⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
Improving Multimodal Contrastive Learning of Sentence Embeddings with Object-Phrase Alignment
Authors:Kaiyan Zhao, Zhongtao Miao, Yoshimasa Tsuruoka
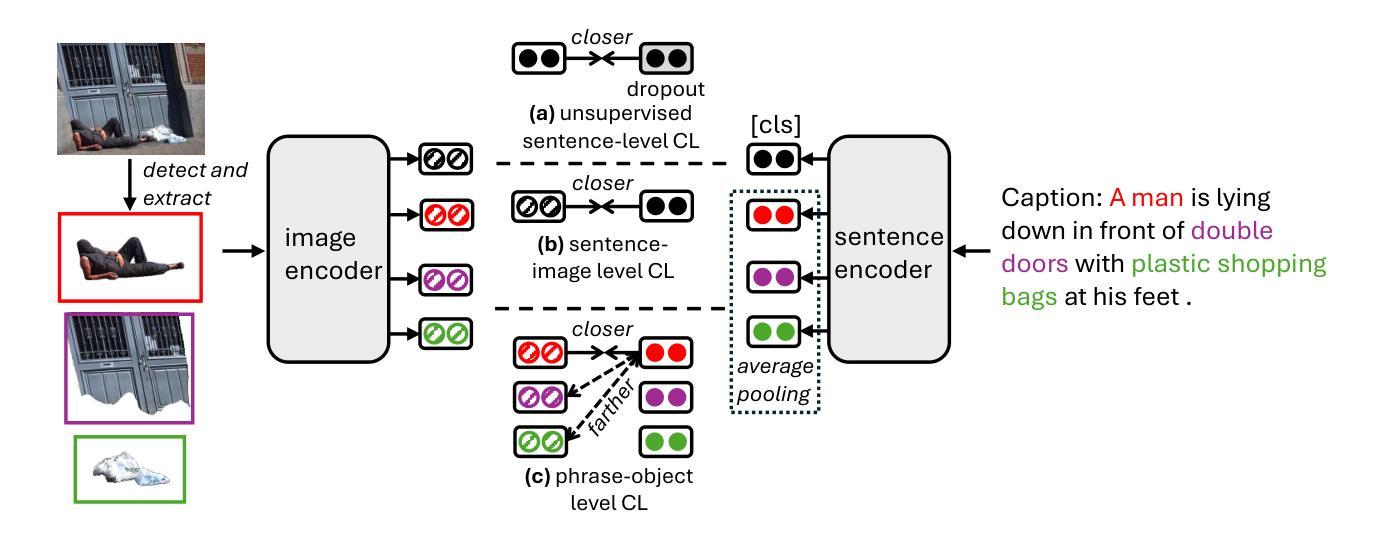
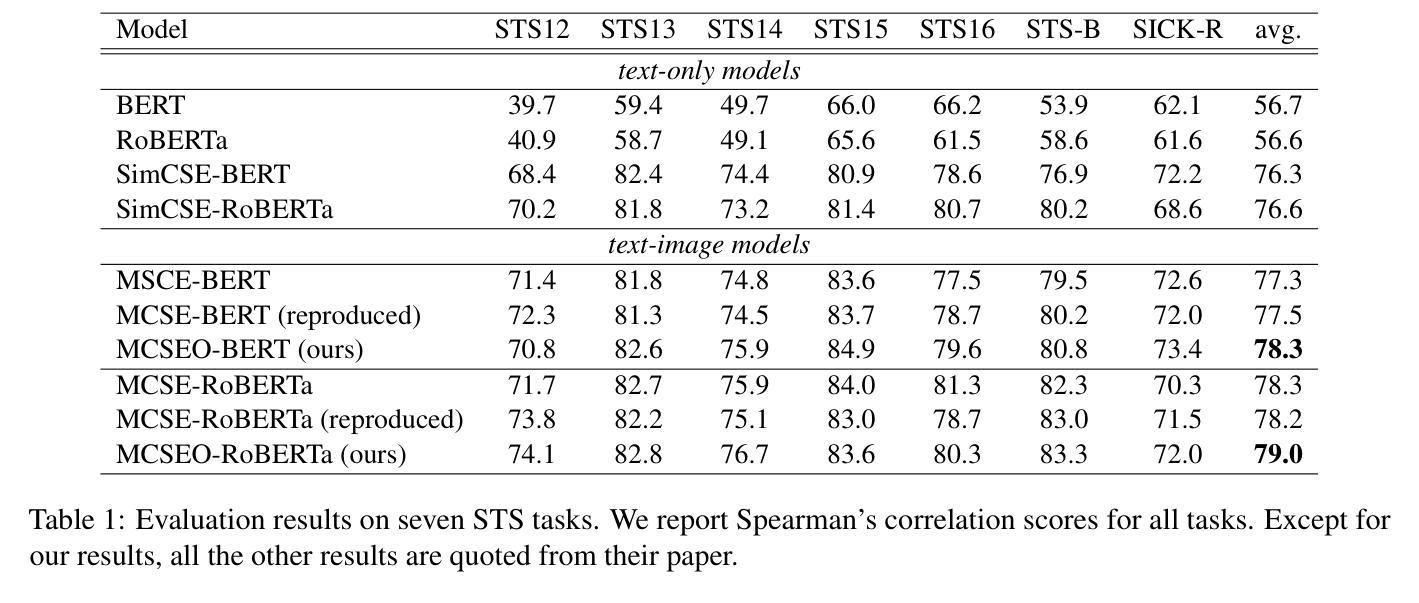
Multimodal sentence embedding models typically leverage image-caption pairs in addition to textual data during training. However, such pairs often contain noise, including redundant or irrelevant information on either the image or caption side. To mitigate this issue, we propose MCSEO, a method that enhances multimodal sentence embeddings by incorporating fine-grained object-phrase alignment alongside traditional image-caption alignment. Specifically, MCSEO utilizes existing segmentation and object detection models to extract accurate object-phrase pairs, which are then used to optimize a contrastive learning objective tailored to object-phrase correspondence. Experimental results on semantic textual similarity (STS) tasks across different backbone models demonstrate that MCSEO consistently outperforms strong baselines, highlighting the significance of precise object-phrase alignment in multimodal representation learning.
多模态句子嵌入模型在训练过程中除了文本数据外,通常还利用图像-字幕对。然而,这种配对往往包含噪声,包括图像或字幕方面的冗余或无关信息。为了解决这一问题,我们提出了MCSEO方法,通过结合传统的图像-字幕对齐和精细的对象短语对齐,增强多模态句子嵌入。具体来说,MCSEO利用现有的分割和对象检测模型来提取精确的对象短语对,然后用于优化针对对象短语对应关系的对比学习目标。在不同主干模型上的语义文本相似性(STS)任务的实验结果表明,MCSEO持续优于强基线,突显了精确对象短语对齐在多模态表示学习中的重要性。
论文及项目相关链接
PDF Work in progress
Summary
本文提出了一种名为MCSEO的方法,用于优化多模态句子嵌入。该方法通过结合精细的对象短语对齐与传统的图像-字幕对齐,提高了多模态句子嵌入的质量。MCSEO利用现有的分割和对象检测模型来提取准确的对象短语对,然后使用针对对象短语对应关系的对比学习目标进行优化。实验结果表明,MCSEO在跨不同骨干模型的语义文本相似性任务上始终优于强大的基线,突显了精确的对象短语对齐在多模态表示学习中的重要性。
Key Takeaways
- MCSEO方法旨在优化多模态句子嵌入,通过结合精细的对象短语对齐来提升模型性能。
- MCSEO利用现有技术提取对象短语对,这些对用于优化对比学习目标。
- 对比学习用于增强对象短语对应关系,有助于提高多模态表示学习的效果。
- 实验结果表明MCSEO在语义文本相似性任务上表现优异。
- MCSEO方法适用于多种不同的骨干模型,具有普遍适用性。
- 冗余和无关信息在多模态数据中的存在是一个问题,而MCSEO方法可以有效解决这一问题。
点此查看论文截图

MR-CLIP: Efficient Metadata-Guided Learning of MRI Contrast Representations
Authors:Mehmet Yigit Avci, Pedro Borges, Paul Wright, Mehmet Yigitsoy, Sebastien Ourselin, Jorge Cardoso
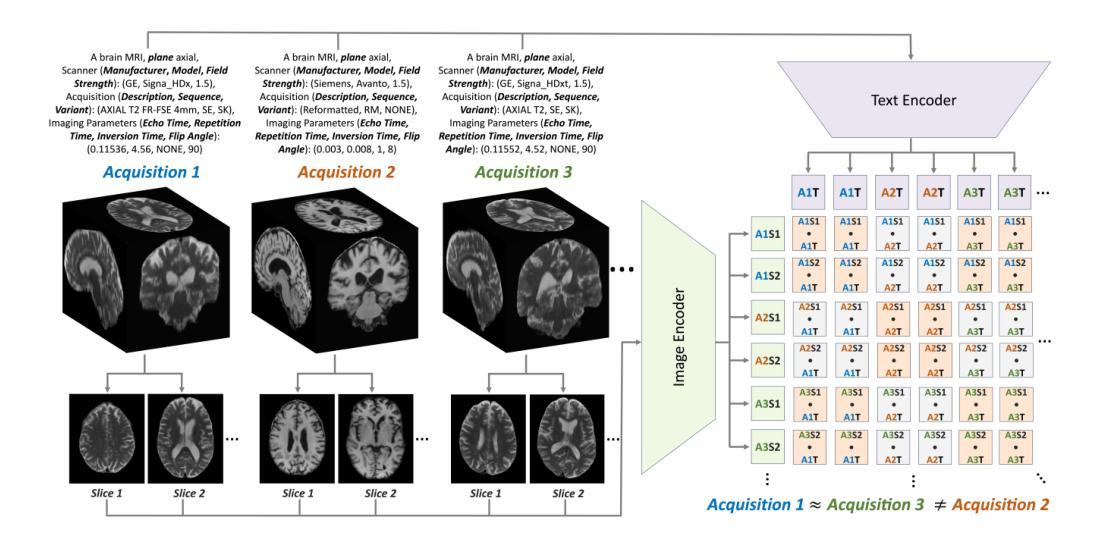
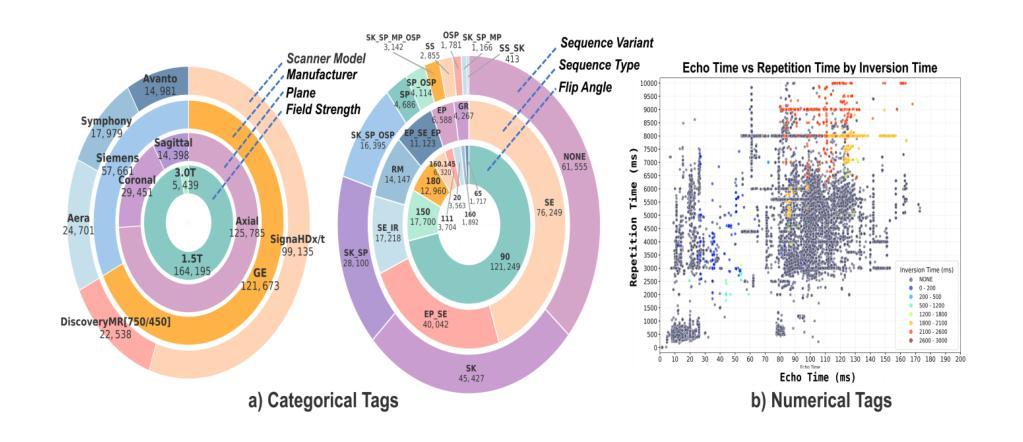
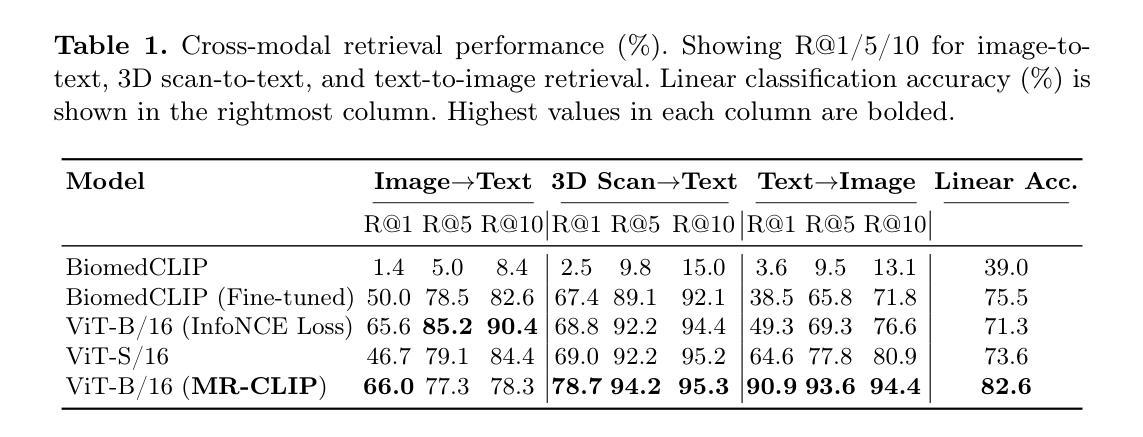
Accurate interpretation of Magnetic Resonance Imaging scans in clinical systems is based on a precise understanding of image contrast. This contrast is primarily governed by acquisition parameters, such as echo time and repetition time, which are stored in the DICOM metadata. To simplify contrast identification, broad labels such as T1-weighted or T2-weighted are commonly used, but these offer only a coarse approximation of the underlying acquisition settings. In many real-world datasets, such labels are entirely missing, leaving raw acquisition parameters as the only indicators of contrast. Adding to this challenge, the available metadata is often incomplete, noisy, or inconsistent. The lack of reliable and standardized metadata complicates tasks such as image interpretation, retrieval, and integration into clinical workflows. Furthermore, robust contrast-aware representations are essential to enable more advanced clinical applications, such as achieving modality-invariant representations and data harmonization. To address these challenges, we propose MR-CLIP, a multimodal contrastive learning framework that aligns MR images with their DICOM metadata to learn contrast-aware representations, without relying on manual labels. Trained on a diverse clinical dataset that spans various scanners and protocols, MR-CLIP captures contrast variations across acquisitions and within scans, enabling anatomy-invariant representations. We demonstrate its effectiveness in cross-modal retrieval and contrast classification, highlighting its scalability and potential for further clinical applications. The code and weights are publicly available at https://github.com/myigitavci/MR-CLIP.
磁共振成像在临床系统中的准确解读,基于对图像对比度的精确理解。这种对比度主要由采集参数决定,例如回波时间和重复时间,这些参数都存储在DICOM元数据中。为了简化对比度的识别,通常使用T1加权或T2加权等广泛标签,但这些仅提供了对基础采集设置的粗略近似。在许多真实世界的数据集中,这些标签完全缺失,只留下原始采集参数作为对比度的唯一指标。除此之外,现有的元数据通常不完整、嘈杂或不一致。缺乏可靠和标准化的元数据使图像解读、检索和整合到临床工作流程等任务变得复杂。此外,稳健的对比度感知表示对于实现更先进的临床应用至关重要,例如实现模态不变表示和数据协调。为了应对这些挑战,我们提出了MR-CLIP,这是一种多模态对比学习框架,它将MR图像与它们的DICOM元数据对齐,以学习对比度感知表示,而无需依赖手动标签。在跨越各种扫描器和协议的临床数据集上进行训练,MR-CLIP捕捉了跨采集和扫描内的对比度变化,实现了解剖结构不变的表示。我们在跨模态检索和对比度分类中展示了其有效性,突显了其可扩展性和潜在的临床应用价值。代码和权重可在https://github.com/myigitavci/MR-CLIP上公开获得。
论文及项目相关链接
Summary
本文介绍了磁共振成像(MRI)在临床系统中的准确解读依赖于对图像对比度的精确理解。文章强调了对比度的识别受到采集参数如回声时间和重复时间的影响,而这些信息被存储在DICOM元数据中。然而,现实世界的数据集中通常缺乏可靠的标准化元数据,这增加了图像解读、检索和集成到临床工作流程中的难度。为解决这些问题,本文提出了MR-CLIP,一个跨模态对比学习框架,通过MRI图像与其DICOM元数据的对齐来学习对比感知表示,无需依赖手动标签。该框架在跨越不同扫描仪和协议的多样临床数据集上进行训练,能够捕捉不同采集和扫描内的对比度变化,实现解剖结构不变的表示。
Key Takeaways
- 磁共振成像(MRI)的解读依赖于对图像对比度的精确理解。
- 图像对比度主要由回声时间和重复时间等采集参数决定,这些信息存储在DICOM元数据中。
- 在现实世界的临床数据集中,可靠的标准化元数据缺失,增加了图像解读和临床应用的难度。
- MR-CLIP是一个跨模态对比学习框架,通过对齐MRI图像和DICOM元数据来学习对比感知表示。
- MR-CLIP无需依赖手动标签,能够捕捉不同采集和扫描内的对比度变化。
- MR-CLIP在多样临床数据集上进行训练,并实现了解剖结构不变的表示。
点此查看论文截图