⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-06 更新
Text2Lip: Progressive Lip-Synced Talking Face Generation from Text via Viseme-Guided Rendering
Authors:Xu Wang, Shengeng Tang, Fei Wang, Lechao Cheng, Dan Guo, Feng Xue, Richang Hong
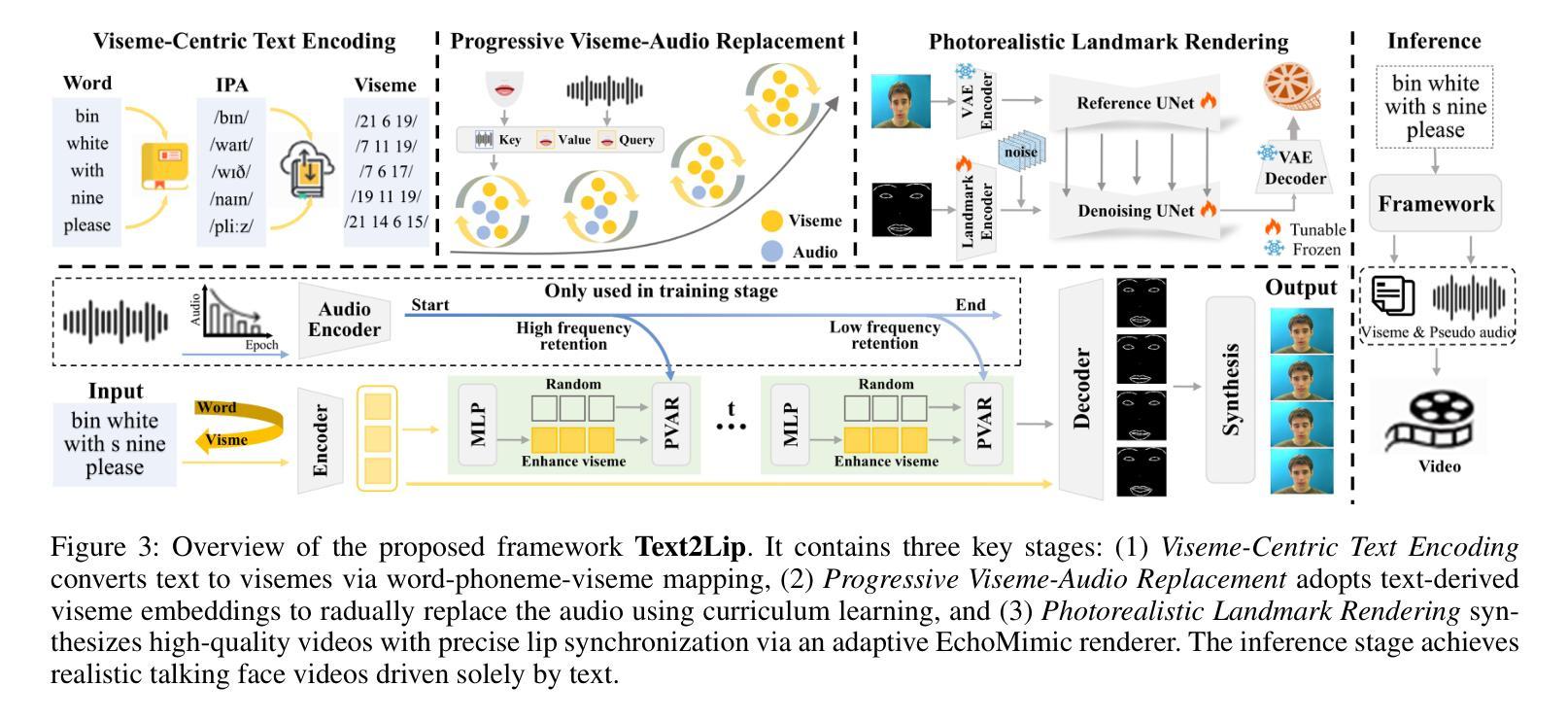
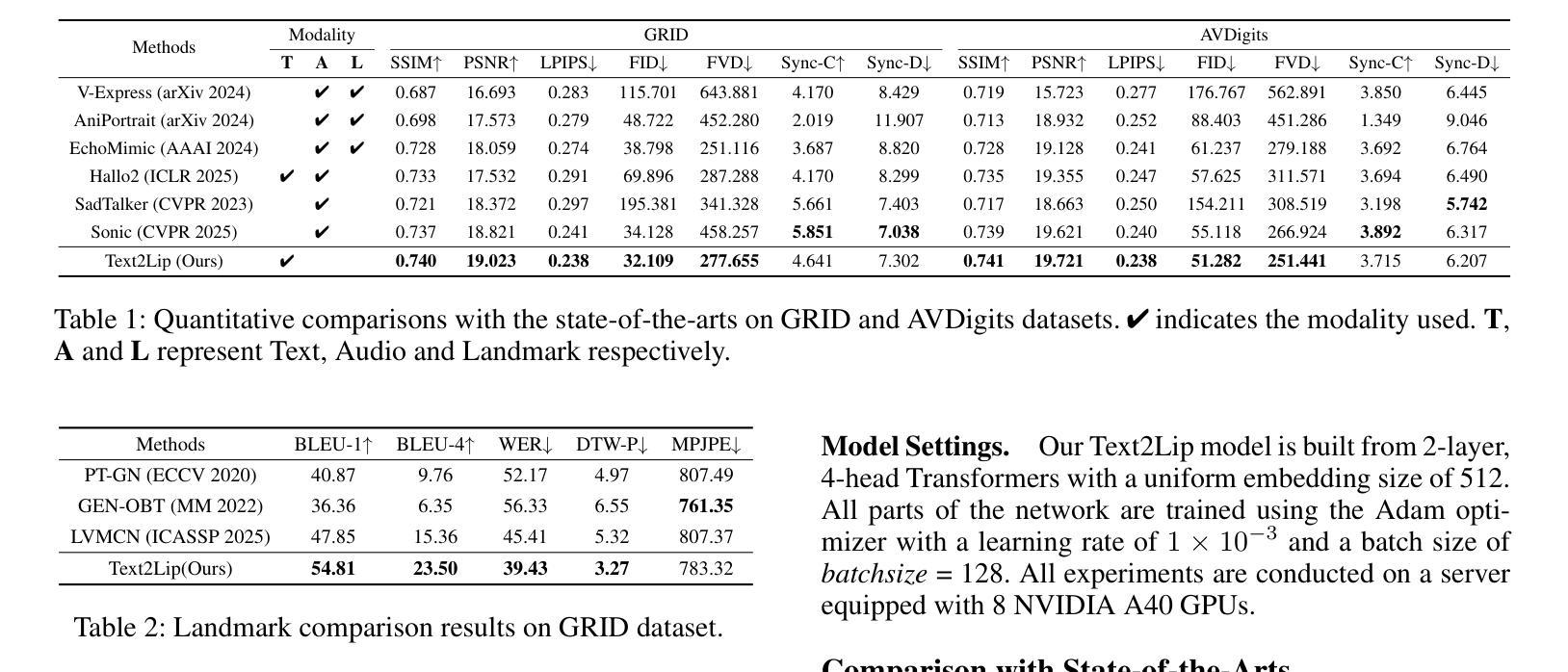
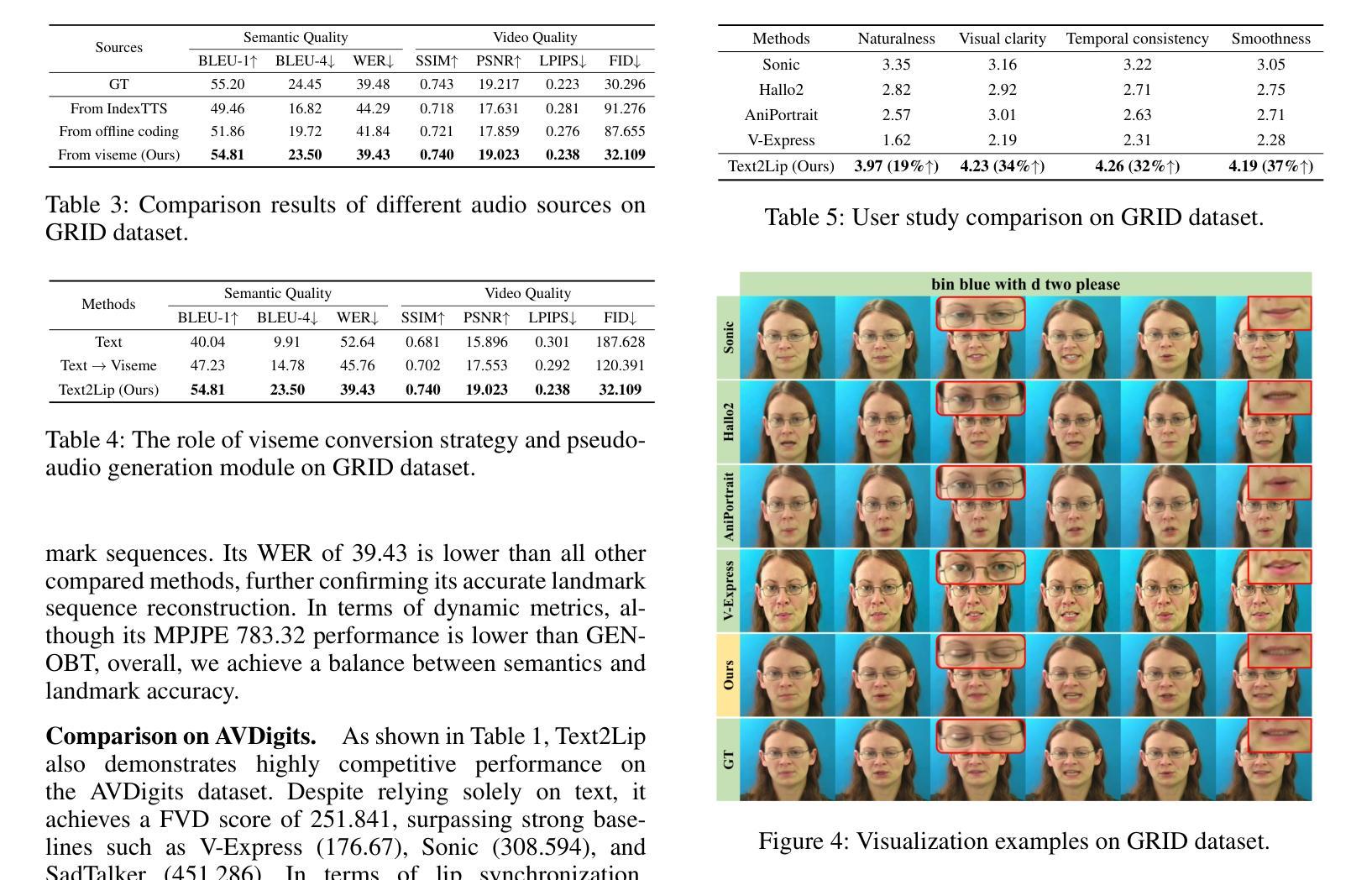
Generating semantically coherent and visually accurate talking faces requires bridging the gap between linguistic meaning and facial articulation. Although audio-driven methods remain prevalent, their reliance on high-quality paired audio visual data and the inherent ambiguity in mapping acoustics to lip motion pose significant challenges in terms of scalability and robustness. To address these issues, we propose Text2Lip, a viseme-centric framework that constructs an interpretable phonetic-visual bridge by embedding textual input into structured viseme sequences. These mid-level units serve as a linguistically grounded prior for lip motion prediction. Furthermore, we design a progressive viseme-audio replacement strategy based on curriculum learning, enabling the model to gradually transition from real audio to pseudo-audio reconstructed from enhanced viseme features via cross-modal attention. This allows for robust generation in both audio-present and audio-free scenarios. Finally, a landmark-guided renderer synthesizes photorealistic facial videos with accurate lip synchronization. Extensive evaluations show that Text2Lip outperforms existing approaches in semantic fidelity, visual realism, and modality robustness, establishing a new paradigm for controllable and flexible talking face generation. Our project homepage is https://plyon1.github.io/Text2Lip/.
生成语义连贯且视觉准确的说话面部,需要弥合语言意义与面部动作之间的差距。虽然音频驱动的方法仍然很普遍,但它们对高质量配对音频视觉数据的依赖,以及声音与唇部运动之间的内在模糊映射给可扩展性和稳健性带来了重大挑战。为了解决这些问题,我们提出了Text2Lip,这是一个以语音音素为中心的框架,通过将文本输入嵌入到结构化语音音素序列中,建立可解释的语音视觉桥梁。这些中间级别的单元作为语言为基础的先验条件用于唇部运动预测。此外,我们设计了一种基于课程学习的渐进语音音素音频替换策略,使模型能够从真实音频逐渐过渡到从增强的语音音素特征通过跨模态注意力重建的伪音频。这允许在音频存在和音频缺失的场景中实现稳健生成。最后,一个基于地标引导的渲染器合成具有准确唇部同步的逼真面部视频。大量评估表明,Text2Lip在语义保真度、视觉逼真度和模态稳健性方面优于现有方法,为可控和灵活的说话面部生成建立了新范式。我们的项目主页是https://plyon1.github.io/Text2Lip/。
论文及项目相关链接
Summary
本文提出了一个名为Text2Lip的框架,它建立了一种可解释的语音视觉桥梁,通过将文本输入嵌入到结构化的可见语音序列中,以应对音频驱动方法的挑战。该框架通过设计一种渐进的可见语音音频替换策略,使模型能够在真实音频和由增强可见语音特征通过跨模态注意力重建的伪音频之间进行逐步过渡,从而实现音频存在和音频缺失场景中的稳健生成。最后,通过地标引导渲染器合成具有准确唇同步的光栅化面部视频。Text2Lip在语义保真度、视觉现实性和模态稳健性方面表现出优于现有方法的效果,为可控和灵活的说话人面部生成建立了新范式。
Key Takeaways
- Text2Lip框架建立了语音与面部动作之间的桥梁,通过嵌入文本输入到结构化的可见语音序列中。
- 引入可见语音序列作为中间层级单位,为唇部运动预测提供语言基础先验。
- 设计了一种基于课程学习的渐进可见语音音频替换策略,使模型能在真实和伪音频之间过渡。
- 框架能在音频存在和缺失的场景中实现稳健的生成。
- 地标引导渲染器能合成具有准确唇同步的光栅化面部视频。
- Text2Lip在语义保真度、视觉现实性和模态稳健性方面优于现有方法。
点此查看论文截图

Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos
Authors:Laura Pedrouzo-Rodriguez, Pedro Delgado-DeRobles, Luis F. Gomez, Ruben Tolosana, Ruben Vera-Rodriguez, Aythami Morales, Julian Fierrez
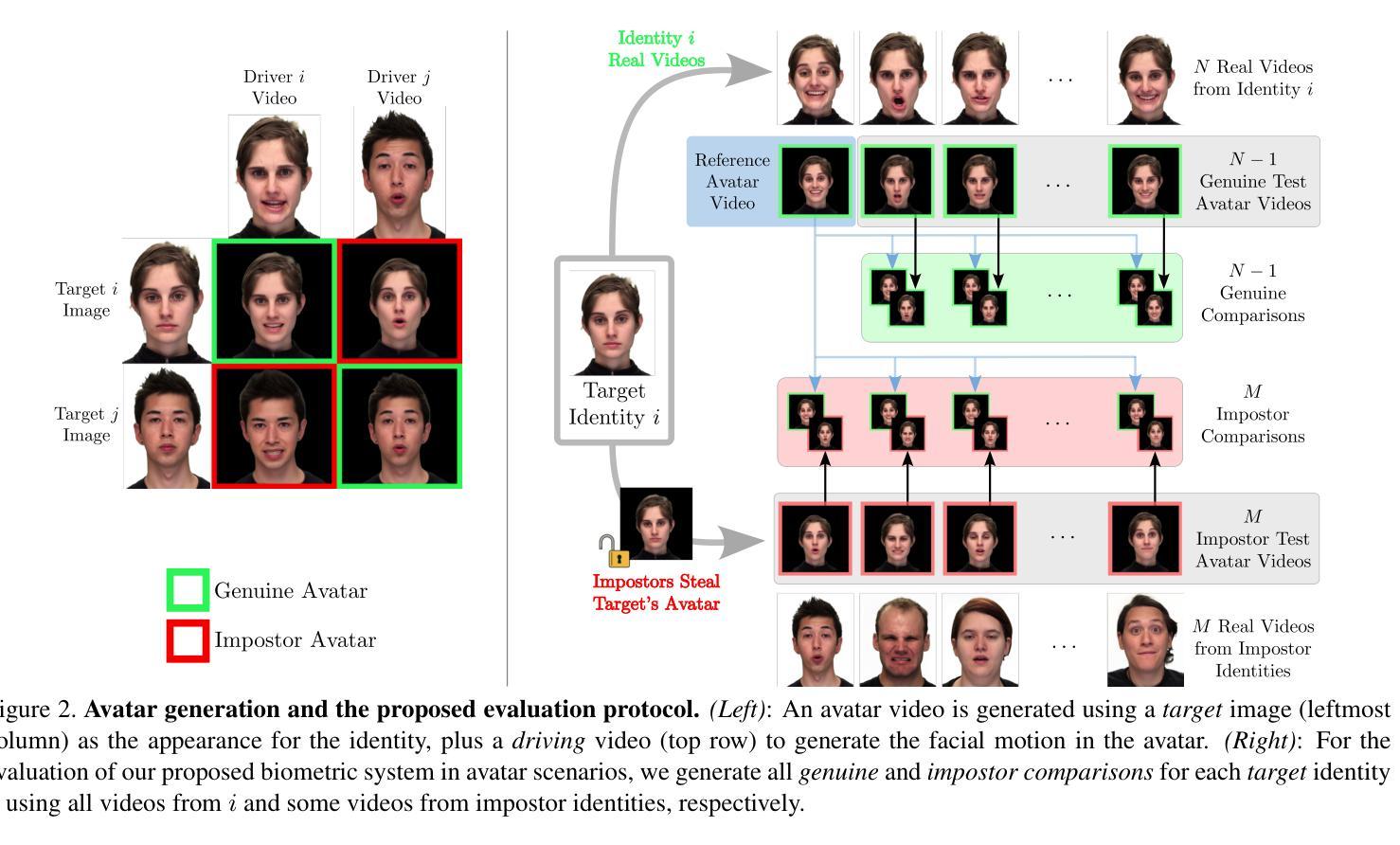
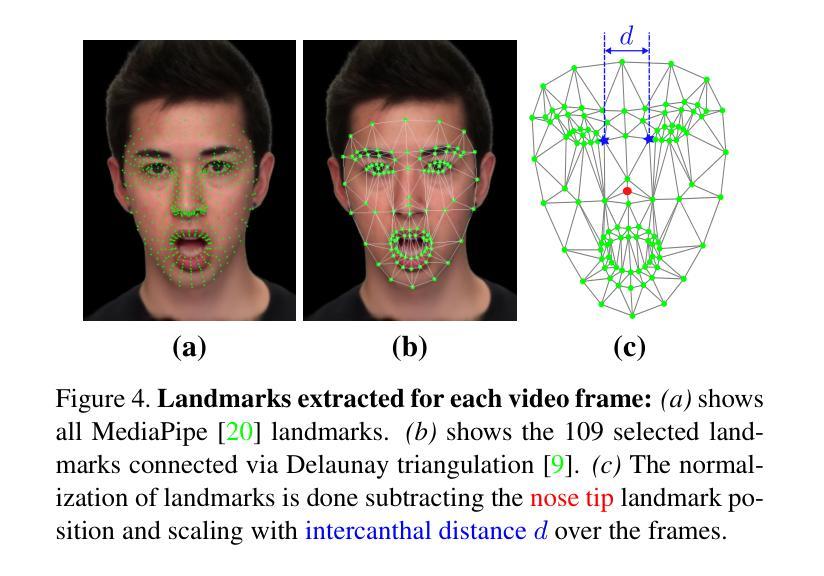
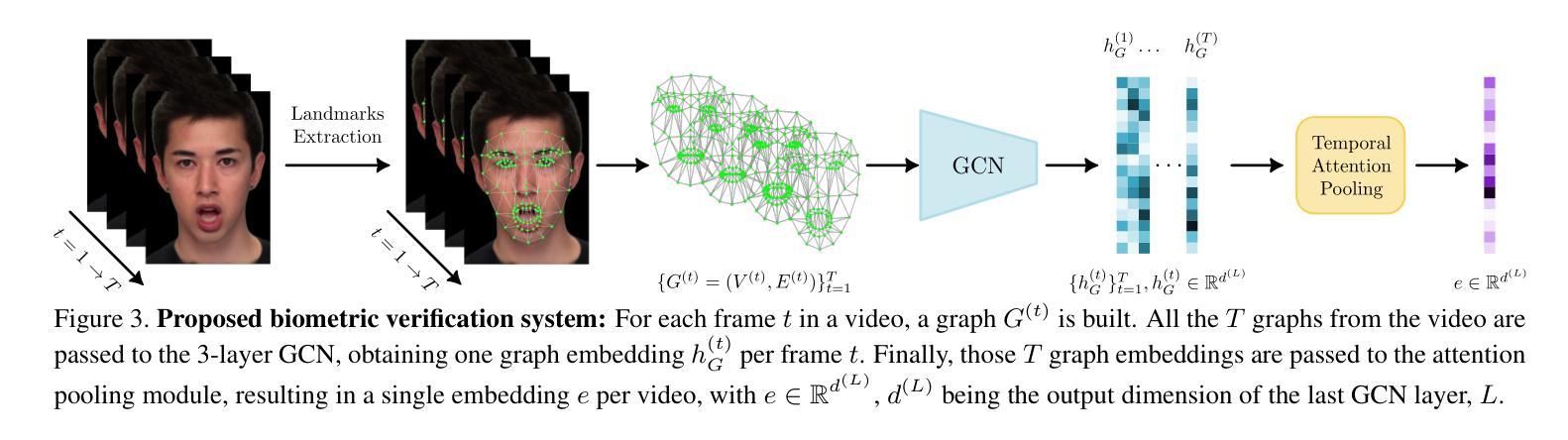
Photorealistic talking-head avatars are becoming increasingly common in virtual meetings, gaming, and social platforms. These avatars allow for more immersive communication, but they also introduce serious security risks. One emerging threat is impersonation: an attacker can steal a user’s avatar, preserving his appearance and voice, making it nearly impossible to detect its fraudulent usage by sight or sound alone. In this paper, we explore the challenge of biometric verification in such avatar-mediated scenarios. Our main question is whether an individual’s facial motion patterns can serve as reliable behavioral biometrics to verify their identity when the avatar’s visual appearance is a facsimile of its owner. To answer this question, we introduce a new dataset of realistic avatar videos created using a state-of-the-art one-shot avatar generation model, GAGAvatar, with genuine and impostor avatar videos. We also propose a lightweight, explainable spatio-temporal Graph Convolutional Network architecture with temporal attention pooling, that uses only facial landmarks to model dynamic facial gestures. Experimental results demonstrate that facial motion cues enable meaningful identity verification with AUC values approaching 80%. The proposed benchmark and biometric system are available for the research community in order to bring attention to the urgent need for more advanced behavioral biometric defenses in avatar-based communication systems.
逼真度极高的数字人头在虚拟会议、游戏以及社交平台上的使用正变得越来越普遍。这些数字人头提供了沉浸式的交流体验,但同时也带来了严重的安全风险。一个新兴威胁是伪装:攻击者可以窃取用户的数字人头,保留其外观和声音,仅凭视觉或听觉几乎无法检测到其欺诈性使用。本文探讨了这种数字人头介导场景中的生物识别技术挑战。我们主要的问题是,当数字人头的外观是其所有者的复制品时,个人的面部运动模式是否可以作为可靠的行为生物识别来验证其身份。为了回答这个问题,我们使用最先进的单镜头数字人头生成模型GAGAvatar制作了真实的数字人头视频数据集,包括原始和假冒的数字人头视频。我们还提出了一种轻量级、可解释的空间时间图卷积网络架构,该架构具有时间注意力池化功能,仅使用面部地标来模拟动态的面部表情。实验结果表明,面部运动线索能够实现有意义的身份验证,AUC值接近80%。所提出的基准测试和生物识别系统可供研究界使用,旨在提醒人们注意在基于数字人头的通信系统中对更先进的行为生物识别防御的迫切需求。
论文及项目相关链接
PDF Accepted at the IEEE International Joint Conference on Biometrics (IJCB 2025)
Summary
基于逼真度极高的头像化身的虚拟交流带来了更沉浸式的体验,但同时也带来严重的安全风险,如身份冒充。本研究探索了在这种虚拟环境下生物识别验证的挑战性问题。研究是否可以通过面部动作模式作为可靠的行为生物特征来验证身份,当虚拟化身的外表是其所有者模仿的真实面庞时,是否可以识破。实验介绍了一个真实虚拟人物视频的新数据集并据此建立了简单的面部图形网络,专注于建模面部动态表情的空间时间序列特点。实验结果显示面部动作特征为身份认证提供了重要依据,AUC值接近百分之八十。这一发现有望推动相关领域对先进行为生物特征保护的需求。
Key Takeaways
- 逼真的头像化身在虚拟会议、游戏和社交平台中越来越普遍,带来了沉浸式体验的同时也存在严重的安全风险。
- 身份冒充成为了一个新兴威胁,攻击者可以通过盗取用户的化身,模拟其外观和声音来进行欺诈行为。
- 本研究探讨了如何在这种化身环境下进行生物识别验证的挑战。研究主要关注的是通过面部动作模式作为行为生物特征进行身份验证的可行性。当化身外观是所有者外表的模仿时,传统的识别方式失效。这带来了一种新的安全验证需求。
- 研究人员引入了一个新的数据集,包含真实和假冒的化身视频,用于验证身份验证系统的有效性。该数据集使用最先进的单镜头化身生成模型GAGAvatar创建。
- 研究提出了一种轻量级、可解释的空间时间图卷积网络架构,该架构使用面部地标来建模动态的面部表情和动作模式。实验结果表明,面部动作特征为身份验证提供了有意义的信息。AUC值接近百分之八十,表明其有效性。
点此查看论文截图