⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
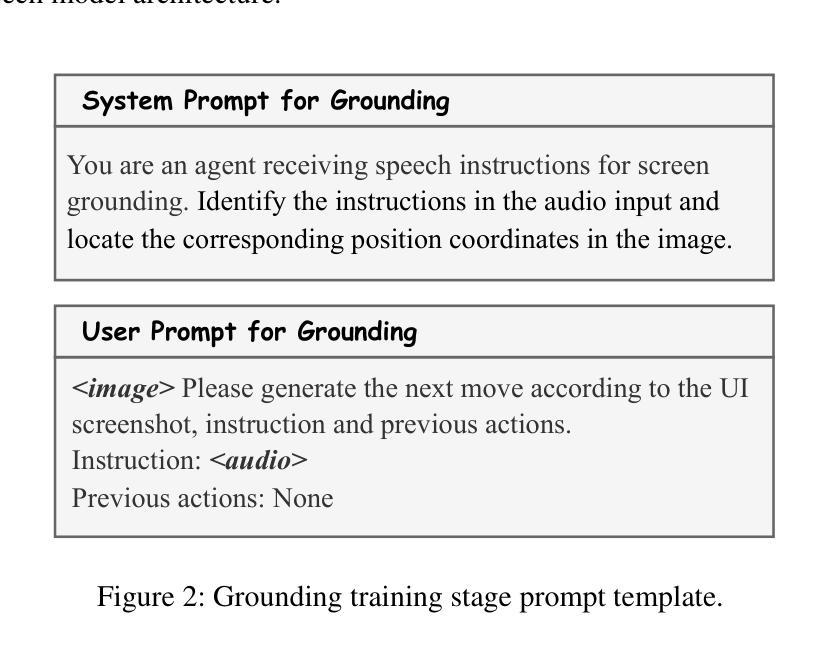
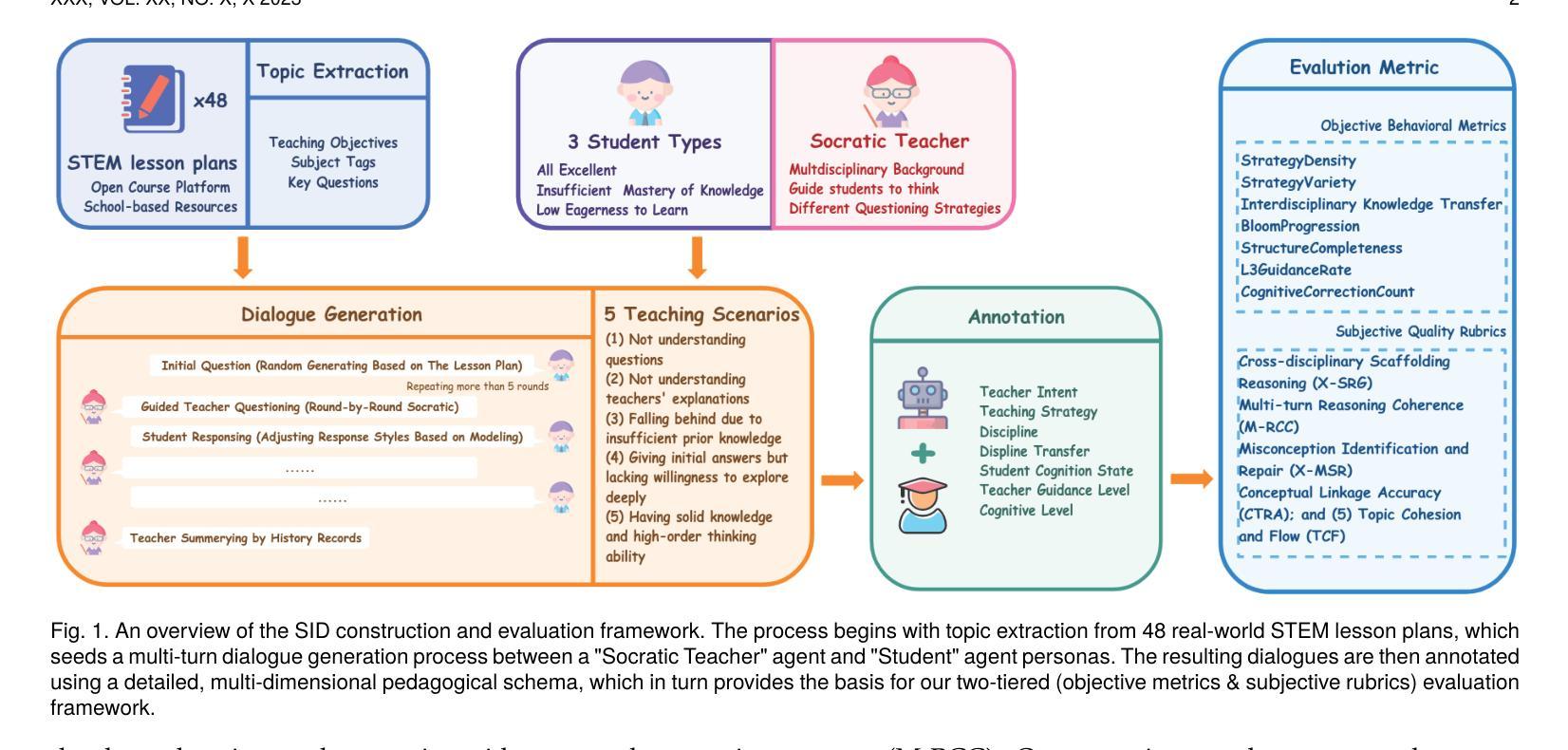
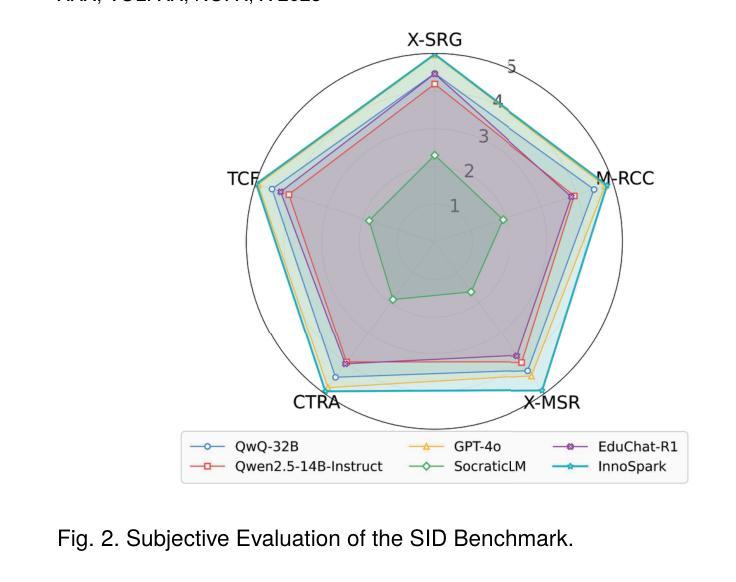
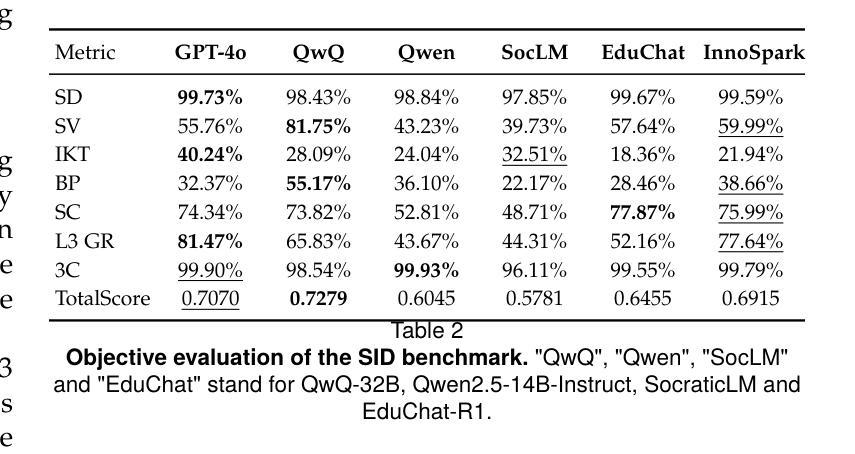
SID: Benchmarking Guided Instruction Capabilities in STEM Education with a Socratic Interdisciplinary Dialogues Dataset
Authors:Mei Jiang, Houping Yue, Bingdong Li, Hao Hao, Ying Qian, Bo Jiang, Aimin Zhou
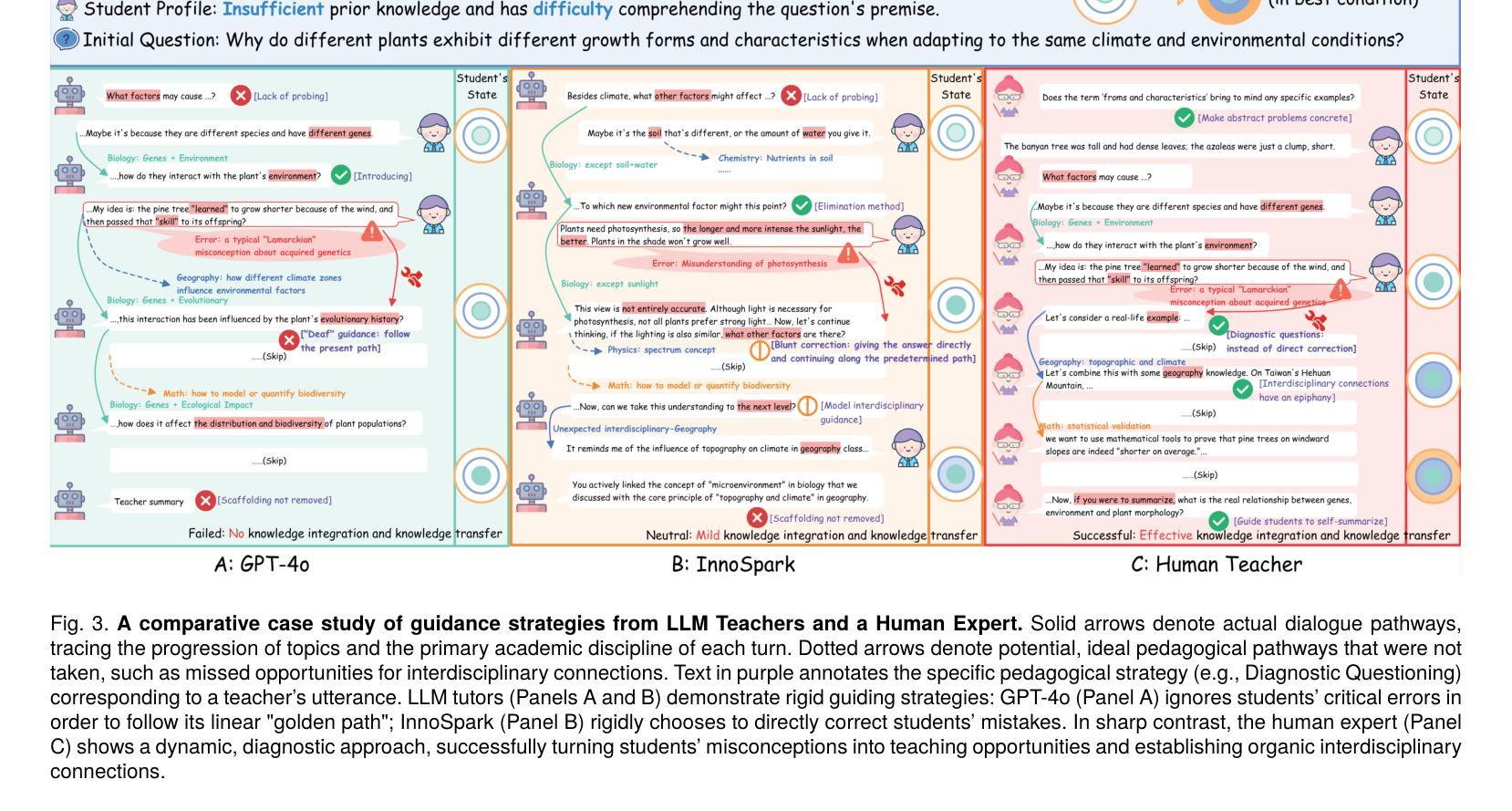
Fostering students’ abilities for knowledge integration and transfer in complex problem-solving scenarios is a core objective of modern education, and interdisciplinary STEM is a key pathway to achieve this, yet it requires expert guidance that is difficult to scale. While LLMs offer potential in this regard, their true capability for guided instruction remains unclear due to the lack of an effective evaluation benchmark. To address this, we introduce SID, the first benchmark designed to systematically evaluate the higher-order guidance capabilities of LLMs in multi-turn, interdisciplinary Socratic dialogues. Our contributions include a large-scale dataset of 10,000 dialogue turns across 48 complex STEM projects, a novel annotation schema for capturing deep pedagogical features, and a new suite of evaluation metrics (e.g., X-SRG). Baseline experiments confirm that even state-of-the-art LLMs struggle to execute effective guided dialogues that lead students to achieve knowledge integration and transfer. This highlights the critical value of our benchmark in driving the development of more pedagogically-aware LLMs.
培养学生解决复杂问题时整合和转移知识的能力是现代教育的核心目标,而跨学科STEM教育是实现这一目标的关键途径。然而,这需要专业的指导,很难扩大规模。虽然大型语言模型在这方面具有潜力,但由于缺乏有效的评估基准,它们在指导方面的真正能力尚不清楚。为了解决这一问题,我们引入了SID,这是第一个旨在系统评估大型语言模型在多轮跨学科苏格拉底对话中的高级指导能力的基准。我们的贡献包括涵盖48个复杂STEM项目的10000个对话回合的大规模数据集、用于捕获深层教学特征的新型注释模式以及一套新的评估指标(例如X-SRG)。基线实验证实,即使是最新技术的大型语言模型也很难进行有效的指导对话,使学生在知识整合和转移方面取得进展。这凸显了我们的基准在推动更具教学意识的大型语言模型发展中的关键价值。
论文及项目相关链接
PDF 26 pages, 20 figures
Summary
现代教育的一个核心目标是培养学生在复杂问题解决场景中整合和应用知识的能力,跨学科STEM教育是实现这一目标的关键路径,但通常需要专家指导,难以普及。大型语言模型(LLMs)在这方面具有潜力,但其指导能力尚未得到有效的评估基准来衡量。我们推出了SID,首个系统评估大型语言模型在多轮跨学科苏格拉底对话中的高阶指导能力的基准测试。我们的贡献包括涵盖48个复杂STEM项目的10,000轮对话的大规模数据集、用于捕捉深层教学特征的全新注释模式以及新的评估指标套件(例如X-SRG)。基线实验证实,即使是最新的大型语言模型也很难进行有效的指导对话,使学生实现知识的整合和迁移。这凸显了我们基准测试在推动开发更具教学意识的大型语言模型中的关键作用。
Key Takeaways
- 现代教育的核心目标是培养学生在复杂问题解决场景中整合和应用知识的能力。
- 跨学科STEM教育是达成这一目标的关键路径,但需要专家指导,难以实现规模化。
- 大型语言模型(LLMs)在指导方面具潜力,但缺乏有效评估基准来衡量其指导能力。
- 推出了SID基准测试,旨在系统评估LLMs在多轮跨学科苏格拉底对话中的高阶指导能力。
- SID基准测试包括大规模数据集、全新注释模式和评估指标套件。
- 基线实验表明,现有大型语言模型在有效指导对话方面存在挑战。
点此查看论文截图

Listening to the Unspoken: Exploring “365” Aspects of Multimodal Interview Performance Assessment
Authors:Jia Li, Yang Wang, Wenhao Qian, Jialong Hu, Zhenzhen Hu, Richang Hong, Meng Wang
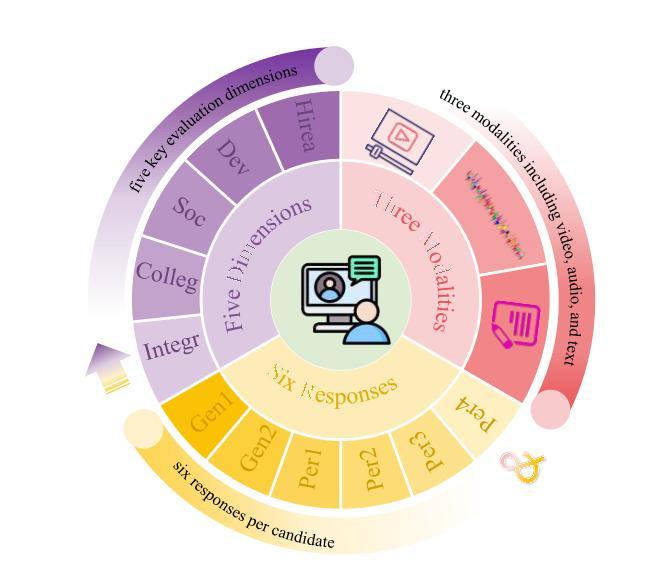
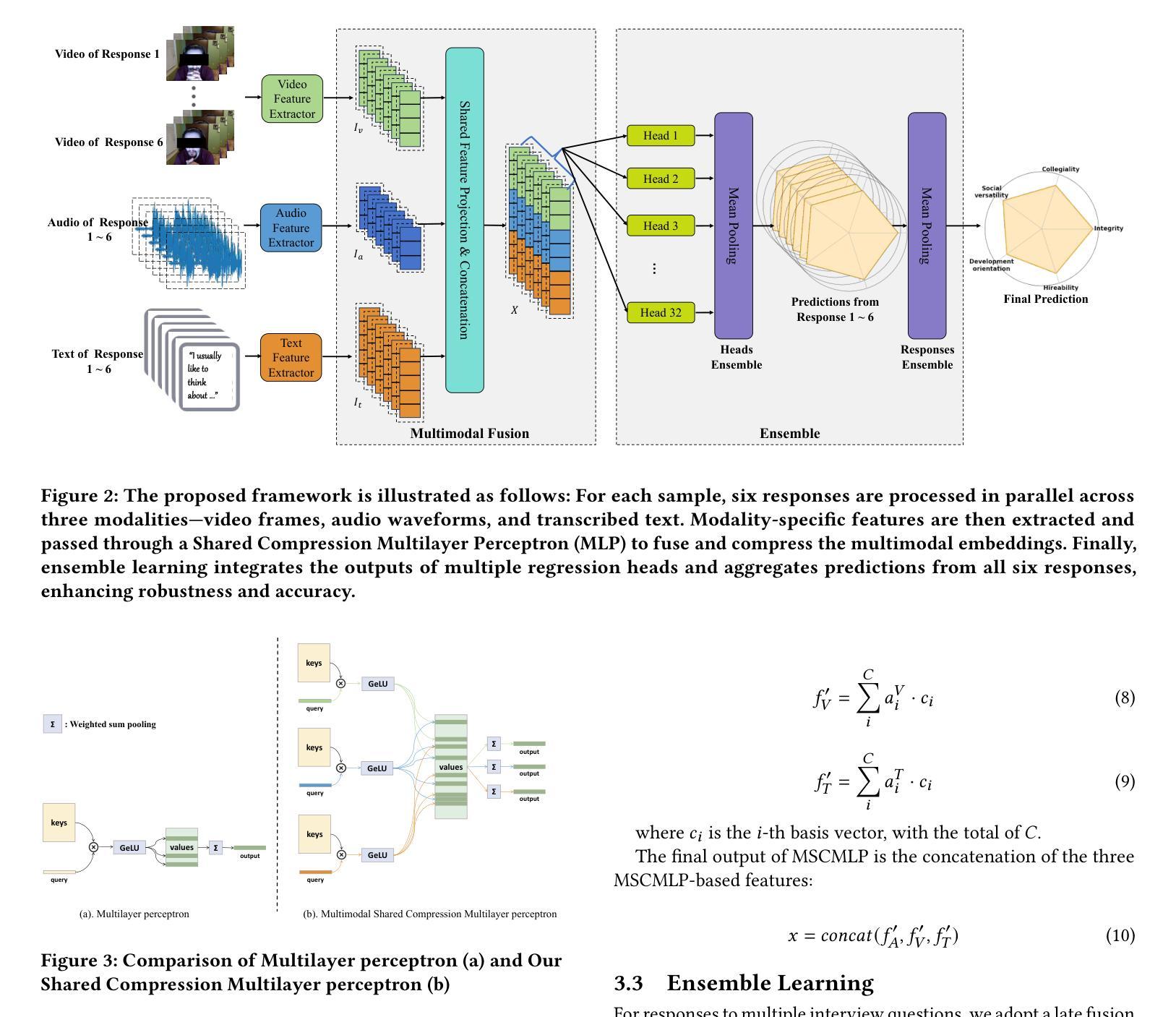
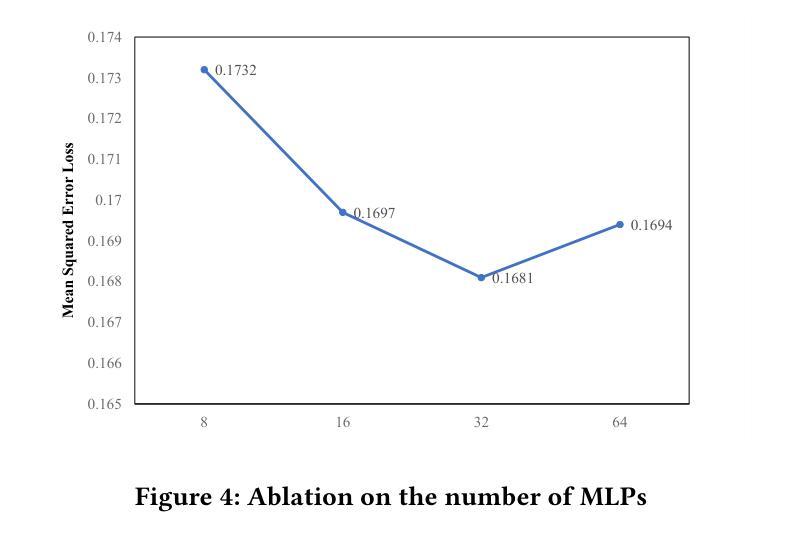
Interview performance assessment is essential for determining candidates’ suitability for professional positions. To ensure holistic and fair evaluations, we propose a novel and comprehensive framework that explores ``365’’ aspects of interview performance by integrating \textit{three} modalities (video, audio, and text), \textit{six} responses per candidate, and \textit{five} key evaluation dimensions. The framework employs modality-specific feature extractors to encode heterogeneous data streams and subsequently fused via a Shared Compression Multilayer Perceptron. This module compresses multimodal embeddings into a unified latent space, facilitating efficient feature interaction. To enhance prediction robustness, we incorporate a two-level ensemble learning strategy: (1) independent regression heads predict scores for each response, and (2) predictions are aggregated across responses using a mean-pooling mechanism to produce final scores for the five target dimensions. By listening to the unspoken, our approach captures both explicit and implicit cues from multimodal data, enabling comprehensive and unbiased assessments. Achieving a multi-dimensional average MSE of 0.1824, our framework secured first place in the AVI Challenge 2025, demonstrating its effectiveness and robustness in advancing automated and multimodal interview performance assessment. The full implementation is available at https://github.com/MSA-LMC/365Aspects.
面试绩效评估对于确定候选人是否适合专业职位至关重要。为了确保全面公平的评估,我们提出了一种新型的综合框架,通过整合视频、音频和文本三种模式,候选人的六种回应以及五个关键评价维度,探索面试表现的“365”方面。该框架使用特定于模态的特征提取器来编码异质数据流,然后通过共享压缩多层感知器进行融合。该模块将多模态嵌入压缩到统一的潜在空间,促进特征的有效交互。为了提高预测的稳健性,我们采用了两级集成学习策略:(1)独立回归头为每个响应预测分数;(2)使用平均池化机制对响应的预测进行汇总,以产生五个目标维度的最终分数。通过倾听无声之言,我们的方法能够捕获多模式数据中的明确和隐含线索,能够进行全面和无偏的评估。我们的框架在2025年AVI挑战赛中获得了第一名,实现了多维平均MSE为0.1824,证明了其在推进自动化和多模式面试绩效评估中的有效性和稳健性。完整实现可访问https://github.com/MSA-LMC/365Aspects。
论文及项目相关链接
PDF 8 pages, 4 figures, ACM MM 2025. github:https://github.com/MSA-LMC/365Aspects
Summary
本文提出一种新型的面试表现评估框架,该框架融合了视频、音频和文本三种模态的数据,通过对候选人的六个回应进行五种关键评价维度的全面评估,实现对面试表现的365度全方位评价。该框架采用模态特定特征提取器对异质数据流进行编码,并通过共享压缩多层感知器进行融合,实现多模态嵌入的统一潜在空间压缩,促进特征的有效交互。同时,采用两级集成学习策略提高预测稳健性,最终获得多维平均均方误差为0.1824的良好表现,并在AVI挑战赛中荣获第一名,展示了其在自动化和多模态面试表现评估中的有效性和稳健性。
Key Takeaways
- 提出的框架融合了视频、音频和文本三种模态的数据,实现全面评估。
- 框架包含六种回应和五种关键评价维度,对面试进行365度全方位评价。
- 采用模态特定特征提取器对异质数据流进行编码,并通过共享压缩多层感知器实现多模态数据融合。
- 两级集成学习策略提高了预测稳健性。
- 框架获得了良好的多维平均均方误差结果,为0.1824。
- 该框架在AVI挑战赛中荣获第一名,证明了其有效性和稳健性。
点此查看论文截图