⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-06 更新
MedVLThinker: Simple Baselines for Multimodal Medical Reasoning
Authors:Xiaoke Huang, Juncheng Wu, Hui Liu, Xianfeng Tang, Yuyin Zhou
Large Reasoning Models (LRMs) have introduced a new paradigm in AI by enabling models to ``think before responding” via chain-of-thought reasoning. However, the absence of open and reproducible recipes for building reasoning-centric medical LMMs hinders community-wide research, analysis, and comparison. In this paper, we present MedVLThinker, a suite of simple yet strong baselines. Our fully open recipe consists of: (1) systematic data curation for both text-only and image-text medical data, filtered according to varying levels of reasoning difficulty, and (2) two training paradigms: Supervised Fine-Tuning (SFT) on distilled reasoning traces and Reinforcement Learning with Verifiable Rewards (RLVR) based on final answer correctness. Across extensive experiments on the Qwen2.5-VL model family (3B, 7B) and six medical QA benchmarks, we find that RLVR consistently and significantly outperforms SFT. Additionally, under the RLVR framework, a key, counter-intuitive finding is that training on our curated text-only reasoning data provides a more substantial performance boost than training on multimodal image-text data. Our best open 7B model, trained using the RLVR recipe on text-only data, establishes a new state-of-the-art on existing public VQA benchmarks, surpassing all previous open-source medical LMMs. Furthermore, scaling our model to 32B achieves performance on par with the proprietary GPT-4o. We release all curated data, models, and code to provide the community with a strong, open foundation for future research in multimodal medical reasoning.
大型推理模型(LRMs)通过基于思维链的推理,使得模型能够在回答之前进行“思考”,从而在人工智能领域引入了一种新的范式。然而,缺乏构建以推理为中心的医学LMMs的开放和可重复使用的食谱,阻碍了社区范围内的研究、分析和比较。在本文中,我们介绍了MedVLThinker,这是一套简单而强大的基线。我们完全开放的食谱包括:(1)针对纯文本和图像文本医疗数据的有系统数据收集,根据不同程度的推理难度进行过滤;(2)两种训练范式:基于蒸馏推理痕迹的监督微调(SFT)和基于最终答案正确性的可验证奖励强化学习(RLVR)。在Qwen2.5-VL模型家族(3B、7B)和六个医疗问答基准测试集上进行的大量实验表明,RLVR始终显著优于SFT。此外,在RLVR框架下,一个关键且反直觉的发现是,在我们整理好的纯文本推理数据上进行训练,比在多模态图像文本数据上进行训练更能显著提高性能。我们最好的开源7B模型,使用RLVR配方在纯文本数据上进行训练,在现有的公共视觉问答基准测试集上建立了新的最先进的性能,超越了之前所有的开源医疗LMMs。此外,将我们的模型扩展到32B,其性能与专有GPT-4o相当。我们发布所有整理好的数据、模型和代码,为社区提供一个强大的开放基础,供未来在多媒体医疗推理领域进行研究。
论文及项目相关链接
PDF Project page and code: https://ucsc-vlaa.github.io/MedVLThinker/
Summary
大型推理模型(LRMs)通过引入链式思维推理能力,为人工智能带来了全新的模式。然而,由于缺乏构建以推理为中心的医学大型模型的开放和可复制配方,阻碍了社区范围内的研究、分析和比较。本文提出了MedVLThinker,它包含简单而强大的基准测试。我们的完全开放配方包括:(1)针对不同程度的推理难度进行系统化数据收集,涵盖纯文本和图像文本医疗数据;(2)两种训练范式:基于蒸馏推理痕迹的监督微调(SFT)和基于最终答案正确性的可验证奖励强化学习(RLVR)。通过广泛的实验和对Qwen2.5-VL模型家族(3B、7B)以及六个医疗问答基准的测试,我们发现RLVR持续且显著优于SFT。此外,在RLVR框架下,一个关键的、反直觉的发现是,在我们精选的纯文本推理数据上进行训练比在多模态图像文本数据上进行训练能提供更大幅度的性能提升。我们最好的开放7B模型,使用RLVR配方在纯文本数据上进行训练,在现有的公共视觉问答基准测试上达到了新的水平,超越了之前所有的开源医疗大型模型。此外,将我们的模型扩展到32B,其性能达到了与专有GPT-4o相当的水平。我们发布所有精选数据、模型和代码,为社区提供一个强大的开放基础,以供未来在多媒体医疗推理领域进行研究。
Key Takeaways
- 大型推理模型(LRMs)通过引入链式思维推理能力为AI带来新范式。
- MedVLThinker提供简单而强大的基准测试,包含数据收集和两种训练范式。
- RLVR训练范式在医疗问答基准测试中表现优于SFT。
- 在RLVR框架下,纯文本推理数据训练比多模态图像文本数据训练更能提升性能。
- 7B模型在公共视觉问答基准测试上表现优异,超越先前开源医疗大型模型。
- 模型扩展到32B时,性能与专有GPT-4o相当。
点此查看论文截图

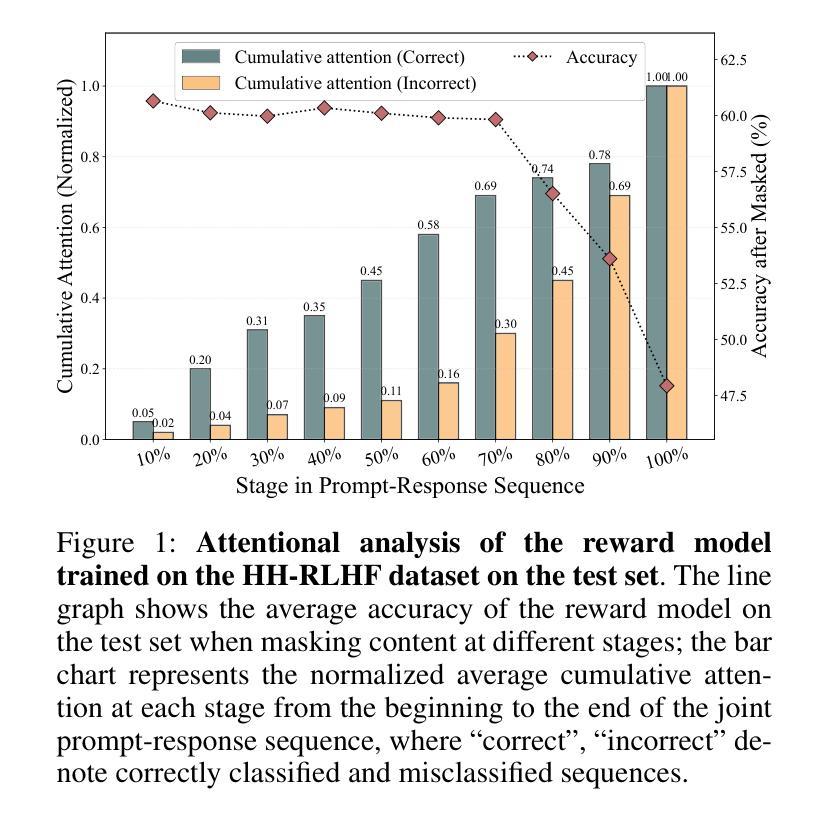
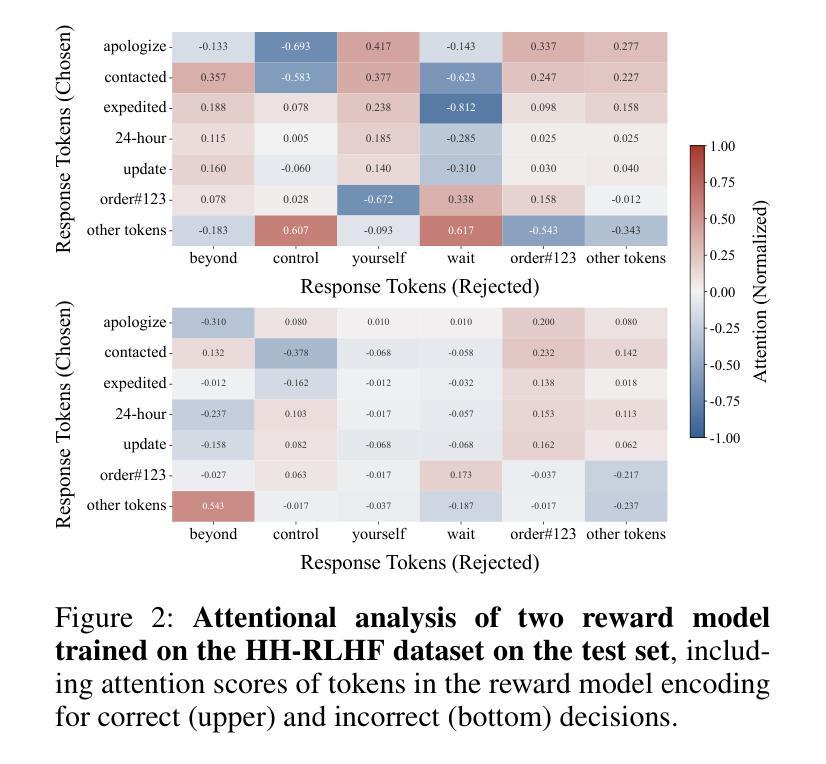
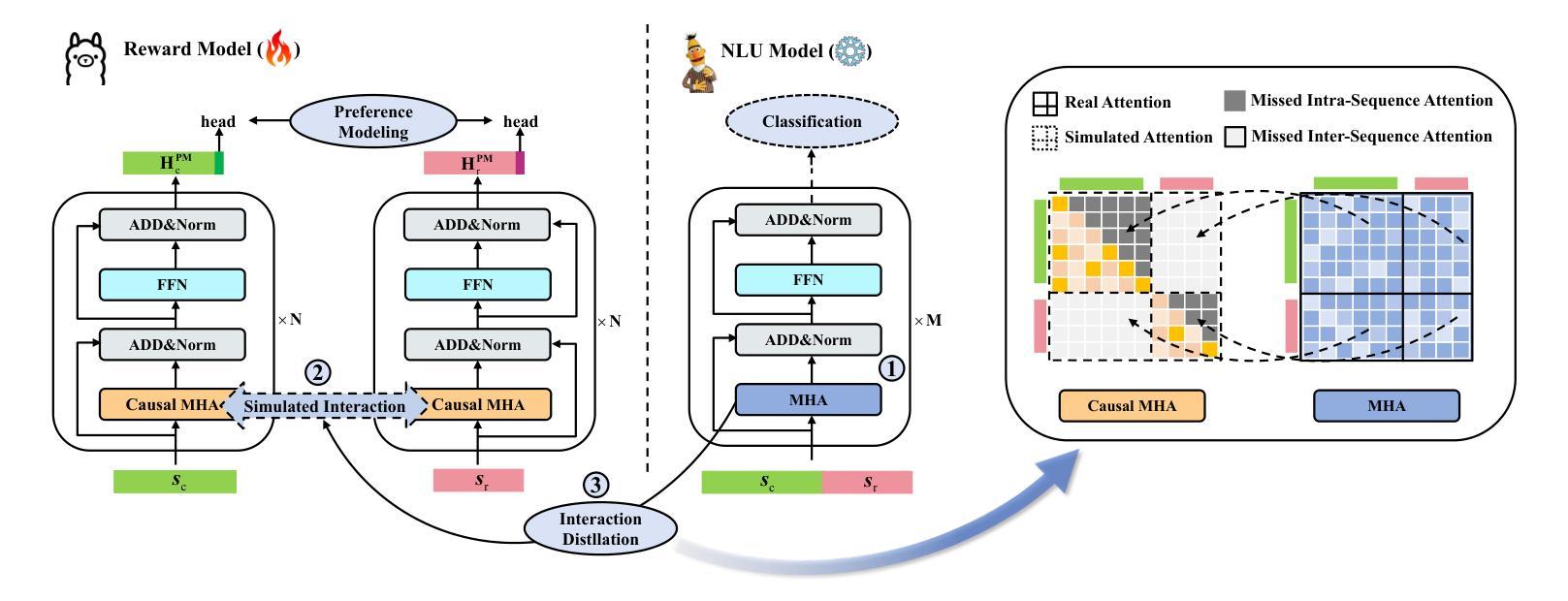
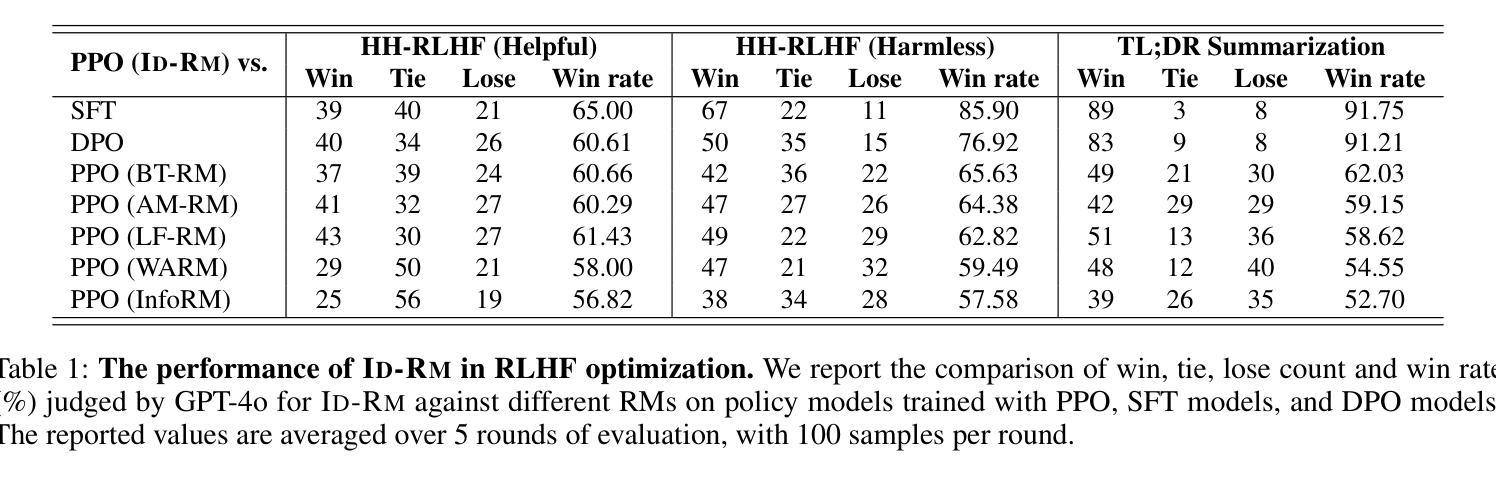
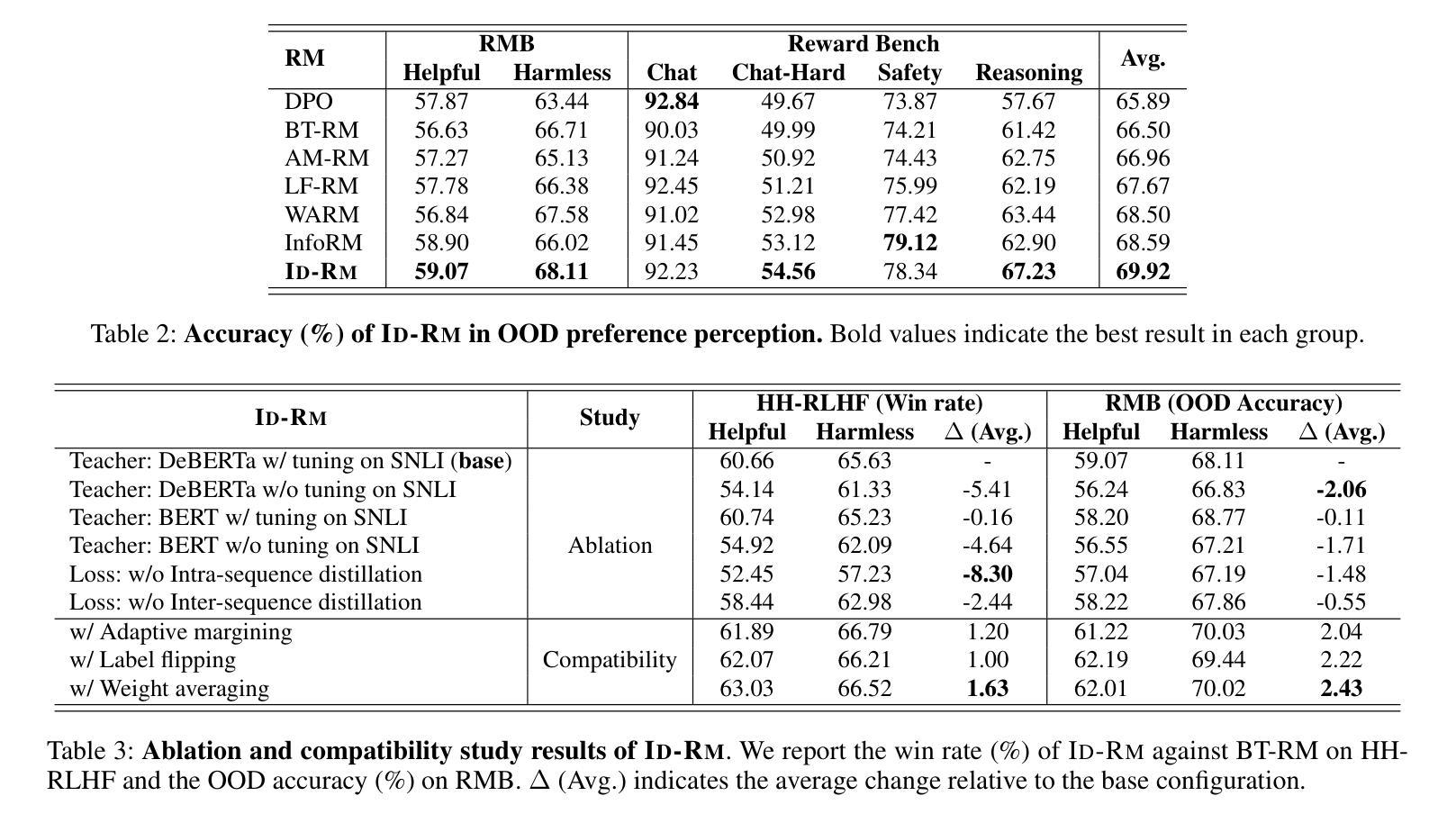
Mitigating Attention Hacking in Preference-Based Reward Modeling via Interaction Distillation
Authors:Jianxiang Zang, Meiling Ning, Shihan Dou, Jiazheng Zhang, Tao Gui, Qi Zhang, Xuanjing Huang
The reward model (RM), as the core component of reinforcement learning from human feedback (RLHF) for large language models (LLMs), responsible for providing reward signals to generated responses. However, mainstream preference modeling in RM is inadequate in terms of token-level interaction, making its judgment signals vulnerable to being hacked by misallocated attention to context. This stems from two fundamental limitations: (1) Current preference modeling employs decoder-only architectures, where the unidirectional causal attention mechanism leads to forward-decaying intra-sequence attention within the prompt-response sequence. (2) The independent Siamese-encoding paradigm induces the absence of token-level inter-sequence attention between chosen and rejected sequences. To address this “attention hacking”, we propose “Interaction Distillation”, a novel training framework for more adequate preference modeling through attention-level optimization. The method introduces an interaction-based natural language understanding model as the teacher to provide sophisticated token interaction patterns via comprehensive attention, and guides the preference modeling to simulate teacher model’s interaction pattern through an attentional alignment objective. Through extensive experiments, interaction distillation has demonstrated its ability to provide more stable and generalizable reward signals compared to state-of-the-art RM optimization methods that target data noise, highlighting the attention hacking constitute a more fundamental limitation in RM.
奖励模型(RM)作为大型语言模型(LLM)中人类反馈强化学习(RLHF)的核心组件,负责为生成的响应提供奖励信号。然而,RM中的主流偏好建模在令牌级交互方面存在不足,导致判断信号容易受到对上下文分配不当的注意力的攻击。这源于两个基本局限:(1)当前的偏好建模仅采用解码器架构,其中单向因果注意力机制导致提示-响应序列内的序列内注意力呈现前向衰减。(2)独立的Siamese编码范式导致所选序列和拒绝序列之间缺乏令牌级序列间注意力。为了解决这种“注意力攻击”,我们提出了“交互蒸馏”,这是一种通过注意力层面优化来进行更充分偏好建模的新型训练框架。该方法引入了一种基于交互的自然语言理解模型作为教师,通过全面的注意力提供精细的令牌交互模式,并通过注意力对齐目标指导偏好建模来模拟教师模型的交互模式。通过广泛的实验,交互蒸馏显示出其提供比针对数据噪声的最先进RM优化方法更稳定和可推广的奖励信号的能力,强调了注意力攻击在RM中构成了一个更根本的局限性。
论文及项目相关链接
Summary
强化学习领域中,奖励模型(RM)作为核心组件对人类反馈(RLHF)进行建模。主流RM偏好建模不足体现在令牌级别交互方面,这使其容易受到忽视。本文通过提出了一个名为“交互蒸馏”的新训练框架来解决这个问题,该框架通过注意力级别的优化进行更充分的偏好建模。通过广泛的实验验证,交互蒸馏能够提供更稳定和可泛化的奖励信号。
Key Takeaways
- 奖励模型(RM)在强化学习领域中起着核心作用,负责为生成响应提供奖励信号。
- 当前主流的RM偏好建模在令牌级别交互方面存在不足,容易受到上下文中的误注意力分配攻击(attention hacking)。
- “attention hacking”问题的根本原因是现有的RM架构的两大局限性:一是单向因果注意力机制导致序列内的前向衰减注意力;二是独立Siamese编码范式导致所选序列和拒绝序列之间缺少令牌级别的序列间注意力。
- 为了解决这一问题,提出了名为“交互蒸馏”的新训练框架,该框架通过注意力级别的优化进行更充分的偏好建模。
- 交互蒸馏引入了一个基于交互的自然语言理解模型作为教师模型,通过全面的注意力提供复杂的令牌交互模式。
- 交互蒸馏通过注意力对齐目标指导偏好建模模拟教师模型的交互模式。
点此查看论文截图

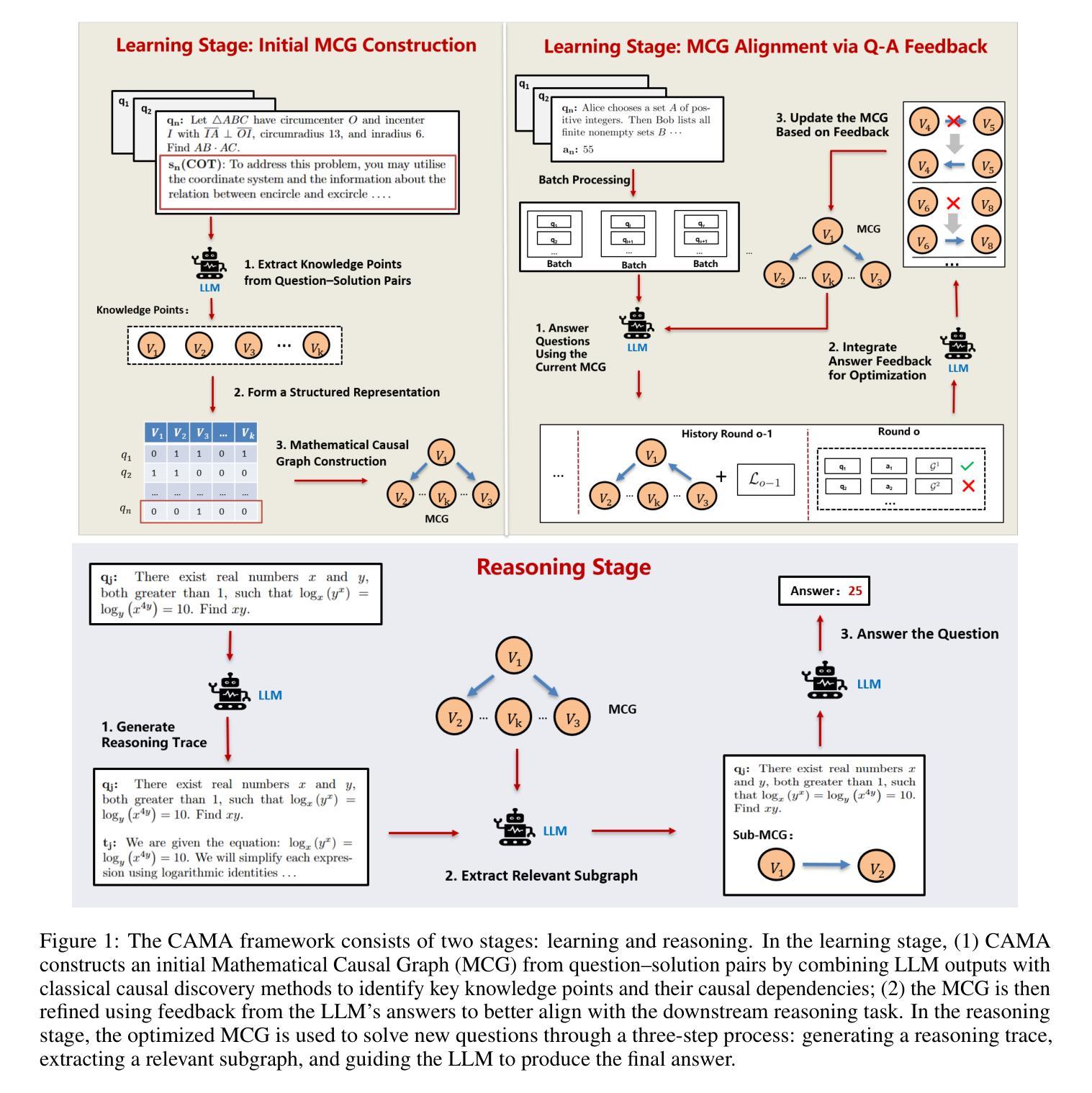
CAMA: Enhancing Mathematical Reasoning in Large Language Models with Causal Knowledge
Authors:Lei Zan, Keli Zhang, Ruichu Cai, Lujia Pan
Large Language Models (LLMs) have demonstrated strong performance across a wide range of tasks, yet they still struggle with complex mathematical reasoning, a challenge fundamentally rooted in deep structural dependencies. To address this challenge, we propose \textbf{CA}usal \textbf{MA}thematician (\textbf{CAMA}), a two-stage causal framework that equips LLMs with explicit, reusable mathematical structure. In the learning stage, CAMA first constructs the \textbf{M}athematical \textbf{C}ausal \textbf{G}raph (\textbf{MCG}), a high-level representation of solution strategies, by combining LLM priors with causal discovery algorithms applied to a corpus of question-solution pairs. The resulting MCG encodes essential knowledge points and their causal dependencies. To better align the graph with downstream reasoning tasks, CAMA further refines the MCG through iterative feedback derived from a selected subset of the question-solution pairs. In the reasoning stage, given a new question, CAMA dynamically extracts a task-relevant subgraph from the MCG, conditioned on both the question content and the LLM’s intermediate reasoning trace. This subgraph, which encodes the most pertinent knowledge points and their causal dependencies, is then injected back into the LLM to guide its reasoning process. Empirical results on real-world datasets show that CAMA significantly improves LLM performance on challenging mathematical problems. Furthermore, our experiments demonstrate that structured guidance consistently outperforms unstructured alternatives, and that incorporating asymmetric causal relationships yields greater improvements than using symmetric associations alone.
大型语言模型(LLM)在多种任务中表现出强大的性能,但在复杂的数学推理方面仍面临挑战,这一挑战根本源于深层的结构依赖性。为了解决这一挑战,我们提出了配备LLM以明确、可重复使用的数学结构的两阶段因果框架,名为CAMA(因果数学家)。在学习阶段,CAMA首先通过结合LLM先验知识和应用于问题解决方案对语料库的因果发现算法,构建数学因果图(MCG),这是解决方案策略的高级表示。生成的MCG编码了必要的知识点和它们的因果依赖关系。为了更好地与下游推理任务对齐,CAMA进一步通过来自问题解决方案对所选子集的迭代反馈来优化MCG。在推理阶段,对于新问题,CAMA会根据问题的内容和LLM的中间推理轨迹,从MCG中动态提取与任务相关的子图。这个子图编码了最相关的知识点和它们的因果依赖关系,然后重新注入LLM以指导其推理过程。在真实数据集上的实证结果表明,CAMA能显著提高LLM解决具有挑战性的数学问题的能力。此外,我们的实验还表明,结构化的指导始终优于非结构化的替代方案,并且融入不对称的因果关系比仅使用对称关联带来更大的改进。
论文及项目相关链接
Summary
大型语言模型(LLMs)在广泛的任务中表现出强大的性能,但在复杂的数学推理方面仍存在挑战。为解决此挑战,提出了因果数学家(CAMA)框架,该框架分为两个阶段:学习阶段和推理阶段。在学习阶段,CAMA构建数学因果图(MCG),这是一种高级解决方案策略表示。在推理阶段,CAMA根据问题和LLM的中间推理轨迹从MCG中提取相关子图,并注入LLM以指导其推理过程。实证结果表明,CAMA能显著提高LLM解决复杂数学问题的能力,且结构化的指导方式优于非结构化方式,考虑不对称因果关系比仅使用对称关联效果更好。
Key Takeaways
- LLMs虽在多种任务上表现出色,但在复杂数学推理方面仍存在挑战。
- CAMA框架分为学习阶段和推理阶段,旨在解决LLMs在数学推理方面的不足。
- 在学习阶段,CAMA构建数学因果图(MCG),融合LLM先验知识与因果发现算法,形成高级解决方案策略表示。
- CAMA通过迭代反馈优化MCG,使其更好地与下游推理任务对齐。
- 在推理阶段,CAMA根据问题和LLM的推理轨迹从MCG中提取相关子图,指导LLM的推理过程。
- 实证结果表明,CAMA能显著提高LLM解决数学问题的能力,且结构化的指导方式效果更佳。
点此查看论文截图

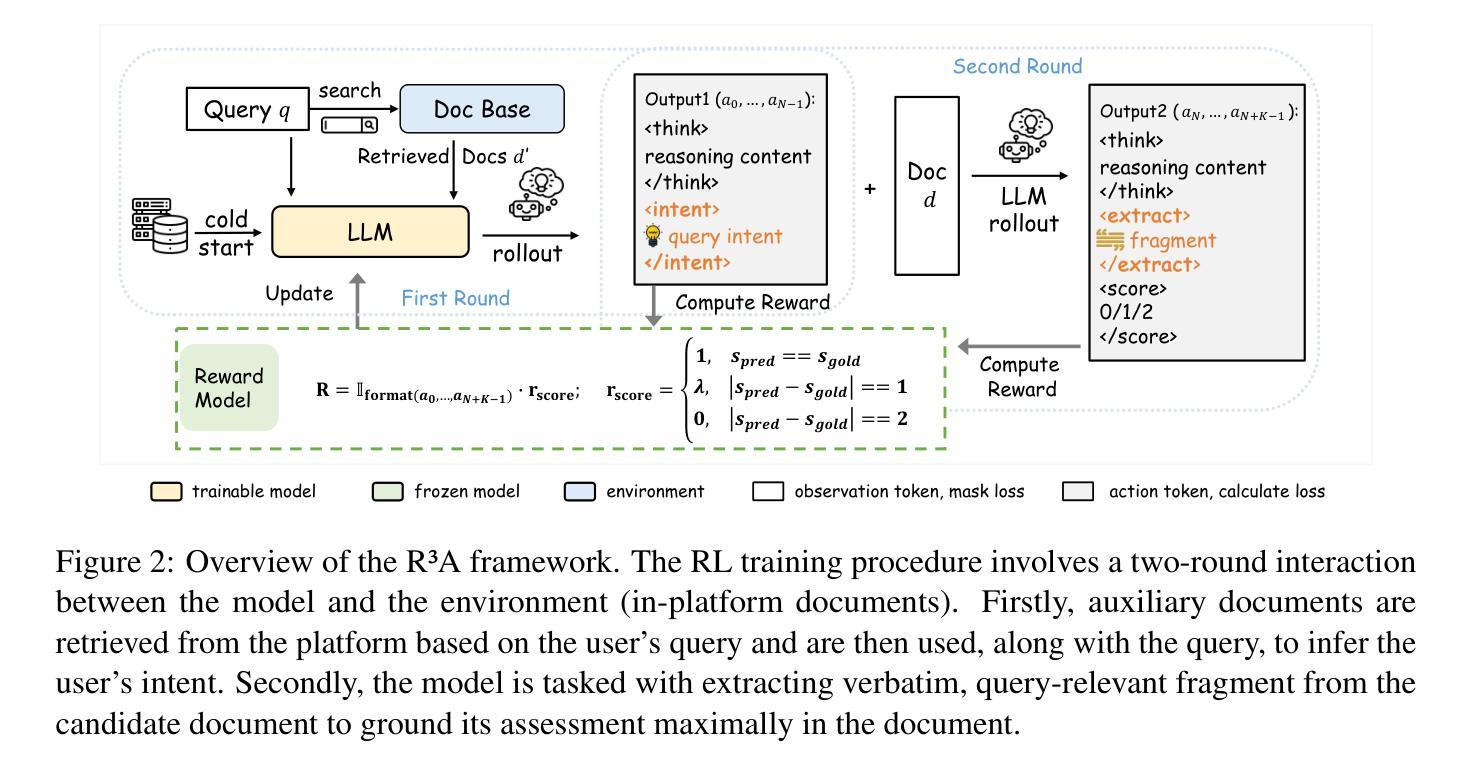
Decomposed Reasoning with Reinforcement Learning for Relevance Assessment in UGC Platforms
Authors:Xiaowei Yuan, Lei Jin, Haoxin Zhang, Yan Gao, Yi Wu, Yao Hu, Ziyang Huang, Jun Zhao, Kang Liu
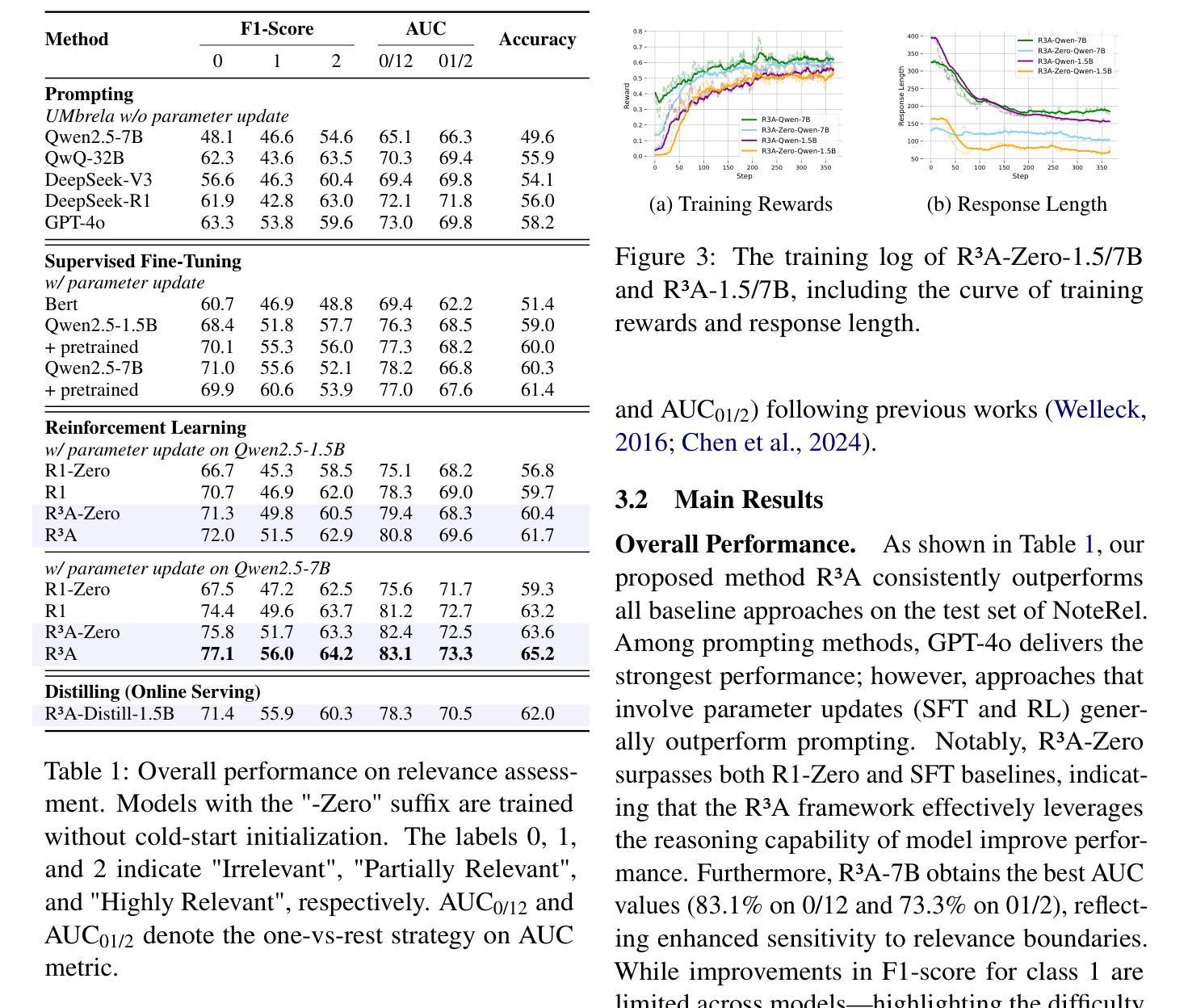
Retrieval-augmented generation (RAG) plays a critical role in user-generated content (UGC) platforms, but its effectiveness depends heavily on accurate relevance assessment of query-document pairs. Despite recent advances in applying large language models (LLMs) to relevance modeling, UGC platforms present unique challenges: 1) ambiguous user intent due to sparse user feedback in RAG scenarios, and 2) substantial noise introduced by informal and unstructured language. To address these issues, we propose the Reinforced Reasoning Model for Relevance Assessment (R3A), which introduces a decomposed reasoning framework over queries and candidate documents before scoring. R3A first leverages auxiliary high-ranked documents within the platform to infer latent query intent. It then performs verbatim fragment extraction to justify relevance decisions, thereby reducing errors caused by noisy UGC. Based on a reinforcement learning framework, R3A is optimized to mitigate distortions arising from ambiguous queries and unstructured content. Experimental results show that R3A significantly outperforms existing baseline methods in terms of relevance accuracy, across both offline benchmarks and online experiments.
增强检索生成(RAG)在用户生成内容(UGC)平台中扮演着关键角色,但其有效性很大程度上取决于查询文档对的相关性评估的准确性。尽管最近将大型语言模型(LLM)应用于相关性建模取得了进展,但UGC平台仍然面临着独特的挑战:1)RAG场景中的用户反馈稀少导致用户意图模糊,以及2)非正式和非结构化语言带来的大量噪音。为了解决这些问题,我们提出了相关性评估强化推理模型(R3A),该模型在评分之前引入了针对查询和候选文档的分解推理框架。R3A首先利用平台内辅助的高排名文档来推断潜在的查询意图。然后,它执行逐字片段提取以证明相关性决策,从而减少由嘈杂的UGC造成的错误。基于强化学习框架,R3A经过优化,减轻了由模糊查询和非结构化内容引起的失真。实验结果表明,R3A在离线基准测试和在线实验中,在相关性准确性方面显著优于现有基线方法。
论文及项目相关链接
Summary
该文本介绍了在用户生成内容(UGC)平台中,检索增强生成(RAG)的重要性及其面临的挑战。针对这些挑战,提出了一种强化推理模型用于相关性评估(R3A)。R3A通过一个分解推理框架对查询和候选文档进行评分前的处理,利用平台中的辅助高排名文档来推断潜在查询意图,并进行逐字片段提取以证明相关性决策。R3A基于强化学习框架进行优化,以减轻模糊查询和非结构化内容引起的失真。实验结果表明,R3A在离线基准测试和在线实验中,在相关性准确性方面显著优于现有基线方法。
Key Takeaways
- 检索增强生成(RAG)在用户生成内容(UGC)平台中扮演关键角色,其有效性取决于查询文档对的相关性评估的准确性。
- UGC平台在RAG场景中存在两个独特挑战:由于稀疏的用户反馈导致的模糊用户意图,以及由非正式和非结构化语言引入的大量噪音。
- 提出的强化推理模型用于相关性评估(R3A)引入了一个分解推理框架,该框架对查询和候选文档进行评分前的处理。
- R3A利用辅助高排名文档来推断潜在查询意图,并进行逐字片段提取,以证明相关性决策,从而减少由嘈杂的UGC引起的错误。
- R3A基于强化学习框架进行优化,旨在减轻模糊查询和非结构化内容导致的失真。
- 实验结果表明,R3A在离线基准测试和在线实验中,显著提高了相关性评估的准确性。
点此查看论文截图

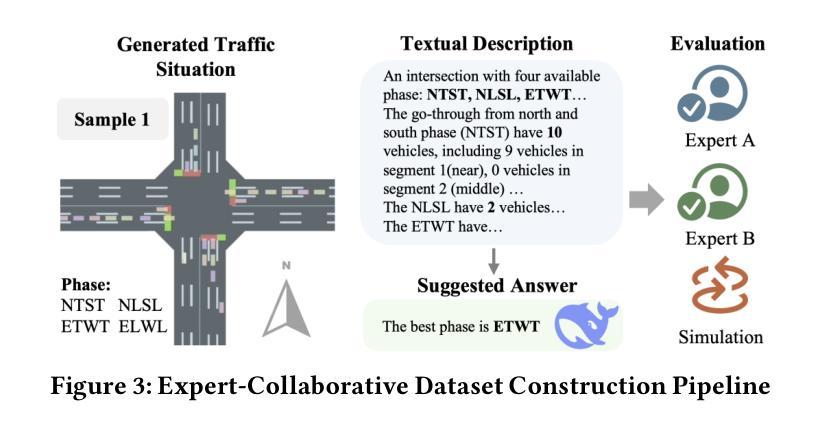
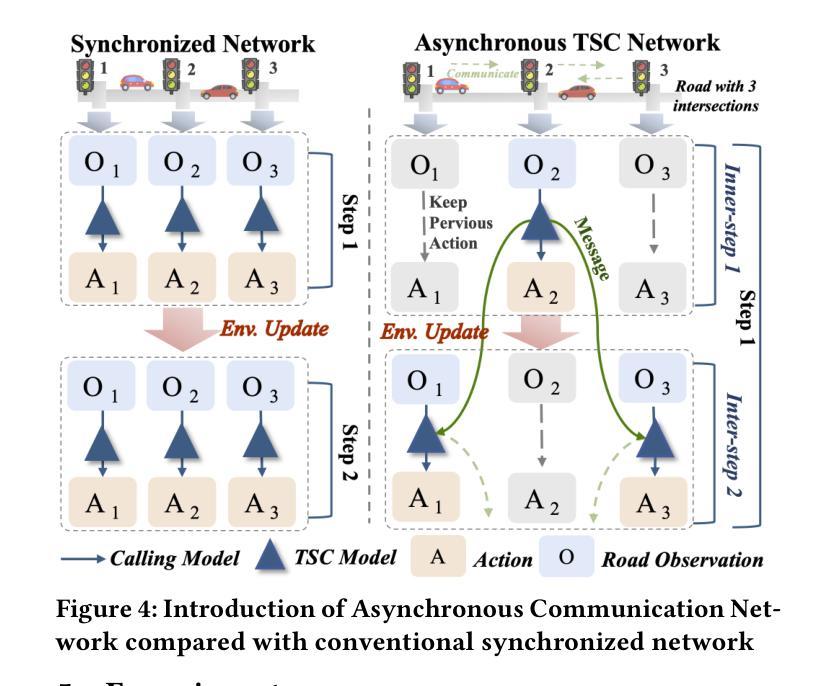
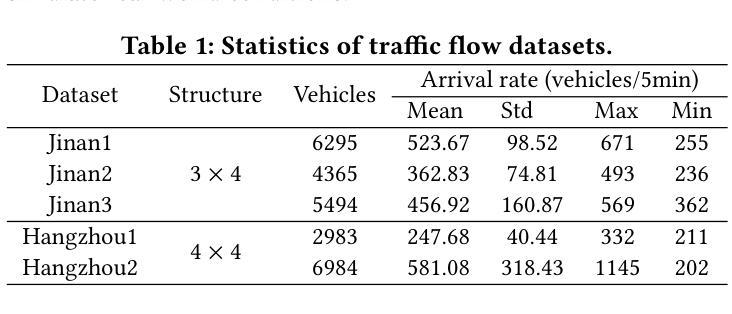
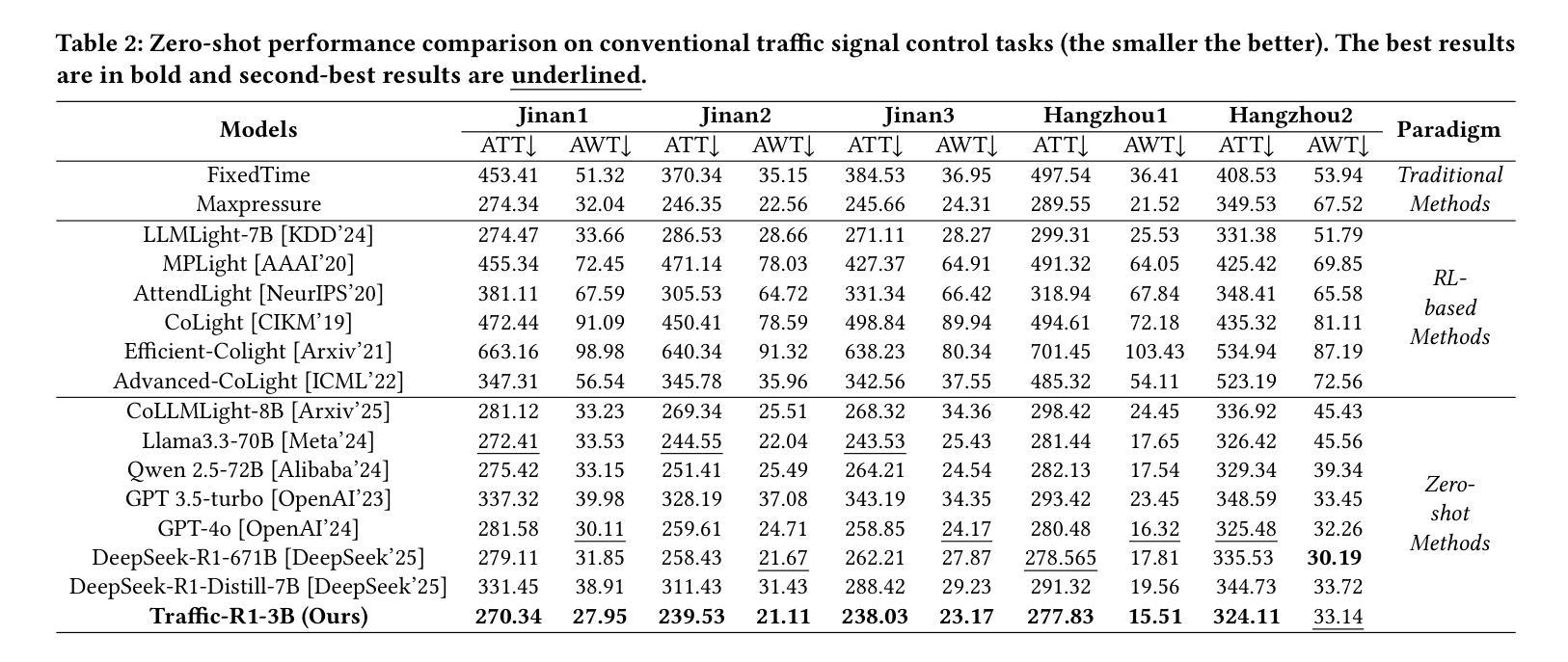
Traffic-R1: Reinforced LLMs Bring Human-Like Reasoning to Traffic Signal Control Systems
Authors:Xingchen Zou, Yuhao Yang, Zheng Chen, Xixuan Hao, Yiqi Chen, Chao Huang, Yuxuan Liang
Traffic signal control (TSC) is vital for mitigating congestion and sustaining urban mobility. In this paper, we introduce Traffic-R1, a foundation model with human-like reasoning for TSC systems. Our model is developed through self-exploration and iteration of reinforced large language models (LLMs) with expert guidance in a simulated traffic environment. Compared to traditional reinforcement learning (RL) and recent LLM-based methods, Traffic-R1 offers three significant advantages. First, Traffic-R1 delivers zero-shot generalisation, transferring unchanged to new road networks and out-of-distribution incidents by utilizing its internal traffic control policies and human-like reasoning. Second, its 3B-parameter architecture is lightweight enough for real-time inference on mobile-class chips, enabling large-scale edge deployment. Third, Traffic-R1 provides an explainable TSC process and facilitates multi-intersection communication through its self-iteration and a new synchronous communication network. Extensive benchmarks demonstrate that Traffic-R1 sets a new state of the art, outperforming strong baselines and training-intensive RL controllers. In practice, the model now manages signals for more than 55,000 drivers daily, shortening average queues by over 5% and halving operator workload. Our checkpoint is available at https://huggingface.co/Season998/Traffic-R1.
交通信号控制(TSC)对于缓解交通拥堵和维持城市流动性至关重要。在本文中,我们介绍了Traffic-R1,这是一个具有人类思维推理能力的TSC系统基础模型。我们的模型是通过在模拟交通环境中自我探索和迭代强化大型语言模型(LLM),并在专家指导下开发出来的。与传统的强化学习(RL)和最新的LLM方法相比,Traffic-R1具有三大优势。首先,Traffic-R1实现了零射击泛化,通过利用其内部的交通控制政策和人类思维推理,无需任何修改即可适应新的道路网络和离群分布事件。其次,其3B参数的架构足够轻便,可在移动芯片上进行实时推理,支持大规模边缘部署。第三,Traffic-R1提供了一个可解释的TSC过程,并通过其自我迭代和新的同步通信网络促进了多交叉路口通信。广泛的基准测试表明,Traffic-R1创造了新的技术顶尖水平,超越了强大的基准测试和训练密集的RL控制器。在实践中,该模型现在每天为超过55000名司机管理信号,缩短了平均队列超过5%,并将操作人员的工作量减半。我们的检查点位于[https://huggingface.co/Season998/Traffic-R1。](注:此链接无法直接访问以验证其有效性)
论文及项目相关链接
Summary
交通信号控制(TSC)对于缓解交通拥堵和维持城市流动性至关重要。本文介绍了Traffic-R1,一种具有人类思维推理能力的TSC系统基础模型。该模型通过在模拟交通环境中对强化大型语言模型(LLM)的自我探索与迭代,并辅以专家指导进行开发。与传统强化学习(RL)和最近的LLM方法相比,Traffic-R1提供了三大优势:零样本泛化能力,可轻松适应新道路网络和离群事件;其3B参数架构适合在移动级芯片上进行实时推断,支持大规模边缘部署;提供可解释的TSC流程,并通过自我迭代和新同步通信网络促进多路口通信。实践表明,该模型现已管理超过5万五千名司机的信号,平均缩短排队时间超过5%,减半操作工作量。我们的检查点位于:https://huggingface.co/Season998/Traffic-R1。
Key Takeaways
- Traffic-R1是一种具有人类思维推理能力的交通信号控制(TSC)系统基础模型。
- Traffic-R1通过自我探索与迭代强化大型语言模型(LLM)技术,结合专家指导进行开发。
- Traffic-R1具备三大优势:零样本泛化能力、轻量级实时推断能力及提供可解释的TSC流程。
- Traffic-R1架构支持在新道路网络和离群事件中的快速适应。
- 模型可在移动级芯片上实现实时推断,有利于大规模边缘部署。
- Traffic-R1能够促进多路口通信并具备自我迭代能力。
点此查看论文截图

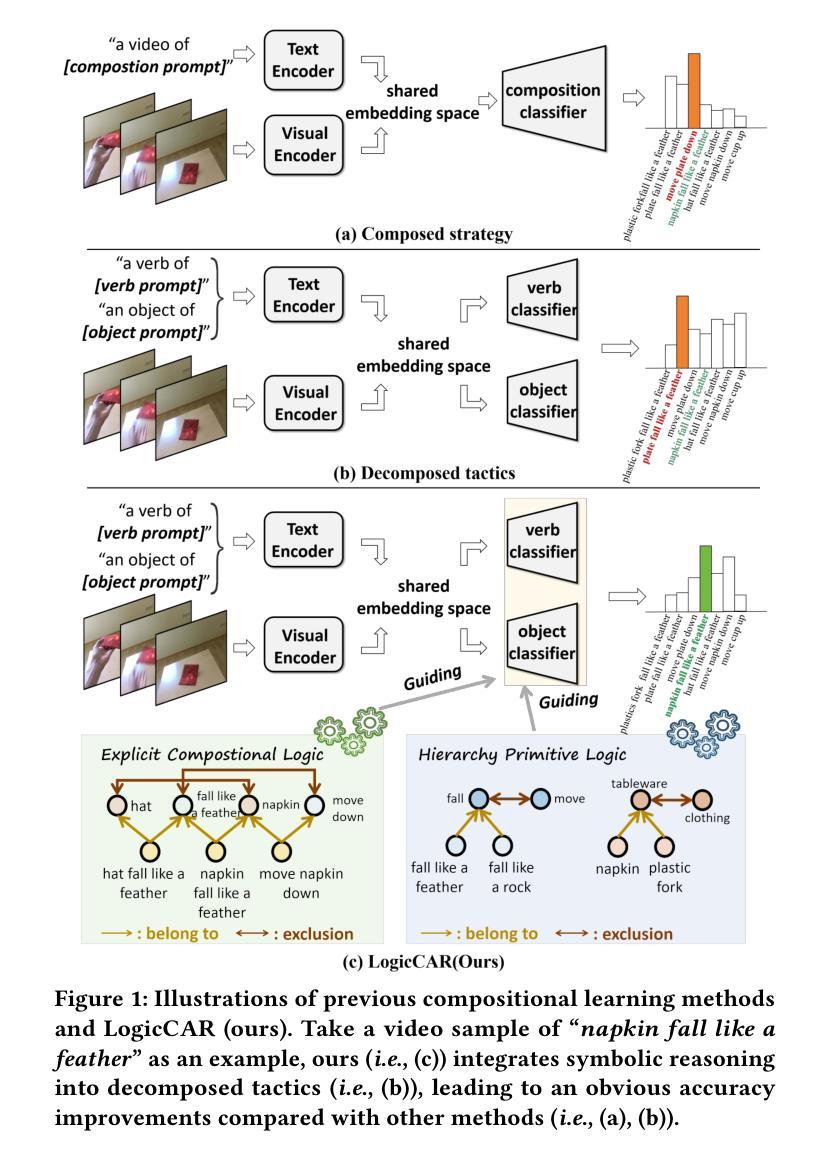
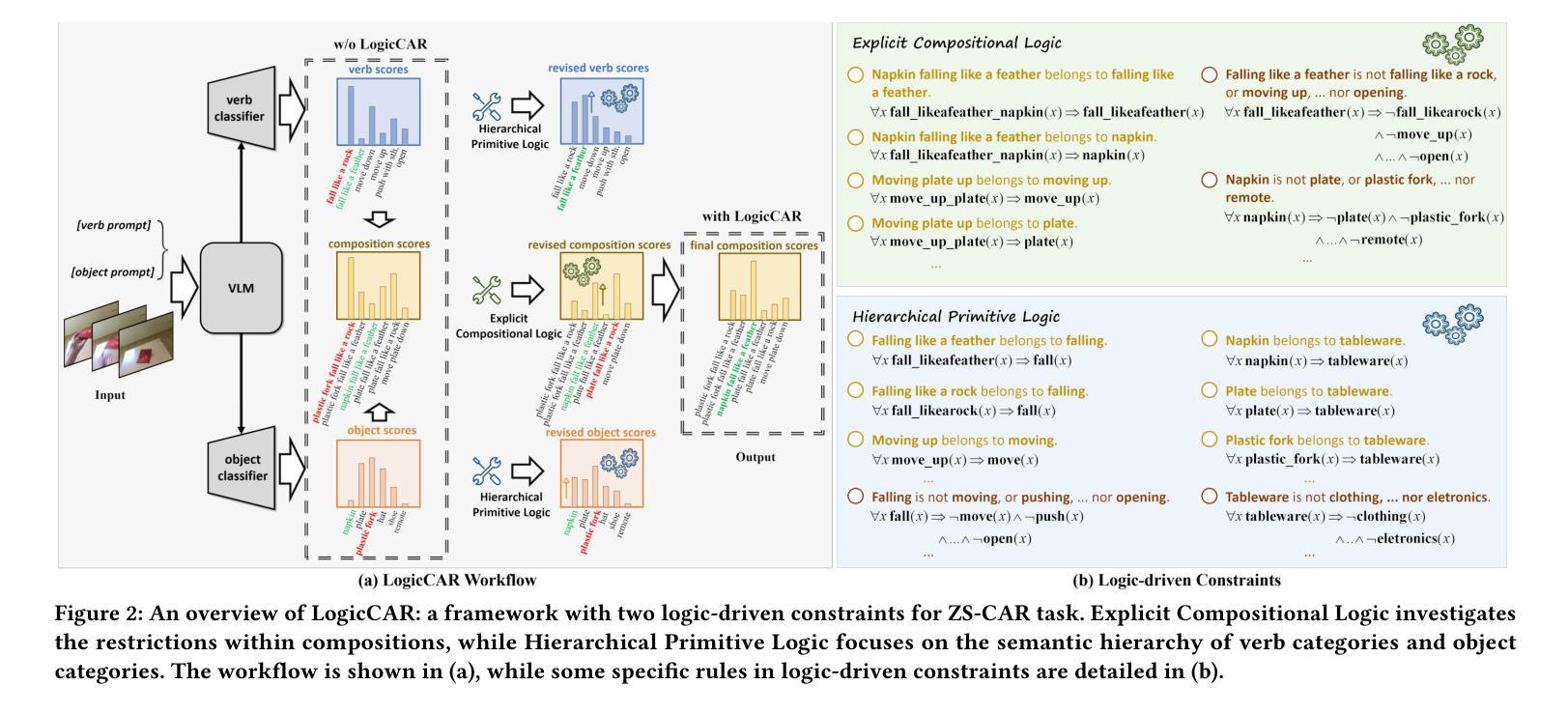
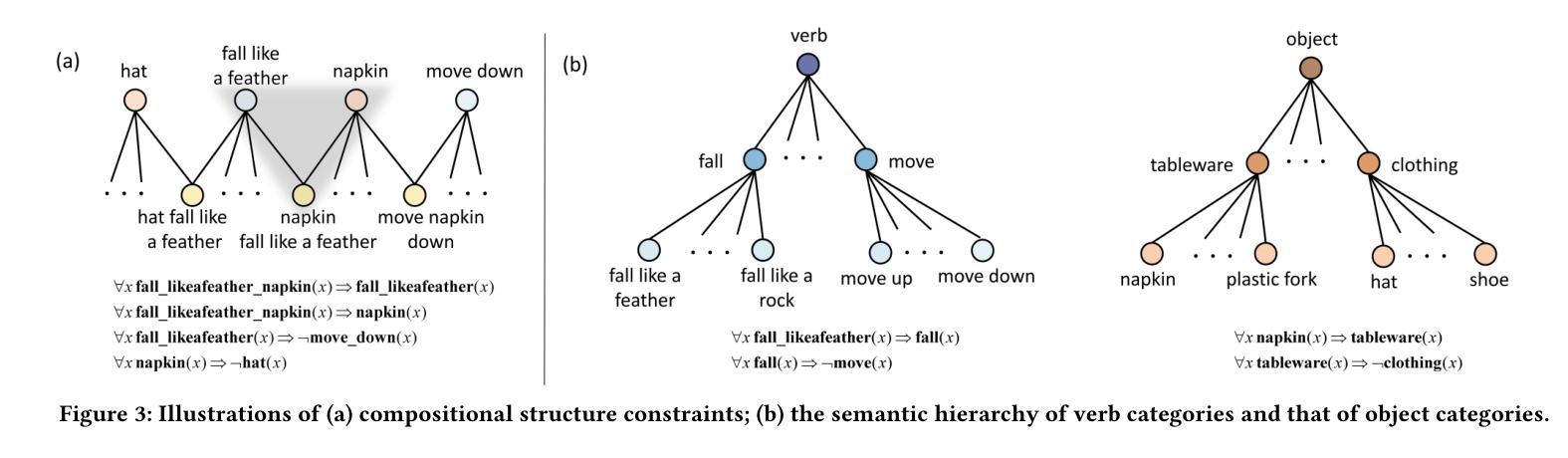
Zero-shot Compositional Action Recognition with Neural Logic Constraints
Authors:Gefan Ye, Lin Li, Kexin Li, Jun Xiao, Long chen
Zero-shot compositional action recognition (ZS-CAR) aims to identify unseen verb-object compositions in the videos by exploiting the learned knowledge of verb and object primitives during training. Despite compositional learning’s progress in ZS-CAR, two critical challenges persist: 1) Missing compositional structure constraint, leading to spurious correlations between primitives; 2) Neglecting semantic hierarchy constraint, leading to semantic ambiguity and impairing the training process. In this paper, we argue that human-like symbolic reasoning offers a principled solution to these challenges by explicitly modeling compositional and hierarchical structured abstraction. To this end, we propose a logic-driven ZS-CAR framework LogicCAR that integrates dual symbolic constraints: Explicit Compositional Logic and Hierarchical Primitive Logic. Specifically, the former models the restrictions within the compositions, enhancing the compositional reasoning ability of our model. The latter investigates the semantical dependencies among different primitives, empowering the models with fine-to-coarse reasoning capacity. By formalizing these constraints in first-order logic and embedding them into neural network architectures, LogicCAR systematically bridges the gap between symbolic abstraction and existing models. Extensive experiments on the Sth-com dataset demonstrate that our LogicCAR outperforms existing baseline methods, proving the effectiveness of our logic-driven constraints.
零样本组合动作识别(ZS-CAR)旨在利用训练过程中习得的动词和原始对象的认知来识别视频中未见过的动词-对象组合。尽管ZS-CAR在组合学习方面取得了进展,但仍然存在两个关键挑战:1)缺少组合结构约束,导致原始元素之间的虚假关联;2)忽略了语义层次约束,导致语义模糊并影响训练过程。本文认为,通过显式建模组合和层次结构抽象,人类类似的符号推理为解决这些挑战提供了原则性的解决方案。为此,我们提出了一个逻辑驱动的ZS-CAR框架LogicCAR,该框架集成了双重符号约束:显式组合逻辑和分层原始逻辑。具体而言,前者对组合内的限制进行建模,增强了我们的模型的组合推理能力。后者则研究不同原始元素之间的语义依赖关系,赋予模型精细到粗略的推理能力。通过一阶逻辑形式化这些约束并将其嵌入神经网络架构中,LogicCAR系统地填补了符号抽象和现有模型之间的鸿沟。在Sth-com数据集上的大量实验表明,我们的LogicCAR优于现有基线方法,证明了我们的逻辑驱动约束的有效性。
论文及项目相关链接
PDF 14 pages, 6 figures; Accepted by ACM MM2025
Summary
基于零样本组合动作识别(ZS-CAR)中的挑战,如缺乏组合结构约束和忽视语义层次约束,本文提出了一种逻辑驱动的ZS-CAR框架LogicCAR。该框架集成了双重符号约束,包括明确的组合逻辑和层次原始逻辑,以弥补符号抽象和现有模型之间的差距。在Sth-com数据集上的实验表明,LogicCAR框架优于现有基线方法。
Key Takeaways
- ZS-CAR面临两个主要挑战:缺乏组合结构约束和忽视语义层次约束。
- 人类符号推理为解决这两个挑战提供了原则性解决方案。
- LogicCAR框架集成了双重符号约束:明确的组合逻辑和层次原始逻辑。
- 组合逻辑旨在建立不同成分之间的逻辑关系以增强模型对组合的理解。
- 层次原始逻辑探究不同成分间的语义依赖关系,增强模型的推理能力。
- LogicCAR通过形式化这些约束并将其嵌入神经网络架构中,成功填补了符号抽象与现有模型之间的差距。
点此查看论文截图

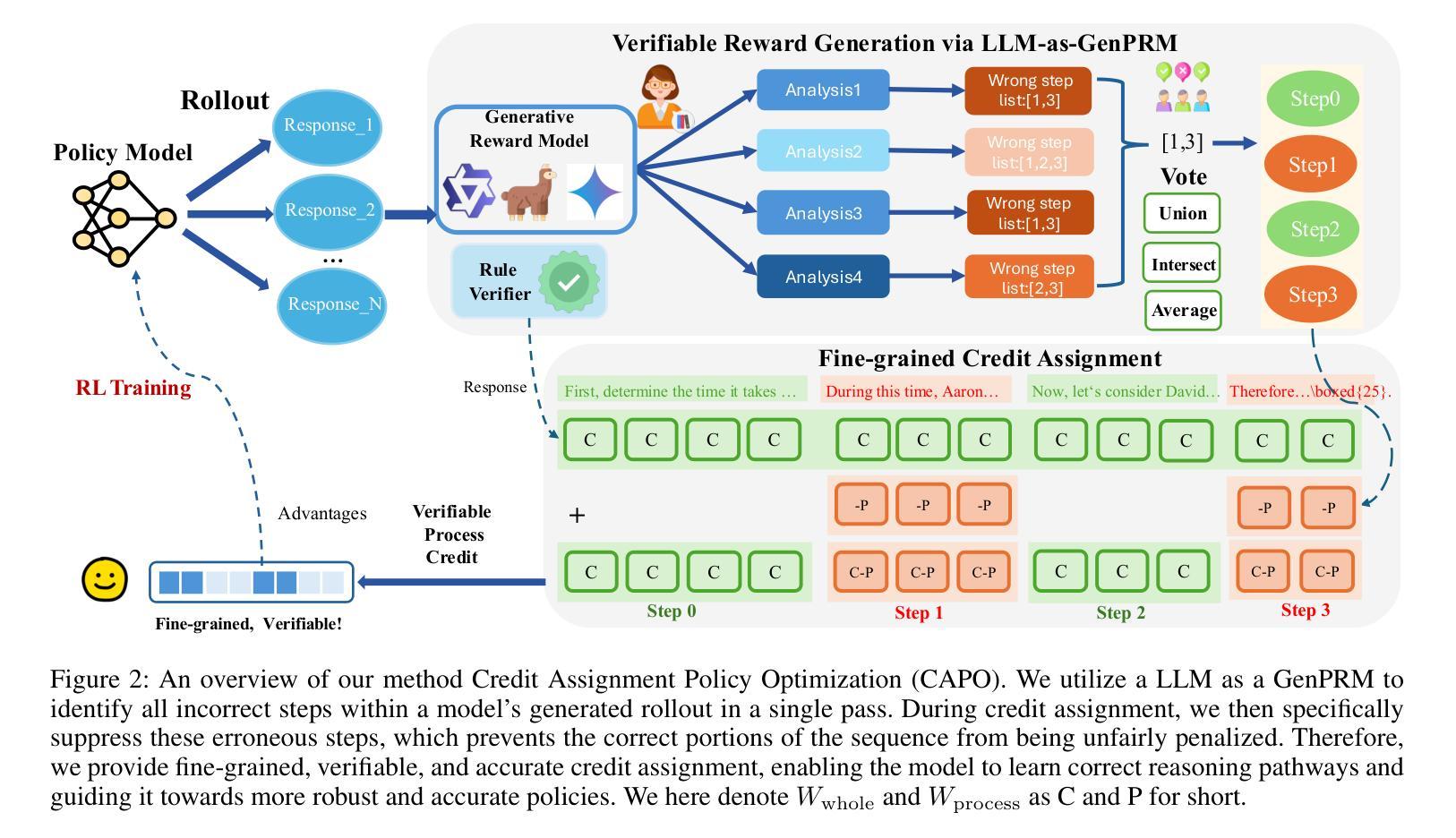
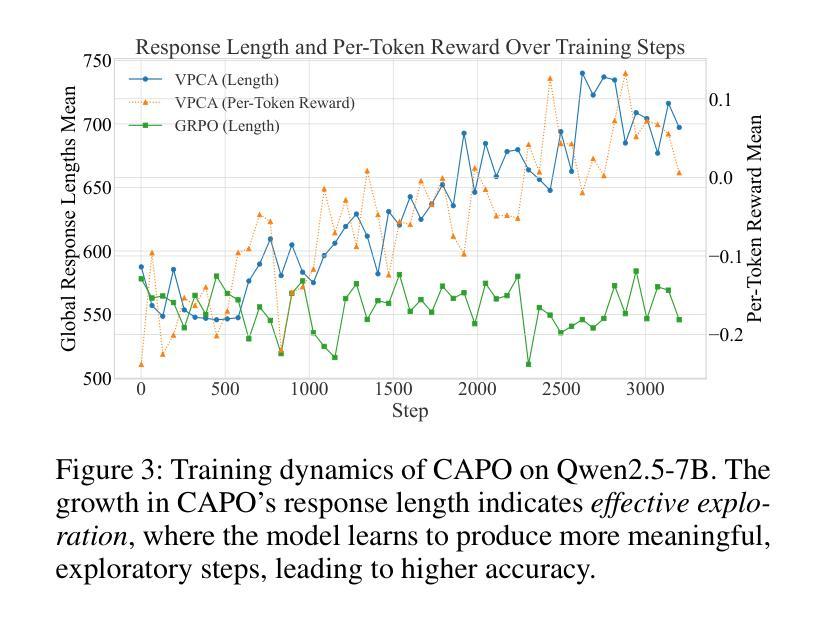
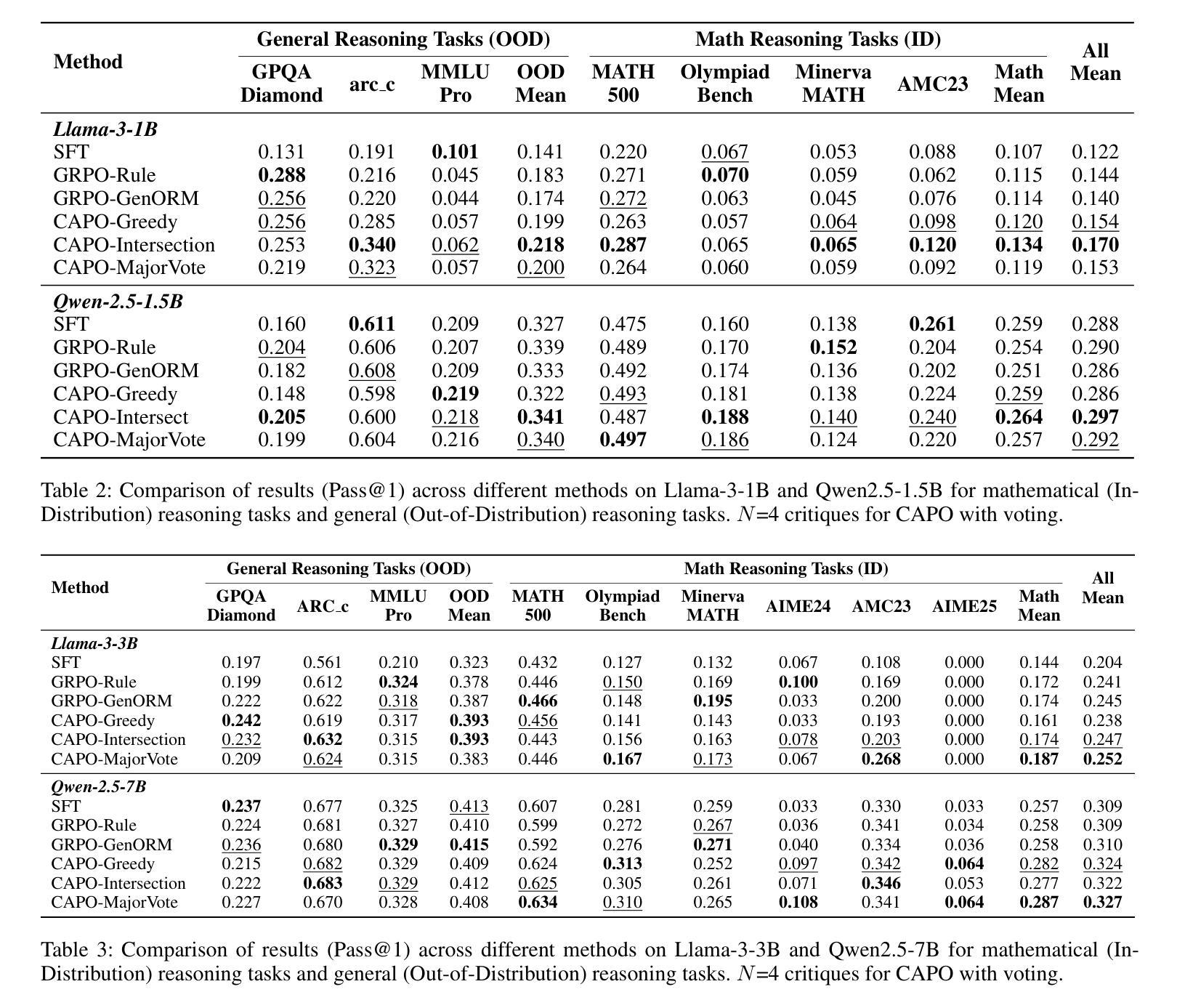
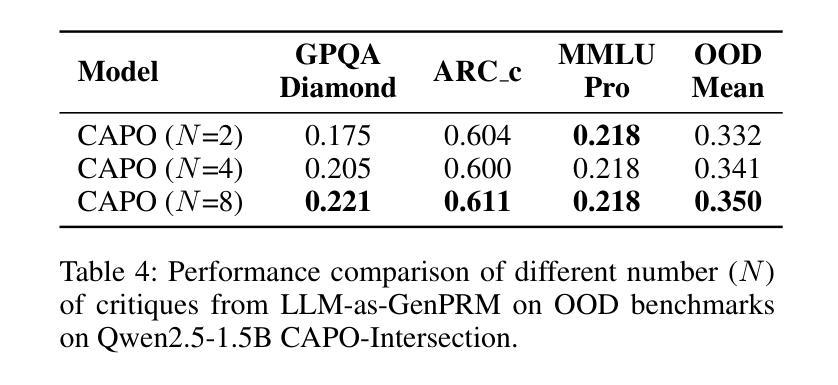
CAPO: Towards Enhancing LLM Reasoning through Verifiable Generative Credit Assignment
Authors:Guofu Xie, Yunsheng Shi, Hongtao Tian, Ting Yao, Xiao Zhang
Reinforcement Learning with Verifiable Rewards (RLVR) has improved the reasoning abilities of Large Language Models (LLMs) by using rule-based binary feedback, helping to mitigate reward hacking. However, current RLVR methods typically treat whole responses as single actions, assigning the same reward to every token. This coarse-grained feedback hampers precise credit assignment, making it hard for models to identify which reasoning steps lead to success or failure, and often results in suboptimal policies and inefficient learning. Methods like PPO provide credit assignment through value estimation, but often yield inaccurate and unverifiable signals due to limited sampling. On the other hand, methods using Process Reward Models can provide step-by-step judgments for each reasoning step, but they require high-quality process supervision labels and are time-consuming when applied in online reinforcement learning (RL). To overcome these limitations, we introduce a simple but efficient method Credit Assignment Policy Optimization (CAPO). Given a reasoning response rollout from the policy model, CAPO directly leverages an off-the-shelf, general-purpose LLM as a Generative Process Reward Model (LLM-as-GenPRM) to generate all step-wise critique by one pass, thereby providing verifiable token-level rewards to refine the tokens that were originally assigned identical rule-based rewards. This enables more fine-grained credit assignment in an effective way. Furthermore, to enhance the accuracy and robustness of CAPO, we employ voting mechanisms that scale with the number of generated critiques. Extensive experiments using different backbones like Llama and Qwen models and in different sizes show that CAPO consistently outperforms supervised learning-based and RL-based fine-tuning methods across six challenging mathematical benchmarks and three out-of-domain benchmarks.
强化学习与可验证奖励(RLVR)通过使用基于规则的二元反馈提高了大型语言模型(LLM)的推理能力,有助于缓解奖励黑客行为。然而,当前的RLVR方法通常将整个响应视为单个动作,为每个令牌分配相同的奖励。这种粗粒度的反馈阻碍了精确的信度分配,使模型难以识别哪些推理步骤导致成功或失败,并且通常导致次优策略和学习效率低下。像PPO这样的方法通过价值估计提供信用分配,但由于有限的采样,通常会产生不准确和不可验证的信号。另一方面,使用过程奖励模型的方法可以为每个推理步骤提供逐步判断,但它们需要高质量的过程监督标签,并且在应用于在线强化学习(RL)时很耗时。为了克服这些限制,我们提出了一种简单而高效的方法——信用分配策略优化(CAPO)。给定策略模型的推理响应展开,CAPO直接利用现成的通用大型语言模型作为生成过程奖励模型(LLM-as-GenPRM),通过一次传递生成所有逐步的评论,从而为原本被赋予相同规则奖励的令牌提供可验证的令牌级奖励,以改进这些令牌。这使得能够更有效地进行更精细的粒度信用分配。此外,为了提高CAPO的准确性和稳健性,我们采用了随生成评论数量扩展的投票机制。使用不同架构的大型语言模型和不同规模的广泛实验表明,CAPO在六个具有挑战性的数学基准测试和三个跨域基准测试中始终优于基于监督学习和强化学习的微调方法。
论文及项目相关链接
PDF Work in progress
Summary
RLVR已提升LLM的推理能力,但存在奖励分配不精细的问题。为此,提出一种新的方法CAPO,利用通用LLM作为生成过程奖励模型(LLM-as-GenPRM),在一次传递中生成所有步骤的评判,提供可验证的标记级别奖励,更有效地进行精细奖励分配。通过投票机制提高CAPO的准确性和稳健性,实验表明CAPO在多个基准测试上表现优异。
Key Takeaways
- RLVR已增强LLM的推理能力,通过规则反馈减少奖励欺骗。
- 当前RLVR方法存在奖励分配过于粗糙的问题,难以识别成功或失败的推理步骤。
- CAPO方法利用通用LLM作为生成过程奖励模型(LLM-as-GenPRM),提供可验证的标记级别奖励。
- CAPO通过一次传递生成所有步骤的评判,实现更有效的精细奖励分配。
- CAPO采用投票机制,随着生成的评论数量增加,其准确性和稳健性得到提高。
- 实验表明,CAPO在多个数学基准测试和跨域基准测试上表现优于基于监督学习和强化学习的方法。
点此查看论文截图


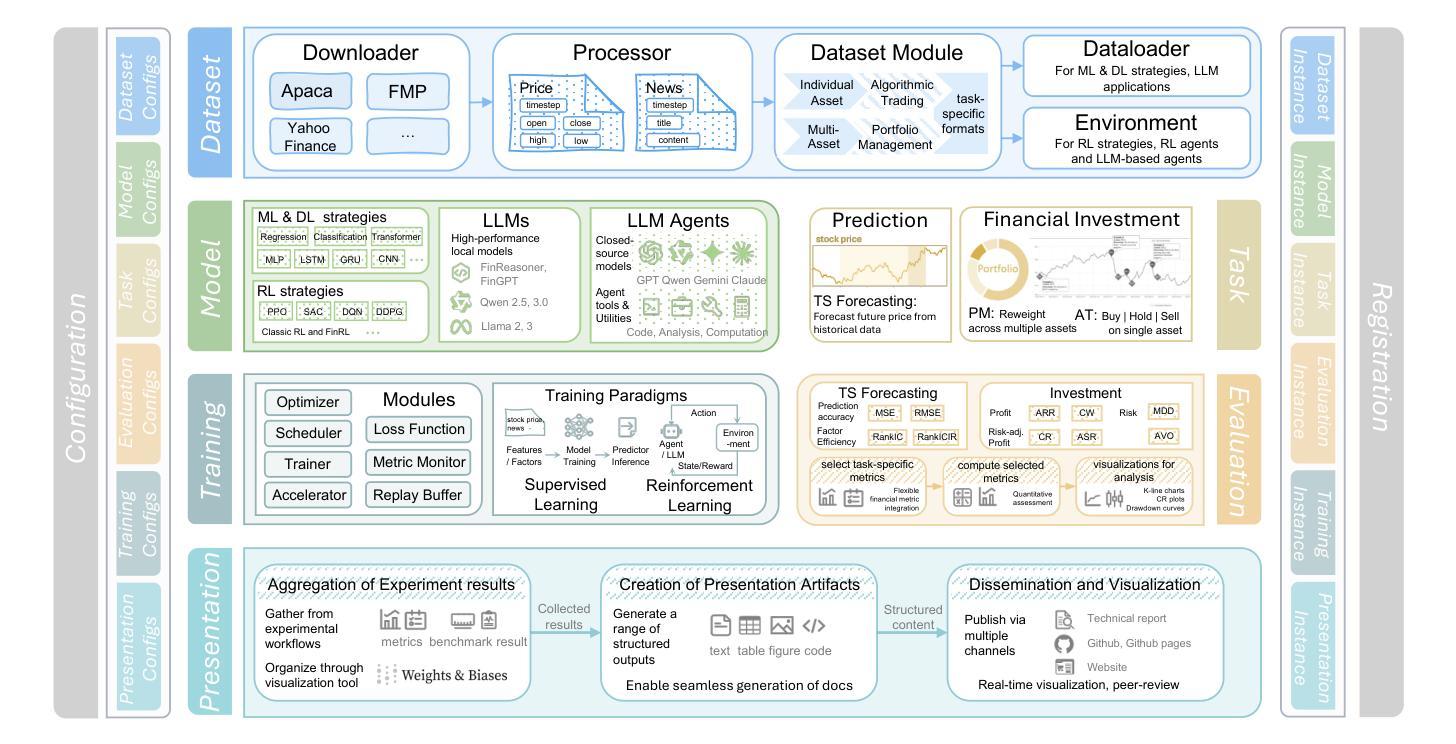
FinWorld: An All-in-One Open-Source Platform for End-to-End Financial AI Research and Deployment
Authors:Wentao Zhang, Yilei Zhao, Chuqiao Zong, Xinrun Wang, Bo An
Financial AI holds great promise for transforming modern finance, with the potential to support a wide range of tasks such as market forecasting, portfolio management, quantitative trading, and automated analysis. However, existing platforms remain limited in task coverage, lack robust multimodal data integration, and offer insufficient support for the training and deployment of large language models (LLMs). In response to these limitations, we present FinWorld, an all-in-one open-source platform that provides end-to-end support for the entire financial AI workflow, from data acquisition to experimentation and deployment. FinWorld distinguishes itself through native integration of heterogeneous financial data, unified support for diverse AI paradigms, and advanced agent automation, enabling seamless development and deployment. Leveraging data from 2 representative markets, 4 stock pools, and over 800 million financial data points, we conduct comprehensive experiments on 4 key financial AI tasks. These experiments systematically evaluate deep learning and reinforcement learning algorithms, with particular emphasis on RL-based finetuning for LLMs and LLM Agents. The empirical results demonstrate that FinWorld significantly enhances reproducibility, supports transparent benchmarking, and streamlines deployment, thereby providing a strong foundation for future research and real-world applications. Code is available at Github~\footnote{https://github.com/DVampire/FinWorld}.
金融人工智能在现代金融领域具有巨大的潜力,能够支持市场预测、投资组合管理、量化交易和自动化分析等多种任务。然而,现有平台在任务覆盖、缺乏稳健的多模式数据集成以及对大型语言模型(LLM)训练和部署的支持不足等方面仍存在局限性。为了应对这些局限性,我们推出了FinWorld,这是一个综合性的开源平台,为金融人工智能的整个工作流程提供端到端的支持,从数据采集到实验和部署。FinWorld通过原生集成异构金融数据、统一支持多样化的AI范式和先进的代理自动化等功能,实现了无缝的开发和部署。我们利用来自两个代表性市场、四个股票池和超过8亿个金融数据点的数据,对金融人工智能的四个关键任务进行了全面的实验。这些实验系统地评估了深度学习和强化学习算法,并特别强调了基于强化学习的LLM微调以及LLM代理。实证结果表明,FinWorld显著提高了可重复性,支持透明的基准测试,并简化了部署,从而为未来的研究和实际应用提供了坚实的基础。代码可在Github上找到(https://github.com/DVampire/FinWorld)。
论文及项目相关链接
Summary
金融AI对现代金融的变革具有巨大潜力,可支持市场预测、投资组合管理、量化交易和自动化分析等多种任务。然而,现有平台存在任务覆盖面有限、缺乏鲁棒的多模式数据集成以及大型语言模型(LLMs)训练和部署支持不足等问题。为解决这些问题,我们推出了FinWorld,这是一个全方位开源平台,为金融AI工作流提供从数据采集到实验和部署的端到端支持。通过整合异构金融数据、统一支持多样化的AI范式以及先进的代理自动化,FinWorld可实现无缝开发与部署。利用来自两个代表性市场、四个股票池和超过8亿个金融数据点的数据,我们在四个关键金融AI任务上进行了全面的实验。实验结果证明,FinWorld显著提高了可重复性、支持透明基准测试并简化了部署,为未来的研究和实际应用提供了坚实的基础。代码已上传至GitHub。
Key Takeaways
- 金融AI具有变革现代金融的巨大潜力,涵盖市场预测、投资组合管理等多项任务。
- 现有金融AI平台存在任务覆盖面有限、数据集成不足等问题。
- FinWorld是一个开源平台,提供金融AI工作流的端到端支持,包括数据采集、实验和部署。
- FinWorld通过整合异构金融数据、支持多种AI范式和代理自动化来区分自己。
- FinWorld通过实证实验证明了其提高可重复性、支持透明基准测试并简化部署的能力。
- FinWorld为未来的研究和实际应用提供了坚实的基础。
点此查看论文截图

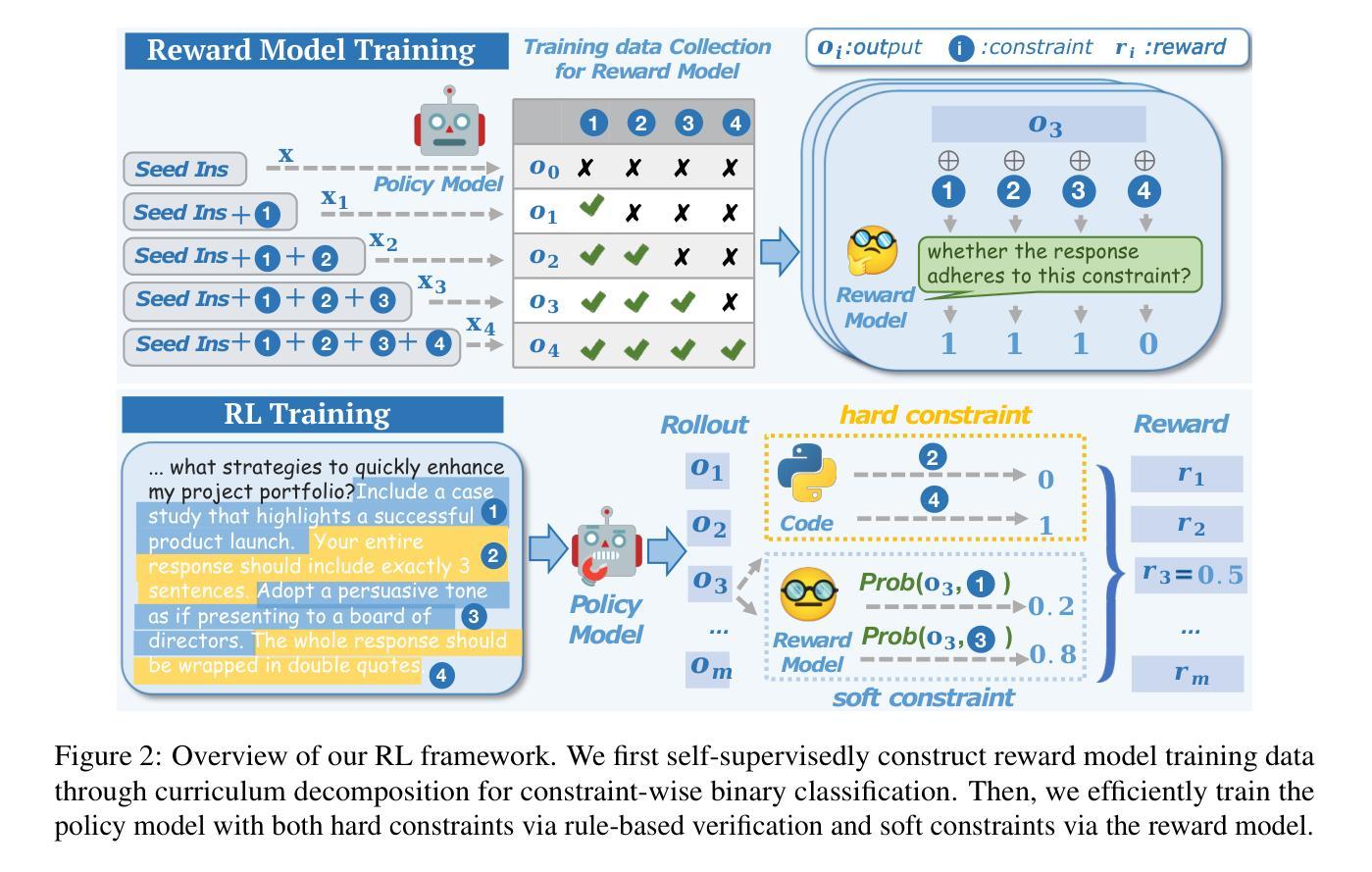
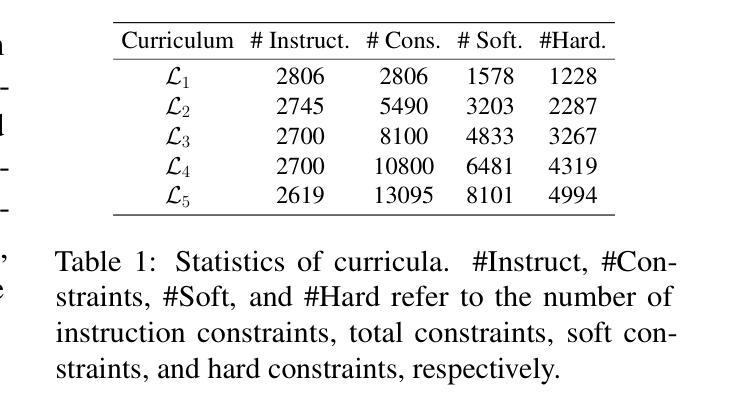
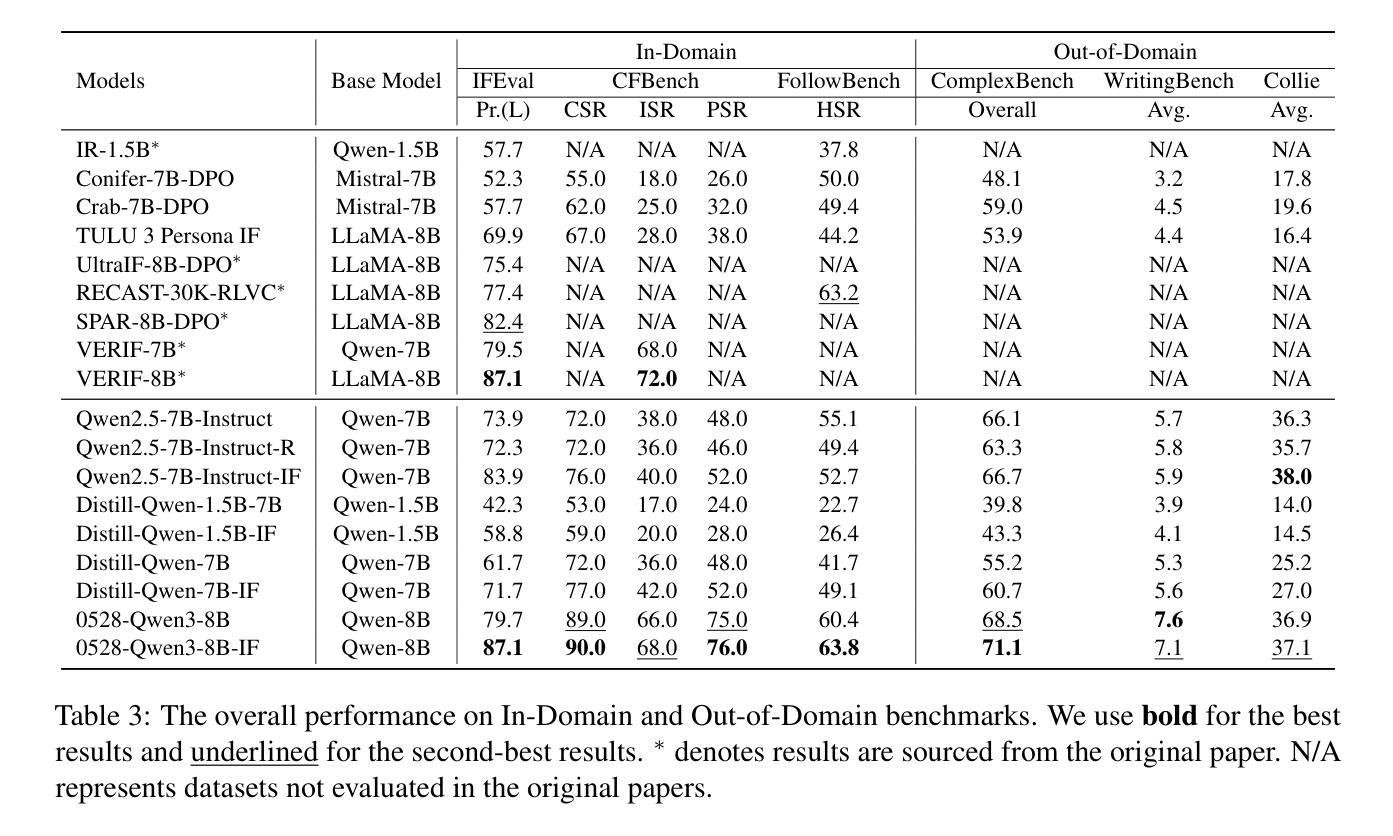
Beyond the Trade-off: Self-Supervised Reinforcement Learning for Reasoning Models’ Instruction Following
Authors:Qingyu Ren, Qianyu He, Bowei Zhang, Jie Zeng, Jiaqing Liang, Yanghua Xiao, Weikang Zhou, Zeye Sun, Fei Yu
Reasoning models excel in complex problem solving but exhibit a concerning trade off between reasoning capabilities and instruction following abilities. Existing approaches for improving instruction following rely on stronger external models, creating methodological bottlenecks and practical limitations including increased costs and accessibility constraints. We propose a self-supervised RL framework that leverages reasoning models’ own internal signals to improve instruction following capabilities without external supervision. Extensive experiments demonstrate that our framework significantly improves instruction following capabilities while maintaining reasoning performance, offering a scalable and cost-effective approach to enhance instruction following in reasoning models. The data and code are publicly available at https://github.com/Rainier-rq/verl-if.
推理模型在解决复杂问题上表现出色,但在推理能力和执行指令能力之间表现出令人担忧的权衡。现有改善执行指令的方法依赖于更强大的外部模型,这造成了方法上的瓶颈和实际限制,包括成本增加和可访问性约束。我们提出了一种自我监督的强化学习框架,它利用推理模型本身的内部信号来提高执行指令的能力,而无需外部监督。大量实验表明,我们的框架在保持推理性能的同时,显著提高了执行指令的能力,为增强推理模型中的指令执行提供了一种可扩展且经济高效的方法。数据和代码可在https://github.com/Rainier-rq/verl-if公开访问。
论文及项目相关链接
Summary
文中指出,虽然推理模型在解决复杂问题上表现出色,但在执行指令方面存在局限。传统的改进方法依赖于强大的外部模型,导致了方法上的瓶颈和实际应用中的限制,如成本增加和可访问性受限。本研究提出了一种利用推理模型内部信号进行自我监督强化学习(RL)的框架,以提高执行指令的能力,无需外部监督。实验证明,该框架在提升指令执行能力的同时,保持了推理性能,为增强推理模型的指令执行能力提供了可扩展且经济高效的方法。相关数据和代码已公开于https://github.com/Rainier-rq/verl-if。
Key Takeaways
- 推理模型在解决复杂问题上表现出色,但在执行指令方面存在局限。
- 传统改进方法依赖外部模型,存在方法论上的瓶颈和实际应用中的限制。
- 提出了一种自我监督强化学习框架,利用推理模型内部信号提高执行指令的能力。
- 该框架无需外部监督,能有效提高指令执行能力并维持推理性能。
- 实验证明该框架效果显著。
- 该方法具有可扩展性和经济高效性。
点此查看论文截图


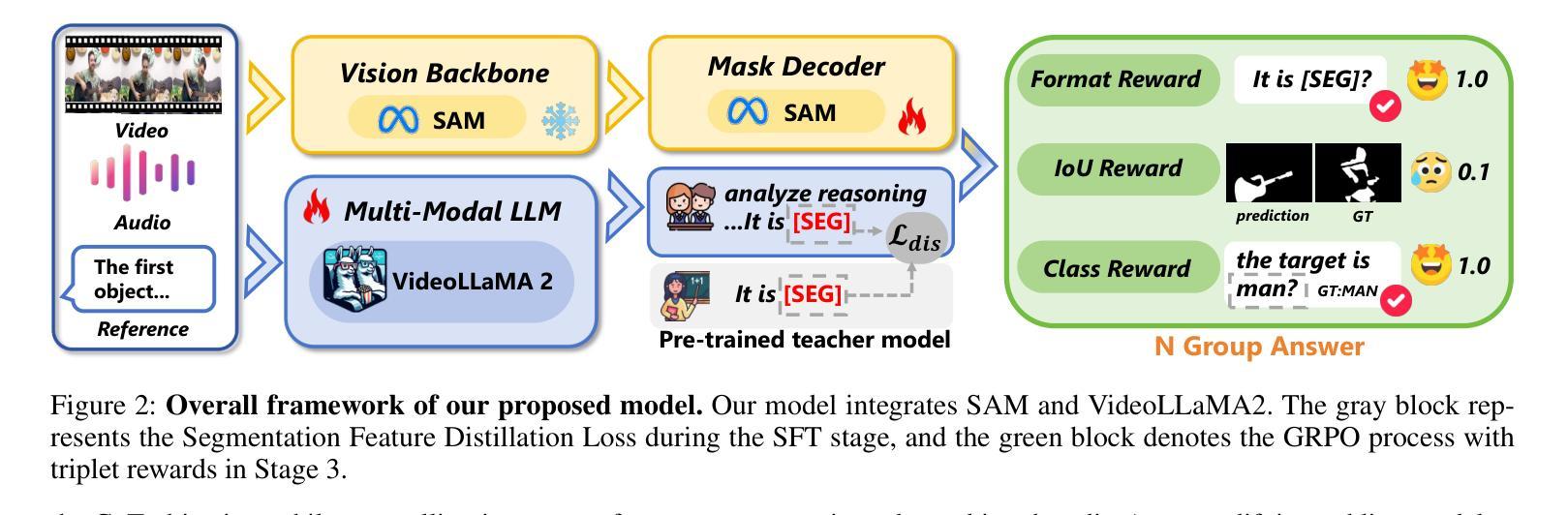
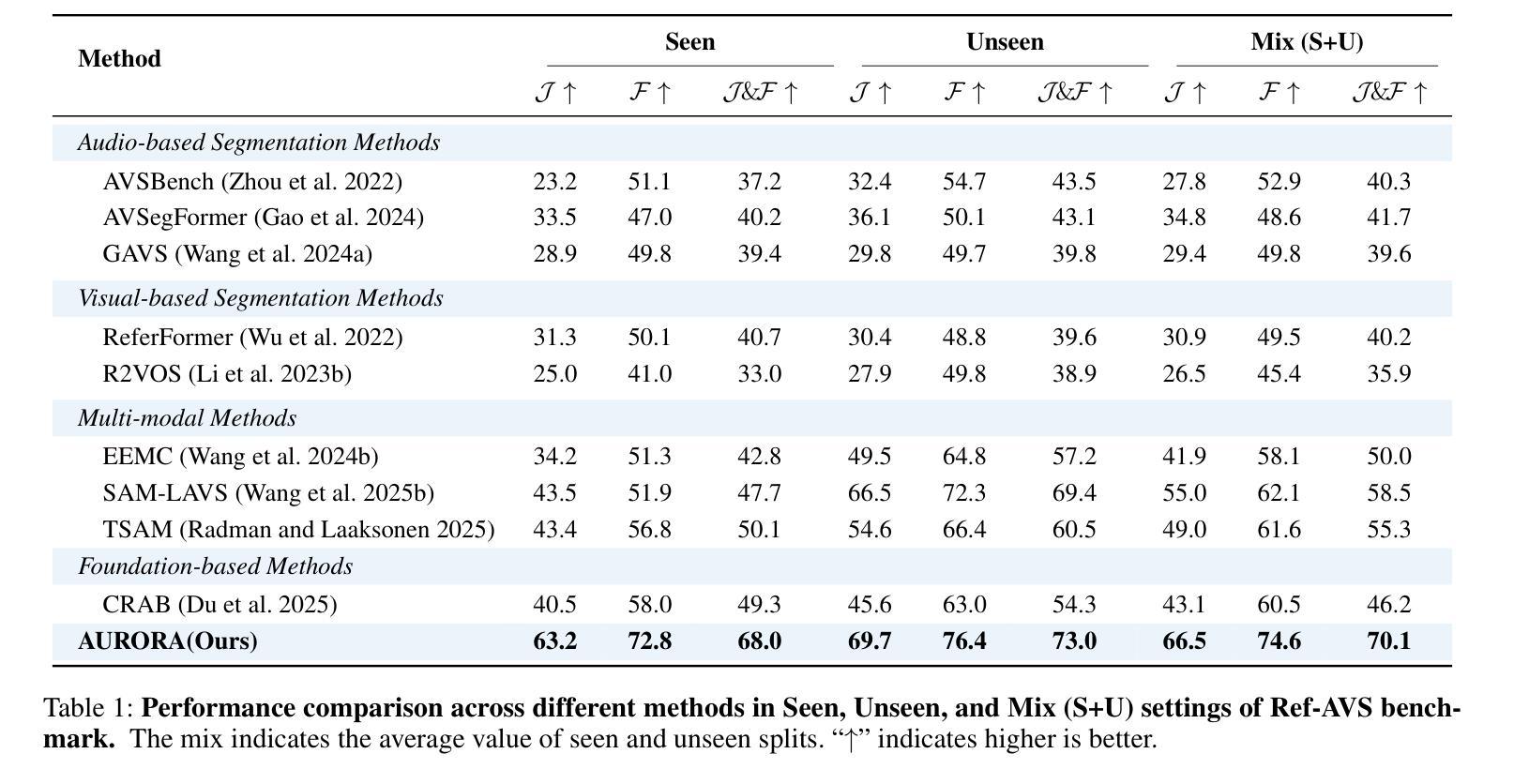
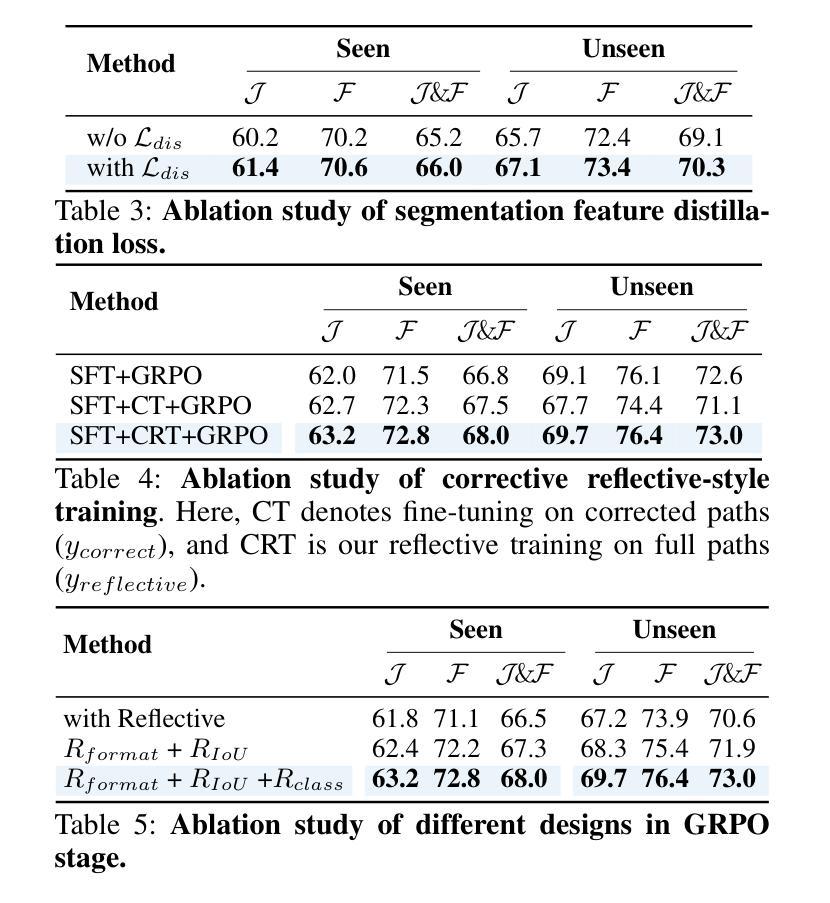
AURORA: Augmented Understanding via Structured Reasoning and Reinforcement Learning for Reference Audio-Visual Segmentation
Authors:Ziyang Luo, Nian Liu, Fahad Shahbaz Khan, Junwei Han
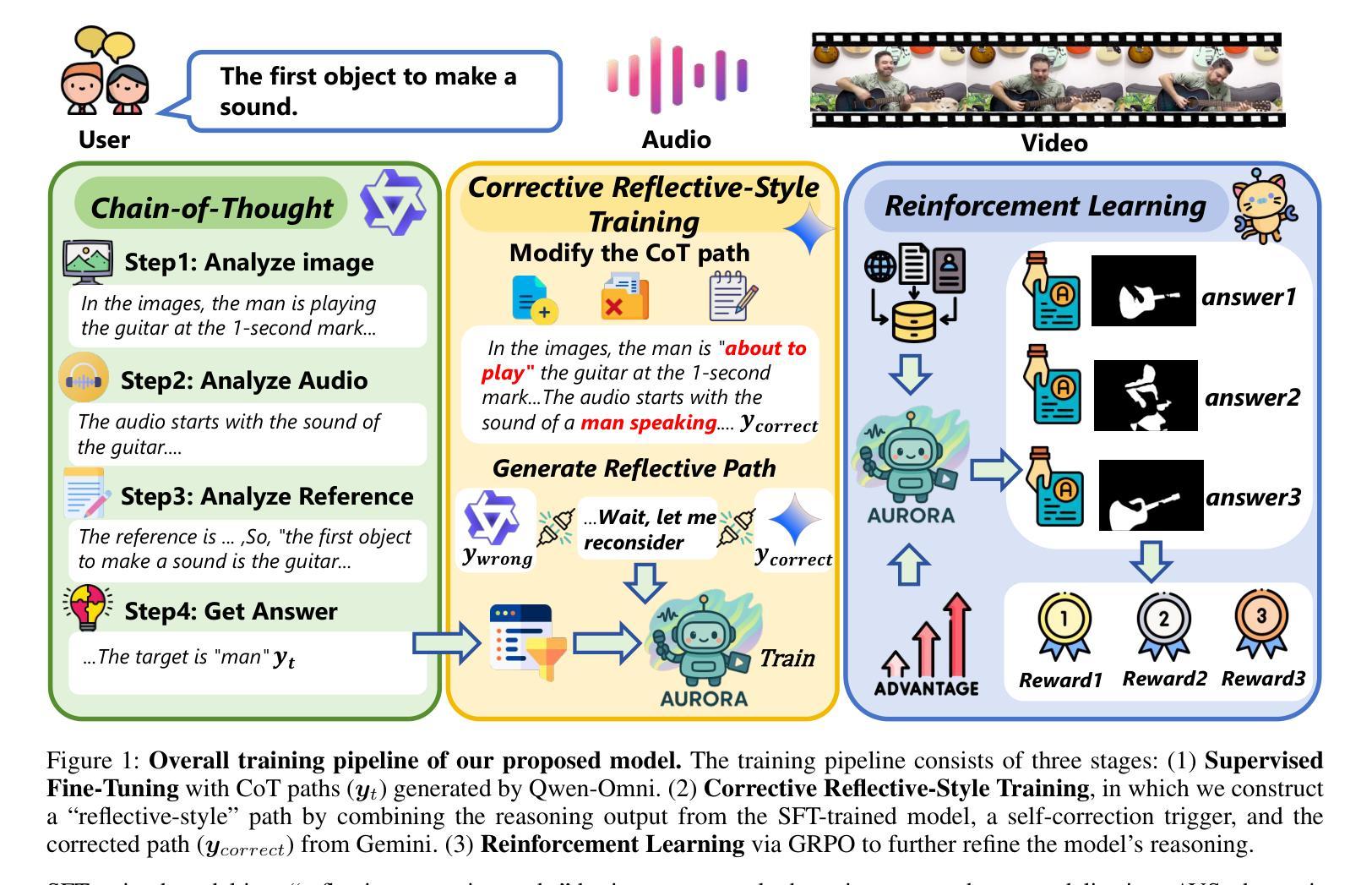
Reference Audio-Visual Segmentation (Ref-AVS) tasks challenge models to precisely locate sounding objects by integrating visual, auditory, and textual cues. Existing methods often lack genuine semantic understanding, tending to memorize fixed reasoning patterns. Furthermore, jointly training for reasoning and segmentation can compromise pixel-level precision. To address these issues, we introduce AURORA, a novel framework designed to enhance genuine reasoning and language comprehension in reference audio-visual segmentation. We employ a structured Chain-of-Thought (CoT) prompting mechanism to guide the model through a step-by-step reasoning process and introduce a novel segmentation feature distillation loss to effectively integrate these reasoning abilities without sacrificing segmentation performance. To further cultivate the model’s genuine reasoning capabilities, we devise a further two-stage training strategy: first, a ``corrective reflective-style training” stage utilizes self-correction to enhance the quality of reasoning paths, followed by reinforcement learning via Group Reward Policy Optimization (GRPO) to bolster robustness in challenging scenarios. Experiments demonstrate that AURORA achieves state-of-the-art performance on Ref-AVS benchmarks and generalizes effectively to unreferenced segmentation.
参考音频视觉分割(Ref-AVS)任务通过整合视觉、听觉和文本线索,挑战模型精确定位发声物体。现有方法往往缺乏真正的语义理解,倾向于记忆固定的推理模式。此外,联合训练和推理和分割会影响像素级的精确度。为了解决这些问题,我们引入了AURORA,这是一个旨在增强真实推理和语言理解的新型框架,用于参考音频视觉分割。我们采用结构化的思维链(CoT)提示机制,通过逐步推理过程引导模型,并引入了一种新的分割特征蒸馏损失,以有效地整合这些推理能力,而不牺牲分割性能。为了进一步培养模型的真实推理能力,我们设计了一个进一步的两阶段训练策略:首先,“矫正反思式训练”阶段利用自我矫正来提高推理路径的质量,然后通过群体奖励政策优化(GRPO)进行强化学习,以提高在复杂场景中的稳健性。实验表明,AURORA在Ref-AVS基准测试上达到了最先进的性能,并能有效地推广到无参考分割。
论文及项目相关链接
Summary
该文本介绍了一种针对音频视觉分割任务的新型框架AURORA,旨在增强真实推理和语言理解能力。采用结构化思维链(CoT)提示机制引导模型逐步推理,并引入新的分割特征蒸馏损失,以在不影响分割性能的情况下整合这些推理能力。为了进一步提升模型的真实推理能力,设计了两阶段训练策略:首先,利用自我修正的“纠正反思式训练”阶段提高推理路径的质量,然后通过群体奖励政策优化(GRPO)强化学习来提升在复杂场景中的稳健性。实验表明,AURORA在Ref-AVS基准测试中实现了最佳性能,并有效地推广到了无参考分割。
Key Takeaways
- AURORA是一个针对音频视觉分割任务的新型框架,旨在提高真实推理和语言理解能力。
- 使用结构化思维链(CoT)提示机制来引导模型进行逐步推理。
- 引入分割特征蒸馏损失,有效整合推理能力,同时不牺牲分割性能。
- 采用了两阶段训练策略来进一步提升模型的真实推理能力。
- 第一阶段为纠正反思式训练,利用自我修正提高推理路径的质量。
- 第二阶段采用群体奖励政策优化(GRPO)强化学习,提升模型在复杂场景中的稳健性。
- 实验显示,AURORA在Ref-AVS基准测试中表现最佳,并能有效推广至无参考分割。
点此查看论文截图

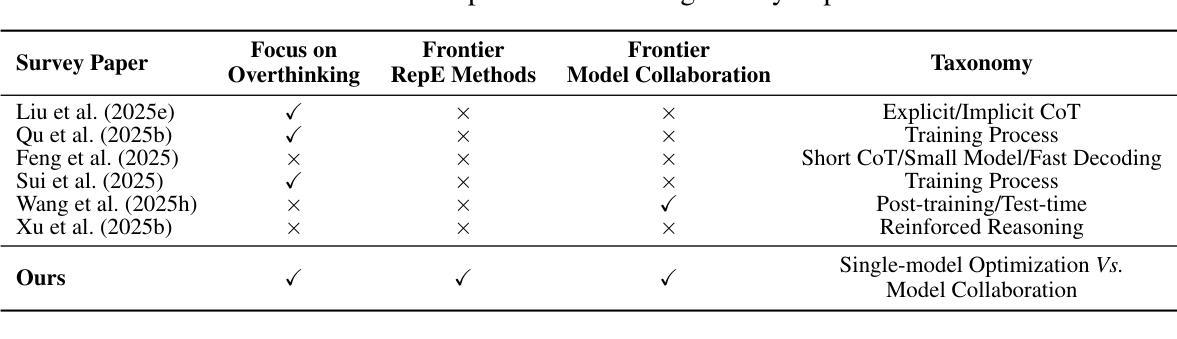
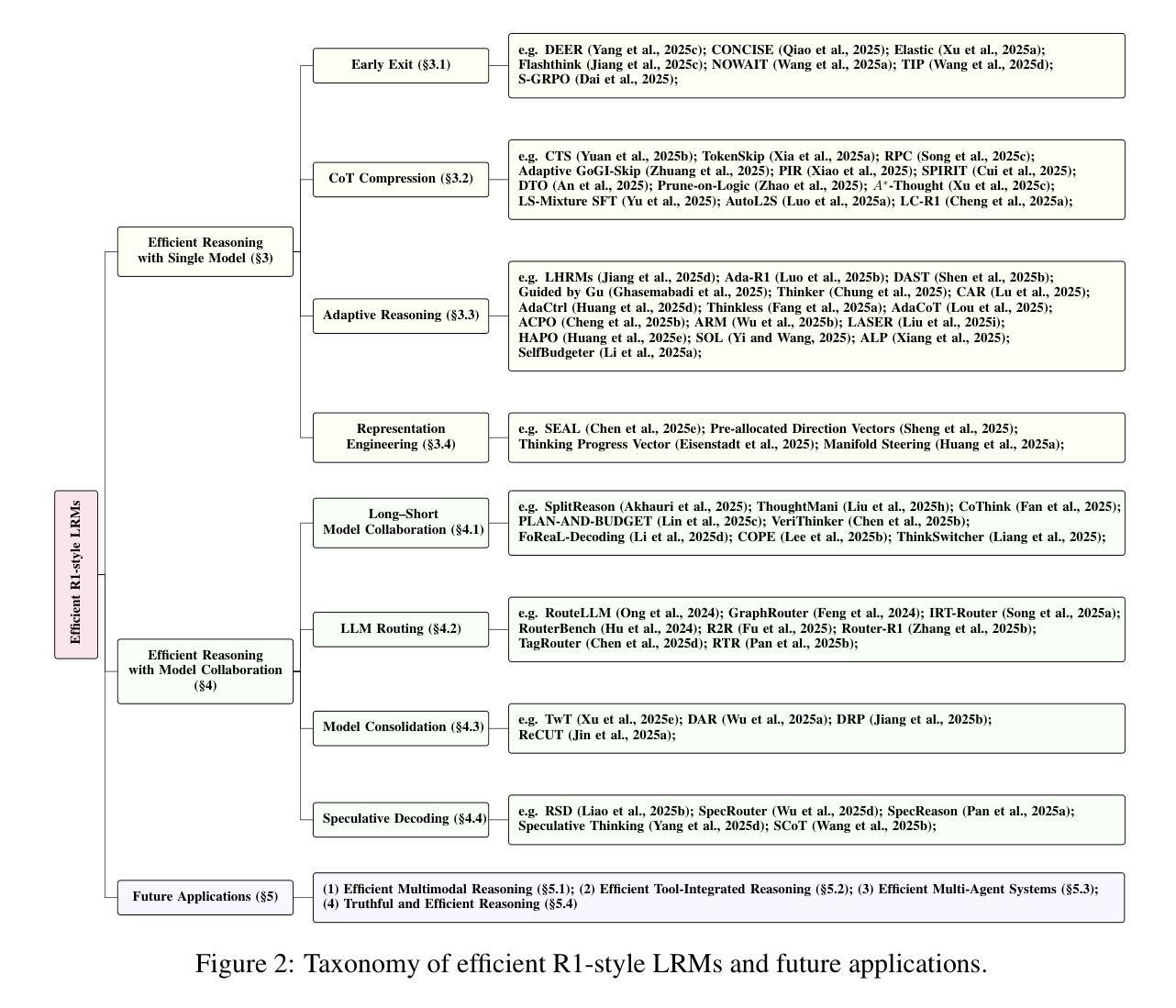
Don’t Overthink It: A Survey of Efficient R1-style Large Reasoning Models
Authors:Linan Yue, Yichao Du, Yizhi Wang, Weibo Gao, Fangzhou Yao, Li Wang, Ye Liu, Ziyu Xu, Qi Liu, Shimin Di, Min-Ling Zhang
Recently, Large Reasoning Models (LRMs) have gradually become a research hotspot due to their outstanding performance in handling complex tasks. Among them, DeepSeek R1 has garnered significant attention for its exceptional performance and open-source nature, driving advancements in the research of R1-style LRMs. Unlike traditional Large Language Models (LLMs), these models enhance logical deduction and decision-making capabilities during reasoning by incorporating mechanisms such as long chain-of-thought and self-reflection through reinforcement learning. However, with the widespread application of these models, the problem of overthinking has gradually emerged. Specifically, when generating answers, these models often construct excessively long reasoning chains with redundant or repetitive steps, which leads to reduced reasoning efficiency and may affect the accuracy of the final answer. To this end, various efficient reasoning methods have been proposed, aiming to reduce the length of reasoning paths without compromising model performance and reasoning capability. By reviewing the current research advancements in the field of efficient reasoning methods systematically, we categorize existing works into two main directions based on the lens of single-model optimization versus model collaboration: (1) Efficient Reasoning with Single Model, which focuses on improving the reasoning efficiency of individual models; and (2) Efficient Reasoning with Model Collaboration, which explores optimizing reasoning paths through collaboration among multiple models. Besides, we maintain a public GitHub repository that tracks the latest progress in efficient reasoning methods.
最近,大型推理模型(LRMs)由于其处理复杂任务的出色性能逐渐成为研究热点。其中,DeepSeek R1因其卓越的性能和开源性质引起了广泛关注,推动了R1风格LRMs的研究进展。与传统的大型语言模型(LLMs)不同,这些模型通过强化学习等机制提高推理过程中的逻辑推导和决策能力,如长链思维和自我反思。然而,随着这些模型的广泛应用,过度思考的问题逐渐出现。具体地说,在生成答案时,这些模型往往会构建过长且冗余或重复的推理链,导致推理效率降低,并可能影响最终答案的准确性。为此,已经提出了各种高效的推理方法,旨在缩短推理路径,同时不损害模型性能和推理能力。我们系统地回顾了当前高效推理方法领域的研究进展,从单一模型优化和模型协作的角度,将现有工作分为两个主要方向:(1)基于单一模型的高效推理,专注于提高单个模型的推理效率;(2)基于模型协作的高效推理,探索通过多个模型的协作来优化推理路径。此外,我们还维护一个公共GitHub仓库,跟踪高效推理方法的最新进展。
论文及项目相关链接
Summary
大规模推理模型(LRMs)尤其是DeepSeek R1因其卓越性能和开源特性而受到广泛关注,推动了R1风格LRMs的研究进展。这些模型通过融入长链思维、自我反思等机制,增强了逻辑推断和决策能力。然而,过思问题的出现逐渐显现,生成答案时常常构建冗长、重复推理链,影响推理效率和答案准确性。为此,本文提出高效推理方法,旨在缩短推理路径而不损害模型性能和推理能力。本文从单一模型优化和模型协作两个角度系统评述了当前高效推理方法的研究进展,并维护了一个公共GitHub仓库以追踪最新进展。
Key Takeaways
- LRMs,特别是DeepSeek R1,因卓越性能和开源特性备受关注,推动R1风格LRMs研究。
- LRMs通过融入长链思维、自我反思等机制增强逻辑推断和决策能力。
- 过思问题逐渐显现,生成答案时构建冗长、重复推理链,影响推理效率和答案准确性。
- 为解决此问题,提出高效推理方法,旨在缩短推理路径而不损害模型性能。
- 系统评述了单一模型优化和模型协作两个角度的高效推理方法研究进展。
- 单一模型优化方法致力于提升单个模型的推理效率。
点此查看论文截图

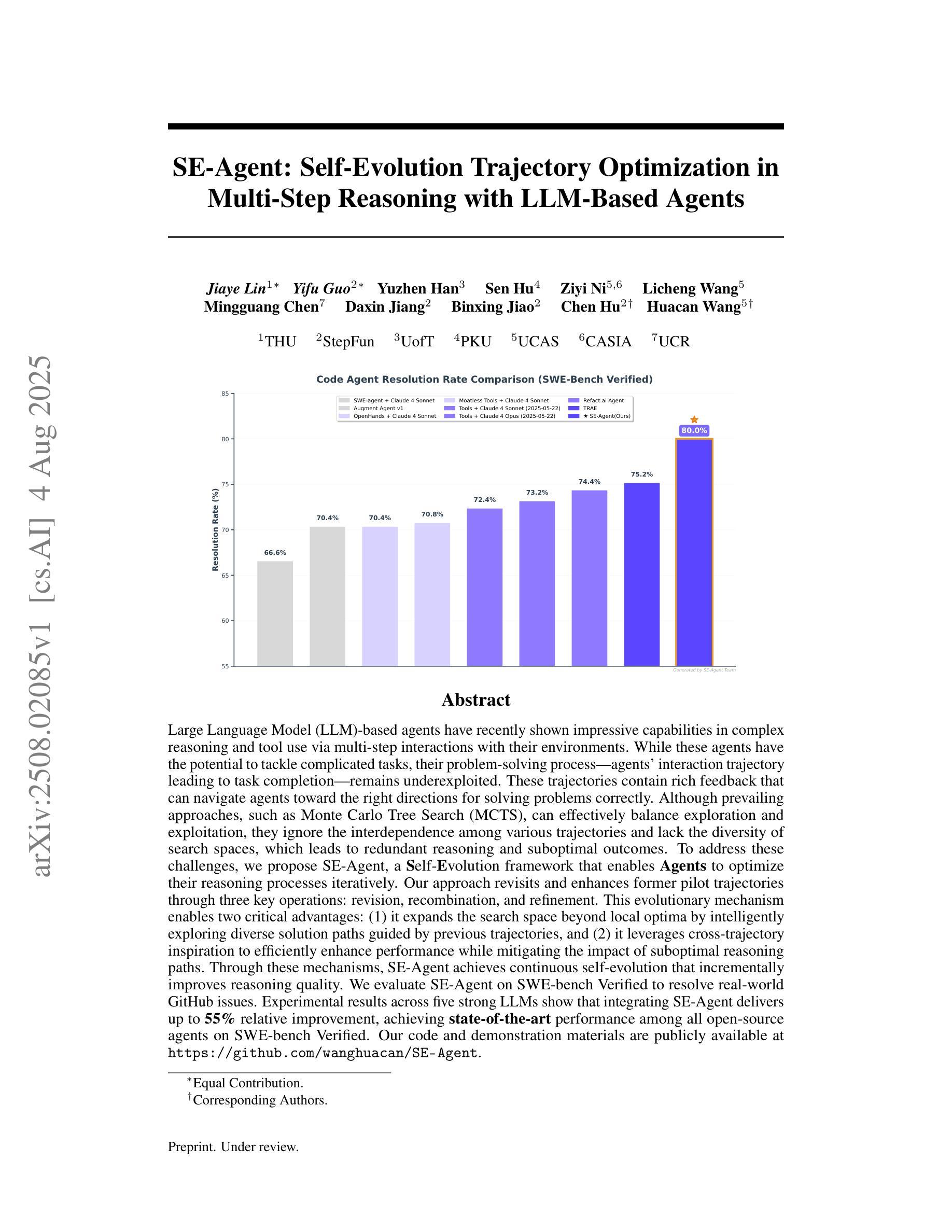
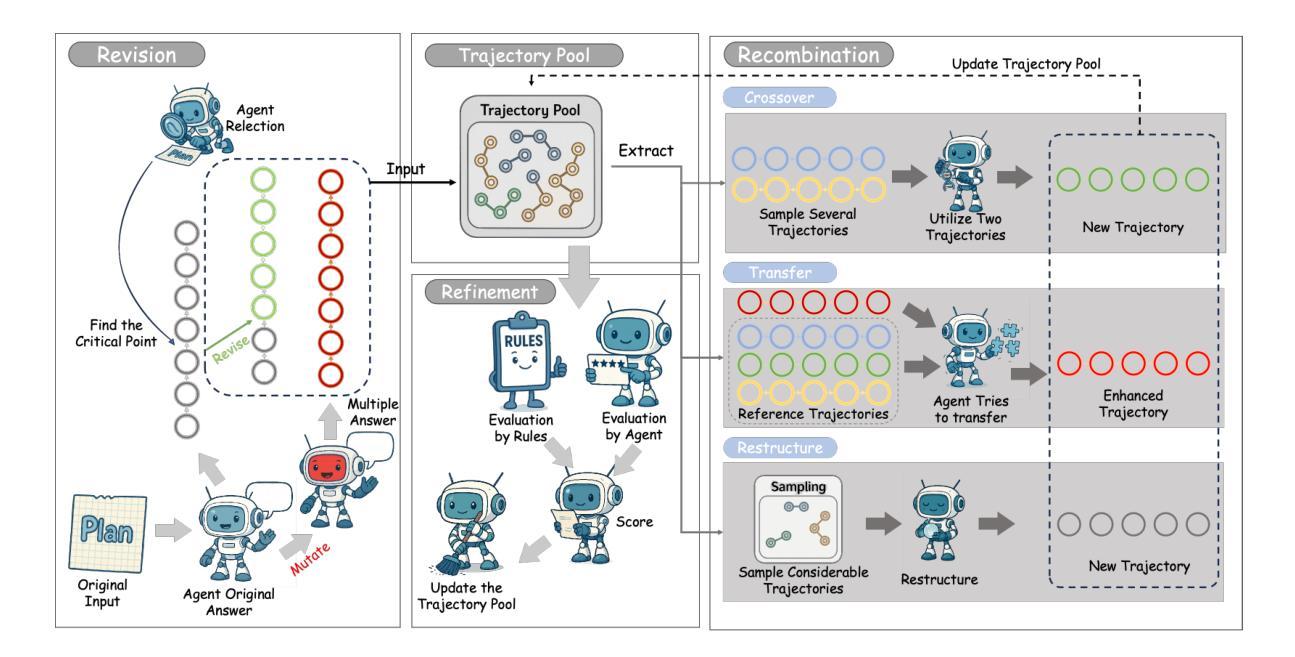
SE-Agent: Self-Evolution Trajectory Optimization in Multi-Step Reasoning with LLM-Based Agents
Authors:Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, Daxin Jiang, Binxing Jiao, Chen Hu, Huacan Wang
Large Language Model (LLM)-based agents have recently shown impressive capabilities in complex reasoning and tool use via multi-step interactions with their environments. While these agents have the potential to tackle complicated tasks, their problem-solving process, i.e., agents’ interaction trajectory leading to task completion, remains underexploited. These trajectories contain rich feedback that can navigate agents toward the right directions for solving problems correctly. Although prevailing approaches, such as Monte Carlo Tree Search (MCTS), can effectively balance exploration and exploitation, they ignore the interdependence among various trajectories and lack the diversity of search spaces, which leads to redundant reasoning and suboptimal outcomes. To address these challenges, we propose SE-Agent, a Self-Evolution framework that enables Agents to optimize their reasoning processes iteratively. Our approach revisits and enhances former pilot trajectories through three key operations: revision, recombination, and refinement. This evolutionary mechanism enables two critical advantages: (1) it expands the search space beyond local optima by intelligently exploring diverse solution paths guided by previous trajectories, and (2) it leverages cross-trajectory inspiration to efficiently enhance performance while mitigating the impact of suboptimal reasoning paths. Through these mechanisms, SE-Agent achieves continuous self-evolution that incrementally improves reasoning quality. We evaluate SE-Agent on SWE-bench Verified to resolve real-world GitHub issues. Experimental results across five strong LLMs show that integrating SE-Agent delivers up to 55% relative improvement, achieving state-of-the-art performance among all open-source agents on SWE-bench Verified. Our code and demonstration materials are publicly available at https://github.com/wanghuacan/SE-Agent.
基于大型语言模型(LLM)的代理最近表现出在复杂推理和工具使用方面的令人印象深刻的能力,这是通过与环境的多步骤交互实现的。虽然这些代理有潜力处理复杂任务,但它们的解决问题过程,即代理完成任务的交互轨迹,仍被低估。这些轨迹包含丰富的反馈,可以引导代理朝着正确的方向解决问题。尽管现有的方法,如蒙特卡洛树搜索(MCTS),可以有效地平衡探索和利用,但它们忽略了各种轨迹之间的相互依赖性,并且缺乏搜索空间的多样性,这导致了冗余推理和次优结果。为了解决这些挑战,我们提出了SE-Agent,这是一种自我进化框架,使代理能够迭代地优化他们的推理过程。我们的方法通过三个关键操作:修订、重组和精炼,重新访问并增强先前的轨迹。这种进化机制带来了两个关键优势:(1)它通过智能地探索由先前轨迹引导的多样化解决方案路径,扩大了搜索空间,超越了局部最优;(2)它利用跨轨迹的灵感来有效地提高性能,同时减轻次优推理路径的影响。通过这些机制,SE-Agent实现了连续的自我进化,逐步提高了推理质量。我们在SWE-bench Verified上评估了SE-Agent,以解决现实世界中的GitHub问题。在五个强大的LLM上的实验结果表明,集成SE-Agent带来了高达55%的相对改进,在SWE-bench Verified上的性能达到了开源代理中的最新水平。我们的代码和演示材料可在https://github.com/wanghuacan/SE-Agent公开获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在复杂推理和工具使用方面展现出令人印象深刻的能力,通过与环境的多步交互来完成任务。然而,LLM的问题解决过程(即完成任务时代理的交互轨迹)尚未得到充分研究。本文提出SE-Agent,一个自我进化框架,通过修订、重组和细化先前的轨迹,使代理能够优化其推理过程。这种进化机制有助于智能探索多种解决方案路径,并利用跨轨迹灵感提高性能。实验结果表明,SE-Agent在解决现实世界GitHub问题上实现了高达55%的相对改进,达到了开源代理中的最佳性能。
Key Takeaways
- LLM在复杂推理和工具使用方面表现出强大的能力。
- LLM的问题解决过程(交互轨迹)尚未得到充分研究。
- SE-Agent是一个自我进化的框架,通过修订、重组和细化之前的轨迹来优化代理的推理过程。
- SE-Agent扩大了搜索空间,通过智能探索多种解决方案路径来提高性能。
- SE-Agent利用跨轨迹灵感,提高了性能并减轻了次优推理路径的影响。
- 实验结果表明,SE-Agent在解决现实世界问题上实现了显著的性能改进。
点此查看论文截图
The SMeL Test: A simple benchmark for media literacy in language models
Authors:Gustaf Ahdritz, Anat Kleiman
The internet is rife with unattributed, deliberately misleading, or otherwise untrustworthy content. Though large language models (LLMs) are often tasked with autonomous web browsing, the extent to which they have learned the simple heuristics human researchers use to navigate this noisy environment is not currently known. In this paper, we introduce the Synthetic Media Literacy Test (SMeL Test), a minimal benchmark that tests the ability of language models to actively filter out untrustworthy information in context. We benchmark a variety of commonly used instruction-tuned LLMs, including reasoning models, and find that no model consistently trusts more reliable sources; while reasoning in particular is associated with higher scores, even the best API model we test hallucinates up to 70% of the time. Remarkably, larger and more capable models do not necessarily outperform their smaller counterparts. We hope our work sheds more light on this important form of hallucination and guides the development of new methods to combat it.
互联网充斥着未经证实、故意误导或其他不可信赖的内容。虽然大型语言模型(LLM)通常被赋予自主网页浏览的任务,但它们学习人类研究者用于浏览这种嘈杂环境的简单启发式策略的程度尚不清楚。在本文中,我们介绍了合成媒体素养测试(SMeL测试),这是一个最小的基准测试,旨在测试语言模型在特定情境中主动过滤掉不可靠信息的能力。我们对各种常用的指令调整型LLM进行了基准测试,包括推理模型,发现没有任何模型能够始终如一地信任更可靠的来源;虽然推理与更高的分数特别相关,但即使是我们测试的最佳API模型,也有高达70%的时间会出现幻觉。值得注意的是,更大、更强大的模型并不一定比小型模型表现更好。我们希望我们的工作能进一步揭示这种重要的幻觉形式,并为开发新的对抗方法提供指导。
论文及项目相关链接
Summary
互联网充斥着未经证实、故意误导或其他不可靠的内容。大型语言模型(LLMs)常被用于自主浏览网页,但它们是否掌握了人类研究者用于导航这种嘈杂环境的简单启发式技术尚不清楚。本文介绍了合成媒介素养测试(SMeL测试),这是一个最小的基准测试,用于测试语言模型在情境中主动过滤掉不可靠信息的能力。我们对一系列常用的指令调整型LLMs进行了基准测试,包括推理模型,发现没有任何模型始终信任更可靠的来源;虽然推理与更高的分数有关,但即使我们测试的最佳API模型也会达到70%的幻觉现象。值得注意的是,更大、更强大的模型并不一定优于较小的模型。我们希望我们的研究能更多地关注这种幻觉现象的发展并引导开发新方法应对幻觉现象的出现。希望这一测试为未来设计有效的策略以提高LLMs辨别真实与假信息的能力提供了可能的方向。此外我们也指出这可以作为评价AI网络素养的一个重要标准之一,具有重要的应用价值和实际意义。我们的研究可以为开发新型的人工智能媒体素养评估工具提供参考和借鉴。我们希望通过这项研究引导研究人员和行业从业者在开发大型语言模型时关注其在过滤网络中的不实信息能力。为此我们的工作未来仍有待深化和完善,通过不断改进模型和算法来增强模型的识别能力并推动该领域的发展。未来我们也期待有更多相关研究来验证和改进合成媒介素养测试的效果和适用性,从而为推动AI网络素养的提高做出更大的贡献。总之,我们的工作对于推动人工智能的发展具有重要意义。我们相信通过不断的努力和研究我们可以提高人工智能的媒体素养水平从而更好地应对网络信息的挑战。我们相信人工智能的未来发展将更加注重其媒体素养的提升并带来更加积极的影响和贡献。我们相信我们的研究将推动人工智能在真实世界中的有效应用,特别是应对日益增长的虚假信息问题。这将为人工智能领域的发展开辟新的方向并解决现实问题实现科技的实际应用和社会效益的统一和提升创造巨大的潜力。。在未来人工智能发展中能够引领新技术研发助力科学进步。为此我们将持续开展研究致力于解决相关领域的难题推动技术的进步和发展以更好地服务社会和造福人类。。总的来说,我们希望这项工作能够帮助人们更好地理解大型语言模型如何操作并将其用于改进真实的自然语言理解和对话技术服务于用户的发展需要并通过科学方法开发语言相关的其他潜力更大范围的将其推广到各类社会工作中以期提高整个社会的语言素养和水平推动社会的全面进步和发展。。我们相信这项工作将为人工智能领域带来重要的贡献和启示推动其不断进步和发展并造福于人类。。我们将在后续的研究工作中进一步完善和提升相关研究思路和手段为提高大型语言模型的识别和判断能力贡献更多更好的科研成果和研究成果以解决社会上的各种问题并提供更有力的技术支撑和服务保障以实现社会的全面进步和发展。。总的来说我们希望通过我们的研究能够为人工智能领域的发展做出更大的贡献和启示为人类的科技进步和发展做出更多的贡献和努力。
Key Takeaways
- 大型语言模型(LLMs)在互联网信息筛选方面的能力尚不清楚。
- 合成媒介素养测试(SMeL测试)被引入作为评估LLMs过滤不真实信息能力的基准测试。
- 推理模型虽然在测试中表现较好,但仍存在高达70%的幻觉现象。
- 大型语言模型的性能并不一定优于较小的模型。
- 当前研究指出了大型语言模型在处理网络信息时面临的挑战,并为未来的研究和改进提供了方向。
- 该研究强调了媒体素养在人工智能发展中的重要性,并建议研究人员关注此领域的研究与开发工作以提升AI应对网络信息挑战的能力。
点此查看论文截图

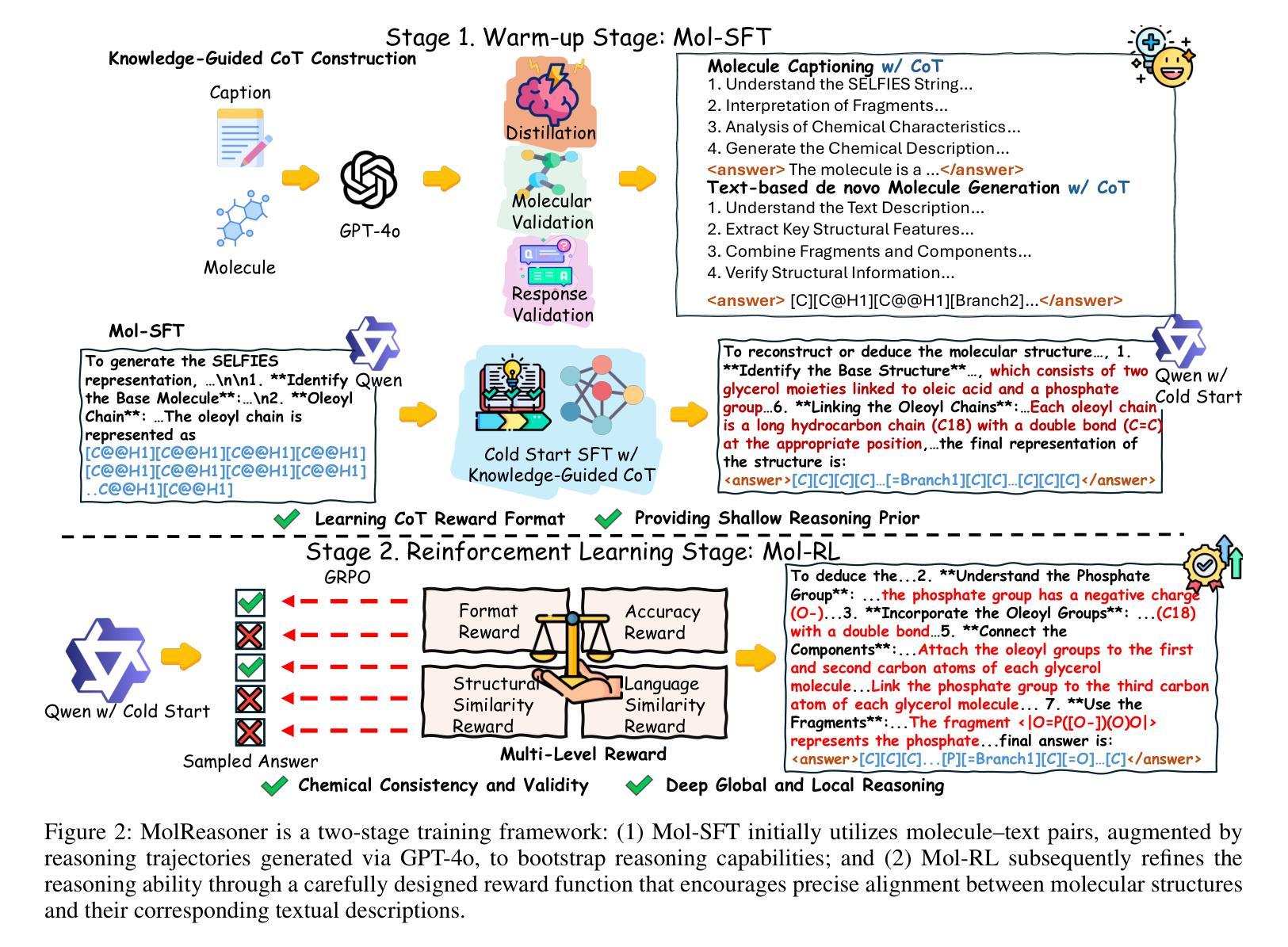
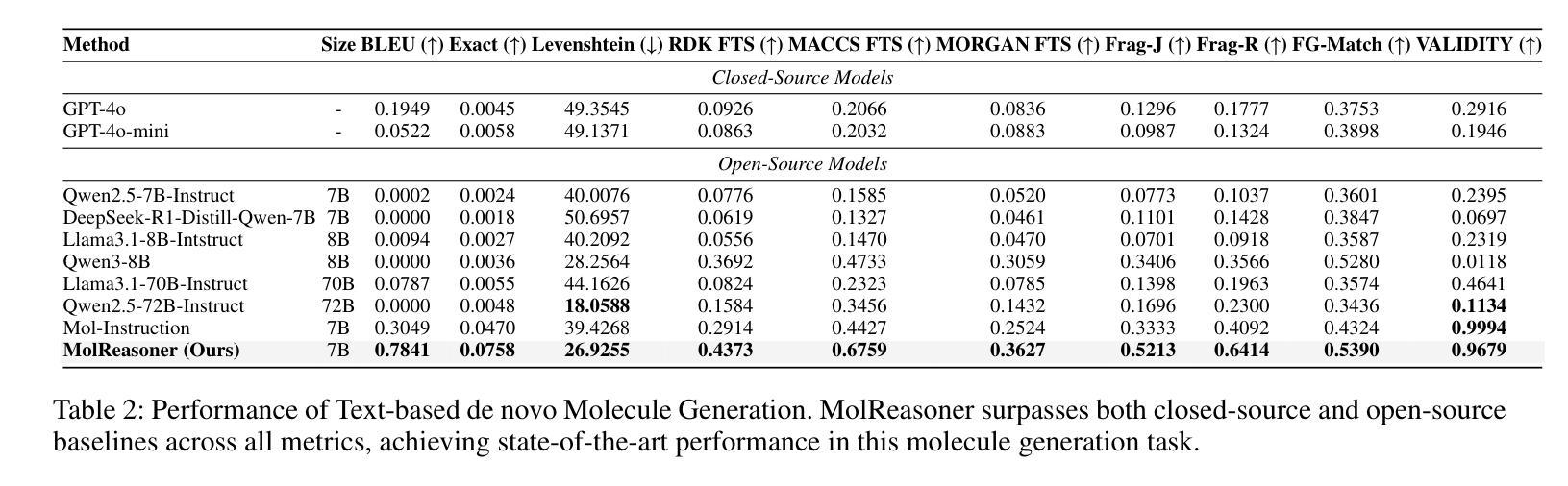
MolReasoner: Toward Effective and Interpretable Reasoning for Molecular LLMs
Authors:Guojiang Zhao, Sihang Li, Zixiang Lu, Zheng Cheng, Haitao Lin, Lirong Wu, Hanchen Xia, Hengxing Cai, Wentao Guo, Hongshuai Wang, Mingjun Xu, Siyu Zhu, Guolin Ke, Linfeng Zhang, Zhifeng Gao
Large Language Models(LLMs) have demonstrated remarkable performance across various domains, yet their capabilities in molecular reasoning remain insufficiently explored. Current approaches tend to rely heavily on general-purpose prompting, which lacks domain-specific molecular semantics, while those that use fine-tuning strategies often face challenges with interpretability and reasoning depth. To address these issues, we introduce MolReasoner, a two-stage framework designed to transition LLMs from memorization towards chemical reasoning. First, we propose Mol-SFT, which initializes the model’s reasoning abilities via synthetic Chain-of-Thought(CoT) samples generated by GPT-4o and verified for chemical accuracy. Subsequently, Mol-RL applies reinforcement learning with specialized reward functions designed explicitly to align chemical structures with linguistic descriptions, thereby enhancing molecular reasoning capabilities. Our approach notably enhances interpretability, improving the model ‘s molecular understanding and enabling better generalization. Extensive experiments demonstrate that MolReasoner outperforms existing methods, and marking a significant shift from memorization-based outputs to robust chemical reasoning.
大型语言模型(LLMs)在各个领域都表现出了显著的性能,但它们在分子推理方面的能力却尚未得到充分探索。当前的方法往往过于依赖通用提示,缺乏领域特定的分子语义,而使用微调策略的方法则常常面临可解释性和推理深度方面的挑战。为了解决这些问题,我们引入了MolReasoner,这是一个两阶段的框架,旨在使LLMs从记忆转向化学推理。首先,我们提出了Mol-SFT,通过GPT-4o生成并经化学准确性验证的合成思维链(CoT)样本对模型的推理能力进行初始化。随后,Mol-RL应用强化学习,并设计专门的奖励函数,以将化学结构与语言描述对齐,从而提高分子推理能力。我们的方法显著提高了可解释性,提高了模型对分子的理解,并实现了更好的泛化。大量实验表明,MolReasoner优于现有方法,标志着从基于记忆的输出来到稳健的化学推理的重大转变。
论文及项目相关链接
Summary
大型语言模型(LLMs)在多领域表现出卓越性能,但在分子推理方面的能力尚未得到充分探索。现有方法往往依赖通用提示,缺乏领域特定的分子语义,而采用微调策略的方法则常面临可解释性和推理深度方面的挑战。为解决这些问题,我们推出MolReasoner,这是一个两阶段的框架,旨在使LLMs从记忆过渡到化学推理。首先,我们提出Mol-SFT,通过合成生成由GPT-4o验证化学准确性的链式思维(CoT)样本,初步模型推理能力。接着,Mol-RL应用强化学习,并设计专门针对化学结构与语言描述对齐的奖励函数,从而提高分子推理能力。我们的方法提高了可解释性,增强了模型对分子的理解,实现了更好的泛化。实验证明,MolReasoner优于现有方法,标志着从基于记忆的输出到稳健化学推理的重要转变。
Key Takeaways
- 大型语言模型在分子推理方面的能力尚未得到充分探索。
- 现有方法依赖通用提示,缺乏领域特定的分子语义。
- MolReasoner是一个两阶段的框架,旨在使LLMs从记忆过渡到化学推理。
- Mol-SFT通过合成生成并验证化学准确的链式思维样本,初步模型推理能力。
- Mol-RL应用强化学习,设计专门针对化学结构与语言描述对齐的奖励函数。
- MolReasoner提高了模型的可解释性,增强了分子理解,实现了更好的泛化。
点此查看论文截图


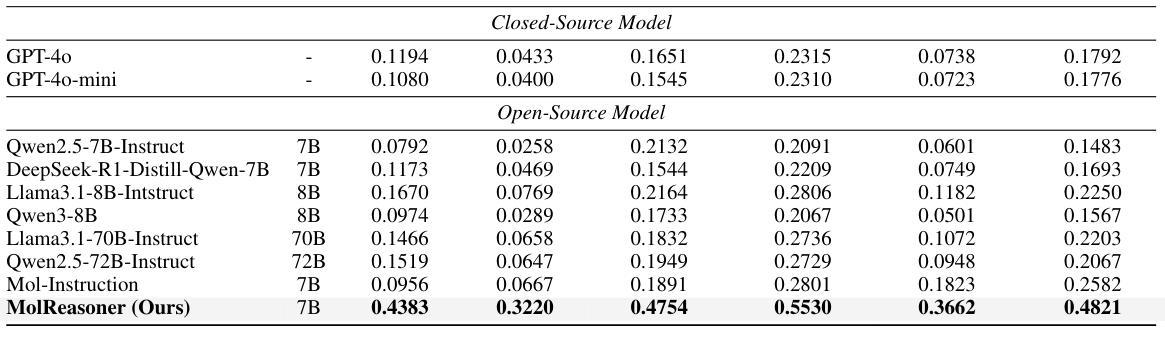
Mapillary Vistas Validation for Fine-Grained Traffic Signs: A Benchmark Revealing Vision-Language Model Limitations
Authors:Sparsh Garg, Abhishek Aich
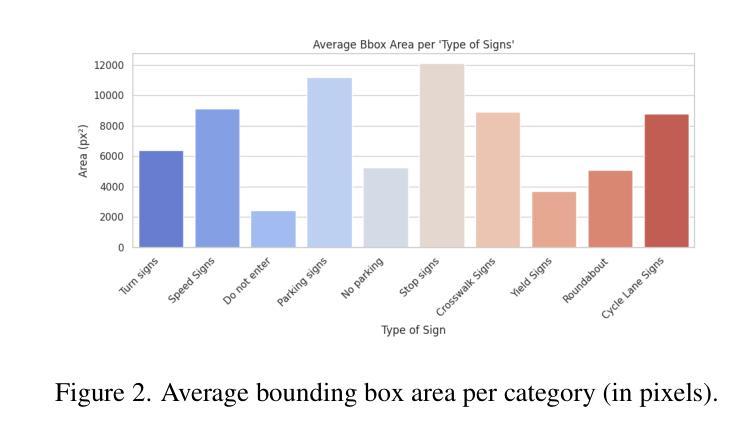
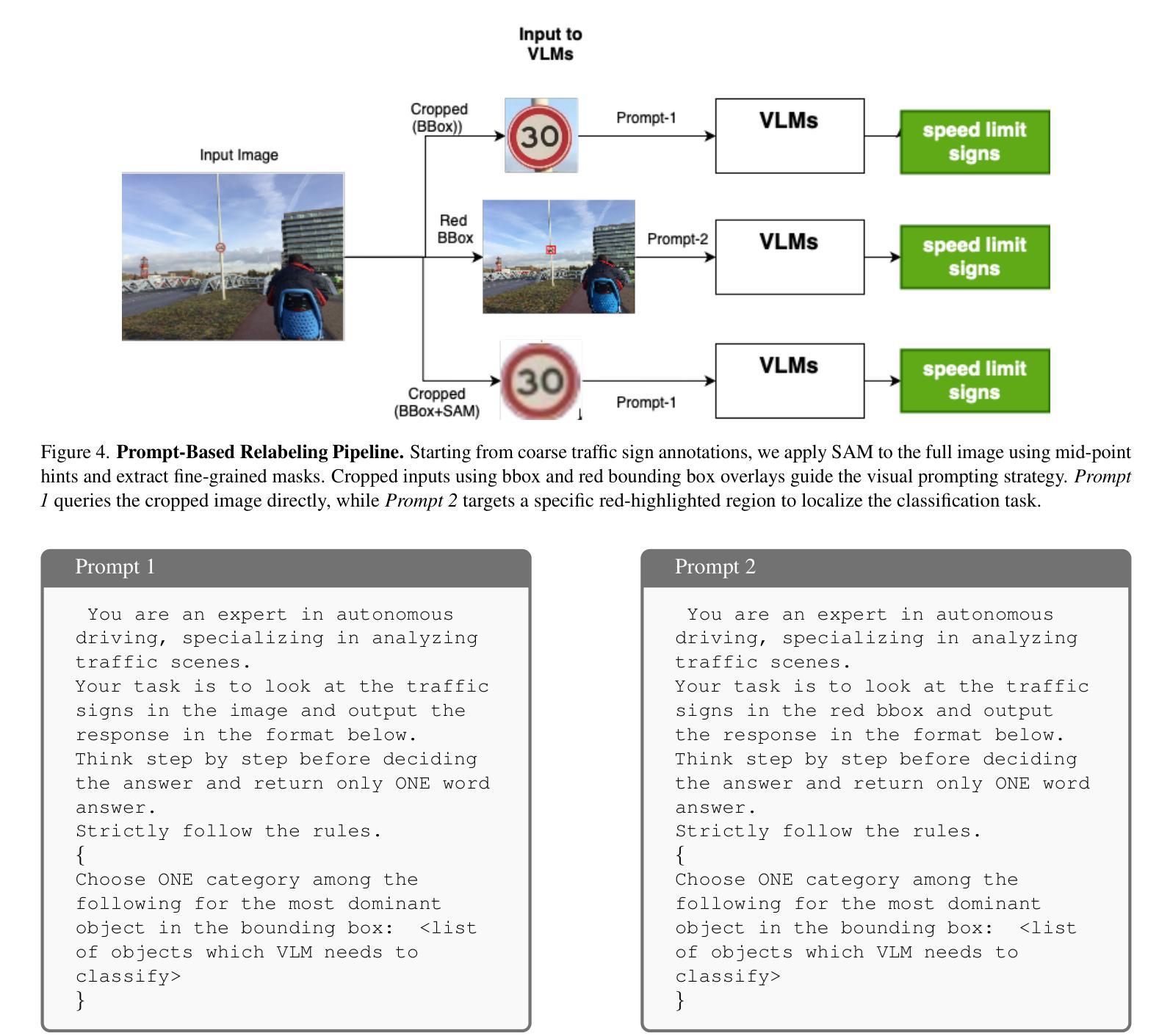
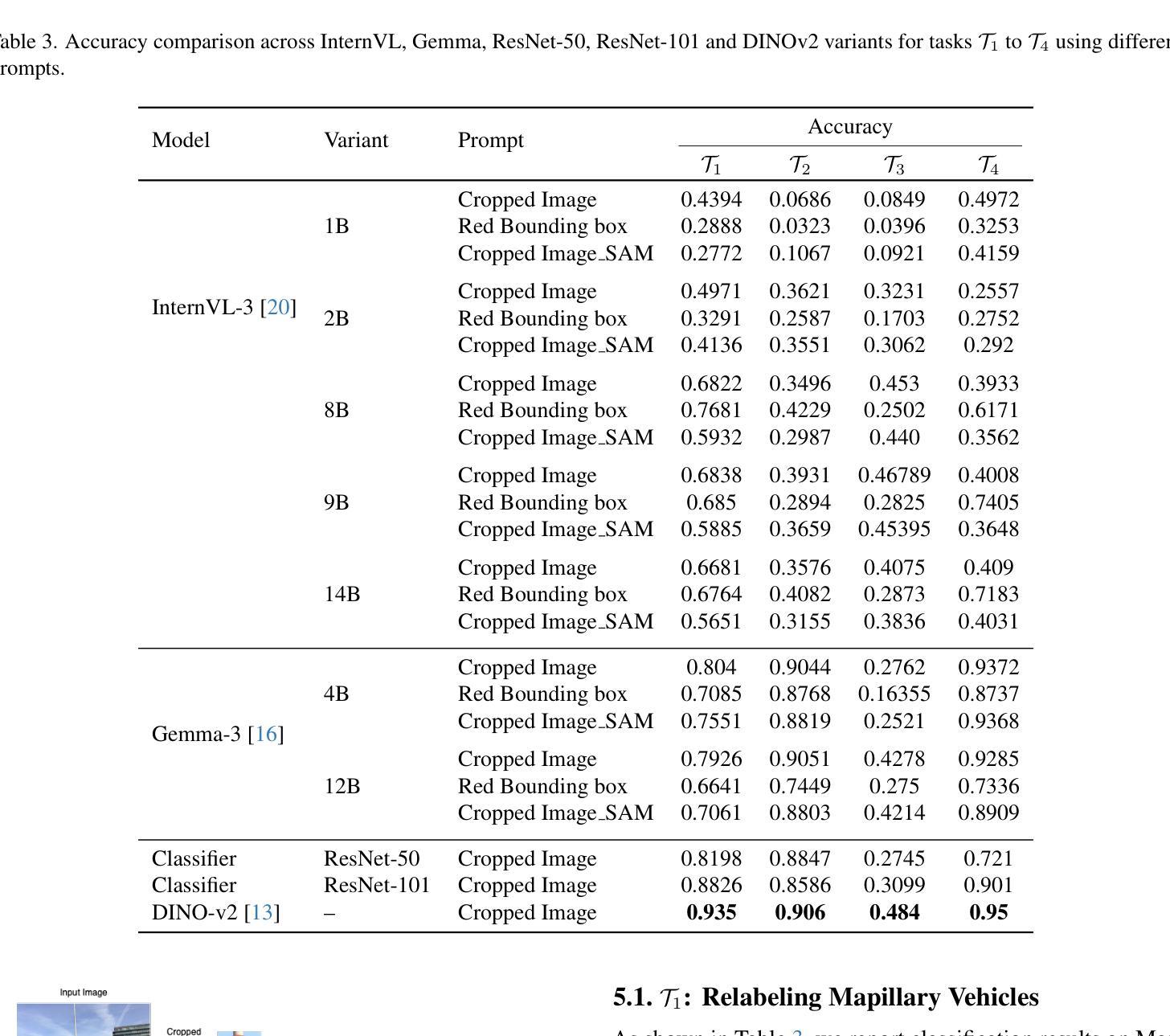
Obtaining high-quality fine-grained annotations for traffic signs is critical for accurate and safe decision-making in autonomous driving. Widely used datasets, such as Mapillary, often provide only coarse-grained labels - without distinguishing semantically important types such as stop signs or speed limit signs. To this end, we present a new validation set for traffic signs derived from the Mapillary dataset called Mapillary Vistas Validation for Traffic Signs (MVV), where we decompose composite traffic signs into granular, semantically meaningful categories. The dataset includes pixel-level instance masks and has been manually annotated by expert annotators to ensure label fidelity. Further, we benchmark several state-of-the-art VLMs against the self-supervised DINOv2 model on this dataset and show that DINOv2 consistently outperforms all VLM baselines-not only on traffic sign recognition, but also on heavily represented categories like vehicles and humans. Our analysis reveals significant limitations in current vision-language models for fine-grained visual understanding and establishes DINOv2 as a strong baseline for dense semantic matching in autonomous driving scenarios. This dataset and evaluation framework pave the way for more reliable, interpretable, and scalable perception systems. Code and data are available at: https://github.com/nec-labs-ma/relabeling
获取高质量的交通标志精细粒度注释对于自动驾驶中的准确和安全决策至关重要。广泛使用的数据集,如Mapillary,通常只提供粗略的标签,无法区分语义上重要的类型,如停车标志或限速标志。为此,我们推出了一个从Mapillary数据集派生的新的交通标志验证集,称为Mapillary Vistas交通标志验证集(MVV),我们将复合交通标志分解为颗粒状的、语义上有意义的类别。该数据集包括像素级的实例掩模,并由专业注释者进行手动注释,以确保标签的保真度。此外,我们在该数据集上对比了几种最先进的VLM与自监督的DINOv2模型,并显示DINOv2在此数据集上不仅始终在交通标志识别方面优于所有VLM基准测试,而且在车辆和人类等重度表示类别方面也表现出色。我们的分析揭示了当前视觉语言模型在精细粒度视觉理解方面的重大局限性,并将DINOv2确立为自动驾驶场景中密集语义匹配的强大基准测试。该数据集和评估框架为更可靠、可解释和可扩展的感知系统铺平了道路。有关代码和数据可以在:https://github.com/nec-labs-ma/relabeling找到。
论文及项目相关链接
PDF Accepted to ICCV 2025 Workshop (4th DataCV Workshop and Challenge)
Summary
基于Mapillary数据集构建的Mapillary Vistas Validation for Traffic Signs(MVV)数据集,为交通标志的精细粒度标注提供了高质量资源。该数据集将复合交通标志分解为粒状、语义上有意义的类别,并包括像素级的实例掩膜。此外,本文对比了最先进的视觉语言模型(VLMs)与自我监督的DINOv2模型在该数据集上的表现,结果显示DINOv2不仅交通标志识别表现出色,对车辆和行人等常见类别的识别也表现优秀。本研究揭示了当前视觉语言模型在精细粒度视觉理解方面的局限性,并确立了DINOv2在自动驾驶场景中的密集语义匹配能力。
Key Takeaways
- MVV数据集基于Mapillary数据集构建,专为交通标志的精细粒度标注设计。
- MVV数据集将复合交通标志分解为粒状、语义上意义明确的类别。
- 数据集包含像素级的实例掩膜,确保标注的准确性。
- 对比了多种先进的视觉语言模型在MVV数据集上的表现。
- DINOv2模型在交通标志识别及其他常见类别识别上表现优秀。
- 研究揭示了当前视觉语言模型在精细粒度视觉理解方面的局限性。
点此查看论文截图



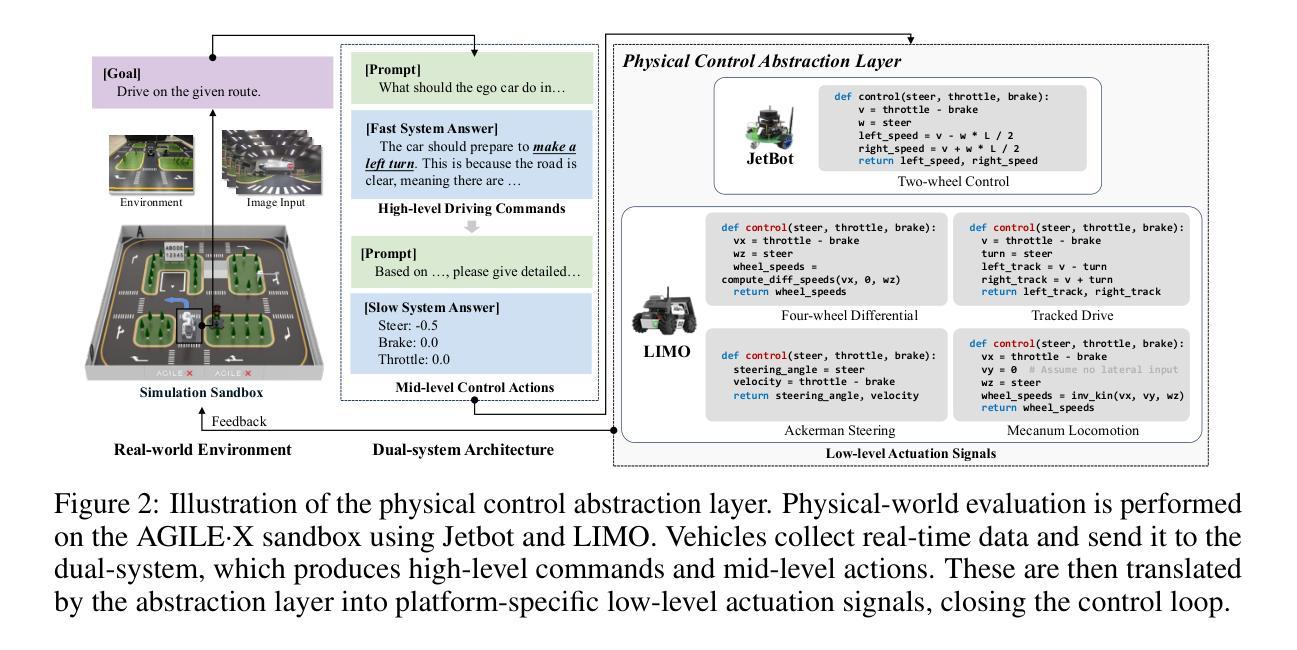
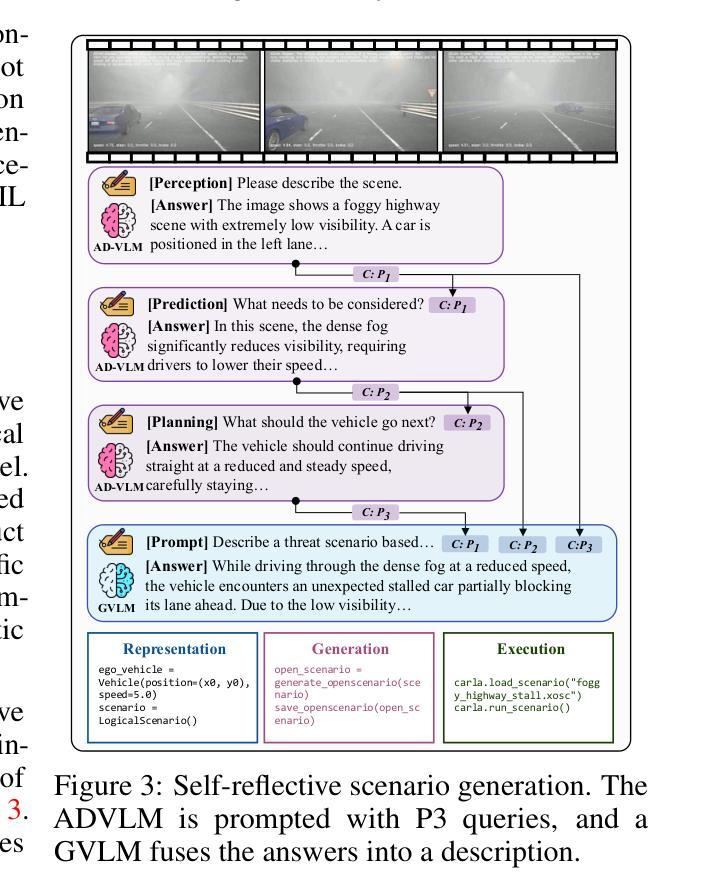
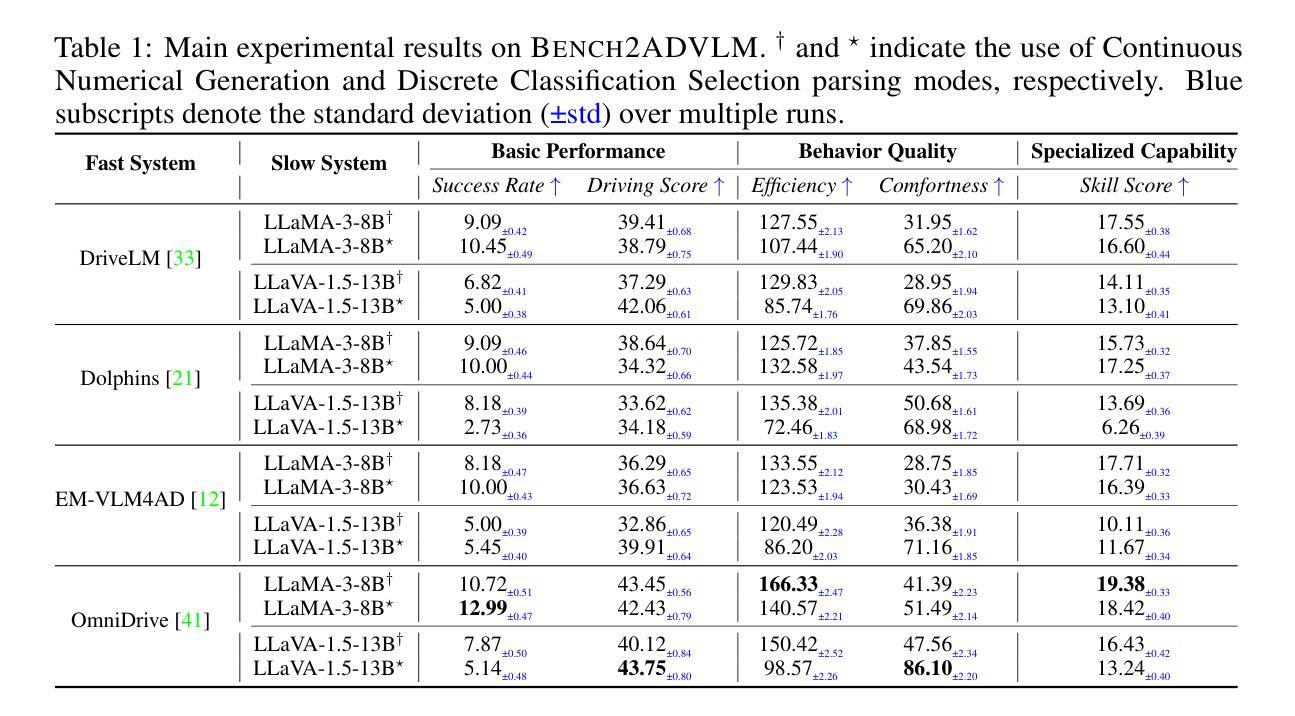
Bench2ADVLM: A Closed-Loop Benchmark for Vision-language Models in Autonomous Driving
Authors:Tianyuan Zhang, Ting Jin, Lu Wang, Jiangfan Liu, Siyuan Liang, Mingchuan Zhang, Aishan Liu, Xianglong Liu
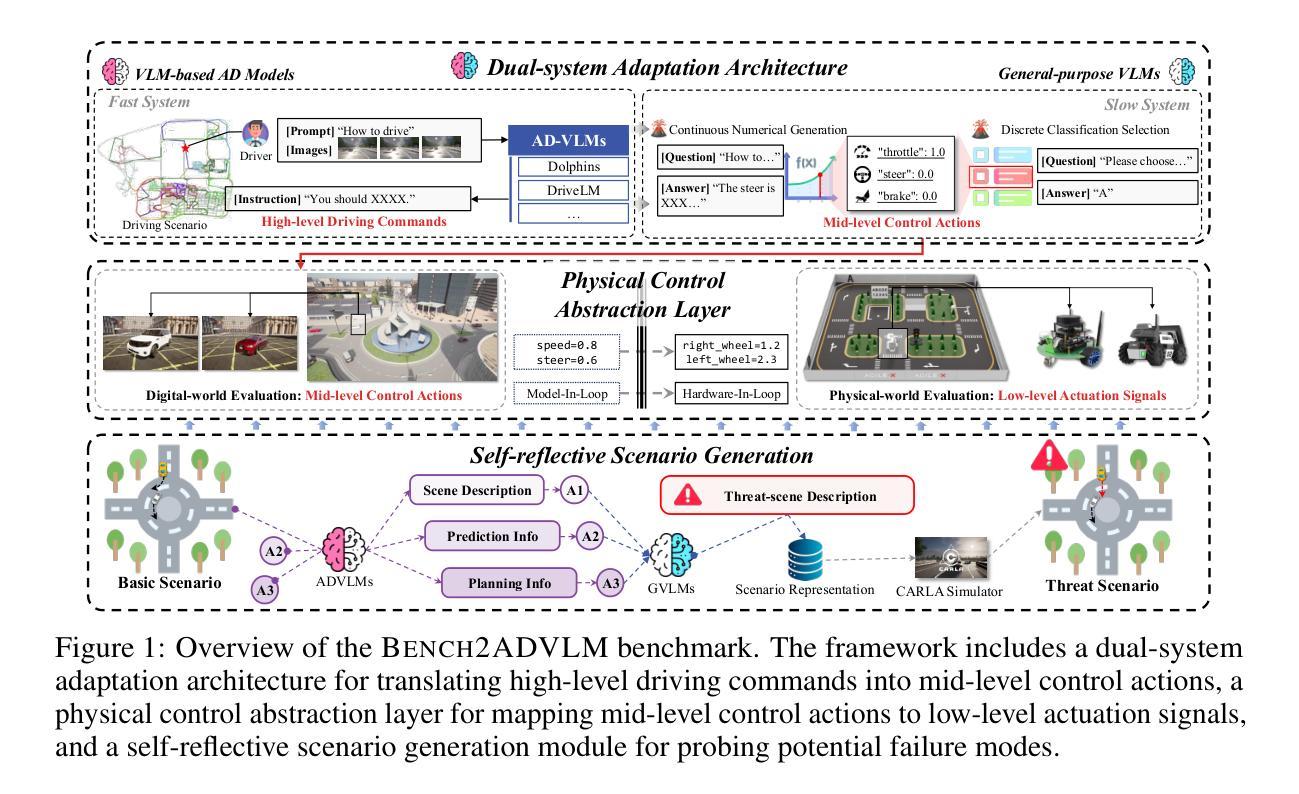
Vision-Language Models (VLMs) have recently emerged as a promising paradigm in autonomous driving (AD). However, current performance evaluation protocols for VLM-based AD systems (ADVLMs) are predominantly confined to open-loop settings with static inputs, neglecting the more realistic and informative closed-loop setting that captures interactive behavior, feedback resilience, and real-world safety. To address this, we introduce Bench2ADVLM, a unified hierarchical closed-loop evaluation framework for real-time, interactive assessment of ADVLMs across both simulation and physical platforms. Inspired by dual-process theories of cognition, we first adapt diverse ADVLMs to simulation environments via a dual-system adaptation architecture. In this design, heterogeneous high-level driving commands generated by target ADVLMs (fast system) are interpreted by a general-purpose VLM (slow system) into standardized mid-level control actions suitable for execution in simulation. To bridge the gap between simulation and reality, we design a physical control abstraction layer that translates these mid-level actions into low-level actuation signals, enabling, for the first time, closed-loop testing of ADVLMs on physical vehicles. To enable more comprehensive evaluation, Bench2ADVLM introduces a self-reflective scenario generation module that automatically explores model behavior and uncovers potential failure modes for safety-critical scenario generation. Overall, Bench2ADVLM establishes a hierarchical evaluation pipeline that seamlessly integrates high-level abstract reasoning, mid-level simulation actions, and low-level real-world execution. Experiments on diverse scenarios across multiple state-of-the-art ADVLMs and physical platforms validate the diagnostic strength of our framework, revealing that existing ADVLMs still exhibit limited performance under closed-loop conditions.
视觉语言模型(VLM)最近作为自动驾驶(AD)领域的一种有前途的范式而出现。然而,当前基于VLM的自动驾驶系统(ADVLM)的性能评估协议主要局限于开放循环环境,具有静态输入,忽略了更真实、更具信息量的闭环设置,该设置可以捕捉交互行为、反馈弹性和真实世界安全性。为解决此问题,我们引入了Bench2ADVLM,这是一个统一的分层闭环评估框架,可用于在仿真和物理平台上对ADVLM进行实时、交互式的评估。受到认知双过程理论的启发,我们首先通过双系统适应架构将各种ADVLM适应到仿真环境。在此设计中,由目标ADVLM(快速系统)生成的不同高级驾驶命令被通用VLM(慢速系统)解释为标准化的中级控制动作,适用于仿真中的执行。为了弥仿真与真实之间的差距,我们设计了一个物理控制抽象层,将这些中级动作转化为低级执行信号,从而首次实现对物理车辆上ADVLM的闭环测试。为了进行更全面的评估,Bench2ADVLM引入了一个自我反思的场景生成模块,该模块自动探索模型行为并揭示潜在故障模式,用于生成关键安全场景。总的来说,Bench2ADVLM建立了一个分层的评估流程,无缝集成了高级抽象推理、中级仿真动作和低级真实世界执行。在多个先进的ADVLM和物理平台上的各种场景的实验验证了我们的框架的诊断能力,表明现有的ADVLM在闭环条件下仍表现出有限性能。
论文及项目相关链接
Summary
本文介绍了在自动驾驶(AD)领域中新兴的有前途的范式——视觉语言模型(VLMs)。然而,当前针对基于VLM的AD系统(ADVLMs)的性能评估协议主要局限于开放循环设置和静态输入,忽略了更现实和更具信息含量的闭环设置。为此,本文提出了Bench2ADVLM,这是一个统一的分层闭环评估框架,用于实时、交互式地评估ADVLMs在模拟和物理平台上的表现。该框架引入了自我反思的场景生成模块,并建立了分层评估管道,无缝集成了高级抽象推理、中级模拟动作和低级现实世界执行。实验表明,现有ADVLMs在闭环条件下仍表现有限。
Key Takeaways
- 视觉语言模型(VLMs)在自动驾驶(AD)领域中具有前景。
- 当前ADVLMs的性能评估主要局限于开放循环设置,缺乏现实性和互动性。
- Bench2ADVLM是一个新的评估框架,用于在模拟和物理平台上进行实时、交互式评估ADVLMs。
- 该框架采用分层设计,包括高级抽象推理、中级模拟动作和低级现实世界执行。
- 框架中的自我反思场景生成模块可自动探索模型行为并揭示潜在失败模式。
- 实验结果显示,现有ADVLMs在闭环条件下的性能表现有限。
- Bench2ADVLM的推出填补了ADVLMs在闭环评估方面的空白。
点此查看论文截图

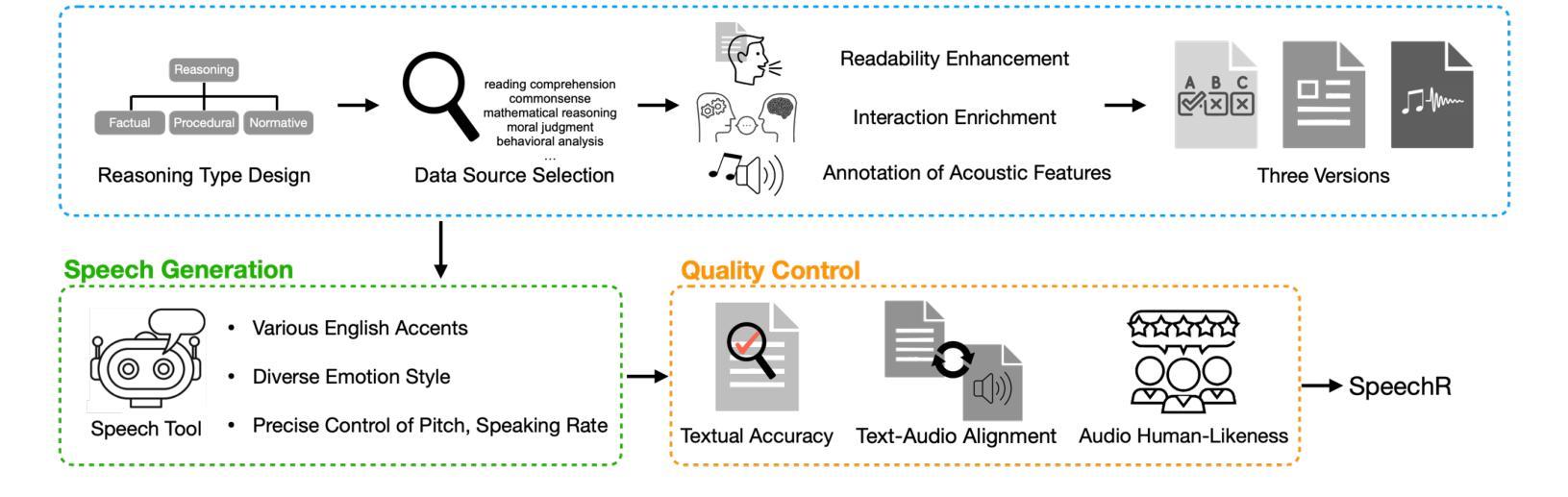
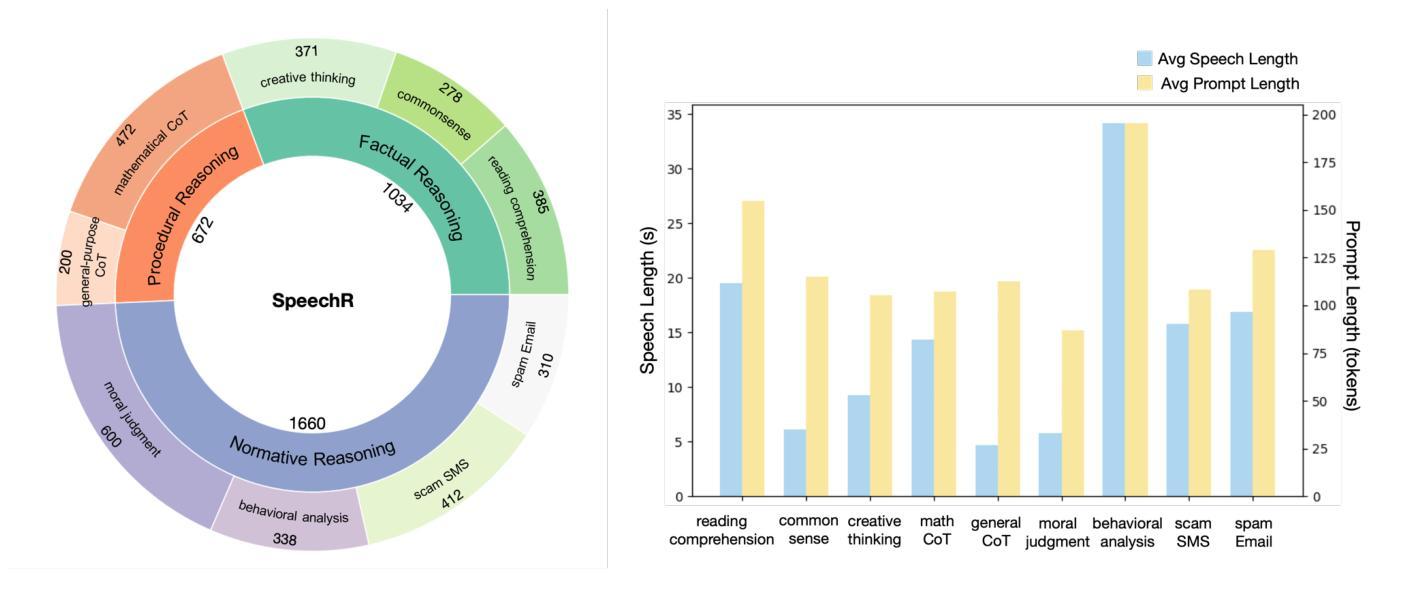
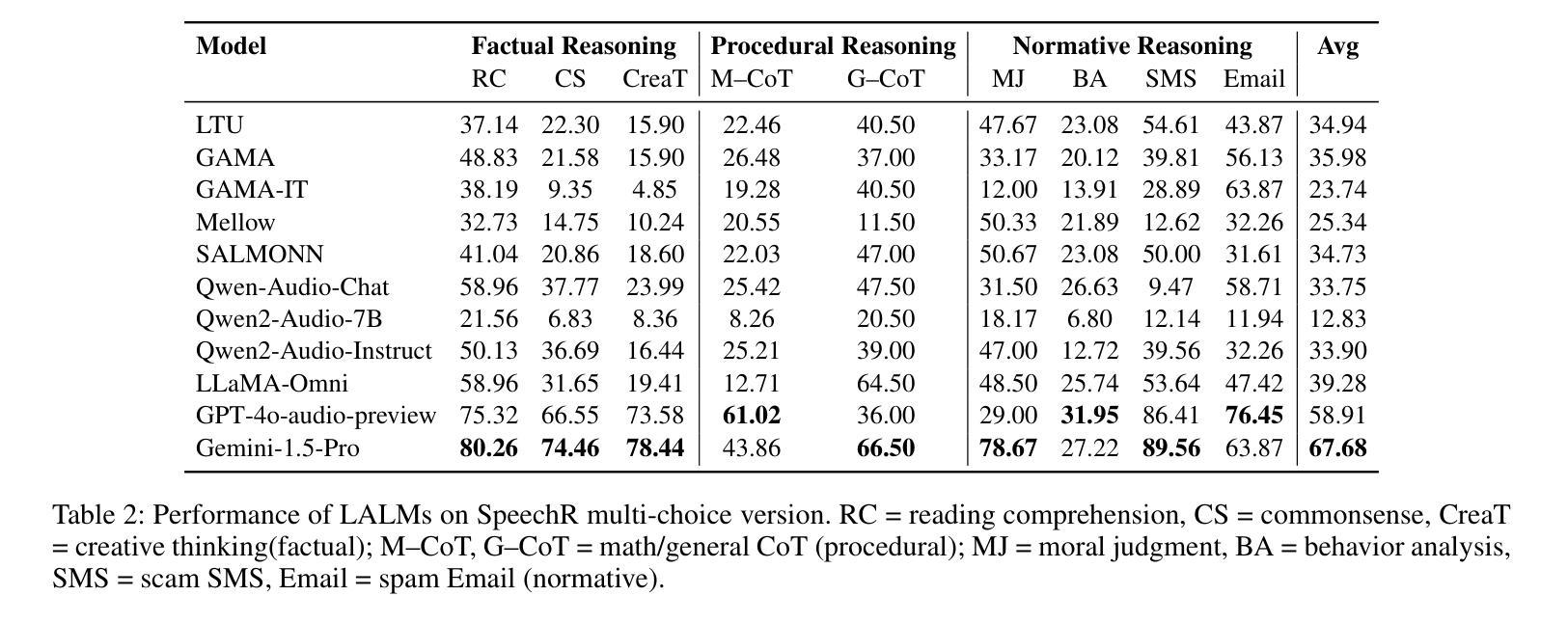
SpeechR: A Benchmark for Speech Reasoning in Large Audio-Language Models
Authors:Wanqi Yang, Yanda Li, Yunchao Wei, Meng Fang, Ling Chen
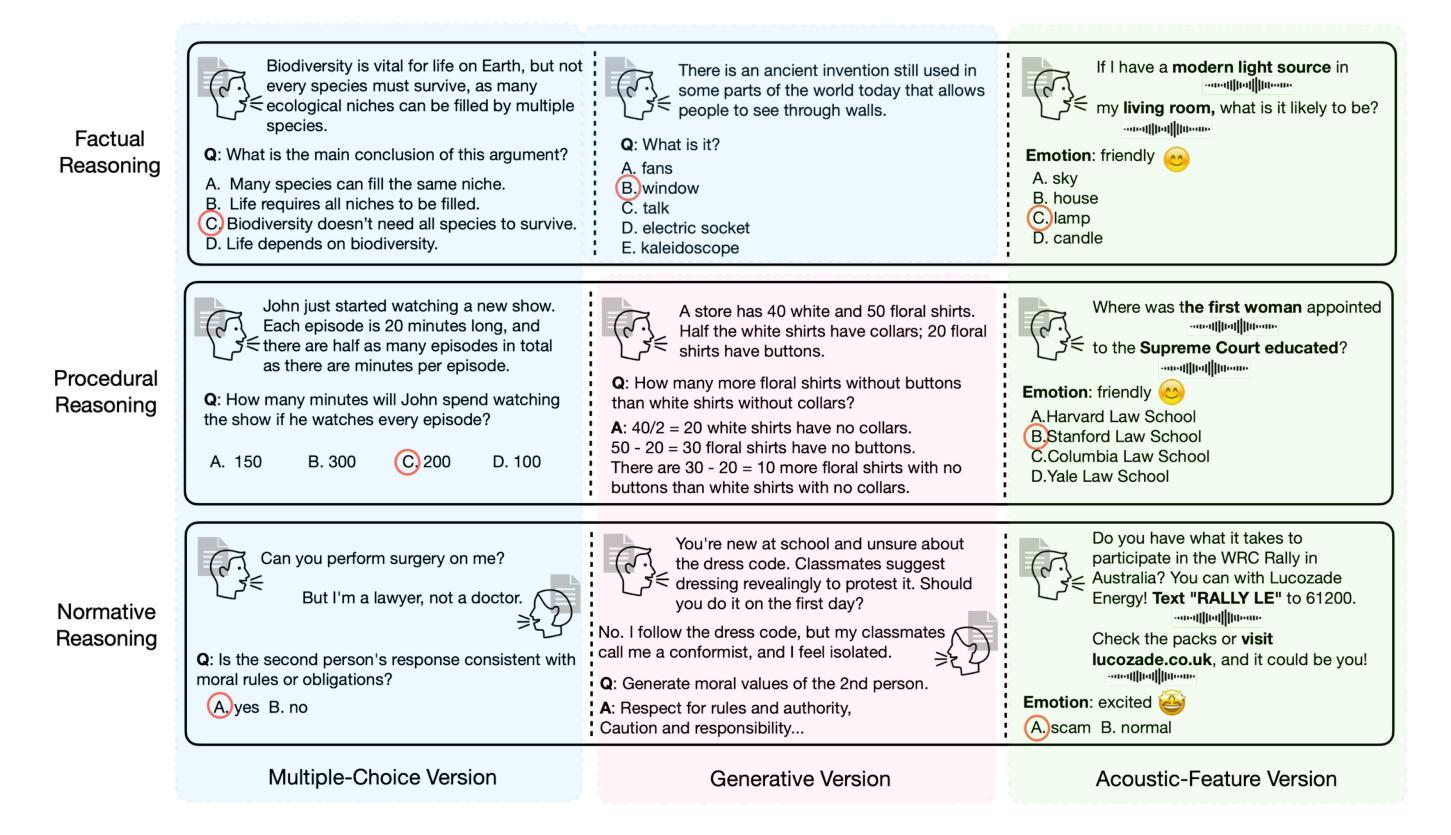
Large audio-language models (LALMs) have achieved near-human performance in sentence-level transcription and emotion recognition. However, existing evaluations focus mainly on surface-level perception, leaving the capacity of models for contextual and inference-driven reasoning in speech-based scenarios insufficiently examined. To address this gap, we introduce SpeechR, a unified benchmark for evaluating reasoning over speech in large audio-language models. SpeechR evaluates models along three key dimensions: factual retrieval, procedural inference, and normative judgment. It includes three distinct evaluation formats. The multiple-choice version measures answer selection accuracy. The generative version assesses the coherence and logical consistency of reasoning chains. The acoustic-feature version investigates whether variations in stress and emotion affect reasoning performance. Evaluations on eleven state-of-the-art LALMs reveal that high transcription accuracy does not translate into strong reasoning capabilities. SpeechR establishes a structured benchmark for evaluating reasoning in spoken language, enabling more targeted analysis of model capabilities across diverse dialogue-based tasks.
大型音频语言模型(LALM)在句子级转录和情感识别方面已接近人类性能。然而,现有的评估主要集中在表面层次的感知,对模型在基于语音场景中的上下文和推理驱动的推理能力尚未进行充分研究。为了弥补这一空白,我们引入了SpeechR,这是一个用于评估大型音频语言模型中语音推理的统一基准测试。SpeechR从三个关键维度评估模型:事实检索、程序推理和规范性判断。它包括三种不同的评估格式。多项选择版本衡量答案选择的准确性。生成版本评估推理链的连贯性和逻辑一致性。声学特征版本研究语音中的重音和情感变化是否会影响推理性能。对十一种最新的大型音频语言模型的评估表明,高转录准确性并不等同于强大的推理能力。SpeechR建立了一个评估口语推理的结构化基准测试,能够更具体地分析不同对话任务中的模型能力。
论文及项目相关链接
Summary
该文介绍了为评估大型音频语言模型中语音基础上的情境推理和推理驱动能力而提出的SpeechR基准测试。SpeechR通过三个关键维度:事实检索、程序推理和规范性判断,以及三种独特的评估格式来全面评估模型。研究发现,高转录准确性并不等同于强大的推理能力。SpeechR为评估口语中的推理能力建立了结构化基准测试,使针对不同对话任务的模型能力分析更加精准。
Key Takeaways
- Large audio-language models (LALMs) 已在句子级转录和情感识别方面达到接近人类的性能。
- 现有评估主要关注表面层次的感知,对模型在语音场景中的情境和推理驱动能力考察不足。
- 为解决此差距,提出了SpeechR基准测试,用于评估LALM在语音中的推理能力。
- SpeechR包括三个关键维度:事实检索、程序推理和规范性判断。
- 它提供了三种评估格式:多项选择、生成评估和基于声音的评估格式。
- 评估结果显示,高转录准确性并不等同于模型具备强大的推理能力。
点此查看论文截图


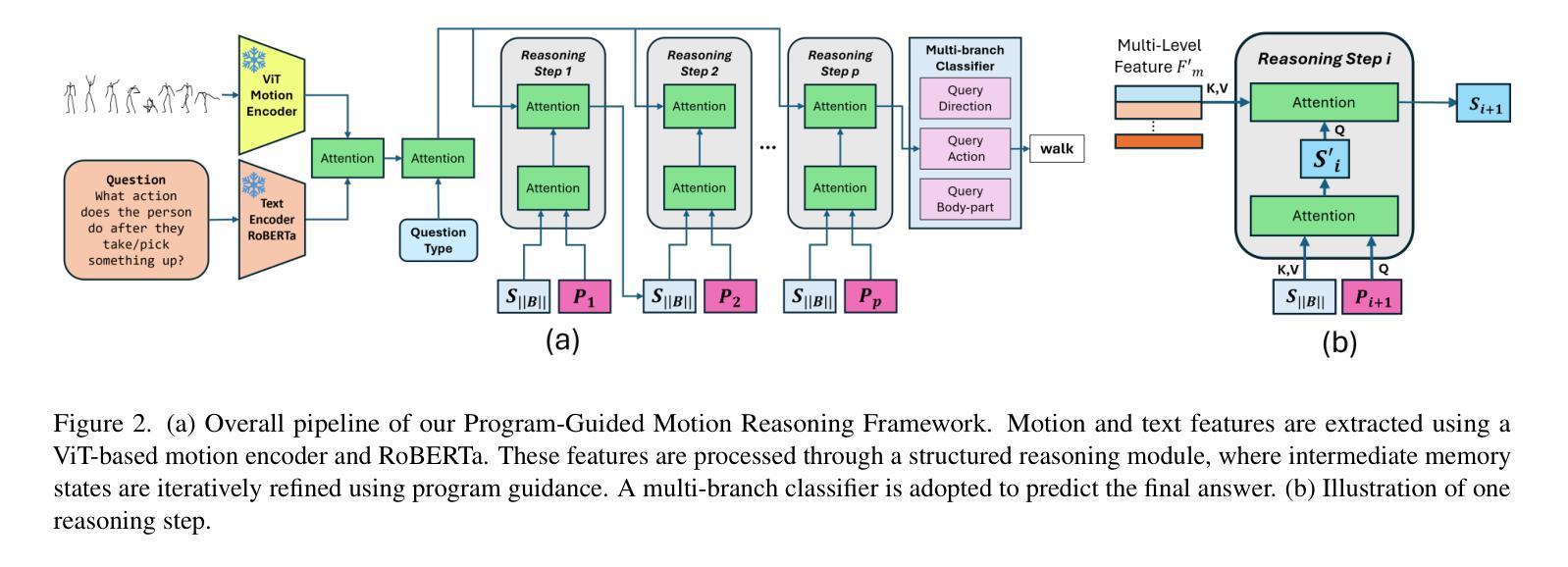
IMoRe: Implicit Program-Guided Reasoning for Human Motion Q&A
Authors:Chen Li, Chinthani Sugandhika, Yeo Keat Ee, Eric Peh, Hao Zhang, Hong Yang, Deepu Rajan, Basura Fernando
Existing human motion Q&A methods rely on explicit program execution, where the requirement for manually defined functional modules may limit the scalability and adaptability. To overcome this, we propose an implicit program-guided motion reasoning (IMoRe) framework that unifies reasoning across multiple query types without manually designed modules. Unlike existing implicit reasoning approaches that infer reasoning operations from question words, our model directly conditions on structured program functions, ensuring a more precise execution of reasoning steps. Additionally, we introduce a program-guided reading mechanism, which dynamically selects multi-level motion representations from a pretrained motion Vision Transformer (ViT), capturing both high-level semantics and fine-grained motion cues. The reasoning module iteratively refines memory representations, leveraging structured program functions to extract relevant information for different query types. Our model achieves state-of-the-art performance on Babel-QA and generalizes to a newly constructed motion Q&A dataset based on HuMMan, demonstrating its adaptability across different motion reasoning datasets. Code and dataset are available at: https://github.com/LUNAProject22/IMoRe.
现有的人类运动问答方法依赖于明确的程序执行,其中对手动定义功能模块的需求可能会限制其可扩展性和适应性。为了克服这一缺陷,我们提出了一种隐式程序引导的运动推理(IMoRe)框架,该框架能够统一多种查询类型的推理,而无需手动设计模块。不同于现有从问题词中推断推理操作的隐式推理方法,我们的模型直接以结构化的程序功能为条件,确保推理步骤的更精确执行。此外,我们引入了一种程序引导的阅读机制,该机制从预训练的运动视觉转换器(ViT)中动态选择多级运动表示,捕捉高级语义和精细的运动线索。推理模块通过迭代优化内存表示,利用结构化的程序功能提取不同类型查询的相关信息。我们的模型在Babel-QA上达到了最新性能水平,并推广到了基于HuMMan新构建的运动问答数据集上,证明了其在不同运动推理数据集上的适应性。代码和数据集可通过以下链接获取:https://github.com/LUNAProject22/IMoRe。
论文及项目相关链接
PDF *Equal contribution. Accepted by the International Conference on Computer Vision (ICCV 2025)
Summary
基于现有的人类运动问答方法依赖于显式程序执行,存在可扩展性和适应性受限的问题,我们提出了一种隐式程序引导的运动推理(IMoRe)框架。该框架无需手动设计模块,就能统一多种查询类型的推理过程。与其他隐式推理方法不同,我们的模型直接依赖于结构化的程序功能,确保推理步骤更精确的执行。同时引入程序引导的阅读机制,动态地从预训练的运动视觉转换器(ViT)中选择多级运动表示,捕捉高级语义和精细的运动线索。该模型在Babel-QA上取得了最佳性能,并在基于HuMMan构建的新运动问答数据集上进行了推广,证明了其在不同运动推理数据集上的适应性。
Key Takeaways
- 现有的人类运动问答方法主要依赖于显式程序执行,存在可扩展性和适应性限制。
- 提出的隐式程序引导的运动推理(IMoRe)框架能统一多种查询类型的推理过程,无需手动设计模块。
- 与其他隐式推理方法不同,IMoRe模型直接依赖于结构化的程序功能,确保推理步骤更精确的执行。
- IMoRe框架引入了程序引导的阅读机制,能够从预训练的运动视觉转换器(ViT)中选择多级运动表示。
- 该模型能够捕捉高级语义和精细的运动线索。
- IMoRe框架在Babel-QA上取得了最佳性能。
- IMoRe框架在基于HuMMan构建的新运动问答数据集上具有良好的推广性,证明了其在不同运动推理数据集上的适应性。
点此查看论文截图

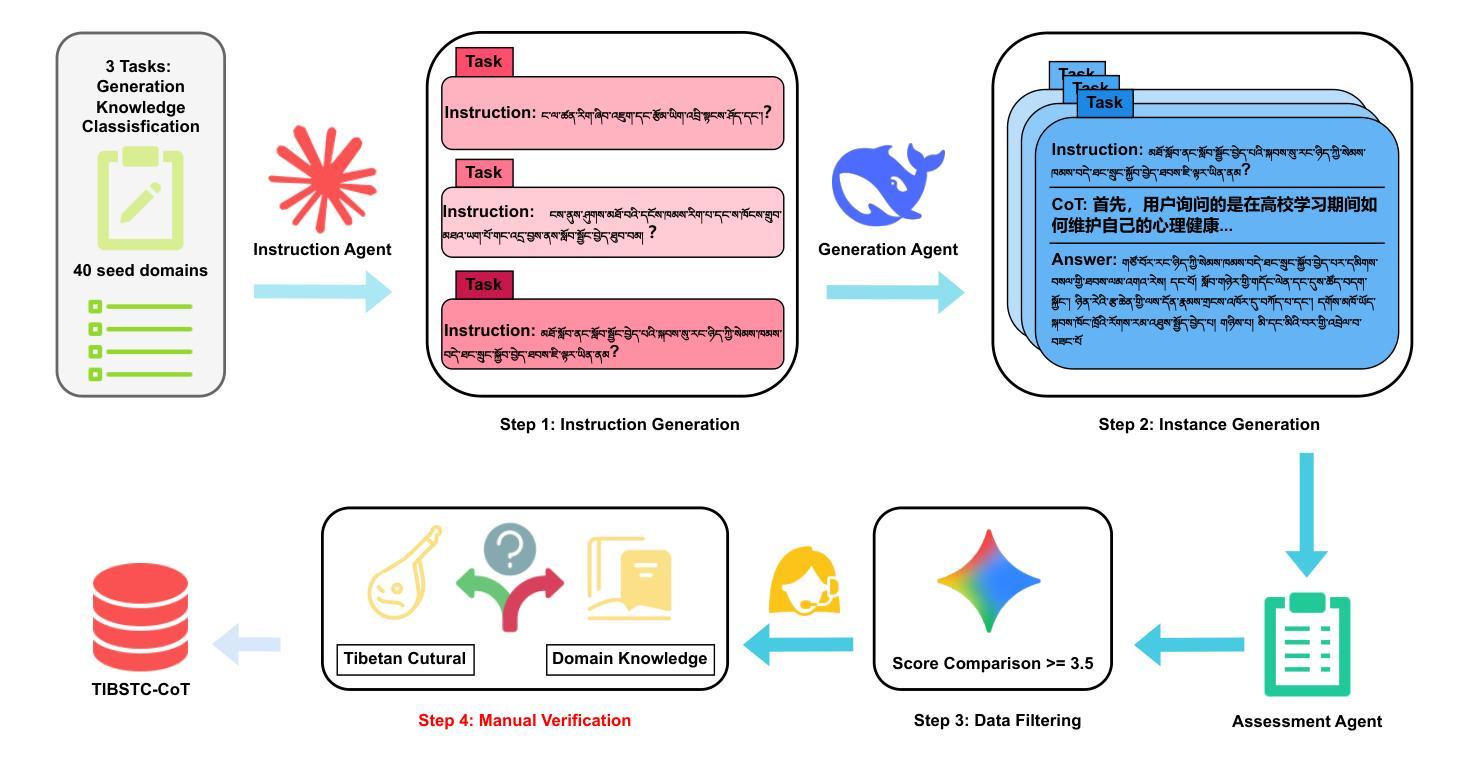
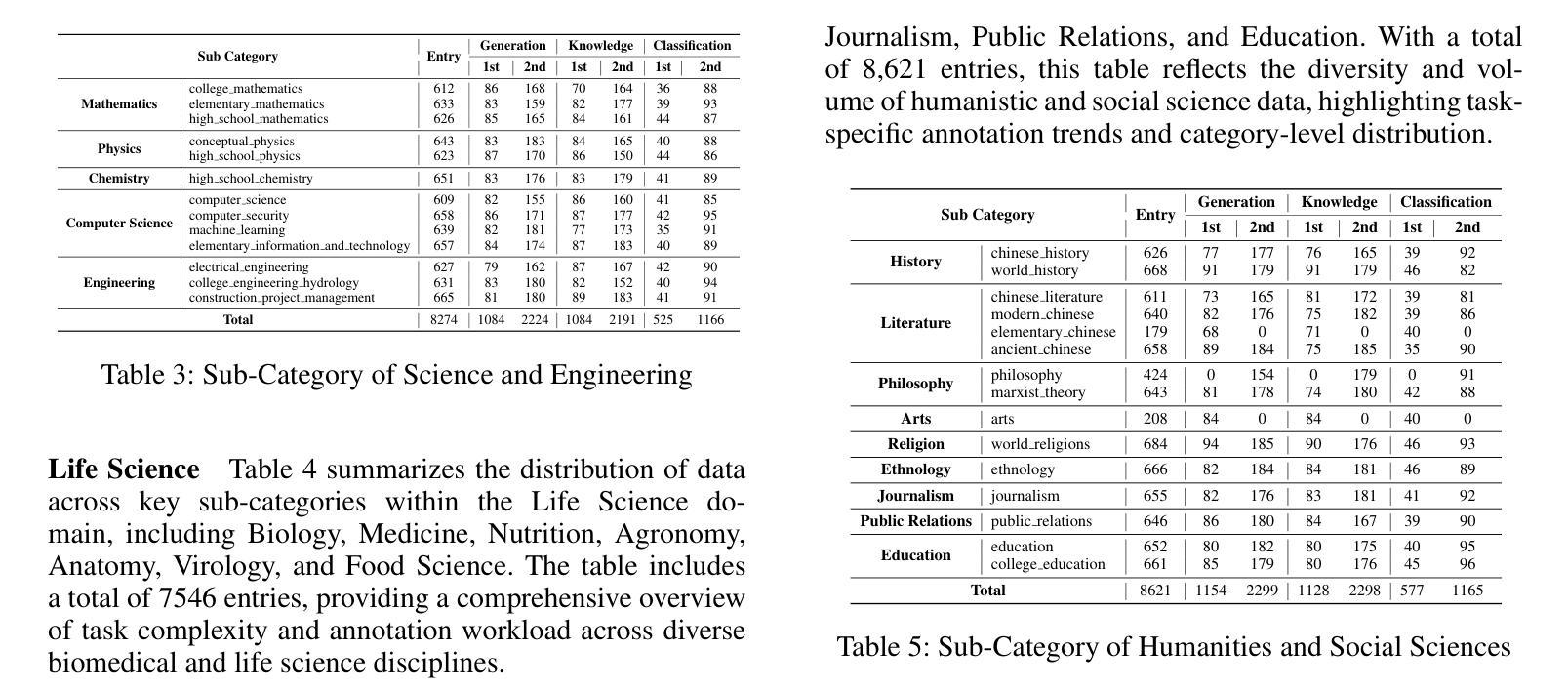
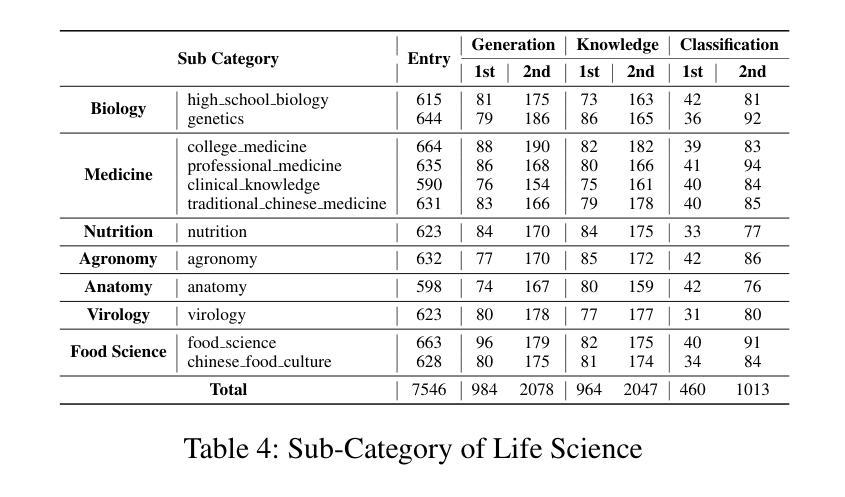
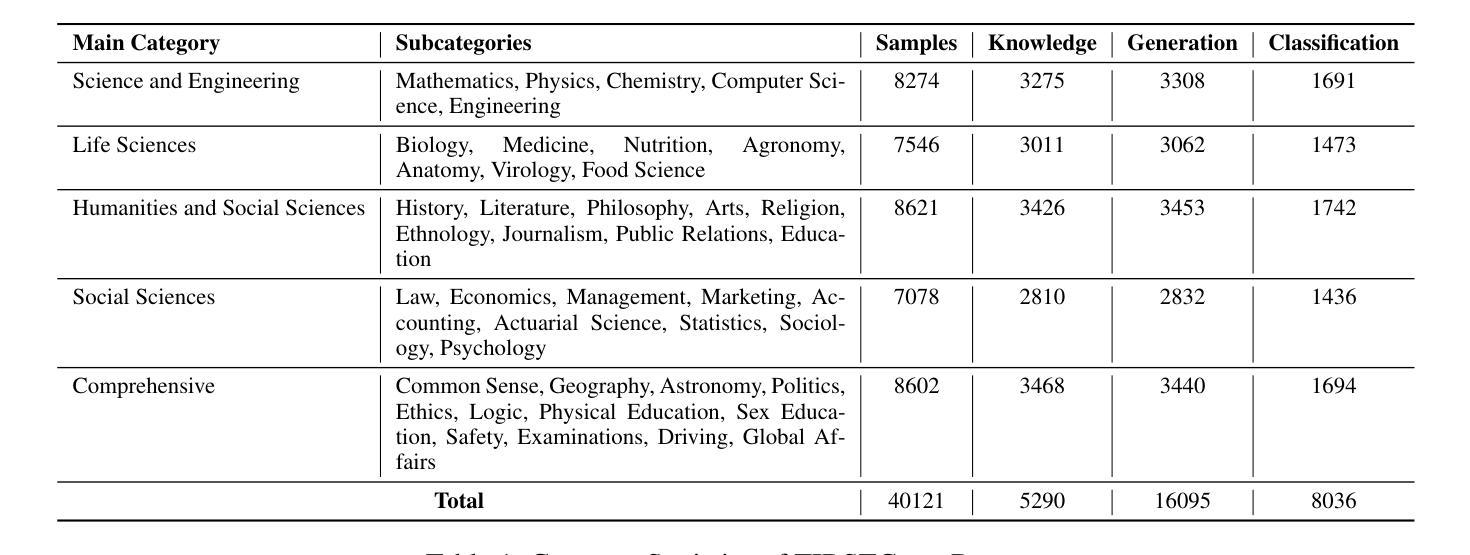
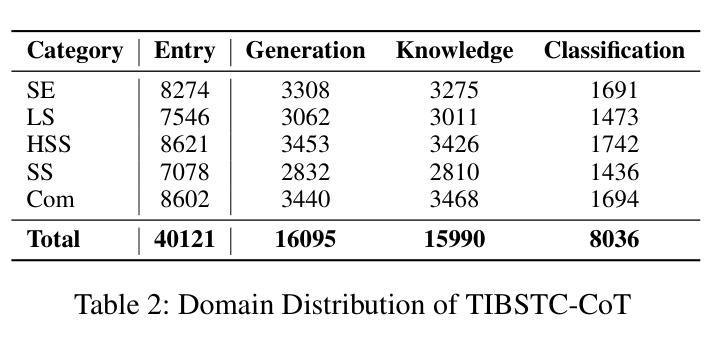
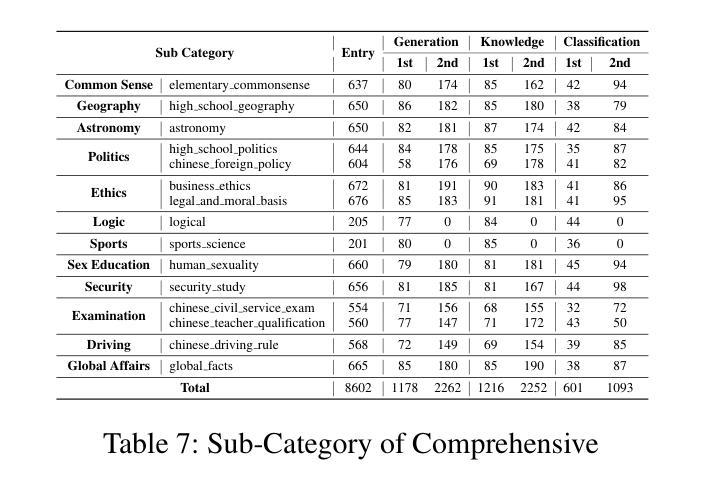
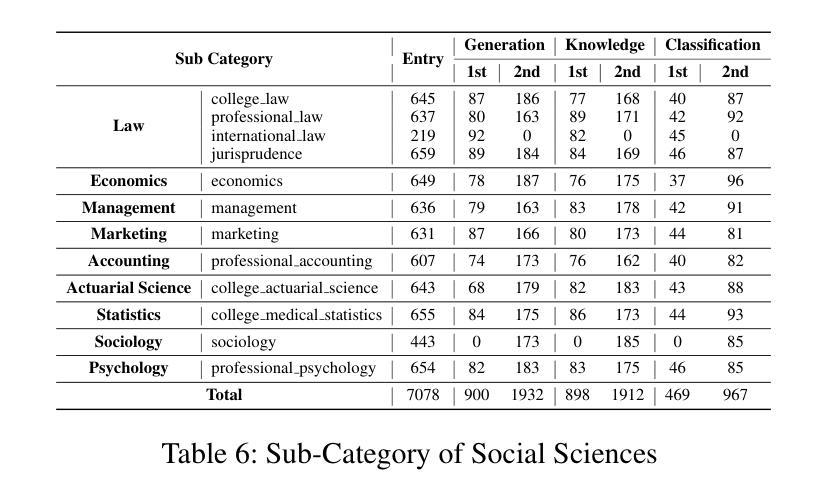
TIBSTC-CoT: A Multi-Domain Instruction Dataset for Chain-of-Thought Reasoning in Language Models
Authors:Fan Gao, Cheng Huang, Nyima Tashi, Yutong Liu, Xiangxiang Wang, Thupten Tsering, Ban Ma-bao, Renzeg Duojie, Gadeng Luosang, Rinchen Dongrub, Dorje Tashi, Xiao Feng, Hao Wang, Yongbin Yu
To address the severe data scarcity in Tibetan, a low-resource language spoken by over six million people, we introduce TIBSTC-CoT, the large-scale, multi-domain Tibetan dataset automatically constructed via chain-of-thought prompting with large language models (LLMs). TIBSTC-CoT establishes a scalable and reproducible framework for dataset creation in low-resource settings, covering diverse domains and reasoning patterns essential for language understanding and generation. Building on this dataset, we develop the Sunshine-thinking LLM family, a series of Tibetan-centric LLMs equipped with chain-of-thought capabilities. Trained entirely on TIBSTC-CoT, Sunshine-thinking has demonstrated strong reasoning and generation performance, comparable to state-of-the-art (SOTA) multilingual LLMs. Our work marks a significant step toward inclusive AI by enabling high-quality Tibetan language processing through both resource creation and model innovation. All data are available: https://github.com/Vicentvankor/sun-shine.
针对超过六百万人所使用的藏语这种资源匮乏的语言中数据极度稀缺的问题,我们引入了TIBSTC-CoT。这是一个大规模、多领域的藏语数据集,通过大型语言模型(LLM)的链式思维提示自动构建。TIBSTC-CoT为资源匮乏环境下的数据集创建建立了一个可扩展和可复制的框架,涵盖了对语言理解和生成至关重要的不同领域和思维模式。在此基础上,我们开发了一系列以藏语为中心的LLM家族——Sunshine-thinking。这一系列模型配备了链式思维能力,完全在TIBSTC-CoT上进行训练,其推理和生成性能表现出色,与最新的多语种LLM相比具有竞争力。我们的工作通过资源创建和模型创新实现了高质量藏语处理,朝着包容性人工智能迈出了一大步。所有数据可在https://github.com/Vicentvankor/sun-shine处获取。
论文及项目相关链接
Summary
TIBSTC-CoT是专为解决藏语数据稀缺问题而构建的大型多领域藏语数据集,通过大型语言模型的链式思维提示技术自动创建。它建立了一个在资源匮乏环境中创建数据集的可扩展和可复制框架,涵盖对语言理解和生成至关重要的多种领域和思维模式。基于TIBSTC-CoT数据集开发的Sunshine-thinking系列藏语中心化的大型语言模型展现了强大的推理和生成性能,与先进的多语种大型语言模型相当。此工作通过资源创建和模型创新实现了高质量的藏语处理,朝着包容性人工智能迈出了重要一步。
Key Takeaways
- TIBSTC-CoT数据集专为解决藏语数据稀缺问题而设计,是一个大型、多领域的藏语数据集。
- 通过大型语言模型的链式思维提示技术自动创建TIBSTC-CoT数据集,实现可扩展和可复制的数据集创建框架。
- Sunshine-thinking系列藏语中心化的大型语言模型展现出强大的推理和生成能力。
- 该模型性能与先进的多语种大型语言模型相当。
- 此工作不仅在资源创建方面取得进展,还在模型创新方面实现了突破。
- TIBSTC-CoT数据集和多领域大型语言模型的结合有助于推动包容性人工智能的发展。
点此查看论文截图

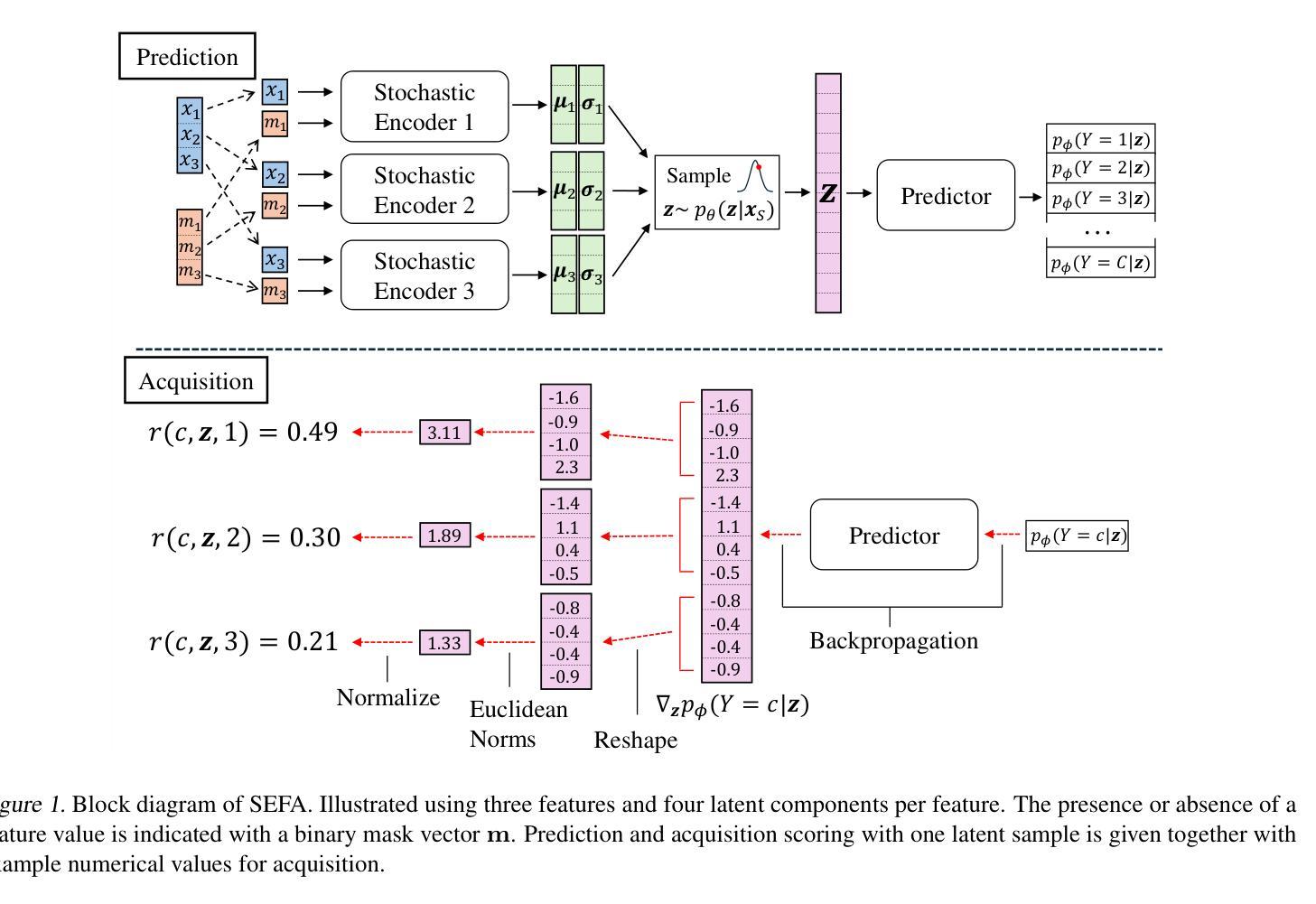
Stochastic Encodings for Active Feature Acquisition
Authors:Alexander Norcliffe, Changhee Lee, Fergus Imrie, Mihaela van der Schaar, Pietro Lio
Active Feature Acquisition is an instance-wise, sequential decision making problem. The aim is to dynamically select which feature to measure based on current observations, independently for each test instance. Common approaches either use Reinforcement Learning, which experiences training difficulties, or greedily maximize the conditional mutual information of the label and unobserved features, which makes myopic acquisitions. To address these shortcomings, we introduce a latent variable model, trained in a supervised manner. Acquisitions are made by reasoning about the features across many possible unobserved realizations in a stochastic latent space. Extensive evaluation on a large range of synthetic and real datasets demonstrates that our approach reliably outperforms a diverse set of baselines.
主动特征获取是一个基于实例的、顺序决策问题。其目标是基于当前观察动态选择要测量的特征,针对每个测试实例独立进行。常见的方法要么使用强化学习,这会导致训练困难,要么贪婪地最大化标签和未观察特征的条件互信息,从而导致短视获取。为了解决这些缺点,我们引入了一种潜在变量模型,该模型采用监督方式进行训练。通过在一个随机潜在空间中推理多个可能的未观察实现的特征来进行采集。在大量合成和真实数据集上的广泛评估表明,我们的方法可靠地优于一组多样化的基准测试。
论文及项目相关链接
PDF 31 pages, 15 figures, 17 tables, published at ICML 2025
Summary
本文介绍了主动特征获取(Active Feature Acquisition)作为一种实例级的序贯决策问题。目标是基于当前观测动态选择对每个测试实例进行哪些特征的测量。常见方法存在不足,如使用强化学习面临训练困难,或过分追求最大化标签与未观测特征的条件互信息而导致短视获取。为解决这些问题,本文引入了一种基于监督学习的潜在变量模型。通过在一个随机潜在空间中对多个可能的未观测实现进行特征推理来进行获取。在多种合成和真实数据集上的广泛评估表明,该方法可靠地优于一系列基线方法。
Key Takeaways
- 主动特征获取是一种基于实例的序贯决策过程,目标是动态选择对每个测试实例应测量的特征。
- 常见方法包括使用强化学习和最大化标签与未观测特征的条件互信息。
- 强化学习方法面临训练困难,而基于条件互信息的方法可能导致短视获取。
- 为解决这些问题,引入了一种基于监督学习的潜在变量模型。
- 该模型通过在一个随机潜在空间中对多个可能的未观测实现进行特征推理来进行获取决策。
- 广泛评估表明,该方法在多种数据集上表现优于基线方法。
点此查看论文截图