⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation
Authors:Wonjun Kang, Byeongkeun Ahn, Minjae Lee, Kevin Galim, Seunghyuk Oh, Hyung Il Koo, Nam Ik Cho
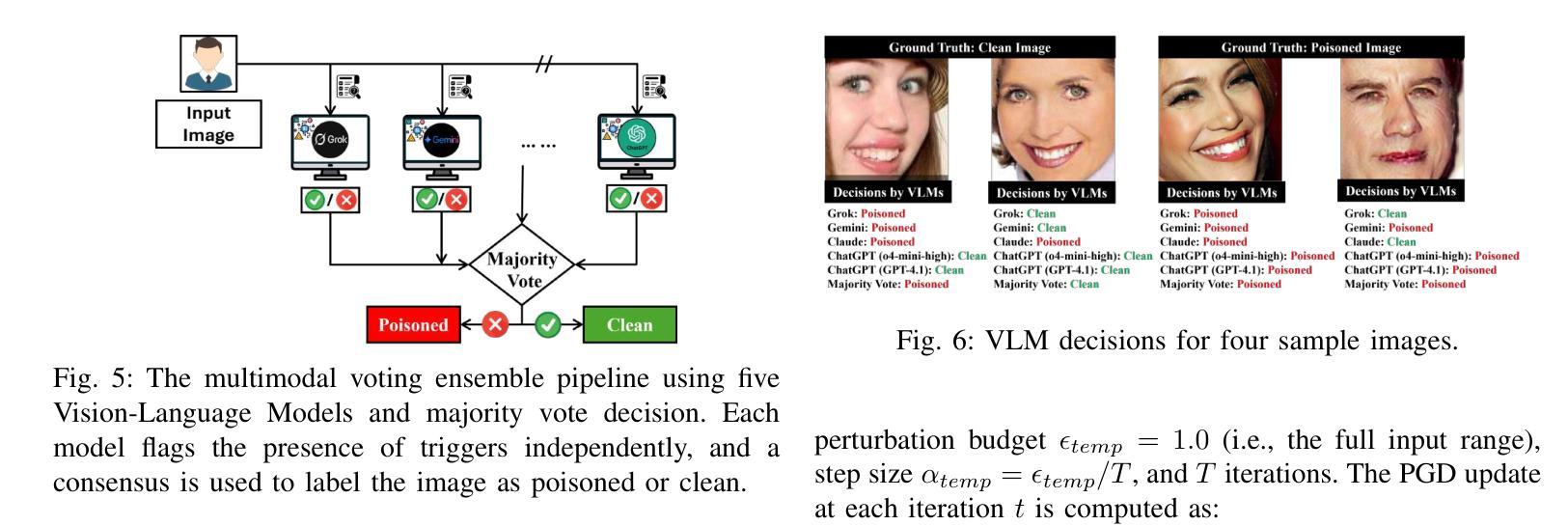
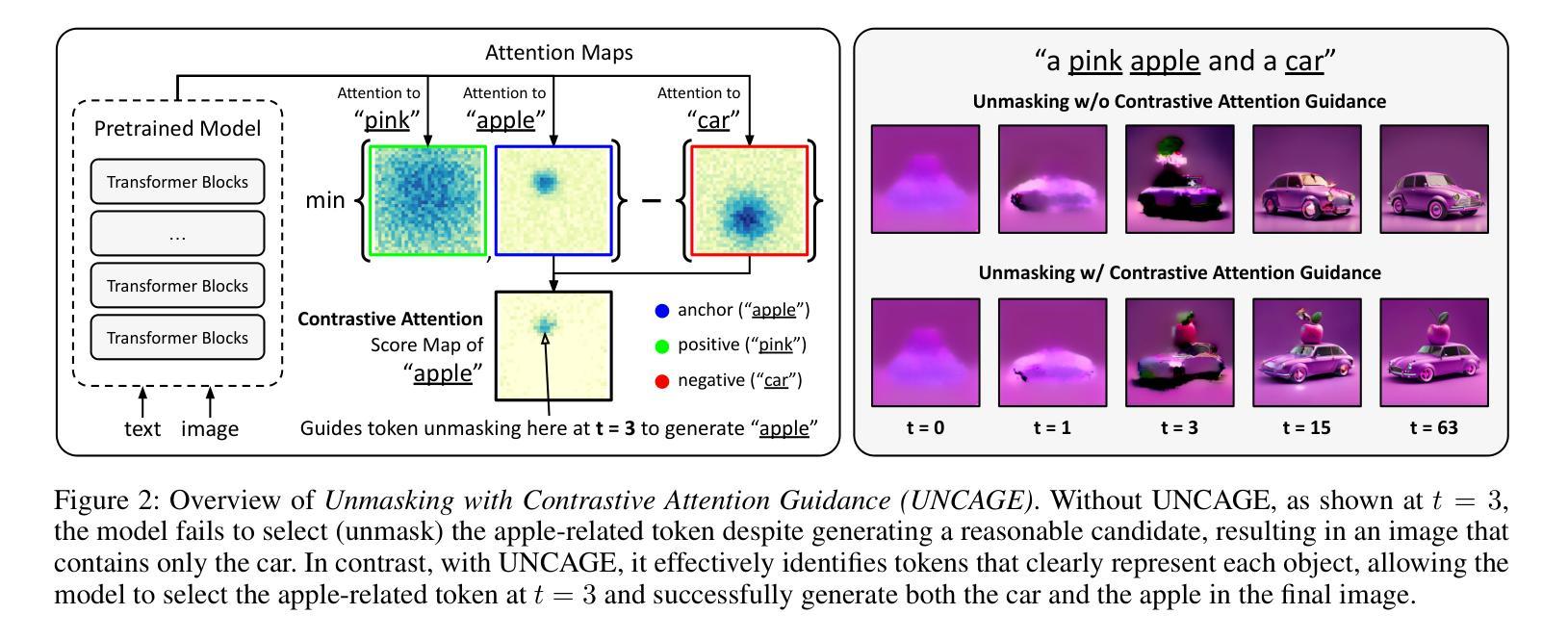
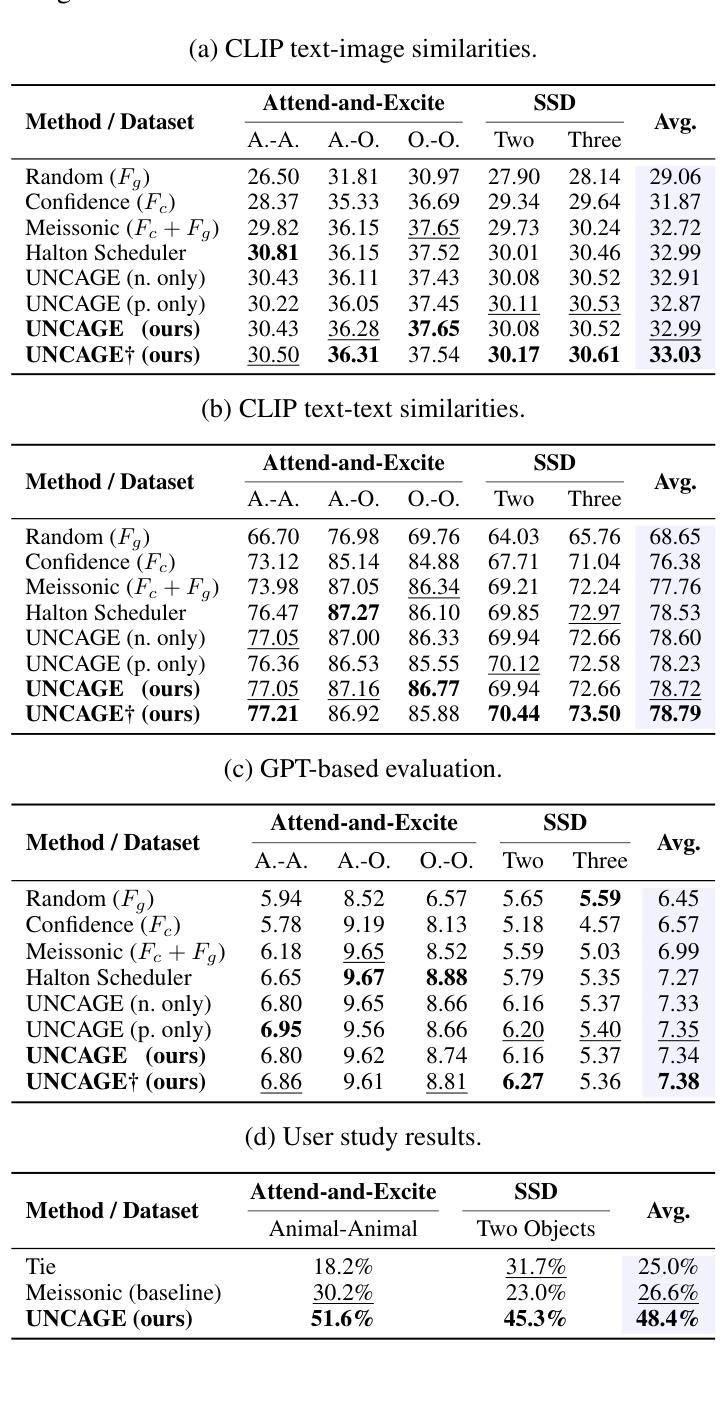
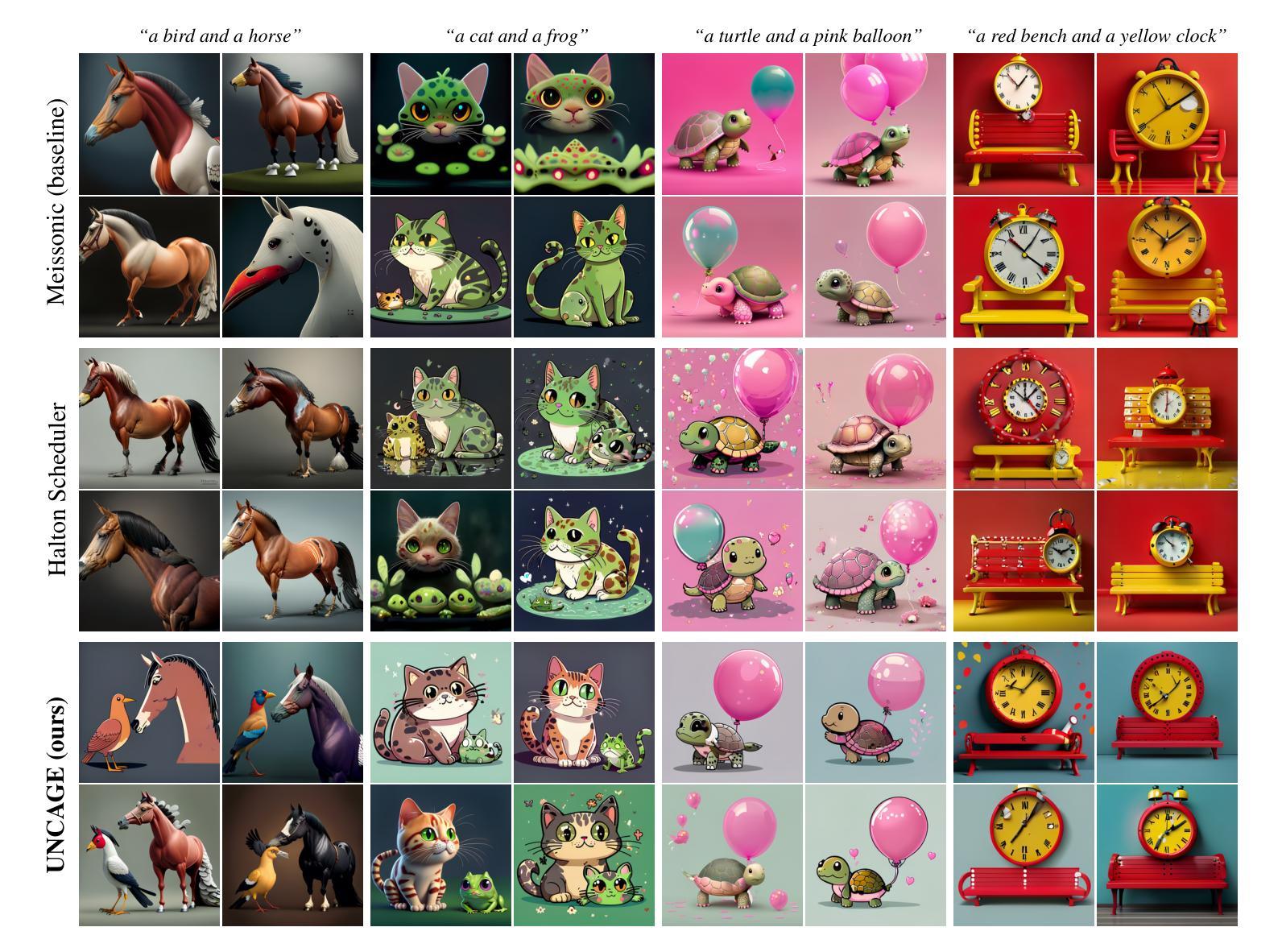
Text-to-image (T2I) generation has been actively studied using Diffusion Models and Autoregressive Models. Recently, Masked Generative Transformers have gained attention as an alternative to Autoregressive Models to overcome the inherent limitations of causal attention and autoregressive decoding through bidirectional attention and parallel decoding, enabling efficient and high-quality image generation. However, compositional T2I generation remains challenging, as even state-of-the-art Diffusion Models often fail to accurately bind attributes and achieve proper text-image alignment. While Diffusion Models have been extensively studied for this issue, Masked Generative Transformers exhibit similar limitations but have not been explored in this context. To address this, we propose Unmasking with Contrastive Attention Guidance (UNCAGE), a novel training-free method that improves compositional fidelity by leveraging attention maps to prioritize the unmasking of tokens that clearly represent individual objects. UNCAGE consistently improves performance in both quantitative and qualitative evaluations across multiple benchmarks and metrics, with negligible inference overhead. Our code is available at https://github.com/furiosa-ai/uncage.
文本到图像(T2I)生成已经积极使用扩散模型(Diffusion Models)和自回归模型(Autoregressive Models)进行研究。最近,掩码生成式转换器(Masked Generative Transformers)作为自回归模型的替代方案,通过双向注意力和并行解码克服了因果注意力和自回归解码的固有局限性,从而实现了高效且高质量的图像生成。然而,组合T2I生成仍然具有挑战性,因为即使是最先进的扩散模型也往往无法准确绑定属性并实现适当的文本-图像对齐。虽然扩散模型针对此问题已进行了广泛研究,但掩码生成式转换器也表现出类似的局限性,但在这方面尚未得到探索。为了解决这个问题,我们提出了无训练的方法Unmasking with Contrastive Attention Guidance(UNCAGE),该方法利用注意力图来优先对清晰表示单个对象的令牌进行解掩,从而提高组合保真度。UNCAGE在多个基准和指标上的定量和定性评估中始终提高了性能,并且推理开销微乎其微。我们的代码位于https://github.com/furiosa-ai/uncage。
论文及项目相关链接
PDF Code is available at https://github.com/furiosa-ai/uncage
Summary
文本到图像(T2I)生成研究中,扩散模型和自回归模型备受关注。近期,掩盖生成性转换器作为自回归模型的替代方案,通过双向注意和并行解码克服固有局限,实现高效高质量图像生成。然而,组合式T2I生成仍具挑战,即使最先进的扩散模型也难以准确绑定属性并实现适当的文本-图像对齐。为解决这一问题,提出一种无需训练的新型方法——对比注意力引导下的揭露(UNCAGE),利用注意力图优先揭露清晰代表单个对象的符号,提高组合保真度。UNCAGE在多个基准测试和指标下的定量和定性评估中表现优异,且推理时间增加较少。
Key Takeaways
- 文本到图像(T2I)生成中,扩散模型和自回归模型是主要研究方法。
- 掩盖生成性转换器能克服自回归模型的固有局限,实现高效高质量图像生成。
- 组合式T2I生成存在挑战,即使先进模型也难以实现准确属性绑定和文本-图像对齐。
- UNCAGE是一种新型无需训练的解决方案,利用注意力图优先揭露代表单个对象的符号。
- UNCAGE在多个基准测试中表现优异,提高了组合保真度。
- UNCAGE对推理时间的影响较小。
点此查看论文截图

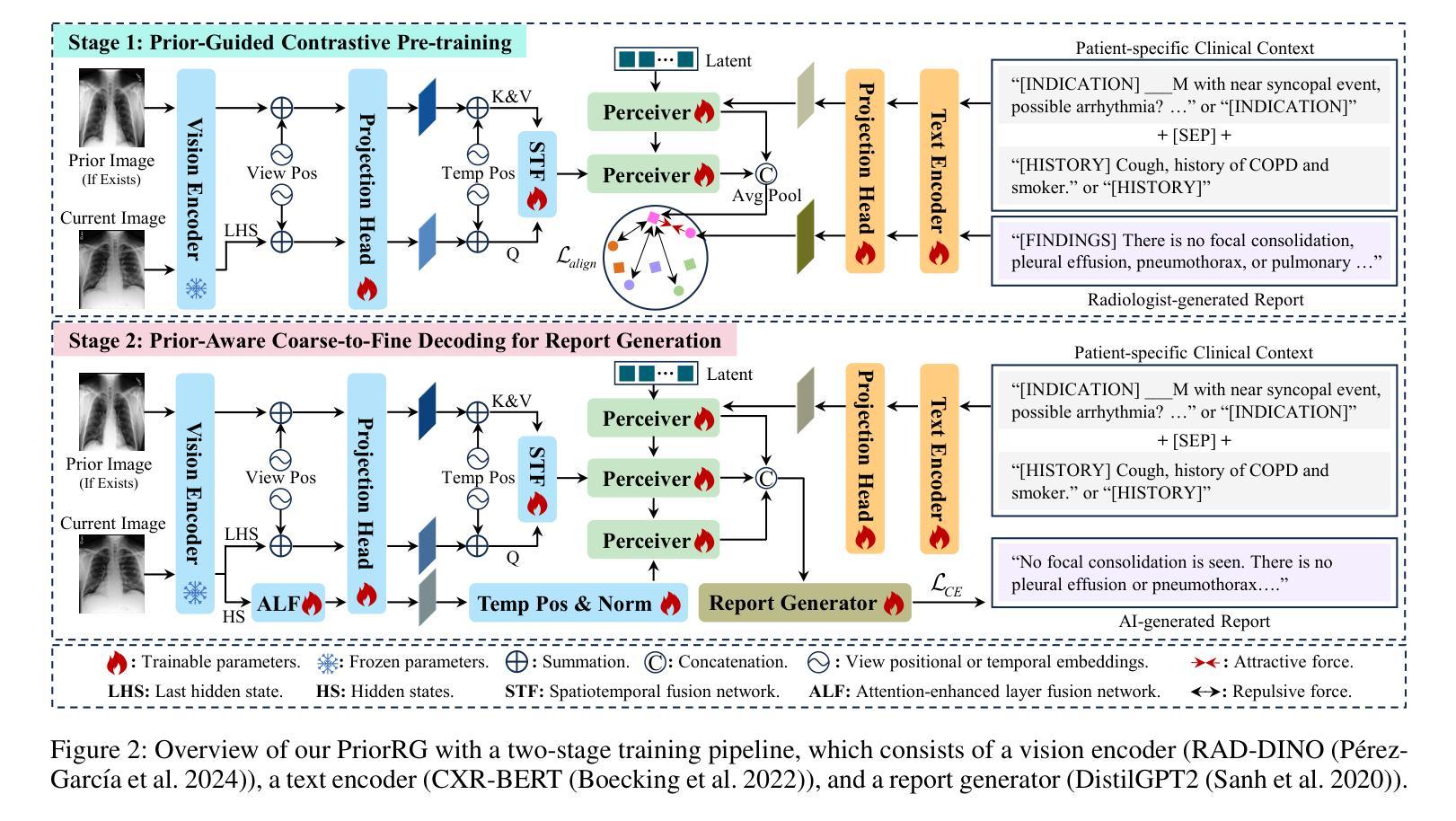
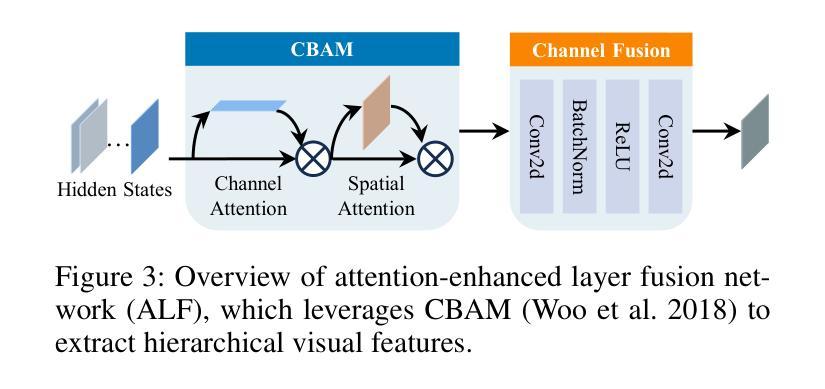
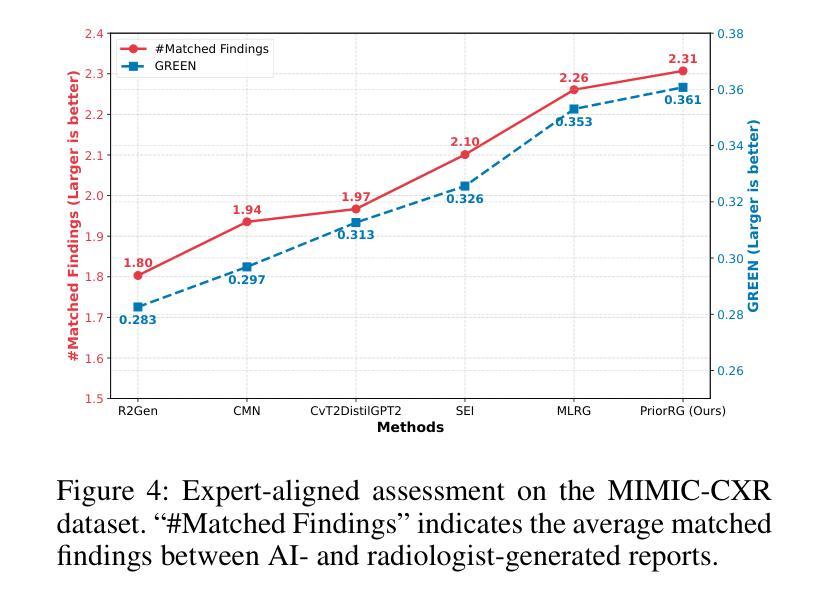
PriorRG: Prior-Guided Contrastive Pre-training and Coarse-to-Fine Decoding for Chest X-ray Report Generation
Authors:Kang Liu, Zhuoqi Ma, Zikang Fang, Yunan Li, Kun Xie, Qiguang Miao
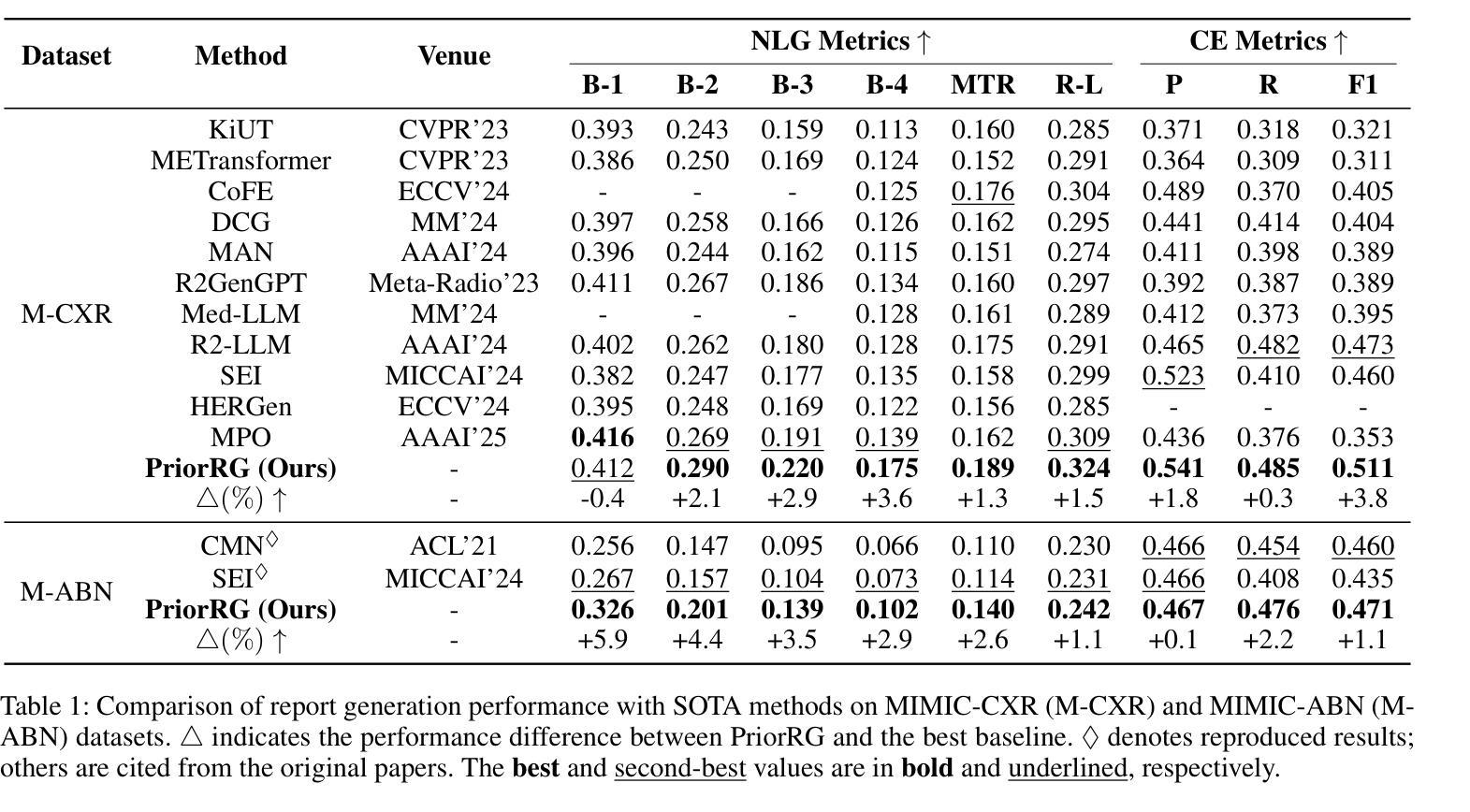
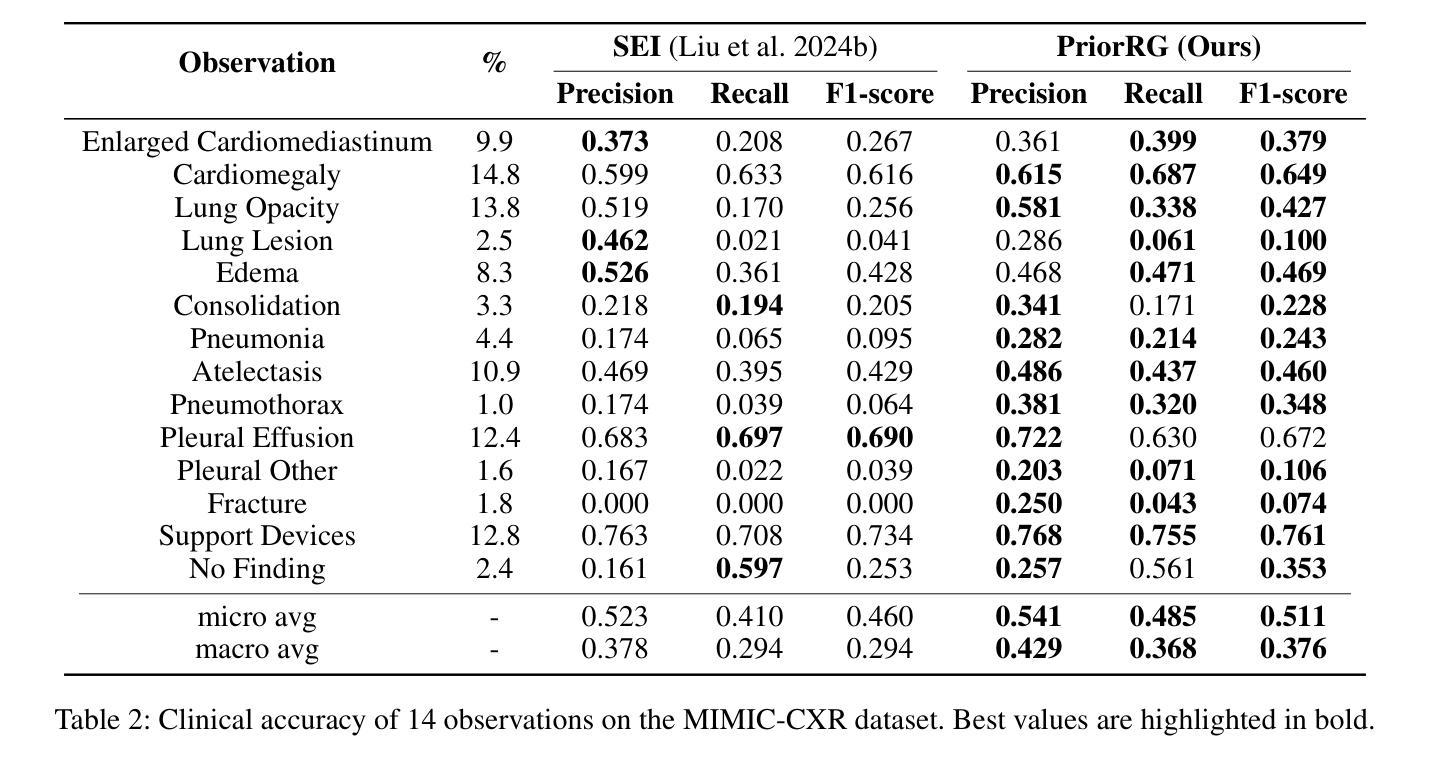
Chest X-ray report generation aims to reduce radiologists’ workload by automatically producing high-quality preliminary reports. A critical yet underexplored aspect of this task is the effective use of patient-specific prior knowledge – including clinical context (e.g., symptoms, medical history) and the most recent prior image – which radiologists routinely rely on for diagnostic reasoning. Most existing methods generate reports from single images, neglecting this essential prior information and thus failing to capture diagnostic intent or disease progression. To bridge this gap, we propose PriorRG, a novel chest X-ray report generation framework that emulates real-world clinical workflows via a two-stage training pipeline. In Stage 1, we introduce a prior-guided contrastive pre-training scheme that leverages clinical context to guide spatiotemporal feature extraction, allowing the model to align more closely with the intrinsic spatiotemporal semantics in radiology reports. In Stage 2, we present a prior-aware coarse-to-fine decoding for report generation that progressively integrates patient-specific prior knowledge with the vision encoder’s hidden states. This decoding allows the model to align with diagnostic focus and track disease progression, thereby enhancing the clinical accuracy and fluency of the generated reports. Extensive experiments on MIMIC-CXR and MIMIC-ABN datasets demonstrate that PriorRG outperforms state-of-the-art methods, achieving a 3.6% BLEU-4 and 3.8% F1 score improvement on MIMIC-CXR, and a 5.9% BLEU-1 gain on MIMIC-ABN. Code and checkpoints will be released upon acceptance.
胸部X光片报告生成旨在通过自动生成高质量初步报告来减轻放射科医生的工作量。该任务的一个关键但尚未被充分探索的方面是有效利用患者特定先验知识,包括临床背景(例如,症状、病史)和最近的先前图像——放射科医生在进行诊断推理时通常会依赖这些信息。大多数现有方法都是从单张图像生成报告,忽略了这些重要的先验信息,因此无法捕捉诊断意图或疾病进展。为了弥补这一差距,我们提出了PriorRG,这是一种新的胸部X光片报告生成框架,通过两阶段训练管道模拟现实临床工作流程。在第一阶段,我们引入了一种基于先验的对比预训练方案,利用临床背景来指导时空特征提取,使模型更紧密地符合放射学报告中的内在时空语义。在第二阶段,我们提出了一种基于先验的粗到细解码方法,用于报告生成,该方法逐步将患者特定的先验知识与视觉编码器的隐藏状态相结合。这种解码方式使模型能够与诊断重点对齐并跟踪疾病进展,从而提高生成报告的临床准确性和流畅性。在MIMIC-CXR和MIMIC-ABN数据集上的大量实验表明,PriorRG优于现有最先进的方法,在MIMIC-CXR上实现了BLEU-4得分提高3.6%,F1得分提高3.8%,在MIMIC-ABN上BLEU-1得分提高了5.9%。代码和检查点将在接受后发布。
论文及项目相关链接
Summary
本文提出一种新型的胸部X光报告生成框架PriorRG,旨在减轻放射科医生的工作负担。该框架模拟真实临床工作流程,通过两阶段训练管道生成报告。第一阶段利用临床上下文信息引导时空特征提取;第二阶段采用基于先验知识的粗到细解码方式,逐步将患者特定先验知识与视觉编码器的隐藏状态相结合,提高报告的临床准确性和流畅性。实验结果表明,PriorRG在MIMIC-CXR和MIMIC-ABN数据集上优于现有方法。
Key Takeaways
- 胸部X光报告生成旨在减轻放射科医生工作负担,自动产生高质量初步报告。
- 现有方法多忽略患者特定先验信息,包括临床上下文和最新先前图像,影响诊断意图和疾病进展的捕捉。
- PriorRG框架模拟真实临床工作流程,通过两阶段训练管道生成报告:第一阶段利用临床上下文信息引导时空特征提取;第二阶段采用基于先验知识的解码方式。
- PriorRG框架能提高报告的临床准确性和流畅性。
- 在MIMIC-CXR和MIMIC-ABN数据集上,PriorRG表现优于现有方法,实现了显著的BLEU-4、F1分数提升。
- PriorRG框架的代码和检查点将在接受后公布。
点此查看论文截图

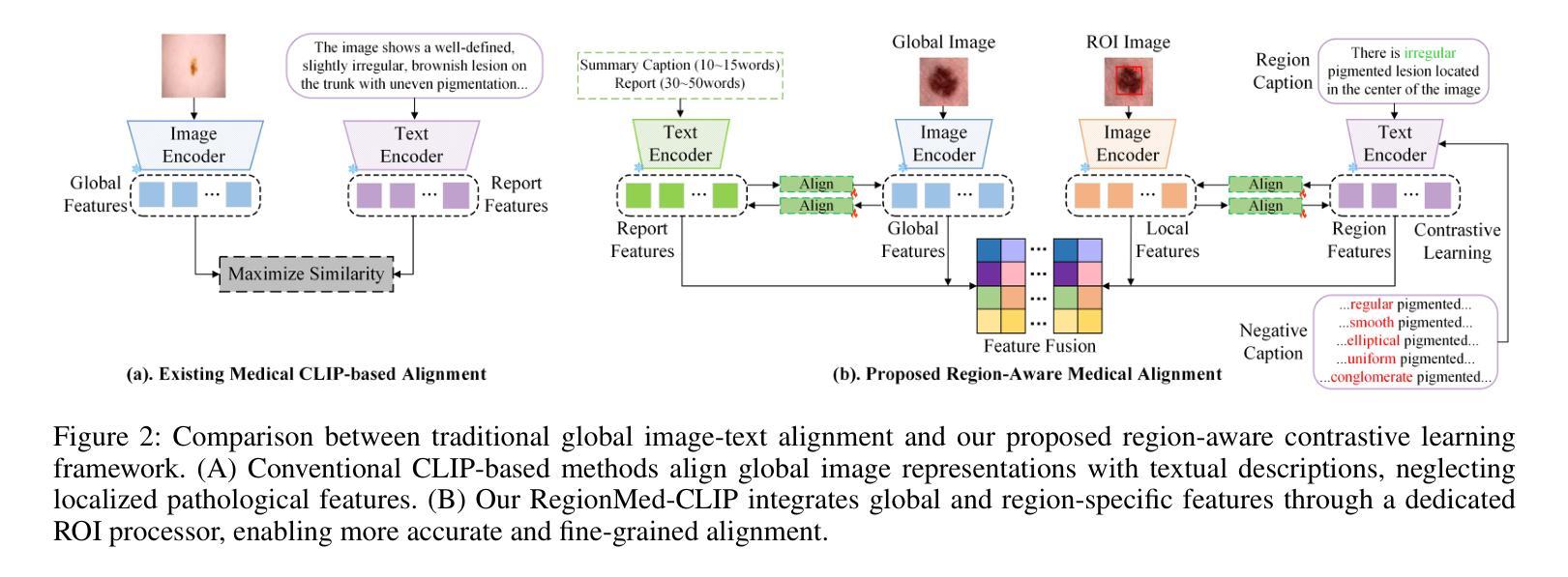
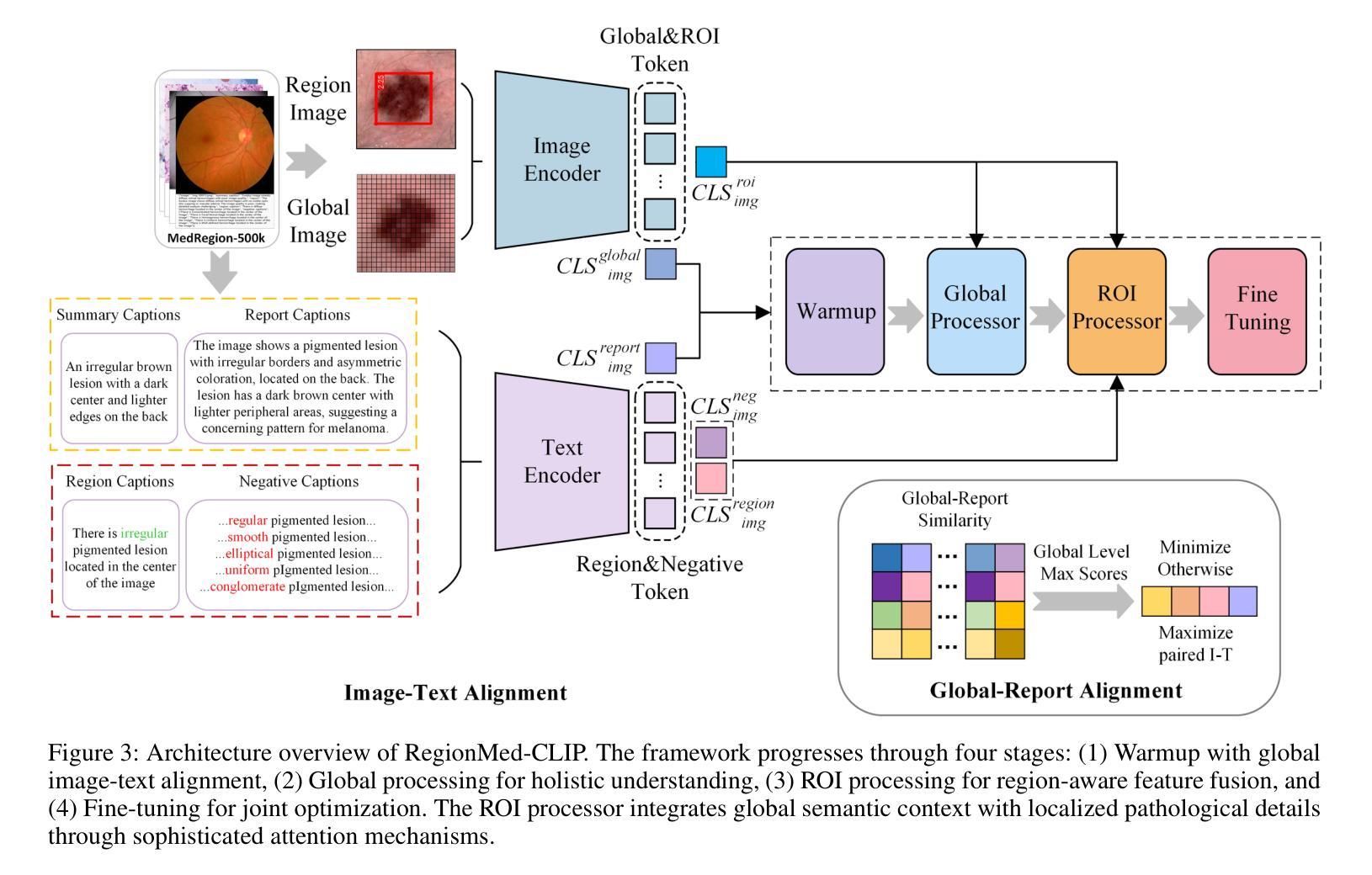
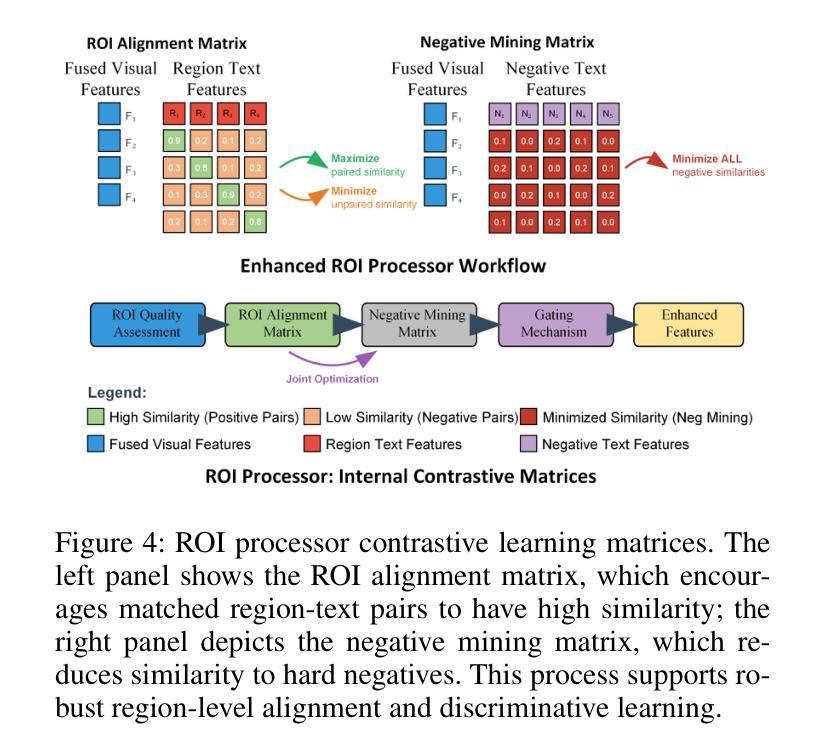
RegionMed-CLIP: A Region-Aware Multimodal Contrastive Learning Pre-trained Model for Medical Image Understanding
Authors:Tianchen Fang, Guiru Liu
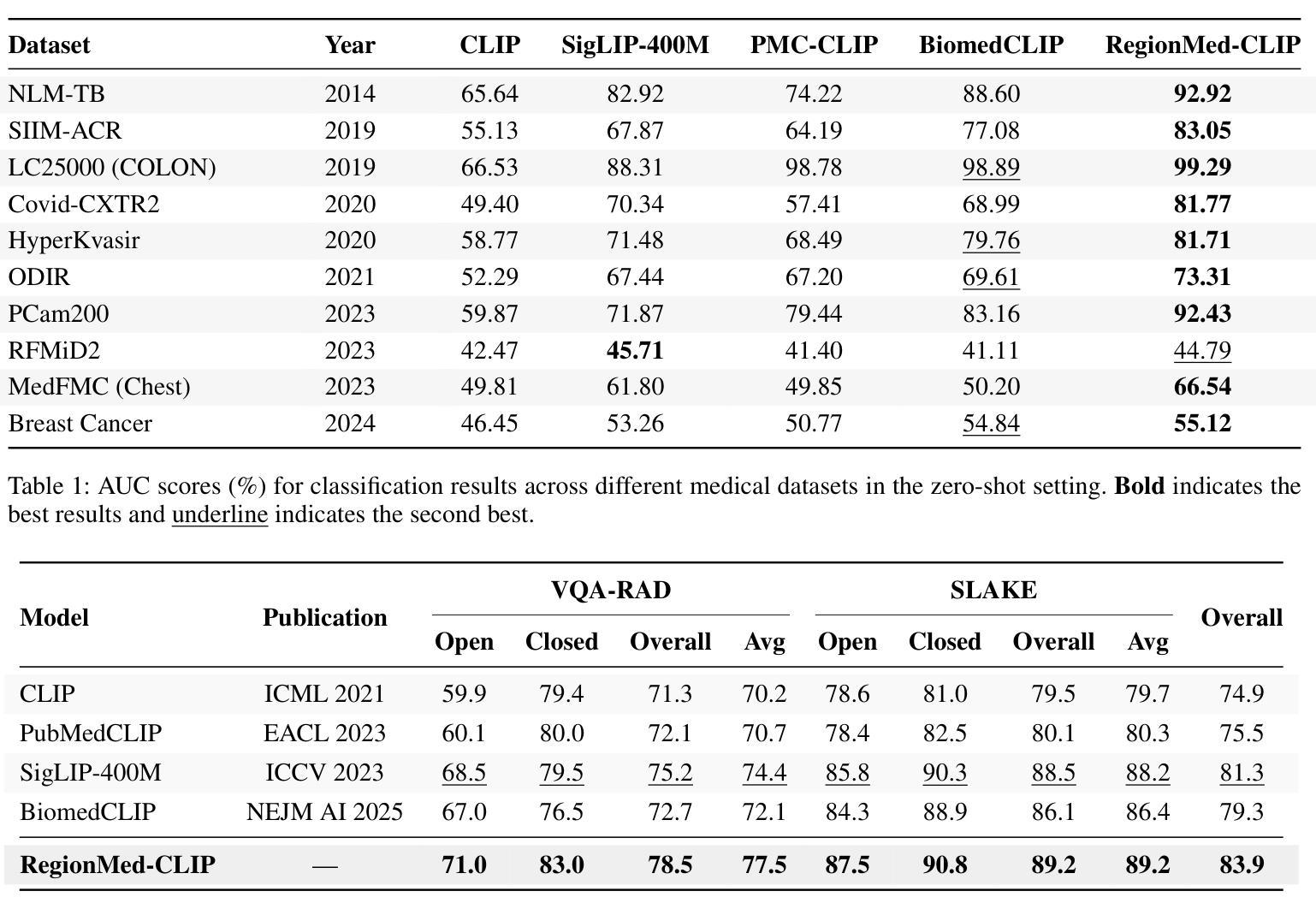
Medical image understanding plays a crucial role in enabling automated diagnosis and data-driven clinical decision support. However, its progress is impeded by two primary challenges: the limited availability of high-quality annotated medical data and an overreliance on global image features, which often miss subtle but clinically significant pathological regions. To address these issues, we introduce RegionMed-CLIP, a region-aware multimodal contrastive learning framework that explicitly incorporates localized pathological signals along with holistic semantic representations. The core of our method is an innovative region-of-interest (ROI) processor that adaptively integrates fine-grained regional features with the global context, supported by a progressive training strategy that enhances hierarchical multimodal alignment. To enable large-scale region-level representation learning, we construct MedRegion-500k, a comprehensive medical image-text corpus that features extensive regional annotations and multilevel clinical descriptions. Extensive experiments on image-text retrieval, zero-shot classification, and visual question answering tasks demonstrate that RegionMed-CLIP consistently exceeds state-of-the-art vision language models by a wide margin. Our results highlight the critical importance of region-aware contrastive pre-training and position RegionMed-CLIP as a robust foundation for advancing multimodal medical image understanding.
医疗图像理解在推动自动化诊断和基于数据的临床决策支持方面发挥着至关重要的作用。然而,其进展受到两个主要挑战的限制:高质量标注医疗数据的有限可用性,以及对全局图像特征的过度依赖,这往往导致忽略细微但临床上重要的病理区域。为了解决这些问题,我们引入了RegionMed-CLIP,这是一个区域感知多模态对比学习框架,它显式地结合了局部病理信号和整体语义表示。我们的方法的核心是一个创新的兴趣区域(ROI)处理器,该处理器自适应地整合了精细的局部特征与全局上下文,辅以一种增强层次多模态对齐的渐进式训练策略。为了实现大规模的区域级别表示学习,我们构建了MedRegion-500k,这是一个具有广泛区域注释和多层临床描述的综合医学图像文本语料库。在图像文本检索、零样本分类和视觉问答任务上的大量实验表明,RegionMed-CLIP一致且大幅度地超越了最先进的视觉语言模型。我们的研究结果强调了区域感知对比预训练的关键重要性,并将RegionMed-CLIP定位为推动多模态医疗图像理解发展的稳健基础。
论文及项目相关链接
Summary
RegionMed-CLIP是一种针对医疗图像理解的新方法,通过结合局部病理信号和整体语义表示,解决高质量标注医疗数据有限和过度依赖全局图像特征的问题。该方法通过自适应集成细粒度区域特征与全局上下文的核心区域处理器,以及增强层次化多模态对齐的渐进训练策略,实现了显著的性能提升。为支持大规模区域级别表示学习,构建了MedRegion-500k医疗图像文本语料库,包含丰富的区域注释和多层临床描述。实验结果表明,RegionMed-CLIP在图像文本检索、零样本分类和视觉问答任务上均显著超越了当前最先进的视觉语言模型。
Key Takeaways
- RegionMed-CLIP解决了医疗图像理解中的两大挑战:高质量标注医疗数据的有限性和对全局图像特征的过度依赖。
- 该方法通过结合局部病理信号和整体语义表示,提高了医疗图像理解的性能。
- RegionMed-CLIP的核心是自适应集成细粒度区域特征与全局上下文的区域处理器。
- 渐进训练策略增强了层次化多模态对齐,进一步提升了性能。
- 为支持大规模区域级别表示学习,构建了MedRegion-500k医疗图像文本语料库。
- RegionMed-CLIP在图像文本检索、零样本分类和视觉问答任务上的表现均超越了当前最先进的视觉语言模型。
点此查看论文截图