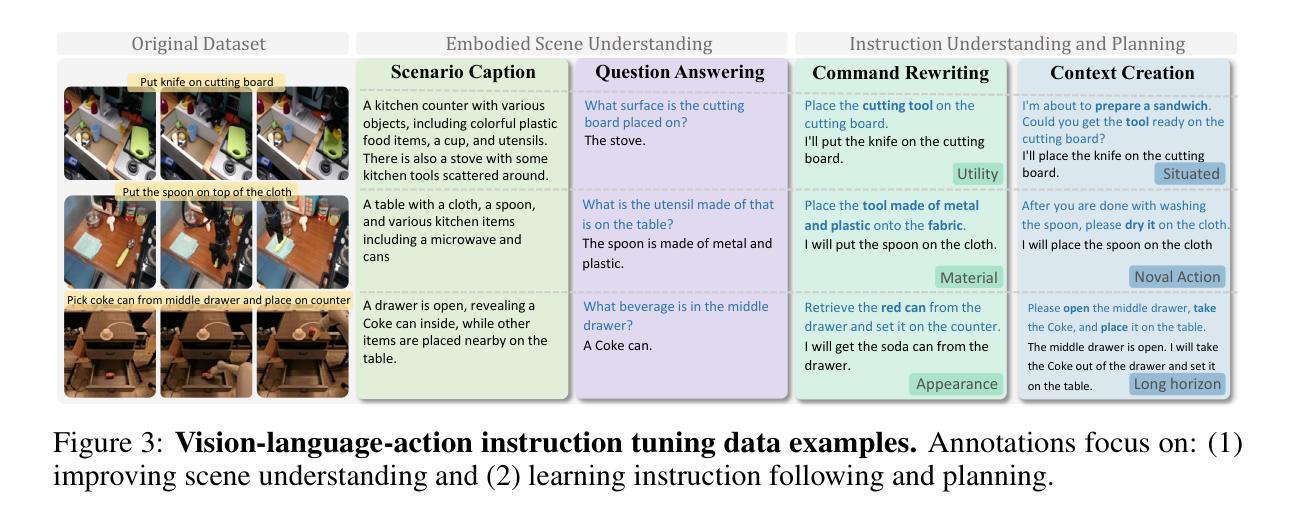
InstructVLA: Vision-Language-Action Instruction Tuning from Understanding to Manipulation
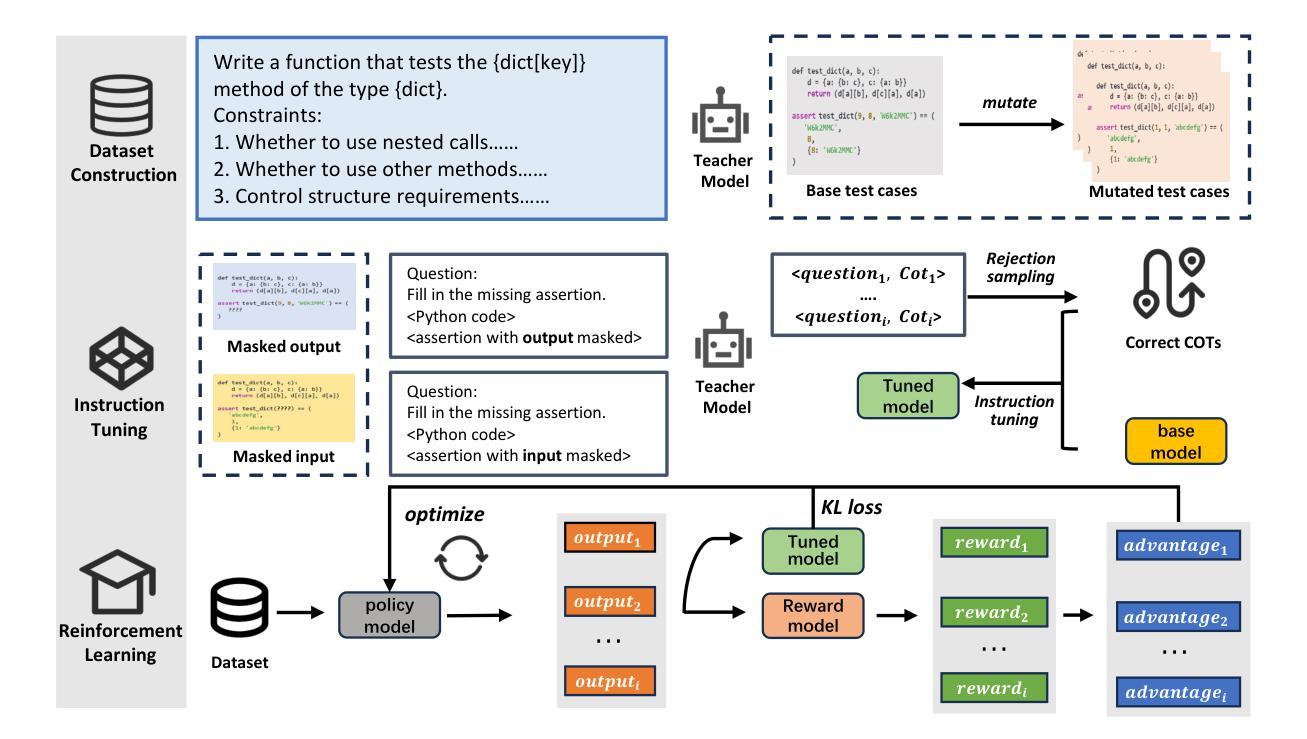
Authors:Shuai Yang, Hao Li, Yilun Chen, Bin Wang, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, Jiangmiao Pang
To operate effectively in the real world, robots must integrate multimodal reasoning with precise action generation. However, existing vision-language-action (VLA) models often sacrifice one for the other, narrow their abilities to task-specific manipulation data, and suffer catastrophic forgetting of pre-trained vision-language capabilities. To bridge this gap, we introduce InstructVLA, an end-to-end VLA model that preserves the flexible reasoning of large vision-language models (VLMs) while delivering leading manipulation performance. InstructVLA introduces a novel training paradigm, Vision-Language-Action Instruction Tuning (VLA-IT), which employs multimodal training with mixture-of-experts adaptation to jointly optimize textual reasoning and action generation on both standard VLM corpora and a curated 650K-sample VLA-IT dataset. On in-domain SimplerEnv tasks, InstructVLA achieves 30.5% improvement over SpatialVLA. To evaluate generalization, we introduce SimplerEnv-Instruct, an 80-task benchmark requiring closed-loop control and high-level instruction understanding, where it outperforms a fine-tuned OpenVLA by 92% and an action expert aided by GPT-4o by 29%. Additionally, InstructVLA surpasses baseline VLMs on multimodal tasks and exhibits inference-time scaling by leveraging textual reasoning to boost manipulation performance in both simulated and real-world settings. These results demonstrate InstructVLA’s potential for bridging intuitive and steerable human-robot interaction with efficient policy learning.
为了在现实世界中进行有效的操作,机器人必须将多模态推理与精确的动作生成结合起来。然而,现有的视觉-语言-动作(VLA)模型往往顾此失彼,局限于特定任务的操纵数据,并遭受预训练视觉-语言能力的灾难性遗忘。为了弥补这一差距,我们引入了InstructVLA,这是一种端到端的VLA模型,它能够在保留大型视觉-语言模型(VLM)的灵活推理能力的同时,提供领先的操纵性能。InstructVLA引入了一种新的训练范式——视觉-语言-动作指令调整(VLA-IT),它采用多模态训练与混合专家适应相结合的方法,以联合优化文本推理和动作生成,在标准VLM语料库和定制的65万样本VLA-IT数据集上进行操作。在域内的SimplerEnv任务上,InstructVLA较SpatialVLA提高了30.5%。为了评估泛化能力,我们引入了SimplerEnv-Instruct,这是一个包含80个任务的基准测试,要求闭环控制和高级指令理解,InstructVLA的表现超越了微调后的OpenVLA(提升了92%),以及由GPT-4o辅助的动作专家(提升了29%)。此外,InstructVLA在多模态任务上超越了基本的VLM,并借助文本推理提高了模拟和真实环境下的操作性能,实现了推理时间的缩放。这些结果展示了InstructVLA在桥接直观和可引导的人机交互与高效策略学习方面的潜力。
论文及项目相关链接
PDF 38 pages
Summary
本文介绍了InstructVLA模型,该模型旨在桥接现实世界中机器人操作的视觉、语言和动作能力。它采用一种新型训练范式VLA-IT,结合了多模式训练与混合专家适应策略,以优化文本推理和动作生成。在特定任务环境下,InstructVLA相较于其他模型有显著性能提升,并展现出良好的泛化能力。此外,InstructVLA还利用文本推理提升了模拟和真实环境下的操作性能,显示出其在人机交互领域的潜力。
Key Takeaways
- InstructVLA是一个端对端的视觉-语言-动作(VLA)模型,旨在解决机器人在现实世界中操作时的多模式推理和精确动作生成问题。
- 现有VLA模型常在视觉、语言和动作方面有所取舍,能力局限于特定任务数据,并容易忘记预训练的视觉-语言能力。
- InstructVLA引入了一种新的训练范式VLA-IT,通过多模式训练和混合专家适应策略来优化文本推理和动作生成。
- InstructVLA在特定任务环境下性能显著提升,相较于SpatialVLA有30.5%的改进。
- InstructVLA展现出良好的泛化能力,在新的80任务基准测试中表现优异,相较于其他模型有显著提高。
- InstructVLA利用文本推理提升了在模拟和真实环境下的操作性能,实现推理时间的推断扩展。
点此查看论文截图


URPO: A Unified Reward & Policy Optimization Framework for Large Language Models
Authors:Songshuo Lu, Hua Wang, Zhi Chen, Yaohua Tang
Large-scale alignment pipelines typically pair a policy model with a separately trained reward model whose parameters remain frozen during reinforcement learning (RL). This separation creates a complex, resource-intensive pipeline and suffers from a performance ceiling due to a static reward signal. We propose a novel framework, Unified Reward & Policy Optimization (URPO), that unifies instruction-following (“player”) and reward modeling (“referee”) within a single model and a single training phase. Our method recasts all alignment data-including preference pairs, verifiable reasoning, and open-ended instructions-into a unified generative format optimized by a single Group-Relative Policy Optimization (GRPO) loop. This enables the model to learn from ground-truth preferences and verifiable logic while simultaneously generating its own rewards for open-ended tasks. Experiments on the Qwen2.5-7B model demonstrate URPO’s superiority. Our unified model significantly outperforms a strong baseline using a separate generative reward model, boosting the instruction-following score on AlpacaEval from 42.24 to 44.84 and the composite reasoning average from 32.66 to 35.66. Furthermore, URPO cultivates a superior internal evaluator as a byproduct of training, achieving a RewardBench score of 85.15 and surpassing the dedicated reward model it replaces (83.55). By eliminating the need for a separate reward model and fostering a co-evolutionary dynamic between generation and evaluation, URPO presents a simpler, more efficient, and more effective path towards robustly aligned language models.
大规模对齐管道通常会将策略模型与单独训练的奖励模型配对,在强化学习(RL)过程中,奖励模型的参数保持冻结。这种分离导致了一个复杂且资源密集型的管道,并由于静态奖励信号而受到性能上限的限制。我们提出了一种新型框架,即统一奖励与策略优化(URPO),它在一个单一模型和单一训练阶段内统一了指令遵循(“玩家”)和奖励建模(“裁判”)。我们的方法将所有对齐数据——包括偏好对、可验证的推理和开放性指令——重新转换为统一的生成格式,通过单个组相对策略优化(GRPO)循环进行优化。这使模型能够从真实偏好和可验证逻辑中学习,同时为其自身开放任务生成奖励。在Qwen2.5-7B模型上的实验证明了URPO的优越性。我们的统一模型显著优于使用单独生成奖励模型的强大基线,在AlpacaEval上将指令遵循分数从42.24提高到44.84,复合推理平均分从32.66提高到35.66。此外,URPO作为训练的副产品,培养了一个优越的内部评估者,其RewardBench分数达到85.15,超越了其所替代的专用奖励模型(83.55)。通过消除对单独奖励模型的需求,并在生成和评估之间促进协同进化动态,URPO为稳健对齐语言模型提供了更简单、更高效、更有效的途径。
论文及项目相关链接
Summary
本文提出一种新型框架Unified Reward & Policy Optimization (URPO),它将指令遵循的“玩家”和奖励建模的“裁判”统一在一个单一模型和单一训练阶段中。URPO通过优化一个统一的生成格式,融合了偏好对、可验证推理和开放式指令,采用单一Group-Relative Policy Optimization (GRPO)循环进行学习。实验表明,URPO在Qwen2.5-7B模型上的表现优于传统方法,显著提高了指令遵循和复合推理的平均得分。此外,URPO作为训练的副产品,培养出卓越的内部评估者,超越专用的奖励模型。通过消除对单独奖励模型的需求,促进生成和评估之间的协同进化动态,URPO为构建稳健对齐的语言模型提供了更简单、更高效、更有效的途径。
Key Takeaways
- URPO框架将指令遵循和奖励建模统一在单一模型和单一训练阶段中,提高了效率。
- URPO采用生成格式优化,融合了多种数据,如偏好对、可验证推理和开放式指令。
- 通过Group-Relative Policy Optimization (GRPO)循环,模型能同时从真实偏好和可验证逻辑中学习,并生成开放式任务奖励。
- 实验显示URPO在Qwen2.5-7B模型上的表现优于传统方法,提高了指令遵循和复合推理得分。
- URPO培养了一个卓越的内部评估者,超越了传统的奖励模型。
- URPO消除了对单独奖励模型的需求,促进了生成和评估之间的协同进化。
点此查看论文截图


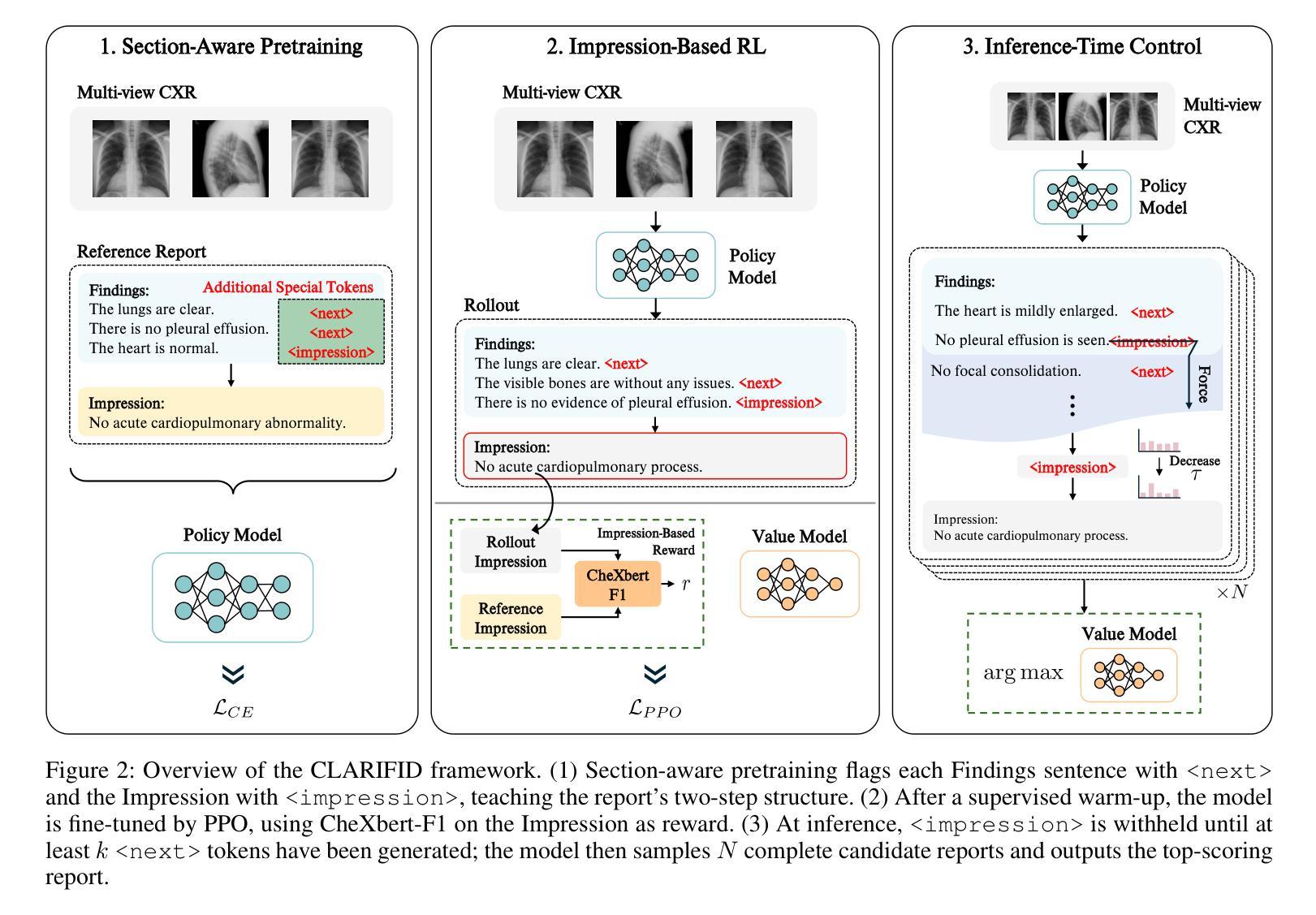
CLARIFID: Improving Radiology Report Generation by Reinforcing Clinically Accurate Impressions and Enforcing Detailed Findings
Authors:Kyeongkyu Lee, Seonghwan Yoon, Hongki Lim
Automatic generation of radiology reports has the potential to alleviate radiologists’ significant workload, yet current methods struggle to deliver clinically reliable conclusions. In particular, most prior approaches focus on producing fluent text without effectively ensuring the factual correctness of the reports and often rely on single-view images, limiting diagnostic comprehensiveness. We propose CLARIFID, a novel framework that directly optimizes diagnostic correctness by mirroring the two-step workflow of experts. Specifically, CLARIFID (1) learns the logical flow from Findings to Impression through section-aware pretraining, (2) is fine-tuned with Proximal Policy Optimization in which the CheXbert F1 score of the Impression section serves as the reward, (3) enforces reasoning-aware decoding that completes “Findings” before synthesizing the “Impression”, and (4) fuses multiple chest X-ray views via a vision-transformer-based multi-view encoder. During inference, we apply a reasoning-aware next-token forcing strategy followed by report-level re-ranking, ensuring that the model first produces a comprehensive Findings section before synthesizing the Impression and thereby preserving coherent clinical reasoning. Experimental results on the MIMIC-CXR dataset demonstrate that our method achieves superior clinical efficacy and outperforms existing baselines on both standard NLG metrics and clinically aware scores.
自动生成的放射学报告有潜力减轻放射科医师巨大的工作量,但当前的方法在临床可靠结论的生成上仍存在困难。尤其是,大多数早期的方法集中在生成流畅文本上,并未有效确保报告的准确性,并且通常依赖于单视图图像,限制了诊断的全面性。我们提出了CLARIFID这一新型框架,它通过模拟专家的两步工作流程来直接优化诊断的正确性。具体来说,CLARIFID(1)通过分段预训练学习从检查结果到印象的逻辑流程,(2)使用近端策略优化进行微调,其中印象部分的CheXbert F1分数作为奖励,(3)强制实施推理感知解码,在完成“检查结果”后再合成“印象”,(4)通过基于视觉变压器的多视图编码器融合多个胸部X光片视图。在推理过程中,我们采用了推理感知的下一个令牌强制策略,然后进行报告级别的重新排序,确保模型首先生成全面的检查结果部分,然后再合成印象,从而保持连贯的临床推理。在MIMIC-CXR数据集上的实验结果表明,我们的方法达到了优越的临床效果,在标准自然语言生成指标和临床意识得分上都超越了现有基线。
论文及项目相关链接
Summary
本文提出一种名为CLARIFID的新框架,用于自动生成放射学报告,以减轻放射科医生的工作负担。该框架通过模仿专家两步工作流程直接优化诊断正确性,包括学习逻辑流程、精细调整政策优化、实施推理感知解码和融合多视角的胸部X光片。实验结果表明,该方法在MIMIC-CXR数据集上实现了卓越的临床效果,优于现有基线标准。
Key Takeaways
- 自动生成放射学报告具有减轻放射科医生工作负担的潜力。
- 当前方法在临床可靠性方面存在挑战,需要确保报告的事实正确性。
- CLARIFID框架通过模仿专家工作流程直接优化诊断正确性。
- CLARIFID框架包括学习逻辑流程、精细调整政策优化、推理感知解码和多视角融合等技术环节。
- CLARIFID在MIMIC-CXR数据集上实现了卓越的临床效果。
- 与现有基线相比,CLARIFID在标准自然语言生成指标和临床意识评分上表现更优。
点此查看论文截图


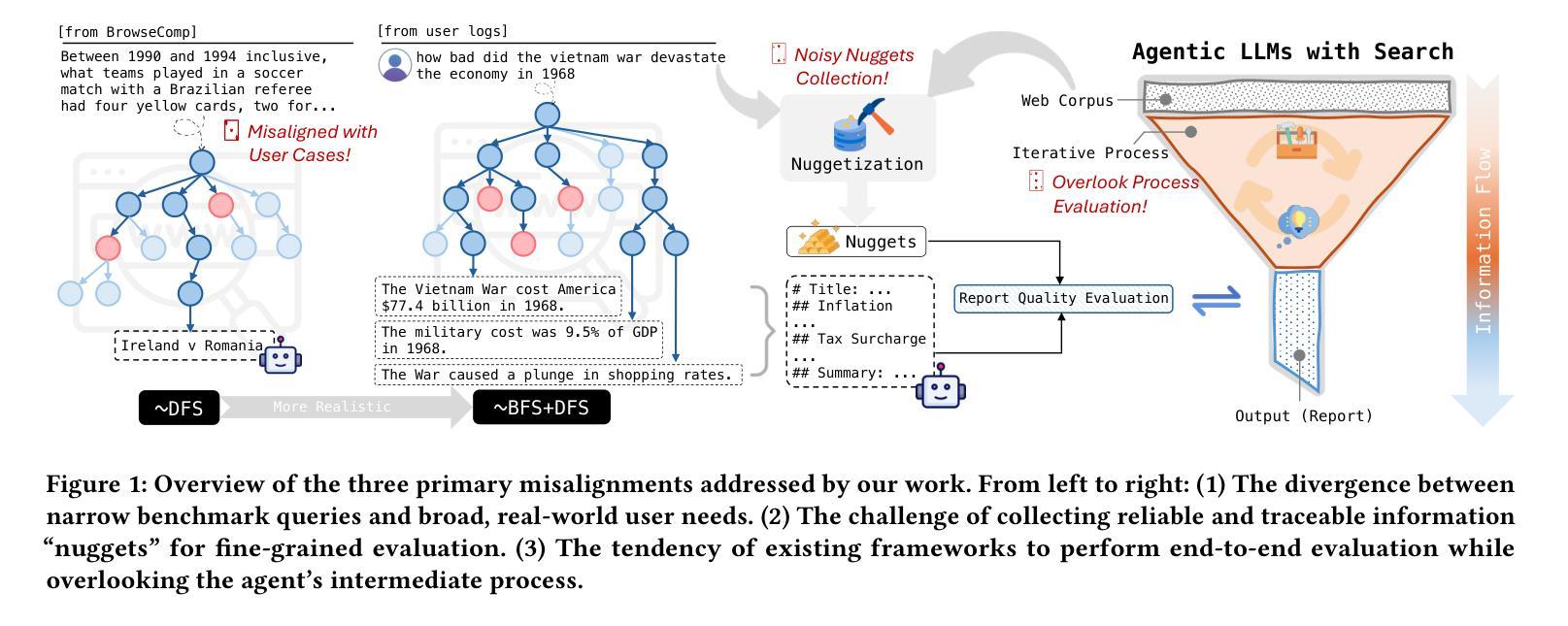
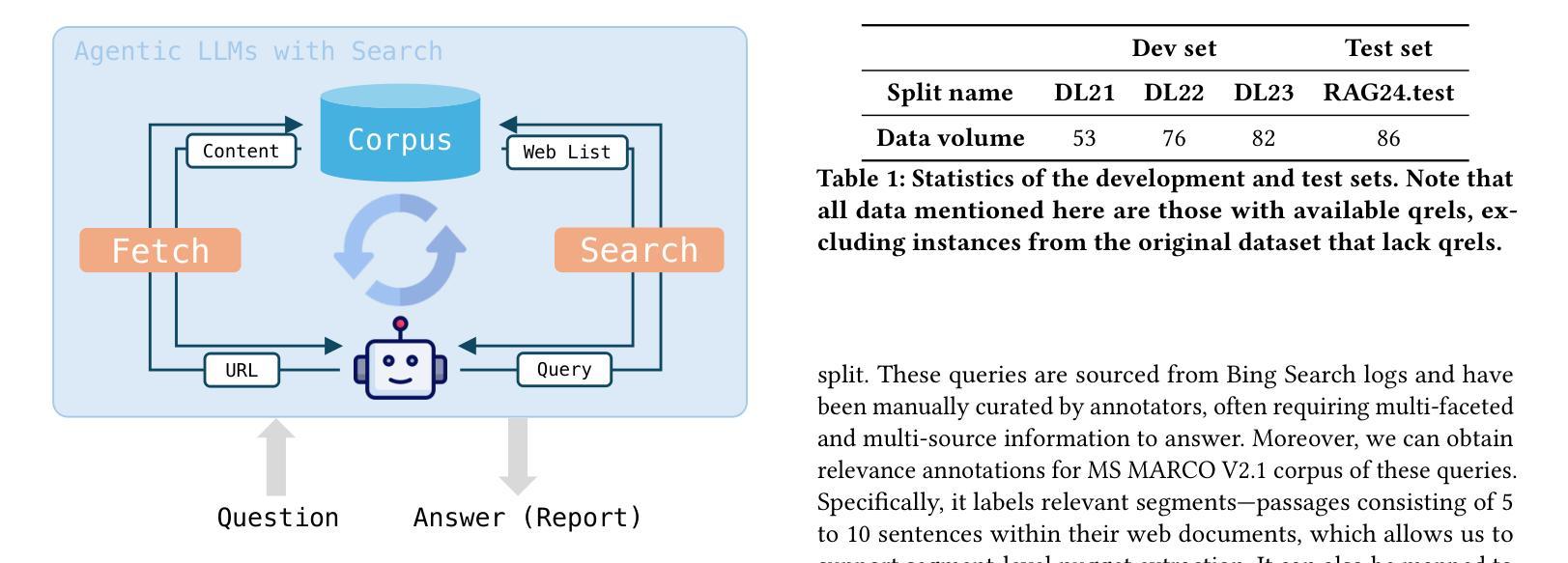
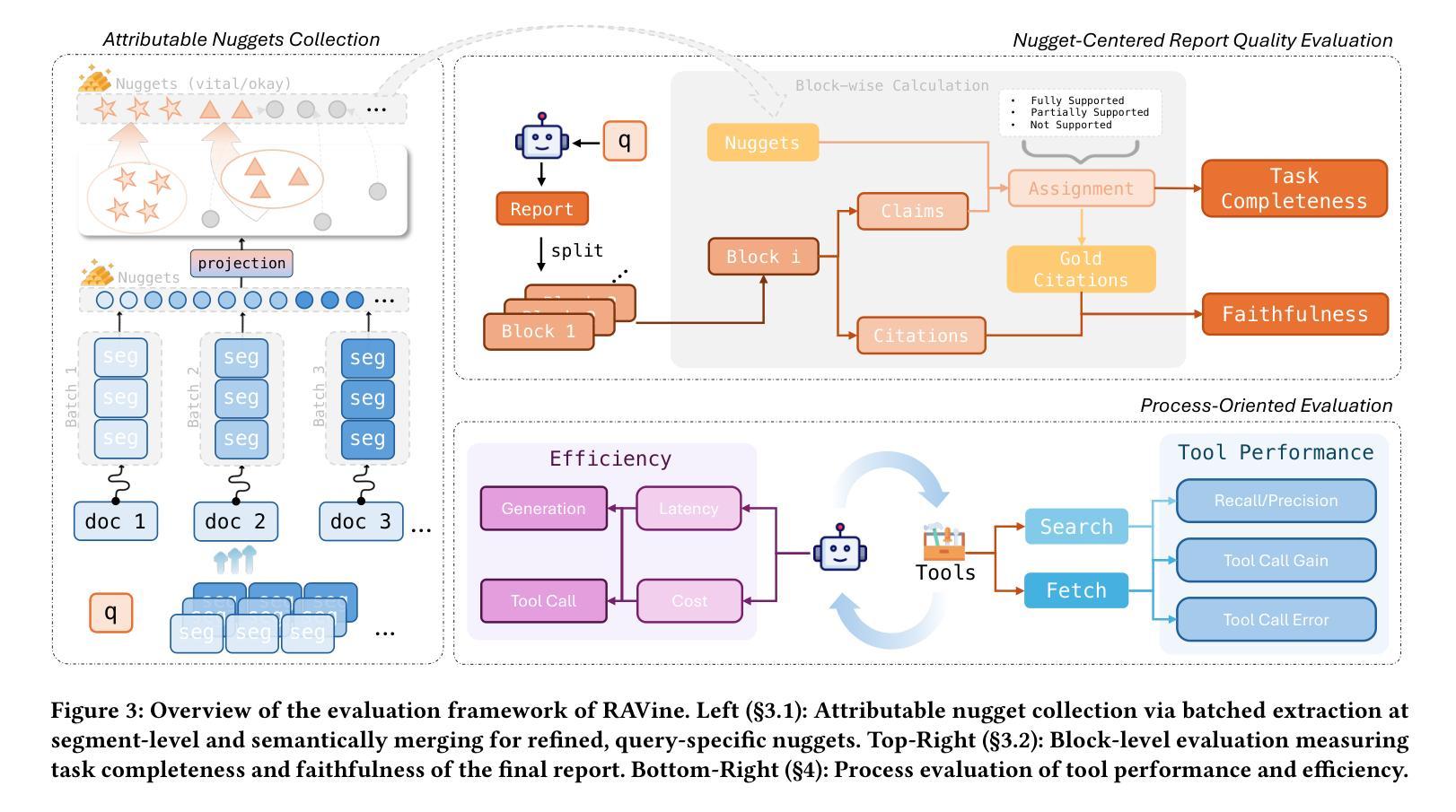
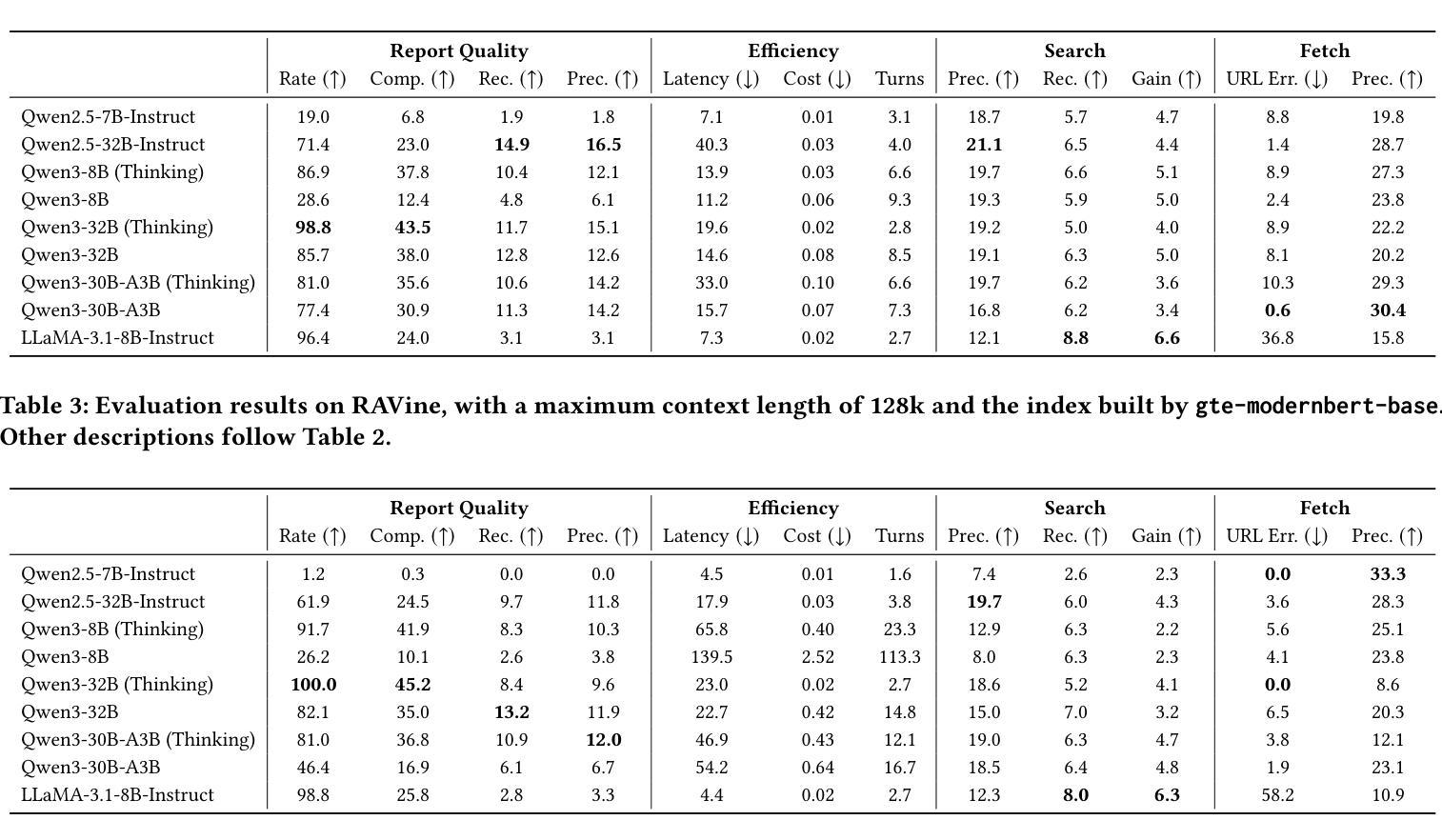
RAVine: Reality-Aligned Evaluation for Agentic Search
Authors:Yilong Xu, Xiang Long, Zhi Zheng, Jinhua Gao
Agentic search, as a more autonomous and adaptive paradigm of retrieval augmentation, is driving the evolution of intelligent search systems. However, existing evaluation frameworks fail to align well with the goals of agentic search. First, the complex queries commonly used in current benchmarks often deviate from realistic user search scenarios. Second, prior approaches tend to introduce noise when extracting ground truth for end-to-end evaluations, leading to distorted assessments at a fine-grained level. Third, most current frameworks focus solely on the quality of final answers, neglecting the evaluation of the iterative process inherent to agentic search. To address these limitations, we propose RAVine – a Reality-Aligned eValuation framework for agentic LLMs with search. RAVine targets multi-point queries and long-form answers that better reflect user intents, and introduces an attributable ground truth construction strategy to enhance the accuracy of fine-grained evaluation. Moreover, RAVine examines model’s interaction with search tools throughout the iterative process, and accounts for factors of efficiency. We benchmark a series of models using RAVine and derive several insights, which we hope will contribute to advancing the development of agentic search systems. The code and datasets are available at https://github.com/SwordFaith/RAVine.
代理搜索作为一种更加自主和适应性的检索增强范式,正在推动智能搜索系统的进化。然而,现有的评估框架与代理搜索的目标并不完全契合。首先,当前基准测试中常用的复杂查询常常偏离现实用户搜索场景。其次,先前的方法在提取端到端评估的基准真实数据时往往引入噪声,导致精细级别的评估失真。第三,大多数当前框架只关注最终答案的质量,忽视了代理搜索所固有的迭代过程的评估。为了解决这些局限性,我们提出了RAVine——一个与现实对齐的代理LLM搜索评估框架。RAVine旨在针对多点查询和长答案,以更好地反映用户意图,并引入可归属的基准真实数据构建策略,以提高精细评估的准确性。此外,RAVine还研究了模型在搜索工具迭代过程中的交互作用以及效率因素。我们使用RAVine对一系列模型进行基准测试,并获得了若干见解,我们希望这些见解能为推动代理搜索系统的发展做出贡献。代码和数据集可在https://github.com/SwordFaith/RAVine找到。
论文及项目相关链接
Summary
Agentic搜索作为更自主和适应性的检索增强范式,正推动智能搜索系统的进化。然而,现有的评估框架与agentic搜索的目标并不吻合。为解决此问题,我们提出了RAVine评估框架,该框架旨在针对多要点查询和长答案,更好地反映用户意图,并引入可归属的地面真实构建策略,提高精细评估的准确性。此外,RAVine还关注模型在搜索工具中的交互过程并考虑效率因素。我们使用该框架对一系列模型进行了基准测试,并获得了有助于推动agentic搜索系统发展的见解。
Key Takeaways
- Agentic搜索是智能搜索系统的重要发展方向,强调自主性和适应性。
- 现有评估框架与agentic搜索目标不吻合,存在对现实用户搜索场景的偏离、评估噪声和忽视迭代过程的问题。
- RAVine评估框架旨在解决这些问题,注重多要点查询和长答案的评估,更接近用户真实意图。
- RAVine引入可归属的地面真实构建策略,提高精细评估的准确性。
- RAVine关注模型在搜索工具中的交互过程,并考虑效率因素。
- 通过RAVine框架对一系列模型的基准测试,获得了有助于推动agentic搜索系统发展的见解。
点此查看论文截图

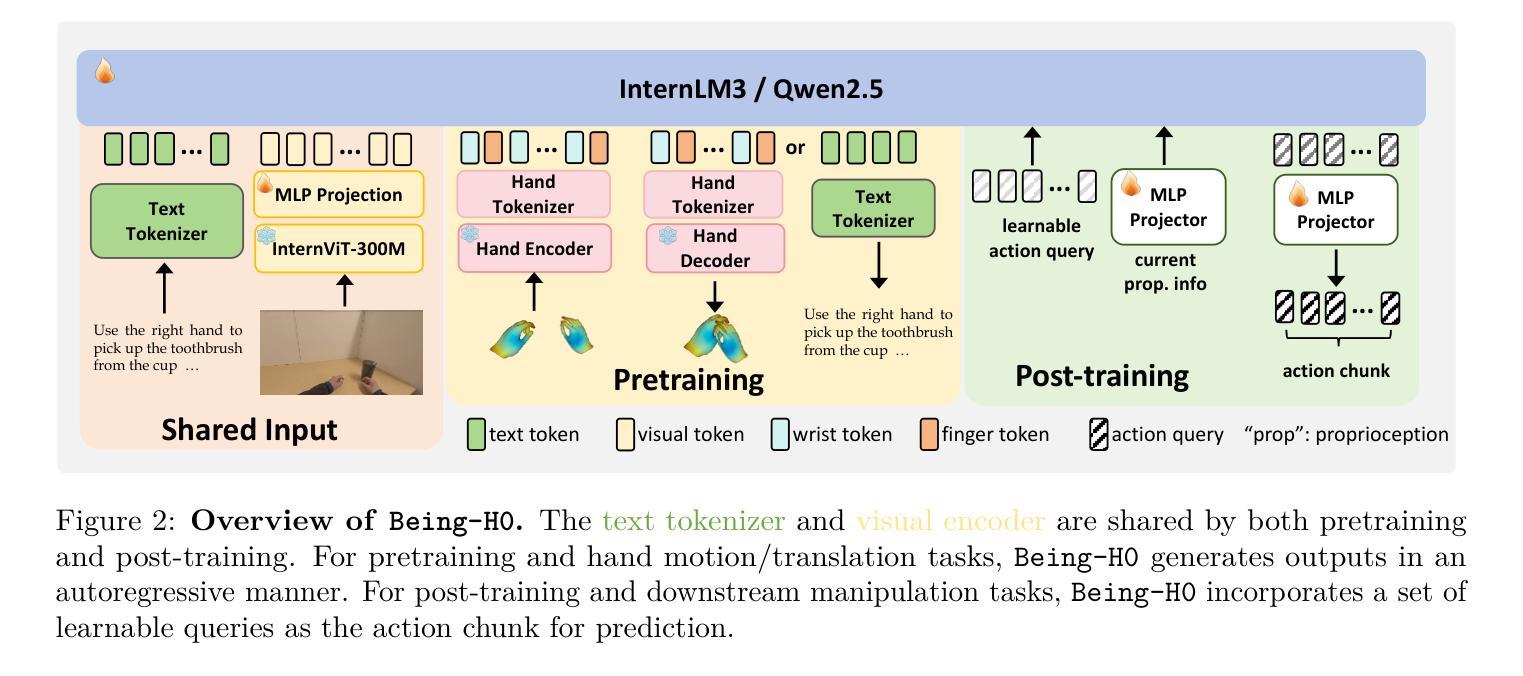
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
Authors:Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, Zongqing Lu
We introduce Being-H0, a dexterous Vision-Language-Action model (VLA) trained on large-scale human videos. Existing VLAs struggle with complex manipulation tasks requiring high dexterity and generalize poorly to novel scenarios and tasks, primarily due to their reliance on synthetic data with significant sim-to-real gaps or teleoperated demonstrations lacking scale and diversity. To address this data bottleneck, we propose leveraging human hands as a foundation manipulator, capitalizing on the rich dexterity and scalability present in web data. Our approach centers on physical instruction tuning, a novel training paradigm that combines large-scale VLA pretraining from human videos, physical space alignment for 3D reasoning, and post-training adaptation for robotic tasks. Additionally, we introduce a part-level motion tokenization method which achieves millimeter-level reconstruction accuracy to model precise hand trajectories for action learning. To support our proposed paradigm, we further develop a comprehensive data curation pipeline that integrates heterogeneous sources – including motion capture, VR, and RGB-only videos – into a large-scale dataset with millions of motion-based instructional instances. We empirically show the excellence of Being-H0 in hand motion generation and instruction following, and it also scales well with model and data sizes. Importantly, we observe the expected gains of Being-H0 in real-world robotic manipulation as physical instruction tuning is applied. More details are available at https://beingbeyond.github.io/Being-H0.
我们介绍了Being-H0,这是一个在大规模人类视频上训练的灵巧视觉语言动作模型(VLA)。现有的VLA在处理需要高度灵活性的复杂操作任务时遇到困难,并且在新型场景和任务中的泛化能力较差,这主要是因为它们依赖于存在模拟到现实差距的合成数据,或者缺乏规模和多样性的遥控演示。为了解决数据瓶颈问题,我们提议利用人类的手作为基础操纵器,利用网络数据的丰富灵活性和可扩展性。我们的方法以物理指令微调为核心,这是一种新型的训练范式,结合了人类视频的大规模VLA预训练、物理空间对齐进行3D推理和针对机器人任务的后期训练适应。此外,我们引入了一种部分级别的运动标记化方法,实现毫米级的重建精度,以模拟精确的手部轨迹进行动作学习。为了支持我们提出的范式,我们进一步开发了一个综合数据整理管道,该管道整合了包括动作捕捉、虚拟现实和仅RGB视频在内的各种来源,构建了一个大规模数据集,其中包含数百万基于动作的教学实例。我们从实证上展示了Being-H0在手部运动生成和指令遵循方面的卓越性能,并且它随着模型和数据规模的扩大而表现良好。重要的是,我们观察到在现实世界机器人操作应用Being-H0后产生了预期的效果提升。更多详细信息请访问:https://beingbeyond.github.io/Being-H0。
论文及项目相关链接
PDF 37 pages
Summary
基于大规模人类视频数据,我们引入了名为“Being-H0”的灵巧视觉语言动作模型(VLA)。现有VLAs在处理需要高灵巧性的复杂操作任务时表现挣扎,对于新场景和任务的泛化能力较差。这主要是因为它们依赖于存在显著模拟到现实差距的合成数据或缺乏规模和多样性的遥控演示。为了解决这个问题,我们提出利用人类手部作为基础操纵器,借助网络数据的丰富灵巧性和可扩展性。我们的方法以物理指令微调为中心,这是一个新颖的训练范式,它结合了人类视频的大规模VLA预训练、用于3D推理的物理空间对齐和用于机器人任务的后期训练适应。此外,我们还引入了一种部分级运动标记方法,实现了毫米级的重建精度,以模拟手部轨迹进行动作学习。为了支持我们的提议范式,我们进一步开发了一个综合数据整理管道,该管道整合了动作捕捉、虚拟现实和仅RGB视频等异质来源,形成一个包含数千万个动作指令实例的大规模数据集。我们在手部运动生成和指令遵循方面展示了Being-H0的卓越表现,它在模型和数据大小方面表现良好。在现实世界机器人操作应用物理指令微调后,我们观察到Being-H0的优异表现。更多详细信息请参见[链接地址]。
Key Takeaways
- Being-H0是一个基于大规模人类视频的灵巧视觉语言动作模型(VLA)。
- 现有VLAs在处理复杂操作任务时存在困难,泛化能力有限。
- 利用人类手部数据作为训练基础,结合网络数据的丰富性和可扩展性。
- 提出物理指令微调训练范式,结合预训练、物理空间对齐和后期训练适应。
- 引入部分级运动标记方法,实现精确的手部轨迹模拟。
- 开发综合数据整理管道,整合多种来源数据形成大规模数据集。
点此查看论文截图