⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
Dynamically Adaptive Reasoning via LLM-Guided MCTS for Efficient and Context-Aware KGQA
Authors:Yingxu Wang, Shiqi Fan, Mengzhu Wang, Siwei Liu
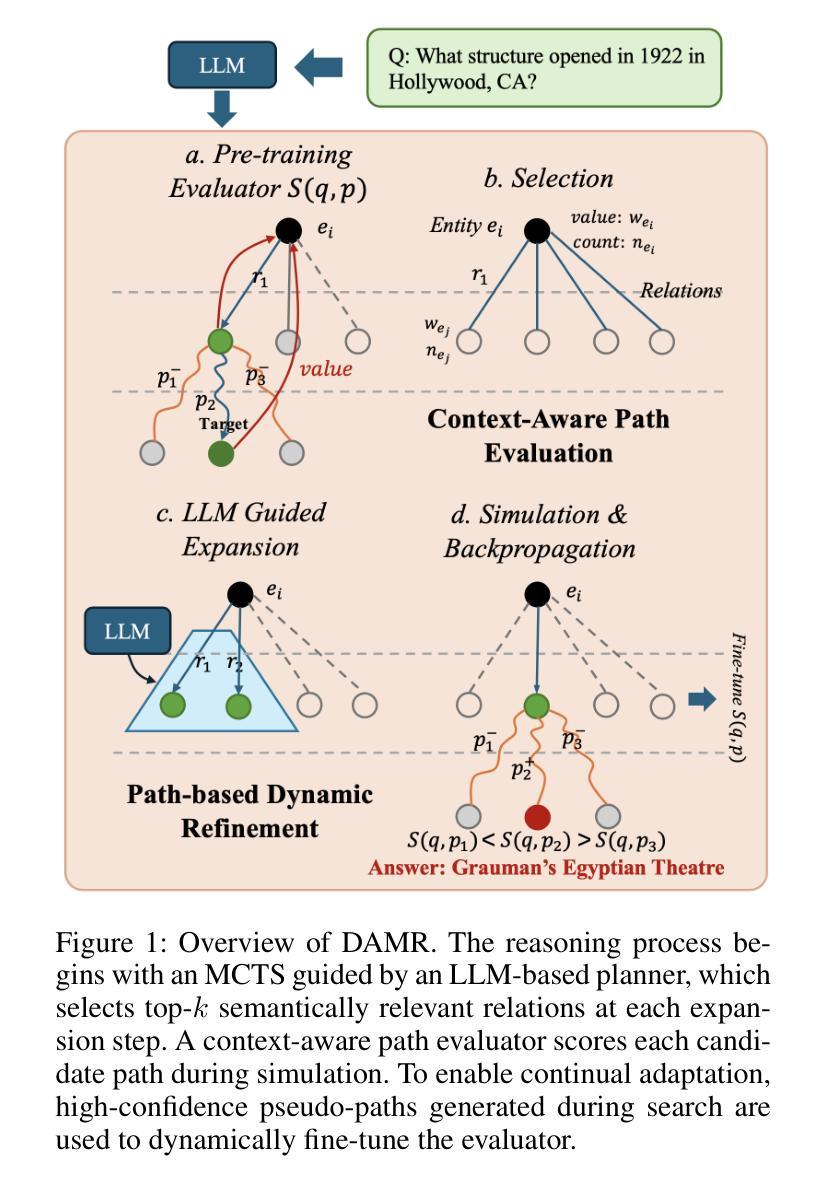
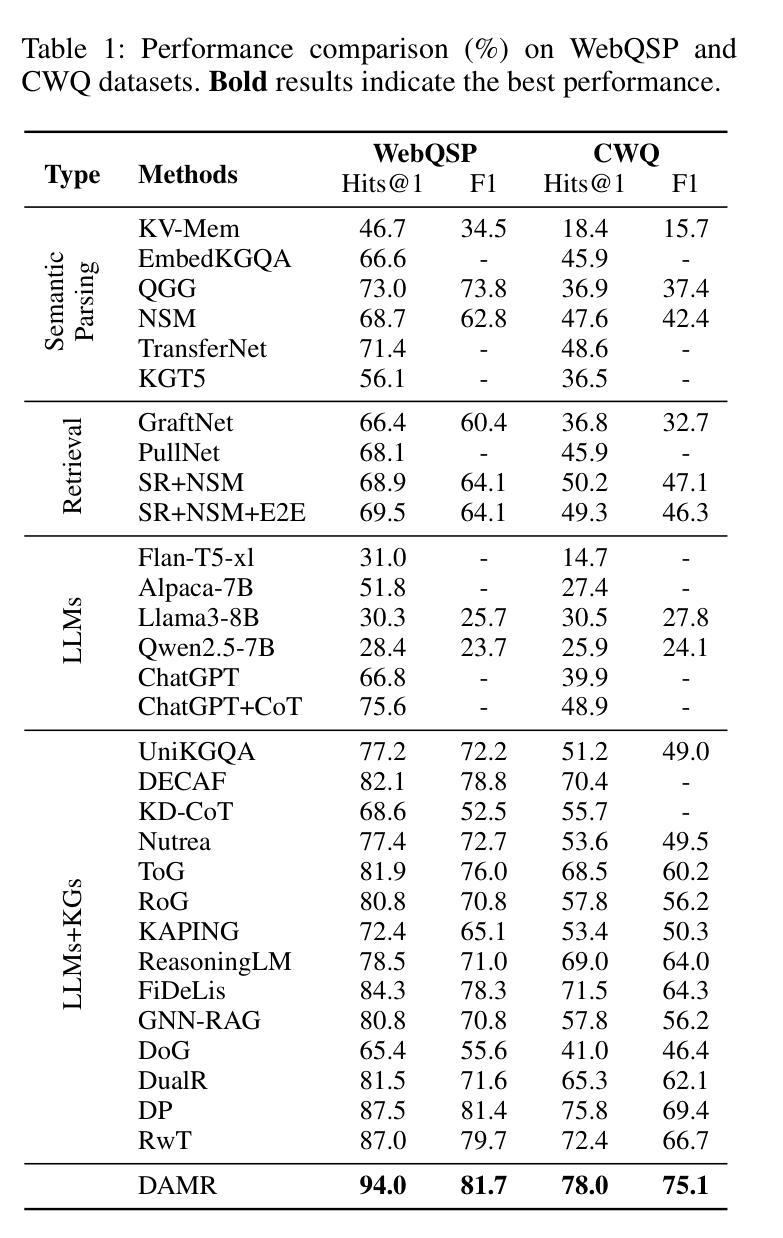
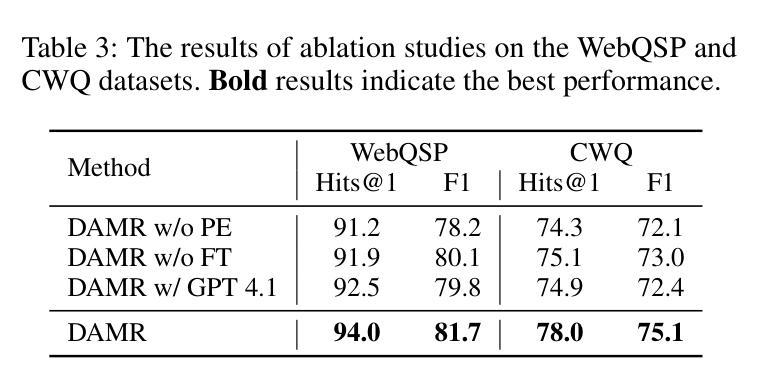
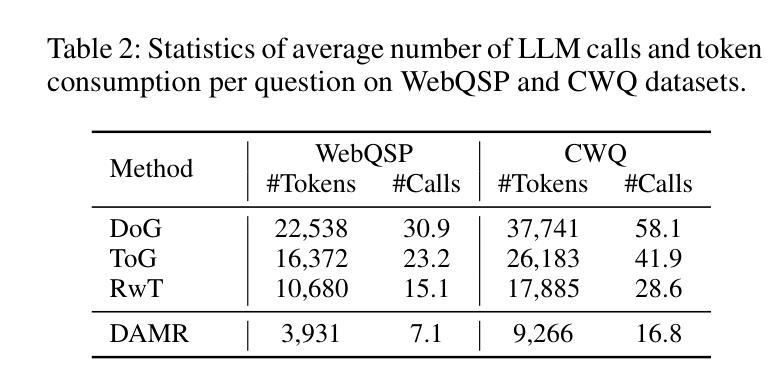
Knowledge Graph Question Answering (KGQA) aims to interpret natural language queries and perform structured reasoning over knowledge graphs by leveraging their relational and semantic structures to retrieve accurate answers. Recent KGQA methods primarily follow either retrieve-then-reason paradigm, relying on GNNs or heuristic rules for static paths extraction, or dynamic path generation strategies that use large language models (LLMs) with prompting to jointly perform retrieval and reasoning. However, the former suffers from limited adaptability due to static path extraction and lack of contextual refinement, while the latter incurs high computational costs and struggles with accurate path evaluation due to reliance on fixed scoring functions and extensive LLM calls. To address these issues, this paper proposes Dynamically Adaptive MCTS-based Reasoning (DAMR), a novel framework that integrates symbolic search with adaptive path evaluation for efficient and context-aware KGQA. DAMR employs a Monte Carlo Tree Search (MCTS) backbone guided by an LLM-based planner, which selects top-$k$ relevant relations at each step to reduce search space. To improve path evaluation accuracy, we introduce a lightweight Transformer-based scorer that performs context-aware plausibility estimation by jointly encoding the question and relation sequence through cross-attention, enabling the model to capture fine-grained semantic shifts during multi-hop reasoning. Furthermore, to alleviate the scarcity of high-quality supervision, DAMR incorporates a dynamic pseudo-path refinement mechanism that periodically generates training signals from partial paths explored during search, allowing the scorer to continuously adapt to the evolving distribution of reasoning trajectories. Extensive experiments on multiple KGQA benchmarks show that DAMR significantly outperforms state-of-the-art methods.
知识图谱问答(KGQA)旨在解释自然语言查询,并利用知识图谱的关系和语义结构进行结构化推理,以获取准确答案。最近的KGQA方法主要遵循“检索后推理”的模式,依赖于图神经网络(GNNs)或启发式规则进行静态路径提取,或者使用大型语言模型(LLMs)的提示来联合执行检索和推理的动态路径生成策略。然而,前者由于静态路径提取和缺乏上下文细化而适应性有限,后者则由于依赖于固定的评分函数和大量的LLM调用而计算成本高,并且在路径评估方面存在困难。为了解决这些问题,本文提出了基于动态自适应蒙特卡洛树搜索(MCTS)的推理(DAMR),这是一种将符号搜索与自适应路径评估相结合的新型框架,用于高效且上下文感知的KGQA。DAMR采用蒙特卡洛树搜索(MCTS)作为骨干,以基于LLM的规划器为指导,在每个步骤选择前k个相关关系来减少搜索空间。为了提高路径评估的准确性,我们引入了一个轻量级的基于Transformer的评分者,通过跨注意力联合编码问题和关系序列,进行上下文感知的可行性估计,使模型能够在多跳推理过程中捕捉细微的语义变化。此外,为了缓解高质量监督的稀缺性,DAMR结合了动态伪路径细化机制,定期从搜索过程中探索的部分路径生成训练信号,使评分者能够不断适应不断变化的推理轨迹分布。在多个KGQA基准测试上的广泛实验表明,DAMR显著优于最新方法。
论文及项目相关链接
摘要
本文提出一种名为DAMR(动态自适应蒙特卡洛树搜索推理)的新型框架,旨在解决知识图谱问答(KGQA)中的核心问题。DAMR结合了符号搜索和自适应路径评估,实现了高效且具备上下文感知的KGQA。它通过蒙特卡洛树搜索(MCTS)骨干和基于LLM的规划器,选择每一步的前k个相关关系来缩小搜索空间。为提高路径评估的准确性,引入了一个轻量级的基于Transformer的评分器,通过跨注意力机制联合编码问题和关系序列,进行上下文感知的合理性估计。此外,为缓解高质量监督数据的稀缺性,DAMR采用动态伪路径优化机制,从搜索过程中探索的部分路径生成训练信号,使评分器能够不断适应不断变化的推理轨迹分布。在多个KGQA基准测试上的广泛实验表明,DAMR显著优于现有方法。
关键见解
- KGQA旨在利用知识图谱的关系和语义结构来解答自然语言查询,近期方法主要遵循检索-推理范式。
- 现有方法存在适应性有限和计算成本高的问题,缺乏上下文精修或固定评分函数不准确。
- DAMR框架结合了符号搜索和自适应路径评估,实现高效和上下文感知的KGQA。
- DAMR使用Monte Carlo树搜索(MCTS)和LLM规划器来缩小搜索空间,并选出最相关的关系。
- 引入基于Transformer的评分器进行上下文感知的合理性估计,通过联合编码问题和关系序列。
- DAMR采用动态伪路径优化机制,从搜索过程中生成训练信号,使模型能够适应变化的推理轨迹。
- 在多个基准测试上的实验表明,DAMR在KGQA任务上显著优于现有方法。
点此查看论文截图

Analysing Temporal Reasoning in Description Logics Using Formal Grammars
Authors:Camille Bourgaux, Anton Gnatenko, Michaël Thomazo
We establish a correspondence between (fragments of) $\mathcal{TEL}^\bigcirc$, a temporal extension of the $\mathcal{EL}$ description logic with the LTL operator $\bigcirc^k$, and some specific kinds of formal grammars, in particular, conjunctive grammars (context-free grammars equipped with the operation of intersection). This connection implies that $\mathcal{TEL}^\bigcirc$ does not possess the property of ultimate periodicity of models, and further leads to undecidability of query answering in $\mathcal{TEL}^\bigcirc$, closing a question left open since the introduction of $\mathcal{TEL}^\bigcirc$. Moreover, it also allows to establish decidability of query answering for some new interesting fragments of $\mathcal{TEL}^\bigcirc$, and to reuse for this purpose existing tools and algorithms for conjunctive grammars.
我们建立了$\mathcal{TEL}^\bigcirc$(一种带有LTL运算符$\bigcirc^k$的$\mathcal{EL}$描述逻辑的时态扩展)的片段与某些特定类型的正式语法之间的对应关系,特别是与结合语法(配备交集操作的上下文无关语法)。这种联系意味着$\mathcal{TEL}^\bigcirc$不具有模型的最终周期性属性,并且进一步导致$\mathcal{TEL}^\bigcirc$中的查询回答不可判定,自$\mathcal{TEL}^\bigcirc$引入以来这一问题一直悬而未决。此外,它还允许为$\mathcal{TEL}^\bigcirc$的一些有趣新片段建立查询回答的判定性,并为此目的重用结合语法的现有工具和算法。
论文及项目相关链接
PDF This is an extended version of a paper appearing at the 28th European Conference on Artificial Intelligence (ECAI 2025). 20 pages
Summary
本文建立了描述逻辑$\mathcal{TEL}^\bigcirc$(一种带有LTL操作符$\bigcirc^k$的$\mathcal{EL}$描述逻辑的时空扩展)与某些特定类型的正式语法之间的对应关系,特别是与结合语法(带有交集操作的上下文无关语法)的对应。这一联系表明$\mathcal{TEL}^\bigcirc$不具有模型的最终周期性属性,并进一步导致$\mathcal{TEL}^\bigcirc$中的查询回答变得不可判定,从而解决了一个自$\mathcal{TEL}^\bigcirc$引入以来就悬而未决的问题。此外,它还允许为$\mathcal{TEL}^\bigcirc$的一些新有趣片段建立查询回答的判定性,并为此目的重用结合语法的现有工具和算法。
Key Takeaways
- 建立了$\mathcal{TEL}^\bigcirc$与特定类型的正式语法(特别是结合语法)之间的对应关系。
- $\mathcal{TEL}^\bigcirc$不具有模型的最终周期性属性。
- $\mathcal{TEL}^\bigcirc$中的查询回答变得不可判定,解决了一个长期存在的问题。
- 对于$\mathcal{TEL}^\bigcirc$的一些新片段,可以建立查询回答的判定性。
- 可以利用现有工具和算法来解决结合语法的问题。
- 这种联系对于理解和分析$\mathcal{TEL}^\bigcirc$的性质和限制提供了新的视角和方法。
点此查看论文截图

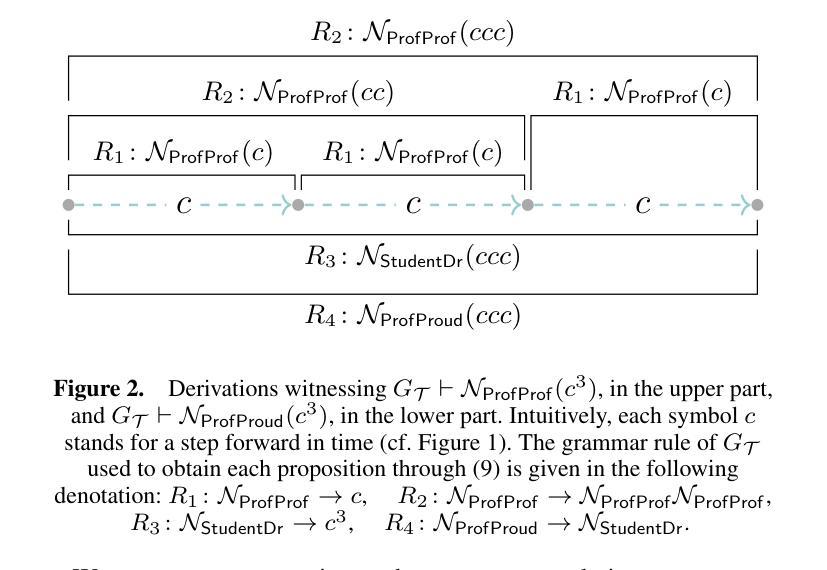


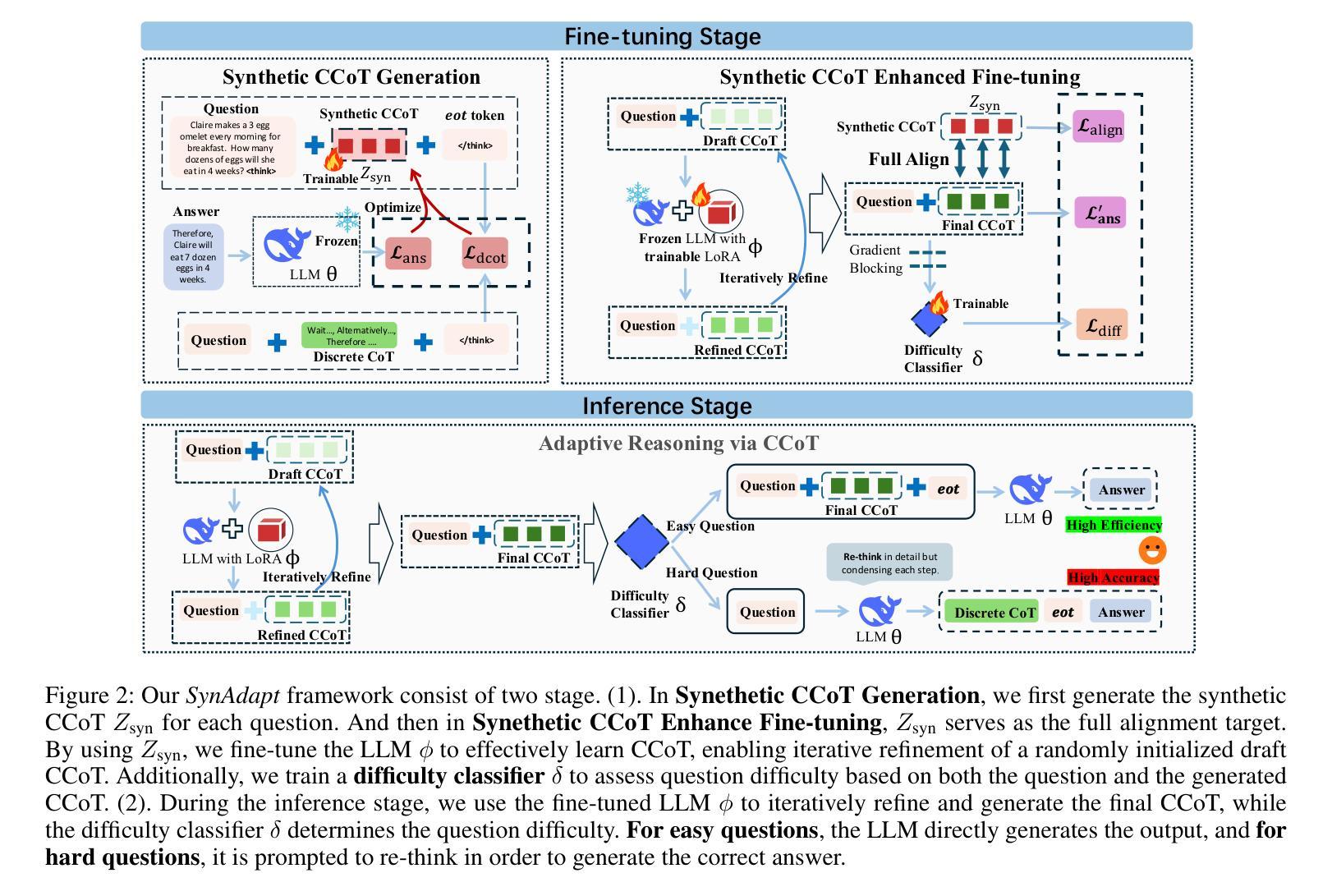
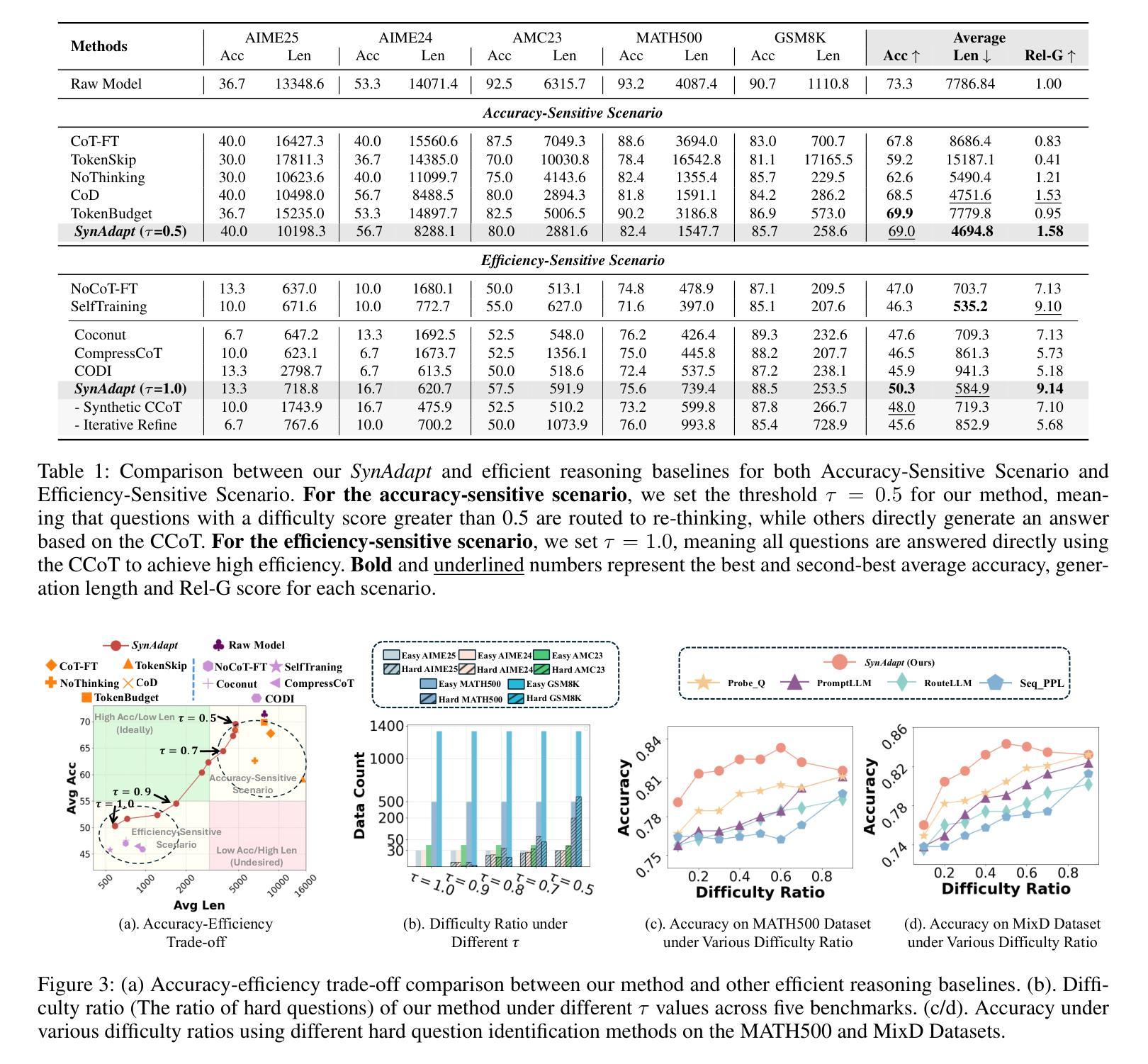
SynAdapt: Learning Adaptive Reasoning in Large Language Models via Synthetic Continuous Chain-of-Thought
Authors:Jianwei Wang, Ziming Wu, Fuming Lai, Shaobing Lian, Ziqian Zeng
While Chain-of-Thought (CoT) reasoning improves model performance, it incurs significant time costs due to the generation of discrete CoT tokens (DCoT). Continuous CoT (CCoT) offers a more efficient alternative, but existing CCoT methods are hampered by indirect fine-tuning, limited alignment, or inconsistent targets. To overcome these limitations, we propose \textit{SynAdapt}, an innovative efficient reasoning framework. Specifically, \textit{SynAdapt} generates the synthetic CCoT to serve as a precise and effective alignment target for LLMs. This synthetic CCoT explicitly guides the LLM to learn CCoT and derive accurate answers directly. Furthermore, relying solely on CCoT is insufficient for solving hard questions. To address this, \textit{SynAdapt} integrates a difficulty classifier that leverages both question context and CCoT to identify hard questions. CCoT can effectively help identify hard questions after some brief reasoning. We then adaptively prompt the LLM to re-think these hard questions for improved performance. Extensive experimental results across various benchmarks from different difficulty levels strongly demonstrate the effectiveness of our method, achieving the best accuracy-efficiency trade-off.
虽然链式思维(CoT)推理能提高模型性能,但由于生成离散CoT标记(DCoT)而产生了显著的时间成本。连续CoT(CCoT)提供了更高效的替代方案,但现有的CCoT方法受到间接微调、对齐有限或目标不一致的限制。为了克服这些局限性,我们提出了创新的高效推理框架SynAdapt。具体来说,SynAdapt生成合成CCoT,作为大型语言模型精确有效的对齐目标。这种合成CCoT明确指导大型语言模型学习CCoT并直接推导出准确答案。此外,仅依赖CCoT解决难题是不足够的。为此,SynAdapt集成难度分类器,利用问题上下文和CCoT来识别难题。CCoT在短暂推理后能有效帮助识别难题。然后,我们自适应地提示大型语言模型重新思考这些难题以提高性能。在不同难度级别的多个基准测试上的大量实验结果充分证明了我们的方法的有效性,实现了最佳的准确性-效率权衡。
论文及项目相关链接
Summary
这是一项关于提高大型语言模型性能的报告。文章探讨了如何通过结合连续认知链(CCoT)和合成认知链(Synthetic CCoT)来提高模型的推理能力。报告提出了一种名为SynAdapt的创新框架,该框架通过生成合成CCoT作为精确有效的对齐目标来指导模型学习。此外,报告还介绍了集成难度分类器的方法,用于识别难以回答的问题并促使模型重新思考这些问题以提高性能。该方法的实验结果表现出最佳的性能效率权衡。
Key Takeaways
- Chain-of-Thought (CoT) 提高了模型性能,但由于离散CoT标记(DCoT)的产生产生了显著的时间成本。
- 连续CoT(CCoT)作为一种更高效的替代方法受到了关注,但现有CCoT方法存在间接微调、对齐有限或目标不一致等局限性。
- SynAdapt是一个创新的推理框架,它通过生成合成CCoT作为精确有效的对齐目标来克服这些限制,并指导大型语言模型(LLM)学习CCoT并得出准确答案。
- 仅依赖CCoT无法解决复杂问题。SynAdapt结合了难度分类器,该分类器利用问题上下文和CCoT来识别难以回答的问题,并促使模型重新思考这些问题以提高性能。
点此查看论文截图

Thinking Machines: Mathematical Reasoning in the Age of LLMs
Authors:Andrea Asperti, Alberto Naibo, Claudio Sacerdoti Coen
Large Language Models (LLMs) have shown remarkable abilities in structured reasoning and symbolic tasks, with coding emerging as a particular area of strength. This success has sparked growing interest in applying LLMs to mathematics, both in informal problem-solving and formal theorem proving. However, progress in formal mathematics has proven to be significantly more difficult, despite surface-level similarities between programming and proof construction. This discrepancy raises important questions about how LLMs ``reason’’, how they are supervised, and whether they internally track a notion of computational or deductive state. In this article, we address the state-of-the-art of the discipline, focusing on recent models and benchmarks, and explore three central issues at the intersection of machine learning and mathematical cognition: (i) the trade-offs between formal and informal mathematics as training domains; (ii) the deeper reasons why proof generation remains more brittle than code synthesis; (iii) and the question of whether LLMs represent, or merely mimic, a notion of evolving logical state. Our goal is not to draw hard boundaries, but to identify where the current limits lie, and how they might be extended.
大型语言模型(LLM)在结构推理和符号任务方面表现出卓越的能力,其中编程成为了一个特别擅长的领域。这一成功引发了将LLM应用于数学(无论是非正式的问题解决还是正式定理证明)的兴趣不断增长。然而,尽管编程和证明构建之间存在表面相似性,但在正式数学方面的进展却证明要困难得多。这种差异引发了关于LLM如何“推理”、如何监督以及它们是否内部跟踪计算或演绎状态等重要问题。在本文中,我们介绍了该学科的最新发展,重点关注最近的模型和基准测试,并探讨了机器学习与数学认知交叉的三个核心问题:(i)正式和非正式数学作为训练领域的权衡;(ii)证明生成仍然比代码合成更脆弱背后的深层原因;(iii)以及LLM是否代表或仅仅是模仿不断变化的逻辑状态的问题。我们的目标不是划定明确的界限,而是确定当前存在的限制以及如何扩展这些限制。
论文及项目相关链接
Summary
大型语言模型(LLMs)在结构化推理和符号任务方面表现出显著的能力,编程成为其优势领域之一。这引发了将LLMs应用于数学(包括非正式问题解决和形式化定理证明)的兴趣。尽管编程和证明构建之间存在表面相似性,但在数学形式化方面的进展要困难得多。本文关注该领域的最新进展,探讨机器学习与数学认知交叉的三个核心问题:正式与非正式数学的训练领域之间的权衡、证明生成相较于代码合成更为脆弱的原因,以及LLMs是真正代表还是仅模仿逻辑状态的演变。我们的目标不是划定界限,而是确定当前存在的限制以及如何扩展。
Key Takeaways
- 大型语言模型(LLMs)在结构化推理和符号任务上表现优秀,尤其在编程领域。
- LLMs被应用于数学问题解决和定理证明,但形式化数学的进展较为困难。
- LLMs在证明生成方面相较于代码合成更为脆弱。
- 目前存在三个核心问题:正式与非正式数学的训练领域权衡、证明生成脆弱性的深层原因、LLMs是否真正代表逻辑状态的演变。
- 机器学习与数学认知的交叉是一个活跃的研究领域。
- 现有的研究旨在了解LLMs的界限,并寻找扩展其能力的方法。
点此查看论文截图

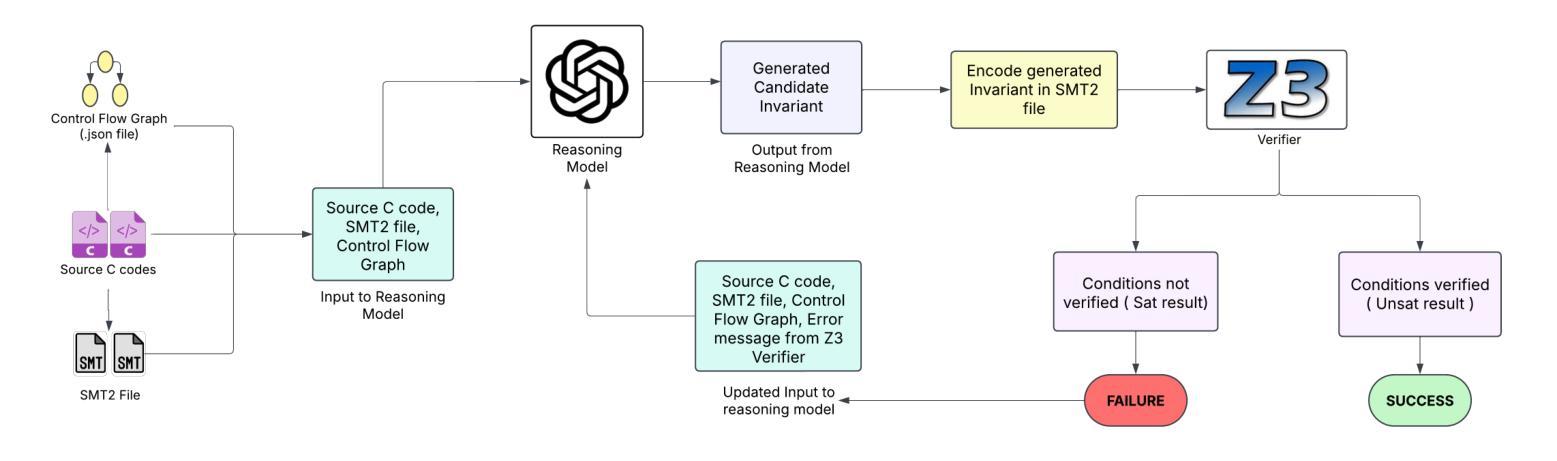
Loop Invariant Generation: A Hybrid Framework of Reasoning optimised LLMs and SMT Solvers
Authors:Varun Bharti, Shashwat Jha, Dhruv Kumar, Pankaj Jalote
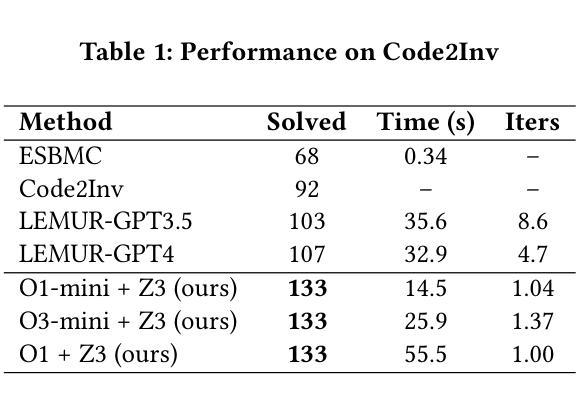
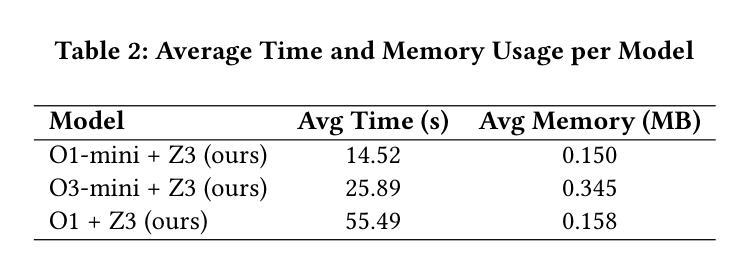
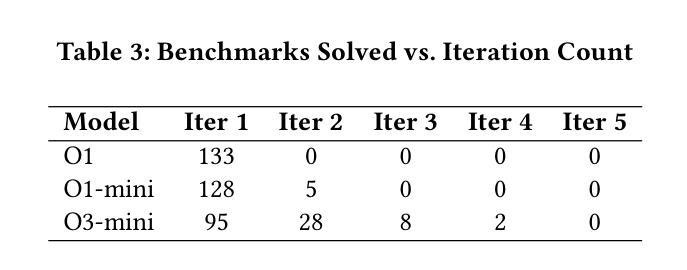
Loop invariants are essential for proving the correctness of programs with loops. Developing loop invariants is challenging, and fully automatic synthesis cannot be guaranteed for arbitrary programs. Some approaches have been proposed to synthesize loop invariants using symbolic techniques and more recently using neural approaches. These approaches are able to correctly synthesize loop invariants only for subsets of standard benchmarks. In this work, we investigate whether modern, reasoning-optimized large language models can do better. We integrate OpenAI’s O1, O1-mini, and O3-mini into a tightly coupled generate-and-check pipeline with the Z3 SMT solver, using solver counterexamples to iteratively guide invariant refinement. We use Code2Inv benchmark, which provides C programs along with their formal preconditions and postconditions. On this benchmark of 133 tasks, our framework achieves 100% coverage (133 out of 133), outperforming the previous best of 107 out of 133, while requiring only 1-2 model proposals per instance and 14-55 seconds of wall-clock time. These results demonstrate that LLMs possess latent logical reasoning capabilities which can help automate loop invariant synthesis. While our experiments target C-specific programs, this approach should be generalizable to other imperative languages.
循环不变式对于证明带有循环的程序正确性至关重要。开发循环不变式具有挑战性,且无法为任意程序保证完全自动综合。已经提出一些使用符号技术和最近使用神经网络方法综合循环不变式的方法。这些方法仅能为标准基准测试集的子集正确综合循环不变式。在这项工作中,我们调查现代、经过优化推理的大型语言模型是否能做得更好。我们将OpenAI的O1、O1-mini和O3-mini与Z3 SMT求解器紧密结合生成和检查管道,使用求解器反例来迭代指导不变式细化。我们使用Code2Inv基准测试集,该测试集提供C程序及其正式的前置条件和后置条件。在这133项任务的基准测试中,我们的框架实现了100%覆盖率(133项中的133项),超过了之前的最佳成绩(133项中的107项),同时每个实例仅需1-2个模型提案,墙钟时间14-55秒。这些结果表明,大型语言模型具备潜在的逻辑推理能力,有助于自动化综合循环不变式。虽然我们的实验针对C特定程序,但此方法应可推广到其他命令式语言。
论文及项目相关链接
PDF Under Review
Summary
本文探讨了循环不变式在证明带有循环的程序正确性方面的重要性。由于开发循环不变式具有挑战性,且无法为任意程序实现全自动综合,因此已提出一些使用符号技术和神经网络方法进行合成的方法。然而,这些方法仅能为标准基准测试集的子集正确合成循环不变式。本研究旨在探究现代大型语言模型是否能更好地进行推理。研究整合了OpenAI的O1、O1-mini和O3-mini模型,与Z3 SMT求解器构建紧密耦合的生成和检查管道,利用求解器反例迭代地引导不变式优化。在Code2Inv基准测试集上,研究框架实现了100%的覆盖率,优于之前的最佳成绩,且每个实例仅需1-2个模型提案,墙钟时间14-55秒。结果证明大型语言模型具备潜在的逻辑推理能力,有助于自动化合成循环不变式。尽管本研究针对C语言程序,但此方法应可推广到其他命令式语言。
Key Takeaways
- 循环不变式对证明带有循环的程序正确性至关重要。
- 开发循环不变式具有挑战性,全自动综合无法实现。
- 现有方法仅能正确合成循环不变式的标准基准测试集的子集。
- 现代大型语言模型具备潜在逻辑推理能力,有助于自动化合成循环不变式。
- 研究整合了OpenAI的多个模型与Z3 SMT求解器,构建生成和检查管道。
- 在Code2Inv基准测试集上,研究框架实现了100%的覆盖率,优于之前的最佳成绩。
点此查看论文截图

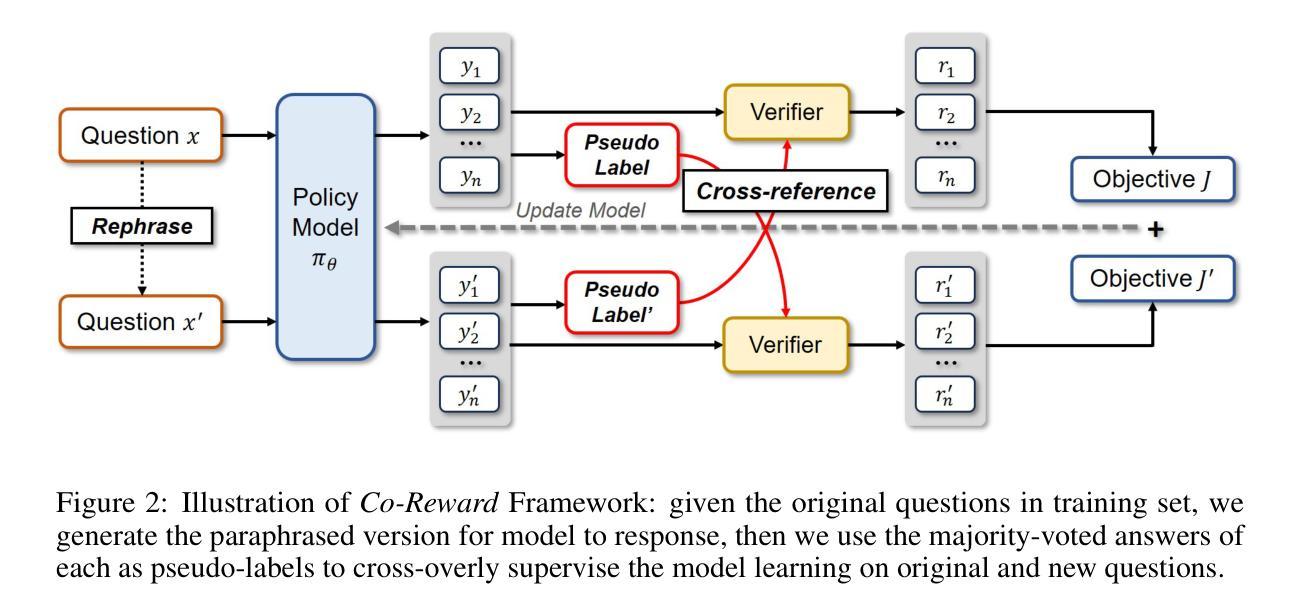
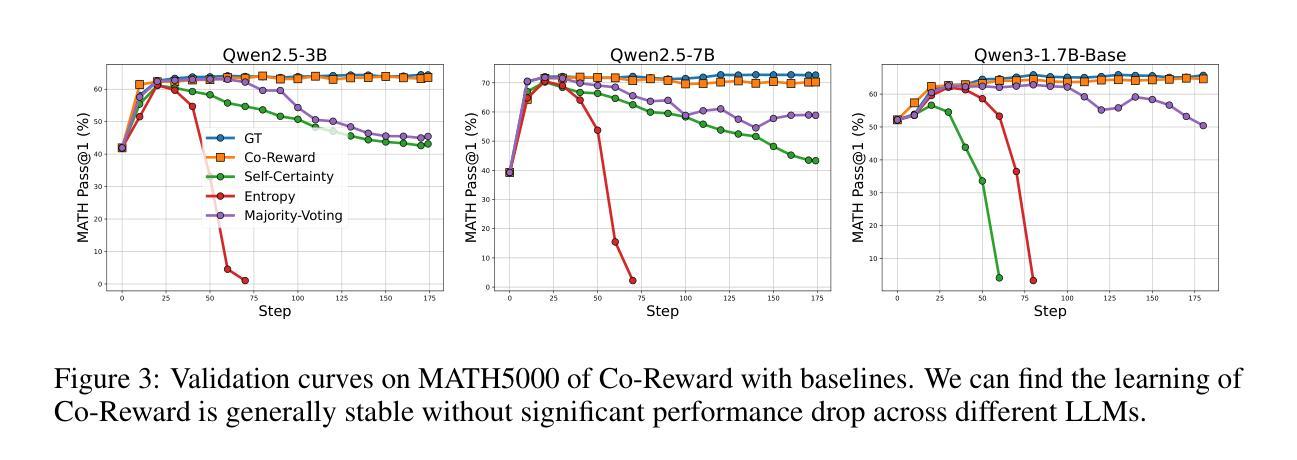
Co-Reward: Self-supervised Reinforcement Learning for Large Language Model Reasoning via Contrastive Agreement
Authors:Zizhuo Zhang, Jianing Zhu, Xinmu Ge, Zihua Zhao, Zhanke Zhou, Xuan Li, Xiao Feng, Jiangchao Yao, Bo Han
Although reinforcement learning with verifiable rewards (RLVR) shows promise in improving the reasoning ability of large language models (LLMs), the scaling up dilemma remains due to the reliance on human annotated labels especially for complex tasks. Recent alternatives that explore various self-reward signals exhibit the eliciting potential of LLM reasoning, but suffer from the non-negligible collapse issue. Inspired by the success of self-supervised learning, we propose \textit{Co-Reward}, a novel RL framework that leverages contrastive agreement across semantically analogical questions as a reward basis. Specifically, we construct a similar question for each training sample (without labels) and synthesize their individual surrogate labels through a simple rollout voting, and then the reward is constructed by cross-referring the labels of each question pair to enforce the internal reasoning consistency across analogical inputs. Intuitively, such a self-supervised reward-shaping mechanism increases the difficulty of learning collapse into a trivial solution, and promotes stable reasoning elicitation and improvement through expanding the input sample variants. Empirically, Co-Reward achieves superior performance compared to other self-reward baselines on multiple reasoning benchmarks and LLM series, and reaches or even surpasses ground-truth (GT) labeled reward, with improvements of up to $+6.8%$ on MATH500 over GT reward on Llama-3.2-3B-Instruct. Our code is publicly available at https://github.com/tmlr-group/Co-Reward.
尽管通过可验证奖励的强化学习(RLVR)在提升大型语言模型(LLM)的推理能力方面显示出潜力,但由于其特别是在复杂任务上对人类标注标签的依赖,规模化扩展难题仍然存在。最近探索各种自我奖励信号的替代方案展示了LLM推理的激发潜力,但存在不可忽视的崩溃问题。受自监督学习成功的启发,我们提出了名为“Co-Reward”的新型强化学习框架,它利用语义类似问题之间的对比一致性作为奖励基础。具体来说,我们为每个训练样本构建一个类似的问题(无标签),并通过简单的滚动投票合成各自的替代标签,然后通过交叉引用每对问题的标签来构建奖励,以加强类似输入之间的内部推理一致性。直观地看,这种自监督的奖励塑造机制增加了学习崩溃到简单解决方案的难度,并通过扩大输入样本变体促进了稳定的推理激发和提升。从经验上看,Co-Reward在多个推理基准测试和LLM系列上相对于其他自我奖励基线实现了优越的性能,甚至达到或超越了基于真实标签的奖励,在Llama-3.2-3B-Instruct的MATH500任务上相对于真实奖励提升了+6.8%。我们的代码已公开在https://github.com/tmlr-group/Co-Reward上可用。
论文及项目相关链接
Summary
强化学习结合可验证奖励(RLVR)在提升大型语言模型(LLM)的推理能力方面展现出潜力,但仍面临扩展难题,特别是在复杂任务上依赖人工标注标签的问题。当前一些尝试采用自我奖励信号的替代方案展现出激发LLM推理的潜力,但又面临不可忽视的崩溃问题。受自监督学习的启发,我们提出一种名为“Co-Reward”的新型强化学习框架,它利用语义类似问题之间的对比一致性作为奖励基础。通过构建每个训练样本的相似问题并合成各自的代理标签,以及通过交叉引用每对问题的标签来构建奖励,强化内部推理的一致性。这种自监督的奖励机制提高了学习崩溃到简单解决方案的难度,促进了稳定的推理激发和改进,并通过扩展输入样本变体来实现。在多个推理基准测试和LLM系列上,Co-Reward相较于其他自我奖励基线表现出卓越性能,甚至达到或超越了基于真实标签的奖励水平,在Llama-3.2-3B-Instruct上的MATH500任务上相较于真实奖励提升了+6.8%。我们的代码已公开在https://github.com/tmlr-group/Co-Reward。
Key Takeaways
- 强化学习结合可验证奖励(RLVR)在提升大型语言模型(LLM)推理能力方面存在扩展难题。
- 当前替代方案尝试采用自我奖励信号来激发LLM推理潜力,但面临模型崩溃问题。
- 提出名为“Co-Reward”的新型强化学习框架,利用对比一致性作为奖励基础。
- 通过构建相似问题并合成代理标签,以及交叉引用问题对来构建奖励,强化内部推理一致性。
- Co-Reward采用自监督奖励机制,提高了学习稳定性并减少了模型崩溃风险。
- Co-Reward在多个基准测试和LLM系列上表现优越,甚至超越基于真实标签的奖励。
点此查看论文截图

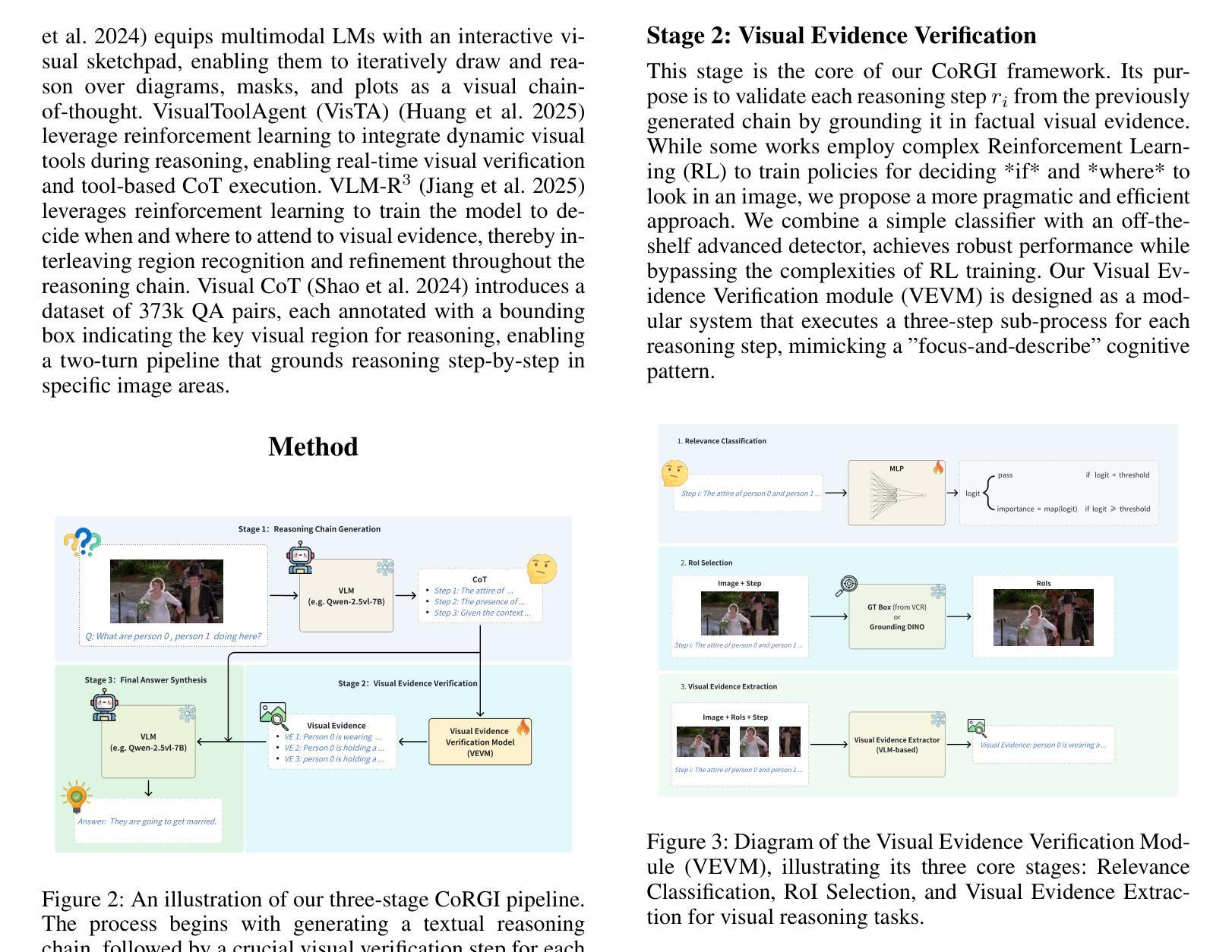
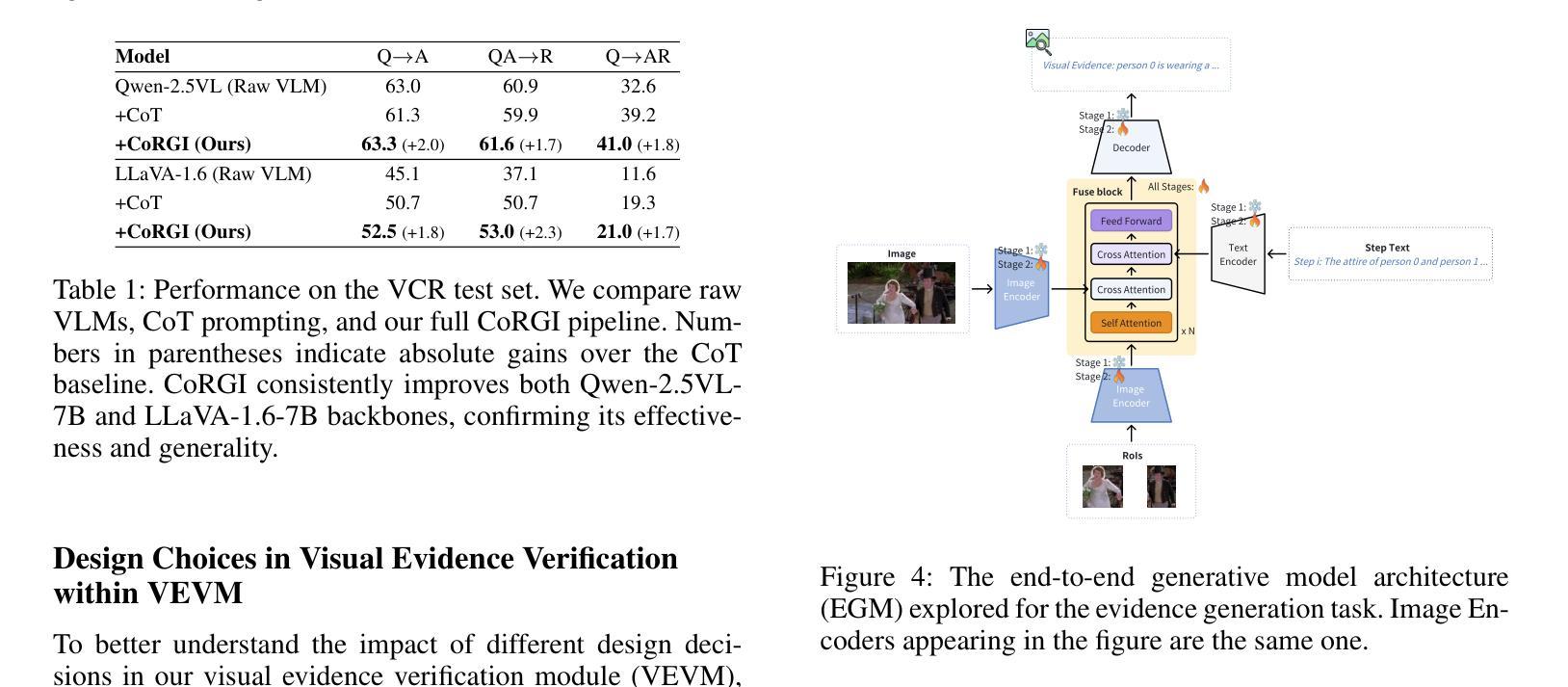
CoRGI: Verified Chain-of-Thought Reasoning with Visual Grounding
Authors:Shixin Yi, Lin Shang
Chain-of-Thought (CoT) prompting has shown promise in improving reasoning in vision-language models (VLMs), but it often produces explanations that are linguistically fluent yet lack grounding in visual content. We observe that such hallucinations arise in part from the absence of an explicit verification mechanism during multi-step reasoning. To address this, we propose \textbf{CoRGI}(\textbf{C}hain \textbf{o}f \textbf{R}easoning with \textbf{G}rounded \textbf{I}nsights), a modular framework that introduces visual verification into the reasoning process. CoRGI follows a three-stage pipeline: it first generates a textual reasoning chain, then extracts supporting visual evidence for each reasoning step via a dedicated module (VEVM), and finally synthesizes the textual rationale with visual evidence to generate a grounded, verified answer. The framework can be integrated with existing VLMs without end-to-end retraining. We evaluate CoRGI on the VCR benchmark and find that it improves reasoning performance on two representative open-source VLM backbones, Qwen-2.5VL and LLaVA-1.6. Ablation studies confirm the contribution of each step in the verification module, and human evaluations suggest that CoRGI leads to more factual and helpful explanations. We also examine alternative designs for the visual verification step and discuss potential limitations of post-hoc verification frameworks. These findings highlight the importance of grounding intermediate reasoning steps in visual evidence to enhance the robustness of multimodal reasoning.
Chain-of-Thought(CoT)提示在提升视觉语言模型(VLMs)的推理能力方面显示出潜力,但它产生的解释在语言学上很流畅,却在视觉内容上缺乏依据。我们观察到,这种幻觉部分源于多步骤推理过程中缺乏明确的验证机制。为了解决这一问题,我们提出了CoRGI(Chain of Reasoning with Grounded Insights),这是一个引入视觉验证到推理过程中的模块化框架。CoRGI遵循一个三阶段的流程:首先生成文本推理链,然后通过专用模块(VEVM)为每个推理步骤提取支持性的视觉证据,最后结合文本理性和视觉证据来生成有依据的、经过验证的答案。该框架可以与现有的VLMs集成,而无需进行端到端的再训练。我们在VCR基准测试上对CoRGI进行了评估,发现它在两个代表性的开源VLM主干(Qwen-2.5VL和LLaVA-1.0)上提高了推理性能。消融研究证实了验证模块中每一步的贡献,人类评估表明CoRGI产生的解释更加真实和有帮助。我们还探讨了视觉验证步骤的替代设计,并讨论了事后验证框架的潜在局限性。这些发现强调了将中间推理步骤建立在视觉证据上的重要性,以提高多模式推理的稳健性。
论文及项目相关链接
PDF Preparing for AAAI 2026, Multimodal Reasoning
Summary:链式思维(Chain-of-Thought,CoT)提示在提升视觉语言模型(VLMs)的推理能力方面展现出潜力,但往往产生的解释语言流畅却缺乏视觉内容的支撑。为解决这一问题,本文提出CoRGI框架,引入视觉验证进行推理。CoRGI遵循三阶段流程:生成文本推理链,通过专用模块提取每个推理步骤的支持视觉证据(VEVM),最后合成文本理由与视觉证据,生成有支撑的验证答案。该框架可整合至现有VLMs而无需端到端重训。在VCR基准测试上的评估表明,CoRGI在两种代表性开源VLM骨架上提升了推理性能。
Key Takeaways:
- 链式思维(CoT)提示在视觉语言模型的推理中展现潜力,但解释缺乏视觉内容的支撑。
- 引入视觉验证机制的CoRGI框架旨在解决此问题。
- CoRGI遵循三阶段流程:生成文本推理链,提取视觉证据,合成验证答案。
- CoRGI可整合至现有VLMs,无需端到端重训。
- 在VCR基准测试上,CoRGI提高了推理性能。
- 消融研究证实了验证模块中每一步的贡献。
- 人类评估表明,CoRGI产生的解释更真实、更有帮助。
点此查看论文截图


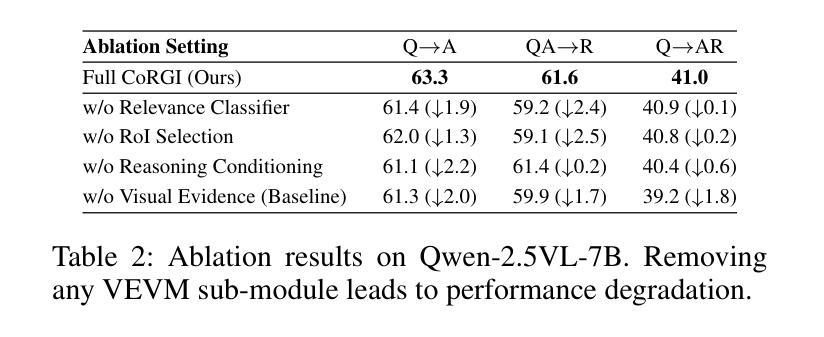
PilotRL: Training Language Model Agents via Global Planning-Guided Progressive Reinforcement Learning
Authors:Keer Lu, Chong Chen, Bin Cui, Huang Leng, Wentao Zhang
Large Language Models (LLMs) have shown remarkable advancements in tackling agent-oriented tasks. Despite their potential, existing work faces challenges when deploying LLMs in agent-based environments. The widely adopted agent paradigm ReAct centers on integrating single-step reasoning with immediate action execution, which limits its effectiveness in complex tasks requiring long-term strategic planning. Furthermore, the coordination between the planner and executor during problem-solving is also a critical factor to consider in agent design. Additionally, current approaches predominantly rely on supervised fine-tuning, which often leads models to memorize established task completion trajectories, thereby restricting their generalization ability when confronted with novel problem contexts. To address these challenges, we introduce an adaptive global plan-based agent paradigm AdaPlan, aiming to synergize high-level explicit guidance with execution to support effective long-horizon decision-making. Based on the proposed paradigm, we further put forward PilotRL, a global planning-guided training framework for LLM agents driven by progressive reinforcement learning. We first develop the model’s ability to follow explicit guidance from global plans when addressing agent tasks. Subsequently, based on this foundation, we focus on optimizing the quality of generated plans. Finally, we conduct joint optimization of the model’s planning and execution coordination. Experiments indicate that PilotRL could achieve state-of-the-art performances, with LLaMA3.1-8B-Instruct + PilotRL surpassing closed-sourced GPT-4o by 3.60%, while showing a more substantial gain of 55.78% comparing to GPT-4o-mini at a comparable parameter scale.
大型语言模型(LLMs)在面向代理的任务方面取得了显著的进步。尽管它们具有潜力,但在基于代理的环境中部署LLMs时,现有工作面临挑战。广泛采用的ReAct代理范式侧重于将单步推理与即时行动执行相结合,这限制了其在需要长期战略规划的复杂任务中的有效性。此外,在问题解决过程中,规划者和执行者之间的协调也是代理设计需要考虑的关键因素。另外,当前的方法主要依赖于监督微调,这往往导致模型记忆已建立的任务完成轨迹,从而在面对新的问题上下文时限制其泛化能力。为了解决这些挑战,我们引入了基于自适应全局计划的代理范式AdaPlan,旨在将高级显式指导与执行相结合,以支持有效的长期决策。基于这一范式,我们进一步提出了PilotRL,这是一个由逐步强化学习驱动的LLM代理全局规划引导训练框架。我们首先发展模型在解决代理任务时遵循全局计划中的显式指导的能力。然后在此基础上,我们专注于优化生成的计划的质量。最后,我们对模型的规划和执行协调进行了联合优化。实验表明,PilotRL可以达到最新技术水平,LLaMA3.1-8B-Instruct + PilotRL在封闭源码GPT-4o上超越了3.60%,在参数规模相当的情况下,相对于GPT-4o-mini显示出更大的提升,达到了55.78%。
论文及项目相关链接
Summary
大型语言模型(LLMs)在处理面向代理的任务方面取得了显著进展,但在代理环境中部署时仍面临挑战。现有工作主要集中在整合即时行动执行的单步推理上,这限制了其在需要长期战略规划的复杂任务中的有效性。此外,代理设计中解决问题的规划者和执行者之间的协调也是关键考量因素。为了解决这些挑战,提出了自适应全局计划代理范式AdaPlan,旨在协同高级显式指导与执行,支持有效的长期决策。基于该范式,进一步提出了PilotRL,一个由渐进强化学习驱动的LLM代理全局规划引导训练框架。实验表明,PilotRL能够达到领先水平,LLaMA3.1-8B-Instruct + PilotRL超越闭源GPT-4o 3.60%,在参数规模相近的情况下,相对于GPT-4o-mini有更大的提升。
Key Takeaways
- 大型语言模型(LLMs)在处理面向代理的任务方面已展现出显著进展。
- 在复杂的需要长期战略规划的任务中,现有的代理模型存在局限性。
- AdaPlan代理范式旨在协同高级显式指导与执行,以支持长期决策。
- PilotRL是一个基于全局规划的LLM训练框架,通过渐进强化学习驱动。
- PilotRL通过结合显式指导和计划优化来提升代理的性能。
- 实验结果表明PilotRL能够达到领先水平,超越其他模型。
点此查看论文截图

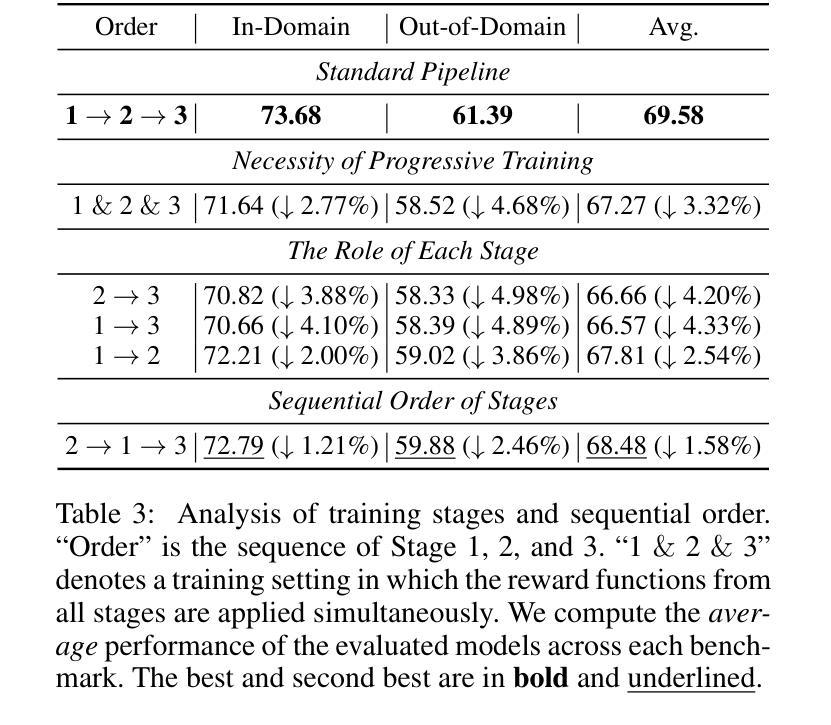
Oedipus and the Sphinx: Benchmarking and Improving Visual Language Models for Complex Graphic Reasoning
Authors:Jianyi Zhang, Xu Ji, Ziyin Zhou, Yuchen Zhou, Shubo Shi, Haoyu Wu, Zhen Li, Shizhao Liu
Evaluating the performance of visual language models (VLMs) in graphic reasoning tasks has become an important research topic. However, VLMs still show obvious deficiencies in simulating human-level graphic reasoning capabilities, especially in complex graphic reasoning and abstract problem solving, which are less studied and existing studies only focus on simple graphics. To evaluate the performance of VLMs in complex graphic reasoning, we propose ReasonBench, the first evaluation benchmark focused on structured graphic reasoning tasks, which includes 1,613 questions from real-world intelligence tests. ReasonBench covers reasoning dimensions related to location, attribute, quantity, and multi-element tasks, providing a comprehensive evaluation of the performance of VLMs in spatial, relational, and abstract reasoning capabilities. We benchmark 11 mainstream VLMs (including closed-source and open-source models) and reveal significant limitations of current models. Based on these findings, we propose a dual optimization strategy: Diagrammatic Reasoning Chain (DiaCoT) enhances the interpretability of reasoning by decomposing layers, and ReasonTune enhances the task adaptability of model reasoning through training, all of which improves VLM performance by 33.5%. All experimental data and code are in the repository: https://huggingface.co/datasets/cistine/ReasonBench.
评估视觉语言模型(VLMs)在图形推理任务中的性能已成为一个重要的研究课题。然而,VLMs在模拟人类水平的图形推理能力方面仍存在明显的不足,特别是在复杂的图形推理和抽象问题解决方面。这些方面的相关研究较少,现有研究只关注简单的图形。为了评估VLMs在复杂图形推理中的性能,我们提出了ReasonBench,这是首个专注于结构化图形推理任务的评估基准,包括1613个来自现实世界智力测试的问题。ReasonBench涵盖了与位置、属性、数量和多元任务相关的推理维度,全面评估了VLMs在空间、关系和抽象推理能力方面的性能。我们对11种主流的VLMs(包括封闭源代码和开源模型)进行了基准测试,并揭示了当前模型的重要局限性。基于这些发现,我们提出了双重优化策略:Diagrammatic Reasoning Chain(DiaCoT)通过分解层次提高推理的可解释性,ReasonTune通过训练提高模型推理的任务适应性,这两者共同提高了VLM的性能,达到33.5%的提升。所有实验数据和代码可在以下仓库中找到:https://huggingface.co/datasets/cistine/ReasonBench 。
论文及项目相关链接
Summary:
视觉语言模型(VLMs)在图形推理任务中的性能评估已成为重要研究话题。然而,VLMs在模拟人类级别的图形推理能力方面仍存在明显不足,特别是在复杂图形推理和抽象问题解决方面研究较少。为此,本文提出了ReasonBench,这是首个专注于结构化图形推理任务的评估基准,包括1613个来自现实世界智力测试的问题。ReasonBench涵盖了与位置、属性、数量和多元任务相关的推理维度,全面评估了VLMs在空间、关系和抽象推理方面的性能。作者对11种主流VLMs进行了评估,并提出了双重优化策略:Diagrammatic Reasoning Chain(DiaCoT)通过分解层次增强推理的解读性,ReasonTune通过训练增强模型推理的任务适应性,整体提高了VLMs的性能33.5%。相关实验数据和代码已公开在huggingface.co/datasets/cistine/ReasonBench。
Key Takeaways:
- VLMs在模拟人类级别的图形推理能力上存在明显不足,尤其在复杂图形推理和抽象问题解决方面研究较少。
- 提出了ReasonBench,它是首个专注于结构化图形推理任务的评估基准,旨在全面评估VLMs的推理性能。
- ReasonBench覆盖了多种图形推理维度,如位置、属性、数量和多元任务。
- 对11种主流VLMs进行了评估,发现了现有模型的重要局限性。
- 提出了双重优化策略,包括Diagrammatic Reasoning Chain(DiaCoT)和ReasonTune,提高了VLMs的性能。
- DiaCoT通过分解层次增强推理的解读性。
点此查看论文截图

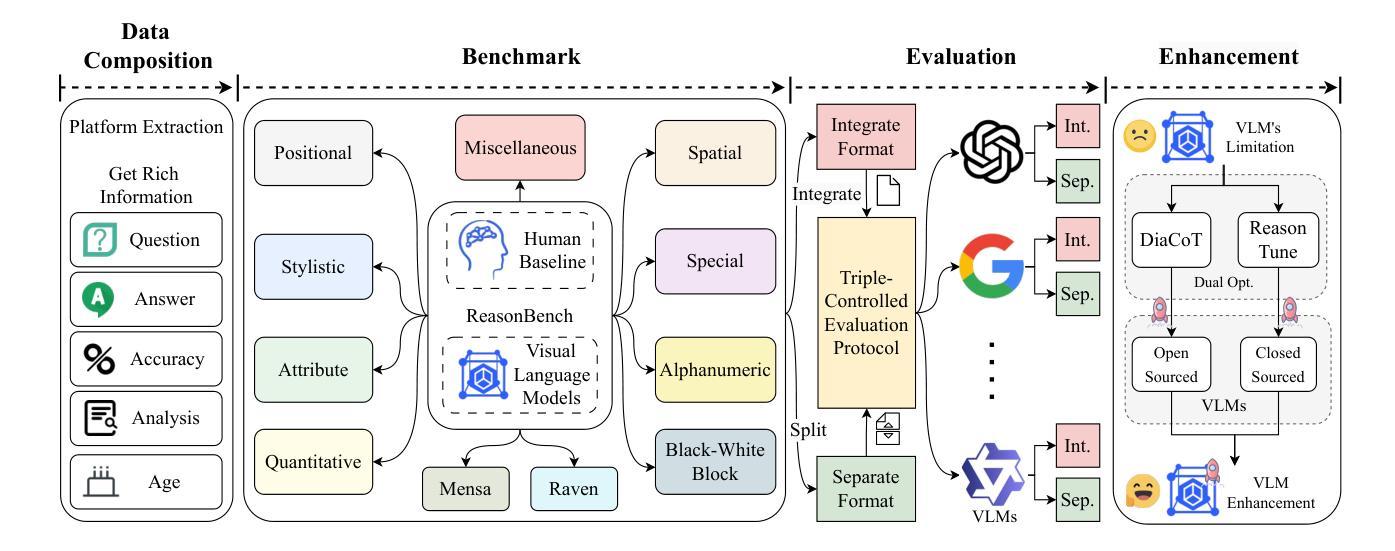
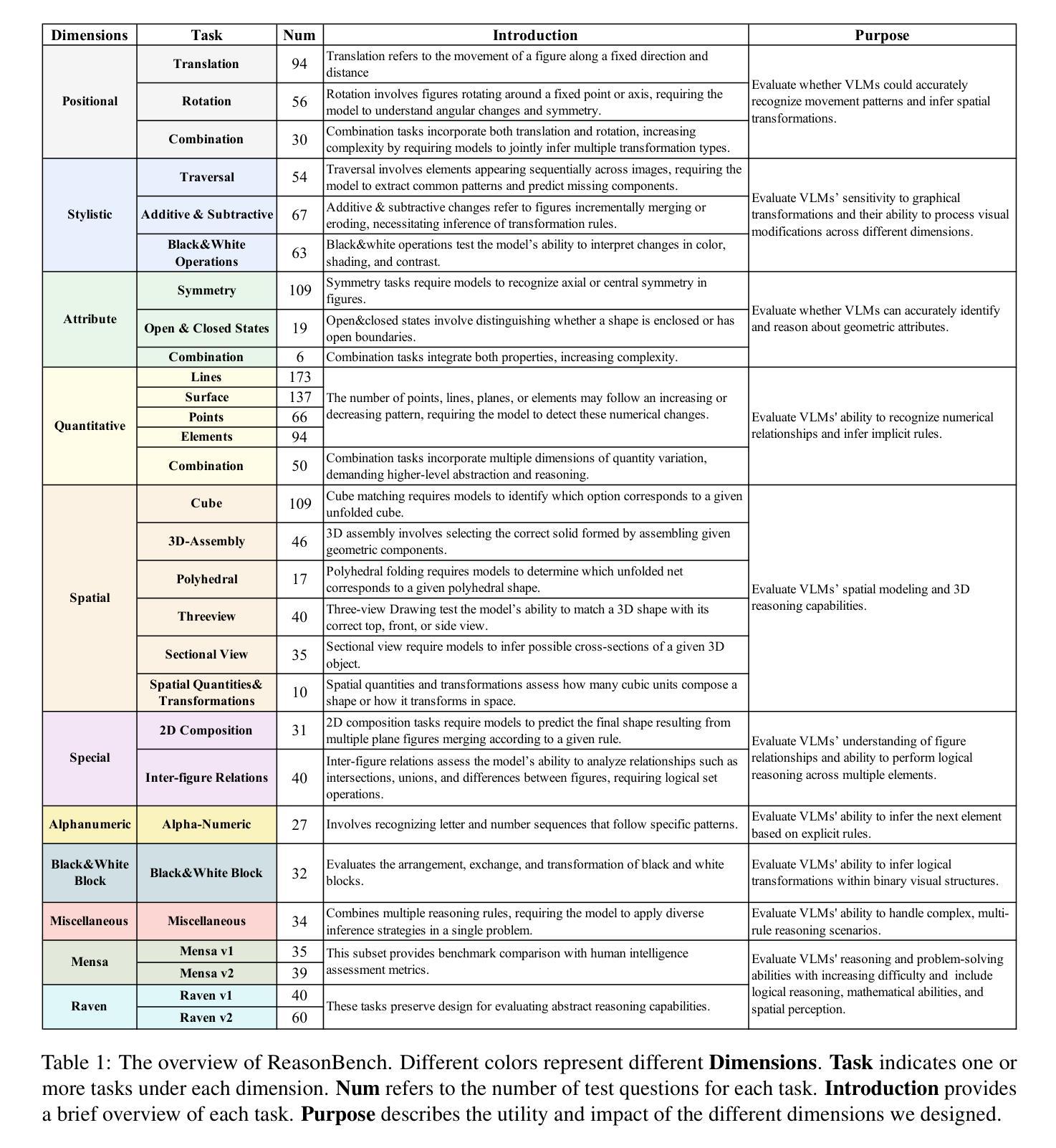
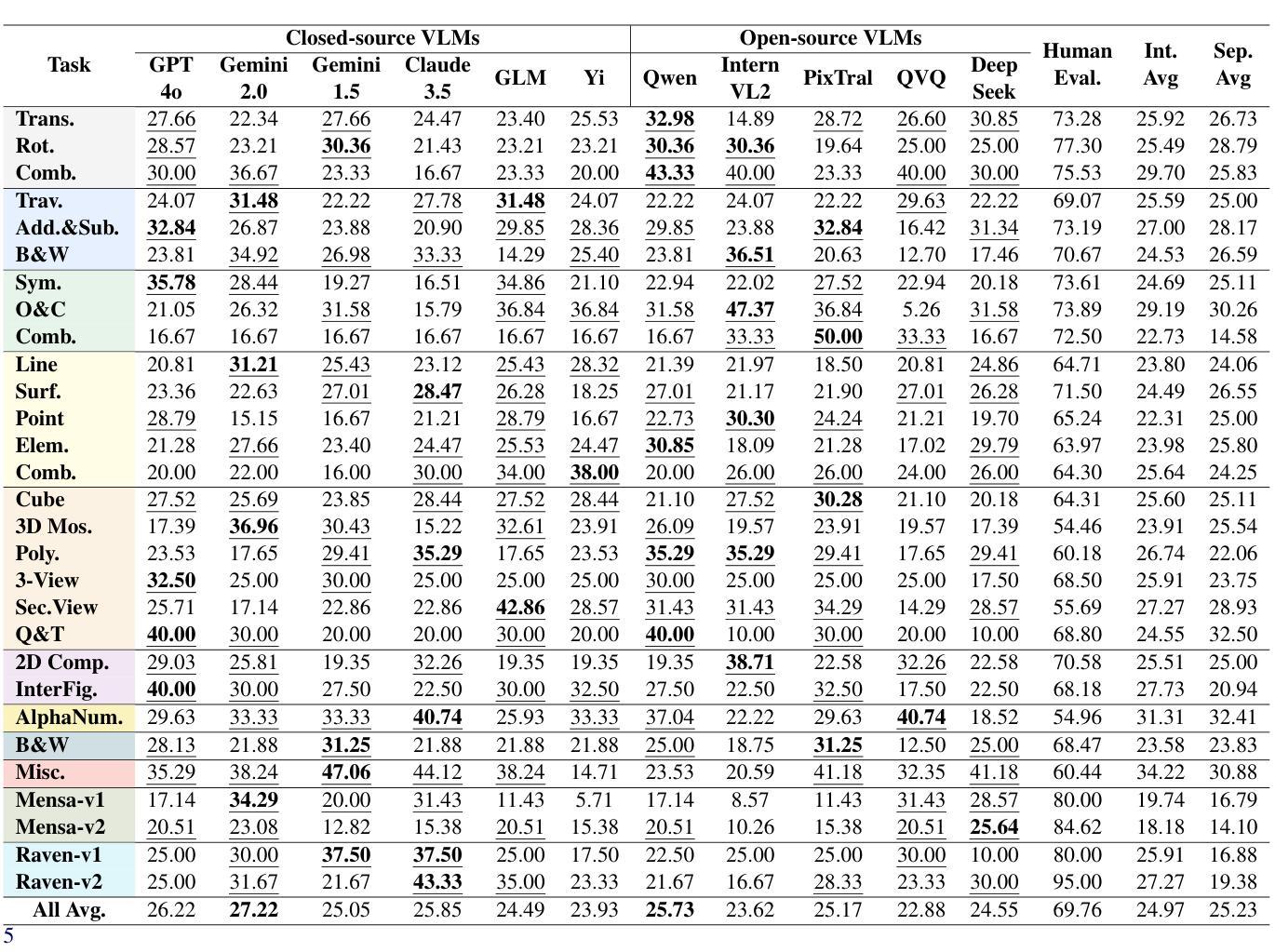
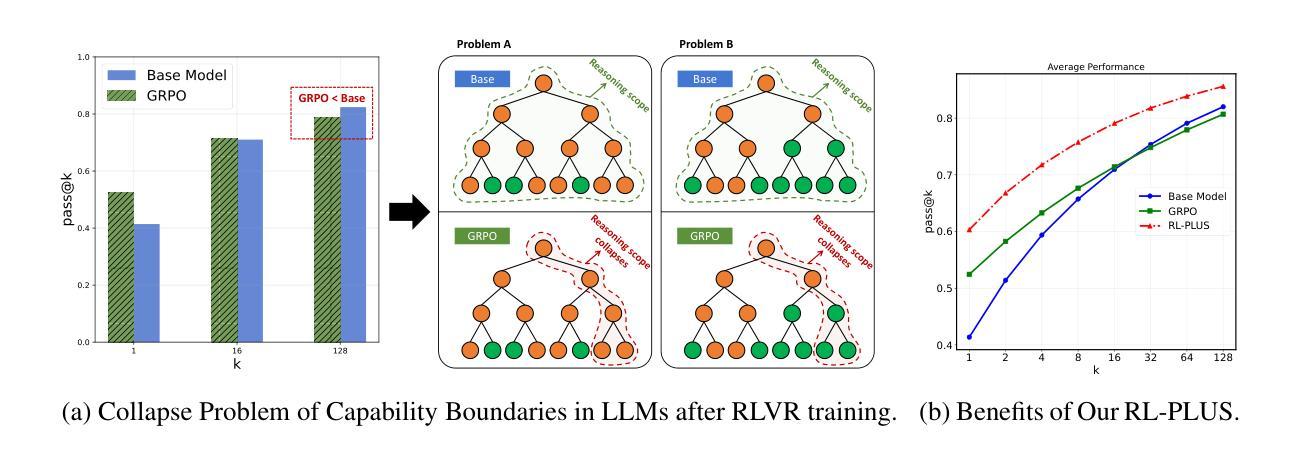
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Authors:Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, Jue Chen, Binhua Li, Zhi Jin, Fei Huang, Yongbin Li, Ge Li
Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM’s immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM’s problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1% to 69.2%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
强化学习与可验证奖励(RLVR)已经显著提高了大型语言模型(LLM)的复杂推理能力。然而,由于其固有的在线策略、LLM的巨大动作空间和稀疏奖励,RLVR在突破基础LLM的内在能力边界方面遇到了困难。此外,RLVR可能导致能力边界崩溃,缩小LLM的解决问题范围。为了解决这一问题,我们提出了RL-PLUS,这是一种新的方法,它将内部剥削(即思考)与外部数据(即学习)协同起来,以实现更强的推理能力并超越基础模型的边界。RL-PLUS集成了两个核心组件:多重重要性采样,以解决外部数据分布不匹配的问题;基于探索的优势函数,引导模型走向高价值、未探索的推理路径。我们提供理论分析和大量实验来证明我们方法的优越性和通用性。结果表明,RL-PLUS在六个数学推理基准测试上实现了与现有RLVR方法相比的卓越性能,并在六个离分布推理任务上表现出卓越性能。此外,它在不同的模型家族中实现了持续且显著的收益,平均相对改进范围从21.1%到69.2%。而且,多个基准测试的Pass@k曲线表明,RL-PLUS有效地解决了能力边界崩溃问题。
论文及项目相关链接
Summary
强化学习与可验证奖励(RLVR)显著提高了大型语言模型(LLM)的复杂推理能力。然而,RLVR难以突破基础LLM的内在能力边界,且可能导致能力边界崩溃。为解决这些问题,我们提出了RL-PLUS这一新方法,它通过内部利用(即思考)与外部数据(即学习)的协同作用,增强了推理能力并超越了基础模型的边界。RL-PLUS包括两个核心组件:多重重要性采样以解决外部数据分布不匹配的问题,以及基于探索的优势函数来引导模型走向高价值、未被探索的推理路径。实验结果显示,RL-PLUS在六个数学推理基准测试中实现了卓越性能,并在六个超出分布范围的推理任务中表现出卓越性能。它在不同的模型家族中实现了持续且显著的改进,平均相对改进范围从21.1%到69.2%。此外,Pass@k曲线表明RL-PLUS有效地解决了能力边界崩溃问题。
Key Takeaways
- RLVR提高了LLM的推理能力,但存在突破能力边界和可能导致能力边界崩溃的问题。
- RL-PLUS通过内部利用与外部数据的协同作用,增强了推理能力并超越了基础模型的边界。
- RL-PLUS包括两个核心组件:多重重要性采样和基于探索的优势函数。
- RL-PLUS在多个数学推理基准测试中表现出卓越性能,并在超出分布范围的推理任务中展现出显著优势。
- RL-PLUS在不同模型家族中实现了显著改进,平均相对改进范围较大。
- RL-PLUS通过解决分布不匹配问题和引导模型探索高价值路径,实现了对RLVR方法的改进。
点此查看论文截图

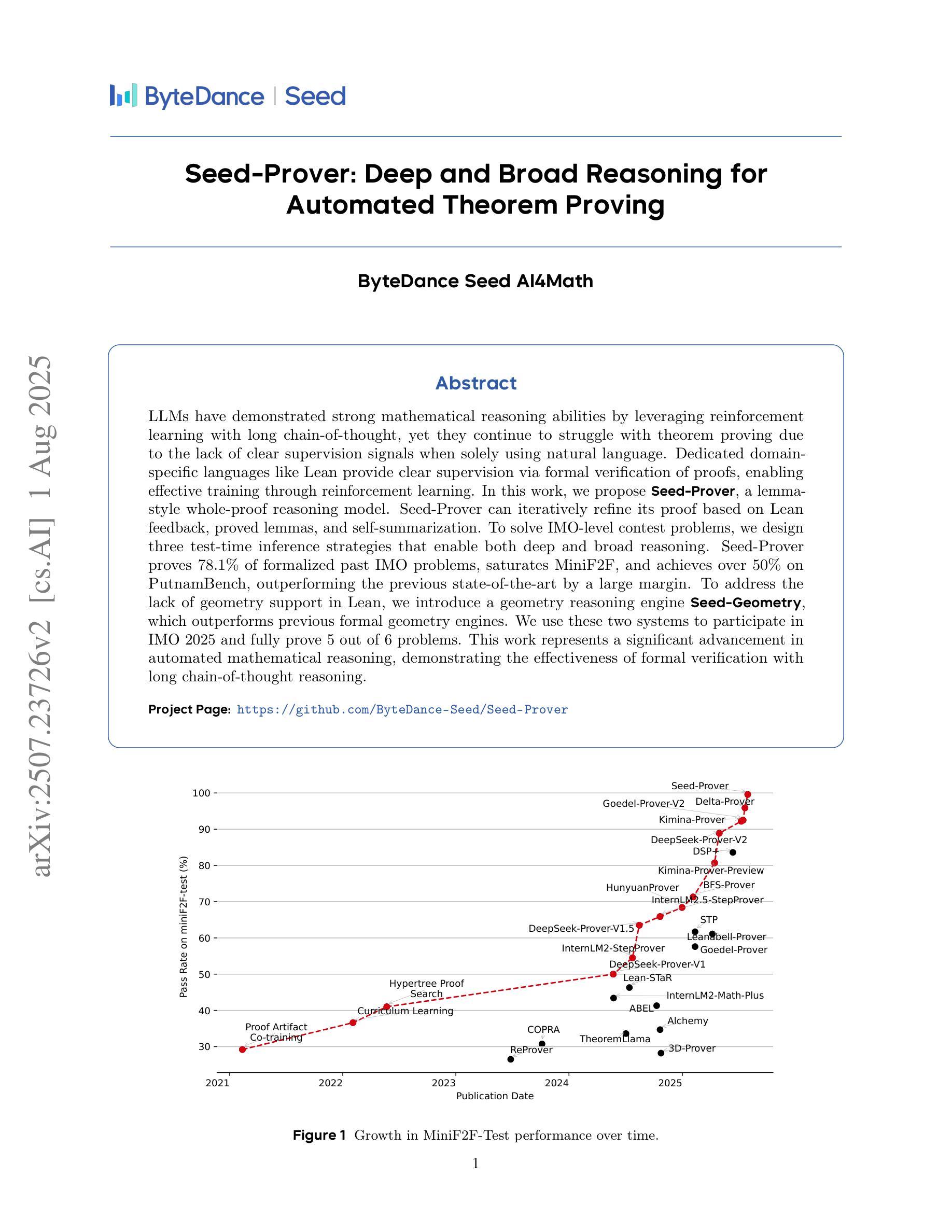
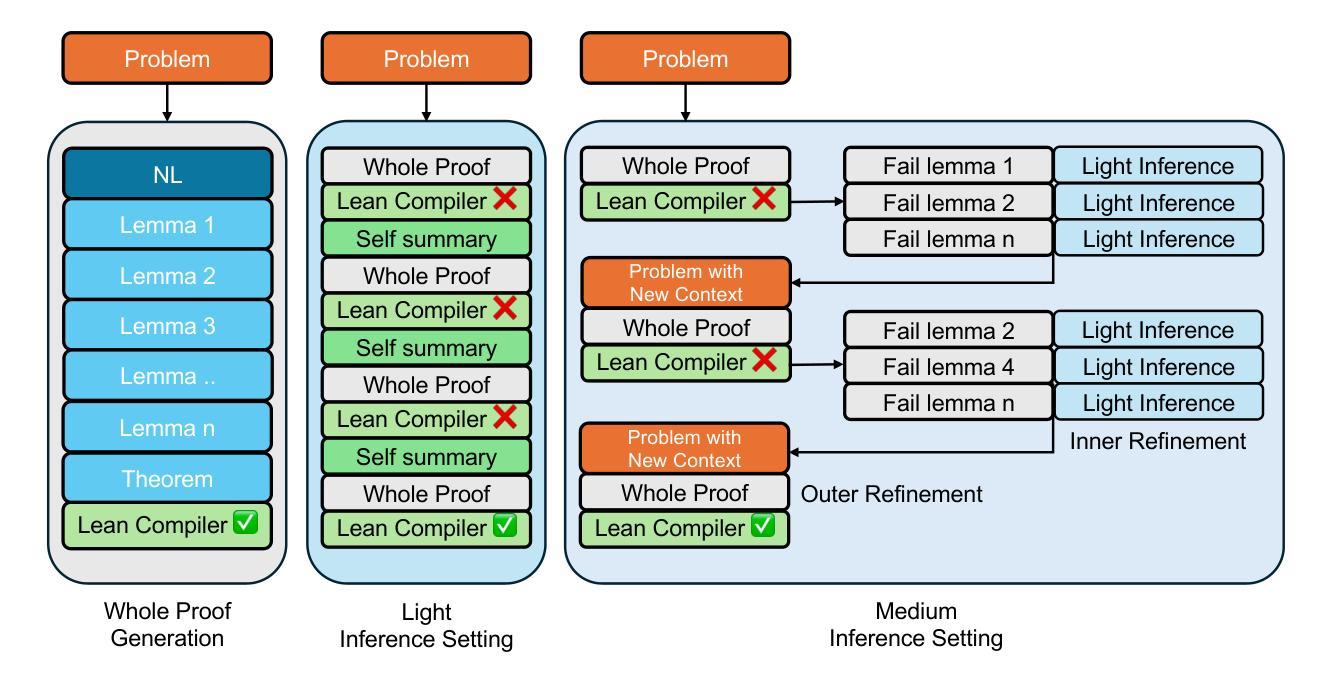
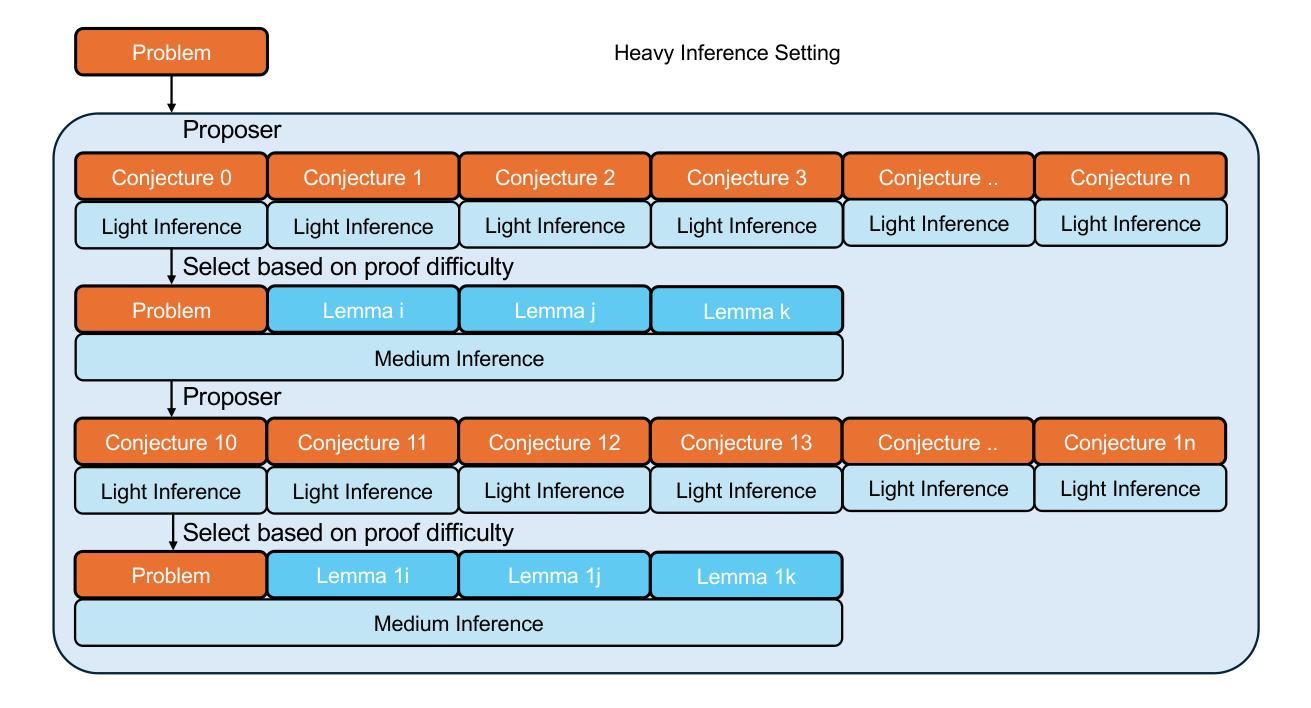
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Authors:Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, Cheng Ren, Jiawei Shen, Wenlei Shi, Tong Sun, He Sun, Jiahui Wang, Siran Wang, Zhihong Wang, Chenrui Wei, Shufa Wei, Yonghui Wu, Yuchen Wu, Yihang Xia, Huajian Xin, Fan Yang, Huaiyuan Ying, Hongyi Yuan, Zheng Yuan, Tianyang Zhan, Chi Zhang, Yue Zhang, Ge Zhang, Tianyun Zhao, Jianqiu Zhao, Yichi Zhou, Thomas Hanwen Zhu
LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
大型语言模型(LLMs)已经展现出强大的数学推理能力,它们通过利用强化学习和长链思维来实现这一点。然而,当仅使用自然语言时,由于缺乏明确的监督信号,它们在定理证明方面仍面临困难。专用领域语言(如Lean)通过证明的形式验证提供明确监督,从而能够通过强化学习进行有效训练。在这项工作中,我们提出了\textbf{Seed-Prover},一个以引理风格进行的全程证明推理模型。Seed-Prover可以基于Lean反馈、已证明的引理和自我总结来迭代地完善其证明。为解决IMO级别的竞赛问题,我们设计了三种测试时推理策略,以实现深度和广度推理。Seed-Prover证明了78.1%的正式化过去IMO问题,在MiniF2F中达到饱和状态,并在PutnamBench上达到50%以上,大大超过了之前的最先进水平。为了解决Lean中缺乏几何支持的问题,我们引入了一个几何推理引擎\textbf{Seed-Geometry},它的性能超过了之前的正式几何引擎。我们使用这两个系统参加了2025年IMO,并完全证明了6个问题的5个。这项工作在自动化数学推理方面取得了重大进展,展示了形式验证与长链思维推理的有效性。
论文及项目相关链接
Summary
大型语言模型(LLMs)通过强化学习与长链思维展现出强大的数学推理能力,但在定理证明方面仍存在困难。本研究提出一种名为Seed-Prover的基于莱恩(Lean)的推理模型,该模型通过反馈、已证明的引理和自我总结来迭代完善证明。为解决IMO级别的竞赛问题,我们设计了三种测试时推理策略,实现了深度与广度推理。Seed-Prover模型能够证明形式化IMO问题的78.1%,饱和MiniF2F,并在PutnamBench上取得了超过一半的准确率,大大超过了之前的技术水平。此外,为解决莱恩中缺乏几何支持的问题,我们引入了Seed-Geometry几何推理引擎,其性能优于之前的正式几何引擎。两个系统共同参与了IMO 2025的竞赛,成功证明了五个问题中的六个。这项工作标志着自动化数学推理的重大进展,证明了形式验证与长链思维推理的有效性。
Key Takeaways
- LLMs展现出强大的数学推理能力,但仍面临定理证明的挑战。
- 缺乏清晰的监督信号是LLMs在定理证明中遇到困难的原因之一。
- Seed-Prover模型通过迭代完善证明,结合了反馈、已证明的引理和自我总结。
- Seed-Prover模型在IMO级别问题上表现出强大的性能,证明率超过78%。
- Seed-Geometry几何推理引擎解决了莱恩中的几何支持缺失问题。
- 两个系统共同参与了IMO 2025竞赛,成功证明多数问题。
点此查看论文截图

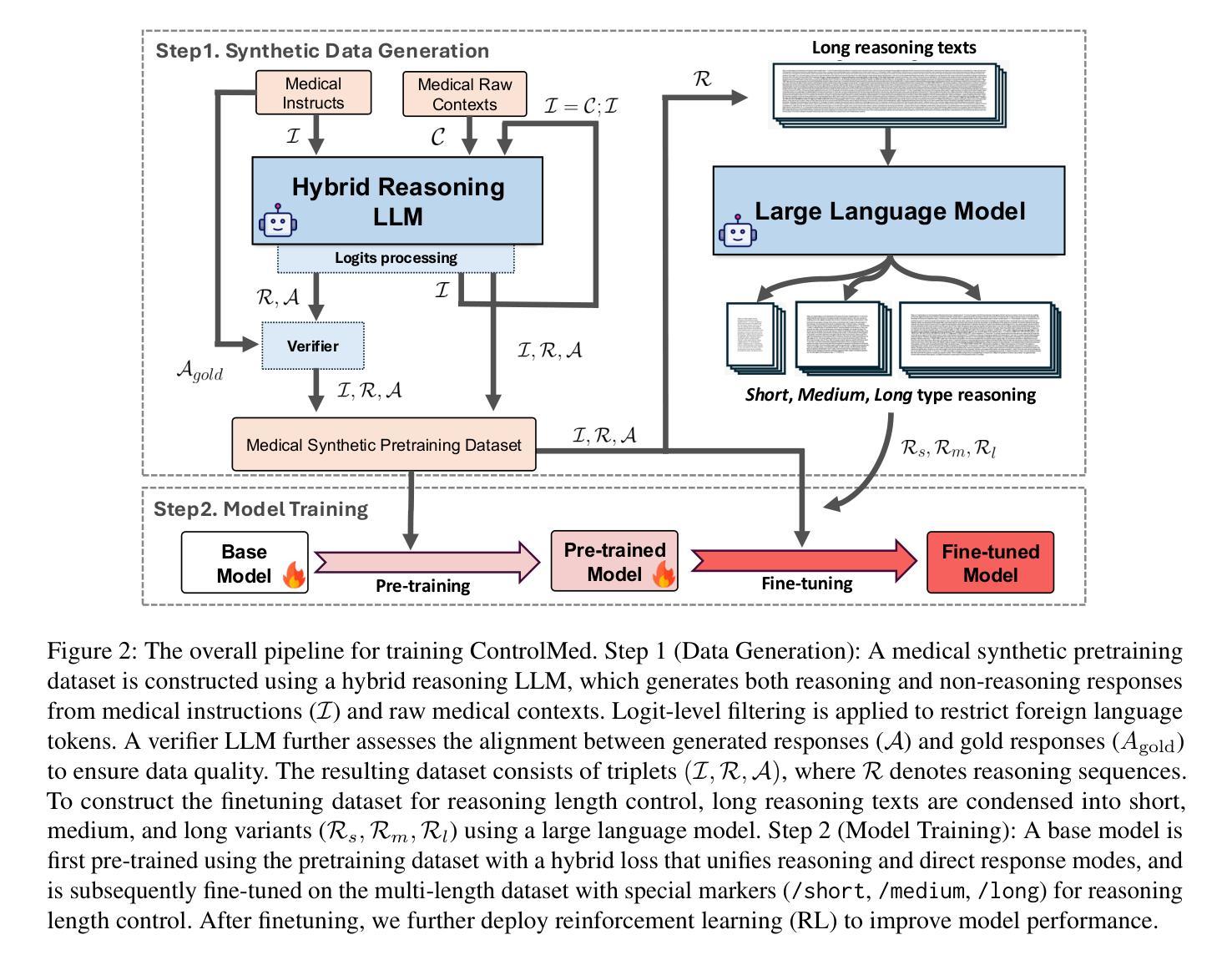
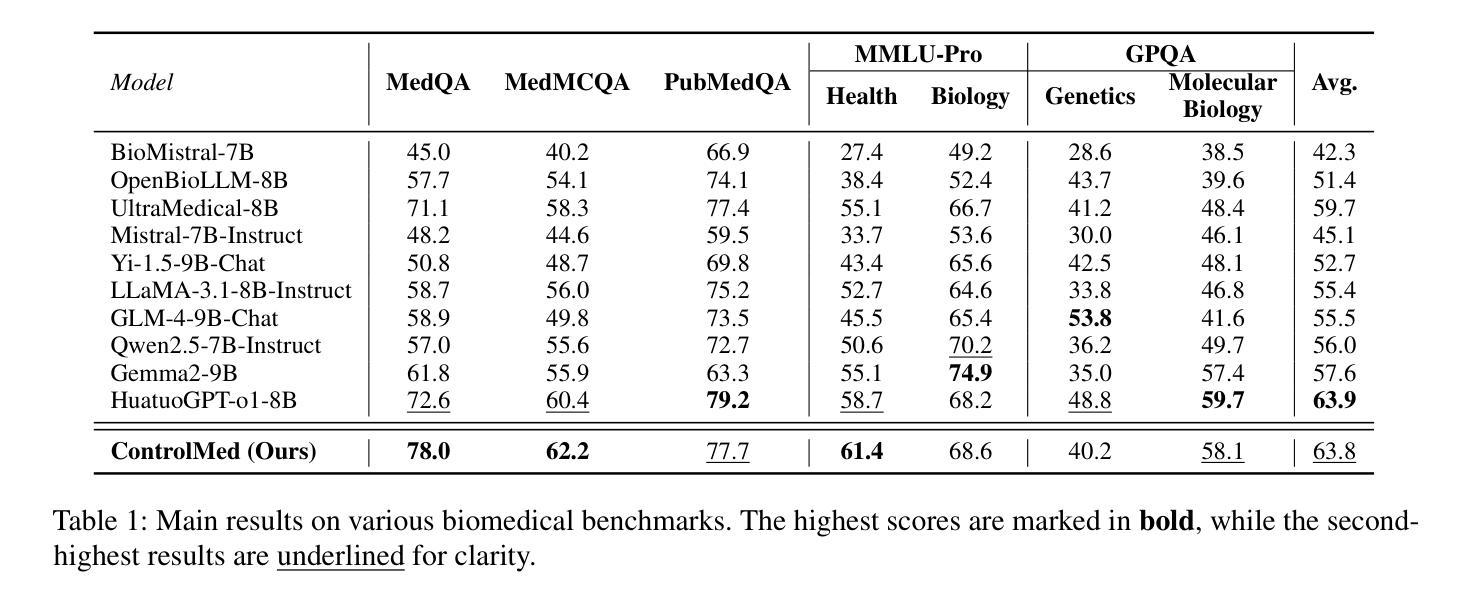
ControlMed: Adding Reasoning Control to Medical Language Model
Authors:Sung-Min Lee, Siyoon Lee, Juyeon Kim, Kyoungmin Roh
Reasoning Large Language Models (LLMs) with enhanced accuracy and explainability are increasingly being adopted in the medical domain, as the life-critical nature of clinical decision-making demands reliable support. Despite these advancements, existing reasoning LLMs often generate unnecessarily lengthy reasoning processes, leading to significant computational overhead and response latency. These limitations hinder their practical deployment in real-world clinical environments. To address these challenges, we introduce \textbf{ControlMed}, a medical language model that enables users to actively control the length of the reasoning process at inference time through fine-grained control markers. ControlMed is trained through a three-stage pipeline: 1) pre-training on a large-scale synthetic medical instruction dataset covering both \textit{direct} and \textit{reasoning responses}; 2) supervised fine-tuning with multi-length reasoning data and explicit length-control markers; and 3) reinforcement learning with model-based reward signals to enhance factual accuracy and response quality. Experimental results on a variety of English and Korean medical benchmarks demonstrate that our model achieves similar or better performance compared to state-of-the-art models. Furthermore, users can flexibly balance reasoning accuracy and computational efficiency by controlling the reasoning length as needed. These findings demonstrate that ControlMed is a practical and adaptable solution for clinical question answering and medical information analysis.
在医疗领域,对增强准确度和解释性的大型语言模型(LLMs)推理的需求越来越大,因为临床决策的生命关键性质需要可靠的支持。尽管有这些进展,现有的推理LLMs经常产生不必要的冗长推理过程,导致巨大的计算负担和响应延迟。这些限制阻碍了它们在现实世界临床环境中的实际部署。为了解决这些挑战,我们引入了ControlMed,这是一种医学语言模型,通过精细的控制标记,使用户能够在推理时主动控制推理过程的长度。ControlMed通过三个阶段进行训练:1)在涵盖直接和推理响应的大规模合成医疗指令数据集上进行预训练;2)使用多长度推理数据和明确的长度控制标记进行有监督的微调;3)使用模型基础的奖励信号进行强化学习,以提高事实准确性和响应质量。在多种英语和韩语医疗基准测试上的实验结果表明,我们的模型达到了与最先进模型相似或更好的性能。此外,用户可以根据需要灵活平衡推理准确性和计算效率,通过控制推理长度。这些结果表明,ControlMed是临床问答和医疗信息分析的实际可行和适应性强的解决方案。
论文及项目相关链接
PDF 13 pages
Summary
在医疗领域,大型语言模型(LLMs)的推理能力日益受到重视,并出现了具有更高准确性和解释性的增强模型。然而,现有模型往往产生冗长的推理过程,导致计算开销和响应延迟较大,限制了在实际临床环境中的部署。为解决这一问题,我们推出ControlMed医学语言模型,通过精细的控制标记,使用户能够在推理时控制推理过程的长度。ControlMed通过三阶段训练管道实现:1)在涵盖直接和推理响应的大规模合成医疗指令数据集上进行预训练;2)使用多长度推理数据和明确的长度控制标记进行有监督微调;3)使用模型基础奖励信号进行强化学习,以提高事实准确性和响应质量。在多种英语和韩语医疗基准测试上的实验结果表明,我们的模型在性能上达到了或超越了最先进的模型。此外,用户可以根据需要灵活地平衡推理准确性和计算效率。这表明ControlMed是临床问答和医疗信息分析的实用且可适应的解决方案。
Key Takeaways
- 大型语言模型(LLMs)在医疗领域的推理能力得到重视,增强模型具有更高的准确性和解释性。
- 现有模型存在冗长的推理过程,导致计算开销和响应延迟大,影响实际部署。
- ControlMed医学语言模型通过精细控制标记实现推理过程长度的灵活控制。
- ControlMed采用三阶段训练管道,包括预训练、有监督微调和强化学习。
- 实验结果表明,ControlMed模型性能达到或超越最先进的模型。
- 用户可灵活平衡推理准确性和计算效率,以满足不同需求。
点此查看论文截图

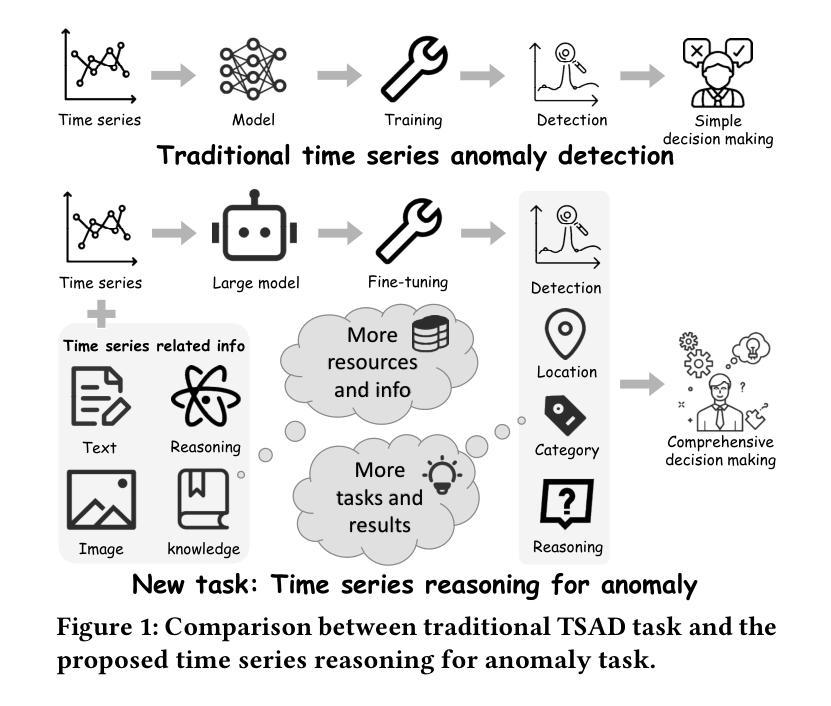
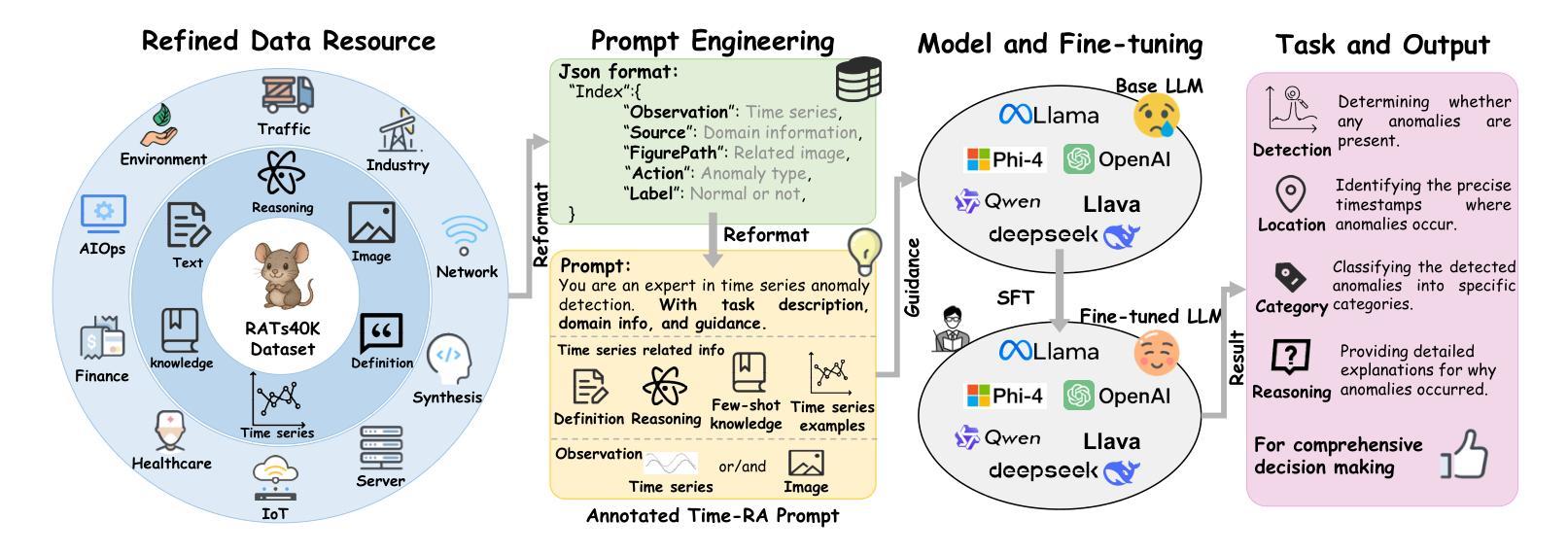
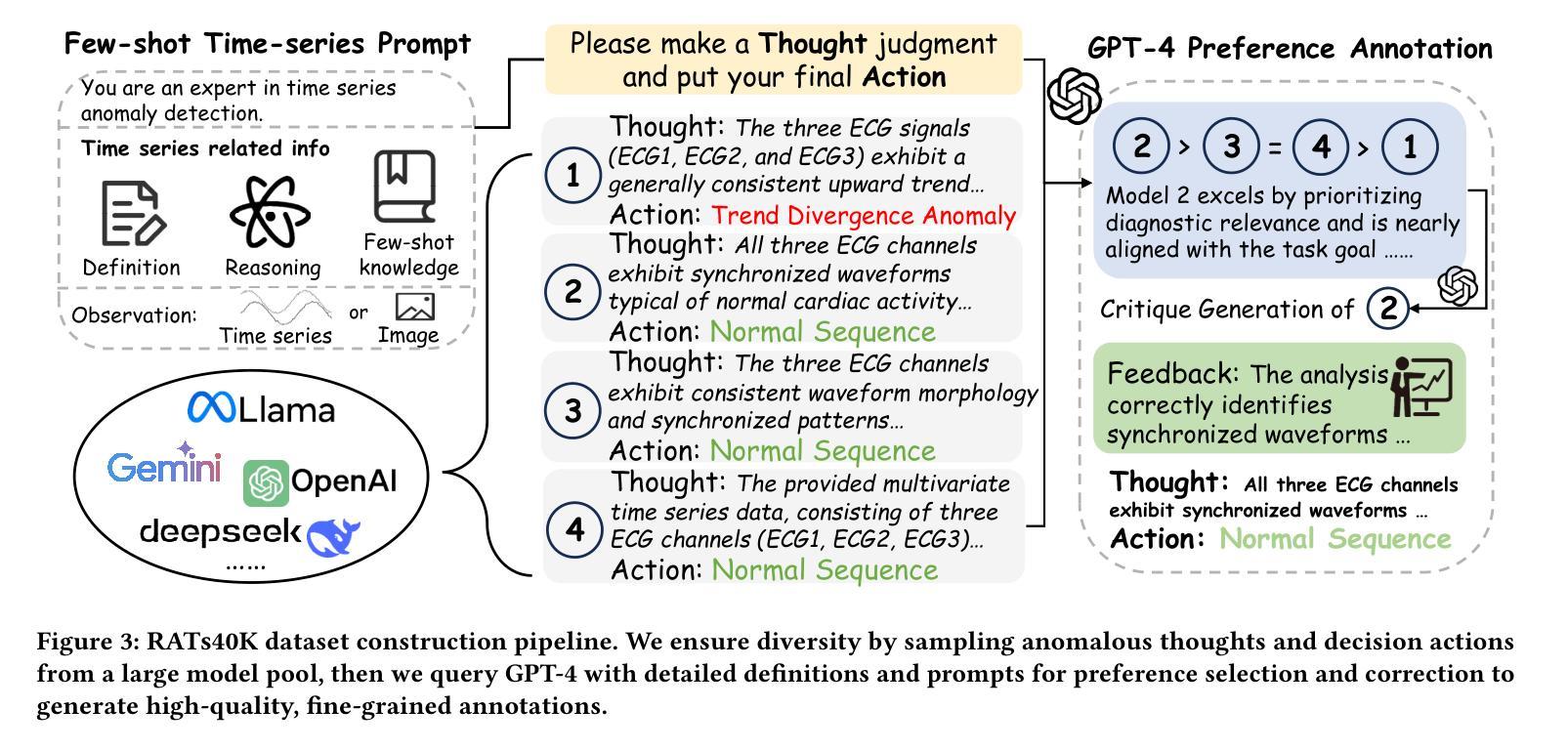
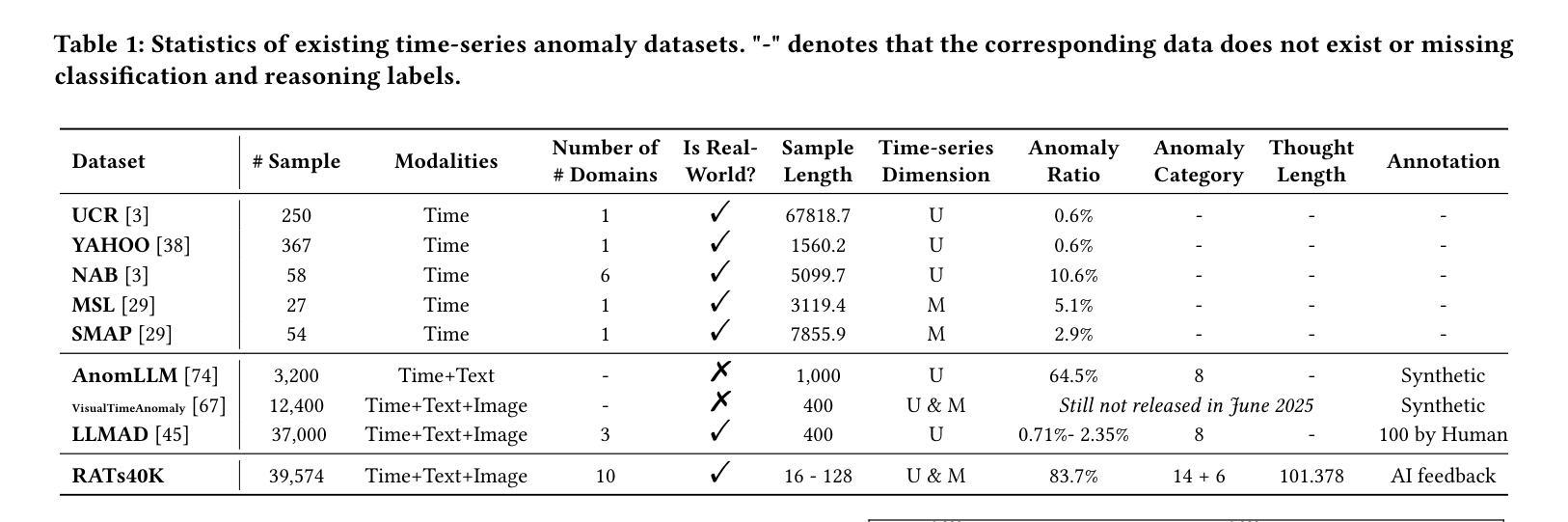
Time-RA: Towards Time Series Reasoning for Anomaly with LLM Feedback
Authors:Yiyuan Yang, Zichuan Liu, Lei Song, Kai Ying, Zhiguang Wang, Tom Bamford, Svitlana Vyetrenko, Jiang Bian, Qingsong Wen
Time series anomaly detection is critical across various domains, yet current approaches often limit analysis to mere binary anomaly classification without detailed categorization or further explanatory reasoning. To address these limitations, we propose a novel task, Time-series Reasoning for Anomaly (Time-RA) that transforms classical time series anomaly detection from a discriminative into a generative, reasoning-intensive task leveraging Large Language Models (LLMs). Also, we introduce the first real-world multimodal benchmark dataset, RATs40K, explicitly annotated for anomaly reasoning, comprising approximately 40,000 samples across 10 real-world domains. Each sample includes numeric time series data, contextual text information, and visual representations, each annotated with fine-grained categories (14 types for univariate anomalies and 6 for multivariate anomalies) and structured explanatory reasoning. We develop a sophisticated annotation framework utilizing ensemble-generated labels refined through GPT-4-driven feedback, ensuring accuracy and interpretability. Extensive benchmarking of LLMs and multimodal LLMs demonstrates the capabilities and limitations of current models, highlighting the critical role of supervised fine-tuning. Our dataset and task pave the way for significant advancements in interpretable time series anomaly detection and reasoning. The code (https://github.com/yyysjz1997/Time-RA) and dataset (https://huggingface.co/datasets/Time-RA/RATs40K) have been fully open-sourced to support and accelerate future research in this area.
时间序列异常检测在各个领域都至关重要,然而当前的方法往往仅限于简单的二元异常分类,缺乏详细的分类和进一步的解释推理。为了解决这些局限性,我们提出了一种新的任务,即时间序列异常推理(Time-RA),它将经典的时间序列异常检测从判别式任务转变为利用大型语言模型(LLM)的生成式、推理密集型任务。此外,我们还推出了首个面向异常推理的现实世界多模态基准数据集RATs40K,该数据集包含大约40,000个跨10个现实领域的样本,明确标注了异常推理。每个样本包括数值时间序列数据、上下文文本信息和视觉表示,每种数据都标注了精细的类别(单变量异常14类,多元异常6类)和结构化解释推理。我们开发了一个复杂的注释框架,利用群体生成的标签通过GPT-4驱动的反馈进行修正,确保准确性和可解释性。对LLM和多模态LLM的广泛基准测试展示了当前模型的能力和局限性,突显了监督微调的重要作用。我们的数据集和任务为可解释时间序列异常检测和推理的显著进步铺平了道路。代码(https://github.com/yyysjz1997/Time-RA)和数据集(https://huggingface.co/datasets/Time-RA/RATs40K)已完全开源,以支持和加速该领域未来的研究。
论文及项目相关链接
PDF Under review. 19 pages, 8 figures, 12 tables. Code and dataset are publicly available
Summary
本文提出了一项新的任务——时间序列异常推理(Time-RA),旨在将经典的时间序列异常检测从判别式任务转变为利用大型语言模型的生成式、推理密集型任务。此外,还介绍了首个用于异常推理的现实世界多模态基准数据集RATs40K,包含大约40,000个跨10个现实领域的样本。每个样本都包括数值时间序列数据、上下文文本信息和视觉表示,并都进行了精细的类别标注和结构化解释推理。开发了一个复杂的标注框架,利用GPT-4驱动的反馈对集体生成的标签进行精炼,确保准确性和可解释性。对LLMs和多模态LLMs的广泛基准测试展示了当前模型的能力和局限性,强调了监督微调的重要作用。本文的数据集和任务为可解释的时间序列异常检测和推理的显著进步铺平了道路。
Key Takeaways
- 引入了一个新的任务——时间序列异常推理(Time-RA),将传统的时间序列异常检测转变为生成式任务,利用大型语言模型进行推理。
- 介绍了首个用于异常推理的多模态基准数据集RATs40K,包含大量精细标注的样本,涵盖数值时间序列数据、上下文文本信息和视觉表示。
- 开发了一个复杂的标注框架,利用GPT-4驱动的反馈提高标注准确性。
- 对当前的大型语言模型进行了广泛的基准测试,揭示了其在时间序列异常检测中的能力和局限性。
- 数据集和任务的发布为时间序列异常检测和推理的研究铺平了道路。
- 该研究强调了监督微调在时间序列异常检测中的重要作用。
点此查看论文截图

MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization
Authors:Xingxuan Li, Yao Xiao, Dianwen Ng, Hai Ye, Yue Deng, Xiang Lin, Bin Wang, Zhanfeng Mo, Chong Zhang, Yueyi Zhang, Zonglin Yang, Ruilin Li, Lei Lei, Shihao Xu, Han Zhao, Weiling Chen, Feng Ji, Lidong Bing
Large language models have recently evolved from fluent text generation to advanced reasoning across diverse domains, giving rise to reasoning language models. Among these domains, mathematical reasoning serves as a representative benchmark as it requires precise multi-step logic and abstract reasoning, which can be generalized to other tasks. While closed-source RLMs such as GPT-o3 demonstrate impressive reasoning capabilities, their proprietary nature limits transparency and reproducibility. Although many open-source projects aim to close this gap, most of them lack sufficient openness by omitting critical resources such as datasets and detailed training configurations, which hinders reproducibility. To contribute toward greater transparency in RLM development, we introduce the MiroMind-M1 series, a set of fully open-source RLMs built on the Qwen-2.5 backbone that match or exceed the performance of existing open-source RLMs. Specifically, our models are trained in two stages: SFT on a carefully curated corpus of 719K math-reasoning problems with verified CoT trajectories, followed by RLVR on 62K challenging and verifiable problems. To enhance the robustness and efficiency of the RLVR process, we introduce Context-Aware Multi-Stage Policy Optimization, an algorithm that integrates length-progressive training with an adaptive repetition penalty to encourage context-aware RL training. Our model achieves state-of-the-art or competitive performance and superior token efficiency among Qwen-2.5-based open-source 7B and 32B models on the AIME24, AIME25, and MATH benchmarks. To facilitate reproducibility, we release the complete stack: models (MiroMind-M1-SFT-7B, MiroMind-M1-RL-7B, MiroMind-M1-RL-32B); datasets (MiroMind-M1-SFT-719K, MiroMind-M1-RL-62K); and all training and evaluation configurations. We hope these resources will support further research and foster community advancement.
最近,大型语言模型已经从流畅的文本生成发展到跨多个领域的先进推理,从而产生了推理语言模型。在这些领域中,数学推理作为一个代表性基准,它要求精确的多步骤逻辑和抽象推理,可以推广到其他任务。虽然闭源RLM(如GPT-o3)展示了令人印象深刻的推理能力,但其专有性质限制了透明度和可重复性。尽管许多开源项目旨在缩小这一差距,但其中大多数由于缺乏关键资源(如数据集和详细的训练配置)而缺乏足够的开放性,从而阻碍了可重复性。为了促进RLM开发中的更大透明度,我们推出了MiroMind-M1系列,这是一系列基于Qwen-2.5架构的完全开源RLM,其性能可与现有开源RLM相�� 媲美甚至更胜一筹。具体来说,我们的模型分为两个阶段进行训练:首先在精心挑选的71.9万道数学推理问题数据集上进行SFT训练,这些问题都有经过验证的解题步骤(CoT轨迹),然后在6.2万道具有挑战性和可验证性的问题上进行RLVR训练。为了提高RLVR过程的稳健性和效率,我们引入了Context-Aware Multi-Stage Policy Optimization算法,该算法将长度渐进训练与自适应重复惩罚相结合,以鼓励上下文感知的RL训练。我们的模型在AIME24、AIME25和MATH基准测试中取得了最新或竞争性的性能和出色的令牌效率,在基于Qwen-2.5的开源7B和32B模型中表现尤为出色。为了便于复制,我们发布了完整的堆栈:模型(MiroMind-M1-SFT-7B、MiroMind-M1-RL-7B、MiroMind-M1-RL-32B)、数据集(MiroMind-M1-SFT-719K、MiroMind-M1-RL-62K)以及所有的训练和评估配置。我们希望这些资源能够支持进一步的研究并推动社区的发展。
论文及项目相关链接
PDF Technical report
Summary
大型语言模型已从流畅文本生成发展到跨域高级推理,产生了推理语言模型。数学推理作为精确多步骤逻辑和抽象推理的代表领域,在模型中显得尤为重要。开源推理语言模型MiroMind-M1系列的出现,旨在促进透明度,并使用Qwen-2.5为框架,其性能达到或超过了现有开源推理语言模型的水平。模型分为两个阶段进行训练,第一阶段是在精心挑选的71万数学推理问题语料库上进行SFT训练,第二阶段则是在6.2万具有挑战性的可验证问题上实施RLVR训练。为增强RLVR过程的稳健性和效率,引入了Context-Aware Multi-Stage Policy Optimization算法。模型在AIME24、AIME25和MATH基准测试中取得了卓越或竞争性的表现。为促进可复制性,团队公开了完整的模型、数据集以及所有训练和评估配置。
Key Takeaways
- 大型语言模型已进化至跨域高级推理,数学推理是其中的重要领域。
- MiroMind-M1系列是一种开源推理语言模型,基于Qwen-2.5框架构建。
- 模型分为两个阶段进行训练:首先在71万数学推理问题上进行SFT训练,然后在6.2万挑战性可验证问题上实施RLVR训练。
- 引入Context-Aware Multi-Stage Policy Optimization算法以增强模型的稳健性和效率。
- MiroMind-M1模型在多个基准测试中表现卓越,达到或超过现有模型性能。
- 为促进研究和社区发展,团队公开了完整的模型、数据集及训练和评估配置。
点此查看论文截图

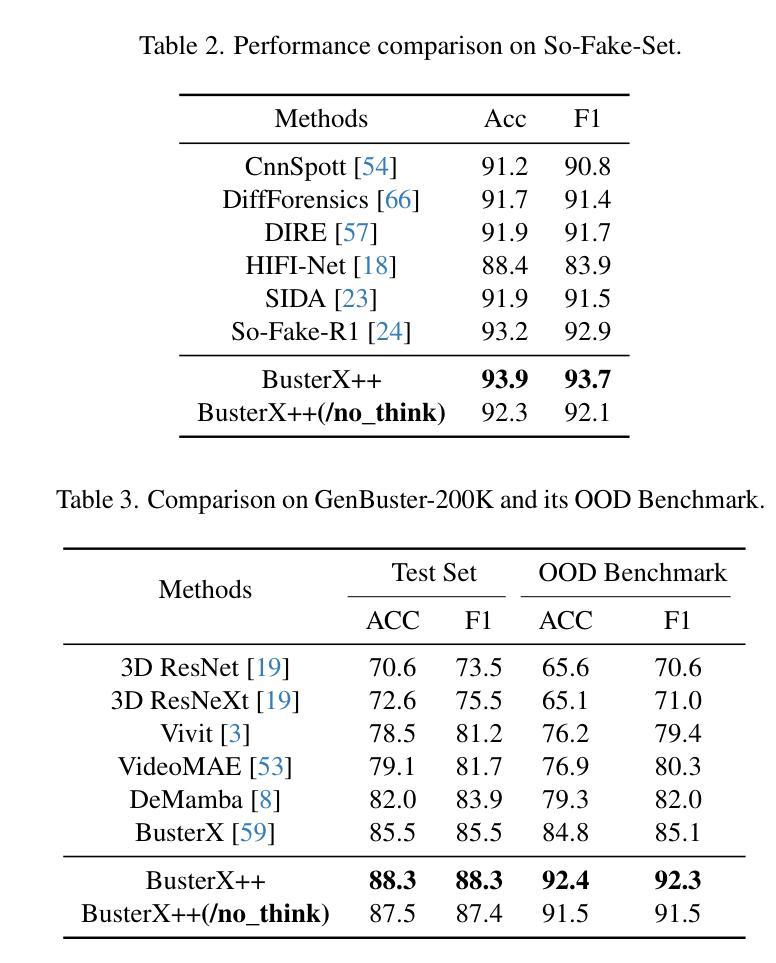
BusterX++: Towards Unified Cross-Modal AI-Generated Content Detection and Explanation with MLLM
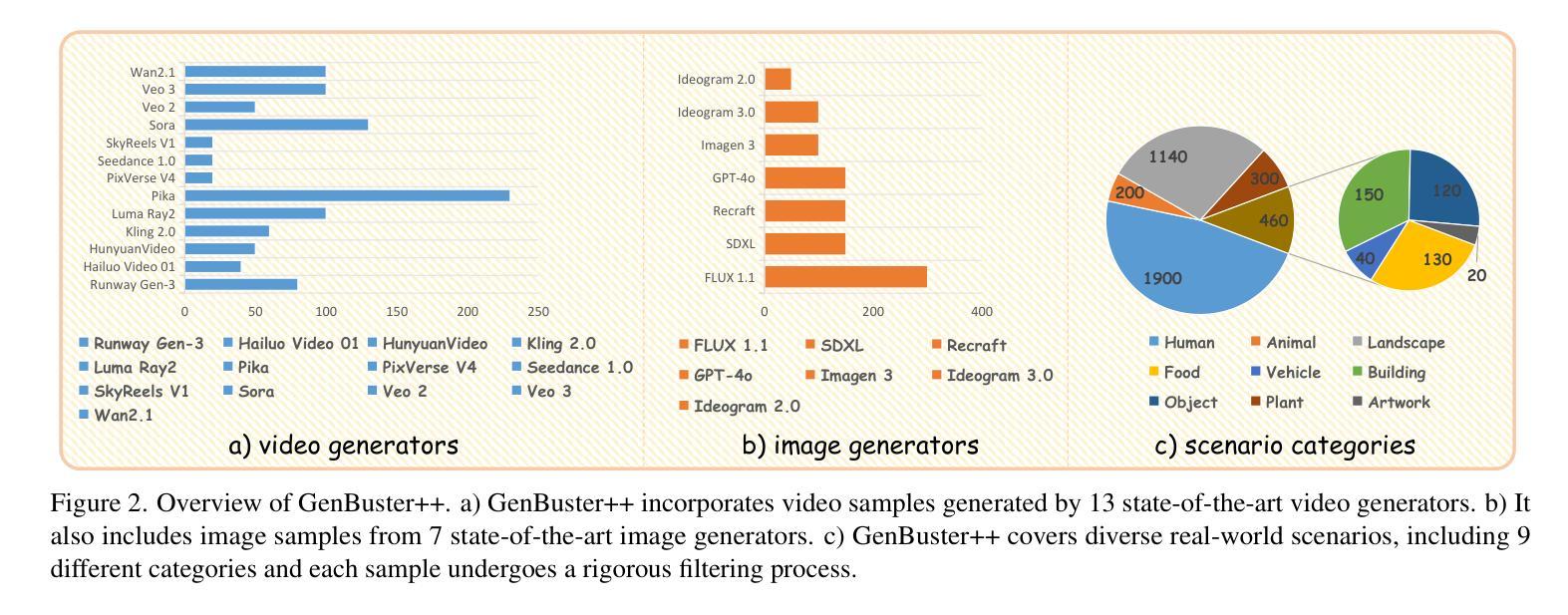
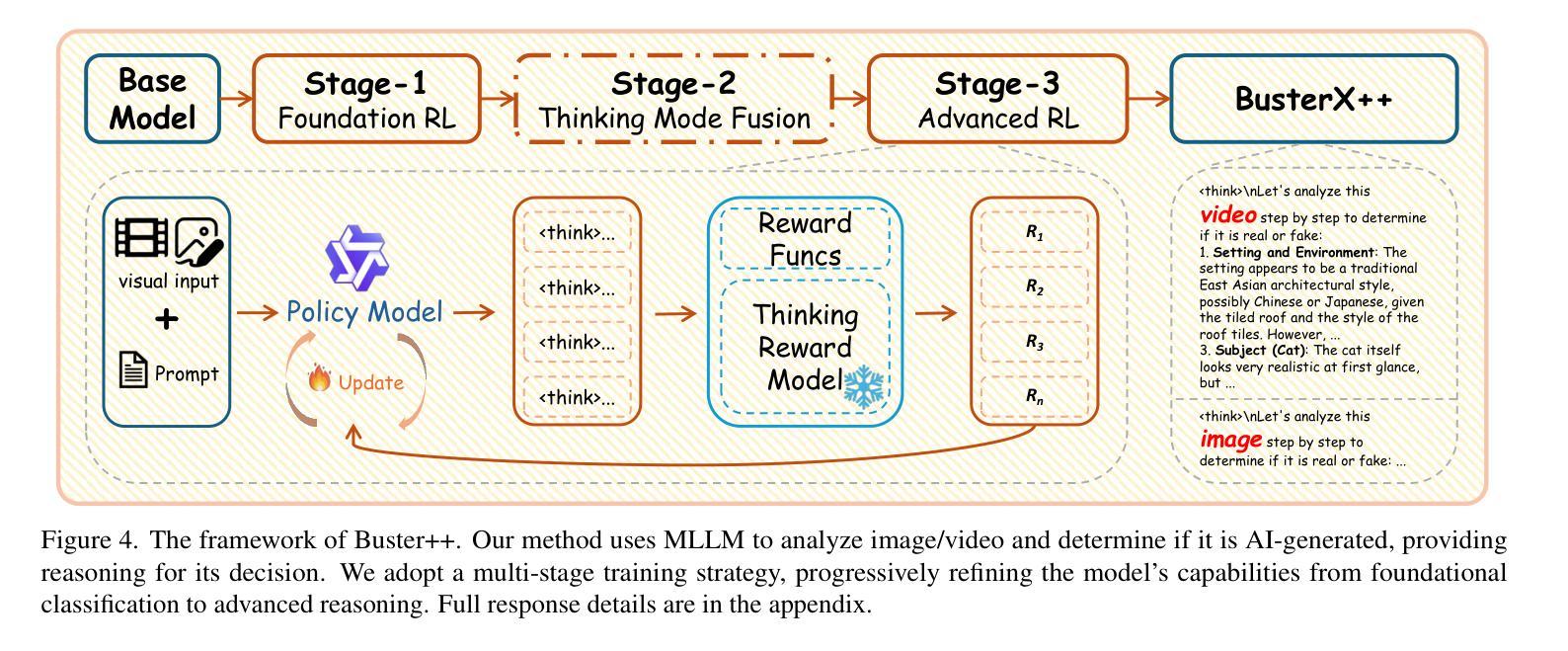
Authors:Haiquan Wen, Tianxiao Li, Zhenglin Huang, Yiwei He, Guangliang Cheng
Recent advances in generative AI have dramatically improved image and video synthesis capabilities, significantly increasing the risk of misinformation through sophisticated fake content. In response, detection methods have evolved from traditional approaches to multimodal large language models (MLLMs), offering enhanced transparency and interpretability in identifying synthetic media. However, current detection systems remain fundamentally limited by their single-modality design. These approaches analyze images or videos separately, making them ineffective against synthetic content that combines multiple media formats. To address these challenges, we introduce \textbf{BusterX++}, a novel framework designed specifically for cross-modal detection and explanation of synthetic media. Our approach incorporates an advanced reinforcement learning (RL) post-training strategy that eliminates cold-start. Through Multi-stage Training, Thinking Reward, and Hybrid Reasoning, BusterX++ achieves stable and substantial performance improvements. To enable comprehensive evaluation, we also present \textbf{GenBuster++}, a cross-modal benchmark leveraging state-of-the-art image and video generation techniques. This benchmark comprises 4,000 images and video clips, meticulously curated by human experts using a novel filtering methodology to ensure high quality, diversity, and real-world applicability. Extensive experiments demonstrate the effectiveness and generalizability of our approach.
近年来,生成式人工智能的最新进展极大地提高了图像和视频合成能力,同时也显著增加了通过复杂虚假内容传播误信息的风险。对此,检测方法已经从传统方法进化到多模态大型语言模型(MLLMs),在识别合成媒体时提供了增强透明度和可解释性。然而,当前检测系统的基本局限性在于其单模态设计。这些方法分别分析图像或视频,对于结合多种媒体格式的合成内容,它们的效果大打折扣。为了应对这些挑战,我们推出了**BusterX++,这是一个专为跨模态检测和设计合成媒体解释而设计的新型框架。我们的方法采用先进的强化学习(RL)后训练策略,消除了冷启动。通过多阶段训练、思考奖励和混合推理,BusterX++实现了稳定且显著的性能改进。为了进行全面的评估,我们还推出了GenBuster++**,这是一个利用最新图像和视频生成技术的跨模态基准测试。该基准测试包含4000张图像和视频片段,由人类专家使用新型过滤方法精心挑选,以确保高质量、多样性和现实世界的适用性。大量实验证明了我们的方法的有效性和泛化能力。
论文及项目相关链接
Summary
近期生成式AI技术的快速发展显著提升了图像和视频合成能力,增加了通过复杂虚假内容传播误导信息的可能性。为应对此挑战,检测手段已从传统方法进化到多模态大型语言模型(MLLMs),提高了在识别合成媒体时的透明度和可解释性。然而,当前检测系统的基本局限在于其单模态设计,无法有效应对融合多种媒体格式的综合合成内容。为解决此问题,我们推出全新框架**BusterX++,专门用于跨模态检测并解释合成媒体。通过先进的强化学习(RL)后训练策略,结合多阶段训练、思考奖励和混合推理,BusterX++实现了稳定且显著的性能提升。为进行全面评估,我们还推出了GenBuster++**跨模态基准测试,利用最先进的图像和视频生成技术,包含4000张图像和视频片段,由人类专家通过新颖过滤方法精心挑选,确保高质量、多样性和现实应用可行性。实验证明了我们方法的有效性和泛化能力。
Key Takeaways
- 生成式AI技术在图像和视频合成方面取得显著进步,增加了虚假内容传播的风险。
- 传统检测手段存在局限性,多模态大型语言模型(MLLMs)提供更高的透明度和可解释性。
- 当前检测系统主要是单模态的,无法有效应对跨多种媒体格式的综合合成内容。
- 引入新型框架BusterX++,专门用于跨模态检测并解释合成媒体,具有强化学习后训练策略、多阶段训练等特点。
- BusterX++通过结合强化学习、多阶段训练等实现性能显著提升。
- 提出GenBuster++跨模态基准测试,用于全面评估图像和视频合成检测方法的性能。
点此查看论文截图



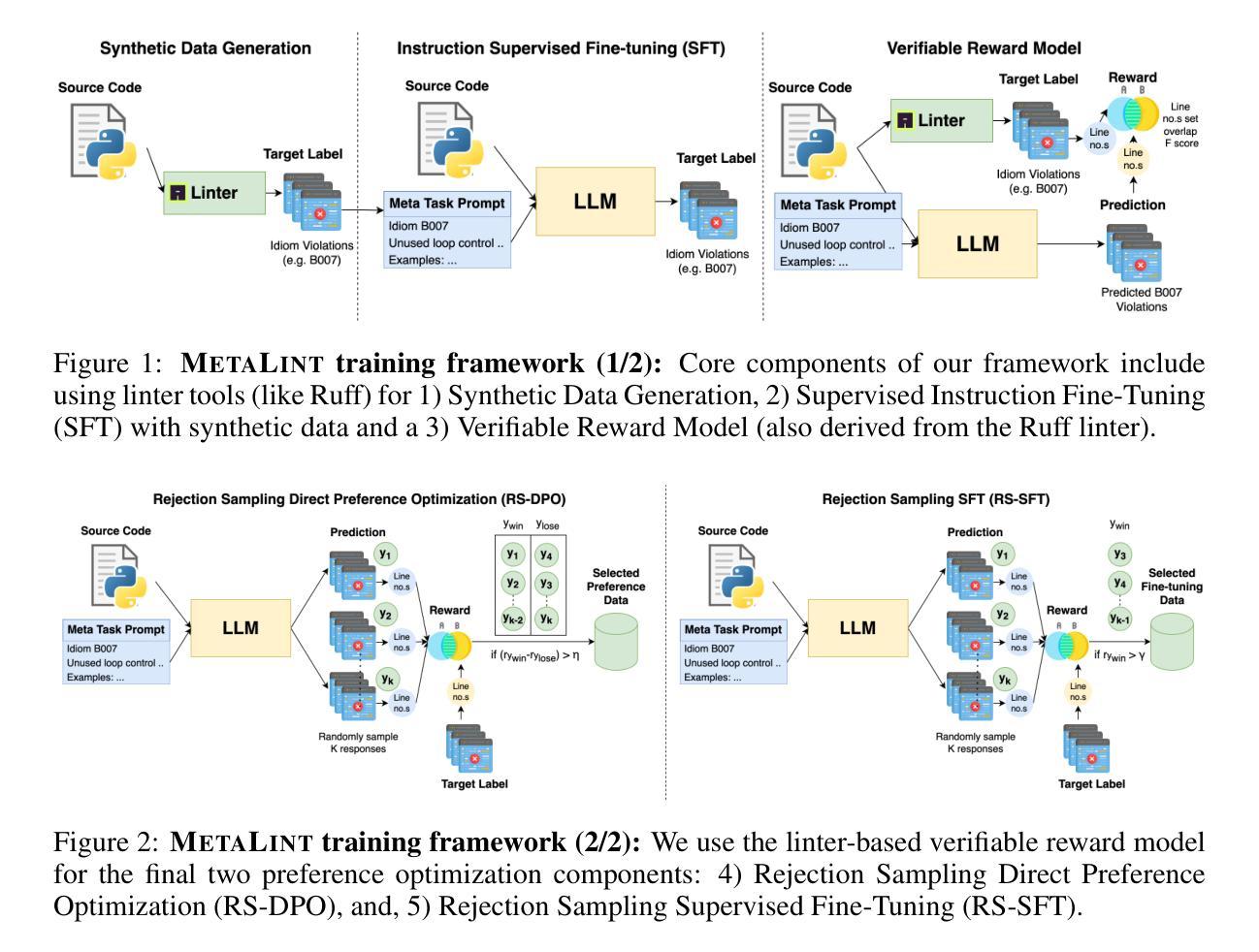
MetaLint: Generalizable Idiomatic Code Quality Analysis through Instruction-Following and Easy-to-Hard Generalization
Authors:Atharva Naik, Lawanya Baghel, Dhakshin Govindarajan, Darsh Agrawal, Daniel Fried, Carolyn Rose
Large Language Models, though successful in code generation, struggle with code quality analysis because they are limited by static training data and can’t easily adapt to evolving best practices. We introduce MetaLint, a new instruction-following framework that formulates code quality analysis as the task of detecting and fixing problematic semantic code fragments or code idioms based on high-level specifications. Unlike conventional approaches that train models on static, rule-based data, MetaLint employs instruction tuning on synthetic linter-generated data to support easy-to-hard generalization, enabling models to adapt to novel or complex code patterns without retraining. To evaluate this, we construct a benchmark of challenging idioms inspired by real-world coding standards such as Python Enhancement Proposals (PEPs) and assess whether MetaLint-trained models reason adaptively or simply memorize. Our results show that MetaLint improves generalization to unseen PEP idioms, achieving a 70.37% F-score on idiom detection with the highest recall (70.43%) among all evaluated models. It also achieves 26.73% on localization, competitive for its 4B parameter size and comparable to larger state-of-the-art models like o3-mini, highlighting its potential for future-proof code quality analysis.
大型语言模型虽然在代码生成方面取得了成功,但在代码质量分析方面却遇到了困难,因为它们受限于静态训练数据,无法轻松适应不断变化的最佳实践。我们引入了MetaLint,这是一种新的指令遵循框架,它将代码质量分析制定为基于高级规范检测并修复问题语义代码片段或代码惯用法的任务。与传统的在静态、基于规则的数据上训练模型的方法不同,MetaLint采用合成linter生成数据的指令微调,支持从易到难的泛化,使模型能够适应新的或复杂的代码模式,无需重新训练。为了评估这一点,我们构建了一个以现实世界编码标准(如Python增强提案(PEPs))为灵感的挑战idiom的基准测试,并评估MetaLint训练的模型是适应性推理还是简单记忆。我们的结果表明,MetaLint在未见过的PEP惯用法中的泛化能力得到了提高,在idiom检测方面达到了70.37%的F分数,在所有评估模型中召回率最高(70.43%)。在定位方面,它达到了26.73%,对于其4B的参数大小来说具有竞争力,并与较大的最新模型(如o3-mini)相当,这突显了其在未来代码质量分析方面的潜力。
论文及项目相关链接
Summary:大型语言模型在代码生成方面表现出色,但在代码质量分析方面却存在困难,因为它们受限于静态训练数据,无法轻松适应不断变化的最佳实践。为此,我们引入了MetaLint,这是一种新的指令遵循框架,它将代码质量分析制定为检测并修复基于高级规范的问题语义代码片段或代码惯用法的任务。与传统的在静态规则基础上训练模型的方法不同,MetaLint采用合成linter生成数据的指令微调方法,支持从易到难的泛化,使模型能够自适应于新型或复杂的代码模式,无需重新训练。我们的实验结果表明,MetaLint在未见过的PEP惯用法上的泛化能力得到了提高,在idiom检测方面达到了70.37%的F-score,其中召回率最高(70.43%),在定位方面也取得了26.73%的竞争力成绩。这突显了其在未来代码质量分析中的潜力。
Key Takeaways:
- 大型语言模型在代码生成方面表现良好,但在代码质量分析方面存在挑战。
- MetaLint是一种新的指令遵循框架,用于解决代码质量分析问题。
- MetaLint通过合成linter生成数据的指令微调方法支持模型从易到难的泛化。
- MetaLint能够在不重新训练的情况下使模型适应新型或复杂的代码模式。
- MetaLint通过检测并修复问题语义代码片段或代码惯用法来完成任务。
- 在未见过的PEP惯用法评估中,MetaLint显示出良好的泛化能力。
点此查看论文截图

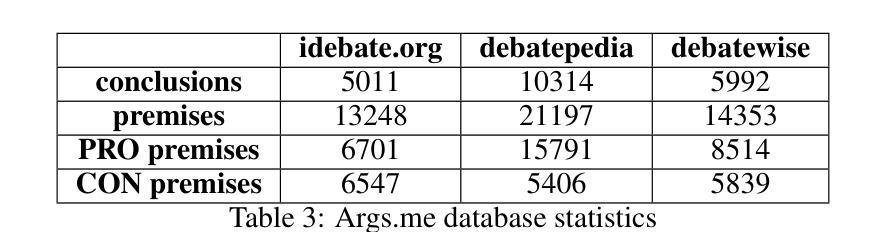
A comprehensive study of LLM-based argument classification: from LLAMA through GPT-4o to Deepseek-R1
Authors:Marcin Pietroń, Rafał Olszowski, Jakub Gomułka, Filip Gampel, Andrzej Tomski
Argument mining (AM) is an interdisciplinary research field that integrates insights from logic, philosophy, linguistics, rhetoric, law, psychology, and computer science. It involves the automatic identification and extraction of argumentative components, such as premises and claims, and the detection of relationships between them, such as support, attack, or neutrality. Recently, the field has advanced significantly, especially with the advent of large language models (LLMs), which have enhanced the efficiency of analyzing and extracting argument semantics compared to traditional methods and other deep learning models. There are many benchmarks for testing and verifying the quality of LLM, but there is still a lack of research and results on the operation of these models in publicly available argument classification databases. This paper presents a study of a selection of LLM’s, using diverse datasets such as Args.me and UKP. The models tested include versions of GPT, Llama, and DeepSeek, along with reasoning-enhanced variants incorporating the Chain-of-Thoughts algorithm. The results indicate that ChatGPT-4o outperforms the others in the argument classification benchmarks. In case of models incorporated with reasoning capabilities, the Deepseek-R1 shows its superiority. However, despite their superiority, GPT-4o and Deepseek-R1 still make errors. The most common errors are discussed for all models. To our knowledge, the presented work is the first broader analysis of the mentioned datasets using LLM and prompt algorithms. The work also shows some weaknesses of known prompt algorithms in argument analysis, while indicating directions for their improvement. The added value of the work is the in-depth analysis of the available argument datasets and the demonstration of their shortcomings.
论证挖掘(AM)是一个跨学科的研究领域,融合了逻辑、哲学、语言学、修辞学、法律、心理学和计算机科学等领域的见解。它涉及自动识别和提取论证性成分,如前提和主张,以及检测它们之间的关系,如支持、攻击或中立。最近,随着大型语言模型(LLM)的出现,该领域取得了显著进展,与传统的分析方法和其他的深度学习模型相比,大型语言模型在分析提取论证语义方面的效率大大提高。尽管有很多基准测试用于检验和验证LLM的质量,但在公开可用的论证分类数据库中关于这些模型操作的研究和结果仍然缺乏。本文使用Args.me和UKP等不同的数据集对一系列LLM进行了研究。测试的模型包括GPT、Llama和DeepSeek的版本,以及采用Chain-of-Thoughts算法的推理增强变体。结果表明,在论证分类基准测试中,ChatGPT-4o的表现优于其他模型。在融入推理能力的模型中,Deepseek-R1表现出其优越性。然而,尽管GPT-4o和Deepseek-R1具有优势,但它们仍然会出现错误。本文讨论了所有模型最常见的错误。据我们所知,所呈现的工作是使用LLM和提示算法对所述数据集进行的首次更广泛的分析。该工作还显示了已知提示算法在论证分析中的一些弱点,并指出了改进方向。该工作的附加值是对现有论证数据集进行深入分析和展示其不足。
论文及项目相关链接
Summary
本文主要介绍了论证挖掘(AM)这一跨学科研究领域,它结合了逻辑、哲学、语言学、修辞学、法律、心理学和计算机科学等领域的见解。文章重点介绍了大型语言模型(LLM)在论证语义分析提取方面的进展,并使用Args.me和UKP等数据集对GPT、Llama和DeepSeek等模型进行了测试。结果显示,ChatGPT-4o在论证分类基准测试中表现最佳,而Deepseek-R1在结合推理能力方面展现出优势。但即便是最优模型也存在错误,文章也讨论了最常见的错误。这篇文章是对使用LLM和提示算法进行数据集广泛分析的首次尝试,并指出了改进方向。
Key Takeaways
- 论证挖掘(AM)是一个涉及多个学科的研究领域,包括逻辑、哲学、语言学等,旨在自动识别和提取论证成分以及它们之间的关系。
- 大型语言模型(LLM)在论证语义分析和提取方面有着显著的优势,相较于传统方法和其他深度学习模型,其效率更高。
- 使用Args.me和UKP等数据集的测试表明,ChatGPT-4o在论证分类基准测试中表现最佳。
- 结合推理能力的Deepseek-R1模型在特定情境下展现出优势。
- 尽管GPT-4o和Deepseek-R1表现优秀,但它们仍会犯错误,文章讨论了这些错误中最常见的一些。
- 本文是对使用大型语言模型和提示算法进行数据集广泛分析的首次尝试,展示了数据集在分析中的短板。
点此查看论文截图



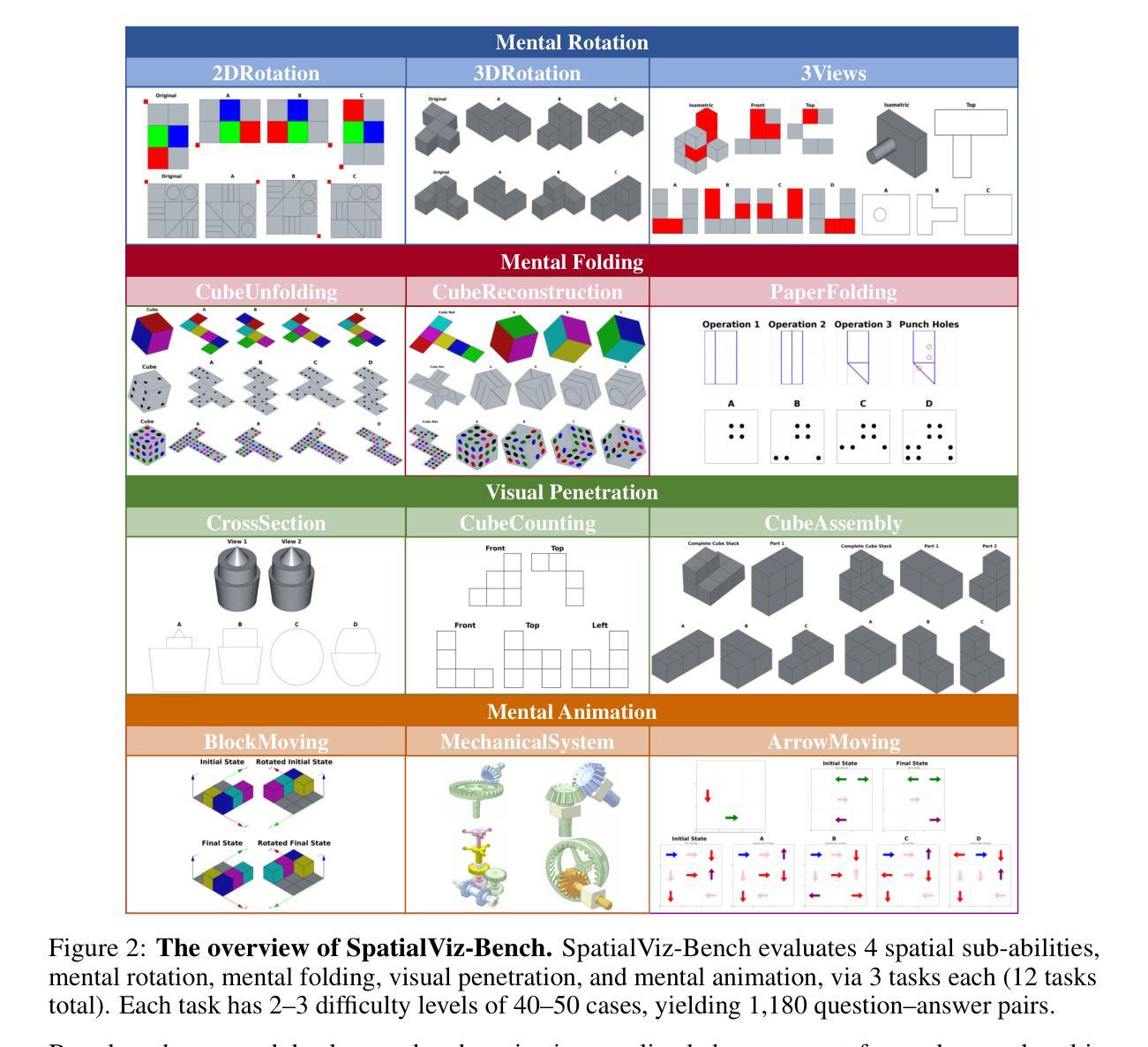
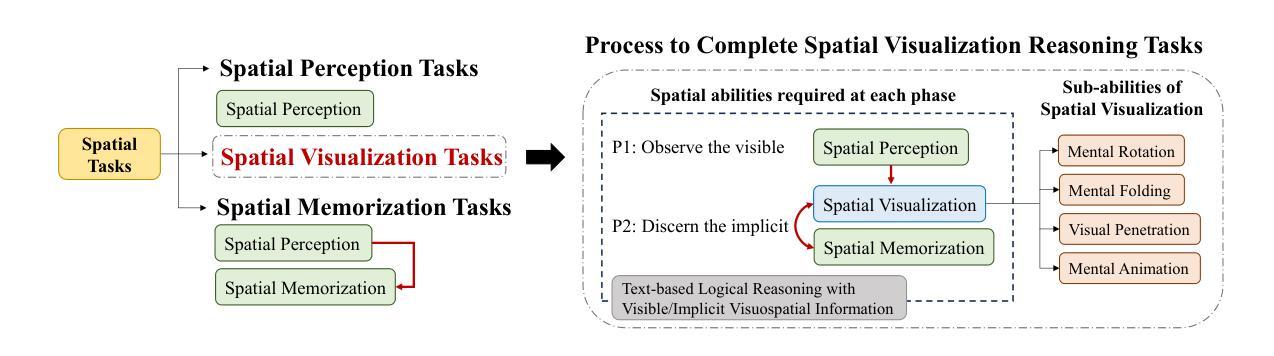
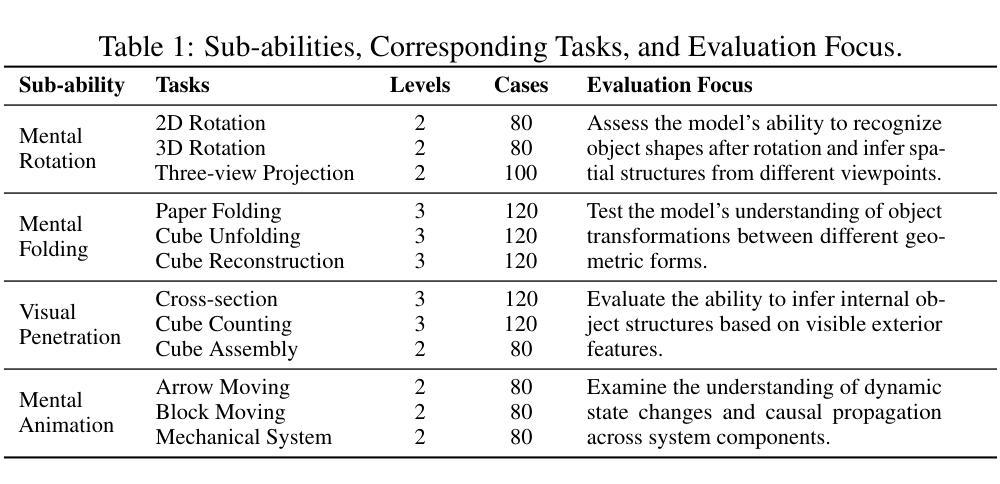
SpatialViz-Bench: Automatically Generated Spatial Visualization Reasoning Tasks for MLLMs
Authors:Siting Wang, Luoyang Sun, Cheng Deng, Kun Shao, Minnan Pei, Zheng Tian, Haifeng Zhang, Jun Wang
Humans can directly imagine and manipulate visual images in their minds, a capability known as spatial visualization. While multi-modal Large Language Models (MLLMs) support imagination-based reasoning, spatial visualization remains insufficiently evaluated, typically embedded within broader mathematical and logical assessments. Existing evaluations often rely on IQ tests or math competitions that may overlap with training data, compromising assessment reliability. To this end, we introduce SpatialViz-Bench, a comprehensive multi-modal benchmark for spatial visualization with 12 tasks across 4 sub-abilities, comprising 1,180 automatically generated problems. Our evaluation of 33 state-of-the-art MLLMs not only reveals wide performance variations and demonstrates the benchmark’s strong discriminative power, but also uncovers counter-intuitive findings: models show difficulty perception misaligned with human intuition, exhibit dramatic 2Dto-3D performance cliffs, default to formulaic derivation over visualization, and paradoxically suffer performance degradation from Chain-of-Thought prompting in open-source models. Through statistical and qualitative analysis of error types, SpatialViz-Bench demonstrates that state-of-the-art MLLMs continue to exhibit deficiencies in spatial visualization tasks, thereby addressing a significant lacuna in the field. The benchmark data and evaluation code are publicly available.
人类能够在大脑中直接想象和操作视觉图像,这种能力被称为空间可视化。尽管多模态大型语言模型(MLLMs)支持基于想象的推理,但对空间可视化的评估仍然不足,通常嵌入在更广泛的数学和逻辑评估中。现有的评估通常依赖于可能与训练数据重叠的智商测试或数学竞赛,这可能会影响评估的可靠性。为此,我们引入了SpatialViz-Bench,这是一个全面的多模态空间可视化基准测试,包含4个子能力领域的12项任务,共计1180个自动生成的问题。我们对33个最先进的大型语言模型进行了评估,不仅揭示了性能上的巨大差异,证明了基准测试的强大鉴别力,还发现了具有悖常理的结果:模型存在与人类直觉相悖的感知困难、明显的二维到三维性能下降、倾向于公式推导而非可视化、以及在开源模型中遇到“思维链”提示时的表现反而下降等问题。通过对错误类型的统计和定性分析,SpatialViz-Bench显示,目前最先进的MLLM在空间可视化任务上仍然存在缺陷,从而填补了该领域的空白。基准测试数据和评估代码均已公开可用。
论文及项目相关链接
Summary
空间可视化是人类能够在大脑中直接想象和操作视觉图像的能力。虽然多模态大型语言模型(MLLMs)支持基于想象的推理,但空间可视化尚未得到充分评估,通常嵌入在更广泛的数学和逻辑评估中。为此,我们引入了SpatialViz-Bench,这是一个全面的多模态空间可视化基准测试,包含12项任务,涵盖4种子能力,共1180个自动生成的问题。我们对33个最先进的大型语言模型进行了评估,不仅揭示了广泛的性能差异并证明了基准测试的强鉴别力,还发现了令人困惑的结果:模型在感知方面存在与人类直觉的偏差、二维到三维性能悬崖明显、倾向于公式推导而非可视化以及开放式模型中的思维链提示反而导致性能下降。SpatialViz-Bench展示了当前大型语言模型在空间可视化任务上的不足,为解决该领域的一个重要空白提供了途径。基准数据和评估代码已公开可用。
Key Takeaways
- 人类拥有空间可视化能力,可以直接在大脑中想象和操作视觉图像。
- 多模态大型语言模型(MLLMs)支持基于想象的推理,但空间可视化能力的评估尚不充分。
- 现有评估方法常依赖于可能与训练数据重叠的智商测试或数学竞赛,影响评估可靠性。
- SpatialViz-Bench是一个全面的多模态空间可视化基准测试,包含12项任务,旨在更准确地评估模型的空间可视化能力。
- 评估结果显示,不同模型在空间可视化任务上的性能差异显著,表明基准测试具有很强的鉴别力。
- 模型在感知方面存在与人类直觉的偏差,且在二维到三维转换的任务中表现显著下降。
点此查看论文截图


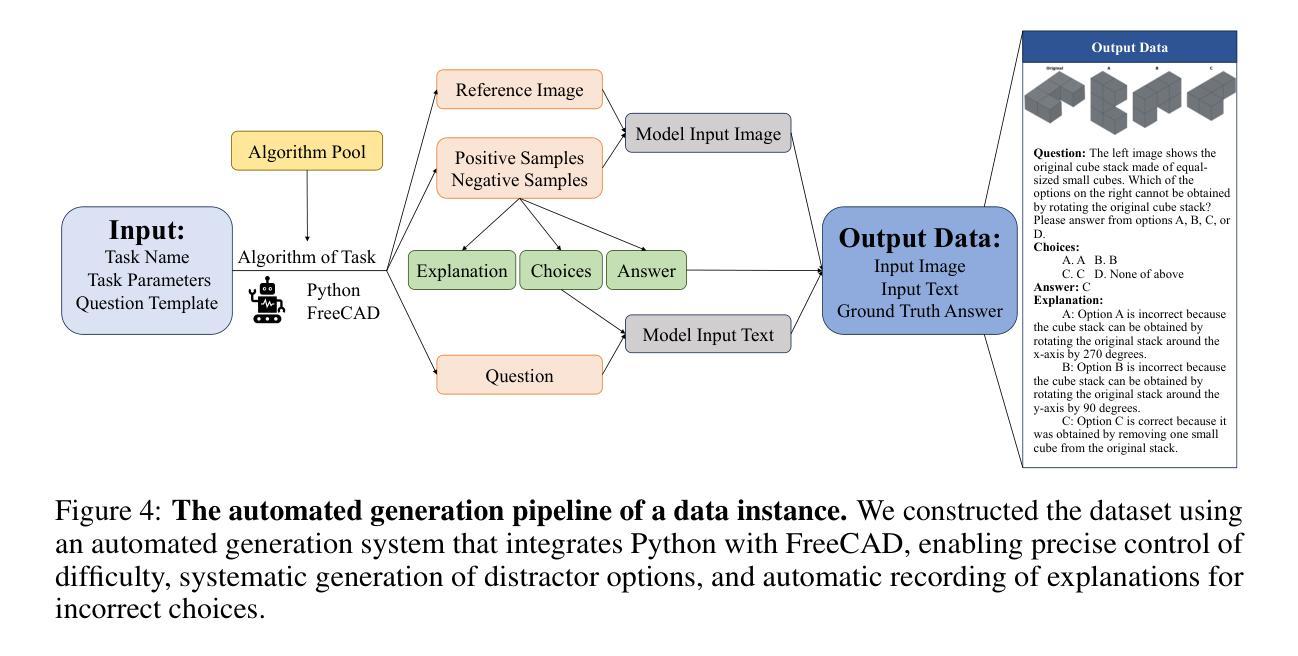
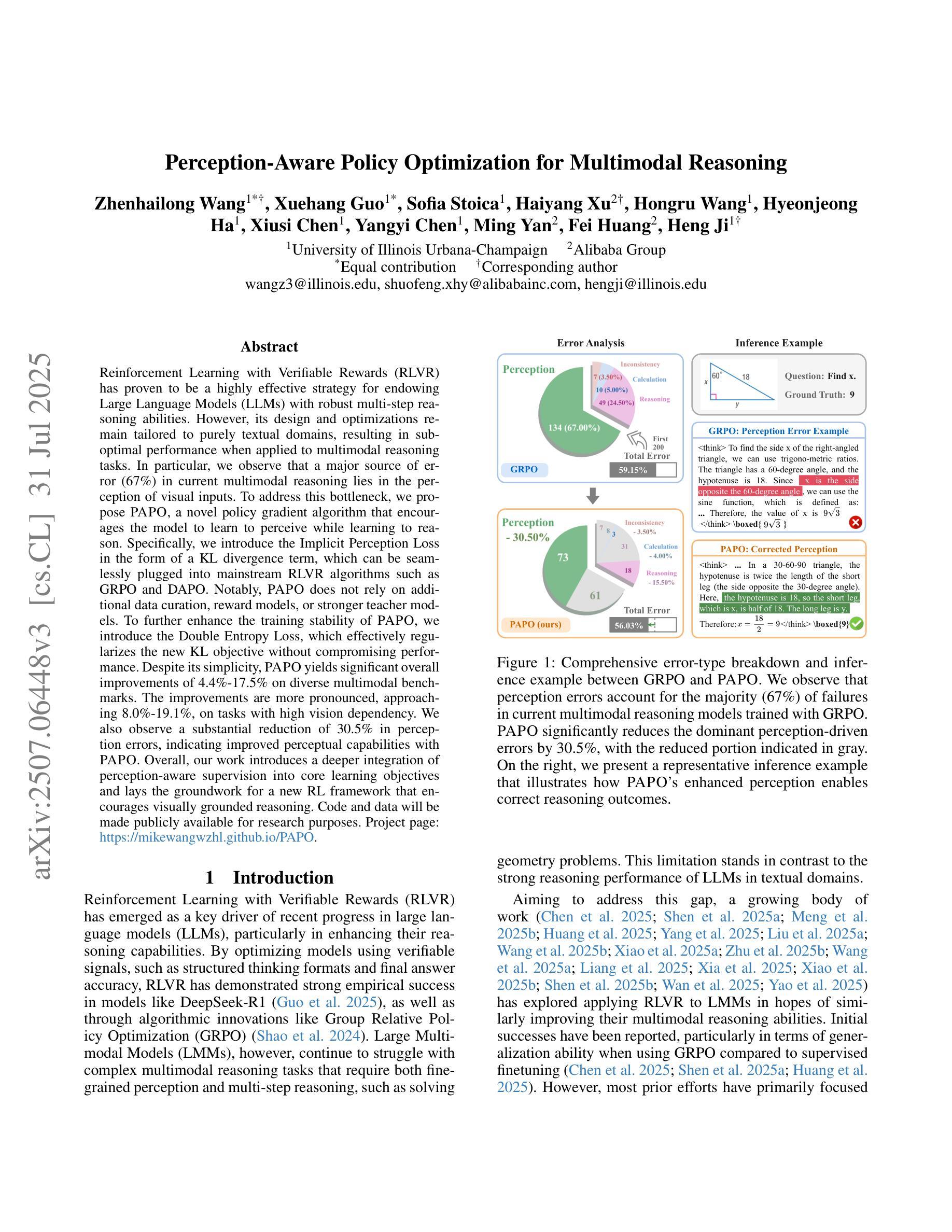
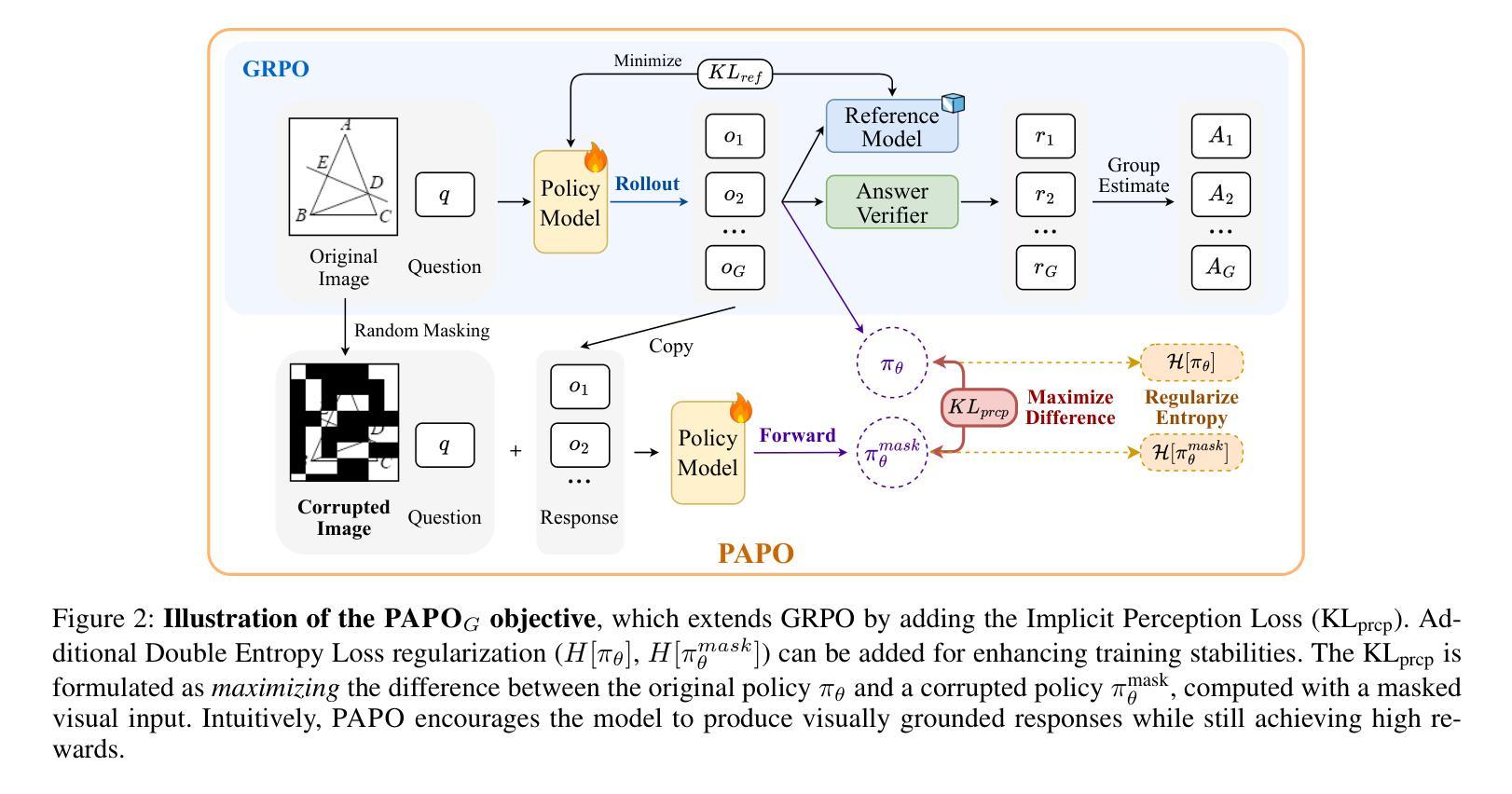
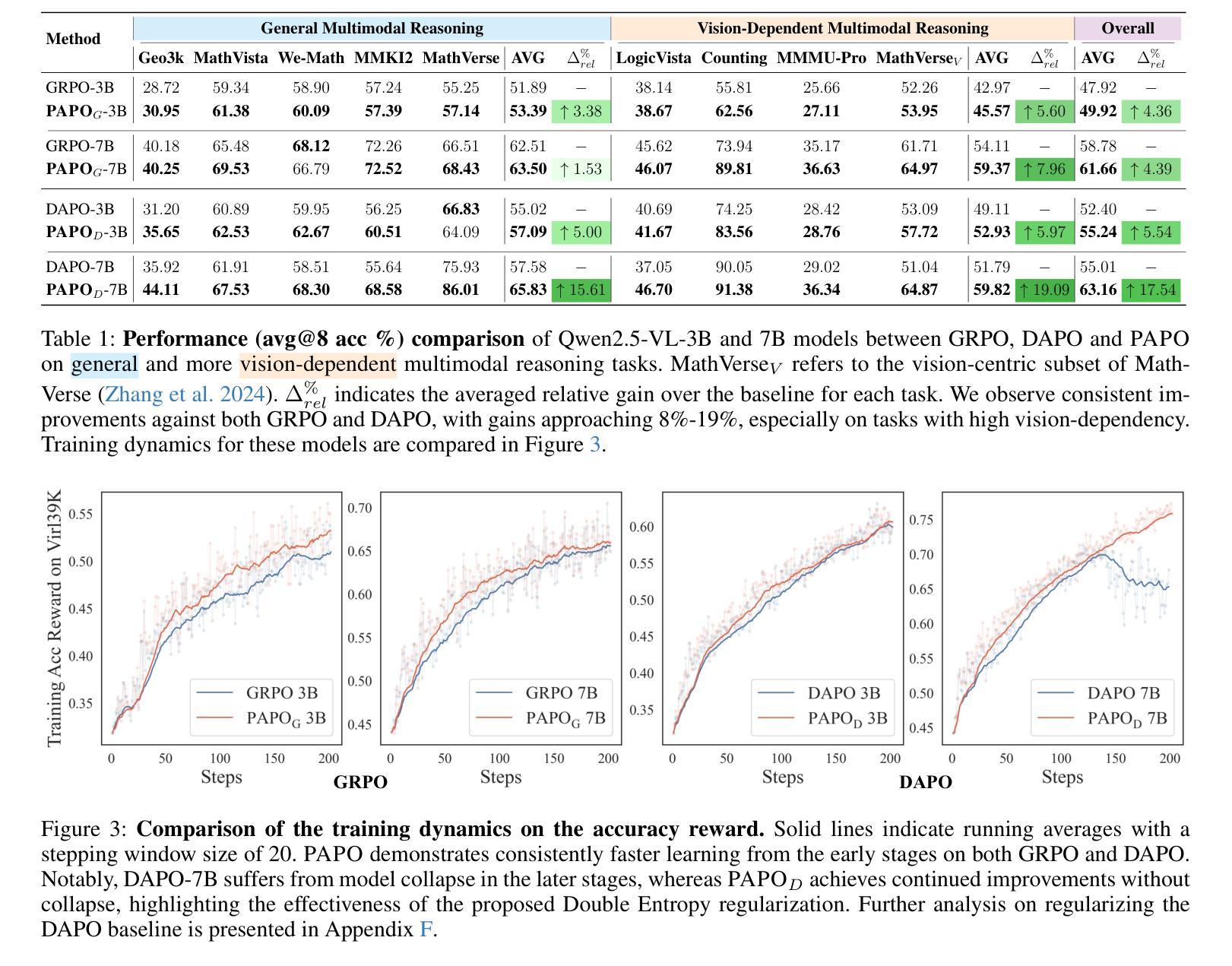
Perception-Aware Policy Optimization for Multimodal Reasoning
Authors:Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, Heng Ji
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose PAPO, a novel policy gradient algorithm that encourages the model to learn to perceive while learning to reason. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term, which can be seamlessly plugged into mainstream RLVR algorithms such as GRPO and DAPO. Notably, PAPO does not rely on additional data curation, reward models, or stronger teacher models. To further enhance the training stability of PAPO, we introduce the Double Entropy Loss, which effectively regularizes the new KL objective without compromising performance. Despite its simplicity, PAPO yields significant overall improvements of 4.4%-17.5% on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%-19.1%, on tasks with high vision dependency. We also observe a substantial reduction of 30.5% in perception errors, indicating improved perceptual capabilities with PAPO. Overall, our work introduces a deeper integration of perception-aware supervision into core learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Code and data will be made publicly available for research purposes. Project page: https://mikewangwzhl.github.io/PAPO.
强化学习与可验证奖励(RLVR)已被证明是赋予大型语言模型(LLM)强大的多步推理能力的一种高度有效的策略。然而,其设计和优化仍然针对纯文本领域,在应用于多模态推理任务时表现不佳。特别是,我们观察到当前多模态推理中的误差主要来源于视觉输入的感知。为了解决这一瓶颈,我们提出了PAPO,这是一种新的策略梯度算法,鼓励模型在学习的过程中学会感知。具体来说,我们以KL散度项的形式引入了隐感知损失,它可以无缝地插入到主流的RLVR算法中,如GRPO和DAPO。值得注意的是,PAPO不依赖于额外的数据整理、奖励模型或更强大的教师模型。为了进一步提高PAPO的训练稳定性,我们引入了双重熵损失,它有效地正则化了新的KL目标,而不会影响性能。尽管PAPO很简单,但在多种多模态基准测试中,它使总体性能提高了4.4%~17.5%。在高度依赖视觉的任务中,改进更为显著,达到了8.0%~19.1%。我们还观察到感知错误减少了30.5%,这表明PAPO提高了感知能力。总的来说,我们的工作将感知感知监督更深入地集成到核心学习目标中,并为鼓励视觉基础推理的新RL框架奠定了基础。为了研究目的,代码和数据将公开提供。项目页面:链接。
论文及项目相关链接
Summary
强化学习通过可验证奖励(RLVR)策略成功为大型语言模型(LLM)赋予了强大的多步推理能力。然而,RLVR的设计和优化仍然仅限于纯文本领域,导致在应对多模态推理任务时的表现不佳。为改善对视觉输入的感知误差这一关键问题,本文提出了名为PAPO的新型策略梯度算法。该算法引入了隐式感知损失,以KL散度项的形式出现,可无缝集成到主流的RLVR算法中,如GRPO和DAPO。PAPO不依赖额外的数据整理、奖励模型或更强大的教师模型。为提高PAPO的训练稳定性,本文引入了双重熵损失,有效正则化了新的KL目标,且不损害性能。在多样化的多模态基准测试中,尽管方法简单,但PAPO实现了显著的总体改进,改进幅度为4.4%~17.5%,在高度依赖视觉的任务上表现更为突出,达到8%~19.1%。同时观察到感知错误减少了30.5%,这表明PAPO增强了感知能力。总的来说,本研究将感知感知监督更深地整合到核心学习目标中,并为鼓励视觉推理的新型RL框架奠定了基础。
Key Takeaways
- RLVR策略虽有效,但仍局限于文本领域,多模态推理任务表现不佳。
- 当前多模态推理的主要误差来源在于视觉输入的感知。
- PAPO是一种新型策略梯度算法,旨在解决多模态推理中的感知瓶颈问题。
- PAPO引入隐式感知损失和双重熵损失来提高性能和稳定性。
- PAPO在不依赖额外资源的情况下,在多种多模态基准测试上实现了显著的改进。
- 在高度依赖视觉的任务上,PAPO的改进更为显著,同时显著减少了感知错误。
点此查看论文截图
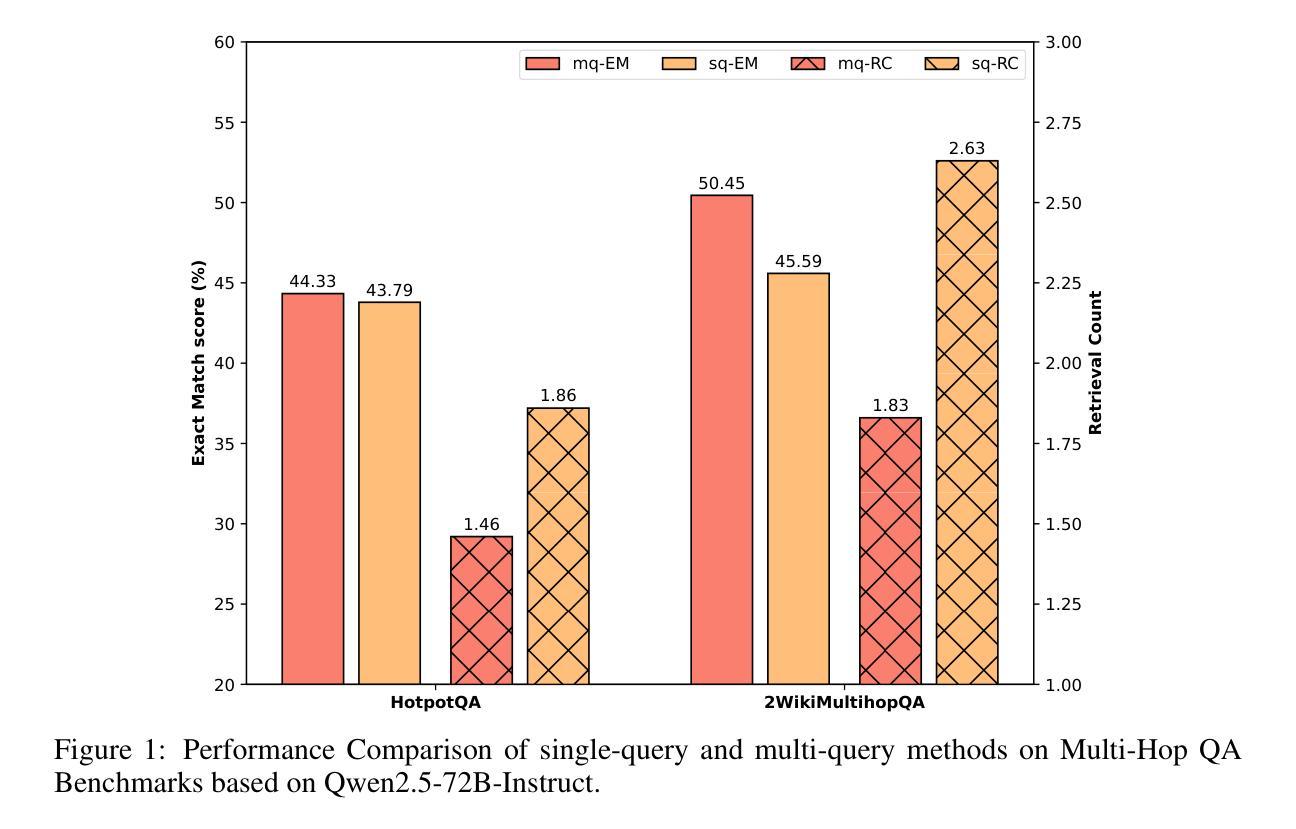
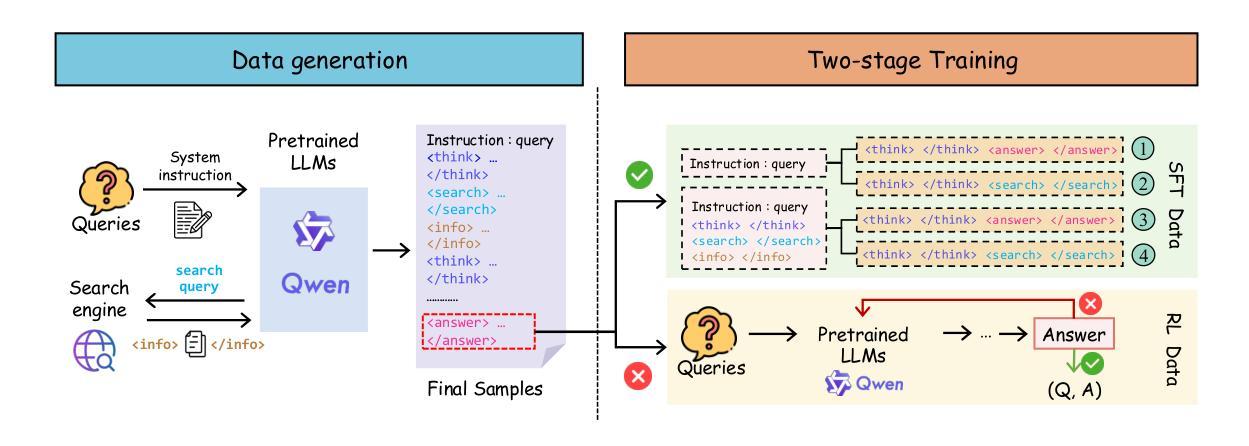
RAG-R1 : Incentivize the Search and Reasoning Capabilities of LLMs through Multi-query Parallelism
Authors:Zhiwen Tan, Jiaming Huang, Qintong Wu, Hongxuan Zhang, Chenyi Zhuang, Jinjie Gu
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, while LLMs remain prone to generating hallucinated or outdated responses due to their static internal knowledge. Recent advancements in Retrieval-Augmented Generation (RAG) methods have aimed to enhance models’ search and reasoning capabilities through reinforcement learning (RL). Although these methods demonstrate promising results, they face challenges in training stability and encounter issues such as substantial inference time and restricted capabilities due to reliance on single-query mode. In this paper, we propose RAG-R1, a novel training framework designed to enable LLMs to adaptively leverage internal and external knowledge during the reasoning process. We further expand the generation and retrieval processes within the framework from single-query mode to multi-query parallelism, with the aim of reducing inference time and enhancing the model’s capabilities. Extensive experiments on seven question-answering benchmarks demonstrate that our method outperforms the strongest baseline by up to 13.2% and decreases inference time by 11.1%.
大型语言模型(LLM)在各种任务中表现出了显著的能力,但由于其内部知识的静态性,LLM仍容易生成虚构或过时的回应。最近,增强检索生成(RAG)方法的进步旨在通过强化学习(RL)提高模型的搜索和推理能力。尽管这些方法显示出有希望的结果,但它们面临着训练稳定性方面的挑战,并遇到了由于依赖单查询模式而导致的问题,如推理时间延长和能力受限。在本文中,我们提出了RAG-R1,这是一个新的训练框架,旨在使LLM能够在推理过程中自适应地利用内部和外部知识。我们进一步在框架内将生成和检索过程从单查询模式扩展到多查询并行处理,旨在减少推理时间并提高模型的能力。在七个问答基准测试上的大量实验表明,我们的方法比最强基线高出13.2%,并将推理时间减少了11.1%。
论文及项目相关链接
Summary:大型语言模型(LLM)在多种任务中表现出卓越的能力,但其生成回应时易产生虚构或过时信息。为提高模型的搜索和推理能力,最近出现了增强生成(RAG)方法,通过强化学习(RL)增强模型性能。尽管这些方法前景广阔,但仍面临训练稳定性挑战,且存在推理时间长、能力受限等问题。本文提出RAG-R1,一种新型训练框架,旨在使LLM在推理过程中自适应利用内外部知识。此外,本文扩展了框架内的生成和检索过程,从单查询模式转变为多查询并行模式,旨在缩短推理时间并增强模型能力。在七个问答基准测试上的广泛实验表明,我们的方法比最强基线高出13.2%,并将推理时间缩短了11.1%。
Key Takeaways:
- 大型语言模型(LLM)在多种任务中表现出卓越的能力,但易生成虚构或过时回应,需改进。
- 近期出现的增强生成(RAG)方法通过强化学习(RL)提高模型的搜索和推理能力。
- RAG方法面临训练稳定性挑战,推理时间长,能力受限。
- 本文提出RAG-R1训练框架,使LLM能自适应利用内外部知识。
- RAG-R1框架扩展了生成和检索过程,从单查询模式转变为多查询并行模式。
- RAG-R1在七个问答基准测试上表现优异,超过最强基线13.2%,并缩短推理时间11.1%。
- RAG-R1的提出为LLM的进步提供了新的方向和可能。
点此查看论文截图