⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
TSPO: Temporal Sampling Policy Optimization for Long-form Video Language Understanding
Authors:Canhui Tang, Zifan Han, Hongbo Sun, Sanping Zhou, Xuchong Zhang, Xin Wei, Ye Yuan, Jinglin Xu, Hao Sun
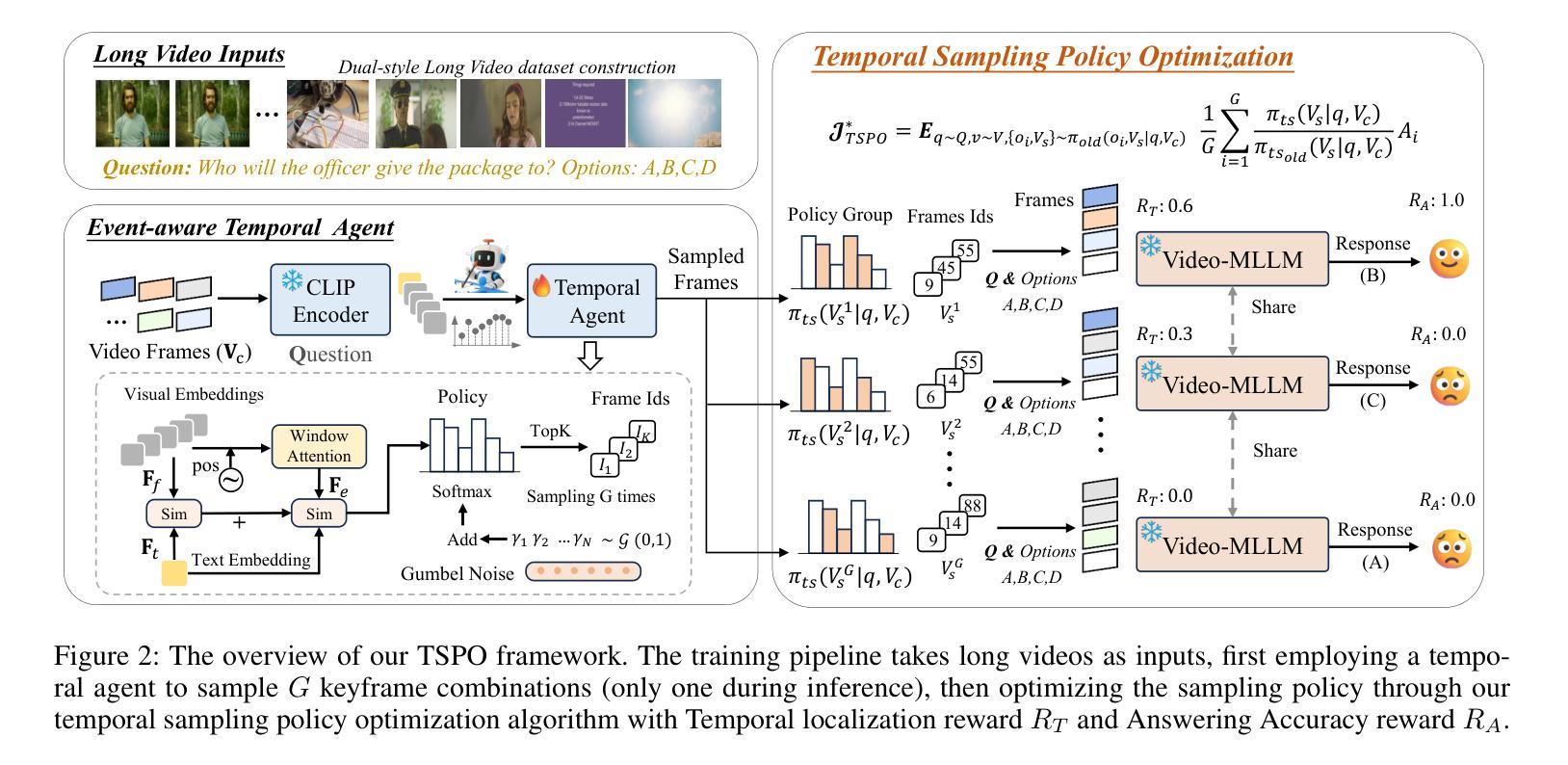
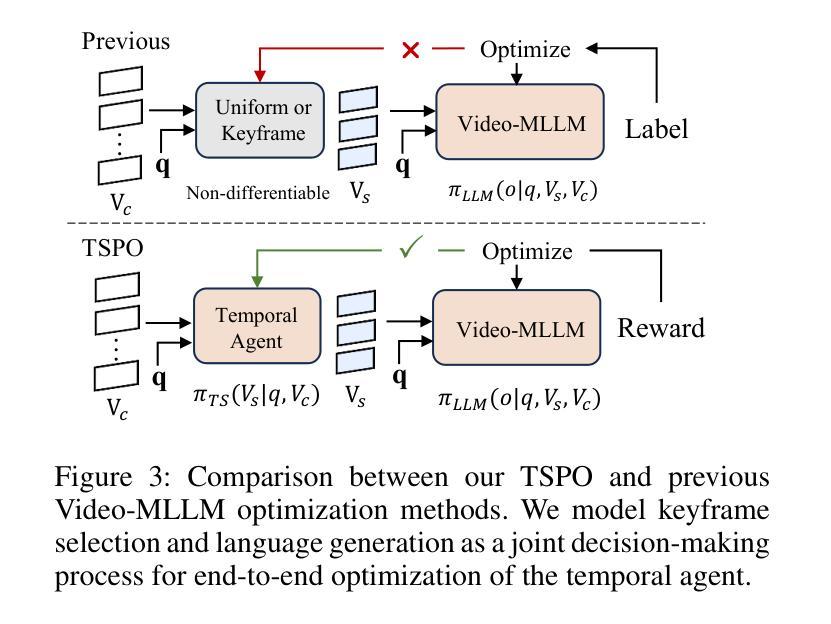
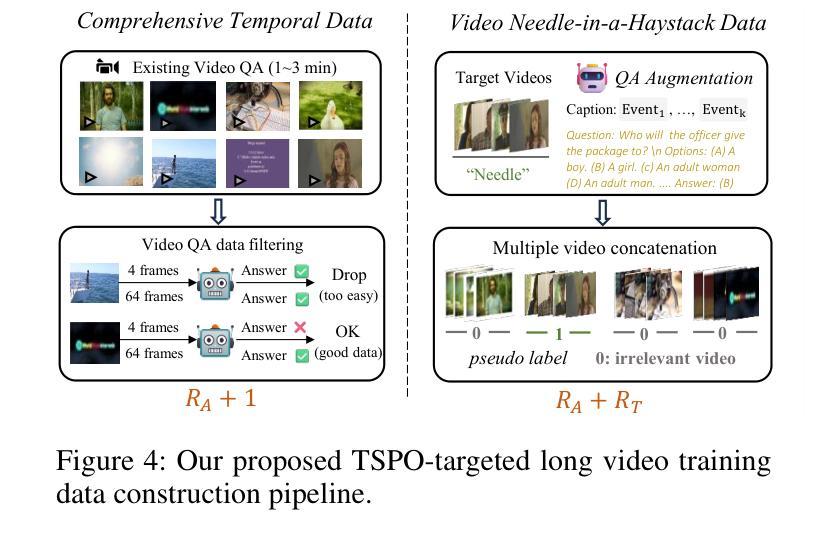
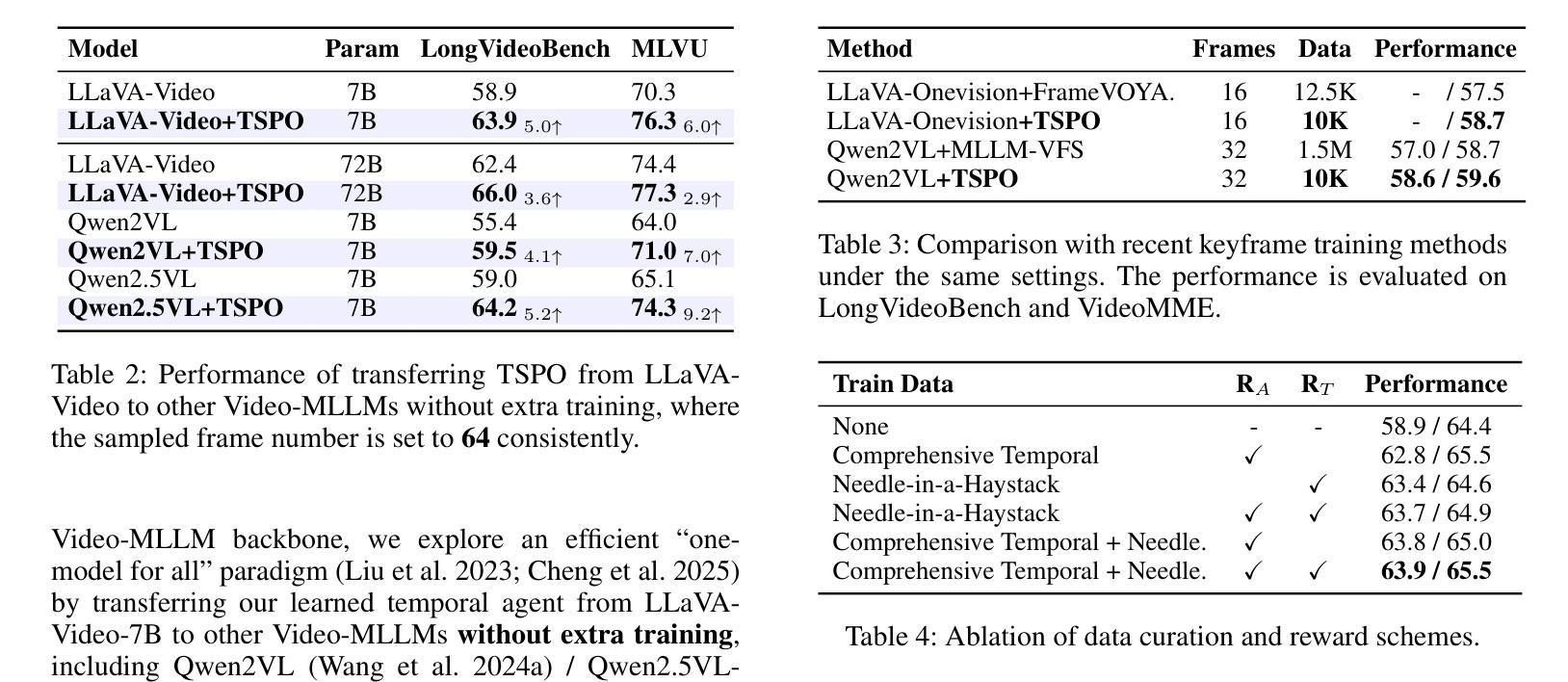
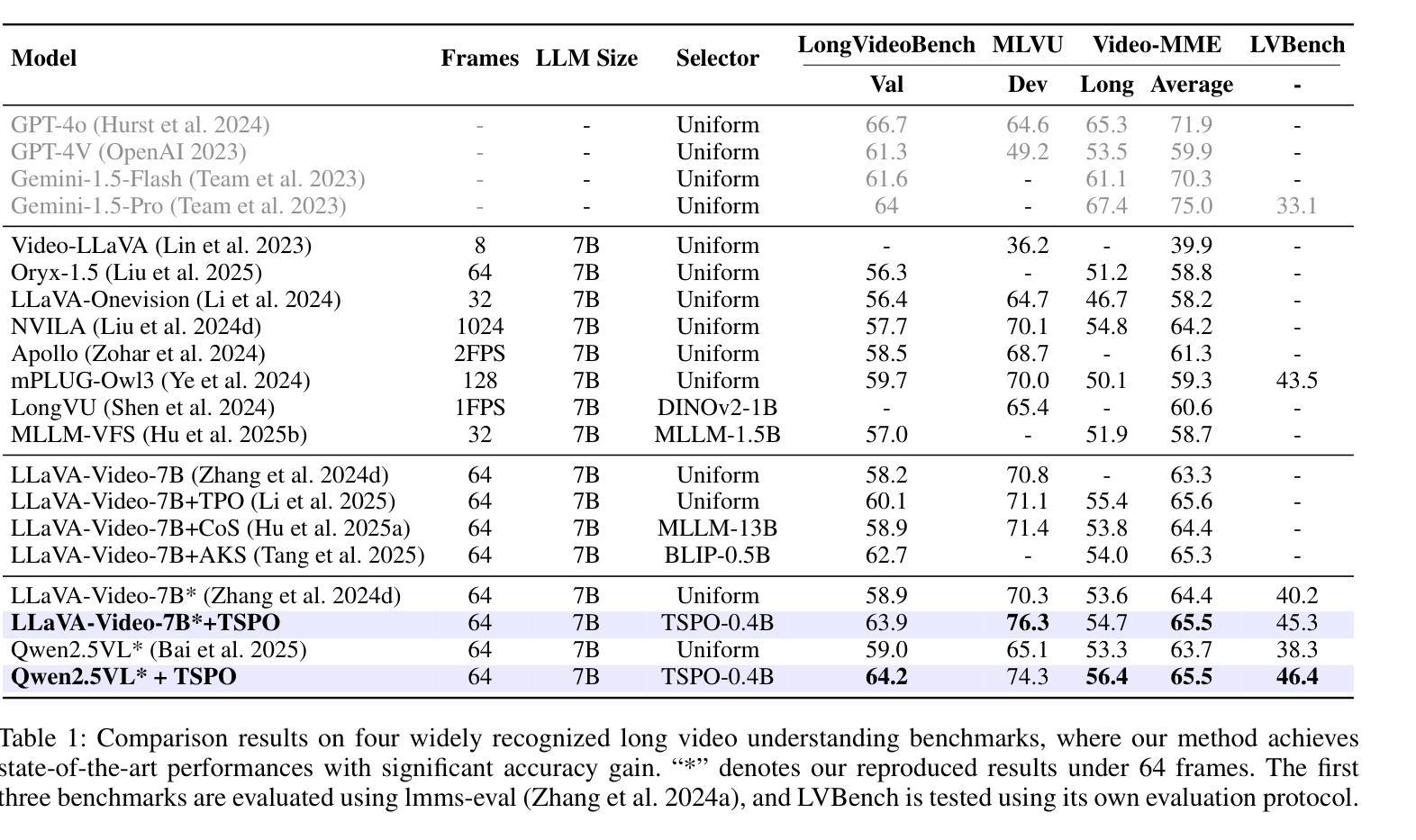
Multimodal Large Language Models (MLLMs) have demonstrated significant progress in vision-language tasks, yet they still face challenges when processing long-duration video inputs. The limitation arises from MLLMs’ context limit and training costs, necessitating sparse frame sampling before feeding videos into MLLMs. Existing video MLLMs adopt training-free uniform sampling or keyframe search, which may miss critical events or be constrained by the pre-trained models’ event understanding capabilities. Meanwhile, building a training-based method remains challenging due to the unsupervised and non-differentiable nature of sparse frame sampling. To address these problems, we propose Temporal Sampling Policy Optimization (TSPO), advancing MLLMs’ long-form video-language understanding via reinforcement learning. Specifically, we first propose a trainable event-aware temporal agent, which captures event-query correlation for performing probabilistic keyframe selection. Then, we propose the TSPO reinforcement learning paradigm, which models keyframe selection and language generation as a joint decision-making process, enabling end-to-end group relative optimization with efficient rule-based rewards. Furthermore, for the TSPO’s training, we propose a long video training data construction pipeline with comprehensive temporal data and video Needle-in-a-Haystack data. Finally, we incorporate rule-based answering accuracy and temporal locating reward mechanisms to optimize the temporal sampling policy. Comprehensive experiments show that our TSPO achieves state-of-the-art performance across multiple long video understanding benchmarks, and shows transferable ability across different cutting-edge Video-MLLMs. Our code is available at https://github.com/Hui-design/TSPO
多模态大型语言模型(MLLMs)在视觉语言任务方面取得了显著进展,但在处理长时视频输入时仍面临挑战。这一限制源于MLLMs的上下文限制和训练成本,因此在将视频输入MLLMs之前需要进行稀疏帧采样。现有的视频MLLMs采用无训练的统一采样或关键帧搜索,这可能会错过重要事件或受到预训练模型的事件理解能力的限制。同时,由于稀疏帧采样的无监督和非可微特性,构建基于训练的方法仍然具有挑战性。为了解决这些问题,我们提出了时序采样策略优化(TSPO),通过强化学习推进MLLMs对长格式视频语言的理解。具体来说,我们首先提出一个可训练的事件感知时序代理,用于捕捉事件查询相关性,执行概率关键帧选择。然后,我们提出了TSPO强化学习范式,将关键帧选择和语言生成建模为联合决策过程,实现端到端的组相对优化,具有高效的基于规则的奖励。此外,为了TSPO的训练,我们提出了长视频训练数据构建管道,包括全面的时序数据和视频“大海捞针”数据。最后,我们结合基于规则的回答准确度和时间定位奖励机制来优化时序采样策略。综合实验表明,我们的TSPO在多个长视频理解基准测试中达到了最先进的性能,并展示了在不同前沿视频MLLMs之间的可迁移能力。我们的代码可在https://github.com/Hui-design/TSPO找到。
论文及项目相关链接
摘要
多模态大型语言模型在处理长视频输入时仍面临挑战,主要是由于上下文限制和训练成本。本文提出一种基于强化学习的时序采样策略优化(TSPO)方法,通过训练事件感知的时序代理,以及建立TSPO强化学习范式,来提高大型语言模型对长视频的语言理解。此外,本文还提出了长视频训练数据构建管道和基于规则的奖励机制来优化时序采样策略。实验表明,TSPO在多个长视频理解基准测试中取得了最佳性能,并展示了在不同前沿视频多模态大型语言模型中的迁移能力。
关键见解
- 多模态大型语言模型在处理长视频时面临挑战,主要是由于上下文限制和训练成本。
- 提出了基于强化学习的时序采样策略优化(TSPO)方法,以提高大型语言模型对长视频的语言理解。
- TSPO通过训练事件感知的时序代理和建立TSPO强化学习范式来实现,将关键帧选择和语言生成作为联合决策过程。
- 提出了一种长视频训练数据构建管道,包括全面的时间数据和视频“大海捞针”数据,以支持TSPO的训练。
- 通过规则回答准确性和时间定位奖励机制来优化时序采样策略。
- 实验表明,TSPO在多个长视频理解基准测试中表现最佳。
- TSPO具有在不同前沿视频多模态大型语言模型中的迁移能力。
点此查看论文截图