⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-05 更新
HiPrune: Training-Free Visual Token Pruning via Hierarchical Attention in Vision-Language Models
Authors:Jizhihui Liu, Feiyi Du, Guangdao Zhu, Niu Lian, Jun Li, Bin Chen
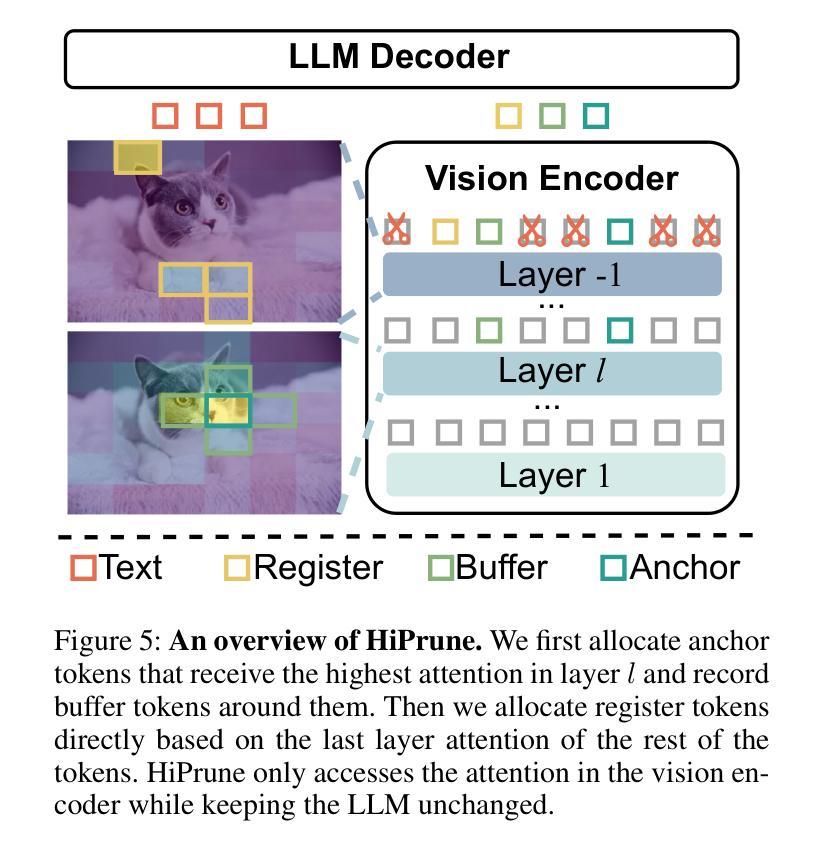
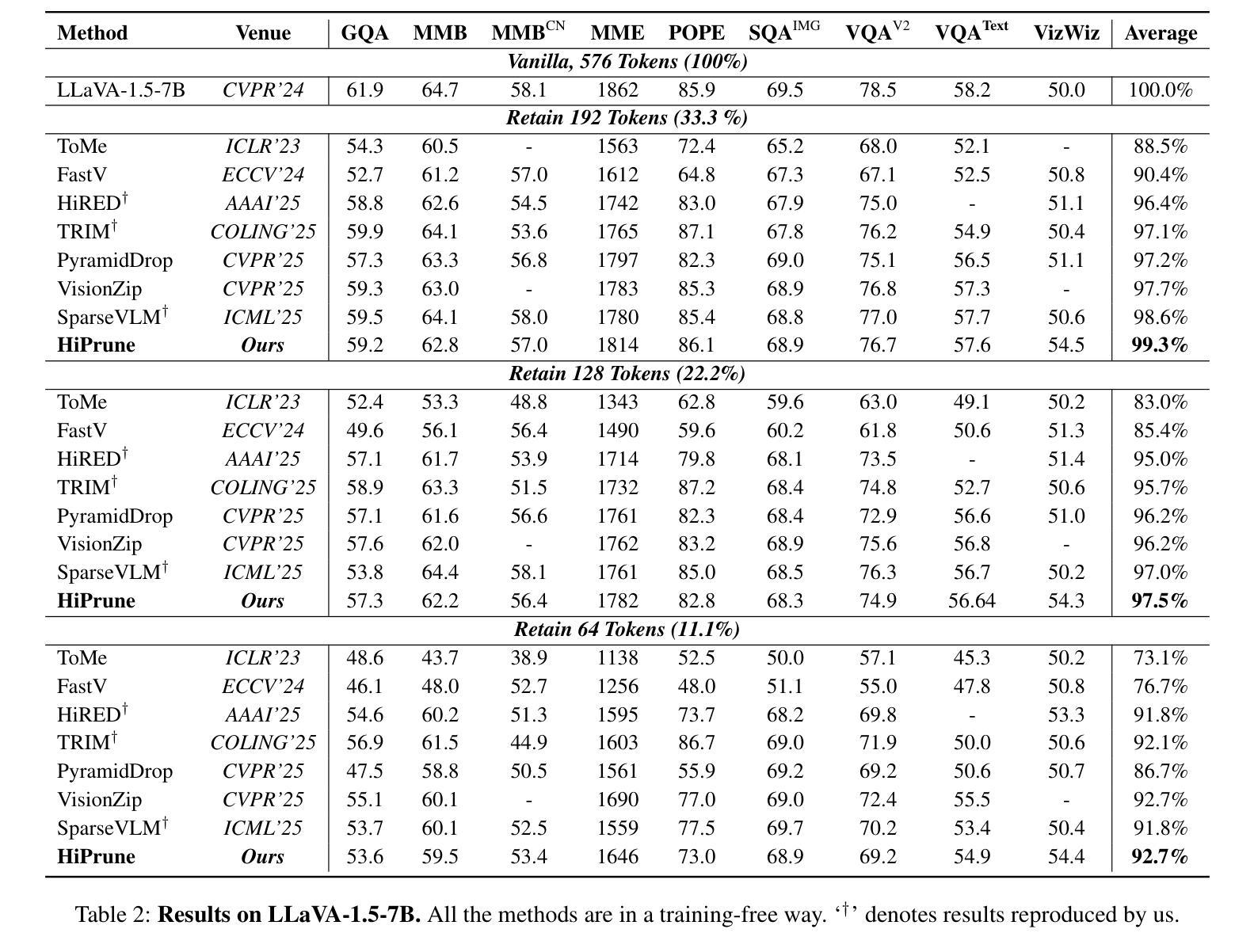
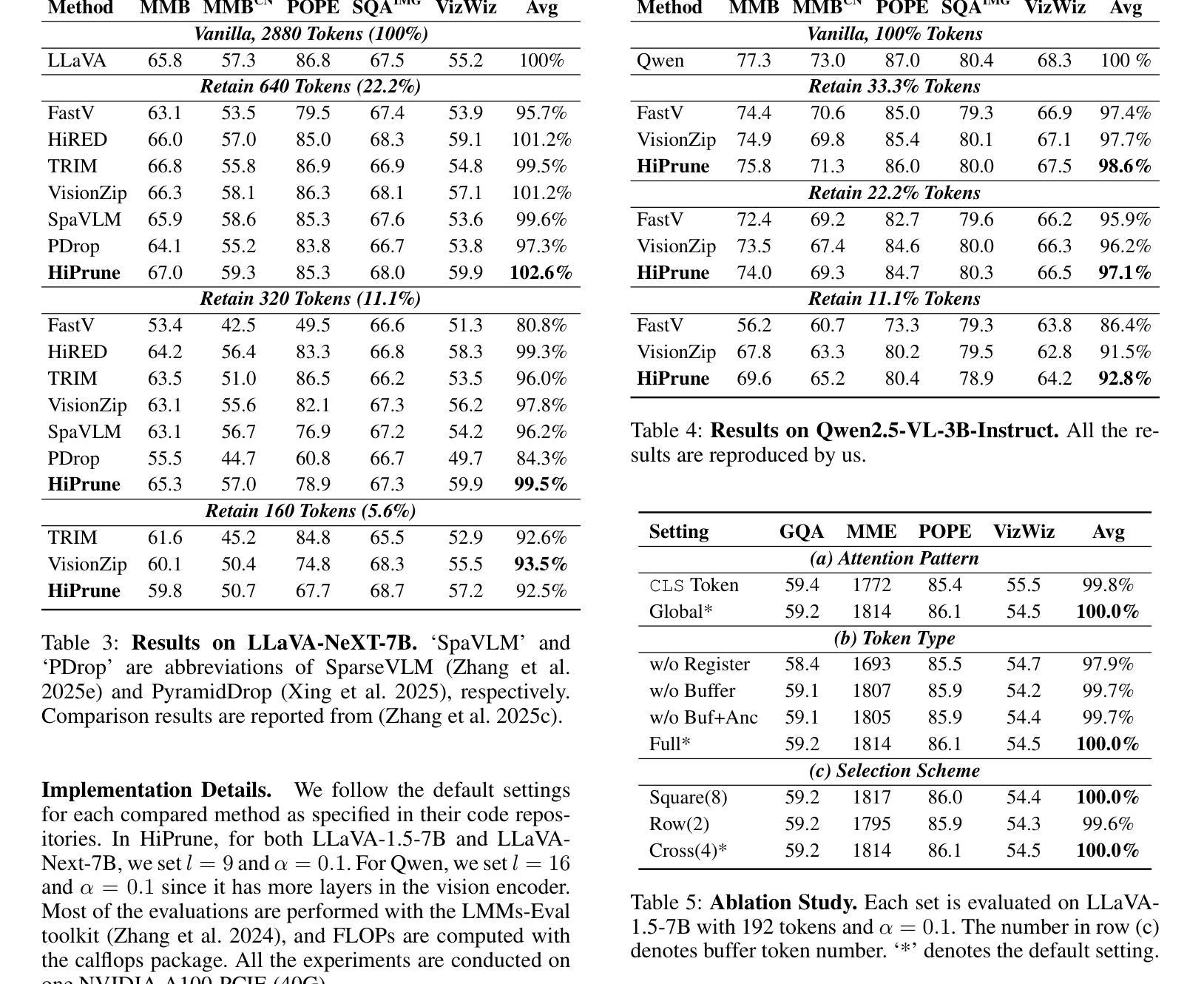
Vision-Language Models (VLMs) encode images into lengthy sequences of visual tokens, leading to excessive computational overhead and limited inference efficiency. While prior efforts prune or merge tokens to address this issue, they often rely on special tokens (e.g., CLS) or require task-specific training, hindering scalability across architectures. In this paper, we propose HiPrune, a training-free and model-agnostic token Pruning framework that exploits the Hierarchical attention structure within vision encoders. We identify that middle layers attend to object-centric regions, while deep layers capture global contextual features. Based on this observation, HiPrune selects three types of informative tokens: (1) Anchor tokens with high attention in object-centric layers, (2) Buffer tokens adjacent to anchors for spatial continuity, and (3) Register tokens with strong attention in deep layers for global summarization. Our method requires no retraining and integrates seamlessly with any ViT-based VLM. Extensive experiments on LLaVA-1.5, LLaVA-NeXT, and Qwen2.5-VL demonstrate that HiPrune achieves state-of-the-art pruning performance, preserving up to 99.3% task accuracy with only 33.3% tokens, and maintaining 99.5% accuracy with just 11.1% tokens. Meanwhile, it reduces inference FLOPs and latency by up to 9$\times$, showcasing strong generalization across models and tasks. Code is available at https://github.com/Danielement321/HiPrune.
视觉语言模型(VLMs)将图像编码为冗长的视觉令牌序列,导致计算开销过大和推理效率低下。虽然之前的努力通过删除或合并令牌来解决这个问题,但它们通常依赖于特殊令牌(例如CLS),或需要进行特定任务的训练,这阻碍了它们在架构之间的可扩展性。在本文中,我们提出了HiPrune,这是一个无需训练且模型无关的令牌删除框架,它利用视觉编码器中的分层注意力结构。我们发现中层关注对象为中心的区域,而深层捕获全局上下文特征。基于此观察,HiPrune选择了三种类型的信息令牌:(1)在对象中心层中具有高注意力的锚定令牌,(2)与锚点相邻的缓冲区令牌以确保空间连续性,以及(3)在深层中具有强烈注意力的寄存器令牌以实现全局摘要。我们的方法无需重新训练,可以无缝集成到任何基于ViT的VLM中。在LLaVA-1.5、LLaVA-NeXT和Qwen2.5-VL上的广泛实验表明,HiPrune达到了先进的删除性能,仅保留33.3%的令牌就能保持高达99.3%的任务准确性,而仅保留11.1%的令牌时,仍能保持99.5%的准确性。同时,它最多可以减少9倍的推理浮点运算量和延迟时间,展示出在模型和任务之间的强大泛化能力。代码可在https://github.com/Danielement321/HiPrune上找到。
论文及项目相关链接
摘要
视觉语言模型(VLMs)将图像编码为冗长的视觉令牌序列,导致计算开销过大和推理效率低下。尽管先前的努力通过删除或合并令牌来解决这个问题,但它们通常依赖于特殊令牌(如CLS令牌),或需要进行特定任务的训练,阻碍了其在不同架构中的可扩展性。本文提出了HiPrune,这是一种无需训练且模型无关的令牌删除框架,它利用视觉编码器中的分层注意力结构。我们发现中层关注对象为中心的区域,而深层捕获全局上下文特征。基于此观察,HiPrune选择了三种类型的具有信息量的令牌:具有对象中心层高注意力的锚定令牌、与锚点相邻的缓冲区令牌以实现空间连续性以及在深层中具有强烈注意力的寄存器令牌以实现全局摘要。我们的方法无需重新训练,可无缝集成到任何基于ViT的VLM中。在LLaVA-1.5、LLaVA-NeXT和Qwen2.5-VL上的大量实验表明,HiPrune达到了最先进的删除性能,在保留高达99.3%的任务准确性的同时仅使用33.3%的令牌,并在仅使用11.1%的令牌时保持99.5%的准确性。同时,它最多可将推理FLOPs和延迟时间减少9倍,展示了在模型和任务之间的强大泛化能力。相关代码可在https://github.com/Danielement321/HiPrune中找到。
要点提炼
- VLMs通过将图像编码为冗长的视觉令牌序列而导致计算开销和推理效率低下。
- 现有方法使用特殊令牌或任务特定训练来解决这一问题,限制了其在不同架构中的适用性。
- 提出了一种无需训练和模型无关的令牌删除框架——HiPrune,利用视觉编码器中的分层注意力结构。
- HiPrune通过观察发现中层关注对象中心区域,深层捕获全局上下文特征来选择关键令牌。
- HiPrune实现了高效的令牌选择,能够在保留高任务准确性的同时大大减少令牌的数目。
- HiPrune具有强大的泛化能力,可无缝集成到任何基于ViT的VLM中,并显著减少推理开销和延迟时间。
点此查看论文截图

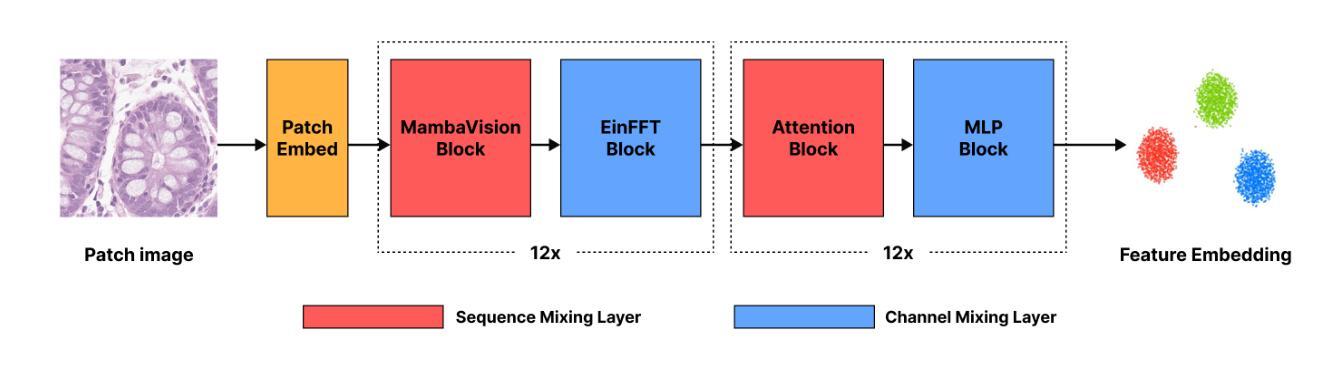
$MV_{Hybrid}$: Improving Spatial Transcriptomics Prediction with Hybrid State Space-Vision Transformer Backbone in Pathology Vision Foundation Models
Authors:Won June Cho, Hongjun Yoon, Daeky Jeong, Hyeongyeol Lim, Yosep Chong
Spatial transcriptomics reveals gene expression patterns within tissue context, enabling precision oncology applications such as treatment response prediction, but its high cost and technical complexity limit clinical adoption. Predicting spatial gene expression (biomarkers) from routine histopathology images offers a practical alternative, yet current vision foundation models (VFMs) in pathology based on Vision Transformer (ViT) backbones perform below clinical standards. Given that VFMs are already trained on millions of diverse whole slide images, we hypothesize that architectural innovations beyond ViTs may better capture the low-frequency, subtle morphological patterns correlating with molecular phenotypes. By demonstrating that state space models initialized with negative real eigenvalues exhibit strong low-frequency bias, we introduce $MV_{Hybrid}$, a hybrid backbone architecture combining state space models (SSMs) with ViT. We compare five other different backbone architectures for pathology VFMs, all pretrained on identical colorectal cancer datasets using the DINOv2 self-supervised learning method. We evaluate all pretrained models using both random split and leave-one-study-out (LOSO) settings of the same biomarker dataset. In LOSO evaluation, $MV_{Hybrid}$ achieves 57% higher correlation than the best-performing ViT and shows 43% smaller performance degradation compared to random split in gene expression prediction, demonstrating superior performance and robustness, respectively. Furthermore, $MV_{Hybrid}$ shows equal or better downstream performance in classification, patch retrieval, and survival prediction tasks compared to that of ViT, showing its promise as a next-generation pathology VFM backbone. Our code is publicly available at: https://github.com/deepnoid-ai/MVHybrid.
空间转录组学揭示了组织内的基因表达模式,为实现精准医疗应用(如预测治疗反应)提供了可能,但其高昂的成本和技术复杂性限制了其在临床的采用。利用常规病理图像预测空间基因表达(生物标志物)提供了一种实用的替代方案。然而,目前基于视觉转换器(ViT)的病理视觉基础模型(VFM)表现尚未达到临床标准。考虑到VFM已经对数百万张不同的全幻灯片图像进行了训练,我们假设超越ViT的架构创新能更好地捕捉与分子表型相关的低频、微妙的形态模式。通过证明状态空间模型在初始化为负实特征值时具有较强的低频偏向性,我们引入了MVHybrid,这是一种结合状态空间模型(SSM)与ViT的混合架构。我们比较了另外五种用于病理VFM的不同架构,所有架构都使用DINOv2自我监督学习方法在相同的结肠癌数据集上进行预训练。我们使用相同的生物标志物数据集的随机分割和留出一研究(LOSO)设置来评估所有预训练模型。在LOSO评估中,MVHybrid相较于表现最佳的ViT实现了57%更高的相关性,并且在基因表达预测中相较于随机分割显示了43%更小的性能下降,分别显示了其卓越的性能和稳健性。此外,MVHybrid在分类、补丁检索和生存预测任务中的下游性能与ViT相比表现相等或更好,显示出其作为下一代病理VFM架构的潜力。我们的代码公开在:https://github.com/deepnoid-ai/MVHybrid。
论文及项目相关链接
PDF Accepted (Oral) in MICCAI 2025 COMPAYL Workshop
Summary
空间转录组学揭示了组织背景下的基因表达模式,为精准医疗应用如治疗反应预测提供了可能。然而,其高昂的成本和技术复杂性限制了其在临床的广泛应用。通过常规病理图像预测空间基因表达(生物标志物)提供了一种实用替代方案。现有的基于视觉转换器(ViT)的医学视觉基础模型(VFMs)在临床标准下的表现并不理想。本研究引入了一种混合模型架构MVHybrid,结合了状态空间模型(SSMs)与ViT,以捕获与分子表型相关的低频、微妙的形态模式。该研究比较了多种不同的病理VFM架构,并在结直肠癌数据集上进行了预训练。在生物标志物数据集上进行的随机分割和保留一项研究(LOSO)评估中,MVHybrid在基因表达预测方面实现了较高的相关性,并表现出优越的稳健性。此外,MVHybrid在分类、补丁检索和生存预测任务中的下游性能优于ViT,显示出作为下一代病理学VFM前景。研究代码已公开可用。
Key Takeaways
- 空间转录组学可揭示组织背景下的基因表达模式,促进精准医疗应用如治疗反应预测的实现。但成本高和技术复杂限制了其在临床的应用。
- 利用常规病理图像预测空间基因表达是一种实用替代方法。然而,现有的基于视觉转换器的医学视觉基础模型表现不佳。
- 研究引入了一种混合模型架构MVHybrid,结合了状态空间模型和视觉转换器,以更好地捕获与分子表型相关的低频、微妙的形态模式。
- MVHybrid在多种病理学VFM架构的比较中表现出优越的性能和稳健性。在生物标志物数据集上的随机分割和保留一项研究的评估中,其相关性较高。
- MVHybrid在分类、补丁检索和生存预测任务中的下游性能优于传统视觉转换器模型。其作为一种新型的病理学视觉基础模型架构展现出了巨大的潜力。
- 研究代码已公开可用,为未来的研究提供了便利。
点此查看论文截图