⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
Training-Free Class Purification for Open-Vocabulary Semantic Segmentation
Authors:Qi Chen, Lingxiao Yang, Yun Chen, Nailong Zhao, Jianhuang Lai, Jie Shao, Xiaohua Xie
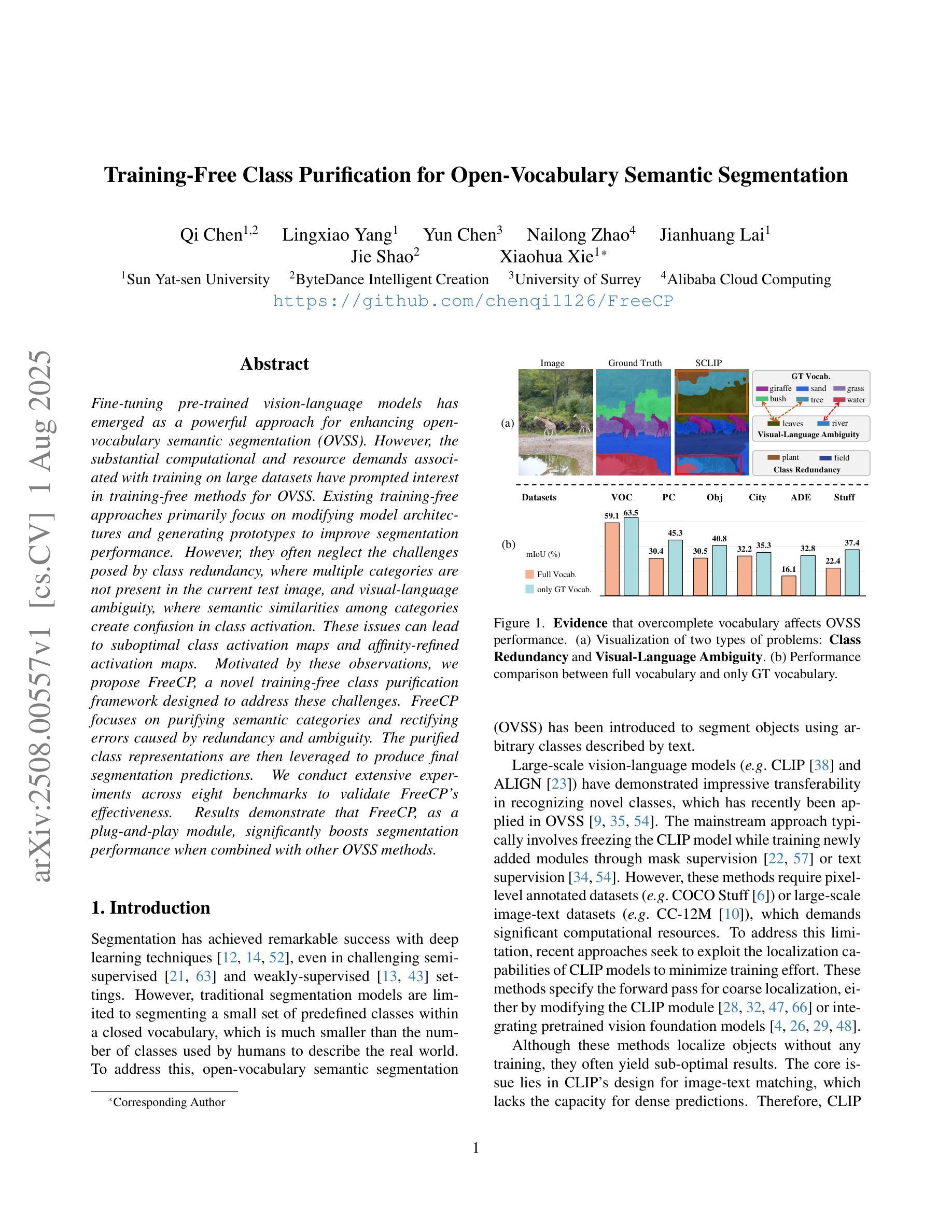
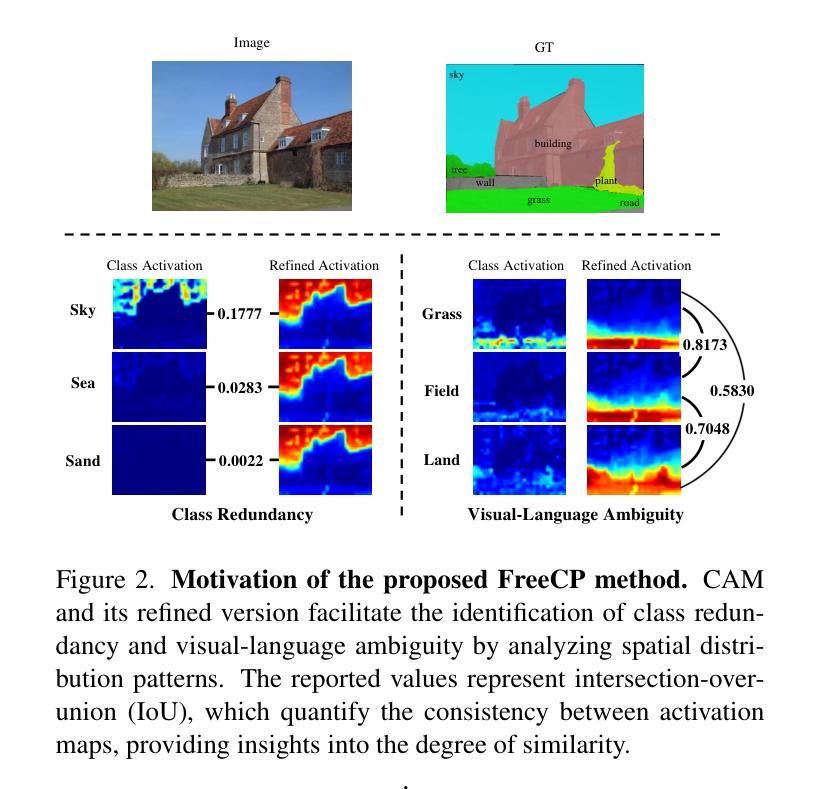
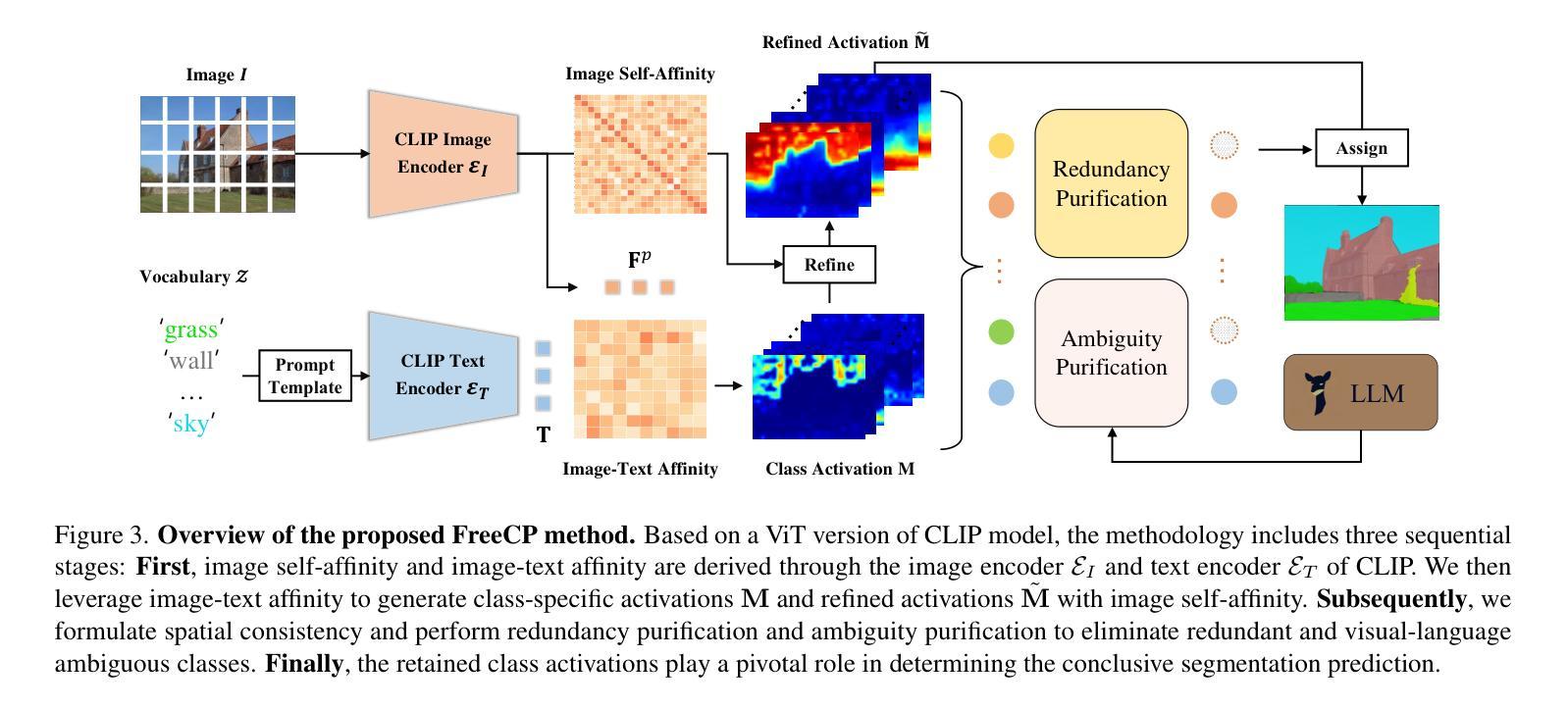
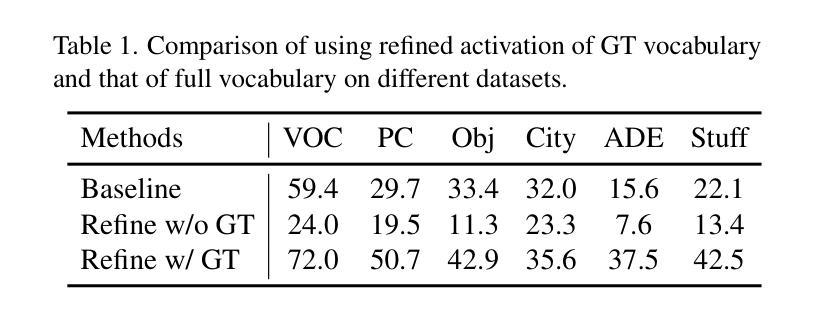
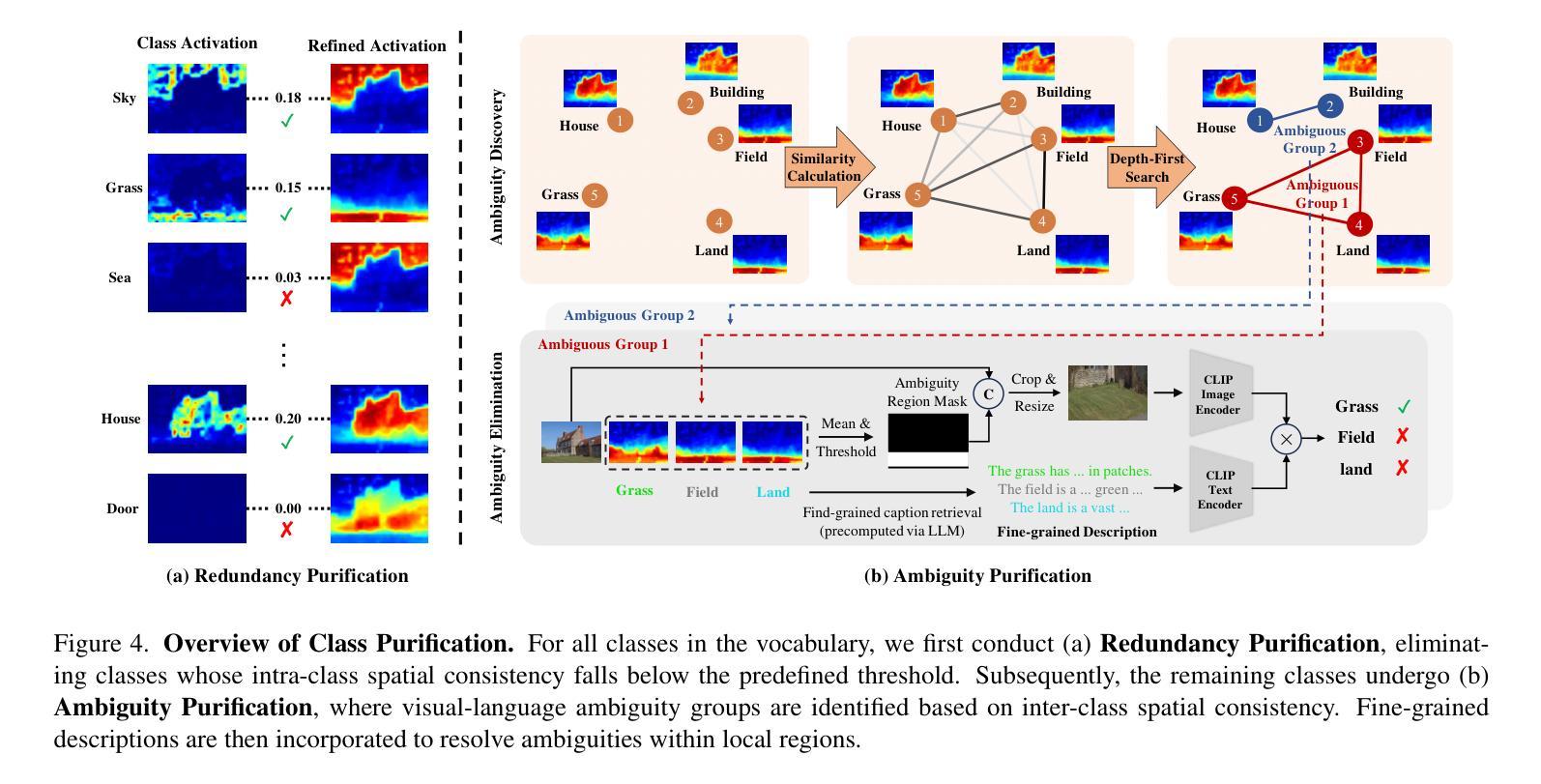
Fine-tuning pre-trained vision-language models has emerged as a powerful approach for enhancing open-vocabulary semantic segmentation (OVSS). However, the substantial computational and resource demands associated with training on large datasets have prompted interest in training-free methods for OVSS. Existing training-free approaches primarily focus on modifying model architectures and generating prototypes to improve segmentation performance. However, they often neglect the challenges posed by class redundancy, where multiple categories are not present in the current test image, and visual-language ambiguity, where semantic similarities among categories create confusion in class activation. These issues can lead to suboptimal class activation maps and affinity-refined activation maps. Motivated by these observations, we propose FreeCP, a novel training-free class purification framework designed to address these challenges. FreeCP focuses on purifying semantic categories and rectifying errors caused by redundancy and ambiguity. The purified class representations are then leveraged to produce final segmentation predictions. We conduct extensive experiments across eight benchmarks to validate FreeCP’s effectiveness. Results demonstrate that FreeCP, as a plug-and-play module, significantly boosts segmentation performance when combined with other OVSS methods.
微调预训练的视觉语言模型已成为增强开放词汇语义分割(OVSS)的强大方法。然而,大规模数据集训练所带来的巨大计算和资源需求促使人们关注无训练方法的OVSS。现有的无训练方法主要集中在修改模型架构和生成原型来提高分割性能。然而,它们往往忽视了类冗余带来的挑战,即当前测试图像中不存在多个类别,以及视觉语言模糊性带来的挑战,即类别之间的语义相似性会造成类激活中的混淆。这些问题可能导致次优的类激活图和亲和力精细激活图。受这些观察的启发,我们提出了FreeCP,一个新型的无训练类净化框架,旨在解决这些挑战。FreeCP专注于净化语义类别并纠正由冗余和模糊引起的错误。净化后的类表示用于生成最终的分割预测。我们在八个基准测试上进行了大量实验,验证了FreeCP的有效性。结果表明,作为一个即插即用的模块,FreeCP与其他OVSS方法相结合,能显著提高分割性能。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
预训练视觉语言模型的微调对于提高开放词汇语义分割(OVSS)的性能具有显著效果。然而,大型数据集的训练带来的巨大计算和资源需求促使人们寻找无需训练的方法。现有的无训练方法主要集中在改进模型架构和生成原型来提高分割性能,但它们忽视了类冗余和视觉语言模糊带来的挑战。为解决这些问题,本文提出了无需训练的分类净化框架FreeCP,用于净化语义类别并纠正冗余和模糊引起的错误。实验结果表明,FreeCP作为即插即用模块,能显著提高与其他OVSS方法结合的分割性能。
Key Takeaways
- 预训练视觉语言模型的微调对于提高开放词汇语义分割性能很重要。
- 无训练方法成为研究焦点,旨在改进模型架构和生成原型以提高分割性能。
- 现有方法忽视了类冗余和视觉语言模糊的挑战。
- 本文提出了无需训练的分类净化框架FreeCP,以解决类冗余和视觉语言模糊的问题。
- FreeCP通过净化语义类别并纠正错误来提高分割性能。
- 实验结果表明,FreeCP能显著提高与其他OVSS方法结合的分割性能。
点此查看论文截图
UIS-Mamba: Exploring Mamba for Underwater Instance Segmentation via Dynamic Tree Scan and Hidden State Weaken
Authors:Runmin Cong, Zongji Yu, Hao Fang, Haoyan Sun, Sam Kwong
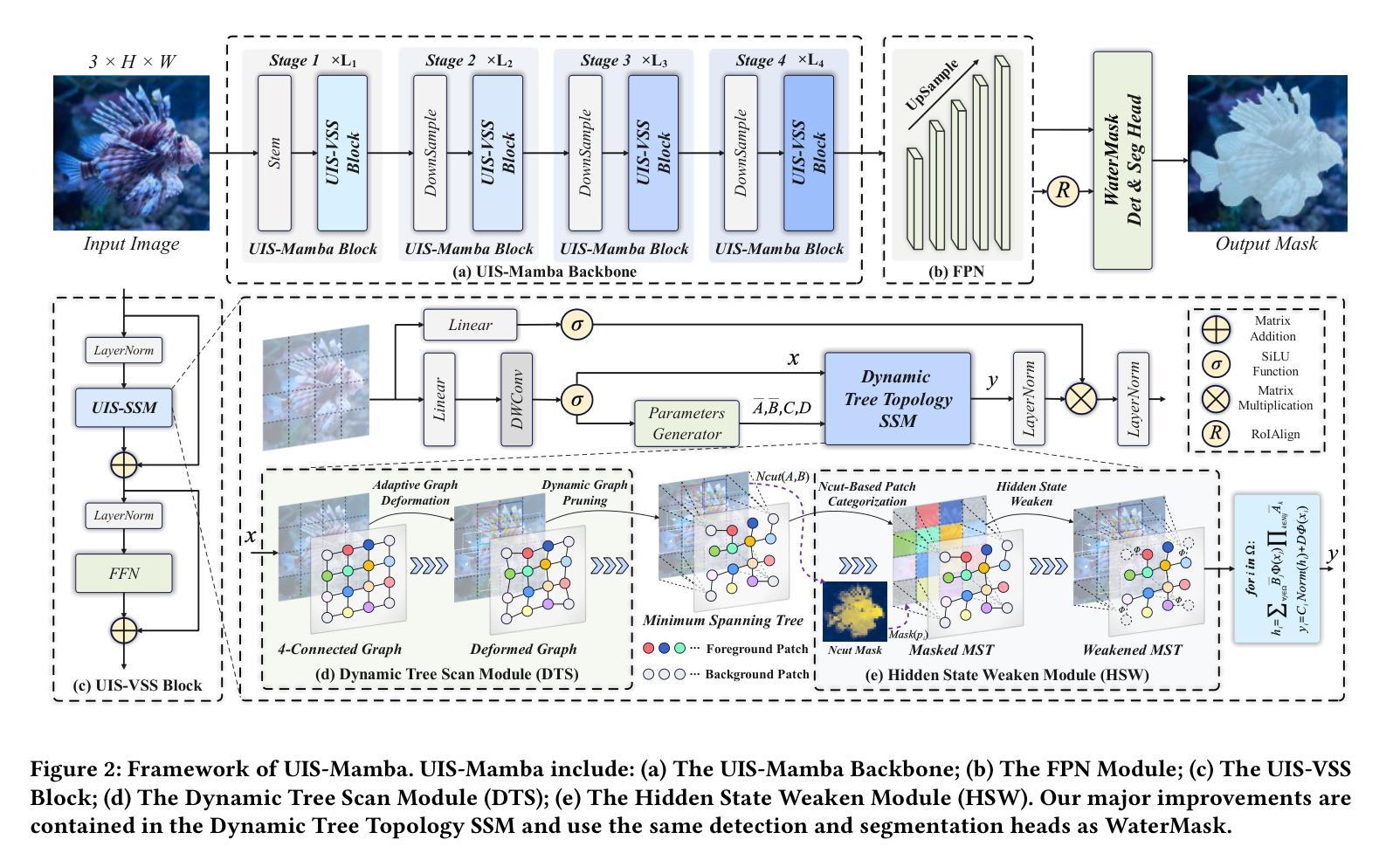
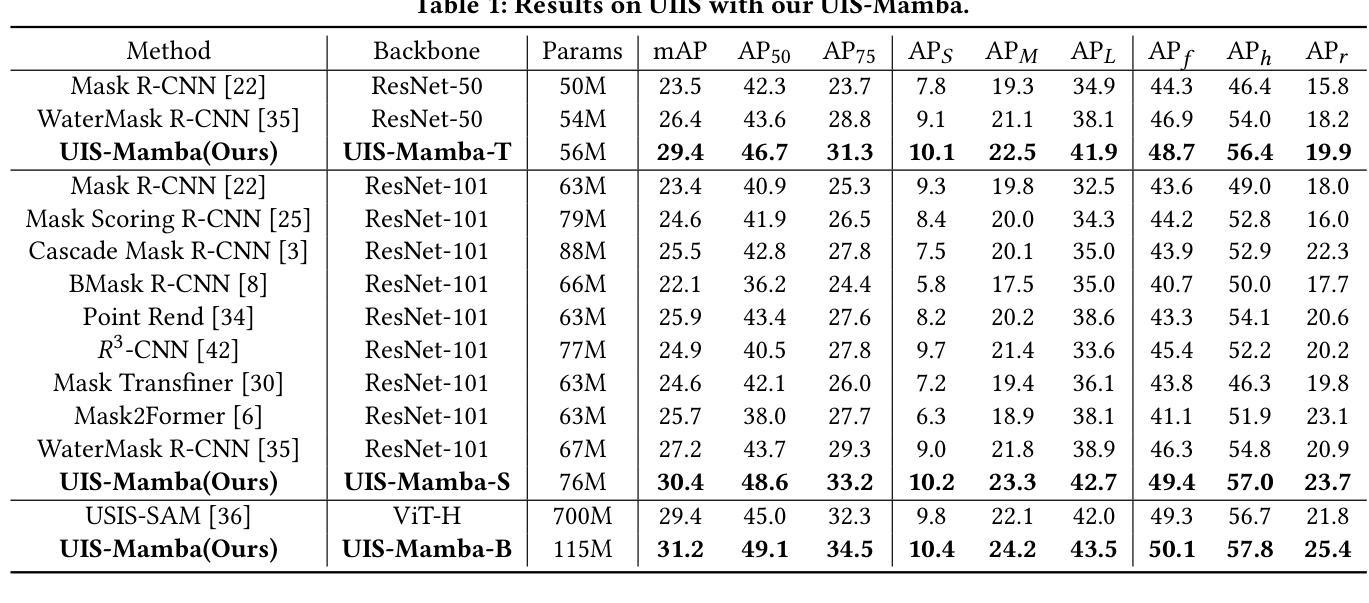
Underwater Instance Segmentation (UIS) tasks are crucial for underwater complex scene detection. Mamba, as an emerging state space model with inherently linear complexity and global receptive fields, is highly suitable for processing image segmentation tasks with long sequence features. However, due to the particularity of underwater scenes, there are many challenges in applying Mamba to UIS. The existing fixed-patch scanning mechanism cannot maintain the internal continuity of scanned instances in the presence of severely underwater color distortion and blurred instance boundaries, and the hidden state of the complex underwater background can also inhibit the understanding of instance objects. In this work, we propose the first Mamba-based underwater instance segmentation model UIS-Mamba, and design two innovative modules, Dynamic Tree Scan (DTS) and Hidden State Weaken (HSW), to migrate Mamba to the underwater task. DTS module maintains the continuity of the internal features of the instance objects by allowing the patches to dynamically offset and scale, thereby guiding the minimum spanning tree and providing dynamic local receptive fields. HSW module suppresses the interference of complex backgrounds and effectively focuses the information flow of state propagation to the instances themselves through the Ncut-based hidden state weakening mechanism. Experimental results show that UIS-Mamba achieves state-of-the-art performance on both UIIS and USIS10K datasets, while maintaining a low number of parameters and computational complexity. Code is available at https://github.com/Maricalce/UIS-Mamba.
水下实例分割(UIS)任务对于水下复杂场景检测至关重要。Mamba作为一种新兴的状态空间模型,具有固有的线性复杂度和全局感受野,非常适合处理具有长序列特征的图像分割任务。然而,由于水下场景的特殊性,将Mamba应用于UIS面临许多挑战。现有的固定补丁扫描机制无法在严重的水下色彩失真和模糊的实例边界的情况下保持扫描实例的内部连续性,而复杂的水下背景的隐藏状态也可能阻碍对实例对象的理解。在这项工作中,我们提出了基于Mamba的水下实例分割模型UIS-Mamba,并设计了两款创新模块,即动态树扫描(DTS)和隐藏状态减弱(HSW),以将Mamba迁移到水下任务。DTS模块通过允许补丁动态偏移和缩放,保持实例对象内部特征的连续性,从而引导最小生成树并提供动态局部感受野。HSW模块抑制了复杂背景的干扰,并通过基于Ncut的隐藏状态减弱机制,有效地将状态传播的信息流集中在实例本身上。实验结果表明,UIS-Mamba在UIIS和USIS10K数据集上均达到了最先进的性能,同时保持了较少的参数和计算复杂度。代码可在https://github.com/Maricalce/UIS-Mamba获得。
论文及项目相关链接
PDF ACM MM 2025
Summary
本文介绍了水下实例分割(UIS)任务的重要性以及面临的挑战。针对这些挑战,提出了基于Mamba的水下实例分割模型UIS-Mamba,并设计了两个创新模块:动态树扫描(DTS)和隐藏状态弱化(HSW)。DTS模块通过动态偏移和缩放补丁来保持实例对象内部特征的连续性,提供动态局部感受野。HSW模块抑制复杂背景的干扰,通过基于Ncut的隐藏状态弱化机制有效地将信息传播聚焦于实例本身。实验结果表明,UIS-Mamba在UIIS和USIS10K数据集上取得了最先进的性能,同时保持了较低的参数数量和计算复杂度。
Key Takeaways
- 水下实例分割(UIS)任务对水下复杂场景检测至关重要。
- Mamba作为一种具有内在线性复杂性和全局感受野的新兴状态空间模型,适合处理具有长序列特征的图像分割任务。
- 将Mamba应用于水下实例分割面临挑战,如水下场景的特殊性和现有固定补丁扫描机制的局限性。
- 提出的UIS-Mamba模型通过动态树扫描(DTS)和隐藏状态弱化(HSW)两个创新模块来应对这些挑战。
- DTS模块通过动态偏移和缩放补丁来保持实例对象内部特征的连续性。
- HSW模块通过基于Ncut的隐藏状态弱化机制抑制复杂背景的干扰,专注于实例本身的信息传播。
- UIS-Mamba在UIIS和USIS10K数据集上取得了最先进的性能,同时具有较低的参数数量和计算复杂度。
点此查看论文截图


CorrCLIP: Reconstructing Patch Correlations in CLIP for Open-Vocabulary Semantic Segmentation
Authors:Dengke Zhang, Fagui Liu, Quan Tang
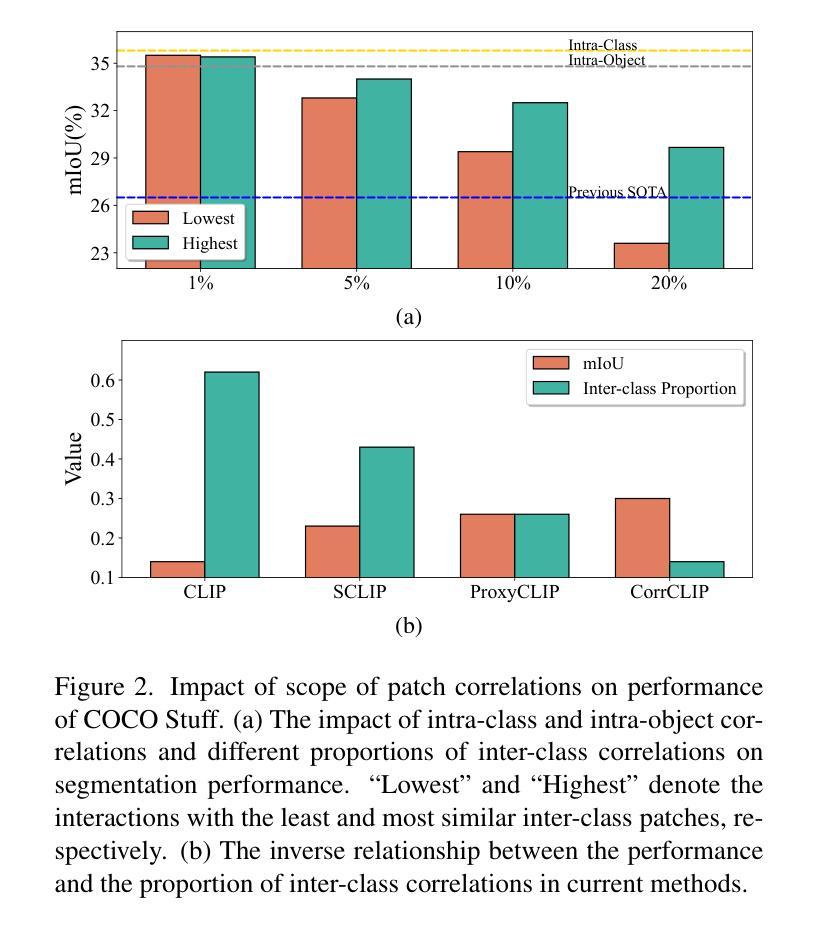
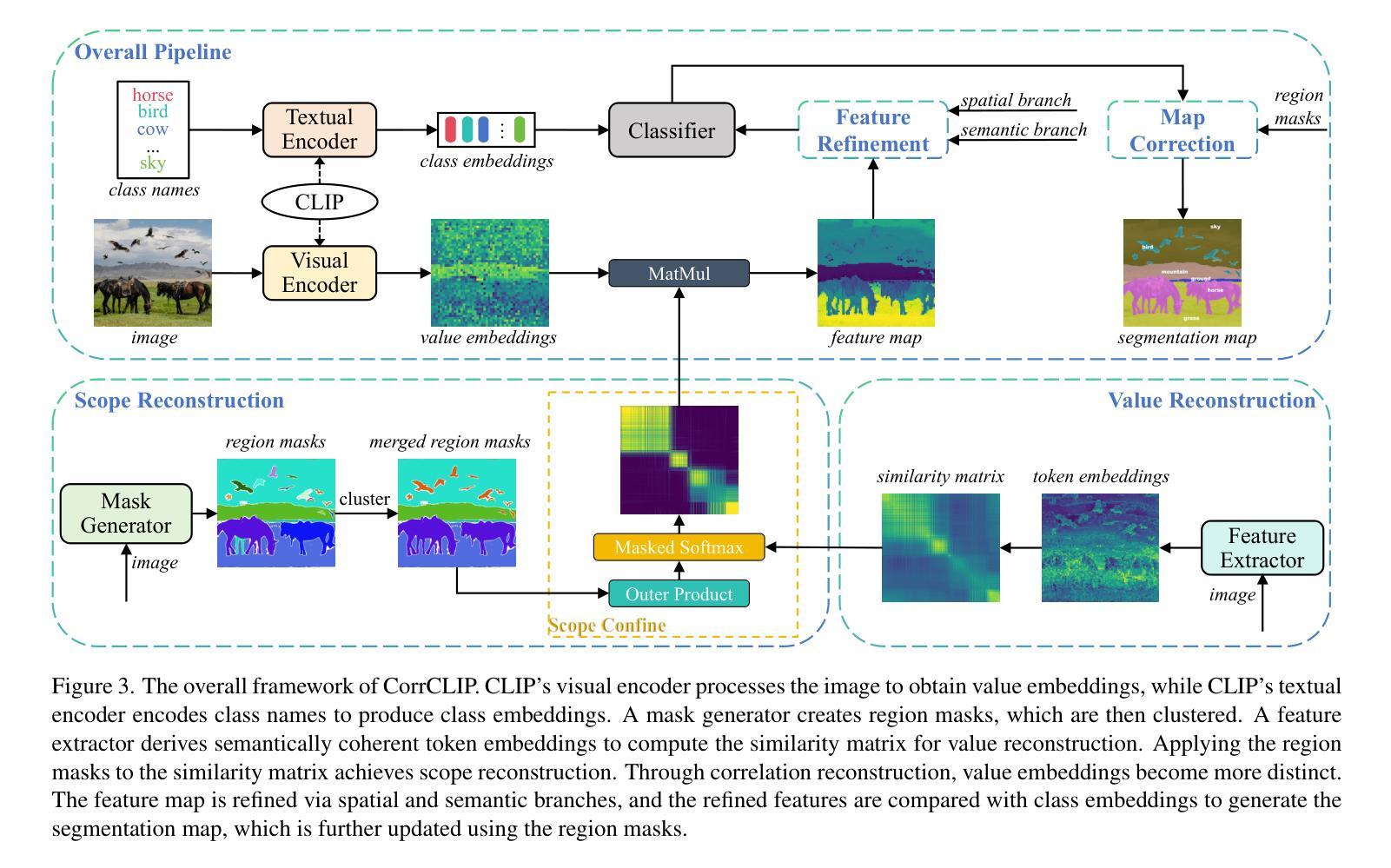
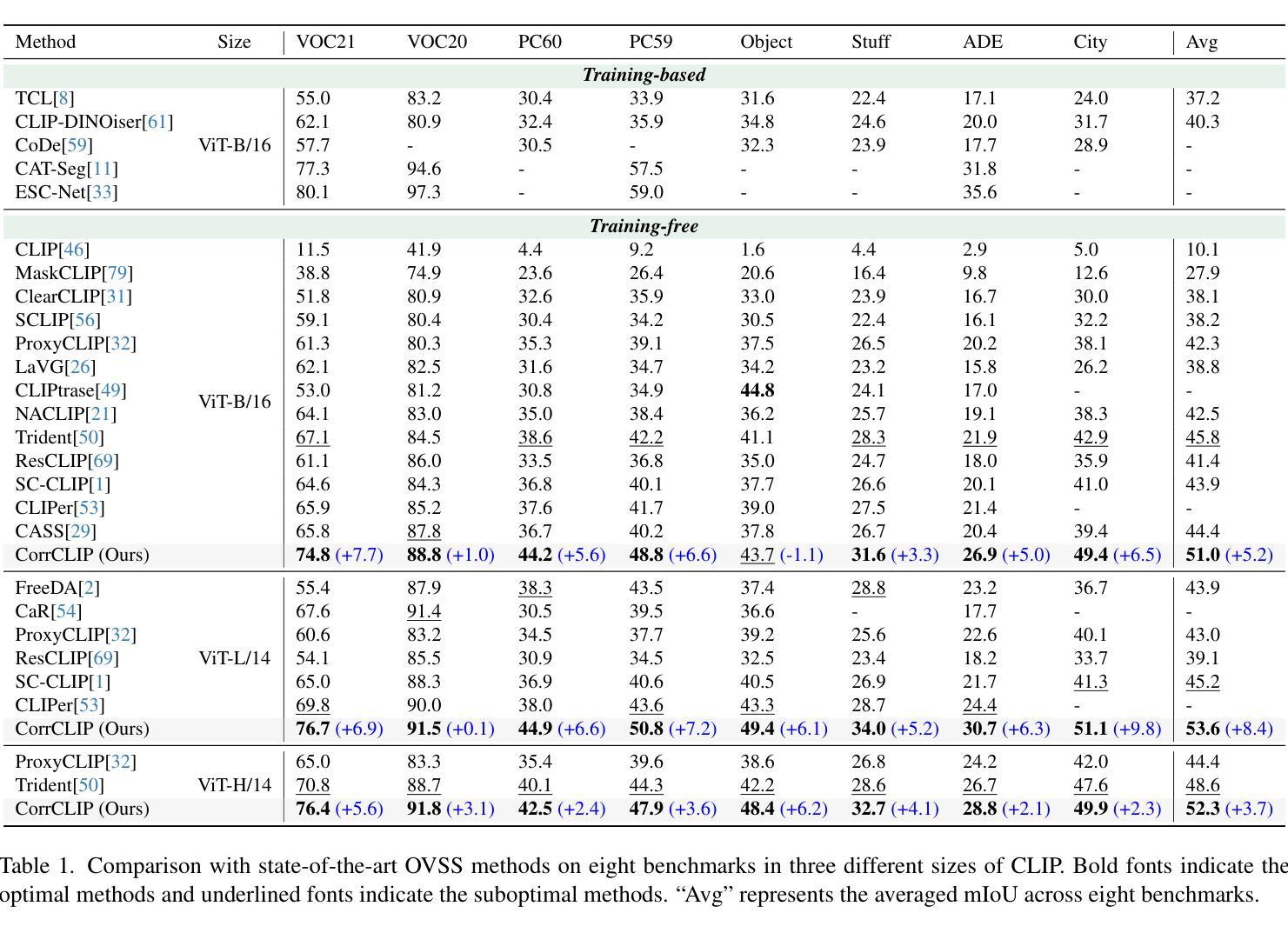
Open-vocabulary semantic segmentation aims to assign semantic labels to each pixel without being constrained by a predefined set of categories. While Contrastive Language-Image Pre-training (CLIP) excels in zero-shot classification, it struggles to align image patches with category embeddings because of its incoherent patch correlations. This study reveals that inter-class correlations are the main reason for impairing CLIP’s segmentation performance. Accordingly, we propose CorrCLIP, which reconstructs the scope and value of patch correlations. Specifically, CorrCLIP leverages the Segment Anything Model (SAM) to define the scope of patch interactions, reducing inter-class correlations. To mitigate the problem that SAM-generated masks may contain patches belonging to different classes, CorrCLIP incorporates self-supervised models to compute coherent similarity values, suppressing the weight of inter-class correlations. Additionally, we introduce two additional branches to strengthen patch features’ spatial details and semantic representation. Finally, we update segmentation maps with SAM-generated masks to improve spatial consistency. Based on the improvement across patch correlations, feature representations, and segmentation maps, CorrCLIP achieves superior performance across eight benchmarks. Codes are available at: https://github.com/zdk258/CorrCLIP.
开放词汇语义分割旨在为每个像素分配语义标签,而不受预设类别集的约束。虽然对比语言图像预训练(CLIP)在零样本分类方面表现出色,但由于其不连贯的补丁相关性,它很难将图像补丁与类别嵌入对齐。本研究表明,类间相关性是损害CLIP分割性能的主要原因。因此,我们提出了CorrCLIP,它重构了补丁相关性的范围和价值。具体来说,CorrCLIP利用万能分割模型(SAM)定义补丁交互的范围,减少类间相关性。为了解决SAM生成的蒙版可能包含属于不同类别的补丁的问题,CorrCLIP结合自监督模型计算连贯的相似度值,抑制类间相关性的权重。此外,我们还引入了另外两个分支,以增强补丁特征的空间细节和语义表示。最后,我们用SAM生成的蒙版更新分割图,以提高空间一致性。基于补丁相关性、特征表示和分割图的改进,CorrCLIP在八个基准测试中实现了卓越的性能。代码可在以下网址找到:https://github.com/zdk258/CorrCLIP。
论文及项目相关链接
PDF Accepted to ICCV 2025 Oral
Summary
本文介绍了开放词汇语义分割技术的新进展。针对Contrastive Language-Image Pre-training(CLIP)在处理图像分割时的不足,提出了一种名为CorrCLIP的新方法。该方法通过重建图像块间的相关性范围和价值,提高了CLIP在语义分割方面的性能。具体来说,CorrCLIP利用Segment Anything Model(SAM)定义图像块交互的范围,减少类间相关性。同时,通过引入自监督模型计算一致的相似度值,抑制类间相关性的权重。此外,还加强了图像块特征的空间细节和语义表示。最终,通过更新分割图,提高了空间一致性,并在八个基准测试中取得了卓越的性能。
Key Takeaways
- 开放词汇语义分割旨在为每个像素分配语义标签,不受预定义类别集的约束。
- Contrastive Language-Image Pre-training(CLIP)在零样本分类方面表现出色,但在图像分割方面存在挑战。
- CorrCLIP方法旨在提高CLIP在语义分割方面的性能,通过重建图像块间的相关性范围和价值来解决类间相关性问题。
- CorrCLIP利用Segment Anything Model(SAM)来定义图像块交互的范围,并减少类间相关性。
- 为了解决SAM生成的掩膜可能包含属于不同类的补丁的问题,CorrCLIP引入了自监督模型来计算一致的相似度值。
- CorrCLIP通过引入两个额外的分支来加强图像块特征的空间细节和语义表示。
点此查看论文截图