⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-06 更新
ASDR: Exploiting Adaptive Sampling and Data Reuse for CIM-based Instant Neural Rendering
Authors:Fangxin Liu, Haomin Li, Bowen Zhu, Zongwu Wang, Zhuoran Song, Habing Guan, Li Jiang
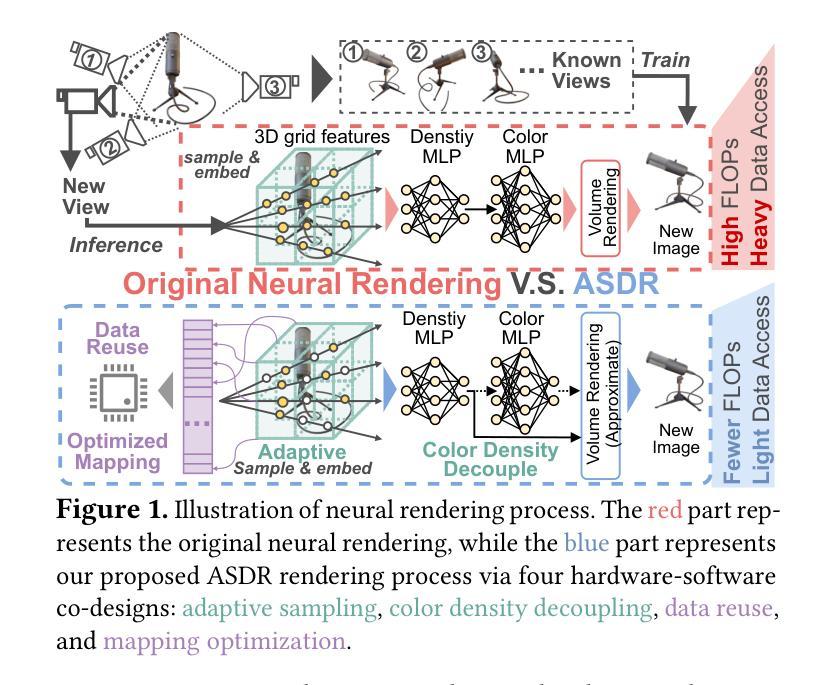
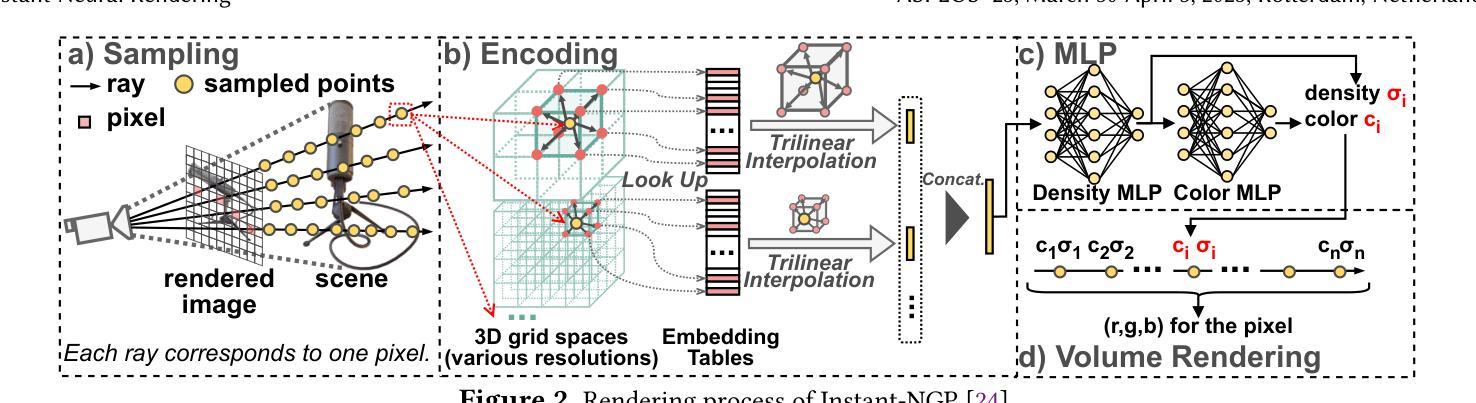
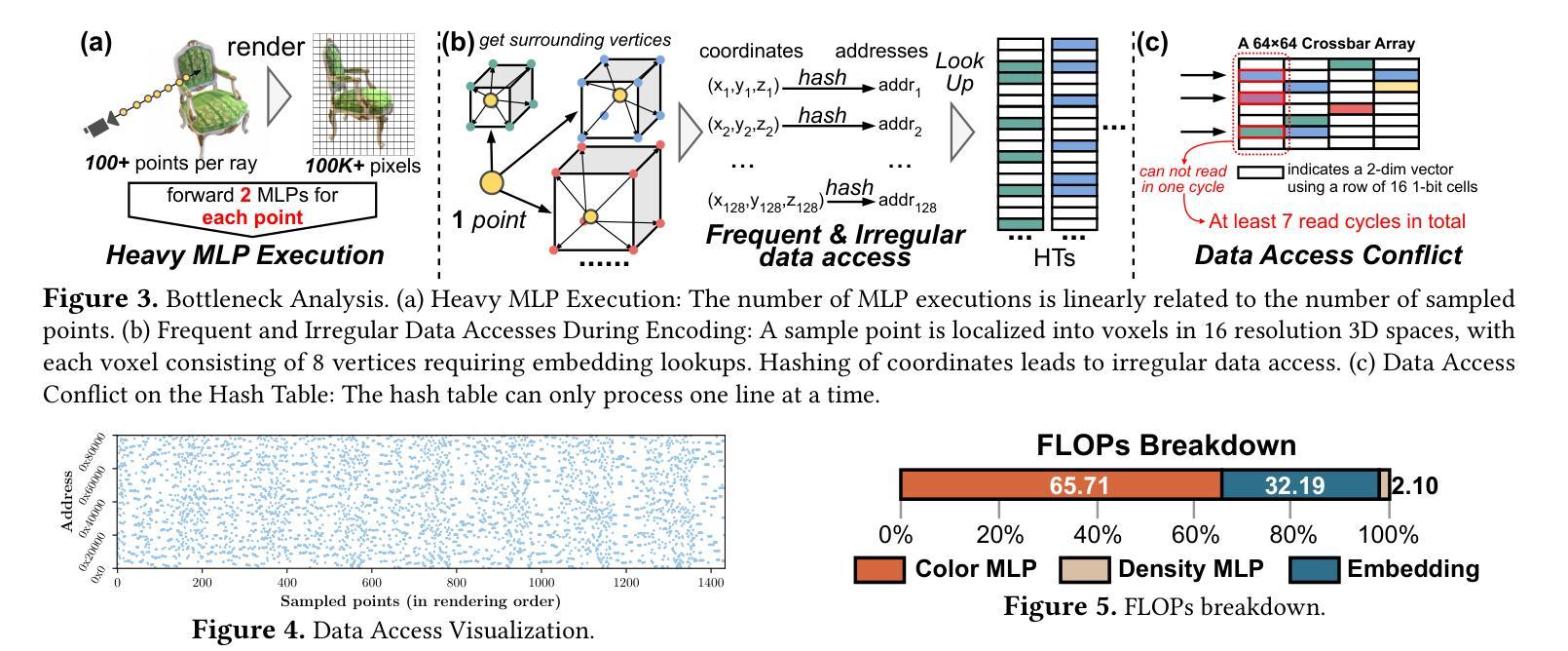
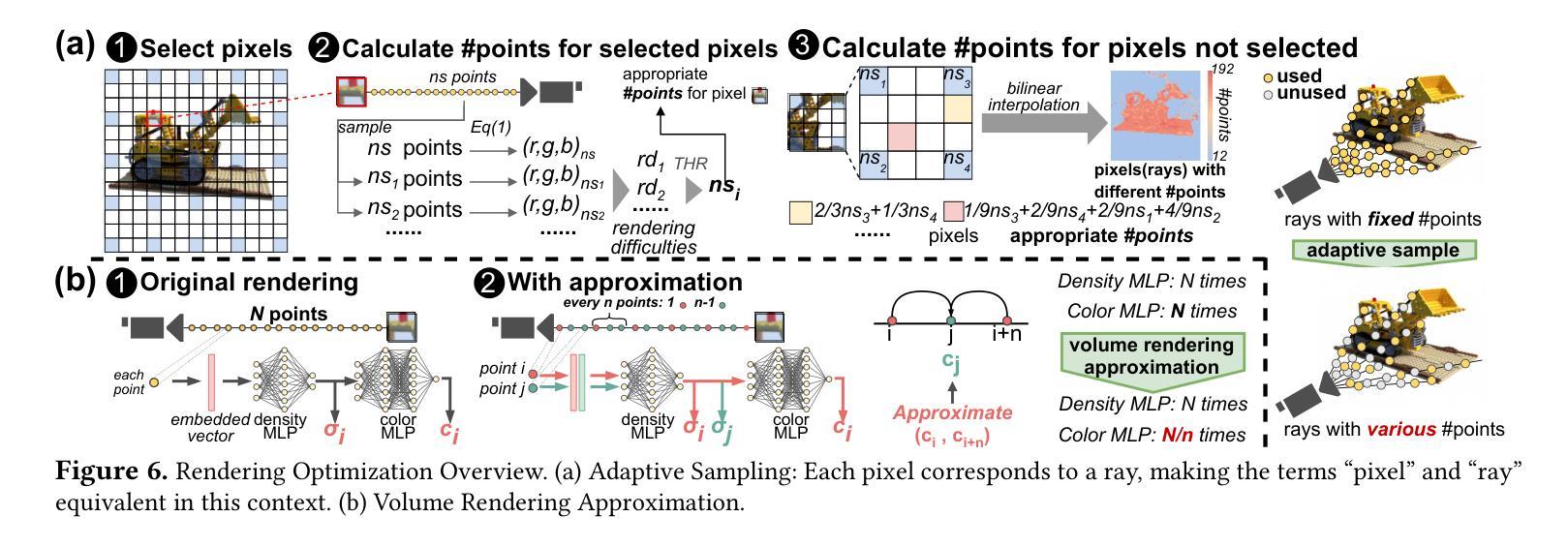
Neural Radiance Fields (NeRF) offer significant promise for generating photorealistic images and videos. However, existing mainstream neural rendering models often fall short in meeting the demands for immediacy and power efficiency in practical applications. Specifically, these models frequently exhibit irregular access patterns and substantial computational overhead, leading to undesirable inference latency and high power consumption. Computing-in-memory (CIM), an emerging computational paradigm, has the potential to address these access bottlenecks and reduce the power consumption associated with model execution. To bridge the gap between model performance and real-world scene requirements, we propose an algorithm-architecture co-design approach, abbreviated as ASDR, a CIM-based accelerator supporting efficient neural rendering. At the algorithmic level, we propose two rendering optimization schemes: (1) Dynamic sampling by online sensing of the rendering difficulty of different pixels, thus reducing access memory and computational overhead. (2) Reducing MLP overhead by decoupling and approximating the volume rendering of color and density. At the architecture level, we design an efficient ReRAM-based CIM architecture with efficient data mapping and reuse microarchitecture. Experiments demonstrate that our design can achieve up to $9.55\times$ and $69.75\times$ speedup over state-of-the-art NeRF accelerators and Xavier NX GPU in graphics rendering tasks with only $0.1$ PSNR loss.
神经辐射场(NeRF)在生成真实感图像和视频方面显示出巨大的潜力。然而,现有的主流神经渲染模型往往在实际应用中难以满足即时性和能效的要求。具体来说,这些模型经常出现不规则的数据访问模式以及大量的计算开销,导致推理延迟和较高的功耗。作为新兴计算范式,计算内存(CIM)具有解决这些访问瓶颈和降低模型执行相关功耗的潜力。为了弥模型性能与现实场景需求之间的差距,我们提出了一种算法与架构协同设计的方法,简称为ASDR,这是一种基于CIM的加速器,支持高效的神经渲染。在算法层面,我们提出了两种渲染优化方案:(1)通过在线感知不同像素的渲染难度进行动态采样,从而减少内存访问和计算开销。(2)通过解耦并近似颜色和密度的体积渲染来减少MLP的开销。在架构层面,我们设计了一种基于ReRAM的高效CIM架构,具有高效的数据映射和重用微架构。实验表明,我们的设计在图形渲染任务中比最先进的NeRF加速器和Xavier NX GPU加速高达9.55倍和69.75倍,同时只有0.1的峰值信噪比损失。
论文及项目相关链接
PDF Accepted by the 2025 International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2025). The paper will be presented at ASPLOS 2026
摘要
神经网络辐射场(NeRF)在生成真实感图像和视频方面展现出巨大潜力。然而,现有主流神经渲染模型在实际应用中难以满足即时性和能效需求。本文通过计算内存(CIM)技术来解决访问瓶颈,减少模型执行时的功耗,提出了一种基于CIM的加速器算法架构协同设计方法(简称ASDR),支持高效神经渲染。算法层面,我们提出两种渲染优化方案:动态采样,在线感知不同像素的渲染难度以降低内存访问和计算开销;分离并近似颜色和密度的体积渲染以减少MLP开销。架构层面,我们设计了一种高效的基于ReRAM的CIM架构,具有高效的数据映射和重用微架构。实验表明,我们的设计在图形渲染任务中相较于最新NeRF加速器和Xavier NX GPU,速度提升可达9.55倍和69.75倍,同时只有0.1 PSNR损失。
关键见解
- 神经网络辐射场(NeRF)在生成真实感图像和视频方面表现出卓越性能。
- 现有神经渲染模型存在即时性和能效问题,难以满足实际应用需求。
- 计算内存(CIM)技术有助于解决访问瓶颈,降低模型执行功耗。
- 提出一种基于CIM的加速器算法架构协同设计方法(ASDR),支持高效神经渲染。
- 在算法层面,通过动态采样和体积渲染的分离近似优化渲染性能。
- 在架构层面,设计高效的基于ReRAM的CIM架构,具有优秀的数据映射和重用特性。
点此查看论文截图

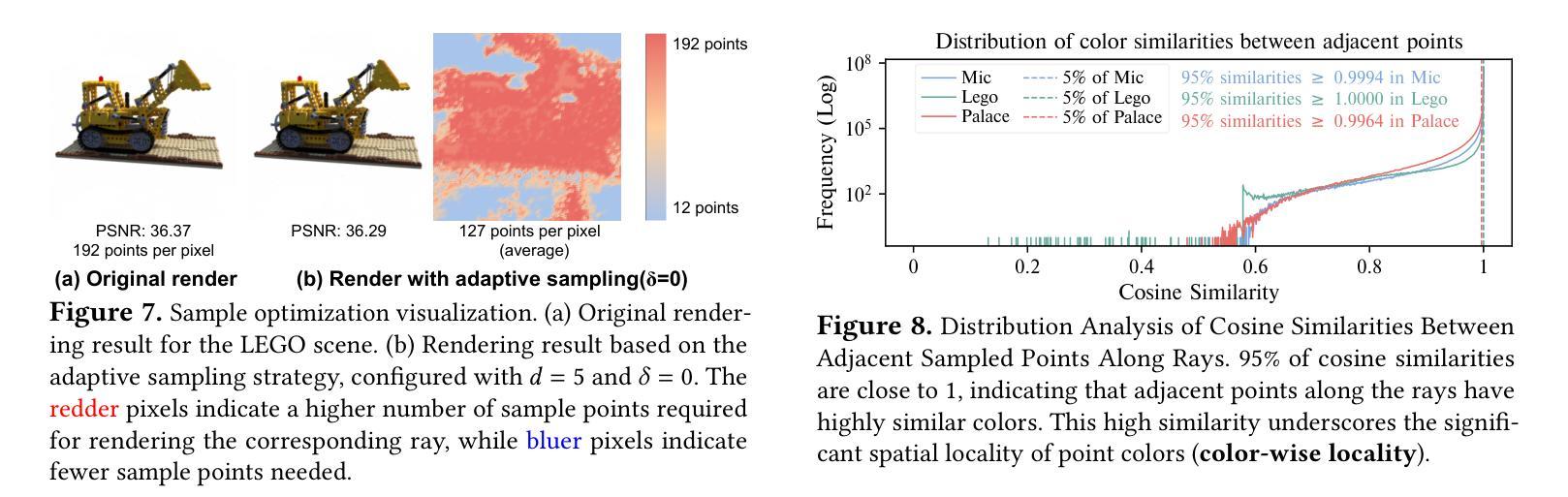

Imbalance-Robust and Sampling-Efficient Continuous Conditional GANs via Adaptive Vicinity and Auxiliary Regularization
Authors:Xin Ding, Yun Chen, Yongwei Wang, Kao Zhang, Sen Zhang, Peibei Cao, Xiangxue Wang
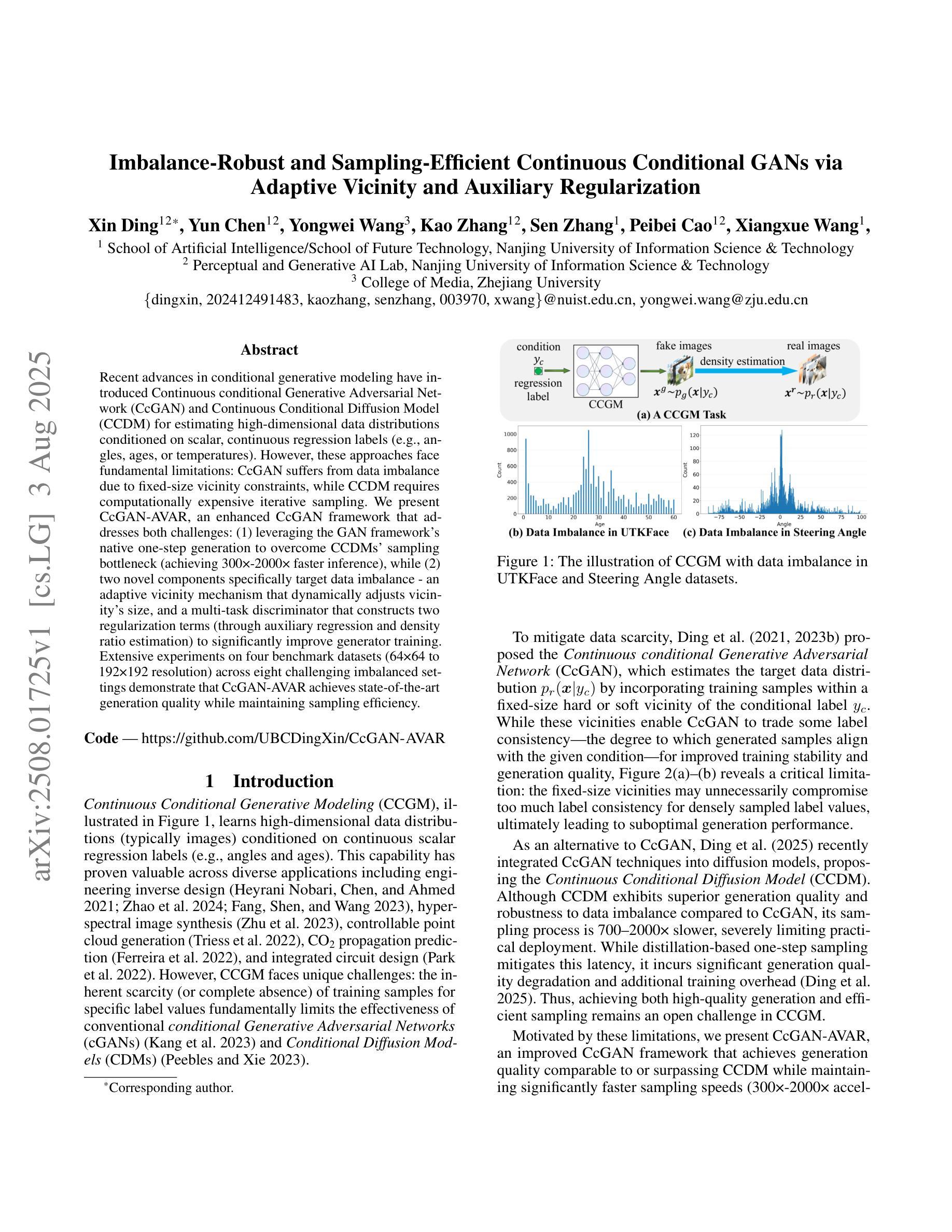
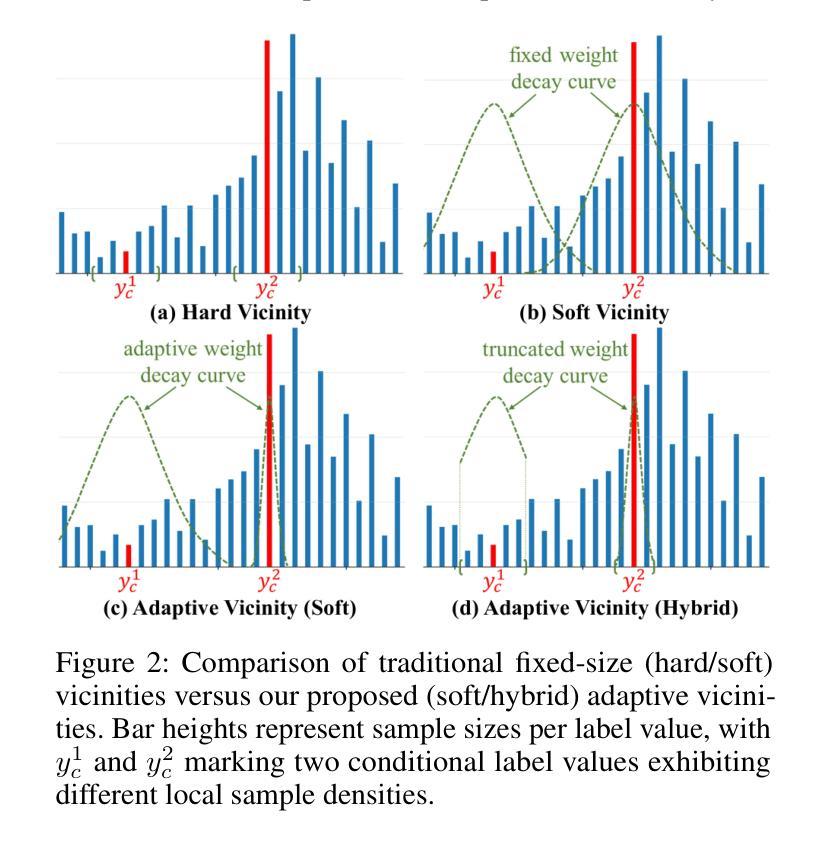
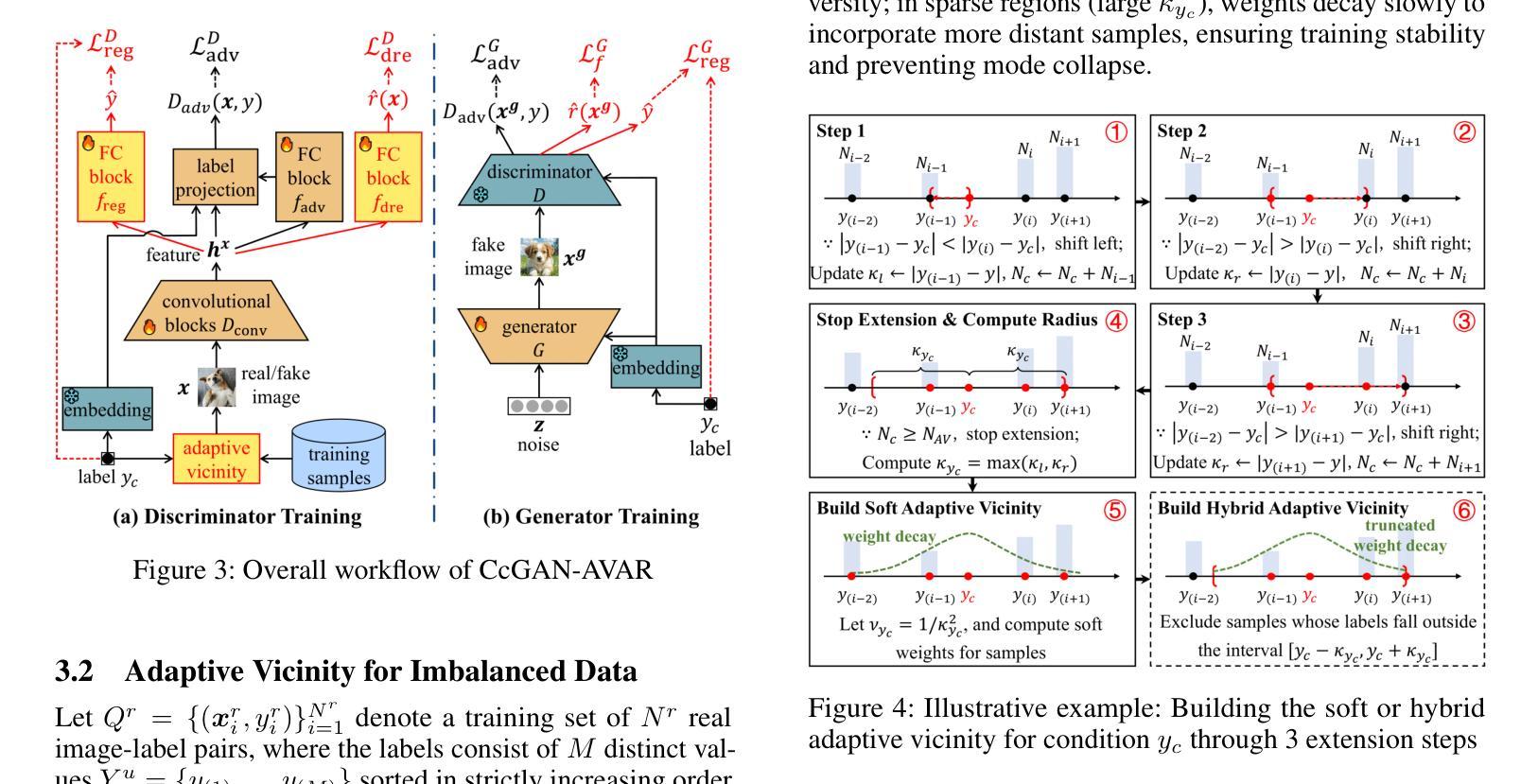
Recent advances in conditional generative modeling have introduced Continuous conditional Generative Adversarial Network (CcGAN) and Continuous Conditional Diffusion Model (CCDM) for estimating high-dimensional data distributions conditioned on scalar, continuous regression labels (e.g., angles, ages, or temperatures). However, these approaches face fundamental limitations: CcGAN suffers from data imbalance due to fixed-size vicinity constraints, while CCDM requires computationally expensive iterative sampling. We present CcGAN-AVAR, an enhanced CcGAN framework that addresses both challenges: (1) leveraging the GAN framework’s native one-step generation to overcome CCDMs’ sampling bottleneck (achieving 300x-2000x faster inference), while (2) two novel components specifically target data imbalance - an adaptive vicinity mechanism that dynamically adjusts vicinity’s size, and a multi-task discriminator that constructs two regularization terms (through auxiliary regression and density ratio estimation) to significantly improve generator training. Extensive experiments on four benchmark datasets (64x64 to 192x192 resolution) across eight challenging imbalanced settings demonstrate that CcGAN-AVAR achieves state-of-the-art generation quality while maintaining sampling efficiency.
最近条件生成模型的进展引入了连续条件生成对抗网络(CcGAN)和连续条件扩散模型(CCDM),用于估计基于标量、连续回归标签的高维数据分布(例如角度、年龄或温度)。然而,这些方法面临根本性局限:CcGAN由于固定大小的邻近约束而受到数据不平衡的影响,而CCDM需要计算昂贵的迭代采样。我们提出了CcGAN-AVAR,这是一种增强的CcGAN框架,解决了这两个挑战:(1)利用GAN框架的一次性生成来克服CCDM的采样瓶颈(实现300倍至2000倍更快的推理速度),同时(2)两个新组件专门解决数据不平衡问题——一种自适应邻近机制,可动态调整邻近大小,以及一个多任务鉴别器,构建两个正则化项(通过辅助回归和密度比率估计),以显著改善生成器训练。在四个基准数据集(分辨率从64x64到192x192)进行的八个具有挑战性的不平衡设置的大量实验表明,CcGAN-AVAR在保持采样效率的同时实现了最先进的生成质量。
论文及项目相关链接
Summary
新一代连续条件生成模型如CcGAN-AVAR在解决高维数据分布估计问题上取得了显著进展,尤其适用于基于连续回归标签的条件生成任务。相较于传统方法如CcGAN和CCDM,CcGAN-AVAR通过改进框架设计克服了数据不平衡和计算成本高昂的问题。它采用一步生成法提升采样效率,同时引入自适应邻近机制和多任务鉴别器改善数据不平衡问题。实验证明,CcGAN-AVAR在多个数据集上实现了出色的生成质量和采样效率。
Key Takeaways
- 连续条件生成模型(如CcGAN-AVAR)适用于基于连续回归标签的高维数据分布估计。
- 传统方法如CcGAN和CCDM存在数据不平衡和计算成本问题。
- CcGAN-AVAR通过改进框架设计克服这些问题,包括一步生成法提升采样效率。
- CcGAN-AVAR引入自适应邻近机制和多任务鉴别器改善数据不平衡问题。
- CcGAN-AVAR在多个数据集上实现了出色的生成质量和采样效率。
- 自适应邻近机制能动态调整邻近大小以应对数据不平衡问题。
点此查看论文截图
Cooperative Perception: A Resource-Efficient Framework for Multi-Drone 3D Scene Reconstruction Using Federated Diffusion and NeRF
Authors:Massoud Pourmandi
The proposal introduces an innovative drone swarm perception system that aims to solve problems related to computational limitations and low-bandwidth communication, and real-time scene reconstruction. The framework enables efficient multi-agent 3D/4D scene synthesis through federated learning of shared diffusion model and YOLOv12 lightweight semantic extraction and local NeRF updates while maintaining privacy and scalability. The framework redesigns generative diffusion models for joint scene reconstruction, and improves cooperative scene understanding, while adding semantic-aware compression protocols. The approach can be validated through simulations and potential real-world deployment on drone testbeds, positioning it as a disruptive advancement in multi-agent AI for autonomous systems.
提案介绍了一种创新的无人机群感知系统,旨在解决与计算限制、低带宽通信和实时场景重建相关的问题。该框架通过联合扩散模型的联邦学习、YOLOv12轻量级语义提取和局部NeRF更新,实现了高效的多智能体3D/4D场景合成,同时保持了隐私和可扩展性。该框架重新设计了用于联合场景重建的生成性扩散模型,提高了合作场景理解的能力,并增加了语义感知压缩协议。该方法可通过模拟和无人机测试平台上的潜在实际部署进行验证,定位其为多智能体人工智能自主系统领域的突破性进展。
论文及项目相关链接
PDF 15 pages, 3 figures, 1 table, 1 algorithm. Preprint based on NeurIPS 2024 template
Summary
该提案提出了一种创新的无人机群感知系统,旨在解决计算限制、低带宽通信和实时场景重建等问题。该系统通过联合场景重建的生成性扩散模型、语义感知压缩协议、联邦学习共享扩散模型、YOLOv12轻量级语义提取和局部NeRF更新,实现了高效的多智能体3D/4D场景合成。
Key Takeaways
- 无人机群感知系统旨在解决计算限制、低带宽通信和实时场景重建问题。
- 系统采用联邦学习、扩散模型和YOLOv12轻量级语义提取技术。
- 通过局部NeRF更新实现高效的多智能体3D/4D场景合成。
- 系统具备隐私保护和可扩展性。
- 语义感知压缩协议用于提高合作场景理解。
- 该系统可通过模拟和无人机测试平台上的真实世界部署进行验证。
点此查看论文截图

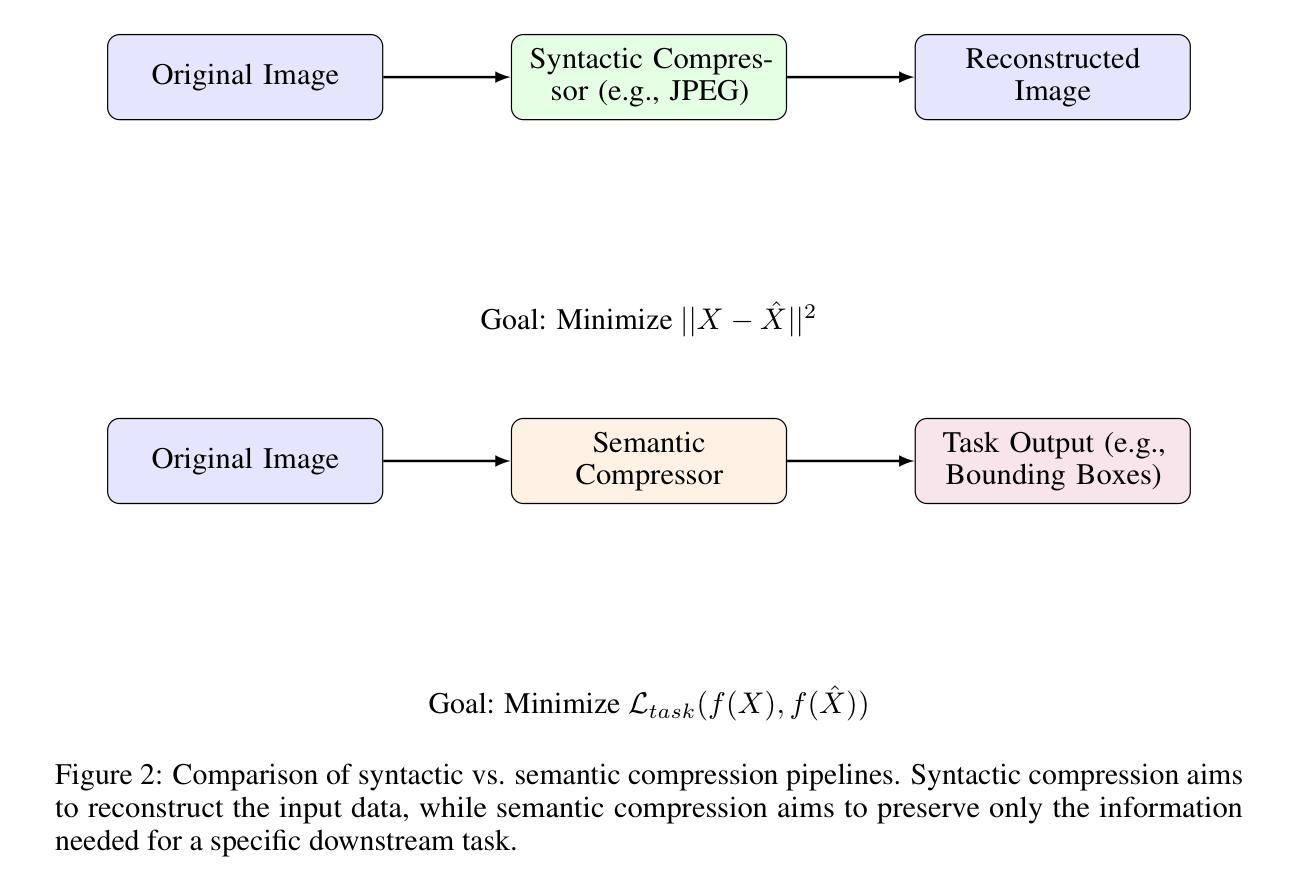
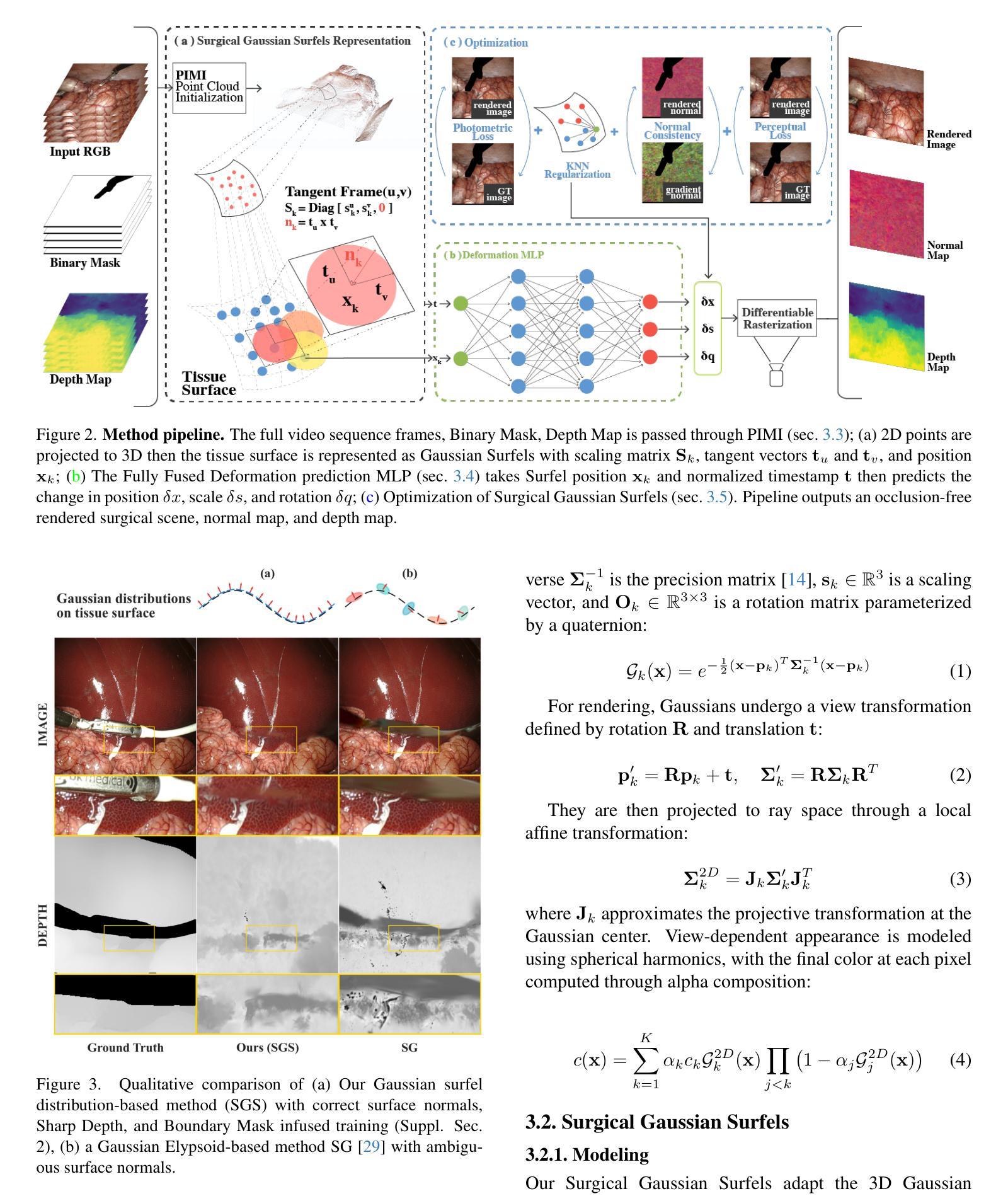
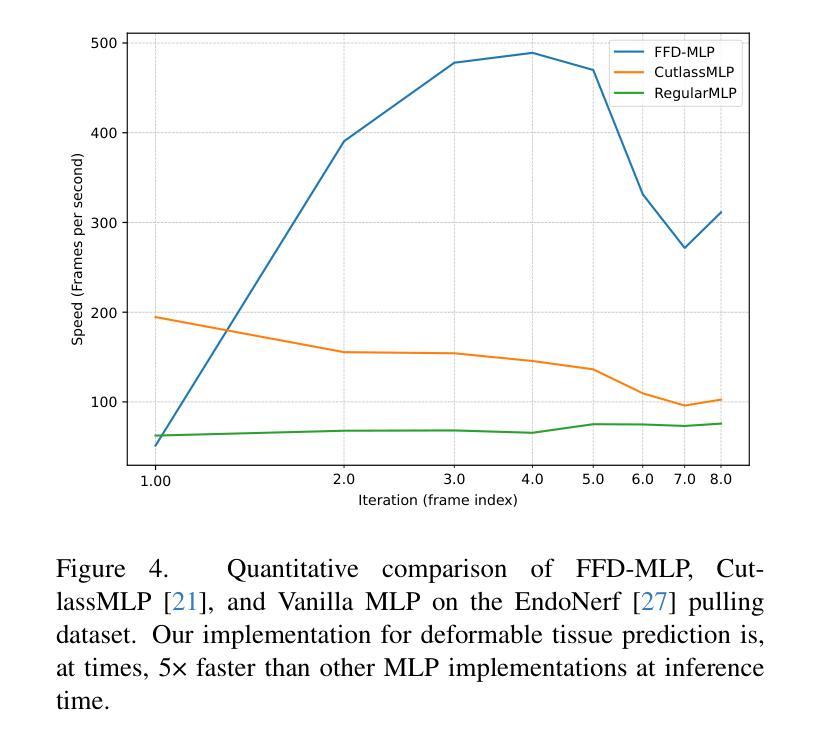
Surgical Gaussian Surfels: Highly Accurate Real-time Surgical Scene Rendering using Gaussian Surfels
Authors:Idris O. Sunmola, Zhenjun Zhao, Samuel Schmidgall, Yumeng Wang, Paul Maria Scheikl, Viet Pham, Axel Krieger
Accurate geometric reconstruction of deformable tissues in monocular endoscopic video remains a fundamental challenge in robot-assisted minimally invasive surgery. Although recent volumetric and point primitive methods based on neural radiance fields (NeRF) and 3D Gaussian primitives have efficiently rendered surgical scenes, they still struggle with handling artifact-free tool occlusions and preserving fine anatomical details. These limitations stem from unrestricted Gaussian scaling and insufficient surface alignment constraints during reconstruction. To address these issues, we introduce Surgical Gaussian Surfels (SGS), which transform anisotropic point primitives into surface-aligned elliptical splats by constraining the scale component of the Gaussian covariance matrix along the view-aligned axis. We also introduce the Fully Fused Deformation Multilayer Perceptron (FFD-MLP), a lightweight Multi-Layer Perceptron (MLP) that predicts accurate surfel motion fields up to 5x faster than a standard MLP. This is coupled with locality constraints to handle complex tissue deformations. We use homodirectional view-space positional gradients to capture fine image details by splitting Gaussian Surfels in over-reconstructed regions. In addition, we define surface normals as the direction of the steepest density change within each Gaussian surfel primitive, enabling accurate normal estimation without requiring monocular normal priors. We evaluate our method on two in-vivo surgical datasets, where it outperforms current state-of-the-art methods in surface geometry, normal map quality, and rendering efficiency, while remaining competitive in real-time rendering performance. We make our code available at https://github.com/aloma85/SurgicalGaussianSurfels
在单目内窥镜视频中,对可变形组织的精确几何重建仍然是机器人辅助微创手术中的一项基本挑战。尽管最近基于神经辐射场(NeRF)和3D高斯原始点的体积和点原始方法已经有效地呈现了手术场景,但它们仍然在处理无工具遮挡物和保留精细解剖细节方面存在困难。这些局限性源于高斯缩放的无限制性和重建过程中表面对齐约束的不足。为了解决这些问题,我们引入了手术高斯曲面元素(Surgical Gaussian Surfels,SGS),通过将高斯协方差矩阵的尺度成分约束在视图对齐轴上,将各向异性点原始点转换为与表面对齐的椭圆平板。我们还引入了全融合变形多层感知器(FFD-MLP),这是一个轻量级的多层感知器(MLP),它能够在比标准MLP快5倍的速度下预测准确的曲面运动场。这与局部约束相结合,可以处理复杂的组织变形。我们通过将高斯曲面元素在过度重建区域中进行拆分来捕捉图像中的细微细节,使用同方向视图空间位置梯度。此外,我们将表面法线定义为每个高斯曲面元素内密度变化最陡峭的方向,从而能够准确估计法线,而无需单目法线先验。我们在两个体内手术数据集上评估了我们的方法,该方法在表面几何、法线图质量和渲染效率方面均优于当前最新技术,同时在实时渲染性能方面保持竞争力。我们的代码可在https://github.com/aloma85/SurgicalGaussianSurfels上获取。
论文及项目相关链接
Summary
最新研究针对机器人辅助微创手术中内镜视频的可变形组织精准几何重建问题提出解决方案。引入Surgical Gaussian Surfels(SGS),通过约束高斯协方差矩阵尺度成分并沿视图对齐轴将点基元转化为表面对齐椭圆平面,解决了工具遮挡造成的伪影和解剖细节保留不足的问题。同时,提出Fully Fused Deformation Multilayer Perceptron(FFD-MLP),预测准确表面运动场,处理复杂组织变形。通过定义高斯surfel基元内密度变化最陡峭方向为表面法线,实现无需单眼法线先验的准确法线估计。在两个活体手术数据集上的评估表明,该方法在表面几何、法线图质量和渲染效率方面优于当前最先进方法,同时保持实时渲染性能竞争力。
Key Takeaways
- 机器人辅助微创手术中的内镜视频可变形组织几何重建仍是挑战。
- 当前基于NeRF和3D高斯基元的方法在处理工具遮挡和保留解剖细节方面存在局限性。
- 引入Surgical Gaussian Surfels(SGS)解决上述问题,通过约束高斯协方差矩阵实现更准确的重建。
- 提出Fully Fused Deformation Multilayer Perceptron(FFD-MLP)预测表面运动场,更快更准确地处理复杂组织变形。
- 利用密度变化定义表面法线,实现无需单眼法线先验的准确法线估计。
- 方法在多个数据集上表现优于现有方法,提高表面几何、法线图和渲染效率。
点此查看论文截图

GAS: Generative Avatar Synthesis from a Single Image
Authors:Yixing Lu, Junting Dong, Youngjoong Kwon, Qin Zhao, Bo Dai, Fernando De la Torre
We present a unified and generalizable framework for synthesizing view-consistent and temporally coherent avatars from a single image, addressing the challenging task of single-image avatar generation. Existing diffusion-based methods often condition on sparse human templates (e.g., depth or normal maps), which leads to multi-view and temporal inconsistencies due to the mismatch between these signals and the true appearance of the subject. Our approach bridges this gap by combining the reconstruction power of regression-based 3D human reconstruction with the generative capabilities of a diffusion model. In a first step, an initial 3D reconstructed human through a generalized NeRF provides comprehensive conditioning, ensuring high-quality synthesis faithful to the reference appearance and structure. Subsequently, the derived geometry and appearance from the generalized NeRF serve as input to a video-based diffusion model. This strategic integration is pivotal for enforcing both multi-view and temporal consistency throughout the avatar’s generation. Empirical results underscore the superior generalization ability of our proposed method, demonstrating its effectiveness across diverse in-domain and out-of-domain in-the-wild datasets.
我们提出了一个统一且可推广的框架,用于从单张图像合成视角一致且时间连贯的虚拟角色,解决了单图像虚拟角色生成的挑战任务。现有的基于扩散的方法通常依赖于稀疏的人体模板(例如深度或法线图),这会导致这些信号与主体真实外观之间的不匹配,从而产生多视角和时间上的不一致性。我们的方法通过结合基于回归的3D人体重建的重建能力与扩散模型的生成能力来弥补这一差距。首先,通过广义NeRF进行初步3D重建人体,提供全面的条件,确保高质量合成忠于参考外观和结构。随后,从广义NeRF派生的几何形状和外观作为视频扩散模型的输入。这种战略性的整合对于在虚拟角色生成过程中强制实施多视角和时间一致性至关重要。经验结果突显了我们所提出方法的出色泛化能力,证明了它在各种领域内外、真实场景数据集中的有效性。
论文及项目相关链接
PDF ICCV 2025; Project Page: https://humansensinglab.github.io/GAS/
Summary
本文提出了一种统一且通用的框架,用于从单张图像合成视角一致、时间连贯的虚拟角色。该框架结合回归式三维人体重建的重建能力与扩散模型的生成能力,解决了现有扩散模型依赖于稀疏人体模板而导致的多视角和时间不一致性问题。首先,通过通用NeRF进行初始三维人体重建,提供全面的条件,确保合成的高质量且忠于参考的外观和结构。接着,从通用NeRF派生的几何和外观作为视频扩散模型的输入,这对于强制执行多视角和时间连贯性至关重要。经验结果表明,该方法具有出色的泛化能力,在多种领域内的和领域外的野外数据集上都表现出其有效性。
Key Takeaways
- 提出了一种统一且通用的框架,用于从单张图像合成虚拟角色。
- 结合回归式三维人体重建与扩散模型的生成能力。
- 通过通用NeRF进行初始三维人体重建,提供全面的条件。
- 解决了现有扩散模型依赖于稀疏人体模板导致的问题。
- 通过视频扩散模型实现多视角和时间连贯性。
- 框架具有出色的泛化能力。
点此查看论文截图


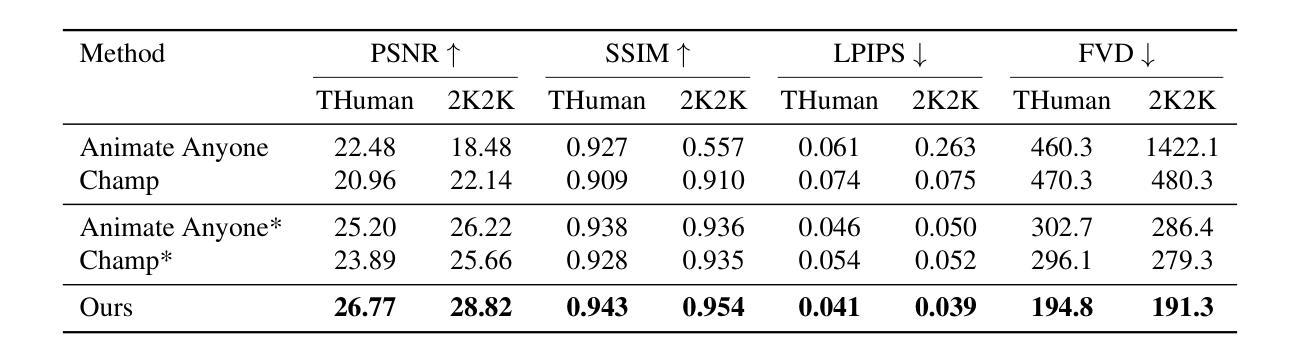
Sequential Gaussian Avatars with Hierarchical Motion Context
Authors:Wangze Xu, Yifan Zhan, Zhihang Zhong, Xiao Sun
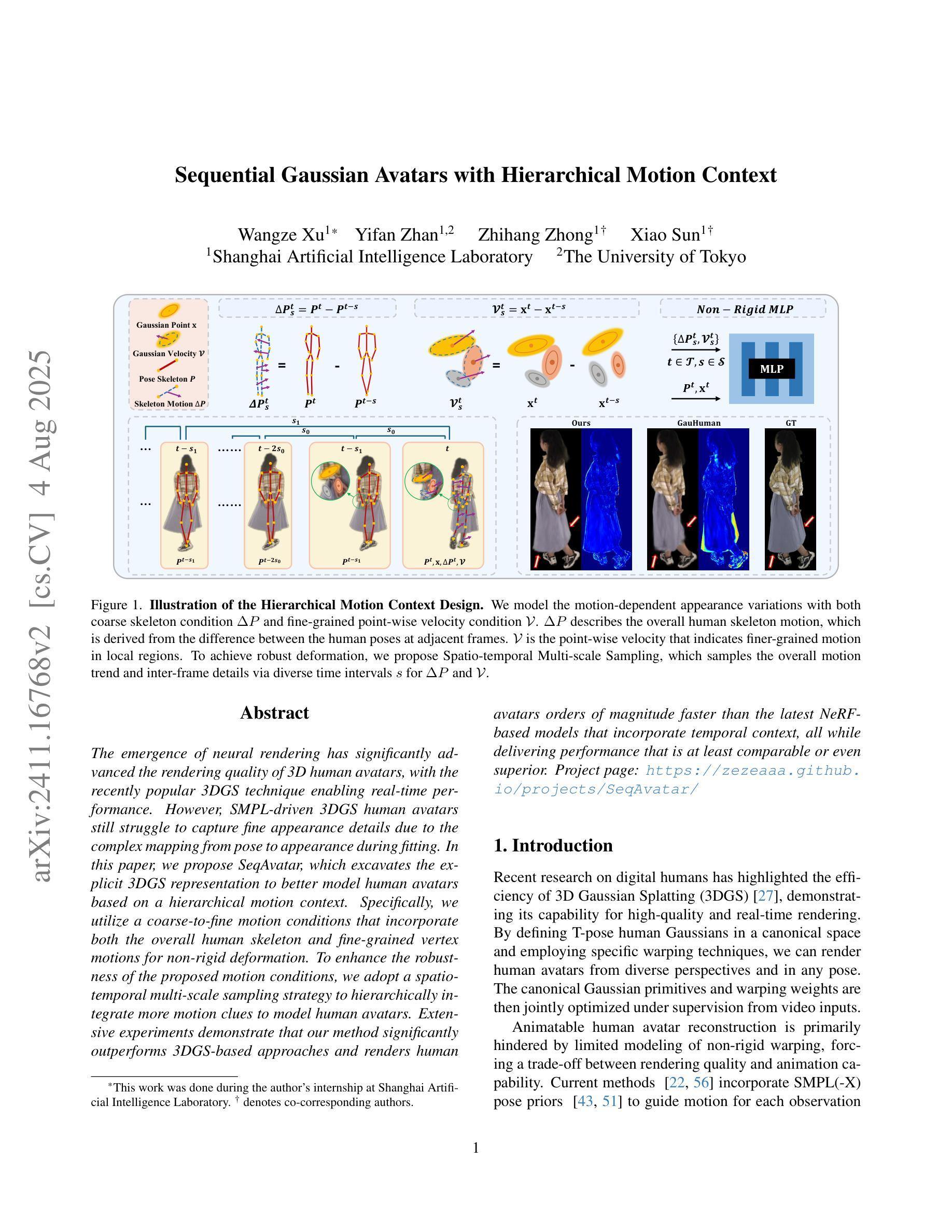
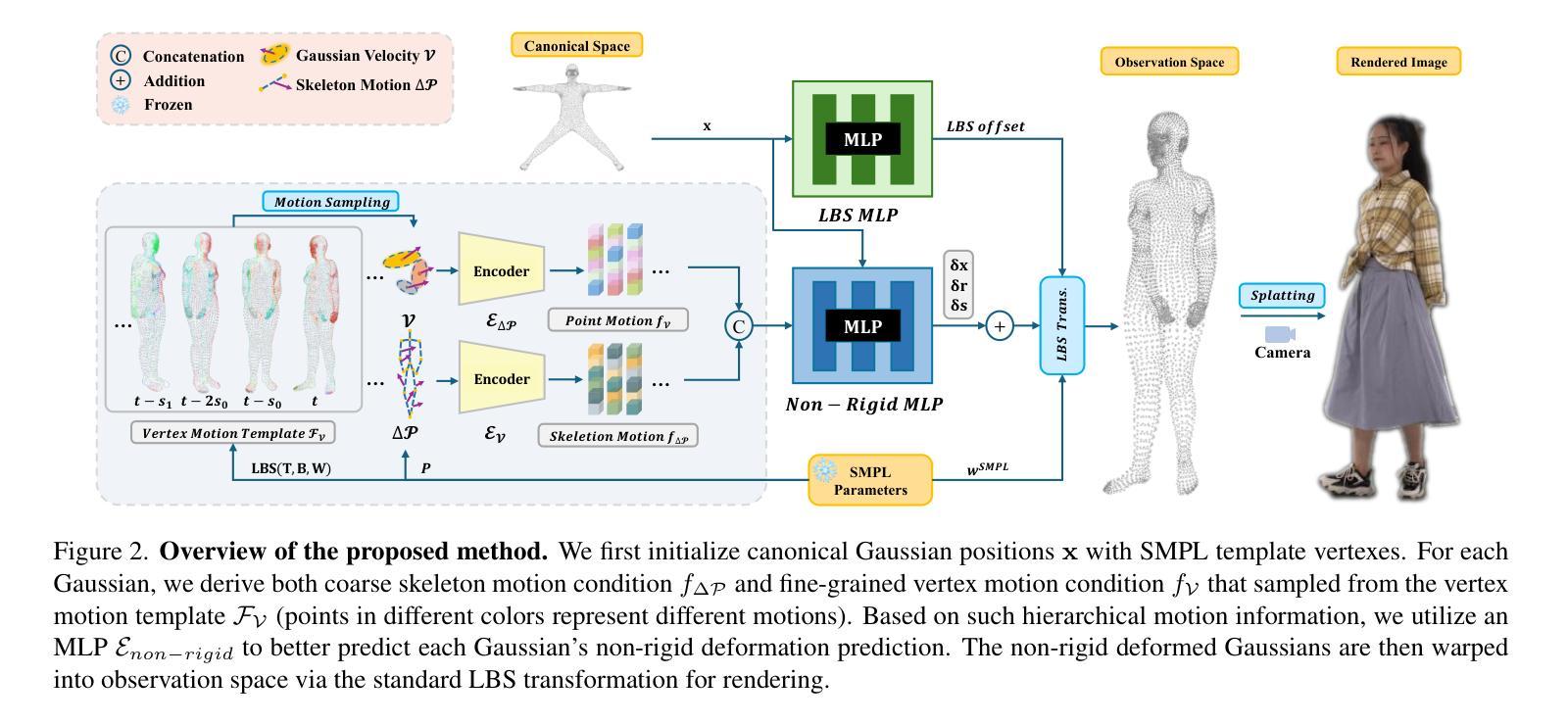
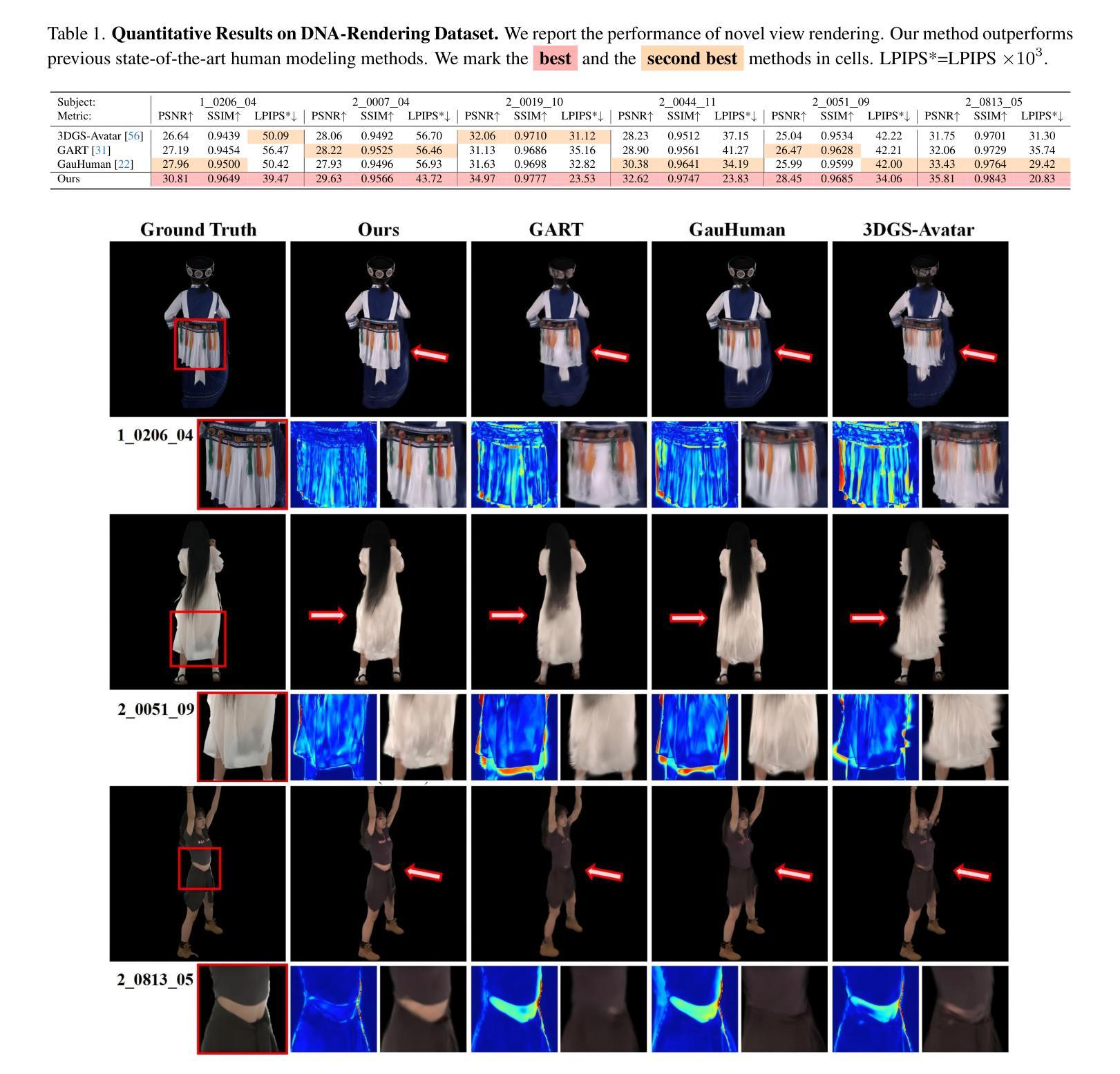
The emergence of neural rendering has significantly advanced the rendering quality of 3D human avatars, with the recently popular 3DGS technique enabling real-time performance. However, SMPL-driven 3DGS human avatars still struggle to capture fine appearance details due to the complex mapping from pose to appearance during fitting. In this paper, we propose SeqAvatar, which excavates the explicit 3DGS representation to better model human avatars based on a hierarchical motion context. Specifically, we utilize a coarse-to-fine motion conditions that incorporate both the overall human skeleton and fine-grained vertex motions for non-rigid deformation. To enhance the robustness of the proposed motion conditions, we adopt a spatio-temporal multi-scale sampling strategy to hierarchically integrate more motion clues to model human avatars. Extensive experiments demonstrate that our method significantly outperforms 3DGS-based approaches and renders human avatars orders of magnitude faster than the latest NeRF-based models that incorporate temporal context, all while delivering performance that is at least comparable or even superior. Project page: https://zezeaaa.github.io/projects/SeqAvatar/
神经渲染的出现极大地提高了3D人类角色模型的渲染质量,最近流行的3DGS技术甚至实现了实时性能。然而,由SMPL驱动的3DGS人类角色模型在拟合过程中仍然难以捕捉精细的外观细节,因为姿势到外观的复杂映射。在本文中,我们提出了SeqAvatar,它挖掘了明确的3DGS表示,基于分层运动上下文更好地建模人类角色。具体来说,我们利用从粗到细的运动条件,结合整体人类骨骼和精细顶点运动进行非刚体变形。为了提高所提出运动条件的稳健性,我们采用时空多尺度采样策略,分层融合更多运动线索来建模人类角色。大量实验表明,我们的方法显著优于基于3DGS的方法,并且与最新融入时间上下文的NeRF模型相比,渲染人类角色模型的速度要快得多,同时性能至少相当甚至更好。项目页面:https://zezeaaa.github.io/projects/SeqAvatar/
论文及项目相关链接
PDF ICCV2025
Summary
神经网络渲染技术的出现极大地提高了3D人类角色模型的渲染质量,流行的3DGS技术可实现实时性能。然而,基于SMPL驱动的3DGS人类角色模型在拟合过程中仍然难以捕捉精细的外观细节。本文提出SeqAvatar,通过挖掘明确的3DGS表示并基于分层运动上下文更好地建模人类角色模型。具体来说,我们利用从粗到细的运动条件,结合整体人类骨骼和精细顶点运动进行非刚性变形。为了提高所提运动条件的稳健性,我们采用时空多尺度采样策略,分层集成更多运动线索来建模人类角色。实验表明,我们的方法显著优于基于3DGS的方法,并且与人类角色建模中融入时序上下文的最新NeRF模型相比,速度要快得多,同时性能至少与之相当甚至更好。
Key Takeaways
- 神经网络渲染提高了3D人类角色模型的渲染质量。
- 流行的3DGS技术可实现实时性能,但难以捕捉精细外观细节。
- SeqAvatar通过挖掘明确的3DGS表示来改进模型。
- SeqAvatar利用从粗到细的运动条件进行建模,结合整体人类骨骼和精细顶点运动。
- 采用时空多尺度采样策略提高运动条件的稳健性。
- 与基于3DGS的方法相比,SeqAvatar表现更优。
- SeqAvatar的渲染速度比最新融入时序上下文的NeRF模型快,且性能至少相当或更好。
点此查看论文截图
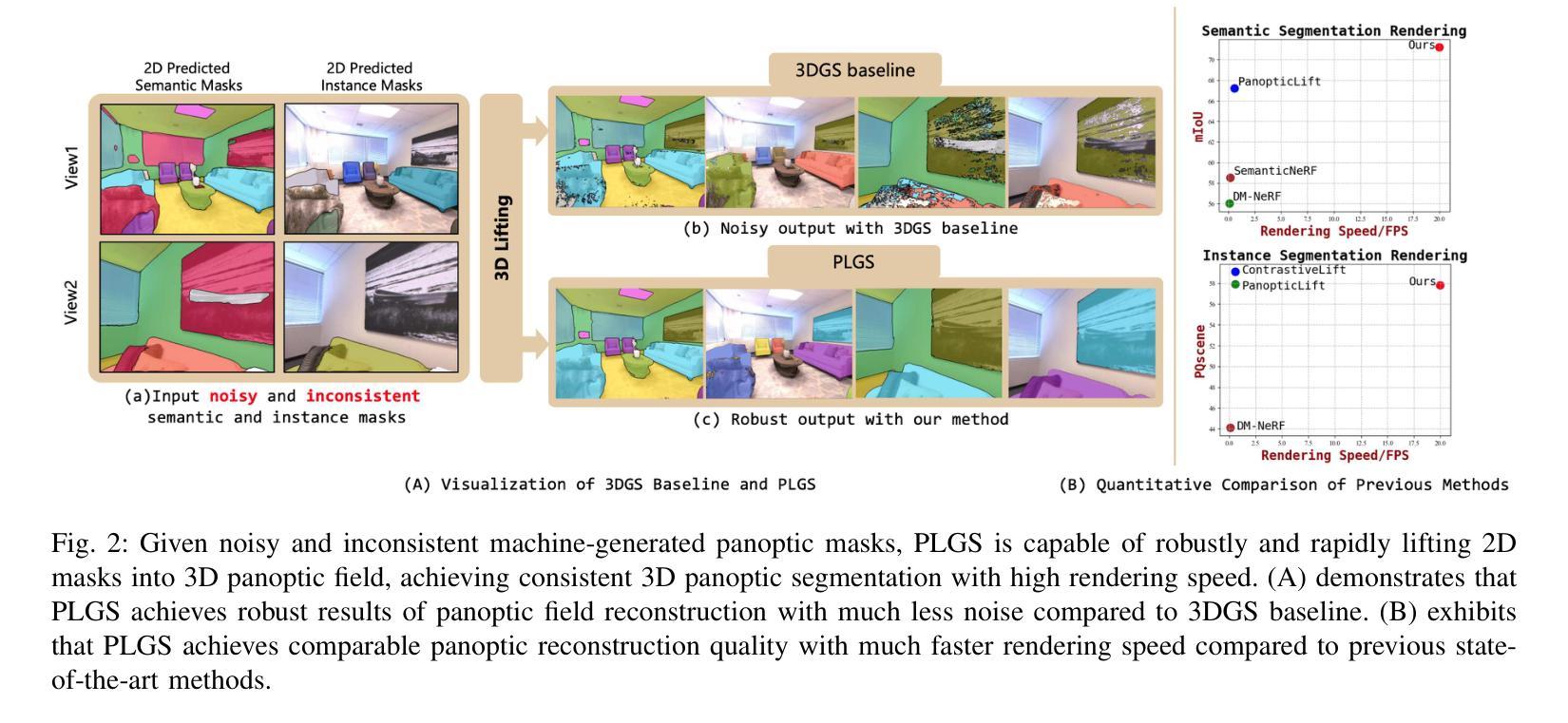
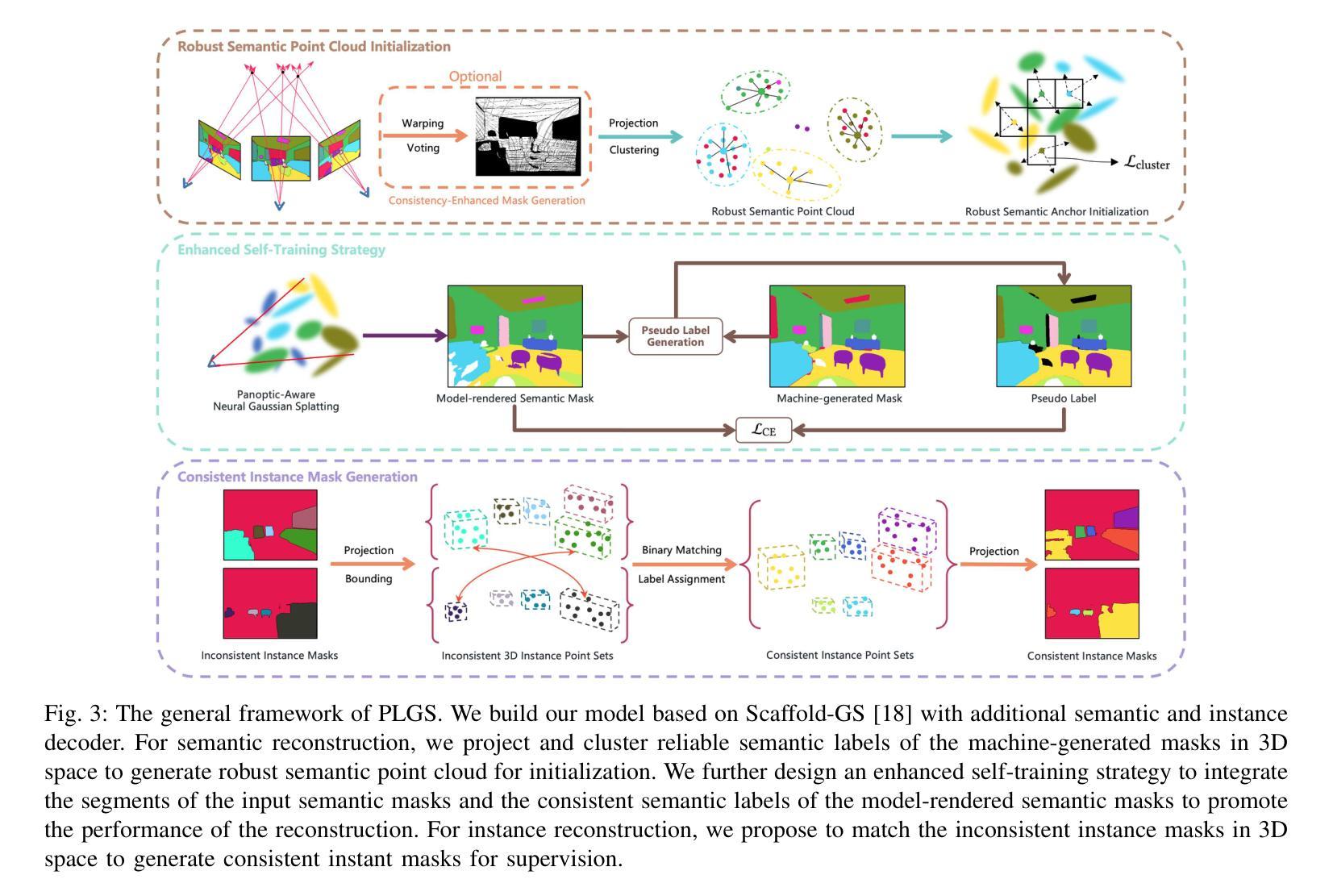
PLGS: Robust Panoptic Lifting with 3D Gaussian Splatting
Authors:Yu Wang, Xiaobao Wei, Ming Lu, Guoliang Kang
Previous methods utilize the Neural Radiance Field (NeRF) for panoptic lifting, while their training and rendering speed are unsatisfactory. In contrast, 3D Gaussian Splatting (3DGS) has emerged as a prominent technique due to its rapid training and rendering speed. However, unlike NeRF, the conventional 3DGS may not satisfy the basic smoothness assumption as it does not rely on any parameterized structures to render (e.g., MLPs). Consequently, the conventional 3DGS is, in nature, more susceptible to noisy 2D mask supervision. In this paper, we propose a new method called PLGS that enables 3DGS to generate consistent panoptic segmentation masks from noisy 2D segmentation masks while maintaining superior efficiency compared to NeRF-based methods. Specifically, we build a panoptic-aware structured 3D Gaussian model to introduce smoothness and design effective noise reduction strategies. For the semantic field, instead of initialization with structure from motion, we construct reliable semantic anchor points to initialize the 3D Gaussians. We then use these anchor points as smooth regularization during training. Additionally, we present a self-training approach using pseudo labels generated by merging the rendered masks with the noisy masks to enhance the robustness of PLGS. For the instance field, we project the 2D instance masks into 3D space and match them with oriented bounding boxes to generate cross-view consistent instance masks for supervision. Experiments on various benchmarks demonstrate that our method outperforms previous state-of-the-art methods in terms of both segmentation quality and speed.
之前的方法采用神经辐射场(NeRF)进行全景提升,但其训练和渲染速度并不令人满意。相比之下,3D高斯贴图(3DGS)由于快速的训练和渲染速度而成为了一项突出的技术。然而,与NeRF不同,传统的3DGS可能无法满足基本平滑假设,因为它不依赖任何参数化结构进行渲染(例如,多层感知机)。因此,传统的3DGS本质上更容易受到嘈杂的2D遮罩监督的影响。在本文中,我们提出了一种新的方法,称为PLGS,它使3DGS能够从嘈杂的2D分割遮罩中生成一致的全景分割遮罩,同时保持比NeRF基方法更高的效率。具体来说,我们建立了一个全景感知结构化3D高斯模型,以引入平滑度并设计有效的降噪策略。对于语义场,我们没有使用运动结构进行初始化,而是构建可靠语义锚点来初始化3D高斯。然后,我们在训练过程中使用这些锚点作为平滑正则化。此外,我们还采用了一种自训练方法,通过合并渲染的遮罩和嘈杂的遮罩来生成伪标签,以增强PLGS的稳健性。对于实例场,我们将2D实例遮罩投影到3D空间中,并与定向边界框进行匹配,以生成用于监督的跨视图一致实例遮罩。在各种基准测试上的实验表明,我们的方法在分割质量和速度方面都优于之前的最先进方法。
论文及项目相关链接
摘要
本文提出一种名为PLGS的新方法,结合了3D高斯涂敷技术(3DGS)和神经网络辐射场(NeRF)的优势,旨在从噪声二维分割掩膜生成一致的全景分割掩膜。该方法建立了全景感知结构化三维高斯模型,引入平滑性并设计有效的降噪策略。语义场方面,采用可靠语义锚点初始化三维高斯模型,作为训练过程中的平滑正则化。此外,还提出了一种利用渲染掩膜与噪声掩膜合并生成伪标签的自我训练方法,以提高PLGS的稳健性。在实例场方面,将二维实例掩膜投影到三维空间,并与定向边界框匹配,生成跨视图一致性的实例掩膜进行监管。实验表明,该方法在分割质量和速度方面均优于先前的方法。
关键见解
- 提出PLGS方法,结合了3DGS的快速训练和渲染速度与NeRF的优越性。
- 建立全景感知结构化三维高斯模型,引入平滑性并设计有效的降噪策略。
- 采用可靠语义锚点初始化三维高斯模型,用作训练过程中的平滑正则化。
- 提出利用渲染掩膜与噪声掩膜合并生成伪标签的自我训练方法。
- 将二维实例掩膜投影到三维空间,并与定向边界框匹配,确保跨视图的一致性。
- 实验表明,PLGS方法在分割质量和速度方面均优于先前技术。
点此查看论文截图