⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
SMOL-MapSeg: Show Me One Label
Authors:Yunshuang Yuan, Frank Thiemann, Thorsten Dahms, Monika Sester
Historical maps are valuable for studying changes to the Earth’s surface. With the rise of deep learning, models like UNet have been used to extract information from these maps through semantic segmentation. Recently, pre-trained foundation models have shown strong performance across domains such as autonomous driving, medical imaging, and industrial inspection. However, they struggle with historical maps. These models are trained on modern or domain-specific images, where patterns can be tied to predefined concepts through common sense or expert knowledge. Historical maps lack such consistency – similar concepts can appear in vastly different shapes and styles. To address this, we propose On-Need Declarative (OND) knowledge-based prompting, which introduces explicit prompts to guide the model on what patterns correspond to which concepts. This allows users to specify the target concept and pattern during inference (on-need inference). We implement this by replacing the prompt encoder of the foundation model SAM with our OND prompting mechanism and fine-tune it on historical maps. The resulting model is called SMOL-MapSeg (Show Me One Label). Experiments show that SMOL-MapSeg can accurately segment classes defined by OND knowledge. It can also adapt to unseen classes through few-shot fine-tuning. Additionally, it outperforms a UNet-based baseline in average segmentation performance.
历史地图对于研究地球表面的变化具有重要价值。随着深度学习的兴起,如UNet等模型已用于通过语义分割从这些地图中提取信息。最近,预训练的基金会模型在自动驾驶、医疗成像和工业检测等领域表现出了强大的性能。然而,它们在处理历史地图时遇到了困难。这些模型是在现代或特定领域的图像上进行训练的,其中模式可以通过常识或专业知识与预定义的概念相关联。历史地图缺乏这种一致性——相似概念可能以非常不同的形状和风格出现。为了解决这个问题,我们提出了按需声明(OND)知识提示方法,它通过引入明确提示来指导模型了解哪些模式对应哪些概念。这允许用户在推理过程中指定目标概念和模式(按需推理)。我们通过替换基础模型SAM的提示编码器,采用我们的OND提示机制并在历史地图上对其进行微调来实现这一点。结果模型被称为SMOL-MapSeg(显示我一个标签)。实验表明,SMOL-MapSeg可以准确地分割由OND知识定义的类别。它还可以通过少量样本微调来适应未见过的类别。此外,它在平均分割性能上优于基于UNet的基线模型。
论文及项目相关链接
Summary
历史地图对于研究地球表面的变化具有重要价值。随着深度学习的兴起,UNet等模型已被用于从地图中提取信息,进行语义分割。尽管预训练的基础模型在自动驾驶、医疗影像和工业检测等领域表现出强大的性能,但它们处理历史地图时却面临困难。原因在于,历史地图缺乏现代或特定领域图像中的一致性,相同概念可能呈现出各种不同的形态和风格。为解决这一问题,我们提出了基于需求宣告(OND)知识提示的方法,通过引入明确的提示来指导模型识别不同模式与概念之间的对应关系。实验表明,SMOL-MapSeg模型能够准确分割由OND知识定义的类别,并能适应未见过的类别进行小样本微调,其平均分割性能优于基于UNet的基线模型。
Key Takeaways
- 历史地图对于研究地球表面变化具有重要价值。
- UNet等模型已被用于从地图中提取信息并进行语义分割。
- 预训练的基础模型在处理历史地图时面临困难,因为历史地图缺乏一致性。
- 提出了一种基于需求宣告(OND)知识提示的方法来解决这一问题。
- OND知识提示可以指导模型识别不同模式与概念之间的对应关系。
- SMOL-MapSeg模型通过结合OND知识和历史地图的微调,实现了准确的语义分割。
点此查看论文截图


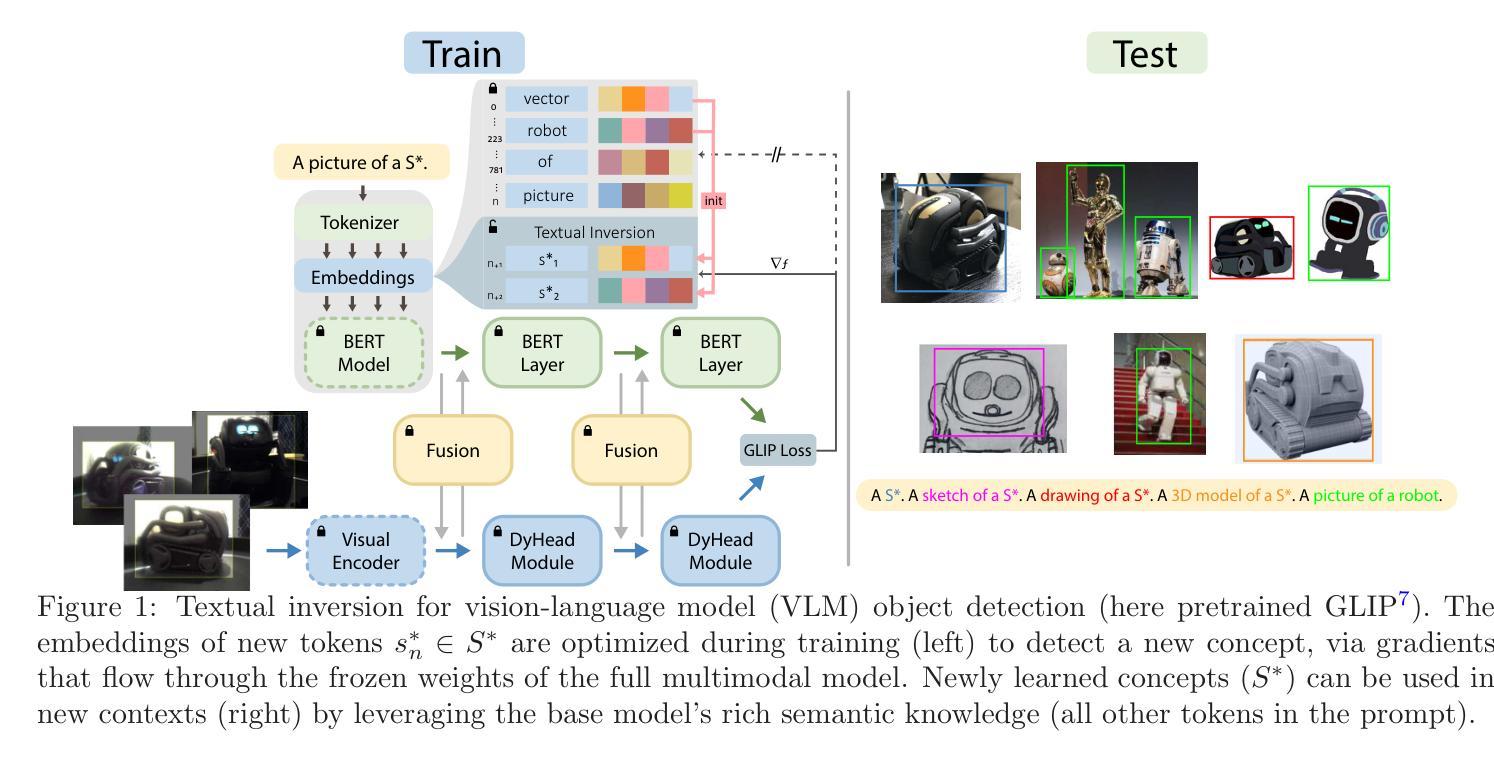
Textual Inversion for Efficient Adaptation of Open-Vocabulary Object Detectors Without Forgetting
Authors:Frank Ruis, Gertjan Burghouts, Hugo Kuijf
Recent progress in large pre-trained vision language models (VLMs) has reached state-of-the-art performance on several object detection benchmarks and boasts strong zero-shot capabilities, but for optimal performance on specific targets some form of finetuning is still necessary. While the initial VLM weights allow for great few-shot transfer learning, this usually involves the loss of the original natural language querying and zero-shot capabilities. Inspired by the success of Textual Inversion (TI) in personalizing text-to-image diffusion models, we propose a similar formulation for open-vocabulary object detection. TI allows extending the VLM vocabulary by learning new or improving existing tokens to accurately detect novel or fine-grained objects from as little as three examples. The learned tokens are completely compatible with the original VLM weights while keeping them frozen, retaining the original model’s benchmark performance, and leveraging its existing capabilities such as zero-shot domain transfer (e.g., detecting a sketch of an object after training only on real photos). The storage and gradient calculations are limited to the token embedding dimension, requiring significantly less compute than full-model fine-tuning. We evaluated whether the method matches or outperforms the baseline methods that suffer from forgetting in a wide variety of quantitative and qualitative experiments.
最近,大型预训练视觉语言模型(VLM)的进展已经在多个目标检测基准测试中达到了最先进的性能,并具备强大的零样本能力。但是,为了在特定目标上获得最佳性能,仍然需要进行某种形式的微调。虽然初始的VLM权重允许很好的少量转移学习,但这通常会失去原始的自然语言查询和零样本能力。受文本反转(TI)在个性化文本到图像扩散模型中的成功的启发,我们为开放词汇对象检测提出了类似的公式。TI允许通过学习新令牌或改进现有令牌来扩展VLM词汇,从而仅从三个示例中准确检测新型或细粒度对象。所学到的令牌与原始VLM权重完全兼容,同时保持冻结状态,保留了原始模型的基准测试性能,并可以利用其现有功能,如零样本域迁移(例如,在仅对真实照片进行训练后检测对象的草图)。存储和梯度计算仅限于令牌嵌入维度,因此所需的计算量远远小于全模型微调。我们通过各种定量和定性实验评估了该方法是否匹配或超越基线方法,这些方法会遭受遗忘的影响。
论文及项目相关链接
Summary
大型预训练视觉语言模型(VLM)的最新进展已在多个目标检测基准测试中达到最新水平,并具备强大的零样本能力,但针对特定目标的最佳性能仍需要进行某种形式的微调。尽管初始的VLM权重允许很好的少量转移学习,但这通常会失去原始的自然语言查询和零样本能力。受文本反转(TI)在个性化文本到图像扩散模型中的成功的启发,我们提出了一种用于开放词汇对象检测的类似公式。TI通过学习新令牌或改进现有令牌来准确检测来自三个示例的新颖或细粒度对象。所学到的令牌与原始的VLM权重完全兼容,同时保持冻结状态,保留了原始模型的基准测试性能,并利用了其现有功能,如零样本域转移(例如,仅在真实照片上进行训练后检测对象的草图)。存储和梯度计算仅限于令牌嵌入维度,与全模型微调相比,需要更少的计算量。我们进行了广泛的定量和定性实验,评估该方法是否达到或超越了基线方法的表现。基线方法在处理时会面临遗忘问题。
Key Takeaways
- 大型预训练视觉语言模型在目标检测方面已达到最新技术水准,具备强大的零样本学习能力。
- 尽管初始模型权重可实现优秀的少量转移学习,但维持原始的自然语言查询和零样本能力至关重要。
- 文本反转(TI)技术可用于开放词汇对象检测,通过新增或改进令牌以准确识别新颖或细粒度对象,仅需少量示例。
- 所引入的令牌与原始VLM权重兼容,可保持模型性能并增强现有功能,如零样本域转移。
- 该方法存储和计算需求相对较低,仅限于令牌嵌入维度,较全模型微调更为高效。
- 方法在广泛的定量和定性实验中表现优秀,与基线方法相比,有效避免了遗忘问题。
点此查看论文截图

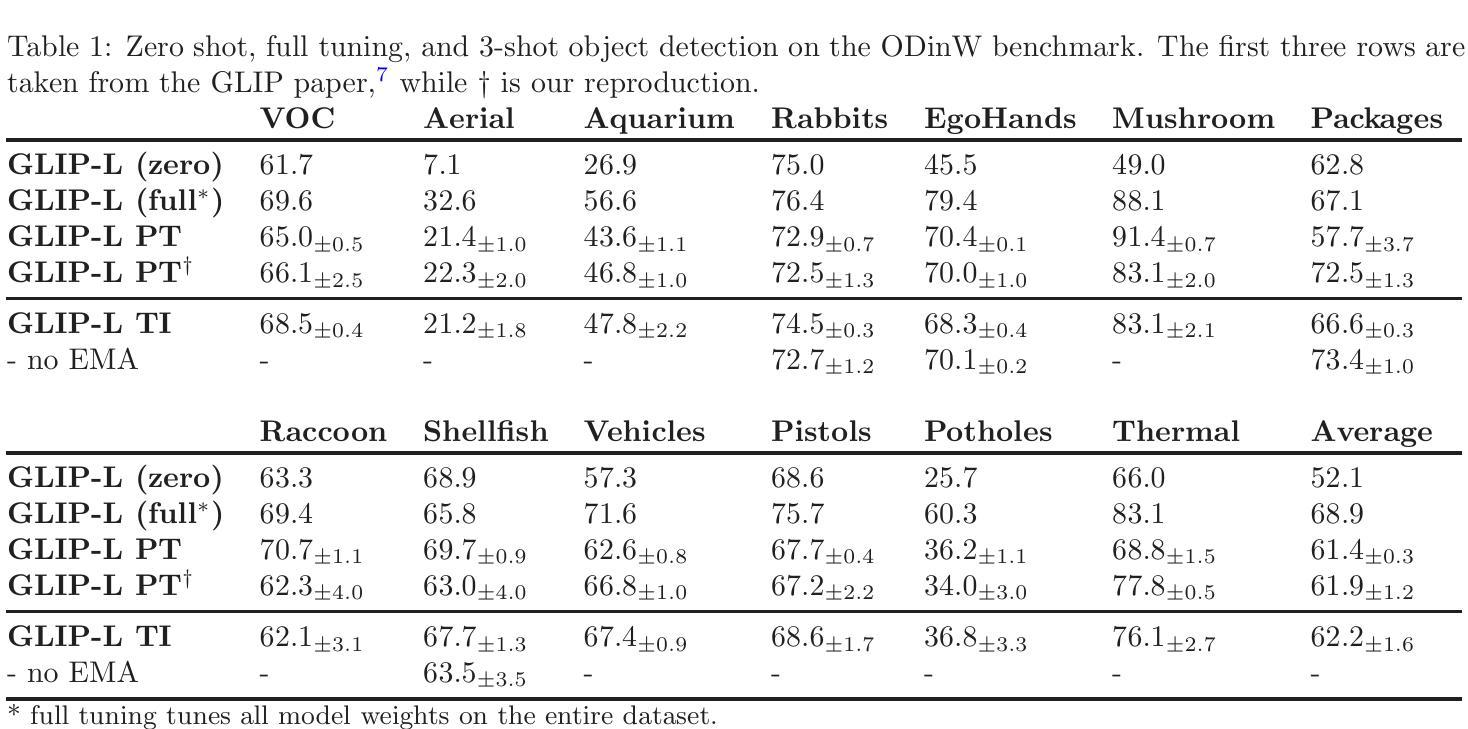
Textual and Visual Guided Task Adaptation for Source-Free Cross-Domain Few-Shot Segmentation
Authors:Jianming Liu, Wenlong Qiu, Haitao Wei
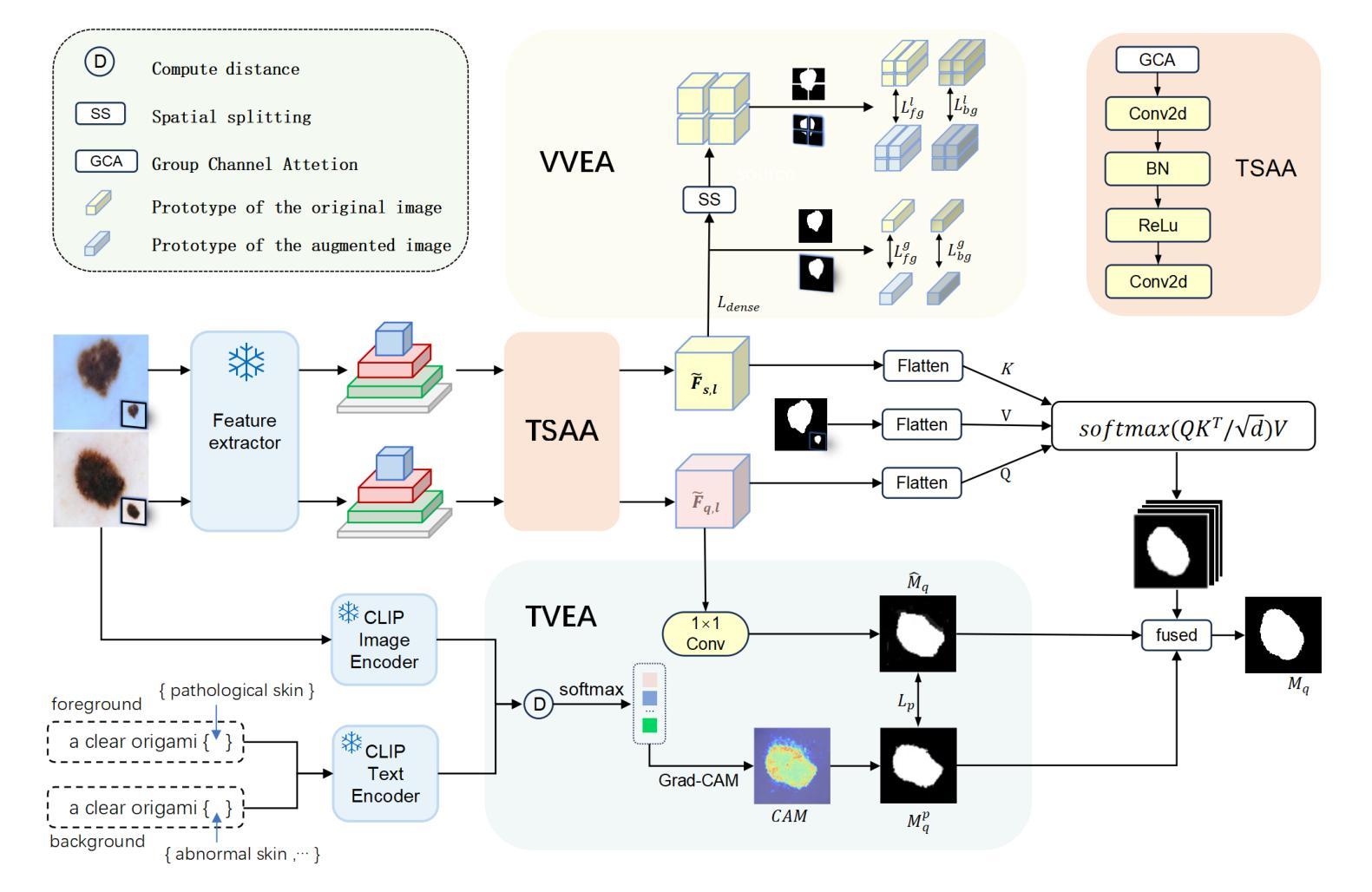
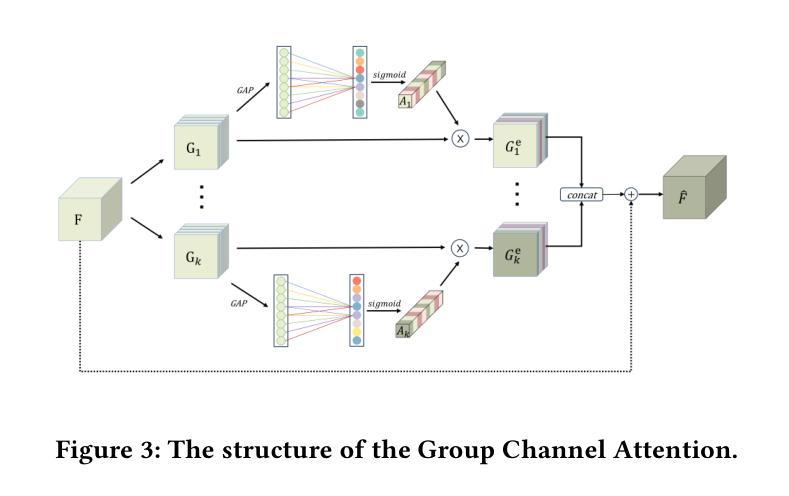
Few-Shot Segmentation(FSS) aims to efficient segmentation of new objects with few labeled samples. However, its performance significantly degrades when domain discrepancies exist between training and deployment. Cross-Domain Few-Shot Segmentation(CD-FSS) is proposed to mitigate such performance degradation. Current CD-FSS methods primarily sought to develop segmentation models on a source domain capable of cross-domain generalization. However, driven by escalating concerns over data privacy and the imperative to minimize data transfer and training expenses, the development of source-free CD-FSS approaches has become essential. In this work, we propose a source-free CD-FSS method that leverages both textual and visual information to facilitate target domain task adaptation without requiring source domain data. Specifically, we first append Task-Specific Attention Adapters (TSAA) to the feature pyramid of a pretrained backbone, which adapt multi-level features extracted from the shared pre-trained backbone to the target task. Then, the parameters of the TSAA are trained through a Visual-Visual Embedding Alignment (VVEA) module and a Text-Visual Embedding Alignment (TVEA) module. The VVEA module utilizes global-local visual features to align image features across different views, while the TVEA module leverages textual priors from pre-aligned multi-modal features (e.g., from CLIP) to guide cross-modal adaptation. By combining the outputs of these modules through dense comparison operations and subsequent fusion via skip connections, our method produces refined prediction masks. Under both 1-shot and 5-shot settings, the proposed approach achieves average segmentation accuracy improvements of 2.18% and 4.11%, respectively, across four cross-domain datasets, significantly outperforming state-of-the-art CD-FSS methods. Code are available at https://github.com/ljm198134/TVGTANet.
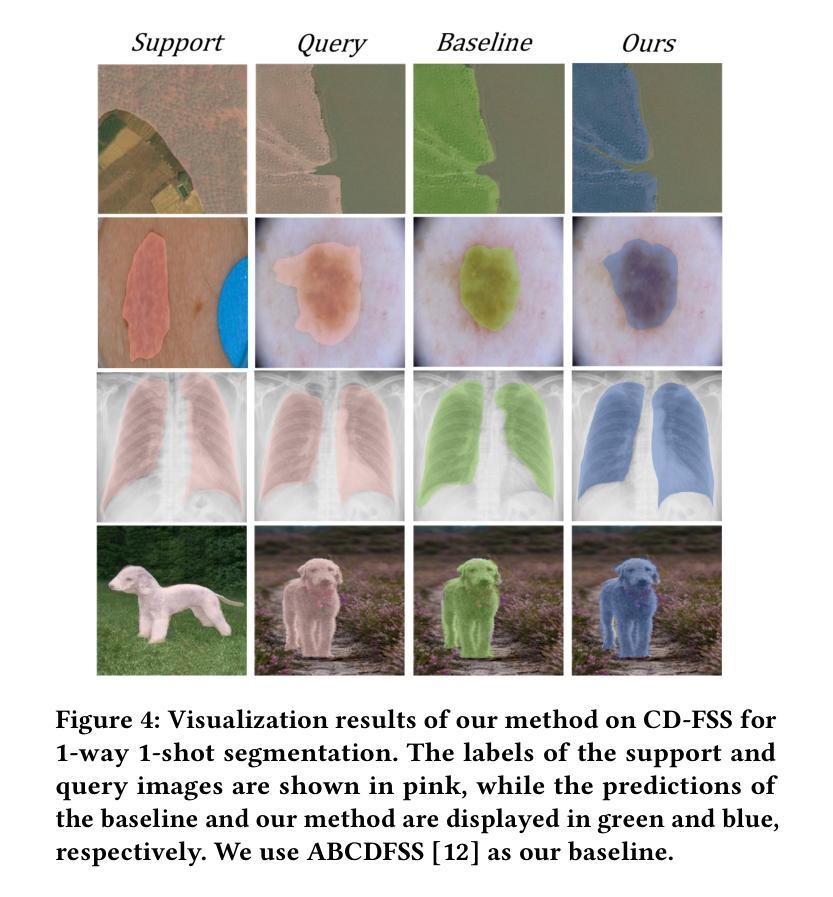
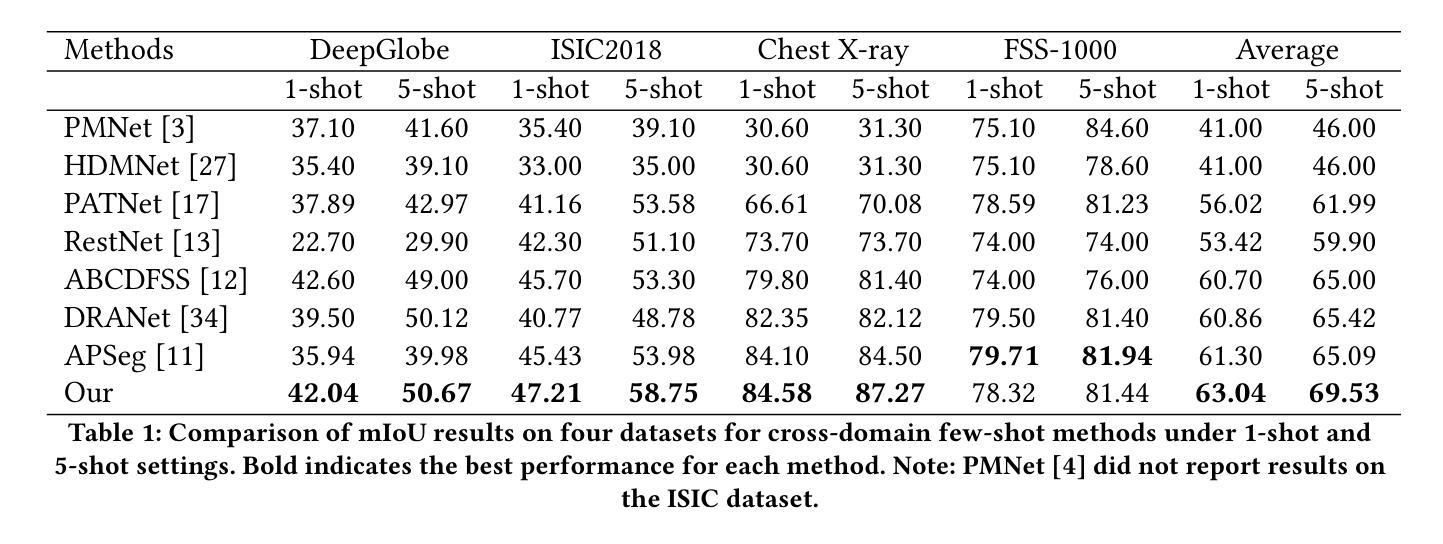
跨域小样本分割(CD-FSS)旨在解决在新对象只有少量标记样本的情况下进行有效分割的问题。然而,当训练和部署之间存在域差异时,其性能会显著下降。针对这种性能下降,提出了跨域小样本分割(CD-FSS)方法,当前CD-FSS方法主要寻求在源域上开发能够跨域推广的分割模型。然而,由于对数据隐私的担忧以及减少数据传输和培训费用的必要性日益加剧,无源域CD-FSS方法的发展变得至关重要。在这项工作中,我们提出了一种无源的CD-FSS方法,它利用文本和视觉信息来促进目标域的任务适应,无需源域数据。具体来说,我们首先将任务特定注意力适配器(TSAA)添加到预训练骨干的特征金字塔上,该适配器将来自共享预训练骨干的多级特征适应到目标任务。然后,通过视觉视觉嵌入对齐(VVEA)模块和文本视觉嵌入对齐(TVEA)模块训练TSAA的参数。VVEA模块利用全局局部视觉特征来对齐不同视角的图像特征,而TVEA模块则利用来自预对齐多模态特征(例如来自CLIP)的文本先验知识来引导跨模态适应。通过将这些模块的输 出通过密集比较操作和随后的跳跃连接融合,我们的方法生成了精细的预测掩模。在1-shot和5-shot设置下,所提出的方法在四个跨域数据集上的平均分割精度分别提高了2.18%和4.11%,显著优于最新的CD-FSS方法。代码可在https://github.com/ljm198134/TVGTANet上找到。
论文及项目相关链接
PDF 10 pages,Accepted at ACMMM2025
Summary
该文本介绍了Few-Shot Segmentation(FSS)在新对象分割领域的应用挑战,特别是在存在领域差异时性能显著下降的问题。为此,提出了Cross-Domain Few-Shot Segmentation(CD-FSS)来减轻性能下降。当前CD-FSS方法主要寻求在源领域开发能够跨领域推广的分割模型。然而,由于对数据隐私的担忧以及减少数据传输和培训费用的必要性,源免费的CD-FSS方法的发展变得至关重要。本研究提出了一种源免费的CD-FSS方法,利用文本和视觉信息来促进目标领域的任务适应,而无需源领域数据。通过添加任务特定注意力适配器(TSAA)和训练这些参数,该方法实现了在跨领域数据集上的显著性能提升。
Key Takeaways
- Few-Shot Segmentation (FSS) 在新对象分割方面表现优秀,但在领域差异大时性能显著下降。
- Cross-Domain Few-Shot Segmentation (CD-FSS) 被提出用于解决领域差异带来的性能下降问题。
- 当前CD-FSS方法主要寻求在源领域开发可跨领域推广的分割模型。
- 出于对数据隐私的考虑及减少数据传输和培训费用的需要,源免费的CD-FSS方法变得重要。
- 本研究通过结合文本和视觉信息,提出了一种源免费的CD-FSS方法,促进目标领域的任务适应,无需源领域数据。
- 方法通过添加任务特定注意力适配器(TSAA)和训练这些参数,实现了跨领域数据集的显著性能提升。
点此查看论文截图

Sculpting Margin Penalty: Intra-Task Adapter Merging and Classifier Calibration for Few-Shot Class-Incremental Learning
Authors:Liang Bai, Hong Song, Jinfu Li, Yucong Lin, Jingfan Fan, Tianyu Fu, Danni Ai, Deqiang Xiao, Jian Yang
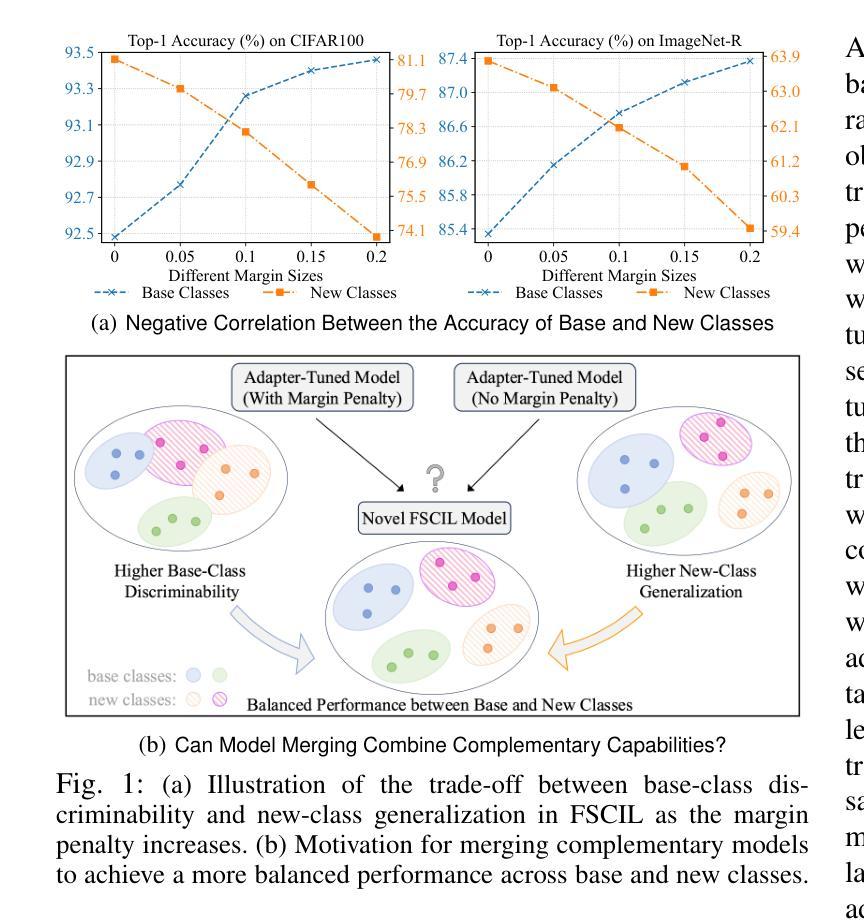
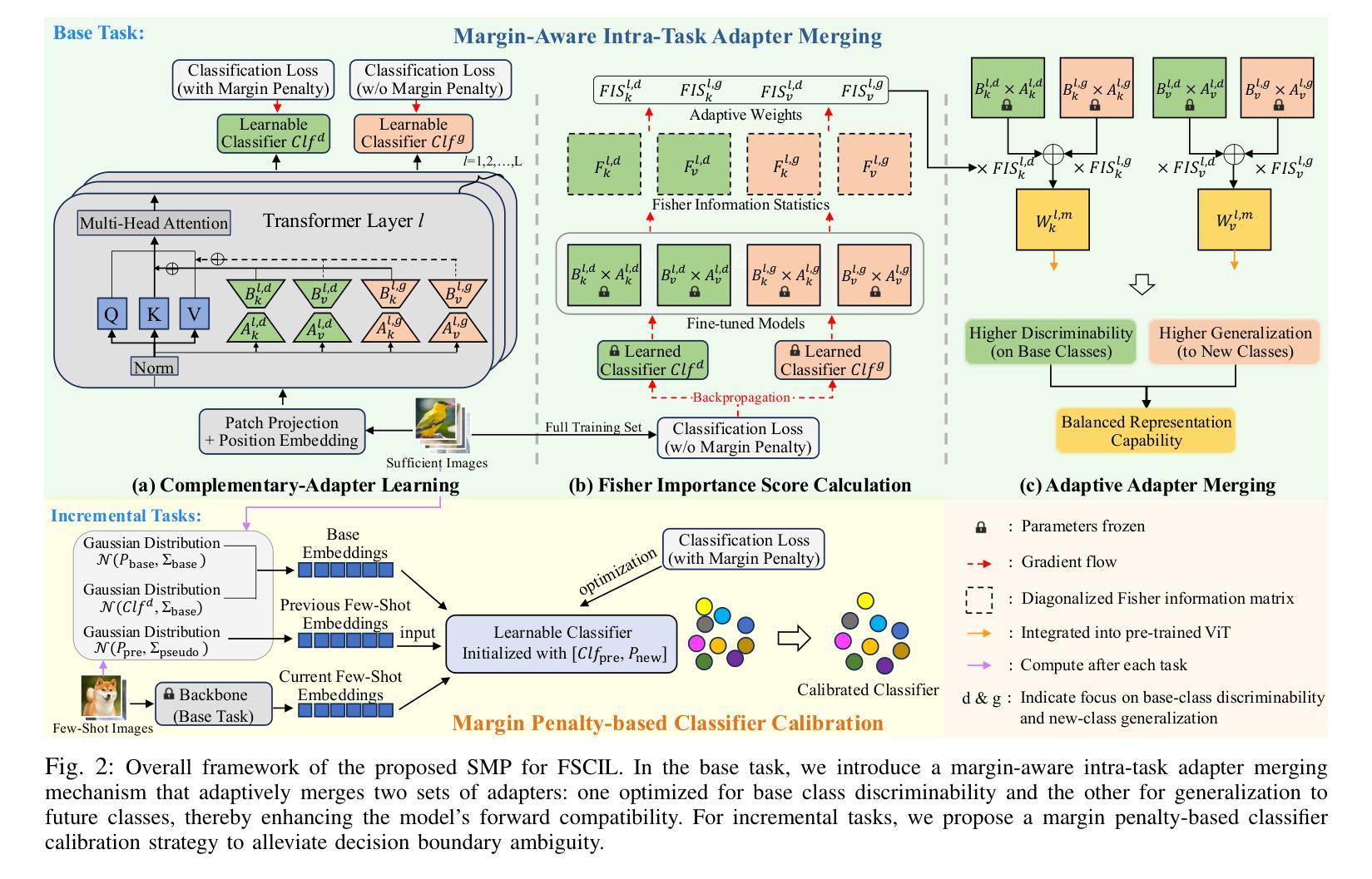
Real-world applications often face data privacy constraints and high acquisition costs, making the assumption of sufficient training data in incremental tasks unrealistic and leading to significant performance degradation in class-incremental learning. Forward-compatible learning, which prospectively prepares for future tasks during base task training, has emerged as a promising solution for Few-Shot Class-Incremental Learning (FSCIL). However, existing methods still struggle to balance base-class discriminability and new-class generalization. Moreover, limited access to original data during incremental tasks often results in ambiguous inter-class decision boundaries. To address these challenges, we propose SMP (Sculpting Margin Penalty), a novel FSCIL method that strategically integrates margin penalties at different stages within the parameter-efficient fine-tuning paradigm. Specifically, we introduce the Margin-aware Intra-task Adapter Merging (MIAM) mechanism for base task learning. MIAM trains two sets of low-rank adapters with distinct classification losses: one with a margin penalty to enhance base-class discriminability, and the other without margin constraints to promote generalization to future new classes. These adapters are then adaptively merged to improve forward compatibility. For incremental tasks, we propose a Margin Penalty-based Classifier Calibration (MPCC) strategy to refine decision boundaries by fine-tuning classifiers on all seen classes’ embeddings with a margin penalty. Extensive experiments on CIFAR100, ImageNet-R, and CUB200 demonstrate that SMP achieves state-of-the-art performance in FSCIL while maintaining a better balance between base and new classes.
现实世界应用常常面临数据隐私限制和高采集成本,使得增量任务中假设存在足够的训练数据变得不现实,并且在类增量学习(Class-Incremental Learning)中导致显著的性能下降。前瞻性学习(前瞻性地在基础任务训练时准备未来的任务)已经成为小样例类增量学习(FSCIL)的一种有前途的解决方案。然而,现有的方法仍然难以平衡基础类的辨识性和新类的泛化性。此外,增量任务期间对原始数据的有限访问通常导致模糊的类间决策边界。为了应对这些挑战,我们提出了SMP(雕刻边界惩罚),这是一种新型的FSCIL方法,它在参数高效的微调范式中,在不同的阶段战略性地整合了边界惩罚。具体来说,我们引入了面向基础任务学习的“边界感知任务内适配器融合(MIAM)”机制。MIAM训练了两套具有不同分类损失的低位适配器:一套带有边界惩罚以增强基础类的辨识性,另一套不带边界约束以促进未来新类的泛化。这些适配器随后进行自适应融合以提高前瞻性兼容性。对于增量任务,我们提出了基于边界惩罚的分类器校准(MPCC)策略,通过微调所有已见类的嵌入上的分类器来完善决策边界。在CIFAR100、ImageNet-R和CUB200上的大量实验表明,SMP在FSCIL中实现了最先进的性能,同时基础类和新类之间保持了更好的平衡。
论文及项目相关链接
PDF 13 pages, 7 figures
Summary
本文介绍了面向少量类别增量的学习(FSCIL)的挑战和解决方案。针对实际应用中的数据隐私约束和高昂的获取成本问题,提出了SMP方法,通过在不同阶段引入边距惩罚,在参数高效的微调框架下实现基础任务学习和增量任务学习的平衡。实验证明,该方法在CIFAR100、ImageNet-R和CUB200数据集上实现了最佳性能。
Key Takeaways
- 实际应用中面临数据隐私约束和高昂的获取成本问题,导致少量类别增量的学习(FSCIL)中假设的充足训练数据不现实,性能下降。
- 现有方法难以平衡基础类别鉴别力和新类别泛化能力。
- SMP方法通过引入边距惩罚,在参数高效的微调框架下实现基础任务学习和增量任务学习的平衡。
- 提出了Margin-aware Intra-task Adapter Merging(MIAM)机制,通过训练两组具有不同分类损失的低位适配器,增强基础类别鉴别力和未来新类别的泛化能力。
- 对于增量任务,提出了基于边距惩罚的分类器校准(MPCC)策略,通过微调所有已见类别的嵌入分类器,优化决策边界。
- 实验证明,SMP方法在CIFAR100、ImageNet-R和CUB200数据集上实现了最佳性能。
- SMP方法实现了对基础任务和增量任务的良好兼容性。
点此查看论文截图

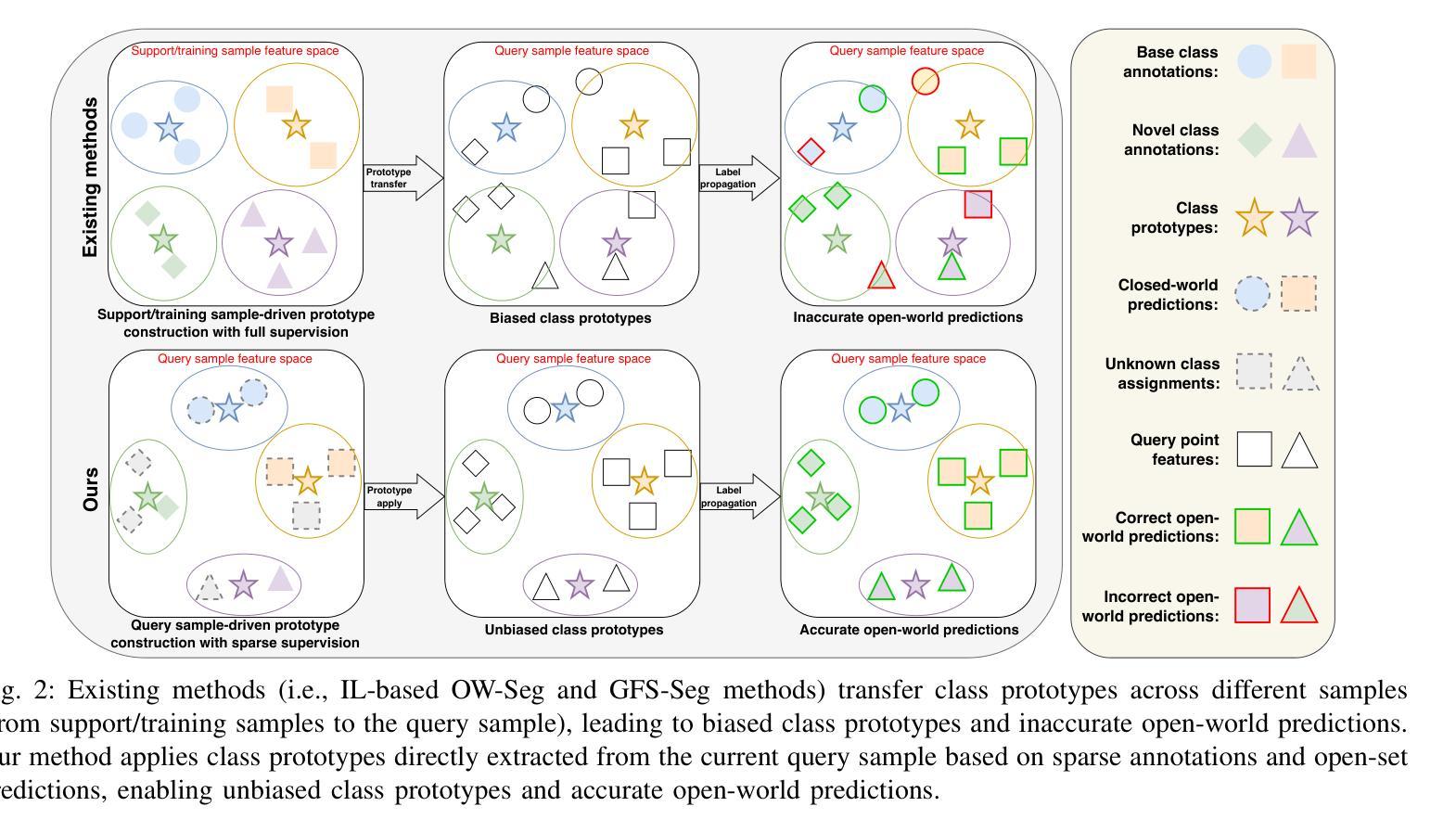
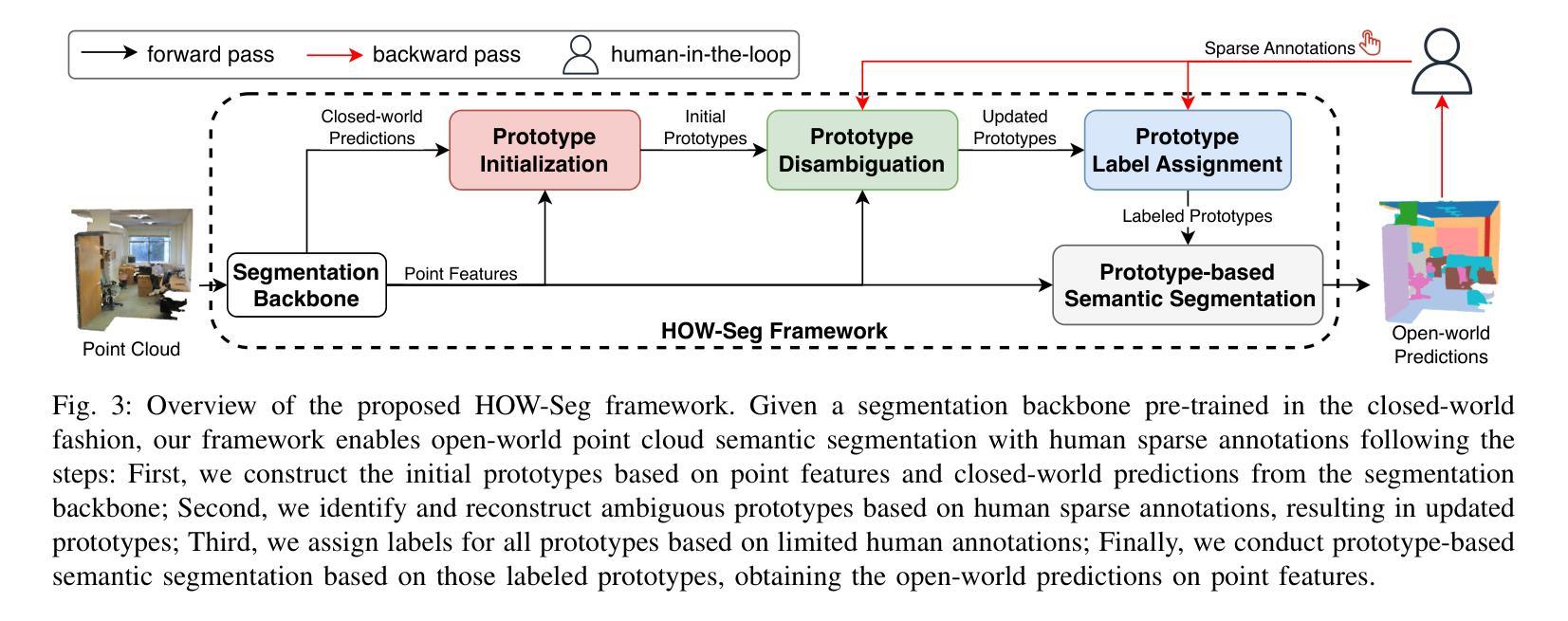
Open-world Point Cloud Semantic Segmentation: A Human-in-the-loop Framework
Authors:Peng Zhang, Songru Yang, Jinsheng Sun, Weiqing Li, Zhiyong Su
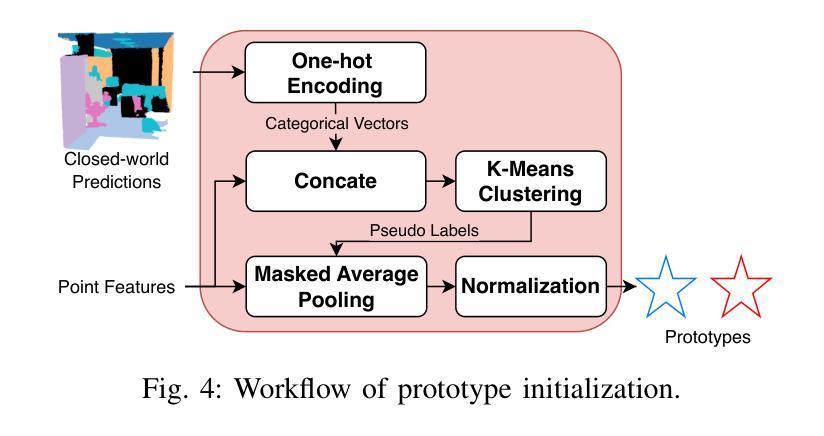
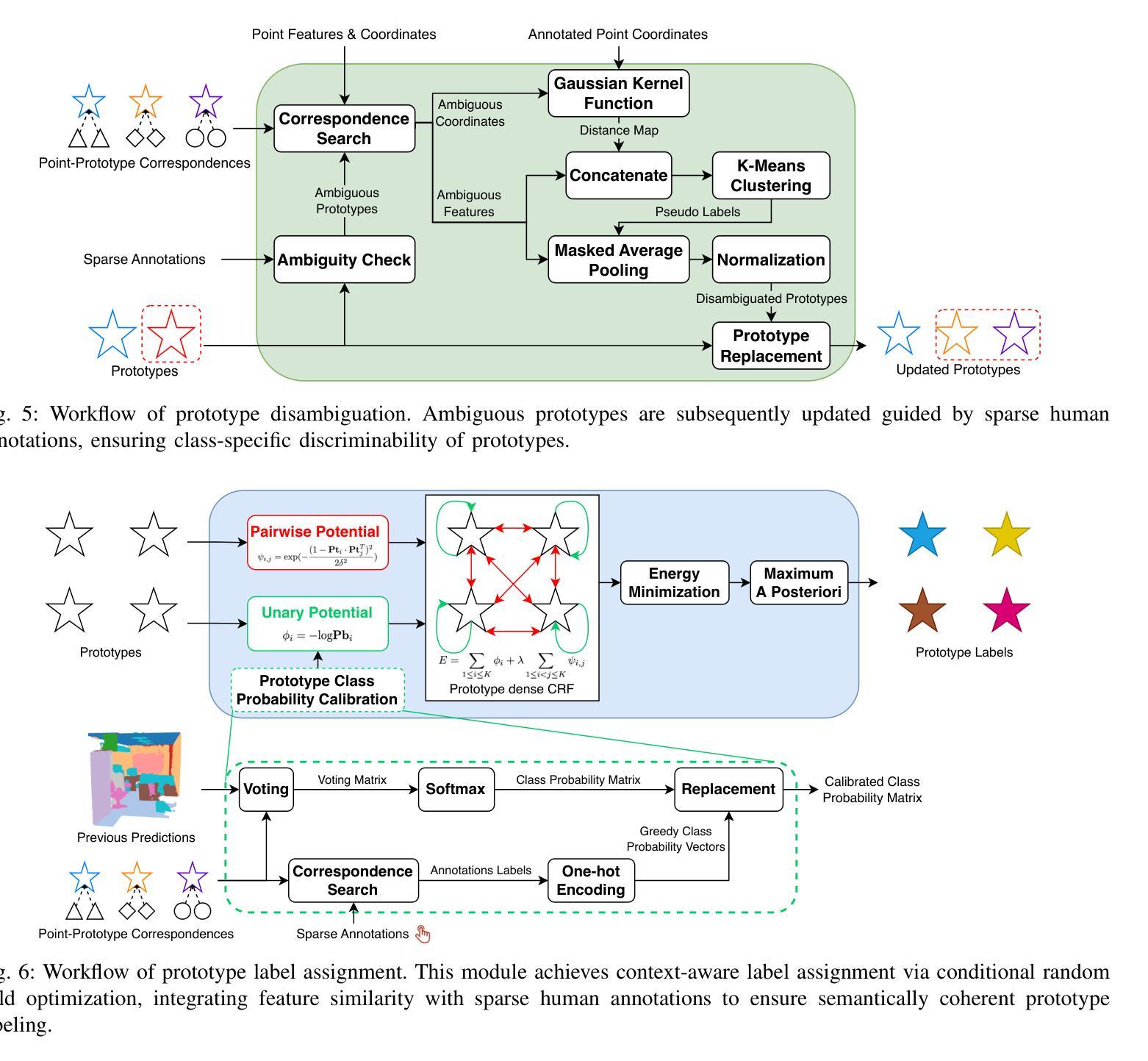
Open-world point cloud semantic segmentation (OW-Seg) aims to predict point labels of both base and novel classes in real-world scenarios. However, existing methods rely on resource-intensive offline incremental learning or densely annotated support data, limiting their practicality. To address these limitations, we propose HOW-Seg, the first human-in-the-loop framework for OW-Seg. Specifically, we construct class prototypes, the fundamental segmentation units, directly on the query data, avoiding the prototype bias caused by intra-class distribution shifts between the support and query data. By leveraging sparse human annotations as guidance, HOW-Seg enables prototype-based segmentation for both base and novel classes. Considering the lack of granularity of initial prototypes, we introduce a hierarchical prototype disambiguation mechanism to refine ambiguous prototypes, which correspond to annotations of different classes. To further enrich contextual awareness, we employ a dense conditional random field (CRF) upon the refined prototypes to optimize their label assignments. Through iterative human feedback, HOW-Seg dynamically improves its predictions, achieving high-quality segmentation for both base and novel classes. Experiments demonstrate that with sparse annotations (e.g., one-novel-class-one-click), HOW-Seg matches or surpasses the state-of-the-art generalized few-shot segmentation (GFS-Seg) method under the 5-shot setting. When using advanced backbones (e.g., Stratified Transformer) and denser annotations (e.g., 10 clicks per sub-scene), HOW-Seg achieves 85.27% mIoU on S3DIS and 66.37% mIoU on ScanNetv2, significantly outperforming alternatives.
开放世界点云语义分割(OW-Seg)旨在预测现实世界场景中基础类和新型类的点标签。然而,现有方法依赖于资源密集型的离线增量学习或密集注释的支持数据,这限制了它们的实用性。为了解决这些局限性,我们提出了HOW-Seg,这是第一个面向OW-Seg的人类循环框架。具体来说,我们在查询数据上直接构建类原型(基本的分割单元),避免了由于支持数据和查询数据之间类内分布变化所导致的原型偏见。通过利用稀疏人类注释作为指导,HOW-Seg能够实现基础类和新型类的基于原型的分割。考虑到初始原型的粒度不足,我们引入了一种分层原型消歧机制来细化模糊的原型,这些原型对应于不同类的注释。为了进一步增强上下文意识,我们在细化后的原型上采用了密集的条件随机字段(CRF)来优化其标签分配。通过迭代的人类反馈,HOW-Seg能够动态改进其预测,实现基础类和新型类的高质量分割。实验表明,在稀疏注释(例如,每个新型类别只需一次点击)的情况下,HOW-Seg在5次射击设置下与最新的广义少样本分割(GFS-Seg)方法相匹配或超越。当使用先进的骨干网络(例如分层转换器)和更密集的注释(例如每个子场景10次点击)时,HOW-Seg在S3DIS上达到了85.27%的mIoU,在ScanNetv2上达到了66.37%的mIoU,显著优于其他方法。
论文及项目相关链接
PDF To be published in IEEE Transactions on Circuits and Systems for Video Technology
Summary
本文介绍了面向开放世界点云语义分割(OW-Seg)的挑战及现有方法的局限性。为了应对这些挑战,提出了一种新型的人机协同方法——HOW-Seg,实现了对基础类别和新型类别的原型基础分割。通过稀疏人工标注作为指导,利用分层原型解析机制和条件随机场(CRF)优化标签分配,提高分割质量。实验证明,在稀疏标注条件下,HOW-Seg达到了或超越了现有的广义少样本分割(GFS-Seg)方法。在更先进的骨干网络和更密集的标注下,HOW-Seg在S3DIS和ScanNetv2上取得了显著的性能提升。
Key Takeaways
- 开放世界点云语义分割(OW-Seg)的目标是预测现实场景中基础类别和新型类别的点标签。
- 现有方法依赖资源密集型的离线增量学习或密集注释的支持数据,限制了其实用性。
- HOW-Seg是首个面向OW-Seg的人机协同框架,直接在查询数据上构建类原型,避免了因支持数据和查询数据之间的类内分布偏移而导致的原型偏见。
- 通过利用稀疏的人工注释作为指导,HOW-Seg实现了对基础类别和新型类别的基于原型的分割。
- 引入分层原型解析机制,以细化模糊的原型,并优化标签分配。
- 通过迭代的人工反馈,HOW-Seg能动态改进其预测。
- 实验表明,在稀疏标注条件下,HOW-Seg性能与现有方法相比具有竞争力;在更先进的骨干网络和更密集的标注下,其性能显著提升。
点此查看论文截图

A Foundational Multi-Modal Model for Few-Shot Learning
Authors:Pengtao Dang, Tingbo Guo, Sha Cao, Chi Zhang
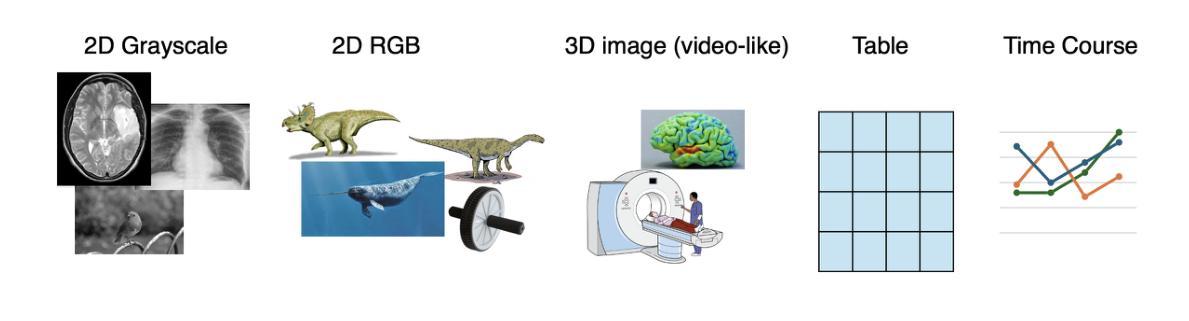
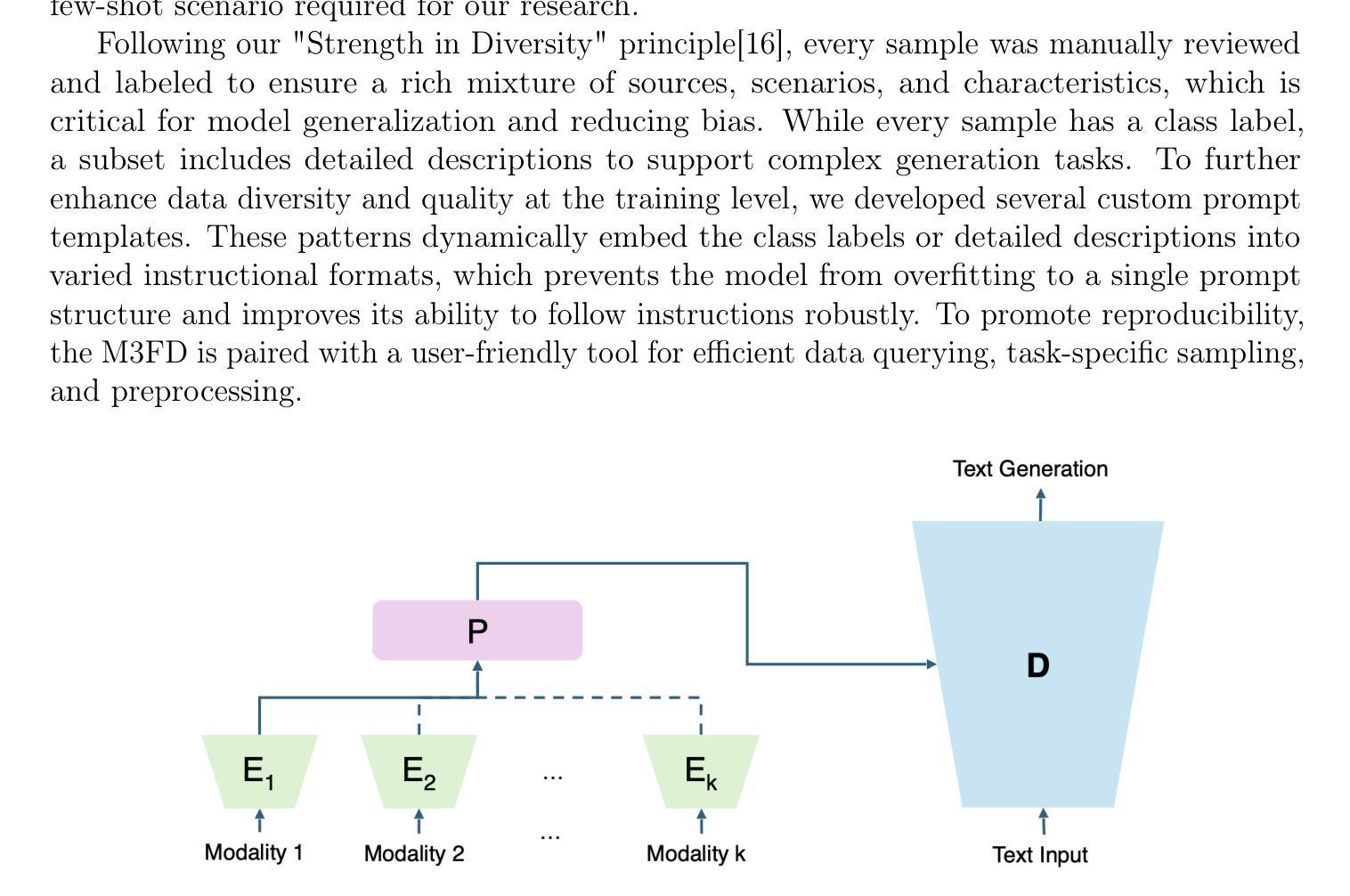
Few-shot learning (FSL) is a machine learning paradigm that aims to generalize models from a small number of labeled examples, typically fewer than 10 per class. FSL is particularly crucial in biomedical, environmental, materials, and mechanical sciences, where samples are limited and data collection is often prohibitively costly, time-consuming, or ethically constrained. In this study, we present an innovative approach to FSL by demonstrating that a Large Multi-Modal Model (LMMM), trained on a set of independent tasks spanning diverse domains, task types, and input modalities, can substantially improve the generalization of FSL models, outperforming models based on conventional meta-learning on tasks of the same type. To support this, we first constructed a Multi-Modal Model Few-shot Dataset (M3FD, over 10K+ few-shot samples), which includes 2D RGB images, 2D/3D medical scans, tabular and time-course datasets, from which we manually curated FSL tasks such as classification. We further introduced M3F (Multi-Modal Model for Few-shot learning framework), a novel Large Multi-Modal Model framework tailored for data-constrained scientific applications. M3F supports a wide range of scientific data types through a modular pipeline. By fine-tuning the model on M3FD, M3F improves model performance, making LMMM feasible for real-world FSL deployment. The source code is located at https://github.com/ptdang1001/M3F. To democratize access to complex FSL data and promote reproducibility for public usage, M3FD is paired with a flexible and user-friendly tool that enables efficient querying, task-specific sampling, and preprocessing. Together, our dataset and framework offer a unified, scalable solution that significantly lowers the barrier to applying LMMMs in data-scarce scientific domains.
少量学习(FSL)是一种机器学习范式,旨在从少量标记样本中推广模型,通常每个类别少于10个样本。在生物医疗、环境、材料和机械科学等领域,由于样本有限,且数据收集往往成本高昂、耗时或受到伦理限制,因此FSL尤为重要。本研究提出了一种基于大量多模态模型(LMMM)的创新少量学习方法。该模型在涵盖不同领域、任务类型和输入模态的独立任务集上进行训练,可以显著改善FSL模型的推广能力,并优于基于传统元学习的相同类型任务模型。为支持这一方法,我们首先构建了多模态模型少量数据集(M3FD,超过10,000个少量样本),其中包括2D RGB图像、2D/3D医学扫描、表格和时序数据集等,我们从这些数据集中手工筛选了如分类等FSL任务。我们还引入了M3F(少量学习的多模态模型框架),这是一个针对数据受限科学应用的新型大型多模态模型框架。M3F通过模块化管道支持广泛的科学数据类型。通过对M3FD进行模型微调,M3F提高了模型性能,使得LMMM在现实世界的FSL部署中切实可行。源代码位于https://github.com/ptdang1001/M3F。为了普及复杂FSL数据的访问并促进公众使用的可重复性,M3FD与一种灵活且用户友好的工具相结合,该工具能够实现高效查询、针对特定任务的采样和预处理。总之,我们的数据集和框架提供统一、可扩展的解决方案,大大降低了在科学领域应用LMMMs的门槛,尤其是在数据稀缺的领域。
论文及项目相关链接
PDF 11 pages, 5 figures
Summary
该研究提出一种基于大型多模态模型(LMMM)的少样本学习(FSL)新方法,通过跨不同领域、任务类型和输入模态的独立任务集进行训练,能显著提升FSL模型的泛化能力。为支持此方法,研究构建了多模态模型少样本数据集(M3FD),并引入专为数据受限科学应用设计的M3F框架。M3F通过微调模型,提升性能,使LMMM在少样本学习的实际应用中变得可行。
Key Takeaways
- 少样本学习(FSL)在样本有限的数据收集成本高昂、耗时或受伦理约束的领域中尤为重要。
- 大型多模态模型(LMMM)在FSL中表现优异,特别是在处理多模态数据时。
- 研究构建了多模态模型少样本数据集(M3FD),包含多种数据类型,如2D RGB图像、2D/3D医疗扫描、表格和时间序列数据集。
- 引入M3F框架,支持多种数据类型,并通过微调模型提升FSL性能。
- M3F框架使LMMM在现实世界中的少样本学习部署变得可行。
- 研究提供灵活的用户友好工具,便于查询特定任务采样和预处理,促进FSL数据的可访问性和复现性。
- 数据集和框架的结合为数据稀缺的科学领域提供了统一、可扩展的解决方案。
点此查看论文截图


Few-Shot Vision-Language Reasoning for Satellite Imagery via Verifiable Rewards
Authors:Aybora Koksal, A. Aydin Alatan
Recent advances in large language and vision-language models have enabled strong reasoning capabilities, yet they remain impractical for specialized domains like remote sensing, where annotated data is scarce and expensive. We present the first few-shot reinforcement learning with verifiable reward (RLVR) framework for satellite imagery that eliminates the need for caption supervision–relying solely on lightweight, rule-based binary or IoU-based rewards. Adapting the “1-shot RLVR” paradigm from language models to vision-language models, we employ policy-gradient optimization with as few as one curated example to align model outputs for satellite reasoning tasks. Comprehensive experiments across multiple remote sensing benchmarks–including classification, visual question answering, and grounding–show that even a single example yields substantial improvements over the base model. Scaling to 128 examples matches or exceeds models trained on thousands of annotated samples. While the extreme one-shot setting can induce mild, task-specific overfitting, our approach consistently demonstrates robust generalization and efficiency across diverse tasks. Further, we find that prompt design and loss weighting significantly influence training stability and final accuracy. Our method enables cost-effective and data-efficient development of domain-specialist vision-language reasoning models, offering a pragmatic recipe for data-scarce fields: start from a compact VLM, curate a handful of reward-checkable cases, and train via RLVR.
最近的大型语言和视觉语言模型的进步已经具备了强大的推理能力,但在遥感等特定领域,由于标注数据稀缺且昂贵,这些模型仍不实用。我们提出了第一个基于可验证奖励的少量样本强化学习(RLVR)框架,用于卫星图像,该框架无需字幕监督——仅依赖轻量级、基于规则的二进制或基于IoU的奖励。我们将语言模型的“1-shot RLVR”范式适应到视觉语言模型,通过仅一个精选样本进行策略梯度优化,以对齐卫星推理任务模型输出。在多个遥感基准测试上的实验——包括分类、视觉问答和接地——表明,即使一个样本也能在基准模型的基础上实现显著改进。扩展到128个样本可与在数千个标注样本上训练的模型相匹配或超越。虽然极端的一次性学习设置可能会导致特定任务的轻微过拟合,但我们的方法在不同的任务中始终展现出稳健的泛化能力和效率。此外,我们发现提示设计和损失权重对训练稳定性和最终精度产生显著影响。我们的方法能够实现成本和数据高效的领域专业视觉语言推理模型开发,为数据稀缺领域提供了实用方案:从紧凑的VLM开始,精选少量可验证奖励的案例,并通过RLVR进行训练。
论文及项目相关链接
PDF ICCV 2025 Workshop on Curated Data for Efficient Learning (CDEL). 10 pages, 3 figures, 6 tables. Our model, training code and dataset will be at https://github.com/aybora/FewShotReasoning
Summary
大规模语言和视觉语言模型的最新进展赋予了强大的推理能力,但在遥感等特定领域仍不适用,因为标注数据稀缺且昂贵。本研究提出了首个无需字幕监督的基于奖励验证的少量强化学习(RLVR)框架,用于卫星图像分析。借助政策梯度优化,只需一个精选示例即可对齐卫星推理任务模型输出。实验表明,即使在单样本情境下,该模型也有显著改善,扩展到大量示例时的性能优异。尽管单样本设置可能导致特定任务过度拟合,但该方法在多样化任务中展现出稳健的泛化能力和效率。此外,提示设计和损失权重对训练稳定性和最终精度有重大影响。此方法为数据稀缺领域提供了实用策略:从紧凑的VLM开始,精选少量可验证奖励的案例,并通过RLVR进行训练。
Key Takeaways
- 近期大型语言和视觉语言模型具备强大的推理能力,但在特定领域如遥感中实用性有限,因标注数据稀缺且成本高。
- 提出了一种基于奖励验证的少量强化学习(RLVR)框架,无需字幕监督,仅依赖轻量级、基于规则的奖励进行卫星图像分析。
- 通过政策梯度优化,仅用一个精选样本即可对齐卫星推理任务的模型输出,实现了显著改进。
- 扩展到大量示例时性能优异,甚至可与数千个标注样本训练的模型相匹敌或更佳。
- 单样本设置可能导致特定任务过度拟合,但该方法在多样化任务中展现出稳健的泛化能力和效率。
- 提示设计和损失权重对模型的训练稳定性和最终精度具有重要影响。
点此查看论文截图

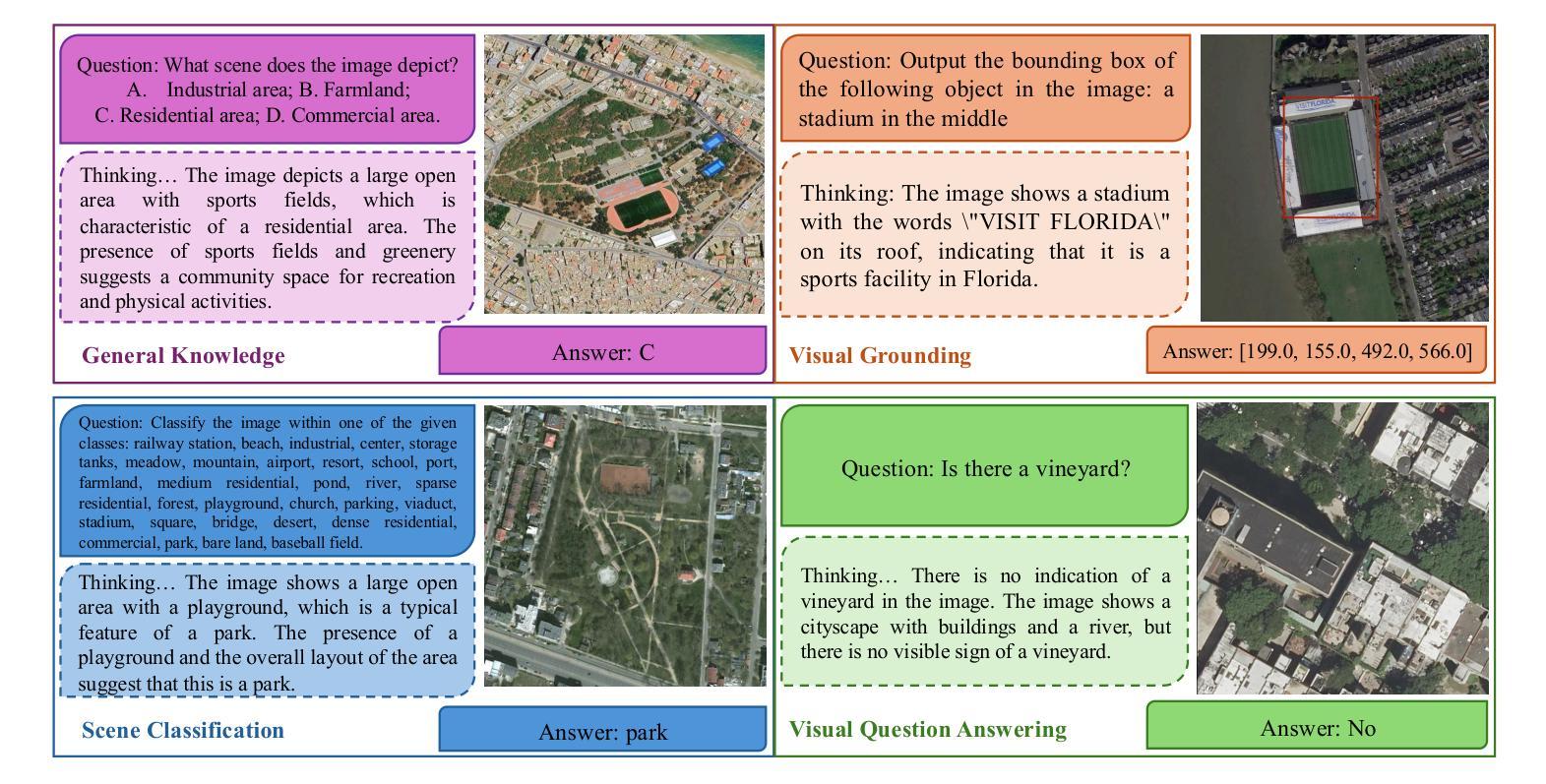
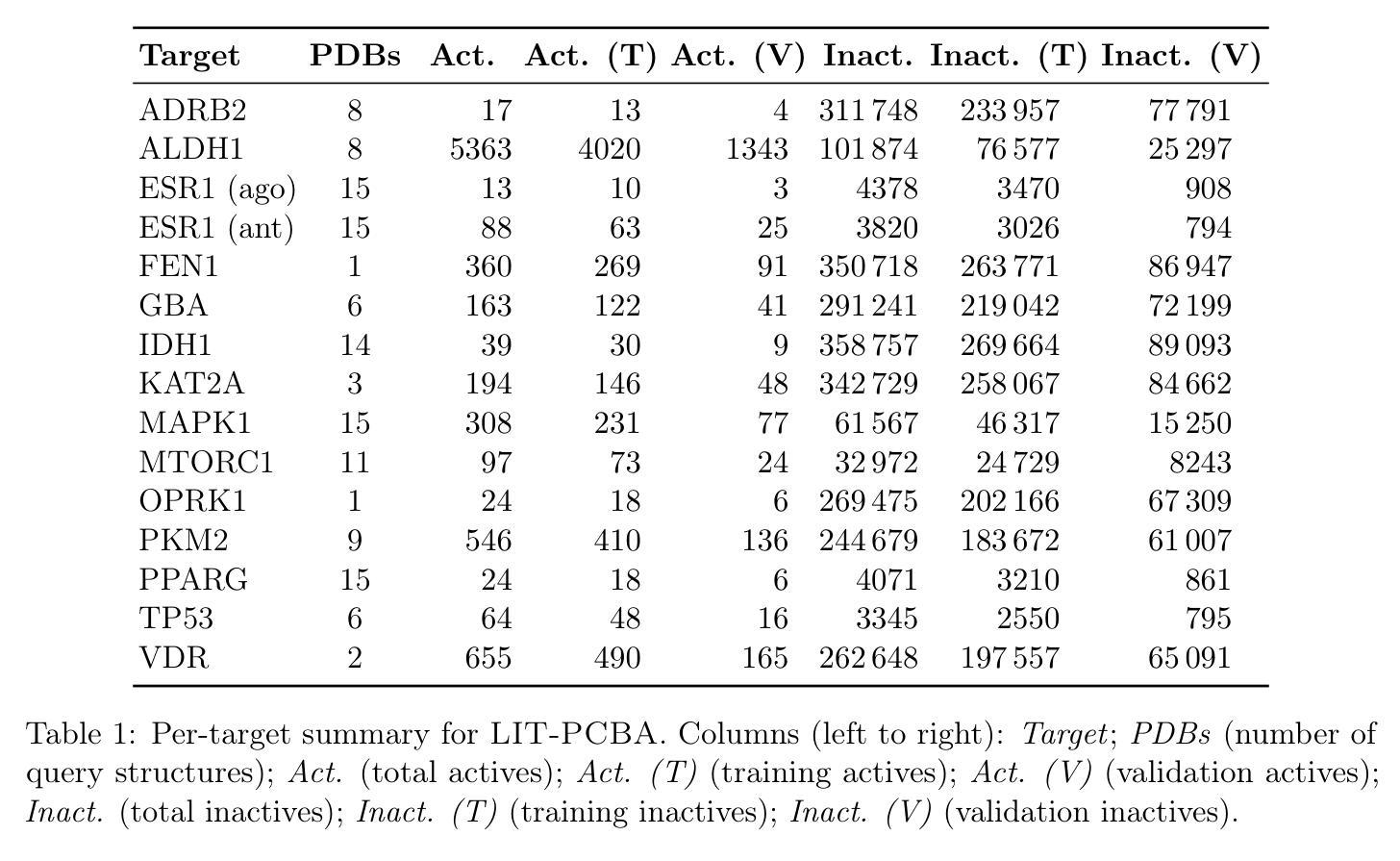
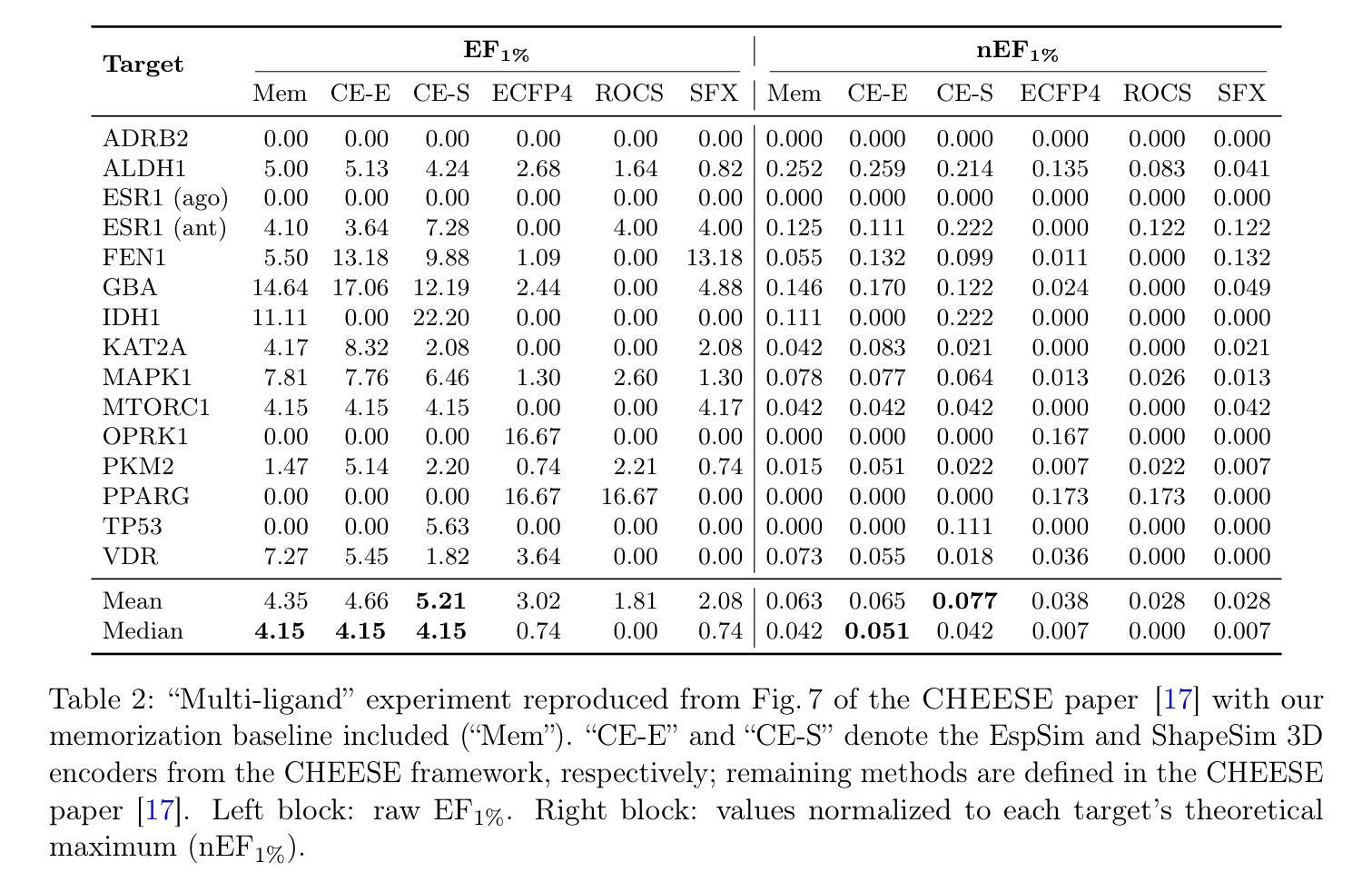
Data Leakage and Redundancy in the LIT-PCBA Benchmark
Authors:Amber Huang, Ian Scott Knight, Slava Naprienko
LIT-PCBA is widely used to benchmark virtual screening models, but our audit reveals that it is fundamentally compromised. We find extensive data leakage and molecular redundancy across its splits, including 2D-identical ligands within and across partitions, pervasive analog overlap, and low-diversity query sets. In ALDH1 alone, for instance, 323 active training – validation analog pairs occur at ECFP4 Tanimoto similarity $\geq 0.6$; across all targets, 2,491 2D-identical inactives appear in both training and validation, with very few corresponding actives. These overlaps allow models to succeed through scaffold memorization rather than generalization, inflating enrichment factors and AUROC scores. These flaws are not incidental – they are so severe that a trivial memorization-based baseline with no learnable parameters can exploit them to match or exceed the reported performance of state-of-the-art deep learning and 3D-similarity models. As a result, nearly all published results on LIT-PCBA are undermined. Even models evaluated in “zero-shot” mode are affected by analog leakage into the query set, weakening claims of generalization. In its current form, the benchmark does not measure a model’s ability to recover novel chemotypes and should not be taken as evidence of methodological progress. All code, data, and baseline implementations are available at: https://github.com/sievestack/LIT-PCBA-audit
LIT-PCBA被广泛用作虚拟筛选模型的基准测试,但我们的审计发现其存在根本上的问题。我们发现其数据分割中存在大量的数据泄露和分子冗余,包括分区内和跨分区的2D相同配体、普遍的类似物重叠以及低多样性的查询集。以ALDH1为例,就有323对活性训练-验证类似物在ECFP4的Tanimoto相似度≥0.6;在所有目标中,2,491个2D相同的不活跃分子同时出现在训练和验证中,而对应的活跃分子却非常少。这些重叠使得模型能够通过支架记忆而非泛化来成功完成任务,从而提高了富集因子和AUROC分数。这些缺陷并非偶然,而是非常严重,以至于一个基于记忆的基础线(没有任何可学习的参数)可以充分利用它们,以达到或超过最新深度学习和3D相似性模型的报告性能。因此,LIT-PCBA上几乎所有的已发布结果都受到了质疑。即使在“零射击”模式下评估的模型也受到了查询集中类似物泄露的影响,削弱了泛化的主张。目前,该基准测试并未衡量模型恢复新型化学类型的能力,并不能作为方法进步的证明。所有代码、数据和基线实施均可在:https://github.com/sievestack/LIT-PCBA-audit找到。
论文及项目相关链接
Summary:
本文揭露了虚拟筛选模型基准测试(LIT-PCBA)存在重大漏洞,测试数据集存在数据泄露、分子冗余等严重问题,无法真实反映模型性能。通过详细分析,发现这些问题导致模型通过记忆支架而非泛化机制成功,从而夸大富集因素和AUROC分数。这些问题严重影响了基准测试的公正性和准确性,几乎所有已发布的关于LIT-PCBA的结果都受到了影响。因此,当前形式的基准测试无法衡量模型恢复新型化学类型的能力,不能作为方法进步的依据。
Key Takeaways:
- LIT-PCBA被广泛用作虚拟筛选模型的基准测试,但存在重大漏洞。
- 数据泄露和分子冗余问题在LIT-PCBA的各分割中普遍存在。
- 发现大量二维相同配体在分割内部和跨分割之间的情况。
- 模拟泛化过程中的错误情况是由于模型通过记忆支架而非泛化机制成功导致的。
- 模型性能评估受到严重影响,数据泄露导致模型泛化能力减弱。
- 当前形式的基准测试无法反映模型恢复新型化学类型的能力。
点此查看论文截图

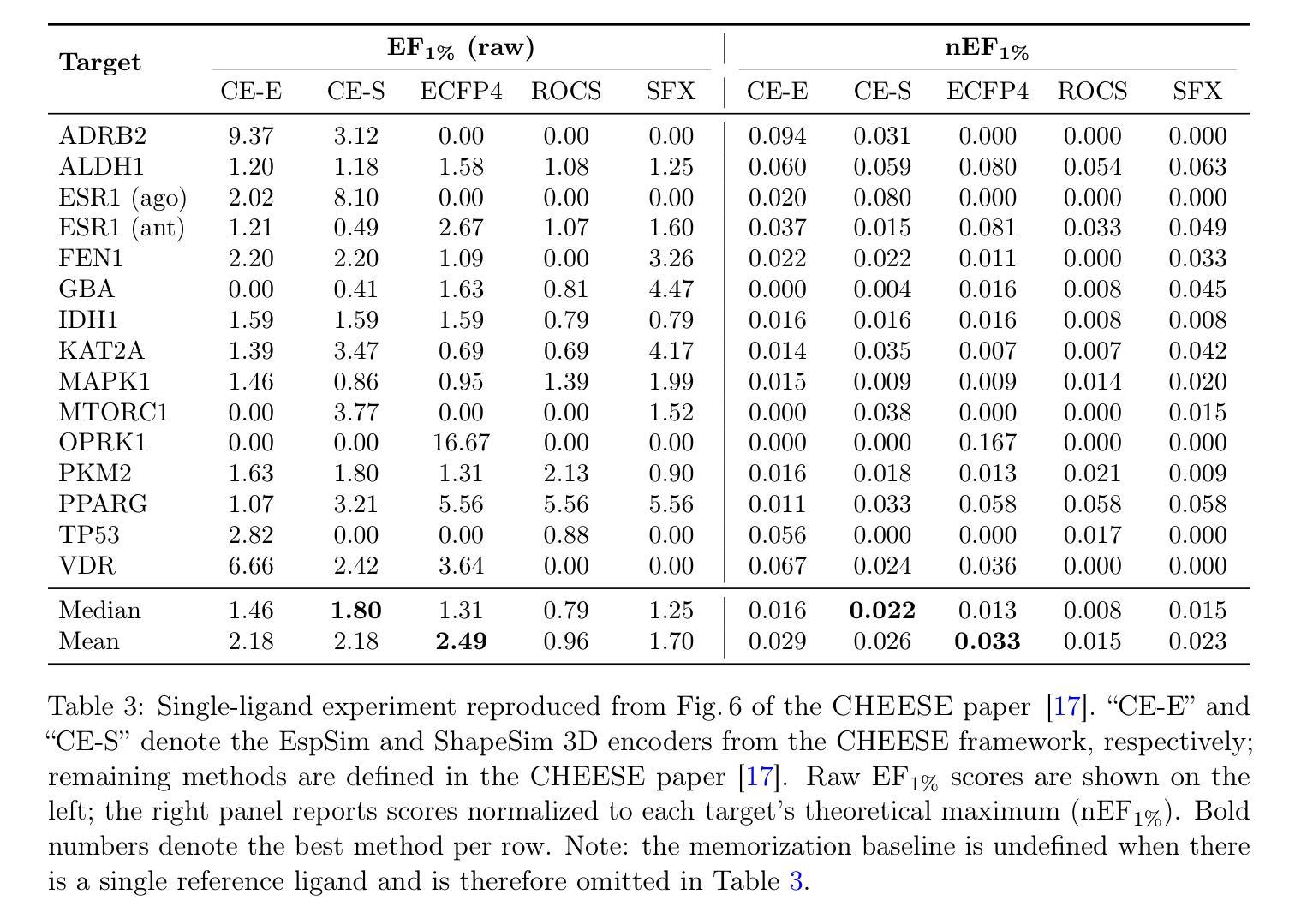
Can open source large language models be used for tumor documentation in Germany? – An evaluation on urological doctors’ notes
Authors:Stefan Lenz, Arsenij Ustjanzew, Marco Jeray, Meike Ressing, Torsten Panholzer
Tumor documentation in Germany is largely done manually, requiring reading patient records and entering data into structured databases. Large language models (LLMs) could potentially enhance this process by improving efficiency and reliability. This evaluation tests eleven different open source LLMs with sizes ranging from 1-70 billion model parameters on three basic tasks of the tumor documentation process: identifying tumor diagnoses, assigning ICD-10 codes, and extracting the date of first diagnosis. For evaluating the LLMs on these tasks, a dataset of annotated text snippets based on anonymized doctors’ notes from urology was prepared. Different prompting strategies were used to investigate the effect of the number of examples in few-shot prompting and to explore the capabilities of the LLMs in general. The models Llama 3.1 8B, Mistral 7B, and Mistral NeMo 12 B performed comparably well in the tasks. Models with less extensive training data or having fewer than 7 billion parameters showed notably lower performance, while larger models did not display performance gains. Examples from a different medical domain than urology could also improve the outcome in few-shot prompting, which demonstrates the ability of LLMs to handle tasks needed for tumor documentation. Open source LLMs show a strong potential for automating tumor documentation. Models from 7-12 billion parameters could offer an optimal balance between performance and resource efficiency. With tailored fine-tuning and well-designed prompting, these models might become important tools for clinical documentation in the future. The code for the evaluation is available from https://github.com/stefan-m-lenz/UroLlmEval. We also release the dataset as a new valuable resource that addresses the shortage of authentic and easily accessible benchmarks in German-language medical NLP.
在德国,肿瘤记录工作大部分是通过手动完成的,需要阅读患者记录并将数据输入结构化数据库。大型语言模型(LLMs)有望通过提高效率可靠性来改进这一过程。本次评估测试了规模从1亿到70亿模型参数的11个不同开源LLMs,在肿瘤记录过程的三个基本任务上:识别肿瘤诊断、分配ICD-10代码以及提取首次诊断日期。为了评估这些LLMs在这些任务上的表现,准备了一个基于泌尿学匿名医生笔记的标注文本片段数据集。使用了不同的提示策略来研究少样本提示中示例数量的影响,并探索LLMs的一般能力。模型Llama 3.1 8B、Mistral 7B和Mistral NeMo 12B在任务中表现相当好。拥有较少训练数据或参数少于7亿的模型表现明显较差,而更大的模型并没有显示出性能提升。来自泌尿学以外的医学领域的例子也能改善少样本提示的结果,这证明了LLMs处理肿瘤记录所需任务的能力。开源LLMs在自动化肿瘤记录方面显示出巨大潜力。参数在7亿到12亿之间的模型可能在性能和资源效率之间提供最佳平衡。通过有针对性的微调以及精心设计提示,这些模型有可能成为未来临床记录的重要工具。评估的代码可从https://github.com/stefan-m-lenz/UroLlmEval获取。我们还发布该数据集作为新的宝贵资源,以解决德国医学NLP领域中真实、易于访问的基准测试数据短缺的问题。
论文及项目相关链接
PDF 53 pages, 5 figures
Summary
在肿瘤记录过程中,采用大型语言模型(LLM)能够提高效率和可靠性。本研究对十一款不同规模的大型语言模型进行了评估,涉及肿瘤诊断识别、ICD-10编码分配和首次诊断日期提取等三项基本任务。结果表明,模型如Llama 3.1 8B、Mistral 7B和Mistral NeMo 12B表现优异,而规模较小或训练数据不足的模型性能较低。不同医学领域的数据在少量提示中也能提高效果,证明LLM处理肿瘤记录任务的能力。开源LLM在自动化肿瘤记录方面显示出巨大潜力,特别是参数在7-12亿之间的模型,在性能和资源效率之间达到最佳平衡。
Key Takeaways
- 大型语言模型(LLM)在肿瘤记录过程中具有应用潜力,能提高效率和可靠性。
- 研究评估了不同规模和类型的LLM在三项基本任务上的表现。
- Llama 3.1 8B、Mistral 7B和Mistral NeMo 12B等模型在评估中表现良好。
- 模型性能与训练数据和参数规模有关,较小规模的模型表现较低。
- 不同医学领域的数据对于提高少量提示的效果具有潜力。
- 参数规模在7-12亿之间的模型可能在性能和资源效率之间达到最佳平衡。
点此查看论文截图

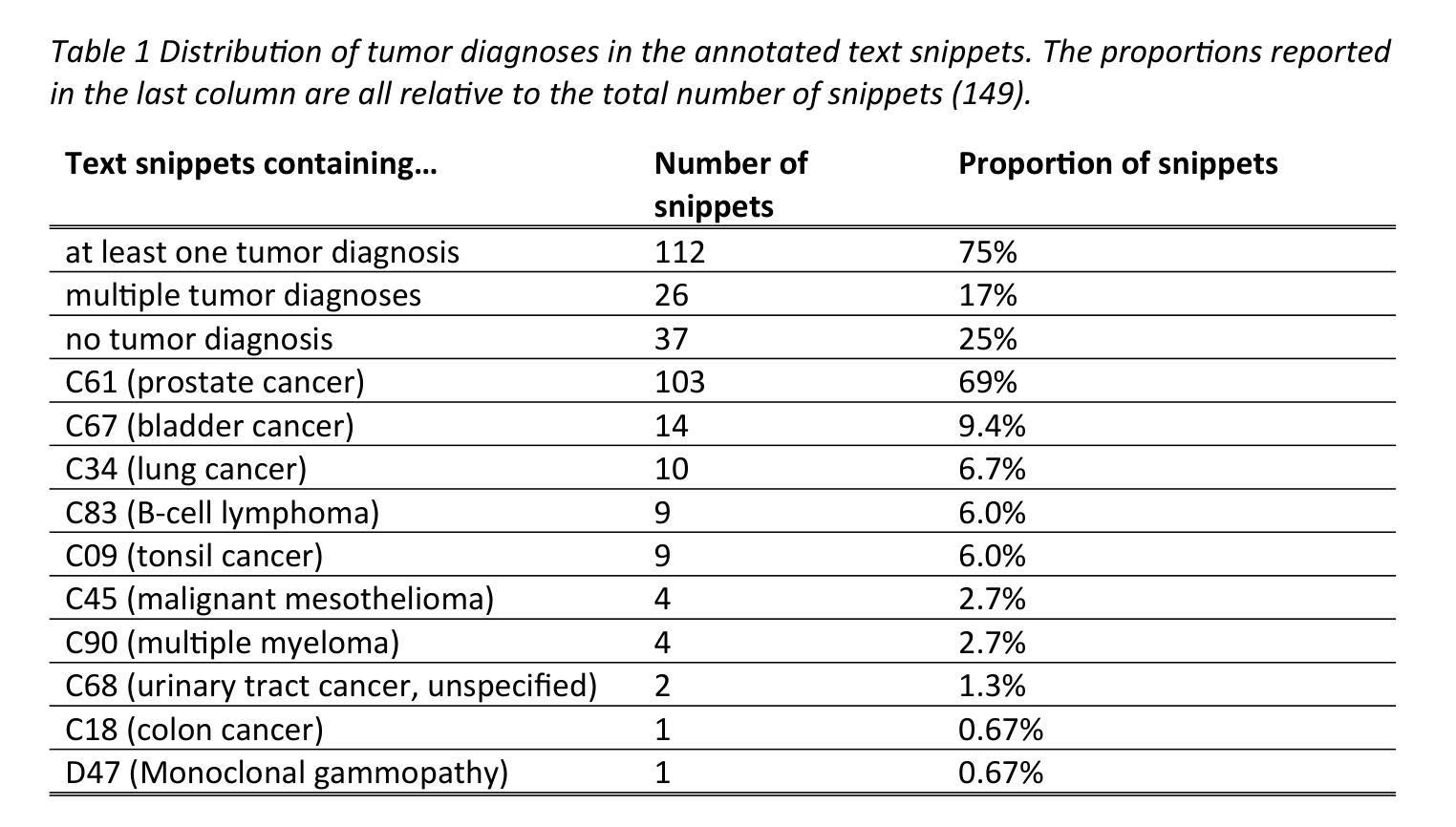
Verbalized Representation Learning for Interpretable Few-Shot Generalization
Authors:Cheng-Fu Yang, Da Yin, Wenbo Hu, Heng Ji, Nanyun Peng, Bolei Zhou, Kai-Wei Chang
Humans recognize objects after observing only a few examples, a remarkable capability enabled by their inherent language understanding of the real-world environment. Developing verbalized and interpretable representation can significantly improve model generalization in low-data settings. In this work, we propose Verbalized Representation Learning (VRL), a novel approach for automatically extracting human-interpretable features for object recognition using few-shot data. Our method uniquely captures inter-class differences and intra-class commonalities in the form of natural language by employing a Vision-Language Model (VLM) to identify key discriminative features between different classes and shared characteristics within the same class. These verbalized features are then mapped to numeric vectors through the VLM. The resulting feature vectors can be further utilized to train and infer with downstream classifiers. Experimental results show that, at the same model scale, VRL achieves a 24% absolute improvement over prior state-of-the-art methods while using 95% less data and a smaller mode. Furthermore, compared to human-labeled attributes, the features learned by VRL exhibit a 20% absolute gain when used for downstream classification tasks. Code is available at: https://github.com/joeyy5588/VRL/tree/main.
人类只需要观察几个例子就能识别物体,这一令人印象深刻的能力得益于他们对真实世界环境固有的理解。在数据稀缺的情况下,开发语言化的可解释表示可以显著改善模型的泛化能力。在这项工作中,我们提出了“语言化表示学习”(VRL)这一新方法,它能够利用少量数据自动提取用于对象识别的可解释特征。我们的方法以自然语言的形式独特地捕捉类间差异和类内共性,通过采用视觉语言模型(VLM)来识别不同类之间的关键判别特征以及同一类内的共享特征。这些语言化的特征然后通过VLM映射到数字向量上。这些特征向量可进一步用于训练和推断下游分类器。实验结果表明,在相同模型规模下,VRL相较于现有最前沿技术实现了绝对改善率为百分之二十四,且在减少百分之九十五的数据和较小模型的情况下仍有效。此外,相较于人工标注的属性,使用VRL学习的特征进行下游分类任务时表现出了绝对增益百分之二十的优势。相关代码可通过以下链接获取:<https://github.com/joeyy558 访问我们的主目录以获取VRL>。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文提出了一种名为Verbalized Representation Learning(VRL)的新方法,该方法能够利用少量数据自动提取人类可解释的特征进行对象识别。通过采用Vision-Language Model(VLM),VRL能够捕捉不同类别之间的差异和同一类别内的共性,将这些特征转化为自然语言,并映射为数字向量。实验结果显示,在相同的模型规模下,VRL相较于最新技术取得了24%的绝对改进,且使用数据更少、模型更小。此外,相较于人工标注的属性,使用VRL学习的特征进行下游分类任务时取得了20%的绝对提升。
Key Takeaways
- 人类只需观察少数例子就能识别物体,这一能力得益于对真实世界环境内在语言的理解。
- 开发可语言化的表示学习(VRL)方法能显著提高模型在数据稀缺环境下的泛化能力。
- VRL是一种新颖的方法,能够自动提取人类可解释的特征进行对象识别,利用少量数据。
- VRL采用Vision-Language Model(VLM)来识别不同类别之间的关键判别特征和同一类别内的共享特性,并将其转化为自然语言。
- VRL将语言化的特征映射为数字向量,这些向量可用于训练和推断下游分类器。
- 实验结果表明,在相同的模型规模下,VRL相较于最新技术有显著的性能提升,且使用更少的数据和更小的模型。
- 与人工标注的属性相比,使用VRL学习的特征进行下游分类任务取得了更好的性能。
点此查看论文截图

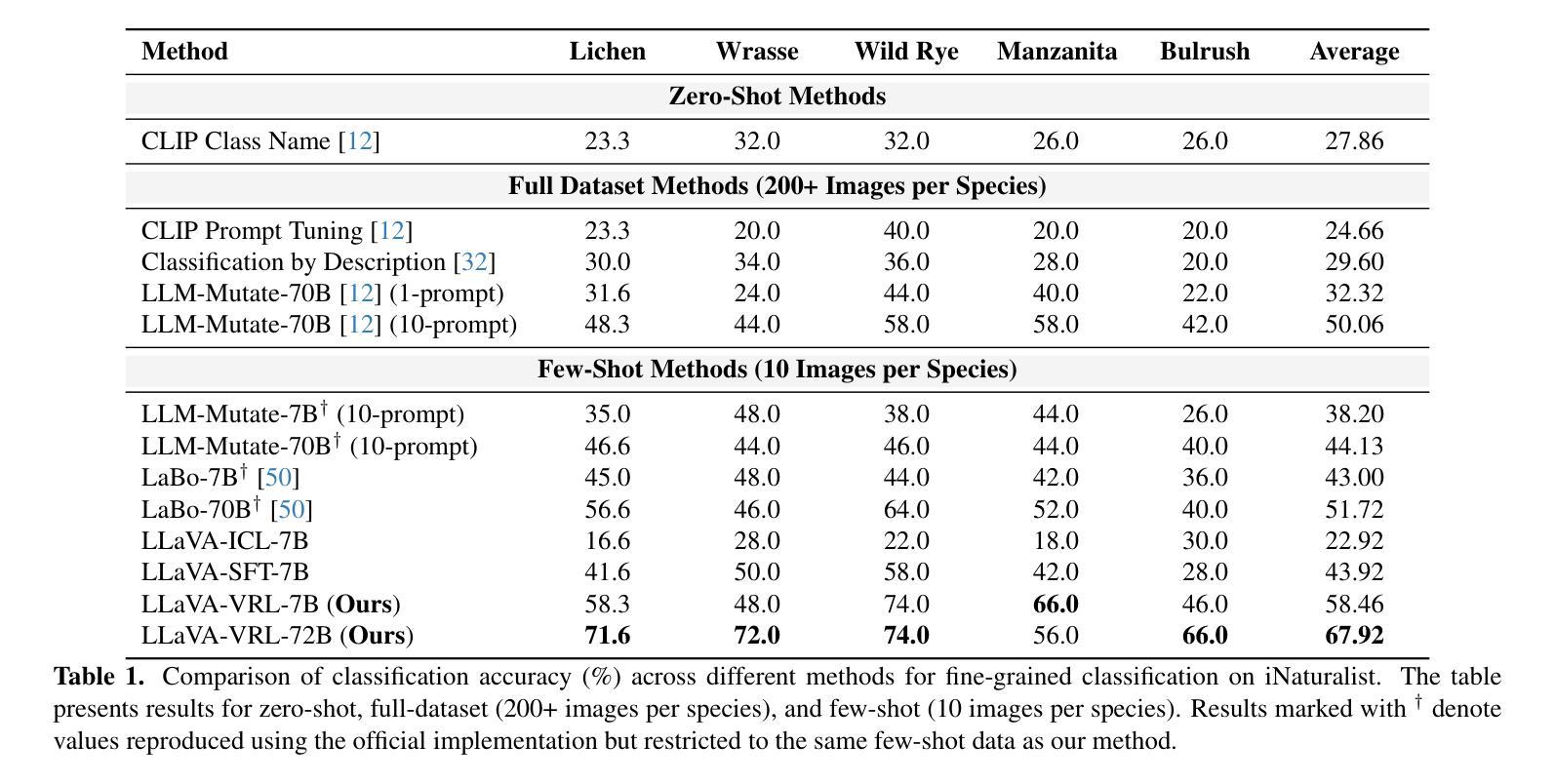
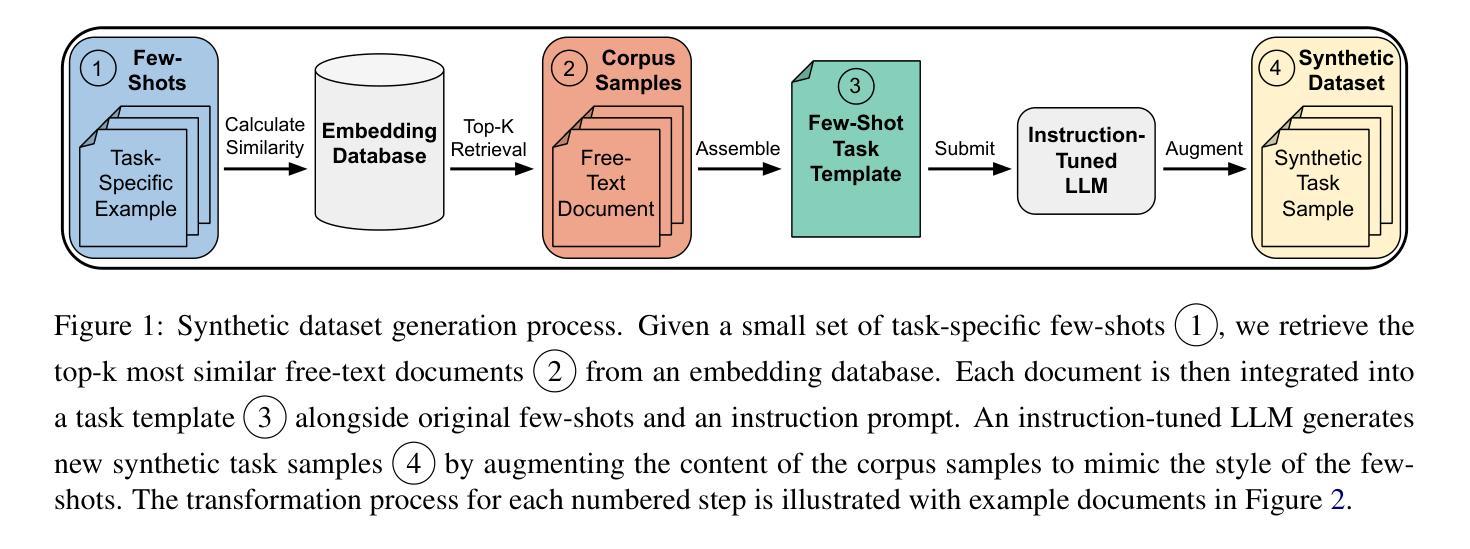
CRAFT Your Dataset: Task-Specific Synthetic Dataset Generation Through Corpus Retrieval and Augmentation
Authors:Ingo Ziegler, Abdullatif Köksal, Desmond Elliott, Hinrich Schütze
Building high-quality datasets for specialized tasks is a time-consuming and resource-intensive process that often requires specialized domain knowledge. We propose Corpus Retrieval and Augmentation for Fine-Tuning (CRAFT), a method for generating synthetic datasets, given a small number of user-written few-shots that demonstrate the task to be performed. Given these examples, CRAFT uses large-scale public web-crawled corpora and similarity-based document retrieval to find other relevant human-written documents. Lastly, instruction-tuned large language models (LLMs) augment the retrieved documents into custom-formatted task samples, which then can be used for fine-tuning. We demonstrate that CRAFT can efficiently generate large-scale task-specific training datasets for four diverse tasks: biology, medicine, and commonsense question-answering (QA), as well as summarization. Our experiments show that CRAFT-based models outperform or match general LLMs on QA tasks, while exceeding models trained on human-curated summarization data by 46 preference points. CRAFT outperforms other synthetic dataset generation methods such as Self- and Evol-Instruct, and remains robust even when the quality of the initial few-shots varies.
构建针对特定任务的高质量数据集是一个既耗时又耗资源的过程,通常需要特定的领域知识。我们提出了基于微调的数据集检索与扩充方法(CRAFT),这是一种生成合成数据集的方法,只需少量用户编写的简短指令即可展示要执行的任务。基于这些示例,CRAFT利用大规模公共网络爬虫语料库和基于相似度的文档检索来找到其他相关的人写文档。最后,通过指令调整的大型语言模型(LLM)将检索到的文档扩充为自定义格式的任务样本,然后可用于微调。我们证明,CRAFT可以有效地为四个不同的任务生成大规模的任务特定训练数据集,包括生物学、医学、常识问答(QA)以及摘要。我们的实验表明,基于CRAFT的模型在问答任务上的表现优于或等同于一般的大型语言模型,并且在摘要方面超过了经过人工编纂的摘要数据训练的模型,高出46个偏好点。CRAFT在其他合成数据集生成方法(如Self-和Evol-Instruct)中表现优异,并且在初始简短指令的质量发生变化时仍然保持稳健。
论文及项目相关链接
PDF Accepted at TACL; Pre-MIT Press publication version. Code and dataset available at: https://github.com/ziegler-ingo/CRAFT
Summary
该文本提出了一种基于语料库检索和扩充的方法(CRAFT),用于生成特定任务的合成数据集。此方法只需少量用户编写的样本示范任务,就能从大规模公共网络爬取的语料库中检索相关文档,并使用指令微调的大型语言模型(LLM)进行扩充,形成定制的任务样本,可用于精细调整。实验表明,CRAFT在多种任务上表现优异,包括生物学、医学、常识问答和摘要等。特别是在问答任务上,基于CRAFT的模型性能优于或匹配通用LLM;在摘要任务上,其表现超过经过人工整理的数据训练的模型。相较于其他合成数据集生成方法,CRAFT具有稳健性,初始样本质量波动也不会影响其性能。
Key Takeaways
- CRAFT是一种基于语料库检索和扩充的合成数据集生成方法。
- CRAFT使用少量用户编写的样本示范任务来生成大规模任务特定训练数据集。
- CRAFT能够从大规模公共网络爬取的语料库中检索相关文档。
- CRAFT利用指令微调的大型语言模型(LLM)扩充检索到的文档,形成定制的任务样本。
- CRAFT在生物学、医学、常识问答和摘要等多种任务上表现优异。
- 在问答任务上,基于CRAFT的模型性能优于或匹配通用LLM。
点此查看论文截图