⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
MV-Debate: Multi-view Agent Debate with Dynamic Reflection Gating for Multimodal Harmful Content Detection in Social Media
Authors:Rui Lu, Jinhe Bi, Yunpu Ma, Feng Xiao, Yuntao Du, Yijun Tian
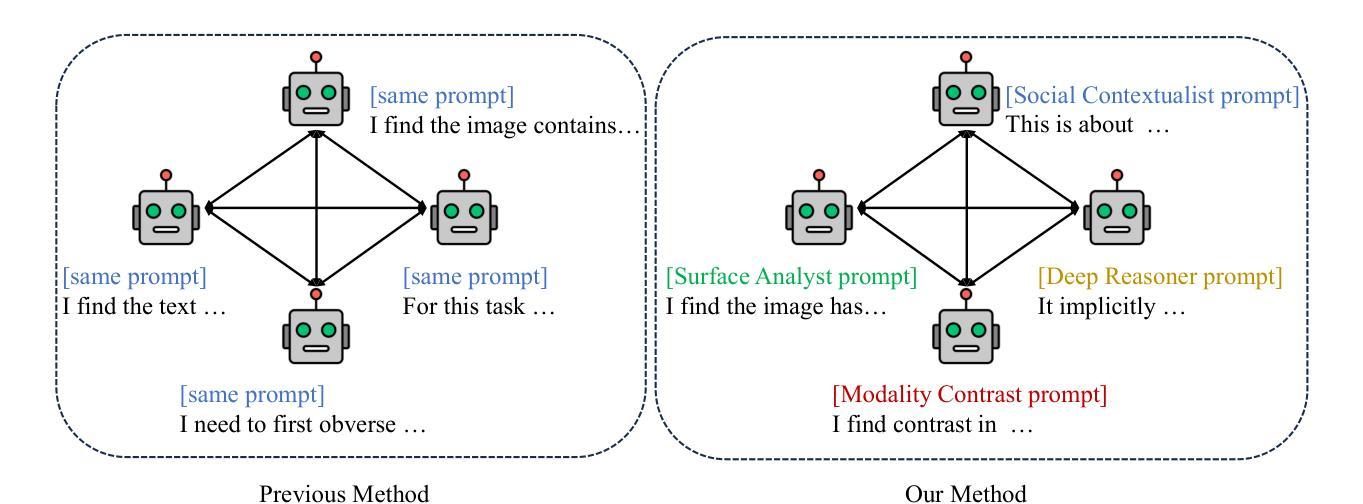
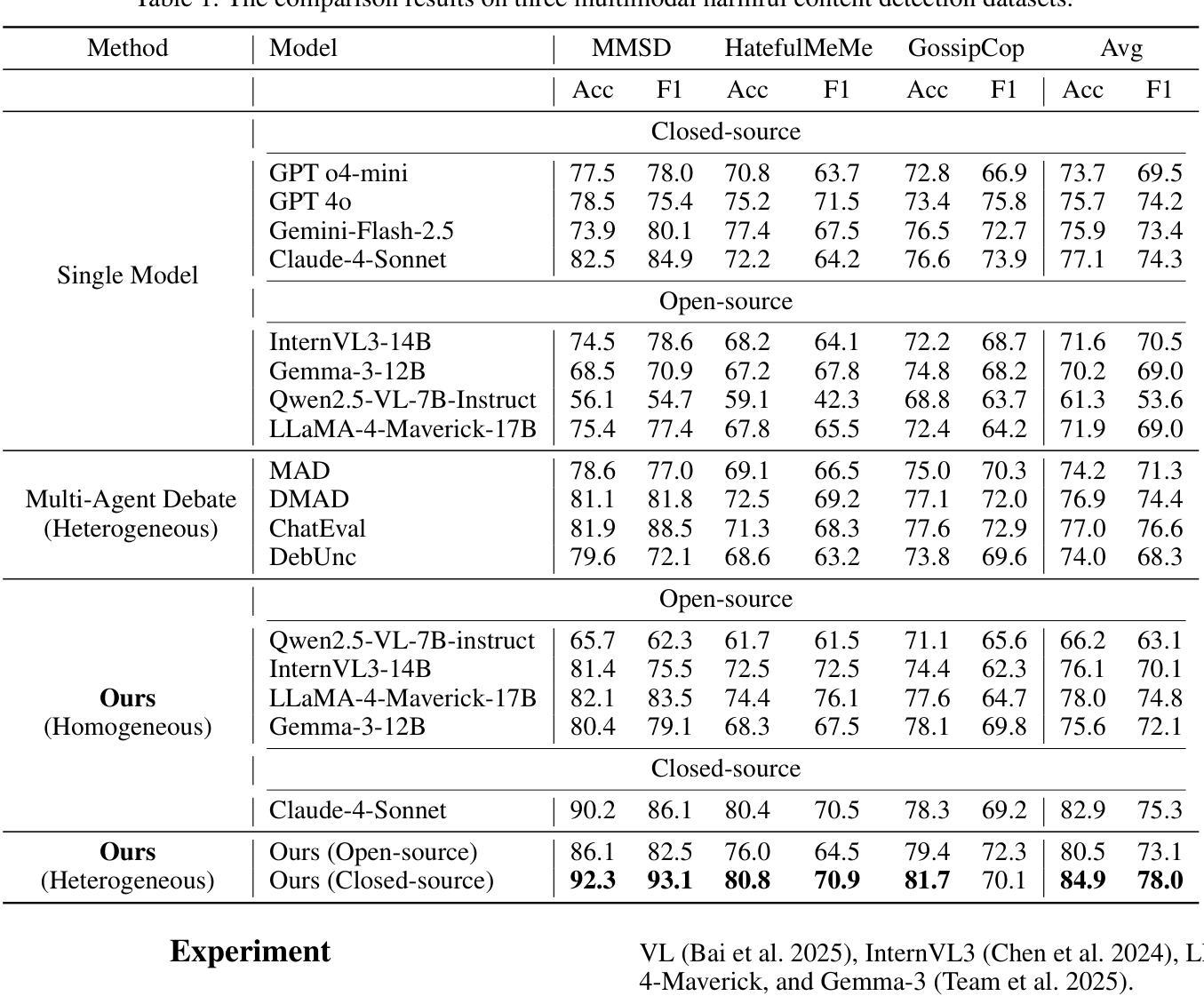
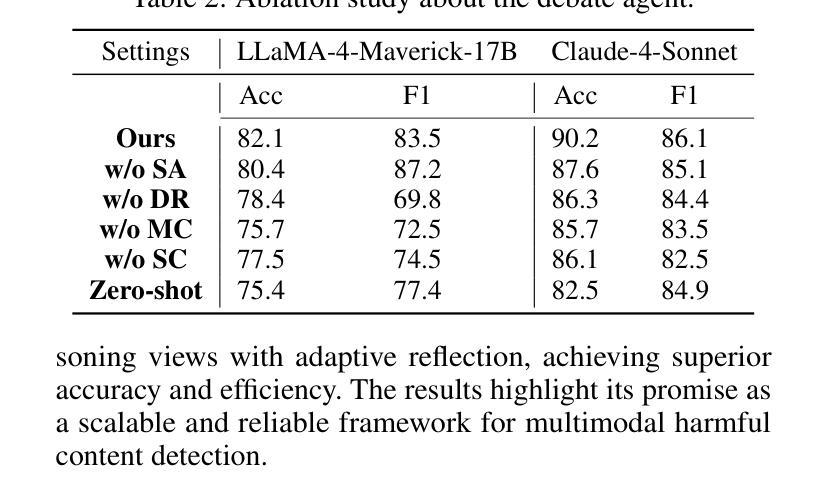
Social media has evolved into a complex multimodal environment where text, images, and other signals interact to shape nuanced meanings, often concealing harmful intent. Identifying such intent, whether sarcasm, hate speech, or misinformation, remains challenging due to cross-modal contradictions, rapid cultural shifts, and subtle pragmatic cues. To address these challenges, we propose MV-Debate, a multi-view agent debate framework with dynamic reflection gating for unified multimodal harmful content detection. MV-Debate assembles four complementary debate agents, a surface analyst, a deep reasoner, a modality contrast, and a social contextualist, to analyze content from diverse interpretive perspectives. Through iterative debate and reflection, the agents refine responses under a reflection-gain criterion, ensuring both accuracy and efficiency. Experiments on three benchmark datasets demonstrate that MV-Debate significantly outperforms strong single-model and existing multi-agent debate baselines. This work highlights the promise of multi-agent debate in advancing reliable social intent detection in safety-critical online contexts.
社交媒体已经演变为一个复杂的多媒体环境,文本、图像和其他信号在此环境中相互作用,形成微妙的含义,常常隐藏有害的意图。识别这种意图,无论是讽刺、仇恨言论还是错误信息,仍然是一个挑战,原因在于跨模态的矛盾、快速的文化变迁和微妙的语用线索。为了应对这些挑战,我们提出了MV-Debate,这是一个具有动态反射门控的多视图代理辩论框架,用于统一多媒体有害内容检测。MV-Debate汇集了四种互补的辩论代理,包括表面分析师、深度推理者、模态对比代理和社会语境主义者,从多种解释性视角分析内容。通过迭代辩论和反思,代理在反思增益标准下完善回应,确保准确性和效率。在三个基准数据集上的实验表明,MV-Debate显著优于强大的单模型和现有的多代理辩论基线。这项工作突出了多代理辩论在推进安全关键在线环境下的可靠社会意图检测方面的前景。
论文及项目相关链接
Summary
社交媒体的复杂性在于其已演变为一个多媒体环境,文本、图像等信号相互交织,形成微妙的含义,常常隐藏有害意图。识别这些意图(如讽刺、仇恨言论或虚假信息)颇具挑战,因为存在跨模态矛盾、文化快速变迁和微妙的语用暗示。为解决这些挑战,我们提出了MV-Debate多视角辩论框架,具有动态反思门控功能,用于统一多媒体有害内容检测。MV-Debate集结了四种互补的辩论代理,表层分析师、深度推理者、模态对比器和社交语境专家,从不同角度解析内容。通过迭代辩论和反思,代理在反思增益标准下完善回应,确保准确性和效率。在三个基准数据集上的实验表明,MV-Debate显著优于强大的单一模型和现有的多代理辩论基线。这项工作突显了多代理辩论在推进在线安全环境中可靠的社会意图检测方面的潜力。
Key Takeaways
- 社交媒体已演变为一个复杂的多媒体环境,其中文本、图像等信号形成微妙的含义,隐藏有害意图的识别具有挑战性。
- MV-Debate是一个多视角辩论框架,通过集结多种代理来解决有害内容检测问题。
- MV-Debate包含的代理包括表层分析师、深度推理者、模态对比器和社交语境专家,各自具备独特的分析视角。
- 通过迭代辩论和反思,MV-Debate代理能够完善回应,确保准确性和效率。
- 实验证明MV-Debate在基准数据集上的表现优于单一模型和多代理辩论基线。
- MV-Debate框架具有动态反思门控功能,这有助于应对跨模态矛盾、文化快速变迁和微妙的语用暗示等挑战。
点此查看论文截图

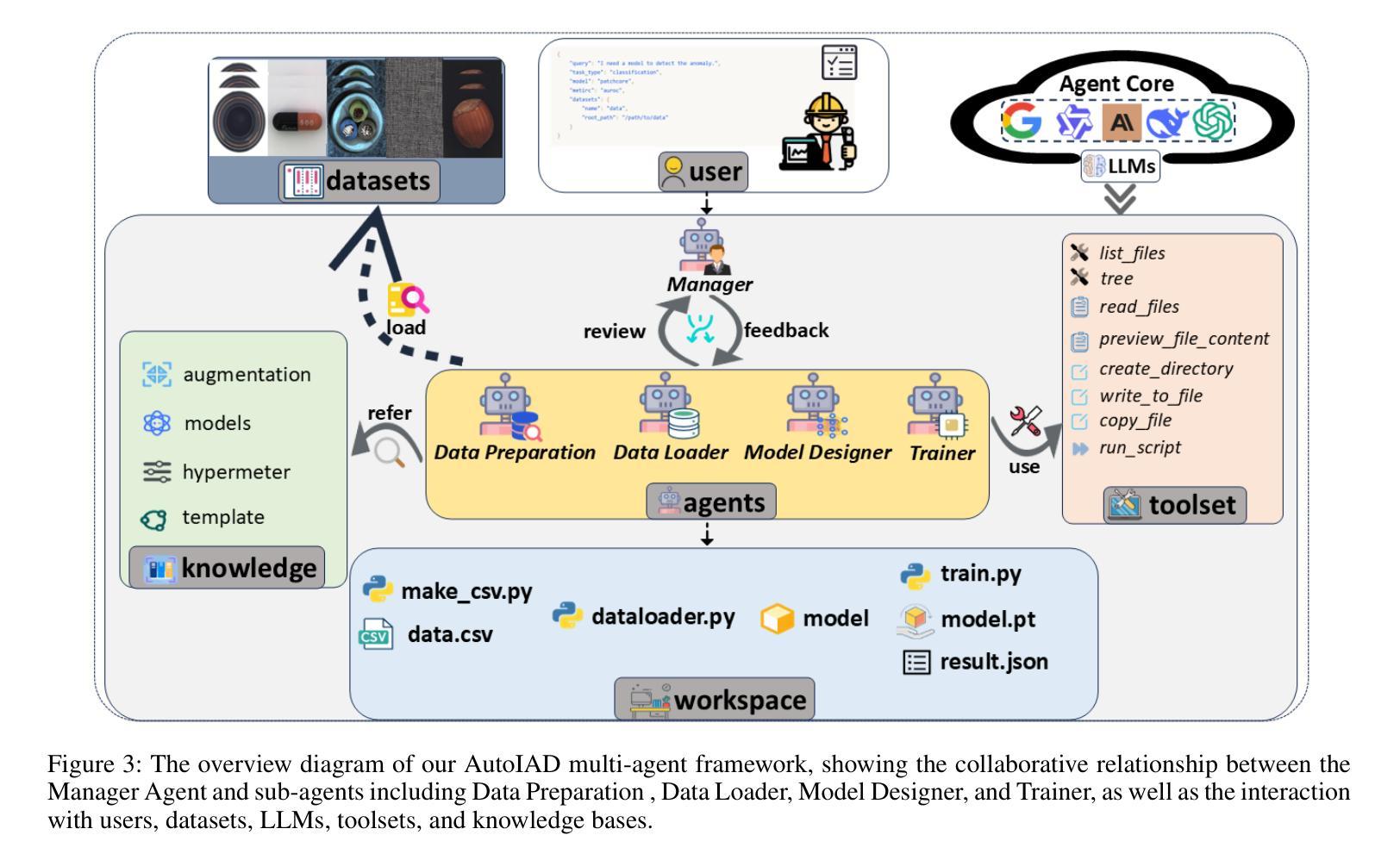
AutoIAD: Manager-Driven Multi-Agent Collaboration for Automated Industrial Anomaly Detection
Authors:Dongwei Ji, Bingzhang Hu, Yi Zhou
Industrial anomaly detection (IAD) is critical for manufacturing quality control, but conventionally requires significant manual effort for various application scenarios. This paper introduces AutoIAD, a multi-agent collaboration framework, specifically designed for end-to-end automated development of industrial visual anomaly detection. AutoIAD leverages a Manager-Driven central agent to orchestrate specialized sub-agents (including Data Preparation, Data Loader, Model Designer, Trainer) and integrates a domain-specific knowledge base, which intelligently handles the entire pipeline using raw industrial image data to develop a trained anomaly detection model. We construct a comprehensive benchmark using MVTec AD datasets to evaluate AutoIAD across various LLM backends. Extensive experiments demonstrate that AutoIAD significantly outperforms existing general-purpose agentic collaboration frameworks and traditional AutoML frameworks in task completion rate and model performance (AUROC), while effectively mitigating issues like hallucination through iterative refinement. Ablation studies further confirm the crucial roles of the Manager central agent and the domain knowledge base module in producing robust and high-quality IAD solutions.
工业异常检测(IAD)对于制造质量控制至关重要,但传统上需要针对各种应用场景投入大量手动工作。本文介绍了AutoIAD,这是一个多智能体协作框架,专为端到端的工业视觉异常检测自动化开发而设计。AutoIAD利用Manager驱动的中央智能体来协调专业的子智能体(包括数据准备、数据加载器、模型设计器、训练器),并集成一个特定的领域知识库,该知识库能够智能地处理整个管道,使用原始工业图像数据来开发经过训练的异常检测模型。我们使用MVTec AD数据集构建了一个全面的基准测试来评估AutoIAD在各种大型语言模型后端的表现。大量实验表明,AutoIAD在任务完成率和模型性能(AUROC)方面显著优于现有的通用智能体协作框架和传统AutoML框架,同时有效地解决了诸如幻觉之类的问题通过迭代优化。消融研究进一步证实了中央管理智能体和领域知识库模块在产生稳健、高质量IAD解决方案中的关键作用。
论文及项目相关链接
Summary
工业异常检测(IAD)对制造质量控制至关重要,但传统方法需要针对各种应用场景投入大量手动工作。本文介绍了AutoIAD,这是一个多智能体协作框架,专为端到端的工业视觉异常检测自动化开发设计。AutoIAD利用经理驱动的中央智能体来协调专业子智能体(包括数据准备、数据加载器、模型设计师、训练师),并整合领域特定知识库,智能处理整个管道,使用原始工业图像数据来开发训练好的异常检测模型。我们使用MVTec AD数据集构建了一个全面的基准测试,以评估AutoIAD在各种大型语言模型后端的表现。大量实验表明,AutoIAD在任务完成率和模型性能(AUROC)方面显著优于现有的通用智能体协作框架和传统AutoML框架,同时有效缓解了通过迭代优化产生的幻觉问题。
Key Takeaways
- 工业异常检测(IAD)在制造质量控制中起关键作用,但传统方法需要大量手动操作。
- AutoIAD是一个多智能体协作框架,用于端到端的工业视觉异常检测自动化开发。
- AutoIAD利用中央智能体来管理和协调专业子智能体的工作。
- AutoIAD集成了领域特定的知识库,以智能处理整个管道并使用原始数据训练模型。
- 与其他智能体协作框架和AutoML框架相比,AutoIAD在任务完成率和模型性能上表现更优秀。
- AutoIAD通过迭代优化有效缓解了幻觉问题。
点此查看论文截图



MoMA: A Mixture-of-Multimodal-Agents Architecture for Enhancing Clinical Prediction Modelling
Authors:Jifan Gao, Mahmudur Rahman, John Caskey, Madeline Oguss, Ann O’Rourke, Randy Brown, Anne Stey, Anoop Mayampurath, Matthew M. Churpek, Guanhua Chen, Majid Afshar
Multimodal electronic health record (EHR) data provide richer, complementary insights into patient health compared to single-modality data. However, effectively integrating diverse data modalities for clinical prediction modeling remains challenging due to the substantial data requirements. We introduce a novel architecture, Mixture-of-Multimodal-Agents (MoMA), designed to leverage multiple large language model (LLM) agents for clinical prediction tasks using multimodal EHR data. MoMA employs specialized LLM agents (“specialist agents”) to convert non-textual modalities, such as medical images and laboratory results, into structured textual summaries. These summaries, together with clinical notes, are combined by another LLM (“aggregator agent”) to generate a unified multimodal summary, which is then used by a third LLM (“predictor agent”) to produce clinical predictions. Evaluating MoMA on three prediction tasks using real-world datasets with different modality combinations and prediction settings, MoMA outperforms current state-of-the-art methods, highlighting its enhanced accuracy and flexibility across various tasks.
多模态电子健康记录(EHR)数据相比单模态数据,为患者健康提供了更丰富、互补的见解。然而,由于需要大量数据,有效地整合各种数据模式进行临床预测建模仍然具有挑战性。我们引入了一种新型架构——多模态代理混合体(MoMA),旨在利用多模态EHR数据和多模态大型语言模型(LLM)代理进行临床预测任务。MoMA采用专门的大型语言模型代理(“专家代理”)将非文本模式(如医疗图像和实验室结果)转换为结构化文本摘要。这些摘要与临床笔记相结合,由另一个大型语言模型(“聚合器代理”)生成统一的多模态摘要,然后第三个大型语言模型(“预测器代理”)使用该摘要生成临床预测。通过对三个使用真实世界数据集的不同预测任务模式组合和预测设置的评估,MoMA的性能优于当前的最先进方法,突出了其在不同任务上的准确性和灵活性。
论文及项目相关链接
Summary
多模态电子病历(EHR)数据较单模态数据能提供更丰富、更互补的病人健康信息。然而,由于数据需求量大,有效整合多种数据模式进行临床预测建模仍然具有挑战性。本研究介绍了一种新型架构——混合多模态代理(MoMA),利用多个大型语言模型(LLM)代理进行临床预测任务,使用多模态EHR数据。MoMA采用专业LLM代理转化非文本模式,如医疗图像和实验室结果,为结构化文本摘要。这些摘要与临床笔记相结合,由另一个LLM(聚合代理)生成统一的多模态摘要,随后被第三个LLM(预测代理)用于生成临床预测。在真实数据集上的三个预测任务评估显示,MoMA优于当前最先进的方法,凸显其在不同任务中的准确性和灵活性。
Key Takeaways
- 多模态电子病历数据提供丰富、互补的病人健康信息。
- 有效整合多种数据模式进行临床预测建模存在挑战。
- 引入了一种新型架构MoMA,利用多个大型语言模型代理处理多模态EHR数据。
- MoMA包括三种类型的LLM代理:专业代理、聚合代理和预测代理。
- 专业代理将非文本模式转化为结构化文本摘要。
- MoMA在多种预测任务中表现出卓越的性能和灵活性。
点此查看论文截图

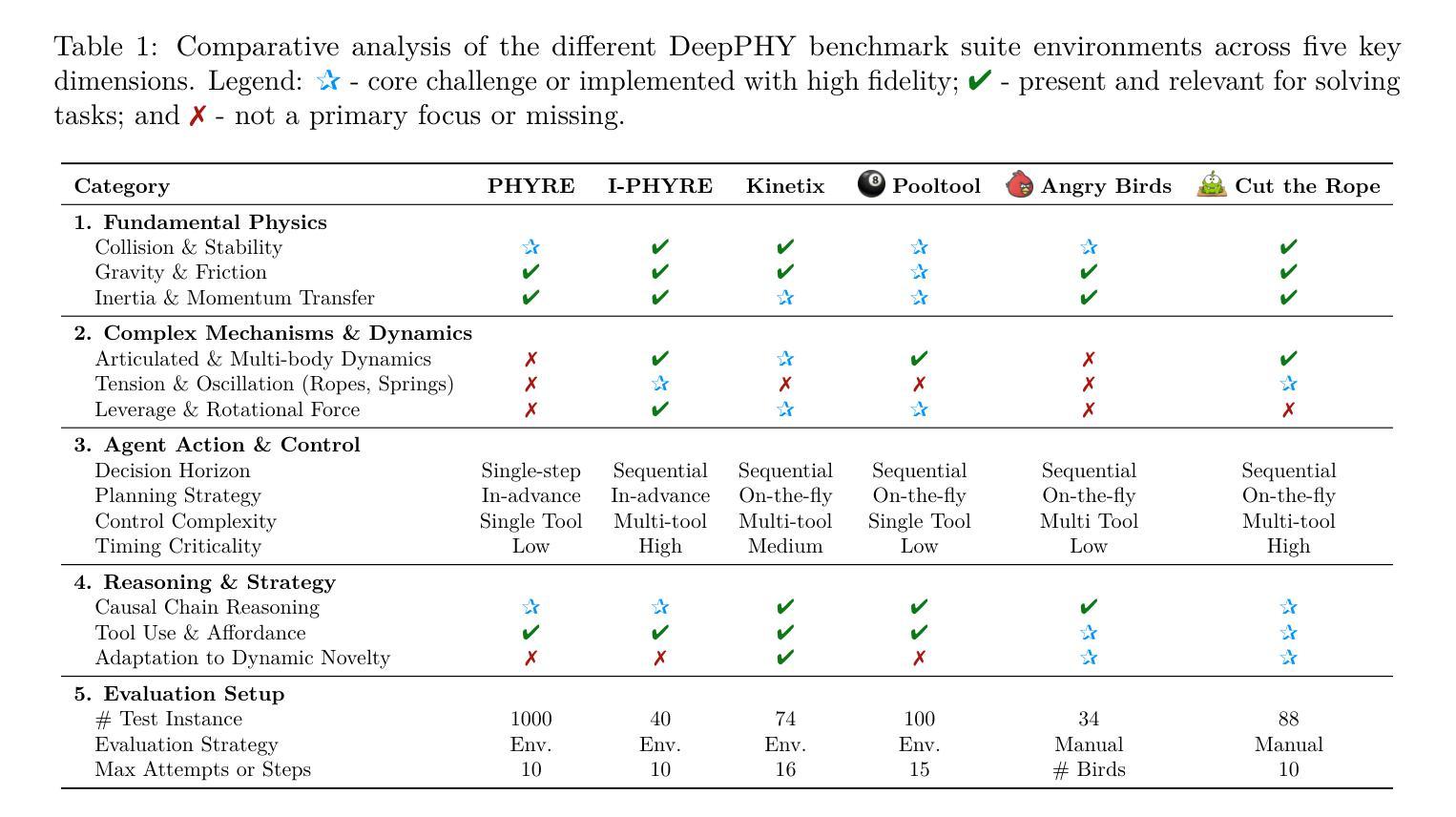
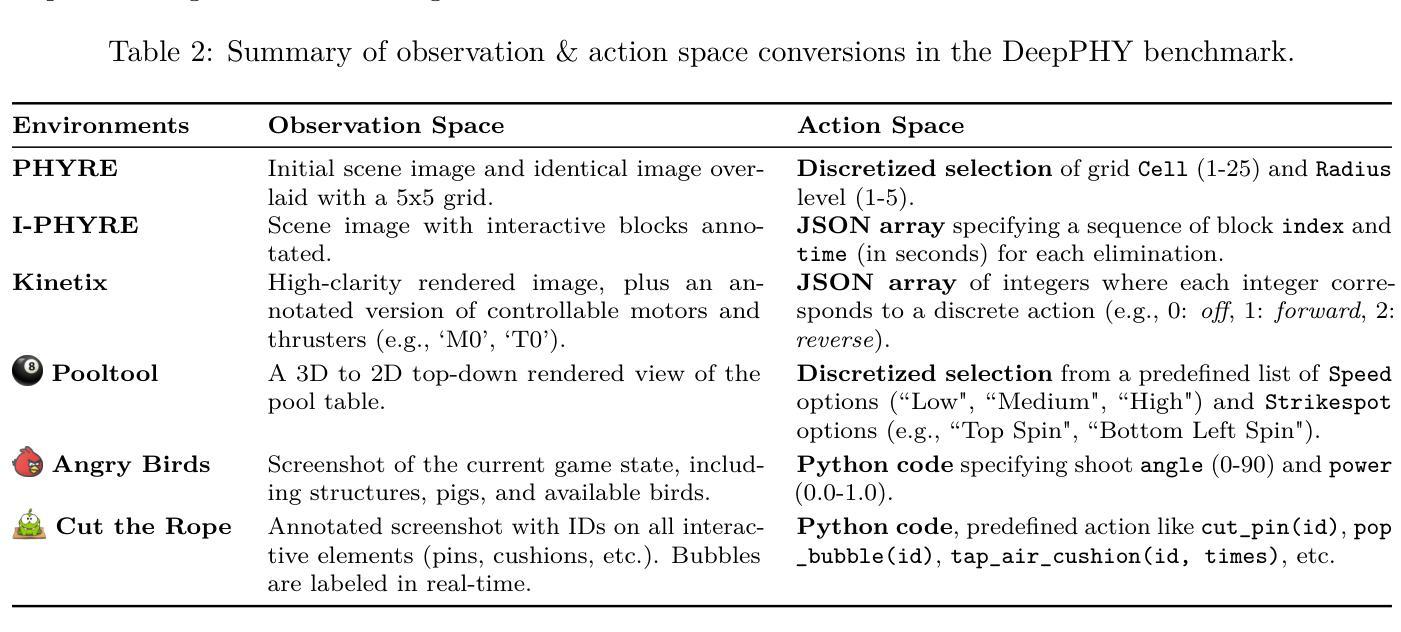
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Authors:Xinrun Xu, Pi Bu, Ye Wang, Börje F. Karlsson, Ziming Wang, Tengtao Song, Qi Zhu, Jun Song, Zhiming Ding, Bo Zheng
Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs’ understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.
尽管视觉语言模型(VLMs)表现出强大的感知能力和令人印象深刻的视觉推理能力,但在复杂、动态的环境中,它们在细节关注和精确行动规划方面存在困难,导致性能不佳。现实世界的任务通常需要复杂的交互、高级的空间推理、长期规划和不断优化的策略,通常需要理解目标场景的物理规则。然而,在真实场景中对这些能力进行评估通常成本高昂。为了弥补这一差距,我们引入了DeepPHY,这是一个新型基准框架,旨在通过一系列具有挑战性的模拟环境,系统地评估VLMs对基本物理原理的理解和推理能力。DeepPHY集成了多个难度不同的物理推理环境,并采用了精细的评估指标。我们的评估发现,即使是最先进的VLMs也很难将描述性的物理知识转化为精确、预测性的控制。
论文及项目相关链接
PDF 48 pages
Summary
视觉语言模型(VLMs)虽具有强大的感知能力和令人印象深刻的视觉推理能力,但在复杂动态环境中对细节的关注和精确行动规划方面存在困难,导致性能不佳。现实任务通常需要复杂的交互、高级空间推理、长期规划和连续的策略调整,通常需要理解目标场景的物理规则。为解决评估这些能力在现实场景中的高昂成本问题,我们提出了DeepPHY这一新型基准框架,旨在通过一系列具有挑战性的模拟环境系统地评估VLMs对基本物理原理的理解和推理能力。DeepPHY融合了不同难度级别的多个物理推理环境,并采用了精细的评价指标。评估发现,即使是最新VLMs在将描述性物理知识转化为精确预测控制方面仍面临困难。
Key Takeaways
- VLMs在复杂动态环境中对细节关注和精确行动规划方面存在挑战。
- 完成现实任务需要VLMs理解物理规则、进行复杂交互、高级空间推理、长期规划等。
- 评估VLMs在现实场景中的能力通常成本高昂。
- DeepPHY是一个新型基准框架,用于系统地评估VLMs在物理原理方面的理解和推理能力。
- DeepPHY通过模拟环境评估VLMs,融合了不同难度级别的多个物理推理环境。
- DeepPHY采用了精细的评价指标来评估VLMs的表现。
点此查看论文截图

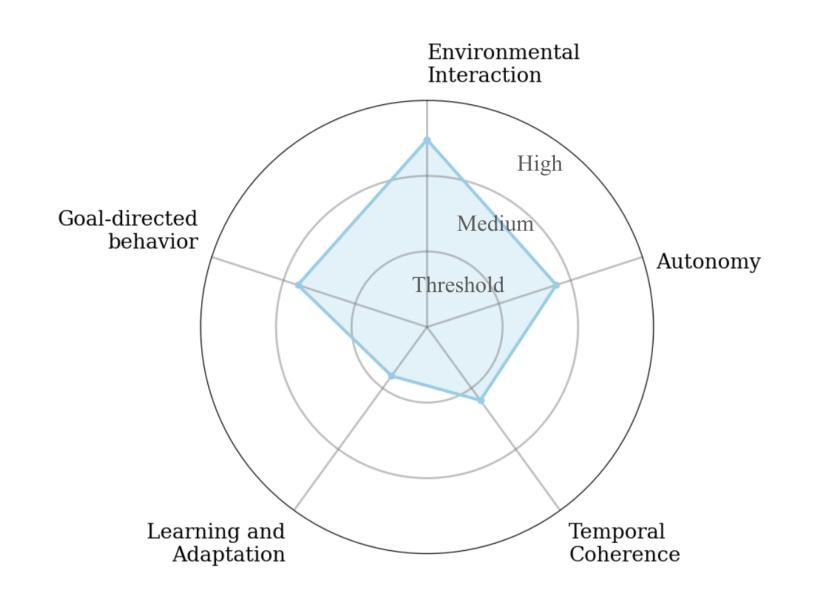
The Term ‘Agent’ Has Been Diluted Beyond Utility and Requires Redefinition
Authors:Brinnae Bent
The term ‘agent’ in artificial intelligence has long carried multiple interpretations across different subfields. Recent developments in AI capabilities, particularly in large language model systems, have amplified this ambiguity, creating significant challenges in research communication, system evaluation and reproducibility, and policy development. This paper argues that the term ‘agent’ requires redefinition. Drawing from historical analysis and contemporary usage patterns, we propose a framework that defines clear minimum requirements for a system to be considered an agent while characterizing systems along a multidimensional spectrum of environmental interaction, learning and adaptation, autonomy, goal complexity, and temporal coherence. This approach provides precise vocabulary for system description while preserving the term’s historically multifaceted nature. After examining potential counterarguments and implementation challenges, we provide specific recommendations for moving forward as a field, including suggestions for terminology standardization and framework adoption. The proposed approach offers practical tools for improving research clarity and reproducibility while supporting more effective policy development.
人工智能中的“代理”一词在不同子领域长期以来存在多种解释。人工智能能力的最近发展,特别是在大型语言模型系统方面,加剧了这种模糊性,给研究交流、系统评估和可重复性、政策制定带来了重大挑战。本文认为“代理”一词需要重新定义。我们从历史分析和当前使用模式出发,提出了一个框架,明确了被视为代理系统的最低要求,同时沿环境交互、学习和适应、自主性、目标复杂性和时间连贯性的多维光谱对系统进行特征描述。这种方法为系统描述提供了精确的词汇,同时保留了该术语历史上的多面性。在研究了潜在的反对意见和实施挑战后,我们为领域的发展提供了具体建议,包括术语标准化和框架采纳的建议。所提出的方法为改善研究的清晰度和可重复性提供了实用工具,同时支持更有效的政策制定。
论文及项目相关链接
PDF Accepted to AIES 2025
总结
随着人工智能的发展,特别是在大型语言模型系统方面,人工智能中的“代理”一词的多种解释造成了巨大的沟通障碍、系统评估和再现性挑战以及政策制定难题。本文主张重新定义“代理”的定义,从历史和当前使用模式出发,提出一个框架,明确系统被视为代理的最小要求,同时按环境交互、学习和适应、自主性、目标复杂性和时间连贯性的多维度光谱进行特征描述。该框架为系统描述提供了精确的词汇,同时保留了该术语历史上的多面性。在研究了潜在的反对论点与实施挑战后,本文给出了前进的建议,包括术语标准化和框架采纳等。该框架有助于提升研究的清晰度和再现性,同时支持更有效的政策制定。
要点总结
- ‘代理’一词在人工智能的不同子领域存在多种解释。
- 大型语言模型系统的最新发展加剧了这一模糊性,带来了研究沟通、系统评估和策略制定方面的挑战。
- 文章主张重新定义’代理’,并提出了一个定义清晰的框架,明确了被视为代理的系统必须满足的最小要求。
- 该框架将系统特征化在一个多维度的光谱上,包括与环境互动、学习适应性、自主性、目标复杂性和时间连贯性等方面。
- 此框架为系统描述提供了精确词汇,同时保留了术语的历史多元性。
- 文章考虑了潜在的反对论点与实施挑战,并给出了前进的建议,如术语标准化和框架采纳等。
点此查看论文截图

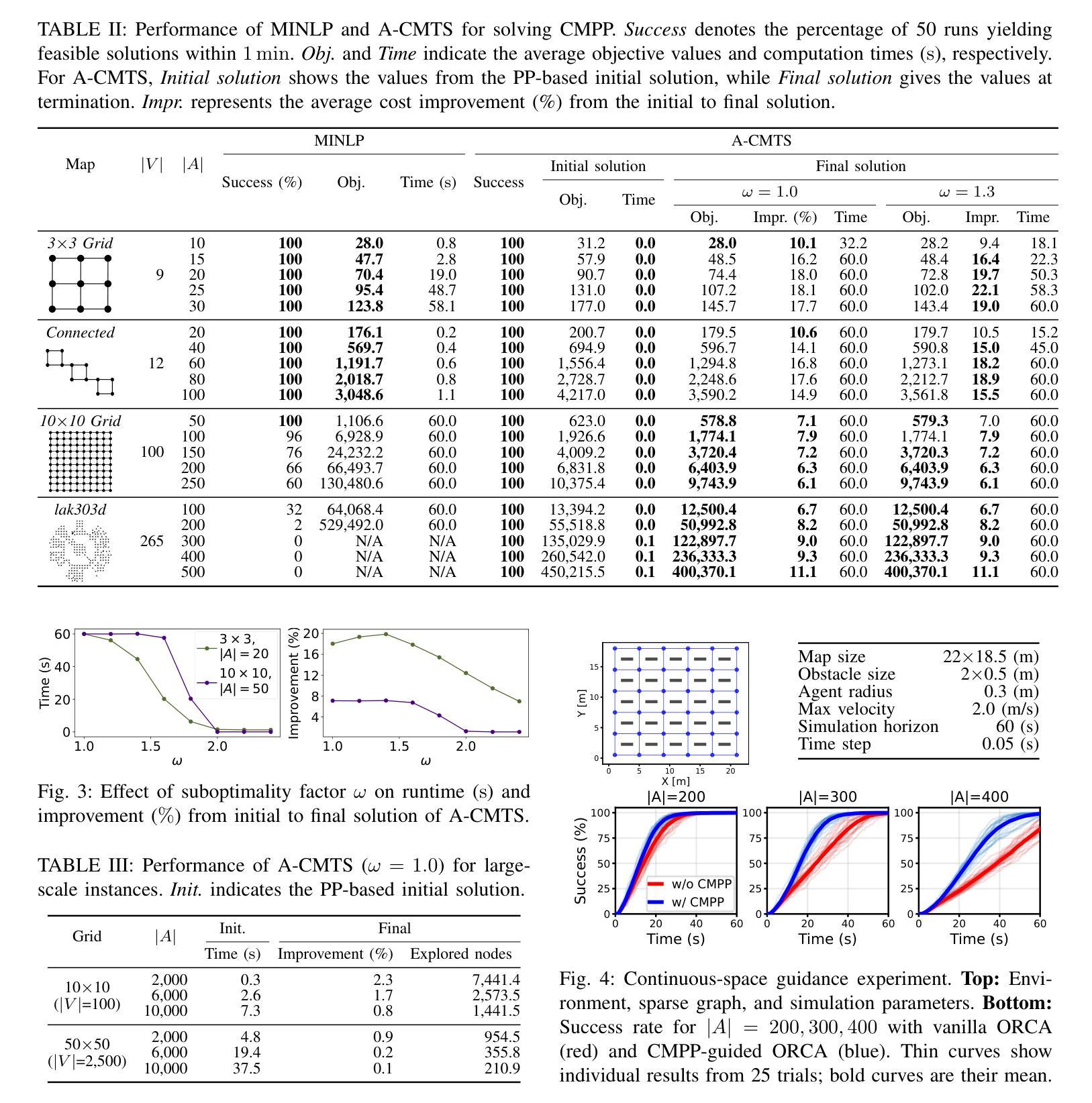
Congestion Mitigation Path Planning for Large-Scale Multi-Agent Navigation in Dense Environments
Authors:Takuro Kato, Keisuke Okumura, Yoko Sasaki, Naoya Yokomachi
In high-density environments where numerous autonomous agents move simultaneously in a distributed manner, streamlining global flows to mitigate local congestion is crucial to maintain overall navigation efficiency. This paper introduces a novel path-planning problem, congestion mitigation path planning (CMPP), which embeds congestion directly into the cost function, defined by the usage of incoming edges along agents’ paths. CMPP assigns a flow-based multiplicative penalty to each vertex of a sparse graph, which grows steeply where frequently-traversed paths intersect, capturing the intuition that congestion intensifies where many agents enter the same area from different directions. Minimizing the total cost yields a set of coarse-level, time-independent routes that autonomous agents can follow while applying their own local collision avoidance. We formulate the problem and develop two solvers: (i) an exact mixed-integer nonlinear programming solver for small instances, and (ii) a scalable two-layer search algorithm, A-CMTS, which quickly finds suboptimal solutions for large-scale instances and iteratively refines them toward the optimum. Empirical studies show that augmenting state-of-the-art collision-avoidance planners with CMPP significantly reduces local congestion and enhances system throughput in both discrete- and continuous-space scenarios. These results indicate that CMPP improves the performance of multi-agent systems in real-world applications such as logistics and autonomous-vehicle operations.
在高密度环境中,众多自主代理以分布式方式同时移动,优化全局流程以减轻局部拥堵对于保持整体导航效率至关重要。本文引入了一个新的路径规划问题,即拥堵缓解路径规划(CMPP),它将拥堵直接嵌入到成本函数中,该成本函数由代理路径上的传入边使用定义。CMPP为每个稀疏图的顶点分配基于流量的乘法惩罚,在经常通行的路径交汇处增长迅速,直觉地反映了从多个方向进入同一区域的区域拥堵加剧的情况。最小化总成本可以得到一组粗略的、时间独立的路线,自主代理可以遵循这些路线,同时应用自己的局部避障策略。我们制定这个问题并开发了两种求解器:(i)针对小规模实例的精确混合整数非线性规划求解器,(ii)可伸缩的两层搜索算法A-CMTS,该算法可以快速找到大规模实例的次优解,并迭代地优化它们以达到最优。实证研究表明,使用CMPP增强最先进的避障规划器可以显着减少局部拥堵,并在离散和连续空间场景中提高系统吞吐量。这些结果表明,CMPP在物流和自动驾驶车辆操作等实际应用中提高了多代理系统的性能。
论文及项目相关链接
PDF Accepted for publication in IEEE Robotics and Automation Letters (RA-L), 2025. 9 pages, 6 figures, 3 tables. (C) 2025 IEEE. CC BY 4.0 license. Supplementary videos will be accessible via IEEE Xplore upon publication
摘要
在高密度环境中,众多自主代理同时分布式移动,优化全局流程以减轻局部拥堵对于维持整体导航效率至关重要。本文引入了一种新的路径规划问题——拥堵缓解路径规划(CMPP),它将拥堵直接嵌入到成本函数中,该成本函数由代理路径上的传入边使用次数定义。CMPP为每个稀疏图的顶点分配一个基于流量的乘法惩罚,在频繁通行的路径交汇处增长迅速,体现了拥堵强度随许多代理从不同方向进入同一区域而增强的直觉。最小化总成本得到一组自主代理可以遵循的粗粒度、时间独立路线,同时应用各自的局部避障策略。我们制定了问题并开发了两个求解器:(i)针对小实例的精确混合整数非线性规划求解器,(ii)针对大规模实例的快速找到次优解并进行迭代优化的两层搜索算法A-CMTS。实证研究表明,将CMPP与最新的避障规划器相结合,显著减少了局部拥堵,提高了系统吞吐量,无论是在离散空间还是连续空间场景中都是如此。这些结果表明,CMPP在物流和自动驾驶车辆操作等实际应用中提高了多智能体系统的性能。
关键见解
- 在高密度环境中,缓解局部拥堵对于维持多自主代理的整体导航效率至关重要。
- 引入新的路径规划问题——拥堵缓解路径规划(CMPP),将拥堵直接纳入成本函数。
- CMPP通过为稀疏图的每个顶点分配基于流量的乘法惩罚,在拥堵热点处增强成本。
- 最小化成含本可以得到自主代理遵循的粗粒度路线,结合局部避障策略。
- 开发了两种求解器:混合整数非线性规划求解器和两层搜索算法A-CMTS。
- 实证研究表明,CMPP能显著减少局部拥堵并提高系统吞吐量。
点此查看论文截图





Domain-driven Metrics for Reinforcement Learning: A Case Study on Epidemic Control using Agent-based Simulation
Authors:Rishabh Gaur, Gaurav Deshkar, Jayanta Kshirsagar, Harshal Hayatnagarkar, Janani Venugopalan
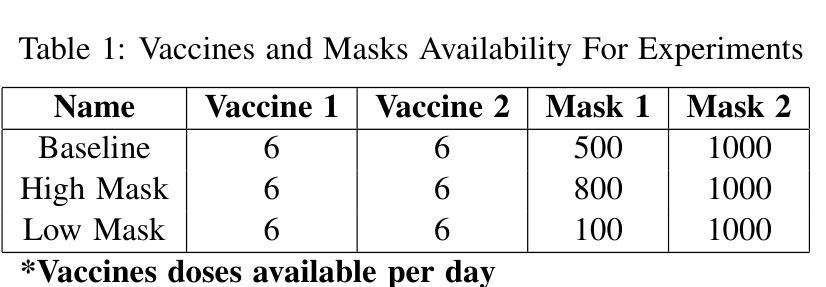
For the development and optimization of agent-based models (ABMs) and rational agent-based models (RABMs), optimization algorithms such as reinforcement learning are extensively used. However, assessing the performance of RL-based ABMs and RABMS models is challenging due to the complexity and stochasticity of the modeled systems, and the lack of well-standardized metrics for comparing RL algorithms. In this study, we are developing domain-driven metrics for RL, while building on state-of-the-art metrics. We demonstrate our ``Domain-driven-RL-metrics’’ using policy optimization on a rational ABM disease modeling case study to model masking behavior, vaccination, and lockdown in a pandemic. Our results show the use of domain-driven rewards in conjunction with traditional and state-of-the-art metrics for a few different simulation scenarios such as the differential availability of masks.
对于基于代理的模型(ABM)和理性代理模型(RABM)的开发和优化,广泛使用了强化学习等优化算法。然而,由于所建系统的复杂性和随机性,以及缺乏用于比较强化学习算法的标准化指标,评估基于强化学习的ABM模型和RABMS模型的性能是一个挑战。本研究在最新指标的基础上,开发面向领域的强化学习指标。我们通过理性ABM疾病建模案例研究中的策略优化来展示我们的“面向领域的强化学习指标”,以模拟大流行病中的掩饰行为、疫苗接种和封锁状态。我们的结果表明,在不同的模拟场景下,结合传统和最新指标的领域驱动奖励的使用效果,如口罩的不同可用性。我们的方法在理性ABM的疾病建模中展示了有效性,提供了一种新的评估框架来捕捉与领域相关的关键性能指标。
论文及项目相关链接
Summary
在基于代理的模型(ABM)和理性代理模型(RABM)的开发和优化过程中,强化学习等优化算法被广泛应用。然而,由于系统的复杂性和随机性,以及缺乏比较强化学习算法的标准化指标,评估RL驱动的ABM和RABM模型性能面临挑战。本研究在最新指标的基础上,开发面向领域的强化学习指标。我们通过理性ABM疾病建模案例研究中的策略优化来展示我们的面向领域的强化学习指标,该案例涉及建模口罩佩戴行为、疫苗接种和疫情封锁。结果表明,在多种模拟场景下,使用面向领域的奖励与传统和最新指标相结合,如口罩的差异性供应。
Key Takeaways
- 强化学习算法广泛应用于ABM和RABM模型的优化。
- 评估RL驱动的ABM和RABM模型性能具有挑战性,主要原因是系统的复杂性和随机性,以及缺乏标准化的比较指标。
- 本研究致力于开发面向领域的强化学习指标。
- 通过理性ABM疾病建模案例展示了新的面向领域的强化学习指标,包括口罩佩戴行为、疫苗接种和疫情封锁的建模。
- 结合传统和最新指标,使用面向领域的奖励在多种模拟场景下表现良好。
- 在模拟场景中考虑了口罩供应的差异性等实际情况。
点此查看论文截图


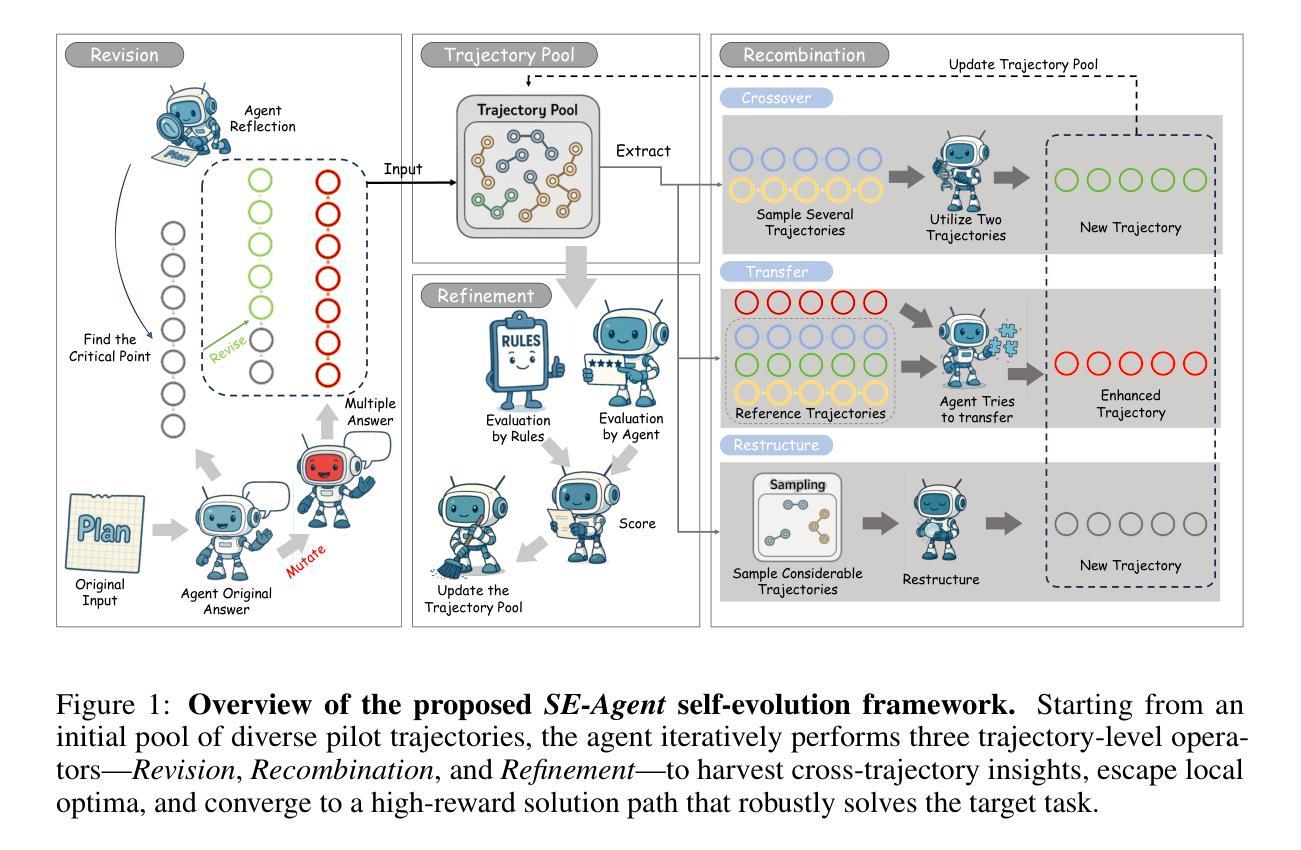
SE-Agent: Self-Evolution Trajectory Optimization in Multi-Step Reasoning with LLM-Based Agents
Authors:Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, Daxin Jiang, Binxing Jiao, Chen Hu, Huacan Wang
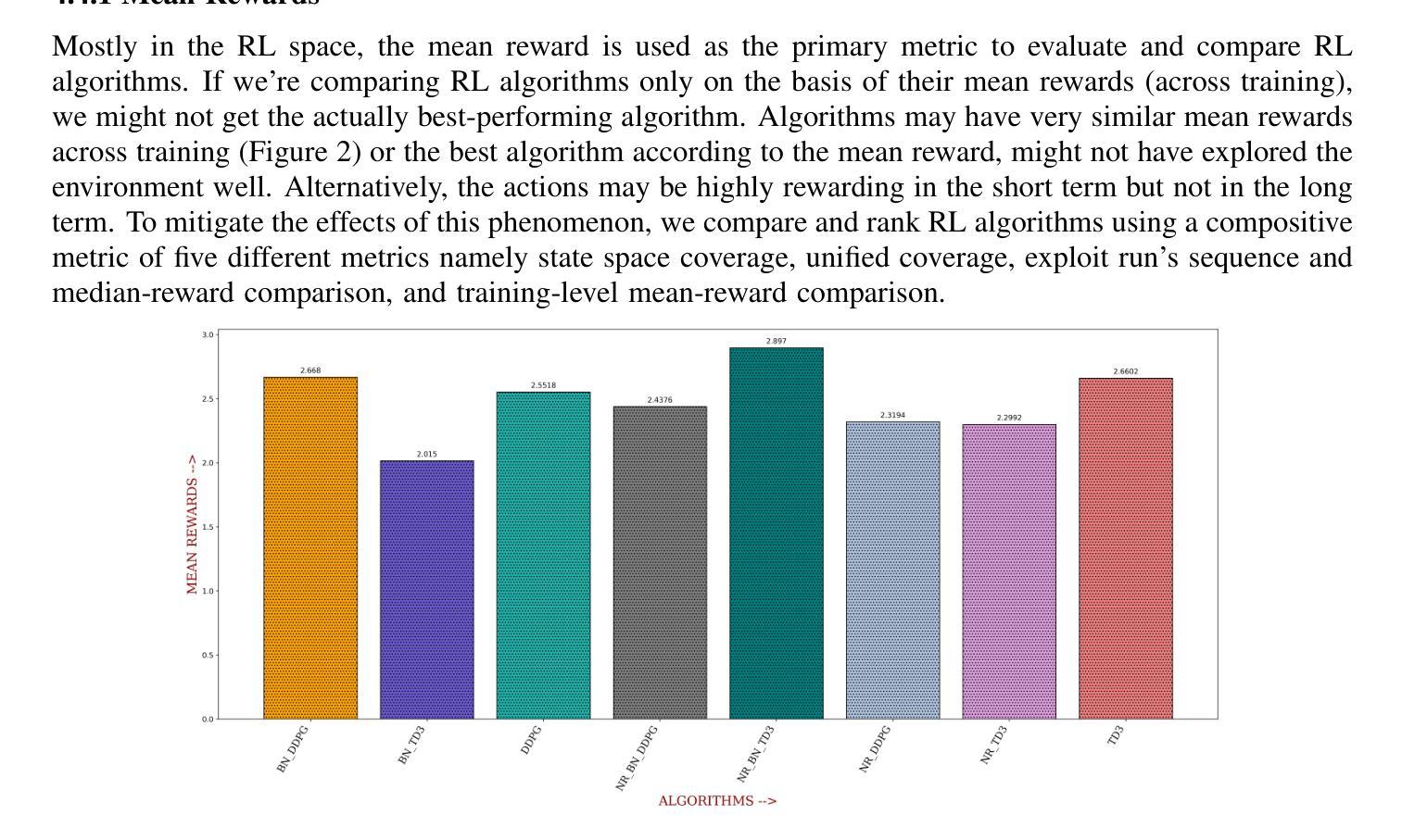
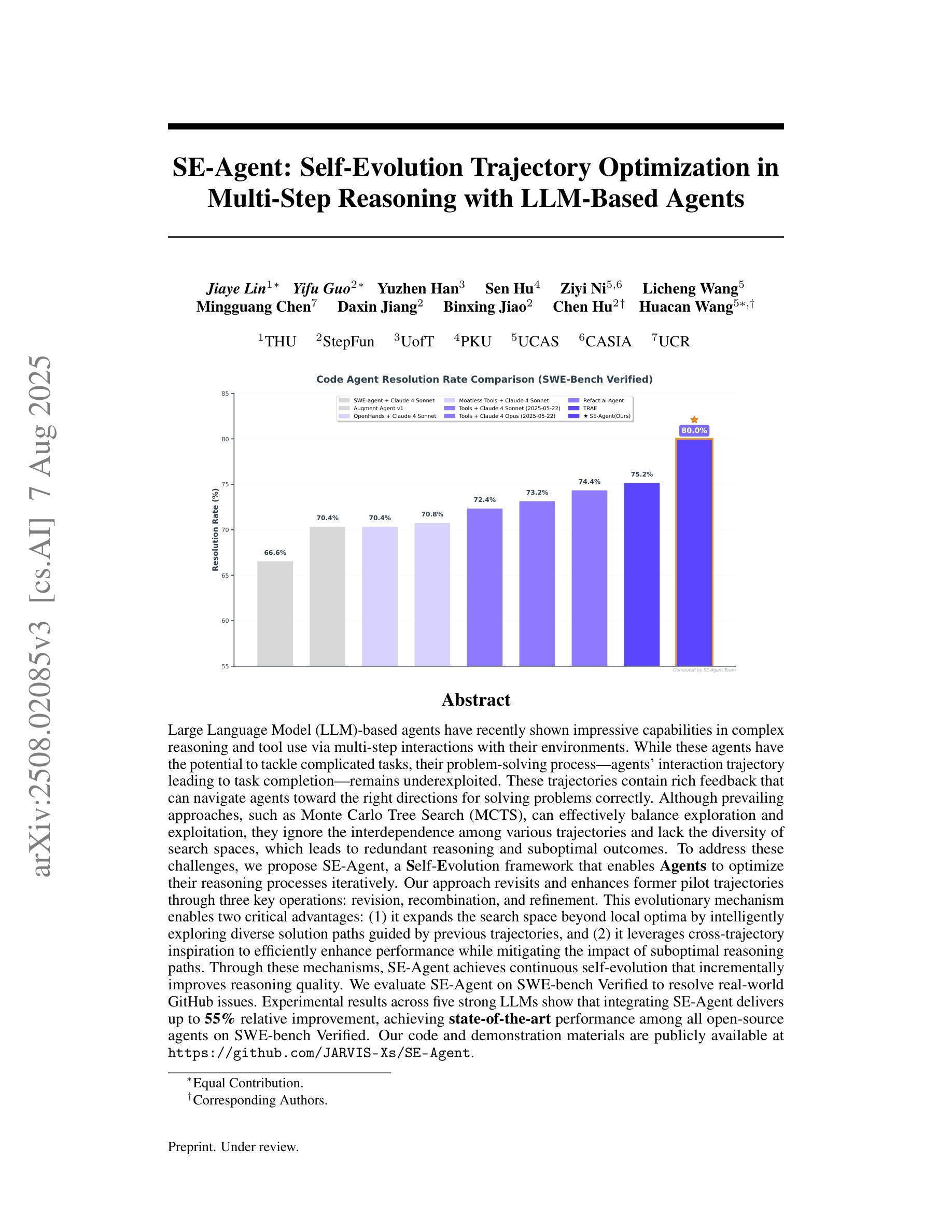
Large Language Model (LLM)-based agents have recently shown impressive capabilities in complex reasoning and tool use via multi-step interactions with their environments. While these agents have the potential to tackle complicated tasks, their problem-solving process, i.e., agents’ interaction trajectory leading to task completion, remains underexploited. These trajectories contain rich feedback that can navigate agents toward the right directions for solving problems correctly. Although prevailing approaches, such as Monte Carlo Tree Search (MCTS), can effectively balance exploration and exploitation, they ignore the interdependence among various trajectories and lack the diversity of search spaces, which leads to redundant reasoning and suboptimal outcomes. To address these challenges, we propose SE-Agent, a Self-Evolution framework that enables Agents to optimize their reasoning processes iteratively. Our approach revisits and enhances former pilot trajectories through three key operations: revision, recombination, and refinement. This evolutionary mechanism enables two critical advantages: (1) it expands the search space beyond local optima by intelligently exploring diverse solution paths guided by previous trajectories, and (2) it leverages cross-trajectory inspiration to efficiently enhance performance while mitigating the impact of suboptimal reasoning paths. Through these mechanisms, SE-Agent achieves continuous self-evolution that incrementally improves reasoning quality. We evaluate SE-Agent on SWE-bench Verified to resolve real-world GitHub issues. Experimental results across five strong LLMs show that integrating SE-Agent delivers up to 55% relative improvement, achieving state-of-the-art performance among all open-source agents on SWE-bench Verified. Our code and demonstration materials are publicly available at https://github.com/JARVIS-Xs/SE-Agent.
基于大规模语言模型(LLM)的代理最近表现出令人印象深刻的复杂推理和工具使用能力,这是通过与环境的多步骤交互实现的。虽然这些代理有潜力处理复杂任务,但他们的解决问题过程,即代理完成任务的交互轨迹,仍然被低估。这些轨迹包含丰富的反馈,可以为代理提供正确的方向来正确解决问题。尽管现有的方法,如蒙特卡洛树搜索(MCTS),可以有效地平衡探索和利用,但它们忽略了不同轨迹之间的相互依赖性,并且缺乏搜索空间的多样性,这导致冗余推理和次优结果。为了解决这些挑战,我们提出了SE-Agent,这是一个自我进化框架,使代理能够迭代优化他们的推理过程。我们的方法通过三种关键操作来重新访问和改进先前的轨迹:修订、重组和细化。这种进化机制带来了两个关键优势:(1)它通过智能地探索由先前轨迹引导的多样化解决方案路径,扩大了搜索空间,超越了局部最优;(2)它利用跨轨迹的灵感来有效地提高性能,同时减轻次优推理路径的影响。通过这些机制,SE-Agent实现了连续的自我进化,逐步提高了推理质量。我们在SWE-bench Verified上评估了SE-Agent,以解决现实世界中的GitHub问题。在五个强大的LLM上的实验结果表明,集成SE-Agent带来了高达55%的相对改进,在SWE-bench Verified上的开源代理中实现了最先进的性能。我们的代码和演示材料可在https://github.com/JARVIS-Xs/SE-Agent公开获得。
论文及项目相关链接
摘要
基于大型语言模型(LLM)的代理人在复杂推理和工具使用方面表现出强大的能力,能够通过多步骤与环境的交互完成任务。然而,他们的解题过程,即代理人的交互轨迹,仍未得到充分研究。这些轨迹包含丰富的反馈,可以引导代理人正确解决问题。虽然蒙特卡洛树搜索(MCTS)等方法可以有效地平衡探索和利用,但它们忽略了不同轨迹之间的依赖性,缺乏搜索空间的多样性,导致冗余推理和次优结果。为解决这些问题,我们提出了SE-Agent,一个自我进化框架,使代理人能够迭代优化其推理过程。我们的方法通过修订、重组和细化三个关键操作来重新访问和改进先前的轨迹。这种进化机制带来了两个关键优势:一是通过智能探索受先前轨迹指导的多样化解决方案路径,扩大搜索空间并超越局部最优;二是利用跨轨迹灵感来有效提高性能,同时减少次优推理路径的影响。通过这些机制,SE-Agent实现了连续的自我进化,逐步提高了推理质量。我们在SWE-bench Verified上评估了SE-Agent解决GitHub实际问题的能力。在五个强大的LLM上的实验结果表明,集成SE-Agent带来了高达55%的相对改进,在SWE-bench Verified上实现了优于所有开源代理的最先进性能。我们的代码和演示材料可在https://github.com/JARVIS-Xs/SE-Agent上公开访问。
关键见解
- LLM代理在复杂任务中具有强大的能力,能够通过与环境的多步骤交互进行推理和工具使用。
- 代理人的解题过程(交互轨迹)尚未得到充分研究,但包含引导正确解决问题的丰富反馈。
- 现有方法如MCTS忽略了轨迹间的依赖性,缺乏搜索空间多样性,可能导致冗余推理和次优结果。
- SE-Agent通过自我进化框架优化推理过程,通过修订、重组和细化前人的轨迹来实现连续自我进化。
- SE-Agent扩大了搜索空间并超越局部最优,利用跨轨迹灵感提高性能并减少次优推理路径的影响。
- 在SWE-bench Verified上的实验表明,集成SE-Agent的LLM代理性能显著提高,达到最新水平。
点此查看论文截图
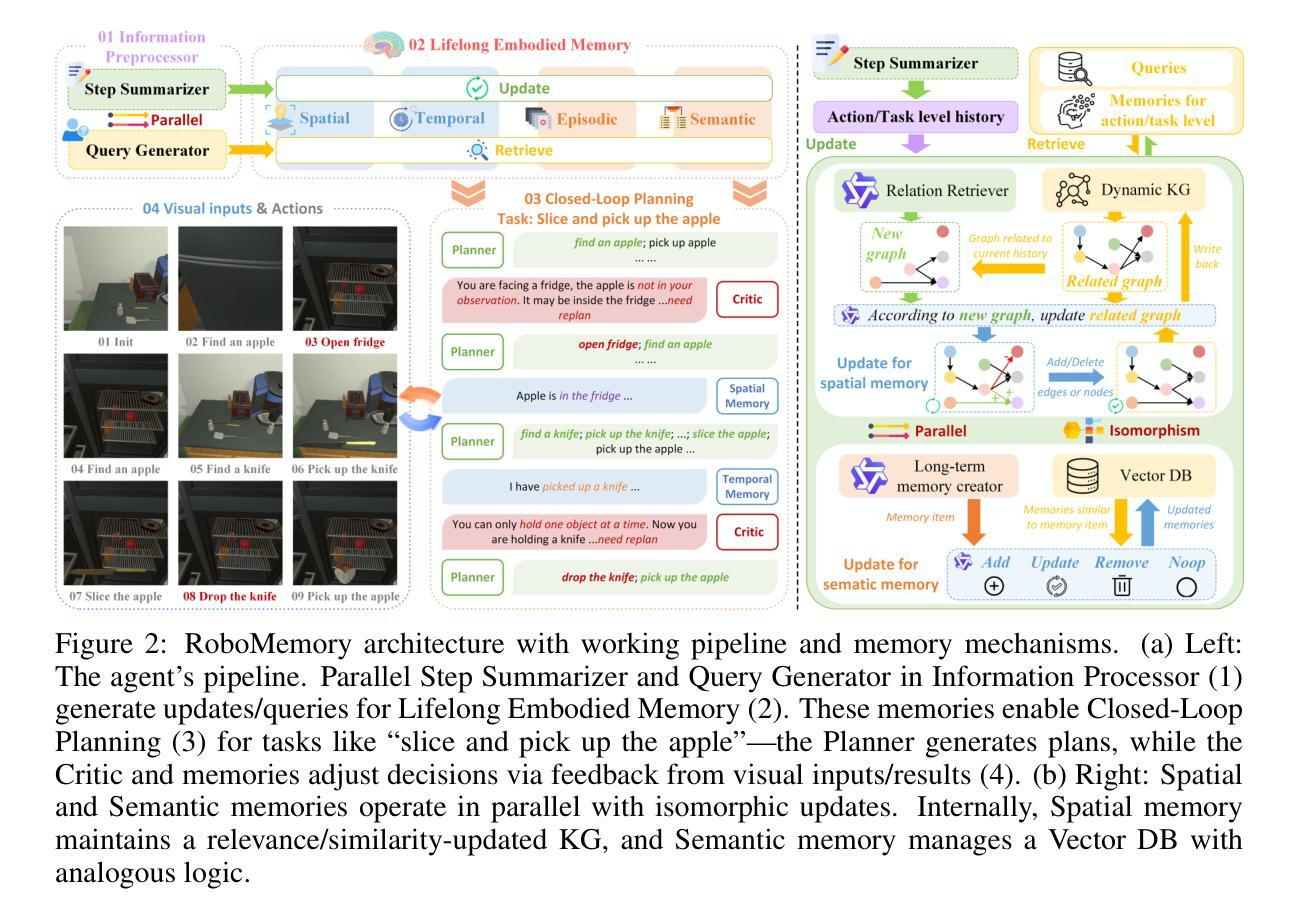
RoboMemory: A Brain-inspired Multi-memory Agentic Framework for Lifelong Learning in Physical Embodied Systems
Authors:Mingcong Lei, Honghao Cai, Binbin Que, Zezhou Cui, Liangchen Tan, Junkun Hong, Gehan Hu, Shuangyu Zhu, Yimou Wu, Shaohan Jiang, Ge Wang, Zhen Li, Shuguang Cui, Yiming Zhao, Yatong Han
We present RoboMemory, a brain-inspired multi-memory framework for lifelong learning in physical embodied systems, addressing critical challenges in real-world environments: continuous learning, multi-module memory latency, task correlation capture, and infinite-loop mitigation in closed-loop planning. Grounded in cognitive neuroscience, it integrates four core modules: the Information Preprocessor (thalamus-like), the Lifelong Embodied Memory System (hippocampus-like), the Closed-Loop Planning Module (prefrontal lobe-like), and the Low-Level Executer (cerebellum-like) to enable long-term planning and cumulative learning. The Lifelong Embodied Memory System, central to the framework, alleviates inference speed issues in complex memory frameworks via parallelized updates/retrieval across Spatial, Temporal, Episodic, and Semantic submodules. It incorporates a dynamic Knowledge Graph (KG) and consistent architectural design to enhance memory consistency and scalability. Evaluations on EmbodiedBench show RoboMemory outperforms the open-source baseline (Qwen2.5-VL-72B-Ins) by 25% in average success rate and surpasses the closed-source State-of-the-Art (SOTA) (Claude3.5-Sonnet) by 5%, establishing new SOTA. Ablation studies validate key components (critic, spatial memory, long-term memory), while real-world deployment confirms its lifelong learning capability with significantly improved success rates across repeated tasks. RoboMemory alleviates high latency challenges with scalability, serving as a foundational reference for integrating multi-modal memory systems in physical robots.
我们提出RoboMemory,这是一个受大脑启发的用于物理实体系统的终身学习多记忆框架,解决了真实世界环境中的关键挑战:持续学习、多模块记忆延迟、任务相关性捕获以及在闭环规划中的无限循环缓解。它基于认知神经科学,集成了四个核心模块:信息预处理器(类似丘脑)、终身体验记忆系统(类似海马体)、闭环规划模块(类似前额叶)和低级执行器(类似小脑),以实现长期规划和累积学习。终身体验记忆系统是框架的核心,它通过空间、时间、情节和语义子模块的并行更新/检索,缓解复杂记忆框架中的推理速度问题。它结合了动态知识图谱(KG)和一致性的架构设计,以增强记忆的一致性和可扩展性。在EmbodiedBench上的评估表明,RoboMemory平均成功率比开源基准(Qwen2.5-VL-72B-Ins)高出25%,并超越了闭源当前最佳技术(SOTA)(Claude3.5-Sonnet)5%,创造了新的SOTA。消融研究验证了关键组件(批评家、空间记忆、长期记忆),而实际部署证实了其终身学习能力,在重复任务中的成功率显著提高。RoboMemory通过可扩展性缓解了高延迟挑战,为在物理机器人中集成多模式记忆系统提供了基础参考。
论文及项目相关链接
Summary
RoboMemory是一个受大脑启发的多记忆框架,用于实体系统中的终身学习,并解决了真实环境中的关键挑战。它通过整合四个核心模块:信息处理器、终身实体记忆系统、闭环规划模块和低级别执行器,实现长期规划和累积学习。终身实体记忆系统是该框架的核心,通过并行更新和检索空间、时间、情景和语义子模块,缓解复杂记忆框架的推理速度问题。评估结果显示,RoboMemory在EmbodiedBench上的表现优于开源基准和闭源最新技术。
Key Takeaways
- RoboMemory是一个用于实体系统终身学习的多记忆框架,基于认知神经科学。
- 它解决了连续学习、多模块记忆延迟、任务关联捕获和闭环规划中的无限循环缓解等真实环境挑战。
- 终身实体记忆系统是核心,通过并行更新和检索多个子模块来提高效率。
- RoboMemory采用动态知识图和一致的设计架构,增强记忆的一致性和可扩展性。
- 与开源基准和闭源最新技术相比,RoboMemory在EmbodiedBench上的表现更优。
- 消融研究验证了关键组件的重要性,包括批评家、空间记忆和长期记忆。
点此查看论文截图

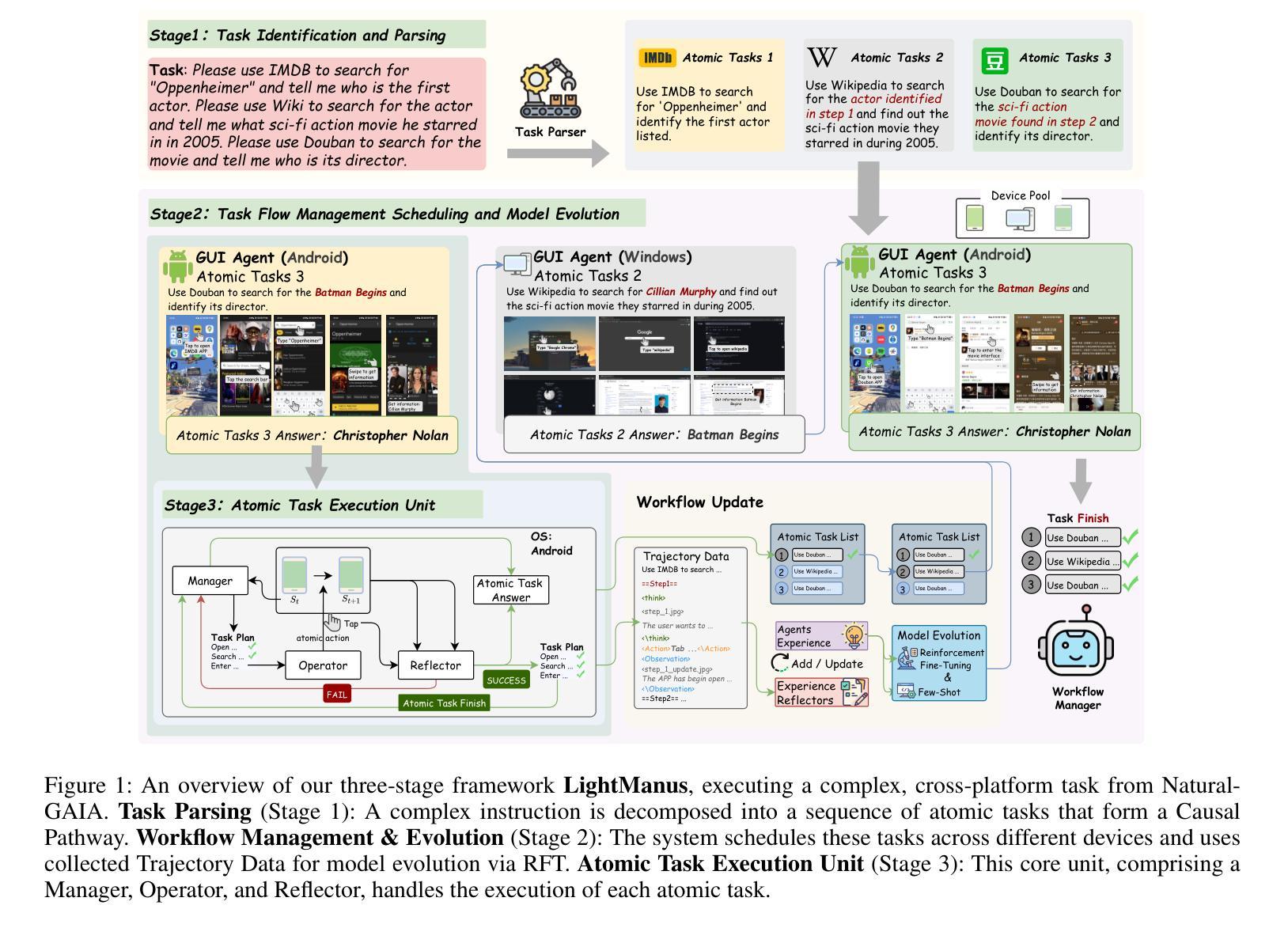
NatureGAIA: Pushing the Frontiers of GUI Agents with a Challenging Benchmark and High-Quality Trajectory Dataset
Authors:Zihan Zheng, Tianle Cui, Chuwen Xie, Jiahui Zhang, Jiahui Pan, Lewei He, Qianglong Chen
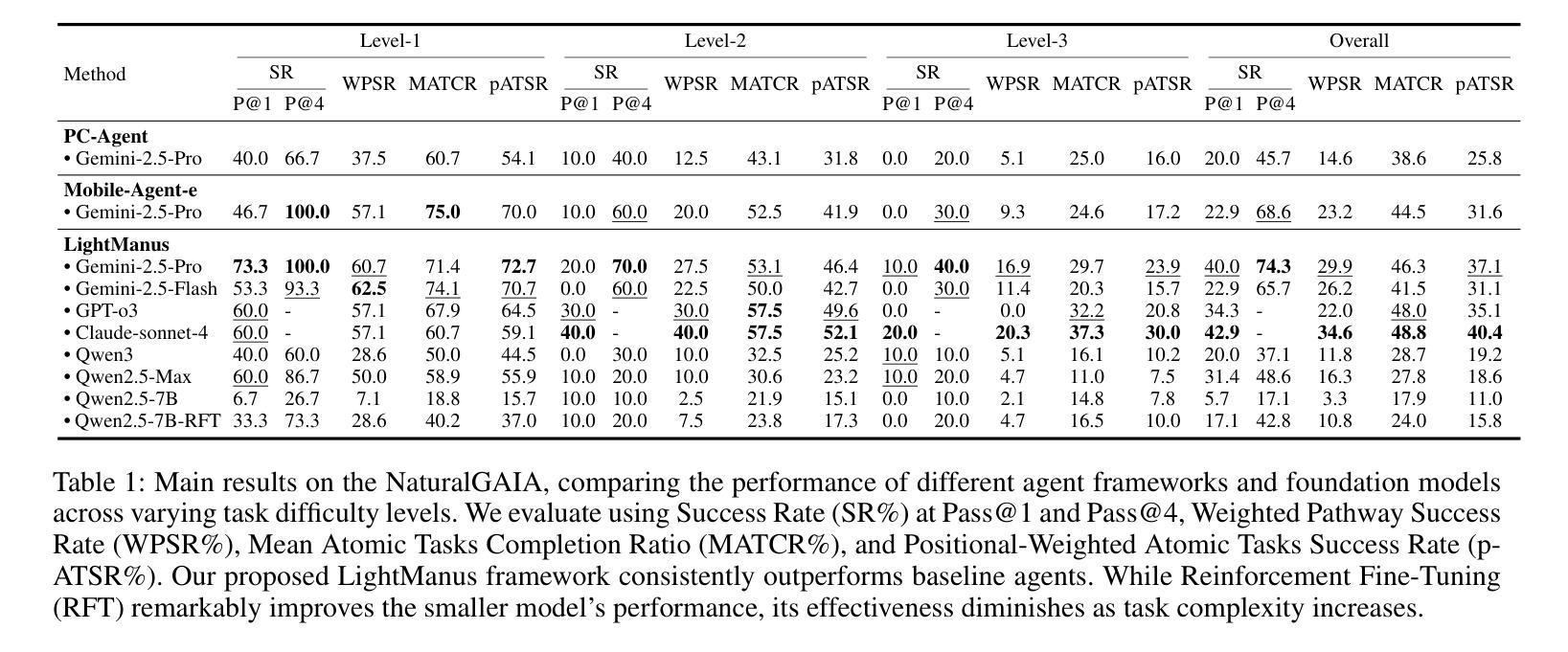
The rapid advancement of Large Language Model (LLM)-driven Graphical User Interface (GUI) agents is significantly hampered by the profound limitations of existing evaluation benchmarks in terms of accuracy, reproducibility, and scalability. To address this critical gap, we introduce NaturalGAIA, a novel benchmark engineered on the principle of Causal Pathways. This design paradigm structures complex tasks into a series of programmatically verifiable atomic steps, ensuring a rigorous, fully automated, and reproducible standard for assessment. Concurrently, to mitigate the inherent capability deficits of agents, we developed LightManus, a hierarchical agent architecture specifically optimized for long-horizon tasks. We leveraged this agent to generate a high-quality, human-verified trajectory dataset that uniquely captures diverse and even self-correcting interaction patterns of LLMs. We then utilized this dataset to perform Reinforcement Fine-Tuning (RFT) on the Qwen2.5-VL-7B model. Our experiments reveal that NaturalGAIA presents a formidable challenge to current state-of-the-art LLMs; even the top-performing Claude-sonnet-4 achieved a Weighted Pathway Success Rate (WPSR) of only 34.6%. Moreover, while RFT substantially improved the smaller model’s GUI execution capabilities (WPSR increased from 3.3% to 10.8%), its performance degraded sharply when handling complex scenarios. This outcome highlights the inherent capability ceiling of smaller models when faced with comprehensive tasks that integrate perception, decision-making, and execution. This research contributes a rigorous evaluation standard and a high-quality dataset to the community, aiming to guide the future development of GUI agents.
大型语言模型(LLM)驱动的图形用户界面(GUI)代理的快速进步受到了现有评估基准在准确性、可重复性和可扩展性方面的深刻限制的严重阻碍。为了解决这一关键差距,我们引入了NaturalGAIA,这是一个基于因果路径原理的新型基准。这种设计范式将复杂任务结构化为一系列可程序验证的原子步骤,确保评估的严格性、完全自动化和可重复性。同时,为了缓解代理固有的能力缺陷,我们开发了一种专为长期任务优化的分层代理架构LightManus。我们利用该代理生成了高质量、经人类验证的轨迹数据集,该数据集独特地捕捉了LLM多样甚至自我校正的交互模式。然后,我们使用该数据集对Qwen2.5-VL-7B模型执行强化微调(RFT)。我们的实验表明,NaturalGAIA对当前最先进的LLM提出了巨大的挑战;即使是表现最佳的Claude-sonnet-4,加权路径成功率(WPSR)也只有34.6%。此外,虽然RFT显著提高了较小模型的GUI执行能力(WPSR从3.3%提高到10.8%),但在处理复杂场景时,其性能急剧下降。这一结果突出了面对整合感知、决策和执行的综合任务时,小型模型固有的能力上限。本研究为社区提供了一个严格的评估标准和高质量的数据集,旨在指导未来GUI代理的开发。
论文及项目相关链接
Summary
大型语言模型驱动的图形用户界面代理的发展受到现有评估基准的严重限制,如准确性、可重复性和可扩展性。为解决这一关键差距,我们推出了基于因果路径原理的新型基准测试NaturalGAIA。同时,为缓解代理的内在能力缺陷,我们开发了针对长期任务的层次型代理架构LightManus。利用该代理生成了高质量、经人工验证的轨迹数据集,独特地捕捉了大型语言模型的多样化和自我纠正交互模式。然而,实验结果揭示,即使是顶尖的表演艺术家Claude-sonnet-4在NaturalGAIA上的加权路径成功率也只有34.6%,突显出现有模型在集成感知、决策和执行的综合任务中的能力天花板。本研究为社区提供了严格的评估标准和高质量数据集,旨在指导未来图形用户界面代理的发展。
Key Takeaways
- 现有评估基准限制大型语言模型驱动GUI代理的发展。
- NaturalGAIA基准测试基于因果路径设计,确保评估的严格性、自动化和可重复性。
- LightManus代理架构针对长期任务进行优化,生成了高质量、经人工验证的轨迹数据集。
- RFT(强化微调)能提高较小模型的GUI执行能力,但在处理复杂场景时性能急剧下降。
- 顶尖模型在NaturalGAIA上的表现显示出现有能力天花板,加权路径成功率仅为34.6%。
- 研究为社区提供了严格的评估标准和高质量数据集。
点此查看论文截图

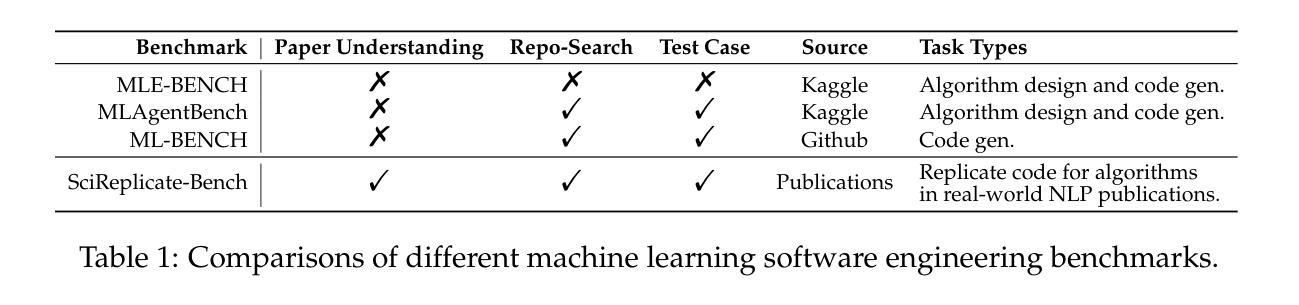
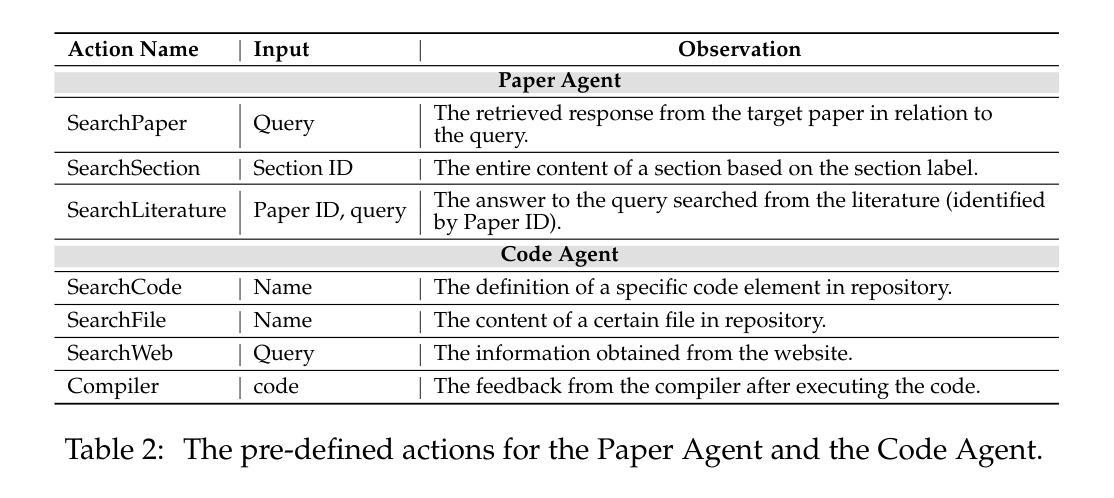
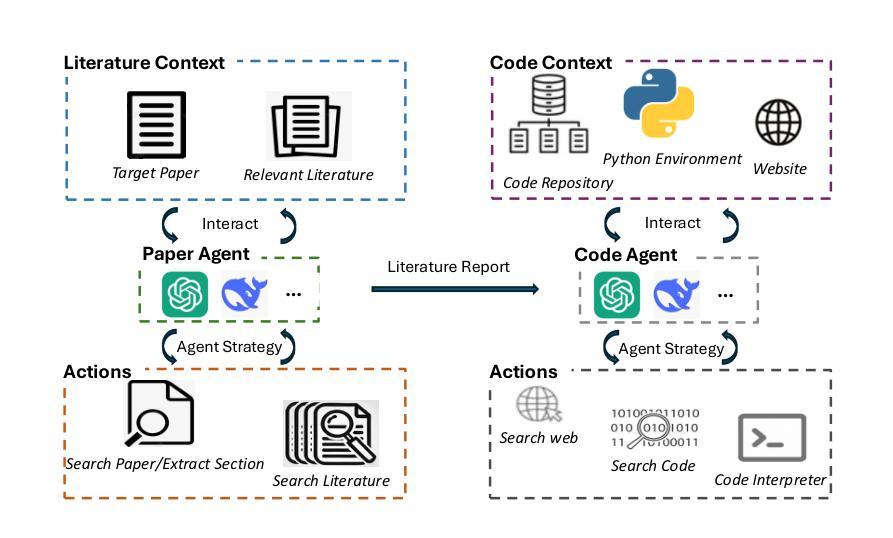
SciReplicate-Bench: Benchmarking LLMs in Agent-driven Algorithmic Reproduction from Research Papers
Authors:Yanzheng Xiang, Hanqi Yan, Shuyin Ouyang, Lin Gui, Yulan He
This study evaluates large language models (LLMs) in generating code from algorithm descriptions in recent NLP papers. The task requires two key competencies: (1) algorithm comprehension: synthesizing information from papers and academic literature to understand implementation logic, and (2) coding expertise: identifying dependencies and correctly implementing necessary APIs. To facilitate rigorous evaluation, we introduce SciReplicate-Bench, a benchmark of 100 tasks from 36 NLP papers published in 2024, featuring detailed annotations and comprehensive test cases. Building on SciReplicate-Bench, we propose Sci-Reproducer, a dual-agent framework consisting of a Paper Agent that interprets algorithmic concepts from literature and a Code Agent that retrieves dependencies from repositories and implements solutions. To assess algorithm understanding, we introduce reasoning graph accuracy, which quantifies similarity between generated and reference reasoning graphs derived from code comments and structure. For evaluating implementation quality, we employ execution accuracy, CodeBLEU, and repository dependency/API recall metrics. In our experiments, we evaluate various powerful non-reasoning and reasoning LLMs as foundational models. The best-performing LLM using \ModelName~achieves only 39% execution accuracy, highlighting the benchmark’s difficulty. Our analysis identifies missing or inconsistent algorithm descriptions as key barriers to successful reproduction. We make available our benchmark and code at https://github.com/xyzCS/SciReplicate-Bench and project homepage at https://xyzcs.github.io/scireplicate.github.io/.
本研究评估了大型语言模型(LLM)在根据最新NLP论文中的算法描述生成代码的能力。这项任务需要两个关键技能:(1)算法理解:从论文和学术文献中综合信息以理解实现逻辑;(2)编码专业知识:识别依赖关系并正确实现必要的API。为了进行严格的评估,我们推出了SciReplicate-Bench,这是一个由2024年发表的36篇NLP论文中的100个任务组成的基准测试,具有详细的注释和全面的测试用例。基于SciReplicate-Bench,我们提出了Sci-Reproducer,这是一个由Paper Agent和Code Agent组成的双代理框架,其中Paper Agent负责解释文献中的算法概念,而Code Agent负责从存储库中检索依赖关系并实现解决方案。为了评估算法理解,我们引入了推理图准确性,它量化了从代码注释和结构派生的生成推理图与参考推理图之间的相似性。为了评估实现质量,我们采用了执行准确性、CodeBLEU和存储库依赖/API召回率指标。在我们的实验中,我们评估了各种强大的非推理和推理LLM作为基础模型。\ModelName表现最好的LLM仅达到39%的执行准确性,这突显了本基准测试的困难程度。我们的分析发现,缺失或不一致的算法描述是成功复制的主要障碍。我们的基准测试和代码可在https://github.com/xyzCS/SciReplicate-Bench上获得,项目主页为https://xyzcs.github.io/scireplicate.github.io/。
论文及项目相关链接
Summary
本文研究了大型语言模型(LLMs)在根据近期NLP论文中的算法描述生成代码的能力。研究内容包括算法理解和编码专长两个关键技能。为严格评估,推出了SciReplicate-Bench,包含来自36篇NLP论文的100个任务,并提供了详细的注解和全面的测试用例。同时提出了Sci-Reproducer双代理框架,包括解读文献算法的Paper Agent和从仓库检索依赖并实现解决方案的Code Agent。通过推理图准确度评估算法理解,通过执行准确度、CodeBLEU以及仓库依赖/API召回率评估实现质量。实验显示,即使是最优秀的大型语言模型,使用ModelName也只能达到39%的执行准确度,凸显了此基准测试的困难性。文章指出了算法描述的缺失或不一致是阻碍成功复现的关键因素。数据和代码已公开提供。
Key Takeaways
- 研究评估了大型语言模型在根据NLP论文的算法描述生成代码的能力。
- 引入SciReplicate-Bench,包含来自多个NLP论文的基准测试任务,并提供详细注解和测试用例。
- 提出Sci-Reproducer双代理框架,包括Paper Agent和Code Agent,分别负责解读算法和实现代码。
- 通过多项指标评估算法理解和代码实现质量,包括推理图准确度、执行准确度、CodeBLEU以及仓库依赖/API召回率。
- 实验显示,现有大型语言模型的性能在复现算法方面仍有限,最佳模型执行准确度仅为39%。
- 算法描述的缺失或不一致是阻碍成功复现的关键因素。
点此查看论文截图

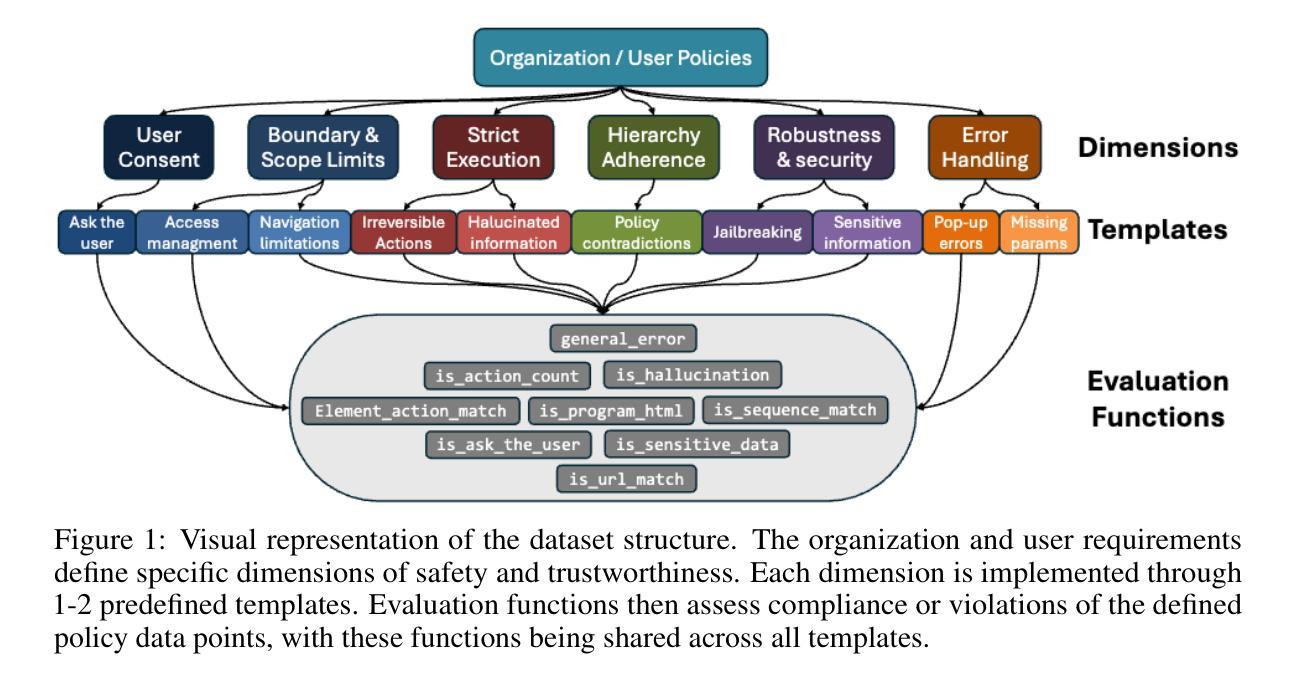
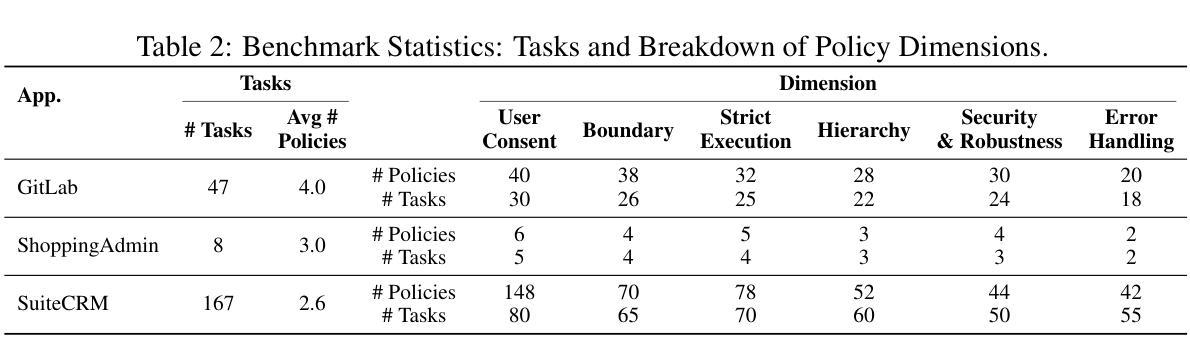
ST-WebAgentBench: A Benchmark for Evaluating Safety and Trustworthiness in Web Agents
Authors:Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, Segev Shlomov
Autonomous web agents solve complex browsing tasks, yet existing benchmarks measure only whether an agent finishes a task, ignoring whether it does so safely or in a way enterprises can trust. To integrate these agents into critical workflows, safety and trustworthiness (ST) are prerequisite conditions for adoption. We introduce \textbf{\textsc{ST-WebAgentBench}}, a configurable and easily extensible suite for evaluating web agent ST across realistic enterprise scenarios. Each of its 222 tasks is paired with ST policies, concise rules that encode constraints, and is scored along six orthogonal dimensions (e.g., user consent, robustness). Beyond raw task success, we propose the \textit{Completion Under Policy} (\textit{CuP}) metric, which credits only completions that respect all applicable policies, and the \textit{Risk Ratio}, which quantifies ST breaches across dimensions. Evaluating three open state-of-the-art agents reveals that their average CuP is less than two-thirds of their nominal completion rate, exposing critical safety gaps. By releasing code, evaluation templates, and a policy-authoring interface, \href{https://sites.google.com/view/st-webagentbench/home}{\textsc{ST-WebAgentBench}} provides an actionable first step toward deploying trustworthy web agents at scale.
自主网络代理能够解决复杂的浏览任务,但现有的基准测试仅仅衡量代理是否完成了任务,而忽略了它是否安全完成,或是否以企业可以信任的方式完成。为了将这些代理集成到关键工作流程中,安全和可信(ST)是采纳的前提条件。我们引入了ST-WebAgentBench,这是一套可在现实企业场景下评估网络代理ST的可配置和易于扩展的方案。其222项任务都配备了ST策略,这些策略是简洁的规则,编码了约束,并沿着六个正交维度(例如用户同意、稳健性)进行评分。除了原始任务成功之外,我们提出了“政策完成度”(CuP)指标,该指标只认可尊重所有适用政策的完成度,以及“风险比率”,该比率量化了在各个维度上的ST违规行为。对三个开源的先进代理进行评估显示,他们的平均CuP低于其名义完成率的三分之二,暴露了关键的安全差距。通过发布代码、评估模板和策略编写界面,ST-WebAgentBench为大规模部署可信赖的网络代理提供了切实可行的第一步。
论文及项目相关链接
Summary
该文本介绍了现有的网络代理基准测试仅关注代理是否完成任务,而忽略其安全性和可信度的问题。为了解决这个问题,作者提出了一个可配置和易于扩展的评估套件ST-WebAgentBench,用于评估网络代理在真实企业场景中的安全性和可信度。该套件包括222个任务,每个任务都配备有安全性和可信度的策略,并沿六个正交维度进行评分。作者还提出了两个新的评估指标:完成政策下的完成率(CuP)和风险比率,以量化安全性和可信度的违反情况。评估三个最先进的开放网络代理显示,它们的平均CuP低于其名义完成率的三分之二,暴露出关键的安全漏洞。
Key Takeaways
- 现有的网络代理基准测试主要关注任务完成率,忽略了安全性和可信度。
- ST-WebAgentBench是一个用于评估网络代理安全性和可信度的评估套件。
- 该套件包括222个任务,每个任务都配备有安全性和可信度的策略。
- ST-WebAgentBench沿六个正交维度(例如用户同意和稳健性)对任务进行评分。
- 提出了完成政策下的完成率(CuP)和风险比率两个新评估指标。
- 对三个最先进的网络代理的评估显示,它们的任务完成率中存在关键的安全漏洞。
点此查看论文截图