⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
FLUX-Makeup: High-Fidelity, Identity-Consistent, and Robust Makeup Transfer via Diffusion Transformer
Authors:Jian Zhu, Shanyuan Liu, Liuzhuozheng Li, Yue Gong, He Wang, Bo Cheng, Yuhang Ma, Liebucha Wu, Xiaoyu Wu, Dawei Leng, Yuhui Yin, Yang Xu
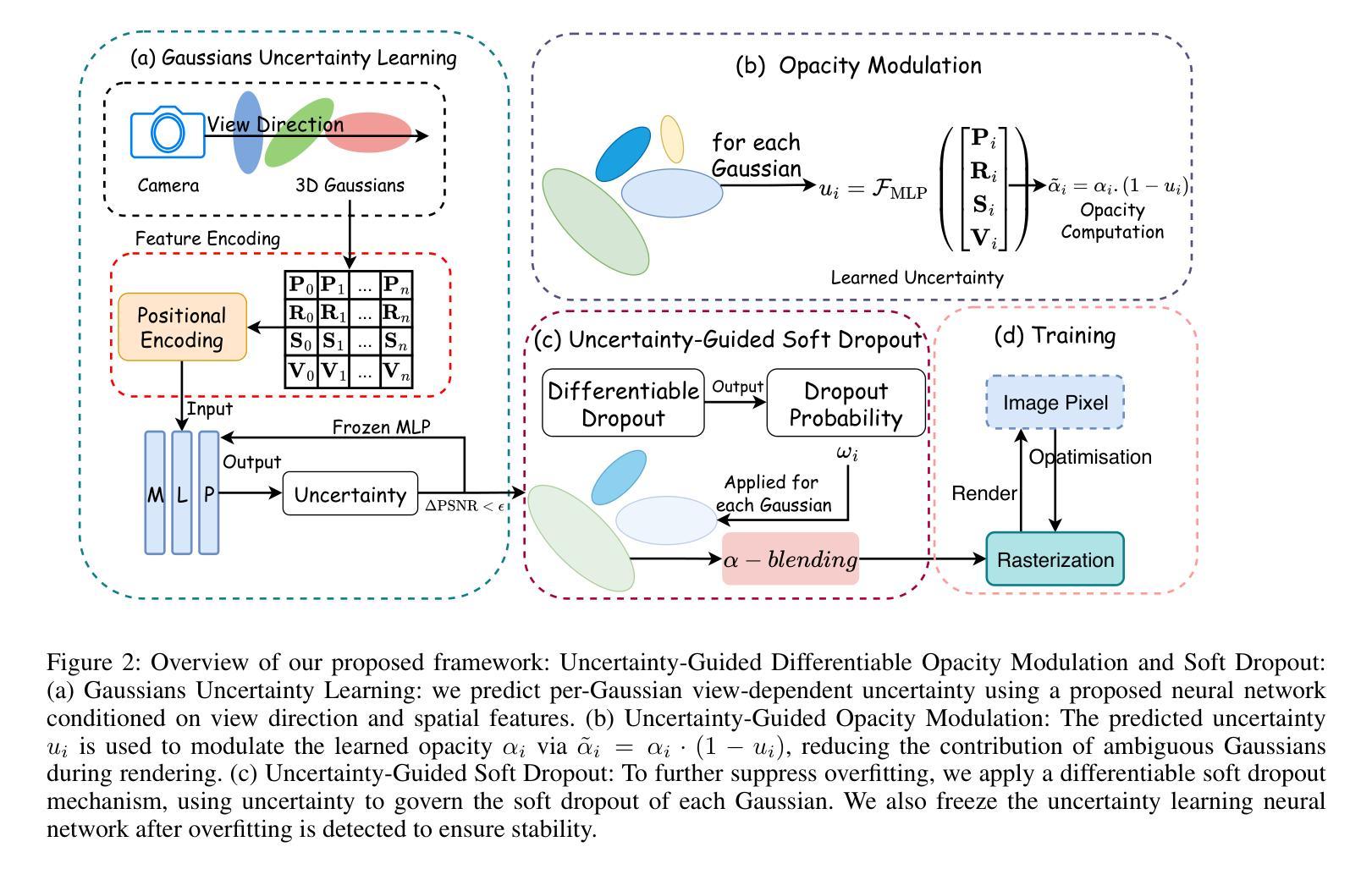
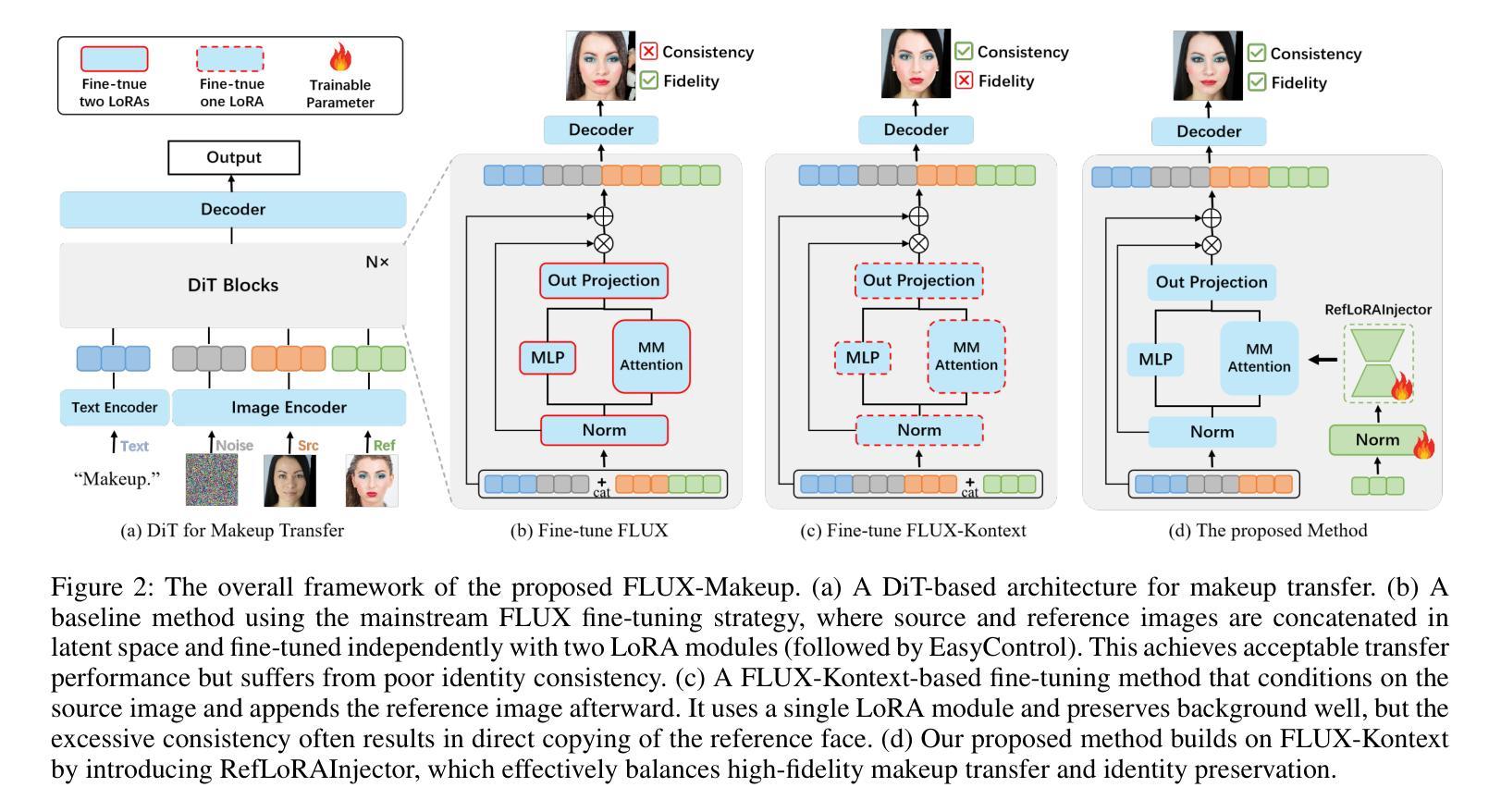
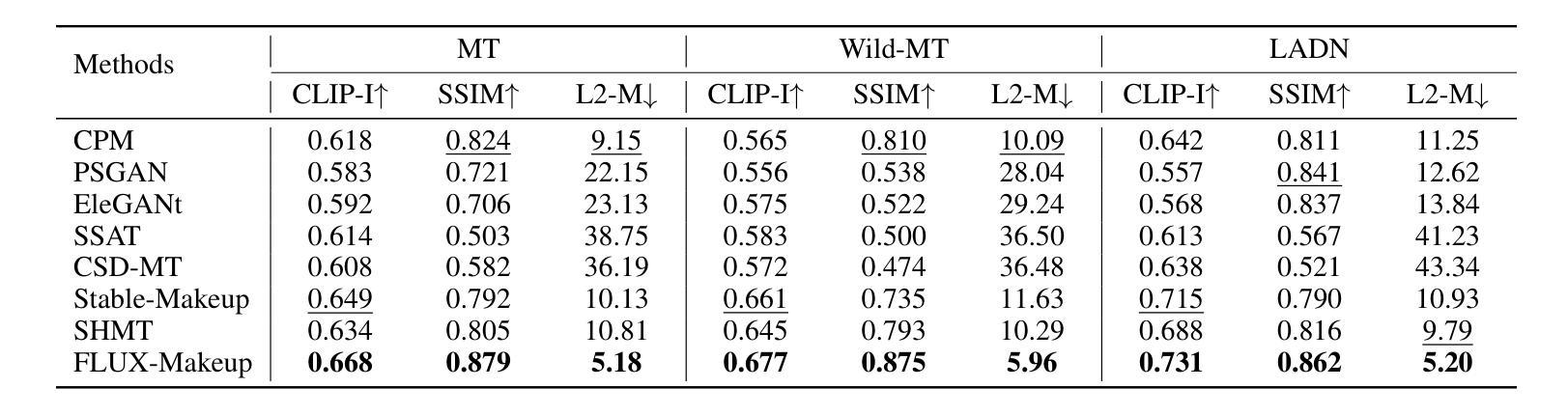
Makeup transfer aims to apply the makeup style from a reference face to a target face and has been increasingly adopted in practical applications. Existing GAN-based approaches typically rely on carefully designed loss functions to balance transfer quality and facial identity consistency, while diffusion-based methods often depend on additional face-control modules or algorithms to preserve identity. However, these auxiliary components tend to introduce extra errors, leading to suboptimal transfer results. To overcome these limitations, we propose FLUX-Makeup, a high-fidelity, identity-consistent, and robust makeup transfer framework that eliminates the need for any auxiliary face-control components. Instead, our method directly leverages source-reference image pairs to achieve superior transfer performance. Specifically, we build our framework upon FLUX-Kontext, using the source image as its native conditional input. Furthermore, we introduce RefLoRAInjector, a lightweight makeup feature injector that decouples the reference pathway from the backbone, enabling efficient and comprehensive extraction of makeup-related information. In parallel, we design a robust and scalable data generation pipeline to provide more accurate supervision during training. The paired makeup datasets produced by this pipeline significantly surpass the quality of all existing datasets. Extensive experiments demonstrate that FLUX-Makeup achieves state-of-the-art performance, exhibiting strong robustness across diverse scenarios.
化妆迁移旨在将参考面部的妆容风格应用到目标面部,并在实际应用中得到了越来越多的采用。现有的基于生成对抗网络(GAN)的方法通常依赖于精心设计的损失函数来平衡迁移质量和面部身份一致性,而基于扩散的方法则常常依赖于额外的面部控制模块或算法来保持身份。然而,这些辅助组件往往引入额外的错误,导致迁移结果不理想。为了克服这些限制,我们提出了FLUX-Makeup,这是一个高保真、身份一致、稳健的化妆迁移框架,无需任何辅助面部控制组件。相反,我们的方法直接利用源-参考图像对来实现优越的迁移性能。具体来说,我们的框架建立在FLUX-Kontext之上,将源图像作为其本地条件输入。此外,我们引入了RefLoRAInjector,这是一个轻量级的化妆特征注入器,它将参考路径与主干网络分离,从而实现化妆相关信息的有效和全面提取。同时,我们设计了一个稳健且可扩展的数据生成管道,以在训练过程中提供更准确的监督。由此管道产生的配套化妆数据集的质量显著超过了所有现有数据集的质量。大量实验表明,FLUX-Makeup达到了最先进的性能,在多种场景中表现出强大的稳健性。
论文及项目相关链接
Summary
本文提出了一种基于GAN的高保真、身份一致、鲁棒的化妆转移框架——FLUX-Makeup。该框架无需任何辅助面部控制组件,直接使用源参考图像对实现优越的转移性能。通过引入RefLoRAInjector,实现了参考路径与主干的解耦,提高了化妆相关信息的提取效率。同时设计了一个强大的数据生成管道,为训练提供更准确的监督。
Key Takeaways
- FLUX-Makeup是一个基于GAN的化妆转移框架,实现了高保真、身份一致和鲁棒的化妆转移。
- 该框架消除了对辅助面部控制组件的需求,直接使用源参考图像对进行化妆转移,简化了流程。
- 引入了RefLoRAInjector,实现了参考路径与主干的解耦,使得化妆相关信息的提取更加高效和全面。
- 设计了一个强大的数据生成管道,提高了配对化妆数据集的质量,为训练提供更准确的监督。
- FLUX-Makeup框架建立在FLUX-Kontext之上,使用源图像作为其本地条件输入。
- 该框架在多种场景下都表现出了强大的鲁棒性,实现了最先进的性能。
点此查看论文截图



Single-Step Reconstruction-Free Anomaly Detection and Segmentation via Diffusion Models
Authors:Mehrdad Moradi, Marco Grasso, Bianca Maria Colosimo, Kamran Paynabar
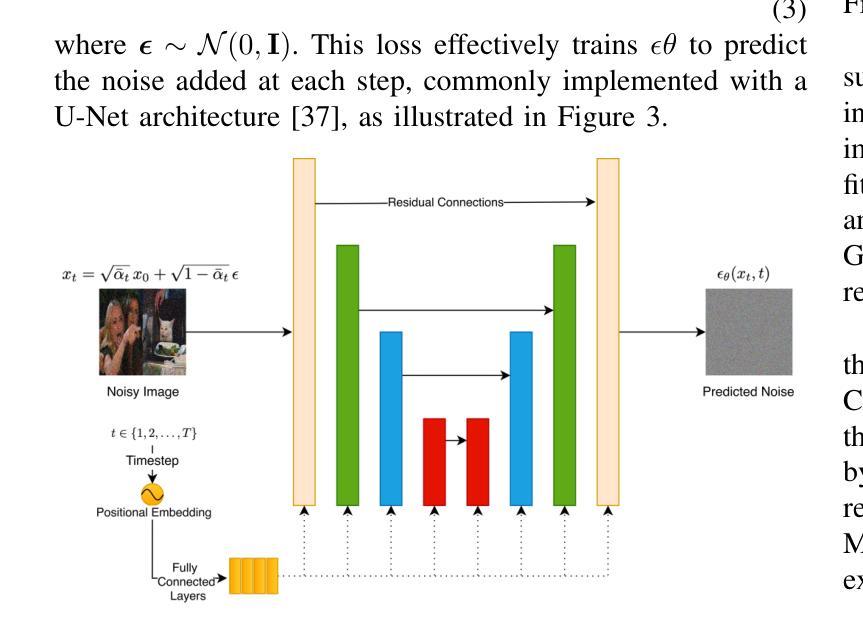
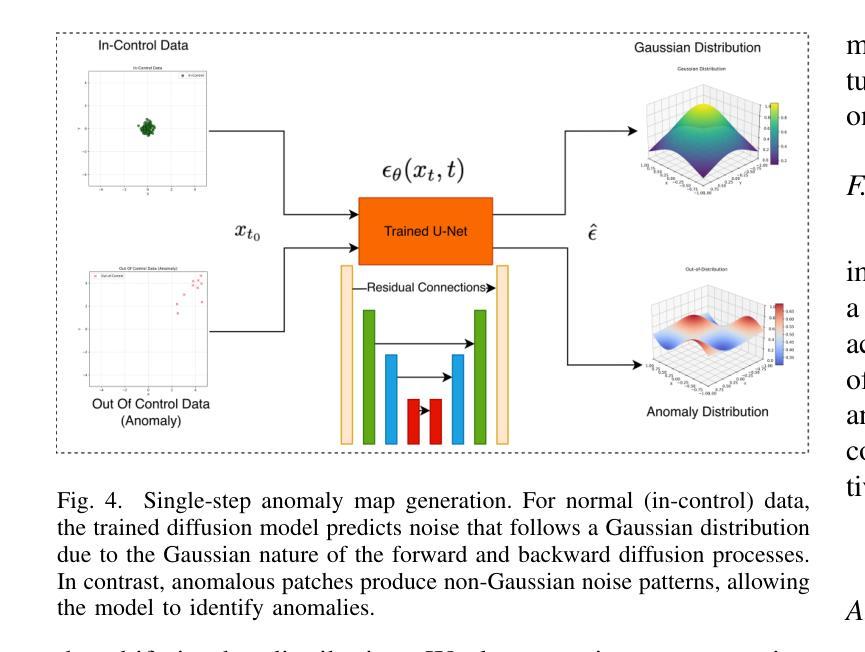
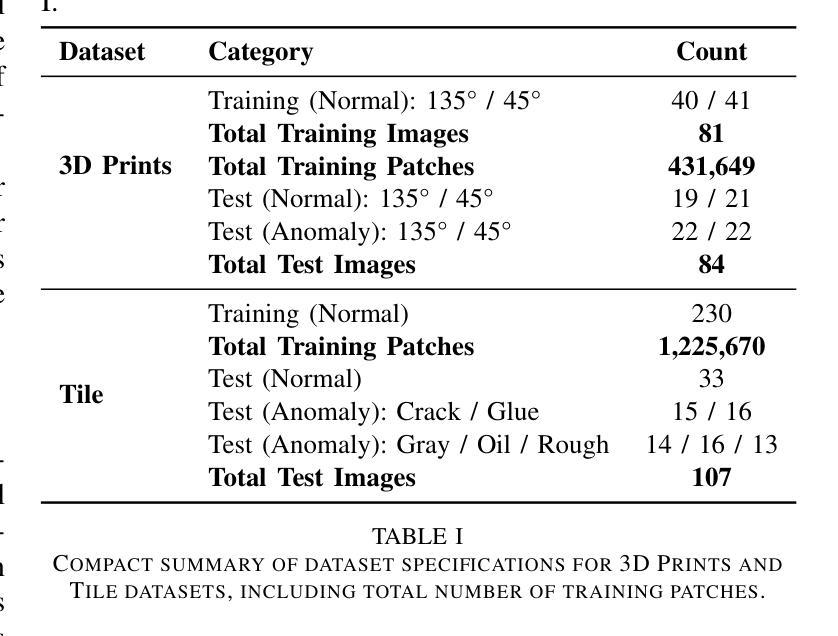
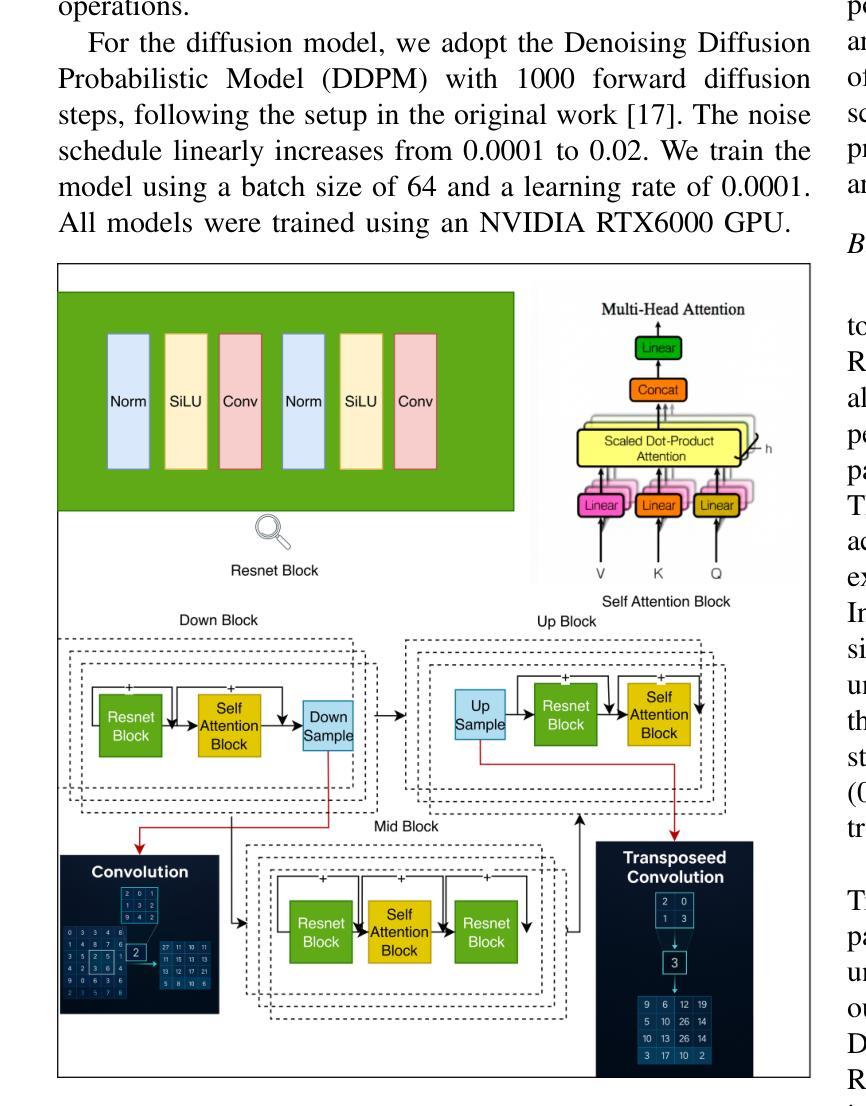
Generative models have demonstrated significant success in anomaly detection and segmentation over the past decade. Recently, diffusion models have emerged as a powerful alternative, outperforming previous approaches such as GANs and VAEs. In typical diffusion-based anomaly detection, a model is trained on normal data, and during inference, anomalous images are perturbed to a predefined intermediate step in the forward diffusion process. The corresponding normal image is then reconstructed through iterative reverse sampling. However, reconstruction-based approaches present three major challenges: (1) the reconstruction process is computationally expensive due to multiple sampling steps, making real-time applications impractical; (2) for complex or subtle patterns, the reconstructed image may correspond to a different normal pattern rather than the original input; and (3) Choosing an appropriate intermediate noise level is challenging because it is application-dependent and often assumes prior knowledge of anomalies, an assumption that does not hold in unsupervised settings. We introduce Reconstruction-free Anomaly Detection with Attention-based diffusion models in Real-time (RADAR), which overcomes the limitations of reconstruction-based anomaly detection. Unlike current SOTA methods that reconstruct the input image, RADAR directly produces anomaly maps from the diffusion model, improving both detection accuracy and computational efficiency. We evaluate RADAR on real-world 3D-printed material and the MVTec-AD dataset. Our approach surpasses state-of-the-art diffusion-based and statistical machine learning models across all key metrics, including accuracy, precision, recall, and F1 score. Specifically, RADAR improves F1 score by 7% on MVTec-AD and 13% on the 3D-printed material dataset compared to the next best model. Code available at: https://github.com/mehrdadmoradi124/RADAR
生成模型在过去十年中在异常检测和分割方面取得了显著的成功。最近,扩散模型作为一种强大的替代方法出现,超越了先前的GAN和VAE等方法。在典型的基于扩散的异常检测中,模型是在正常数据上进行训练的,然后在推理过程中,异常图像被扰动到前向扩散过程中的一个预定的中间步骤。然后通过迭代反向采样重建相应的正常图像。然而,基于重建的方法存在三大挑战:(1)重建过程由于多次采样步骤而计算量大,使得实时应用不切实际;(2)对于复杂或细微的模式,重建的图像可能对应于不同的正常模式,而不是原始输入;(3)选择合适的中间噪声水平是一个挑战,因为它依赖于应用程序,并且通常假设对异常的先验知识,这在无监督设置中并不成立。我们引入了基于注意力扩散模型的实时无重建异常检测(RADAR),克服了基于重建的异常检测的局限性。与当前最先进的方法不同,RADAR直接从扩散模型中生成异常图,提高了检测准确性和计算效率。我们在现实世界的3D打印材料和MVTec-AD数据集上评估了RADAR。我们的方法在包括准确性、精确度、召回率和F1分数等关键指标上超越了最先进的扩散模型和统计机器学习模型。具体来说,RADAR在MVTec-AD数据集上的F1分数提高了7%,在3D打印材料数据集上提高了13%。代码可在:https://github.com/mehrdadmoradi124/RADAR获取。
论文及项目相关链接
PDF 9 pages, 8 figures, 2 tables. Submitted to an IEEE conference
Summary
扩散模型在异常检测和分割方面表现出显著的成功,但重建方法存在计算成本高、可能对应到不同正常模式以及选择适当噪声水平困难等问题。我们引入无需重建的异常检测雷达系统(RADAR),利用基于注意力的扩散模型直接生成异常地图,提高检测精度和计算效率,并在真实世界的3D打印材料和MVTec-AD数据集上超越现有方法。
Key Takeaways
- 扩散模型在异常检测中展现出强大的性能,成为近期研究热点。
- 传统扩散模型在异常检测中采用重建方法,存在计算成本高、对应正常模式不同和噪声水平选择困难等问题。
- 提出的RADAR系统无需重建,直接利用扩散模型生成异常地图,提高了检测效率和精度。
- RADAR系统在真实世界数据集上进行评估,显著超越了现有方法和统计机器学习模型。
- RADAR系统在MVTec-AD数据集上F1得分提高了7%,在3D打印材料数据集上提高了13%。
- 该系统代码已公开可用,为研究者提供了进一步探索的基础。
点此查看论文截图