⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
MM2CT: MR-to-CT translation for multi-modal image fusion with mamba
Authors:Chaohui Gong, Zhiying Wu, Zisheng Huang, Gaofeng Meng, Zhen Lei, Hongbin Liu
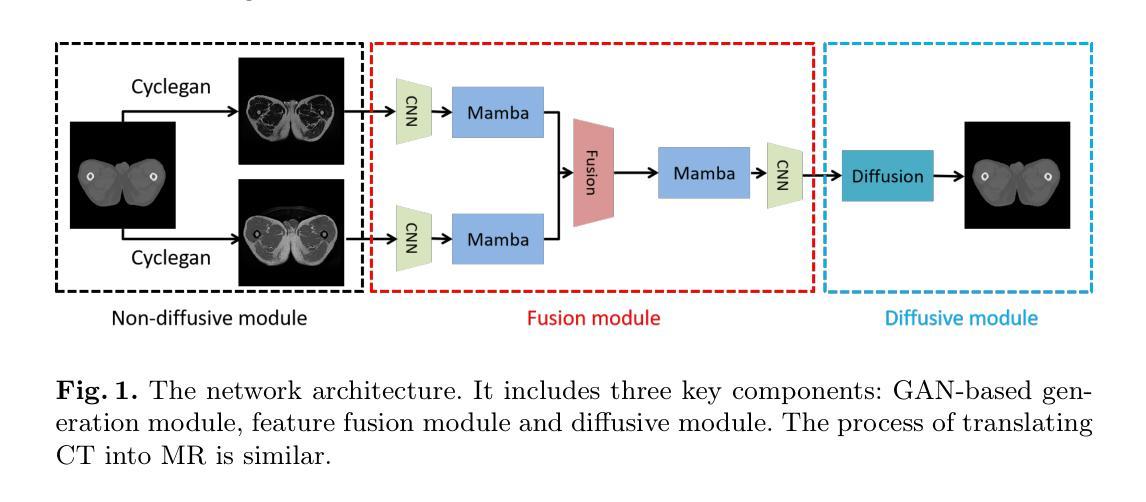
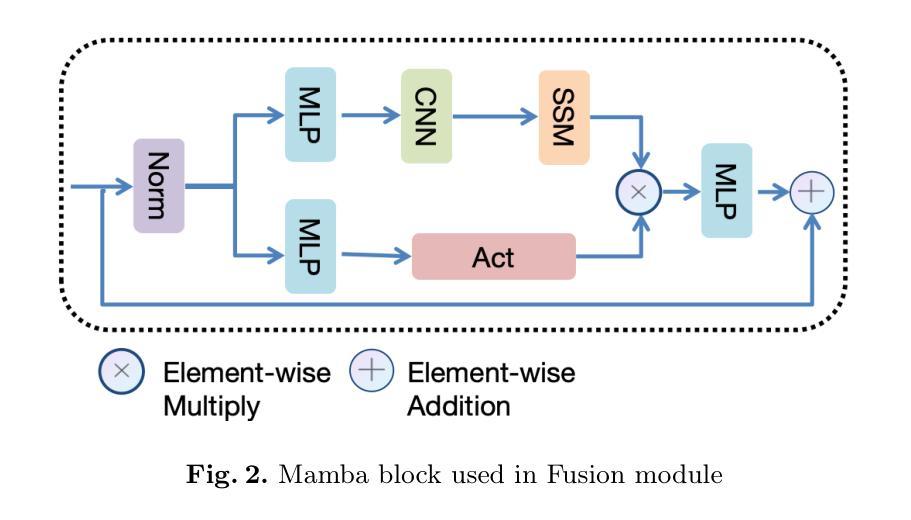
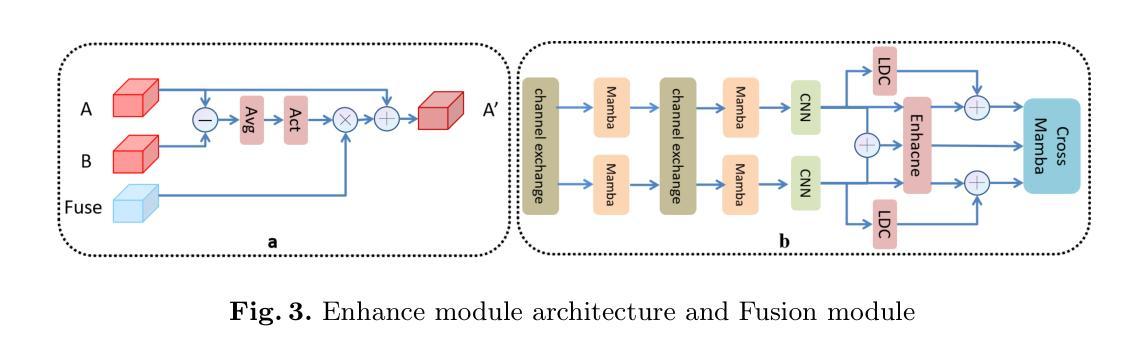
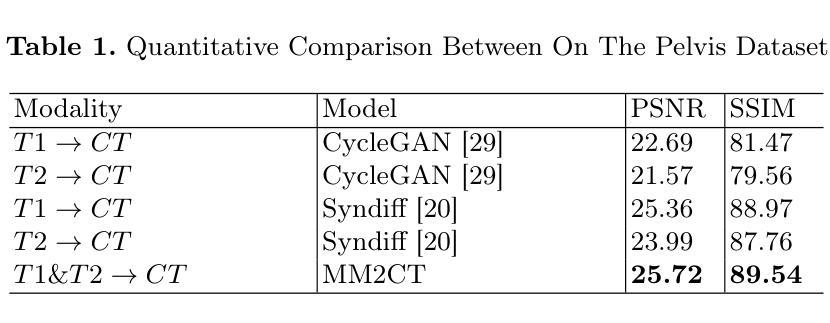
Magnetic resonance (MR)-to-computed tomography (CT) translation offers significant advantages, including the elimination of radiation exposure associated with CT scans and the mitigation of imaging artifacts caused by patient motion. The existing approaches are based on single-modality MR-to-CT translation, with limited research exploring multimodal fusion. To address this limitation, we introduce Multi-modal MR to CT (MM2CT) translation method by leveraging multimodal T1- and T2-weighted MRI data, an innovative Mamba-based framework for multi-modal medical image synthesis. Mamba effectively overcomes the limited local receptive field in CNNs and the high computational complexity issues in Transformers. MM2CT leverages this advantage to maintain long-range dependencies modeling capabilities while achieving multi-modal MR feature integration. Additionally, we incorporate a dynamic local convolution module and a dynamic enhancement module to improve MRI-to-CT synthesis. The experiments on a public pelvis dataset demonstrate that MM2CT achieves state-of-the-art performance in terms of Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR). Our code is publicly available at https://github.com/Gots-ch/MM2CT.
磁共振(MR)到计算机断层扫描(CT)的翻译具有显著优势,包括消除与CT扫描相关的辐射暴露以及减轻由患者运动引起的成像伪影。现有方法基于单模态MR-to-CT翻译,对多模态融合的研究有限。为了解决这一局限性,我们引入了多模态MR到CT(MM2CT)翻译方法,该方法利用T1和T2加权MRI数据的多模态信息,以及基于Mamba的多模态医学图像合成创新框架。Mamba有效地克服了卷积神经网络中局部感受野的局限性和变压器中的高计算复杂性。MM2CT利用这一优势,在保持长期依赖建模能力的同时,实现了多模态MR特征融合。此外,我们结合了动态局部卷积模块和动态增强模块,以提高MRI到CT的合成效果。在公共骨盆数据集上的实验表明,MM2CT在结构相似性指数度量(SSIM)和峰值信噪比(PSNR)方面达到了最先进的性能。我们的代码公开在https://github.com/Gots-ch/MM2CT。
论文及项目相关链接
Summary:磁共振(MR)到计算机断层扫描(CT)转换具有消除CT扫描相关的辐射暴露和减轻患者运动引起的成像伪影等显著优势。现有方法主要基于单模态MR-to-CT转换,对多模态融合的研究有限。我们引入多模态MR到CT(MM2CT)转换方法,利用T1和T2加权MRI数据的多模态信息,采用创新的Mamba框架进行多模态医学图像合成。Mamba有效克服了CNN的局部感受野限制和Transformer的高计算复杂性。MM2CT利用这一优势,在保持长距离依赖建模能力的同时,实现了多模态MR特征集成。此外,我们引入了动态局部卷积模块和动态增强模块,以提高MRI到CT的合成效果。在公共骨盆数据集上的实验表明,MM2CT在结构相似性指数度量(SSIM)和峰值信噪比(PSNR)方面达到了最新水平。
Key Takeaways:
- MR到CT转换能消除辐射暴露和减轻成像伪影。
- 现有方法主要基于单模态转换,缺乏多模态融合研究。
- 引入MM2CT方法,利用多模态MRI数据,采用Mamba框架进行多模态医学图像合成。
- Mamba克服了CNN的局部感受野限制和Transformer的高计算复杂性。
- MM2CT集成了多模态MR特征,并引入了动态局部卷积模块和动态增强模块提高合成效果。
- 在公共骨盆数据集上,MM2CT达到了最新性能水平,体现在SSIM和PSNR指标上。
- 代码已公开可用。
点此查看论文截图

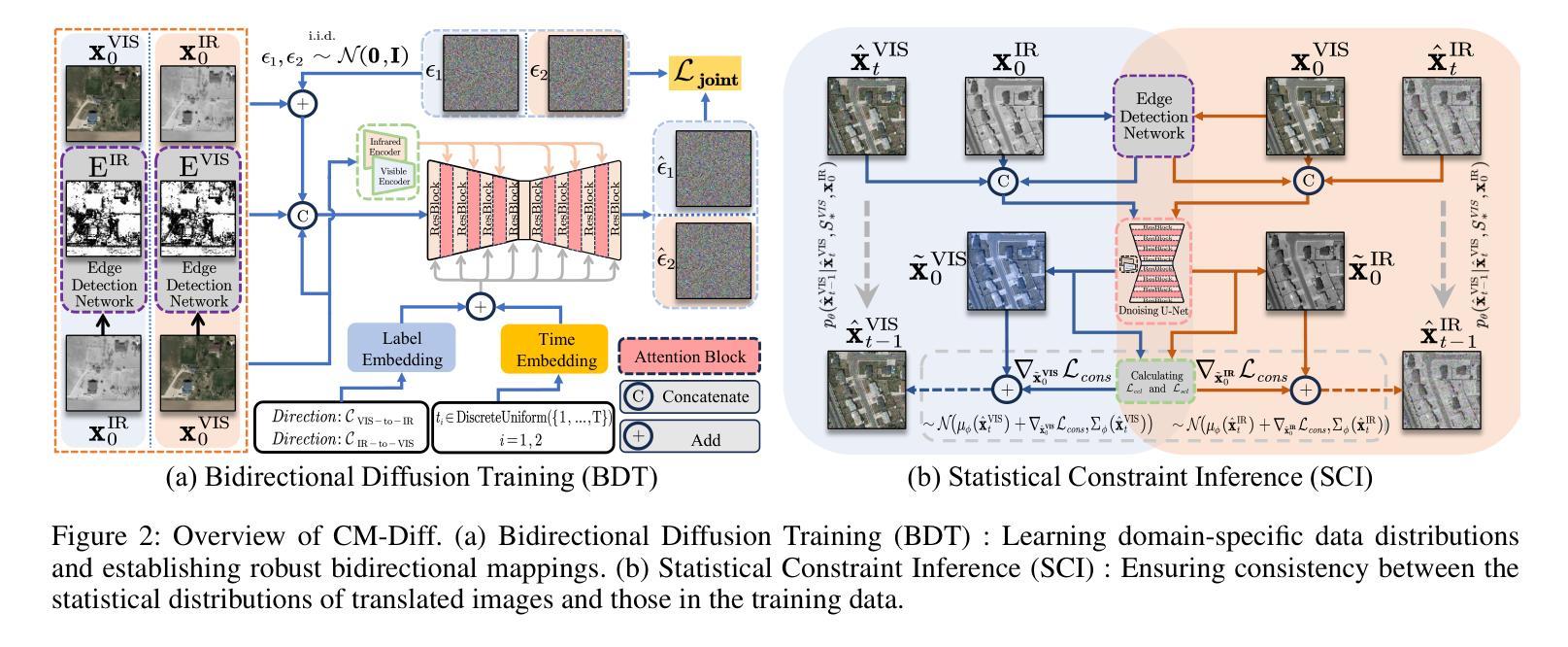
CM-Diff: A Single Generative Network for Bidirectional Cross-Modality Translation Diffusion Model Between Infrared and Visible Images
Authors:Bin Hu, Chenqiang Gao, Shurui Liu, Junjie Guo, Fang Chen, Fangcen Liu, Junwei Han
Image translation is one of the crucial approaches for mitigating information deficiencies in the infrared and visible modalities, while also facilitating the enhancement of modality-specific datasets. However, existing methods for infrared and visible image translation either achieve unidirectional modality translation or rely on cycle consistency for bidirectional modality translation, which may result in suboptimal performance. In this work, we present the bidirectional cross-modality translation diffusion model (CM-Diff) for simultaneously modeling data distributions in both the infrared and visible modalities. We address this challenge by combining translation direction labels for guidance during training with cross-modality feature control. Specifically, we view the establishment of the mapping relationship between the two modalities as the process of learning data distributions and understanding modality differences, achieved through a novel Bidirectional Diffusion Training (BDT). Additionally, we propose a Statistical Constraint Inference (SCI) to ensure the generated image closely adheres to the data distribution of the target modality. Experimental results demonstrate the superiority of our CM-Diff over state-of-the-art methods, highlighting its potential for generating dual-modality datasets.
图像翻译是缓解红外和可见模式信息缺陷的关键方法之一,同时还可以促进模式特定数据集的增强。然而,现有的红外和可见图像翻译方法要么实现单向模式翻译,要么依赖于循环一致性进行双向模式翻译,这可能导致性能不佳。在这项工作中,我们提出了双向跨模态翻译扩散模型(CM-Diff),以同时建模红外和可见模式中的数据分布。我们通过结合训练过程中的翻译方向标签指导与跨模式特征控制来解决这一挑战。具体来说,我们将建立两种模式之间的映射关系视为学习数据分布、理解模式差异的过程,通过一种新的双向扩散训练(BDT)来实现。此外,我们提出统计约束推理(SCI)以确保生成的图像紧密符合目标模式的数据分布。实验结果表明,我们的CM-Diff优于最先进的方法,突显其在生成双模态数据集方面的潜力。
论文及项目相关链接
Summary:
本工作提出了一种双向跨模态翻译扩散模型(CM-Diff),实现了红外和可见模态的数据分布的建模与转换。结合训练过程中的翻译方向标签与跨模态特征控制来解决这一挑战。通过双向扩散训练和统计约束推理,实现模态间映射关系的建立,并生成符合目标模态数据分布的图像。实验结果表明,CM-Diff相较于现有方法表现更优,在生成双模态数据集方面具有潜力。
Key Takeaways:
- 双向跨模态翻译扩散模型(CM-Diff)实现了红外和可见模态的数据分布的建模与转换。
- 模型结合了翻译方向标签与跨模态特征控制来解决信息转换的挑战。
- 通过双向扩散训练(BDT)建立两个模态之间的映射关系,并理解模态差异。
- 统计约束推理(SCI)确保生成的图像符合目标模态的数据分布。
- 模型性能通过实验结果得到验证,表现出优于现有方法的潜力。
- CM-Diff模型在生成双模态数据集方面具有重要意义。
点此查看论文截图