⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-06 更新
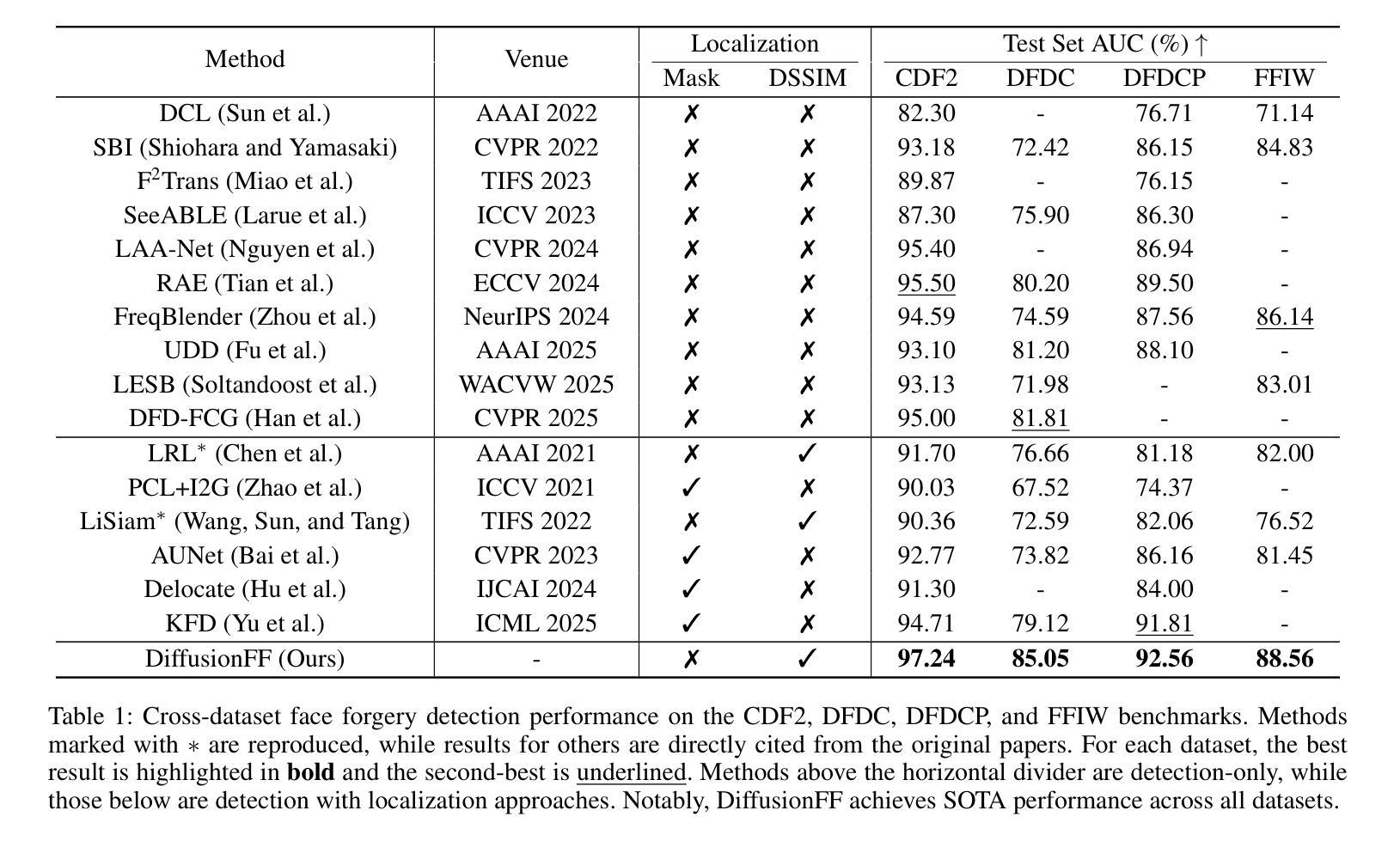
DiffusionFF: Face Forgery Detection via Diffusion-based Artifact Localization
Authors:Siran Peng, Haoyuan Zhang, Li Gao, Tianshuo Zhang, Bao Li, Zhen Lei
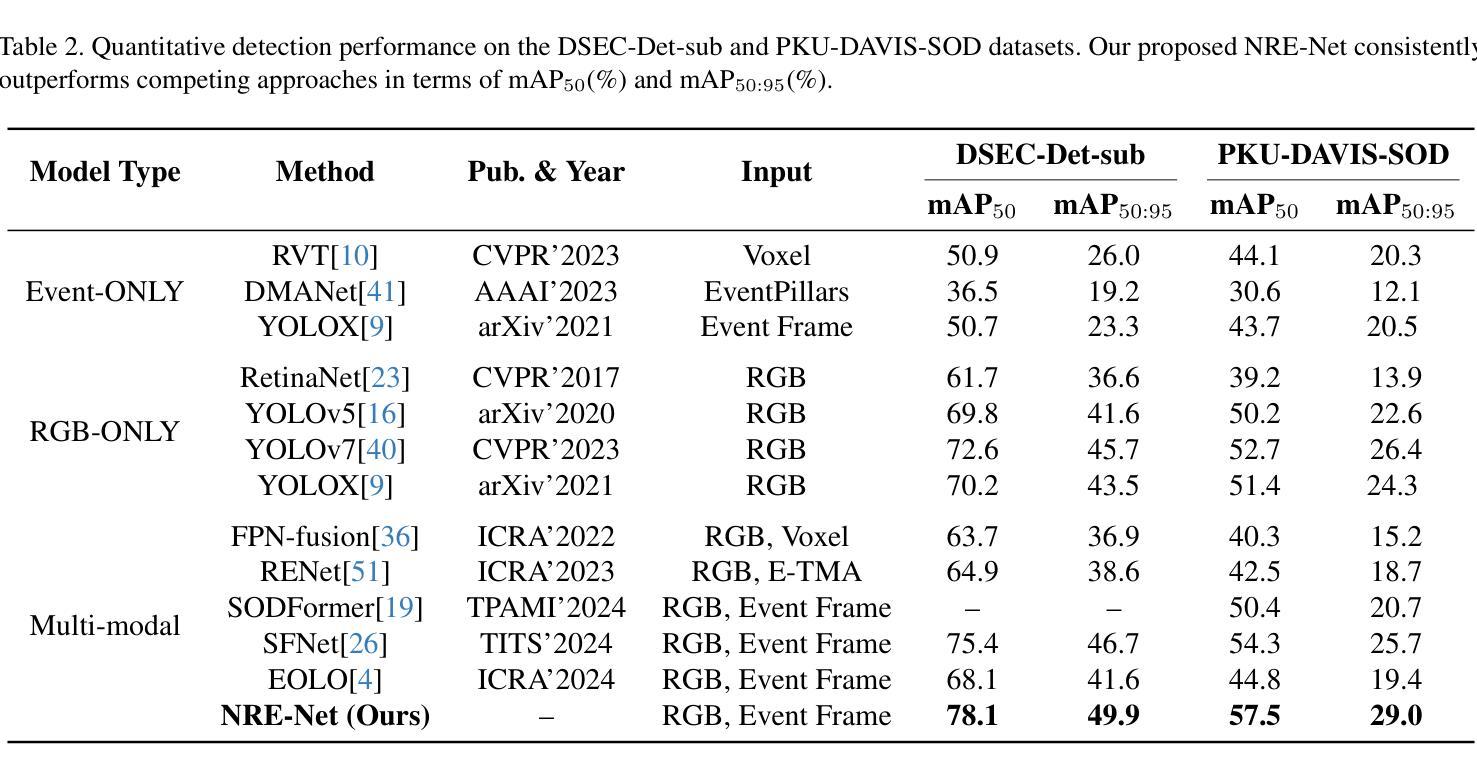
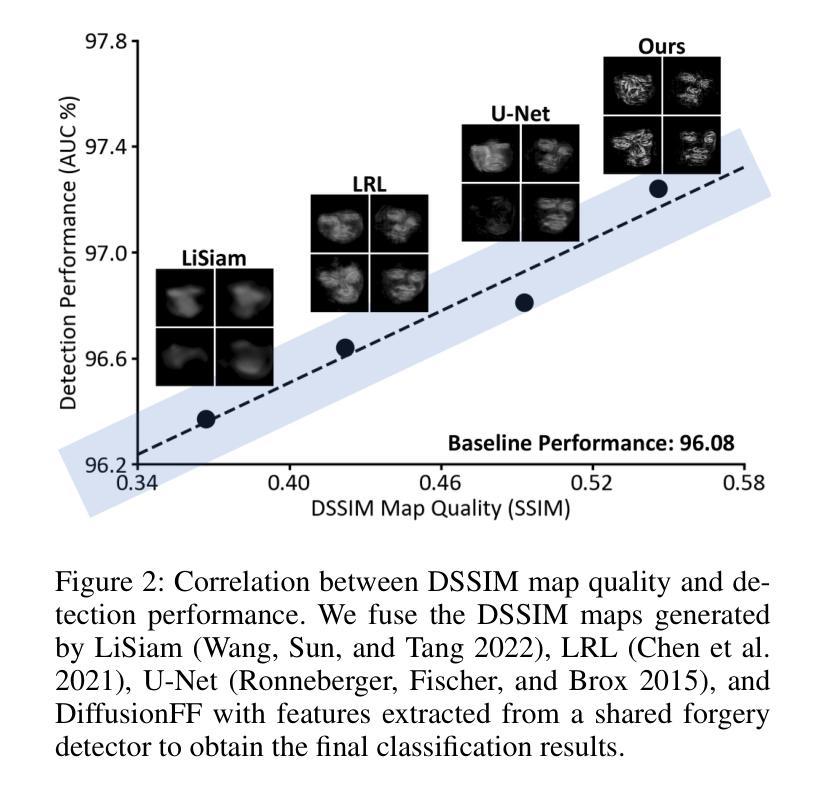
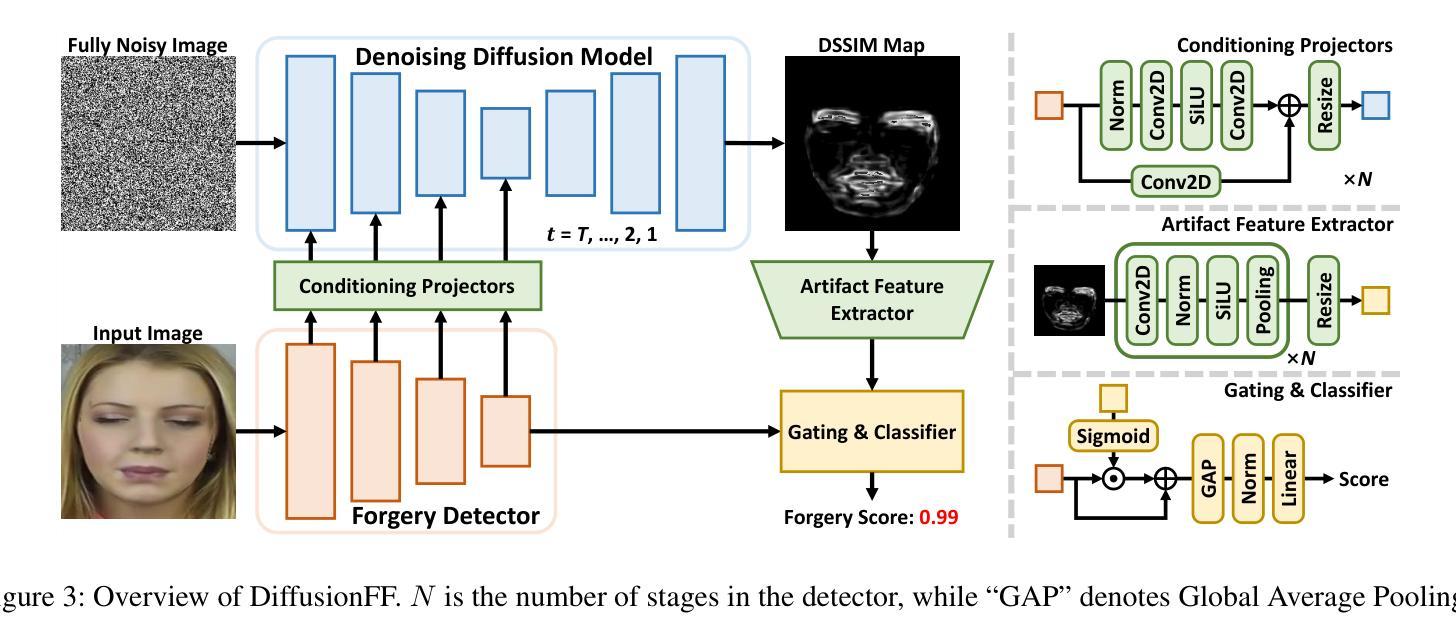
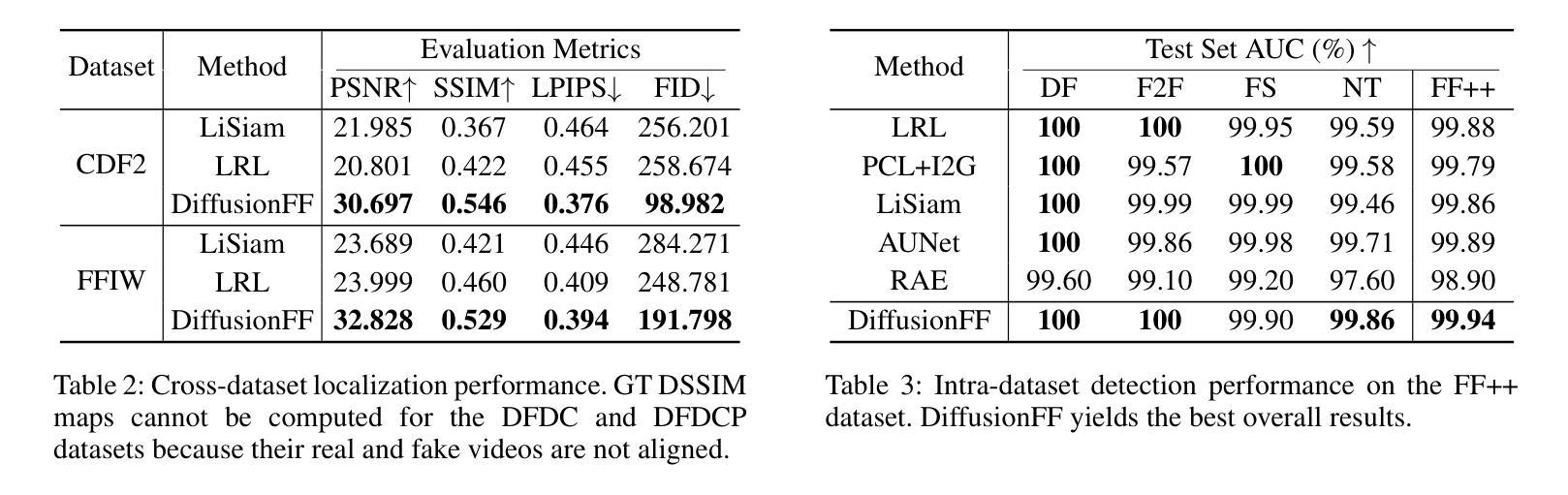
The rapid evolution of deepfake generation techniques demands robust and accurate face forgery detection algorithms. While determining whether an image has been manipulated remains essential, the ability to precisely localize forgery artifacts has become increasingly important for improving model explainability and fostering user trust. To address this challenge, we propose DiffusionFF, a novel framework that enhances face forgery detection through diffusion-based artifact localization. Our method utilizes a denoising diffusion model to generate high-quality Structural Dissimilarity (DSSIM) maps, which effectively capture subtle traces of manipulation. These DSSIM maps are then fused with high-level semantic features extracted by a pretrained forgery detector, leading to significant improvements in detection accuracy. Extensive experiments on both cross-dataset and intra-dataset benchmarks demonstrate that DiffusionFF not only achieves superior detection performance but also offers precise and fine-grained artifact localization, highlighting its overall effectiveness.
随着深度伪造生成技术的快速发展,对鲁棒性和精确性的人脸伪造检测算法的需求也越来越高。确定图像是否被操纵仍然至关重要,但精确定位伪造痕迹的能力在提高模型解释性和增强用户信任方面变得越来越重要。为了应对这一挑战,我们提出了DiffusionFF这一新型框架,它通过基于扩散的伪迹定位技术来提升人脸伪造检测的效果。我们的方法利用去噪扩散模型生成高质量的结构相似性(DSSIM)图,有效地捕捉微妙的操作痕迹。这些DSSIM图然后与由预训练的伪造检测器提取的高级语义特征相融合,从而大大提高了检测精度。跨数据集和内部数据集的基准测试实验表明,DiffusionFF不仅实现了出色的检测性能,而且提供了精确和精细的伪迹定位,凸显了其整体有效性。
论文及项目相关链接
Summary
针对深度伪造技术快速发展的现状,需要鲁棒且精确的人脸伪造检测算法。除了判断图像是否被操纵外,能够精确定位伪造痕迹的能力对于提高模型的可解释性和用户信任度也至关重要。为此,我们提出了DiffusionFF这一新型框架,它通过基于扩散的痕迹定位技术提升了人脸伪造检测的效果。该方法利用去噪扩散模型生成高质量的结构相似性(DSSIM)图,有效捕捉细微的伪造痕迹。随后,这些DSSIM图与预训练伪造检测器提取的高级语义特征相融合,显著提高了检测准确性。跨数据集和内部数据集的广泛实验表明,DiffusionFF不仅实现了卓越的检测性能,而且提供了精确和精细的痕迹定位,凸显了其整体有效性。
Key Takeaways
- 深度伪造技术的快速发展使人脸伪造检测面临挑战。
- 精确定位伪造痕迹对于提高模型的可解释性和用户信任度至关重要。
- DiffusionFF框架通过基于扩散的痕迹定位技术提升人脸伪造检测效果。
- DiffusionFF利用去噪扩散模型生成高质量的结构相似性(DSSIM)图,捕捉细微的伪造痕迹。
- DSSIM图与预训练伪造检测器的高级语义特征融合,提高了检测准确性。
- 跨数据集和内部数据集的广泛实验证明DiffusionFF实现了卓越的检测性能。
点此查看论文截图


DisFaceRep: Representation Disentanglement for Co-occurring Facial Components in Weakly Supervised Face Parsing
Authors:Xiaoqin Wang, Xianxu Hou, Meidan Ding, Junliang Chen, Kaijun Deng, Jinheng Xie, Linlin Shen
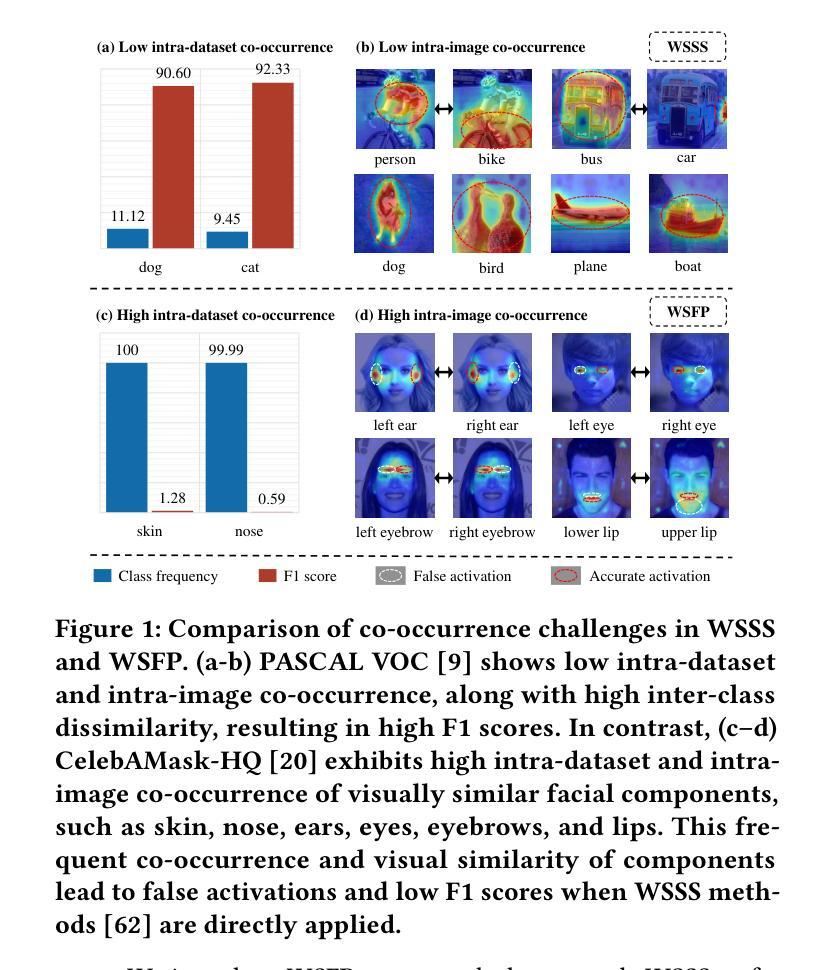
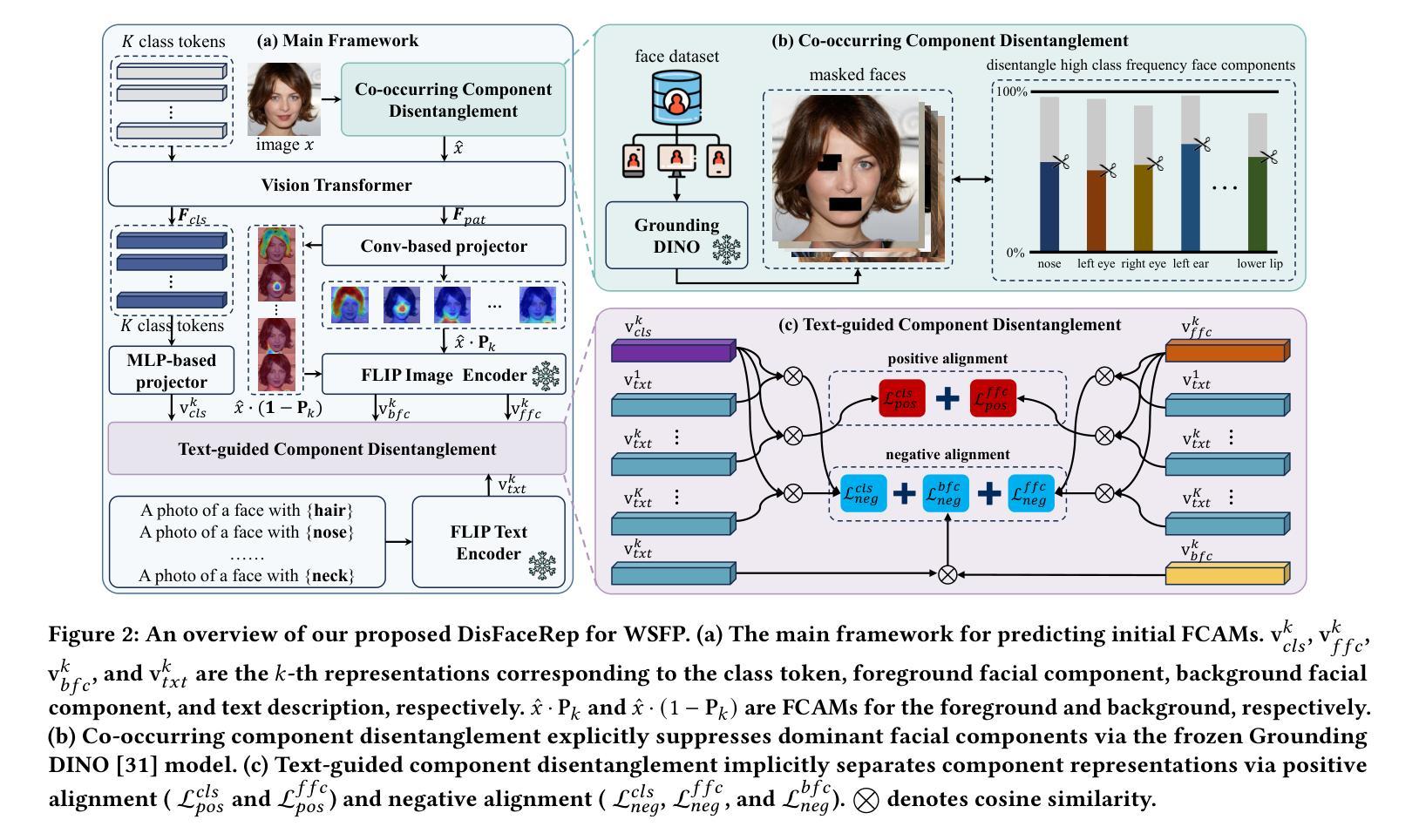
Face parsing aims to segment facial images into key components such as eyes, lips, and eyebrows. While existing methods rely on dense pixel-level annotations, such annotations are expensive and labor-intensive to obtain. To reduce annotation cost, we introduce Weakly Supervised Face Parsing (WSFP), a new task setting that performs dense facial component segmentation using only weak supervision, such as image-level labels and natural language descriptions. WSFP introduces unique challenges due to the high co-occurrence and visual similarity of facial components, which lead to ambiguous activations and degraded parsing performance. To address this, we propose DisFaceRep, a representation disentanglement framework designed to separate co-occurring facial components through both explicit and implicit mechanisms. Specifically, we introduce a co-occurring component disentanglement strategy to explicitly reduce dataset-level bias, and a text-guided component disentanglement loss to guide component separation using language supervision implicitly. Extensive experiments on CelebAMask-HQ, LaPa, and Helen demonstrate the difficulty of WSFP and the effectiveness of DisFaceRep, which significantly outperforms existing weakly supervised semantic segmentation methods. The code will be released at \href{https://github.com/CVI-SZU/DisFaceRep}{\textcolor{cyan}{https://github.com/CVI-SZU/DisFaceRep}}.
面部解析旨在将面部图像分割为关键组件,如眼睛、嘴唇和眉毛。尽管现有方法依赖于密集的像素级注释,但获取这些注释的成本高昂且劳动密集型。为了降低注释成本,我们引入了弱监督面部解析(WSFP),这是一个新的任务设置,它仅使用弱监督(如图像级标签和自然语言描述)执行密集的面部组件分割。WSFP面临独特的挑战,因为面部组件的高共现和视觉相似性导致激活模糊和解析性能下降。为了解决这一问题,我们提出了DisFaceRep,一个表示分离框架,旨在通过显式机制和隐式机制分离共现的面部组件。具体来说,我们引入了一种共现组件分离策略,以明确减少数据集级别的偏见,以及一种文本引导组件分离损失,以利用语言监督隐式地引导组件分离。在CelebAMask-HQ、LaPa和Helen上的大量实验证明了WSFP的难度以及DisFaceRep的有效性,后者显著优于现有的弱监督语义分割方法。代码将在https://github.com/CVI-SZU/DisFaceRep上发布。
论文及项目相关链接
PDF Accepted by ACM MM 2025
Summary
面部解析旨在将面部图像分割为眼睛、嘴唇、眉毛等关键组件。现有方法依赖密集像素级注释,但获取这些注释成本高昂且费时。为了减少标注成本,我们引入了弱监督面部解析(WSFP)这一新任务设置,它仅使用弱监督(如图像级标签和自然语言描述)即可执行密集面部组件分割。WSFP面临面部组件高共现和视觉相似性带来的独特挑战,导致激活模糊和解析性能下降。为了解决这一问题,我们提出了DisFaceRep,一种表示分离框架,旨在通过显式机制和隐式机制分离共现的面部组件。我们在减少数据集级别偏见和用语言监督引导组件分离方面提出了策略。在CelebAMask-HQ、LaPa和Helen上的实验证明了WSFP的难度以及DisFaceRep的有效性,它显著优于现有的弱监督语义分割方法。
Key Takeaways
- 面部解析的目标是分割面部图像的关键组件。
- 现有方法依赖密集像素级注释,但获取这些注释成本高昂。
- 为了降低标注成本,引入了弱监督面部解析(WSFP)这一新任务设置。
- WSFP面临面部组件高共现和视觉相似性带来的挑战。
- 提出了DisFaceRep框架来分离共现的面部组件,包括显式机制和隐式机制。
- DisFaceRep通过减少数据集级别偏见和引导组件分离策略来解决WSFP的挑战。
点此查看论文截图


Survivability of Backdoor Attacks on Unconstrained Face Recognition Systems
Authors:Quentin Le Roux, Yannick Teglia, Teddy Furon, Philippe Loubet-Moundi, Eric Bourbao
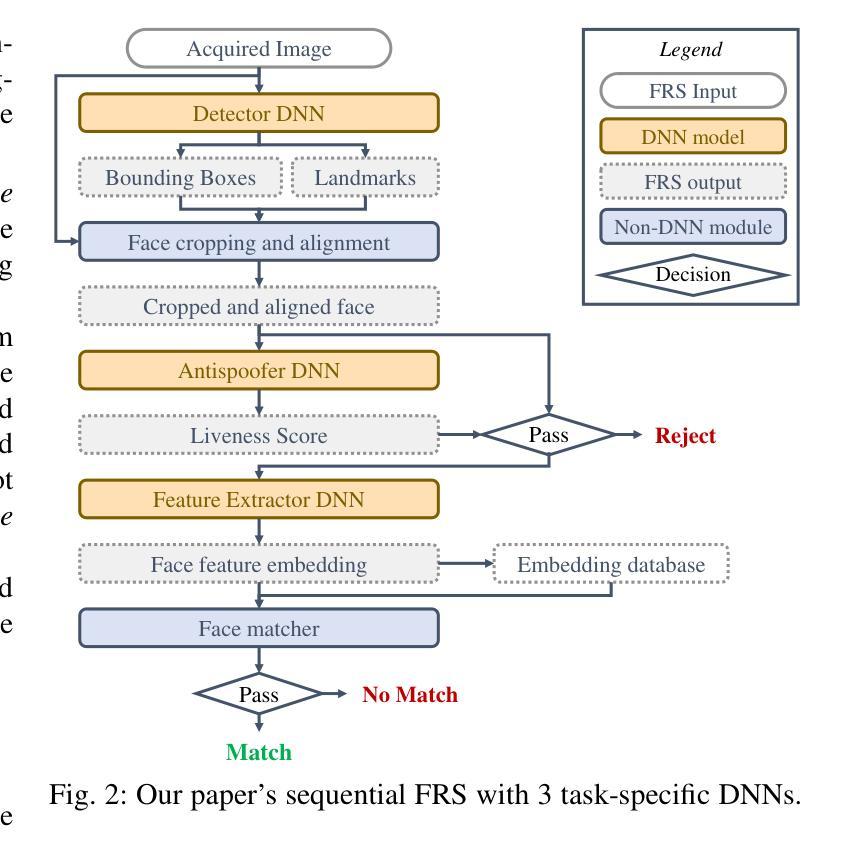
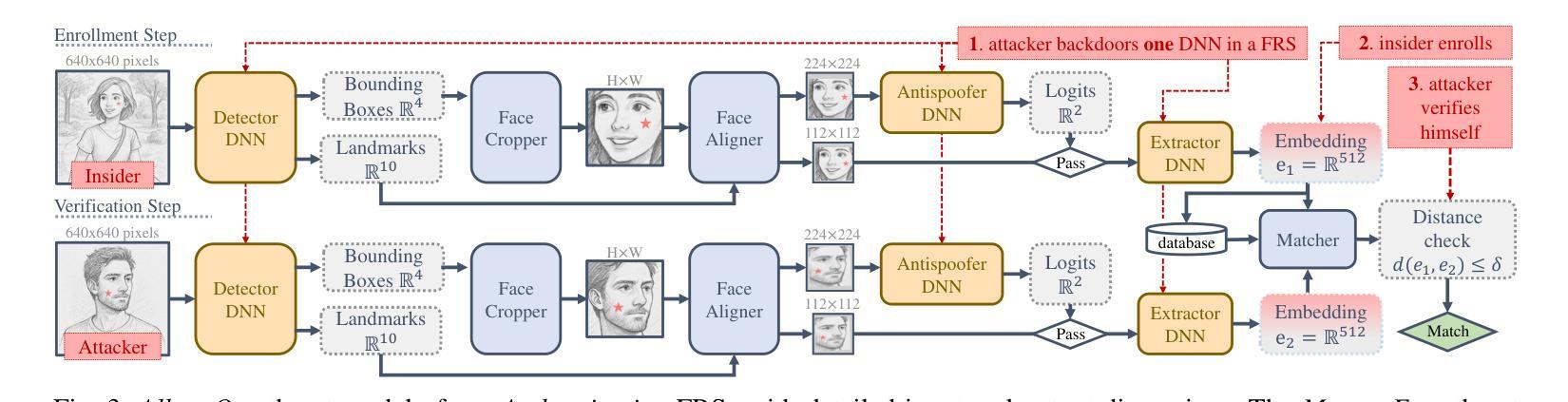
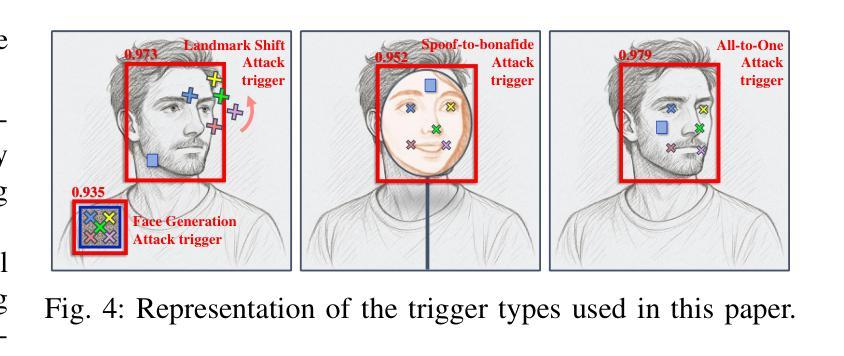
The widespread use of deep learning face recognition raises several security concerns. Although prior works point at existing vulnerabilities, DNN backdoor attacks against real-life, unconstrained systems dealing with images captured in the wild remain a blind spot of the literature. This paper conducts the first system-level study of backdoors in deep learning-based face recognition systems. This paper yields four contributions by exploring the feasibility of DNN backdoors on these pipelines in a holistic fashion. We demonstrate for the first time two backdoor attacks on the face detection task: face generation and face landmark shift attacks. We then show that face feature extractors trained with large margin losses also fall victim to backdoor attacks. Combining our models, we then show using 20 possible pipeline configurations and 15 attack cases that a single backdoor enables an attacker to bypass the entire function of a system. Finally, we provide stakeholders with several best practices and countermeasures.
深度学习面部识别的广泛应用引发了若干安全问题。尽管早期的研究指出了现有的漏洞,但针对真实、无约束的系统(处理野外拍摄图像)的深度神经网络(DNN)后门攻击仍是文献中的盲点。本文对基于深度学习的面部识别系统中的后门进行了首次系统级别的研究。通过全面探索DNN后门在这些管道上的可行性,本文产生了四项贡献。我们首次展示了面部检测任务中的两种后门攻击:面部生成和面部地标转移攻击。然后,我们证明了使用大边界损失训练的面部特征提取器也会受到后门攻击的影响。通过结合我们的模型,然后使用20种可能的管道配置和15种攻击情况,我们证明了一个单一的后门可以使攻击者绕过系统的整个功能。最后,我们向利益相关者提供了若干最佳实践和对策。
论文及项目相关链接
摘要
人脸识别领域中深度学习的广泛应用引发了诸多安全问题。尽管先前的研究指出了存在的漏洞,但针对真实环境中的无约束系统(处理野外拍摄的图像)的深度学习神经网络后门攻击仍是文献中的盲点。本文对深度学习人脸识别系统中的后门进行了首次系统级别的研究,通过全面探索神经网络后门在这些管道上的可行性,得出了四项贡献。我们首次展示了针对人脸识别任务的两种后门攻击:人脸生成和人脸关键点偏移攻击。我们还证明,使用大间隔损失训练的人脸特征提取器也会受到后门攻击的影响。通过结合我们的模型,我们在20种可能的管道配置和15种攻击案例中展示了,单个后门能够使攻击者绕过系统的全部功能。最后,我们为利益相关者提供了若干最佳实践和对策。
要点
- 深度学习人脸识别广泛应用带来安全风险。
- 针对真实环境中无约束系统处理野外拍摄图像存在后门攻击盲点。
- 对深度学习人脸识别系统的后门进行了首次系统级别研究。
- 展示了两种针对人脸识别任务的后门攻击方式:人脸生成和人脸关键点偏移攻击。
- 人脸特征提取器使用大间隔损失训练也会受到后门攻击影响。
- 单个后门能绕过人脸识别系统的全部功能。
点此查看论文截图