⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
Unraveling Hidden Representations: A Multi-Modal Layer Analysis for Better Synthetic Content Forensics
Authors:Tom Or, Omri Azencot
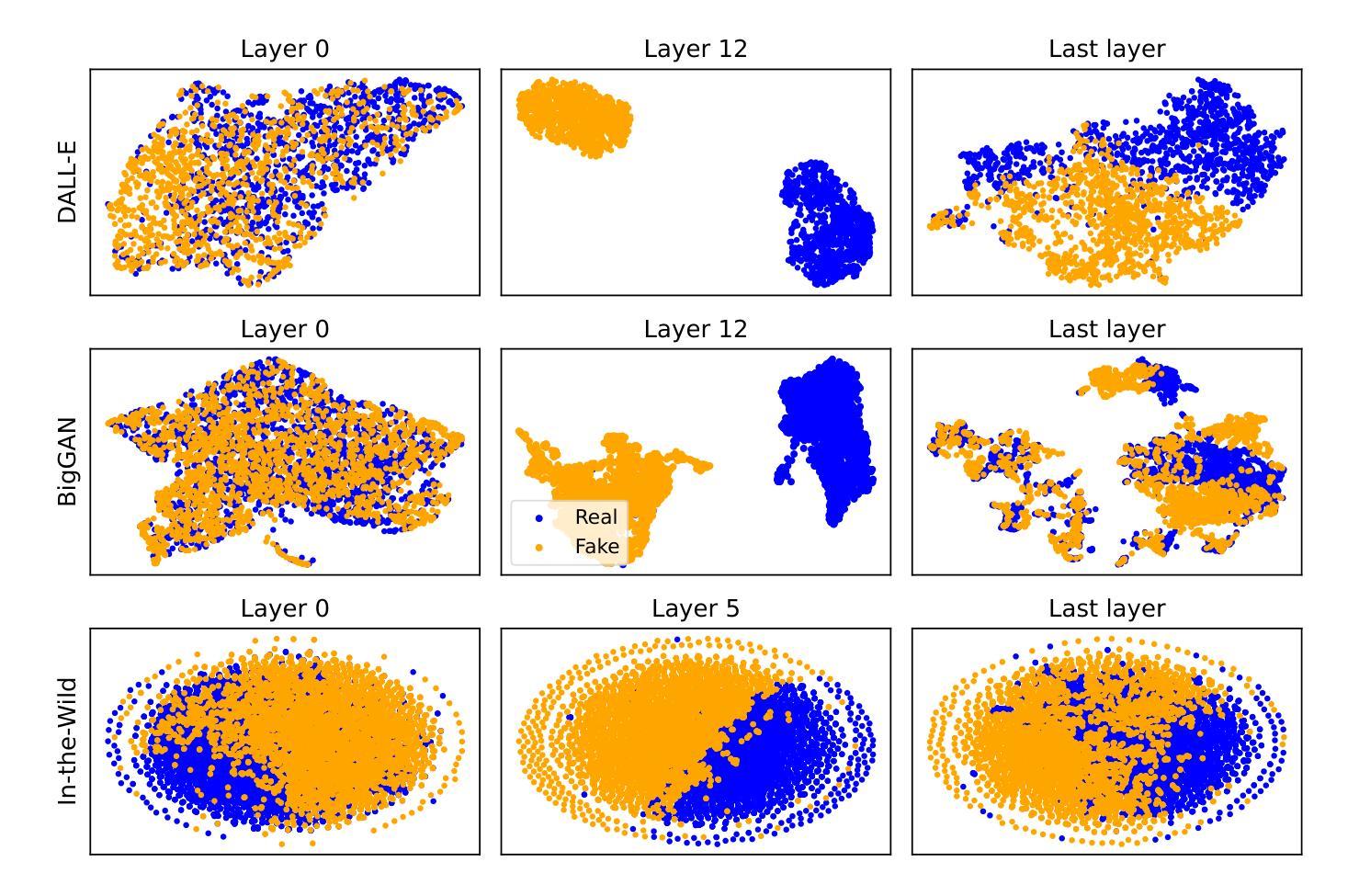
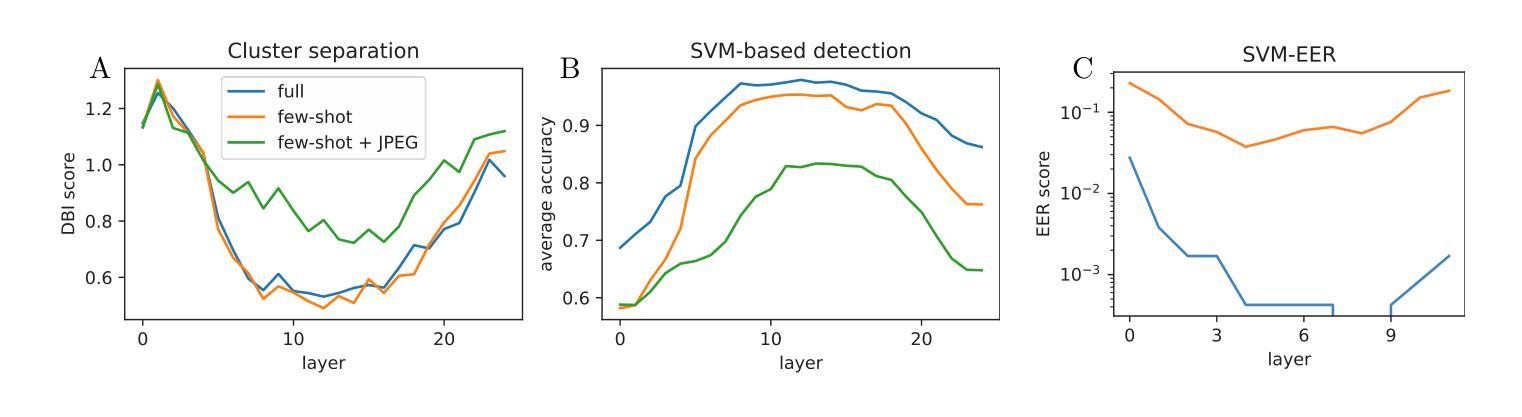
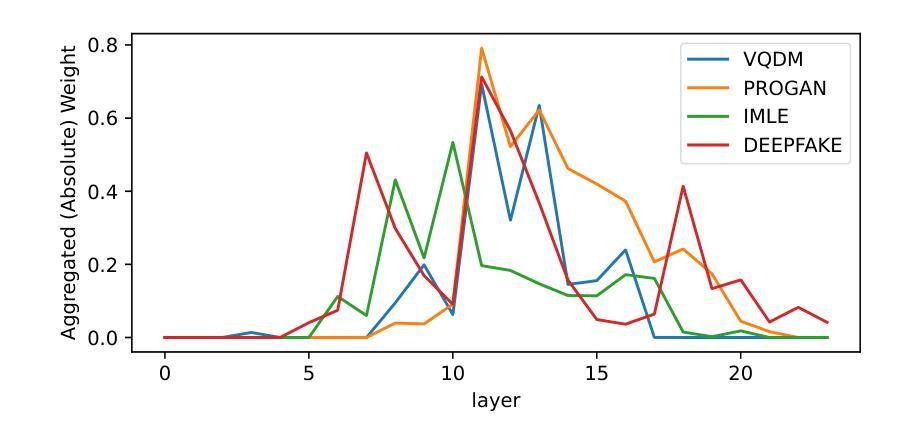
Generative models achieve remarkable results in multiple data domains, including images and texts, among other examples. Unfortunately, malicious users exploit synthetic media for spreading misinformation and disseminating deepfakes. Consequently, the need for robust and stable fake detectors is pressing, especially when new generative models appear everyday. While the majority of existing work train classifiers that discriminate between real and fake information, such tools typically generalize only within the same family of generators and data modalities, yielding poor results on other generative classes and data domains. Towards a universal classifier, we propose the use of large pre-trained multi-modal models for the detection of generative content. Effectively, we show that the latent code of these models naturally captures information discriminating real from fake. Building on this observation, we demonstrate that linear classifiers trained on these features can achieve state-of-the-art results across various modalities, while remaining computationally efficient, fast to train, and effective even in few-shot settings. Our work primarily focuses on fake detection in audio and images, achieving performance that surpasses or matches that of strong baseline methods.
生成模型在多个数据领域取得了显著成果,包括图像和文本等。然而,恶意用户利用合成媒体传播虚假信息和深度伪造。因此,对新生成模型的稳健和稳定虚假检测器的需求尤为迫切。虽然现有的大多数工作都是训练分类器来区分真实和虚假信息,但这些工具通常仅在相同生成器和数据模式的家族内通用化,对其他生成类和数据领域的检测结果较差。为了建立一个通用分类器,我们建议使用大型预训练多模态模型来检测生成内容。实际上,我们展示了这些模型的潜在代码自然地捕捉了区分真实和虚假信息的信息。基于这一观察,我们证明在这些特征上训练的线性分类器可以在各种模式下达到最先进的检测结果,同时保持计算效率高、训练速度快,甚至在少量样本设置中也有效。我们的工作主要集中在音频和图像的虚假检测上,性能超过了或匹配了强大的基线方法。
论文及项目相关链接
Summary
生成模型在多数据领域取得了显著成果,包括图像和文本等。然而,恶意用户利用合成媒体传播虚假信息,因此迫切需要稳健的虚假检测器,尤其是新的生成模型不断涌现的情况下。现有的大多数工具主要通过训练分类器来区分真实和虚假信息,但它们通常只在同一生成器和数据模式家族内通用,对其他生成类别和数据领域的表现较差。本研究提出使用大型预训练多模态模型来检测生成内容,以构建通用分类器。我们观察到这些模型的潜在代码能够自然地捕捉区分真实和虚假信息的信息,并在此基础上训练线性分类器实现跨多种模式的卓越成果。该模型计算效率高、训练速度快,甚至在样本量较小的情况下依然有效。我们的工作主要集中在音频和图像的虚假检测上,性能超过了或匹配了强大的基线方法。
Key Takeaways
- 生成模型在多数据领域表现出色,但合成媒体被恶意利用传播虚假信息,需要开发稳健的虚假检测器。
- 现有工具主要训练分类器来区分真实和虚假信息,但通用性有限,表现不佳。
- 提出使用大型预训练多模态模型检测生成内容,实现跨多种模式的优秀性能。
- 模型的潜在代码可以捕捉区分真实和虚假信息的信息。
- 通过训练线性分类器,在特征上取得了最先进的成果,同时保持了计算效率和快速训练。
- 该模型在样本量较小的情况下依然有效。
点此查看论文截图

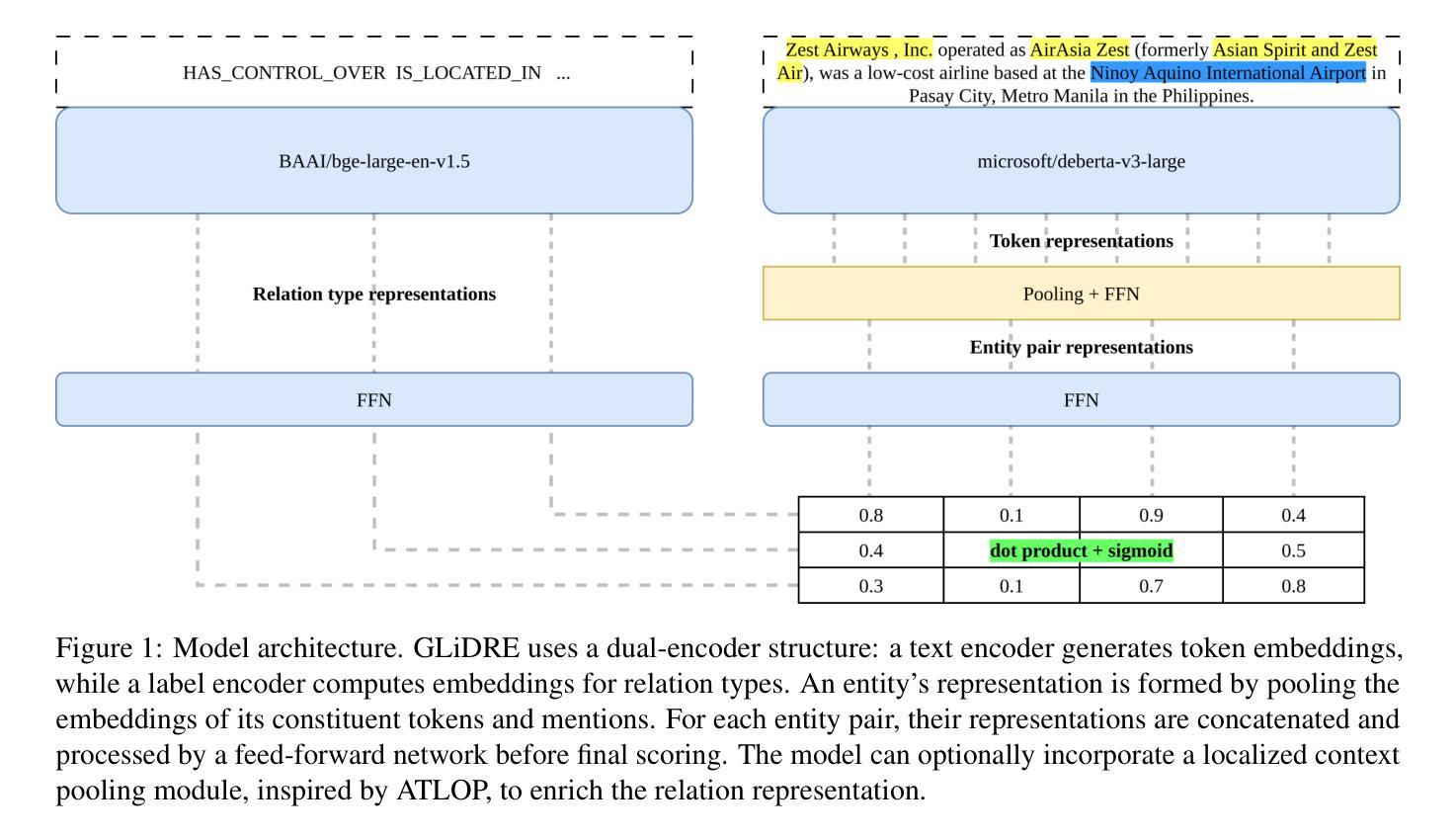
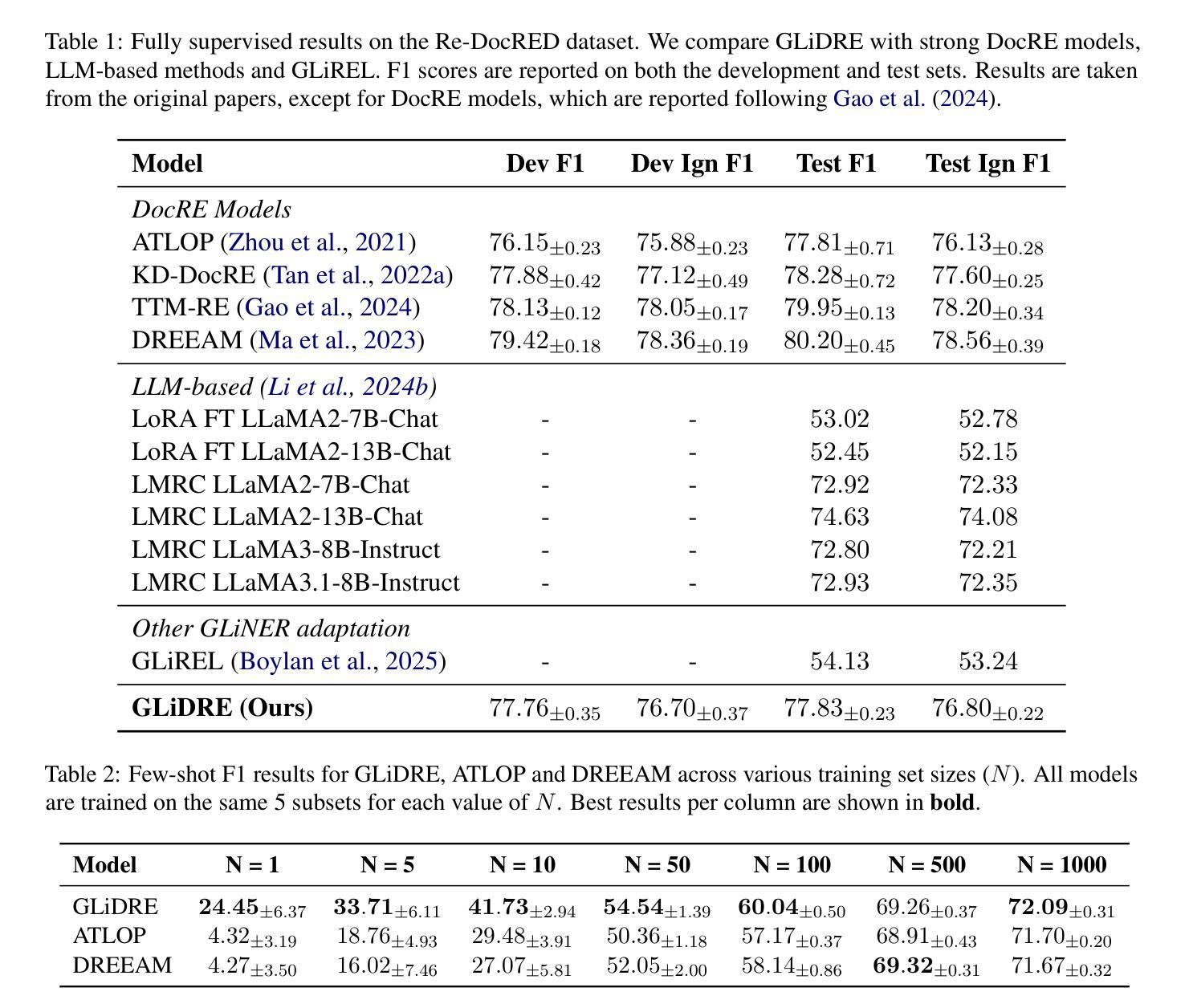
GLiDRE: Generalist Lightweight model for Document-level Relation Extraction
Authors:Robin Armingaud, Romaric Besançon
Relation Extraction (RE) is a fundamental task in Natural Language Processing, and its document-level variant poses significant challenges, due to the need to model complex interactions between entities across sentences. Current approaches, largely based on the ATLOP architecture, are commonly evaluated on benchmarks like DocRED and Re-DocRED. However, their performance in zero-shot or few-shot settings remains largely underexplored due to the task’s complexity. Recently, the GLiNER model has shown that a compact NER model can outperform much larger Large Language Models. With a similar motivation, we introduce GLiDRE, a new model for document-level relation extraction that builds on the key ideas of GliNER. We benchmark GLiDRE against state-of-the-art models across various data settings on the Re-DocRED dataset. Our results demonstrate that GLiDRE achieves state-of-the-art performance in few-shot scenarios. Our code is publicly available.
关系抽取(RE)是自然语言处理中的一项基本任务,其文档级变体带来了重大挑战,因为需要建模跨句子的实体之间的复杂交互。当前的方法大多基于ATLOP架构,通常会在DocRED和Re-DocRED等基准测试集上进行评估。然而,它们在零样本或少样本设置中的性能由于任务的复杂性而尚未得到充分探索。最近,GLiNER模型显示了一个紧凑的命名实体识别模型可以表现出优于更大规模的语言模型的性能。基于同样的动机,我们介绍了GLiDRE,这是一个新的文档级关系抽取模型,它建立在GliNER的关键思想之上。我们在Re-DocRED数据集的各种数据设置上与最先进的模型对GLiDRE进行了基准测试。我们的结果表明,GLiDRE在少样本场景中达到了最先进的性能。我们的代码是公开的。
论文及项目相关链接
PDF Submitted to ARR July
Summary
GLiDRE模型是一种新型的文档级关系抽取模型,基于GliNER的关键思想构建。该模型在Re-DocRED数据集上的性能表现达到了先进水平,特别是在小样本场景下。
Key Takeaways
- 关系抽取(RE)是自然语言处理中的一项基本任务,其文档级变体由于需要建模跨句子的实体之间的复杂交互而具有挑战。
- 当前的方法大多基于ATLOP架构,并在DocRED和Re-DocRED等基准测试上进行评估。
- 这些方法在零样本或少样本设置下的性能由于任务的复杂性而尚未得到充分探索。
- GLiDRE模型是一种新型的文档级关系抽取模型,借鉴了GliNER的思想。
- 在Re-DocRED数据集上,GLiDRE模型在各种数据设置下的性能达到了先进水平。
- GLiDRE模型在小样本场景下的表现尤其突出。
点此查看论文截图

DACTYL: Diverse Adversarial Corpus of Texts Yielded from Large Language Models
Authors:Shantanu Thorat, Andrew Caines
Existing AIG (AI-generated) text detectors struggle in real-world settings despite succeeding in internal testing, suggesting that they may not be robust enough. We rigorously examine the machine-learning procedure to build these detectors to address this. Most current AIG text detection datasets focus on zero-shot generations, but little work has been done on few-shot or one-shot generations, where LLMs are given human texts as an example. In response, we introduce the Diverse Adversarial Corpus of Texts Yielded from Language models (DACTYL), a challenging AIG text detection dataset focusing on one-shot/few-shot generations. We also include texts from domain-specific continued-pre-trained (CPT) language models, where we fully train all parameters using a memory-efficient optimization approach. Many existing AIG text detectors struggle significantly on our dataset, indicating a potential vulnerability to one-shot/few-shot and CPT-generated texts. We also train our own classifiers using two approaches: standard binary cross-entropy (BCE) optimization and a more recent approach, deep X-risk optimization (DXO). While BCE-trained classifiers marginally outperform DXO classifiers on the DACTYL test set, the latter excels on out-of-distribution (OOD) texts. In our mock deployment scenario in student essay detection with an OOD student essay dataset, the best DXO classifier outscored the best BCE-trained classifier by 50.56 macro-F1 score points at the lowest false positive rates for both. Our results indicate that DXO classifiers generalize better without overfitting to the test set. Our experiments highlight several areas of improvement for AIG text detectors.
现有的AIG(AI生成)文本检测器在现实世界环境中表现不佳,尽管它们在内部测试中取得了成功,这表明它们可能不够稳健。为了解决这个问题,我们对构建这些检测器的机器学习程序进行了严格检查。当前大多数AIG文本检测数据集都集中在零样本生成上,而对于少样本或一次生成的研究很少,后者给语言模型提供人类文本作为示例。作为回应,我们引入了来自语言模型的多样化对抗文本语料库(DACTYL),这是一个具有挑战性的AIG文本检测数据集,专注于一次/少次生成。我们还包括来自特定领域持续预训练(CPT)语言模型的文本,其中我们使用内存高效的优化方法对所有参数进行全面训练。许多现有的AIG文本检测器在我们的数据集上表现困难,这表明它们可能容易受到一次/少次和CPT生成的文本的攻击。我们还使用两种方法来训练自己的分类器:标准二进制交叉熵(BCE)优化和一种更新的方法——深度X风险优化(DXO)。尽管BCE训练的分类器在DACTYL测试集上略微优于DXO分类器,但后者在异常值(OOD)文本上表现出色。在我们使用异常值学生作文数据集的学生作文检测模拟部署场景中,最佳DXO分类器在最低误报率的情况下,比最佳BCE训练的分类器高出50.56个宏F1分数点。我们的结果表明,DXO分类器可以更好地泛化并不会过度拟合测试集。我们的实验突出了AIG文本检测器的几个改进领域。
论文及项目相关链接
PDF MPhil in Advanced Computer Science thesis for University of Cambridge
Summary
本文介绍了现有的人工智能生成文本检测器在现实环境中的表现问题,分析其机器学习流程并指出其可能存在的局限性。文章重点介绍了一个新的数据集DACTYL,专注于一次或少数次生成的人工智能文本检测,并发现许多现有检测器在该数据集上表现不佳。此外,文章还介绍了使用两种不同优化方法训练的分类器性能比较,并发现DXO优化方法虽然略微逊于BCE优化方法的分类器在DACTYL测试集上的表现,但在处理出分布式文本时表现出更高的能力。这些结果表明DXO分类器能够更好地推广,且不过拟合测试集。总之,文章为未来人工智能生成文本检测器的改进指明了方向。
Key Takeaways
- 现有的人工智能生成文本检测器在现实环境中表现欠佳,存在稳健性问题。
- 引入了一个新的数据集DACTYL,专门用于一次或少数次生成的人工智能文本检测。
- 许多现有检测器在DACTYL数据集上表现不佳,表明对一次或少数次生成和CPT生成的文本存在潜在漏洞。
- 使用两种不同优化方法训练的分类器性能比较显示,DXO优化方法在出分布式文本处理方面表现出更高的能力。
- 在模拟部署场景中,DXO分类器在检测学生论文时表现出更好的泛化性能。
- 文章指出了人工智能生成文本检测器的潜在改进方向。
点此查看论文截图

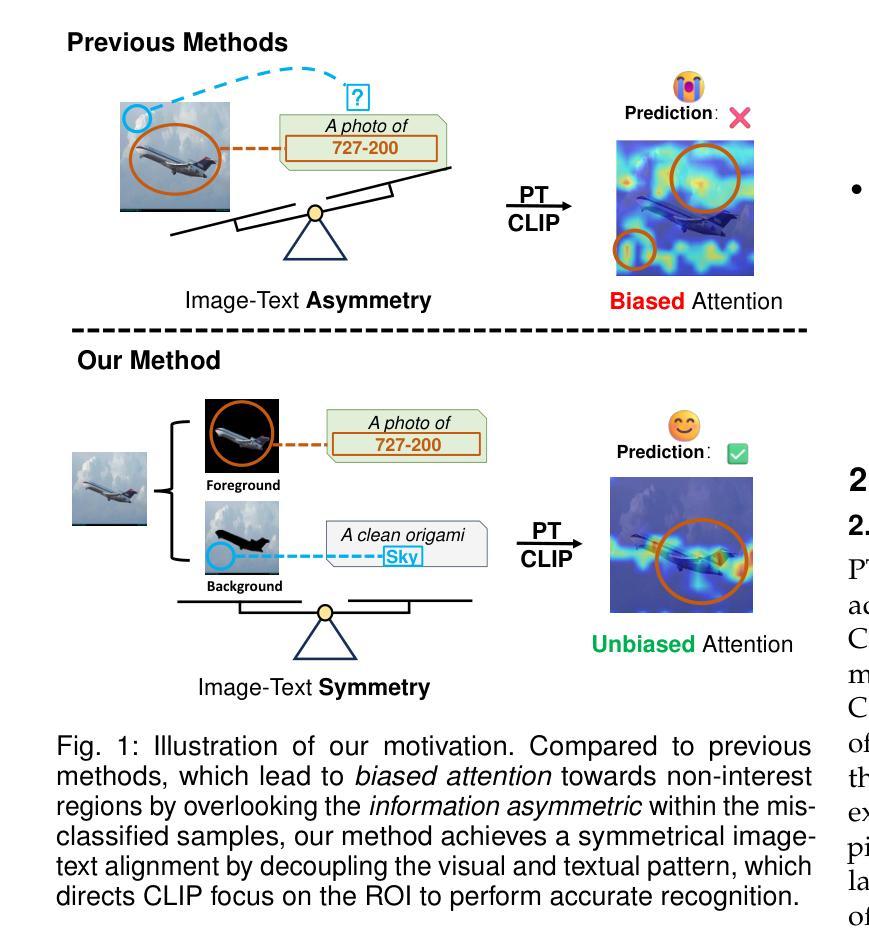
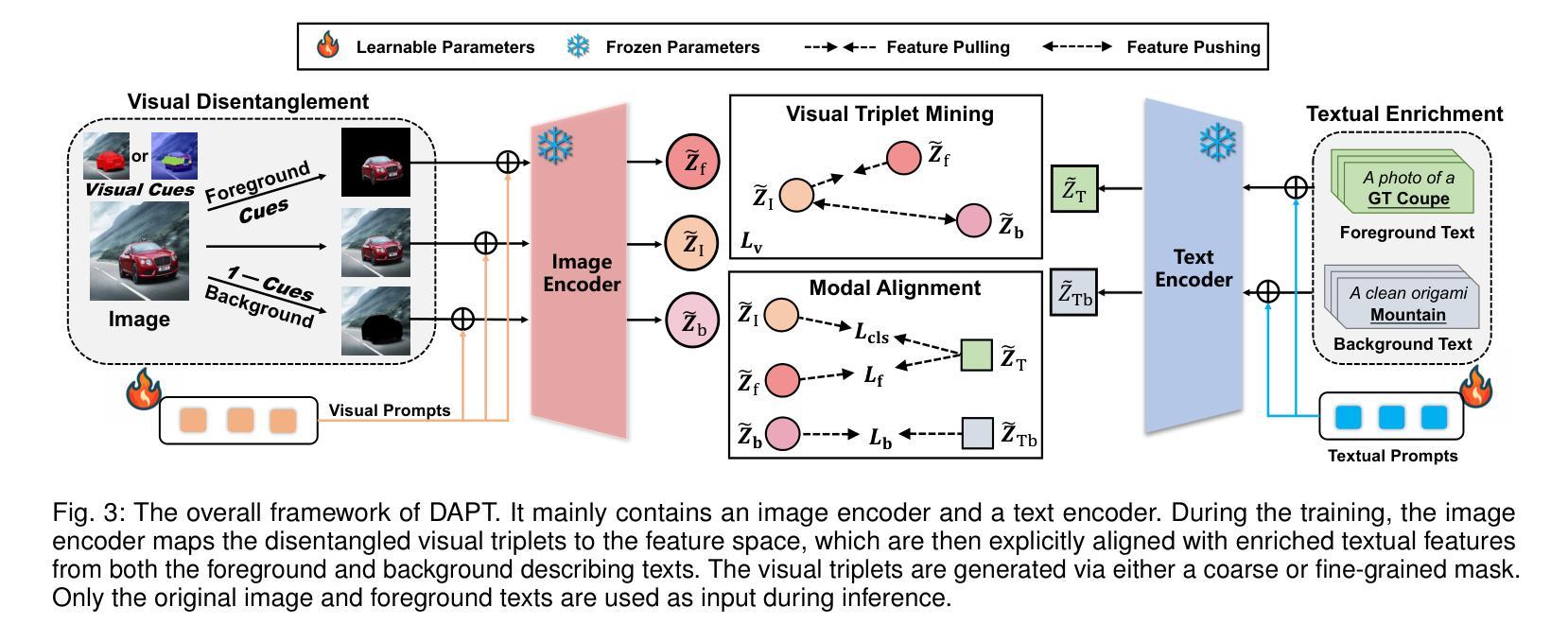
Decouple before Align: Visual Disentanglement Enhances Prompt Tuning
Authors:Fei Zhang, Tianfei Zhou, Jiangchao Yao, Ya Zhang, Ivor W. Tsang, Yanfeng Wang
Prompt tuning (PT), as an emerging resource-efficient fine-tuning paradigm, has showcased remarkable effectiveness in improving the task-specific transferability of vision-language models. This paper delves into a previously overlooked information asymmetry issue in PT, where the visual modality mostly conveys more context than the object-oriented textual modality. Correspondingly, coarsely aligning these two modalities could result in the biased attention, driving the model to merely focus on the context area. To address this, we propose DAPT, an effective PT framework based on an intuitive decouple-before-align concept. First, we propose to explicitly decouple the visual modality into the foreground and background representation via exploiting coarse-and-fine visual segmenting cues, and then both of these decoupled patterns are aligned with the original foreground texts and the hand-crafted background classes, thereby symmetrically strengthening the modal alignment. To further enhance the visual concentration, we propose a visual pull-push regularization tailored for the foreground-background patterns, directing the original visual representation towards unbiased attention on the region-of-interest object. We demonstrate the power of architecture-free DAPT through few-shot learning, base-to-novel generalization, and data-efficient learning, all of which yield superior performance across prevailing benchmarks. Our code will be released at https://github.com/Ferenas/DAPT.
摘要翻译:
提示调整(PT)作为一种新兴的资源高效微调范式,在提高视觉语言模型的特定任务迁移性方面表现出显著的有效性。本文深入探讨了PT中以前被忽视的信息不对称问题,其中视觉模式大多传递的上下文信息多于面向对象的文本模式。相应地,粗略对齐这两种模式可能会导致偏向性注意力,使模型仅专注于上下文区域。为了解决这一问题,我们提出了基于直观“先分离再对齐”概念的DAPT有效PT框架。首先,我们提议通过利用粗细视觉分段线索显式地将视觉模式分解为前景和背景表示,然后将这两种分解的模式与原始前景文本和手工背景类别对齐,从而对称地加强模态对齐。为了进一步增强视觉集中度,我们针对前景背景模式提出了视觉推拉正则化,引导原始视觉表示在感兴趣区域上实现无偏注意。我们通过小样本学习、基础到新颖的泛化和数据高效学习展示了无架构DAPT的威力,所有这些方法在流行的基准测试中均表现出卓越的性能。我们的代码将在https://github.com/Ferenas/DAPT发布。
详细翻译:
提示调整(Prompt Tuning,PT)作为一种资源高效的微调模式,其在提高视觉语言模型的特定任务迁移能力方面展现出了令人瞩目的效果。然而,在PT中存在一个被忽视的信息不对称问题。在视觉模态中,大多数情况下传递的上下文信息远多于面向对象的文本模态。因此,如果粗略地对这两种模式进行对齐,可能会导致模型过度关注上下文区域而忽略其他重要信息。为了解决这个问题,我们提出了基于直观“先分离再对齐”(Decouple-before-Align)理念的DAPT框架。
论文及项目相关链接
PDF 16 pages, Accepted at IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Summary
本文探讨了Prompt Tuning(PT)在视觉语言模型中的任务特定迁移能力,并揭示了其中信息不对称的问题。针对视觉模态与文本模态之间的信息差异,提出了基于解耦对齐的DAPT框架。通过粗粒度视觉分割将视觉模态分为前景和背景表示,并与文本进行对齐,以改善模态对齐问题。同时,通过设计一种视觉拉推正则化方法,使模型更加关注前景背景模式的关键区域。该架构灵活的DAPT方法在少样本学习、基础到新颖的泛化能力以及数据效率学习方面表现出卓越的性能。
Key Takeaways
- Prompt Tuning(PT)在视觉语言模型中提高了任务特定迁移能力。
- 存在视觉模态与文本模态之间的信息不对称问题,其中视觉模态提供更多上下文信息。
- DAPT框架旨在解决这一问题,通过解耦对齐改善模态间的对齐问题。
- 利用粗粒度视觉分割将视觉模态分为前景和背景表示。
- 通过前景与背景表示与文本的对应对齐来强化模态对称性。
- 提出视觉拉推正则化方法,提高模型对前景背景关键区域的关注。
点此查看论文截图



H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation
Authors:Hongzhe Bi, Lingxuan Wu, Tianwei Lin, Hengkai Tan, Zhizhong Su, Hang Su, Jun Zhu
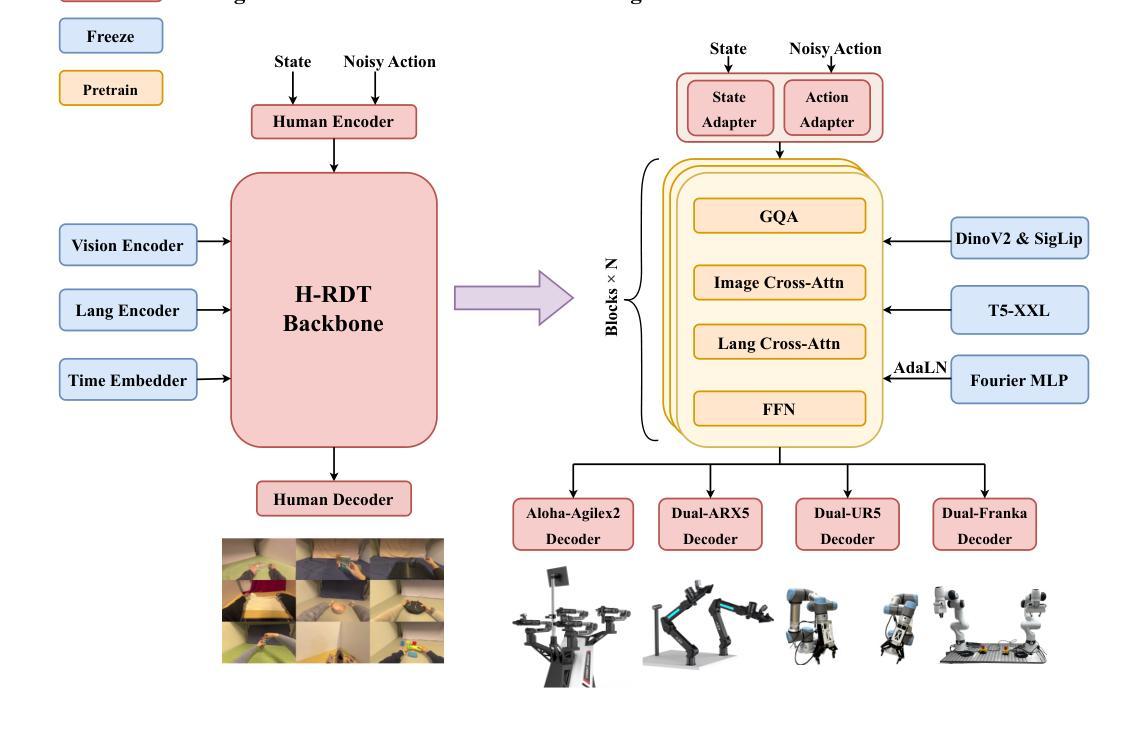
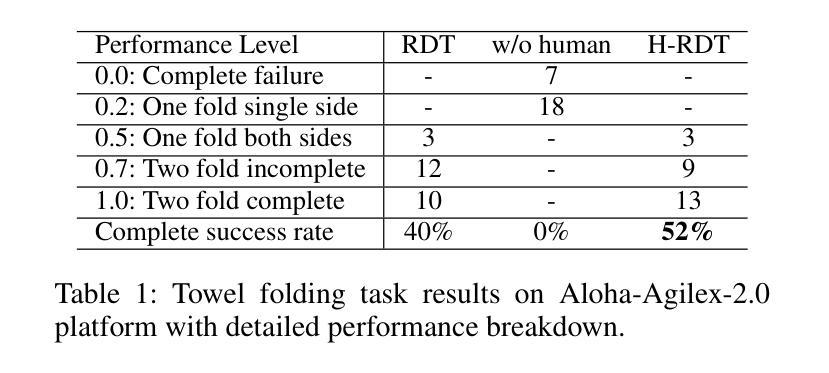
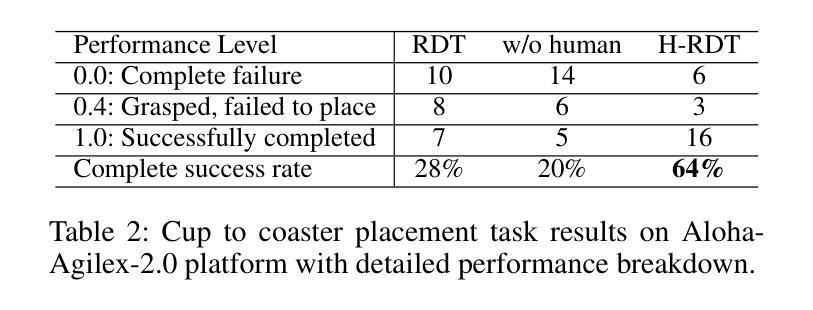
Imitation learning for robotic manipulation faces a fundamental challenge: the scarcity of large-scale, high-quality robot demonstration data. Recent robotic foundation models often pre-train on cross-embodiment robot datasets to increase data scale, while they face significant limitations as the diverse morphologies and action spaces across different robot embodiments make unified training challenging. In this paper, we present H-RDT (Human to Robotics Diffusion Transformer), a novel approach that leverages human manipulation data to enhance robot manipulation capabilities. Our key insight is that large-scale egocentric human manipulation videos with paired 3D hand pose annotations provide rich behavioral priors that capture natural manipulation strategies and can benefit robotic policy learning. We introduce a two-stage training paradigm: (1) pre-training on large-scale egocentric human manipulation data, and (2) cross-embodiment fine-tuning on robot-specific data with modular action encoders and decoders. Built on a diffusion transformer architecture with 2B parameters, H-RDT uses flow matching to model complex action distributions. Extensive evaluations encompassing both simulation and real-world experiments, single-task and multitask scenarios, as well as few-shot learning and robustness assessments, demonstrate that H-RDT outperforms training from scratch and existing state-of-the-art methods, including Pi0 and RDT, achieving significant improvements of 13.9% and 40.5% over training from scratch in simulation and real-world experiments, respectively. The results validate our core hypothesis that human manipulation data can serve as a powerful foundation for learning bimanual robotic manipulation policies.
模仿学习在机器人操作方面面临一个根本挑战:缺乏大规模、高质量机器人演示数据。最近的机器人基础模型通常会在跨形态机器人数据集上进行预训练,以增加数据规模,然而,由于不同机器人形态之间的形态多样性和行动空间差异,统一训练面临重大挑战。在本文中,我们提出了H-RDT(人类到机器人扩散转换器),这是一种利用人类操作数据增强机器人操作能力的新方法。我们的关键见解是,带有配对3D手姿势注释的大规模第一人称人类操作视频提供了丰富的行为先验,能够捕捉自然操作策略,并有益于机器人策略学习。我们介绍了一种两阶段训练范式:(1)在大规模第一人称人类操作数据上进行预训练;(2)使用模块化动作编码器和解码器,在机器人特定数据上进行跨形态微调。H-RDT建立在具有2B参数的扩散转换器架构上,通过流程匹配来模拟复杂的动作分布。全面的评估包括仿真和真实实验、单任务和多任务场景,以及小样本学习和稳健性评估,结果表明,H-RDT优于从头开始训练以及现有最先进的方法,包括Pi0和RDT,在仿真和真实实验中分别比从头开始训练提高了13.9%和40.5%。结果验证了我们的核心假设,即人类操作数据可以作为学习双手机器人操作策略的有力基础。
论文及项目相关链接
Summary
本文提出了H-RDT(人类到机器人的扩散转换器),这是一种利用人类操作数据增强机器人操作能力的新方法。该方法借助大规模的第一人称人类操作视频和配套的3D手部姿态注释,通过两阶段训练模式,实现了对机器人操作策略的学习。首先,在大规模的第一人称人类操作数据上进行预训练;然后,在具有模块化动作编码器和解码器的机器人特定数据上进行跨形态微调。H-RDT建立在具有2B参数的扩散转换器架构上,使用流程匹配来模拟复杂的动作分布。实验结果显示,H-RDT在模拟和真实世界的实验中,无论是在单任务还是多任务场景下,以及少样本学习和稳健性评估中,均表现出优于从零开始训练和现有先进方法(包括Pi0和RDT)的效果,模拟和真实实验中的提升分别达到了13.9%和40.5%。验证了人类操作数据作为学习双手机器人操作策略的强大基础这一核心假设。
Key Takeaways
- H-RDT利用大规模的第一人称人类操作视频和配套的3D手部姿态注释数据,为机器人操作提供丰富的行为先验。
- H-RDT采用两阶段训练模式,包括在大量人类操作数据上的预训练和机器人特定数据上的跨形态微调。
- H-RDT建立在具有强大参数的扩散转换器架构上,通过流程匹配模拟复杂的动作分布。
- H-RDT在模拟和真实世界的实验中表现出卓越性能,优于现有的训练方法。
- H-RDT在单任务和多任务场景下均展现出强大的性能,并且在少样本学习和稳健性方面也有显著的提升。
- 借助人类操作数据作为学习双手机器人操作策略的基础被验证为有效。
点此查看论文截图

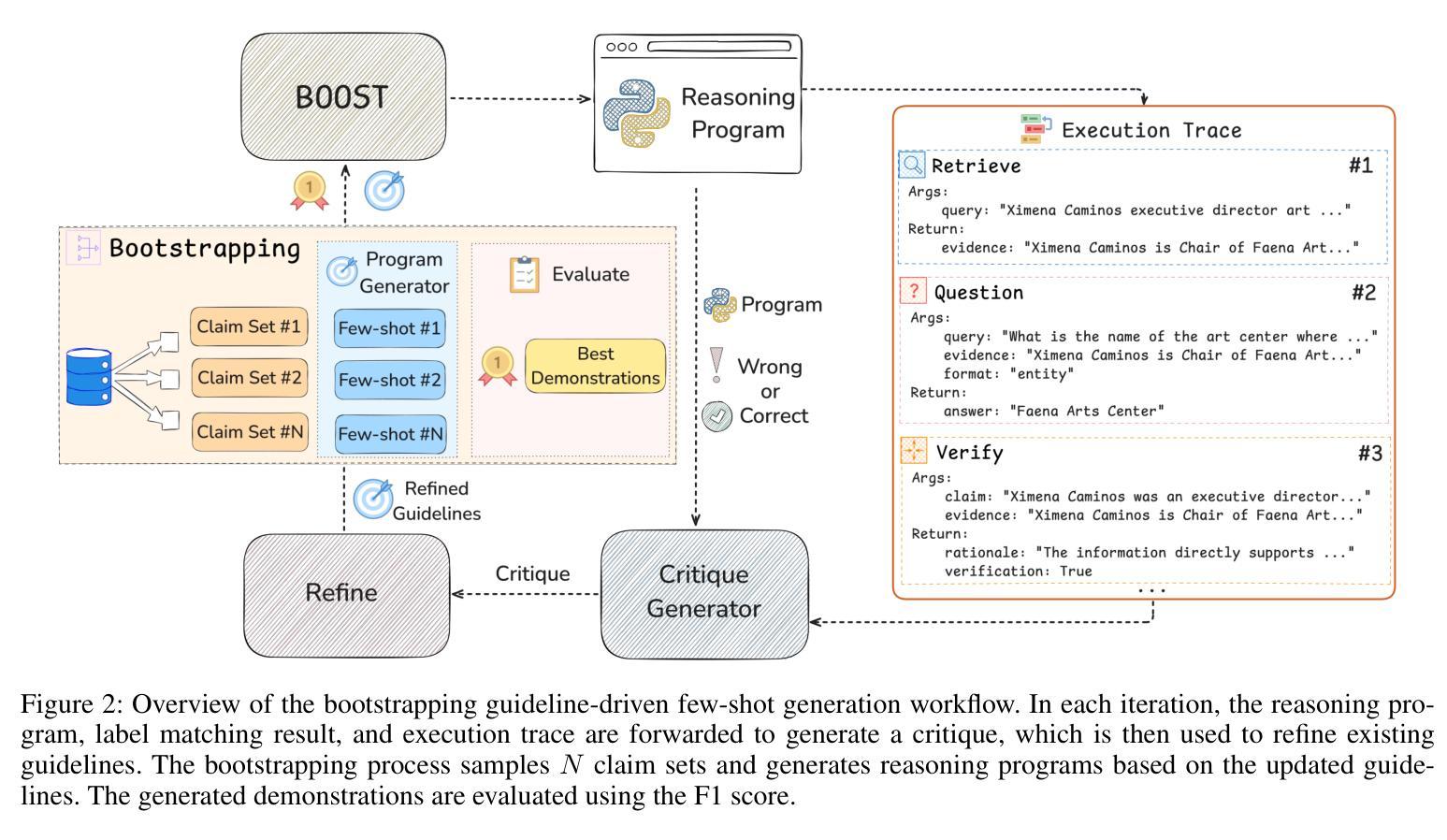
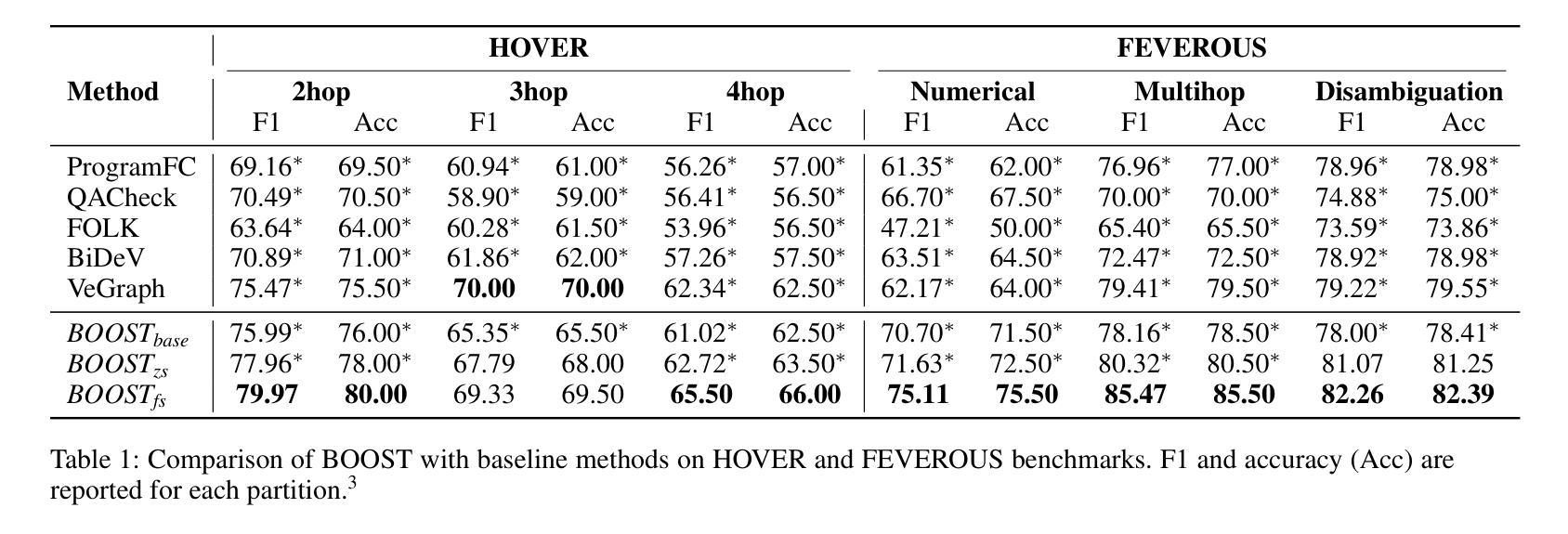
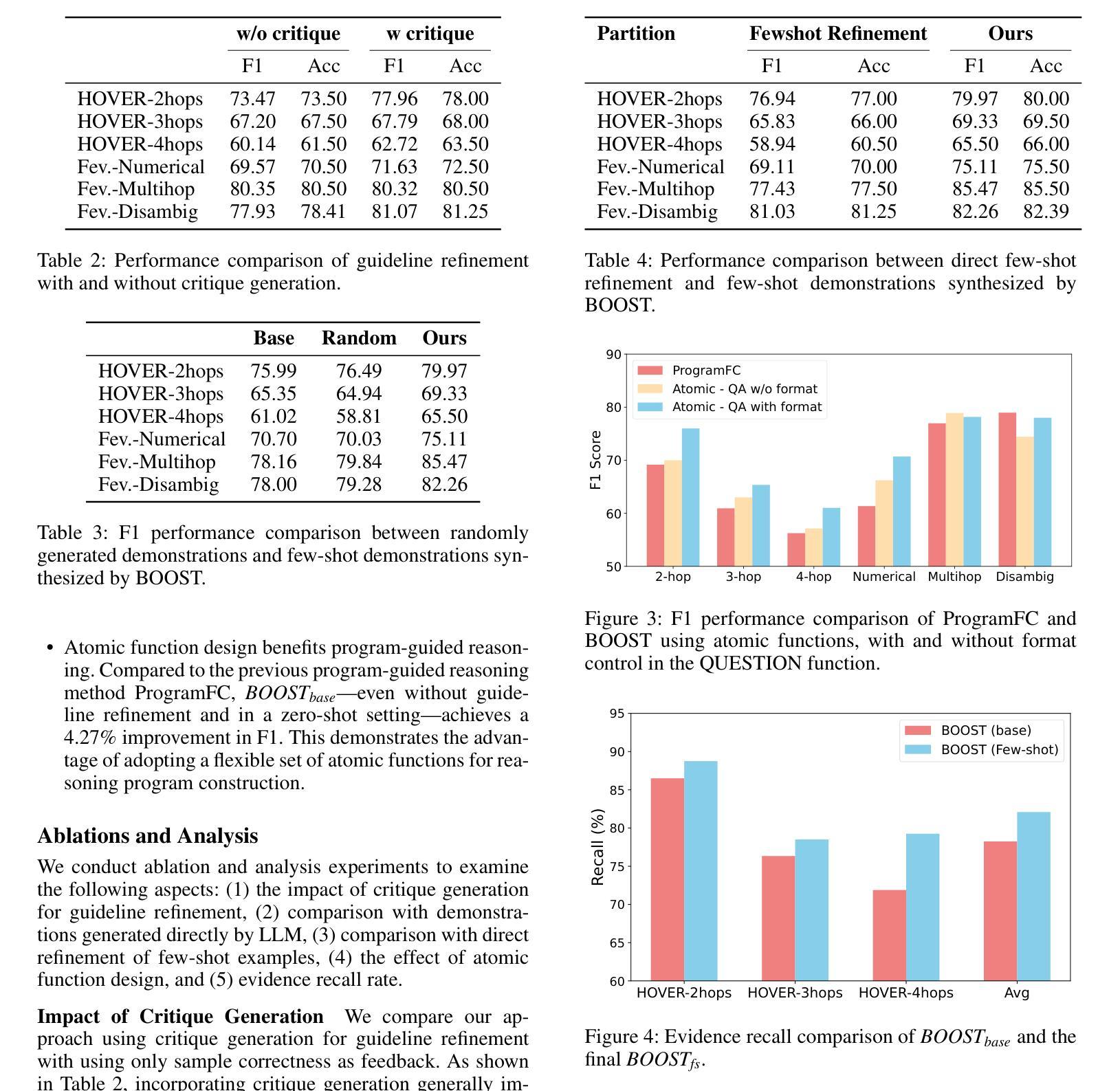
BOOST: Bootstrapping Strategy-Driven Reasoning Programs for Program-Guided Fact-Checking
Authors:Qisheng Hu, Quanyu Long, Wenya Wang
Large language model pipelines have improved automated fact-checking for complex claims, yet many approaches rely on few-shot in-context learning with demonstrations that require substantial human effort and domain expertise. Among these, program-guided reasoning, by decomposing claims into function calls and executing reasoning programs, which has shown particular promise, but remains limited by the need for manually crafted demonstrations. Fundamentally, the underlying principles of effective reasoning program generation still remain underexplored. In this work, we introduce BOOST, a bootstrapping approach for automated few-shot reasoning program generation. BOOST iteratively refines explicit, data-driven guidelines as meta-rules for guiding demonstration creation, using a critique-refine loop that eliminates the need for human intervention. This enables a seamless transition from zero-shot to few-shot program-guided learning, enhancing interpretability and effectiveness. Experimental results show that BOOST outperforms prior few-shot baselines in both zero-shot and few-shot settings for complex claim verification.
大型语言模型管道已经改进了复杂声明的自动化事实核查,然而许多方法依赖于通过演示进行的小样本上下文学习,这需要大量的人力和领域专业知识。其中,程序引导推理通过将声明分解成函数调用并执行推理程序,显示出特别的潜力,但仍受限于需要手动制作的演示。从根本上说,有效推理程序生成的基本原理仍未得到充分探索。在这项工作中,我们介绍了BOOST,这是一种用于自动化小样本推理程序生成的自举方法。BOOST通过批评和修正循环来迭代完善显式、数据驱动的指导方针,将其作为引导演示制作的元规则,从而消除了对人工干预的需求。这实现了从零样本到小样本程序引导学习的无缝过渡,提高了可解释性和有效性。实验结果表明,BOOST在零样本和小样本设置中均优于先前的基线模型,用于复杂声明的验证。
论文及项目相关链接
PDF Work in Progress
Summary
大型语言模型管道改善了复杂声明的自动化事实核查,但许多方法仍依赖于需要巨大人力和领域专业知识的小样本上下文学习示范。其中,程序引导推理通过将声明分解成函数调用并执行推理程序显示出特别的前景,但受限于手工制作的示范需求。本文引入BOOST,一种用于自动化小样本推理程序生成的启动方法。BOOST通过批评和修正循环迭代优化显式、数据驱动的指导方针作为引导示范创建的元规则,消除了对人工干预的需求。这使得从零样本到小样本的程序引导学习无缝过渡,提高了可解释性和有效性。实验结果表明,BOOST在零样本和小样本设置中均优于先前的少样本基线,用于复杂声明验证。
Key Takeaways
- 大型语言模型管道已改善复杂声明的自动化事实核查。
- 当前方法依赖小样本上下文学习示范,需要人力和领域专业知识。
- 程序引导推理通过将声明分解成函数调用进行推理显示出前景。
- 目前的方法受限于手工制作的示范需求。
- 引入BOOST方法,一种用于自动化小样本推理程序生成的启动方法。
- BOOST通过批评和修正循环优化显式、数据驱动的指导方针,消除对人工干预的需求。
点此查看论文截图