⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-08 更新
A Multi-stage Low-latency Enhancement System for Hearing Aids
Authors:Chengwei Ouyang, Kexin Fei, Haoshuai Zhou, Congxi Lu, Linkai Li
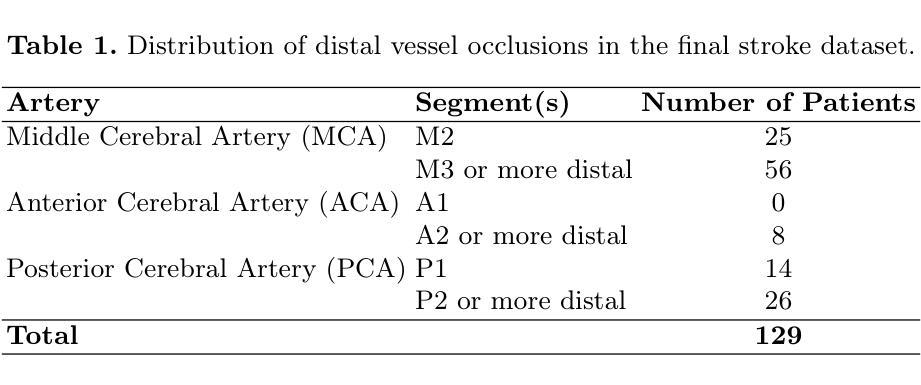
This paper proposes an end-to-end system for the ICASSP 2023 Clarity Challenge. In this work, we introduce four major novelties: (1) a novel multi-stage system in both the magnitude and complex domains to better utilize phase information; (2) an asymmetric window pair to achieve higher frequency resolution with the 5ms latency constraint; (3) the integration of head rotation information and the mixture signals to achieve better enhancement; (4) a post-processing module that achieves higher hearing aid speech perception index (HASPI) scores with the hearing aid amplification stage provided by the baseline system.
本文旨在为ICASSP 2023清晰度挑战赛提出一种端到端系统。在这项工作中,我们引入了四个主要新颖之处:(1)在幅度和复杂域中引入新型的多阶段系统,以更好地利用相位信息;(2)采用不对称窗口对,在5毫秒延迟约束下实现更高的频率分辨率;(3)将头部旋转信息和混合信号相结合,以实现更好的增强效果;(4)后处理模块的实现,该模块借助基线系统提供的助听器放大阶段,实现了更高的助听语音感知指数(HASPI)分数。
论文及项目相关链接
PDF 2 pages, 1 figure, 1 table. accepted to ICASSP 2023
Summary
本文提出一个面向ICASSP 2023 Clarity Challenge的端到端系统,并引入四项重大创新:一是在幅度和复数域的多阶段系统以更好地利用相位信息;二是对称窗口对实现高频分辨率同时满足5毫秒延迟限制;三是整合头部旋转信息和混合信号实现更佳增强效果;四是后处理模块提高听力辅助装置的语音感知指数(HASPI)分数,基于基线系统提供的听力辅助放大阶段。
Key Takeaways
- 引入多阶段系统利用相位信息以提高性能。
- 采用不对称窗口对满足延迟约束并提高频率分辨率。
- 整合头部旋转信息和混合信号以实现更好的声音增强。
- 后处理模块提高听力辅助装置的语音感知指数(HASPI)分数。
- 系统面向ICASSP 2023 Clarity Challenge设计。
- 该系统改进了基线系统的听力辅助放大阶段。
点此查看论文截图

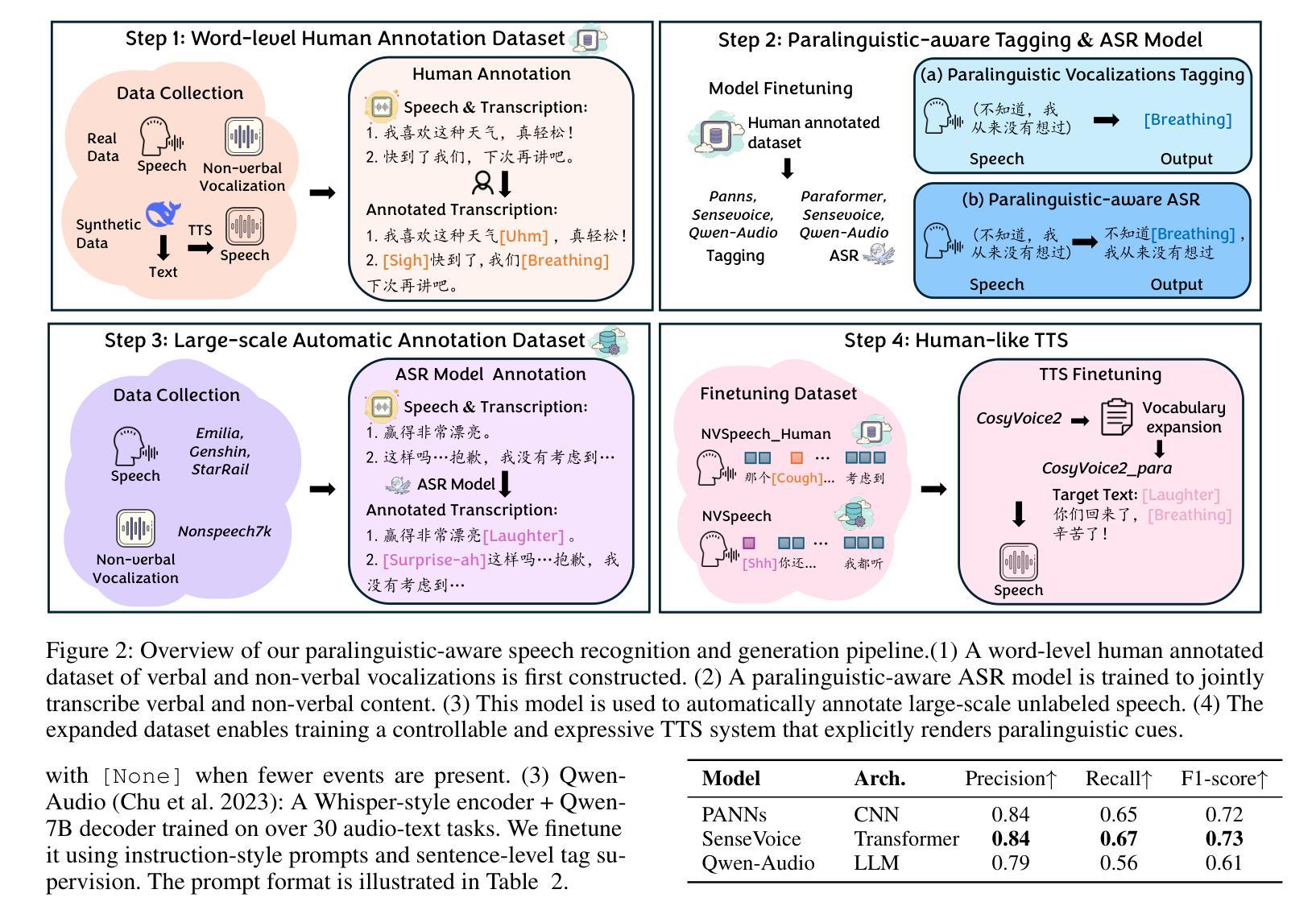
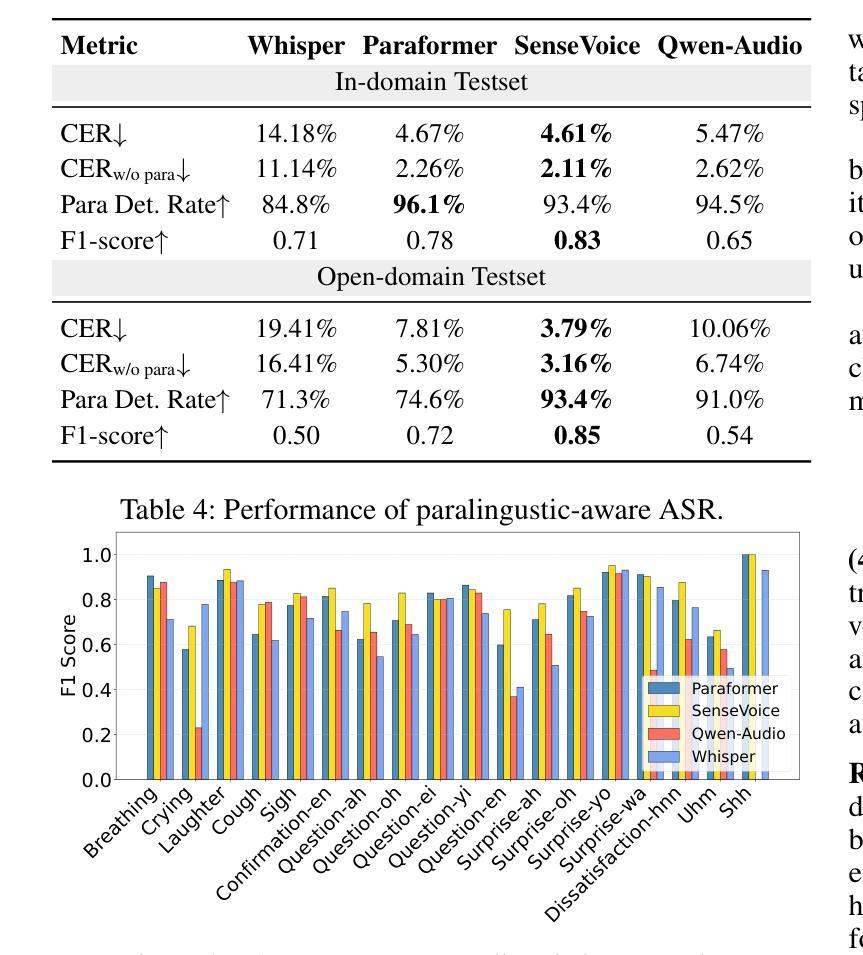
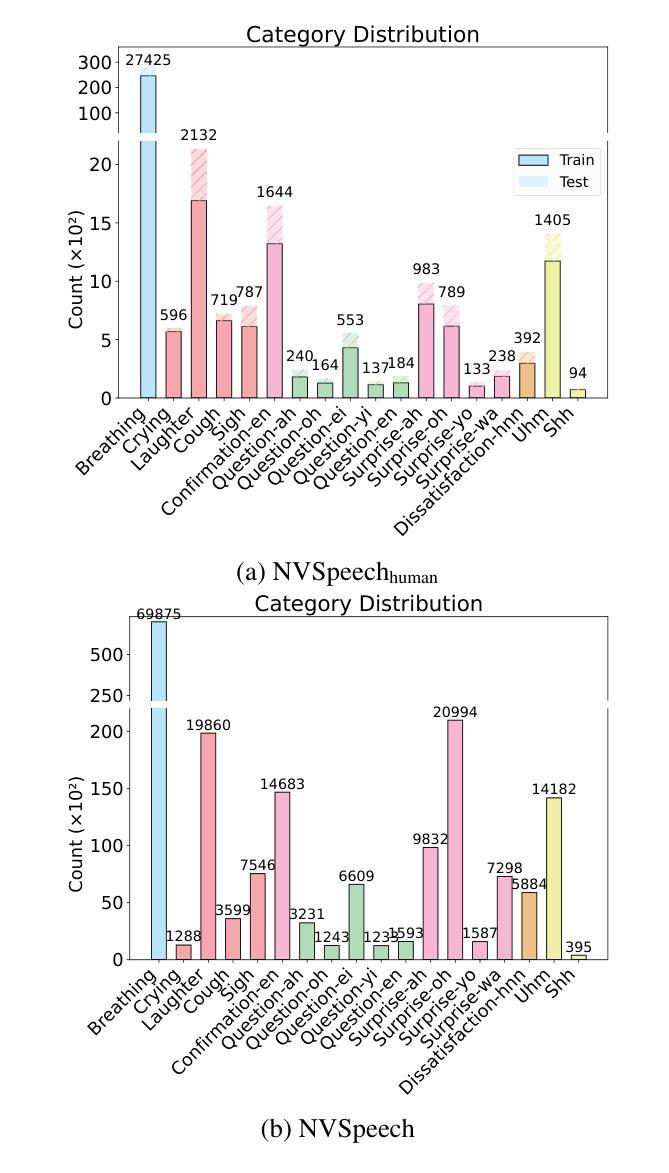
NVSpeech: An Integrated and Scalable Pipeline for Human-Like Speech Modeling with Paralinguistic Vocalizations
Authors:Huan Liao, Qinke Ni, Yuancheng Wang, Yiheng Lu, Haoyue Zhan, Pengyuan Xie, Qiang Zhang, Zhizheng Wu
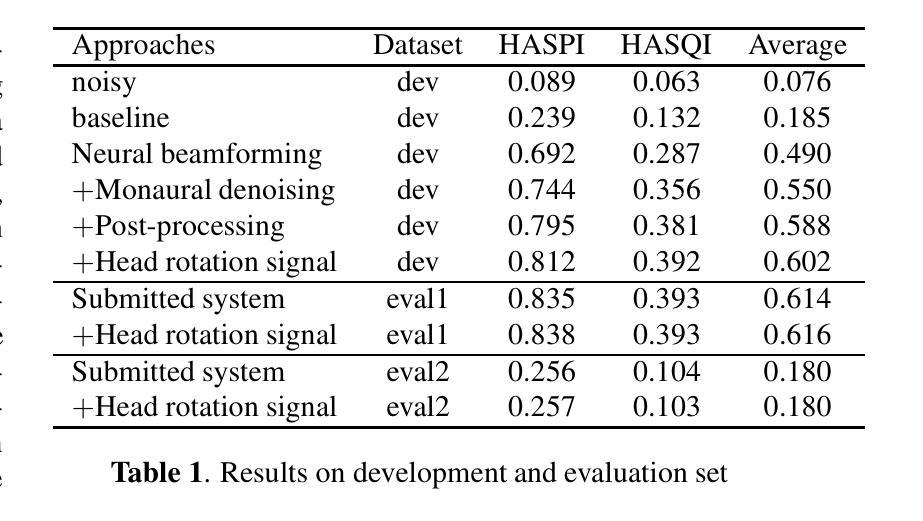
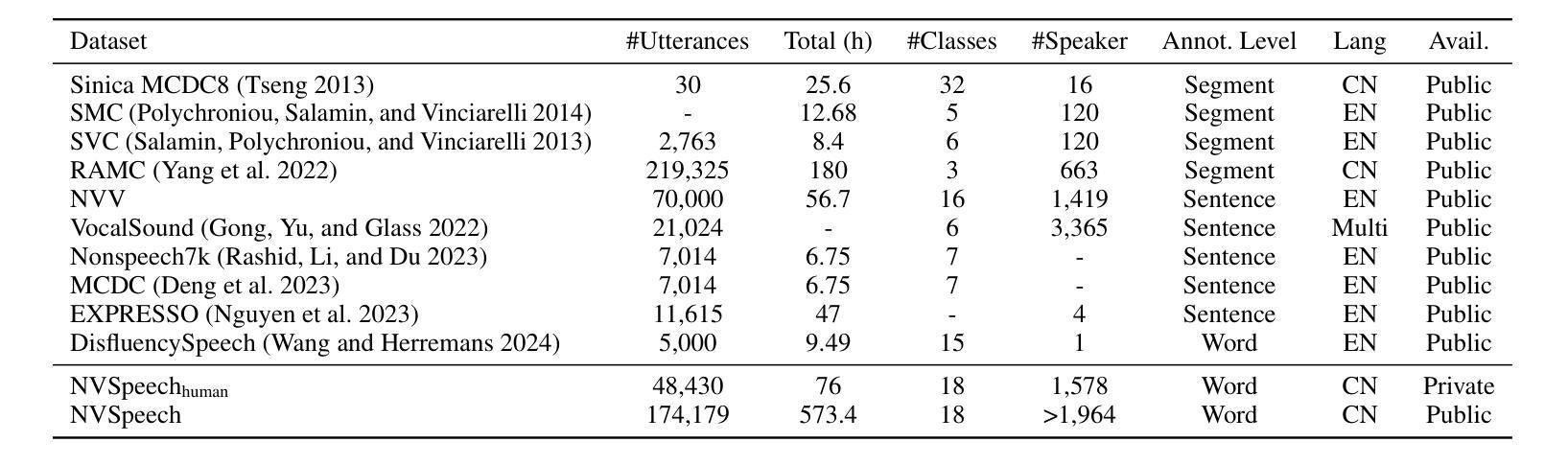
Paralinguistic vocalizations-including non-verbal sounds like laughter and breathing, as well as lexicalized interjections such as “uhm” and “oh”-are integral to natural spoken communication. Despite their importance in conveying affect, intent, and interactional cues, such cues remain largely overlooked in conventional automatic speech recognition (ASR) and text-to-speech (TTS) systems. We present NVSpeech, an integrated and scalable pipeline that bridges the recognition and synthesis of paralinguistic vocalizations, encompassing dataset construction, ASR modeling, and controllable TTS. (1) We introduce a manually annotated dataset of 48,430 human-spoken utterances with 18 word-level paralinguistic categories. (2) We develop the paralinguistic-aware ASR model, which treats paralinguistic cues as inline decodable tokens (e.g., “You’re so funny [Laughter]”), enabling joint lexical and non-verbal transcription. This model is then used to automatically annotate a large corpus, the first large-scale Chinese dataset of 174,179 utterances (573 hours) with word-level alignment and paralingustic cues. (3) We finetune zero-shot TTS models on both human- and auto-labeled data to enable explicit control over paralinguistic vocalizations, allowing context-aware insertion at arbitrary token positions for human-like speech synthesis. By unifying the recognition and generation of paralinguistic vocalizations, NVSpeech offers the first open, large-scale, word-level annotated pipeline for expressive speech modeling in Mandarin, integrating recognition and synthesis in a scalable and controllable manner. Dataset and audio demos are available at https://nvspeech170k.github.io/.
副语言发声——包括非语言性的声音,如笑声和呼吸声,以及词汇化的感叹词,如“呃”和“哦”——是自然口语交流的重要组成部分。尽管它们在传达情感、意图和交互线索方面非常重要,但这些线索在传统的自动语音识别(ASR)和文本到语音(TTS)系统中仍然被忽视。我们提出了NVSpeech,这是一个集成且可扩展的管道,能够识别并合成副语言发声,包括数据集构建、ASR建模和可控TTS。
(1)我们介绍了一个包含48430个人类口语发声、分为18个词汇级副语言类别的手动注释数据集。
(2)我们开发了一个副语言感知ASR模型,该模型将副语言线索视为内联可解码的令牌(例如,“你很有趣[笑声]”),从而实现词汇和非言语的联合转录。然后,该模型被用来自动注释大规模语料库,这是首个大规模的中文数据集,包含174179个发声(573小时),具有词汇级对齐和副语言线索。
论文及项目相关链接
Summary
本文介绍了在自然口语交流中的重要性非言语声音和词汇化插入语,它们能够传递情感、意图和交互线索。针对目前自动语音识别(ASR)和文本到语音(TTS)系统对此类线索的忽视,本文提出了NVSpeech,一个能够识别和合成非言语语音的集成和可扩展管道,包括数据集构建、ASR建模和可控TTS。NVSpeech为普通话的表达性语音建模提供了首个开放的大规模词级注释管道,以可扩展和可控的方式统一识别和生成非言语语音。
Key Takeaways
- 非言语声音和词汇化插入语对自然口语交流至关重要,能传递情感、意图和交互线索。
- NVSpeech是一个集成和可扩展的管道,能够识别和合成非言语语音,包括数据集构建、ASR建模和可控TTS。
- 引入了包含18个词级非言语类别的手动注释数据集,包含48,430个人类语音片段。
- 开发了将非言语线索视为内联可解码标记的ASR模型,实现了词汇和非言语的联合转录。
- 使用此模型自动注释了一个大规模语料库,这是首个大规模中文语料库,包含174,179个语音片段(573小时),具有词级对齐和非言语线索。
- 对零样本TTS模型进行了微调,使其能够在人类和自动标记的数据上显式控制非言语语音,允许在任意标记位置插入上下文感知信息以实现人类般的语音合成。
点此查看论文截图

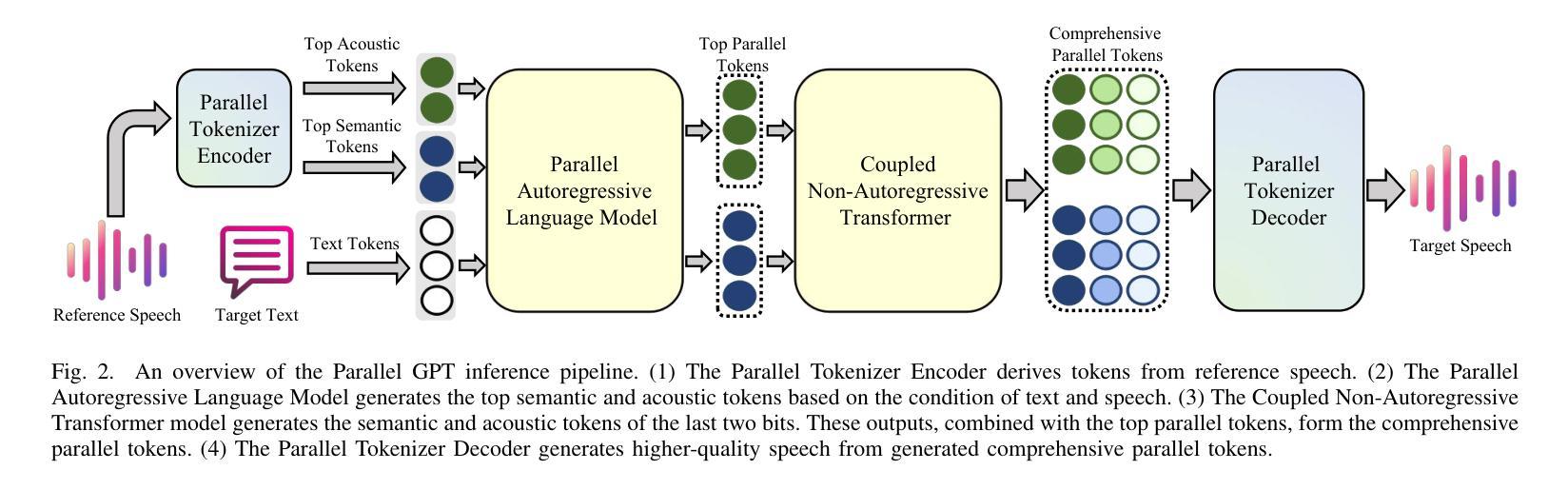
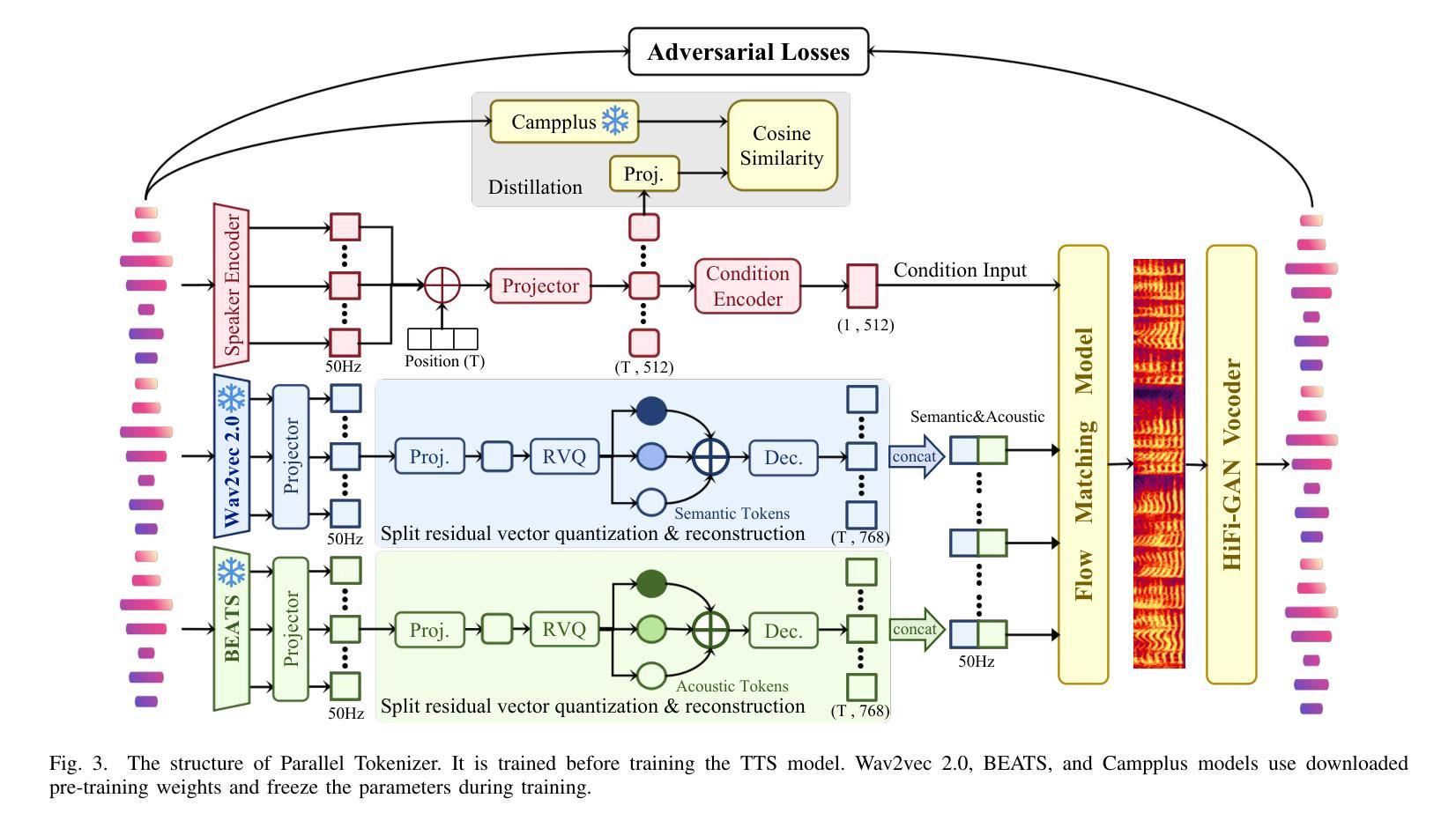
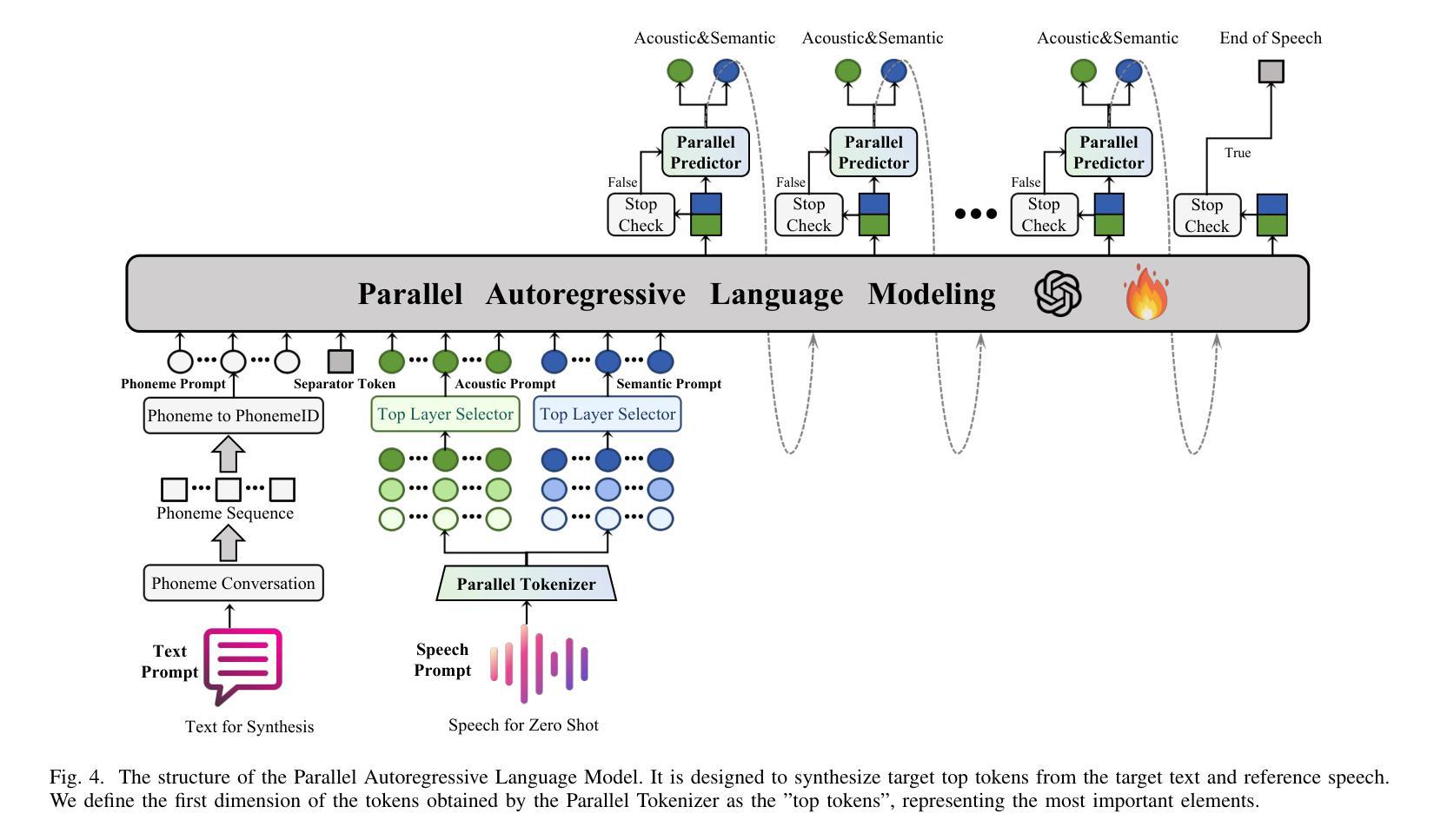
Parallel GPT: Harmonizing the Independence and Interdependence of Acoustic and Semantic Information for Zero-Shot Text-to-Speech
Authors:Jingyuan Xing, Zhipeng Li, Jialong Mai, Xiaofen Xing, Xiangmin Xu
Advances in speech representation and large language models have enhanced zero-shot text-to-speech (TTS) performance. However, existing zero-shot TTS models face challenges in capturing the complex correlations between acoustic and semantic features, resulting in a lack of expressiveness and similarity. The primary reason lies in the complex relationship between semantic and acoustic features, which manifests independent and interdependent aspects.This paper introduces a TTS framework that combines both autoregressive (AR) and non-autoregressive (NAR) modules to harmonize the independence and interdependence of acoustic and semantic information. The AR model leverages the proposed Parallel Tokenizer to synthesize the top semantic and acoustic tokens simultaneously. In contrast, considering the interdependence, the Coupled NAR model predicts detailed tokens based on the general AR model’s output. Parallel GPT, built on this architecture, is designed to improve zero-shot text-to-speech synthesis through its parallel structure. Experiments on English and Chinese datasets demonstrate that the proposed model significantly outperforms the quality and efficiency of the synthesis of existing zero-shot TTS models. Speech demos are available at https://t1235-ch.github.io/pgpt/.
随着语音表征和大语言模型的进步,零样本文本到语音(TTS)的性能得到了提升。然而,现有的零样本TTS模型在捕捉声学特征和语义特征之间的复杂关联方面面临挑战,导致表现力不足和相似性不足。主要原因在于语义和声学特征之间的复杂关系,这种关系表现出独立和相互依存的方面。
论文及项目相关链接
PDF Submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)
Summary
随着语音表征和大型语言模型的进步,零样本文本到语音(TTS)性能有所提升。但现有零样本TTS模型在捕捉声学语义特征复杂关联方面存在挑战,导致表现力不足和相似性缺失。本文引入一种结合自回归(AR)和非自回归(NAR)模块的TTS框架,以协调声学语义信息的独立性和相互依赖性。AR模型利用并行分词器合成顶级语义和声音标记,而耦合的NAR模型基于AR模型的输出预测详细的标记。基于这种架构构建的并行GPT旨在通过其并行结构改进零样本文本到语音的合成。实验表明,该模型在合成质量和效率上显著优于现有零样本TTS模型。
Key Takeaways
- 语音表征和大型语言模型的进步提升了零样本文本到语音(TTS)的性能。
- 现有TTS模型在捕捉声学语义特征复杂关联方面存在挑战,缺乏表达力和相似性。
- 本文结合AR和NAR模块创建了一个TTS框架,以协调声学语义信息的独立和相互依赖关系。
- AR模型利用并行分词器同时合成语义和声音标记。
- NAR模型基于AR模型的输出预测详细的标记,以考虑特征间的相互依赖性。
- 并行GPT的架构改进了零样本文本到语音的合成质量和效率。
- 实验结果表明,该模型在多个数据集上显著优于现有零样本TTS模型。
点此查看论文截图

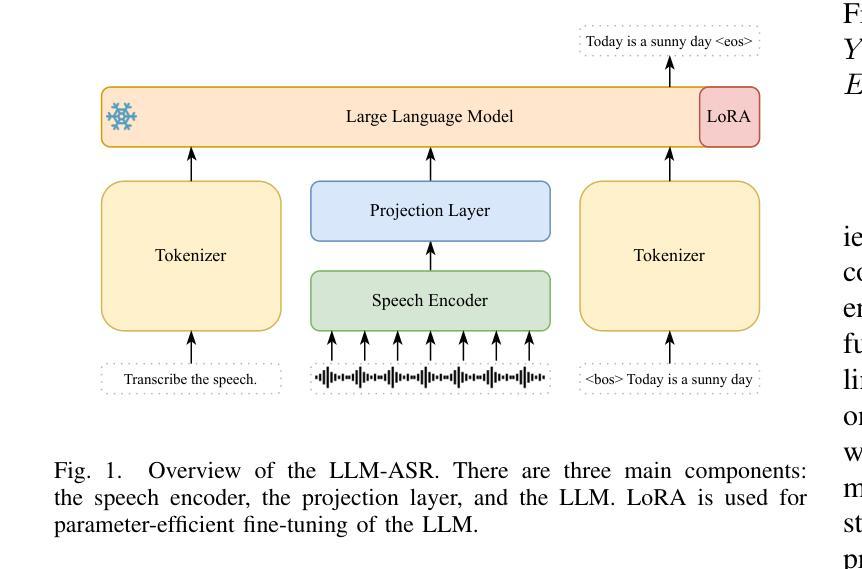
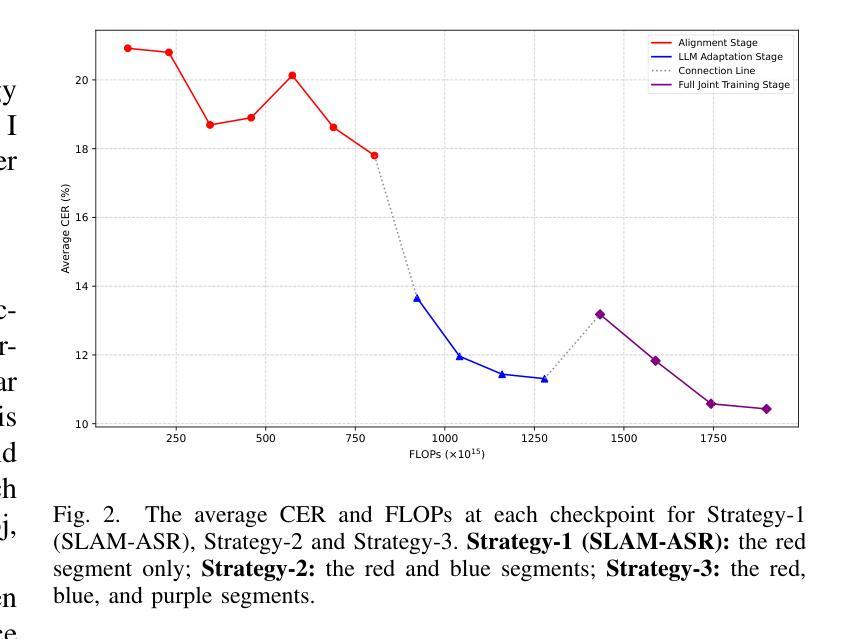
Efficient Scaling for LLM-based ASR
Authors:Bingshen Mu, Yiwen Shao, Kun Wei, Dong Yu, Lei Xie
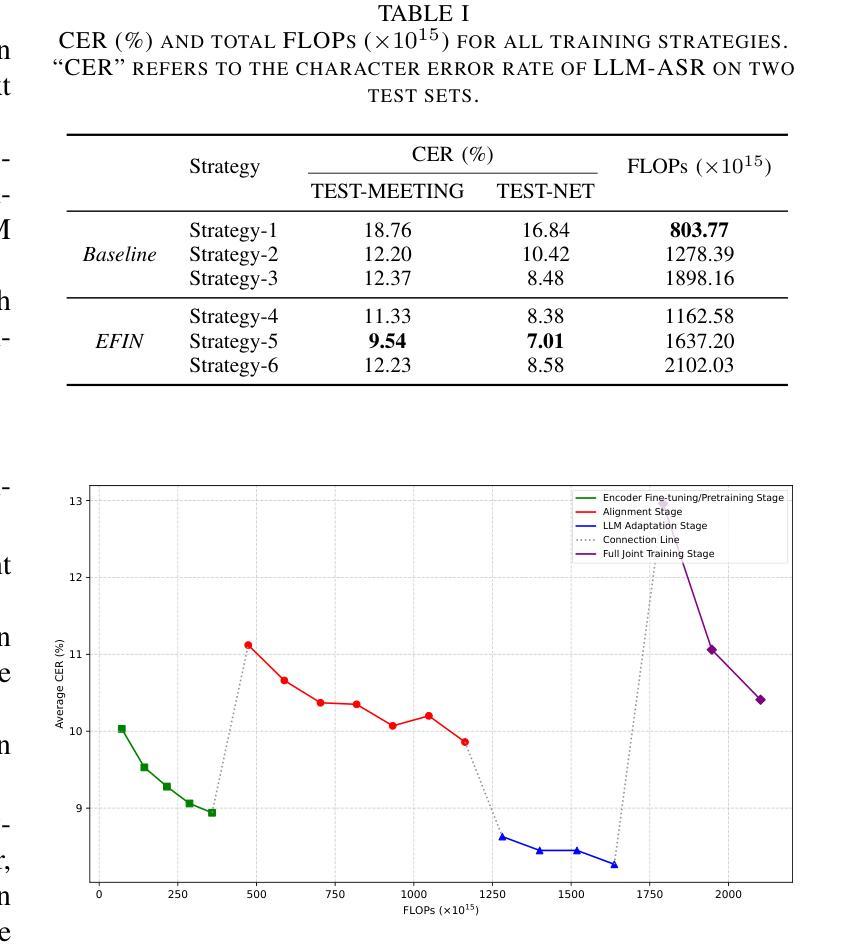
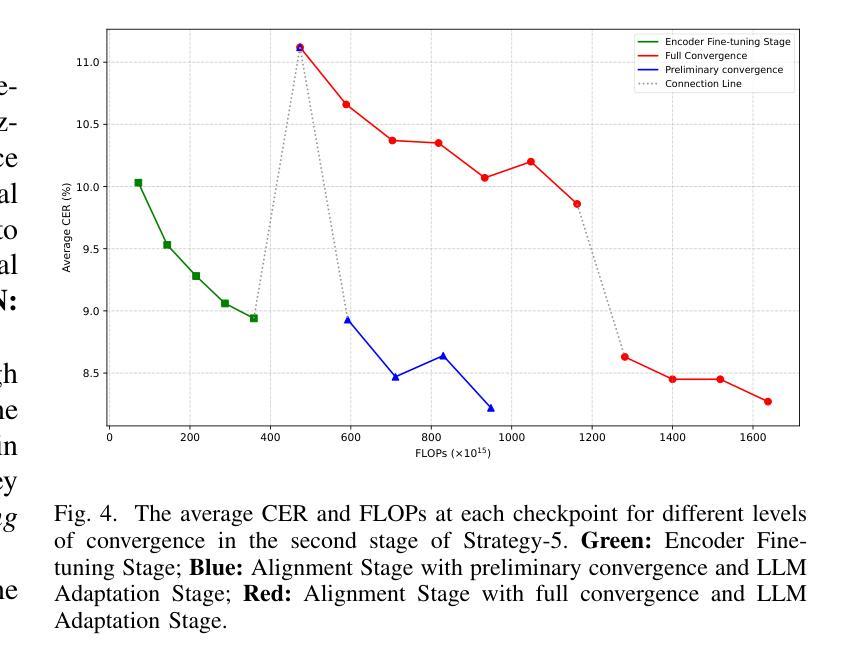
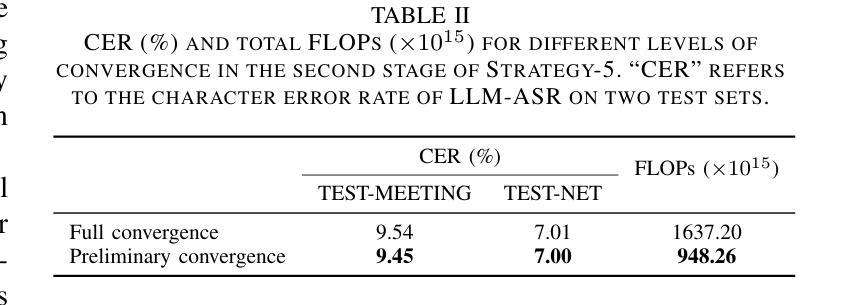
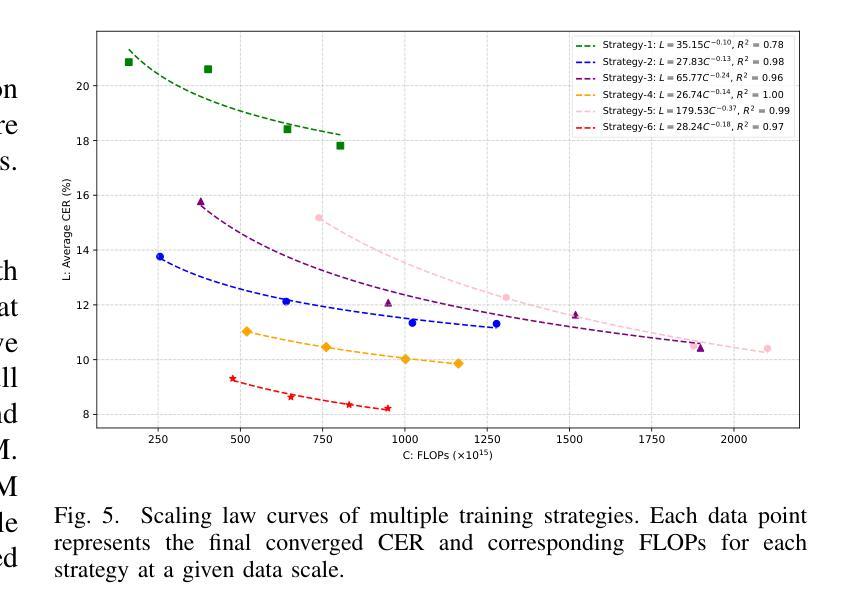
Large language model (LLM)-based automatic speech recognition (ASR) achieves strong performance but often incurs high computational costs. This work investigates how to obtain the best LLM-ASR performance efficiently. Through comprehensive and controlled experiments, we find that pretraining the speech encoder before integrating it with the LLM leads to significantly better scaling efficiency than the standard practice of joint post-training of LLM-ASR. Based on this insight, we propose a new multi-stage LLM-ASR training strategy, EFIN: Encoder First Integration. Among all training strategies evaluated, EFIN consistently delivers better performance (relative to 21.1% CERR) with significantly lower computation budgets (49.9% FLOPs). Furthermore, we derive a scaling law that approximates ASR error rates as a computation function, providing practical guidance for LLM-ASR scaling.
基于大型语言模型(LLM)的自动语音识别(ASR)取得了强大的性能,但往往计算成本较高。这项工作旨在以高效的方式获得最佳的LLM-ASR性能。通过全面且受控的实验,我们发现,在将其与LLM集成之前对语音编码器进行预训练,与LLM-ASR的联合后训练的标准实践相比,可以显著提高扩展效率。基于这一发现,我们提出了一种新的多阶段LLM-ASR训练策略EFIN(Encoder First Integration)。在所有评估的训练策略中,EFIN始终在性能上表现更好(相对于21.1%的CERR),同时计算预算显著降低(49.9%的FLOPs)。此外,我们得出了近似ASR错误率作为计算函数的扩展定律,为LLM-ASR的扩展提供了实际指导。
论文及项目相关链接
PDF Accepted by ASRU 2025
Summary
基于大型语言模型(LLM)的自动语音识别(ASR)性能出色,但计算成本较高。本研究旨在以高效的方式获得最佳的LLM-ASR性能。通过全面且受控的实验,我们发现预训练语音编码器再将其与LLM集成,相较于标准联合后训练方式,能显著提高扩展效率。基于此,我们提出了一种新的多阶段LLM-ASR训练策略——EFIN(编码器优先集成)。在评估的所有训练策略中,EFIN在性能上表现更优秀,相对误差率降低21.1%,计算预算显著降低(FLOPs减少49.9%)。此外,我们还推导出一个近似ASR错误率与计算量的关系公式,为LLM-ASR的扩展提供了实际指导。
Key Takeaways
- 预训练语音编码器再与LLM集成,能提高LLM-ASR的扩展效率。
- EFIN训练策略在性能上表现优越,相对误差率降低21.1%,计算预算减少49.9%。
- EFIN策略是一种多阶段训练策略,包括编码器优先集成。
- 全面的实验验证了EFIN策略的有效性。
- 推导出一个近似ASR错误率与计算量的关系公式,为LLM-ASR的扩展提供指导。
- LLM-ASR在计算成本方面仍有待优化。
点此查看论文截图

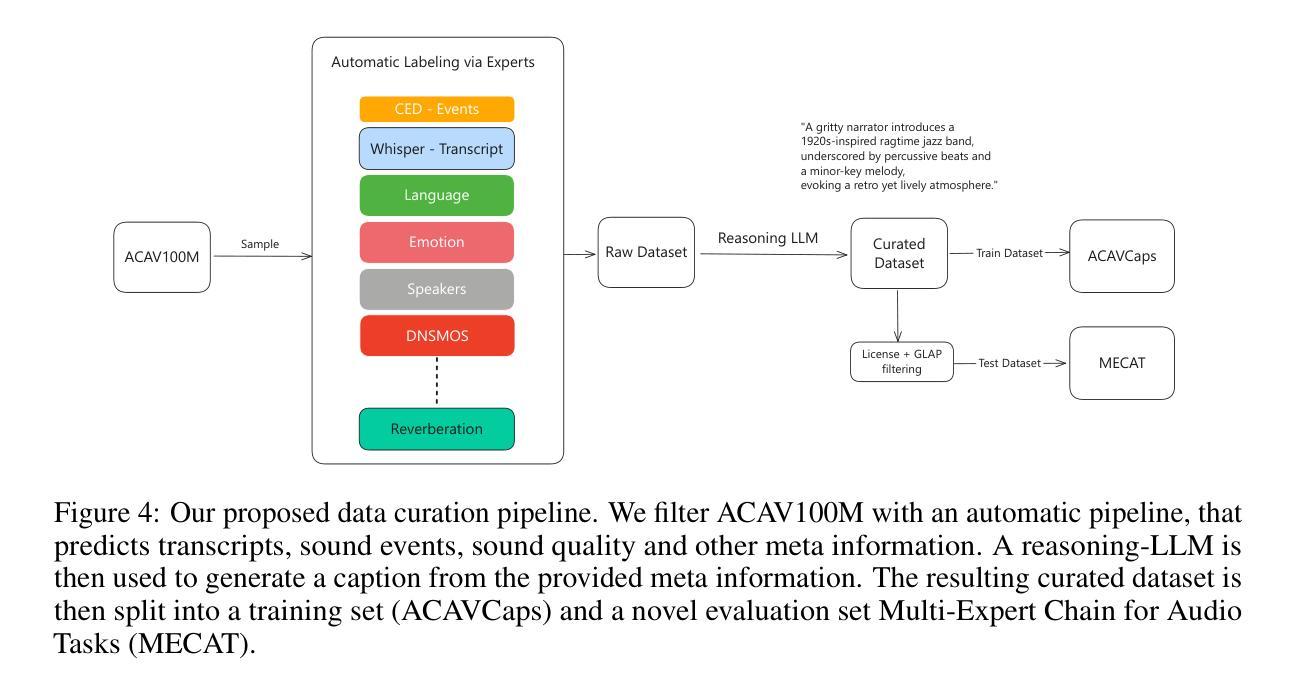
MiDashengLM: Efficient Audio Understanding with General Audio Captions
Authors:Heinrich Dinkel, Gang Li, Jizhong Liu, Jian Luan, Yadong Niu, Xingwei Sun, Tianzi Wang, Qiyang Xiao, Junbo Zhang, Jiahao Zhou
Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
当前的大型音频语言模型(LALM)方法常常依赖于封闭数据源或专有模型,这限制了其通用性和可访问性。本文介绍了MiDashengLM,这是一种新型开放音频语言模型,通过使用我们新型ACAVCaps训练数据集的一般音频字幕,旨在实现高效且全面的音频理解。MiDashengLM完全依赖于公开可用的预训练和监督微调(SFT)数据集,确保完全透明和可重复性。其核心融合了Dasheng这一开源音频编码器,专门用于有效处理各种听觉信息。与之前主要关注基于自动语音识别(ASR)的音频文本对齐的策略不同,我们的策略侧重于一般音频字幕,将语音、声音和音乐信息融合到一种文本表示中,实现对复杂音频场景的整体文本表示。最后,MiDashengLM在首次令牌时间(TTFT)方面提供了高达4倍的加速,并且与同类模型相比,吞吐量高达20倍。检查点数据可以在https://huggingface.co/mispeech/midashenglm-7b和https://github.com/xiaomi-research/dasheng-lm在线获得。
论文及项目相关链接
Summary
MiDashengLM是一个基于公开预训练和监督微调数据集的新型开放音频语言模型,通过通用音频字幕ACAVCaps训练数据集实现高效全面的音频理解。它融合了语音、声音和音乐信息,提供全面的音频场景文本表示,与专注于语音识别音频文本对齐的先前方法不同。此外,MiDashengLM的模型运行速度比同类模型快,提供更快的响应时间。
Key Takeaways
- MiDashengLM是一个用于音频理解的开放音频语言模型,基于公开数据预训练和监督微调数据集。
- 它通过ACAVCaps训练数据集实现高效全面的音频理解。
- MiDashengLM融合了语音、声音和音乐信息,提供全面的音频场景文本表示。
- 与专注于语音识别音频文本对齐的先前方法不同,MiDashengLM的策略侧重于通用音频字幕。
- MiDashengLM模型运行速度更快,提供更快的响应时间,与同类模型相比,时间至第一令牌(TTFT)速度提高了最多4倍,吞吐量提高了高达20倍。
- MiDashengLM使用Dasheng这一开源音频编码器处理各种听觉信息。
点此查看论文截图

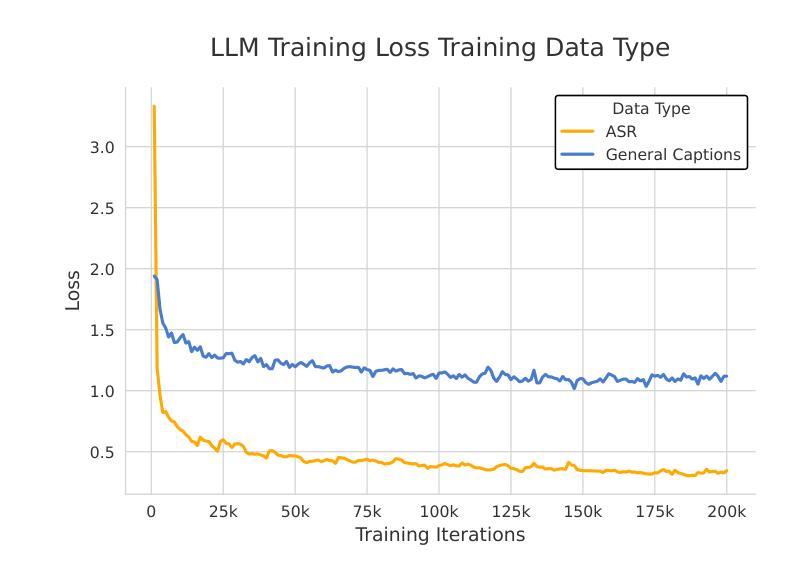
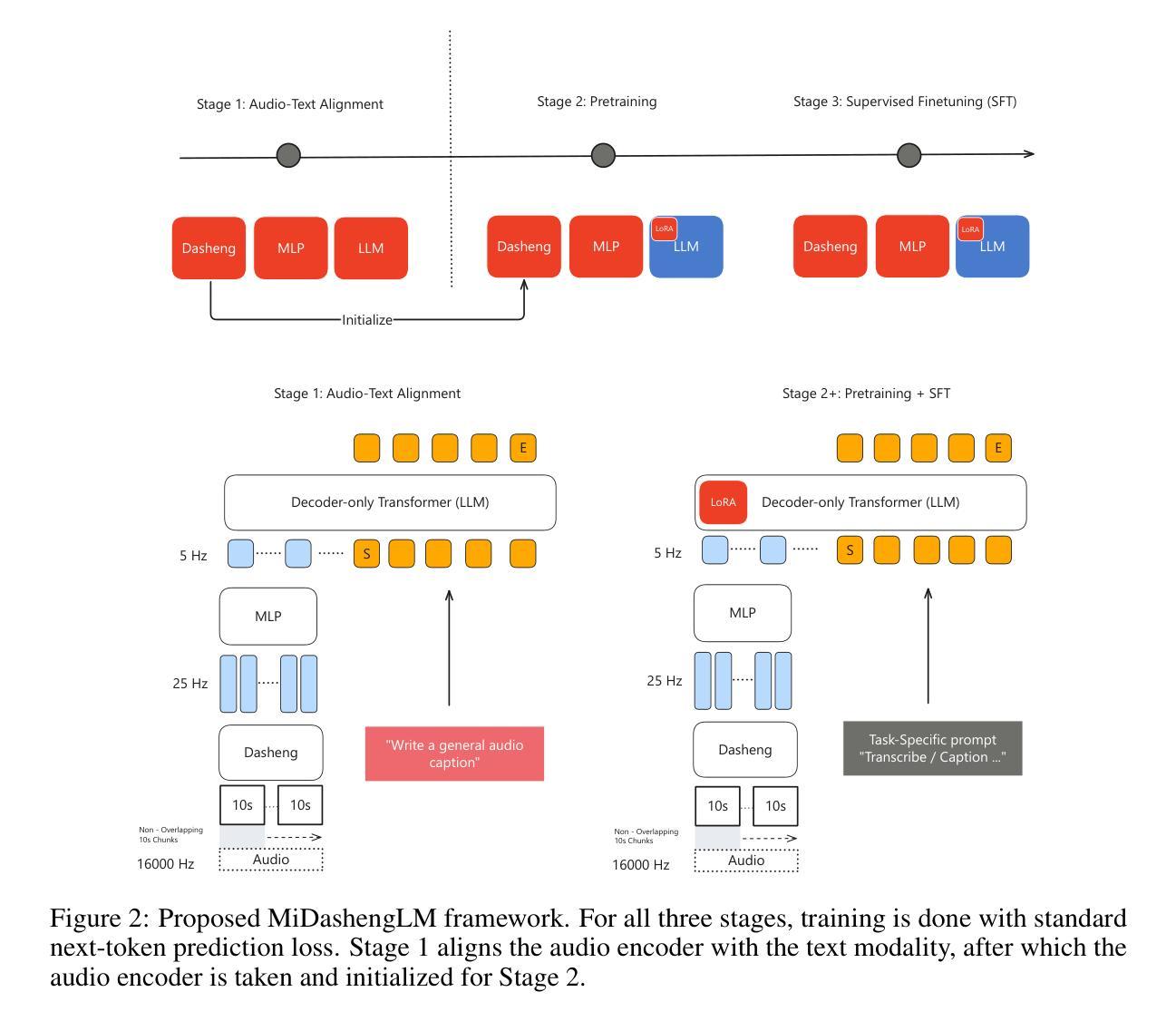
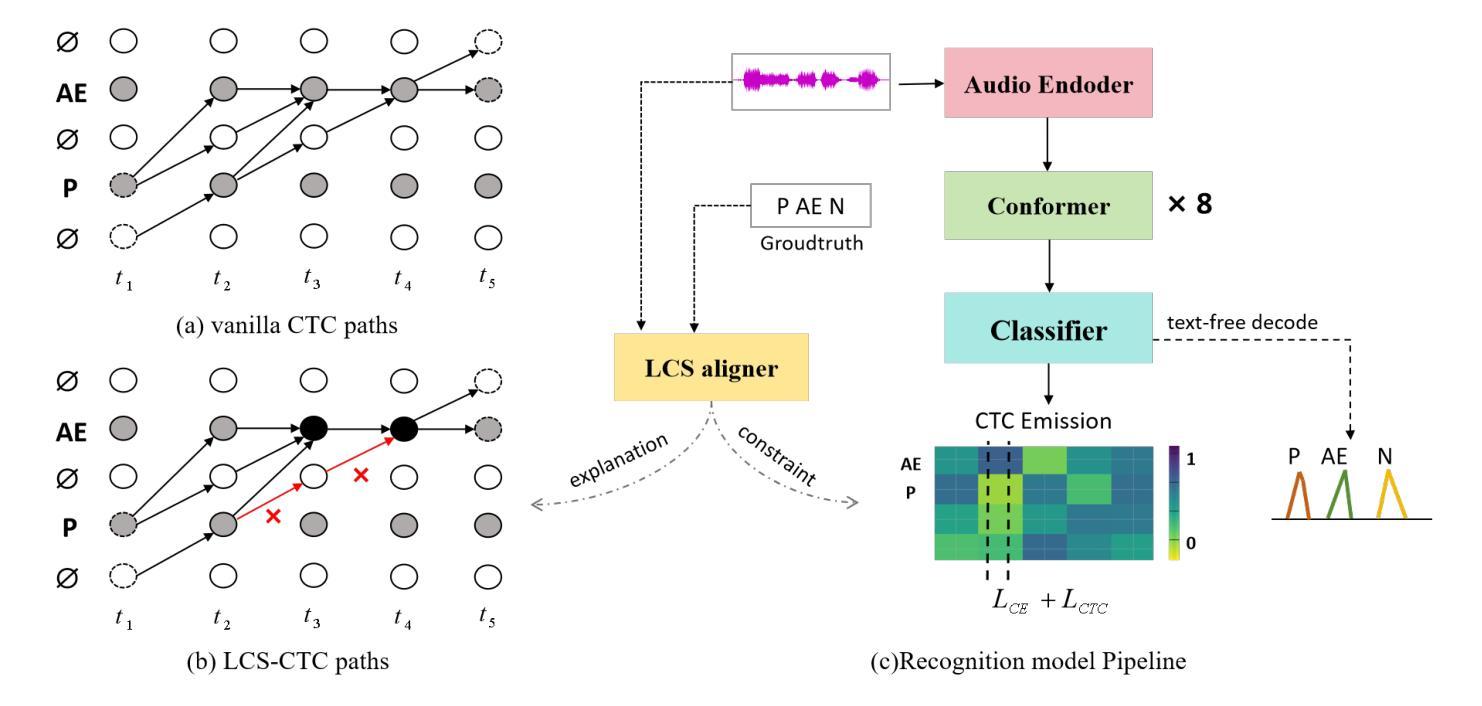
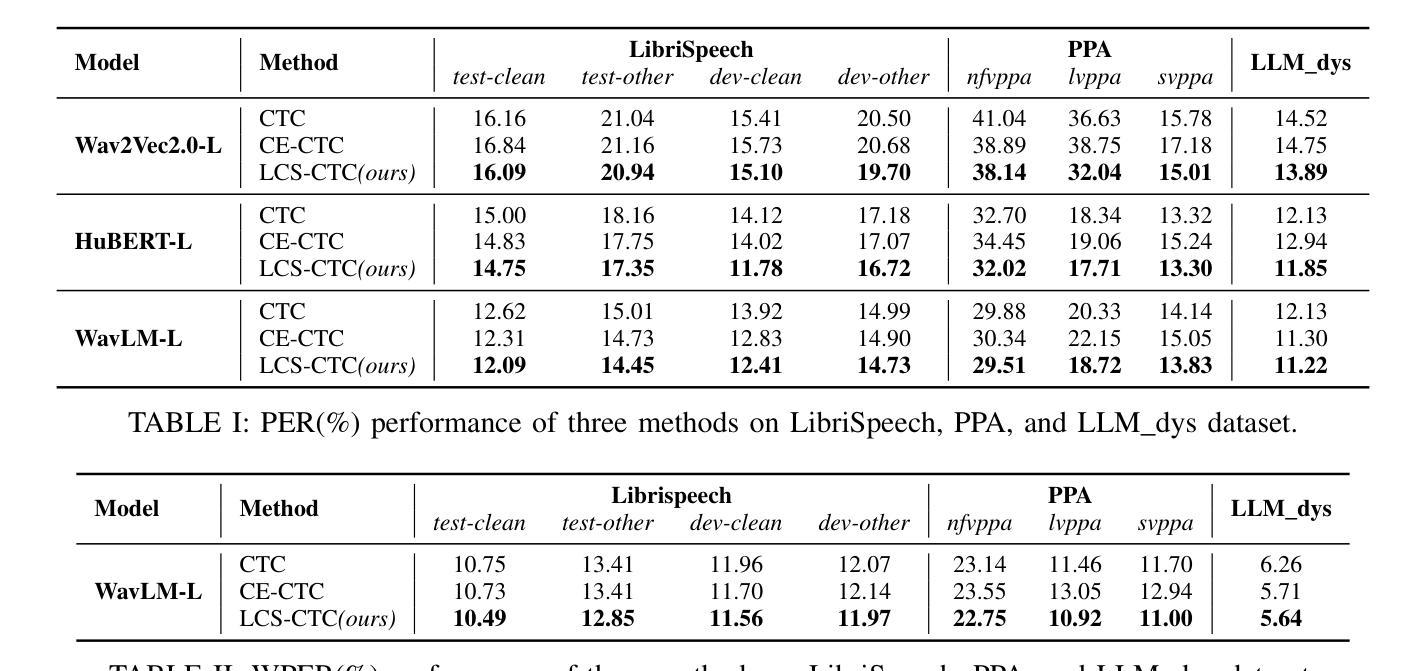
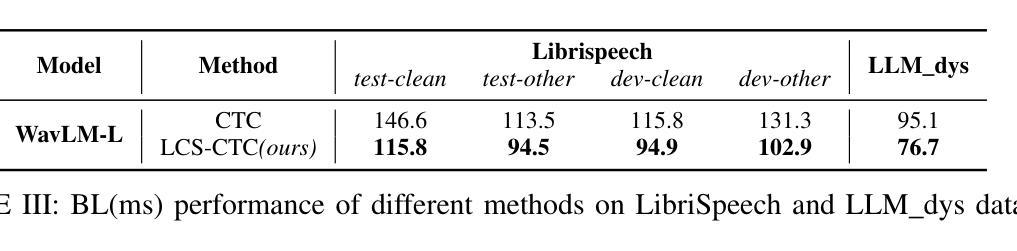
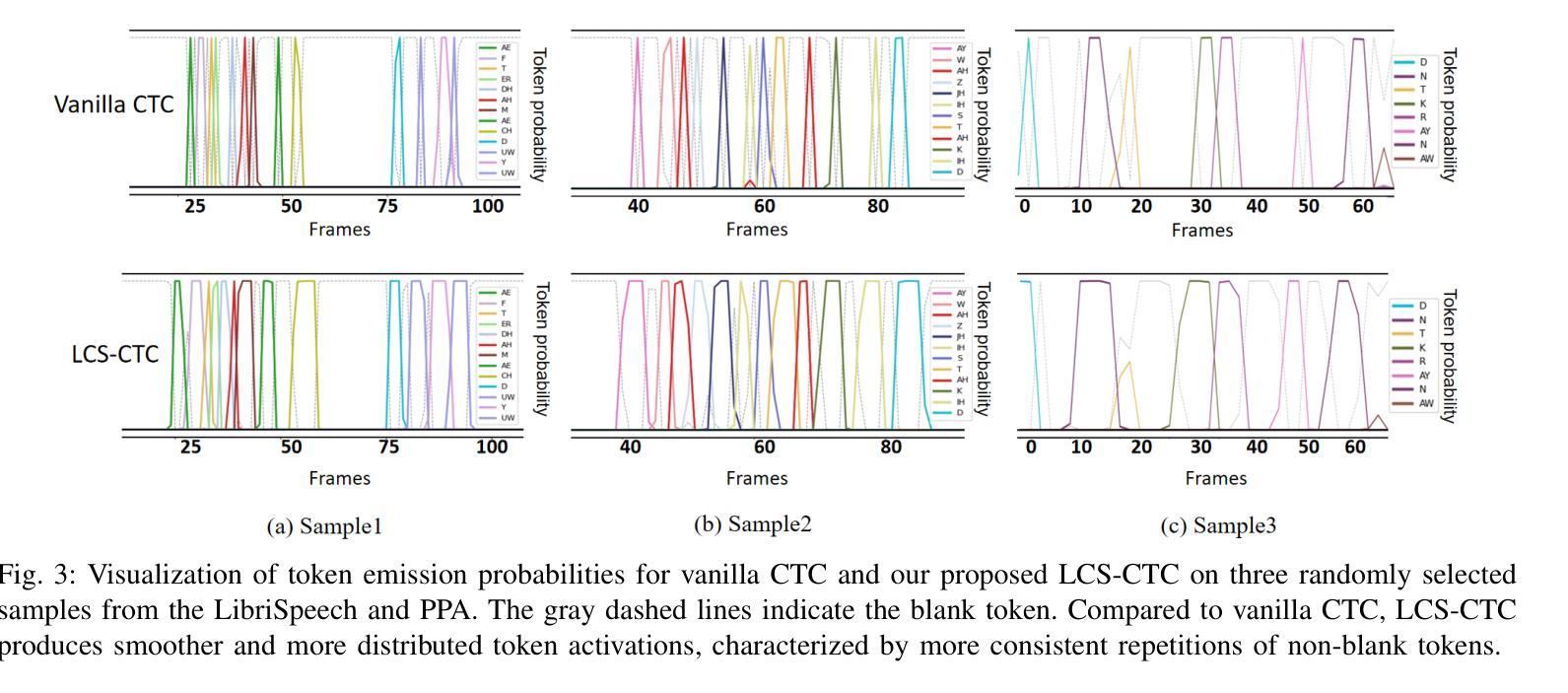
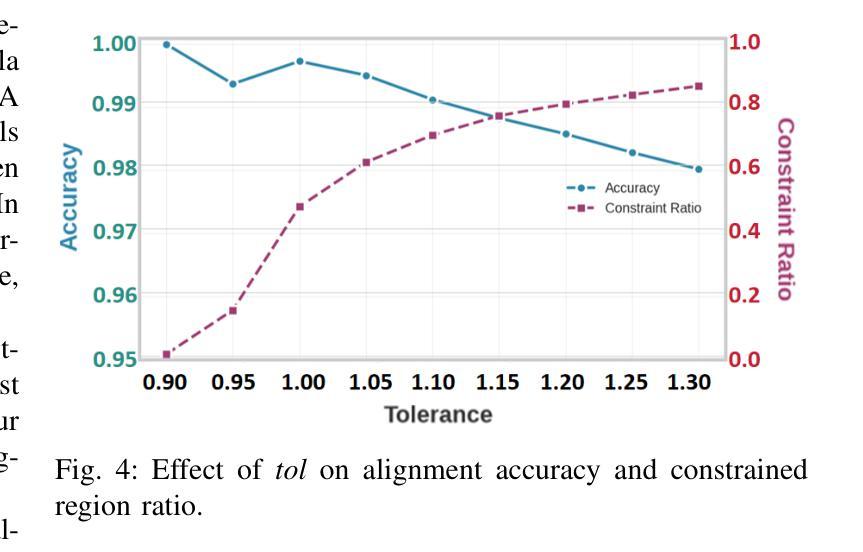
LCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Authors:Zongli Ye, Jiachen Lian, Akshaj Gupta, Xuanru Zhou, Krish Patel, Haodong Li, Hwi Joo Park, Chenxu Guo, Shuhe Li, Sam Wang, Cheol Jun Cho, Zoe Ezzes, Jet M. J. Vonk, Brittany T. Morin, Rian Bogley, Lisa Wauters, Zachary A. Miller, Maria Luisa Gorno-Tempini, Gopala Anumanchipalli
Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
语音发音转录对于精细的语言分析和下游语音应用至关重要。尽管连接时序分类(CTC)由于其效率而广泛应用于此类任务,但在识别性能上往往表现不佳,特别是在不清晰和非流利语音的情况下。在这项工作中,我们提出了LCS-CTC,这是一个两阶段的音素级语音识别框架,它将相似性感知局部对齐算法与受约束的CTC训练目标相结合。通过预测精细的帧-音素成本矩阵并应用改进的最长公共子序列(LCS)算法,我们的方法能够确定高置信度的对齐区域,这些区域用于约束CTC解码路径空间,从而减少过拟合现象并增强泛化能力,从而实现稳健的识别和文本无关的强制对齐。在LibriSpeech和PPA上的实验表明,LCS-CTC持续优于传统的CTC基准测试,这表明其在流利和非流利语音的音素建模上具有统一潜力。
论文及项目相关链接
PDF 2025 ASRU
摘要
文本提出了LCS-CTC,这是一个两阶段的音素级语音识别框架,结合了相似性感知局部对齐算法和约束性CTC训练目标。通过预测精细的帧-音素成本矩阵并应用改进的最长公共子序列算法,LCS-CTC能够确定高置信度的对齐区域,用于约束CTC解码路径空间,从而减少过拟合现象并提高泛化能力。这使得LCS-CTC在鲁棒识别和文本自由强制对齐方面表现优异。实验表明,LCS-CTC在LibriSpeech和PPA上的表现均优于传统CTC基线,显示出其在流利和非流利语音中的音素建模潜力。
关键见解
- Phonetic speech transcription对于精细的语言学分析和下游语音应用至关重要。
- CTC(连接时序分类)在语音任务中由于效率高而广泛使用,但在模糊和非流利语音下的识别性能较差。
- LCS-CTC是一个两阶段的音素级语音识别框架,结合了相似性感知局部对齐算法和约束CTC训练目标。
- LCS-CTC通过预测精细的帧-音素成本矩阵并应用LCS算法确定高置信度对齐区域。
- LCS-CTC能约束CTC解码路径空间,从而减少过拟合和提高泛化能力。
- 实验表明LCS-CTC在LibriSpeech和PPA上的表现优于传统CTC方法。
点此查看论文截图


Taggus: An Automated Pipeline for the Extraction of Characters’ Social Networks from Portuguese Fiction Literature
Authors:Tiago G Canário, Catarina Duarte, Flávio L. Pinheiro, João L. M. Pereira
Automatically identifying characters and their interactions from fiction books is, arguably, a complex task that requires pipelines that leverage multiple Natural Language Processing (NLP) methods, such as Named Entity Recognition (NER) and Part-of-speech (POS) tagging. However, these methods are not optimized for the task that leads to the construction of Social Networks of Characters. Indeed, the currently available methods tend to underperform, especially in less-represented languages, due to a lack of manually annotated data for training. Here, we propose a pipeline, which we call Taggus, to extract social networks from literary fiction works in Portuguese. Our results show that compared to readily available State-of-the-Art tools – off-the-shelf NER tools and Large Language Models (ChatGPT) – the resulting pipeline, which uses POS tagging and a combination of heuristics, achieves satisfying results with an average F1-Score of $94.1%$ in the task of identifying characters and solving for co-reference and $75.9%$ in interaction detection. These represent, respectively, an increase of $50.7%$ and $22.3%$ on results achieved by the readily available State-of-the-Art tools. Further steps to improve results are outlined, such as solutions for detecting relationships between characters. Limitations on the size and scope of our testing samples are acknowledged. The Taggus pipeline is publicly available to encourage development in this field for the Portuguese language.2
自动从虚构作品中识别字符及其交互是一项复杂的任务,需要利用多种自然语言处理(NLP)方法的管道,如命名实体识别(NER)和词性(POS)标注。然而,这些方法并未针对构建角色社交网络的任务进行优化。实际上,目前可用的方法往往表现不佳,特别是在表现较少的语言中,由于缺乏手动注释的数据来进行训练。在这里,我们提出了一种名为“Taggus”的管道,用于从葡萄牙语文学虚构作品中提取社交网络。我们的结果表明,与现成的前沿工具(现成的NER工具和大型语言模型(ChatGPT))相比,使用POS标注和启发式方法相结合的管道在识别角色和解决共引用任务中取得了平均F1分数为94.1%的令人满意的结果,在交互检测中的平均F1分数为75.9%。这分别比现成的前沿工具取得的成果提高了50.7%和22.3%。还概述了提高结果的进一步步骤,例如检测角色之间关系的方法。承认测试样本的大小和范围存在局限性。Taggus管道现公开可用,以鼓励葡萄牙语领域的开发。
论文及项目相关链接
PDF 24 pages, 5 Figures, 4 Tables
Summary:
提出一种名为Taggus的管道,用于从葡萄牙语文学小说中提取社会网络。该管道结合多种自然语言处理方法,如命名实体识别和词性标注,以识别角色及其交互。与现有的最先进的工具和大型语言模型相比,该管道在角色识别、解决共参考和交互检测任务上取得了令人满意的平均F1分数分别为94.1%和75.9%,分别提高了50.7%和22.3%。然而,仍存在限制和进一步改进的空间。Taggus管道公开可用,以促进该领域的发展。
Key Takeaways:
- Taggus管道用于从葡萄牙语文学小说中提取社会网络。
- 管道结合多种自然语言处理方法,如命名实体识别和词性标注。
- 与现有工具相比,Taggus在角色识别、解决共参考和交互检测任务上表现优异。
- Taggus的平均F1分数在角色识别和交互检测任务上分别为94.1%和75.9%。
- Taggus的提出旨在鼓励葡萄牙语领域的进一步发展。
- 目前仍存在限制和进一步改进的空间。
点此查看论文截图

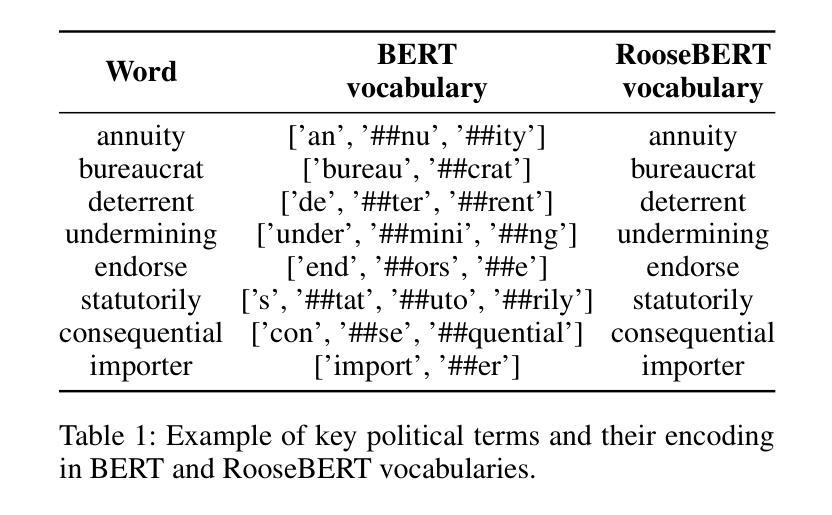
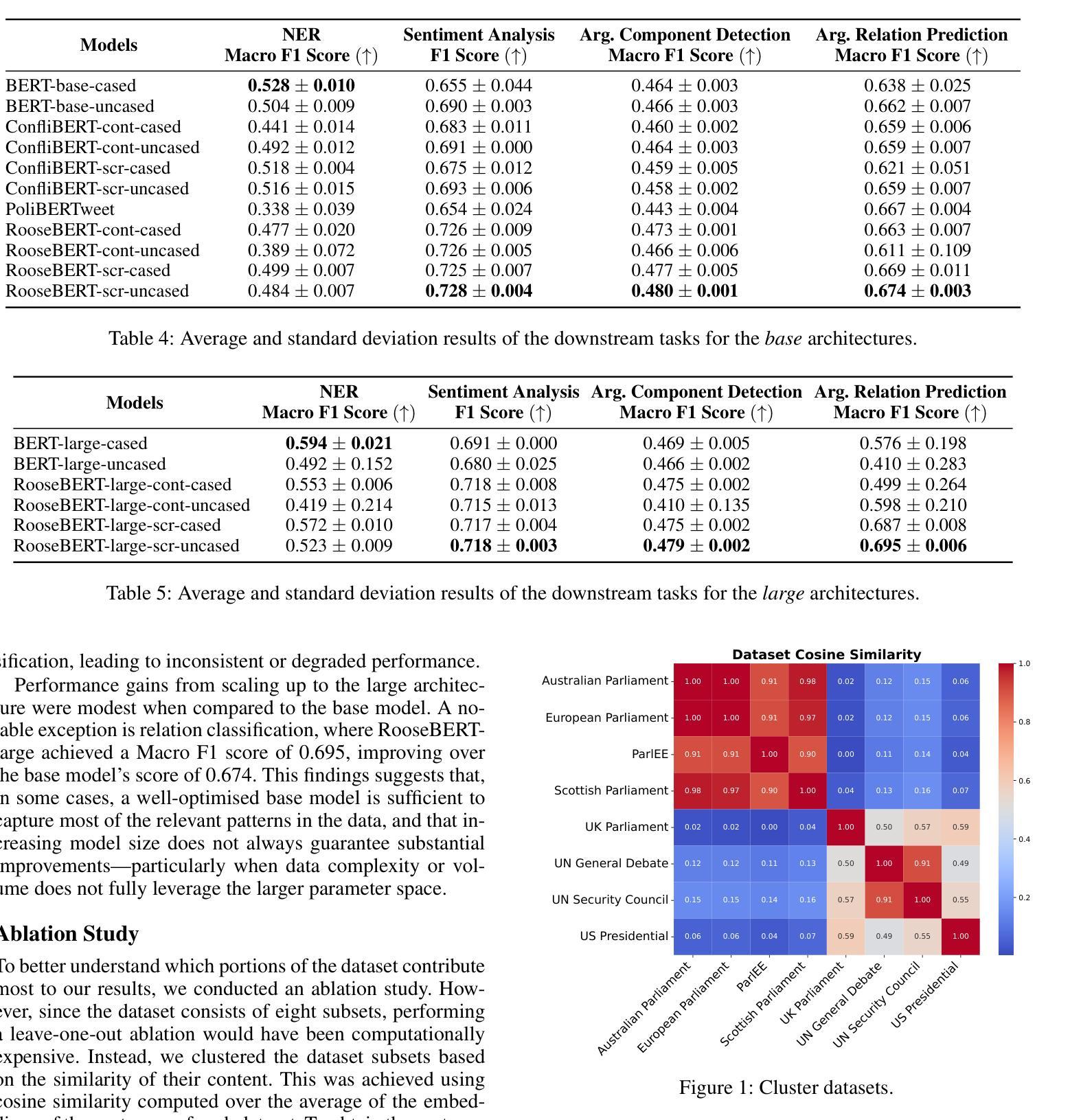
RooseBERT: A New Deal For Political Language Modelling
Authors:Deborah Dore, Elena Cabrio, Serena Villata
The increasing amount of political debates and politics-related discussions calls for the definition of novel computational methods to automatically analyse such content with the final goal of lightening up political deliberation to citizens. However, the specificity of the political language and the argumentative form of these debates (employing hidden communication strategies and leveraging implicit arguments) make this task very challenging, even for current general-purpose pre-trained Language Models. To address this issue, we introduce a novel pre-trained Language Model for political discourse language called RooseBERT. Pre-training a language model on a specialised domain presents different technical and linguistic challenges, requiring extensive computational resources and large-scale data. RooseBERT has been trained on large political debate and speech corpora (8K debates, each composed of several sub-debates on different topics) in English. To evaluate its performances, we fine-tuned it on four downstream tasks related to political debate analysis, i.e., named entity recognition, sentiment analysis, argument component detection and classification, and argument relation prediction and classification. Our results demonstrate significant improvements over general-purpose Language Models on these four tasks, highlighting how domain-specific pre-training enhances performance in political debate analysis. We release the RooseBERT language model for the research community.
随着政治辩论和政治相关讨论的日益增多,需要定义新的计算方法,自动分析这些内容,最终目标是为公民提供政治审议的便利。然而,政治语言的特殊性和这些辩论的论证形式(采用隐蔽的沟通策略和利用隐含的论据)使得这一任务非常具有挑战性,即使对于当前的通用预训练语言模型也是如此。为了解决这一问题,我们引入了一种名为RooseBERT的政治话语语言预训练模型。在特定领域上预训练语言模型面临着不同的技术和语言挑战,需要巨大的计算资源和大规模的数据。RooseBERT已在大量英语政治辩论和演讲语料库(包含8K辩论,每个辩论包含不同主题的几个子辩论)上进行训练。为了评估其性能,我们在与政治辩论分析相关的四个下游任务上对其进行了微调,即命名实体识别、情感分析、论证成分检测和分类以及论证关系预测和分类。我们的结果在这四个任务上显著改进了通用语言模型,证明了领域特定预训练在政治辩论分析中的性能提升。我们向研究界发布RooseBERT语言模型。
论文及项目相关链接
Summary
政治辩论和讨论的增加,呼吁定义新的计算方法来自动分析这些内容,以减轻公民的政治讨论负担。针对政治语言的特殊性和辩论中的论证形式,我们引入了针对政治话语语言的预训练语言模型RooseBERT。它在英语的大型政治辩论和演讲语料库上进行训练,并用于解决四个下游任务,包括命名实体识别、情感分析、论证成分检测和分类以及论证关系预测和分类。结果显示,相较于通用语言模型,RooseBERT在这四个任务上的性能显著提高,突显了领域特定预训练在政治辩论分析中的优势。我们向研究社区发布RooseBERT语言模型。
Key Takeaways
- 政治辩论和讨论的增长需求自动分析的政治内容计算方法的定义。
- RooseBERT是一种针对政治话语语言的预训练语言模型。
- RooseBERT在政治辩论的四个下游任务上表现优异。
- RooseBERT的训练基于大规模的政治辩论和演讲语料库。
- 与通用语言模型相比,RooseBERT的绩效显著提升。
- 预训练特定的语言模型在技术领域面临挑战,需要广泛的计算资源和大规模数据。
点此查看论文截图



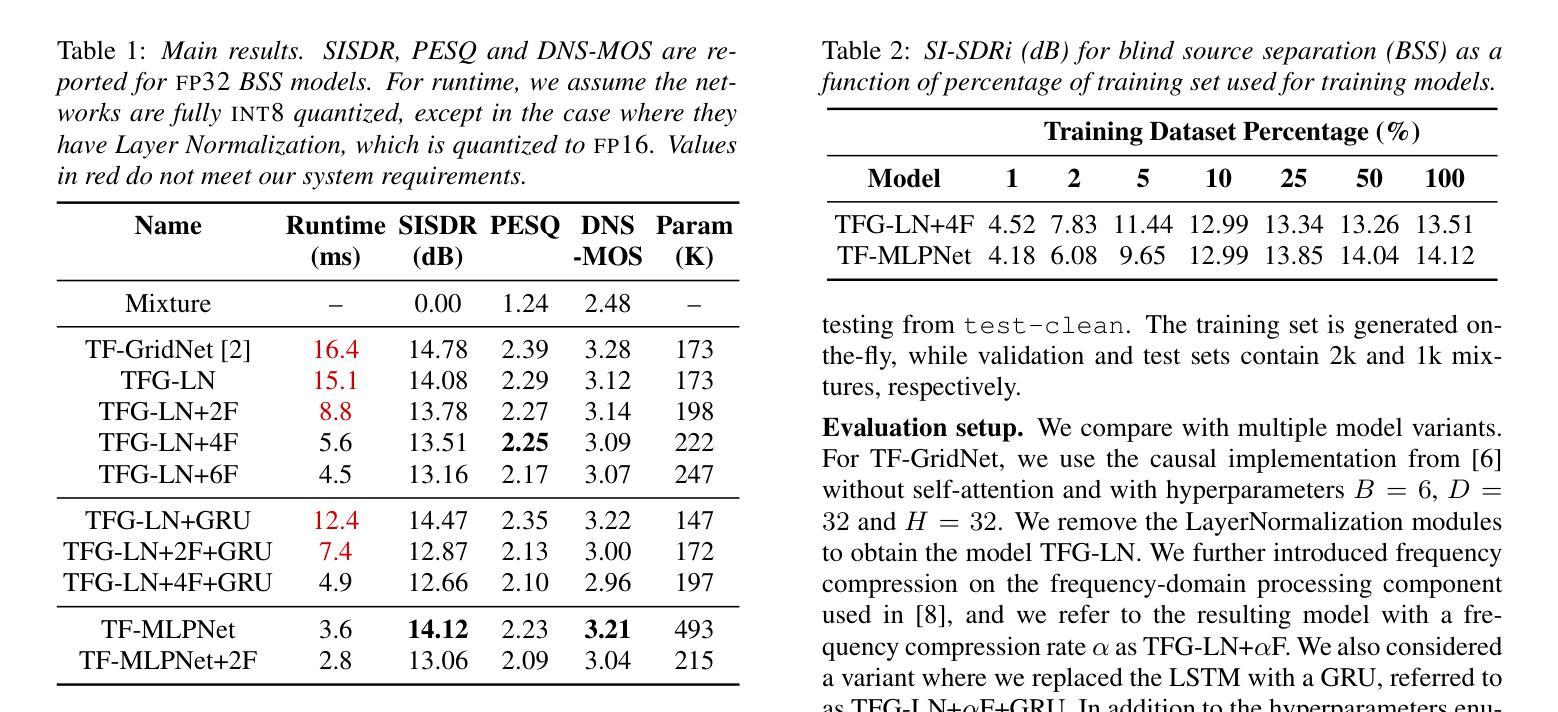
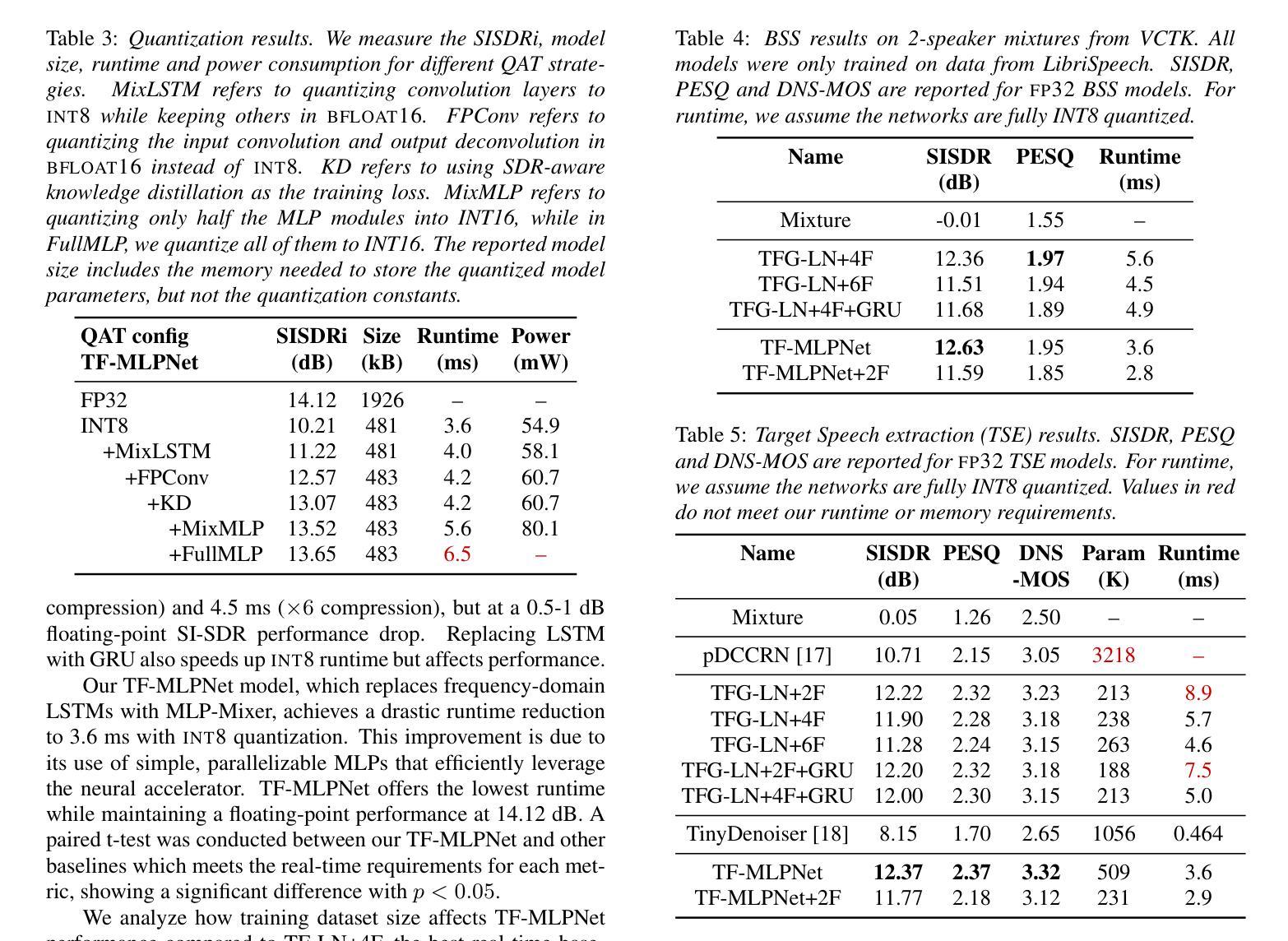
TF-MLPNet: Tiny Real-Time Neural Speech Separation
Authors:Malek Itani, Tuochao Chen, Shyamnath Gollakota
Speech separation on hearable devices can enable transformative augmented and enhanced hearing capabilities. However, state-of-the-art speech separation networks cannot run in real-time on tiny, low-power neural accelerators designed for hearables, due to their limited compute capabilities. We present TF-MLPNet, the first speech separation network capable of running in real-time on such low-power accelerators while outperforming existing streaming models for blind speech separation and target speech extraction. Our network operates in the time-frequency domain, processing frequency sequences with stacks of fully connected layers that alternate along the channel and frequency dimensions, and independently processing the time sequence at each frequency bin using convolutional layers. Results show that our mixed-precision quantization-aware trained (QAT) model can process 6 ms audio chunks in real-time on the GAP9 processor, achieving a 3.5-4x runtime reduction compared to prior speech separation models.
语音分离在可听设备上的应用可以带来变革性的增强和扩展听力能力。然而,由于最先进的语音分离网络计算能力不足,无法在针对可听设备设计的小型、低功耗神经网络加速器上实时运行。我们推出了TF-MLPNet,这是第一个能够在这种低功耗加速器上实时运行且表现优于现有流式模型的语音分离网络,用于盲语音分离和目标语音提取。我们的网络在时频域运行,使用全连接层处理频率序列,这些层在通道和频率维度上交替堆叠,并使用卷积层独立处理每个频率的时间序列。实验结果表明,我们经过混合精度量化感知训练(QAT)的模型可以在GAP9处理器上实时处理长度为6毫秒的音频片段,相较于先前的语音分离模型,实现了约3.5至4倍的运行时缩减。
论文及项目相关链接
PDF The 6th Clarity Workshop on Improving Speech-in-Noise for Hearing Devices (Clarity 2025)
Summary:
实时语音分离网络能在低功耗加速器上实现实时运行,提高听力和增强听力设备的性能。但由于低功耗加速器的计算能力有限,当前先进的语音分离网络无法运行。本文提出TF-MLPNet,首个能在这种低功耗加速器上实时运行的语音分离网络,并且在盲语音分离和目标语音提取方面优于现有流式模型。该网络在时频域运行,处理频率序列,并独立处理每个频率分区的音频时间序,从而达到优异的性能表现。模型在通过混合精度量化训练后能够在最短6毫秒的时间内对音频进行量化和分析,将运行速度提升为之前的语音分离模型的3.5至4倍。
Key Takeaways:
- TF-MLPNet网络实现了实时语音分离技术在低功耗加速器上的应用,显著提升听力设备的性能和增强体验。
- 由于受到硬件能力的限制,大多数当前流行的语音分离模型无法在极低功耗加速器中实施实时操作。然而,本文克服了这一限制,开创了新领域的创新研究机会。这一领域还包括扩大运行模型的规模以适应不同的应用场景和用户需求。
点此查看论文截图

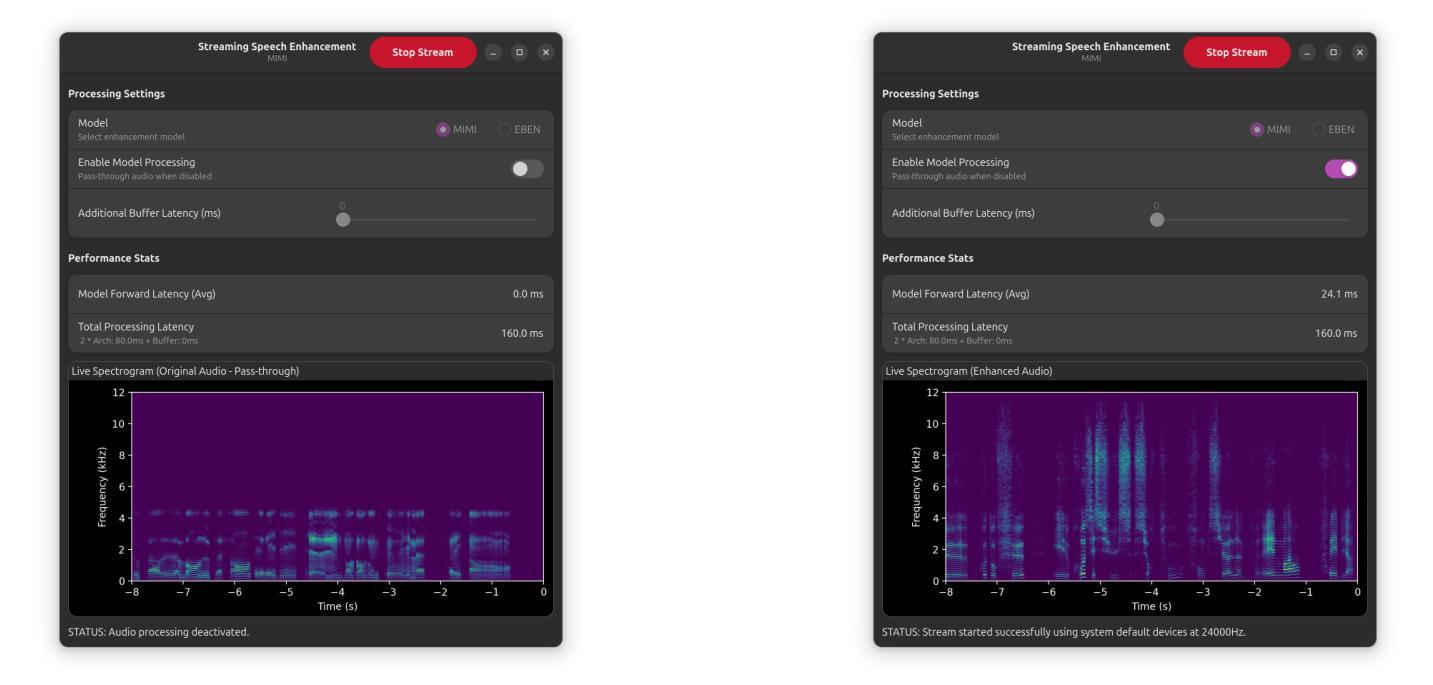
Real-time speech enhancement in noise for throat microphone using neural audio codec as foundation model
Authors:Julien Hauret, Thomas Joubaud, Éric Bavu
We present a real-time speech enhancement demo using speech captured with a throat microphone. This demo aims to showcase the complete pipeline, from recording to deep learning-based post-processing, for speech captured in noisy environments with a body-conducted microphone. The throat microphone records skin vibrations, which naturally attenuate external noise, but this robustness comes at the cost of reduced audio bandwidth. To address this challenge, we fine-tune Kyutai’s Mimi–a neural audio codec supporting real-time inference–on Vibravox, a dataset containing paired air-conducted and throat microphone recordings. We compare this enhancement strategy against state-of-the-art models and demonstrate its superior performance. The inference runs in an interactive interface that allows users to toggle enhancement, visualize spectrograms, and monitor processing latency.
我们展示了一个使用喉头麦克风捕捉语音的实时语音增强演示。这个演示旨在展示从录制到基于深度学习的后处理的完整流程,用于在嘈杂环境中使用身体传导麦克风捕捉语音。喉头麦克风记录皮肤振动,自然地衰减外部噪音,但这种稳健性是以降低音频带宽为代价的。为了解决这一挑战,我们对Kyutai的Mimi进行了微调——这是一种支持实时推理的神经网络音频编解码器——在Vibravox数据集上,该数据集包含气传和喉头麦克风录音的配对记录。我们将这种增强策略与最新模型进行比较,并展示了其卓越性能。推理在一个交互式界面中运行,允许用户切换增强功能、可视化频谱图并监控处理延迟。
论文及项目相关链接
PDF 2 pages, 2 figures
Summary
:该文本介绍了一个使用喉部麦克风进行语音采集的实时语音增强演示。演示的目的是展示从录音到基于深度学习的后处理的完整流程,针对在嘈杂环境中使用身体传导麦克风采集的语音。喉部麦克风记录皮肤振动,自然衰减外部噪音,但这一稳健性是以降低音频带宽为代价的。为解决这一挑战,作者在Vibravox数据集上微调了Kyutai的Mimi——一个支持实时推断的神经音频编解码器,该数据集包含空气传导和喉部麦克风录音的配对记录。作者将这一增强策略与最新模型进行了比较,并展示了其卓越性能。推理在一个交互式界面中运行,允许用户切换增强功能、可视化频谱图并监控处理延迟。
Key Takeaways
- 该文本介绍了一个使用喉部麦克风进行语音采集的实时语音增强演示。
- 演示的目的是展示完整的语音处理流程,包括从录音到基于深度学习的后处理。
- 喉部麦克风能够记录皮肤振动并自然衰减外部噪音,但会降低音频带宽。
- 作者使用Vibravox数据集对Kyutai的Mimi神经音频编解码器进行了微调。
- 作者将提出的语音增强策略与现有先进模型进行了比较。
- 实验结果表明,该策略在语音增强方面表现出卓越性能。
点此查看论文截图

Adaptive Knowledge Distillation for Device-Directed Speech Detection
Authors:Hyung Gun Chi, Florian Pesce, Wonil Chang, Oggi Rudovic, Arturo Argueta, Stefan Braun, Vineet Garg, Ahmed Hussen Abdelaziz
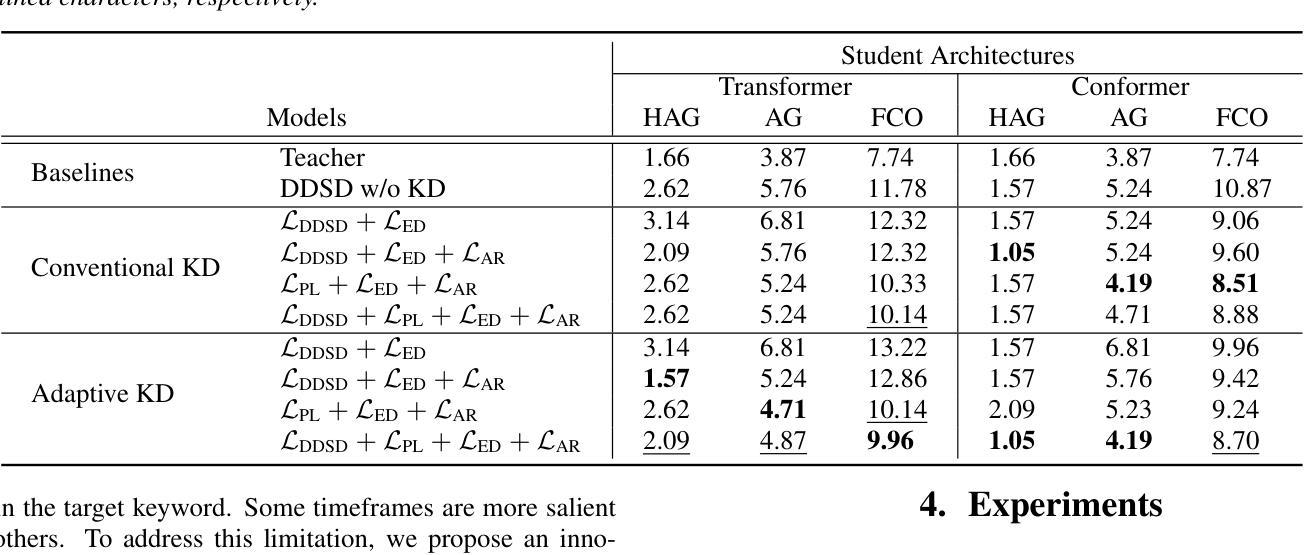
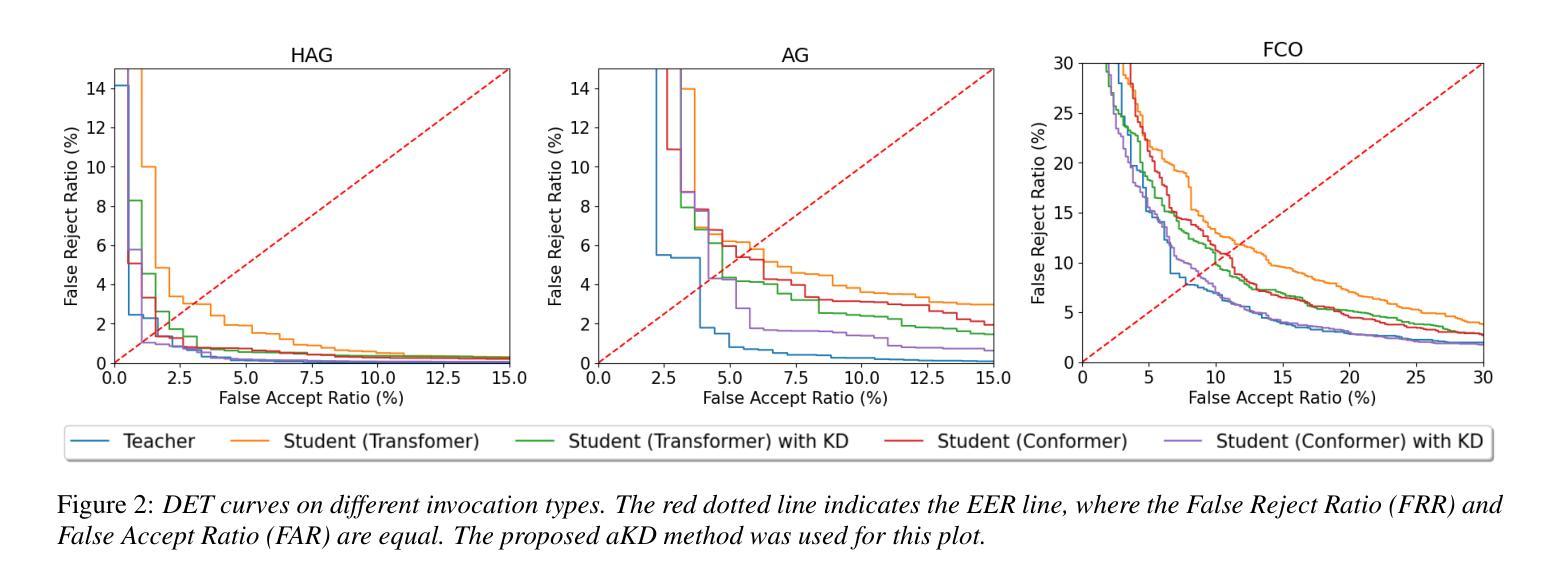
Device-directed speech detection (DDSD) is a binary classification task that separates the user’s queries to a voice assistant (VA) from background speech or side conversations. This is important for achieving naturalistic user experience. To this end, we propose knowledge distillation (KD) to enhance DDSD accuracy while ensuring efficient deployment. Specifically, we introduce a novel adaptive KD method that transfers knowledge from general representations of an ASR large pre-trained acoustic encoder (teacher). We apply task-specific adapters, on top of the (frozen) teacher encoder, trained jointly with the student model on DDSD. We demonstrate that the proposed adaptive KD outperforms the student model without distillation in the keyword and keyword-free (follow-up) invocations, with an improvement of +26% and +19% in terms of Equal Error Rate, respectively. We also show that this approach generalizes across the transformer and conformer-based model architectures.
设备定向语音检测(DDSD)是一项二分类任务,它将用户的查询语音助手(VA)与背景语音或侧面对话区分开来。这对于实现自然主义用户体验至关重要。为此,我们提出知识蒸馏(KD)技术,旨在提高DDSD的准确性,同时确保高效部署。具体来说,我们引入了一种新型自适应KD方法,该方法将从一个大型预训练声学编码器的通用表示(教师模型)中转移知识。我们在(冻结的)教师编码器之上应用了任务特定适配器,并与DDSD上的学生模型联合训练。我们证明,与未经蒸馏的学生模型相比,所提出自适应KD在关键词和关键词无关(后续)调用中表现更优,在等价错误率方面分别提高了+26%和+19%。我们还表明,该方法可应用于基于变压器和卷积变压器模型架构的模型中。
论文及项目相关链接
PDF 5 pages, 2 figures, Interspeech accepted
Summary
设备定向语音检测(DDSD)是区分用户查询语音助手(VA)的语音与背景语音或旁边对话的二元分类任务,对实现自然用户体验至关重要。本研究采用知识蒸馏技术提高DDSD的准确性并保障部署效率。通过引入自适应知识蒸馏方法,从大型预训练声学编码器的通用表示中转移知识(教师)。在冻结的教师编码器之上应用任务特定适配器,并与DDSD的学生模型联合训练。实验表明,自适应知识蒸馏在关键词和关键词自由(跟进)调用中均优于未经蒸馏的学生模型,在同等错误率上分别提高了26%和提高了改善,并且在转换器和卷积变压器模型架构上进行了概括应用。总体上增强了设备的语言处理能力并优化了用户体验。该方法可以看作是基于人工智能与声学建模的新应用工具的一次提升与创新性开发。关键要点列举如下::列出了这篇论文中涉及的几个方面关键研究内容与要点分析的关键观点和信息作为便于读者回顾总结并可以容易吸收总结以及为理论研究后续可能的操作作为参照主要集中于自我研究方向的描述和重要思想方法论这些方向从框架建设思想的适用性具体应用逻辑可以落地的诸多现实环境中所提出的优秀应用路径概述下来总共不超过七点是帮助管理者分析师分析师专业分析后的了解并在日后的实际工作中学习指导学习实践以及对于整个行业未来的发展趋势预测起到重要的参考作用:
Key Takeaways:
点此查看论文截图

AudioGen-Omni: A Unified Multimodal Diffusion Transformer for Video-Synchronized Audio, Speech, and Song Generation
Authors:Le Wang, Jun Wang, Feng Deng, Chen Zhang, Di Zhang, Kun Gai
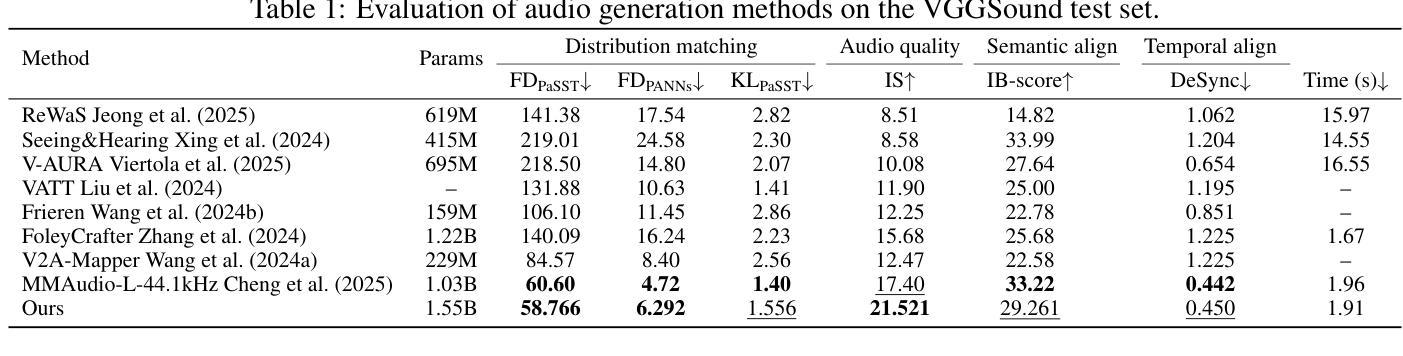
We present AudioGen-Omni - a unified approach based on multimodal diffusion transformers (MMDit), capable of generating high-fidelity audio, speech, and songs coherently synchronized with the input video. AudioGen-Omni introduces a novel joint training paradigm that seamlessly integrates large-scale video-text-audio corpora, enabling a model capable of generating semantically rich, acoustically diverse audio conditioned on multimodal inputs and adaptable to a wide range of audio generation tasks. AudioGen-Omni employs a unified lyrics-transcription encoder that encodes graphemes and phonemes from both sung and spoken inputs into dense frame-level representations. Dense frame-level representations are fused using an AdaLN-based joint attention mechanism enhanced with phase-aligned anisotropic positional infusion (PAAPI), wherein RoPE is selectively applied to temporally structured modalities to ensure precise and robust cross-modal alignment. By unfreezing all modalities and masking missing inputs, AudioGen-Omni mitigates the semantic constraints of text-frozen paradigms, enabling effective cross-modal conditioning. This joint training approach enhances audio quality, semantic alignment, and lip-sync accuracy, while also achieving state-of-the-art results on Text-to-Audio/Speech/Song tasks. With an inference time of 1.91 seconds for 8 seconds of audio, it offers substantial improvements in both efficiency and generality.
我们提出了AudioGen-Omni——一种基于多模式扩散变压器(MMDit)的统一方法,能够生成与输入视频同步的高保真音频、语音和歌曲。AudioGen-Omni引入了一种新的联合训练范式,无缝集成了大规模的视频-文本-音频语料库,使模型能够生成丰富语义、声音多样的音频,能根据多模式输入进行调整,并适应广泛的音频生成任务。AudioGen-Omni采用统一的歌词转录编码器,将歌唱和口语输入中的字母和音素编码成密集的帧级表示。密集的帧级表示通过使用基于AdaLN的联合注意力机制进行融合,增强了相位对齐的异构位置注入(PAAPI),其中RoPE被选择性地应用于时间结构模态,以确保精确和稳定的跨模态对齐。通过解冻所有模态并掩盖缺失的输入,AudioGen-Omni减轻了文本冻结范式的语义约束,实现了有效的跨模态条件。这种联合训练方法提高了音频质量、语义对齐和唇同步精度,同时在文本到音频/语音/歌曲任务上达到了最先进的水平。其推理时间为1.91秒可生成8秒的音频,在效率和通用性方面都有显著提高。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
基于多模态扩散变压器(MMDit)的AudioGen-Omni统一方法,能够生成与输入视频同步的高保真音频、语音和歌曲。该方法引入了一种新型联合训练范式,无缝集成大规模视频-文本-音频语料库,可生成语义丰富、声音多样的音频,并根据多模态输入进行适应,适用于广泛的音频生成任务。
Key Takeaways
- AudioGen-Omni是一种基于多模态扩散变压器(MMDit)的统一方法,能够生成高保真音频、语音和歌曲,并与输入视频同步。
- 引入新型联合训练范式,集成大规模视频-文本-音频语料库。
- 生成语义丰富、声音多样的音频,适应多模态输入。
- 采用统一歌词-转录编码器,对歌唱和口语输入进行编码,生成密集帧级表示。
- 使用基于AdaLN的联合注意机制融合密集帧级表示,增强相位对齐的异构位置注入(PAAPI)。
- 通过解冻所有模态并掩盖缺失输入,缓解文本冻结范式的语义约束,实现有效的跨模态条件。
点此查看论文截图

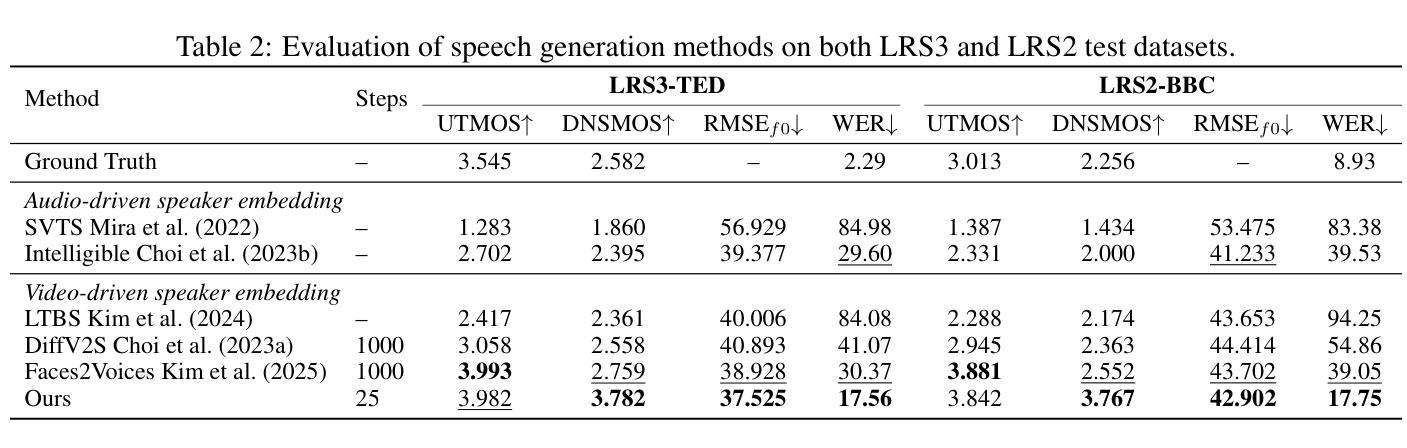
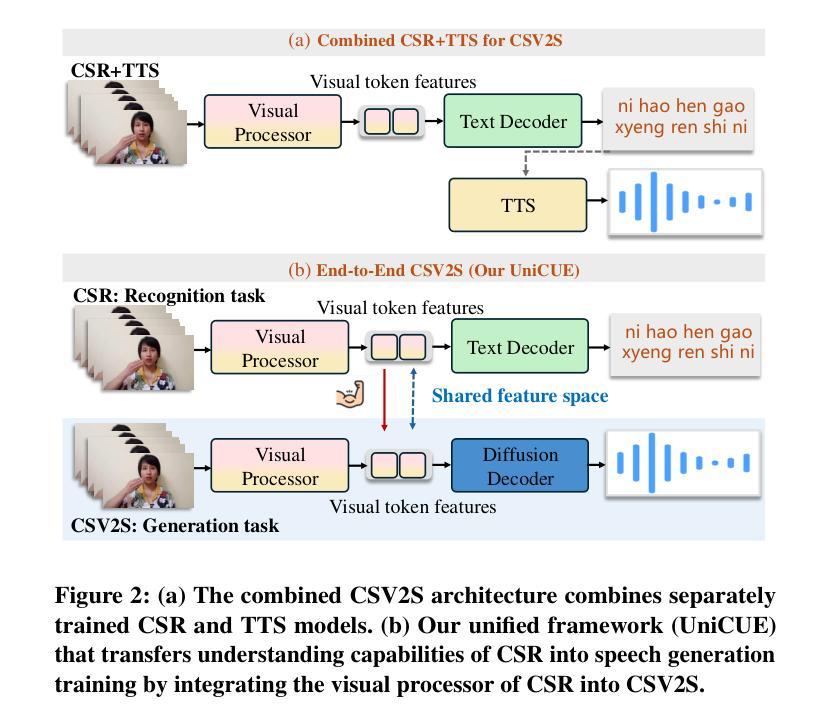
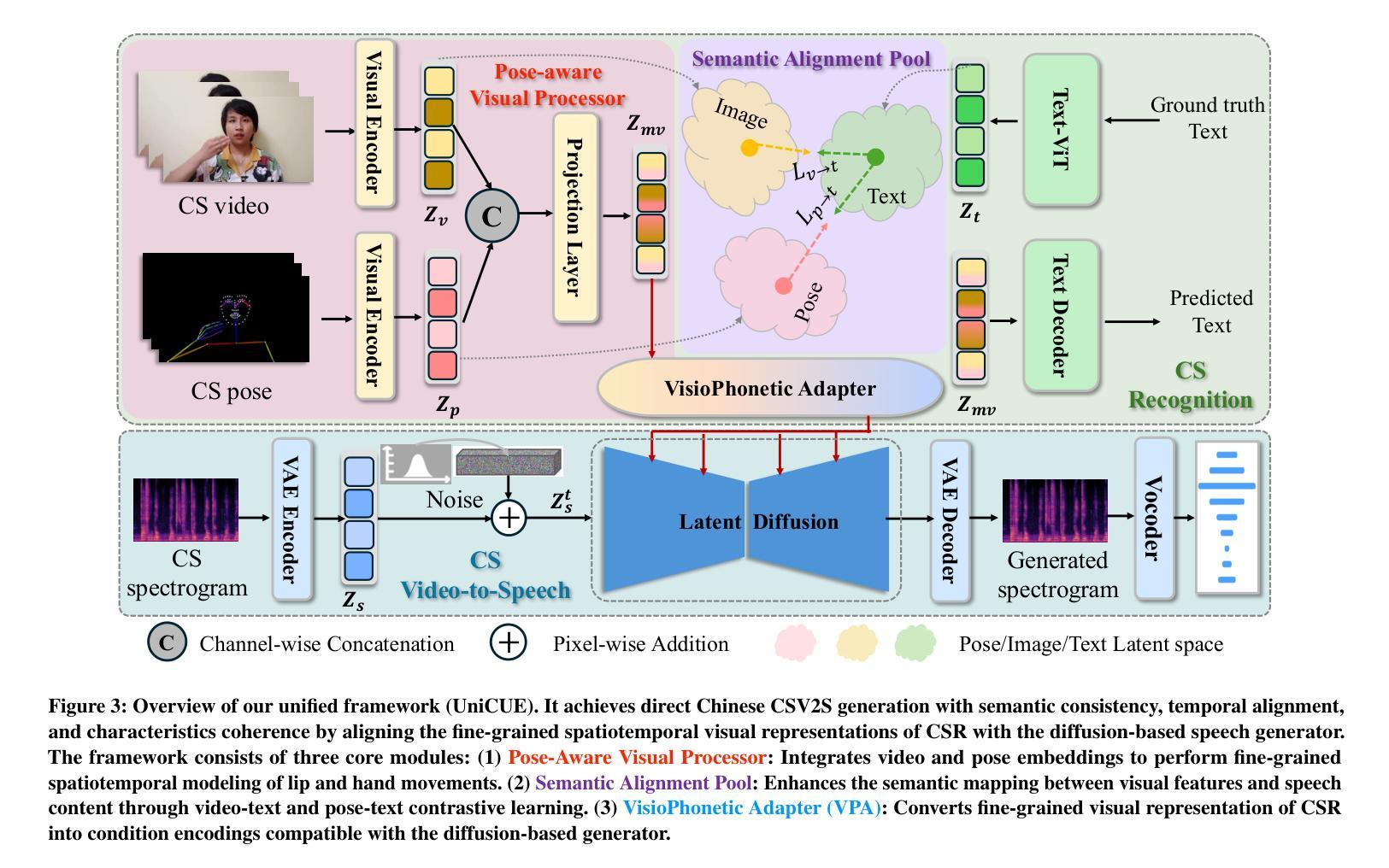
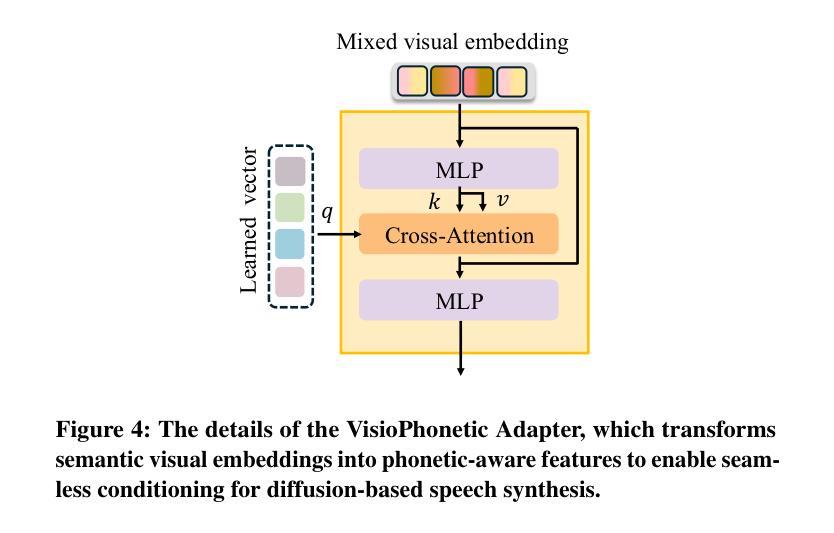
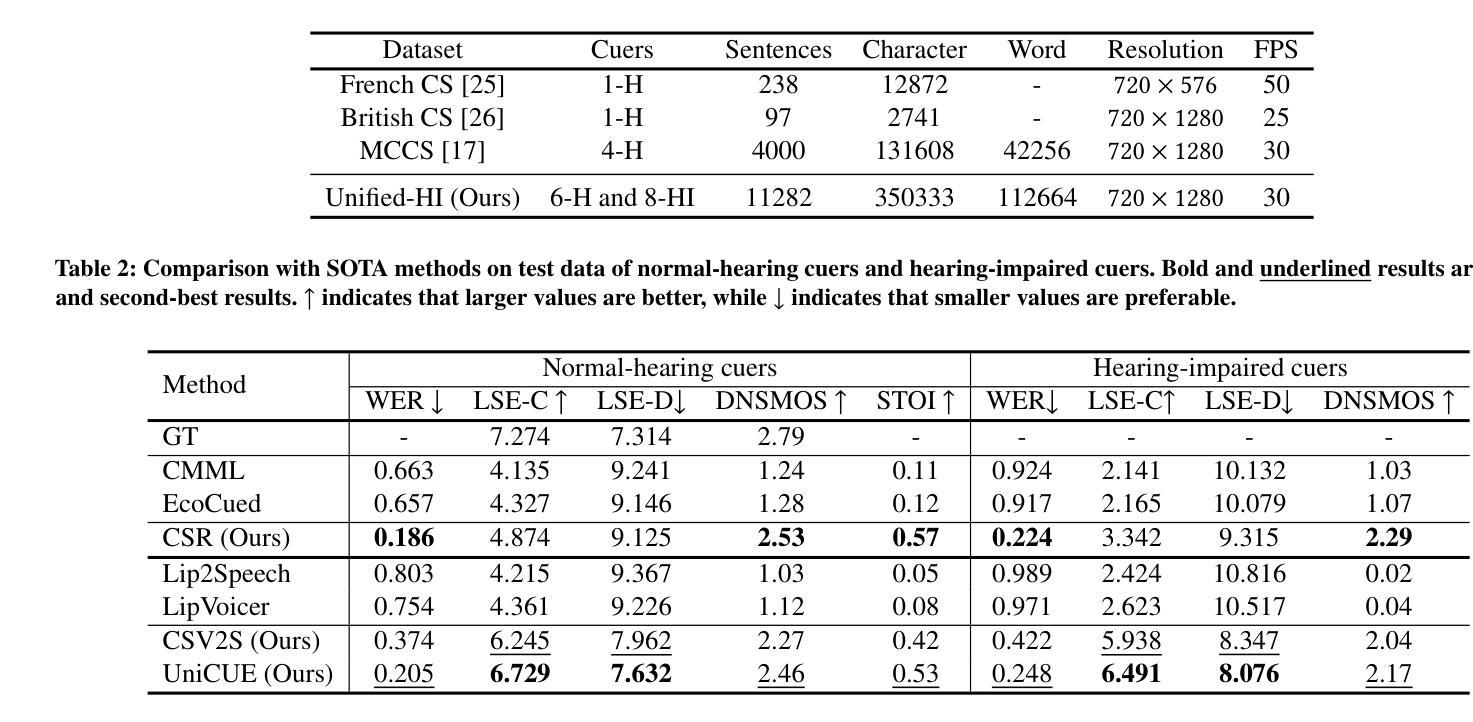
UniCUE: Unified Recognition and Generation Framework for Chinese Cued Speech Video-to-Speech Generation
Authors:Jinting Wang, Shan Yang, Chenxing Li, Dong Yu, Li Liu
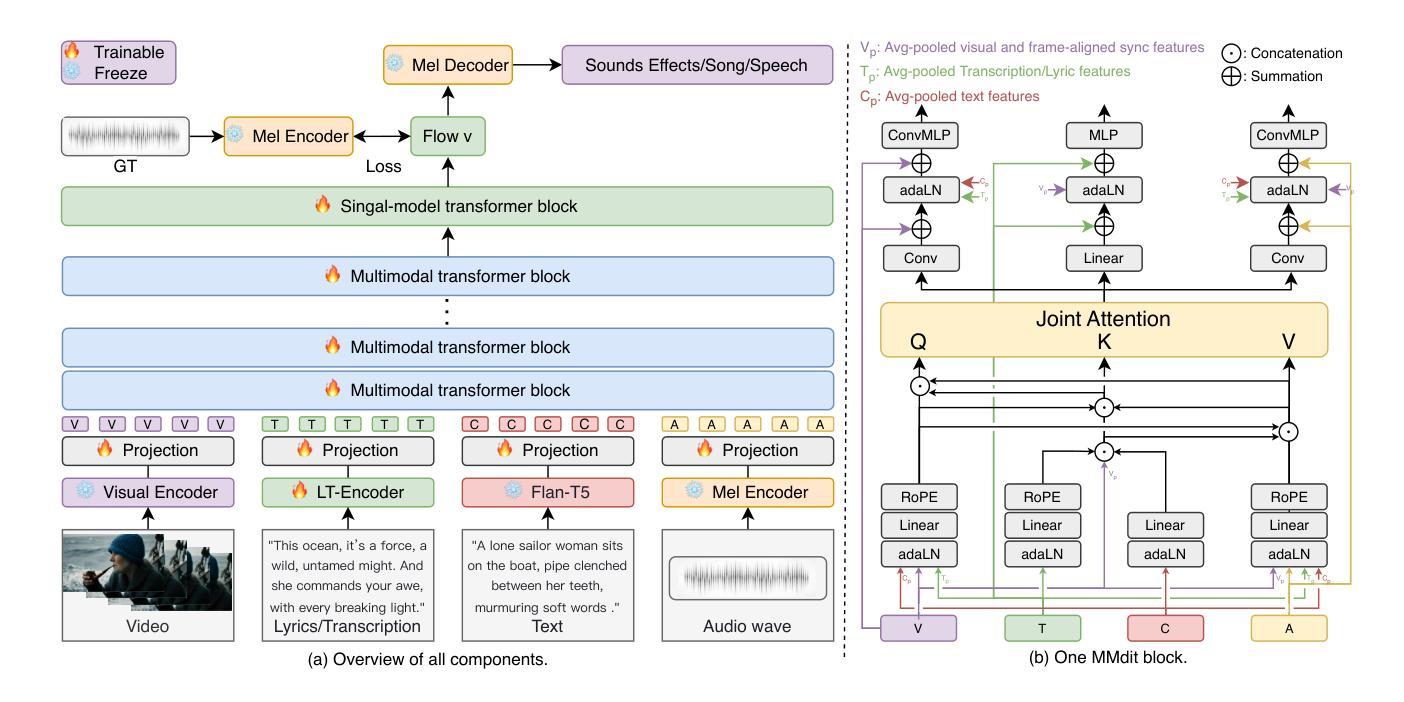
Cued Speech (CS) enhances lipreading via hand coding, offering visual phonemic cues that support precise speech perception for the hearing-impaired. The task of CS Video-to-Speech generation (CSV2S) aims to convert CS videos into intelligible speech signals. Most existing research focuses on CS Recognition (CSR), which transcribes video content into text. Consequently, a common solution for CSV2S is to integrate CSR with a text-to-speech (TTS) system. However, this pipeline relies on text as an intermediate medium, which may lead to error propagation and temporal misalignment between speech and CS video dynamics. In contrast, directly generating audio speech from CS video (direct CSV2S) often suffers from the inherent multimodal complexity and the limited availability of CS data. To address these challenges, we propose UniCUE, the first unified framework for CSV2S that directly generates speech from CS videos without relying on intermediate text. The core innovation of UniCUE lies in integrating an understanding task (CSR) that provides fine-grained CS visual-semantic cues to guide speech generation. Specifically, UniCUE incorporates a pose-aware visual processor, a semantic alignment pool that enables precise visual-semantic mapping, and a VisioPhonetic adapter to bridge the understanding and generation tasks within a unified architecture. To support this framework, we construct UniCUE-HI, a large-scale Mandarin CS dataset containing 11282 videos from 14 cuers, including both hearing-impaired and normal-hearing individuals. Extensive experiments on this dataset demonstrate that UniCUE achieves state-of-the-art performance across multiple evaluation metrics.
提示性言语(Cued Speech,简称CS)通过手语编码增强唇读能力,提供视觉音素线索,支持听力受损者精确感知语音。CS视频到语音生成(CSV2S)的任务旨在将CS视频转换为可理解的语音信号。目前大多数研究集中在CS识别(CSR)上,即将视频内容转录为文本。因此,CSV2S的常见解决方案是将CSR与文本到语音(TTS)系统相结合。然而,此流程依赖于文本作为中间媒介,可能导致误差传播以及语音和CS视频动态之间的时间不对齐。相比之下,直接从CS视频生成音频语音(直接CSV2S)常常面临固有的多模式复杂性和有限的CS数据可用性问题。为了解决这些挑战,我们提出了UniCUE,这是第一个用于CSV2S的统一框架,能够直接从CS视频生成语音,无需依赖中间文本。UniCUE的核心创新在于整合了理解任务(CSR),提供精细的CS视觉语义线索来指导语音生成。具体来说,UniCUE融入了姿态感知视觉处理器、语义对齐池,实现了精确视觉语义映射,以及VisioPhonetic适配器,可在统一架构内搭建理解和生成任务之间的桥梁。为了支持该框架,我们构建了UniCUE-HI,这是一个大规模的中文CS数据集,包含来自14名打手势者的11282个视频,其中包括听障人士和听力正常的人。在该数据集上进行的大量实验表明,UniCUE在多个评估指标上达到了最先进的效果。
论文及项目相关链接
PDF 8 pages, 5 figures
摘要
Cued Speech(CS)通过手语编码增强唇语阅读,为听力受损者提供视觉语音线索以支持精确语音感知。CS视频到语音生成(CSV2S)的任务旨在将CS视频转换为可理解的语音信号。大多数现有研究专注于CS识别(CSR),将视频内容转录为文本。因此,CSV2S的常见解决方案是将CSR与文本到语音(TTS)系统结合。然而,此管道依赖于作为中间媒介的文本,可能导致误差传播和语音与CS视频动态之间的时间不匹配。相比之下,直接从CS视频生成音频语音(直接CSV2S)常常面临内在的多模式复杂性和CS数据有限的问题。为解决这些挑战,我们提出了UniCUE,这是第一个用于CSV2S的统一框架,可直接从CS视频生成语音,无需依赖中间文本。UniCUE的核心创新在于整合了理解任务(CSR),提供精细的CS视觉语义线索来指导语音生成。具体来说,UniCUE结合了姿态感知视觉处理器、语义对齐池(实现精确视觉语义映射)和VisioPhonetic适配器(在统一架构内桥接理解和生成任务)。为支持此框架,我们构建了包含11282个视频的大型普通话CS数据集UniCUE-HI,这些视频来自14名cuers,包括听障和正常听力的人。在该数据集上的大量实验表明,UniCUE在多个评估指标上达到最佳性能。
关键见解
- Cued Speech(CS)通过手语编码增强唇语阅读,为听力受损者提供视觉语音线索。
- CSV2S的目标是将CS视频转化为可理解的语音信号,现有研究多聚焦于CS识别(CSR)。
- 将CSR与文本到语音(TTS)系统结合是CSV2S的常见解决方案,但存在误差传播和时间不匹配的问题。
- 直接从CS视频生成音频语音面临多模式复杂性和CS数据有限性的挑战。
- UniCUE是首个用于CSV2S的统一框架,可直接从CS视频生成语音,无需依赖中间文本。
- UniCUE的核心创新在于整合理解任务(CSR)来指导语音生成,具有姿态感知视觉处理器、语义对齐池和VisioPhonetic适配器。
点此查看论文截图

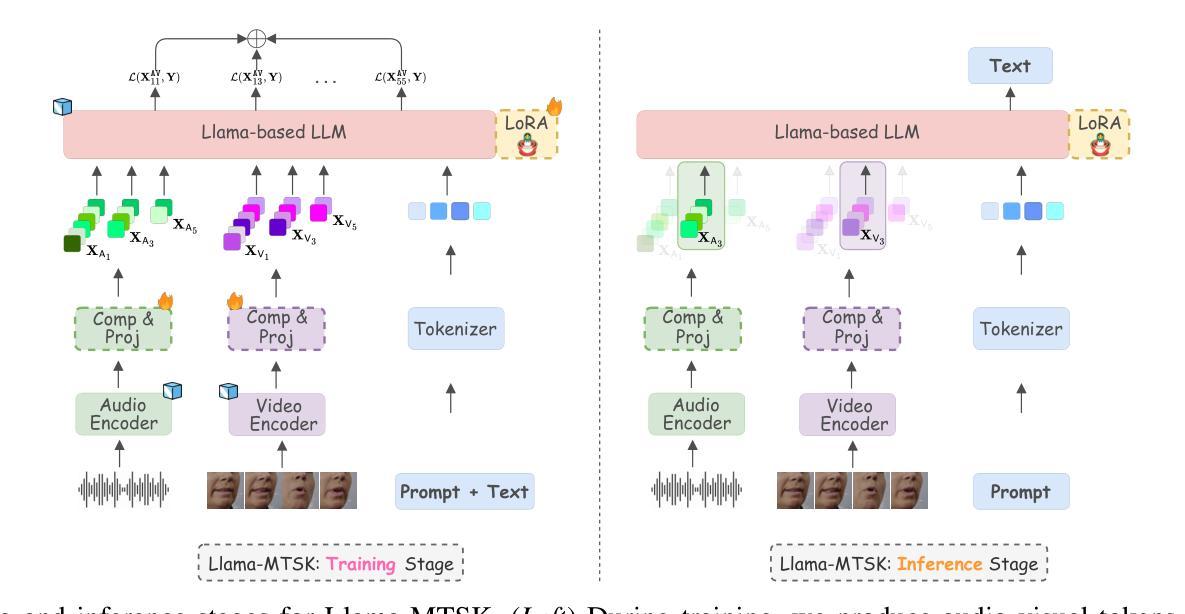
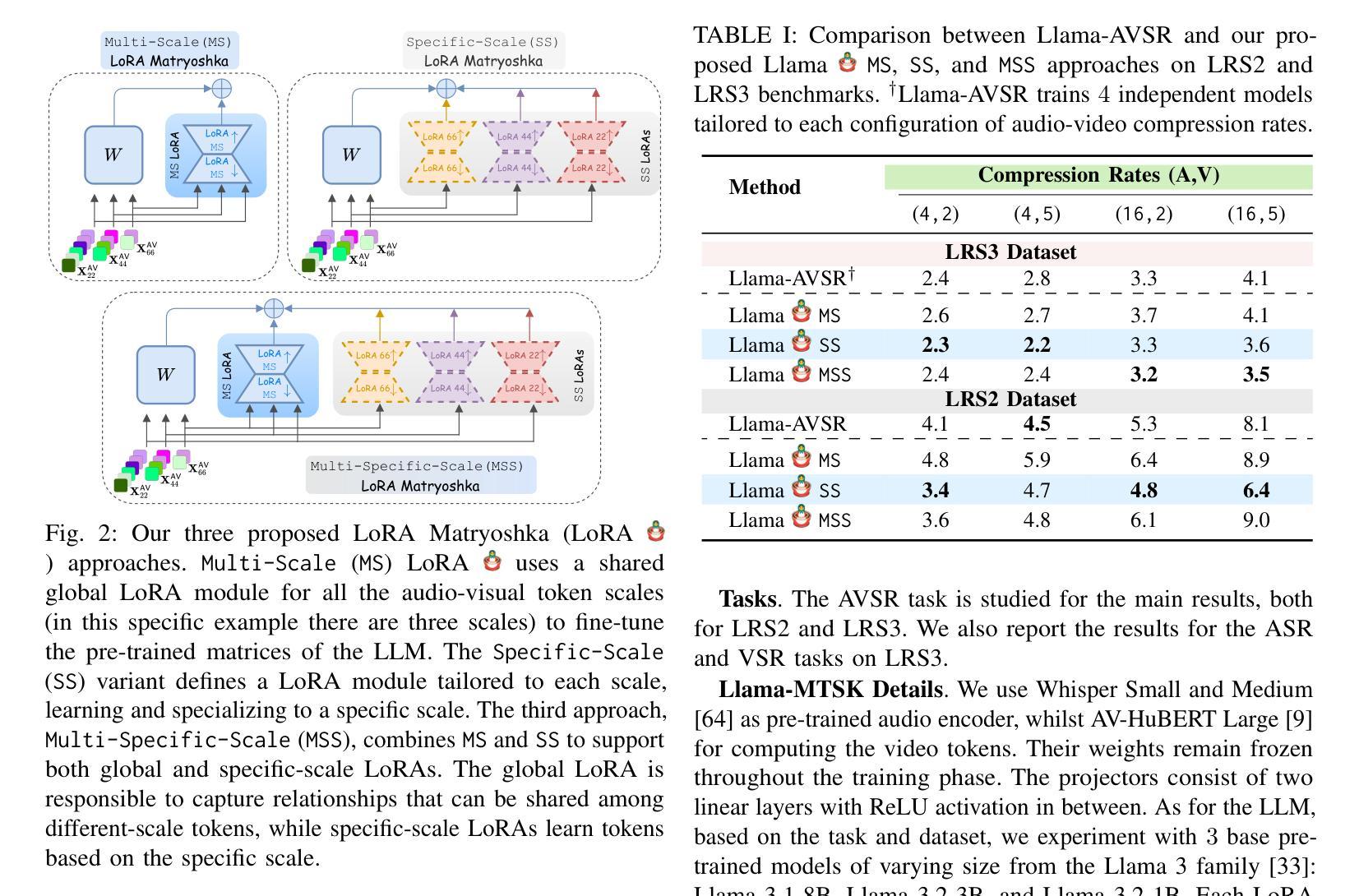
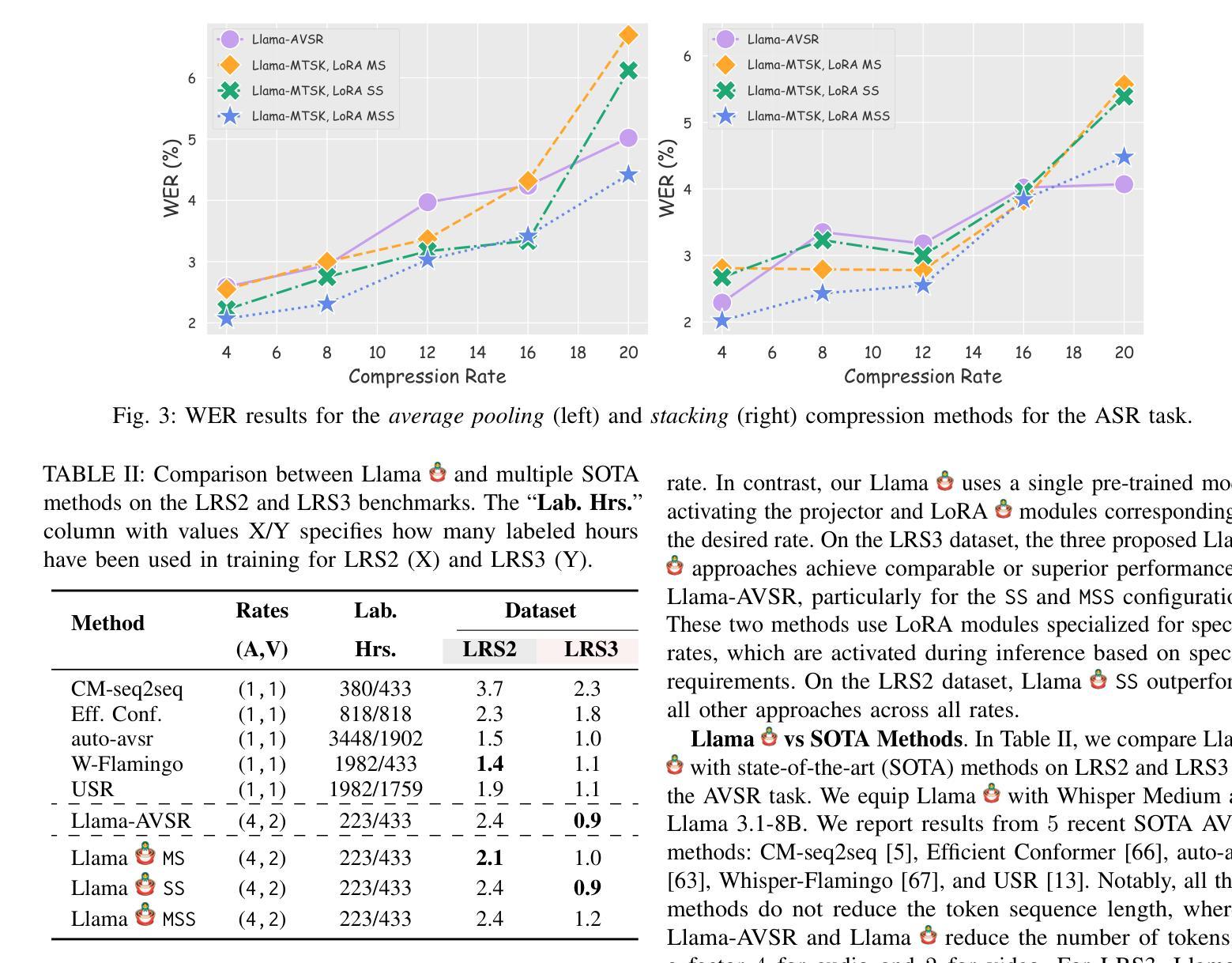
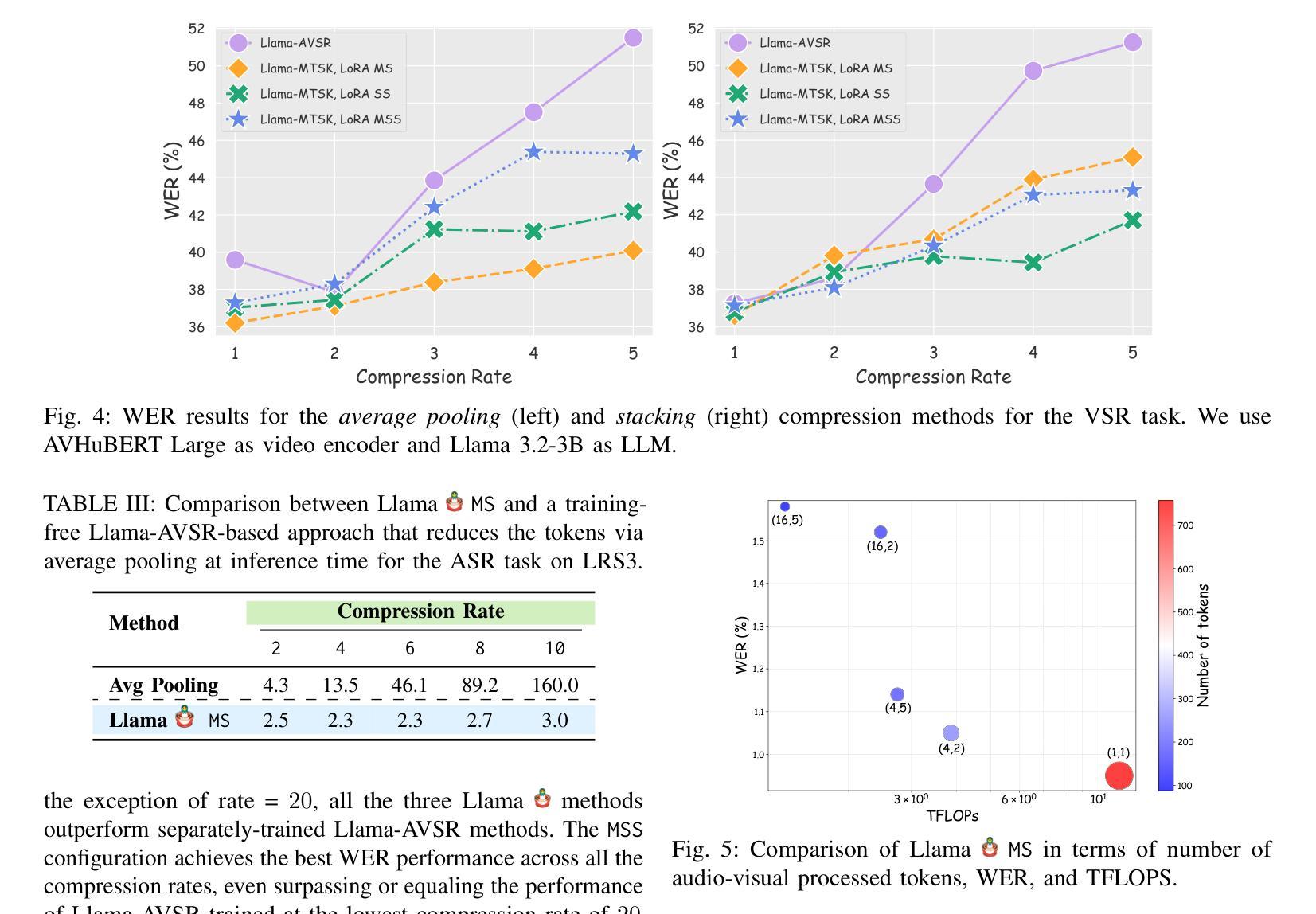
Adaptive Audio-Visual Speech Recognition via Matryoshka-Based Multimodal LLMs
Authors:Umberto Cappellazzo, Minsu Kim, Stavros Petridis
Audio-Visual Speech Recognition (AVSR) leverages audio and visual modalities to improve robustness in noisy environments. Recent advances in Large Language Models (LLMs) show strong performance in speech recognition, including AVSR. However, the long speech representations lead to high computational costs for LLMs. Prior methods compress inputs before feeding them to LLMs, but high compression often harms accuracy. To address this, we propose Llama-MTSK, the first Matryoshka-based Multimodal LLM for AVSR, which flexibly adapts audio-visual token allocation under varying compute constraints. Inspired by Matryoshka Representation Learning, our model encodes representations at multiple granularities with a single architecture, avoiding the need for separate models. For efficient fine-tuning, we introduce three LoRA-based strategies using global and scale-specific modules. Evaluations on major AVSR datasets show Llama-MTSK matches or outperforms models trained at fixed compression levels.
视听语音识别(AVSR)利用音频和视觉模式来提高噪声环境下的稳健性。最近大型语言模型(LLM)在语音识别方面的进展,包括AVSR在内的表现都相当出色。然而,较长的语音表示给LLM带来了较高的计算成本。之前的方法在将输入送入LLM之前先进行压缩,但高压缩往往会损害准确性。为了解决这一问题,我们提出了Llama-MTSK,这是一款基于Matryoshka的AVSR多模态LLM,它能够在不同的计算约束下灵活地适应视听令牌分配。我们的模型受到Matryoshka表示学习的启发,使用单一架构对多个粒度的表示进行编码,避免了需要使用单独模型的需要。为了实现高效的微调,我们引入了三种基于LoRA的策略,使用全局和规模特定的模块。在主要的AVSR数据集上的评估显示,Llama-MTSK的表现与在固定压缩级别下训练的模型相匹配或更胜一筹。
论文及项目相关链接
PDF Accepted to IEEE ASRU 2025
Summary
基于音频视觉多模态融合的语音识别(AVSR)技术能够提高在噪声环境下的稳健性。最新的大型语言模型(LLM)在语音识别方面表现出强大的性能,包括AVSR。然而,由于长语音表示,LLM的计算成本较高。为了解决这个问题,我们提出了基于Matryoshka的多模态LLM——Llama-MTSK,它可以在不同的计算约束下灵活地适应音视频令牌分配。我们的模型通过单一架构对多个粒度进行编码表示,避免了需要单独模型的需求。通过引入三种基于LoRA的策略并使用全局和规模特定的模块,我们实现了高效的微调。在主要的AVSR数据集上的评估显示,Llama-MTSK的表现与在固定压缩级别下训练的模型相匹配或表现更好。
Key Takeaways
- 音频视觉多模态融合(AVSR)能提高噪声环境下的语音识别稳健性。
- 大型语言模型(LLM)在语音识别领域表现出色,包括AVSR。
- LLM在处理长语音表示时存在高计算成本问题。
- Llama-MTSK是首个基于Matryoshka的多模态LLM,可灵活适应不同计算约束下的音视频令牌分配。
- Llama-MTSK通过单一架构编码多个粒度表示,提高了效率并避免了单独模型的需求。
- 通过引入三种基于LoRA的策略,实现了高效的微调。
点此查看论文截图