⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
MuGS: Multi-Baseline Generalizable Gaussian Splatting Reconstruction
Authors:Yaopeng Lou, Liao Shen, Tianqi Liu, Jiaqi Li, Zihao Huang, Huiqiang Sun, Zhiguo Cao
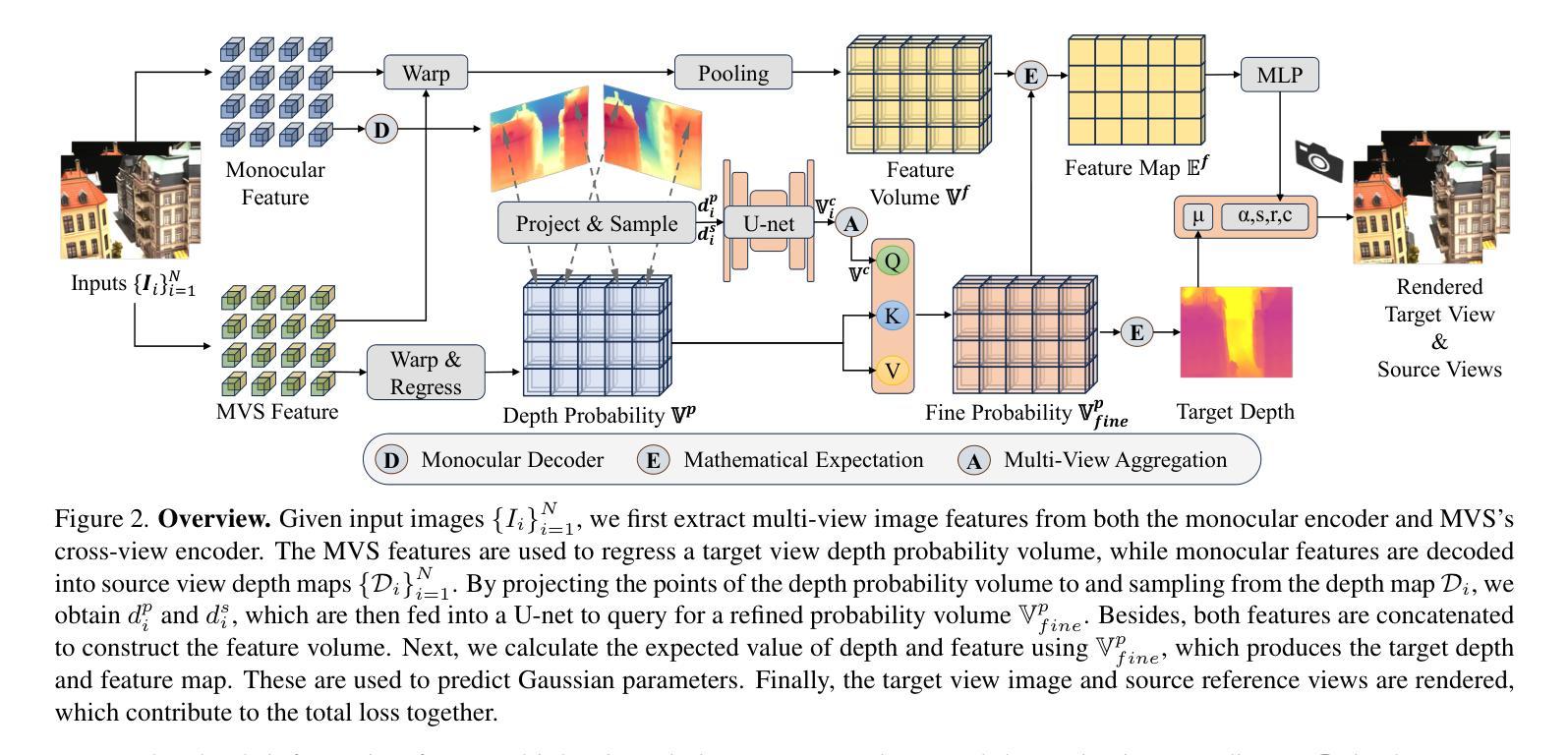
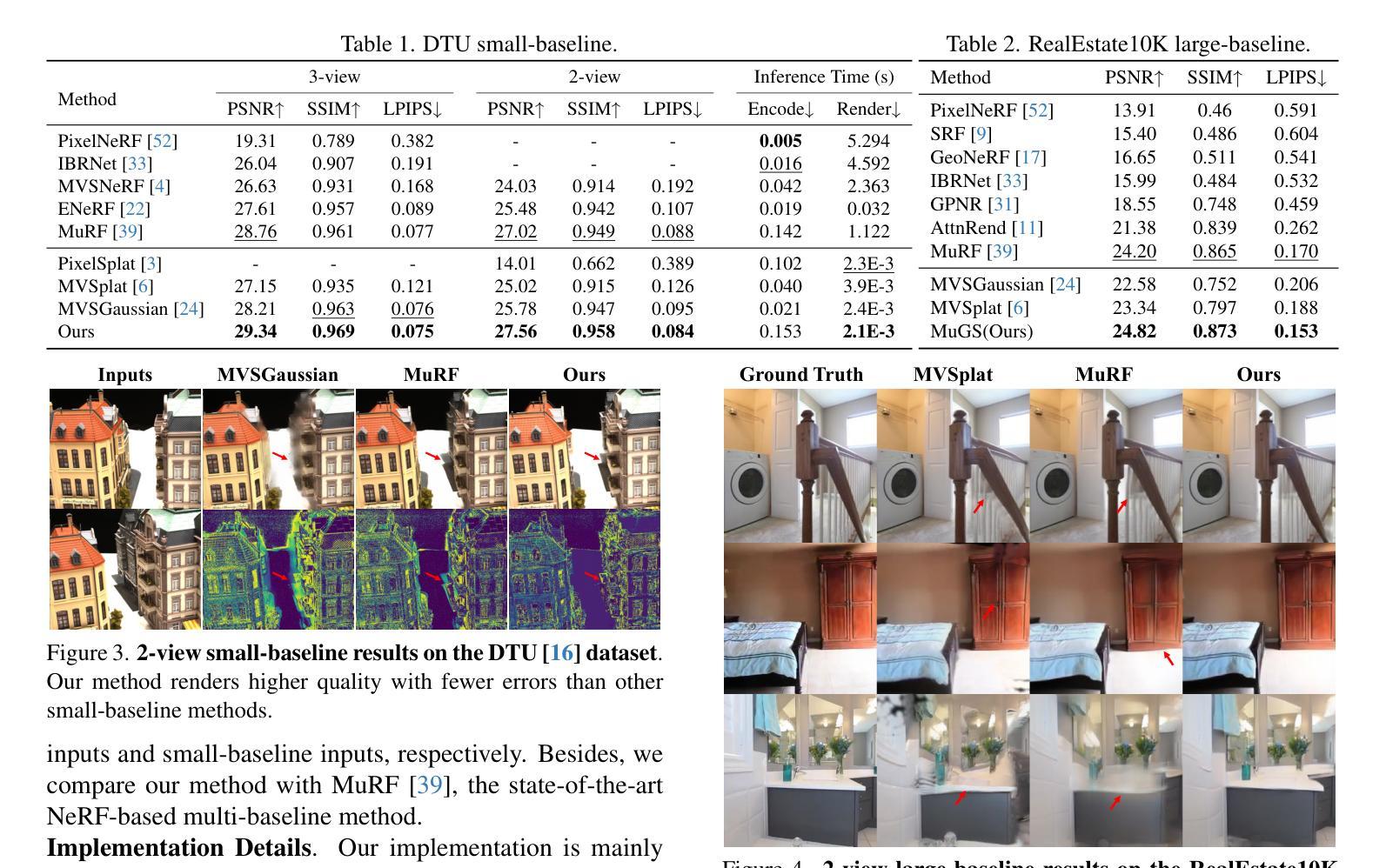
We present Multi-Baseline Gaussian Splatting (MuRF), a generalized feed-forward approach for novel view synthesis that effectively handles diverse baseline settings, including sparse input views with both small and large baselines. Specifically, we integrate features from Multi-View Stereo (MVS) and Monocular Depth Estimation (MDE) to enhance feature representations for generalizable reconstruction. Next, We propose a projection-and-sampling mechanism for deep depth fusion, which constructs a fine probability volume to guide the regression of the feature map. Furthermore, We introduce a reference-view loss to improve geometry and optimization efficiency. We leverage 3D Gaussian representations to accelerate training and inference time while enhancing rendering quality. MuRF achieves state-of-the-art performance across multiple baseline settings and diverse scenarios ranging from simple objects (DTU) to complex indoor and outdoor scenes (RealEstate10K). We also demonstrate promising zero-shot performance on the LLFF and Mip-NeRF 360 datasets.
我们提出了多基线高斯平铺(MuRF),这是一种用于新颖视图合成的广义前馈方法,可以有效处理包括具有小和大基线的稀疏输入视图在内的多种基线设置。具体来说,我们整合了多视图立体(MVS)和单眼深度估计(MDE)的特征,以增强可推广重建的特征表示。接着,我们提出了一种用于深度深度融合的投影和采样机制,它构建了一个精细的概率体积来指导特征图的回归。此外,我们引入了一种参考视图损失,以提高几何和优化效率。我们利用3D高斯表示来加快训练和推理时间,同时提高渲染质量。MuRF在多种基线设置和从简单对象(DTU)到复杂室内和室外场景(RealEstate10K)的多种场景中实现了最新技术性能。我们在LLFF和Mip-NeRF 360数据集上展示了有前景的零样本性能。
论文及项目相关链接
PDF This work is accepted by ICCV 2025
Summary
多基线高斯喷绘(MuRF)是一种广义的前馈方法,用于新颖视角合成,能有效处理包括稀疏输入视图在内的多种基线设置,涵盖小基线和大基线。通过整合多视点立体(MVS)和单眼深度估计(MDE)的特征,提升特征表示的可泛化重建能力。提出一种深度融合投影采样机制,构建精细概率体积以引导特征图的回归。引入参考视图损失提高几何和优化效率。利用三维高斯表示加速训练和推理时间,同时提高渲染质量。MuRF在多种基线设置和从简单对象(DTU)到复杂室内室外场景(RealEstate10K)的多样化场景中实现最先进的性能表现,并在LLFF和Mip-NeRF 360数据集上展示出有前景的零样本性能。
Key Takeaways
- MuRF是一种用于新颖视角合成的方法,适用于多种基线设置,包括稀疏输入视图。
- 综合了多视点立体(MVS)和单眼深度估计(MDE)的特征,增强了特征表示的泛化能力。
- 提出了一种深度融合的投影采样机制,用于构建精细概率体积,引导特征图回归。
- 引入了参考视图损失,以提升几何还原和优化效率。
- 采用三维高斯表示加速训练和推理过程,提高渲染质量。
- MuRF在多种场景中实现先进性能,包括简单对象和复杂室内室外场景。
点此查看论文截图

LiGen: GAN-Augmented Spectral Fingerprinting for Indoor Positioning
Authors:Jie Lin, Hsun-Yu Lee, Ho-Ming Li, Fang-Jing Wu
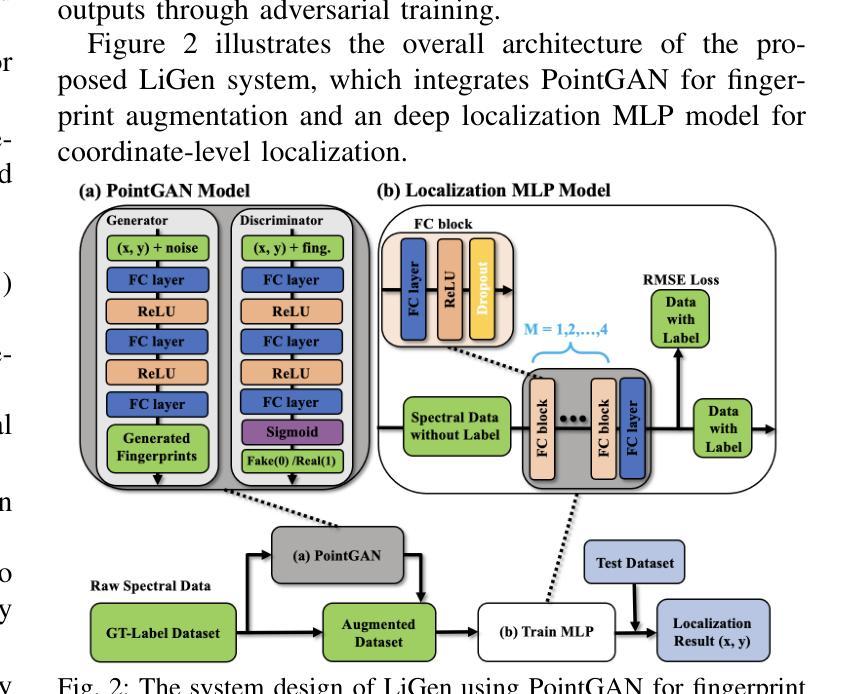
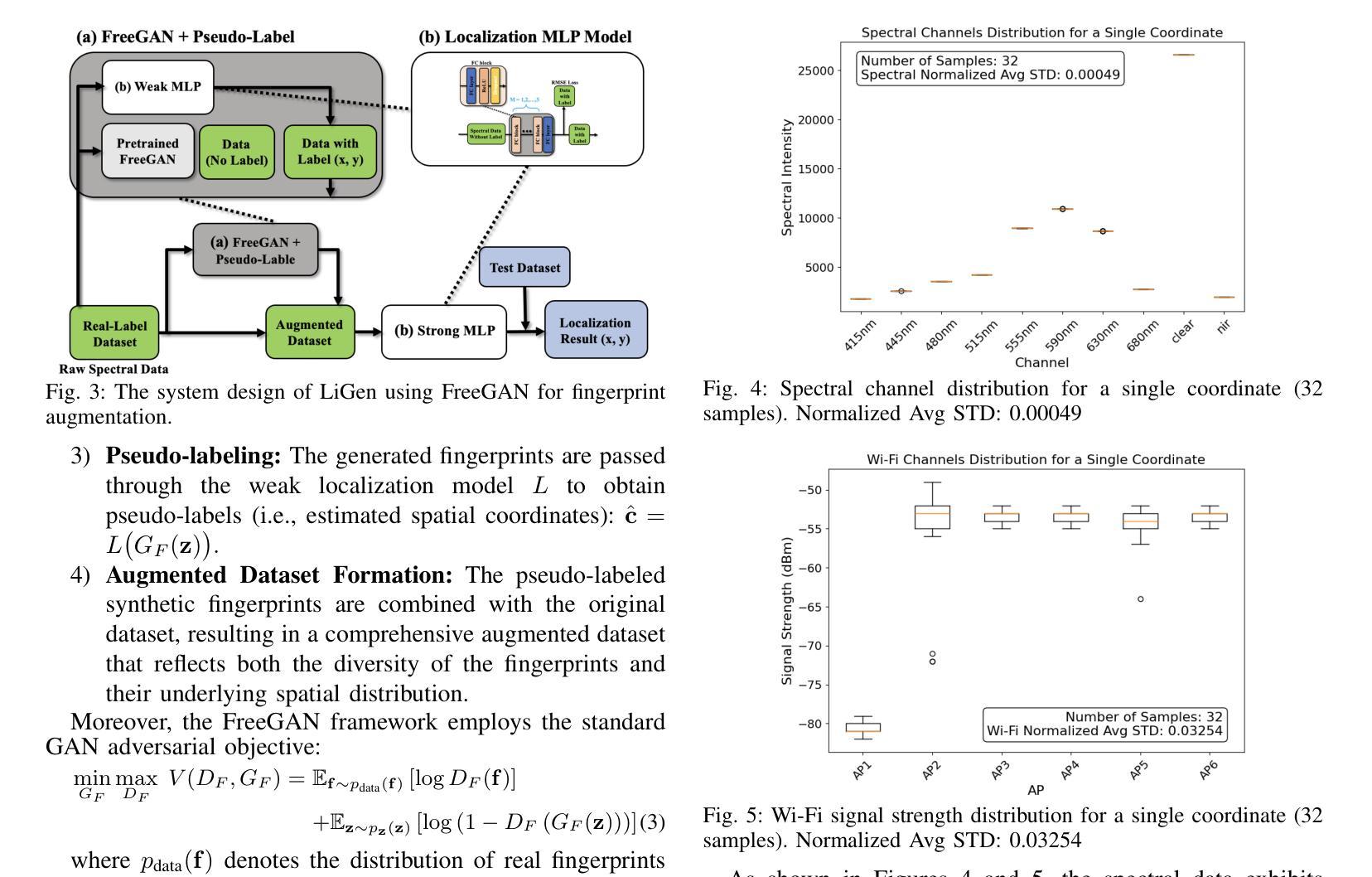
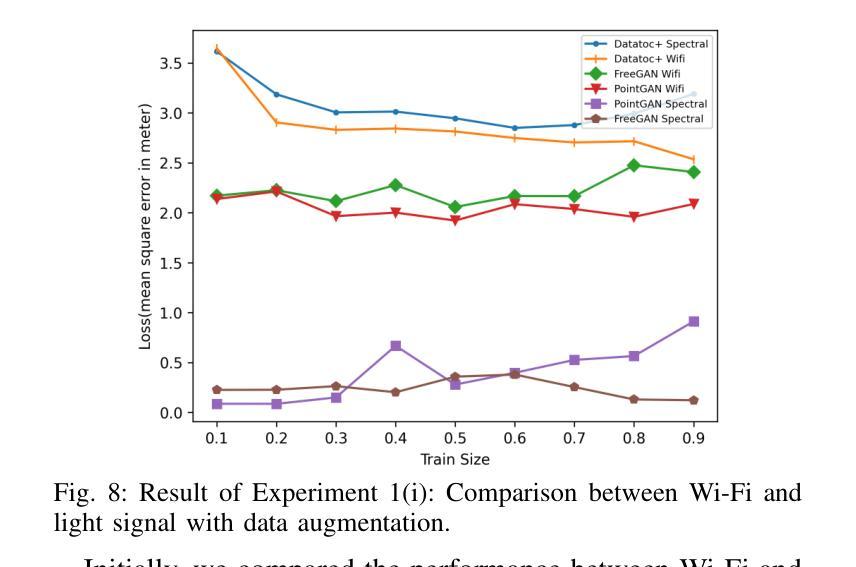
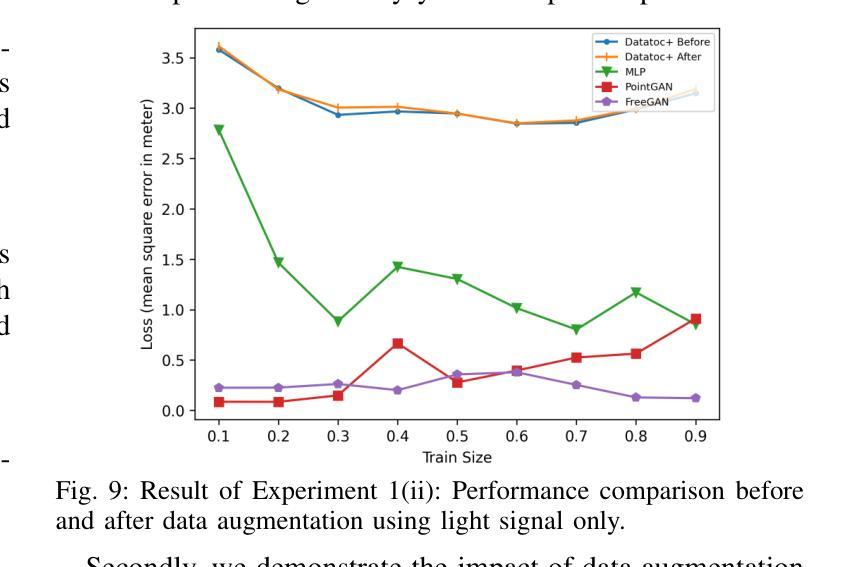
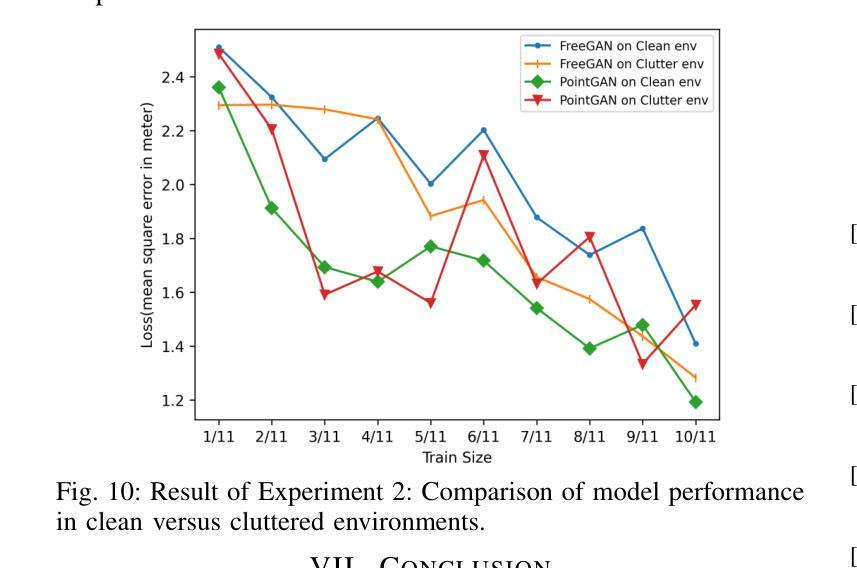
Accurate and robust indoor localization is critical for smart building applications, yet existing Wi-Fi-based systems are often vulnerable to environmental conditions. This work presents a novel indoor localization system, called LiGen, that leverages the spectral intensity patterns of ambient light as fingerprints, offering a more stable and infrastructure-free alternative to radio signals. To address the limited spectral data, we design a data augmentation framework based on generative adversarial networks (GANs), featuring two variants: PointGAN, which generates fingerprints conditioned on coordinates, and FreeGAN, which uses a weak localization model to label unconditioned samples. Our positioning model, leveraging a Multi-Layer Perceptron (MLP) architecture to train on synthesized data, achieves submeter-level accuracy, outperforming Wi-Fi-based baselines by over 50%. LiGen also demonstrates strong robustness in cluttered environments. To the best of our knowledge, this is the first system to combine spectral fingerprints with GAN-based data augmentation for indoor localization.
精确而稳定的室内定位对于智能建筑应用至关重要,但现有的基于Wi-Fi的系统通常容易受到环境条件的干扰。这项工作提出了一种新型的室内定位系统,名为LiGen,它利用环境光的谱强度模式作为指纹,为无线电信号提供了一种更稳定且无基础设施的替代方案。为了解决有限的谱数据问题,我们设计了一个基于生成对抗网络(GANs)的数据增强框架,其中包括两个变体:PointGAN,它根据坐标生成指纹;FreeGAN,它使用一个弱定位模型来标记无条件的样本。我们的定位模型采用多层感知器(MLP)架构在合成数据上进行训练,实现了亚米级精度,比基于Wi-Fi的基线高出50%以上。LiGen在杂乱的环境中表现出强大的稳健性。据我们所知,这是第一个将谱指纹与基于GAN的数据增强相结合的室内定位系统。
论文及项目相关链接
PDF 6 pages, 10 figures
Summary
室内定位对于智能建筑应用至关重要,但现有Wi-Fi系统易受环境影响。本研究提出了一种新型室内定位系统LiGen,利用环境光的谱强度模式作为指纹,为无线电信号提供了一种更稳定且无基础设施的替代方案。为解决谱数据有限的问题,研究团队设计了一个基于生成对抗网络(GANs)的数据增强框架,包括PointGAN和FreeGAN两种变体。LiGen采用多层感知器(MLP)架构训练合成数据,实现了亚米级定位精度,较Wi-Fi基线性能高出超过50%,并在杂乱环境中表现出强鲁棒性。此为首个结合光谱指纹和GAN数据增强的室内定位系统。
Key Takeaways
- 室内定位对智能建筑应用非常重要,但现有Wi-Fi系统存在稳定性问题。
- LiGen系统利用环境光的谱强度模式作为指纹,提供稳定的室内定位。
- 为解决谱数据有限的问题,研究团队采用了基于生成对抗网络(GANs)的数据增强框架。
- LiGen系统包括PointGAN和FreeGAN两种变体,分别用于生成条件和非条件样本的指纹。
- LiGen采用多层感知器(MLP)架构,通过合成数据训练,实现亚米级定位精度。
- LiGen较Wi-Fi基线性能高出超过50%,显示出强鲁棒性。
点此查看论文截图


GENIE: Gaussian Encoding for Neural Radiance Fields Interactive Editing
Authors:Mikołaj Zieliński, Krzysztof Byrski, Tomasz Szczepanik, Przemysław Spurek
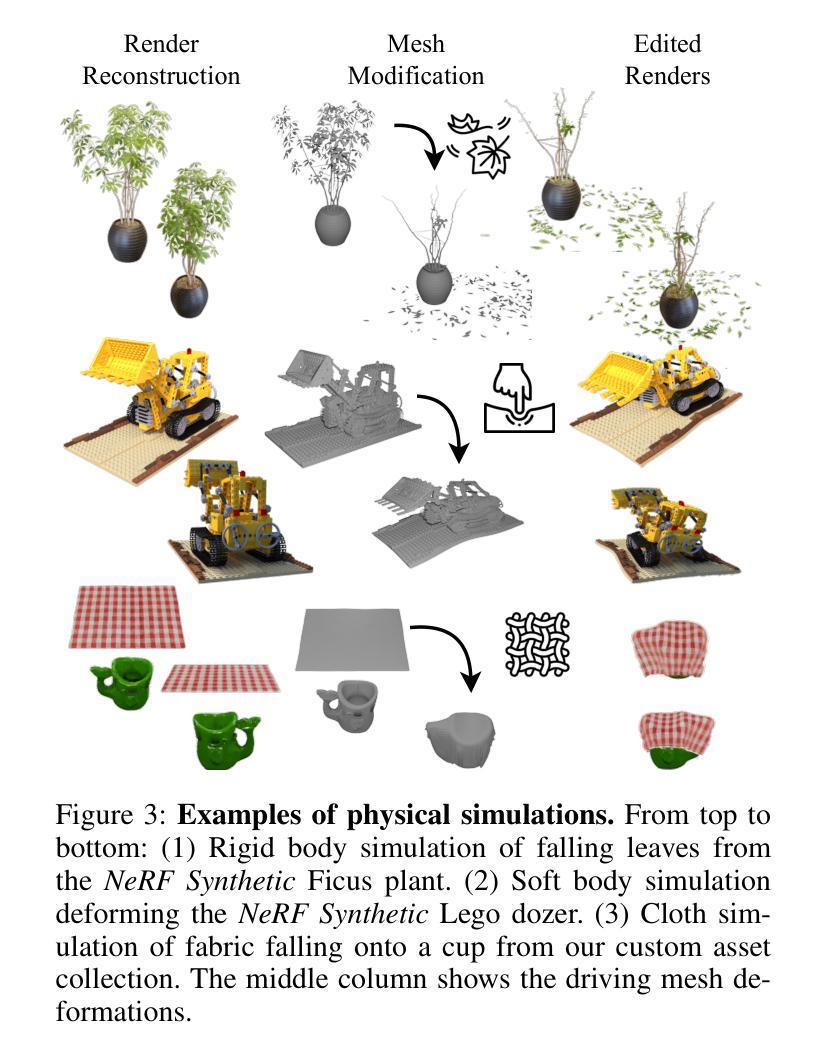
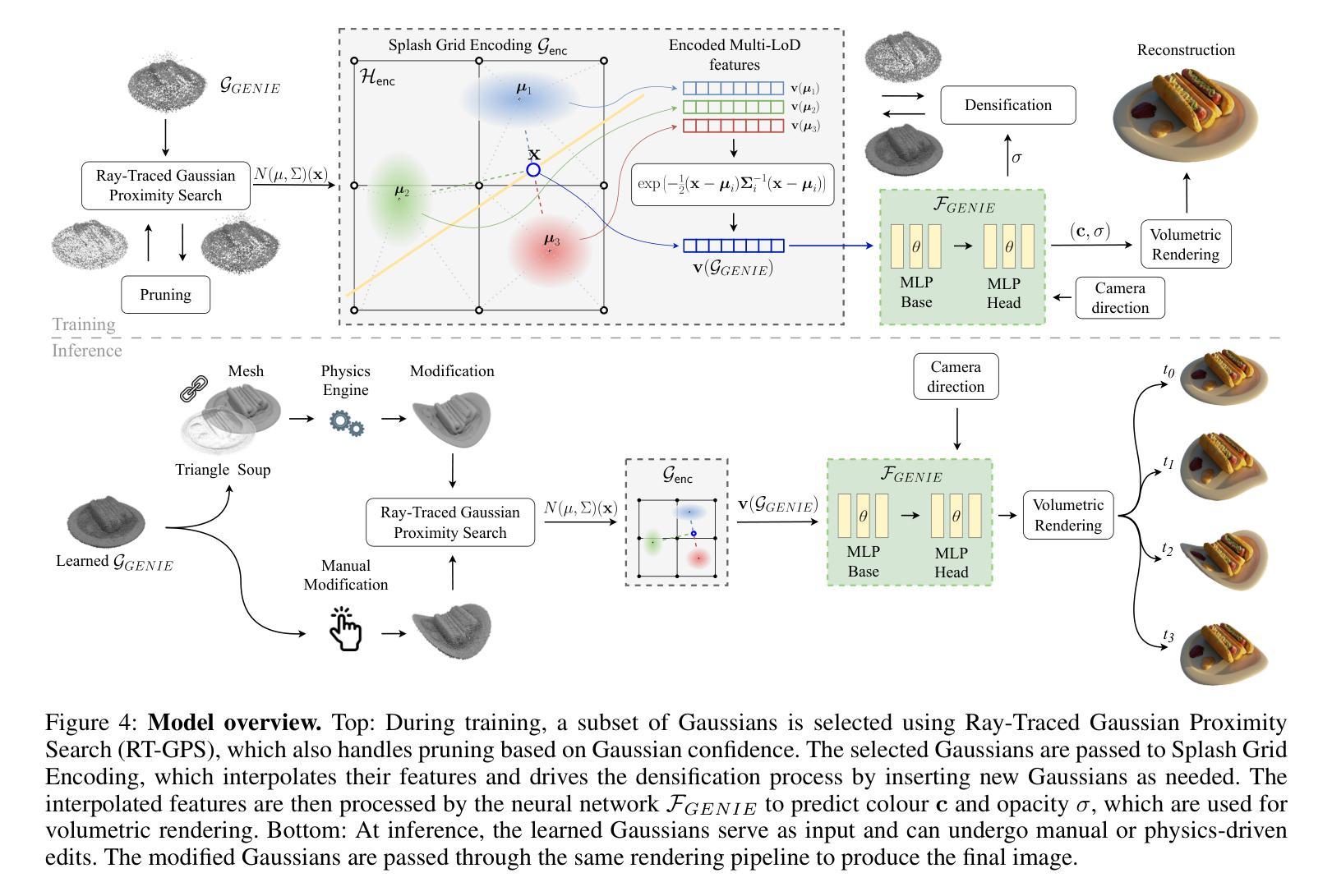
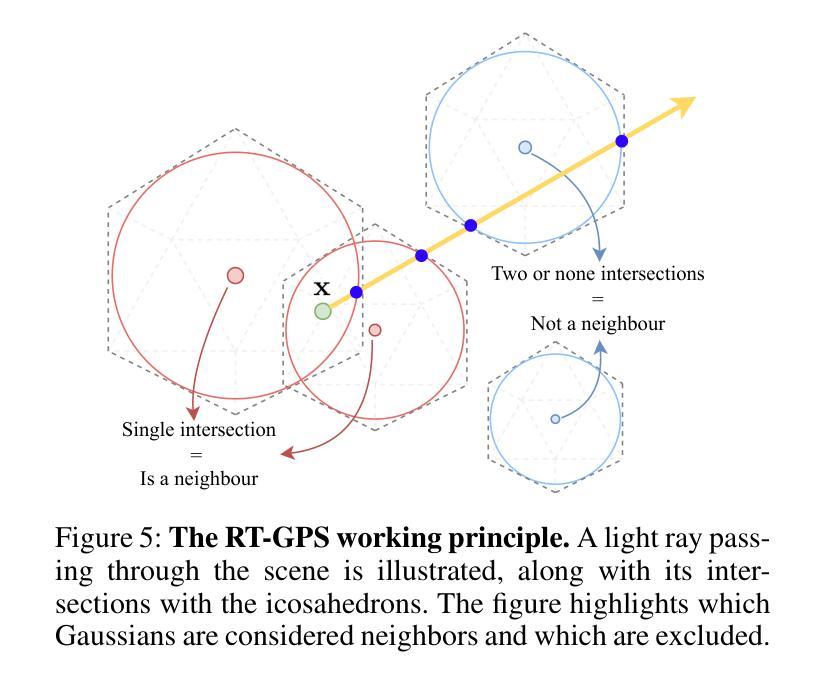
Neural Radiance Fields (NeRF) and Gaussian Splatting (GS) have recently transformed 3D scene representation and rendering. NeRF achieves high-fidelity novel view synthesis by learning volumetric representations through neural networks, but its implicit encoding makes editing and physical interaction challenging. In contrast, GS represents scenes as explicit collections of Gaussian primitives, enabling real-time rendering, faster training, and more intuitive manipulation. This explicit structure has made GS particularly well-suited for interactive editing and integration with physics-based simulation. In this paper, we introduce GENIE (Gaussian Encoding for Neural Radiance Fields Interactive Editing), a hybrid model that combines the photorealistic rendering quality of NeRF with the editable and structured representation of GS. Instead of using spherical harmonics for appearance modeling, we assign each Gaussian a trainable feature embedding. These embeddings are used to condition a NeRF network based on the k nearest Gaussians to each query point. To make this conditioning efficient, we introduce Ray-Traced Gaussian Proximity Search (RT-GPS), a fast nearest Gaussian search based on a modified ray-tracing pipeline. We also integrate a multi-resolution hash grid to initialize and update Gaussian features. Together, these components enable real-time, locality-aware editing: as Gaussian primitives are repositioned or modified, their interpolated influence is immediately reflected in the rendered output. By combining the strengths of implicit and explicit representations, GENIE supports intuitive scene manipulation, dynamic interaction, and compatibility with physical simulation, bridging the gap between geometry-based editing and neural rendering. The code can be found under (https://github.com/MikolajZielinski/genie)
神经辐射场(NeRF)和高斯拼贴(GS)最近已经改变了3D场景表示和渲染的方式。NeRF通过学习神经网络体积表示来实现高保真新型视图合成,但其隐式编码使得编辑和物理交互具有挑战性。相比之下,GS将场景表示为高斯原始数据的显式集合,可实现实时渲染、更快的训练和更直观的操控。这种显式结构使GS特别适合进行交互式编辑以及与基于物理的模拟进行集成。在本文中,我们介绍了GENIE(用于神经辐射场交互式编辑的高斯编码),这是一种结合了NeRF的光照现实渲染质量和GS的可编辑结构化表示的混合模型。我们没有使用球面谐波进行外观建模,而是为每个高斯分配可训练特征嵌入。这些嵌入被用于基于每个查询点的k个最近高斯来条件化NeRF网络。为了使这种条件设置有效,我们引入了基于修改后的光线追踪管道的快速最近高斯搜索——光线追踪高斯邻近搜索(RT-GPS)。我们还集成了多分辨率哈希网格来初始化和更新高斯特征。这些组件共同作用,可实现实时、局部感知的编辑:当高斯原始数据被重新定位或修改时,其插值影响会立即反映在渲染输出中。通过结合隐式和显式表示的优点,GENIE支持直观的场景操作、动态交互以及与物理模拟的兼容性,从而弥合了基于几何的编辑和神经渲染之间的差距。代码可在(https://github.com/MikolajZielinski/genie)找到。
论文及项目相关链接
Summary
NeRF与Gaussian Splatting(GS)的结合实现了高质量的渲染与场景编辑。GENIE模型结合了NeRF的光照真实渲染与GS的明确结构化表示,通过为每个高斯分配可训练特征嵌入,实现了基于k近邻高斯点的NeRF网络条件化。引入的Ray-Traced Gaussian Proximity Search(RT-GPS)技术提高了效率。该模型支持实时、局部感知编辑,可直观操作场景、动态交互,并与物理模拟兼容。
Key Takeaways
- NeRF与GS的结合实现了高质量的渲染与场景编辑,GS的显式结构使其适合交互式编辑和物理模拟。
- GENIE模型结合了NeRF的光照真实渲染与GS的明确结构化表示,通过为每个高斯分配特征嵌入,改善了场景编辑和渲染效果。
- RT-GPS技术实现了高效的近邻高斯点搜索,提高了渲染速度。
- 多分辨率哈希网格用于初始化并更新高斯特征。
- 该模型支持实时、局部感知编辑,实现了直观的场景操作与动态交互。
- 该模型与物理模拟兼容,缩小了基于几何的编辑和神经渲染之间的差距。
点此查看论文截图


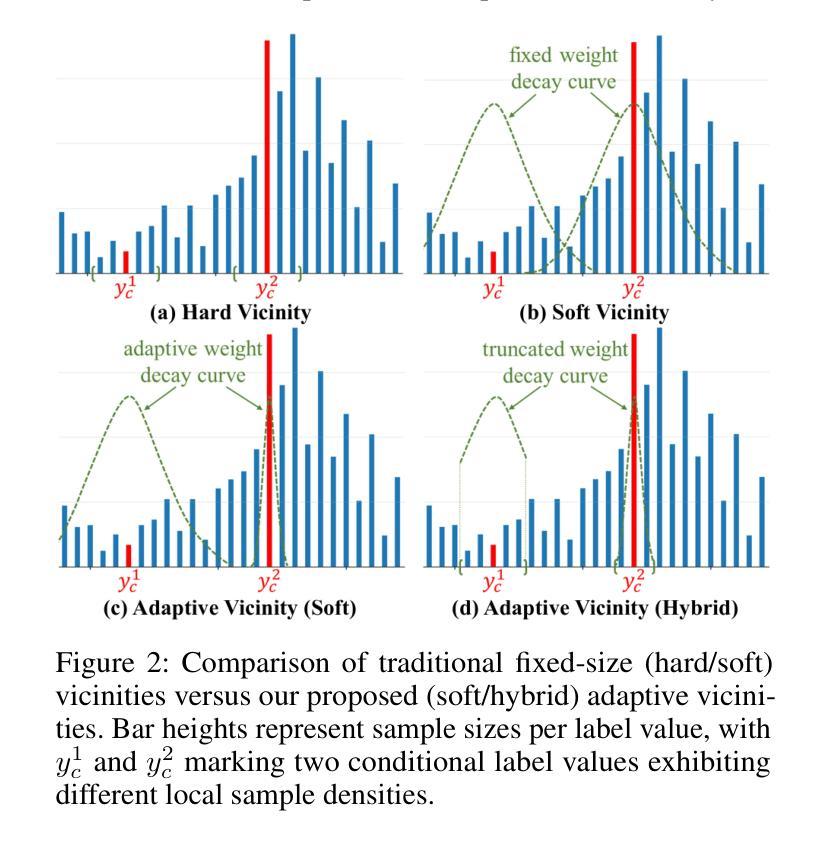
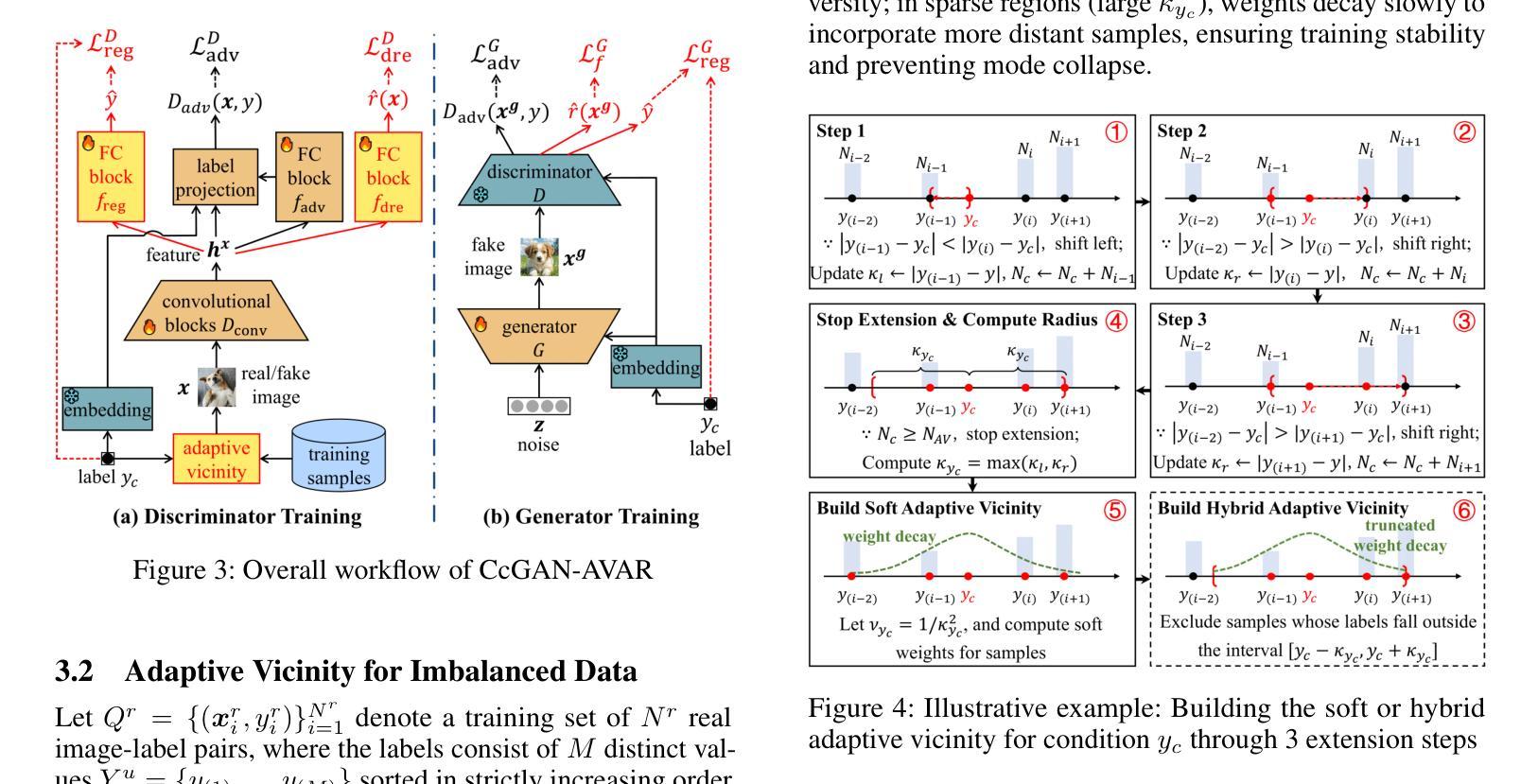
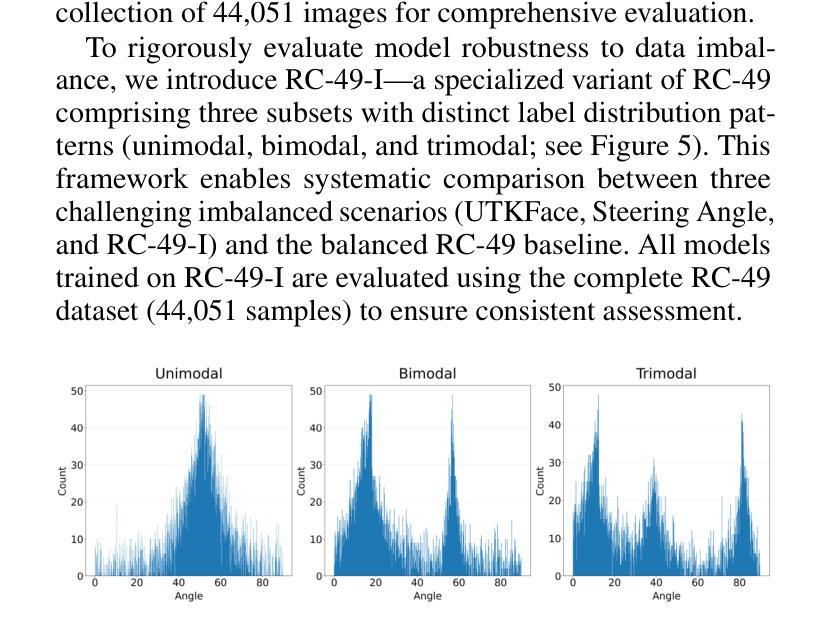
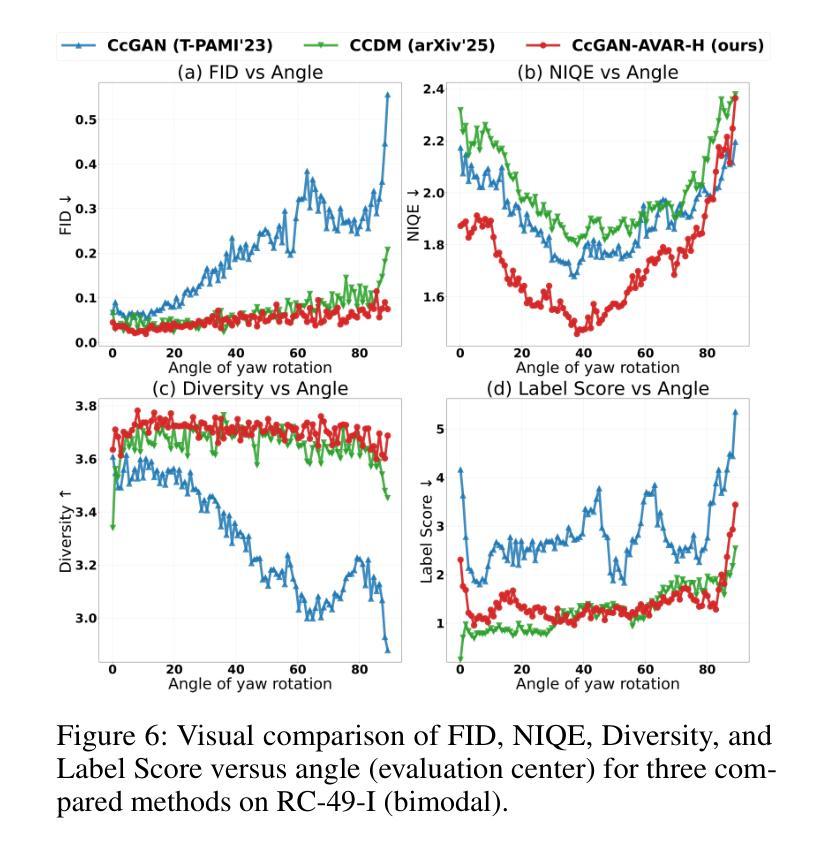
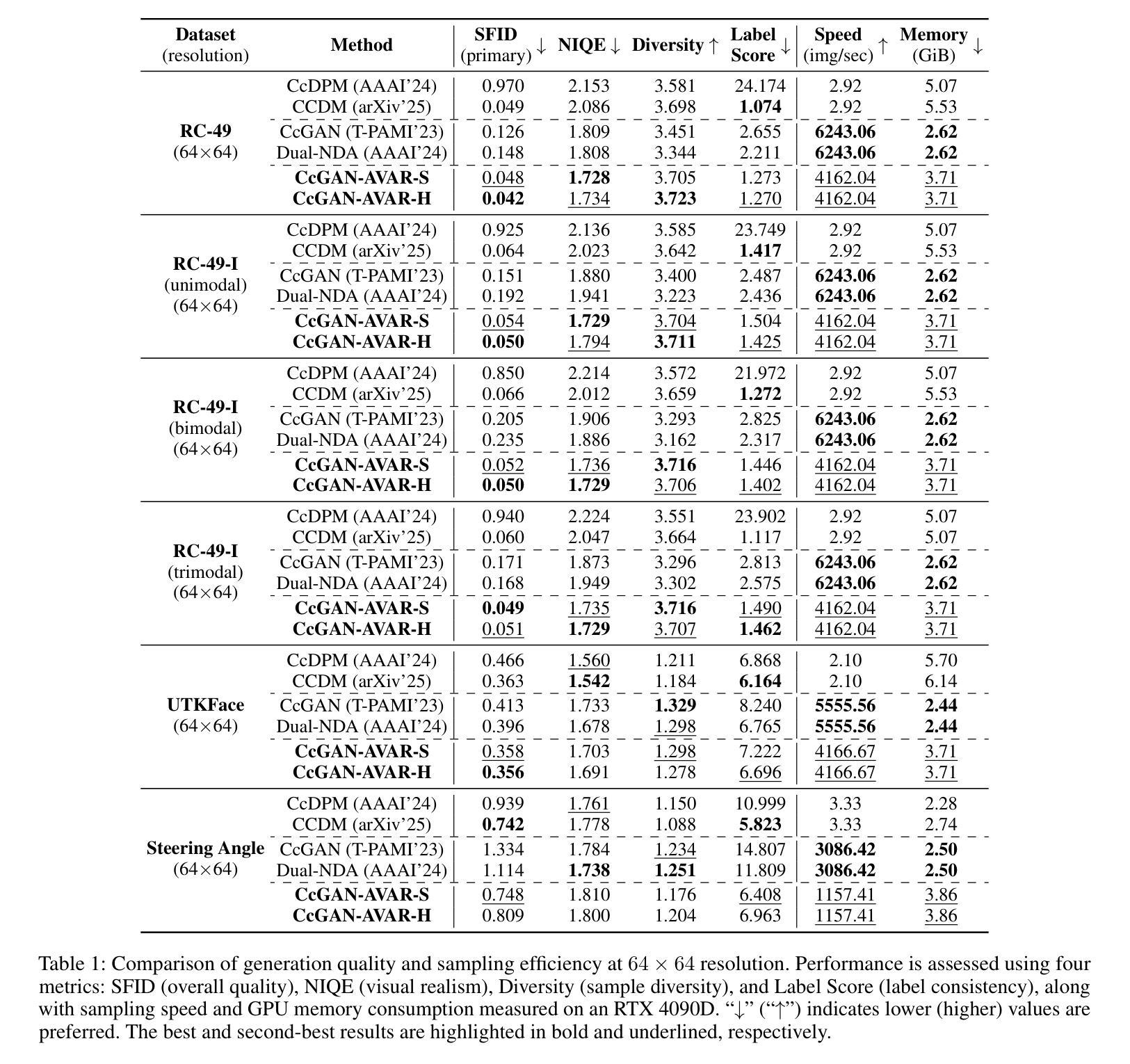
Imbalance-Robust and Sampling-Efficient Continuous Conditional GANs via Adaptive Vicinity and Auxiliary Regularization
Authors:Xin Ding, Yun Chen, Yongwei Wang, Kao Zhang, Sen Zhang, Peibei Cao, Xiangxue Wang
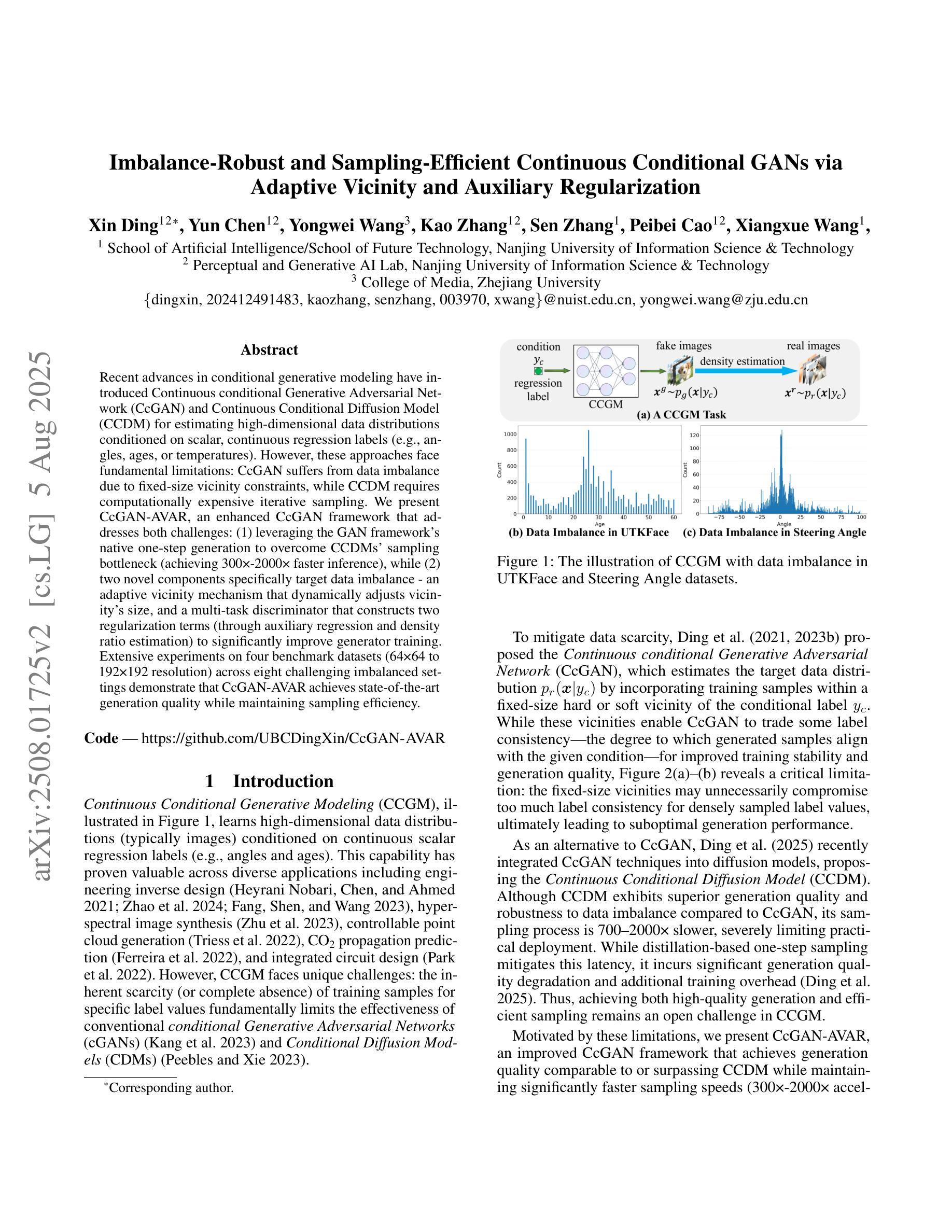
Recent advances in conditional generative modeling have introduced Continuous conditional Generative Adversarial Network (CcGAN) and Continuous Conditional Diffusion Model (CCDM) for estimating high-dimensional data distributions conditioned on scalar, continuous regression labels (e.g., angles, ages, or temperatures). However, these approaches face fundamental limitations: CcGAN suffers from data imbalance due to fixed-size vicinity constraints, while CCDM requires computationally expensive iterative sampling. We present CcGAN-AVAR, an enhanced CcGAN framework that addresses both challenges: (1) leveraging the GAN framework’s native one-step generation to overcome CCDMs’ sampling bottleneck (achieving 300x-2000x faster inference), while (2) two novel components specifically target data imbalance - an adaptive vicinity mechanism that dynamically adjusts vicinity’s size, and a multi-task discriminator that constructs two regularization terms (through auxiliary regression and density ratio estimation) to significantly improve generator training. Extensive experiments on four benchmark datasets (64x64 to 192x192 resolution) across eight challenging imbalanced settings demonstrate that CcGAN-AVAR achieves state-of-the-art generation quality while maintaining sampling efficiency.
近期条件生成模型的发展引入了连续条件生成对抗网络(CcGAN)和连续条件扩散模型(CCDM),用于估计基于标量、连续回归标签的高维数据分布(例如角度、年龄或温度)。然而,这些方法面临根本性局限:CcGAN受到固定大小邻近约束导致的数据不平衡的影响,而CCDM需要计算量大的迭代采样。我们提出了CcGAN-AVAR,这是一个增强的CcGAN框架,解决了这两个挑战:(1)利用GAN框架的一次性生成来克服CCDM的采样瓶颈(实现300倍至2000倍更快的推理速度),同时(2)两个新组件专门解决数据不平衡问题——一个自适应邻近机制,动态调整邻近大小,和一个多任务鉴别器,构建两个正则化项(通过辅助回归和密度比率估计),以显著改善生成器训练。在四个基准数据集(从64x64到192x192分辨率)上进行的八个具有挑战性的不平衡设置的大量实验表明,CcGAN-AVAR在保持采样效率的同时实现了最先进的生成质量。
论文及项目相关链接
Summary
基于连续条件生成对抗网络(CcGAN)和连续条件扩散模型(CCDM)的近期进展,文章提出了CcGAN-AVAR模型,该模型旨在解决在给定标量连续回归标签条件下估计高维数据分布的问题。该模型解决了CcGAN存在的数据不平衡问题和CCDM计算昂贵的迭代采样问题。通过利用GAN框架的一步生成特性,实现了快速的推理过程,并引入两个新组件来解决数据不平衡问题,包括自适应邻近机制和多任务鉴别器。实验结果表明,CcGAN-AVAR在生成质量和采样效率方面均达到了业界最佳水平。
Key Takeaways
- CcGAN-AVAR解决了现有连续条件生成模型面临的数据不平衡和计算昂贵的迭代采样问题。
- 该模型利用GAN的一步生成特性,实现了快速推理。
- CcGAN-AVAR通过自适应邻近机制动态调整邻近大小,解决数据不平衡问题。
- 多任务鉴别器通过辅助回归和密度比率估计构建两个正则化项,显著改善生成器训练。
- CcGAN-AVAR在四个基准数据集上的实验结果表明,它在生成质量方面达到了业界最佳水平。
- 该模型适用于不同分辨率的数据集,从64x64到192x192。
点此查看论文截图
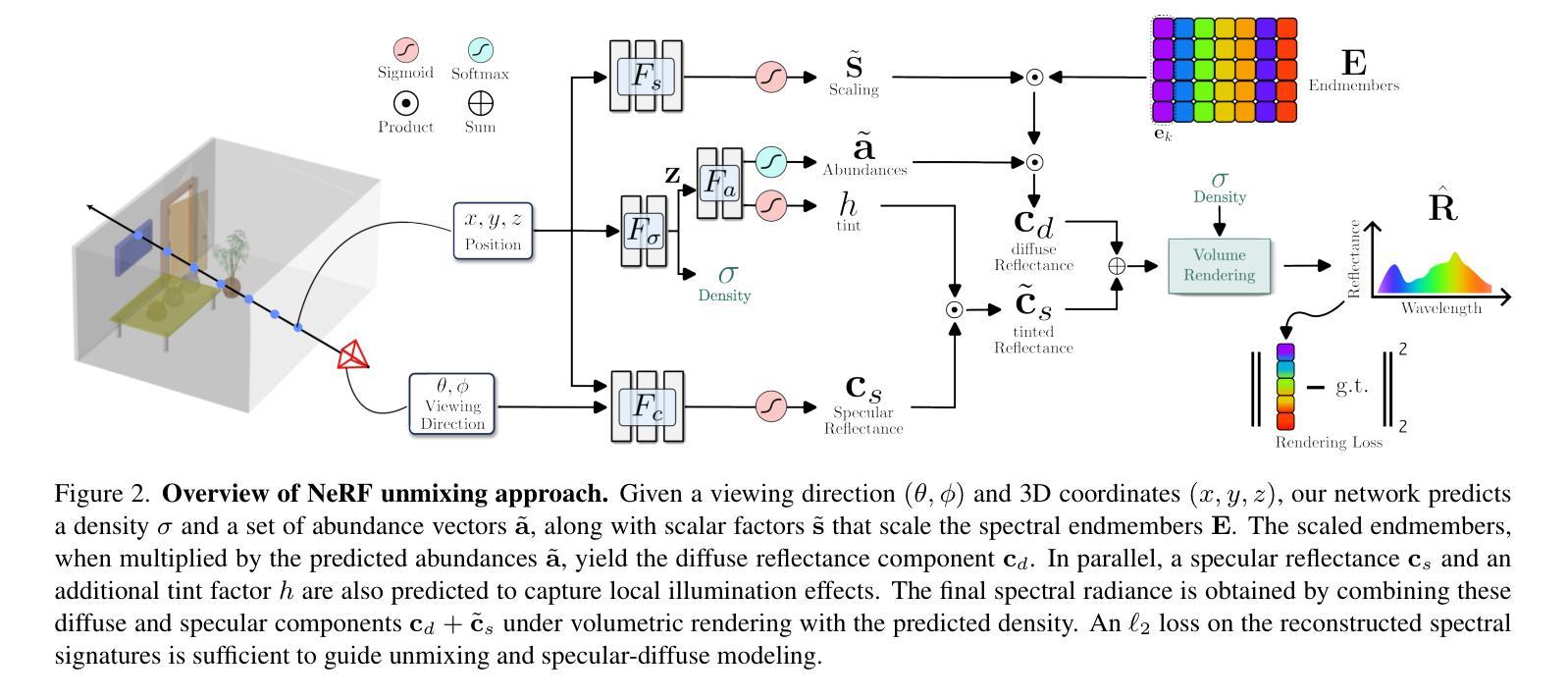
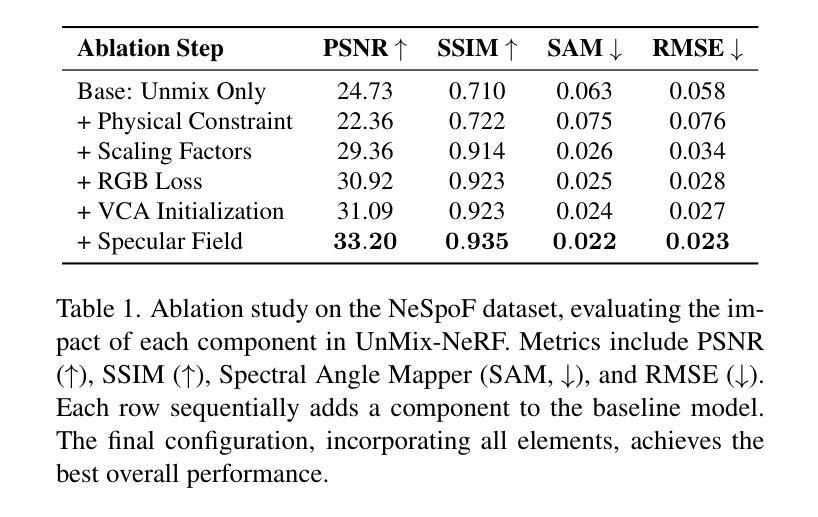
UnMix-NeRF: Spectral Unmixing Meets Neural Radiance Fields
Authors:Fabian Perez, Sara Rojas, Carlos Hinojosa, Hoover Rueda-Chacón, Bernard Ghanem
Neural Radiance Field (NeRF)-based segmentation methods focus on object semantics and rely solely on RGB data, lacking intrinsic material properties. This limitation restricts accurate material perception, which is crucial for robotics, augmented reality, simulation, and other applications. We introduce UnMix-NeRF, a framework that integrates spectral unmixing into NeRF, enabling joint hyperspectral novel view synthesis and unsupervised material segmentation. Our method models spectral reflectance via diffuse and specular components, where a learned dictionary of global endmembers represents pure material signatures, and per-point abundances capture their distribution. For material segmentation, we use spectral signature predictions along learned endmembers, allowing unsupervised material clustering. Additionally, UnMix-NeRF enables scene editing by modifying learned endmember dictionaries for flexible material-based appearance manipulation. Extensive experiments validate our approach, demonstrating superior spectral reconstruction and material segmentation to existing methods. Project page: https://www.factral.co/UnMix-NeRF.
基于神经辐射场(NeRF)的分割方法主要关注对象语义,并且仅依赖于RGB数据,缺乏内在材料属性。这一局限性限制了材料感知的准确性,对于机器人、增强现实、模拟和其他应用而言,这是至关重要的。我们引入了UnMix-NeRF框架,它将光谱混合技术集成到NeRF中,实现了联合高光谱新视角合成和无监督材料分割。我们的方法通过漫反射和镜面反射成分对光谱反射进行建模,其中通过全局端元学习字典表示纯材料特征,而每点的丰度则捕捉其分布。对于材料分割,我们使用沿学习端元的频谱特征预测,从而实现无监督材料聚类。此外,UnMix-NeRF还通过修改学习的端元字典,实现了场景的编辑,以便进行灵活的材料外观操纵。大量的实验验证了我们方法的有效性,表现出优越的光谱重建和材料分割性能。项目页面:https://www.factral.co/UnMix-NeRF。
论文及项目相关链接
PDF Paper accepted at ICCV 2025 main conference
Summary
基于神经辐射场(NeRF)的分割方法主要关注对象语义,并仅依赖于RGB数据,缺乏内在材料属性。本文引入UnMix-NeRF框架,将光谱混合技术集成到NeRF中,实现联合高光谱新视角合成和无监督材料分割。该方法通过漫反射和镜面反射成分模拟光谱反射,其中通过全局端元学习字典表示纯材料签名,每点的丰度捕捉其分布。对于材料分割,使用光谱签名预测和学习的端元进行无监督材料聚类。此外,UnMix-NeRF可通过修改学习的端元字典实现场景编辑,为基于材料的外观操纵提供灵活性。实验证明,该方法在光谱重建和材料分割方面优于现有方法。
Key Takeaways
- UnMix-NeRF框架集成了光谱混合技术到NeRF中。
- 该方法实现了联合高光谱新视角合成和无监督材料分割。
- UnMix-NeRF模拟光谱反射通过漫反射和镜面反射成分。
- 利用全局端元学习字典表示纯材料签名。
- 通过光谱签名预测和学习的端元进行无监督材料聚类。
- UnMix-NeRF能实现场景编辑,具有灵活的材料外观操纵功能。
点此查看论文截图

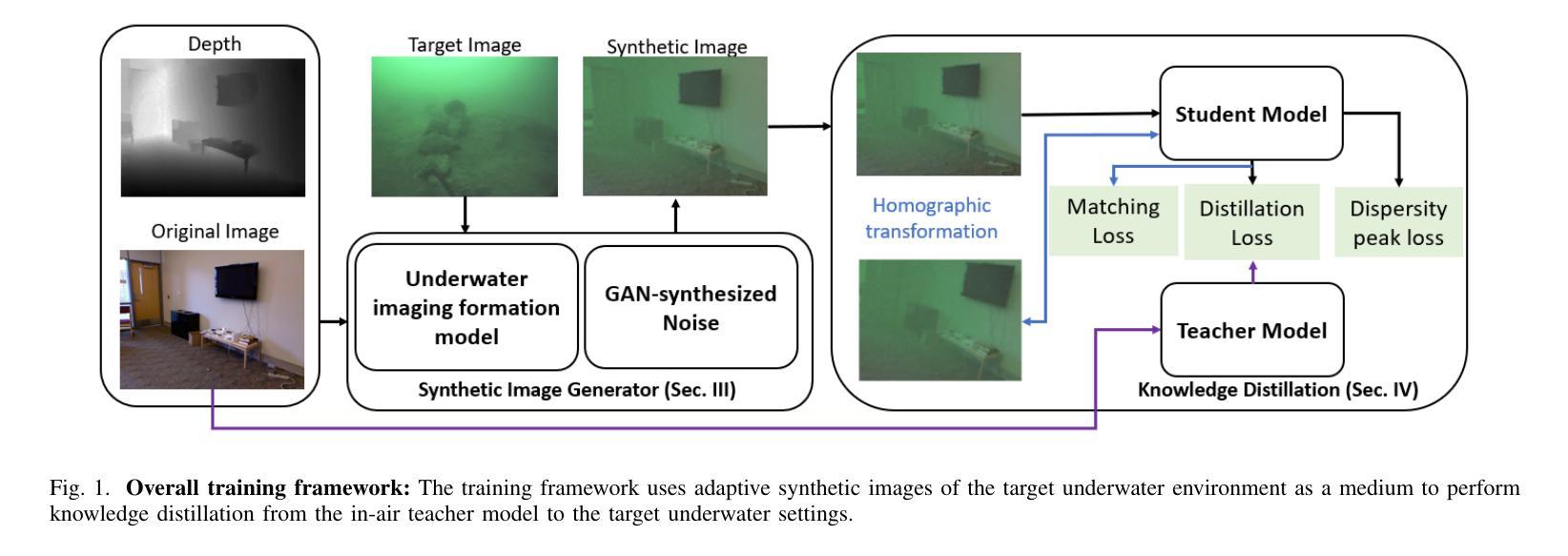
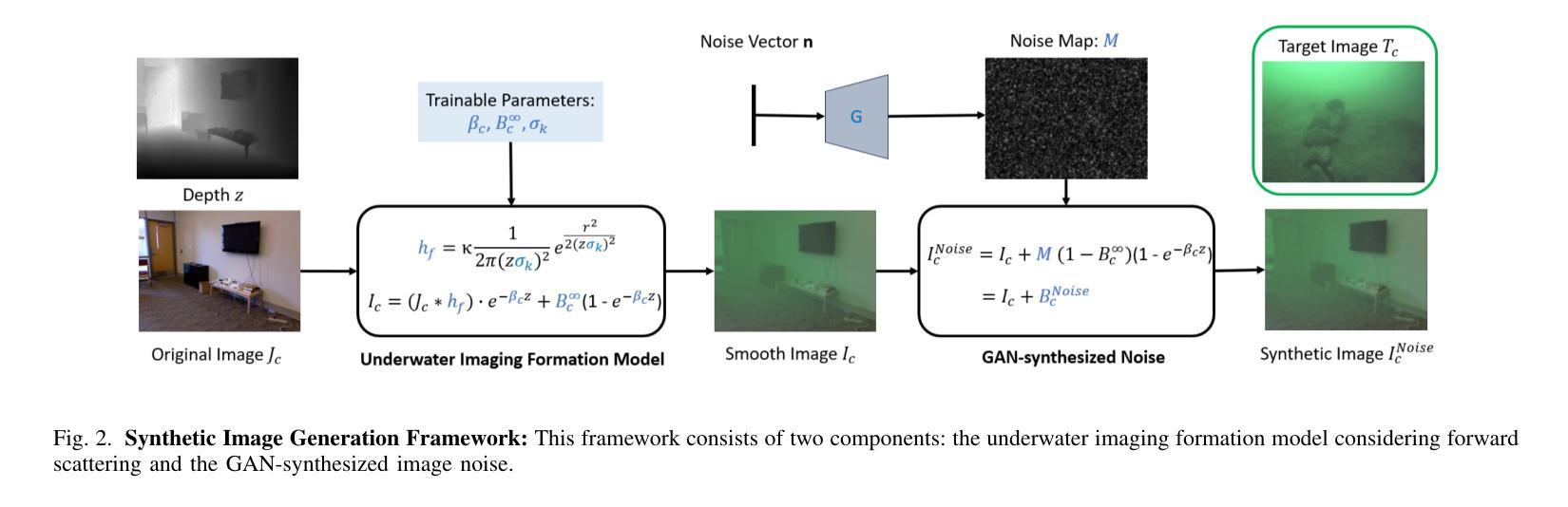
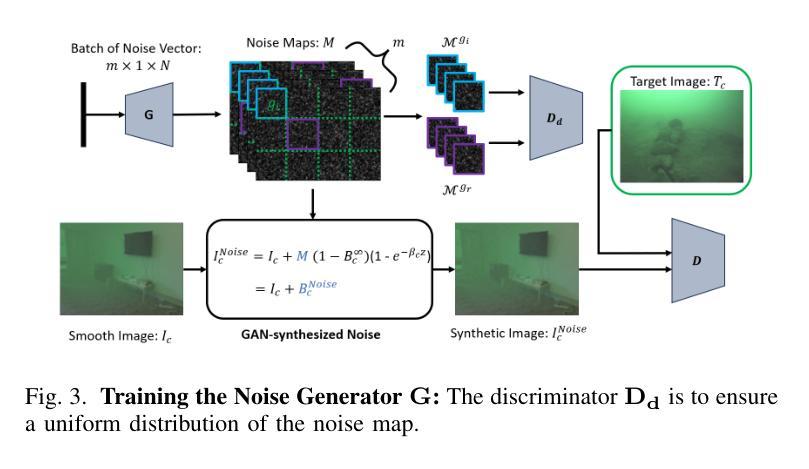
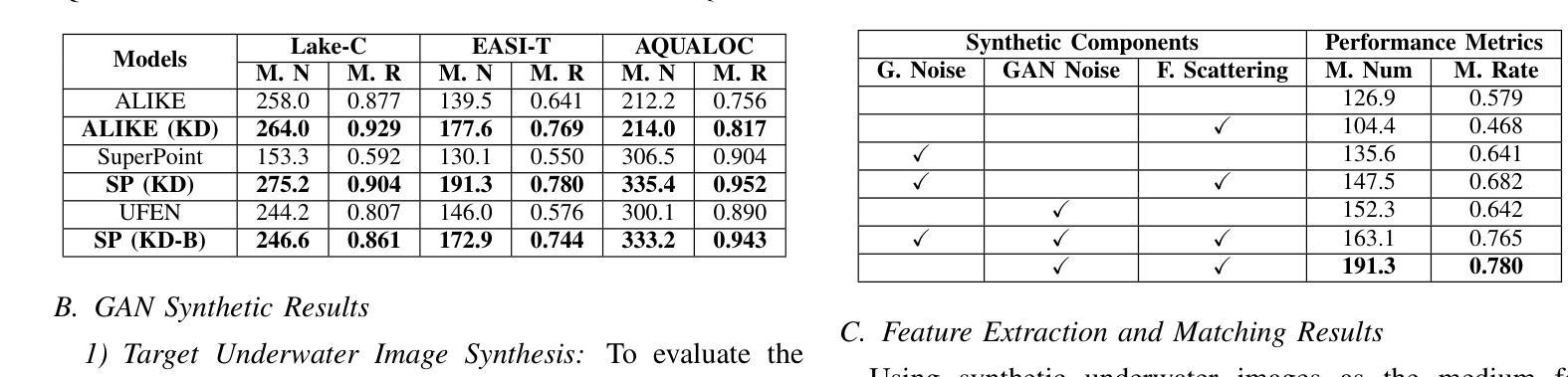
Knowledge Distillation for Underwater Feature Extraction and Matching via GAN-synthesized Images
Authors:Jinghe Yang, Mingming Gong, Ye Pu
Autonomous Underwater Vehicles (AUVs) play a crucial role in underwater exploration. Vision-based methods offer cost-effective solutions for localization and mapping in the absence of conventional sensors like GPS and LiDAR. However, underwater environments present significant challenges for feature extraction and matching due to image blurring and noise caused by attenuation, scattering, and the interference of \textit{marine snow}. In this paper, we aim to improve the robustness of the feature extraction and matching in the turbid underwater environment using the cross-modal knowledge distillation method that transfers the in-air feature extraction and matching models to underwater settings using synthetic underwater images as the medium. We first propose a novel adaptive GAN-synthesis method to estimate water parameters and underwater noise distribution, to generate environment-specific synthetic underwater images. We then introduce a general knowledge distillation framework compatible with different teacher models. The evaluation of GAN-based synthesis highlights the significance of the new components, i.e. GAN-synthesized noise and forward scattering, in the proposed model. Additionally, VSLAM, as a representative downstream application of feature extraction and matching, is employed on real underwater sequences to validate the effectiveness of the transferred model. Project page: https://github.com/Jinghe-mel/UFEN-GAN.
自主水下车辆(AUVs)在水下探测中起着至关重要的作用。在没有GPS和激光雷达等传统传感器的情况下,基于视觉的方法为定位和地图绘制提供了经济高效的解决方案。然而,水下环境由于衰减、散射和“海洋雪”的干扰导致的图像模糊和噪声,给特征提取和匹配带来了重大挑战。在本文中,我们旨在利用跨模态知识蒸馏方法,通过合成水下图像作为媒介,将空气中的特征提取和匹配模型转移到水下环境,从而提高在浑浊水下环境中特征提取和匹配的稳健性。我们首先提出了一种新颖的自适应GAN合成方法,以估计水参数和水下噪声分布,生成特定环境的合成水下图像。然后,我们介绍了一个与不同教师模型兼容的通用知识蒸馏框架。基于GAN的合成评估突出了新组件,即GAN合成噪声和前向散射,在拟议模型中的重要性。此外,VSLAM作为特征提取和匹配的下游应用的代表,被用于真实的水下序列,以验证转移模型的有效性。项目页面:https://github.com/Jinghe-mel/UFEN-GAN。
论文及项目相关链接
Summary
本论文聚焦于在浑浊水下环境中提高特征提取与匹配的稳健性。采用跨模态知识蒸馏方法,借助合成水下图像,将空中特征提取与匹配模型转移至水下场景。创新性地提出自适应GAN合成方法,用于估算水参数和噪声分布,生成针对环境的水下图像。此外,还引入与不同教师模型兼容的一般知识蒸馏框架。通过基于GAN的合成评估验证了新方法的有效性。同时,采用视觉SLAM作为特征提取与匹配下游应用的代表,在真实水下序列上验证了转移模型的有效性。
Key Takeaways
- AUVs在浑浊水下环境中面临特征提取和匹配的挑战。图像模糊和噪声影响特征提取与匹配效果。
- 采用跨模态知识蒸馏方法提高水下环境特征提取与匹配的稳健性。利用合成水下图像将空中模型转移至水下场景。
- 提出自适应GAN合成方法,用于估算水参数和噪声分布,生成环境特定的水下图像。此方法是提高知识蒸馏效率的关键步骤之一。
- 介绍通用知识蒸馏框架,兼容多种教师模型,提升模型的适应性和灵活性。
- 基于GAN的合成评估验证了新方法的有效性,其中GAN合成的噪声和前向散射等要素起到了重要作用。
- 采用视觉SLAM作为特征提取与匹配的下游应用代表,验证转移模型在实际水下场景中的效果。
- 项目页面提供详细信息和代码链接(https://github.com/Jinghe-mel/UFEN-GAN)。
点此查看论文截图


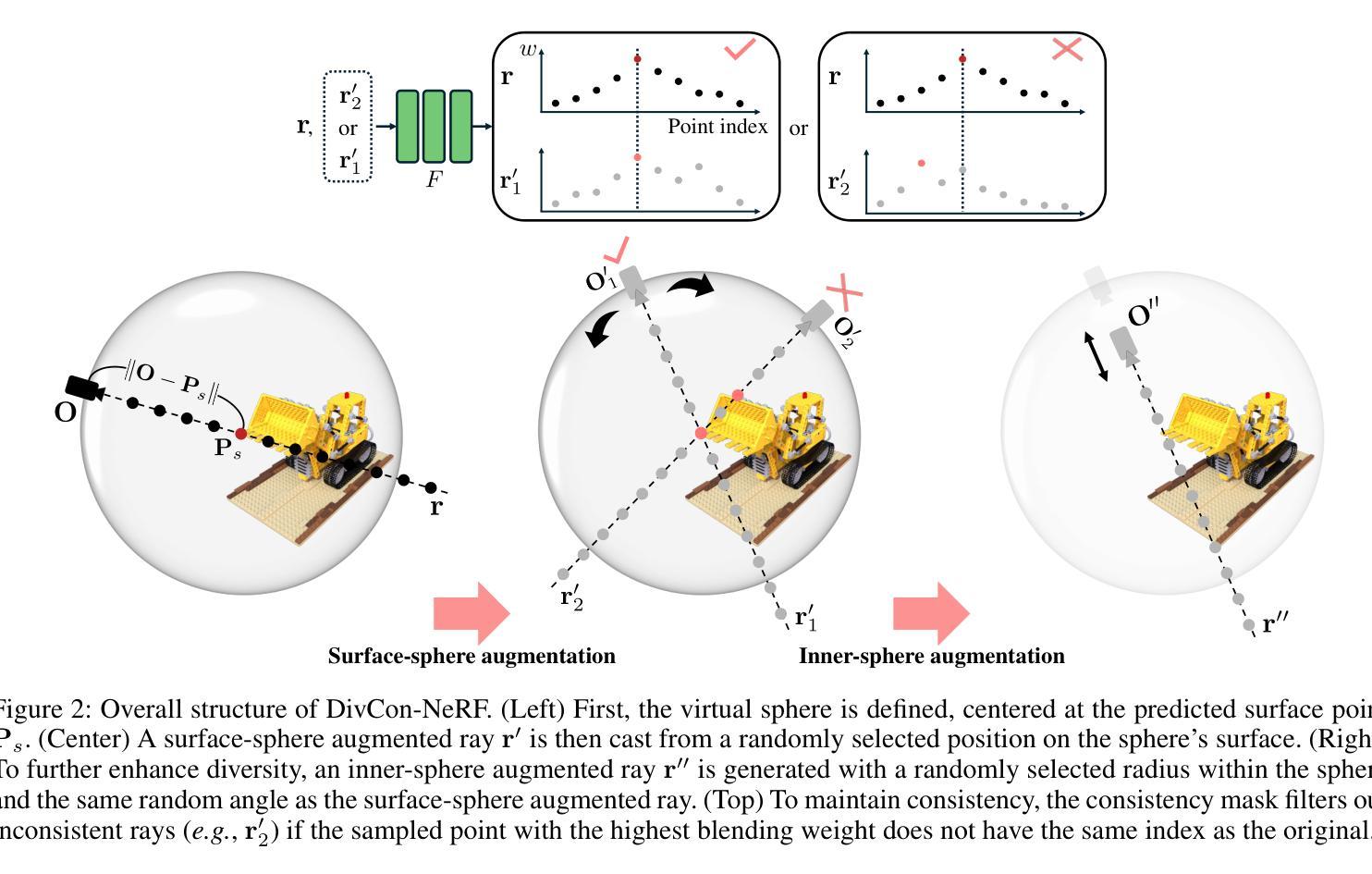
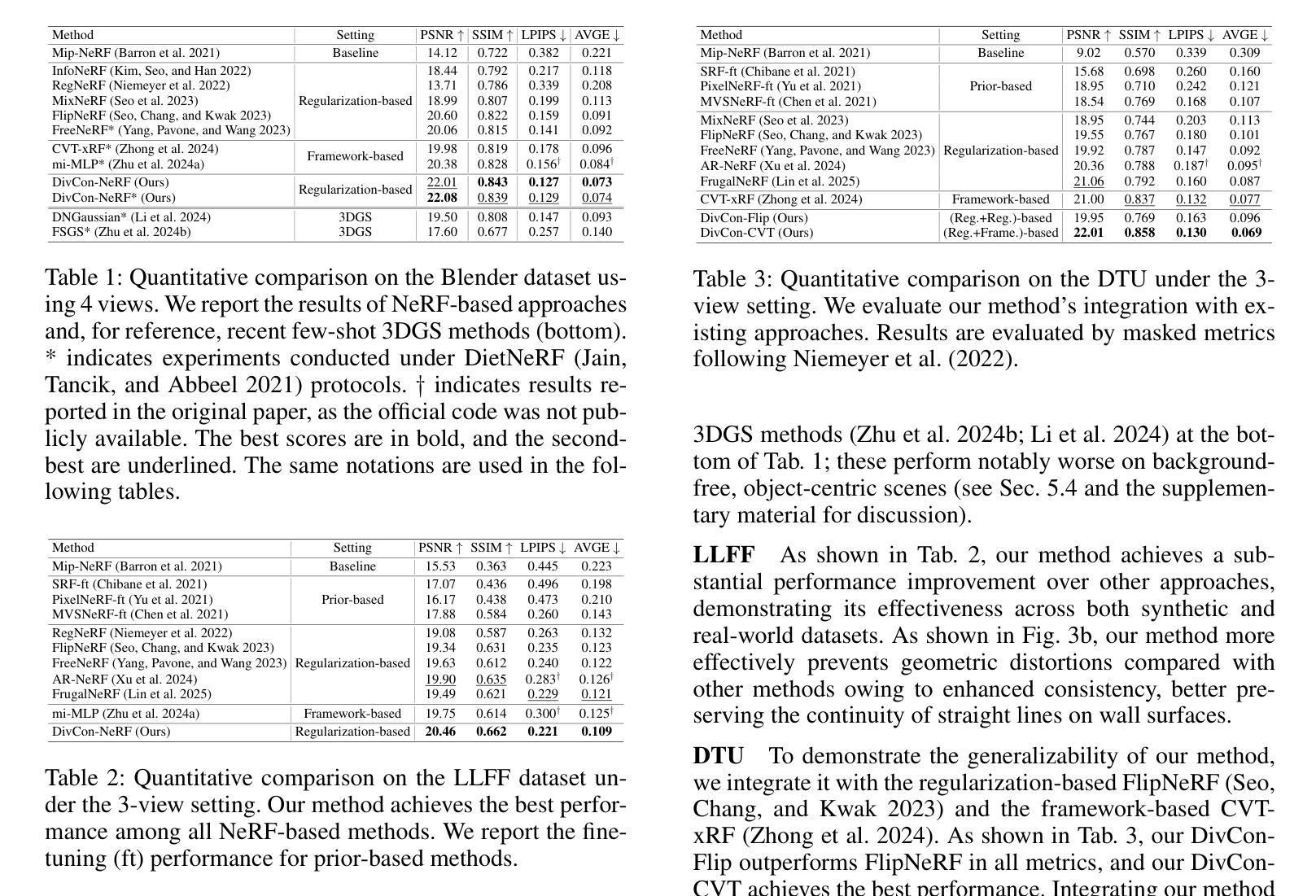
DivCon-NeRF: Diverse and Consistent Ray Augmentation for Few-Shot NeRF
Authors:Ingyun Lee, Jae Won Jang, Seunghyeon Seo, Nojun Kwak
Neural Radiance Field (NeRF) has shown remarkable performance in novel view synthesis but requires numerous multi-view images, limiting its practicality in few-shot scenarios. Ray augmentation has been proposed to alleviate overfitting caused by sparse training data by generating additional rays. However, existing methods, which generate augmented rays only near the original rays, exhibit pronounced floaters and appearance distortions due to limited viewpoints and inconsistent rays obstructed by nearby obstacles and complex surfaces. To address these problems, we propose DivCon-NeRF, which introduces novel sphere-based ray augmentations to significantly enhance both diversity and consistency. By employing a virtual sphere centered at the predicted surface point, our method generates diverse augmented rays from all 360-degree directions, facilitated by our consistency mask that effectively filters out inconsistent rays. We introduce tailored loss functions that leverage these augmentations, effectively reducing floaters and visual distortions. Consequently, our method outperforms existing few-shot NeRF approaches on the Blender, LLFF, and DTU datasets. Furthermore, DivCon-NeRF demonstrates strong generalizability by effectively integrating with both regularization- and framework-based few-shot NeRFs. Our code will be made publicly available.
神经辐射场(NeRF)在新型视图合成中展现出了显著的性能,但需要大量多视图图像,这在少量场景的情况下限制了其实用性。射线增强法被提出来通过生成额外的射线来缓解由稀疏训练数据引起的过拟合问题。然而,现有方法仅在原始射线附近生成增强射线,由于有限的观点、附近障碍物的阻挡以及复杂表面的不一致性,会出现明显的浮点和外观失真。为了解决这些问题,我们提出了DivCon-NeRF,它引入了基于球体的新型射线增强法,以显著提高多样性和一致性。通过以预测的表面点为中心构建一个虚拟球体,我们的方法从所有360度方向生成多样化的增强射线,这得益于我们的一致性掩码,它能有效地过滤出不一致的射线。我们引入了利用这些增强的定制损失函数,有效地减少了浮点和视觉失真。因此,我们的方法在Blender、LLFF和DTU数据集上的少量射击NeRF方法表现优越。此外,DivCon-NeRF通过有效地与基于正则化和框架的少量射击NeRF相结合,表现出强大的泛化能力。我们的代码将公开发布。
论文及项目相关链接
PDF 9 pages, 6 figures
Summary
神经网络辐射场(NeRF)在新型视角合成方面展现出卓越性能,但需依赖大量多视角图像,限制了其在小样本场景中的应用。为解决因稀疏训练数据导致的过拟合问题,研究者提出了射线增强技术。然而,现有方法仅在接近原始射线时生成增强射线,在有限视角和复杂表面下的邻近障碍物的阻碍下,容易出现明显的浮动和外观失真。为此,本文提出DivCon-NeRF方法,引入基于球体的新型射线增强技术,显著提高了多样性和一致性。通过以预测表面点为中心的虚拟球体生成来自所有360度方向的多样化增强射线,并使用一致性掩膜有效过滤出不一致的射线。此外,本文还引入利用这些增强的定制损失函数,有效减少浮动和视觉失真。该方法在Blender、LLFF和DTU数据集上均优于现有小样本NeRF方法,并展示了强大的泛化能力,能有效整合正则化和框架式小样本NeRFs。
Key Takeaways
- NeRF技术在新型视角合成领域表现优异,但受限于需要大量多视角图像,对小样本场景实用性有限。
- 现有射线增强技术主要解决稀疏数据过拟合问题,但存在因视角和障碍物导致的浮动和外观失真问题。
- DivCon-NeRF方法通过引入基于球体的新型射线增强技术,提高多样性和一致性。
- 采用虚拟球体生成增强射线,覆盖全部360度方向,使用一致性掩膜过滤不一致射线。
- 定制损失函数利用增强射线,有效减少浮动和视觉失真。
- DivCon-NeRF在多个数据集上表现优于现有小样本NeRF方法。
点此查看论文截图