⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-06 更新
Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos
Authors:Laura Pedrouzo-Rodriguez, Pedro Delgado-DeRobles, Luis F. Gomez, Ruben Tolosana, Ruben Vera-Rodriguez, Aythami Morales, Julian Fierrez
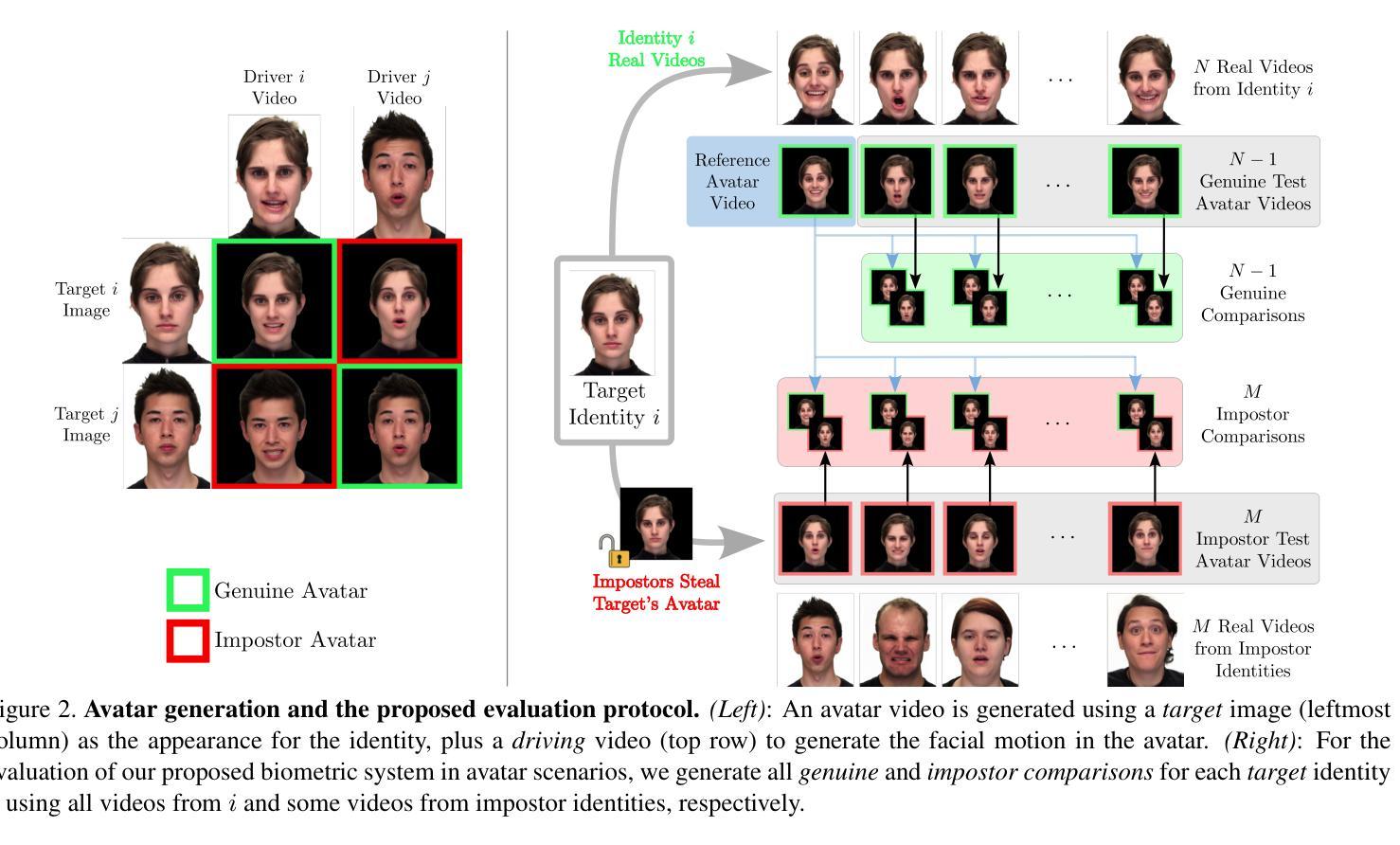
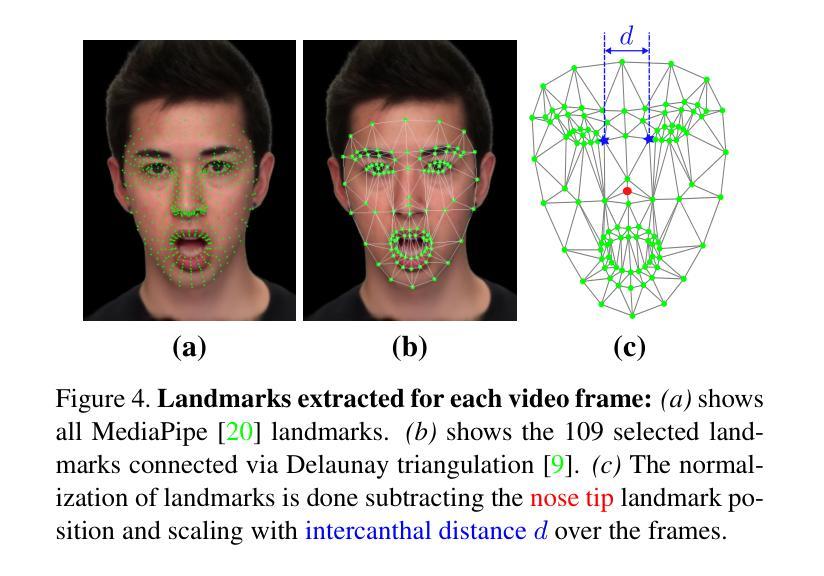
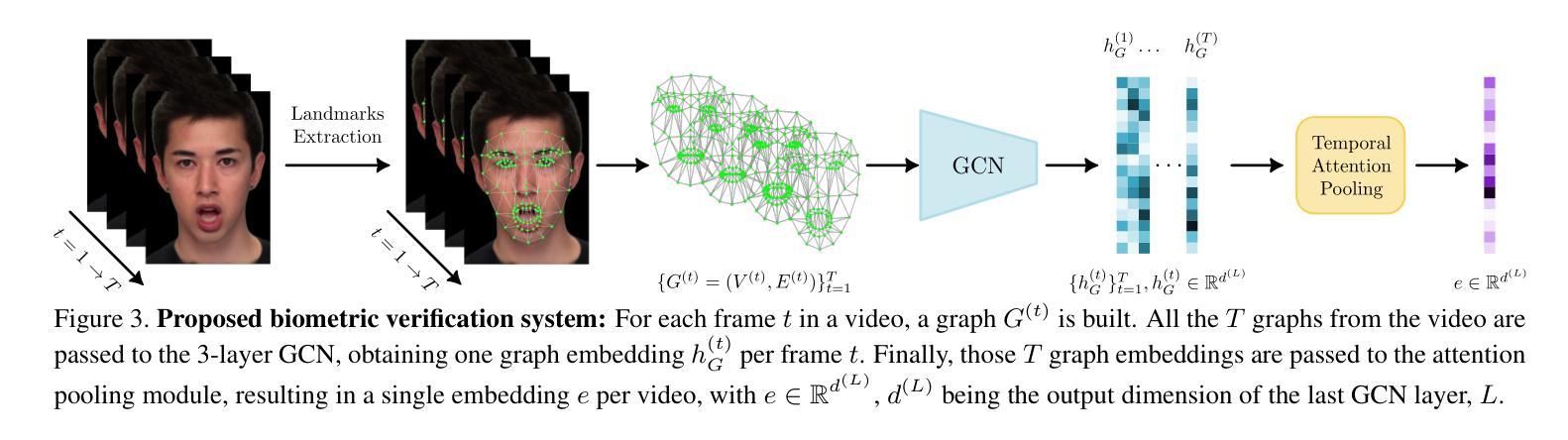
Photorealistic talking-head avatars are becoming increasingly common in virtual meetings, gaming, and social platforms. These avatars allow for more immersive communication, but they also introduce serious security risks. One emerging threat is impersonation: an attacker can steal a user’s avatar, preserving his appearance and voice, making it nearly impossible to detect its fraudulent usage by sight or sound alone. In this paper, we explore the challenge of biometric verification in such avatar-mediated scenarios. Our main question is whether an individual’s facial motion patterns can serve as reliable behavioral biometrics to verify their identity when the avatar’s visual appearance is a facsimile of its owner. To answer this question, we introduce a new dataset of realistic avatar videos created using a state-of-the-art one-shot avatar generation model, GAGAvatar, with genuine and impostor avatar videos. We also propose a lightweight, explainable spatio-temporal Graph Convolutional Network architecture with temporal attention pooling, that uses only facial landmarks to model dynamic facial gestures. Experimental results demonstrate that facial motion cues enable meaningful identity verification with AUC values approaching 80%. The proposed benchmark and biometric system are available for the research community in order to bring attention to the urgent need for more advanced behavioral biometric defenses in avatar-based communication systems.
逼真的人脸虚拟角色在虚拟会议、游戏和社交平台中越来越常见。这些虚拟角色允许更沉浸式的交流,但同时也带来了严重的安全风险。一个新兴威胁是伪装:攻击者可以窃取用户的虚拟角色,保留其外观和声音,仅凭视觉或听觉几乎无法检测到其欺诈使用。在本文中,我们探讨了这种虚拟角色介导场景中的生物识别技术挑战。我们的问题是当虚拟角色的外观与主人相符时,个人的面部动作模式是否可以作为可靠的行为生物特征来验证身份。为了回答这个问题,我们使用最先进的单镜头虚拟角色生成模型GAGAvatar创建了真实虚拟角色视频数据集,其中包含真实和假冒的虚拟角色视频。我们还提出了一种轻便且可解释的时空图卷积网络架构,该架构具有时间注意力池化功能,仅使用面部地标来模拟动态面部动作。实验结果表明,面部运动线索能够实现有意义的身份验证,AUC值接近80%。所提出的基准测试和生物识别系统可供研究界使用,旨在提醒人们关注基于虚拟角色的通信系统中更高级别的行为生物识别防御的紧迫需求。
论文及项目相关链接
PDF Accepted at the IEEE International Joint Conference on Biometrics (IJCB 2025)
Summary
这篇论文探讨了虚拟世界中身份冒充的问题,尤其是在逼真的全动态头像领域。文章提出了一种基于面部运动模式的行为生物识别技术,以验证虚拟头像用户的真实身份。研究引入了一个新数据集,并提出了一种轻量级、可解释的时空图卷积网络架构,该架构利用面部地标模拟动态面部表情。实验结果表明,面部运动线索可用于有效的身份验证。此技术的出现对于应对虚拟世界中日益严重的身份冒充问题具有重要意义。
Key Takeaways
以下是关键见解的要点:
- 虚拟世界中逼真的全动态头像日益普及,引发了身份冒充的安全风险。
- 文章聚焦于面部运动模式作为行为生物识别技术来验证虚拟头像用户的真实身份。
- 研究引入了一个新数据集,包含真实和假冒的头像视频,用于验证身份识别技术。
- 提出了一种基于时空图卷积网络的轻量级身份验证系统架构,利用面部地标进行动态面部表情建模。
- 实验结果显示,基于面部运动线索的身份验证效果良好,AUC值接近80%。
- 此技术的引入对于增强虚拟世界的身份验证安全性至关重要。
点此查看论文截图

MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction
Authors:Zijian Dong, Longteng Duan, Jie Song, Michael J. Black, Andreas Geiger
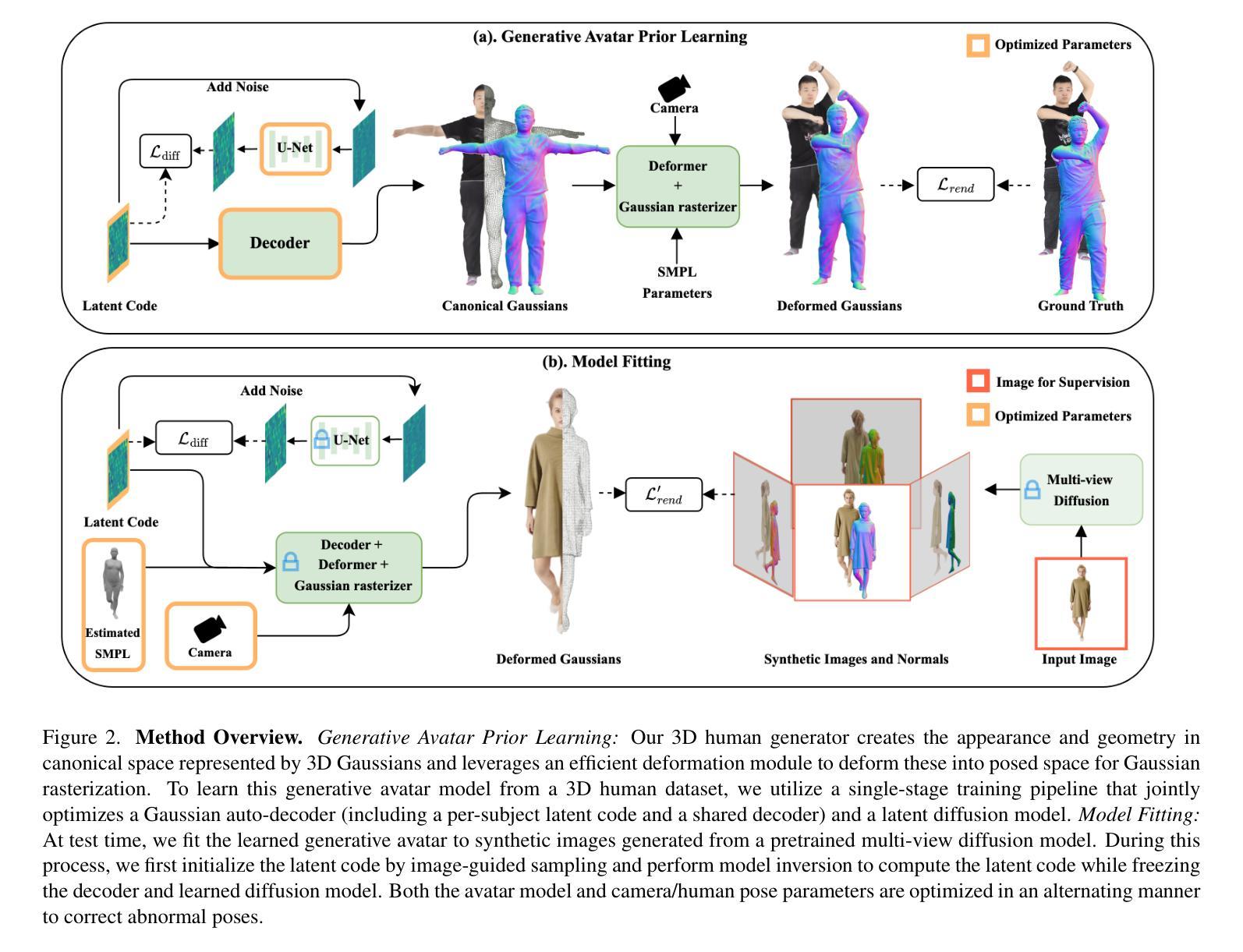
We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to limited 3D training data, such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as model inversion by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides an initialization for model fitting, enforces 3D regularization, and helps in refining pose. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable. For code, see https:// zj-dong.github.io/ MoGA/.
我们提出了一种新型方法MoGA,能够从单视角图像重建高保真3D高斯化身。主要挑战在于推断出未观察到的外观和几何细节,同时确保3D一致性和真实性。之前的大多数方法都依赖于2D扩散模型来合成未观察到的视图,然而,这些生成的视图稀疏且不一致,导致3D伪影和模糊的外观。为了解决这些局限性,我们利用生成化身模型,通过从学习的先验分布中采样变形高斯数据来生成多样化的3D化身。由于3D训练数据有限,仅使用这样的3D模型无法捕获未观察身份的所有图像细节。因此,我们将其整合为先验,通过将输入图像投影到其潜在空间并施加额外的3D外观和几何约束来确保3D一致性。我们的新方法将高斯化身的创建公式化为模型反演,通过将生成的化身拟合到来自2D扩散模型的合成视图来实现。生成的化身为模型拟合提供了初始化,实施了3D正则化,并有助于优化姿势。实验表明,我们的方法超越了最新技术并在真实场景中具有很好的通用性。我们的高斯化身本质上是可动画的。有关代码,请参阅https://zj-dong.github.io/MoGA/。
论文及项目相关链接
PDF ICCV 2025 (Highlight), Project Page: https://zj-dong.github.io/MoGA/
Summary
基于单视图图像,MoGA方法可以重建出高保真度的三维高斯化身。它通过采用生成性化身模型来克服现有方法的不足,并通过模型拟合来创建高斯化身,实现三维一致性并强化现实感。这种方法适用于重建现实世界场景,且重建的化身具有动画表现力。具体细节和代码可参见相关网站。
Key Takeaways
- MoGA是一种基于单视图图像重建高保真三维高斯化身的新方法。
- 该方法主要挑战在于推断出隐藏的外观和几何细节,同时确保三维一致性和真实性。
- 与大多数依赖二维扩散模型的方法相比,MoGA采用生成性化身模型,通过从学习到的先验分布中采样变形高斯来生成多样化的三维化身。
- 由于缺乏三维训练数据,单一的模型无法捕捉所有未见面孔的图像细节。因此,MoGA将其作为一种先验,将输入图像投影到其潜在空间,并施加额外的三维外观和几何约束。
- MoGA将高斯化身创建公式化为模型反求问题,通过拟合生成化身来合成二维扩散模型的合成视图。
- 生成性化身为模型拟合提供了初始化,并强制执行三维正则化和姿态细化。
点此查看论文截图


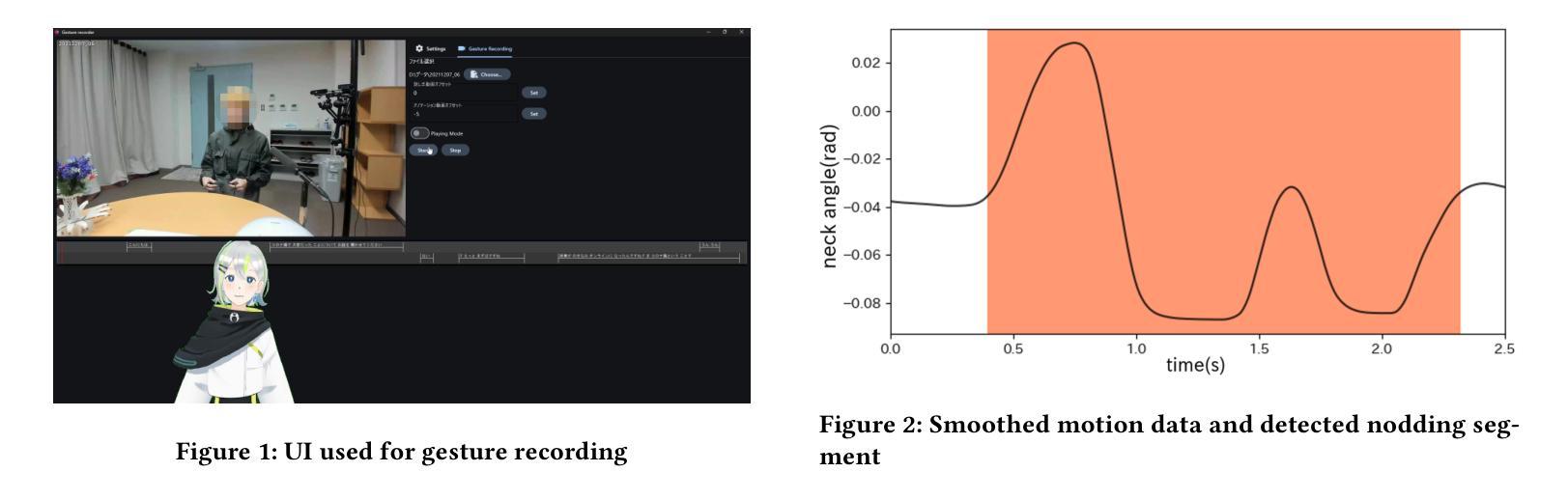
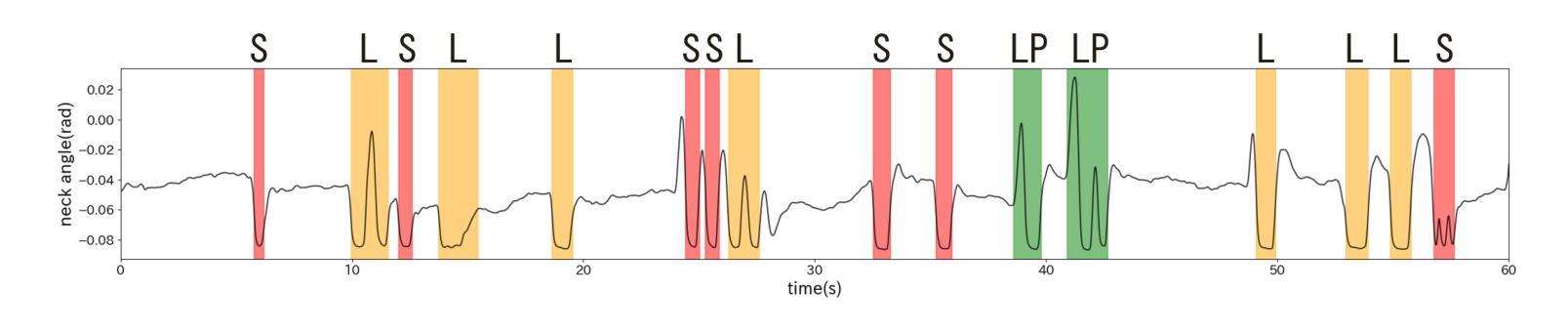
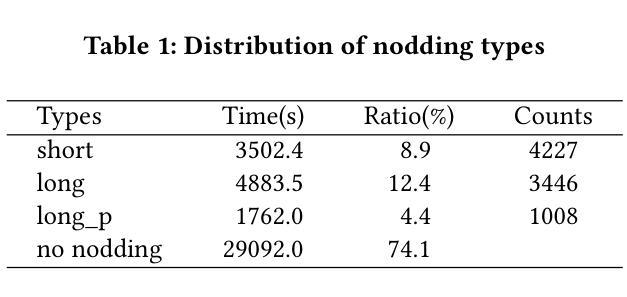
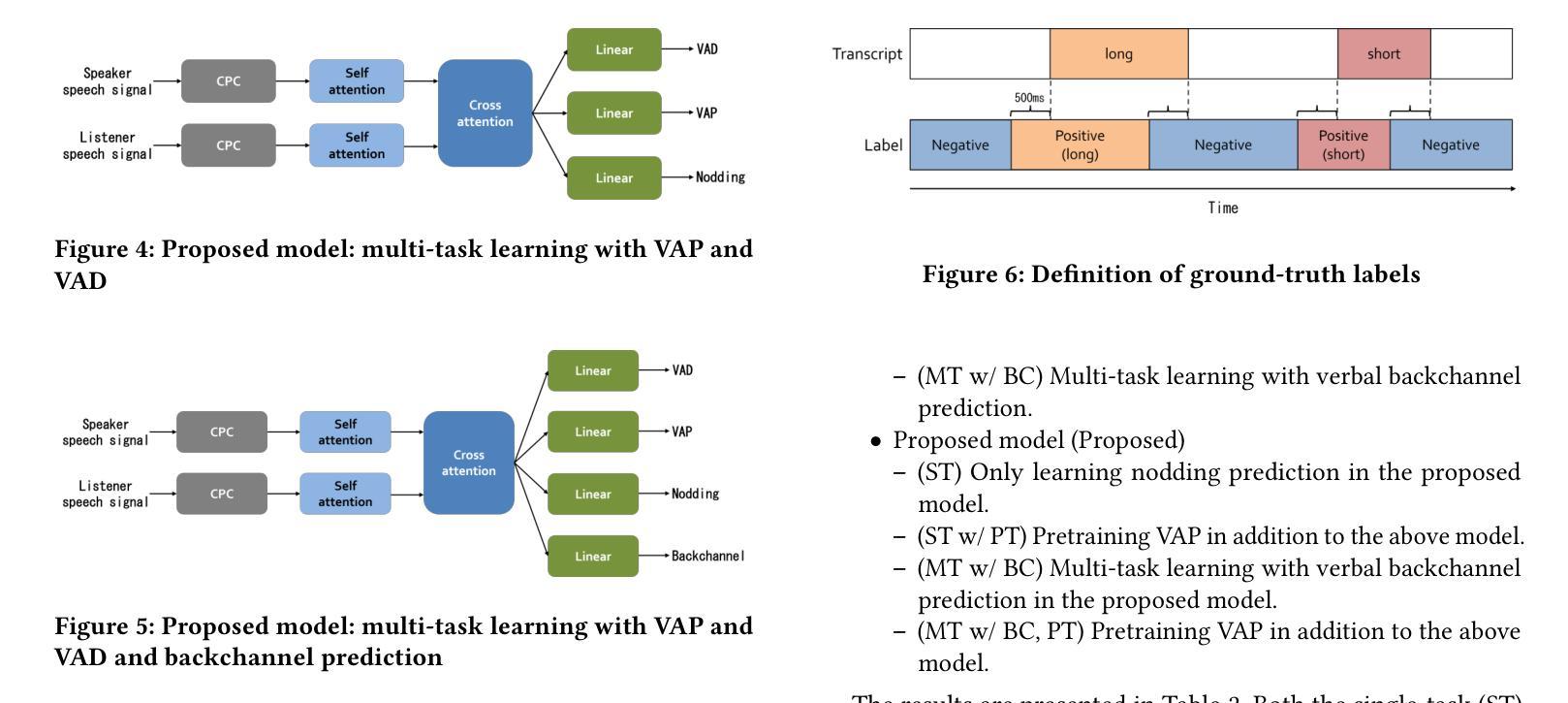
Real-time Generation of Various Types of Nodding for Avatar Attentive Listening System
Authors:Kazushi Kato, Koji Inoue, Divesh Lala, Keiko Ochi, Tatsuya Kawahara
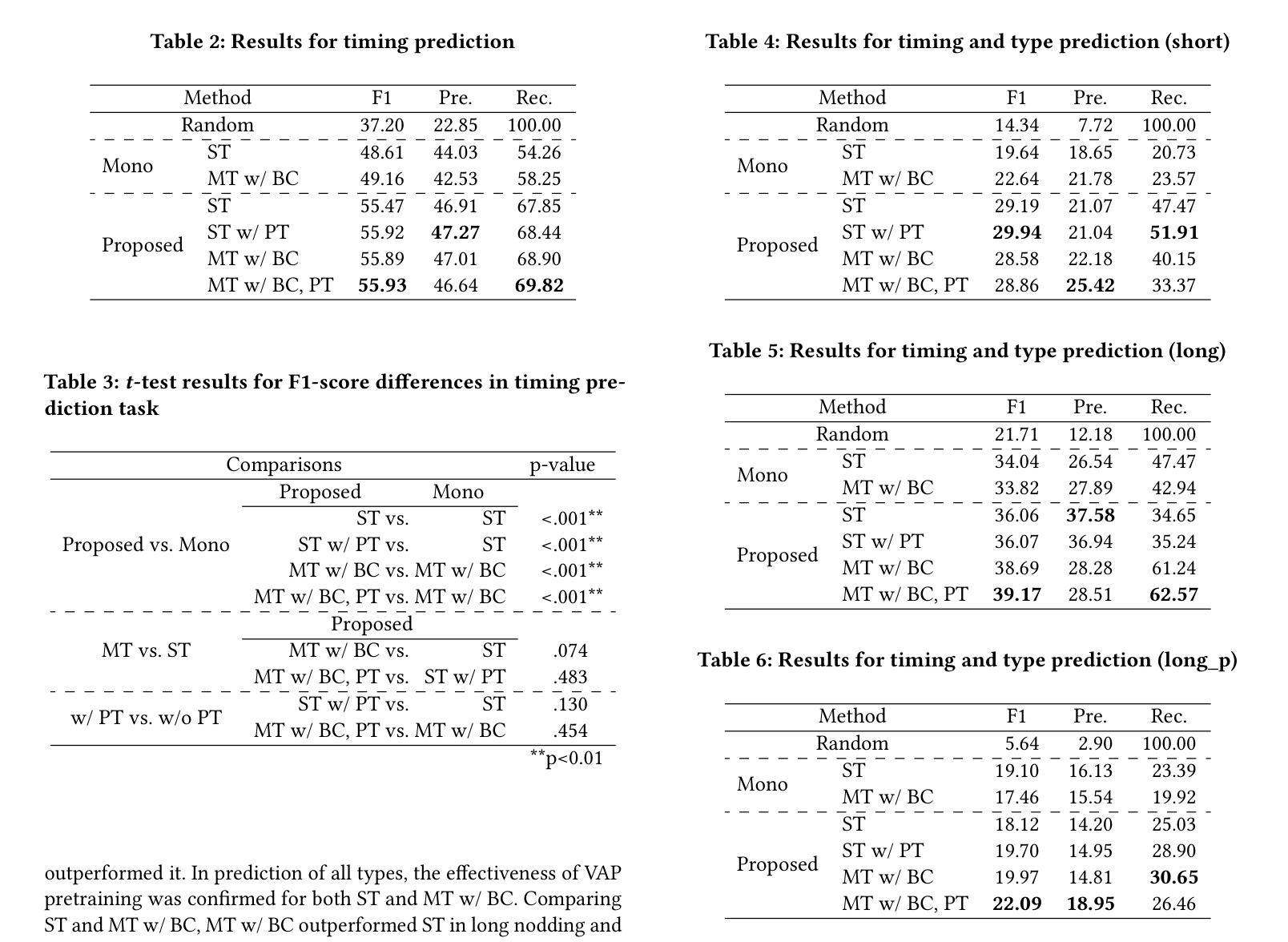
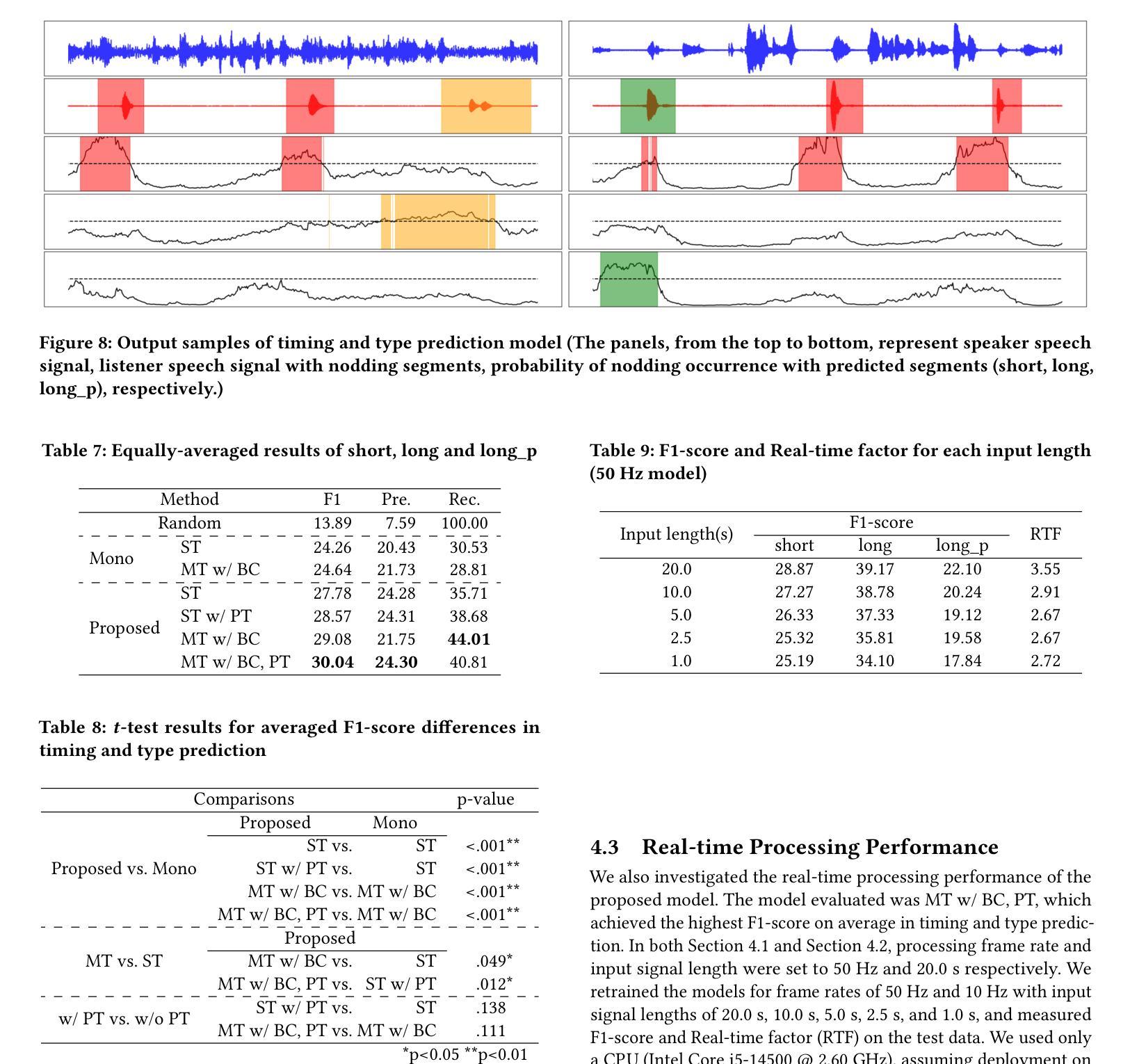
In human dialogue, nonverbal information such as nodding and facial expressions is as crucial as verbal information, and spoken dialogue systems are also expected to express such nonverbal behaviors. We focus on nodding, which is critical in an attentive listening system, and propose a model that predicts both its timing and type in real time. The proposed model builds on the voice activity projection (VAP) model, which predicts voice activity from both listener and speaker audio. We extend it to prediction of various types of nodding in a continuous and real-time manner unlike conventional models. In addition, the proposed model incorporates multi-task learning with verbal backchannel prediction and pretraining on general dialogue data. In the timing and type prediction task, the effectiveness of multi-task learning was significantly demonstrated. We confirmed that reducing the processing rate enables real-time operation without a substantial drop in accuracy, and integrated the model into an avatar attentive listening system. Subjective evaluations showed that it outperformed the conventional method, which always does nodding in sync with verbal backchannel. The code and trained models are available at https://github.com/MaAI-Kyoto/MaAI.
在人类对话中,非言语信息如点头和面部表情与言语信息一样重要,口语对话系统也被期望能够表达这样的非言语行为。我们专注于点头,这在倾听系统中至关重要,并提出一个模型,该模型可以实时预测点头的时机和类型。所提出的模型基于语音活动投影(VAP)模型,该模型可以从听者和说话者的音频预测语音活动。我们将其扩展到连续实时预测各种点头方式,不同于传统模型。此外,与传统模型不同,所提出的模型结合了多任务学习与言语反馈预测,并在一般对话数据上进行预训练。在预测时间和类型任务中,多任务学习的有效性得到了显著证明。我们确认降低处理速率可以在不显著降低准确率的情况下实现实时操作,并将该模型集成到虚拟化身倾听系统中。主观评估表明,它优于传统方法,后者总是与言语反馈同步点头。相关代码和训练好的模型可在https://github.com/MaAI-Kyoto/MaAI处获取。
论文及项目相关链接
PDF Accepted by 27th ACM International Conference on Multimodal Interaction (ICMI ‘25), Long paper
Summary
本文聚焦于对话中的非言语行为——点头,并提出一个实时预测点头时机和类型的模型。该模型基于语音活动投影(VAP)模型,能够预测听者和说话者的音频中的语音活动,并扩展至连续实时预测各种点头行为。通过多任务学习和与语言回馈预测的融合,以及通用对话数据的预训练,模型在预测点头时机和类型方面表现出显著效果。
Key Takeaways
- 点头作为非言语信息在对话中的重要性被强调,并被认为是注意倾听系统的关键要素。
- 提出了一种能够实时预测点头时机和类型的模型。
- 模型基于语音活动投影(VAP)模型构建,可预测听者和说话者的音频中的语音活动。
- 模型通过多任务学习和预训练提升性能,能连续实时预测多种点头行为。
- 进行了与语言回馈预测的融合实验,在客观评价指标上取得优于传统方法的性能。
- 通过降低处理速率实现了模型的实时操作,同时保证了准确性。
点此查看论文截图


PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Authors:Yan Zhang, Yao Feng, Alpár Cseke, Nitin Saini, Nathan Bajandas, Nicolas Heron, Michael J. Black
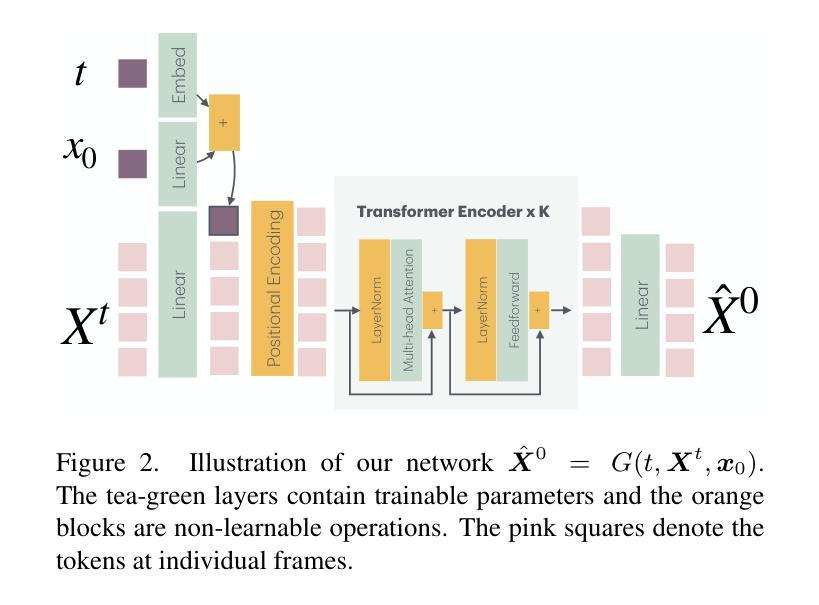
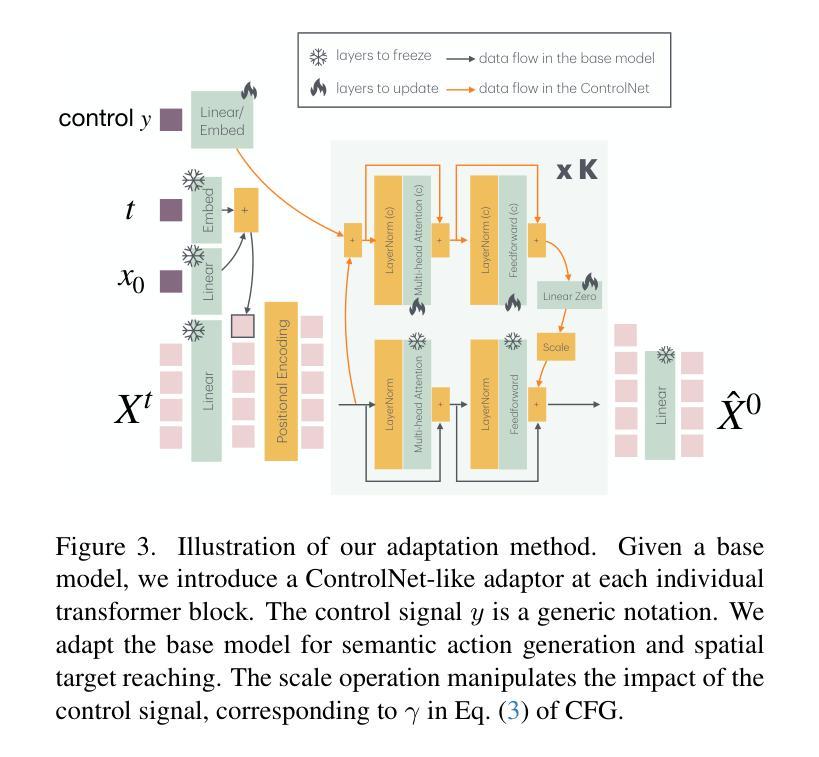
We formulate the motor system of an interactive avatar as a generative motion model that can drive the body to move through 3D space in a perpetual, realistic, controllable, and responsive manner. Although human motion generation has been extensively studied, many existing methods lack the responsiveness and realism of real human movements. Inspired by recent advances in foundation models, we propose PRIMAL, which is learned with a two-stage paradigm. In the pretraining stage, the model learns body movements from a large number of sub-second motion segments, providing a generative foundation from which more complex motions are built. This training is fully unsupervised without annotations. Given a single-frame initial state during inference, the pretrained model not only generates unbounded, realistic, and controllable motion, but also enables the avatar to be responsive to induced impulses in real time. In the adaptation phase, we employ a novel ControlNet-like adaptor to fine-tune the base model efficiently, adapting it to new tasks such as few-shot personalized action generation and spatial target reaching. Evaluations show that our proposed method outperforms state-of-the-art baselines. We leverage the model to create a real-time character animation system in Unreal Engine that feels highly responsive and natural. Code, models, and more results are available at: https://yz-cnsdqz.github.io/eigenmotion/PRIMAL
我们将交互性虚拟角色的运动系统制定为一个生成运动模型,该模型能够驱动角色在三维空间中以持久、真实、可控和响应迅速的方式移动。尽管人类运动生成已经得到了广泛的研究,但许多现有方法缺乏真实人类运动的响应性和真实性。受最新基础模型进展的启发,我们提出了PRIMAL,它采用两阶段范式进行学习。在预训练阶段,模型从大量亚秒级运动片段中学习身体运动,为构建更复杂的动作提供了一个生成基础。这种训练是完全无监督的,无需注释。在推理过程中,给定单帧初始状态,预训练模型不仅能够生成无界、真实、可控的运动,还能使虚拟角色实时响应诱导脉冲。在适应阶段,我们采用类似ControlNet的新型适配器高效微调基础模型,使其适应新任务,如少量个性化动作生成和空间目标达到。评估表明,我们提出的方法优于最新基线。我们利用该模型在Unreal Engine中创建了一个实时角色动画系统,感觉响应迅速、非常自然。代码、模型和更多结果请访问:URL链接。
论文及项目相关链接
PDF ICCV’25 camera ready; main paper and appendix; 19 pages in total
Summary
该文提出一种交互式虚拟角色的运动系统生成模型,能够驱动虚拟角色在三维空间中以持久、真实、可控和响应迅速的方式移动。模型采用两阶段训练法,预训练阶段从大量亚秒级运动片段中学习身体动作,为构建更复杂的动作提供生成基础,适应阶段采用类似ControlNet的适配器进行微调,使其能够适应新任务如个性化动作生成和空间目标达成。该模型被用于创建一个在Unreal Engine中的实时角色动画系统,呈现出高度响应性和自然性。
Key Takeaways
- 提出了一个交互式虚拟角色的运动系统生成模型。
- 模型通过两阶段训练法,预训练阶段从大量亚秒级运动片段中学习身体动作。
- 预训练模型能生成持久、真实、可控的虚拟角色运动。
- 模型具有实时响应诱导脉冲的能力。
- 适应阶段采用类似ControlNet的适配器进行微调,适应新任务如个性化动作生成和空间目标达成。
- 该模型在实时角色动画系统中表现出高度响应性和自然性。
点此查看论文截图

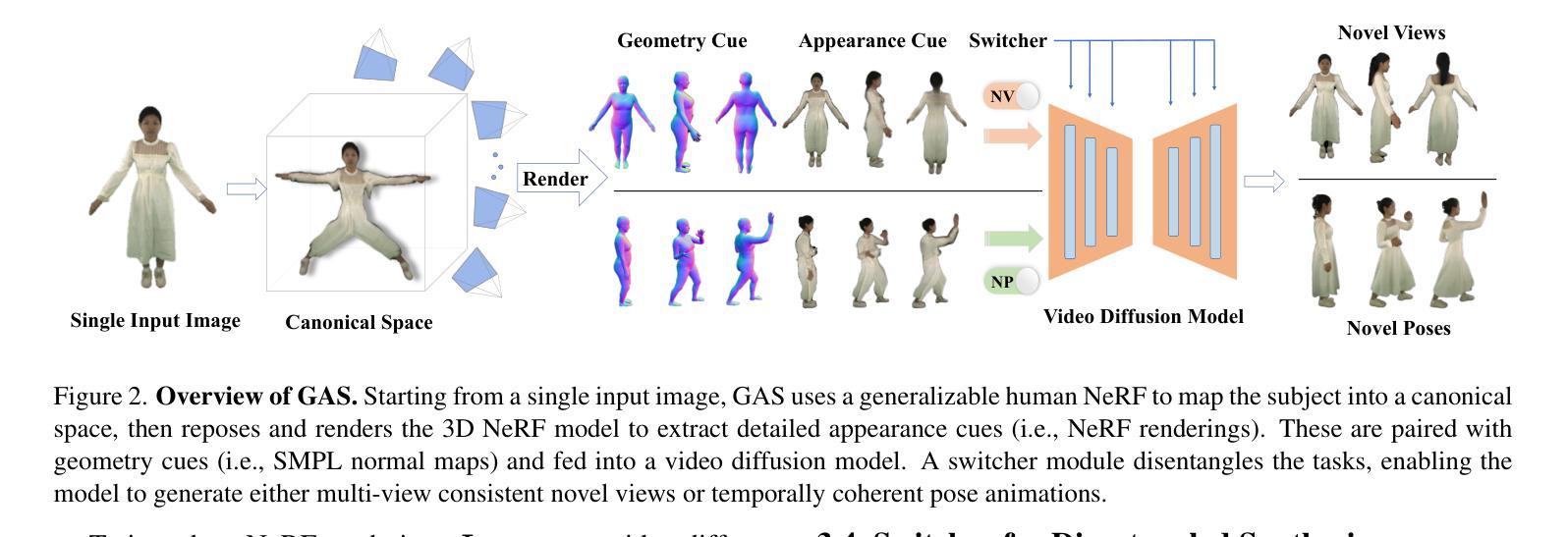
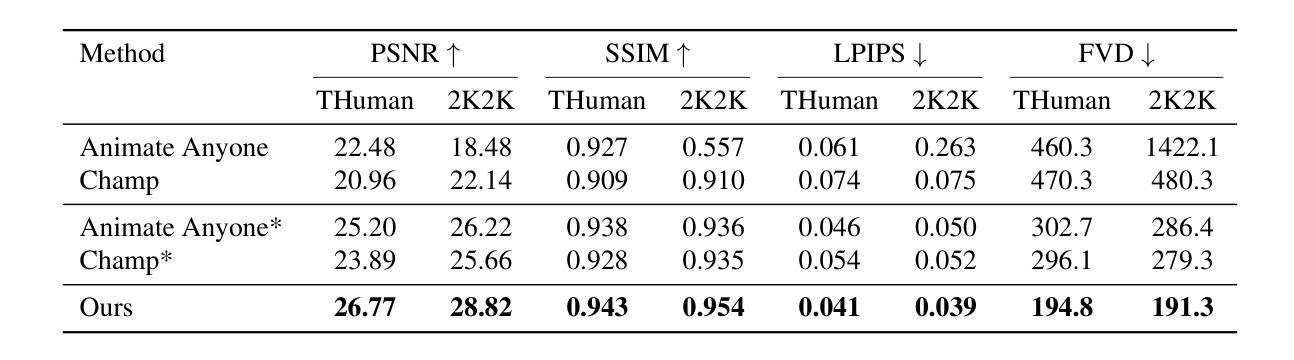
GAS: Generative Avatar Synthesis from a Single Image
Authors:Yixing Lu, Junting Dong, Youngjoong Kwon, Qin Zhao, Bo Dai, Fernando De la Torre
We present a unified and generalizable framework for synthesizing view-consistent and temporally coherent avatars from a single image, addressing the challenging task of single-image avatar generation. Existing diffusion-based methods often condition on sparse human templates (e.g., depth or normal maps), which leads to multi-view and temporal inconsistencies due to the mismatch between these signals and the true appearance of the subject. Our approach bridges this gap by combining the reconstruction power of regression-based 3D human reconstruction with the generative capabilities of a diffusion model. In a first step, an initial 3D reconstructed human through a generalized NeRF provides comprehensive conditioning, ensuring high-quality synthesis faithful to the reference appearance and structure. Subsequently, the derived geometry and appearance from the generalized NeRF serve as input to a video-based diffusion model. This strategic integration is pivotal for enforcing both multi-view and temporal consistency throughout the avatar’s generation. Empirical results underscore the superior generalization ability of our proposed method, demonstrating its effectiveness across diverse in-domain and out-of-domain in-the-wild datasets.
我们提出一个统一和可推广的框架,从单张图像合成视角一致和时间连贯的化身,解决单图像化身生成的挑战任务。现有的基于扩散的方法通常依赖于稀疏的人体模板(例如深度或法线图),这会导致这些信号与主题的真实外观之间的不匹配,从而产生多视角和时间上的不一致性。我们的方法通过结合基于回归的3D人体重建的重建能力与扩散模型的生成能力来弥补这一差距。首先,通过通用的NeRF进行初始3D人体重建,提供全面的条件,确保合成的高质量并与参考外观和结构保持一致。随后,从通用的NeRF派生的几何形状和外观作为视频扩散模型的输入。这种战略性的整合对于在化身生成过程中强制执行多视角和时间一致性至关重要。经验结果突显了我们提出方法的卓越泛化能力,证明了它在各种领域内外、自然场景数据集上的有效性。
论文及项目相关链接
PDF ICCV 2025; Project Page: https://humansensinglab.github.io/GAS/
Summary
单张图像即可生成具有视图一致性和时间连贯性的个性化角色模型框架。该研究通过结合回归式三维人体重建的重建能力与扩散模型的生成能力,克服了基于扩散的传统方法以稀疏人体模板为条件的局限,保证了高质量合成结果与参考外观和结构的忠实度。通过初始化的三维重建人体再通过基于视频的扩散模型进行细化,实现了多视角和时间连贯性的保证。经验结果表明,该方法具有出色的泛化能力,在多种领域内外数据集上都表现出有效性。
Key Takeaways
- 提出了一种从单张图像合成个性化角色模型的统一且可推广的框架。
- 结合了回归式三维人体重建与扩散模型的优点,克服了传统方法的局限。
- 通过结合通用NeRF技术,确保了高质量合成结果与参考外观和结构的忠实度。
- 通过初始化的三维重建人体,进一步利用基于视频的扩散模型进行细化。
- 实现了多视角和时间连贯性的保证,增强了角色模型的逼真度。
- 框架具有良好的泛化能力,能在多种数据集上实现有效性。
- 实证分析表明了该方法的优势。
点此查看论文截图


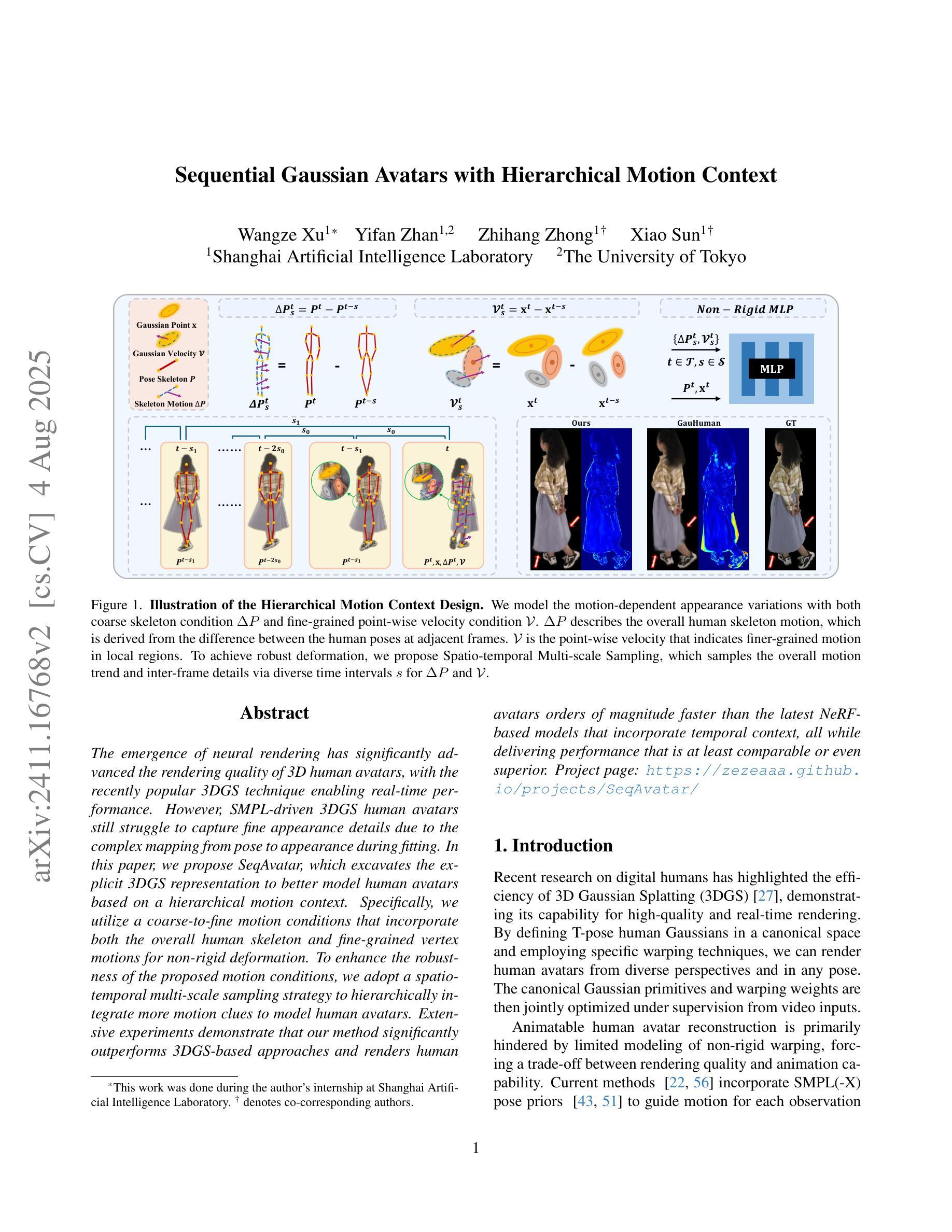
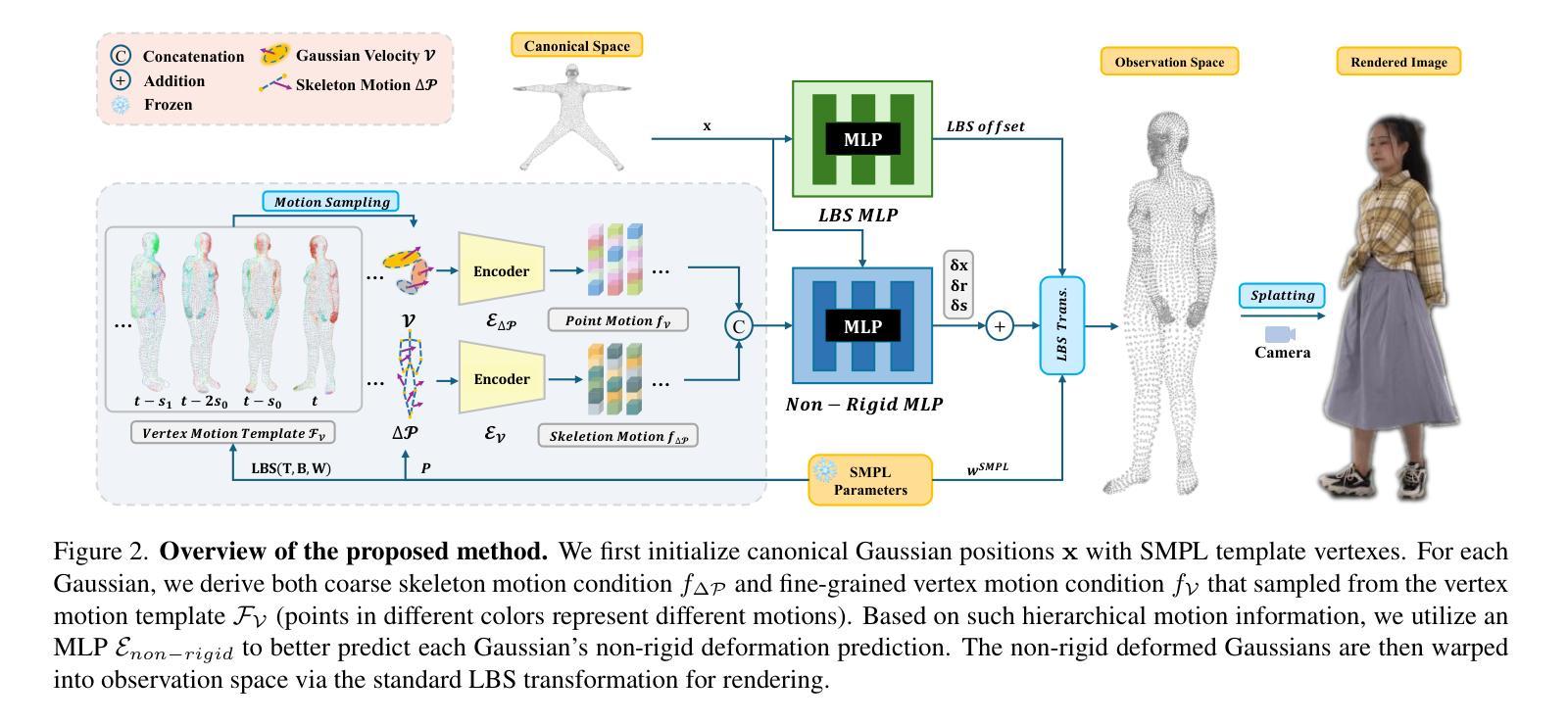
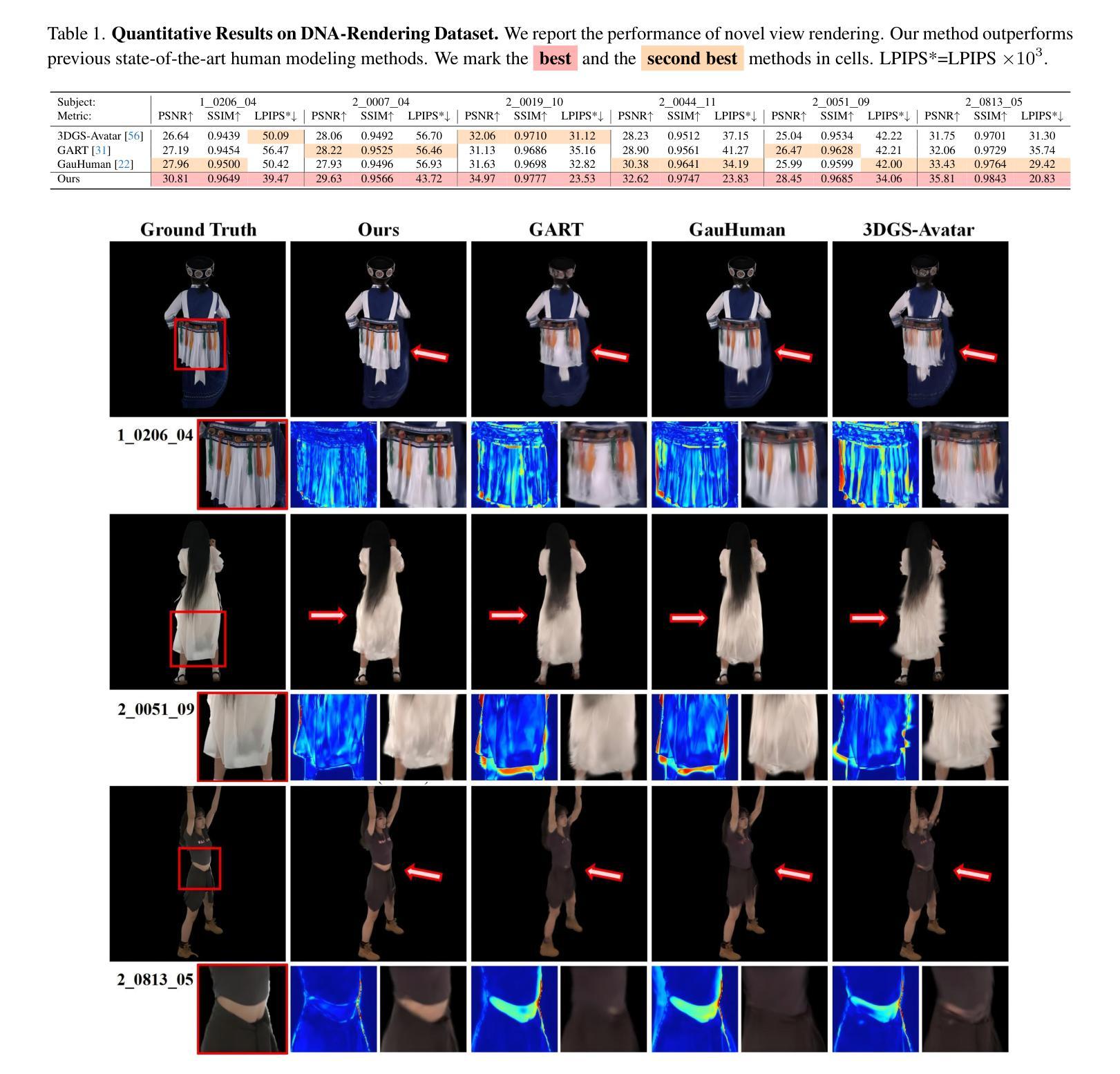
Sequential Gaussian Avatars with Hierarchical Motion Context
Authors:Wangze Xu, Yifan Zhan, Zhihang Zhong, Xiao Sun
The emergence of neural rendering has significantly advanced the rendering quality of 3D human avatars, with the recently popular 3DGS technique enabling real-time performance. However, SMPL-driven 3DGS human avatars still struggle to capture fine appearance details due to the complex mapping from pose to appearance during fitting. In this paper, we propose SeqAvatar, which excavates the explicit 3DGS representation to better model human avatars based on a hierarchical motion context. Specifically, we utilize a coarse-to-fine motion conditions that incorporate both the overall human skeleton and fine-grained vertex motions for non-rigid deformation. To enhance the robustness of the proposed motion conditions, we adopt a spatio-temporal multi-scale sampling strategy to hierarchically integrate more motion clues to model human avatars. Extensive experiments demonstrate that our method significantly outperforms 3DGS-based approaches and renders human avatars orders of magnitude faster than the latest NeRF-based models that incorporate temporal context, all while delivering performance that is at least comparable or even superior. Project page: https://zezeaaa.github.io/projects/SeqAvatar/
神经渲染技术的出现极大地提高了3D人类化身(avatars)的渲染质量,最近流行的3DGS技术能够实现实时性能。然而,由SMPL驱动的3DGS人类化身仍然难以捕捉精细的外观细节,因为在拟合过程中从姿势到外观的映射非常复杂。在本文中,我们提出了SeqAvatar,它挖掘了明确的3DGS表示,以基于分层运动上下文更好地建模人类化身。具体来说,我们利用从粗糙到精细的运动条件,结合整体人类骨骼和精细顶点运动进行非刚性变形。为了提高所提出运动条件的稳健性,我们采用时空多尺度采样策略,分层融合更多运动线索来建模人类化身。大量实验表明,我们的方法显著优于基于3DGS的方法,并且与人类化身渲染速度相比,采用时间上下文的最新NeRF模型提高了多个数量级,同时性能至少相当或更优。项目页面:https://zezeaaa.github.io/projects/SeqAvatar/。
论文及项目相关链接
PDF ICCV2025
Summary
神经网络渲染技术的出现显著提高了3D人类虚拟形象的渲染质量,尤其是3DGS技术的实时性能得到了广泛应用。然而,基于SMPL驱动的3DGS人类虚拟形象在拟合过程中仍然难以捕捉精细的外观细节。针对这一问题,本文提出了SeqAvatar方法,它通过挖掘明确的3DGS表示,基于分层运动上下文建立更好的人类虚拟形象模型。具体而言,该方法采用从粗到细的的运动条件,结合整体人类骨骼和精细顶点运动进行非刚性变形。为提高运动条件的稳健性,还采用了时空多尺度采样策略,分层集成更多的运动线索来模拟人类虚拟形象。实验表明,该方法显著优于基于3DGS的方法,并且比最新结合时间上下文的NeRF模型渲染人类虚拟形象的速度高出数倍,同时性能至少与之相当或更优秀。
Key Takeaways
- 神经网络渲染技术提高了3D人类虚拟形象的渲染质量。
- 3DGS技术实现了实时性能,但在捕捉精细外观细节方面存在挑战。
- SeqAvatar方法通过挖掘明确的3DGS表示来改进人类虚拟形象的建模。
- SeqAvatar采用分层运动上下文和从粗到细的运动条件来处理非刚性变形。
- 为提高稳健性,采用了时空多尺度采样策略集成运动线索。
- 实验显示SeqAvatar显著优于基于3DGS的方法,并且渲染速度更快。
点此查看论文截图