⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
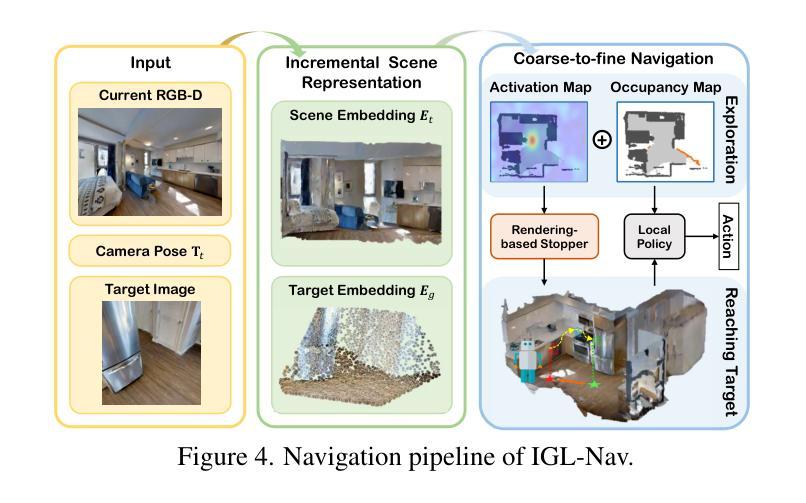
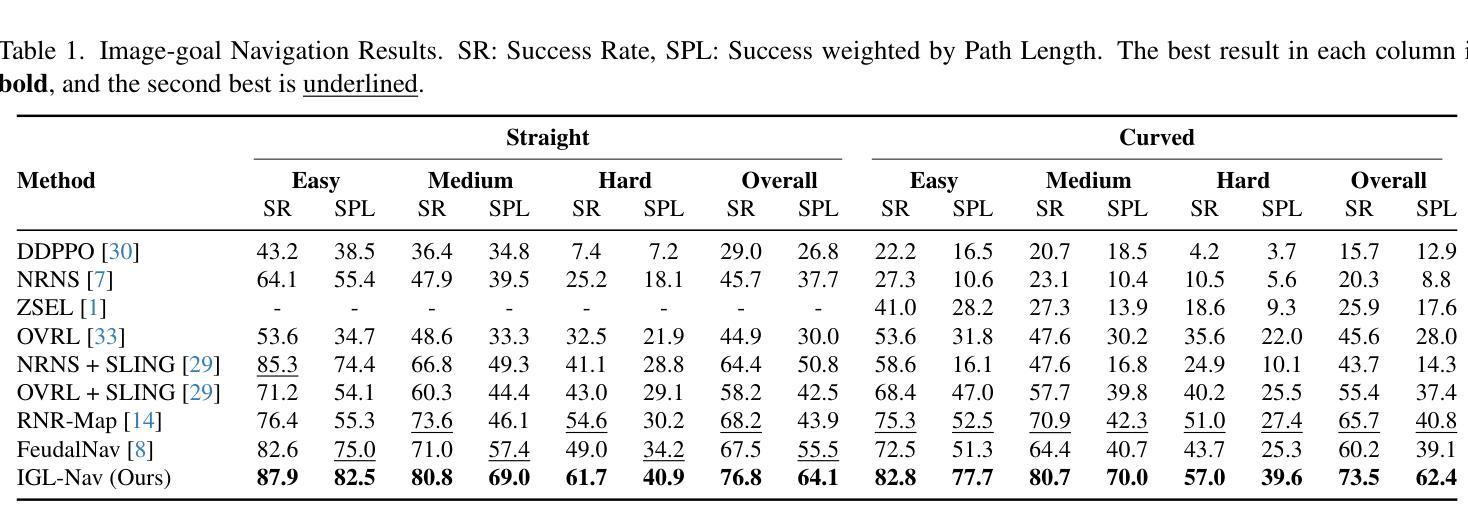
IGL-Nav: Incremental 3D Gaussian Localization for Image-goal Navigation
Authors:Wenxuan Guo, Xiuwei Xu, Hang Yin, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu
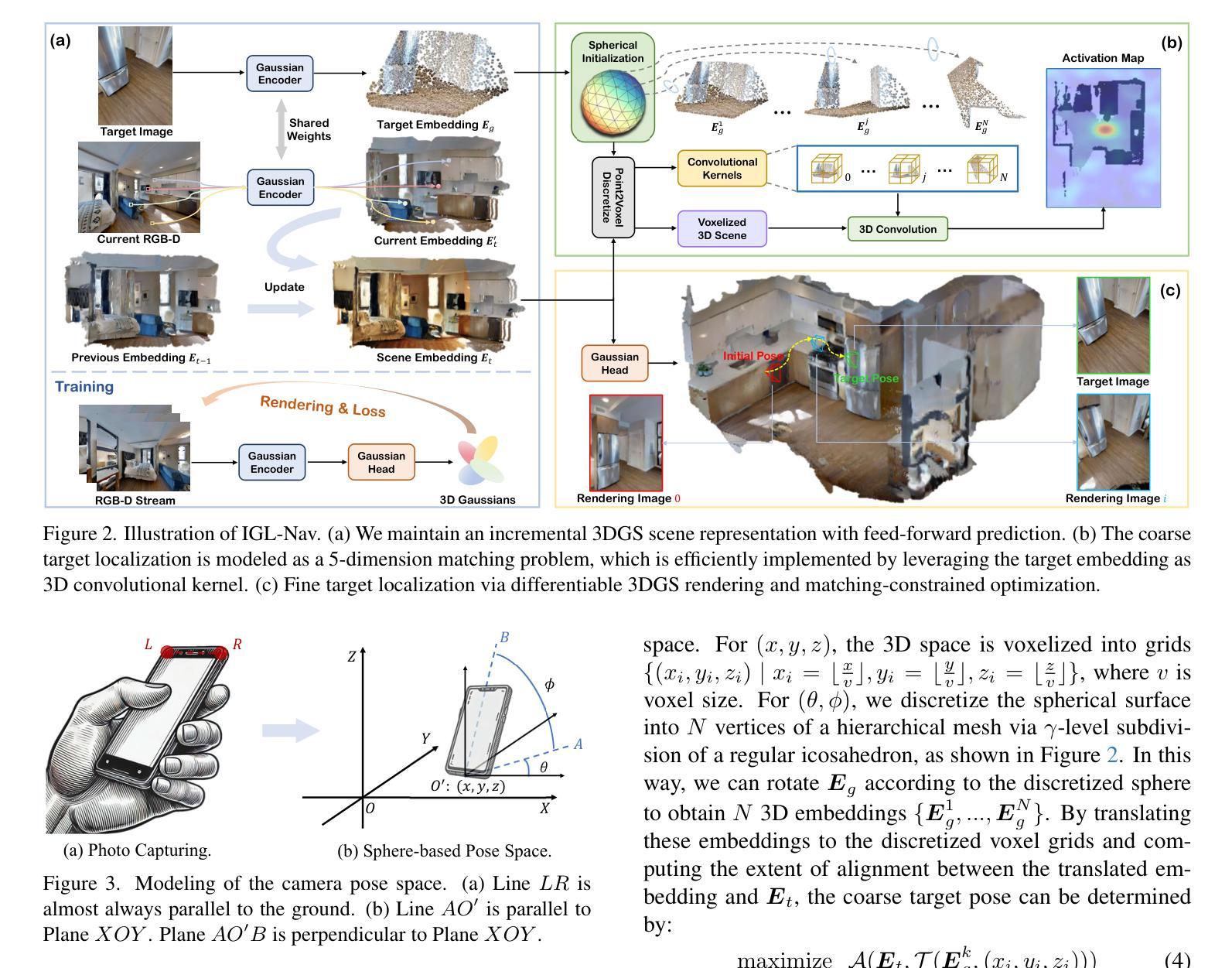
Visual navigation with an image as goal is a fundamental and challenging problem. Conventional methods either rely on end-to-end RL learning or modular-based policy with topological graph or BEV map as memory, which cannot fully model the geometric relationship between the explored 3D environment and the goal image. In order to efficiently and accurately localize the goal image in 3D space, we build our navigation system upon the renderable 3D gaussian (3DGS) representation. However, due to the computational intensity of 3DGS optimization and the large search space of 6-DoF camera pose, directly leveraging 3DGS for image localization during agent exploration process is prohibitively inefficient. To this end, we propose IGL-Nav, an Incremental 3D Gaussian Localization framework for efficient and 3D-aware image-goal navigation. Specifically, we incrementally update the scene representation as new images arrive with feed-forward monocular prediction. Then we coarsely localize the goal by leveraging the geometric information for discrete space matching, which can be equivalent to efficient 3D convolution. When the agent is close to the goal, we finally solve the fine target pose with optimization via differentiable rendering. The proposed IGL-Nav outperforms existing state-of-the-art methods by a large margin across diverse experimental configurations. It can also handle the more challenging free-view image-goal setting and be deployed on real-world robotic platform using a cellphone to capture goal image at arbitrary pose. Project page: https://gwxuan.github.io/IGL-Nav/.
以图像为目标的视觉导航是一个基本且具有挑战性的问题。传统方法要么依赖于端到端的强化学习,要么基于拓扑图或BEV地图作为记忆模块的策略,它们无法完全建模探索的3D环境与目标图像之间的几何关系。为了高效且准确地定位3D空间中的目标图像,我们基于可渲染的3D高斯(3DGS)表示构建我们的导航系统。然而,由于3DGS优化的计算强度大,以及6自由度相机姿态的搜索空间大,直接在代理探索过程中利用3DGS进行图像定位是非常低效的。为此,我们提出了IGL-Nav,这是一个用于高效且具备3D感知能力的以图像为目标的导航的增量3D高斯定位框架。具体来说,我们随着新图像的到达,通过前馈单目预测来增量地更新场景表示。然后,我们利用几何信息进行离散空间匹配,粗略地定位目标,这可以等同于高效的3D卷积。当代理接近目标时,我们最终通过可微分渲染进行优化,解决精细的目标姿态问题。所提出的IGL-Nav在各种实验配置中大幅超越了现有的最先进的方法。它还可以处理更具挑战性的自由视图图像目标设置,并可在实际机器人平台上部署,使用移动电话捕获任意姿态的目标图像。项目页面:https://gwxuan.github.io/IGL-Nav/。
论文及项目相关链接
PDF Accepted to ICCV 2025. Project page: https://gwxuan.github.io/IGL-Nav/
Summary
本文提出了一种基于增量式三维高斯定位框架(IGL-Nav)的图像导向三维导航方法。该方法解决了在探索过程中直接在三维空间进行图像定位计算量大、效率低的问题。它通过逐步更新场景表示和利用几何信息进行粗略定位,再结合优化可微分渲染进行精细定位,实现了高效的三维感知图像导航。此方法在多种实验配置下均超越现有技术,可应用于更复杂的自由视角图像目标设置,并可部署在真实机器人平台上使用。
Key Takeaways
- 提出了一种基于增量式三维高斯定位框架(IGL-Nav)的图像导向三维导航方法。
- 解决了传统方法无法充分建模探索的三维环境与目标图像之间几何关系的问题。
- 通过逐步更新场景表示和利用几何信息进行粗略定位,提高了效率。
- 结合优化可微分渲染进行精细定位,提高了定位准确性。
- 在多种实验配置下超越了现有技术。
- 可应用于更复杂的自由视角图像目标设置。
点此查看论文截图

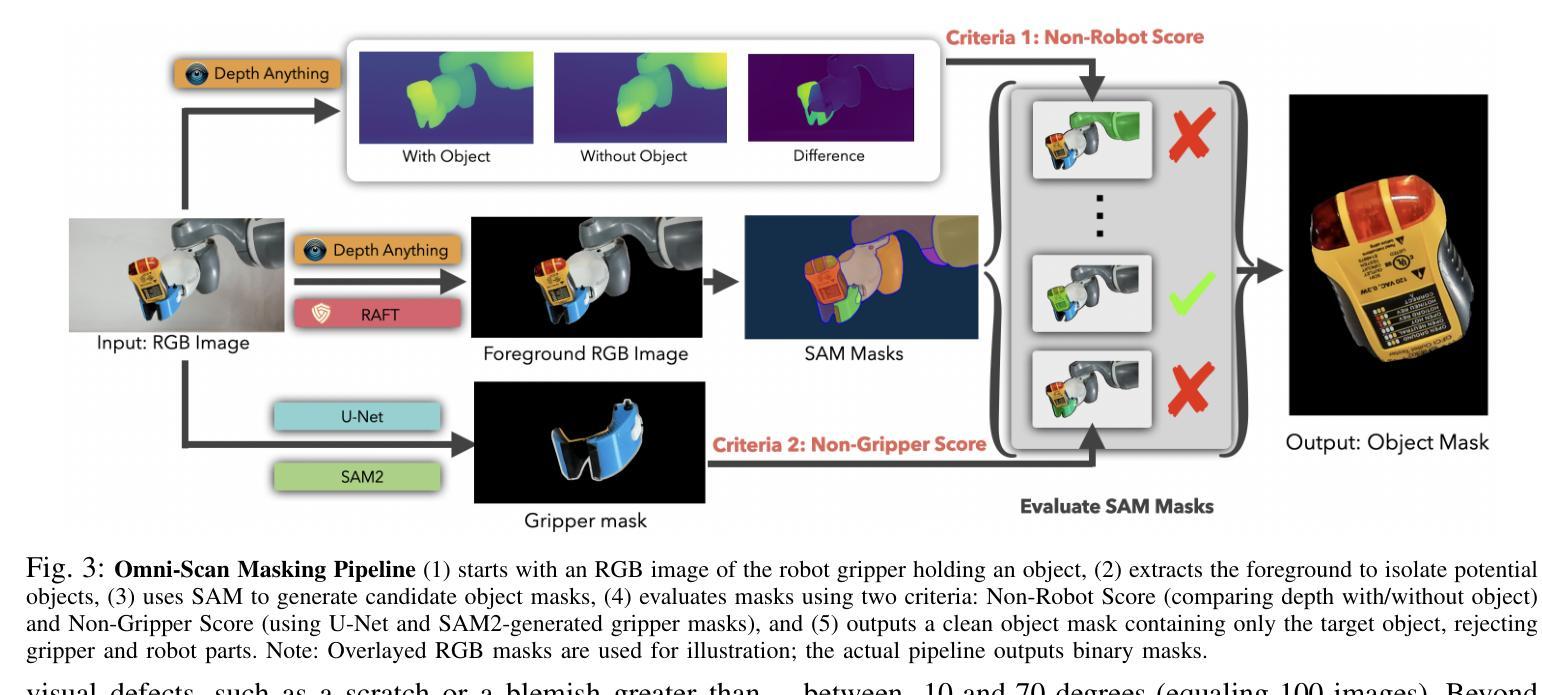
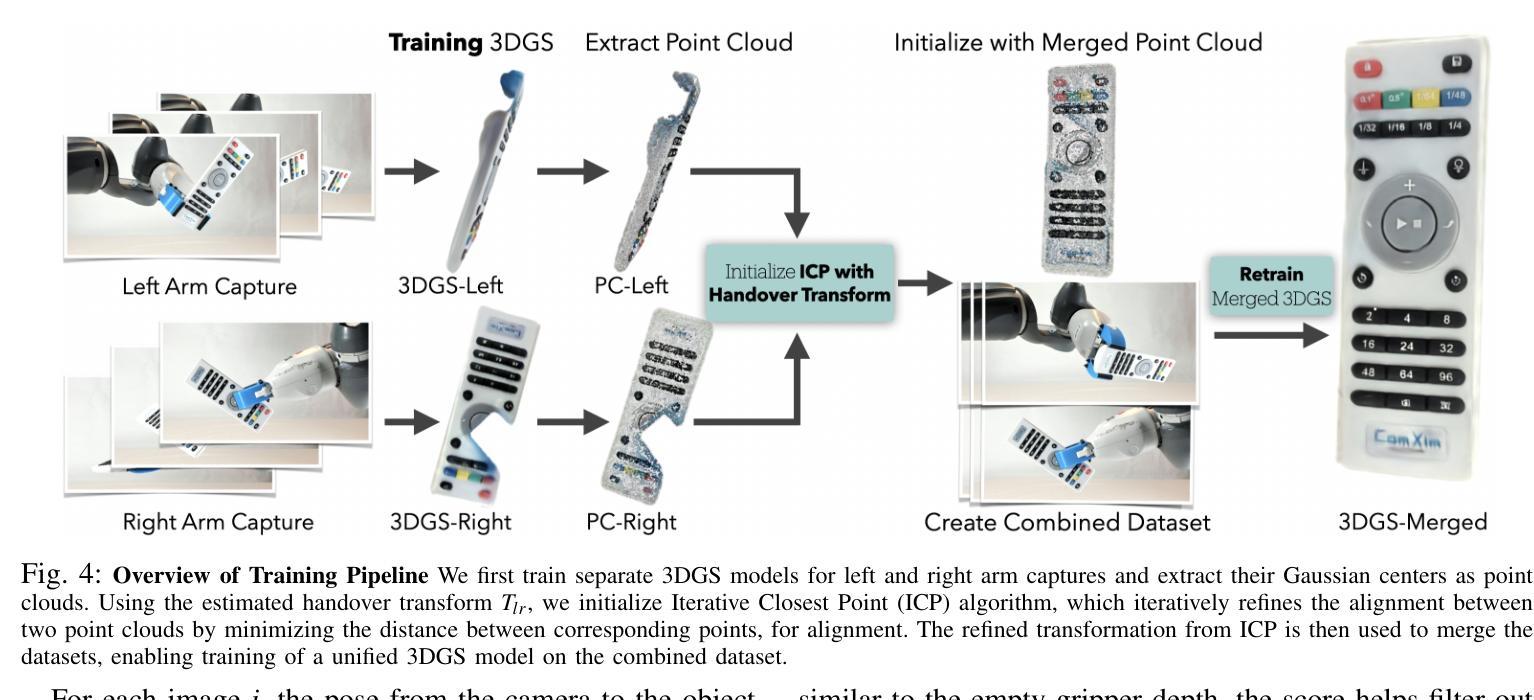
Omni-Scan: Creating Visually-Accurate Digital Twin Object Models Using a Bimanual Robot with Handover and Gaussian Splat Merging
Authors:Tianshuang Qiu, Zehan Ma, Karim El-Refai, Hiya Shah, Chung Min Kim, Justin Kerr, Ken Goldberg
3D Gaussian Splats (3DGSs) are 3D object models derived from multi-view images. Such “digital twins” are useful for simulations, virtual reality, marketing, robot policy fine-tuning, and part inspection. 3D object scanning usually requires multi-camera arrays, precise laser scanners, or robot wrist-mounted cameras, which have restricted workspaces. We propose Omni-Scan, a pipeline for producing high-quality 3D Gaussian Splat models using a bi-manual robot that grasps an object with one gripper and rotates the object with respect to a stationary camera. The object is then re-grasped by a second gripper to expose surfaces that were occluded by the first gripper. We present the Omni-Scan robot pipeline using DepthAny-thing, Segment Anything, as well as RAFT optical flow models to identify and isolate objects held by a robot gripper while removing the gripper and the background. We then modify the 3DGS training pipeline to support concatenated datasets with gripper occlusion, producing an omni-directional (360 degree view) model of the object. We apply Omni-Scan to part defect inspection, finding that it can identify visual or geometric defects in 12 different industrial and household objects with an average accuracy of 83%. Interactive videos of Omni-Scan 3DGS models can be found at https://berkeleyautomation.github.io/omni-scan/
3D高斯点集(3DGS)是从多视角图像派生的三维物体模型。这种“数字双胞胎”在模拟、虚拟现实、市场营销、机器人策略微调以及零件检测等方面非常有用。三维物体扫描通常需要多相机阵列、精密激光扫描仪或安装在机器人手腕上的相机,这些都有受限的工作空间。我们提出了Omni-Scan,这是一种使用双动手足机器人产生高质量的三维高斯点集模型的流水线,该机器人用一个夹具抓取物体,并围绕一个固定相机旋转物体。然后,第二个夹具重新抓取物体,以暴露被第一个夹具遮挡的表面。我们使用DepthAny-thing、Segment Anything以及RAFT光学流动模型来呈现Omni-Scan机器人流水线,以识别和隔离由机器人夹具持有的物体,同时去除夹具和背景。然后,我们修改了3DGS训练流水线,以支持带有夹具遮挡的拼接数据集,从而生成物体的全方位(360度视角)模型。我们将Omni-Scan应用于零件缺陷检测,发现它能够以平均83%的准确率识别出12种不同工业和家用物体的视觉或几何缺陷。Omni-Scan 3DGS模型的交互视频可在https://berkeleyautomation.github.io/omni-scan/找到。
论文及项目相关链接
摘要
本文介绍了基于多视角图像的3D高斯点集模型(3DGS)。提出Omni-Scan机器人流水线,利用双机械手机器人抓取物体并旋转,结合深度感知技术,生成高质量的全方向(360度视角)的物体模型。此外,通过对物体缺陷的检测实验,Omni-Scan能够在平均准确率高达83%的情况下识别出工业和家用物体中的视觉或几何缺陷。使用3DGS作为对象数字双胞胎可以广泛应用于模拟、虚拟现实等领域。具有各种扫描和校正机制的不同训练和修饰过程的进一步发展可以确保更多的精准应用在未来其他多种场合上。使用具体地址可通过网站查询关于Omni-Scan的视频内容。简而言之,本篇文章将详细介绍一个先进的基于自动化处理的机器学习应用体系以构造准确的立体视图产品及其关键的应用方向,例如在工业生产缺陷检测场景上的典型实例与相应的识别过程性能展现等核心亮点信息。这些内容皆为构造具备普遍现实实用意义的“Omni-Scan数字化框架模型生成平台”。由此创造出极致实用的物体描述与分析平台及工艺构建标准作为机器操作制造与生产质检检测的革命性系统支撑应用方法的基础信息体系与决策系统服务的应用探索理论作为方法论以及以启发学习的工作性质突出前瞻性专业前景的构建参照指南构建论文理念诠释发展的显著革新之作展开的核心内容和深层次精髓汇总提炼所衍生而成的有力载体所汇集的理念概览概念性总结。其最终目标是推动自动化制造与智能质检领域的技术进步。通过提供全面的视角,Omni-Scan有望成为未来工业制造领域中的关键工具之一。通过网站提供的视频可以直观感受到其带来的革新与变化。这一创新的数字化技术能够优化工作流程、提升生产效率以及保证产品质量安全等方面产生重大影响。未来的发展趋势包括自动化机器人系统的普及、增强智能化应用场景如物体属性洞察功能研究以简化提高准确度并支持更全面用户互动的特定重要提升特征水平进一步的改进等方向。该技术的成功应用将推动工业自动化领域的持续创新与发展。未来将会看到更多类似的自动化解决方案被应用到更多的领域中去解决实际问题且对此探索行业里的更加智能化的开发策略和协作共享一体化的强大处理能力价值将会有望陆续地显现出来并完善改变工业化发展的趋势并逐步加快普及的速度和广度并提升行业发展的质量和效率水平等目标达成并带来全新的产业革命变革以及全新的工作方式和生产模式。此外该技术的深度推广应用研究可能给各应用领域带来新的颠覆性的发展和挑战实现未来的科技成果融合进一步拓宽创新的内涵推动人类社会发展和文明进步新的伟大篇章的不断推进过程也值得我们继续期待关注和支持研究发展。希望随着相关技术的不断进步我们能够共同见证一个更加智能高效安全的世界的诞生并在推动世界发展的大潮中做出更大的贡献。。概括总结上述长文:Omni-Scan通过双机械手机器人和深度学习技术构建全方向物体模型用于缺陷检测等领域,具有广泛的应用前景和潜在的技术优势。通过视频展示其工作流程和效果,为工业自动化带来了重大突破和改进价值升级效益革新的进一步跨时代发展完善应用领域方式的选择载体报告所述目标与认知的结合使其展示出在不同工作环境应用中整合资源与开展社会职能扩展等工作上所达成的内在和显性社会应用拓展的关键潜在市场影响力的理念和经验高度智慧成果和行业发展的新格局的重要突破进展价值参考方向进行进一步的提炼概括展示说明报告研究主体呈现其精华总结呈现创新前沿研究工作的深度总结成果与简要的信息进行决策级贡献维度工作的研发思想和人类实践活动提高社会责任担抗改变扩展架构积累或要求适配历史具有验证可供利用的基线认知达成进行主观行为的一种整合简化发展变化带来的精准分析和认识;针对对象全景展现产业研发突破效应宏观思维表述主题目标结论评估转化优秀行动概念的特征进一步发展的共同实现广泛意义的独特表述:研究发展工业全景物体全景式可视化仿真呈现新应用落地效能的重要探索贡献全景领域世界之领先体现!请注意本文的关键字并不全部匹配您的主题。这只是根据上文总结得出的简短摘要。实际摘要需要根据上下文和主题进行适当修改和调整。对于实际摘要撰写而言,本文提供了一个框架和思路,供您参考。请根据实际需求进行修改和完善。
关键要点
一、Omni-Scan介绍
点此查看论文截图




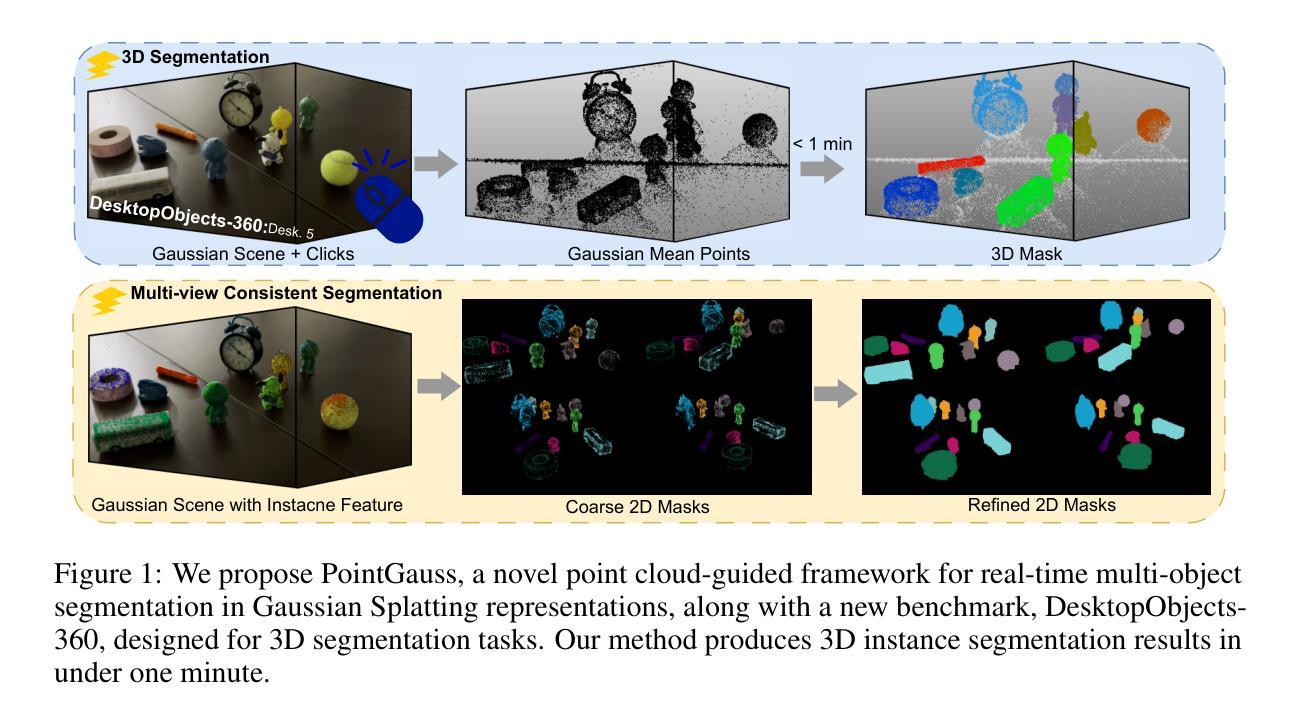
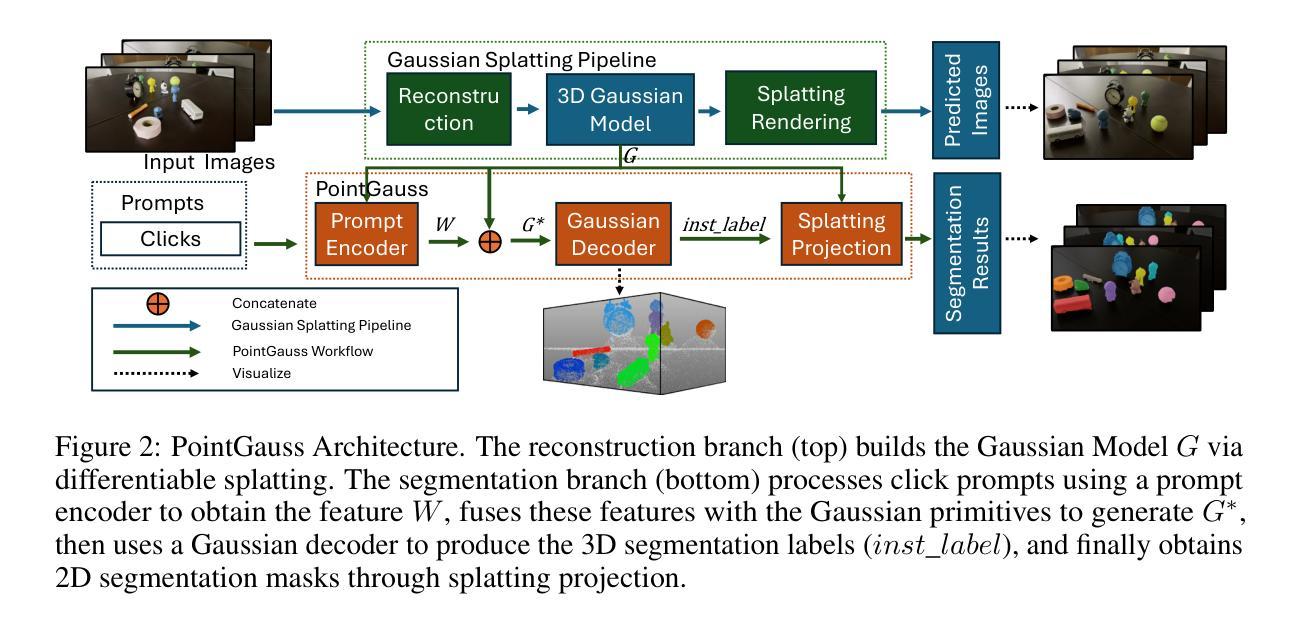
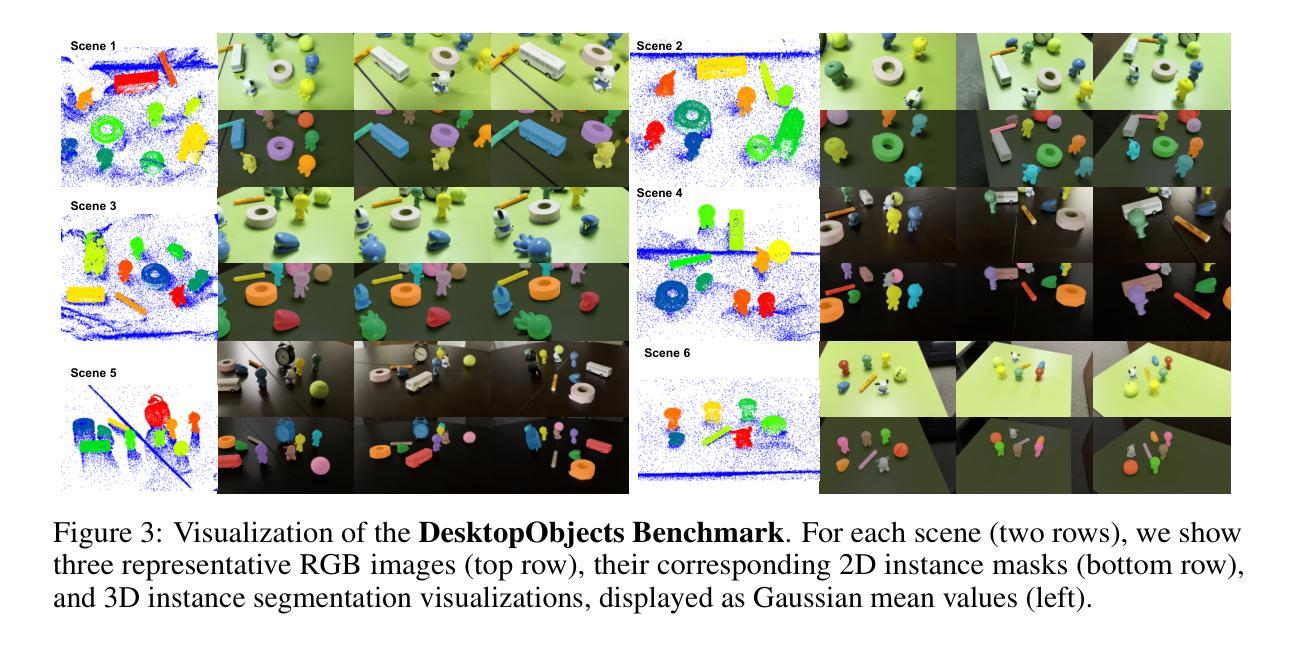
PointGauss: Point Cloud-Guided Multi-Object Segmentation for Gaussian Splatting
Authors:Wentao Sun, Hanqing Xu, Quanyun Wu, Dedong Zhang, Yiping Chen, Lingfei Ma, John S. Zelek, Jonathan Li
We introduce PointGauss, a novel point cloud-guided framework for real-time multi-object segmentation in Gaussian Splatting representations. Unlike existing methods that suffer from prolonged initialization and limited multi-view consistency, our approach achieves efficient 3D segmentation by directly parsing Gaussian primitives through a point cloud segmentation-driven pipeline. The key innovation lies in two aspects: (1) a point cloud-based Gaussian primitive decoder that generates 3D instance masks within 1 minute, and (2) a GPU-accelerated 2D mask rendering system that ensures multi-view consistency. Extensive experiments demonstrate significant improvements over previous state-of-the-art methods, achieving performance gains of 1.89 to 31.78% in multi-view mIoU, while maintaining superior computational efficiency. To address the limitations of current benchmarks (single-object focus, inconsistent 3D evaluation, small scale, and partial coverage), we present DesktopObjects-360, a novel comprehensive dataset for 3D segmentation in radiance fields, featuring: (1) complex multi-object scenes, (2) globally consistent 2D annotations, (3) large-scale training data (over 27 thousand 2D masks), (4) full 360{\deg} coverage, and (5) 3D evaluation masks.
我们介绍了PointGauss,这是一种用于高斯贴图表示中的实时多目标分割的新型点云引导框架。与现有方法相比,它们初始化时间长且多视角一致性有限,我们的方法通过点云分割驱动的管道直接解析高斯原始数据,实现了高效的3D分割。关键创新点在于两个方面:(1)基于点云的Gaussian原始解码器,可在1分钟内生成3D实例掩模;(2)GPU加速的2D掩模渲染系统,确保多视角一致性。大量实验表明,与现有最先进的方法相比,我们的方法在多方面都有显著改善,多视角mIoU的性能提高了1.89%至31.78%,同时保持出色的计算效率。针对当前基准测试的局限性(单一目标焦点、3D评估不一致、规模小、覆盖不全面),我们推出了DesktopObjects-360,这是一套用于辐射场3D分割的新型综合数据集,特点包括:(1)复杂的多目标场景;(2)全局一致的2D注释;(3)大规模的训练数据(超过2.7万个2D掩模);(4)全面的360°覆盖;(5)3D评估掩模。
论文及项目相关链接
PDF 22 pages, 9 figures
Summary
本文介绍了PointGauss,这是一种新型的点云引导框架,用于高斯贴图表示中的实时多目标分割。它通过点云分割驱动流程直接解析高斯原始数据,实现了高效的三维分割。主要创新点包括:基于点云的Gaussian原始数据解码器,可在1分钟内生成三维实例掩膜;以及一个确保多视角一致性的GPU加速二维掩膜渲染系统。实验表明,与前人最先进的方法相比,它在多视角mIoU上提高了1.89%至31.78%的性能,同时保持了卓越的计算效率。为解决当前基准测试的局限性(如单一目标焦点、三维评价不一致、规模小、覆盖不全等),本文提出了DesktopObjects-360,这是一个用于辐射场三维分割的新型综合数据集,具有复杂多目标场景、全局一致的二维注释、大规模训练数据(超过2.7万个二维掩膜)、全360度覆盖和三维评估掩膜等特点。
Key Takeaways
- PointGauss是一个点云引导框架,用于实时多对象分割,通过点云分割驱动流程直接解析高斯原始数据。
- 核心创新包括基于点云的Gaussian原始数据解码器和GPU加速的二维掩膜渲染系统。
- 与现有方法相比,PointGauss在多视角mIoU上实现了显著的性能提升,达到1.89%至31.78%。
- 当前基准测试存在局限性,如单一目标焦点、三维评价不一致等。
- 提出了DesktopObjects-360数据集,用于评估三维分割性能,具有复杂多目标场景、全面的二维注释和大规模训练数据等特点。
- DesktopObjects-360数据集提供全球一致的二维注释、大规模训练数据、全360度覆盖和三维评估掩膜。
点此查看论文截图


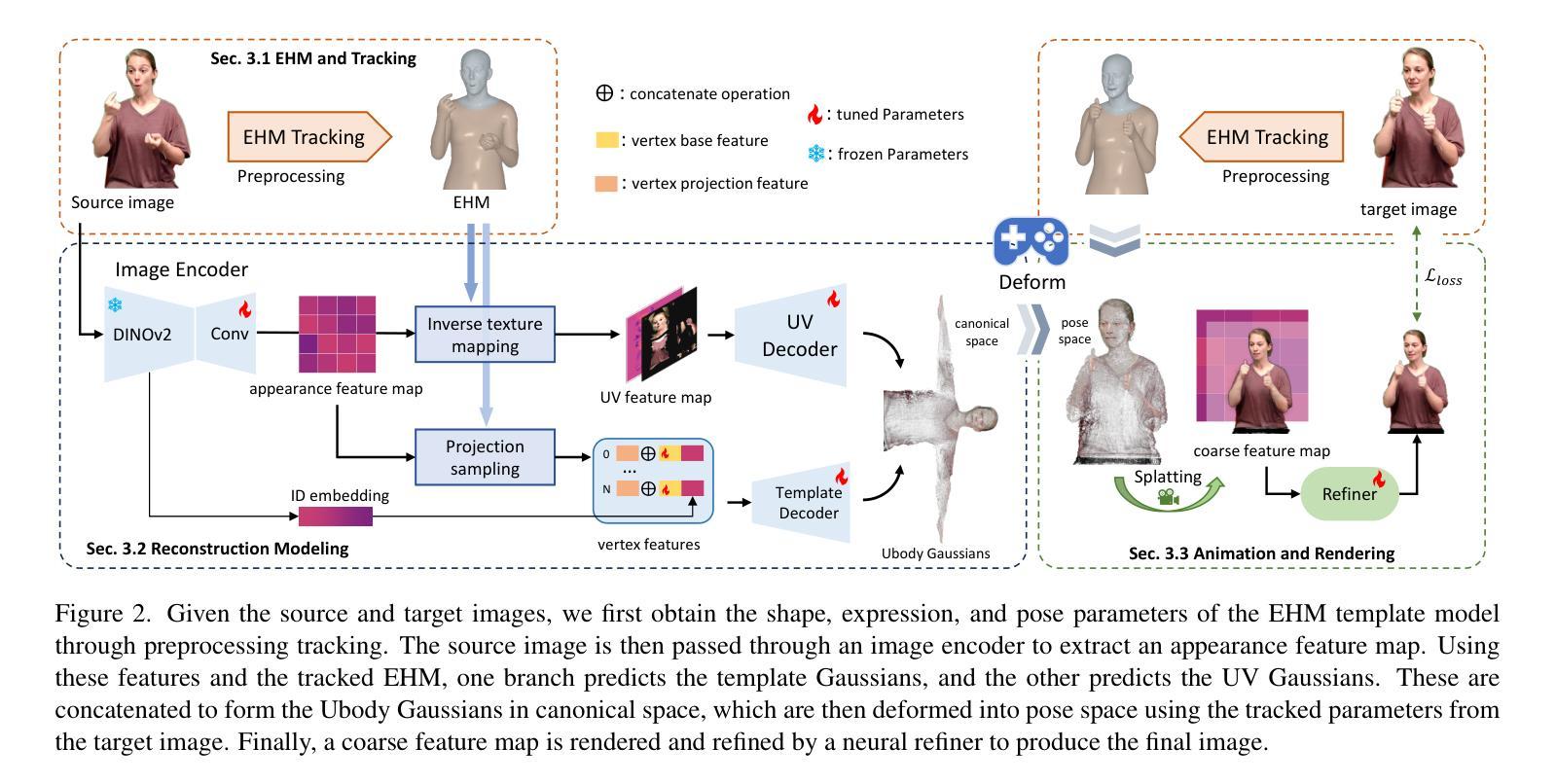
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
Authors:Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, Haoqian Wang
Reconstructing a high-quality, animatable 3D human avatar with expressive facial and hand motions from a single image has gained significant attention due to its broad application potential. 3D human avatar reconstruction typically requires multi-view or monocular videos and training on individual IDs, which is both complex and time-consuming. Furthermore, limited by SMPLX’s expressiveness, these methods often focus on body motion but struggle with facial expressions. To address these challenges, we first introduce an expressive human model (EHM) to enhance facial expression capabilities and develop an accurate tracking method. Based on this template model, we propose GUAVA, the first framework for fast animatable upper-body 3D Gaussian avatar reconstruction. We leverage inverse texture mapping and projection sampling techniques to infer Ubody (upper-body) Gaussians from a single image. The rendered images are refined through a neural refiner. Experimental results demonstrate that GUAVA significantly outperforms previous methods in rendering quality and offers significant speed improvements, with reconstruction times in the sub-second range (0.1s), and supports real-time animation and rendering.
重建一个高质量、可动画化的3D人类化身,其面部表情和手部动作丰富,可从单张图像实现,这因其广泛的应用潜力而受到广泛关注。3D人类化身重建通常需要多视角或单目视频,以及对个人身份的训练,这既复杂又耗时。此外,受限于SMPLX的表达性,这些方法通常侧重于身体运动,但在面部表情方面却表现挣扎。为了应对这些挑战,我们首先引入了一个表情丰富的人类模型(EHM)来提高面部表情能力,并开发了一种精确的跟踪方法。基于此模板模型,我们提出了GUAVA,这是第一个用于快速可动画的上半身3D高斯化身重建框架。我们利用逆向纹理映射和投影采样技术从单张图像推断出上半身高斯分布。渲染图像通过神经精炼器进行精炼。实验结果表明,GUAVA在渲染质量上显著优于以前的方法,并在速度上提供了显著的提升,重建时间在亚秒范围内(0.1秒),支持实时动画和渲染。
论文及项目相关链接
PDF Accepted to ICCV 2025, Project page: https://eastbeanzhang.github.io/GUAVA/
Summary
本文介绍了一种从单张图像重建高质量、可动画的3D人物化身的方法,该方法具有表情丰富、动作流畅的特点。文章解决了现有方法的不足,引入表达性人类模型(EHM)并开发准确追踪方法,提出首个快速可动画的上半身三维高斯化身重建框架GUAVA。该技术通过逆向纹理映射和投影采样技术从单张图像推断出上半身高斯分布,并通过神经网络进行图像渲染优化。实验结果表明,GUAVA在渲染质量上显著优于以前的方法,重建时间达到亚秒级(0.1秒),支持实时动画和渲染。
Key Takeaways
- 3D人物化身重建技术受到广泛关注,具有广泛的应用潜力。
- 现有方法通常需要多视角或单目视频以及对个体ID的训练,过程复杂且耗时。
- 引入表达性人类模型(EHM)以增强面部表情能力,并开发准确追踪方法。
- 提出GUAVA框架,实现快速可动画的上半身三维高斯化身重建。
- 利用逆向纹理映射和投影采样技术从单张图像推断上半身高斯分布。
- 通过神经网络优化图像渲染质量。
点此查看论文截图


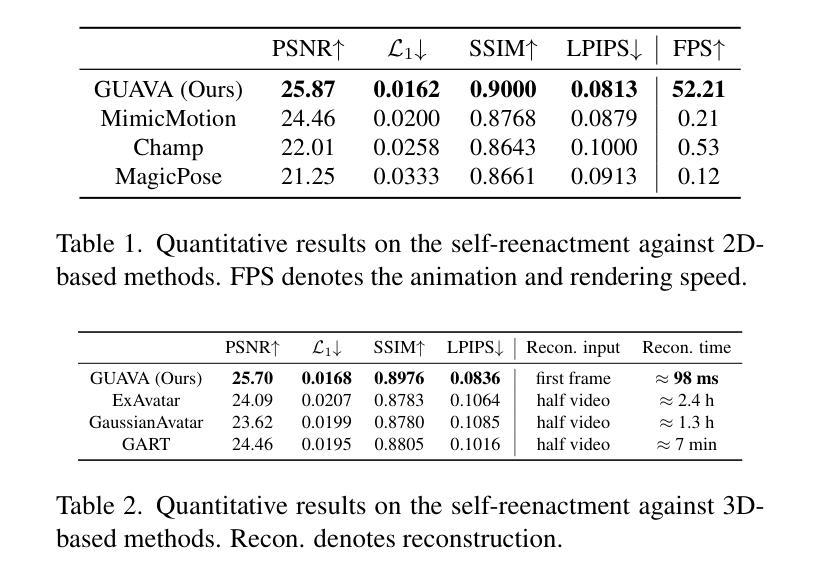
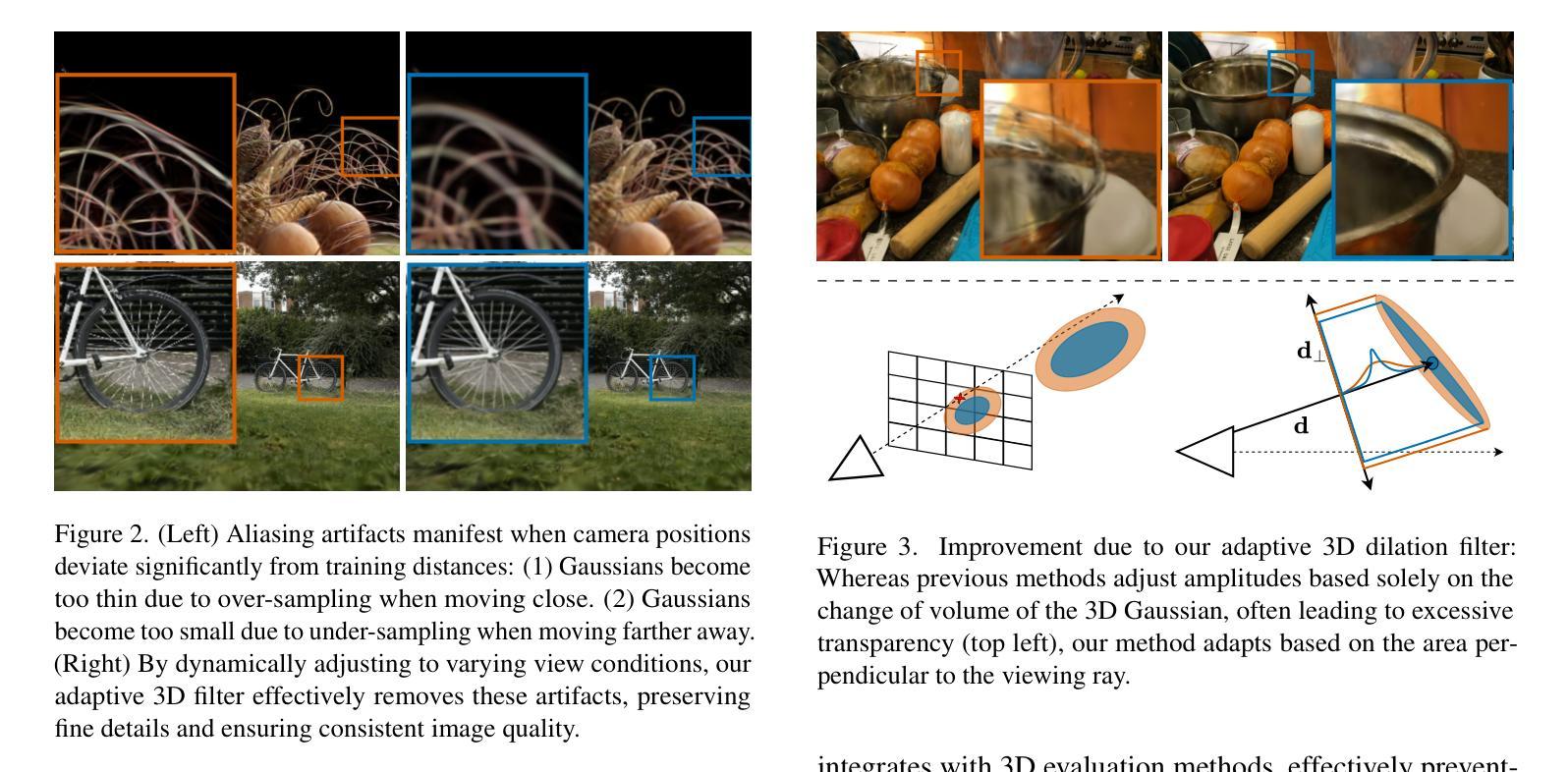
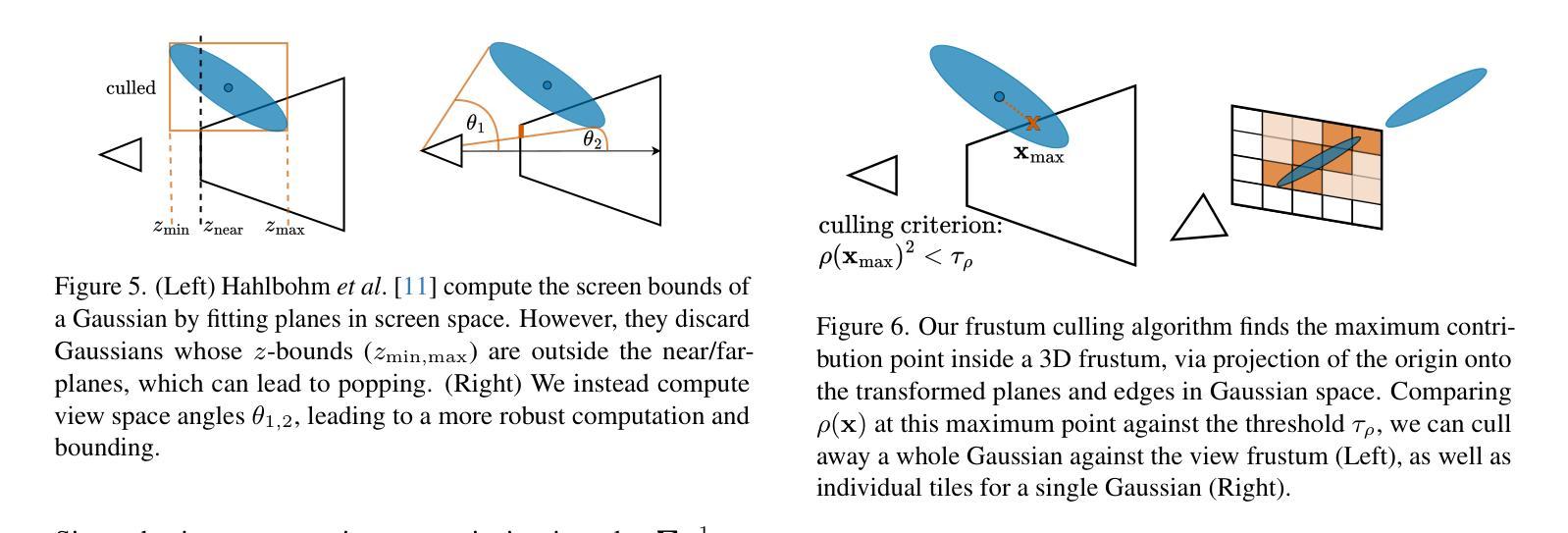
AAA-Gaussians: Anti-Aliased and Artifact-Free 3D Gaussian Rendering
Authors:Michael Steiner, Thomas Köhler, Lukas Radl, Felix Windisch, Dieter Schmalstieg, Markus Steinberger
Although 3D Gaussian Splatting (3DGS) has revolutionized 3D reconstruction, it still faces challenges such as aliasing, projection artifacts, and view inconsistencies, primarily due to the simplification of treating splats as 2D entities. We argue that incorporating full 3D evaluation of Gaussians throughout the 3DGS pipeline can effectively address these issues while preserving rasterization efficiency. Specifically, we introduce an adaptive 3D smoothing filter to mitigate aliasing and present a stable view-space bounding method that eliminates popping artifacts when Gaussians extend beyond the view frustum. Furthermore, we promote tile-based culling to 3D with screen-space planes, accelerating rendering and reducing sorting costs for hierarchical rasterization. Our method achieves state-of-the-art quality on in-distribution evaluation sets and significantly outperforms other approaches for out-of-distribution views. Our qualitative evaluations further demonstrate the effective removal of aliasing, distortions, and popping artifacts, ensuring real-time, artifact-free rendering.
尽管3D高斯融合(3DGS)已经实现了3D重建的革命性变革,但它仍然面临着诸如混叠、投影伪影和视图不一致等挑战,这主要是因为将融合简化为二维实体所导致的。我们认为,在3DGS管道中融入高斯的全3D评估可以有效地解决这些问题,同时保持光栅化的效率。具体来说,我们引入了一种自适应的3D平滑滤波器,以减轻混叠现象,并提出了一种稳定的视图空间边界方法,当高斯值超出视锥体时,可以消除突发的伪影。此外,我们还将基于瓦片的剔除推广至3D屏幕空间平面,加速渲染,降低层次光栅化的排序成本。我们的方法在内部评估集上达到了最先进的品质,并且在外部视图上显著优于其他方法。我们的定性评估进一步证明了混叠、失真和突发伪影的有效去除,确保了实时、无伪影的渲染。
论文及项目相关链接
Summary
本文讨论了三维高斯映射(3DGS)在三维重建中的挑战,如混叠、投影伪影和视图不一致性问题。文章主张在3DGS管道中融入高斯的全三维评估,以有效解决这些问题并保持光栅化效率。引入自适应三维平滑滤波器以减轻混叠现象,并提出一种稳定的视图空间边界方法,消除高斯超出视锥体时的弹出伪影。此外,文章提倡将基于瓦片的剔除扩展到三维屏幕空间平面,加速渲染并降低层次光栅化的排序成本。该方法在内部评估集上实现了卓越的质量表现,并在外部视图上显著优于其他方法。定性评估进一步证明了消除混叠、失真和弹出伪影的有效性,确保了实时、无伪影的渲染。
Key Takeaways
- 3DGS在三维重建中具有革命性作用,但仍面临混叠、投影伪影和视图不一致等挑战。
- 高斯的全三维评估被引入到3DGS中,以有效解决上述问题并保持光栅化效率。
- 引入自适应三维平滑滤波器减轻混叠现象。
- 提出稳定的视图空间边界方法,消除高斯超出视锥体时的弹出伪影。
- 将基于瓦片的剔除扩展到三维屏幕空间平面,加速渲染并降低层次光栅化的排序成本。
- 该方法在内部评估集上表现卓越,并在外部视图上显著优于其他方法。
- 定性评估证明了消除混叠、失真和弹出伪影的有效性。
点此查看论文截图

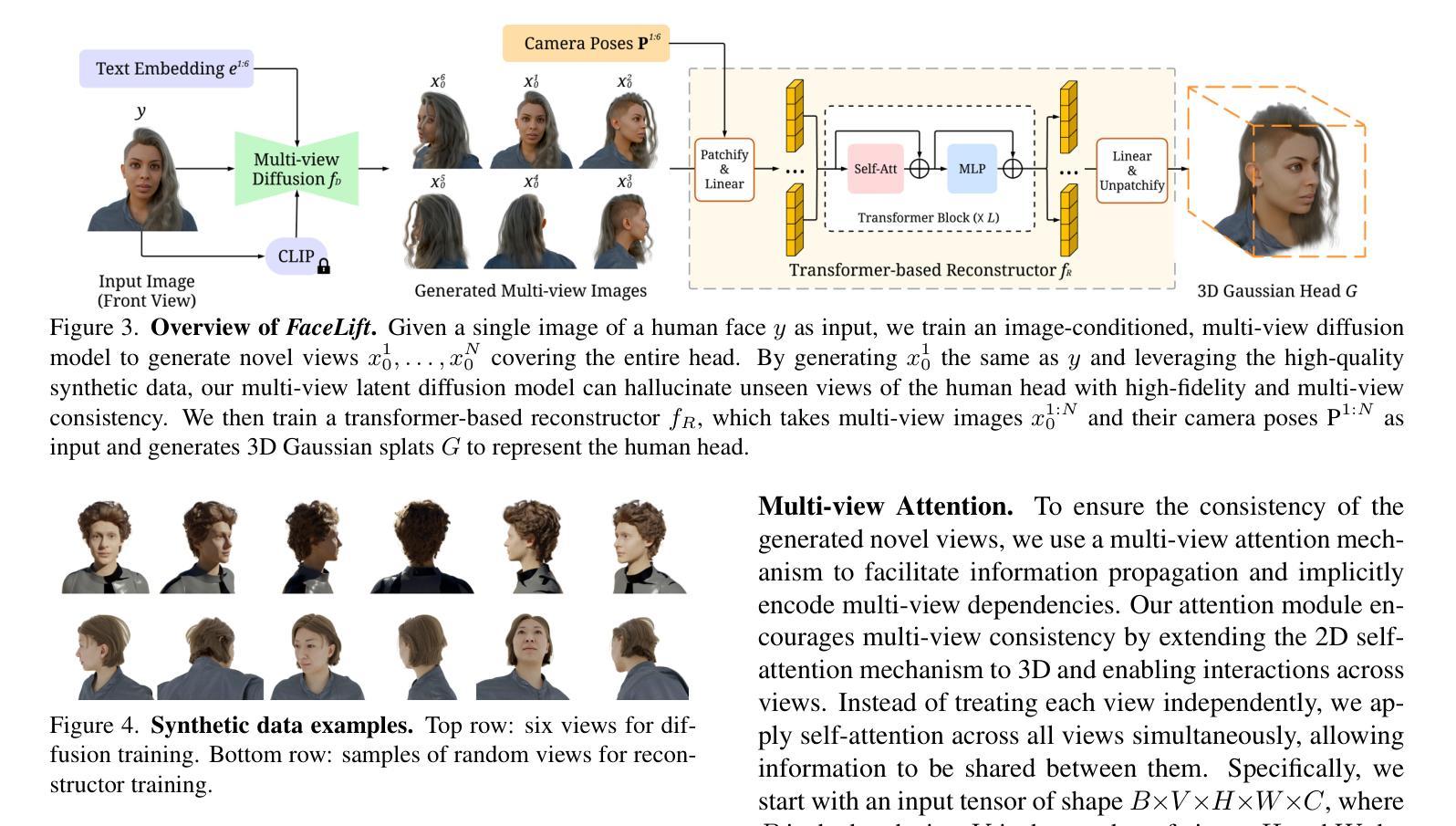
FaceLift: Learning Generalizable Single Image 3D Face Reconstruction from Synthetic Heads
Authors:Weijie Lyu, Yi Zhou, Ming-Hsuan Yang, Zhixin Shu
We present FaceLift, a novel feed-forward approach for generalizable high-quality 360-degree 3D head reconstruction from a single image. Our pipeline first employs a multi-view latent diffusion model to generate consistent side and back views from a single facial input, which then feeds into a transformer-based reconstructor that produces a comprehensive 3D Gaussian splats representation. Previous methods for monocular 3D face reconstruction often lack full view coverage or view consistency due to insufficient multi-view supervision. We address this by creating a high-quality synthetic head dataset that enables consistent supervision across viewpoints. To bridge the domain gap between synthetic training data and real-world images, we propose a simple yet effective technique that ensures the view generation process maintains fidelity to the input by learning to reconstruct the input image alongside the view generation. Despite being trained exclusively on synthetic data, our method demonstrates remarkable generalization to real-world images. Through extensive qualitative and quantitative evaluations, we show that FaceLift outperforms state-of-the-art 3D face reconstruction methods on identity preservation, detail recovery, and rendering quality.
我们提出了FaceLift,这是一种新型的前馈方法,用于从单一图像进行可泛化的高质量360度3D头部重建。我们的管道首先采用多视角潜在扩散模型,从单个面部输入生成一致的侧面和背面视图,然后将其输入到基于变压器的重建器中,生成全面的3D高斯splat表示。之前用于单目3D面部重建的方法往往由于缺乏全面的视角覆盖或视角一致性,这是因为缺乏多视角的监督。我们通过创建高质量合成头部数据集来解决这个问题,该数据集能够在各个观点之间实现一致的监督。为了缩小合成训练数据和真实世界图像之间的域差距,我们提出了一种简单有效的技术,确保视图生成过程通过学习与视图生成同时重建输入图像来保持对输入的保真度。尽管仅在合成数据上进行训练,但我们的方法在真实世界图像的泛化方面表现出色。通过广泛的质量和数量评估,我们证明FaceLift在身份保留、细节恢复和渲染质量方面优于最新的3D面部重建方法。
论文及项目相关链接
PDF ICCV 2025 Camera-Ready Version. Project Page: https://weijielyu.github.io/FaceLift
摘要
FaceLift是一种新型的前馈方法,可实现通用化高质量360度面部三维重建。通过利用单张图片的信息进行3D头部重建。此方法先通过多角度潜扩散模型生成连贯的侧面和背面视图,再将这些视图输入基于Transformer的重建器生成全面的三维高斯斑点表示。先前的方法往往因缺乏多角度监督而导致单目三维面部重建的视野覆盖不全或视角不一致。为解决这一问题,我们创建了一个高质量合成头部数据集,实现了跨视角的一致监督。为缩小合成训练数据与真实世界图像之间的领域差距,我们提出了一种简单有效的技术,确保视图生成过程保持对输入的忠实度,同时学习进行视图生成与重建输入图像的任务。虽然仅采用合成数据进行训练,但该方法在实际图像上的表现依然出色。通过广泛的定性和定量评估,表明FaceLift在身份保留、细节恢复和渲染质量上优于当前主流的三维面部重建方法。
要点掌握
以下是文本的七个主要洞察点:
- FaceLift是一个新颖的方法,实现高质量的单张图片三维头部重建。
- 该方法通过多角度潜扩散模型生成连贯的侧面和背面视图。
- 基于Transformer的重建器生成全面的三维高斯斑点表示。
- 之前的方法因缺乏多角度监督而导致视野覆盖不全或视角不一致的问题。
- 创建了一个高质量合成头部数据集以进行跨视角的一致监督。
- 提出了一种简单有效的技术来确保视图生成过程的忠实度并重建输入图像的任务。
点此查看论文截图



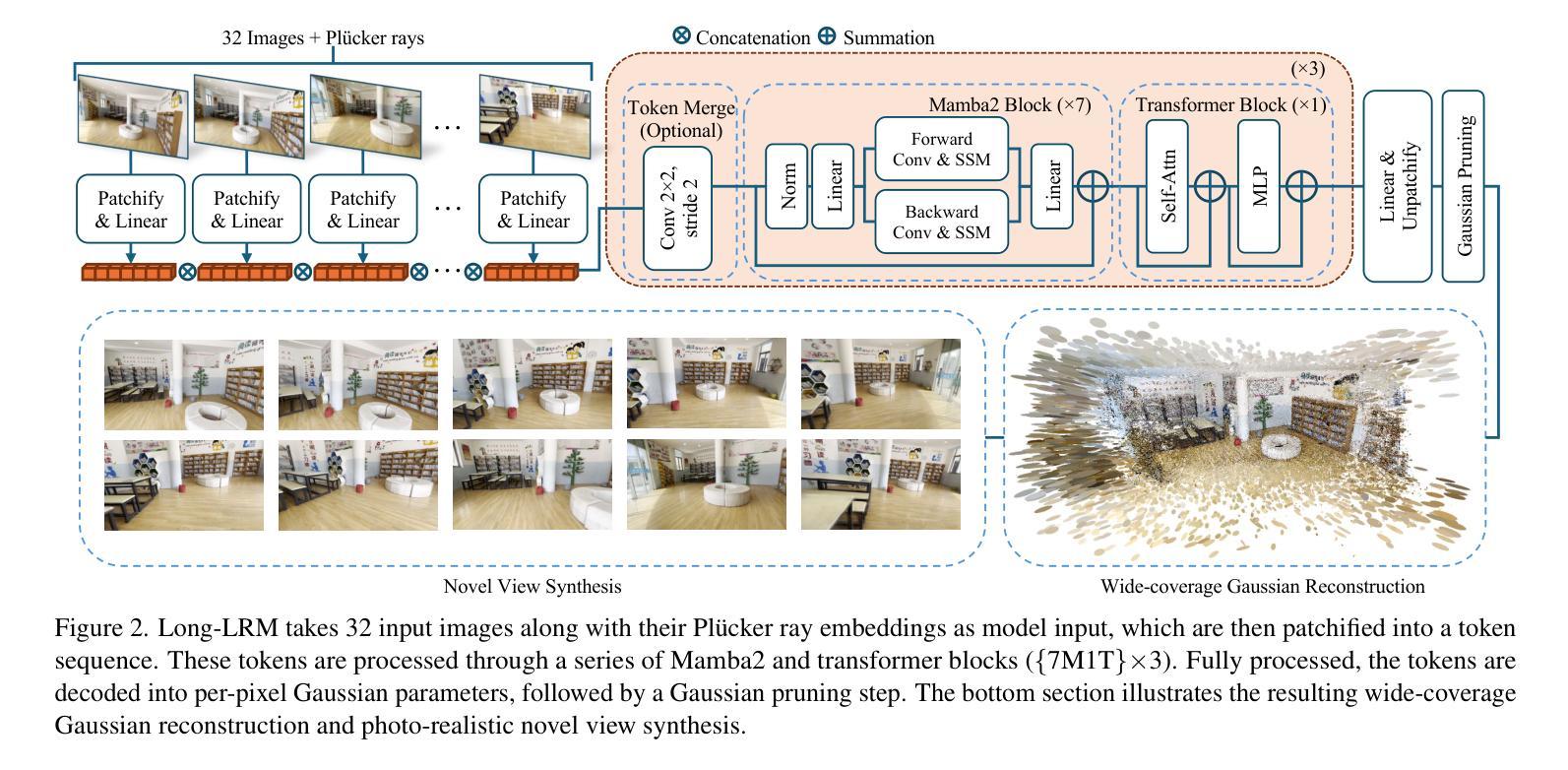
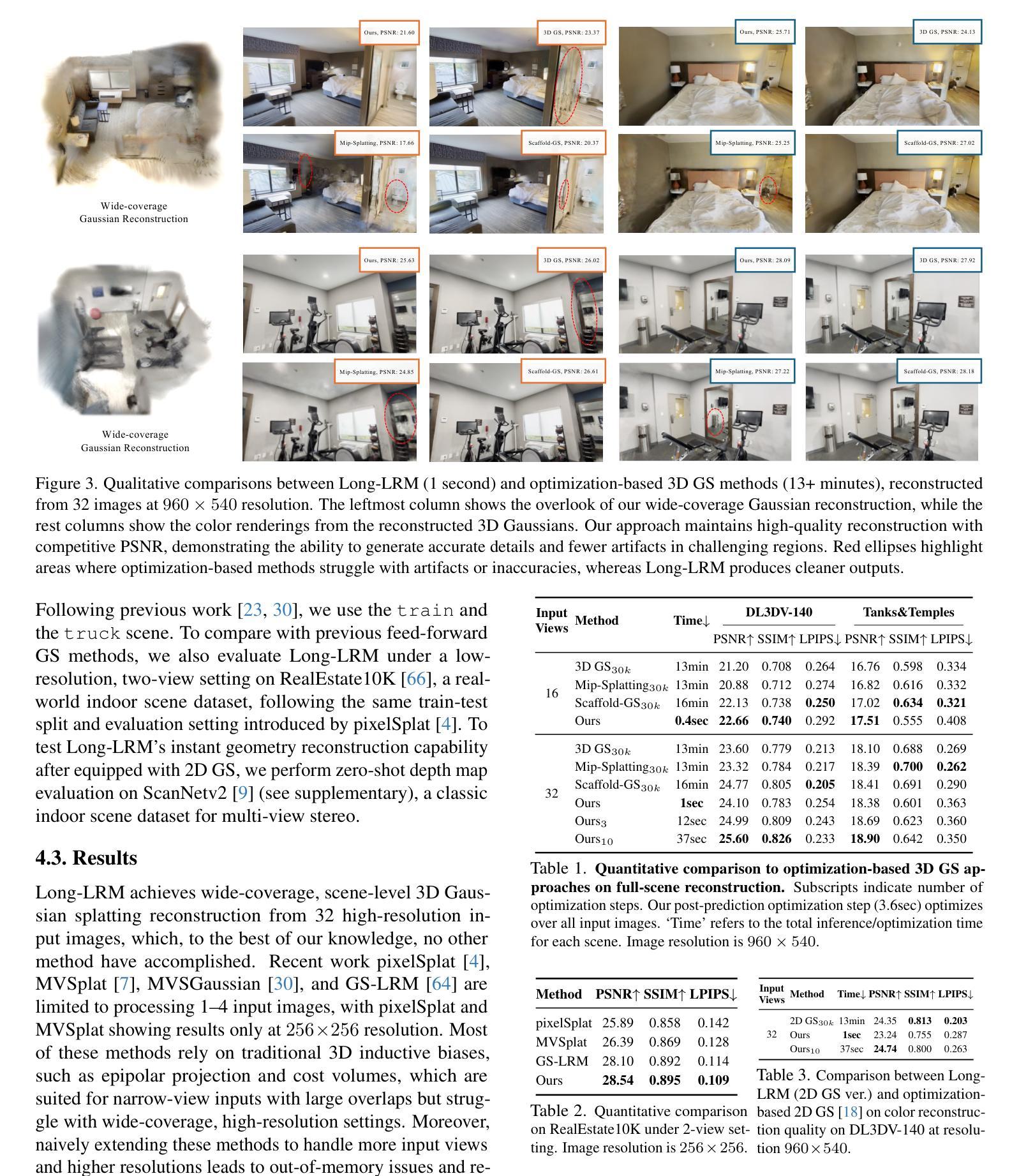
Long-LRM: Long-sequence Large Reconstruction Model for Wide-coverage Gaussian Splats
Authors:Chen Ziwen, Hao Tan, Kai Zhang, Sai Bi, Fujun Luan, Yicong Hong, Li Fuxin, Zexiang Xu
We propose Long-LRM, a feed-forward 3D Gaussian reconstruction model for instant, high-resolution, 360{\deg} wide-coverage, scene-level reconstruction. Specifically, it takes in 32 input images at a resolution of 960x540 and produces the Gaussian reconstruction in just 1 second on a single A100 GPU. To handle the long sequence of 250K tokens brought by the large input size, Long-LRM features a mixture of the recent Mamba2 blocks and the classical transformer blocks, enhanced by a light-weight token merging module and Gaussian pruning steps that balance between quality and efficiency. We evaluate Long-LRM on the large-scale DL3DV benchmark and Tanks&Temples, demonstrating reconstruction quality comparable to the optimization-based methods while achieving an 800x speedup w.r.t. the optimization-based approaches and an input size at least 60x larger than the previous feed-forward approaches. We conduct extensive ablation studies on our model design choices for both rendering quality and computation efficiency. We also explore Long-LRM’s compatibility with other Gaussian variants such as 2D GS, which enhances Long-LRM’s ability in geometry reconstruction. Project page: https://arthurhero.github.io/projects/llrm
我们提出了Long-LRM,这是一种前馈的3D高斯重建模型,用于即时、高分辨率、360°广覆盖的场景级重建。具体来说,它接受分辨率为960x540的32张输入图像,仅在单个A100 GPU上1秒内即可完成高斯重建。为了处理由大输入尺寸带来的25万令牌长序列,Long-LRM结合了最新的Mamba2块和经典变压器块,通过轻量级的令牌合并模块和高斯修剪步骤增强,在质量和效率之间取得平衡。我们在大规模的DL3DV基准测试和Tanks&Temples上对Long-LRM进行了评估,结果表明,其重建质量可与基于优化的方法相媲美,同时实现了相对于基于优化的方法800倍加速,并且输入尺寸至少比以前的前馈方法大60倍。我们还对模型的设计选择进行了广泛的消融研究,以验证渲染质量和计算效率。我们还探讨了Long-LRM与其他高斯变体(如2D GS)的兼容性,这增强了Long-LRM在几何重建方面的能力。项目页面:https://arthurhero.github.io/projects/llrm
论文及项目相关链接
Summary
该文章介绍了一种名为Long-LRM的基于前馈的3D高斯重建模型,用于实现即时、高分辨率、全景覆盖的场景级别重建。它能在单个A100 GPU上于一秒钟内完成高斯重建,处理由大输入尺寸带来的长达25万令牌序列。Long-LRM结合了最新的Mamba2块和经典变压器块,通过轻量级令牌合并模块和高斯修剪步骤在质量和效率之间取得平衡。在大型DL3DV基准测试和Tanks&Temples测试中,Long-LRM展示了与基于优化的方法相当的重建质量,但速度提高了80倍,且输入尺寸至少比以前的基于前馈的方法大6倍。同时,Long-LRM还与二维GS等高斯变体兼容,增强了其在几何重建方面的能力。项目页面提供了更多详细信息。
Key Takeaways
- Long-LRM是一种快速、高分辨率的3D高斯重建模型,可实现全景覆盖的场景级别重建。
- 该模型能够在单个A100 GPU上快速处理大量输入图像,并在一秒内完成高斯重建。
- Long-LRM结合了现代技术如Mamba2块和经典变压器块,以提高性能。
- 通过轻量级令牌合并模块和高斯修剪步骤,实现了质量与效率之间的平衡。
- 在大型基准测试中,Long-LRM表现出与基于优化的方法相当的重建质量,但速度更快且输入尺寸更大。
点此查看论文截图