⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
Uncertainty-Guided Face Matting for Occlusion-Aware Face Transformation
Authors:Hyebin Cho, Jaehyup Lee
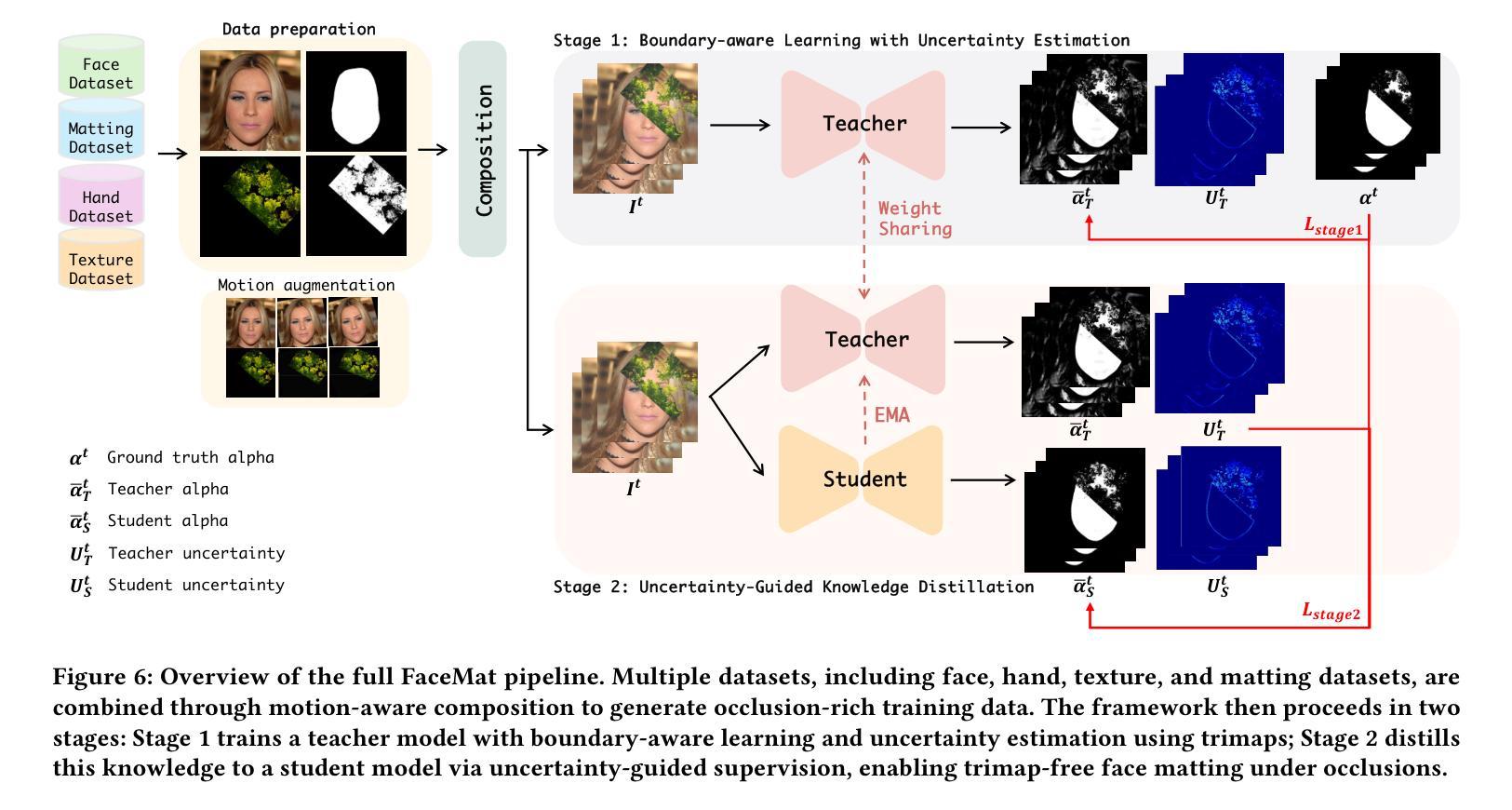
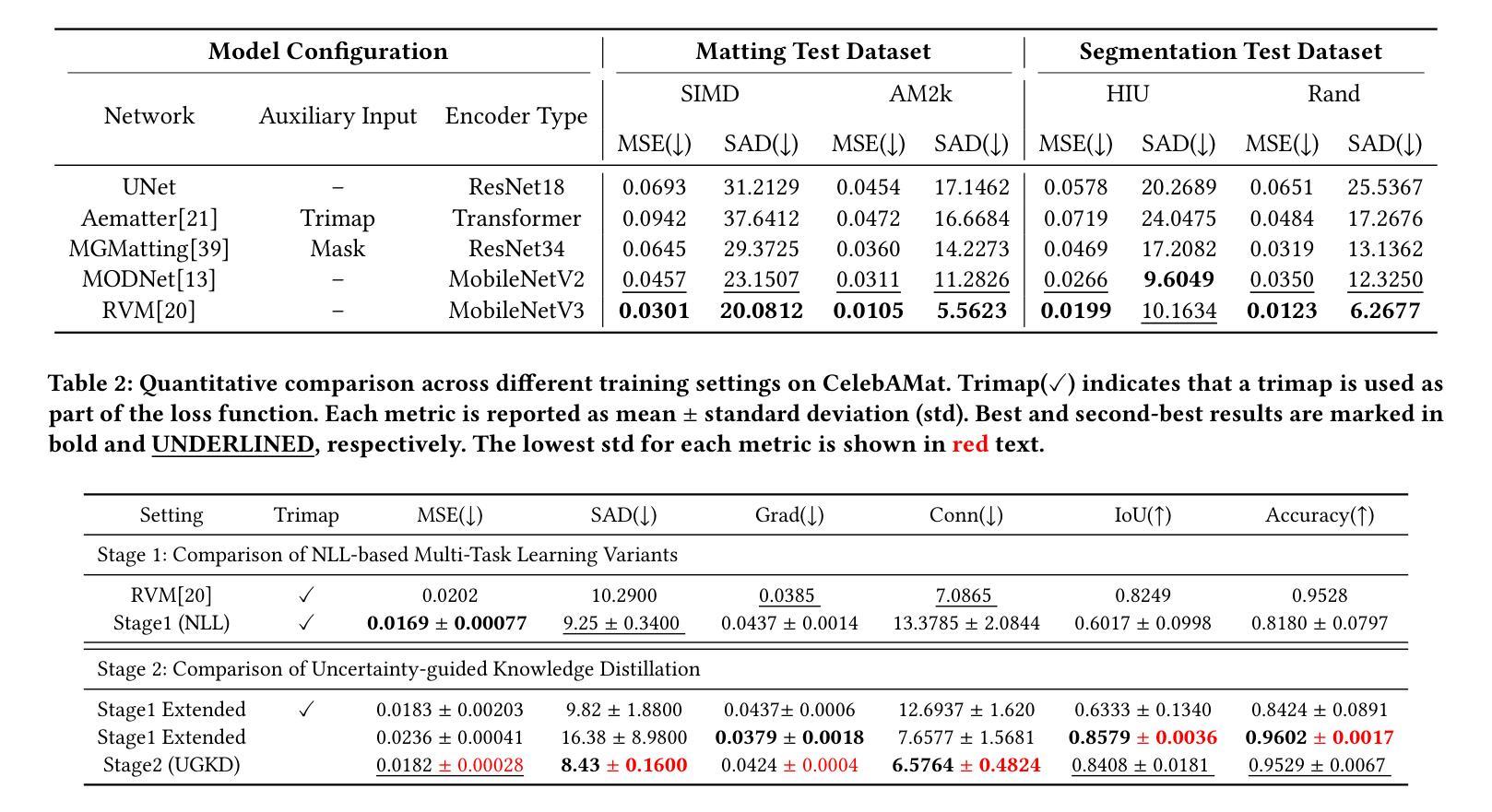
Face filters have become a key element of short-form video content, enabling a wide array of visual effects such as stylization and face swapping. However, their performance often degrades in the presence of occlusions, where objects like hands, hair, or accessories obscure the face. To address this limitation, we introduce the novel task of face matting, which estimates fine-grained alpha mattes to separate occluding elements from facial regions. We further present FaceMat, a trimap-free, uncertainty-aware framework that predicts high-quality alpha mattes under complex occlusions. Our approach leverages a two-stage training pipeline: a teacher model is trained to jointly estimate alpha mattes and per-pixel uncertainty using a negative log-likelihood (NLL) loss, and this uncertainty is then used to guide the student model through spatially adaptive knowledge distillation. This formulation enables the student to focus on ambiguous or occluded regions, improving generalization and preserving semantic consistency. Unlike previous approaches that rely on trimaps or segmentation masks, our framework requires no auxiliary inputs making it well-suited for real-time applications. In addition, we reformulate the matting objective by explicitly treating skin as foreground and occlusions as background, enabling clearer compositing strategies. To support this task, we newly constructed CelebAMat, a large-scale synthetic dataset specifically designed for occlusion-aware face matting. Extensive experiments show that FaceMat outperforms state-of-the-art methods across multiple benchmarks, enhancing the visual quality and robustness of face filters in real-world, unconstrained video scenarios. The source code and CelebAMat dataset are available at https://github.com/hyebin-c/FaceMat.git
面部滤镜已成为短视频内容的关键元素,能够实现风格化和换脸等多种视觉效果。然而,在遮挡物(如手、头发或配饰)存在的情况下,它们的性能往往会下降。为了解决这一局限性,我们引入了面部抠图这一新任务,该任务估计精细的alpha抠图来将遮挡元素与面部区域分开。我们进一步提出了FaceMat,这是一个无需修边、能感知不确定性的框架,可在复杂遮挡下预测高质量的alpha抠图。我们的方法采用两阶段训练管道:教师模型使用负对数似然(NLL)损失联合估计alpha抠图和像素级不确定性,这种不确定性然后用于通过空间自适应知识蒸馏来指导学生模型。这种表述使学生能够关注模糊或遮挡的区域,提高泛化能力并保持语义一致性。与以前依赖修边或分割掩膜的方法不同,我们的框架无需辅助输入,非常适合实时应用。此外,我们通过明确地将皮肤视为前景,遮挡物视为背景,重新制定了抠图目标,从而实现更清晰的合成策略。为了支持这一任务,我们新构建了CelebAMat数据集,这是一个专门为感知遮挡的面部抠图设计的大规模合成数据集。大量实验表明,FaceMat在多个基准测试上的表现优于最先进的方法,提高了现实世界、无约束视频场景中面部滤镜的视觉质量和稳健性。源代码和CelebAMat数据集可在https://github.com/hyebin-c/FaceMat.git上找到。
论文及项目相关链接
PDF Accepted to ACM MM 2025. 9 pages, 8 figures, 6 tables
Summary
本文介绍了面部滤镜在处理短视频时的性能局限,特别是在面对遮挡物时。为解决这一问题,提出了面部抠图的新任务,旨在通过精细的alpha通道抠图技术将遮挡物与面部区域分离。此外,还提出了一种无需辅助输入的、具有不确定性感知的FaceMat框架,能在复杂遮挡条件下预测高质量的alpha通道抠图。该框架采用两阶段训练流程,通过教师模型估计alpha通道抠图和像素级不确定性,并利用这种不确定性引导学生模型通过空间自适应知识蒸馏进行训练。同时,对面部抠图的目标进行了重新构建,明确将皮肤视为前景,遮挡物视为背景。为支持此任务,还构建了CelebAMat大型合成数据集。实验表明,FaceMat在多个基准测试中优于其他最新方法,提高了真实世界无约束视频场景中面部滤镜的视觉质量和稳健性。
Key Takeaways
- 面部滤镜在处理短视频时面临遮挡物的性能局限。
- 引入面部抠图新任务,旨在分离遮挡物与面部区域。
- 提出了一种无需辅助输入的FaceMat框架,具有不确定性感知能力。
- 采用两阶段训练流程,教师模型估计alpha通道抠图和像素级不确定性。
- 利用不确定性指导学生模型训练,提高在模糊或遮挡区域的关注度。
- 重新定义面部抠图目标,明确区分皮肤和遮挡物。
点此查看论文截图