⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
AudioGen-Omni: A Unified Multimodal Diffusion Transformer for Video-Synchronized Audio, Speech, and Song Generation
Authors:Le Wang, Jun Wang, Feng Deng, Chen Zhang, Kun Gai, Di Zhang
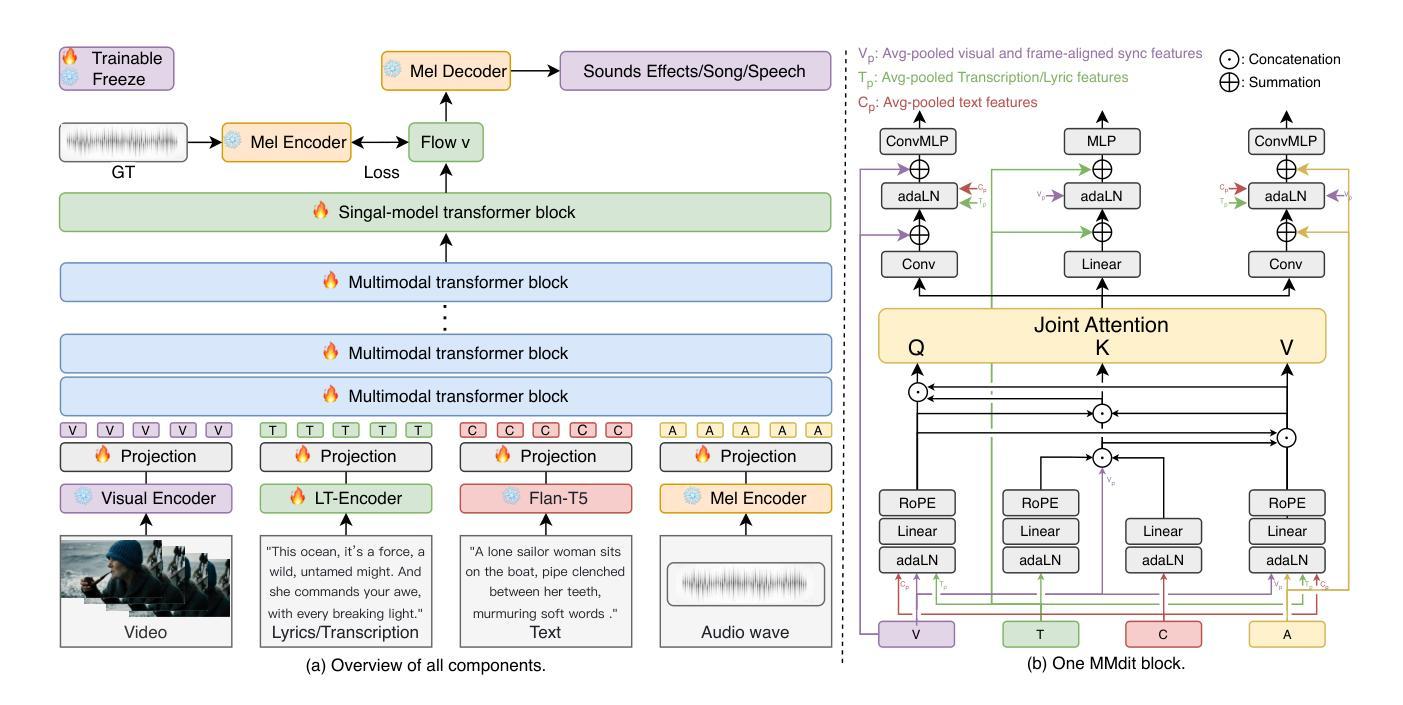
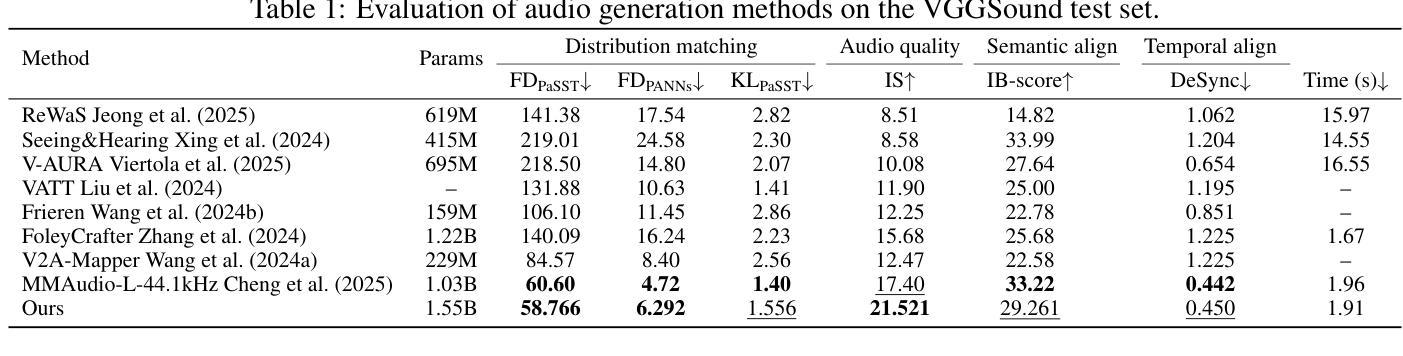
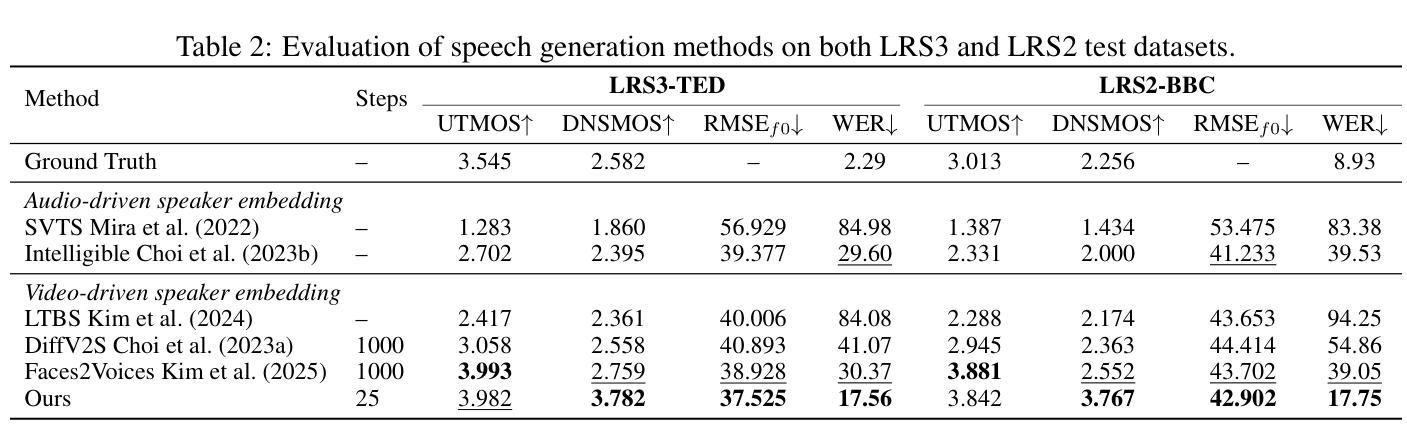
We present AudioGen-Omni - a unified approach based on multimodal diffusion transformers (MMDit), capable of generating high-fidelity audio, speech, and songs coherently synchronized with the input video. AudioGen-Omni introduces a novel joint training paradigm that seamlessly integrates large-scale video-text-audio corpora, enabling a model capable of generating semantically rich, acoustically diverse audio conditioned on multimodal inputs and adaptable to a wide range of audio generation tasks. AudioGen-Omni employs a unified lyrics-transcription encoder that encodes graphemes and phonemes from both sung and spoken inputs into dense frame-level representations. Dense frame-level representations are fused using an AdaLN-based joint attention mechanism enhanced with phase-aligned anisotropic positional infusion (PAAPI), wherein RoPE is selectively applied to temporally structured modalities to ensure precise and robust cross-modal alignment. By unfreezing all modalities and masking missing inputs, AudioGen-Omni mitigates the semantic constraints of text-frozen paradigms, enabling effective cross-modal conditioning. This joint training approach enhances audio quality, semantic alignment, and lip-sync accuracy, while also achieving state-of-the-art results on Text-to-Audio/Speech/Song tasks. With an inference time of 1.91 seconds for 8 seconds of audio, it offers substantial improvements in both efficiency and generality.
我们推出了AudioGen-Omni——一种基于多模式扩散变压器(MMDit)的统一方法,能够生成与输入视频同步的高保真音频、语音和歌曲。AudioGen-Omni引入了一种新型联合训练范式,无缝集成了大规模的视频-文本-音频语料库,使模型能够在多模式输入条件下生成语义丰富、声音多样的音频,并适应各种音频生成任务。AudioGen-Omni采用统一的歌词-转录编码器,将唱声和口语输入中的字母和音素编码为密集的帧级表示。密集的帧级表示通过使用基于AdaLN的联合注意力机制进行融合,增强了相位对齐的异构位置注入(PAAPI),其中RoPE被有选择地应用于临时结构化模式,以确保精确和稳健的跨模式对齐。通过解冻所有模式并屏蔽缺失的输入,AudioGen-Omni减轻了文本冻结范式的语义约束,实现了有效的跨模式条件。这种联合训练方法提高了音频质量、语义对齐和唇同步精度,同时在文本到音频/语音/歌曲的任务上达到了最先进的成果。其推理时间为1.91秒可生成8秒的音频,在效率和通用性方面都有显著提高。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
基于多模态扩散变压器(MMDit)的AudioGen-Omni统一方法,能够生成与输入视频同步的高保真音频、语音和歌曲。它引入了一种新的联合训练范式,将大规模视频-文本-音频语料库无缝集成,使模型能够根据多模态输入生成语义丰富、声音多样的音频,并适应各种音频生成任务。
Key Takeaways
- AudioGen-Omni是一种基于多模态扩散变压器(MMDit)的统一方法,能够生成高保真音频、语音和歌曲,并与输入视频同步。
- 引入了一种新的联合训练范式,集成大规模视频-文本-音频语料库,生成语义丰富、声音多样的音频。
- 采用统一歌词-转录编码器,对唱声和语音输入中的字母和音素进行编码,生成密集帧级表示。
- 通过使用基于AdaLN的联合注意机制和相位对齐的异构定位灌注(PAAPI),融合了密集帧级表示。
- 对模态进行解冻并掩盖缺失输入,减轻了文本冻结范式的语义约束,实现了有效的跨模态条件。
- 联合训练提高了音频质量、语义对齐和唇同步精度,并在文本到音频/语音/歌曲任务上达到最新水平。
点此查看论文截图

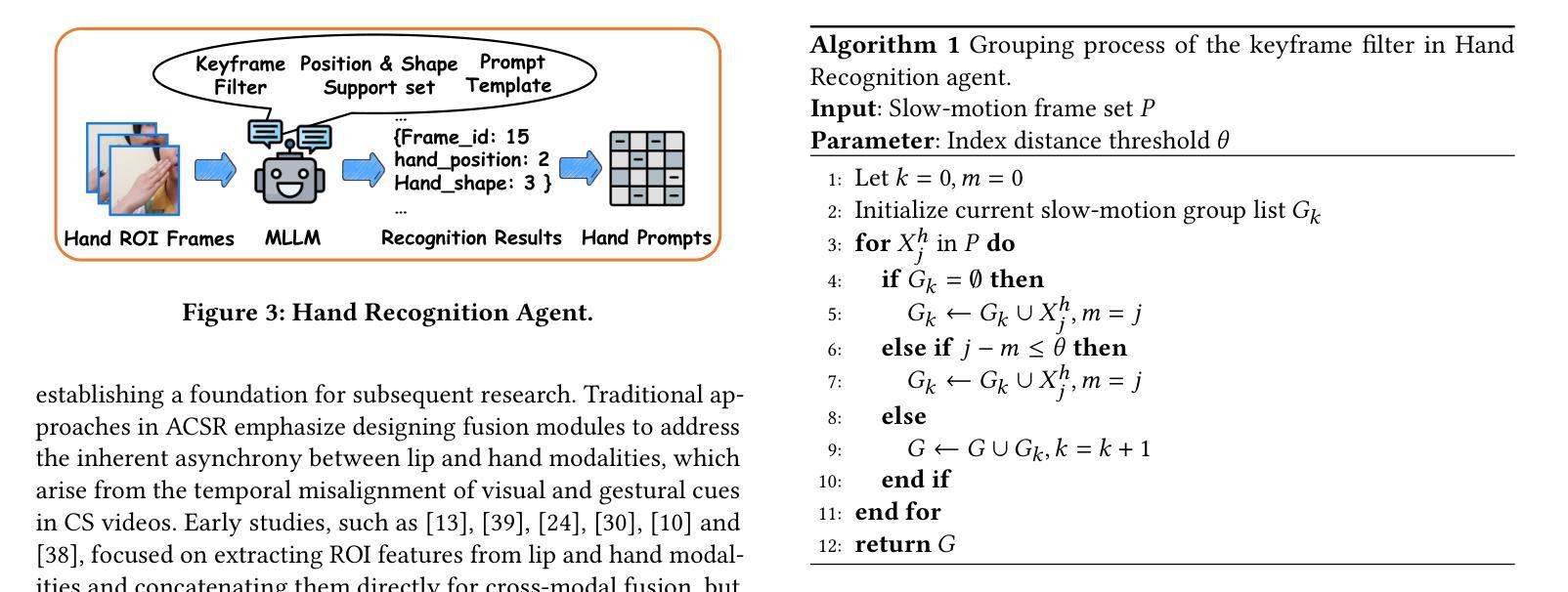
Cued-Agent: A Collaborative Multi-Agent System for Automatic Cued Speech Recognition
Authors:Guanjie Huang, Danny H. K. Tsang, Shan Yang, Guangzhi Lei, Li Liu
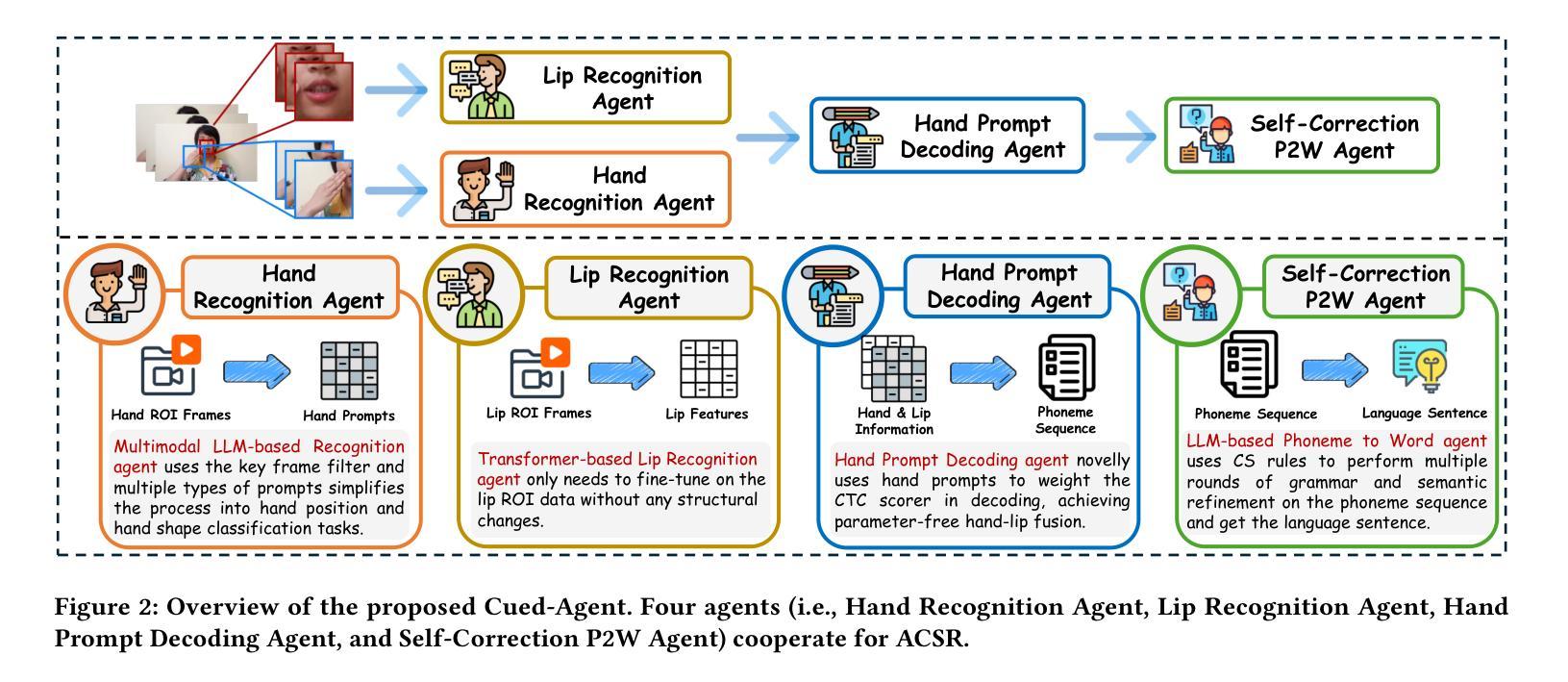
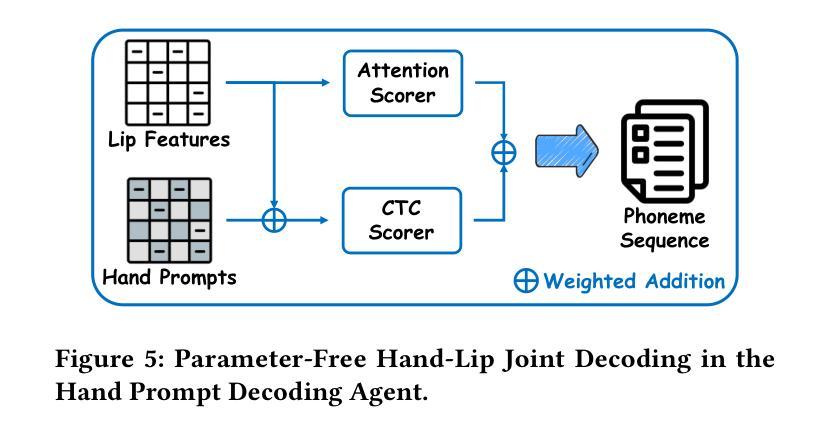
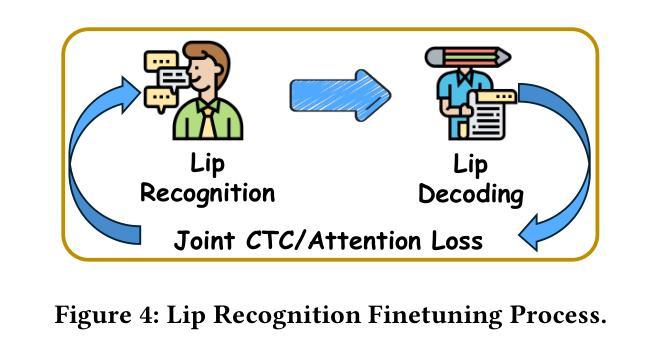
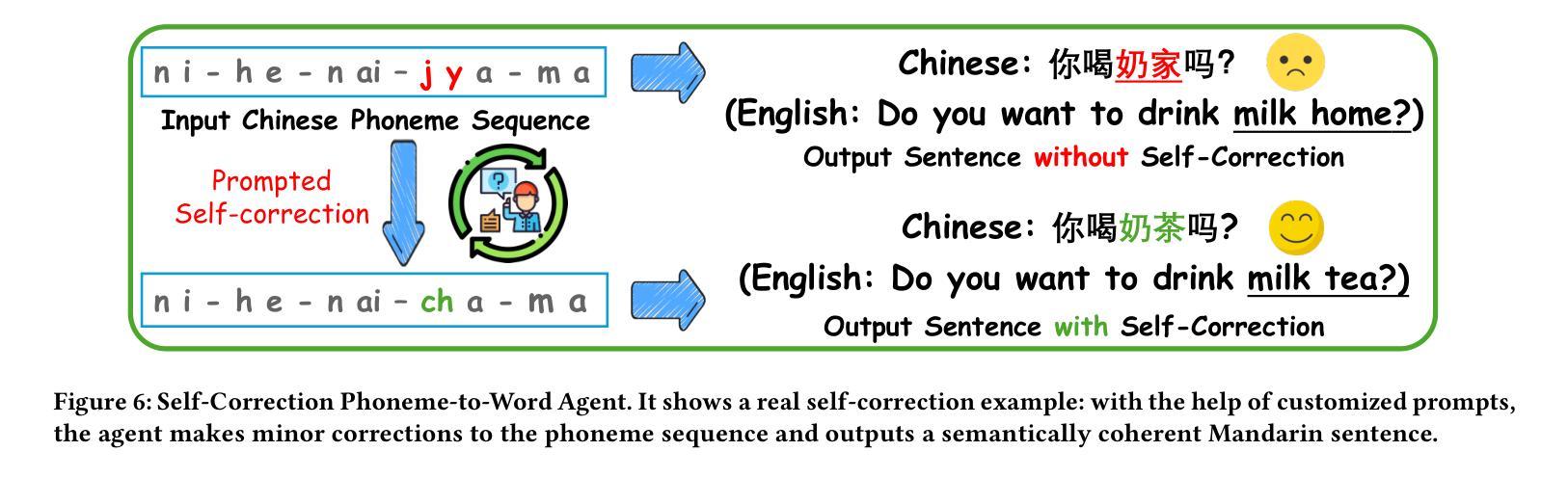
Cued Speech (CS) is a visual communication system that combines lip-reading with hand coding to facilitate communication for individuals with hearing impairments. Automatic CS Recognition (ACSR) aims to convert CS hand gestures and lip movements into text via AI-driven methods. Traditionally, the temporal asynchrony between hand and lip movements requires the design of complex modules to facilitate effective multimodal fusion. However, constrained by limited data availability, current methods demonstrate insufficient capacity for adequately training these fusion mechanisms, resulting in suboptimal performance. Recently, multi-agent systems have shown promising capabilities in handling complex tasks with limited data availability. To this end, we propose the first collaborative multi-agent system for ACSR, named Cued-Agent. It integrates four specialized sub-agents: a Multimodal Large Language Model-based Hand Recognition agent that employs keyframe screening and CS expert prompt strategies to decode hand movements, a pretrained Transformer-based Lip Recognition agent that extracts lip features from the input video, a Hand Prompt Decoding agent that dynamically integrates hand prompts with lip features during inference in a training-free manner, and a Self-Correction Phoneme-to-Word agent that enables post-process and end-to-end conversion from phoneme sequences to natural language sentences for the first time through semantic refinement. To support this study, we expand the existing Mandarin CS dataset by collecting data from eight hearing-impaired cuers, establishing a mixed dataset of fourteen subjects. Extensive experiments demonstrate that our Cued-Agent performs superbly in both normal and hearing-impaired scenarios compared with state-of-the-art methods. The implementation is available at https://github.com/DennisHgj/Cued-Agent.
唇读手势语音(Cued Speech,简称CS)是一种视觉通信系统,它将唇读法与手语编码相结合,为听力受损者提供沟通便利。自动唇读手势语音识别(ACSR)旨在通过AI驱动的方法将手势和唇动转换为文本。传统上,手部和唇部动作之间的时间异步性需要设计复杂的模块以促进有效的多模式融合。然而,受限于数据的可用性,当前的方法在训练这些融合机制方面表现出不足的能力,导致性能不佳。最近,多智能体系统在处理有限数据可用的复杂任务方面表现出了有前景的能力。为此,我们提出了第一个用于ACSR的协作多智能体系统,名为Cued-Agent。它集成了四个专业子智能体:基于多模态大型语言模型的手识别智能体,采用关键帧筛选和唇读手势专家提示策略来解码手部动作;基于预训练Transformer的唇识别智能体,从输入视频中提取唇部特征;手提示解码智能体,以无需训练的方式在推理过程中动态地将手提示与唇部特征相结合;自我纠正的音素到单词智能体,通过语义细化首次实现音素序列到自然语言句子的后处理和端到端转换。为了支持这项研究,我们通过从八名听力受损的参与者中收集数据来扩充现有的普通话CS数据集,建立了一个包含14个主体的混合数据集。大量实验表明,与最先进的方法相比,我们的Cued-Agent在普通和听力受损场景中表现卓越。实施方案可通过https://github.com/DennisHgj/Cued-Agent获取。
论文及项目相关链接
PDF 9 pages
摘要
基于唇读与手势编码的视觉沟通系统Cued Speech(CS),通过AI驱动的方法将CS手势和唇动转化为文本。传统上,手势和唇动之间的时间异步性需要设计复杂的模块进行多模态融合。受数据有限性的限制,当前方法难以充分训练这些融合机制,性能有待提高。近期,多智能体系统在处理有限数据任务时展现出潜力。为此,我们提出首个针对ACSR的协作多智能体系统——Cued-Agent。它集成了四个专业子智能体,包括基于多模态大语言模型的手势识别智能体、基于预训练Transformer的唇识别智能体、训练外的手势提示解码智能体和自我修正的音素到句子的转换智能体。我们扩大了现有的普通话CS数据集,建立了包含14个主体的混合数据集。实验表明,与最新方法相比,我们的Cued-Agent在正常和听力受损场景中的表现均优异。
关键见解
- Cued Speech是一种结合唇读与手势编码的视觉沟通系统,有助于听力受损人士进行交流。
- 自动CS识别(ACSR)旨在将CS手势和唇动转化为文本。
- 传统ACSR面临手势和唇动的时间异步性及数据有限性的挑战。
- 多智能体系统在处理有限数据任务时具有潜力。
- Cued-Agent是首个针对ACSR的协作多智能体系统,集成了多个专业子智能体。
- Cued-Agent在正常和听力受损场景中的表现均优于现有方法。
- 建立了包含14个主体的混合数据集,以支持研究,并提供了在线实施资源。
点此查看论文截图

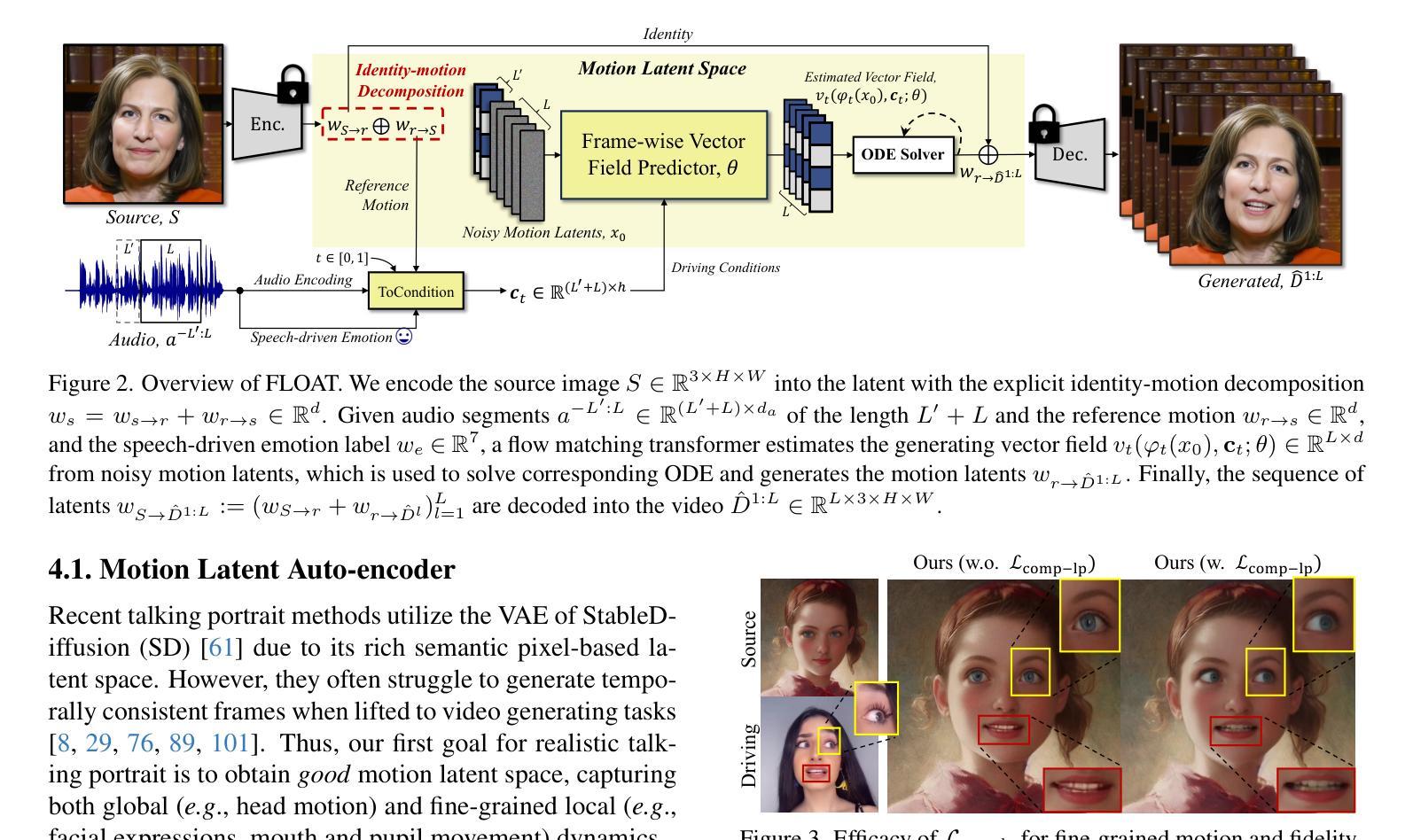
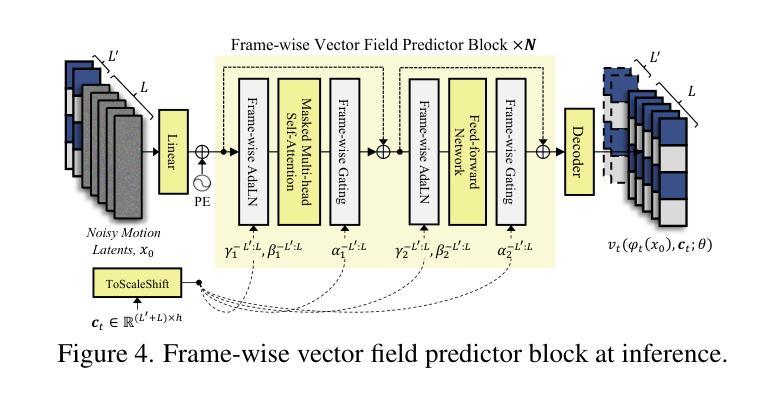
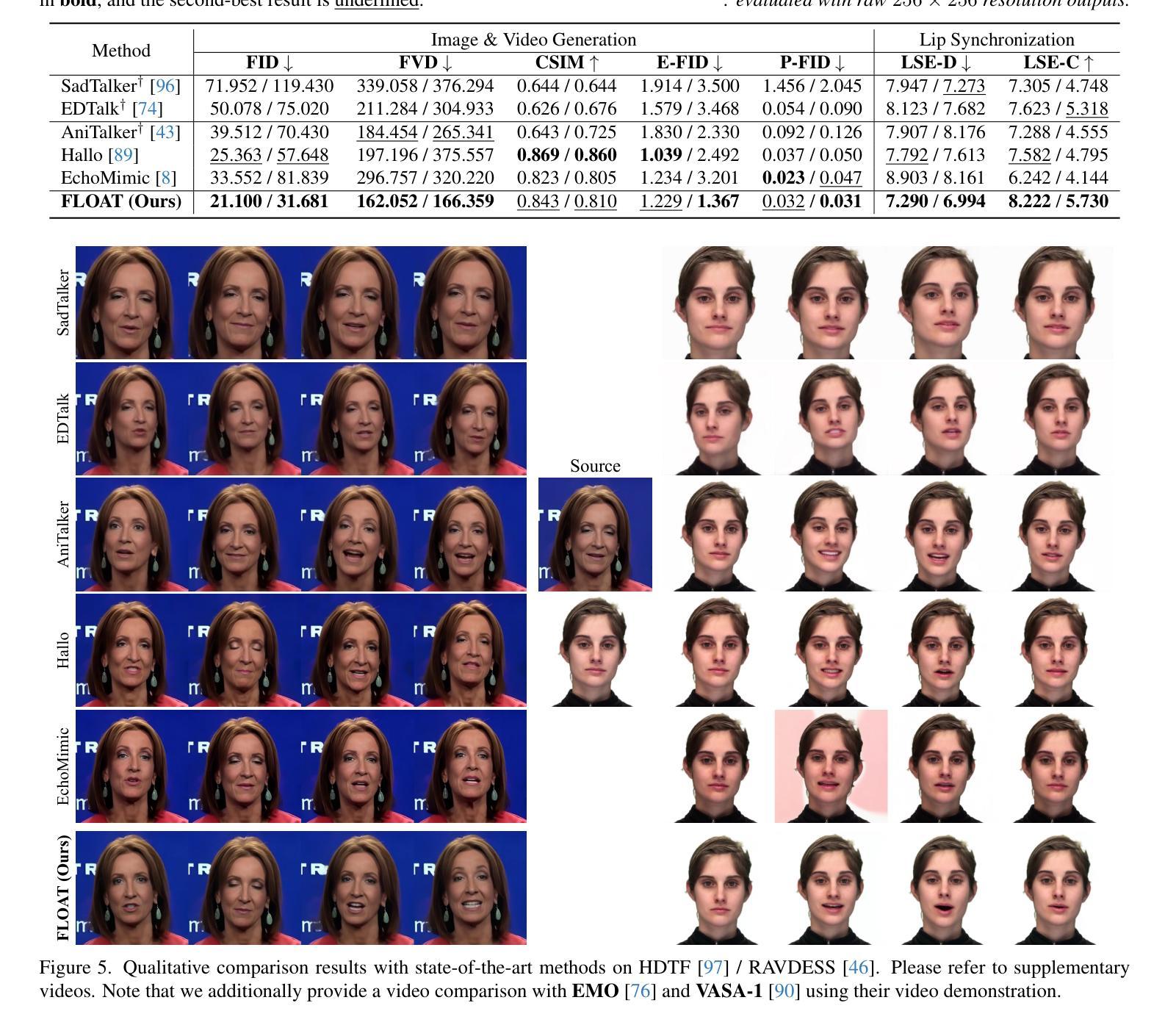
FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
Authors:Taekyung Ki, Dongchan Min, Gyeongsu Chae
With the rapid advancement of diffusion-based generative models, portrait image animation has achieved remarkable results. However, it still faces challenges in temporally consistent video generation and fast sampling due to its iterative sampling nature. This paper presents FLOAT, an audio-driven talking portrait video generation method based on flow matching generative model. Instead of a pixel-based latent space, we take advantage of a learned orthogonal motion latent space, enabling efficient generation and editing of temporally consistent motion. To achieve this, we introduce a transformer-based vector field predictor with an effective frame-wise conditioning mechanism. Additionally, our method supports speech-driven emotion enhancement, enabling a natural incorporation of expressive motions. Extensive experiments demonstrate that our method outperforms state-of-the-art audio-driven talking portrait methods in terms of visual quality, motion fidelity, and efficiency.
随着基于扩散的生成模型的快速发展,肖像图像动画已经取得了显著成果。然而,由于它迭代采样的特性,它在时间一致的视频生成和快速采样方面仍然面临挑战。本文提出了FLOAT,一种基于流匹配生成模型的音频驱动对话肖像视频生成方法。我们利用学习到的正交运动潜在空间,而不是基于像素的潜在空间,实现了时间一致运动的有效生成和编辑。为了实现这一点,我们引入了一个基于变压器的矢量场预测器,并配备了一个有效的帧条件机制。此外,我们的方法支持语音驱动的情感增强,能够实现表情动作的自然融合。大量实验表明,我们的方法在视觉质量、运动保真度和效率方面优于先进的音频驱动对话肖像方法。
论文及项目相关链接
PDF ICCV 2025. Project page: https://deepbrainai-research.github.io/float/
Summary
随着扩散生成模型的快速发展,肖像动画已取得了显著成果,但仍面临视频生成的时序一致性和快速采样挑战。本文提出了基于流匹配生成模型的音频驱动肖像视频生成方法FLOAT。该方法采用学习到的正交运动潜在空间,实现了高效且时序一致的运动生成和编辑。通过引入基于变压器的矢量场预测器和有效的帧条件机制,该方法还支持语音驱动的情感增强,能够自然融入表达性动作。实验表明,该方法在视觉质量、运动保真度和效率方面超越了现有的音频驱动肖像方法。
Key Takeaways
- 扩散生成模型的快速发展推动了肖像动画领域的进步。
- 肖像动画仍面临视频生成的时序一致性和快速采样挑战。
- FLOAT方法采用流匹配生成模型,实现了音频驱动的肖像视频生成。
- FLOAT采用正交运动潜在空间,提高了运动生成和编辑的效率和一致性。
- 通过引入基于变压器的矢量场预测器和帧条件机制,FLOAT支持语音驱动的情感增强。
- 实验表明,FLOAT在视觉质量、运动保真度和效率方面超越了现有方法。
- FLOAT为肖像动画领域提供了一种新的、有效的方法。
点此查看论文截图