⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-06 更新
Enhancing Object Discovery for Unsupervised Instance Segmentation and Object Detection
Authors:Xingyu Feng, Hebei Gao, Hong Li
We propose Cut-Once-and-LEaRn (COLER), a simple approach for unsupervised instance segmentation and object detection. COLER first uses our developed CutOnce to generate coarse pseudo labels, then enables the detector to learn from these masks. CutOnce applies Normalized Cut only once and does not rely on any clustering methods, but it can generate multiple object masks in an image. We have designed several novel yet simple modules that not only allow CutOnce to fully leverage the object discovery capabilities of self-supervised models, but also free it from reliance on mask post-processing. During training, COLER achieves strong performance without requiring specially designed loss functions for pseudo labels, and its performance is further improved through self-training. COLER is a zero-shot unsupervised model that outperforms previous state-of-the-art methods on multiple benchmarks.We believe our method can help advance the field of unsupervised object localization.
我们提出了Cut-Once-and-LEaRn(COLER)方法,这是一种用于无监督实例分割和对象检测的简单方法。COLER首先使用我们开发的CutOnce生成粗略的伪标签,然后让检测器从这些掩膜中学习。CutOnce只应用一次归一化切割,不依赖任何聚类方法,但可以在图像中生成多个对象掩膜。我们设计了几种新颖而简单的模块,这些模块不仅允许CutOnce充分利用自监督模型的对象发现能力,而且还使其摆脱对掩膜后处理的依赖。在训练过程中,COLER在不针对伪标签设计特殊损失函数的情况下实现了强大的性能,并且其性能通过自训练得到了进一步提高。COLER是一种零样本无监督模型,在多个基准测试上超过了以前的最先进方法。我们相信我们的方法可以帮助推动无监督对象定位领域的发展。
论文及项目相关链接
Summary
该文提出了Cut-Once-and-LEaRn(COLER)方法,这是一种用于无监督实例分割和对象检测的简单方法。COLER首先使用开发的CutOnce生成粗略伪标签,然后使检测器从这些标签中学习。CutOnce只应用一次标准化切割,无需依赖任何聚类方法,但可以生成图像中的多个对象掩模。通过几个新的简单模块,CutOnce不仅能够充分利用自监督模型的对象发现能力,而且摆脱了伪标签的依赖。在训练过程中,COLER无需针对伪标签设计特殊设计的损失函数,并且可以通过自训练进一步提高性能。COLER是一个零样本无监督模型,在多个基准测试中超过了最新的技术方法。本文认为该方法有助于推动无监督对象定位领域的发展。
Key Takeaways
- COLER是一种用于无监督实例分割和对象检测的简单方法。
- CutOnce生成伪标签,用于训练检测器。
- CutOnce通过应用一次标准化切割生成多个对象掩模,无需聚类方法。
- 通过新模块的应用,CutOnce能充分利用自监督模型的对象发现能力,并摆脱对伪标签的依赖。
- COLER在训练过程中无需特殊设计的损失函数,可通过自训练进一步提高性能。
- COLER是一个零样本无监督模型,性能优于现有的最新技术方法。
点此查看论文截图

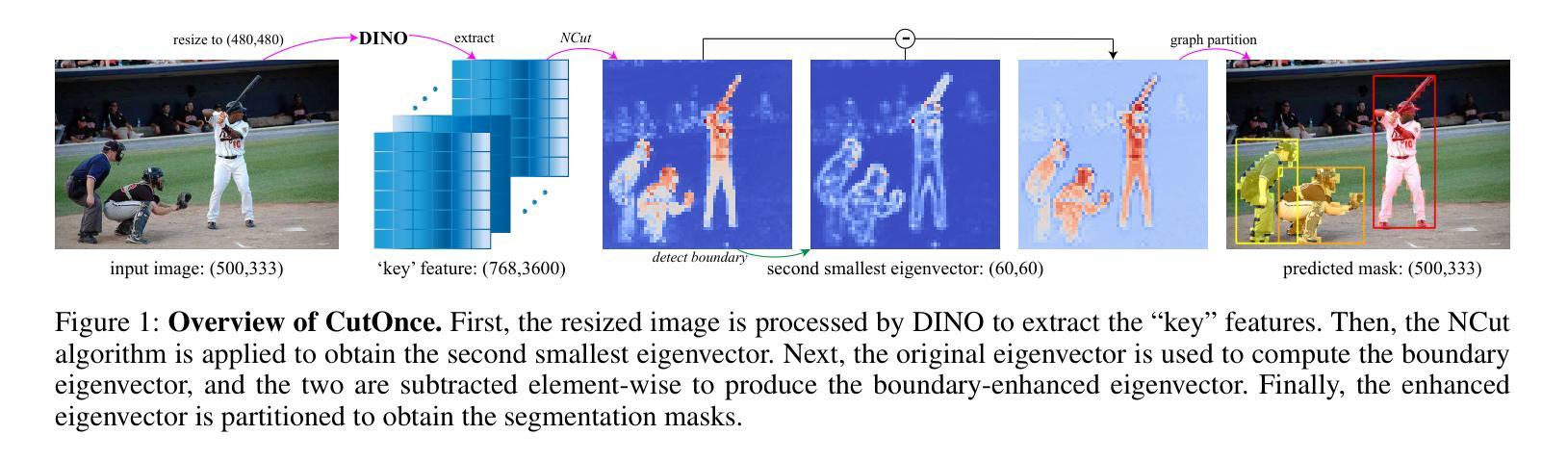
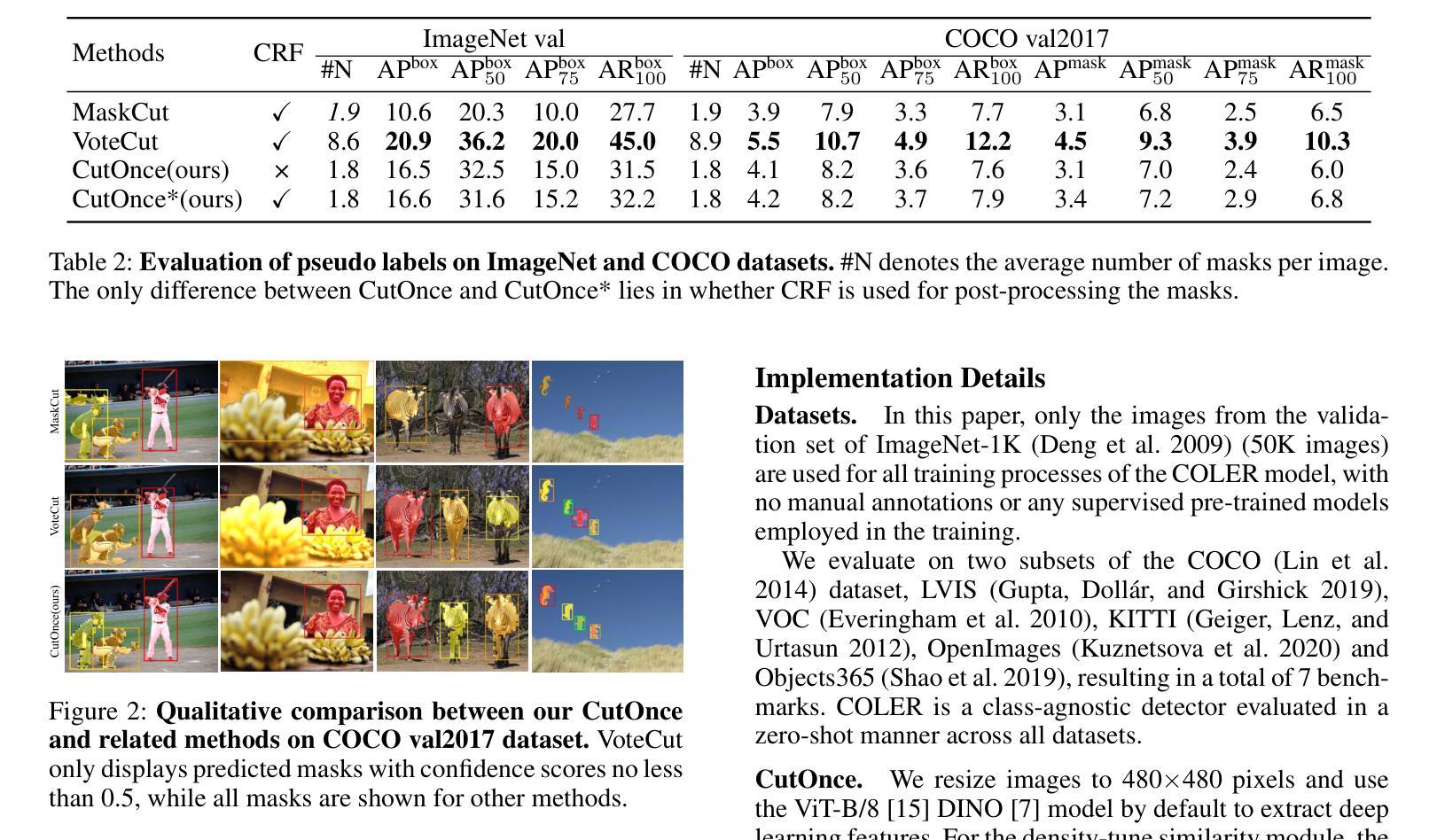
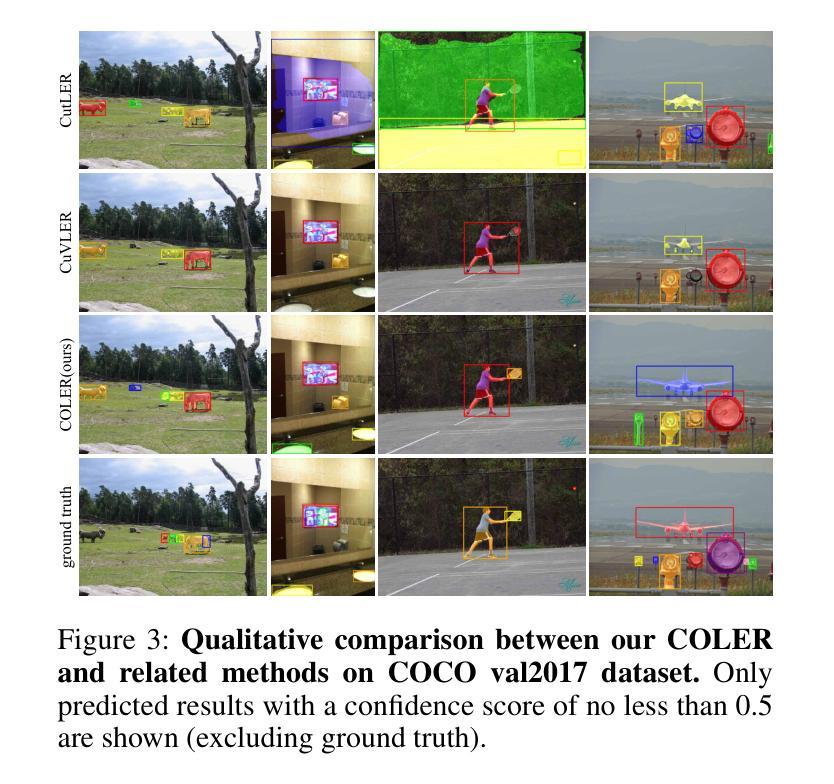
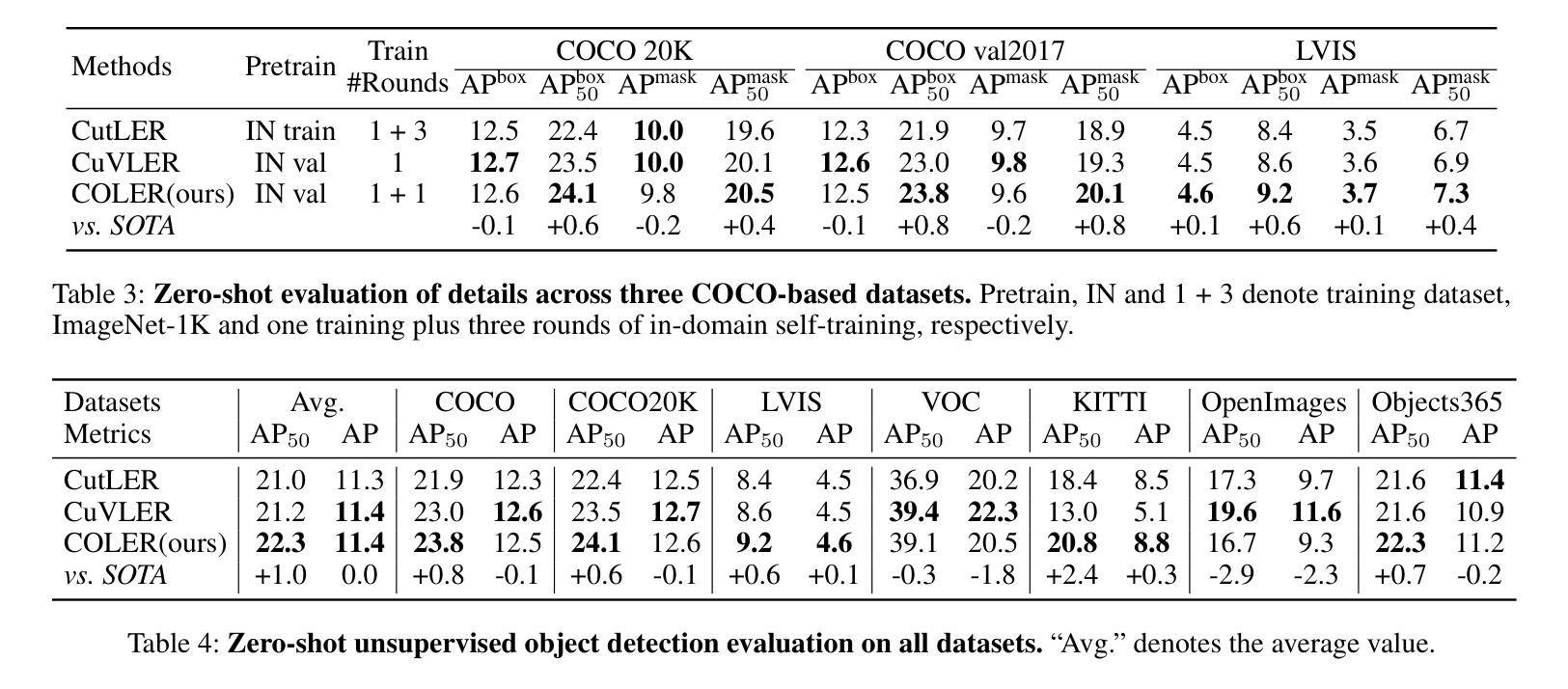
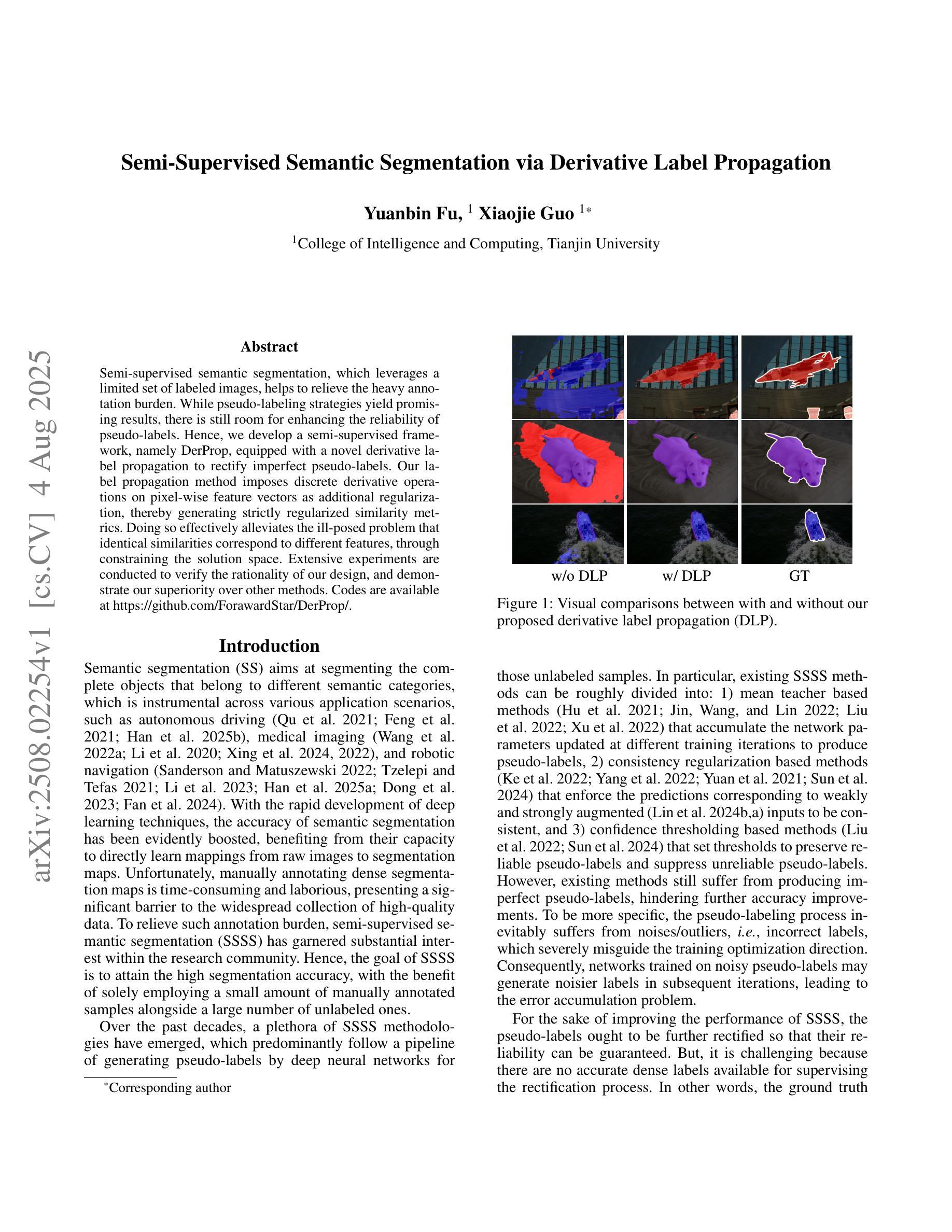
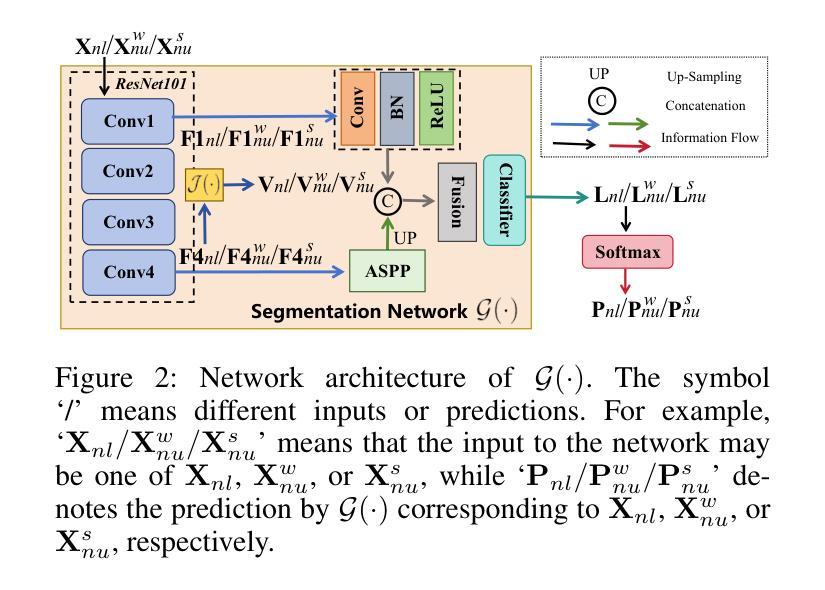
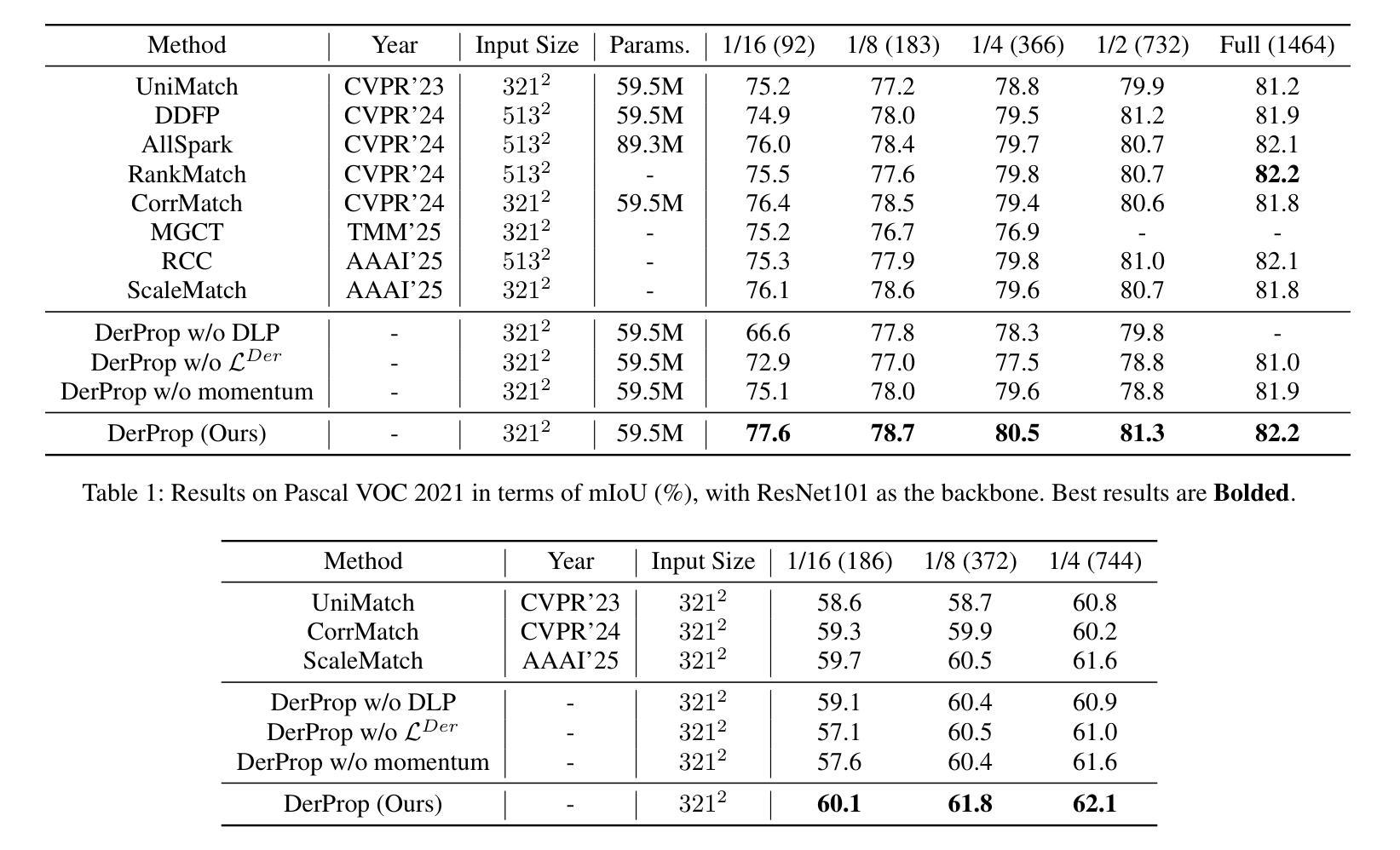
Semi-Supervised Semantic Segmentation via Derivative Label Propagation
Authors:Yuanbin Fu, Xiaojie Guo
Semi-supervised semantic segmentation, which leverages a limited set of labeled images, helps to relieve the heavy annotation burden. While pseudo-labeling strategies yield promising results, there is still room for enhancing the reliability of pseudo-labels. Hence, we develop a semi-supervised framework, namely DerProp, equipped with a novel derivative label propagation to rectify imperfect pseudo-labels. Our label propagation method imposes discrete derivative operations on pixel-wise feature vectors as additional regularization, thereby generating strictly regularized similarity metrics. Doing so effectively alleviates the ill-posed problem that identical similarities correspond to different features, through constraining the solution space. Extensive experiments are conducted to verify the rationality of our design, and demonstrate our superiority over other methods. Codes are available at https://github.com/ForawardStar/DerProp/.
半监督语义分割利用有限的标记图像,有助于减轻繁重的标注负担。虽然伪标签策略取得了令人鼓舞的结果,但提高伪标签的可靠性仍有空间。因此,我们开发了一个名为DerProp的半监督框架,配备了一种新型衍生标签传播方法,以修正不完美的伪标签。我们的标签传播方法将离散导数运算施加于像素级特征向量作为额外的正则化,从而产生严格正则化的相似度度量。这样做可以有效地缓解不适定问题,即相同的相似度对应于不同的特征,通过约束解空间来实现这一点。我们进行了大量实验来验证设计的合理性,并证明我们的方法在性能上优于其他方法。代码可通过https://github.com/ForawardStar/DerProp/获取。
论文及项目相关链接
Summary
本文提出了一种基于有限标记图像集的新型半监督语义分割框架DerProp。该方法引入了一种新型标签传播策略来纠正不完美的伪标签,对像素级特征向量进行离散导数操作,生成严格的规则化相似性度量,有效解决相似特征对应的伪标签错误问题,并在实验上证明了其设计的合理性和超越其他方法的优势。
Key Takeaways
- 提出了一种基于有限标记图像集的新型半监督语义分割框架DerProp。
- 采用新型标签传播策略来纠正伪标签。
- 对像素级特征向量进行离散导数操作,生成规则化的相似性度量。
- 解决相似特征对应的伪标签错误问题。
- 实验验证了设计的合理性以及DerProp相对于其他方法的优越性。
- 代码已经开源并可在网上获取。
点此查看论文截图

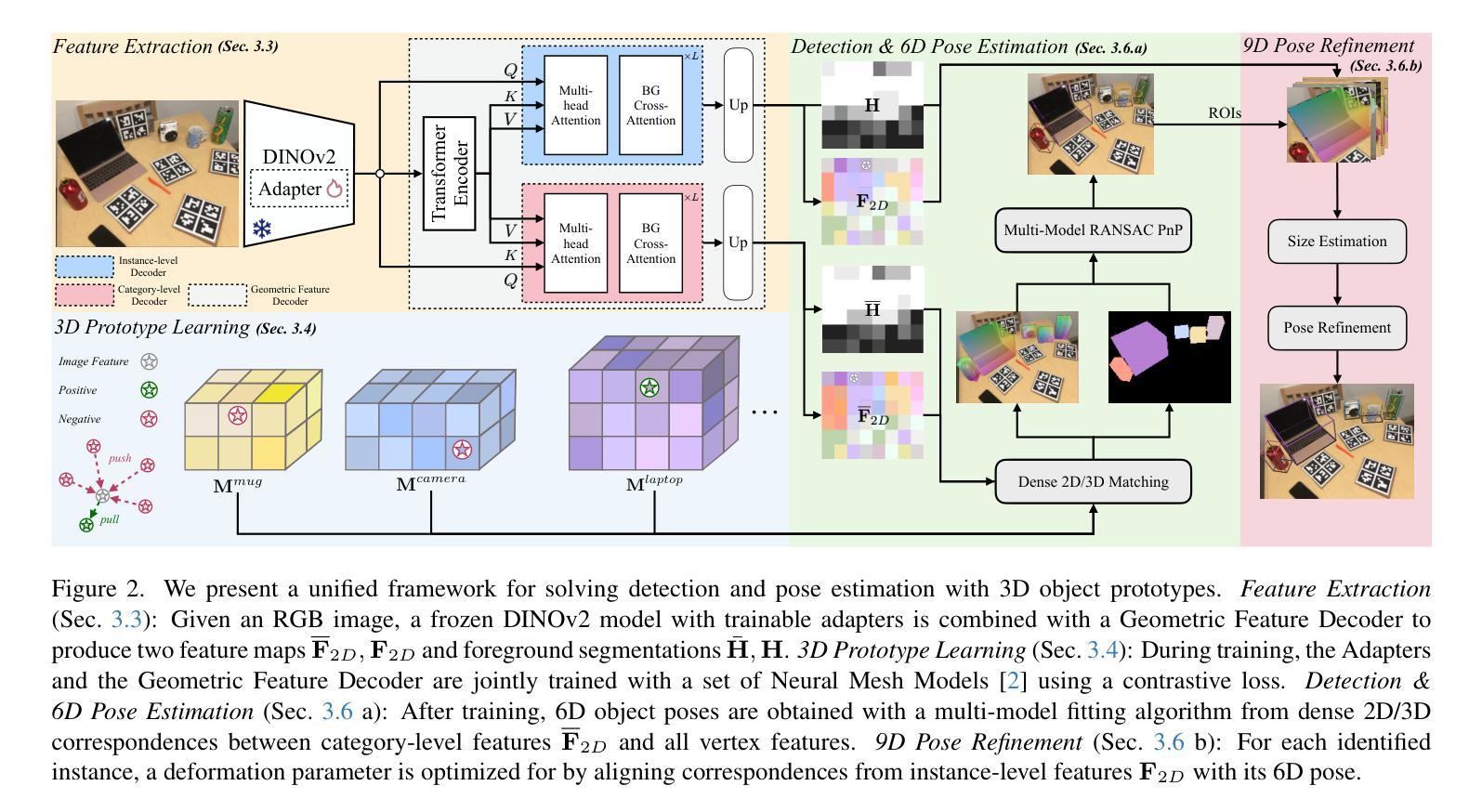
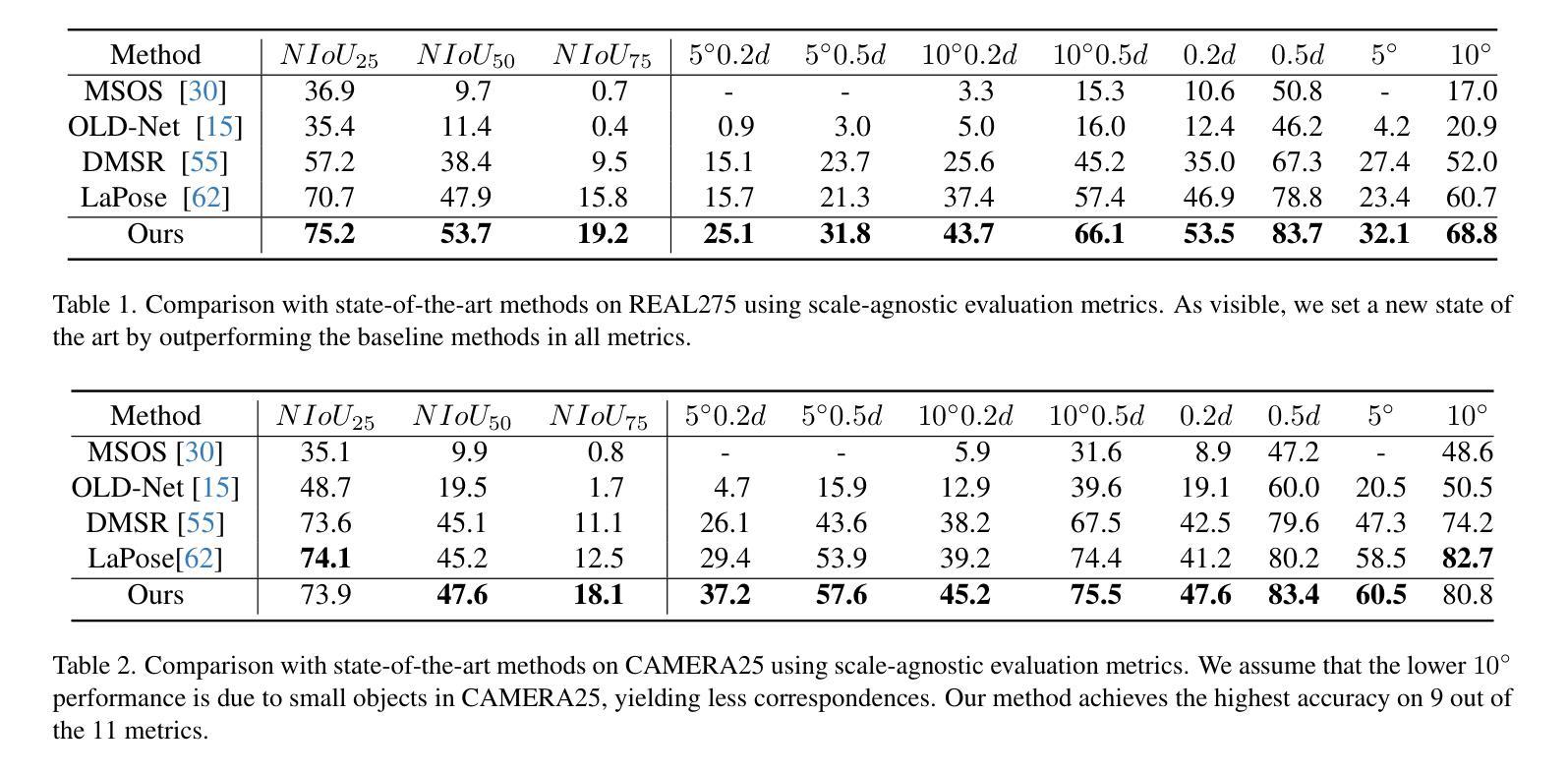
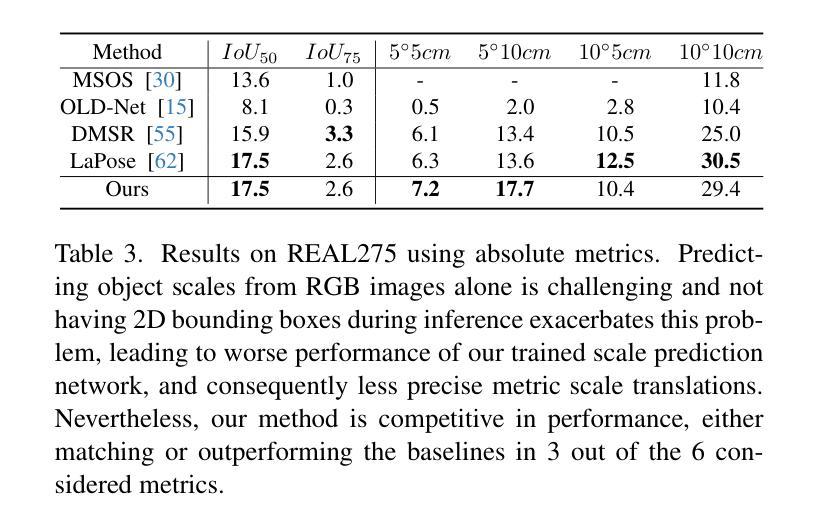
Unified Category-Level Object Detection and Pose Estimation from RGB Images using 3D Prototypes
Authors:Tom Fischer, Xiaojie Zhang, Eddy Ilg
Recognizing objects in images is a fundamental problem in computer vision. Although detecting objects in 2D images is common, many applications require determining their pose in 3D space. Traditional category-level methods rely on RGB-D inputs, which may not always be available, or employ two-stage approaches that use separate models and representations for detection and pose estimation. For the first time, we introduce a unified model that integrates detection and pose estimation into a single framework for RGB images by leveraging neural mesh models with learned features and multi-model RANSAC. Our approach achieves state-of-the-art results for RGB category-level pose estimation on REAL275, improving on the current state-of-the-art by 22.9% averaged across all scale-agnostic metrics. Finally, we demonstrate that our unified method exhibits greater robustness compared to single-stage baselines. Our code and models are available at https://github.com/Fischer-Tom/unified-detection-and-pose-estimation.
识别图像中的物体是计算机视觉中的一个基本问题。虽然检测二维图像中的物体很常见,但许多应用需要确定其在三维空间中的姿态。传统的类别级别的方法依赖于RGB-D输入,这可能并不总是可用,或者采用两阶段的方法,使用独立的模型和表示为检测和姿态估计建模。首次,我们引入了一个统一模型,该模型利用神经网格模型学习的特征和基于多模型的RANSAC将检测和姿态估计集成到一个单一的RGB图像框架中。我们的方法在REAL275的RGB类别级别的姿态估计上取得了最新的结果,在所有尺度无关指标上的平均表现较当前最佳水平提高了22.9%。最后,我们证明了我们的统一方法比单阶段基线展现出更大的稳健性。我们的代码和模型在https://github.com/Fischer-Tom/unified-detection-and-pose-estimation上可用。
论文及项目相关链接
PDF Published at ICCV 2025
Summary
本文介绍了一种新的统一模型,该模型利用神经网络模型和学习的特征以及多模态RANSAC,将物体检测与姿态估计整合到一个框架中,仅使用RGB图像即可实现。该方法在RGB类别级别的姿态估计方面达到了最先进的成果,并表现出较高的稳健性。
Key Takeaways
- 本文解决了计算机视觉中的物体识别问题,并重点关注在图像中的物体检测及其在三维空间中的姿态确定。
- 传统的方法通常依赖于RGB-D输入或两阶段的方法,需要使用独立的模型和表示进行检测和姿态估计。
- 本文首次引入了一种统一模型,该模型将检测和姿态估计整合到一个框架中,仅使用RGB图像。
- 该方法利用神经网络模型和学习的特征,以及多模态RANSAC来实现。
- 该方法在RGB类别级别的姿态估计方面达到了最先进的成果,平均改进了当前最先进技术的22.9%。
- 与单阶段基线相比,该方法表现出更高的稳健性。
点此查看论文截图

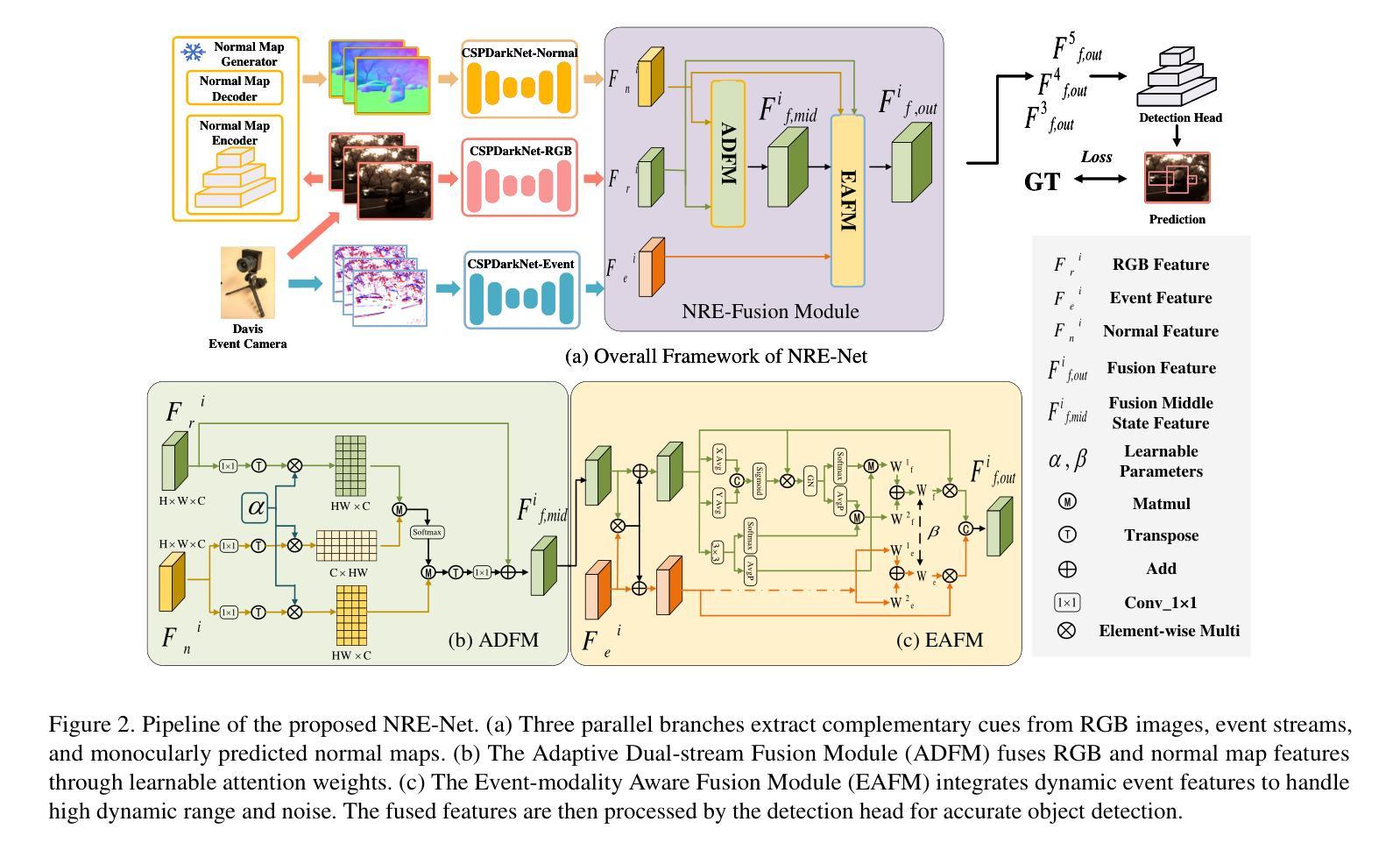
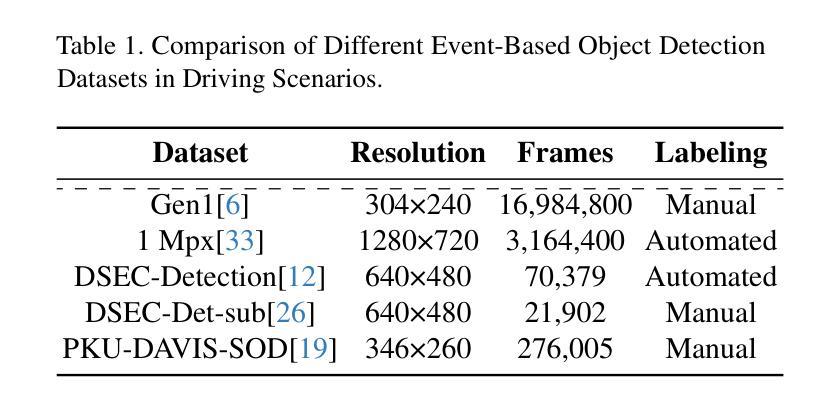
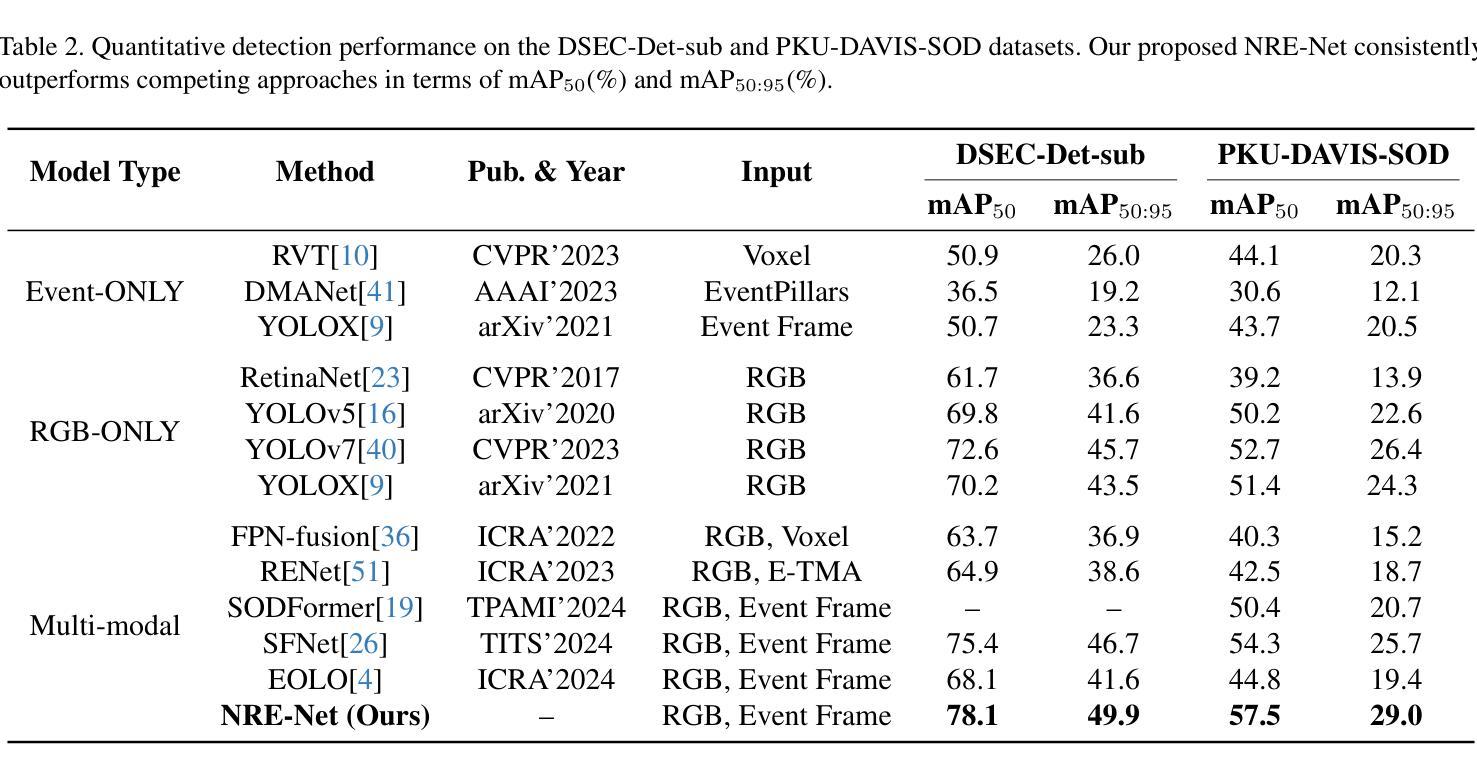
Beyond RGB and Events: Enhancing Object Detection under Adverse Lighting with Monocular Normal Maps
Authors:Mingjie Liu, Hanqing Liu, Chuang Zhu
Accurate object detection under adverse lighting conditions is critical for real-world applications such as autonomous driving. Although neuromorphic event cameras have been introduced to handle these scenarios, adverse lighting often induces distracting reflections from tunnel walls or road surfaces, which frequently lead to false obstacle detections. However, neither RGB nor event data alone is robust enough to address these complexities, and mitigating these issues without additional sensors remains underexplored. To overcome these challenges, we propose leveraging normal maps, directly predicted from monocular RGB images, as robust geometric cues to suppress false positives and enhance detection accuracy. We introduce NRE-Net, a novel multi-modal detection framework that effectively fuses three complementary modalities: monocularly predicted surface normal maps, RGB images, and event streams. To optimize the fusion process, our framework incorporates two key modules: the Adaptive Dual-stream Fusion Module (ADFM), which integrates RGB and normal map features, and the Event-modality Aware Fusion Module (EAFM), which adapts to the high dynamic range characteristics of event data. Extensive evaluations on the DSEC-Det-sub and PKU-DAVIS-SOD datasets demonstrate that NRE-Net significantly outperforms state-of-the-art methods. Our approach achieves mAP50 improvements of 7.9% and 6.1% over frame-based approaches (e.g., YOLOX), while surpassing the fusion-based SFNet by 2.7% on the DSEC-Det-sub dataset and SODFormer by 7.1% on the PKU-DAVIS-SOD dataset.
在恶劣照明条件下准确的目标检测对于自动驾驶等实际应用至关重要。尽管神经形态事件相机已经被引入来处理这些场景,但恶劣的照明条件往往会引起隧道墙壁或路面表面的反射干扰,这经常导致错误的障碍物检测。然而,无论是RGB还是单独的事件数据,都无法足够稳健地应对这些复杂性,而且不依赖额外的传感器来缓解这些问题仍然缺乏足够的探索。为了克服这些挑战,我们提出利用从单目RGB图像直接预测得到的法线图作为稳健的几何线索来抑制误报并增强检测准确性。我们引入了NRE-Net,这是一种新型的多模态检测框架,能够有效地融合三种互补模态:从单目中预测的法线图、RGB图像和事件流。为了优化融合过程,我们的框架采用了两个关键模块:自适应双流融合模块(ADFM),它融合了RGB和法图特征;事件模态感知融合模块(EAFM),它适应了事件数据的高动态范围特性。在DSEC-Det-sub和PKU-DAVIS-SOD数据集上的广泛评估表明,NRE-Net显著优于最先进的方法。我们的方法在基于帧的方法(例如YOLOX)的基础上提高了mAP50的准确度,达到7.9%和6.1%,而在基于融合的方法中,相较于SFNet在DSEC-Det-sub数据集上提高了2.7%,相较于SODFormer在PKU-DAVIS-SOD数据集上提高了7.1%。
论文及项目相关链接
摘要
在恶劣照明条件下准确的目标检测对于自动驾驶等实际应用至关重要。尽管神经形态事件相机已被引入处理这些情况,但恶劣的照明条件经常在隧道墙壁或路面表面引起干扰反射,这经常导致错误的障碍检测。然而,无论是RGB还是事件数据本身都不足以应对这些复杂性,而且不依赖额外传感器来减轻这些问题仍然是一个尚未充分研究的问题。为了克服这些挑战,本文提出了利用从单目RGB图像直接预测得到的法线图作为可靠的几何线索来抑制误报并提高检测准确性。本文介绍了NRE-Net,这是一种新型的多模态检测框架,它有效地融合了三种互补模态:从单目图像预测得到的表面法线图、RGB图像和事件流。为了优化融合过程,我们的框架采用了两个关键模块:自适应双流融合模块(ADFM),它融合了RGB和法线图特征;事件模态感知融合模块(EAFM),它适应了事件数据的高动态范围特性。在DSEC-Det-sub和PKU-DAVIS-SOD数据集上的广泛评估表明,NRE-Net显著优于最先进的方法。我们的方法在DSEC-Det-sub数据集上较基于帧的方法(例如YOLOX)提高了mAP50得分7.9%和6.1%,并在PKU-DAVIS-SOD数据集上较融合方法的SODFormer高出7.1%。
关键见解
- 在恶劣照明条件下,目标检测面临干扰反射问题,导致误报。
- 仅依赖RGB或事件数据不足以解决这些复杂性。
- 提出利用从单目RGB图像直接预测得到的法线图作为几何线索来提高检测准确性。
- 介绍NRE-Net多模态检测框架,融合了RGB图像、事件流和法线图三种模态。
- 框架包含两个关键模块:ADFM和EAFM,分别用于特征融合和适应事件数据的高动态范围特性。
点此查看论文截图

Self-Supervised YOLO: Leveraging Contrastive Learning for Label-Efficient Object Detection
Authors:Manikanta Kotthapalli, Reshma Bhatia, Nainsi Jain
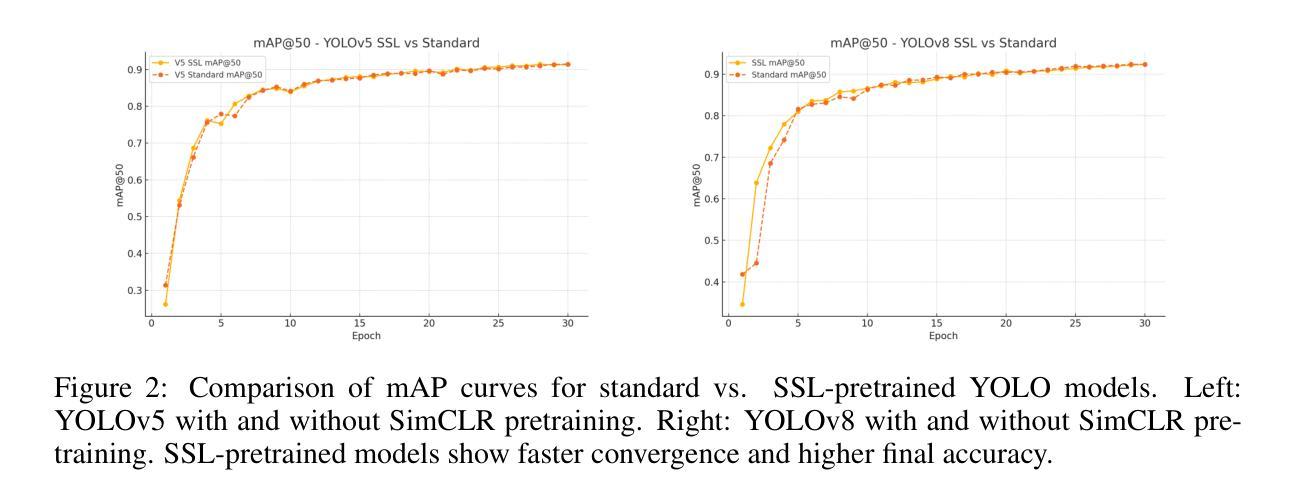
One-stage object detectors such as the YOLO family achieve state-of-the-art performance in real-time vision applications but remain heavily reliant on large-scale labeled datasets for training. In this work, we present a systematic study of contrastive self-supervised learning (SSL) as a means to reduce this dependency by pretraining YOLOv5 and YOLOv8 backbones on unlabeled images using the SimCLR framework. Our approach introduces a simple yet effective pipeline that adapts YOLO’s convolutional backbones as encoders, employs global pooling and projection heads, and optimizes a contrastive loss using augmentations of the COCO unlabeled dataset (120k images). The pretrained backbones are then fine-tuned on a cyclist detection task with limited labeled data. Experimental results show that SSL pretraining leads to consistently higher mAP, faster convergence, and improved precision-recall performance, especially in low-label regimes. For example, our SimCLR-pretrained YOLOv8 achieves a mAP@50:95 of 0.7663, outperforming its supervised counterpart despite using no annotations during pretraining. These findings establish a strong baseline for applying contrastive SSL to one-stage detectors and highlight the potential of unlabeled data as a scalable resource for label-efficient object detection.
单阶段目标检测器,如YOLO系列,在实时视觉应用中实现了最先进的性能,但仍严重依赖于大规模标注数据集进行训练。在这项工作中,我们对对比自监督学习(SSL)进行了系统研究,以减少对标注数据的依赖。我们通过使用SimCLR框架,对YOLOv5和YOLOv8的主干网络进行预训练,利用无标签图像来实现这一目标。我们的方法引入了一个简单有效的流程,将YOLO的卷积主干网络作为编码器,采用全局池化和投影头,并使用COCO无标签数据集(12万张图像)的增强版来优化对比损失。然后,在有限的标注数据上,对预训练的主干网络进行微调,以执行骑行者检测任务。实验结果表明,SSL预训练能持续提高mAP、加快收敛速度并改善精度-召回率性能,特别是在标注数据较少的情况下。例如,我们采用SimCLR预训练的YOLOv8在mAP@50:95上达到了0.7663,尽管在预训练过程中没有使用任何注释,仍优于其有监督的同类模型。这些发现为将对比SSL应用于单阶段检测器建立了强大的基线,并突出了无标签数据作为标签高效目标检测的可扩展资源的潜力。
论文及项目相关链接
PDF 11 pages, 9 figures
Summary
基于YOLO系列的一阶段目标检测器在实时视觉应用中取得了最先进的性能,但它们在训练过程中严重依赖于大规模标签数据集。本文系统性地研究了对比型自监督学习(SSL)技术,以减小对这种依赖程度。通过在未标记的图像上采用SimCLR框架预训练YOLOv5和YOLOv8的backbone部分,研究引入了简单有效的管道线。此方法对YOLO的卷积主干进行适应性调整,将其作为编码器,并利用全局池化和投影头来优化对比损失,并利用COCO无标签数据集的扩充进行优化训练。之后使用有限的标记数据对预训练的backbone进行微调,用于骑行者检测任务。实验结果表明,SSL预训练持续提高了mAP值、加快了收敛速度并改善了精度召回性能,特别是在标签稀缺的情况下。例如,使用SimCLR预训练的YOLOv8在mAP@50:95指标上达到了0.7663,尽管在预训练阶段未使用任何注释,但超越了其有监督训练下的性能水平。这一发现对于将对比型SSL应用在一阶段检测器上具有重要的里程碑意义,并突出了未标记数据作为标签高效目标检测的潜在可扩展资源。
Key Takeaways
- 一阶段目标检测器如YOLO系列在实时视觉应用中表现优异,但对大规模标签数据集依赖性强。
- 对比型自监督学习(SSL)用于减少这种依赖。
- 采用SimCLR框架进行预训练,使用未标记图像对YOLOv5和YOLOv8的backbone进行训练。
- 预训练模型在骑行者检测任务上通过有限的标记数据进行微调。
- SSL预训练提高了mAP值、加快了收敛速度并改善了精度召回性能。
- 在低标签数据情况下,SSL预训练尤为重要。
点此查看论文截图


Referring Remote Sensing Image Segmentation with Cross-view Semantics Interaction Network
Authors:Jiaxing Yang, Lihe Zhang, Huchuan Lu
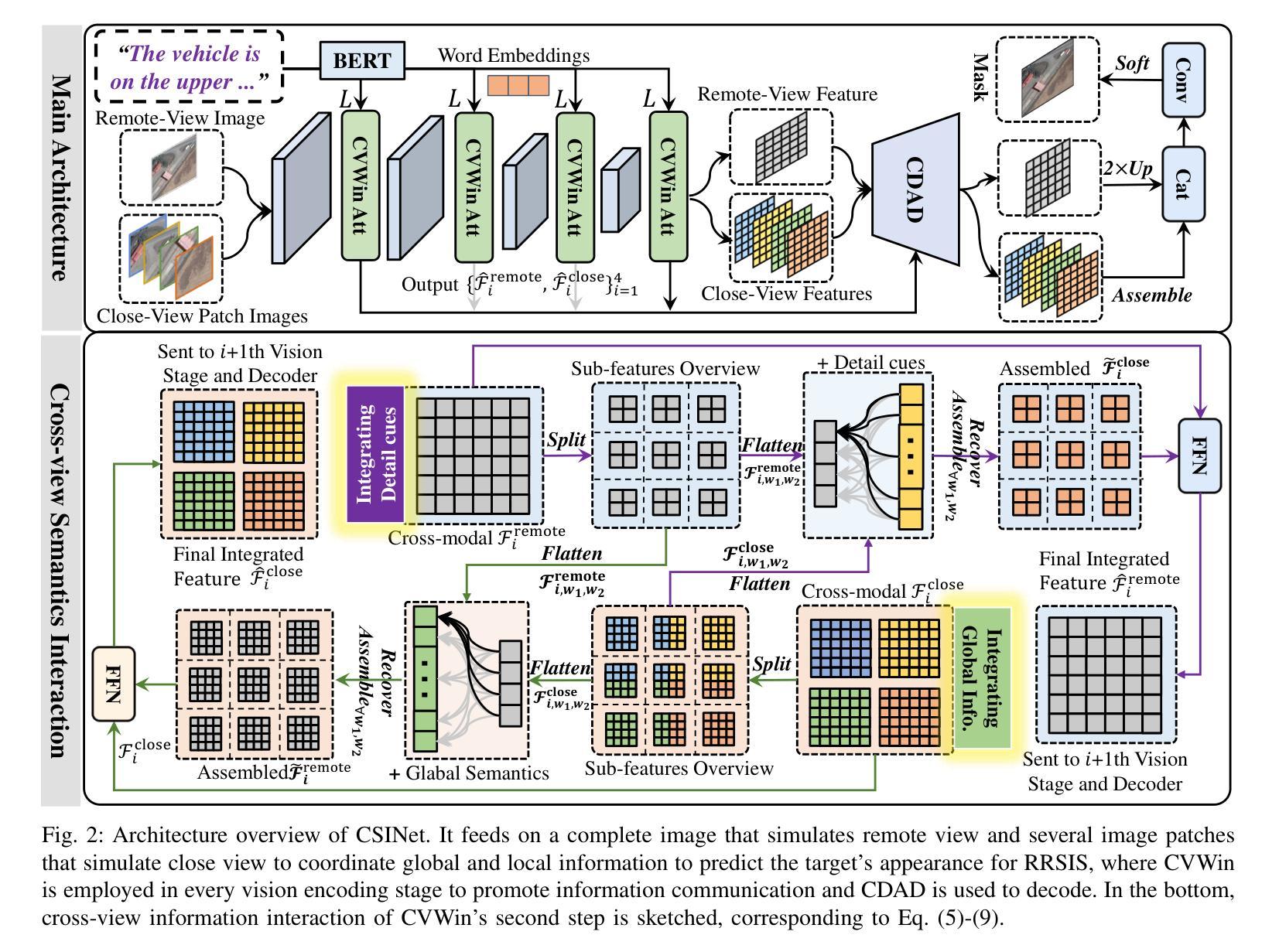
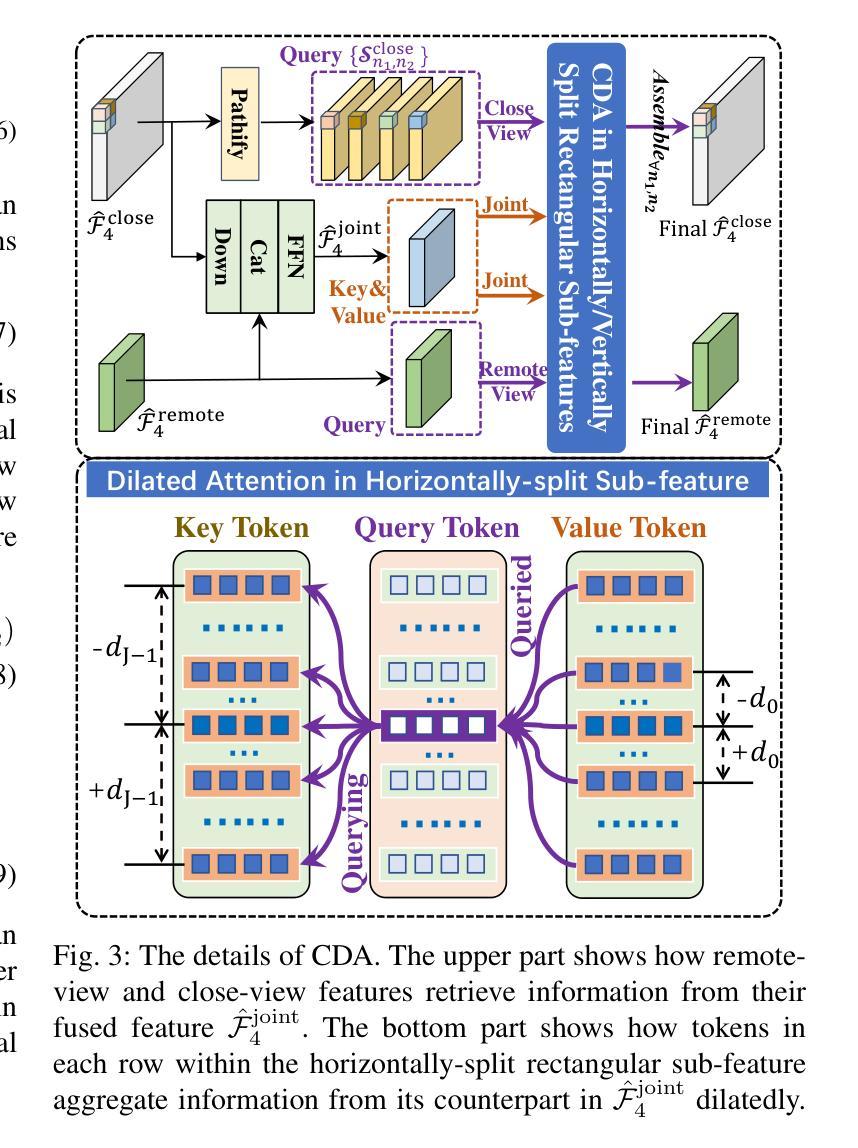
Recently, Referring Remote Sensing Image Segmentation (RRSIS) has aroused wide attention. To handle drastic scale variation of remote targets, existing methods only use the full image as input and nest the saliency-preferring techniques of cross-scale information interaction into traditional single-view structure. Although effective for visually salient targets, they still struggle in handling tiny, ambiguous ones in lots of real scenarios. In this work, we instead propose a paralleled yet unified segmentation framework Cross-view Semantics Interaction Network (CSINet) to solve the limitations. Motivated by human behavior in observing targets of interest, the network orchestrates visual cues from remote and close distances to conduct synergistic prediction. In its every encoding stage, a Cross-View Window-attention module (CVWin) is utilized to supplement global and local semantics into close-view and remote-view branch features, finally promoting the unified representation of feature in every encoding stage. In addition, we develop a Collaboratively Dilated Attention enhanced Decoder (CDAD) to mine the orientation property of target and meanwhile integrate cross-view multiscale features. The proposed network seamlessly enhances the exploitation of global and local semantics, achieving significant improvements over others while maintaining satisfactory speed.
最近,遥感图像分割(RRSIS)已引起了广泛关注。在处理遥感目标的尺度剧变时,现有方法仅使用全图作为输入,并将跨尺度信息交互的显著性优先技术嵌入到传统的单视图结构中。尽管对于视觉上显著的目标这些方法很有效,但在处理现实中大量的小型、模糊的目标时,它们仍然存在问题。在这项工作中,我们提出了一种并行但统一的分割框架——跨视图语义交互网络(CSINet),以解决这些限制。受人类观察感兴趣目标的行为的启发,该网络协调来自远近距离的视觉线索来进行协同预测。在其每个编码阶段,使用跨视图窗口注意力模块(CVWin)将全局和局部语义补充到近视图和远视图分支特征中,最终促进每个编码阶段特征的统一表示。此外,我们开发了一种协同扩张注意力增强解码器(CDAD),以挖掘目标的方向属性,同时集成跨视图的多尺度特征。所提出的网络无缝地增强了全局和局部语义的利用,在保持令人满意的运行速度的同时,实现了对他人成果的显著改进。
论文及项目相关链接
Summary
远程遥感图像分割(RRSIS)领域中的现有方法在处理尺度变化剧烈的遥感目标时存在局限性。为此,本文提出了一种并行统一的分割框架——跨视图语义交互网络(CSINet)。该网络模仿人类观察目标的行为,协调远程和近距离的视觉线索进行协同预测。在每个编码阶段,使用跨视图窗口注意力模块(CVWin)将全局和局部语义信息补充到近距离和远距离分支特征中,促进了每个编码阶段特征的统一表示。此外,还开发了一种协同扩张注意力增强解码器(CDAD),以挖掘目标的定向属性并同时整合跨视图的多尺度特征。所提出的网络无缝地提高了全局和局部语义的利用,在保持令人满意的速度的同时,实现了对其他人显著的提升。
Key Takeaways
- RRSIS领域中现有方法在处理尺度变化剧烈的遥感目标时存在挑战。
- 提出了一种新的并行统一的分割框架CSINet来解决这一问题。
- CSINet模仿人类观察目标的行为,融合远程和近距离的视觉线索进行协同预测。
- 跨视图窗口注意力模块(CVWin)在每个编码阶段融合全局和局部语义信息。
- 开发了一种协同扩张注意力增强解码器(CDAD)以挖掘目标的定向属性并整合多尺度特征。
点此查看论文截图

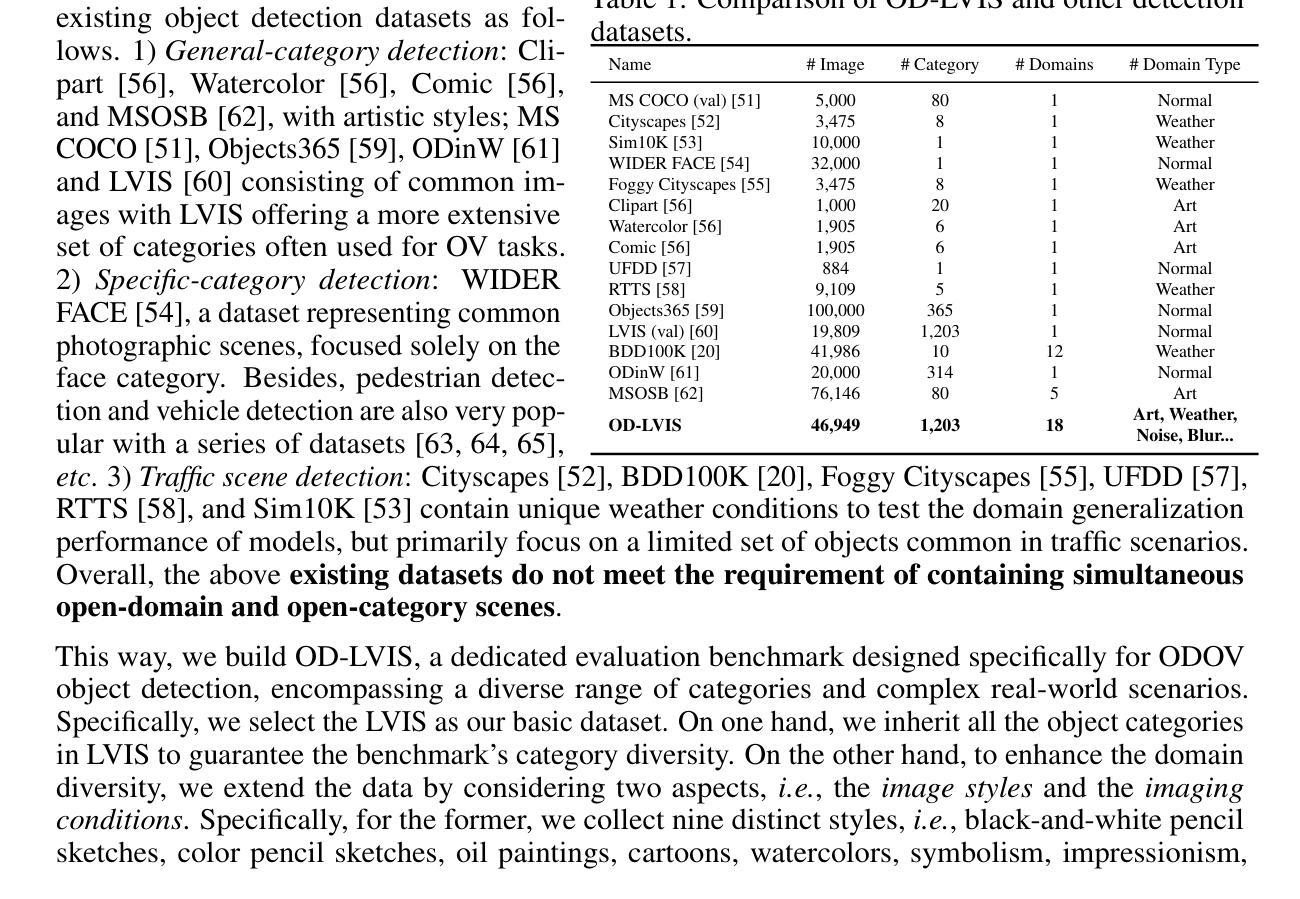
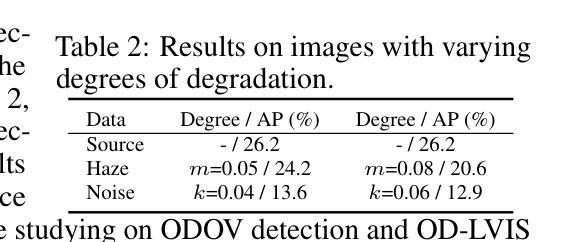
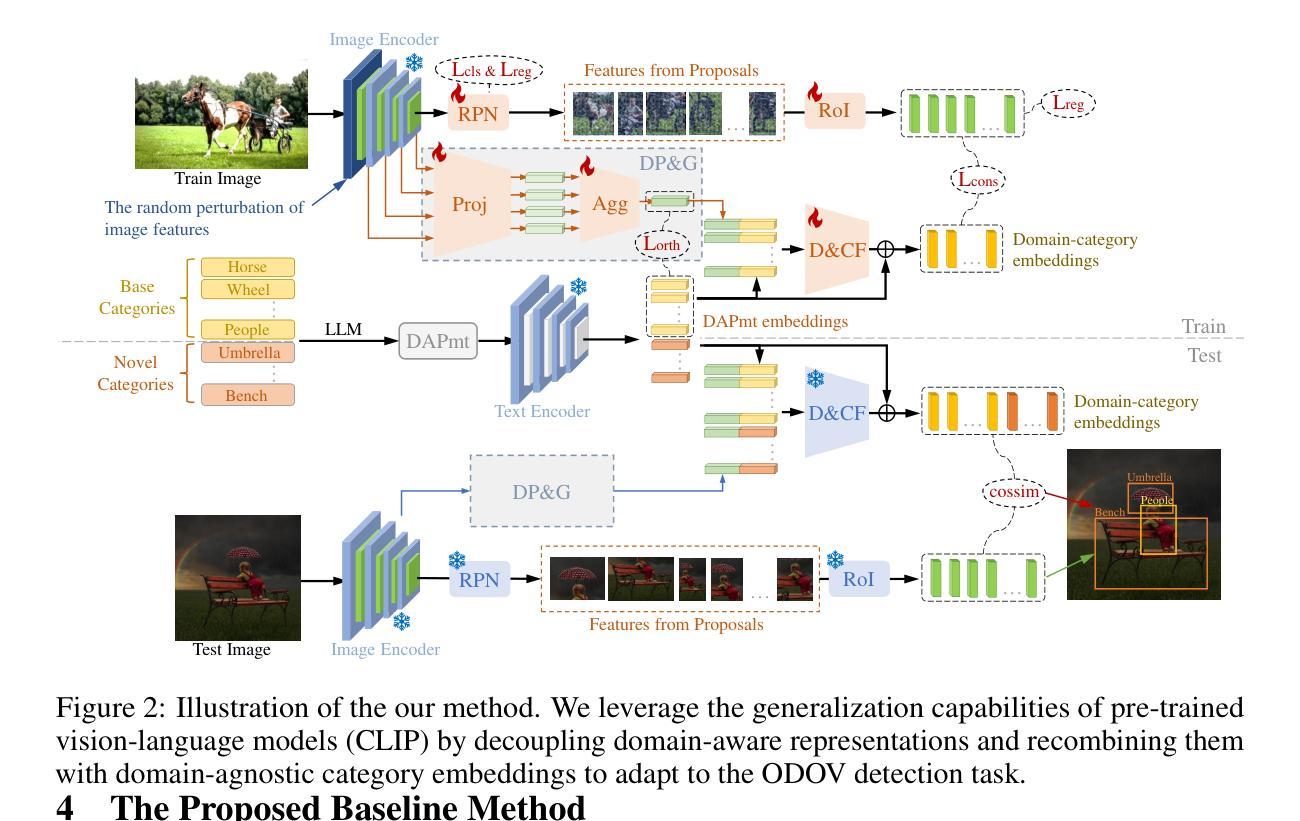
ODOV: Towards Open-Domain Open-Vocabulary Object Detection
Authors:Yupeng Zhang, Ruize Han, Fangnan Zhou, Song Wang, Wei Feng, Liang Wan
In this work, we handle a new problem of Open-Domain Open-Vocabulary (ODOV) object detection, which considers the detection model’s adaptability to the real world including both domain and category shifts. For this problem, we first construct a new benchmark OD-LVIS, which includes 46,949 images, covers 18 complex real-world domains and 1,203 categories, and provides a comprehensive dataset for evaluating real-world object detection. Besides, we develop a novel baseline method for ODOV detection.The proposed method first leverages large language models to generate the domain-agnostic text prompts for category embedding. It further learns the domain embedding from the given image, which, during testing, can be integrated into the category embedding to form the customized domain-specific category embedding for each test image. We provide sufficient benchmark evaluations for the proposed ODOV detection task and report the results, which verify the rationale of ODOV detection, the usefulness of our benchmark, and the superiority of the proposed method.
在这项工作中,我们解决了一个全新的开放域开放词汇表(ODOV)目标检测问题。这个问题考虑了检测模型对现实世界适应性的问题,包括领域和类别迁移。针对此问题,我们首先构建了一个新的基准测试OD-LVIS,其中包括46949张图像,涵盖18个复杂的现实世界领域和1203个类别,为评估现实世界目标检测提供了综合数据集。此外,我们还为ODOV检测开发了一种新的基线方法。该方法首先利用大型语言模型生成与领域无关的文字提示来进行类别嵌入。它进一步从给定的图像中学习领域嵌入,在测试期间,可以将其集成到类别嵌入中,以形成针对每个测试图像的自定义领域特定类别嵌入。我们对提出的ODOV检测任务进行了充分的基准评估并报告了结果,验证了ODOV检测的原理、我们基准测试的实用性和所提出方法的优越性。
论文及项目相关链接
Summary
该文章探讨了开放域开放词汇(ODOV)物体检测的新问题,关注检测模型在现实世界中的适应性,包括领域和类别迁移。为此,构建了新的基准数据集OD-LVIS,包含46,949张图像、涵盖18个复杂现实世界领域和1,203个类别,为评估现实世界物体检测提供了综合数据集。此外,开发了一种针对ODOV检测的基线方法,该方法利用大型语言模型生成与领域无关的文字提示来进行类别嵌入,并从给定图像中学习领域嵌入。在测试阶段,可以将领域嵌入集成到类别嵌入中,形成针对每个测试图像的自定义领域特定类别嵌入。文章提供了对提出的ODOV检测任务的充足基准评估,并报告了结果,验证了ODOV检测的原理、基准数据集的有用性以及所提出方法的优越性。
Key Takeaways
- 文章解决了开放域开放词汇(ODOV)物体检测的新问题,关注模型在现实世界的适应性。
- 构建了新的基准数据集OD-LVIS,包含多种领域的图像和丰富的类别,为评估现实世界物体检测提供了综合数据集。
- 提出了一种针对ODOV检测的基线方法,利用大型语言模型生成文字提示进行类别嵌入。
- 方法通过结合领域嵌入和类别嵌入,形成针对每个测试图像的自定义领域特定类别嵌入。
- 文章进行了充分的实验评估,验证了ODOV检测任务的重要性、基准数据集的有用性以及所提出方法的有效性。
- 该方法对于处理现实世界中复杂领域的物体检测问题具有潜力。
点此查看论文截图


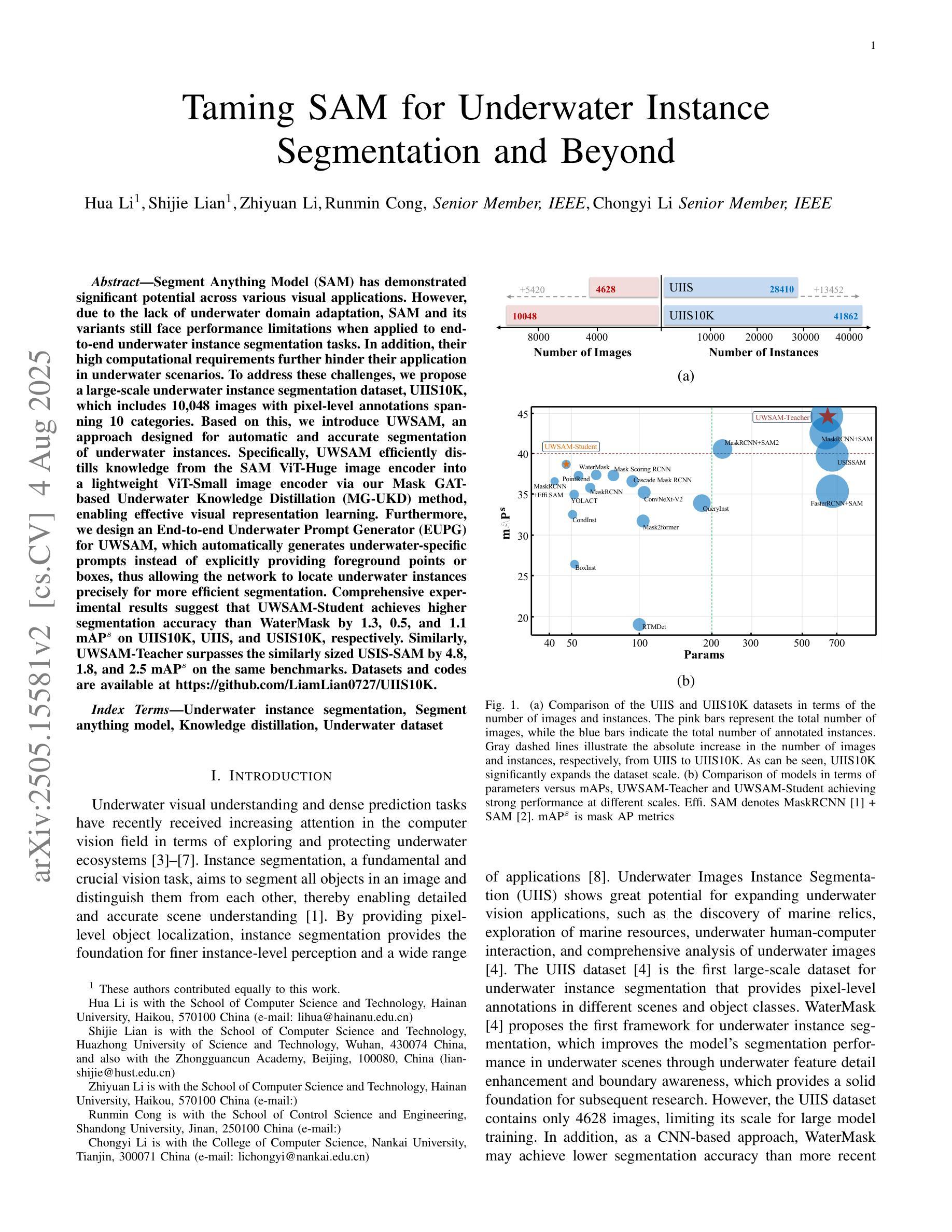
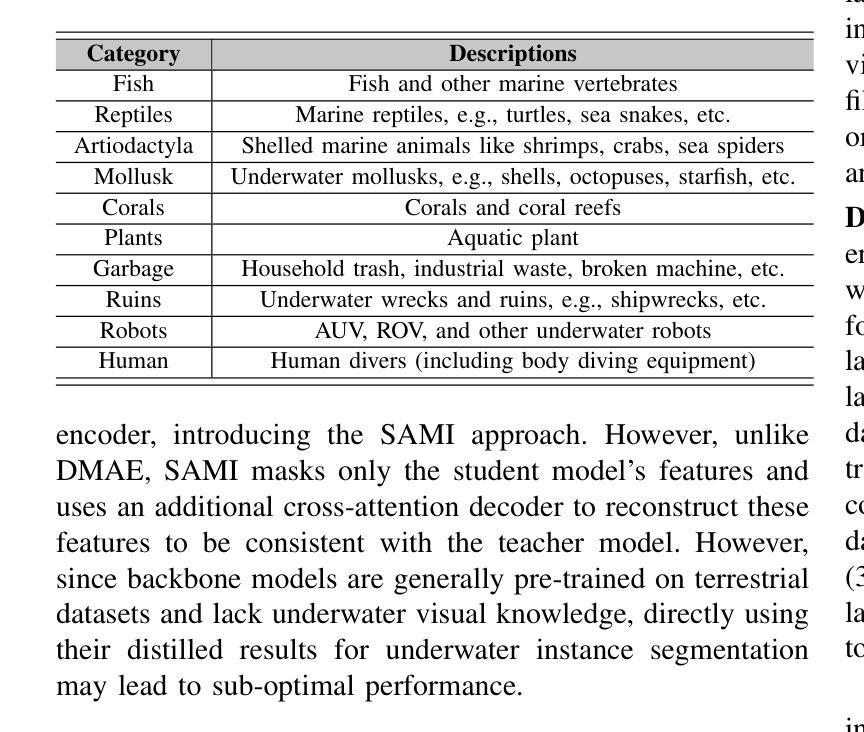
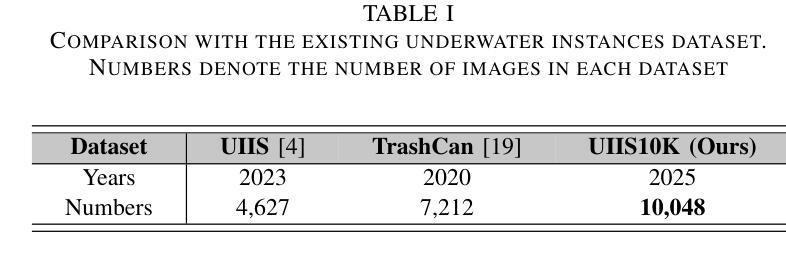
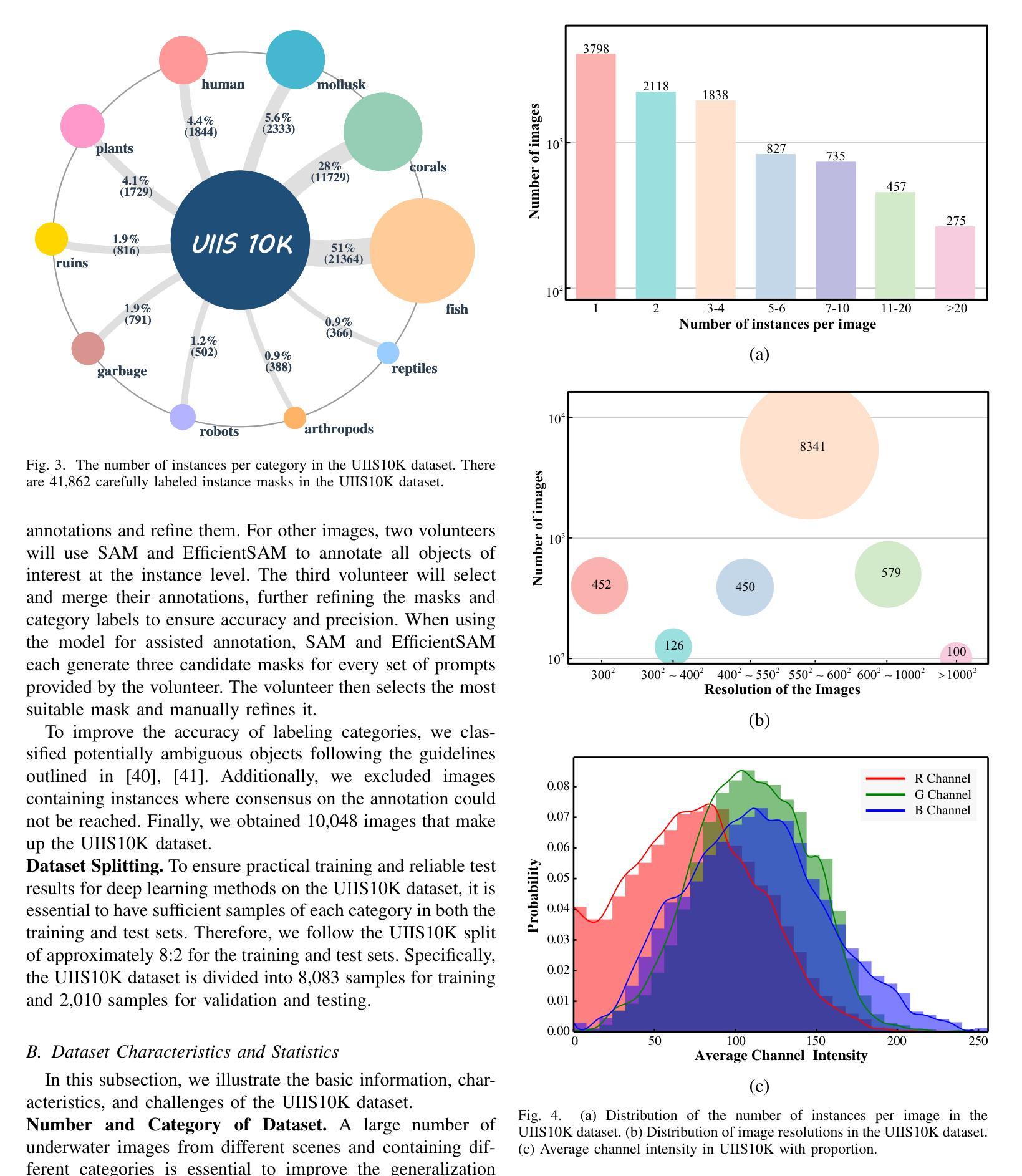
Taming SAM for Underwater Instance Segmentation and Beyond
Authors:Hua Li, Shijie Lian, Zhiyuan Li, Runmin Cong, Chongyi Li
With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at https://github.com/LiamLian0727/UIIS10K.
随着大规模建模的最新突破,Segment Anything Model(SAM)在各种视觉应用中表现出了巨大的潜力。然而,由于缺乏水下领域的专业知识,SAM及其变体在端到端的水下实例分割任务中面临性能局限,而它们较高的计算要求进一步阻碍了在水下场景中的应用。为了应对这一挑战,我们提出了大规模水下实例分割数据集UIIS10K,其中包括10,048张具有像素级注释的10类图像。接着,我们介绍了专为自动和精确水下实例分割而设计的高效模型UWSAM。UWSAM通过基于Mask GAT的水下知识蒸馏(MG-UKD)方法,有效地从SAM的ViT-Huge图像编码器提炼知识,并应用到较小的ViT-Small图像编码器上,以实现有效的视觉表示学习。此外,我们为UWSAM设计了端到端的水下提示生成器(EUPG),它会自动生成水下提示,而不是显式提供前景点或框作为提示,从而使网络能够准确定位水下实例,实现高效分割。综合实验结果表明,我们的模型是有效的,在多个水下实例数据集上实现了对最先进方法的重要性能改进。数据集和代码可在[https://github.com/LiamLian0
论文及项目相关链接
Summary:
随着大规模建模技术的突破,Segment Anything Model(SAM)在多种视觉应用中展现出巨大潜力。然而,由于缺乏水下领域的专业知识,SAM及其变体在端到端的水下实例分割任务中的性能受到限制。为此,我们提出了大规模水下实例分割数据集UIIS10K,包含10,048张带有像素级注释的10类图像。同时,我们引入了面向水下实例自动准确分割的UWSAM模型。它通过Mask GAT基础水下知识蒸馏(MG-UKD)方法,有效地从SAM的ViT-Huge图像编码器中提炼知识,用于小型ViT-Small图像编码器的有效视觉表示学习。此外,我们为UWSAM设计了端到端水下提示生成器(EUPG),能够自动生成水下提示,使网络能够准确定位水下实例,实现高效分割。实验结果表明,我们的模型在多个水下实例数据集上实现了显著的性能提升。
Key Takeaways:
- Segment Anything Model(SAM)在视觉应用中有巨大潜力,但在水下实例分割方面存在性能限制。
- 缺乏水下领域的专业知识是SAM及其变体在水下应用中的一大挑战。
- 提出了大规模水下实例分割数据集UIIS10K,包含10,048张带有像素级注释的图像。
- 引入了面向水下实例分割的UWSAM模型,具有高效的知识提炼和视觉表示学习能力。
- UWSAM通过Mask GAT基础水下知识蒸馏(MG-UKD)方法提升性能。
- 介绍了端到端水下提示生成器(EUPG),能够自动生成水下提示,提高网络定位水下实例的准确性。
点此查看论文截图