⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
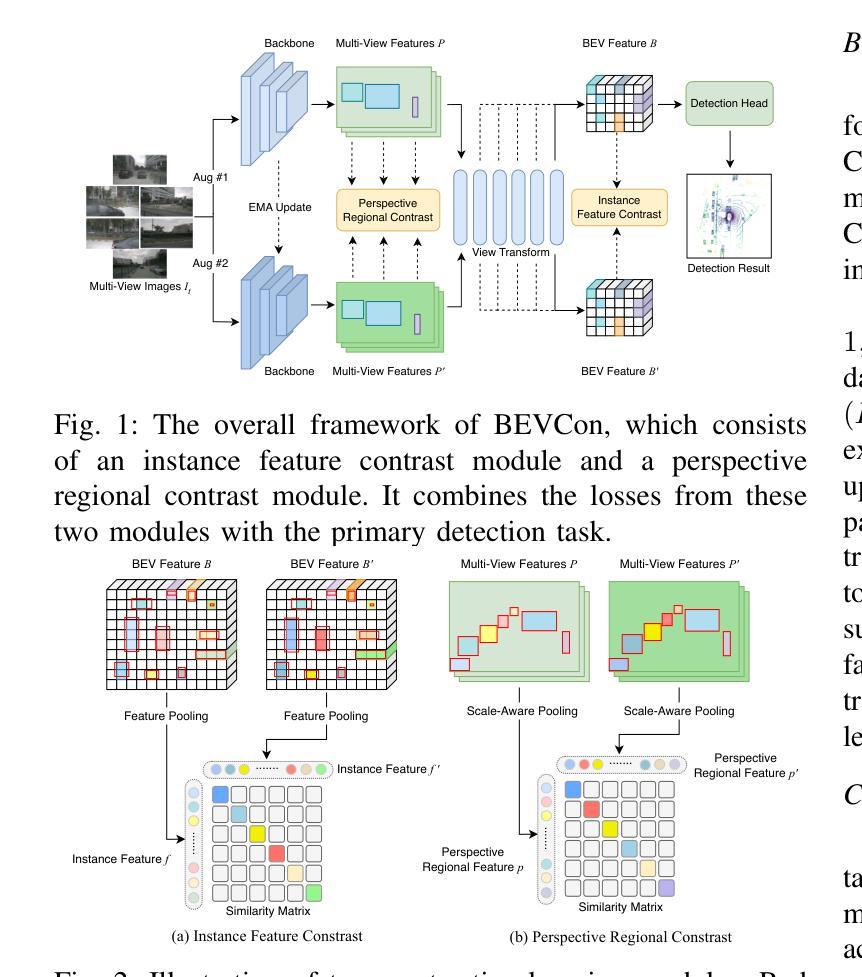
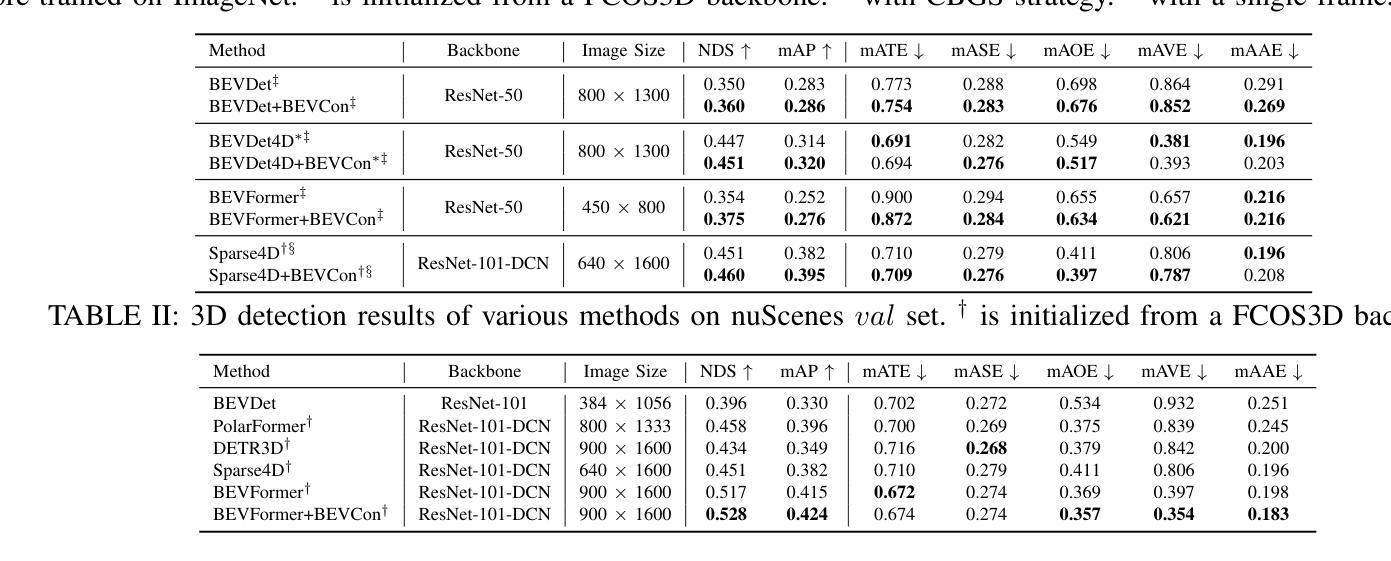
BEVCon: Advancing Bird’s Eye View Perception with Contrastive Learning
Authors:Ziyang Leng, Jiawei Yang, Zhicheng Ren, Bolei Zhou
We present BEVCon, a simple yet effective contrastive learning framework designed to improve Bird’s Eye View (BEV) perception in autonomous driving. BEV perception offers a top-down-view representation of the surrounding environment, making it crucial for 3D object detection, segmentation, and trajectory prediction tasks. While prior work has primarily focused on enhancing BEV encoders and task-specific heads, we address the underexplored potential of representation learning in BEV models. BEVCon introduces two contrastive learning modules: an instance feature contrast module for refining BEV features and a perspective view contrast module that enhances the image backbone. The dense contrastive learning designed on top of detection losses leads to improved feature representations across both the BEV encoder and the backbone. Extensive experiments on the nuScenes dataset demonstrate that BEVCon achieves consistent performance gains, achieving up to +2.4% mAP improvement over state-of-the-art baselines. Our results highlight the critical role of representation learning in BEV perception and offer a complementary avenue to conventional task-specific optimizations.
我们提出了BEVCon,这是一个简单有效的对比学习框架,旨在提高自动驾驶中的鸟瞰视图(BEV)感知。BEV感知提供了周围环境的俯视图表示,对于3D目标检测、分割和轨迹预测任务至关重要。虽然之前的工作主要集中在增强BEV编码器和特定任务的头部,但我们解决了BEV模型中表示学习的未被探索的潜力。BEVCon引入了两个对比学习模块:一个实例特征对比模块,用于优化BEV特征,一个视角视图对比模块,用于增强图像主干。在检测损失之上设计的密集对比学习导致BEV编码器和主干网的特征表示得到改善。在nuScenes数据集上的大量实验表明,BEVCon实现了性能的稳定提升,相比最先进的基线实现了最高+2.4%的mAP提升。我们的结果强调了表示学习在BEV感知中的关键作用,并为传统的针对特定任务的优化提供了补充途径。
论文及项目相关链接
Summary
本文介绍了BEVCon,这是一种简单有效的对比学习框架,旨在提高自动驾驶中的鸟瞰图(BEV)感知能力。BEV感知提供环境的俯视图表示,对于三维物体检测、分割和轨迹预测任务至关重要。BEVCon引入了两个对比学习模块,通过检测损失设计了密集对比学习,提高了BEV编码器和图像骨干网的特征表示能力。在nuScenes数据集上的实验表明,BEVCon实现了性能的提升,平均准确率提高了最多2.4%。本研究强调了表示学习在BEV感知中的关键作用,并为传统的任务特定优化提供了补充途径。
Key Takeaways
- BEVCon是一个对比学习框架,旨在提高自动驾驶中的鸟瞰图(BEV)感知能力。
- BEV感知对于自动驾驶中的三维物体检测、分割和轨迹预测任务至关重要。
- BEVCon引入了两个对比学习模块:一个用于细化BEV特征的实例特征对比模块,另一个用于增强图像骨干网的视角视图对比模块。
- 通过密集对比学习,BEVCon提高了BEV编码器和图像骨干网的特征表示能力。
- 在nuScenes数据集上的实验表明,BEVCon实现了性能的提升,平均准确率提高了最多2.4%。
- 研究结果强调了表示学习在BEV感知中的关键作用。
点此查看论文截图


Discriminating Distal Ischemic Stroke from Seizure-Induced Stroke Mimics Using Dynamic Susceptibility Contrast MRI
Authors:Marijn Borghouts, Richard McKinley, Josien Pluim, Manuel Köstner, Roland Wiest, Ruisheng Su
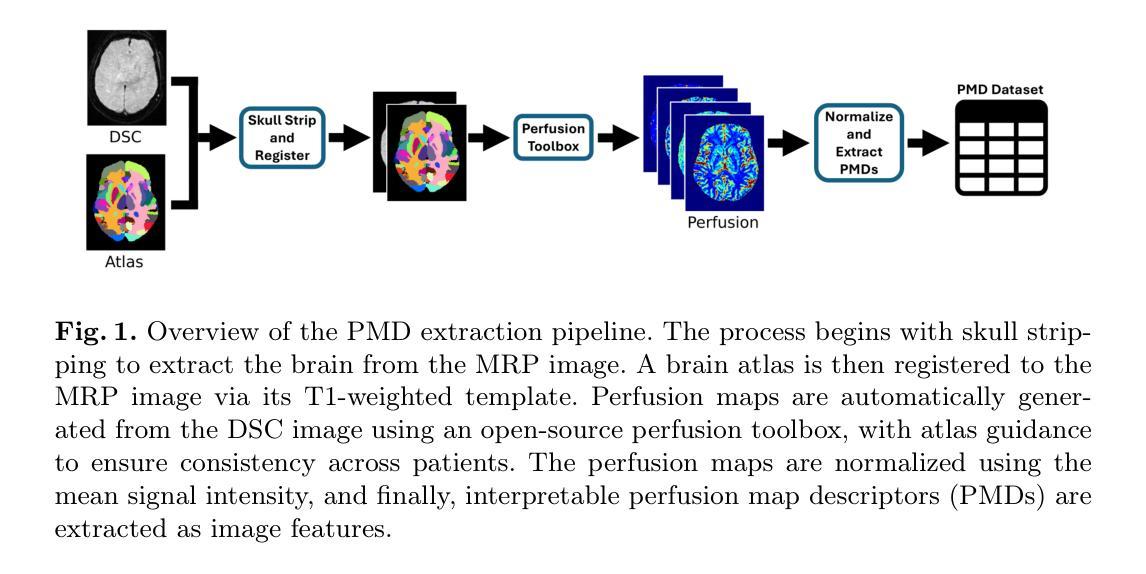
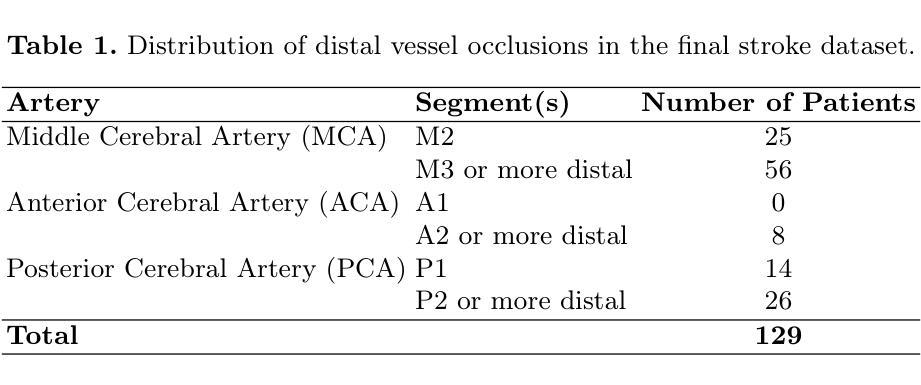
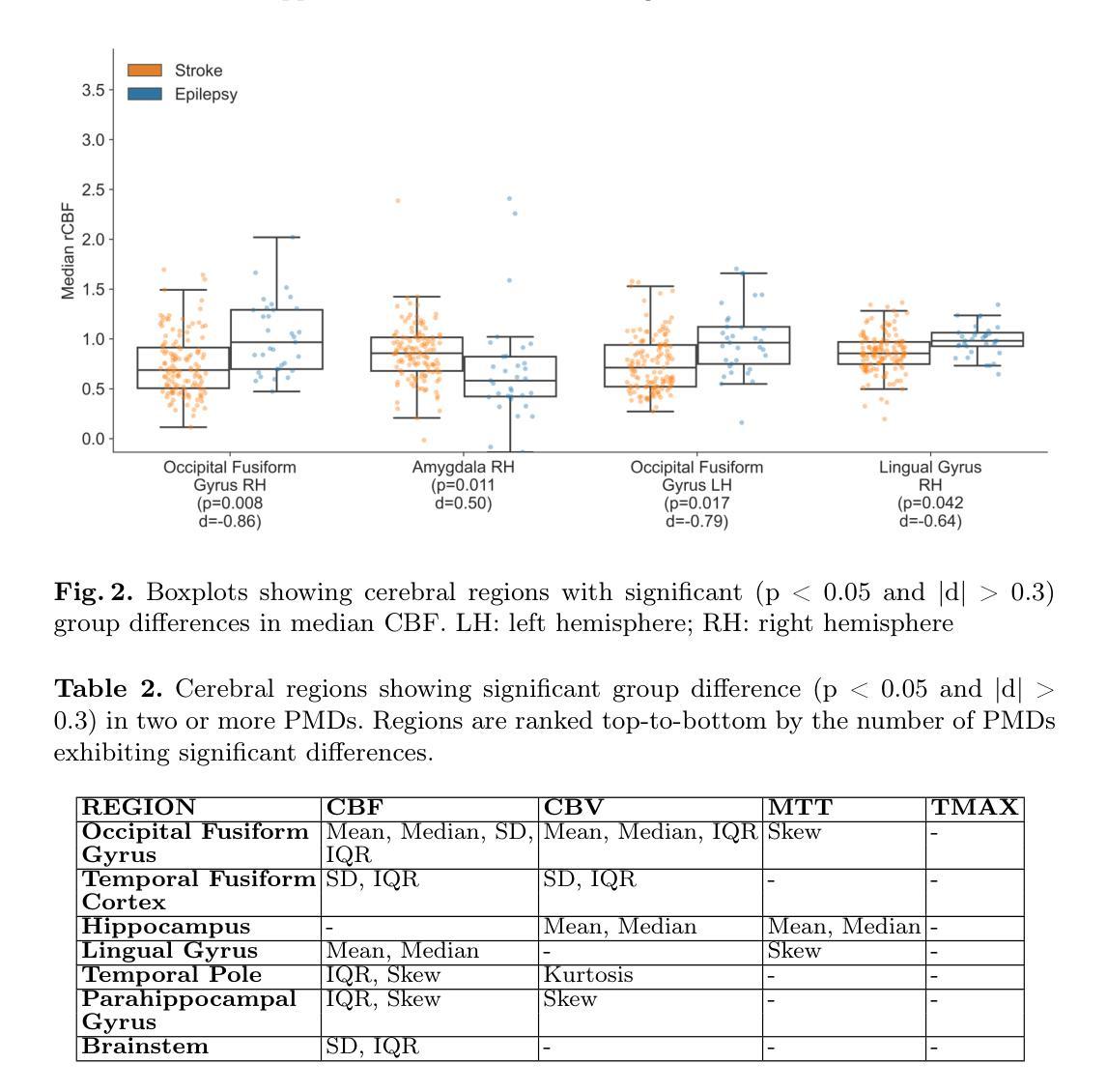
Distinguishing acute ischemic strokes (AIS) from stroke mimics (SMs), particularly in cases involving medium and small vessel occlusions, remains a significant diagnostic challenge. While computed tomography (CT) based protocols are commonly used in emergency settings, their sensitivity for detecting distal occlusions is limited. This study explores the potential of magnetic resonance perfusion (MRP) imaging as a tool for differentiating distal AIS from epileptic seizures, a prevalent SM. Using a retrospective dataset of 162 patients (129 AIS, 33 seizures), we extracted region-wise perfusion map descriptors (PMDs) from dynamic susceptibility contrast (DSC) images. Statistical analyses identified several brain regions, located mainly in the temporal and occipital lobe, exhibiting significant group differences in certain PMDs. Hemispheric asymmetry analyses further highlighted these regions as discriminative. A logistic regression model trained on PMDs achieved an area under the receiver operating characteristic (AUROC) curve of 0.90, and an area under the precision recall curve (AUPRC) of 0.74, with a specificity of 92% and a sensitivity of 73%, suggesting strong performance in distinguishing distal AIS from seizures. These findings support further exploration of MRP-based PMDs as interpretable features for distinguishing true strokes from various mimics. The code is openly available at our GitHub https://github.com/Marijn311/PMD_extraction_and_analysis{github.com/Marijn311/PMD\_extraction\_and\_analysis
将急性缺血性脑卒中(AIS)与脑卒中模仿者(SMs)区分开,特别是在涉及中小血管闭塞的情况下,仍然是一个重要的诊断挑战。虽然基于计算机断层扫描(CT)的协议通常在紧急情况下使用,但它们在检测远端闭塞时的敏感性是有限的。本研究探讨了磁共振灌注(MRP)成像在区分远端AIS与常见的SM癫痫发作中的潜力。我们回顾了162名患者(129名AIS患者和33次癫痫发作)的数据集,从动态磁敏感对比(DSC)图像中提取了区域灌注图描述符(PMDs)。统计分析确定了某些PMDs在主要位于颞叶和枕叶的脑区域中存在显著的群体差异。半球不对称性分析进一步强调了这些区域的辨别能力。使用PMD训练的逻辑回归模型在接收特性曲线下的面积(AUROC)达到了0.90,在精确召回曲线下的面积(AUPRC)达到了0.74,特异性为92%,敏感性为73%,这表明在区分远端AIS和癫痫发作方面表现出色。这些发现支持进一步探索基于MRP的PMDs作为区分真实中风与各种模仿的可解释特征。代码已公开发布在我们的GitHub上:链接。
论文及项目相关链接
Summary
本文探讨了利用磁共振灌注(MRP)成像技术区分急性缺血性中风(AIS)与常见的中风模仿者(SM,如癫痫症)的潜力。通过对动态磁敏感对比(DSC)图像的区域灌注图描述符(PMDs)进行统计分析,发现某些大脑区域在时间和空间上具有显著差异。使用PMD训练的逻辑回归模型在区分AIS和癫痫方面具有优良表现,表明MR成像技术有助于更准确地诊断中风。
Key Takeaways
- 中风与中风模仿者的区分,特别是在涉及中小血管闭塞的情况下,仍是一个重大诊断挑战。
- 计算机断层扫描(CT)在紧急情况下检测远端闭塞的敏感性有限。
- 磁共振灌注(MRP)成像技术在区分远端急性缺血性中风(AIS)与癫痫等中风模仿者方面具有潜力。
- 通过分析动态磁敏感对比(DSC)图像的区域灌注图描述符(PMDs),发现大脑某些区域在时空特征上存在显著差异。
- PMDs的逻辑回归模型在区分AIS和癫痫方面表现出色,具有高的AUROC和AUPRC值,以及高特异性和敏感性。
- 此研究的结果支持进一步探索基于MRP的PMDs作为区分真实中风与各种模仿者的可解释特征。
点此查看论文截图

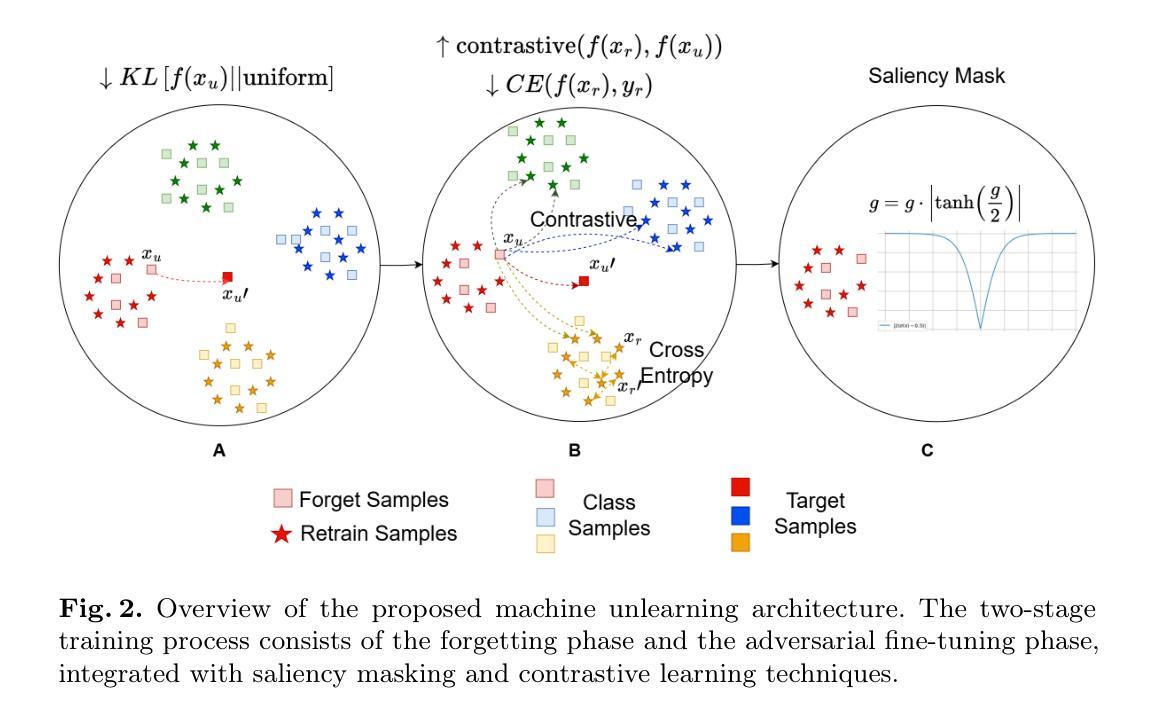
WSS-CL: Weight Saliency Soft-Guided Contrastive Learning for Efficient Machine Unlearning Image Classification
Authors:Thang Duc Tran, Thai Hoang Le
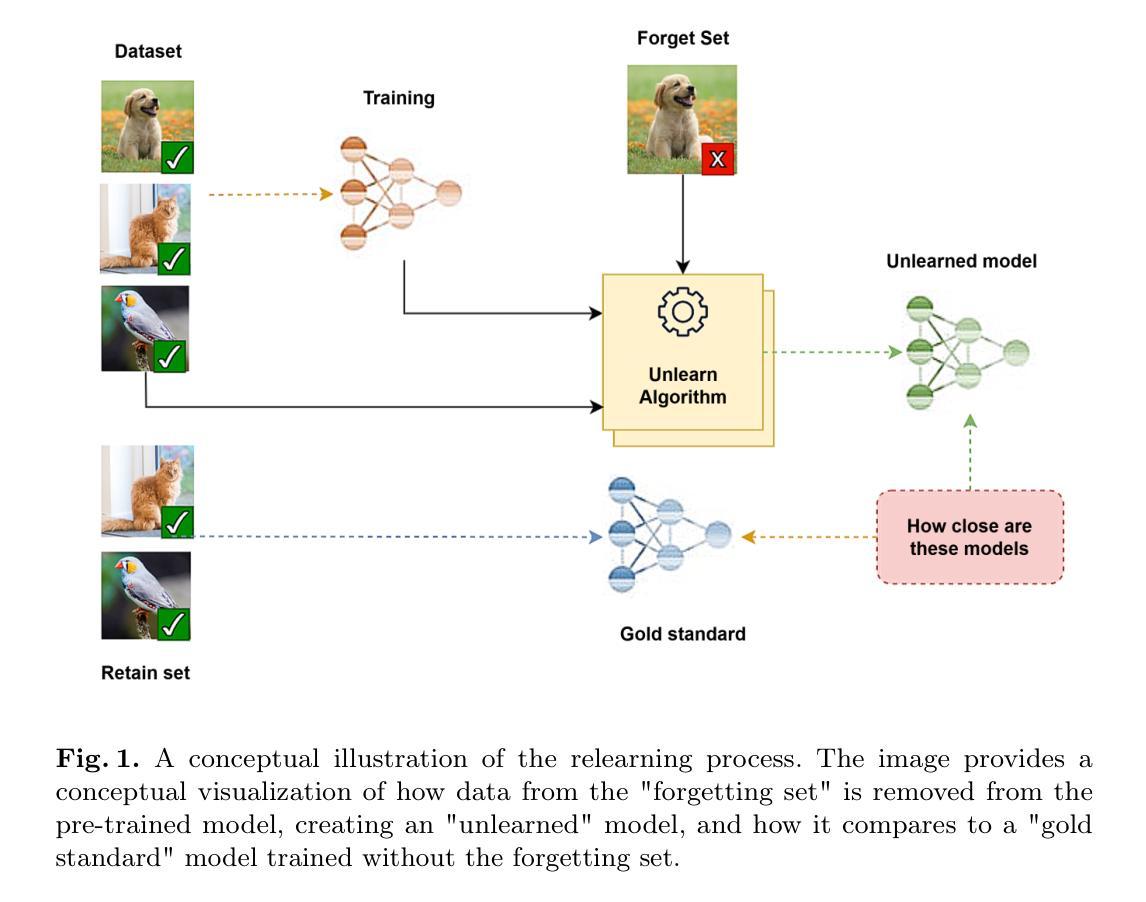
Machine unlearning, the efficient deletion of the impact of specific data in a trained model, remains a challenging problem. Current machine unlearning approaches that focus primarily on data-centric or weight-based strategies frequently encounter challenges in achieving precise unlearning, maintaining stability, and ensuring applicability across diverse domains. In this work, we introduce a new two-phase efficient machine unlearning method for image classification, in terms of weight saliency, leveraging weight saliency to focus the unlearning process on critical model parameters. Our method is called weight saliency soft-guided contrastive learning for efficient machine unlearning image classification (WSS-CL), which significantly narrows the performance gap with “exact” unlearning. First, the forgetting stage maximizes kullback-leibler divergence between output logits and aggregated pseudo-labels for efficient forgetting in logit space. Next, the adversarial fine-tuning stage introduces contrastive learning in a self-supervised manner. By using scaled feature representations, it maximizes the distance between the forgotten and retained data samples in the feature space, with the forgotten and the paired augmented samples acting as positive pairs, while the retained samples act as negative pairs in the contrastive loss computation. Experimental evaluations reveal that our proposed method yields much-improved unlearning efficacy with negligible performance loss compared to state-of-the-art approaches, indicative of its usability in supervised and self-supervised settings.
机器遗忘,即有效地消除特定数据对训练模型的影响,仍然是一个具有挑战性的问题。当前主要关注数据中心或权重基础的机器遗忘策略经常面临精确遗忘、保持稳定性和跨不同领域应用的挑战。在这项工作中,我们针对图像分类,提出了一种新的两阶段高效机器遗忘方法,该方法基于权重显著性,利用权重显著性将遗忘过程集中在关键模型参数上。我们的方法称为基于权重显著性软引导对比学习的图像分类高效机器遗忘法(WSS-CL)。首先,遗忘阶段最大化输出对数几率与聚合伪标签之间的Kullback-Leibler散度,以实现对数概率空间中的高效遗忘。接下来,对抗微调阶段采用自监督的对比学习方式。通过使用缩放特征表示,它最大化遗忘数据和保留数据样本在特征空间中的距离,其中遗忘数据和配对增强样本作为正样本对,而保留的样本在计算对比损失时作为负样本对。实验评估表明,与最新方法相比,我们提出的方法在遗忘效果上取得了显著改进,性能损失微乎其微,这表明其在有监督和自监督设置中的可用性。
论文及项目相关链接
PDF 17th International Conference on Computational Collective Intelligence 2025
Summary
本文提出了一种新的两阶段高效机器遗忘方法,用于图像分类。该方法基于权重重要性,利用权重重要性引导遗忘过程关注模型的关键参数。所提出的方法称为权重重要性软引导对比学习(WSS-CL),显著缩小了与“精确”遗忘的性能差距。首先,遗忘阶段在logit空间内通过最大化输出logit与聚合伪标签之间的Kullback-Leibler散度来实现高效遗忘。接着,对抗微调阶段采用自监督的对比学习方式。通过使用缩放后的特征表示,它最大化被遗忘和保留的数据样本之间的距离,在特征空间中,被遗忘的和配对的增强样本作为正对,而保留的样本作为负对参与对比损失计算。实验评估表明,与现有方法相比,所提出的方法在提高遗忘效率的同时,性能损失微乎其微,显示出其在有监督和自监督设置中的实用性。
Key Takeaways
- 当前机器遗忘方法面临精确遗忘、稳定性及跨域应用性的挑战。
- 提出了一种新的两阶段高效机器遗忘方法WSS-CL,基于权重重要性进行图像分类的遗忘。
- 遗忘阶段最大化logit空间内的输出logit与伪标签之间的Kullback-Leibler散度以实现高效遗忘。
- 对抗微调阶段采用自监督对比学习,利用缩放特征表示来最大化被遗忘和保留数据样本之间的距离。
- 实验评估显示WSS-CL方法显著提高遗忘效率,同时性能损失较小。
- WSS-CL方法适用于有监督和自监督设置。
点此查看论文截图

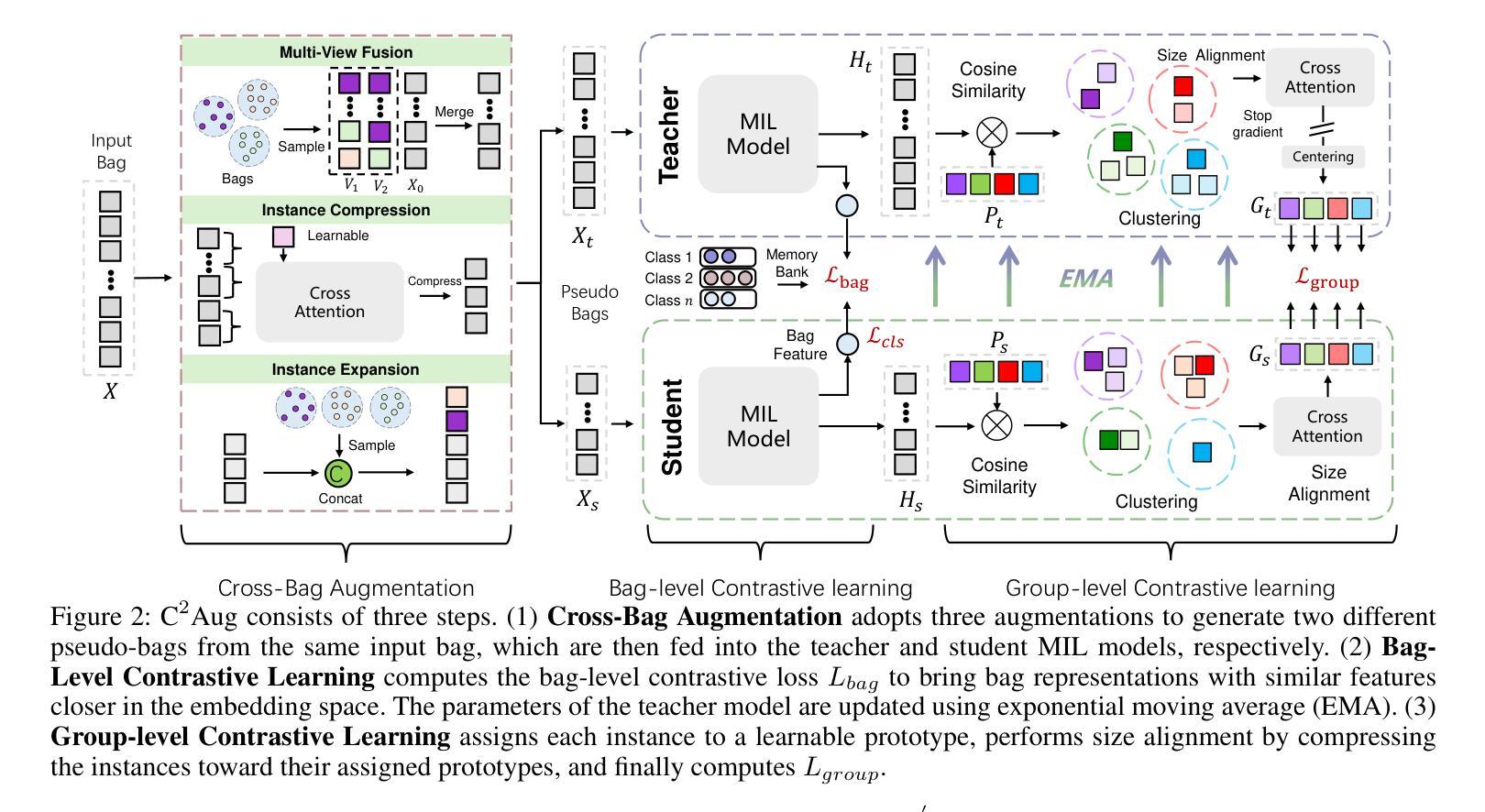
Contrastive Cross-Bag Augmentation for Multiple Instance Learning-based Whole Slide Image Classification
Authors:Bo Zhang, Xu Xinan, Shuo Yan, Yu Bai, Zheng Zhang, Wufan Wang, Wendong Wang
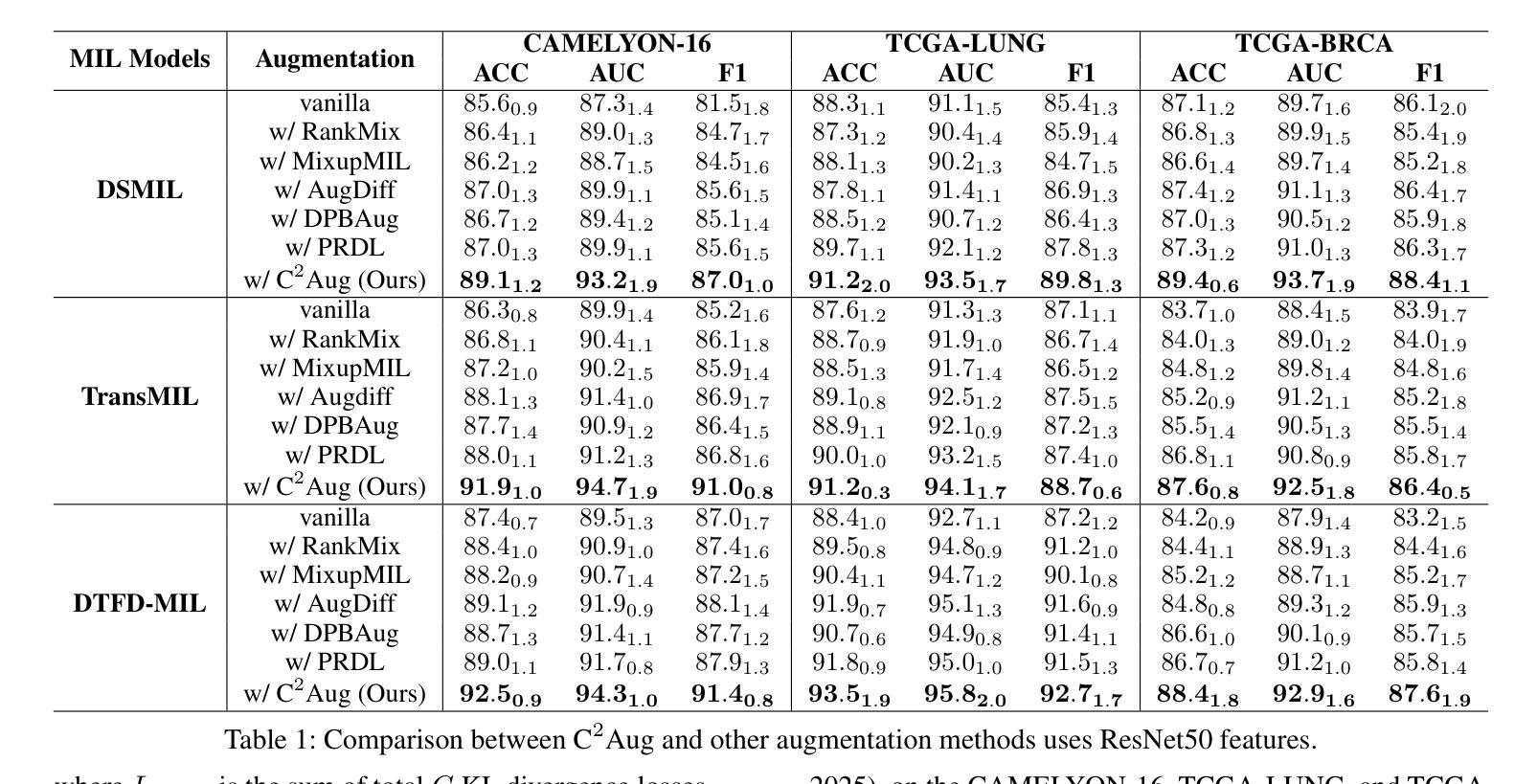
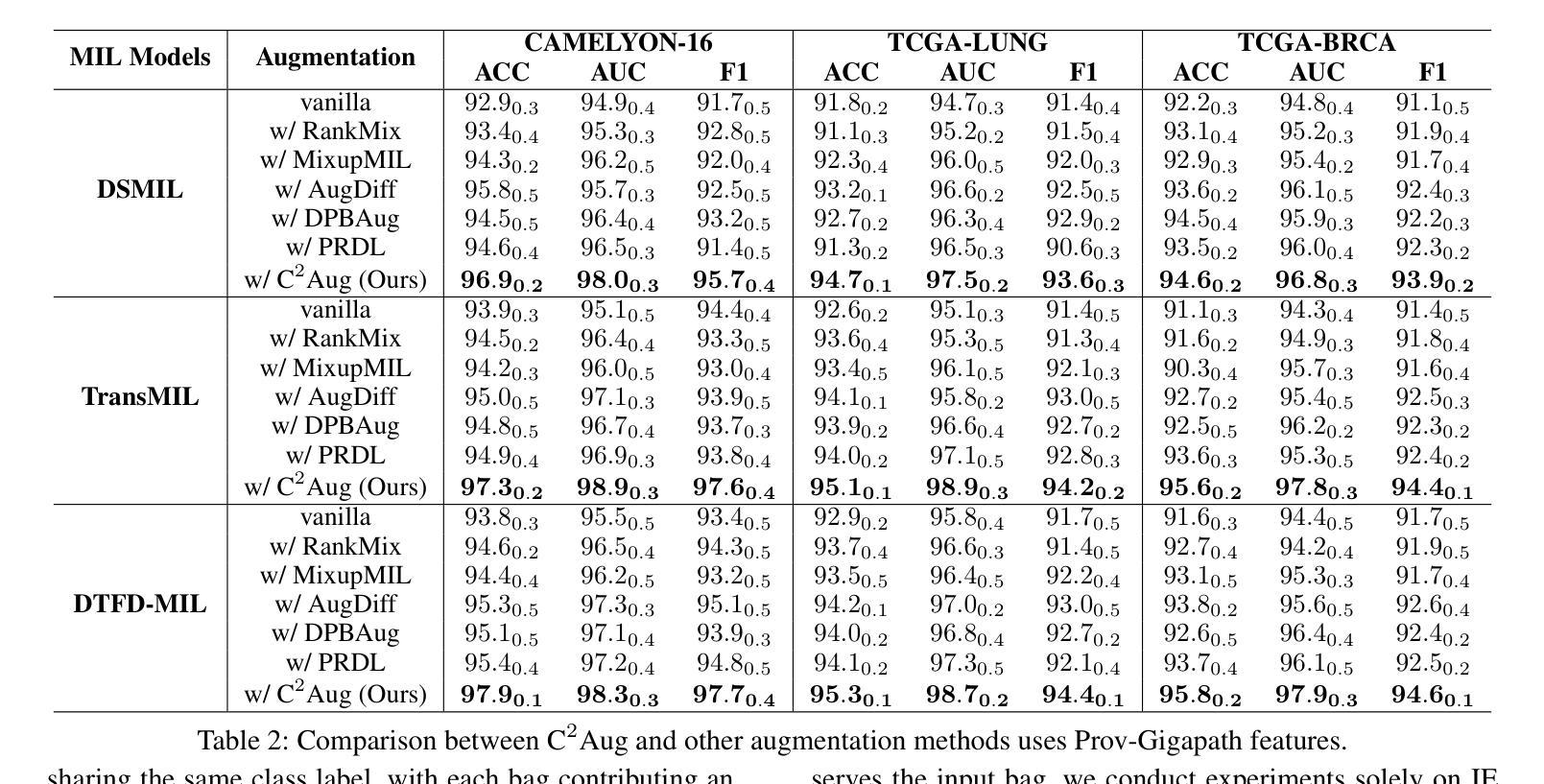
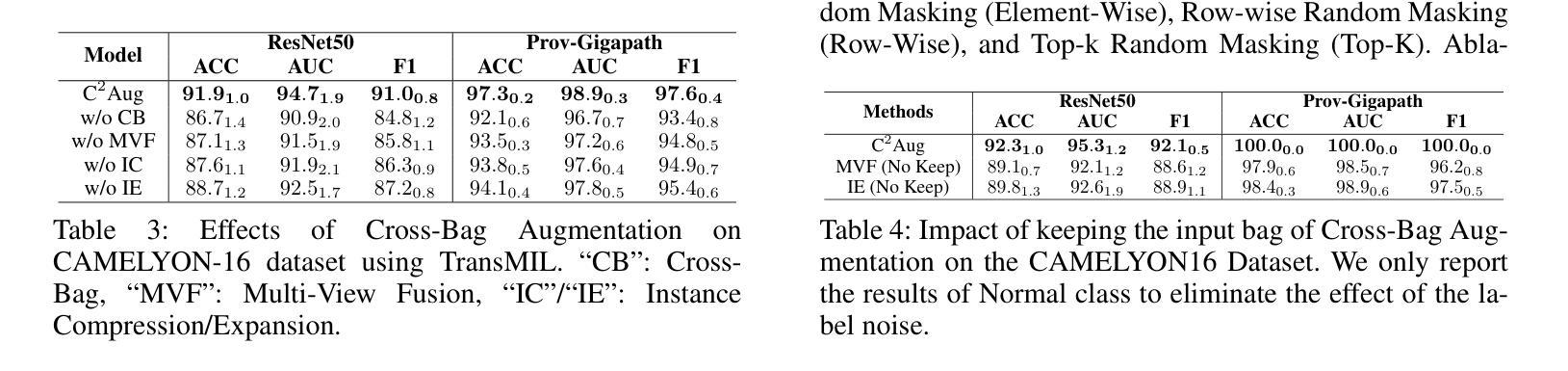
Recent pseudo-bag augmentation methods for Multiple Instance Learning (MIL)-based Whole Slide Image (WSI) classification sample instances from a limited number of bags, resulting in constrained diversity. To address this issue, we propose Contrastive Cross-Bag Augmentation ($C^2Aug$) to sample instances from all bags with the same class to increase the diversity of pseudo-bags. However, introducing new instances into the pseudo-bag increases the number of critical instances (e.g., tumor instances). This increase results in a reduced occurrence of pseudo-bags containing few critical instances, thereby limiting model performance, particularly on test slides with small tumor areas. To address this, we introduce a bag-level and group-level contrastive learning framework to enhance the discrimination of features with distinct semantic meanings, thereby improving model performance. Experimental results demonstrate that $C^2Aug$ consistently outperforms state-of-the-art approaches across multiple evaluation metrics.
针对基于多重实例学习(MIL)的全幻灯片图像(WSI)分类问题,最近的伪包增强方法从有限的包中采样实例,导致多样性受限。为了解决这个问题,我们提出了对比跨包增强(C^2Aug)方法,从同一类别的所有包中采样实例,以增加伪包的多样性。然而,将新实例引入伪包会增加关键实例的数量(例如,肿瘤实例)。这种增加导致包含少数关键实例的伪包的出现率降低,从而限制了模型性能,特别是在肿瘤区域较小的测试幻灯片上。为了解决这个问题,我们引入了包级别和组级别的对比学习框架,以提高具有不同语义意义的特征的辨别力,从而提高模型性能。实验结果表明,C^2Aug在多个评估指标上始终优于最新方法。
论文及项目相关链接
Summary:针对基于多实例学习(MIL)的全幻灯片图像(WSI)分类中的伪包增强方法,由于从有限数量的包中采样实例导致多样性受限的问题,我们提出了对比跨包增强($C^2Aug$)方法。通过从同一类别的所有包中采样实例来增加伪包的多样性。同时,引入对比学习框架,提高特征区分度,从而提高模型性能。实验结果表明,$C^2Aug$在多个评价指标上均优于现有方法。
Key Takeaways:
- 提出对比跨包增强($C^2Aug$)解决现有伪包增强方法多样性受限的问题。
- $C^2Aug$通过从同一类别的所有包中采样实例来增加伪包的多样性。
- 引入新的实例会增加伪包中的关键实例数量,影响模型性能。
- 针对测试幻灯片中小肿瘤区域的问题,引入包级别和组级别的对比学习框架。
- 对比学习框架能提高特征区分度,从而提高模型性能。
- 实验结果表明,$C^2Aug$在多个评价指标上均优于现有方法。
点此查看论文截图