⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
Sample-Aware Test-Time Adaptation for Medical Image-to-Image Translation
Authors:Irene Iele, Francesco Di Feola, Valerio Guarrasi, Paolo Soda
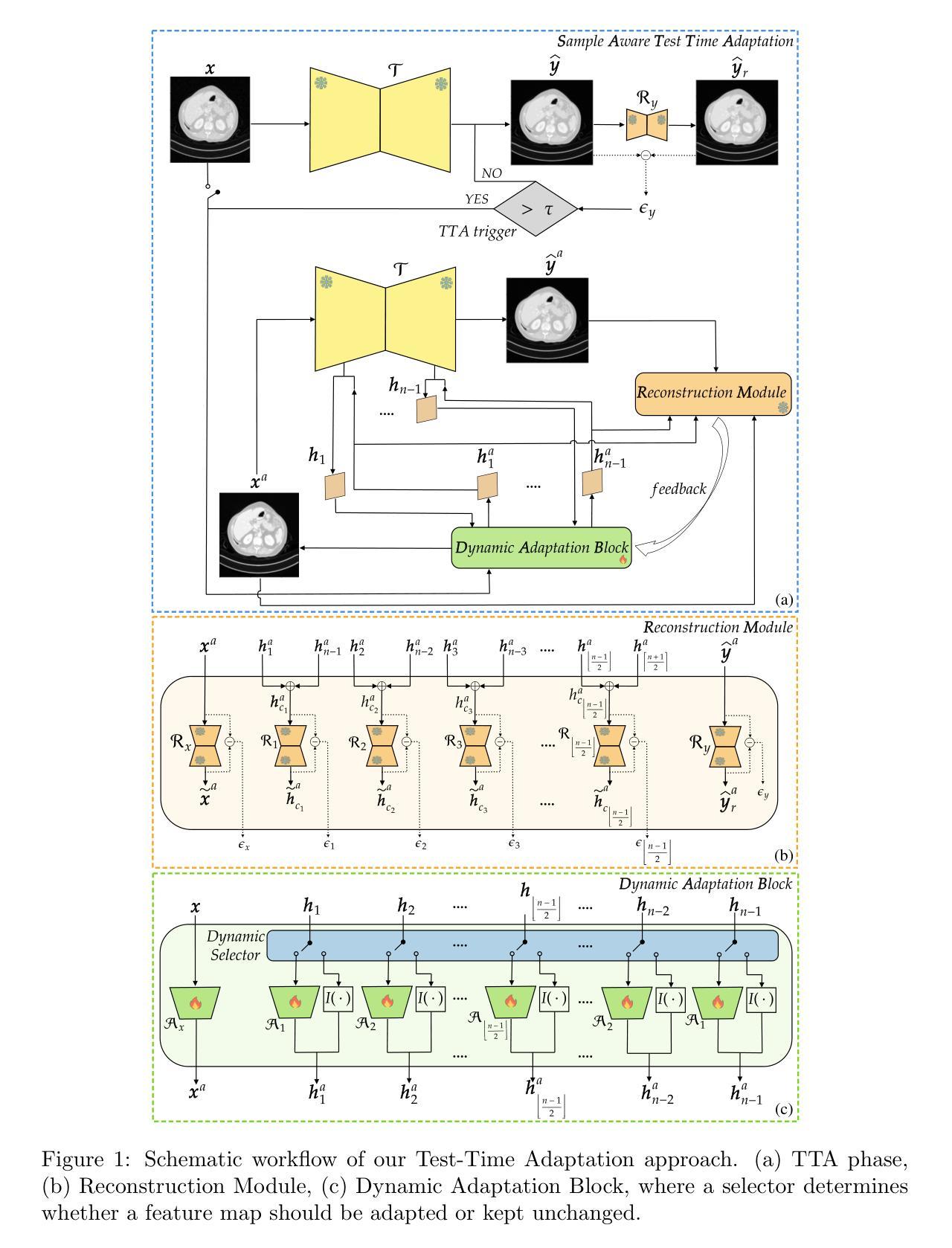
Image-to-image translation has emerged as a powerful technique in medical imaging, enabling tasks such as image denoising and cross-modality conversion. However, it suffers from limitations in handling out-of-distribution samples without causing performance degradation. To address this limitation, we propose a novel Test-Time Adaptation (TTA) framework that dynamically adjusts the translation process based on the characteristics of each test sample. Our method introduces a Reconstruction Module to quantify the domain shift and a Dynamic Adaptation Block that selectively modifies the internal features of a pretrained translation model to mitigate the shift without compromising the performance on in-distribution samples that do not require adaptation. We evaluate our approach on two medical image-to-image translation tasks: low-dose CT denoising and T1 to T2 MRI translation, showing consistent improvements over both the baseline translation model without TTA and prior TTA methods. Our analysis highlights the limitations of the state-of-the-art that uniformly apply the adaptation to both out-of-distribution and in-distribution samples, demonstrating that dynamic, sample-specific adjustment offers a promising path to improve model resilience in real-world scenarios. The code is available at: https://github.com/cosbidev/Sample-Aware_TTA.
图像到图像的翻译在医学成像领域已经成为一项强大的技术,能够完成图像降噪和跨模态转换等任务。然而,它在处理分布外样本时存在性能下降的局限性。为了解决这一局限性,我们提出了一种新型的测试时间适应(TTA)框架,该框架根据每个测试样本的特性动态调整翻译过程。我们的方法引入了一个重建模块来量化域偏移和一个动态适应块,该块有选择地修改预训练翻译模型的内部特征,以减轻偏移,同时不损害对不需要适应的分布内样本的性能。我们在两个医学图像到图像翻译任务上评估了我们的方法:低剂量CT降噪和T1到T2的MRI翻译,与没有TTA的基线翻译模型和先前的TTA方法相比,显示出一致的优势。我们的分析强调了当前技术统一应用于分布外和分布内样本的局限性,表明动态、针对样本的特定调整是在真实世界场景中提高模型韧性的有前途的途径。代码可用在:https://github.com/cosbidev/Sample-Aware_TTA。
论文及项目相关链接
Summary
本文提出一种新型的测试时适应(Test-Time Adaptation,TTA)框架,用于解决图像到图像翻译在处理离群样本时的性能下降问题。该框架通过引入重建模块来量化领域偏移,并通过动态适应块选择性地修改预训练翻译模型的内部特征,以减轻领域偏移的影响,同时不损害对不需要适应的样本的性能。在两个医学图像到图像翻译任务上的评估结果证明了该方法的优越性。
Key Takeaways
- 图像到图像翻译在医学成像等领域展现出强大的应用潜力,如图像去噪和跨模态转换。
- 该技术面临处理离群样本时性能下降的局限。
- 提出一种新型的测试时适应(TTA)框架,通过动态调整翻译过程来处理离群样本。
- 引入重建模块量化领域偏移,并通过动态适应块选择性地修改预训练模型的内部特征。
- 方法在医学图像到图像翻译任务上的评估结果优于基线翻译模型和现有TTA方法。
- 分析强调了现有方法的局限性,即统一适应离群和正常样本的方法在实际场景中可能效果不佳。
- 动态、样本特定的调整是提高模型在现实世界中适应性的有前途的路径。
点此查看论文截图

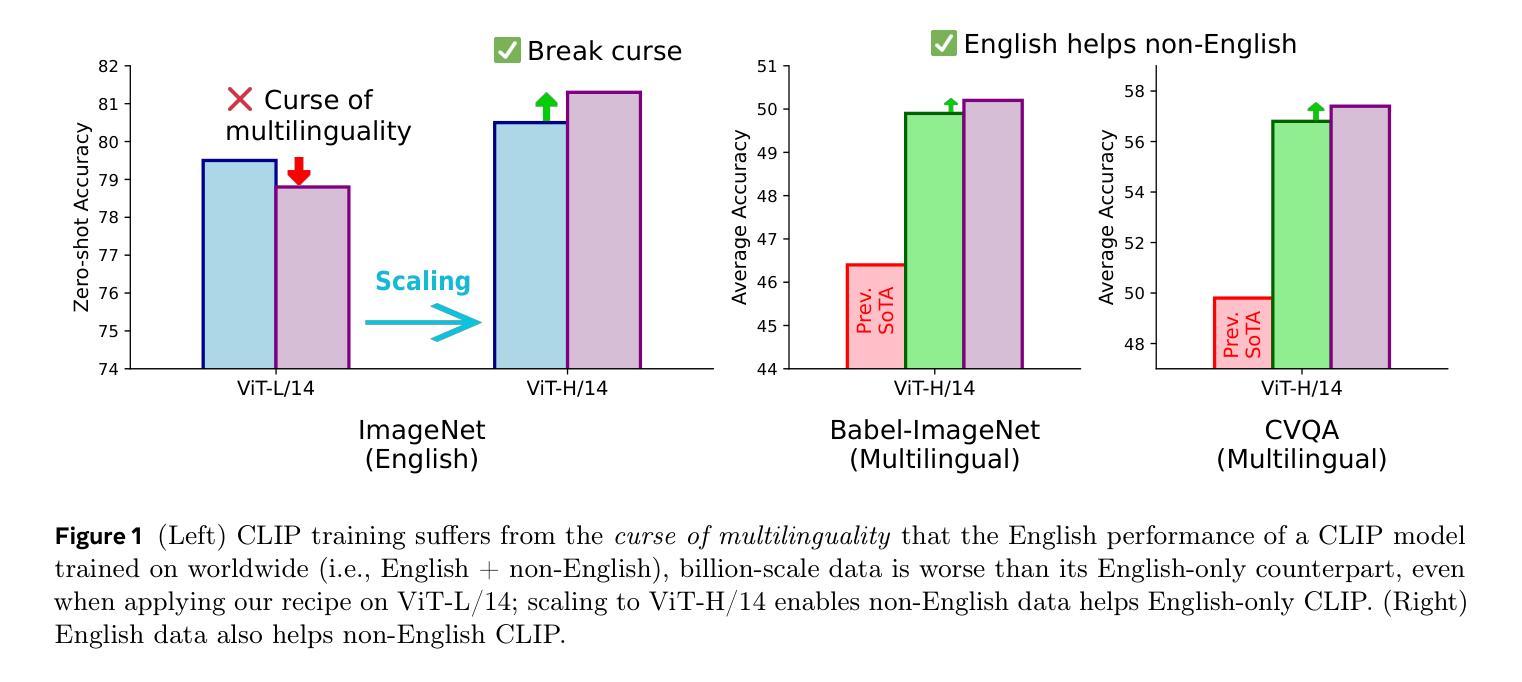
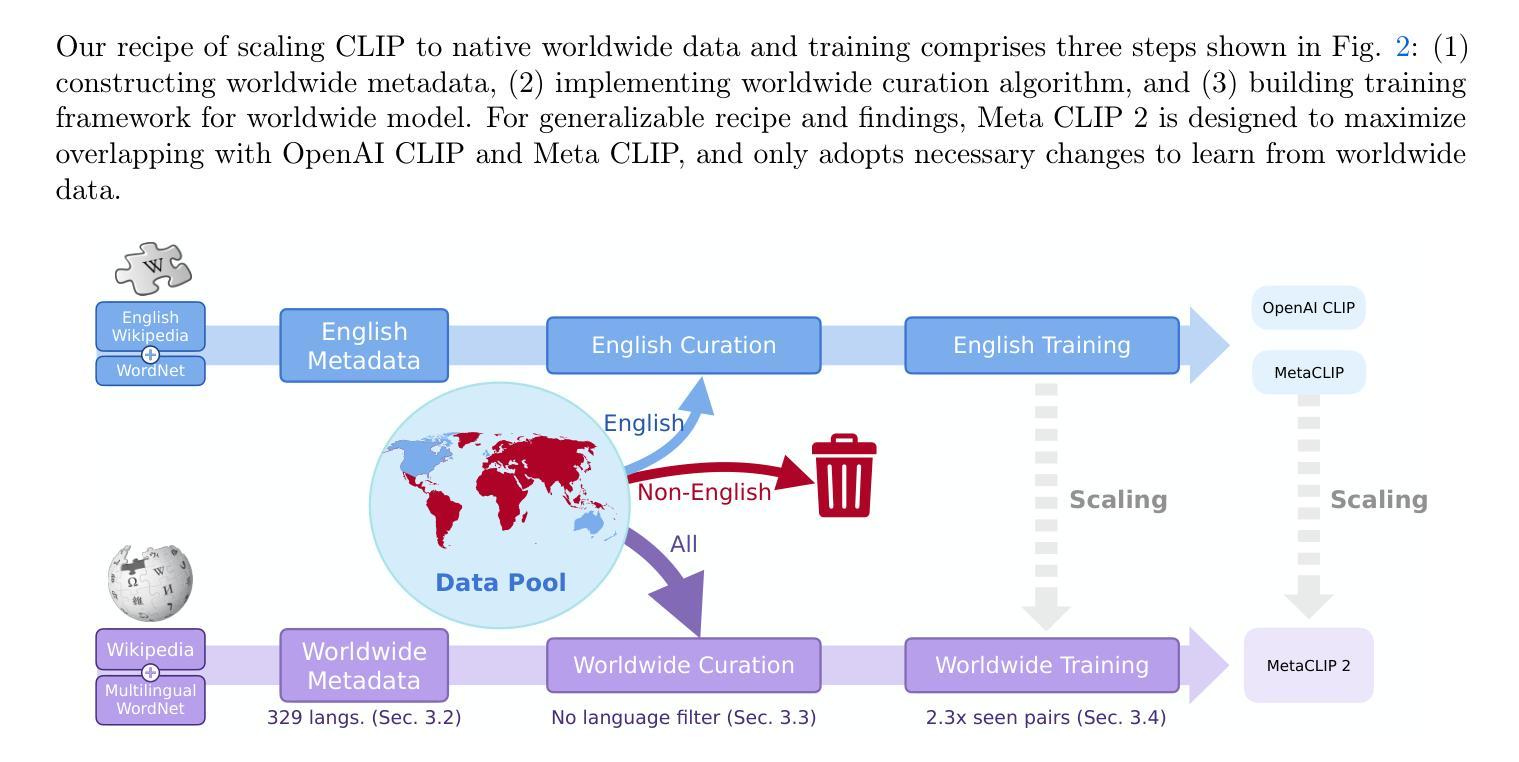
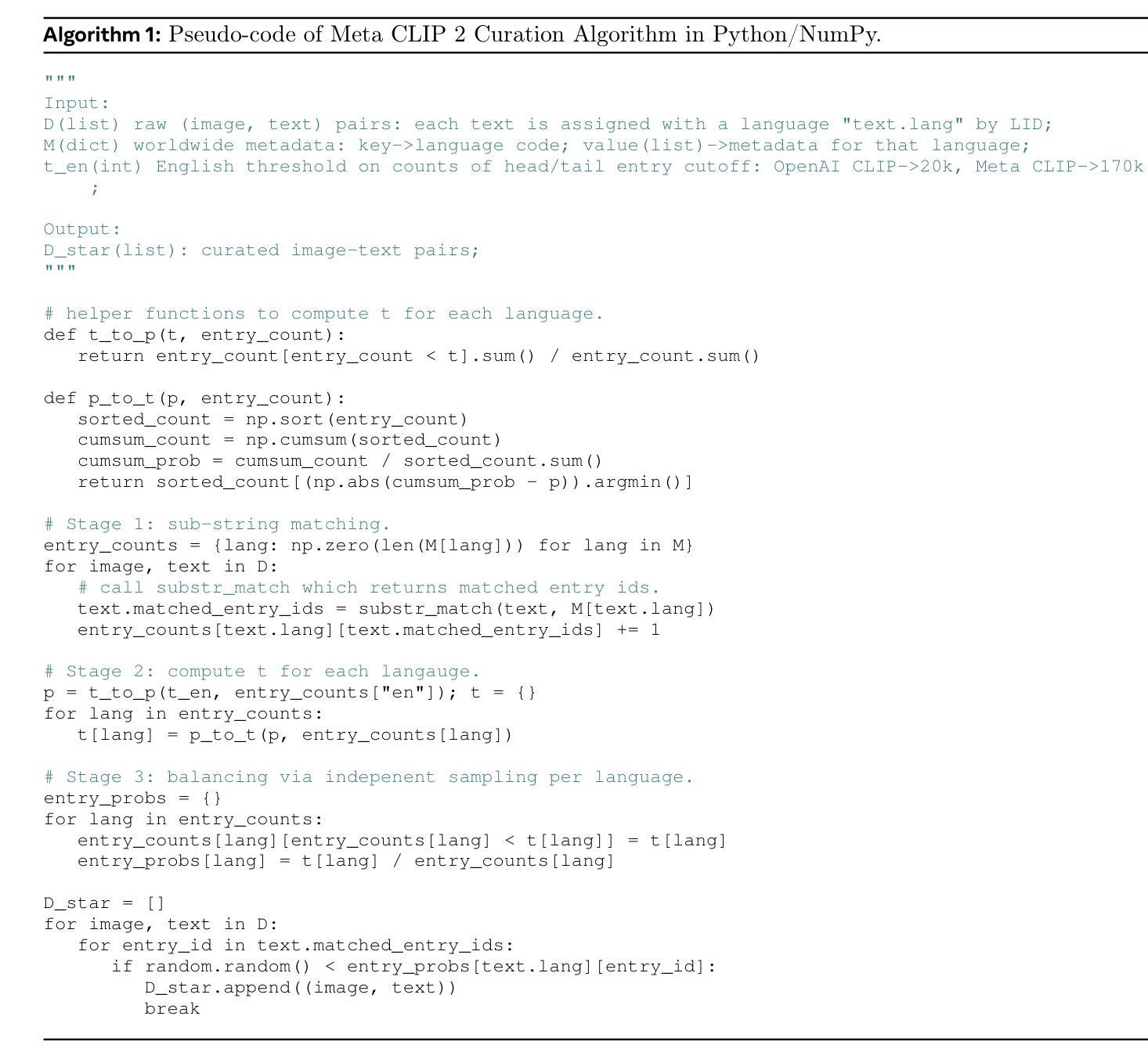
Meta CLIP 2: A Worldwide Scaling Recipe
Authors:Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, Xinlei Chen, Zhuang Liu, Saining Xie, Wen-tau Yih, Shang-Wen Li, Hu Xu
Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP’s training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., “curse of multilinguality” that is common in LLMs. Here, we present Meta CLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, Meta CLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
对比语言图像预训练(CLIP)是一种流行的基础模型,支持零样本分类、检索和多模态大型语言模型(MLLMs)的编码器。尽管CLIP已在来自英语世界的百亿级图像文本对上成功训练,但进一步将CLIP的训练扩展到从世界网页数据上学习仍具有挑战性:(1)没有处理方法可以处理非英语世界的数据点;(2)现有的多语言CLIP的英语性能不如其英语专有的对应模型,即常见的多语言模型中的“多语言诅咒”。在这里,我们推出了Meta CLIP 2,它是从头开始在全世界网页规模的图像文本对上训练CLIP的第一个配方。为了通用化我们的发现,我们进行了严格的消减实验,进行了必要的最小改动以解决上述挑战,并提出了一个配方,可以从英语和非英语世界的数据中相互获益。在零样本ImageNet分类中,Meta CLIP 2 ViT-H/14比其英语专有的对应模型高出0.8%,比mSigLIP高出0.7%,并在多语言基准测试上令人惊讶地达到了新的最先进的水平,如CVQA的57.4%,Babel-ImageNet的50.2%和XM3600的图像到文本检索的64.3%,且没有系统级别的混淆因素(如翻译、专门的架构更改)。
论文及项目相关链接
PDF 10 pages
Summary
本文介绍了Contrastive Language-Image Pretraining(CLIP)模型在面对全球网页规模图像文本对训练时的挑战,并推出了Meta CLIP 2模型。该模型能够在零样本分类、检索和多模态大型语言模型编码等方面提供支持。Meta CLIP 2通过严格的消融实验,解决了非英语世界数据处理和跨语言性能下降的问题,实现了英语和非英语世界数据的互利共赢。在零样本ImageNet分类任务中,Meta CLIP 2超过了其英语版本的对应模型,同时在多语种评估指标上达到新的水平。
Key Takeaways
- CLIP模型已成为流行的基石模型,支持零样本分类、检索和多模态大型语言模型编码。
- 虽然CLIP已经在英语世界的百亿级图像文本对上成功训练,但进一步扩展到全球网页数据仍然面临挑战。
- Meta CLIP 2是首个从全球网页规模的图像文本对训练CLIP的模型。
- Meta CLIP 2解决了非英语世界数据处理的问题,实现了英语和非英语数据的互利共赢。
- Meta CLIP 2在零样本ImageNet分类任务中表现出超越其英语版本的性能。
- Meta CLIP 2在多语种评估指标上达到新的水平,例如CVQA、Babel-ImageNet和XM3600等任务中的图像到文本检索。
点此查看论文截图