⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
Decoupling Continual Semantic Segmentation
Authors:Yifu Guo, Yuquan Lu, Wentao Zhang, Zishan Xu, Dexia Chen, Siyu Zhang, Yizhe Zhang, Ruixuan Wang
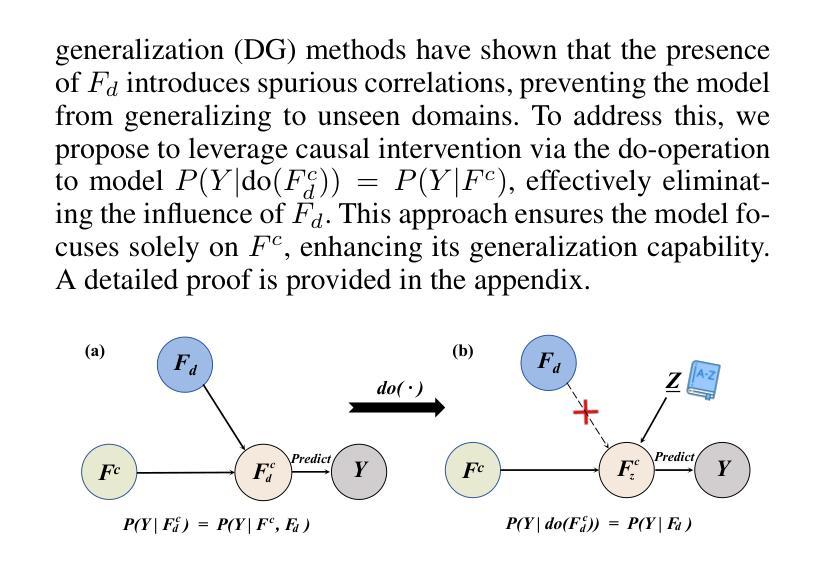
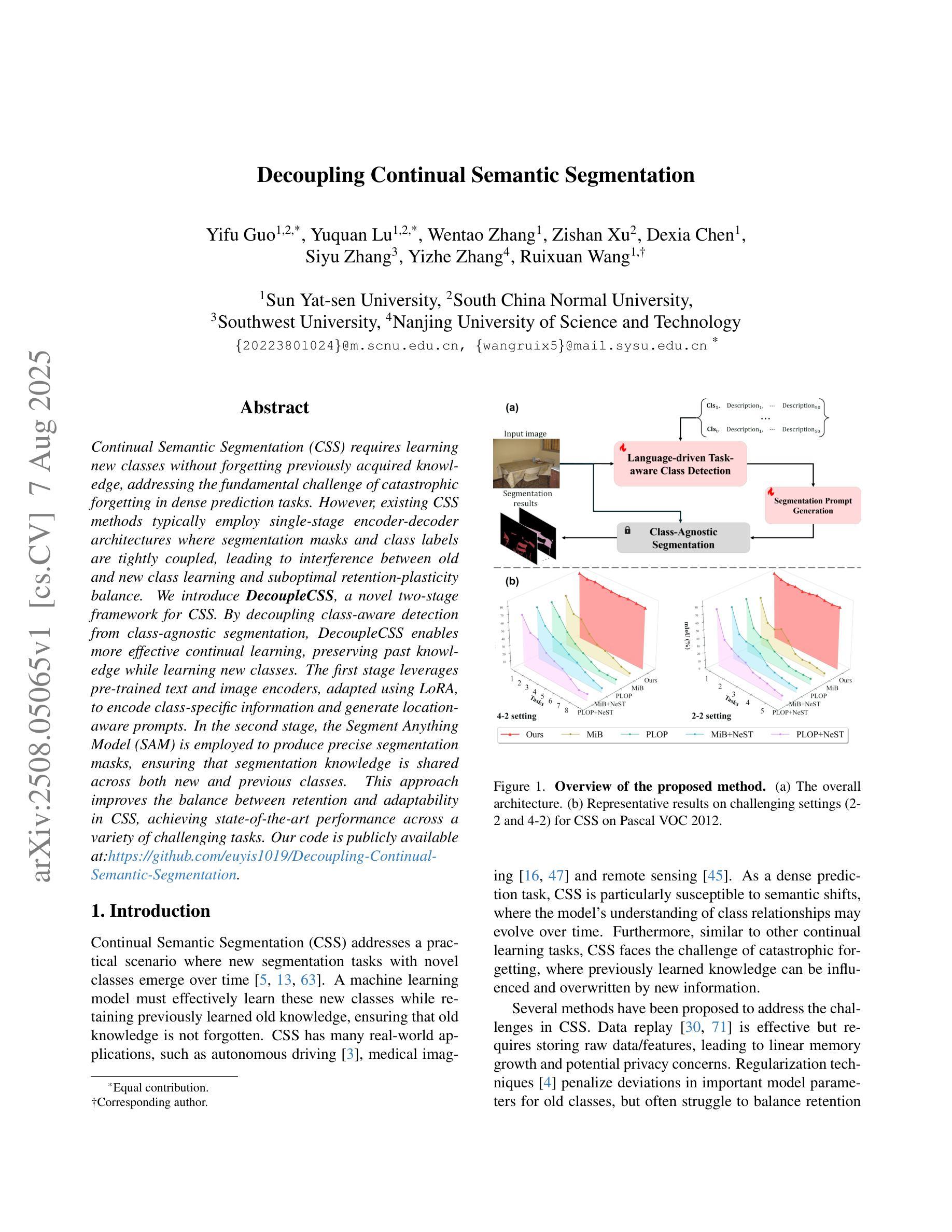
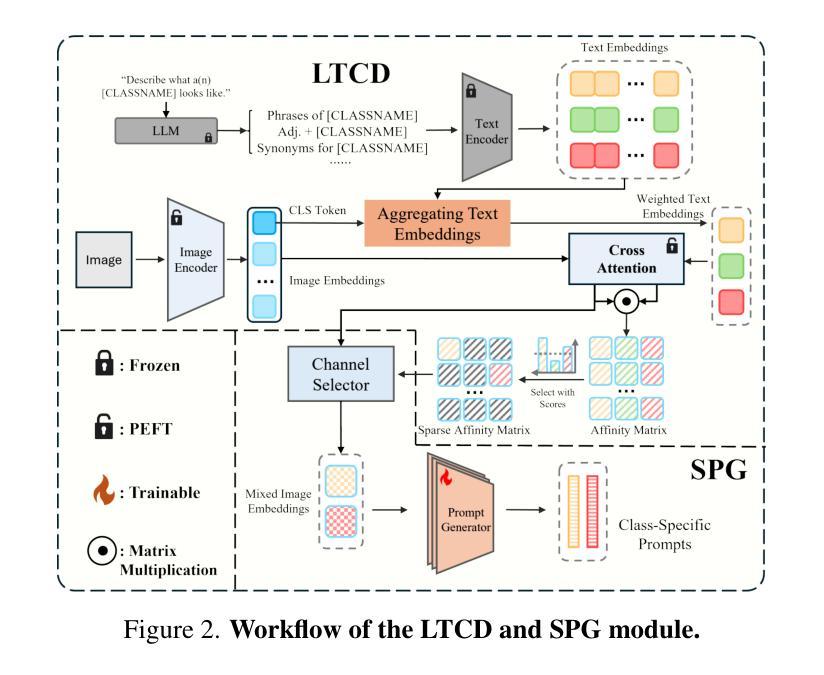
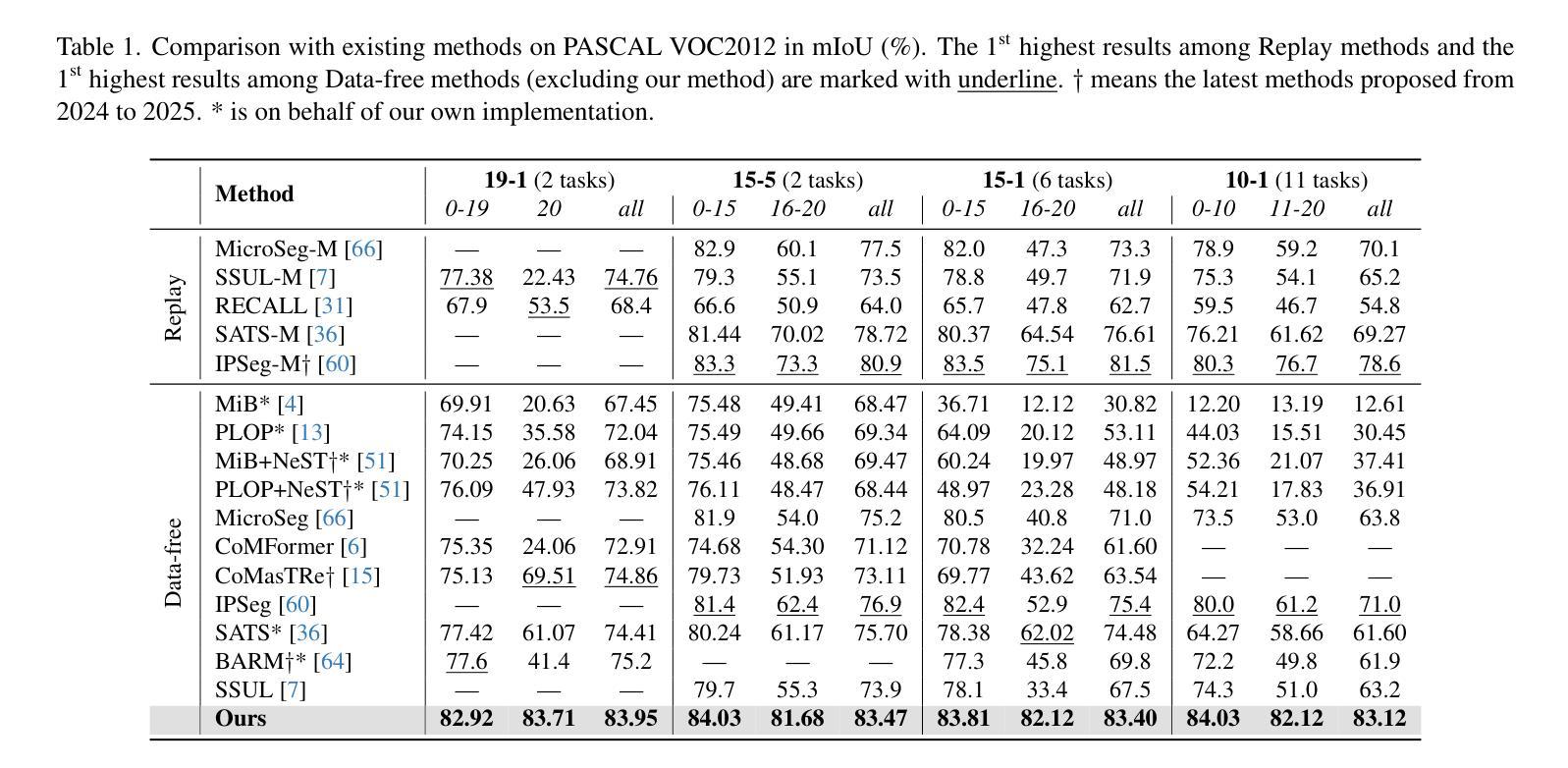
Continual Semantic Segmentation (CSS) requires learning new classes without forgetting previously acquired knowledge, addressing the fundamental challenge of catastrophic forgetting in dense prediction tasks. However, existing CSS methods typically employ single-stage encoder-decoder architectures where segmentation masks and class labels are tightly coupled, leading to interference between old and new class learning and suboptimal retention-plasticity balance. We introduce DecoupleCSS, a novel two-stage framework for CSS. By decoupling class-aware detection from class-agnostic segmentation, DecoupleCSS enables more effective continual learning, preserving past knowledge while learning new classes. The first stage leverages pre-trained text and image encoders, adapted using LoRA, to encode class-specific information and generate location-aware prompts. In the second stage, the Segment Anything Model (SAM) is employed to produce precise segmentation masks, ensuring that segmentation knowledge is shared across both new and previous classes. This approach improves the balance between retention and adaptability in CSS, achieving state-of-the-art performance across a variety of challenging tasks. Our code is publicly available at: https://github.com/euyis1019/Decoupling-Continual-Semantic-Segmentation.
持续语义分割(CSS)要求学习新类别而又不忘先前获得的知识,从而解决密集预测任务中的灾难性遗忘这一基本挑战。然而,现有的CSS方法通常采用单阶段编码器-解码器架构,其中分割掩码和类别标签紧密耦合,导致新旧类别学习之间的干扰以及保留-可塑性平衡不佳。我们引入了DecoupleCSS,这是一种用于CSS的新型两阶段框架。通过解耦类别感知检测与类别无关分割,DecoupleCSS能够实现更有效的持续学习,在学习新类别的同时保留过去的知识。第一阶段利用预训练的文本和图像编码器,通过LoRA进行适应,以编码特定类别的信息并生成位置感知提示。第二阶段采用“任何事物分割模型”(SAM)来生成精确的分割掩码,确保分割知识在新旧类别之间共享。这种方法提高了CSS中的保留能力和适应性之间的平衡,在各种具有挑战性的任务上实现了卓越的性能。我们的代码公开可访问于:https://github.com/euyis1019/Decoupling-Continual-Semantic-Segmentation。
论文及项目相关链接
PDF https://github.com/euyis1019/Decoupling-Continual-Semantic-Segmentation
Summary
持续语义分割(CSS)面临的关键挑战是忘记先前获取的知识,而现有CSS方法通常采用单阶段编码器-解码器架构,其中分割掩码和类别标签紧密耦合,导致新旧类别学习之间的干扰以及保留和适应性的平衡不佳。我们提出DecoupleCSS,一种用于CSS的新型两阶段框架。通过解耦类感知检测与类无关分割,DecoupleCSS实现了更有效的持续学习,在学习新类别的同时保留过去的知识。第一阶段利用预训练的文本和图像编码器,使用LoRA进行适应,以编码特定类别的信息并生成位置感知提示。第二阶段采用“任何内容分割模型”(SAM),生成精确分割掩码,确保分割知识可在新旧类别之间共享。这种方法提高了CSS中的保留和适应性的平衡,并在各种具有挑战性的任务上实现了最先进的性能。
Key Takeaways
- 持续语义分割(CSS)面临灾难性遗忘的挑战。
- 现有CSS方法通常采用单阶段编码器-解码器架构,存在新旧类别学习干扰和保留-塑性平衡问题。
- DecoupleCSS是一种新型两阶段框架,用于解决上述问题。
- DecoupleCSS通过解耦类感知检测和类无关分割,实现更有效的持续学习。
- 第一阶段利用预训练文本和图像编码器,生成位置感知提示。
- 第二阶段采用精确分割模型(SAM),确保分割知识可在新旧类别之间共享。
点此查看论文截图

PerSense: Training-Free Personalized Instance Segmentation in Dense Images
Authors:Muhammad Ibraheem Siddiqui, Muhammad Umer Sheikh, Hassan Abid, Muhammad Haris Khan
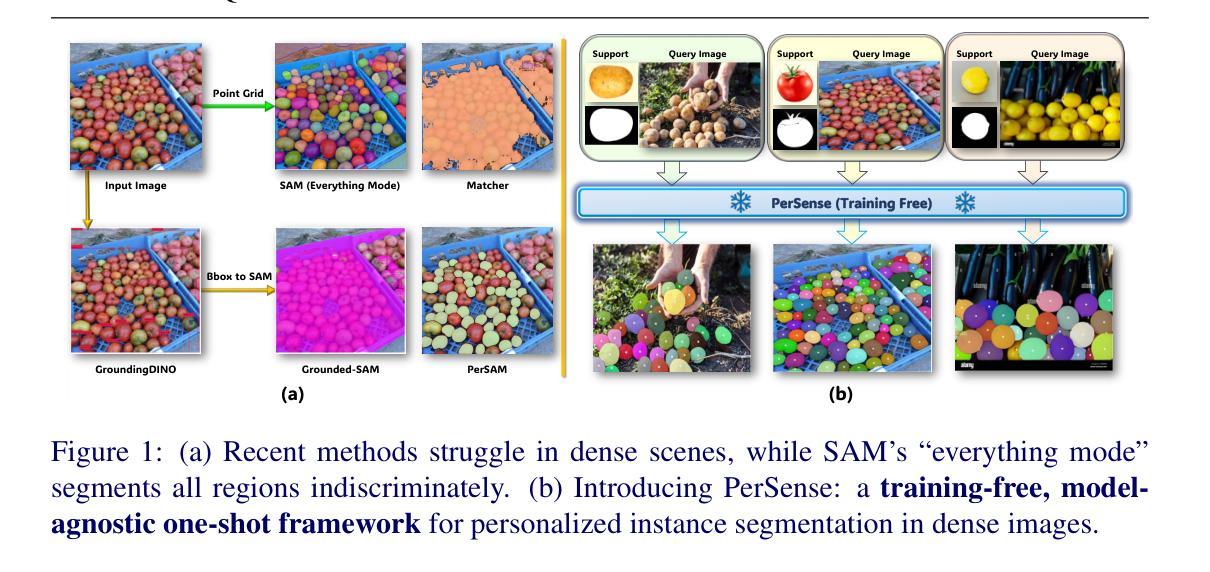
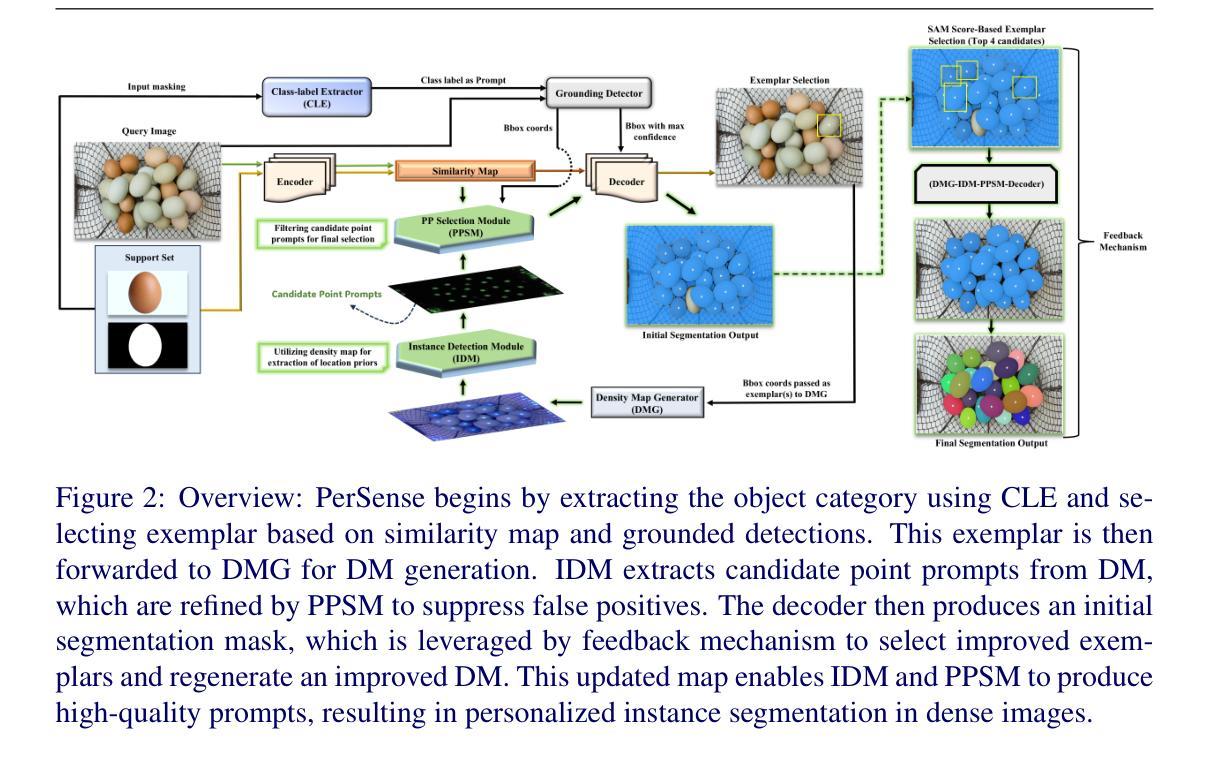
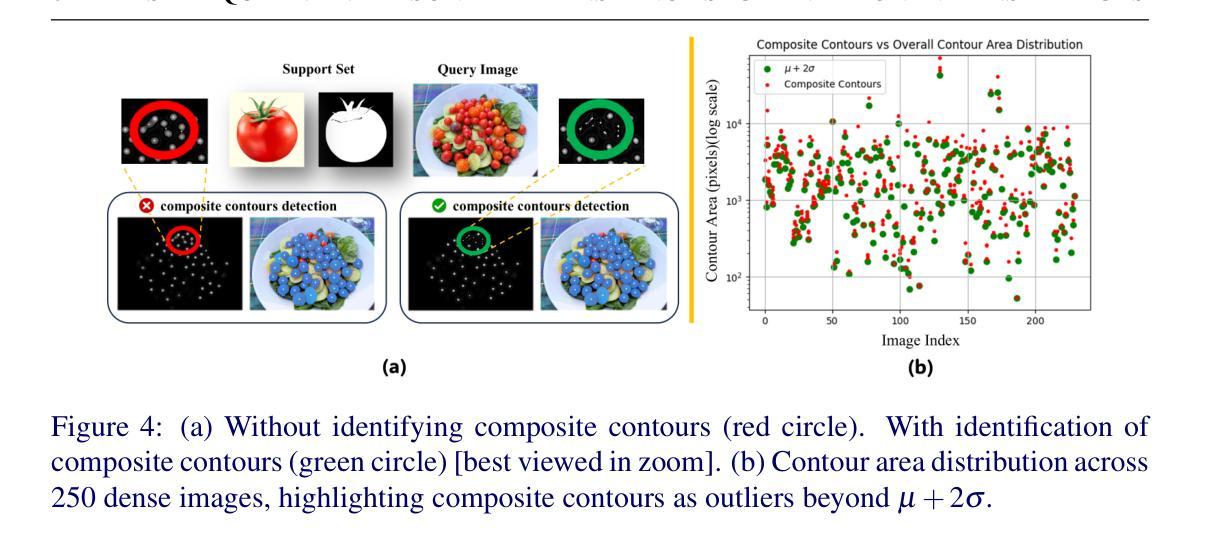
The emergence of foundational models has significantly advanced segmentation approaches. However, challenges still remain in dense scenarios, where occlusions, scale variations, and clutter impede precise instance delineation. To address this, we propose PerSense, an end-to-end, training-free, and model-agnostic one-shot framework for Personalized instance Segmentation in dense images. We start with developing a new baseline capable of automatically generating instance-level point prompts via proposing a novel Instance Detection Module (IDM) that leverages density maps (DMs), encapsulating spatial distribution of objects in an image. To reduce false positives, we design the Point Prompt Selection Module (PPSM), which refines the output of IDM based on adaptive threshold and spatial gating. Both IDM and PPSM seamlessly integrate into our model-agnostic framework. Furthermore, we introduce a feedback mechanism that enables PerSense to improve the accuracy of DMs by automating the exemplar selection process for DM generation. Finally, to advance research in this relatively underexplored area, we introduce PerSense-D, an evaluation benchmark for instance segmentation in dense images. Our extensive experiments establish PerSense’s superiority over SOTA in dense settings.
基础模型的兴起已经极大地推动了分割方法的发展。然而,在密集场景中仍然存在挑战,其中遮挡、尺度变化和杂乱干扰了精确的实例轮廓描绘。为了解决这一问题,我们提出了PerSense,这是一个端到端、无需训练、模型无关的个性化实例分割一次性框架,用于密集图像的实例分割。我们首先开发了一种新的基线方法,能够自动通过提出新颖实例检测模块(IDM)生成实例级点提示,该模块利用密度图(DMs),封装图像中对象的空间分布。为了减少误报,我们设计了点提示选择模块(PPSM),它基于自适应阈值和空间门控对IDM的输出进行细化。IDM和PPSM无缝集成到我们的模型无关的框架中。此外,我们引入了一种反馈机制,使PerSense能够自动化样本选择过程,从而提高密度图的精度。最后,为了推动这一相对未被充分研究的领域的研究进展,我们引入了PerSense-D,这是一个密集图像实例分割的评估基准。我们的大量实验证明了PerSense在密集环境下的表现优于现有技术。
论文及项目相关链接
PDF Technical report of PerSense
Summary
一种名为PerSense的端到端、无需训练、模型无关的一次性框架被提出,用于密集图像中的个性化实例分割。它通过开发一种新的基线方法,自动产生实例级别的点提示,并提出一个新的实例检测模块(IDM),利用密度图(DMs)来捕捉图像中物体的空间分布。为了降低误报,设计了点提示选择模块(PPSM),基于自适应阈值和空间门控对IDM的输出进行细化。此外,引入了一种反馈机制,使PerSense能够自动选择样本进行密度图生成,从而提高密度图的准确性。最后,为了推进这一相对未被充分研究的领域的研究,引入了PerSense-D,这是一个用于密集图像实例分割的评估基准。实验证明,在密集环境下,PerSense优于当前最佳方法。
Key Takeaways
- PerSense是一个无需训练、模型无关的一次性框架,用于密集图像中的个性化实例分割。
- 提出了一种新的基线方法,通过自动生成实例级别的点提示来改善实例分割。
- 引入了实例检测模块(IDM)和利用密度图(DMs)来捕捉图像中物体的空间分布。
- 设计了点提示选择模块(PPSM),以提高检测准确性并降低误报。
- 反馈机制的引入使PerSense能够自动选择样本进行密度图生成,提高DMs的准确性。
- 推出了PerSense-D,这是一个用于密集图像实例分割的评估基准。
点此查看论文截图