⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
GanitBench: A bi-lingual benchmark for evaluating mathematical reasoning in Vision Language Models
Authors:Ashutosh Bandooni, Brindha Subburaj
Benchmarks for evaluating reasoning among Vision Language Models (VLMs) on several fields and domains are being curated more frequently over the last few years. However these are often monolingual, mostly available in English. Additionally there also is a lack of datasets available in Hindi on tasks apart from comprehension and translation. We introduce GanitBench, a tough benchmark consisting of 1527 vision-only questions covering several topics in Mathematics - available in languages English and Hindi. Collected from two major examinations from India, the JEE Advanced and the CBSE Boards examinations, this benchmark includes questions in the form of images comprising of figures essential to a question as well as text. We evaluate two closed source models for the same, in zero-shot Chain-of-Thought (CoT) and two-shot CoT settings. GPT-4o mini is found to be the more dominant model on the benchmark, with it’s highest average accuracy being 38.15%. We also evaluate models through a “Double Lock” constraint, which brings down the performance of the models by considerable margins. We observe that two-shot CoT appears to be a more effective setting under this environment. Performance of the two VLMs also decreases when answering the same questions in the Hindi language. We hope to facilitate the inclusion of languages like Hindi in research through our work.
在过去的几年里,针对多个领域和领域的视觉语言模型(VLMs)推理能力的基准测试越来越频繁地被编纂。然而,这些基准测试通常是单语的,大部分以英语为主。此外,除了理解和翻译任务外,印度语的数据集也缺乏其他任务的数据集。我们推出了GanitBench,这是一个由1527个仅涉及视觉的问题组成的严格基准测试,涵盖了数学中的多个主题,提供英语和印地语两种语言。这些问题来自印度的两大考试——印度工程入学考试高级考试和中央教育局董事会考试,包括图像形式的问题,其中包含问题所必需的基本图形和文本。我们对两款闭源模型进行了评估,分别在零次拍摄的思考链(CoT)和两次拍摄CoT设置中进行评估。GPT-4o mini在基准测试中表现更占优势,其最高平均准确率为38.15%。我们还通过“双重锁定”约束对模型进行了评估,这一约束大大降低了模型的性能。我们发现在这种环境下,两次拍摄CoT似乎是一个更有效的设置。当用印地语回答同样的问题时,这两个VLM的性能也下降了。我们希望通过我们的工作促进像印地语这样的语言纳入研究中。
论文及项目相关链接
PDF 6 pages, 3 figures. Accepted, Presented and Published as part of Proceedings of the 6th International Conference on Recent Advantages in Information Technology (RAIT) 2025
Summary:近期出现了更多针对视觉语言模型(VLMs)的基准测试,这些测试主要关注于多个领域和学科的评价标准。然而,现有的基准测试多为英文且偏向单一语言领域。此外,除理解和翻译任务外,印度语(如印地语)的数据集相对缺乏。本研究介绍了GanitBench基准测试,它包含覆盖多个数学主题的视觉问题共1527个,问题以图像和文本形式呈现。测试从印度的两个主要考试JEE Advanced和CBSE Boards中收集问题。在零次链思维(CoT)和两次链思维(CoT)设置中评估了两个闭源模型。GPT-4o mini在基准测试中表现更出色,最高平均准确度为38.15%。同时,通过“双重锁定”约束评估模型性能,发现两链思维在这种环境下表现更好。在印地语回答同样问题时,两个VLM的性能有所下降。希望通过这项工作促进印地语等语言的研究发展。
Key Takeaways:
- 视觉语言模型(VLMs)评估基准测试正日益频繁地出现,涵盖多个领域和学科。
- 目前存在的基准测试大多以英文为主,缺乏印度语等非西方语言的资源。
- GanitBench基准测试涵盖了英语和印地语的数学相关问题共1527个。
- 评估了两个闭源模型在零次链思维(CoT)和两次链思维(CoT)设置中的表现。
- GPT-4o mini在基准测试中表现最佳,最高平均准确度为38.15%。
- “双重锁定”约束下,两链思维设置表现更佳。
点此查看论文截图


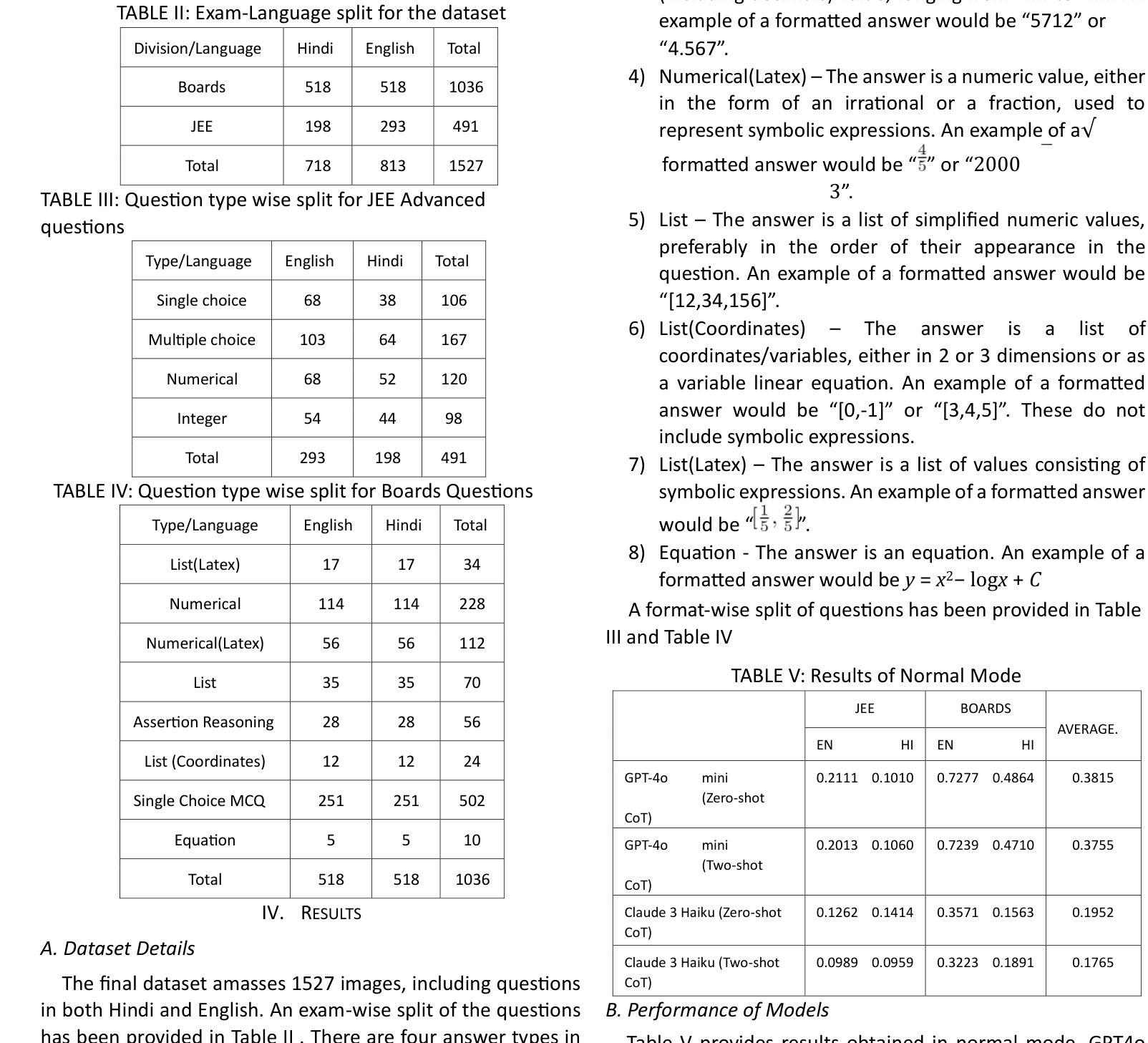
FPG-NAS: FLOPs-Aware Gated Differentiable Neural Architecture Search for Efficient 6DoF Pose Estimation
Authors:Nassim Ali Ousalah, Peyman Rostami, Anis Kacem, Enjie Ghorbel, Emmanuel Koumandakis, Djamila Aouada
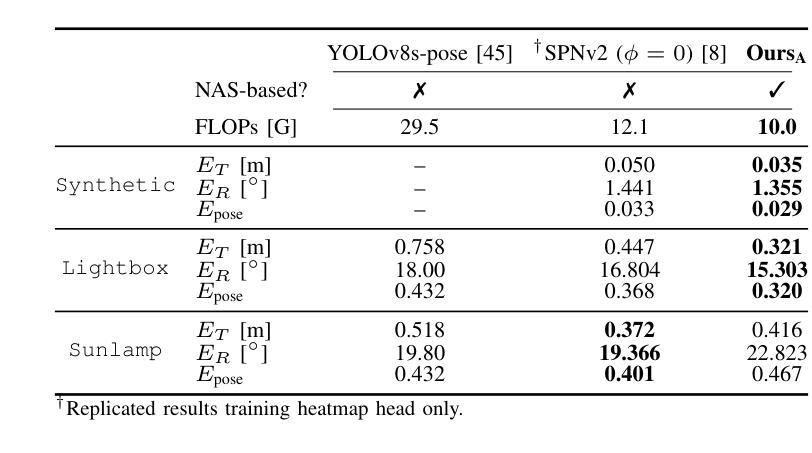
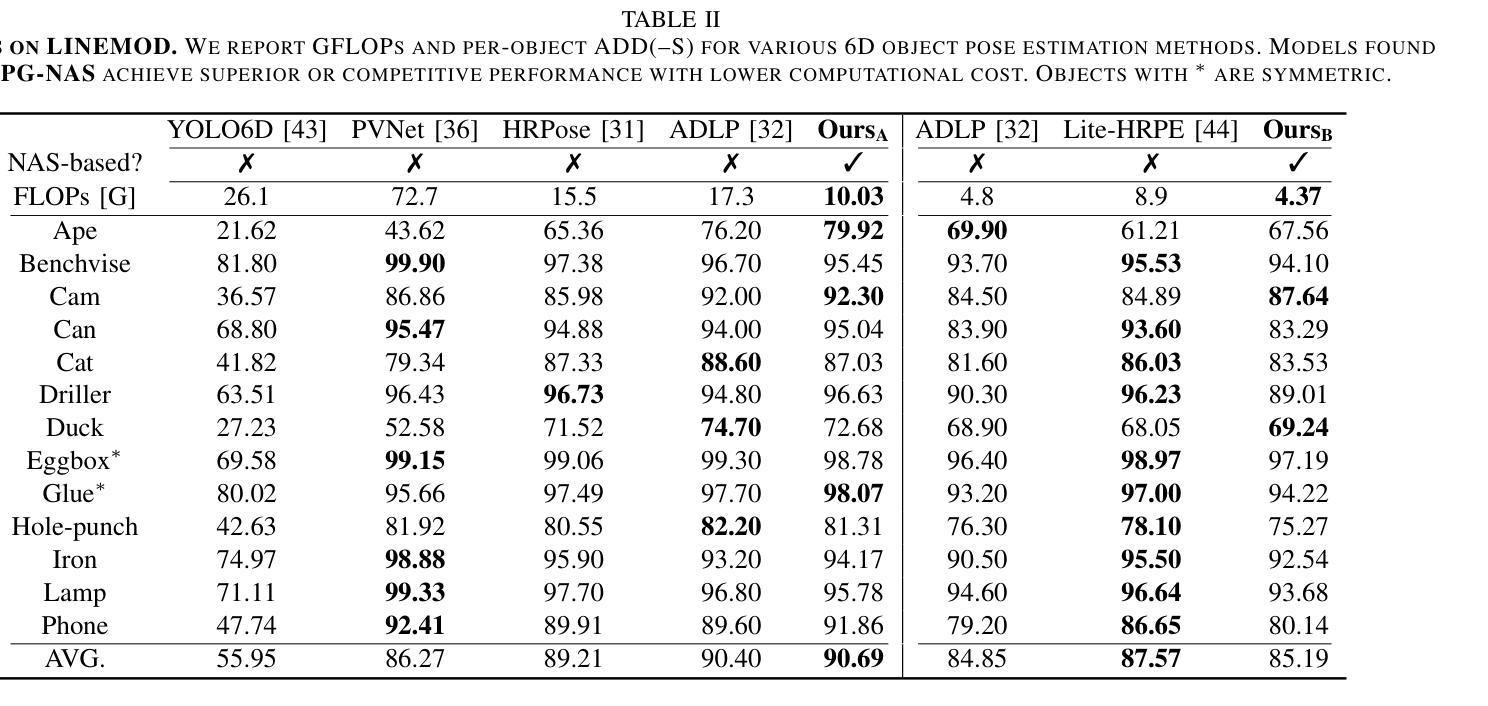
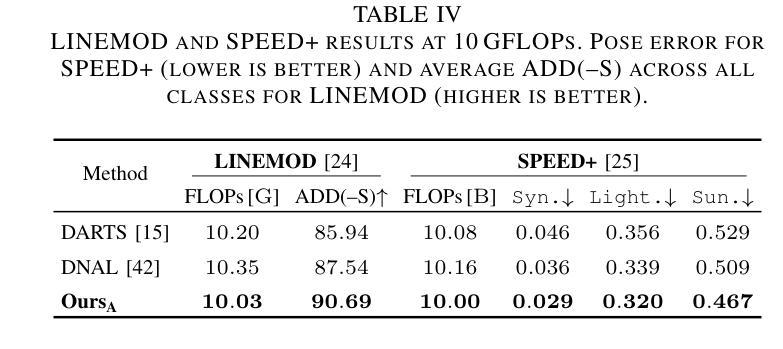
We introduce FPG-NAS, a FLOPs-aware Gated Differentiable Neural Architecture Search framework for efficient 6DoF object pose estimation. Estimating 3D rotation and translation from a single image has been widely investigated yet remains computationally demanding, limiting applicability in resource-constrained scenarios. FPG-NAS addresses this by proposing a specialized differentiable NAS approach for 6DoF pose estimation, featuring a task-specific search space and a differentiable gating mechanism that enables discrete multi-candidate operator selection, thus improving architectural diversity. Additionally, a FLOPs regularization term ensures a balanced trade-off between accuracy and efficiency. The framework explores a vast search space of approximately 10\textsuperscript{92} possible architectures. Experiments on the LINEMOD and SPEED+ datasets demonstrate that FPG-NAS-derived models outperform previous methods under strict FLOPs constraints. To the best of our knowledge, FPG-NAS is the first differentiable NAS framework specifically designed for 6DoF object pose estimation.
我们介绍了FPG-NAS,这是一个面向高效6DoF目标姿态估计的FLOPs感知门控可微神经网络架构搜索框架。从单幅图像估计三维旋转和平移已经被广泛研究,但仍需要大量的计算资源,这在资源受限的场景中应用有限。FPG-NAS通过提出一种针对6DoF姿态估计的专门可微分NAS方法来解决这个问题,该方法具有任务特定的搜索空间和可微分门控机制,能够实现对多个候选操作器的离散选择,从而提高架构的多样性。此外,FLOPs正则化项确保了准确性和效率之间的平衡。该框架探索了大约10\textsuperscript{92}种可能的架构的巨大搜索空间。在LINEMOD和SPEED+数据集上的实验表明,在严格的FLOPs约束下,FPG-NAS衍生的模型性能优于以前的方法。据我们所知,FPG-NAS是专门为6DoF目标姿态估计设计的首个可微分NAS框架。
论文及项目相关链接
PDF Accepted to the 27th IEEE International Workshop on Multimedia Signal Processing (MMSP) 2025
Summary
FPG-NAS是一种面向高效6DoF物体姿态估计的FLOPs感知门控可微神经网络架构搜索框架。它通过提出一种专门针对6DoF姿态估计的可微NAS方法,解决了从单幅图像估计3D旋转和平移的计算需求大的问题。FPG-NAS具有任务特定的搜索空间和可微的门控机制,可实现离散的多候选操作符选择,从而提高架构的多样性。此外,FLOPs正则化项确保了准确性与效率之间的平衡。在LINEMOD和SPEED+数据集上的实验表明,FPG-NAS衍生的模型在严格的FLOPs约束下优于以前的方法。FPG-NAS是首个专门为6DoF物体姿态估计设计的可微NAS框架。
Key Takeaways
- FPG-NAS是一个面向高效6DoF物体姿态估计的神经网络架构搜索框架。
- 它提出了一种任务特定的搜索空间,针对6DoF姿态估计的需求进行优化。
- FPG-NAS采用可微的门控机制,能够实现离散的多候选操作符选择,提高架构的多样性。
- 框架中引入了FLOPs正则化项,以平衡准确性与效率。
- FPG-NAS能在庞大的搜索空间中探索约10\textsuperscript{92}种可能的架构。
- 在LINEMOD和SPEED+数据集上的实验表明,FPG-NAS衍生的模型在严格约束下表现优异。
- FPG-NAS是首个专门为6DoF物体姿态估计设计的可微神经网络架构搜索框架。
点此查看论文截图

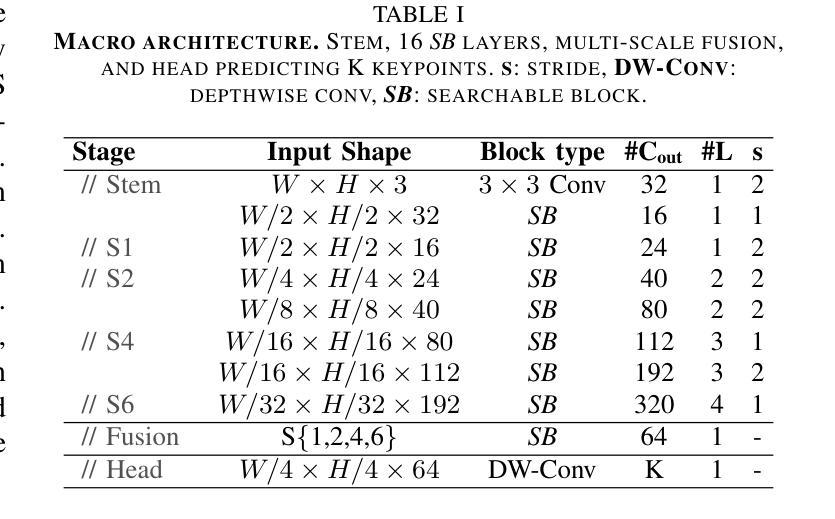
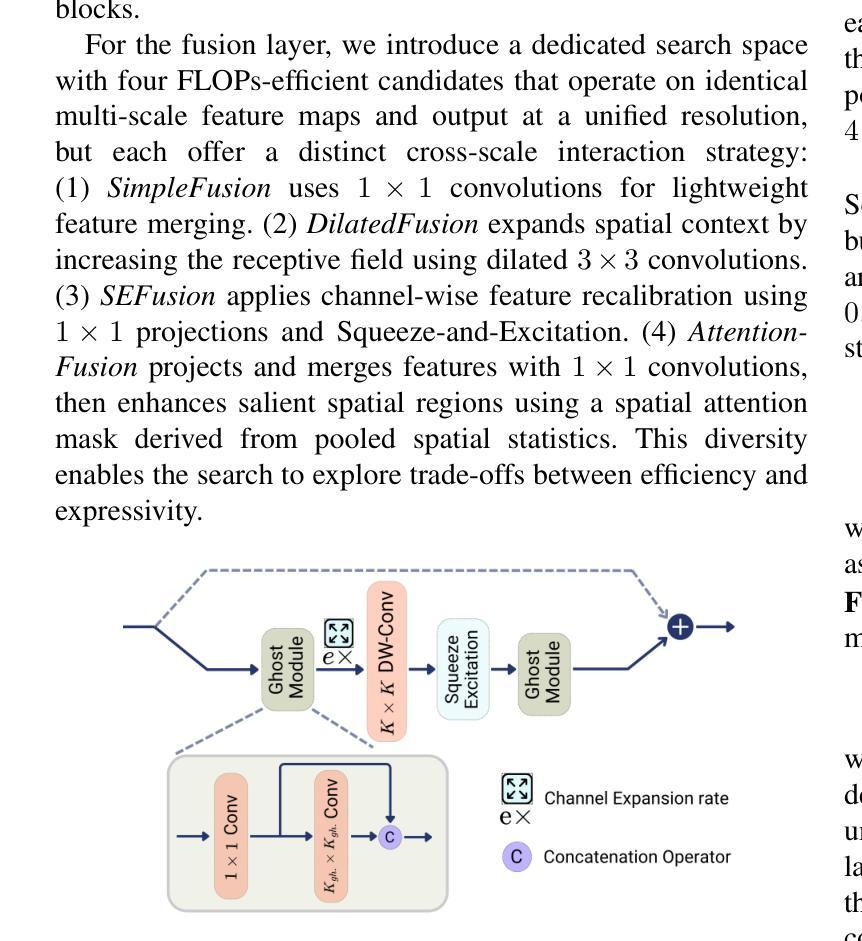
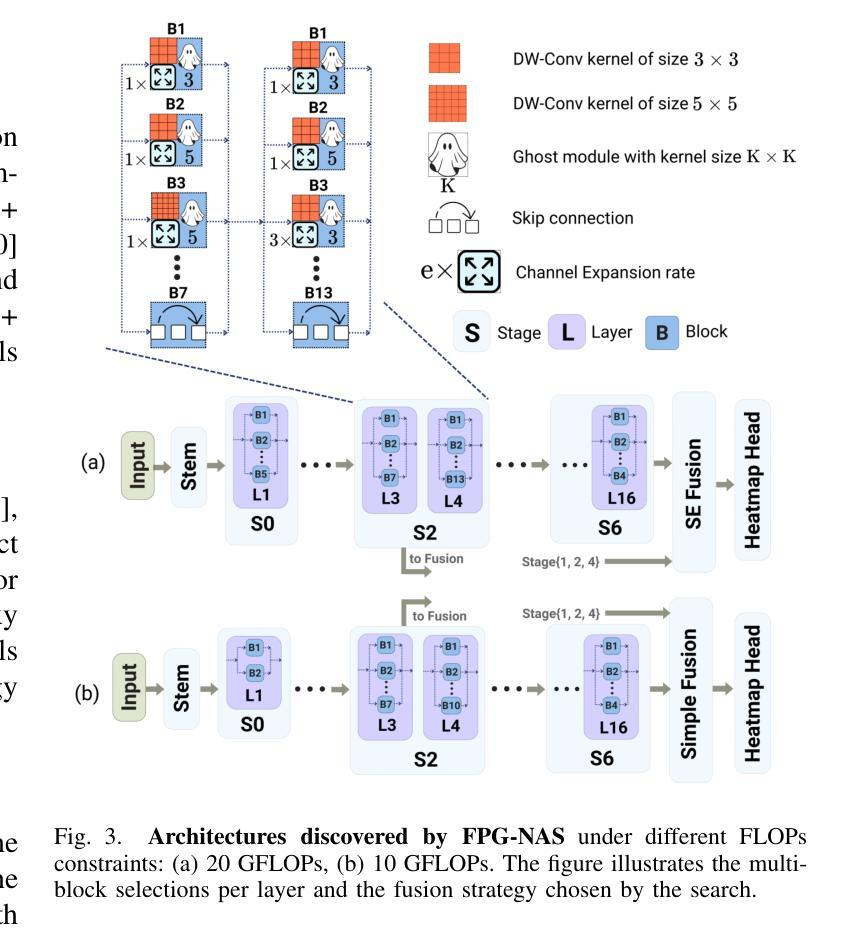
Learning Latent Representations for Image Translation using Frequency Distributed CycleGAN
Authors:Shivangi Nigam, Adarsh Prasad Behera, Shekhar Verma, P. Nagabhushan
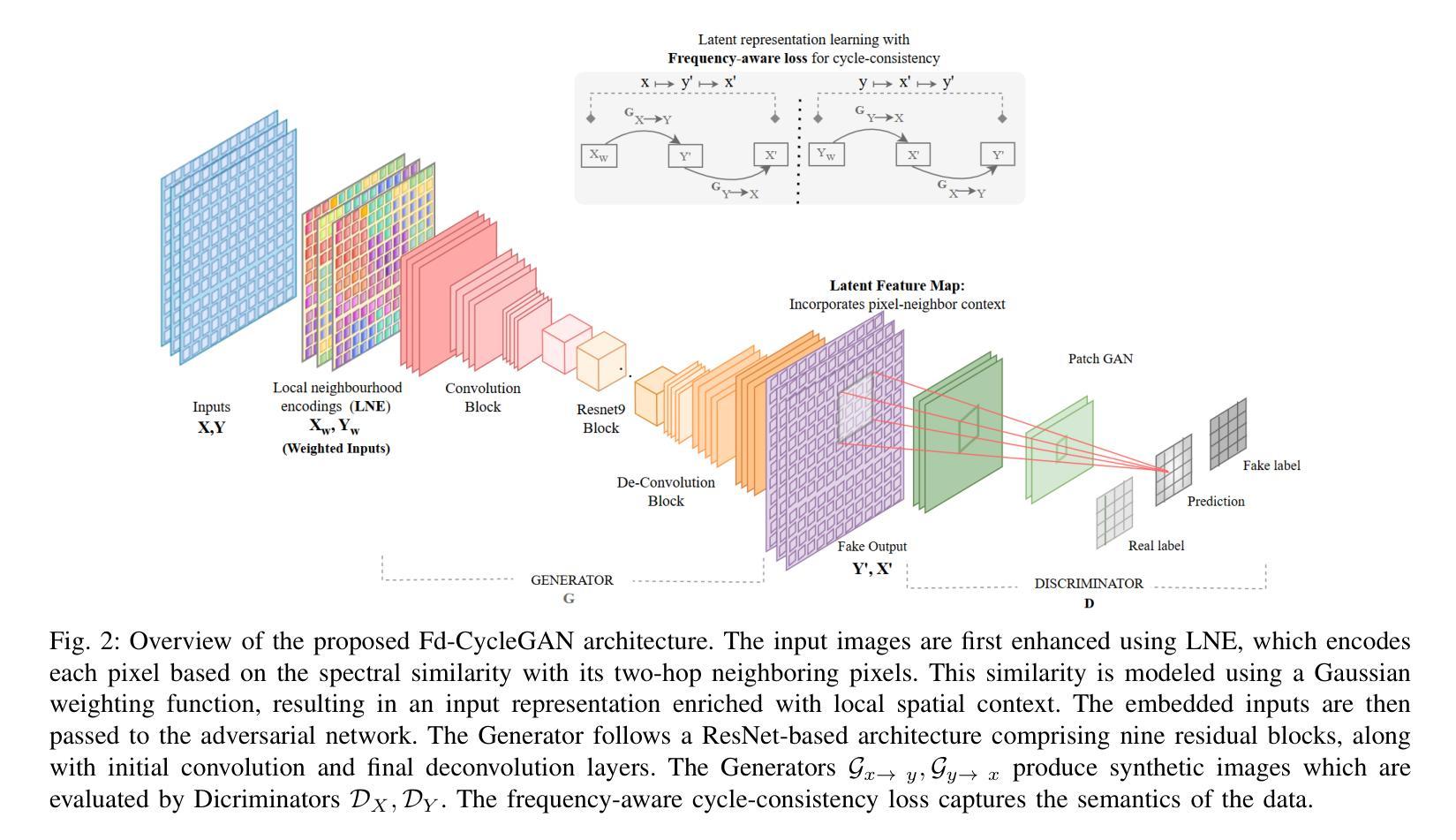
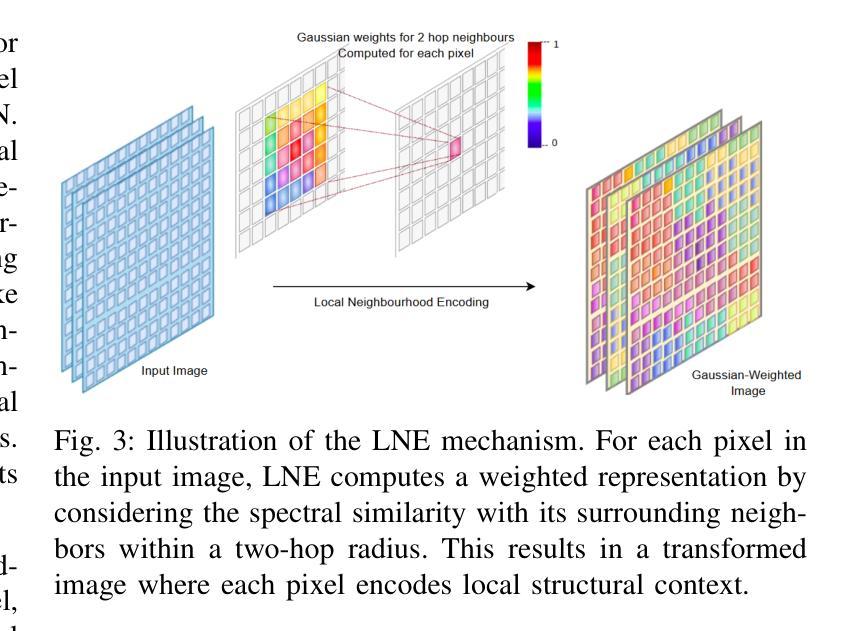
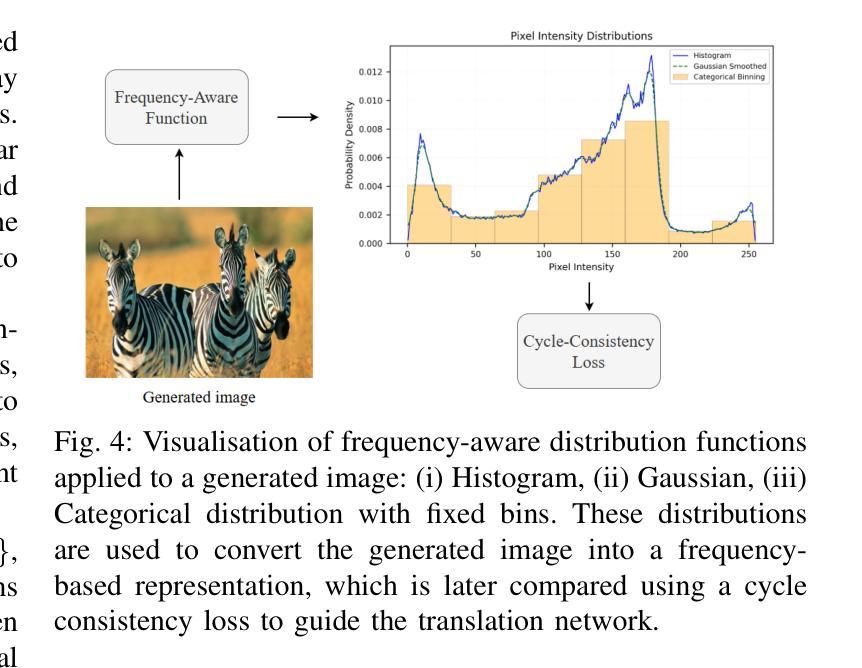
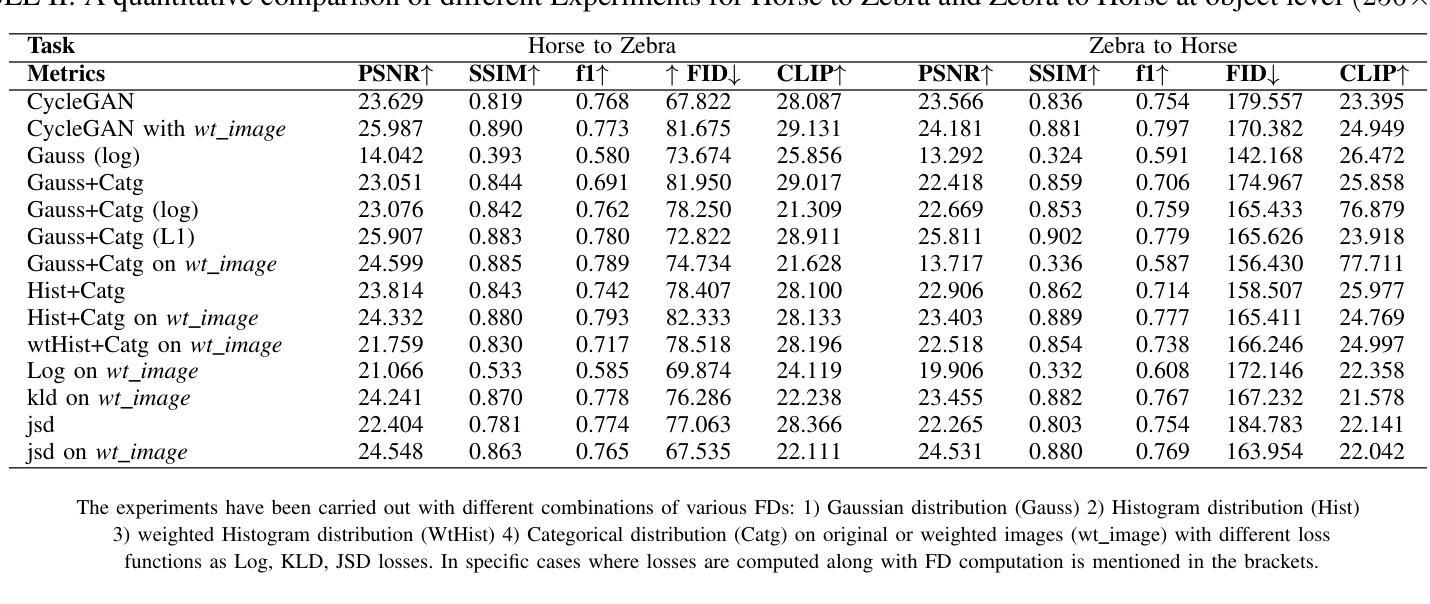
This paper presents Fd-CycleGAN, an image-to-image (I2I) translation framework that enhances latent representation learning to approximate real data distributions. Building upon the foundation of CycleGAN, our approach integrates Local Neighborhood Encoding (LNE) and frequency-aware supervision to capture fine-grained local pixel semantics while preserving structural coherence from the source domain. We employ distribution-based loss metrics, including KL/JS divergence and log-based similarity measures, to explicitly quantify the alignment between real and generated image distributions in both spatial and frequency domains. To validate the efficacy of Fd-CycleGAN, we conduct experiments on diverse datasets – Horse2Zebra, Monet2Photo, and a synthetically augmented Strike-off dataset. Compared to baseline CycleGAN and other state-of-the-art methods, our approach demonstrates superior perceptual quality, faster convergence, and improved mode diversity, particularly in low-data regimes. By effectively capturing local and global distribution characteristics, Fd-CycleGAN achieves more visually coherent and semantically consistent translations. Our results suggest that frequency-guided latent learning significantly improves generalization in image translation tasks, with promising applications in document restoration, artistic style transfer, and medical image synthesis. We also provide comparative insights with diffusion-based generative models, highlighting the advantages of our lightweight adversarial approach in terms of training efficiency and qualitative output.
本文介绍了Fd-CycleGAN,这是一个图像到图像(I2I)翻译框架,它增强了潜在表示学习,以逼近真实数据分布。我们的方法建立在CycleGAN的基础上,融合了局部邻域编码(LNE)和频率感知监督,旨在捕获精细的局部像素语义,同时保持源域的结构连贯性。我们采用基于分布的损失指标,包括KL/JS散度和对数相似度度量,以明确量化真实和生成图像分布在空间域和频率域之间的对齐程度。为了验证Fd-CycleGAN的有效性,我们在多样化的数据集上进行了实验,包括Horse2Zebra、Monet2Photo和合成增强的Strike-off数据集。与基准的CycleGAN和其他先进的方法相比,我们的方法在感知质量、收敛速度和数据模式多样性方面表现出优越性,特别是在低数据情况下。通过有效地捕捉局部和全局分布特征,Fd-CycleGAN实现了视觉上更连贯和语义上更一致的翻译。我们的结果表明,频率引导潜在学习在图像翻译任务中显著提高了泛化能力,并在文档恢复、艺术风格转换和医学图像合成等领域具有广阔的应用前景。此外,我们还提供了与基于扩散的生成模型的比较洞察,突出了我们在训练效率和定性输出方面的轻型对抗性方法的优势。
论文及项目相关链接
PDF This paper is currently under review for publication in an IEEE Transactions. If accepted, the copyright will be transferred to IEEE
Summary
本文提出Fd-CycleGAN框架,一个图像到图像的翻译框架,基于CycleGAN的基础上,引入了局部邻域编码和频率感知监督,旨在提高潜在表示学习以逼近真实数据分布。该框架在多种数据集上进行实验验证,展现出较高的感知质量、更快的收敛速度和较好的模式多样性,尤其在低数据情况下表现优异。Fd-CycleGAN能有效捕捉局部和全局分布特征,实现更视觉连贯和语义一致的翻译,并在文档恢复、艺术风格转换和医学图像合成等领域有广泛应用前景。此外,本文还提供了与基于扩散的生成模型的比较洞察,突显了在对抗性方法中的训练效率和定性输出方面的优势。
Key Takeaways
- Fd-CycleGAN是一个基于CycleGAN的图像到图像翻译框架。
- 引入Local Neighborhood Encoding (LNE)和频率感知监督来增强潜在表示学习。
- 使用分布损失度量来衡量真实和生成图像分布之间的对齐情况。
- 在多个数据集上进行实验验证,表现出较高的感知质量、更快的收敛速度和更好的模式多样性。
- Fd-CycleGAN能捕捉局部和全局分布特征,实现更连贯和语义一致的翻译。
- 适用于文档恢复、艺术风格转换和医学图像合成等领域。
点此查看论文截图

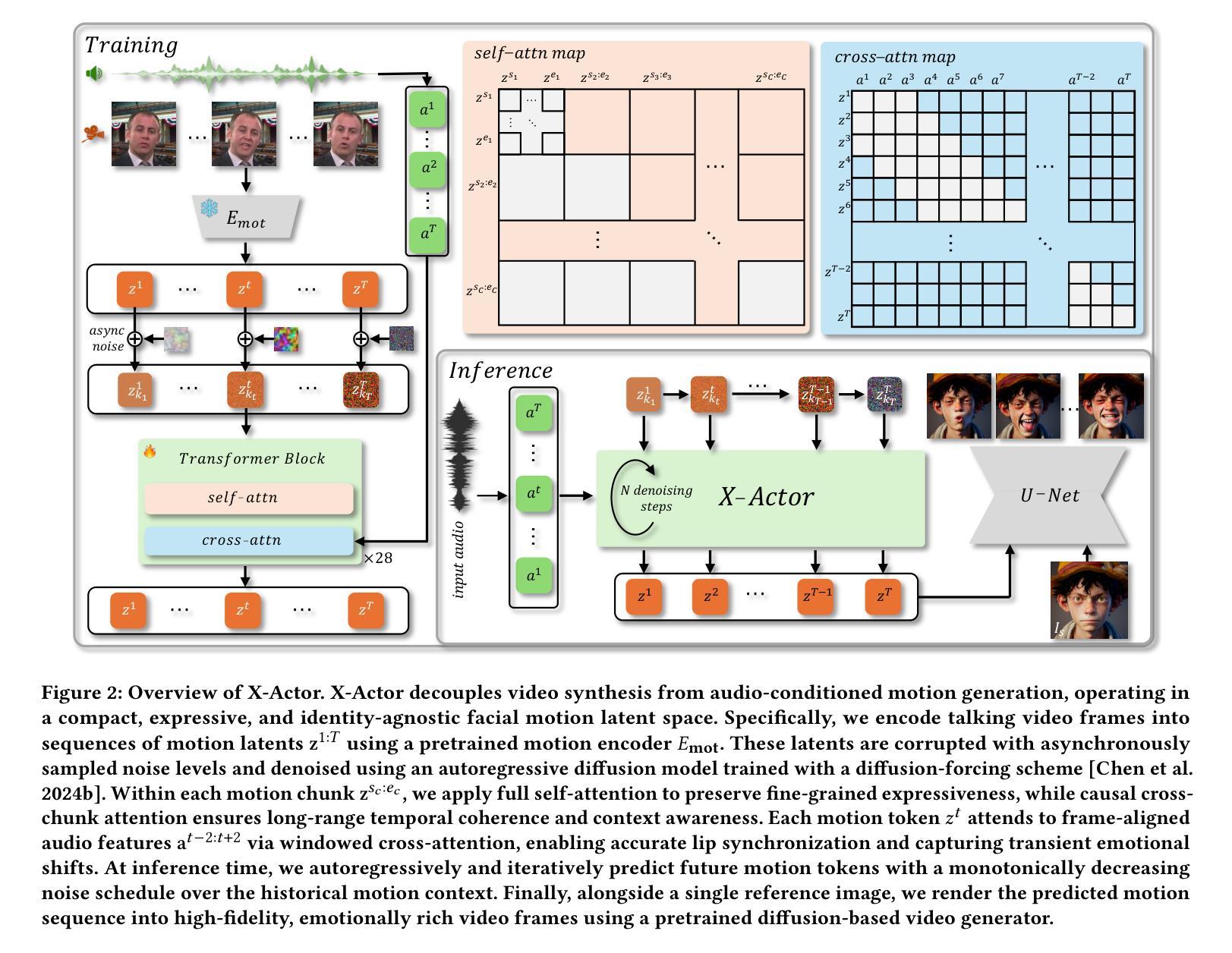
X-Actor: Emotional and Expressive Long-Range Portrait Acting from Audio
Authors:Chenxu Zhang, Zenan Li, Hongyi Xu, You Xie, Xiaochen Zhao, Tianpei Gu, Guoxian Song, Xin Chen, Chao Liang, Jianwen Jiang, Linjie Luo
We present X-Actor, a novel audio-driven portrait animation framework that generates lifelike, emotionally expressive talking head videos from a single reference image and an input audio clip. Unlike prior methods that emphasize lip synchronization and short-range visual fidelity in constrained speaking scenarios, X-Actor enables actor-quality, long-form portrait performance capturing nuanced, dynamically evolving emotions that flow coherently with the rhythm and content of speech. Central to our approach is a two-stage decoupled generation pipeline: an audio-conditioned autoregressive diffusion model that predicts expressive yet identity-agnostic facial motion latent tokens within a long temporal context window, followed by a diffusion-based video synthesis module that translates these motions into high-fidelity video animations. By operating in a compact facial motion latent space decoupled from visual and identity cues, our autoregressive diffusion model effectively captures long-range correlations between audio and facial dynamics through a diffusion-forcing training paradigm, enabling infinite-length emotionally-rich motion prediction without error accumulation. Extensive experiments demonstrate that X-Actor produces compelling, cinematic-style performances that go beyond standard talking head animations and achieves state-of-the-art results in long-range, audio-driven emotional portrait acting.
我们提出了X-Actor,这是一种新型音频驱动肖像动画框架,它能够从单张参考图像和输入音频片段生成逼真、富有情感表达能力的说话人头视频。不同于以往强调唇同步和有限说话场景下的短期视觉保真度的方法,X-Actor能够实现演员级别的、长篇肖像表演,捕捉微妙、动态变化的情感,这些情感与语音的节奏和内容流畅地结合在一起。我们的方法的核心是一个两阶段的解耦生成管道:一个受音频调节的自回归扩散模型,该模型在长时间上下文窗口中预测表情丰富但身份无关的面部运动潜在令牌,紧接着是一个基于扩散的视频合成模块,将这些运动转化为高保真视频动画。我们的自回归扩散模型在脱离视觉和身份线索的紧凑面部运动潜在空间中进行操作,通过扩散强制训练范式有效地捕捉了音频和面部动态之间的长期关联,实现了无限长度的丰富情感运动预测,而不会导致误差累积。大量实验表明,X-Actor产生的表演令人信服,具有电影级的表演水平,超越了标准的说话人头动画,并在长程、音频驱动的情感肖像表演方面达到了最新技术水平。
论文及项目相关链接
PDF Project Page at https://byteaigc.github.io/X-Actor/
Summary
X-Actor是一个新颖的音频驱动肖像动画框架,它可以从单张参考图像和输入音频片段生成生动、情绪化的说话人头视频。不同于以往强调唇同步和短期视觉保真度的方法,X-Actor能够实现演员级别的长期肖像表现,捕捉与语音节奏和内容流畅相关的微妙、动态变化的情绪。其核心是一个两阶段的解耦生成管道:一个音频条件下的自回归扩散模型,在一个长期时间窗口内预测表情丰富但身份无关的面部运动潜在令牌,接着是一个基于扩散的视频合成模块,将这些运动转化为高保真视频动画。通过操作与视觉和身份线索解耦的紧凑面部运动潜在空间,我们的自回归扩散模型有效地捕获了音频和面部动态之间的长期相关性,实现了无误差累积的丰富情感运动预测。广泛的实验表明,X-Actor产生的结果令人信服,电影式的表现超越了标准的说话人头动画,并在长期音频驱动的肖像表演中实现了最佳效果。
Key Takeaways
- X-Actor是一个新颖的音频驱动肖像动画框架,可从单张参考图像和音频片段生成生动、情绪化的说话人头视频。
- 不同于以往方法,X-Actor强调长期肖像表现,捕捉与语音内容和节奏相关的微妙情绪变化。
- X-Actor采用两阶段解耦生成管道:预测面部运动潜在令牌和基于扩散的视频合成。
- 自回归扩散模型有效捕获音频和面部动态之间的长期相关性。
- X-Actor实现了丰富的情感运动预测,无误差累积。
- X-Actor产生的动画结果令人信服,具有电影式的表现力。
点此查看论文截图