⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
Knowledge Distillation for Underwater Feature Extraction and Matching via GAN-synthesized Images
Authors:Jinghe Yang, Mingming Gong, Ye Pu
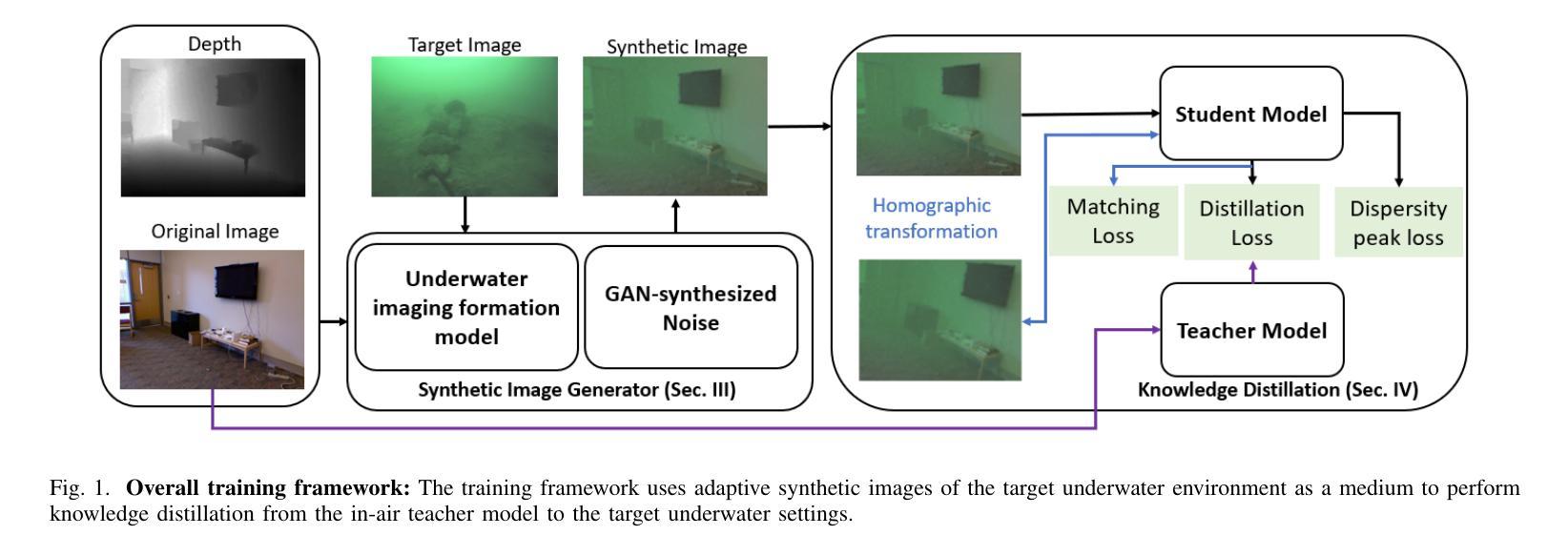
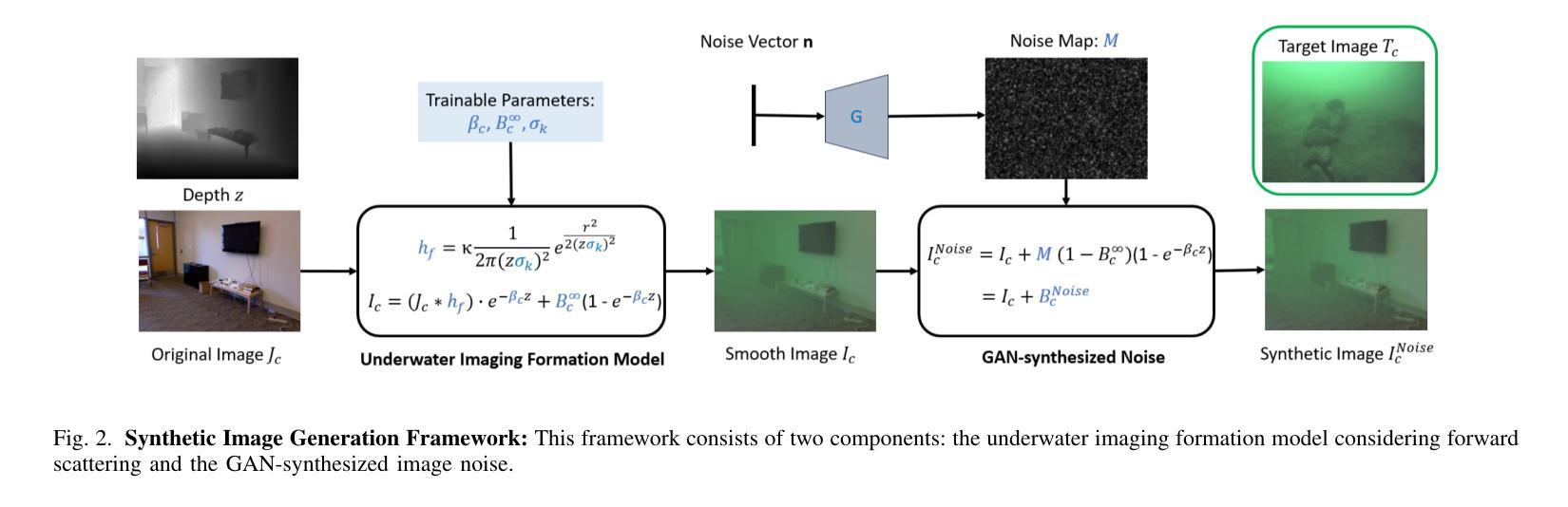
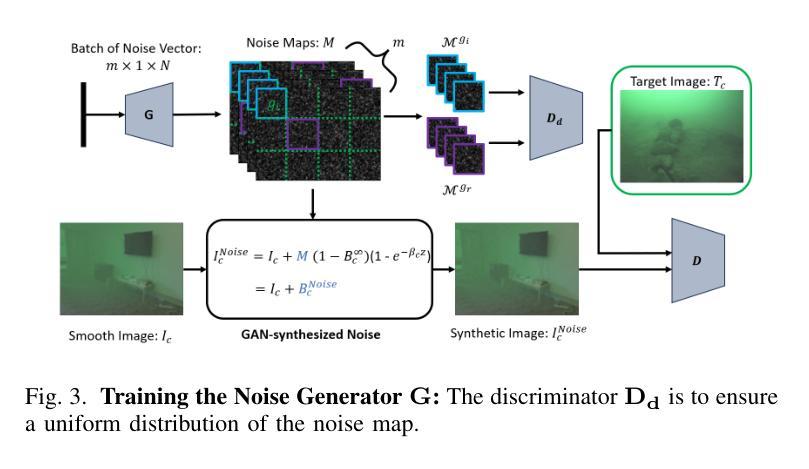
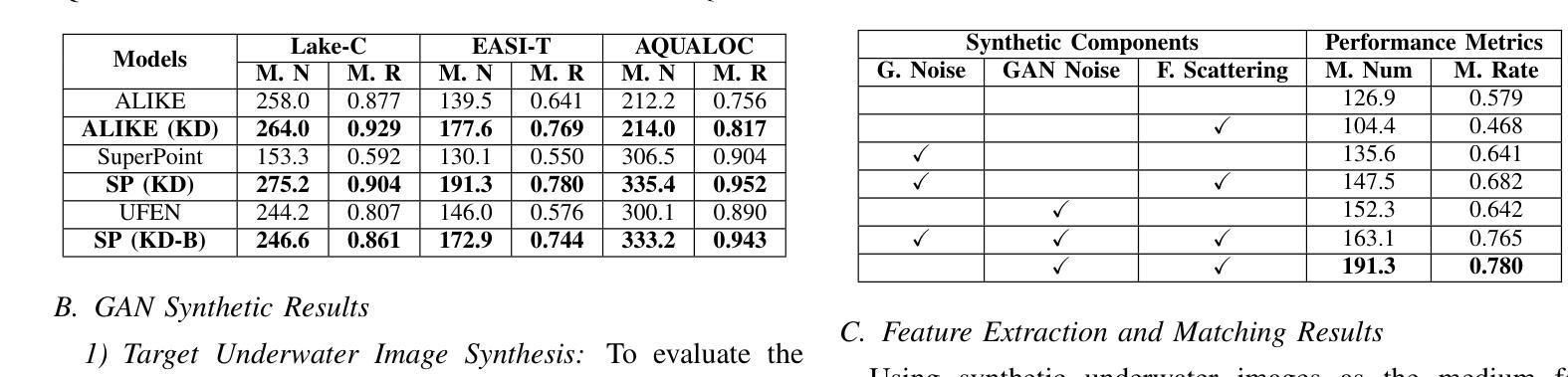
Autonomous Underwater Vehicles (AUVs) play a crucial role in underwater exploration. Vision-based methods offer cost-effective solutions for localization and mapping in the absence of conventional sensors like GPS and LiDAR. However, underwater environments present significant challenges for feature extraction and matching due to image blurring and noise caused by attenuation, scattering, and the interference of \textit{marine snow}. In this paper, we aim to improve the robustness of the feature extraction and matching in the turbid underwater environment using the cross-modal knowledge distillation method that transfers the in-air feature extraction and matching models to underwater settings using synthetic underwater images as the medium. We first propose a novel adaptive GAN-synthesis method to estimate water parameters and underwater noise distribution, to generate environment-specific synthetic underwater images. We then introduce a general knowledge distillation framework compatible with different teacher models. The evaluation of GAN-based synthesis highlights the significance of the new components, i.e. GAN-synthesized noise and forward scattering, in the proposed model. Additionally, VSLAM, as a representative downstream application of feature extraction and matching, is employed on real underwater sequences to validate the effectiveness of the transferred model. Project page: https://github.com/Jinghe-mel/UFEN-GAN.
自主水下车辆(AUVs)在水下探测中扮演着至关重要的角色。在没有GPS和激光雷达等传统传感器的情况下,基于视觉的方法为定位和地图绘制提供了经济高效的解决方案。然而,水下环境由于衰减、散射以及“海洋雪”的干扰所导致的图像模糊和噪声,给特征提取和匹配带来了重大挑战。本文旨在利用跨模态知识蒸馏方法提高浑浊水下环境中特征提取和匹配的稳健性。该方法通过合成水下图像等中介,将在空气中的特征提取和匹配模型转移到水下环境。我们首先提出了一种新颖的自适应GAN合成方法,以估计水参数和水下噪声分布,生成特定环境的合成水下图像。然后,我们介绍了一种与不同教师模型兼容的通用知识蒸馏框架。基于GAN的合成评估突显了新组件(即GAN合成的噪声和前向散射)在提议模型中的重要性。此外,VSLAM作为特征提取和匹配的下游应用的代表,被应用于真实的水下序列中,以验证转移模型的有效性。项目页面:https://github.com/Jinghe-mel/UFEN-GAN。
论文及项目相关链接
Summary
在水下探索中,自主水下车辆(AUVs)发挥着重要作用。在没有GPS和激光雷达等传统传感器的条件下,基于视觉的方法为定位和地图制作提供了经济高效的解决方案。然而,水下环境由于衰减、散射和“海洋雪”的干扰导致的图像模糊和噪声,给特征提取和匹配带来了重大挑战。本文旨在利用跨模态知识蒸馏方法,通过合成水下图像为媒介,将空中特征提取和匹配模型转移到水下环境,提高在浑浊水下环境中特征提取和匹配的稳健性。本文首先提出了一种新型自适应GAN合成方法,用于估计水参数和水下噪声分布,以生成特定环境下的合成水下图像。然后,引入了一种与不同教师模型兼容的一般知识蒸馏框架。基于GAN的合成评估突出了新型组件,即GAN合成的噪声和前向散射在模型中的重要性。此外,还采用了VSLAM作为特征提取和匹配的下游应用代表,对真实水下序列进行验证,以证明转移模型的有效性。
Key Takeaways
- 自主水下车辆(AUVs)在水下探索中起关键作用,尤其在定位和地图制作方面。
- 水下环境对特征提取和匹配带来挑战,如图像模糊和噪声。
- 本文利用跨模态知识蒸馏方法,通过合成水下图像,将空中特征提取模型转移到水下环境。
- 引入了一种自适应GAN合成方法,用于生成特定环境下的合成水下图像。
- GAN合成的噪声和前向散射在模型中起重要作用。
- 通过VSLAM在真实水下序列上的验证,证明了转移模型的有效性。
- 项目页面提供了更多详细信息:链接。
点此查看论文截图


Video Is Worth a Thousand Images: Exploring the Latest Trends in Long Video Generation
Authors:Faraz Waseem, Muhammad Shahzad
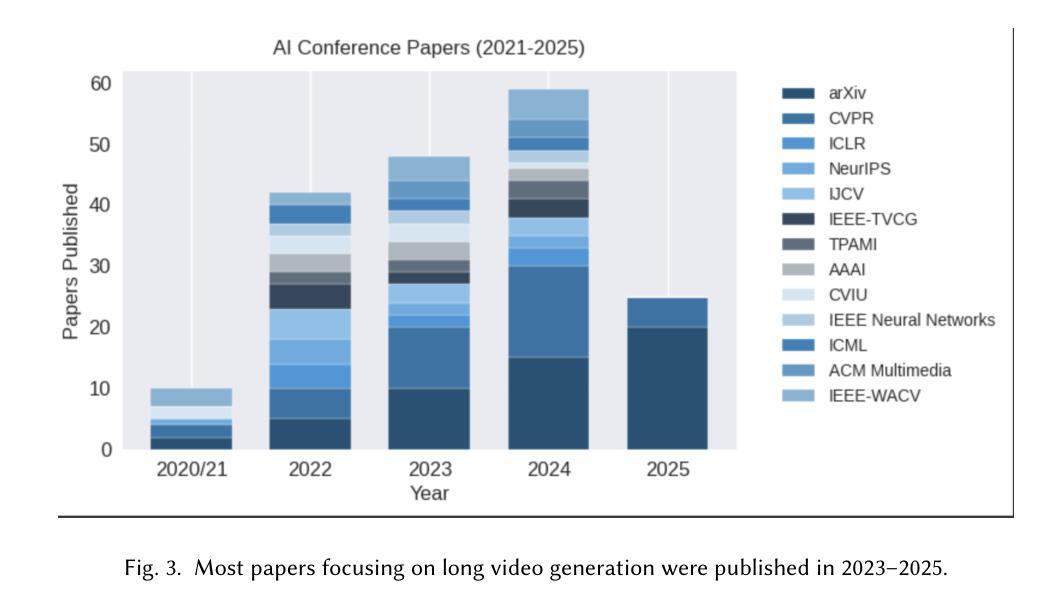
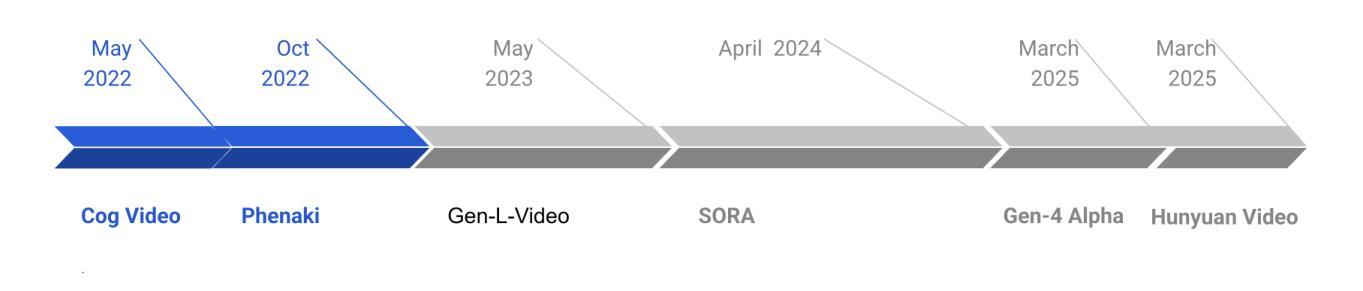
An image may convey a thousand words, but a video composed of hundreds or thousands of image frames tells a more intricate story. Despite significant progress in multimodal large language models (MLLMs), generating extended videos remains a formidable challenge. As of this writing, OpenAI’s Sora, the current state-of-the-art system, is still limited to producing videos that are up to one minute in length. This limitation stems from the complexity of long video generation, which requires more than generative AI techniques for approximating density functions essential aspects such as planning, story development, and maintaining spatial and temporal consistency present additional hurdles. Integrating generative AI with a divide-and-conquer approach could improve scalability for longer videos while offering greater control. In this survey, we examine the current landscape of long video generation, covering foundational techniques like GANs and diffusion models, video generation strategies, large-scale training datasets, quality metrics for evaluating long videos, and future research areas to address the limitations of the existing video generation capabilities. We believe it would serve as a comprehensive foundation, offering extensive information to guide future advancements and research in the field of long video generation.
图像可能传达千言万语,但由数百或数千个图像帧组成的视频则讲述了一个更复杂的故事。尽管多模态大型语言模型(MLLM)取得了重大进展,但生成长视频仍然是一个巨大的挑战。截至本文写作时,当前最先进的系统OpenAI的Sora仍然仅限于生成最长为一分钟的视频。这一限制源于长视频生成的复杂性,这不仅需要生成式人工智能技术来近似密度函数,而且还需要规划、故事发展和保持空间和时间一致性的基本方面存在额外的障碍。将生成式人工智能与分而治之的方法相结合,可以提高长视频的扩展性,同时提供更大的控制力。在本次调查中,我们研究了长视频生成的当前状况,涵盖了诸如GAN和扩散模型等基础技术、视频生成策略、大规模训练数据集、长视频质量评估指标,以及针对现有视频生成能力的局限性的未来研究领域。我们相信这将作为一个全面的基础,为长视频生成领域的未来发展和研究提供广泛的信息指导。
论文及项目相关链接
PDF 35 pages, 18 figures, Manuscript submitted to ACM
Summary
视频生成技术面临生成长视频的难题,当前最先进系统如OpenAI的Sora仅能生成一分钟长度的视频。生成长视频需要处理规划、故事发展、空间和时间一致性的维持等复杂问题。集成生成式AI与分而治之的策略有望提升长视频的生成能力。本文综述了长视频生成领域的技术基础、策略、大型训练数据集、质量评估指标和未来研究方向。
Key Takeaways
- 视频生成技术面临生成长视频的难题,当前系统存在长度限制。
- 生成长视频需要处理规划、故事发展等复杂问题。
- 集成生成式AI与分而治之的策略有望提升长视频的生成能力。
- GANs和扩散模型是视频生成的基础技术。
- 大型训练数据集对长视频生成至关重要。
- 质量评估指标是长视频生成领域的重要研究方向。
点此查看论文截图


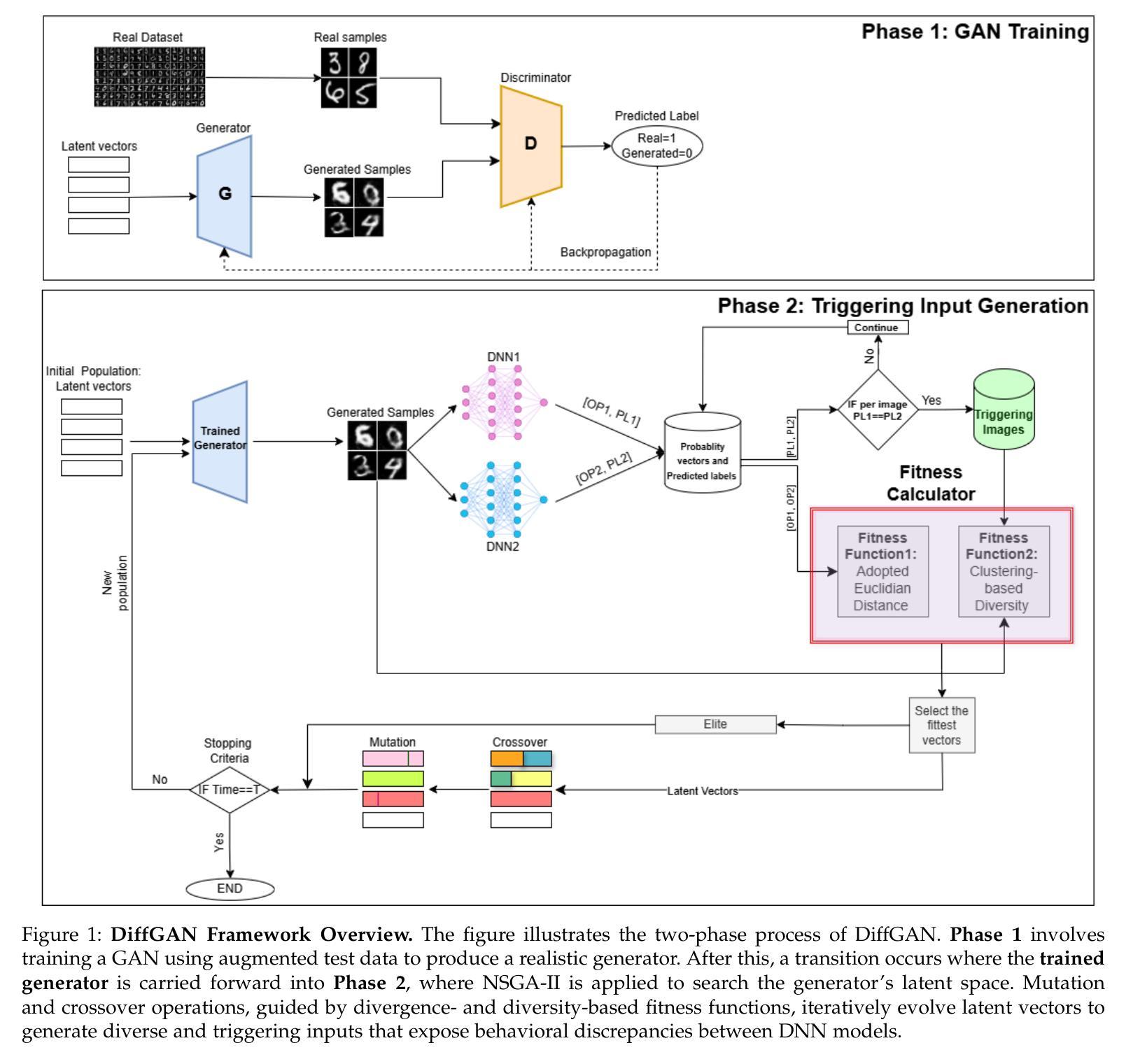
DiffGAN: A Test Generation Approach for Differential Testing of Deep Neural Networks for Image Analysis
Authors:Zohreh Aghababaeyan, Manel Abdellatif, Lionel Briand, Ramesh S
Deep Neural Networks (DNNs) are increasingly deployed across applications. However, ensuring their reliability remains a challenge, and in many situations, alternative models with similar functionality and accuracy are available. Traditional accuracy-based evaluations often fail to capture behavioral differences between models, especially with limited test datasets, making it difficult to select or combine models effectively. Differential testing addresses this by generating test inputs that expose discrepancies in DNN model behavior. However, existing approaches face significant limitations: many rely on model internals or are constrained by available seed inputs. To address these challenges, we propose DiffGAN, a black-box test image generation approach for differential testing of DNN models. DiffGAN leverages a Generative Adversarial Network (GAN) and the Non-dominated Sorting Genetic Algorithm II to generate diverse and valid triggering inputs that reveal behavioral discrepancies between models. DiffGAN employs two custom fitness functions, focusing on diversity and divergence, to guide the exploration of the GAN input space and identify discrepancies between models’ outputs. By strategically searching this space, DiffGAN generates inputs with specific features that trigger differences in model behavior. DiffGAN is black-box, making it applicable in more situations. We evaluate DiffGAN on eight DNN model pairs trained on widely used image datasets. Our results show DiffGAN significantly outperforms a SOTA baseline, generating four times more triggering inputs, with greater diversity and validity, within the same budget. Additionally, the generated inputs improve the accuracy of a machine learning-based model selection mechanism, which selects the best-performing model based on input characteristics and can serve as a smart output voting mechanism when using alternative models.
深度神经网络(DNN)正在越来越广泛地应用于各种应用中。然而,确保其可靠性仍然是一个挑战,并且在许多情况下,存在具有相似功能和准确度的替代模型。传统的基于准确度的评估通常无法捕获模型之间的行为差异,特别是在有限的测试数据集下,这使得难以有效地选择或组合模型。差分测试通过生成暴露DNN模型行为差异的测试输入来解决这个问题。然而,现有方法存在重大局限性:许多方法依赖于模型内部或受可用种子输入的约束。为了解决这些挑战,我们提出了DiffGAN,这是一种用于DNN模型差分测试的黑盒测试图像生成方法。DiffGAN利用生成对抗网络(GAN)和非支配排序遗传算法II,生成多样且有效的触发输入,这些输入揭示了模型之间的行为差异。DiffGAN采用两个自定义的适应度函数,专注于多样性和发散,以指导GAN输入空间的探索,并识别模型输出之间的差异。通过有针对性地搜索这个空间,DiffGAN生成具有特定特征的输入,这些输入会触发模型行为的差异。DiffGAN是黑盒的,使其适用于更多情况。我们在广泛使用的图像数据集上评估了DiffGAN训练的八对DNN模型。结果表明,DiffGAN显著优于最新技术基线,在相同的预算内生成了四倍多的触发输入,具有更大的多样性和有效性。此外,生成的输入提高了基于机器学习模型的选型机制的准确性,该机制根据输入特性选择性能最佳的模型,并且当使用替代模型时,可以作为智能输出投票机制。
论文及项目相关链接
Summary
本文介绍了深度神经网络(DNN)在应用中部署的可靠性挑战。传统基于准确性的评估方法无法捕捉模型间的行为差异,特别是在有限的测试数据集下,使得难以有效选择或组合模型。为解决此问题,本文提出了DiffGAN方法,这是一种用于DNN模型差异测试的黑盒测试图像生成方法。DiffGAN利用生成对抗网络(GAN)和非支配排序遗传算法II生成多样且有效的触发输入,以揭示模型间的行为差异。通过两个自定义的适应度函数(多样性和发散性),DiffGAN能够指导GAN输入空间的探索并识别模型输出之间的差异。在广泛使用的图像数据集上训练的八个DNN模型对上进行的评估显示,DiffGAN显著优于最新基线技术,生成了更多触发输入,并具有更高的多样性和有效性。此外,生成的输入提高了基于机器学习模型的选型机制的准确性。该机制可根据输入特性选择性能最佳的模型,在使用替代模型时可作为智能输出投票机制。
Key Takeaways
- DNN的可靠性是其部署中的一大挑战,尤其在有限的测试数据集下难以有效选择或组合模型。
- 传统基于准确性的评估方法无法捕捉模型间的行为差异。
- DiffGAN是一种黑盒测试图像生成方法,用于DNN模型的差异测试。
- DiffGAN利用GAN和NSGA-II生成多样且有效的触发输入。
- DiffGAN使用两个自定义适应度函数来指导GAN输入空间的探索并识别模型间的行为差异。
- 与最新基线技术相比,DiffGAN能生成更多触发输入,且具有较高的多样性和有效性。
点此查看论文截图