⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Authors:Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, Xu Yang
We present a simple yet theoretically motivated improvement to Supervised Fine-Tuning (SFT) for the Large Language Model (LLM), addressing its limited generalization compared to reinforcement learning (RL). Through mathematical analysis, we reveal that standard SFT gradients implicitly encode a problematic reward structure that may severely restrict the generalization capabilities of model. To rectify this, we propose Dynamic Fine-Tuning (DFT), stabilizing gradient updates for each token by dynamically rescaling the objective function with the probability of this token. Remarkably, this single-line code change significantly outperforms standard SFT across multiple challenging benchmarks and base models, demonstrating greatly improved generalization. Additionally, our approach shows competitive results in offline RL settings, offering an effective yet simpler alternative. This work bridges theoretical insight and practical solutions, substantially advancing SFT performance. The code will be available at https://github.com/yongliang-wu/DFT.
我们对大型语言模型(LLM)的监督微调(SFT)进行了简单但理论上的改进,解决了其与强化学习(RL)相比的有限泛化问题。通过数学分析,我们发现标准SFT梯度隐含了一种问题性的奖励结构,这可能严重限制模型的泛化能力。为了纠正这一点,我们提出了动态微调(DFT),通过动态调整目标函数与令牌概率来稳定每个令牌的梯度更新。值得注意的是,这一简单的代码更改在多个具有挑战性的基准测试和基准模型上大大优于标准SFT,表现出极大的泛化改进。此外,我们的方法在线下强化学习环境中也取得了有竞争力的结果,提供了一个有效且简单的替代方案。这项工作将理论洞察与实用解决方案相结合,极大地提高了SFT的性能。代码将在https://github.com/yongliang-wu/DFT上提供。
论文及项目相关链接
PDF 14 pages, 3 figures
Summary
本文介绍了对大型语言模型的监督微调(SFT)的一种简单而理论上的改进方法,解决了其相对于强化学习(RL)的有限泛化能力问题。通过数学分析,作者发现标准SFT梯度隐含了一个可能严重限制模型泛化能力的问题奖励结构。为了纠正这一问题,作者提出了动态微调(DFT),通过动态调整目标函数的概率来稳定每个标记的梯度更新。这一简单的代码改动在多个挑战基准测试和基础模型上显著优于标准SFT,表现出更好的泛化能力。此外,该方法在离线RL设置中也表现出竞争力,提供了一种有效且简单的替代方案。该研究在理论上有所突破并提供了实际解决方案,大幅提升了SFT的性能。
Key Takeaways
- 文章提出了监督微调(SFT)的理论问题,即其有限的泛化能力与潜在的奖励结构问题。
- 通过数学分析揭示了标准SFT梯度的问题,并进行了深入的讨论。
- 提出了动态微调(DFT)作为解决方案,通过动态调整目标函数概率来稳定梯度更新。
- DFT显著提高了标准SFT的性能,在多个挑战基准测试和基础模型上表现出优势。
- DFT在离线强化学习设置中也显示出竞争力,提供了一种简单有效的替代方案。
- 该研究不仅在理论上有所突破,还提供了实用的解决方案,有助于推动大型语言模型的发展。
点此查看论文截图

Shuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shuffle
Authors:Linghao Zhu, Yiran Guan, Dingkang Liang, Jianzhong Ju, Zhenbo Luo, Bin Qin, Jian Luan, Yuliang Liu, Xiang Bai
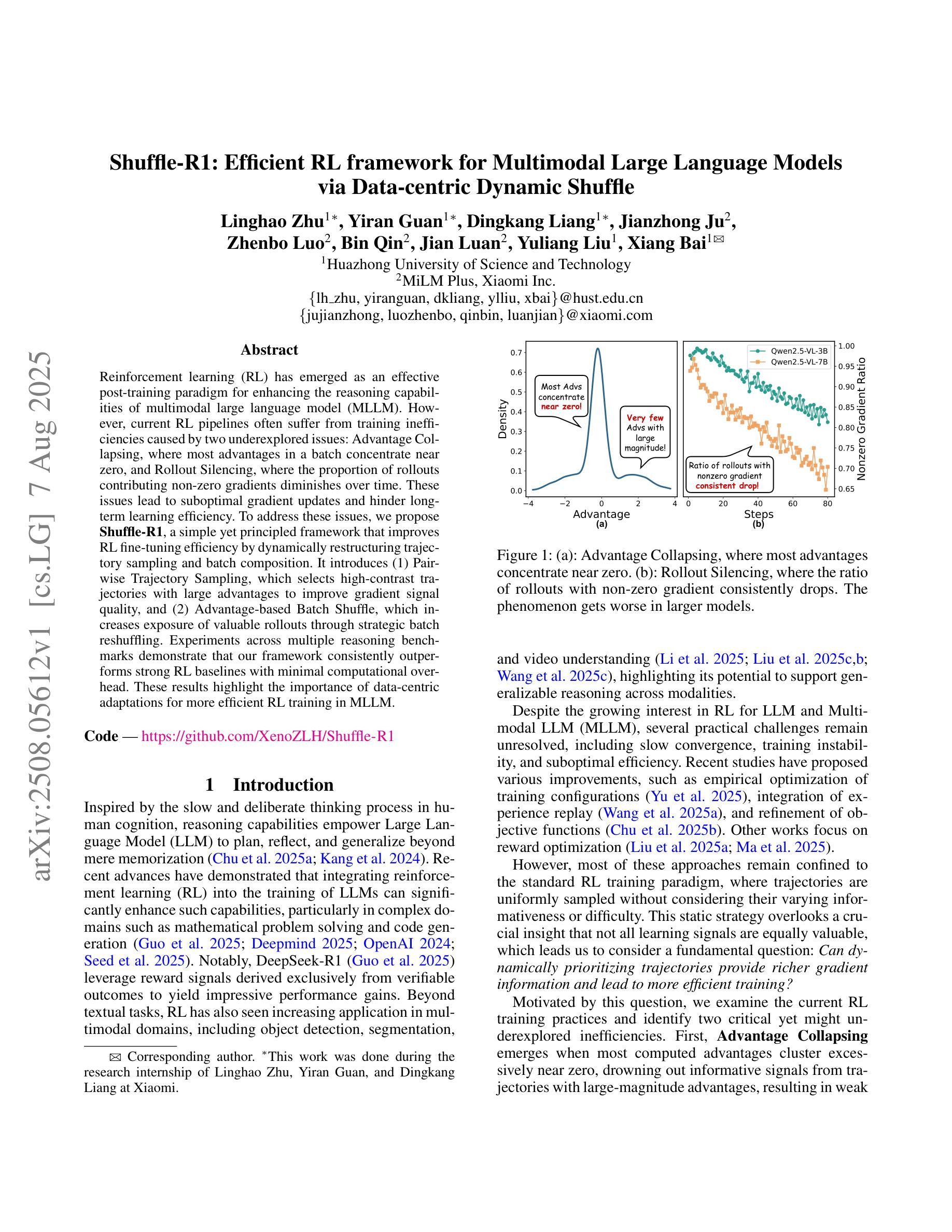
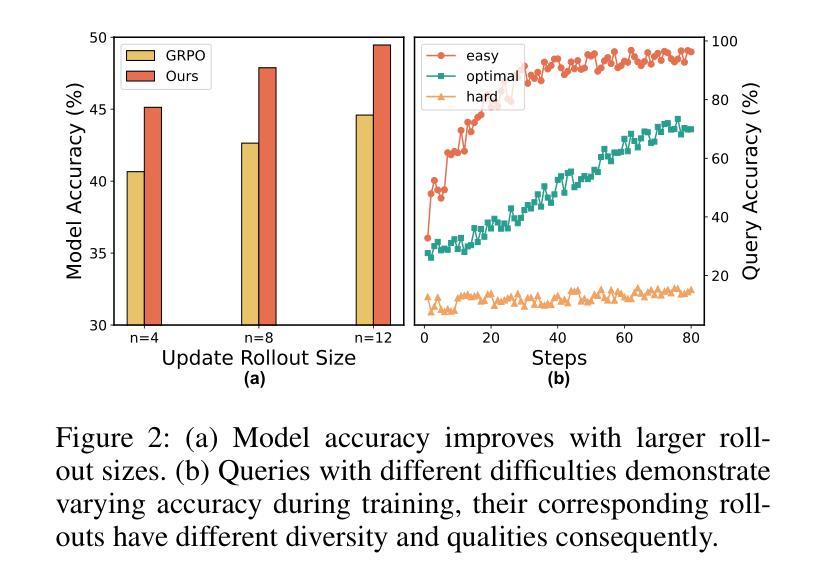
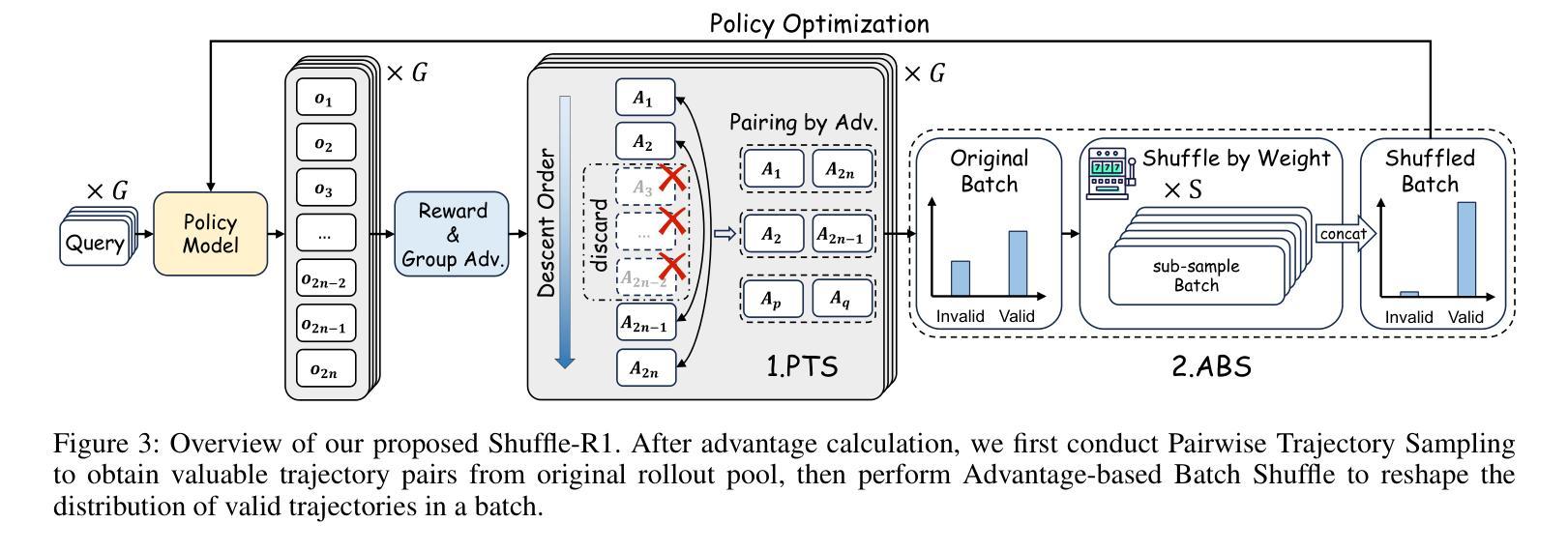
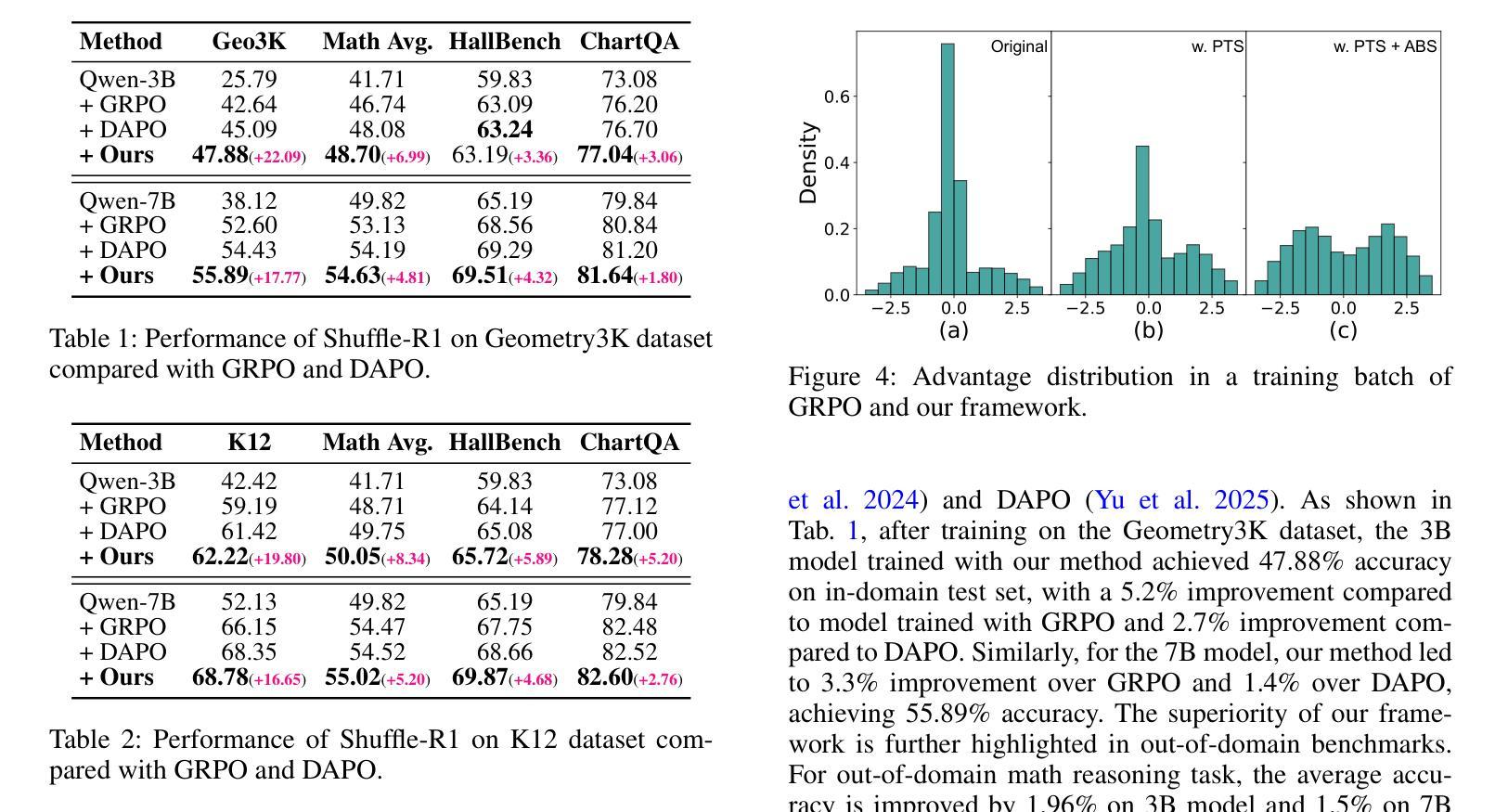
Reinforcement learning (RL) has emerged as an effective post-training paradigm for enhancing the reasoning capabilities of multimodal large language model (MLLM). However, current RL pipelines often suffer from training inefficiencies caused by two underexplored issues: Advantage Collapsing, where most advantages in a batch concentrate near zero, and Rollout Silencing, where the proportion of rollouts contributing non-zero gradients diminishes over time. These issues lead to suboptimal gradient updates and hinder long-term learning efficiency. To address these issues, we propose Shuffle-R1, a simple yet principled framework that improves RL fine-tuning efficiency by dynamically restructuring trajectory sampling and batch composition. It introduces (1) Pairwise Trajectory Sampling, which selects high-contrast trajectories with large advantages to improve gradient signal quality, and (2) Advantage-based Trajectory Shuffle, which increases exposure of valuable rollouts through informed batch reshuffling. Experiments across multiple reasoning benchmarks show that our framework consistently outperforms strong RL baselines with minimal overhead. These results highlight the importance of data-centric adaptations for more efficient RL training in MLLM.
强化学习(RL)已经作为一种有效的训练后范式,用于提高多模态大型语言模型(MLLM)的推理能力。然而,当前的RL管道通常存在两个未充分探索的问题,导致训练效率低下:优势崩塌,即一批次中的大部分优势集中在零附近;以及回合静默,即提供非零梯度的回合比例随时间减少。这些问题导致梯度更新不佳,并阻碍长期学习效率。为了解决这些问题,我们提出了Shuffle-R1,这是一个简单而基于原则的框架,通过动态重构轨迹采样和批次组成来提高RL微调效率。它引入了(1)配对轨迹采样,选择高对比度的轨迹和较大的优势来提高梯度信号质量;(2)基于优势的轨迹洗牌,通过信息批处理洗牌增加有价值的回合的曝光。在多个推理基准测试上的实验表明,我们的框架始终优于强大的RL基线,且开销最小。这些结果突出了数据为中心适应在MLLM中更高效RL训练的重要性。
论文及项目相关链接
Summary:强化学习(RL)作为提高多模态大型语言模型(MLLM)推理能力的后训练范式,但存在训练效率低下的问题。针对优势崩溃和滚动静默这两个未充分探索的问题,提出了Shuffle-R1框架,通过动态重构轨迹采样和批次组成来提高RL微调效率。该框架包括成对轨迹采样和基于优势的轨迹洗牌,以提高梯度信号质量和增加有价值轨迹的暴露。实验结果表明,该框架在多个推理基准测试上始终优于强大的RL基准测试,且几乎不增加开销。这强调了数据为中心适应对于提高MLLM中的RL训练效率的重要性。
Key Takeaways:
- 强化学习(RL)用于提高多模态大型语言模型(MLLM)的推理能力。
- 当前RL管道存在训练效率低下的问题,主要表现为优势崩溃和滚动静默。
- Shuffle-R1框架通过动态重构轨迹采样和批次组成来解决这些问题。
- Shuffle-R1包括成对轨迹采样和基于优势的轨迹洗牌,以提高梯度信号质量和有价值轨迹的暴露。
- 实验证明Shuffle-R1在多个推理基准测试上表现优于强RL基准测试。
- Shuffle-R1框架几乎不增加开销。
点此查看论文截图
Hi3DEval: Advancing 3D Generation Evaluation with Hierarchical Validity
Authors:Yuhan Zhang, Long Zhuo, Ziyang Chu, Tong Wu, Zhibing Li, Liang Pan, Dahua Lin, Ziwei Liu
Despite rapid advances in 3D content generation, quality assessment for the generated 3D assets remains challenging. Existing methods mainly rely on image-based metrics and operate solely at the object level, limiting their ability to capture spatial coherence, material authenticity, and high-fidelity local details. 1) To address these challenges, we introduce Hi3DEval, a hierarchical evaluation framework tailored for 3D generative content. It combines both object-level and part-level evaluation, enabling holistic assessments across multiple dimensions as well as fine-grained quality analysis. Additionally, we extend texture evaluation beyond aesthetic appearance by explicitly assessing material realism, focusing on attributes such as albedo, saturation, and metallicness. 2) To support this framework, we construct Hi3DBench, a large-scale dataset comprising diverse 3D assets and high-quality annotations, accompanied by a reliable multi-agent annotation pipeline. We further propose a 3D-aware automated scoring system based on hybrid 3D representations. Specifically, we leverage video-based representations for object-level and material-subject evaluations to enhance modeling of spatio-temporal consistency and employ pretrained 3D features for part-level perception. Extensive experiments demonstrate that our approach outperforms existing image-based metrics in modeling 3D characteristics and achieves superior alignment with human preference, providing a scalable alternative to manual evaluations. The project page is available at https://zyh482.github.io/Hi3DEval/.
尽管在三维内容生成方面取得了快速发展,但对生成的三维资产的质量评估仍然具有挑战性。现有方法主要依赖于图像指标,仅在对象层面进行操作,这限制了它们捕捉空间连贯性、材料真实性和高保真局部细节的能力。1)为了应对这些挑战,我们引入了Hi3DEval,这是一个专为三维生成内容设计的分层评估框架。它结合了对象层面和部分层面的评估,能够实现多个维度的整体评估以及精细的质量分析。此外,我们通过明确评估材料真实性,将纹理评估扩展到美学外观之外,重点关注如漫反射、饱和度和金属性等属性。2)为了支持该框架,我们构建了Hi3DBench,这是一个包含各种三维资产和高质量注释的大规模数据集,以及可靠的多元注释管道。我们进一步提出了基于混合三维表示的3D感知自动评分系统。具体来说,我们利用视频表示进行对象级和材料主题评估,以增强时空一致性的建模,并利用预训练的3D特征进行部分层面的感知。大量实验表明,我们的方法在建模三维特征方面优于现有的图像指标,与人类偏好高度一致,为手动评估提供了可伸缩的替代方案。项目页面可访问于 https://zyh482.github.io/Hi3DEval/。
论文及项目相关链接
PDF Page: https://zyh482.github.io/Hi3DEval/
Summary
本文介绍了针对3D生成内容的质量评估的挑战,并引入了Hi3DEval这一层次化的评估框架以及Hi3DBench数据集。该框架结合了对象级别和部分级别的评估,能够进行跨多个维度的整体评估以及精细的质量分析。同时,构建了一个大规模数据集Hi3DBench,并开发了基于混合三维表示的自动化评分系统。实验表明,该方法在模拟三维特性方面优于现有图像基础指标,与人类偏好对齐性更高,为手动评估提供了可扩展的替代方案。
Key Takeaways
- 现有3D资产生成质量评估面临挑战,需要更全面的评估方法。
- 引入Hi3DEval层次化评估框架,结合对象级别和部分级别的评估,能够捕捉空间连贯性、材料真实性和高保真局部细节。
- 构建Hi3DBench大规模数据集,包含多样3D资产和高质量注释,支持Hi3DEval框架。
- 开发了基于混合三维表示的自动化评分系统,利用视频表示进行对象级别和材料主题评估,增强时空一致性建模。
- 框架超越了单纯的美学外观纹理评估,明确评估材料真实性,关注如明暗度、饱和度和金属感等属性。
- 实验表明,该方法在模拟三维特性方面优于现有图像基础指标。
点此查看论文截图

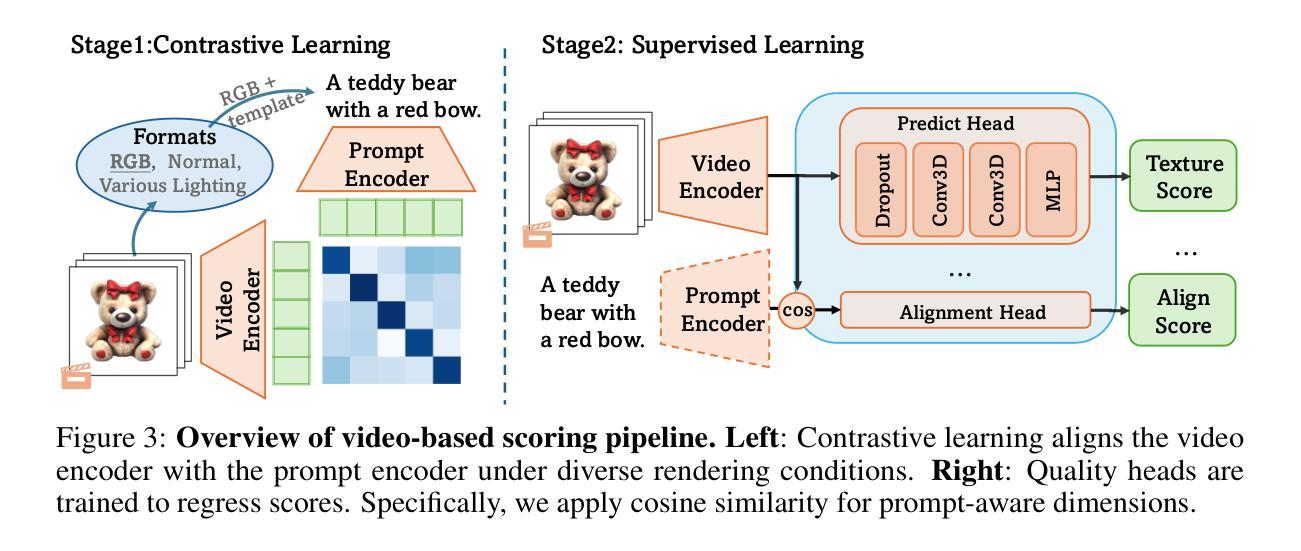
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Authors:Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, Hao Li
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/
链式思维(CoT)推理已被广泛应用于通过分解复杂任务为更简单、连续的子任务来增强大型语言模型(LLM)。然而,将CoT扩展到视觉语言推理任务仍然具有挑战性,因为它通常需要对视觉状态的过渡进行解释以支持推理。现有方法常常因此而苦苦挣扎,因为它们在建模视觉状态过渡方面的能力有限,或者由于架构碎片化而导致视觉轨迹不一致。为了克服这些局限性,我们提出了Uni-CoT,一个统一的链式思维框架,它可以在单个统一模型内实现连贯和基于情境的多模态推理。主要思想是利用既能够理解和生成图像又能够对视觉内容进行推理的模型,并模拟不断演变的视觉状态。然而,对于一个统一模型来说实现这一点并非易事,考虑到计算成本高昂和训练负担沉重。为了解决这个问题,Uni-CoT引入了一种新颖的两级推理模式:用于高级任务规划的宏观层面CoT和用于子任务执行的微观层面CoT。这种设计显著减少了计算开销。此外,我们引入了一种结构化的训练模式,该模式结合了宏观层面CoT的交错图像文本监督与微观层面CoT的多任务目标。这些创新使Uni-CoT能够进行可扩展和连贯的多模态推理。此外,得益于我们的设计,所有实验都能仅使用8个带有各80GB VRAM的A100 GPU高效完成。在基于推理的图像生成基准(WISE)和编辑基准(RISE和KRIS)上的实验结果表明,Uni-CoT展现出卓越的性能和强大的泛化能力,确立了Uni-CoT在多模态推理中的有前途的解决方案地位。项目页面和代码:https://sais-fuxi.github.io/projects/uni-cot/。
论文及项目相关链接
PDF https://sais-fuxi.github.io/projects/uni-cot/
摘要
链式思维(CoT)推理被广泛应用于通过分解复杂任务为更简单的顺序子任务来增强大型语言模型(LLM)。然而,将CoT扩展到视觉语言推理任务仍然具有挑战性,因为它通常需要解释视觉状态的转变为推理提供支持。现有方法往往因为有限的建模视觉状态转换的能力或因结构碎片化导致的视觉轨迹不一致而面临困难。为了克服这些局限性,我们提出了Uni-CoT,一个统一的链式思维框架,能够在单一模型中实现连贯且有根基的多模态推理。它通过结合图像理解和生成能力来实现对视觉内容的推理和建模不断发展的视觉状态。然而,在构建能够执行该功能的统一模型方面存在挑战,因为计算成本高昂且训练负担沉重。为了解决这个问题,Uni-CoT引入了一种新型的两级推理模式:用于高级任务规划的宏观层面CoT和用于子任务执行的微观层面CoT。这种设计显著减少了计算开销。此外,我们引入了一种结构化的训练模式,该模式结合了宏观层面CoT的交错图像文本监督与微观层面CoT的多任务目标。这些创新使Uni-CoT能够执行可扩展且连贯的多模态推理。此外,由于我们的设计,所有实验都能够在仅使用每台配备有8个GPU的服务器上高效完成。在基于推理的图像生成基准测试(WISE)和编辑基准测试(RISE和KRIS)上的实验结果表明,Uni-CoT展示出了超越现有解决方案的性能和强大的泛化能力。有关项目的详细信息请参阅:https://sais-fuxi.github.io/projects/uni-cot/。
关键见解
- Uni-CoT成功地将链式思维(CoT)推理应用于多模态任务,实现了连贯的视觉语言推理。
- 通过引入两级推理模式(宏观和微观层面),Uni-CoT显著降低了计算开销,提高了推理效率。
- Uni-CoT结合了图像理解和生成能力,能够建模不断发展的视觉状态,增强了其在视觉任务中的性能。
- 结构化的训练模式结合了宏观层面CoT的交错图像文本监督与微观层面CoT的多任务目标,有助于提高模型的泛化能力和性能。
- 实验结果表明,Uni-CoT在基于推理的图像生成和编辑任务上表现优异,展现出强大的性能。
- Uni-CoT的设计优化使得其能够在有限的计算资源上高效运行,降低了训练和部署的成本。
点此查看论文截图

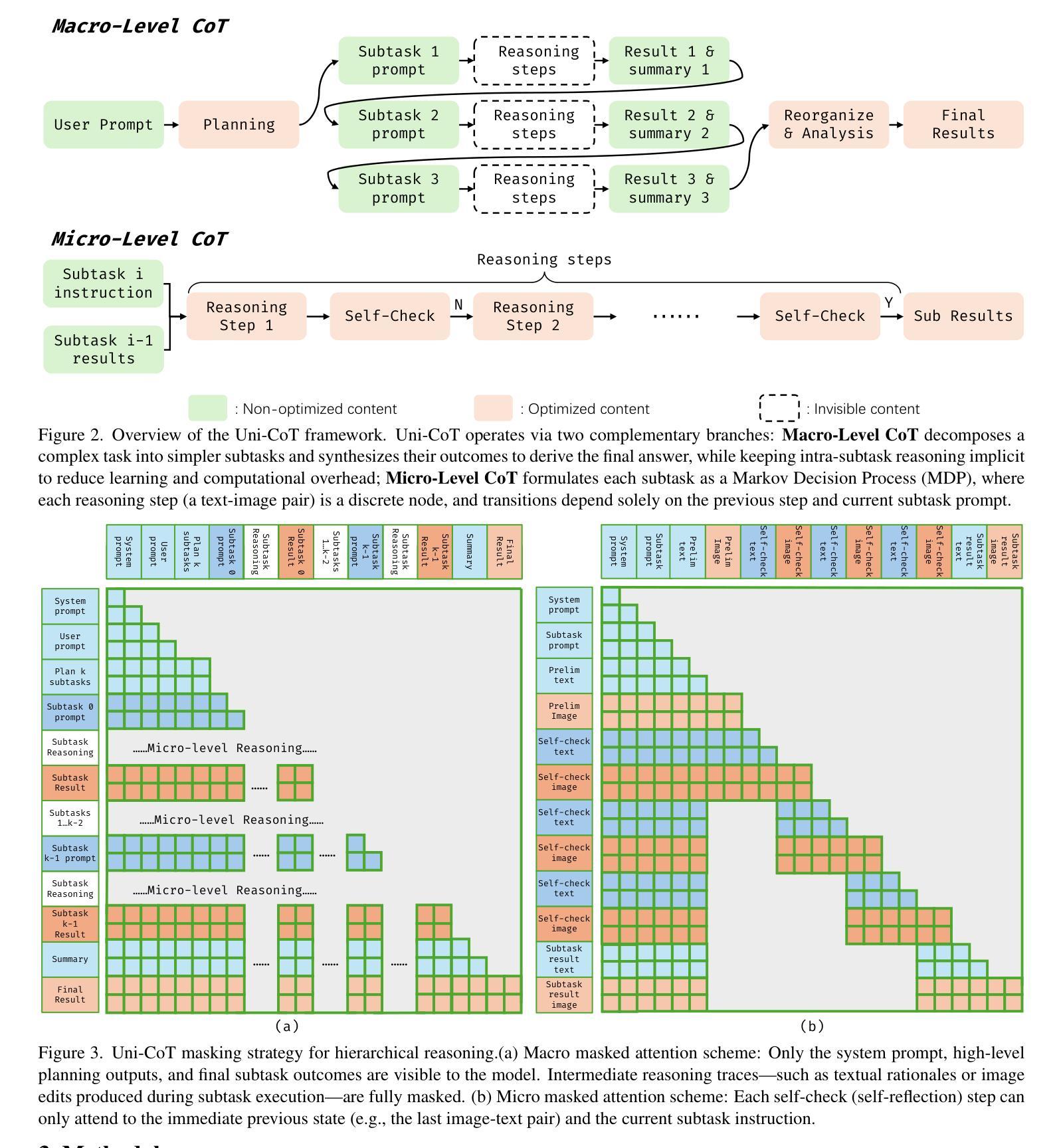
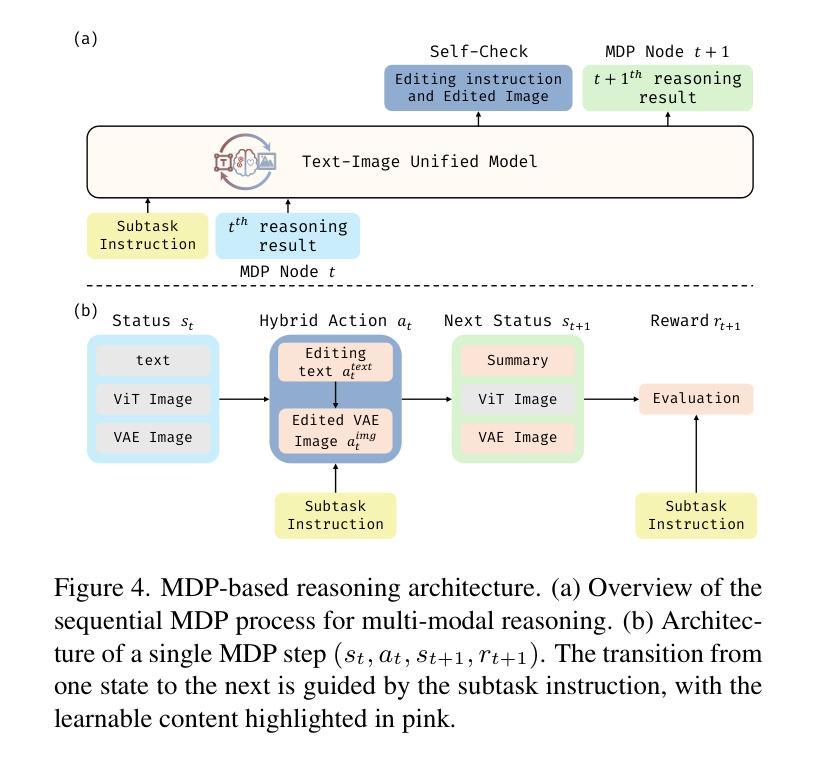
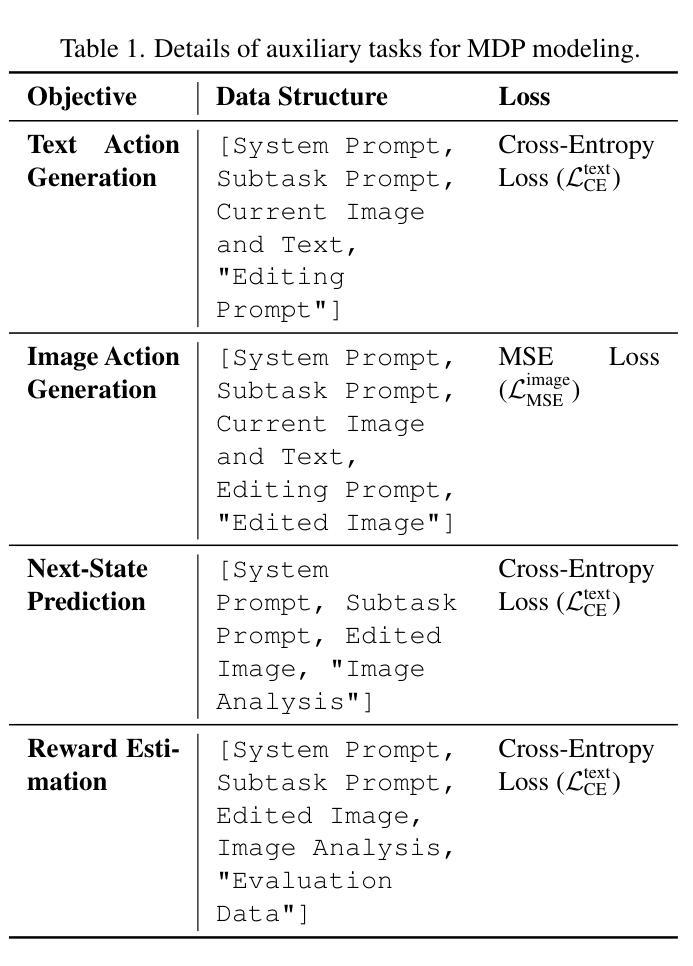
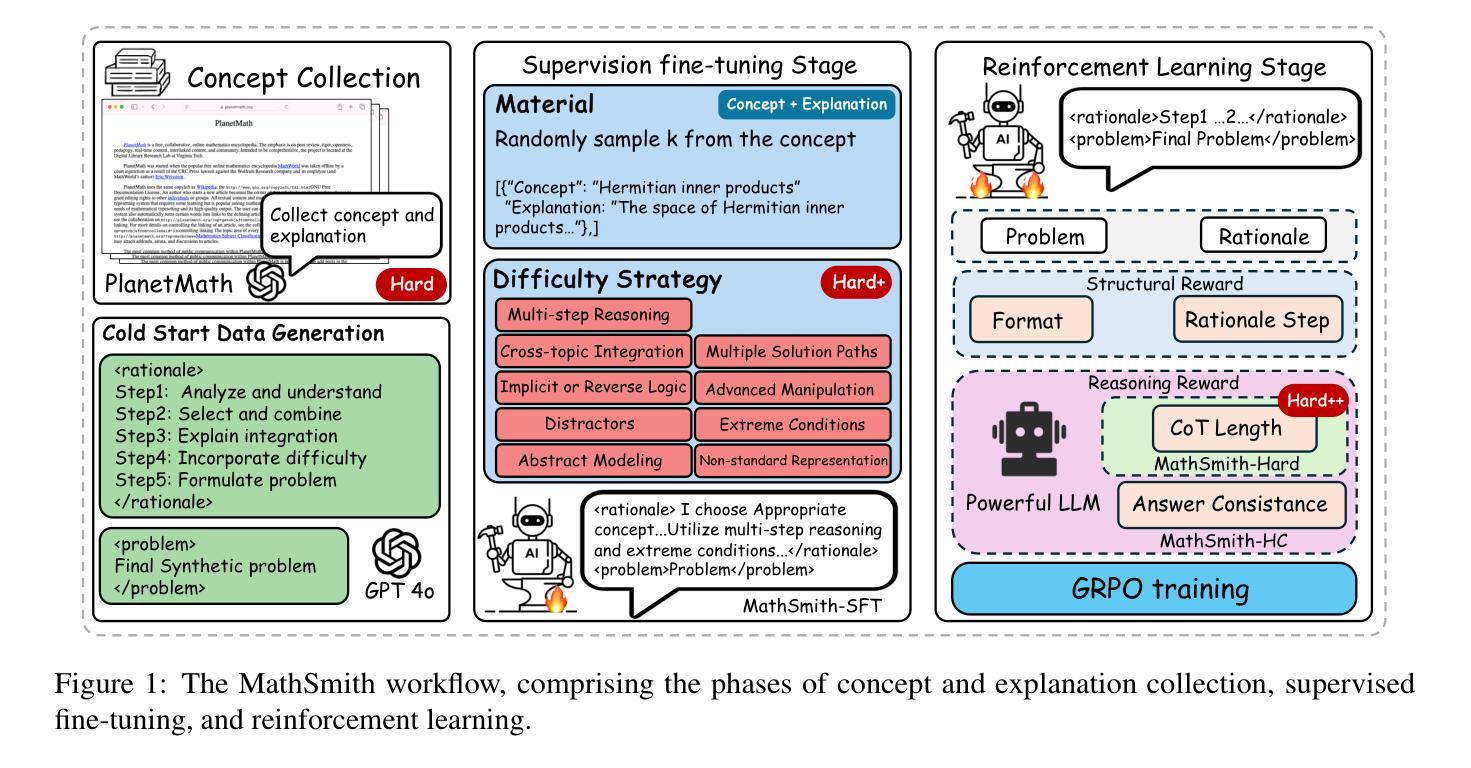
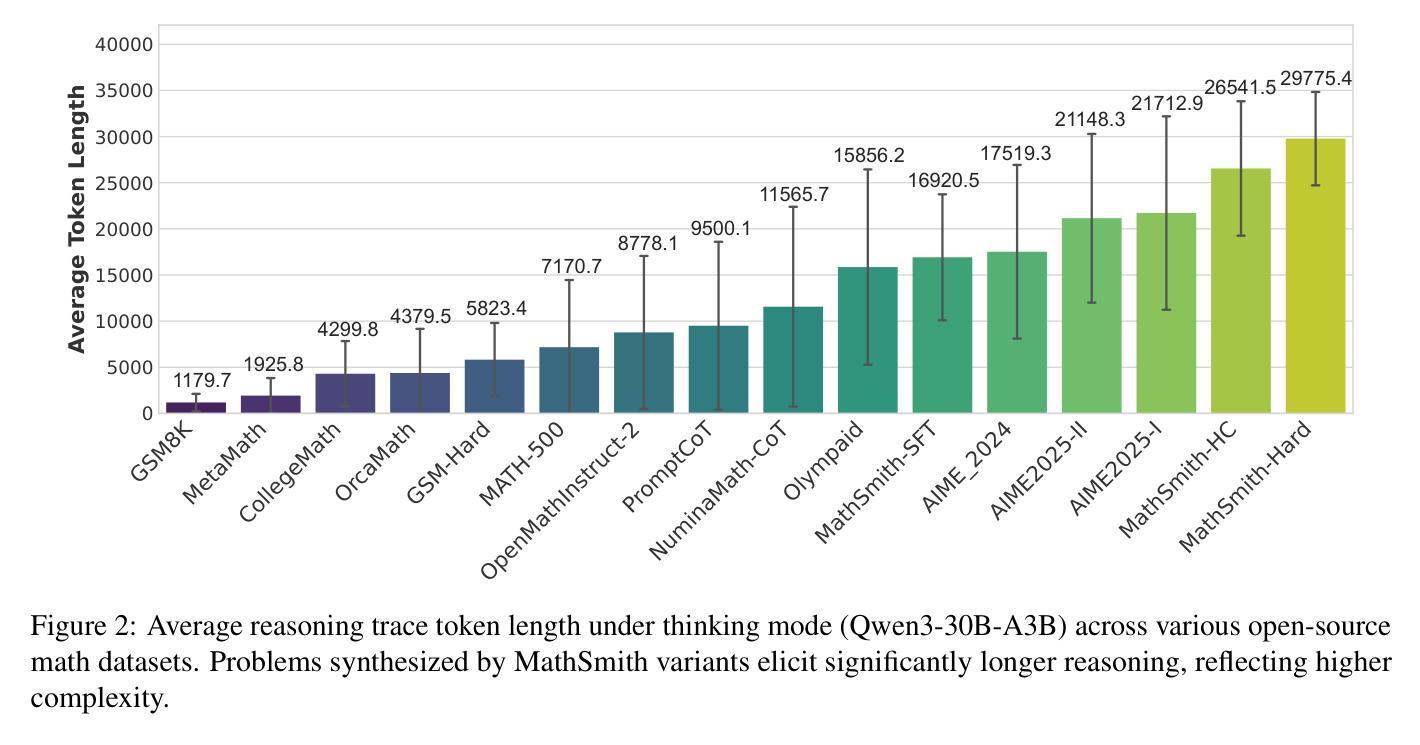
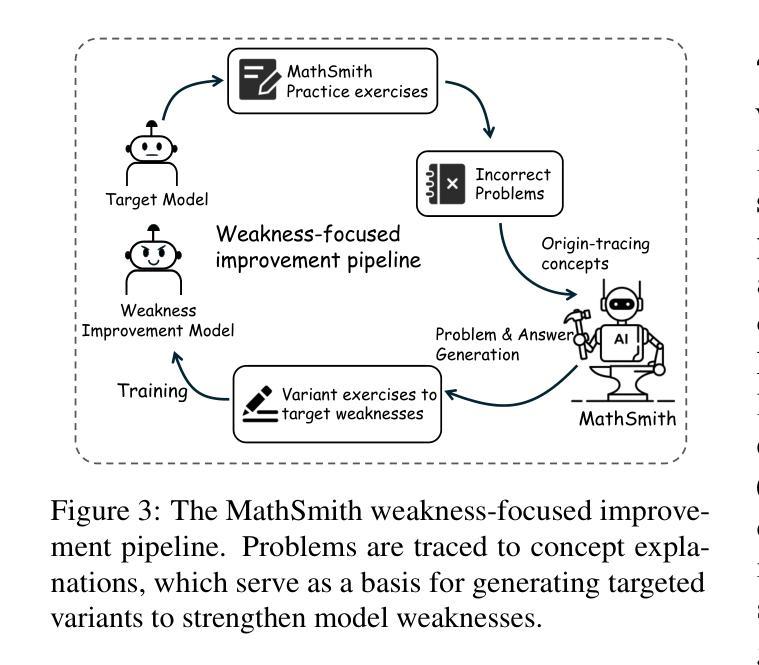
MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy
Authors:Shaoxiong Zhan, Yanlin Lai, Ziyu Lu, Dahua Lin, Ziqing Yang, Fei Tang
Large language models have achieved substantial progress in mathematical reasoning, yet their advancement is limited by the scarcity of high-quality, high-difficulty training data. Existing synthesis methods largely rely on transforming human-written templates, limiting both diversity and scalability. We propose MathSmith, a novel framework for synthesizing challenging mathematical problems to enhance LLM reasoning. Rather than modifying existing problems, MathSmith constructs new ones from scratch by randomly sampling concept-explanation pairs from PlanetMath, ensuring data independence and avoiding contamination. To increase difficulty, we design nine predefined strategies as soft constraints during rationales. We further adopts reinforcement learning to jointly optimize structural validity, reasoning complexity, and answer consistency. The length of the reasoning trace generated under autoregressive prompting is used to reflect cognitive complexity, encouraging the creation of more demanding problems aligned with long-chain-of-thought reasoning. Experiments across five benchmarks, categorized as easy & medium (GSM8K, MATH-500) and hard (AIME2024, AIME2025, OlympiadBench), show that MathSmith consistently outperforms existing baselines under both short and long CoT settings. Additionally, a weakness-focused variant generation module enables targeted improvement on specific concepts. Overall, MathSmith exhibits strong scalability, generalization, and transferability, highlighting the promise of high-difficulty synthetic data in advancing LLM reasoning capabilities.
大规模语言模型在数学推理方面取得了显著进展,但其发展受到高质量、高难度训练数据稀缺的限制。现有的合成方法大多依赖于转换人工编写的模板,这限制了多样性和可扩展性。我们提出了MathSmith,一个合成具有挑战性数学问题以增强大型语言模型推理能力的新型框架。MathSmith不是修改现有问题,而是从零开始构建新问题,通过从PlanetMath随机抽取概念解释对,确保数据独立,避免污染。为了提高问题的难度,我们设计了九种预设策略作为合理推理过程中的软约束。我们进一步采用强化学习来联合优化结构有效性、推理复杂性和答案一致性。在自动回归提示下产生的推理轨迹长度被用来反映认知复杂性,鼓励创建与长链思维推理相符的更具挑战性的问题。在五个基准测试上的实验,被分类为简单和中等难度(GSM8K,MATH-500)以及高难度(AIME2024,AIME2025,OlympiadBench),结果表明MathSmith在短链和长链思维设置下均持续超越现有基线。此外,弱点聚焦的变体生成模块能够实现特定概念的针对性改进。总体上,MathSmith表现出强大的可扩展性、泛化能力和迁移能力,突显了高难度合成数据在提升大型语言模型推理能力方面的潜力。
论文及项目相关链接
Summary
大型语言模型在数学推理方面取得显著进展,但仍受限于高质量、高难度训练数据的稀缺性。现有合成方法主要依赖人类编写模板的转换,限制了多样性和可扩展性。为此,我们提出MathSmith框架,通过从PlanetMath中随机采样概念解释对来构建新的数学问题,确保数据独立性和避免污染。通过九种预设策略作为软约束来增加问题难度。采用强化学习来联合优化结构有效性、推理复杂性和答案一致性。实验结果表明,MathSmith在短链和长链思维推理设置下均优于现有基准测试,显示出其强大的可扩展性、通用性和可迁移性。
Key Takeaways
- 大型语言模型在数学推理方面已取得进展,但缺乏高质量、高难度的训练数据。
- 现有数学问题的合成方法主要依赖人类编写模板,限制了多样性和可扩展性。
- MathSmith框架通过随机采样概念解释对来构建新的数学问题,确保数据独立性。
- MathSmith采用九种预设策略来增加问题难度,并借助强化学习优化结构有效性、推理复杂性和答案一致性。
- MathSmith生成的推理轨迹长度反映了认知复杂性,鼓励创建与长链思维推理对齐的更具挑战性的问题。
- 实验结果表明,MathSmith在多个基准测试中表现优异,包括容易和中等难度的GSM8K和MATH-500,以及高难度的AIME2024、AIME2025和OlympiadBench。
点此查看论文截图

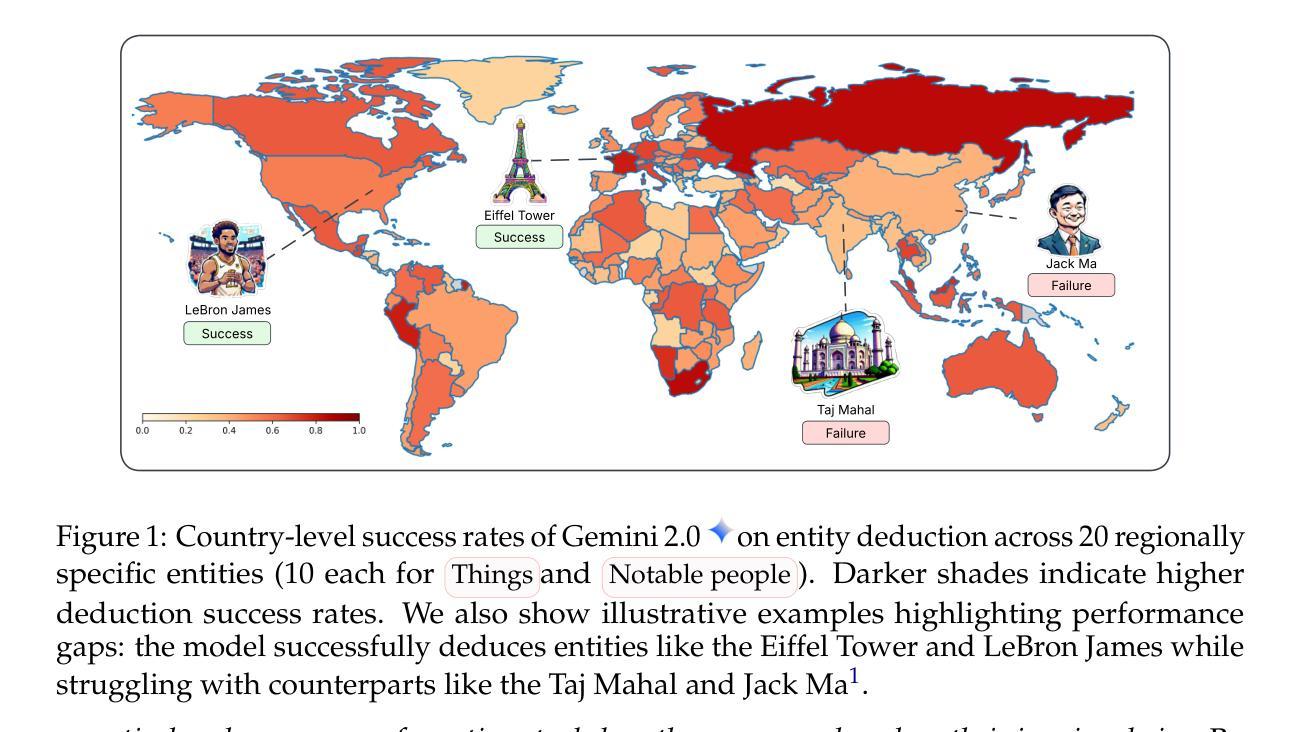
The World According to LLMs: How Geographic Origin Influences LLMs’ Entity Deduction Capabilities
Authors:Harsh Nishant Lalai, Raj Sanjay Shah, Jiaxin Pei, Sashank Varma, Yi-Chia Wang, Ali Emami
Large Language Models (LLMs) have been extensively tuned to mitigate explicit biases, yet they often exhibit subtle implicit biases rooted in their pre-training data. Rather than directly probing LLMs with human-crafted questions that may trigger guardrails, we propose studying how models behave when they proactively ask questions themselves. The 20 Questions game, a multi-turn deduction task, serves as an ideal testbed for this purpose. We systematically evaluate geographic performance disparities in entity deduction using a new dataset, Geo20Q+, consisting of both notable people and culturally significant objects (e.g., foods, landmarks, animals) from diverse regions. We test popular LLMs across two gameplay configurations (canonical 20-question and unlimited turns) and in seven languages (English, Hindi, Mandarin, Japanese, French, Spanish, and Turkish). Our results reveal geographic disparities: LLMs are substantially more successful at deducing entities from the Global North than the Global South, and the Global West than the Global East. While Wikipedia pageviews and pre-training corpus frequency correlate mildly with performance, they fail to fully explain these disparities. Notably, the language in which the game is played has minimal impact on performance gaps. These findings demonstrate the value of creative, free-form evaluation frameworks for uncovering subtle biases in LLMs that remain hidden in standard prompting setups. By analyzing how models initiate and pursue reasoning goals over multiple turns, we find geographic and cultural disparities embedded in their reasoning processes. We release the dataset (Geo20Q+) and code at https://sites.google.com/view/llmbias20q/home.
大型语言模型(LLM)已经进行了广泛的调整,以减轻明确的偏见,然而,它们通常表现出源于其预训练数据的微妙隐含偏见。我们并不主张用可能触发防护机制的由人类设计的问题直接探测LLM,而是提议研究模型在主动提出问题时的行为表现。20问游戏作为一种多回合推理任务,是达到这一目的的绝佳测试平台。我们使用一个新的数据集Geo20Q+,它包含来自不同地区的著名人物和文化重要对象(例如食物、地标、动物),系统地评估实体推理中的地理表现差异。我们在两种游戏设置(标准的20个问题和无限制回合)和七种语言(英语、印地语、普通话、日语、法语、西班牙语和土耳其语)中对流行的LLM进行了测试。我们的结果显示了地理差异:LLM在推断来自全球北方和北西方的实体时比来自全球南方和东部的实体更成功。虽然Wikipedia页面浏览量和预训练语料库频率与性能有轻微关联,但它们未能完全解释这些差异。值得注意的是,游戏所用的语言对性能差距的影响微乎其微。这些发现证明了创造性自由形式的评估框架在揭示LLM中隐藏细微偏见方面的价值,这些偏见在标准提示设置中仍然隐藏。通过分析模型如何在多回合中启动和追求推理目标,我们发现其推理过程中嵌入的地理和文化差异。我们在https://sites.google.com/view/llmbias20q/home发布了数据集(Geo20Q+)和代码。
论文及项目相关链接
PDF Conference on Language Modeling 2025
摘要
大型语言模型(LLMs)虽然经过广泛调整以减轻显性偏见,但它们往往表现出源于预训练数据的微妙隐性偏见。本研究提出了一种新的评估方法,即通过模型自身主动提问的方式来研究其表现。我们以20问游戏(一种多回合推理任务)为测试平台,使用新的数据集Geo20Q+,包括来自不同地区的知名人物和具有文化意义的事物(如食品、地标、动物)。我们在两种游戏配置(标准的20个问题及无限回合)和七种语言(英语、印地语、普通话、日语、法语、西班牙语和土耳其语)中测试了流行的大型语言模型。结果发现地理差异:大型语言模型在推断全球北方和北西方的实体时比全球南方和东方更成功。尽管维基百科页面浏览量和预训练语料库频率与性能轻度相关,但它们无法完全解释这些差异。值得注意的是,游戏所用的语言对性能差距的影响微乎其微。这些发现表明,创造性的自由形式评估框架对于揭示大型语言模型中的微妙偏见具有重要意义,这些偏见在标准提示设置中仍然隐藏。通过分析模型如何启动和追求多回合的推理目标,我们发现其推理过程中嵌入的地理和文化差异。我们在https://sites.google.com/view/llmbias20q/home发布了数据集(Geo20Q+)和代码。
关键见解
- 大型语言模型(LLMs)展现出基于预训练数据的微妙隐性偏见。
- 通过模型主动提问来研究大型语言模型的表现是一种新颖且有效的方法。
- 20问游戏是多回合推理任务的理想测试平台。
- Geo20Q+数据集包含来自不同地区的知名人物和文化物品,用于评估地理性能差异。
- LLMs在推断全球北方和北西方的实体时表现更好,而非全球南方和东方。
- 维基百科页面浏览量和预训练语料库频率与LLMs性能轻度相关,但无法完全解释性能差异。
- 游戏语言对LLMs性能差距的影响较小,强调评估框架的重要性。
点此查看论文截图

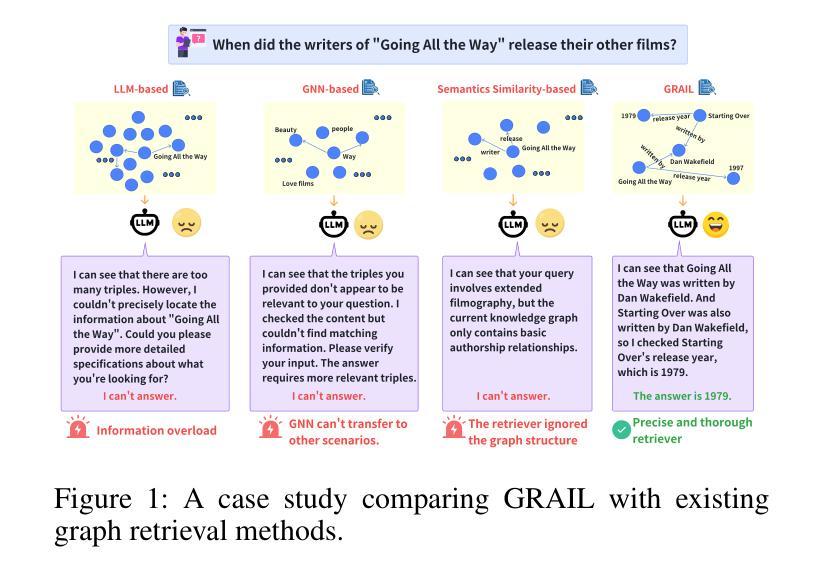
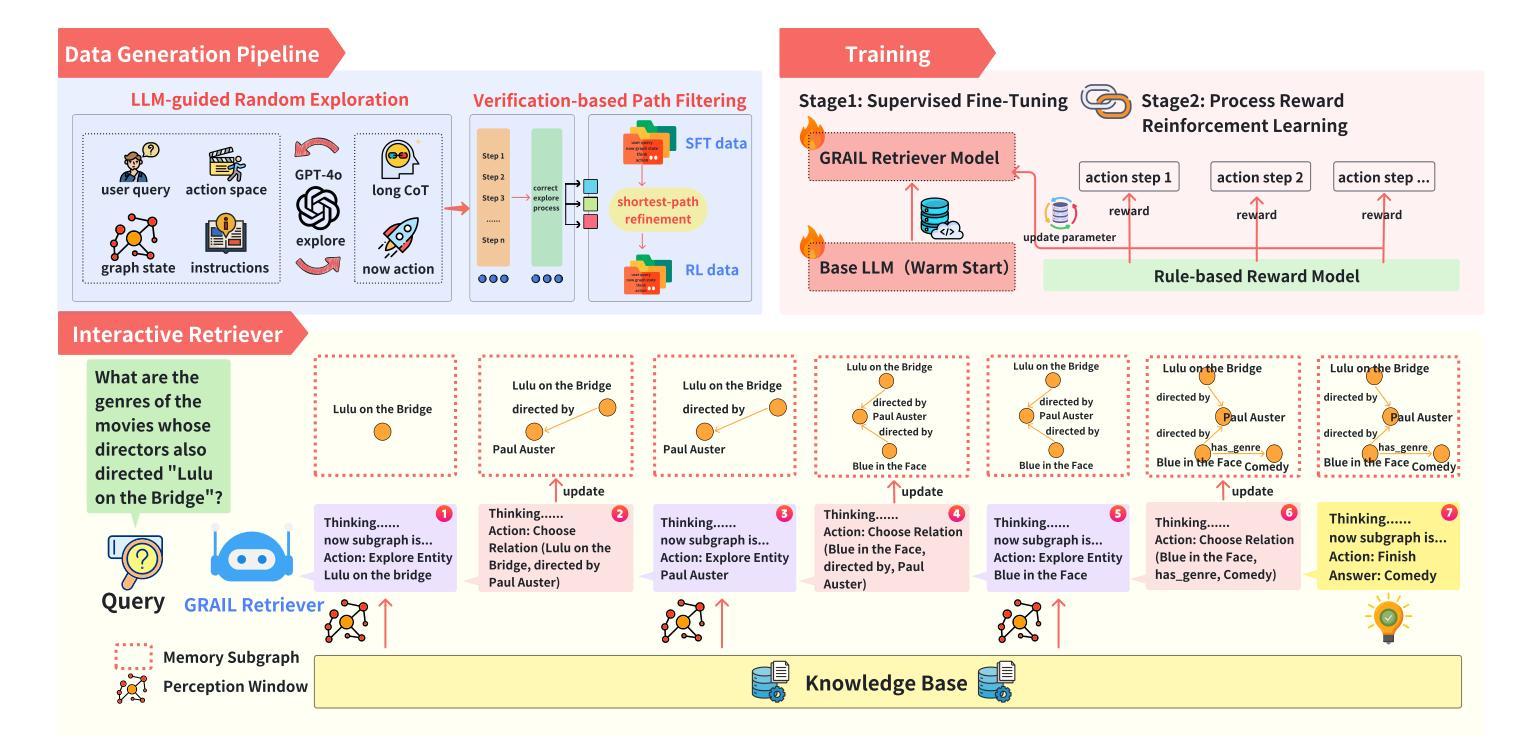
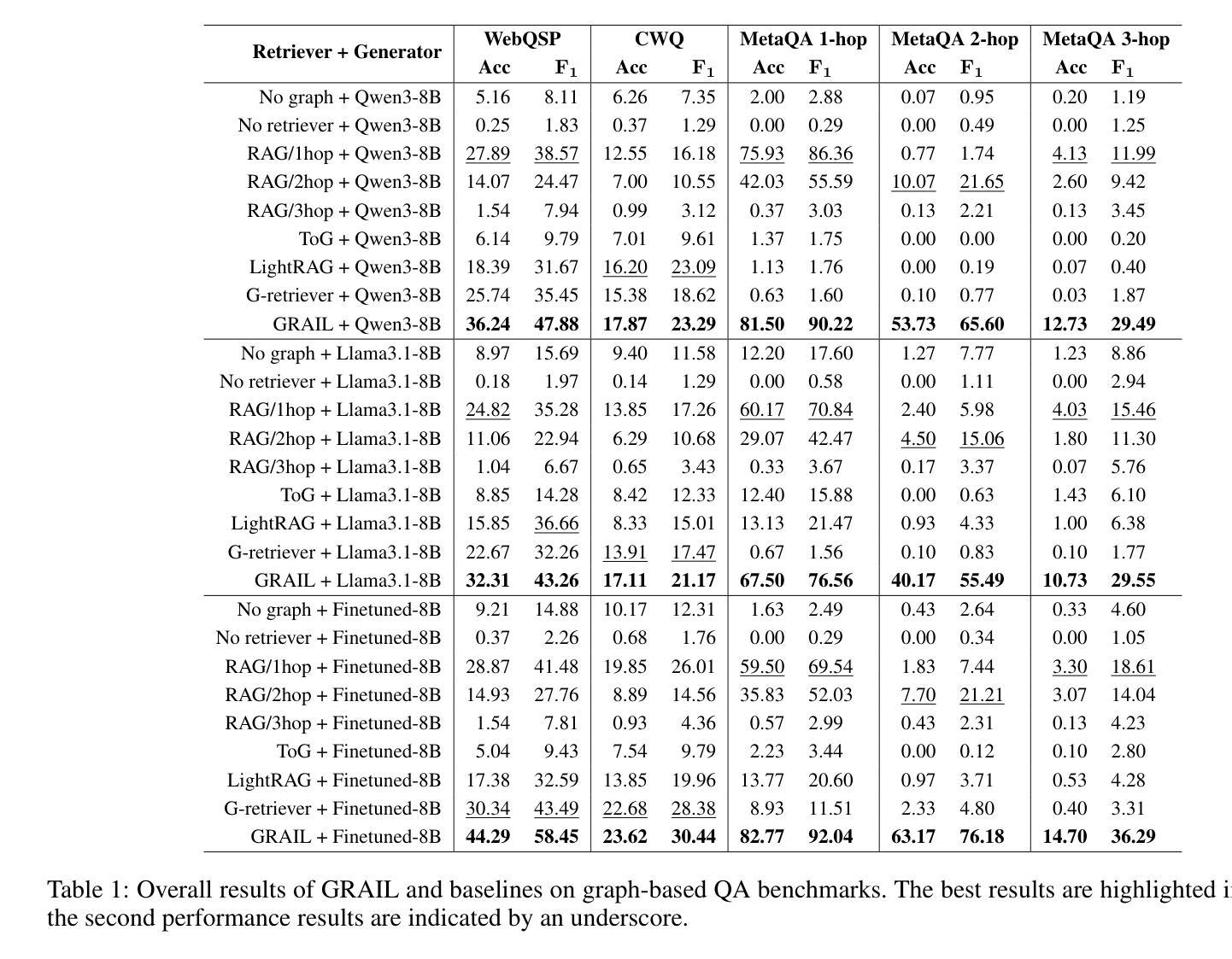
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning
Authors:Ge Chang, Jinbo Su, Jiacheng Liu, Pengfei Yang, Yuhao Shang, Huiwen Zheng, Hongli Ma, Yan Liang, Yuanchun Li, Yunxin Liu
Large Language Models (LLMs) integrated with Retrieval-Augmented Generation (RAG) techniques have exhibited remarkable performance across a wide range of domains. However, existing RAG approaches primarily operate on unstructured data and demonstrate limited capability in handling structured knowledge such as knowledge graphs. Meanwhile, current graph retrieval methods fundamentally struggle to capture holistic graph structures while simultaneously facing precision control challenges that manifest as either critical information gaps or excessive redundant connections, collectively undermining reasoning performance. To address this challenge, we propose GRAIL: Graph-Retrieval Augmented Interactive Learning, a framework designed to interact with large-scale graphs for retrieval-augmented reasoning. Specifically, GRAIL integrates LLM-guided random exploration with path filtering to establish a data synthesis pipeline, where a fine-grained reasoning trajectory is automatically generated for each task. Based on the synthesized data, we then employ a two-stage training process to learn a policy that dynamically decides the optimal actions at each reasoning step. The overall objective of precision-conciseness balance in graph retrieval is decoupled into fine-grained process-supervised rewards to enhance data efficiency and training stability. In practical deployment, GRAIL adopts an interactive retrieval paradigm, enabling the model to autonomously explore graph paths while dynamically balancing retrieval breadth and precision. Extensive experiments have shown that GRAIL achieves an average accuracy improvement of 21.01% and F1 improvement of 22.43% on three knowledge graph question-answering datasets. Our source code and datasets is available at https://github.com/Changgeww/GRAIL.
大型语言模型(LLM)与检索增强生成(RAG)技术的结合已在多个领域展现出卓越的性能。然而,现有的RAG方法主要操作于非结构化数据,在处理结构化知识,如知识图谱方面的能力有限。同时,当前的图检索方法从根本上难以捕捉整体图结构,同时面临精度控制挑战,表现为关键信息缺失或过多冗余连接,共同影响推理性能。为了解决这一挑战,我们提出了GRAIL:图检索增强交互学习,这是一个旨在与大规模图进行交互以进行检索增强推理的框架。具体来说,GRAIL将LLM引导的随机探索与路径过滤相结合,建立数据合成管道,为每个任务自动生成精细的推理轨迹。基于合成数据,然后我们采用两阶段训练过程来学习一个策略,该策略可在每个推理步骤中动态决定最佳行动。图检索中精度简洁性平衡的总体目标被分解为精细的过程监督奖励,以提高数据效率和训练稳定性。在实际部署中,GRAIL采用交互式检索范式,使模型能够自主探索图形路径,同时动态平衡检索广度和精度。大量实验表明,GRAIL在三个知识图谱问答数据集上平均准确率提高了21.01%,F1分数提高了22.43%。我们的源代码和数据集可在https://github.com/Changgeww/GRAIL获得。
论文及项目相关链接
PDF 9 pages,3 figures
摘要
大型语言模型(LLMs)与检索增强生成(RAG)技术结合,在多个领域表现出卓越性能。然而,现有RAG方法主要处理非结构化数据,处理结构化知识(如知识图谱)的能力有限。当前图检索方法难以捕捉整体图结构,同时面临精度控制挑战,表现为关键信息缺失或过多冗余连接,影响了推理性能。为解决此挑战,提出GRAIL:图检索增强交互学习框架,用于与大规模图进行检索增强推理的交互。GRAIL结合LLM引导随机探索与路径过滤,建立数据合成管道,为每项任务自动生成精细推理轨迹。基于合成数据,采用两阶段训练过程学习策略,动态决定每个推理步骤的最佳行动。精度简洁平衡的图检索总体目标被分解为精细过程监督奖励,提高数据效率和训练稳定性。实际应用中,GRAIL采用交互式检索范式,使模型能够自主探索图路径,同时动态平衡检索广度和精度。在三个知识图谱问答数据集上的实验表明,GRAIL平均准确率提高21.01%,F1值提高22.43%。源代码和数据集可访问:https://github.com/Changgeww/GRAIL。
关键见解
- LLMs与RAG结合在多个领域表现优异,但在处理结构化知识(如知识图谱)时存在局限性。
- 当前图检索方法难以捕捉图的完整结构,面临精度控制挑战。
- GRAIL框架通过LLM引导的随机探索和路径过滤来强化图检索。
- GRAIL采用数据合成管道自动生成精细推理轨迹。
- 两阶段训练过程用于学习策略,平衡检索的精度和简洁性。
- 精度简洁平衡的图检索目标通过精细过程监督奖励来提高数据效率和训练稳定性。
- 实验显示,GRAIL在知识图谱问答数据集上的表现有显著改善。
点此查看论文截图

Towards Human-Centric Evaluation of Interaction-Aware Automated Vehicle Controllers: A Framework and Case Study
Authors:Federico Scarì, Olger Siebinga, Arkady Zgonnikov
As automated vehicles (AVs) increasingly integrate into mixed-traffic environments, evaluating their interaction with human-driven vehicles (HDVs) becomes critical. In most research focused on developing new AV control algorithms (controllers), the performance of these algorithms is assessed solely based on performance metrics such as collision avoidance or lane-keeping efficiency, while largely overlooking the human-centred dimensions of interaction with HDVs. This paper proposes a structured evaluation framework that addresses this gap by incorporating metrics grounded in the human-robot interaction literature. The framework spans four key domains: a) interaction effect, b) interaction perception, c) interaction effort, and d) interaction ability. These domains capture both the performance of the AV and its impact on human drivers around it. To demonstrate the utility of the framework, we apply it to a case study evaluating how a state-of-the-art AV controller interacts with human drivers in a merging scenario in a driving simulator. Measuring HDV-HDV interactions as a baseline, this study included one representative metric per domain: a) perceived safety, b) subjective ratings, specifically how participants perceived the other vehicle’s driving behaviour (e.g., aggressiveness or predictability) , c) driver workload, and d) merging success. The results showed that incorporating metrics covering all four domains in the evaluation of AV controllers can illuminate critical differences in driver experience when interacting with AVs. This highlights the need for a more comprehensive evaluation approach. Our framework offers researchers, developers, and policymakers a systematic method for assessing AV behaviour beyond technical performance, fostering the development of AVs that are not only functionally capable but also understandable, acceptable, and safe from a human perspective.
随着自动驾驶车辆(AVs)越来越多地融入到混合交通环境中,评估它们与人类驾驶车辆(HDVs)的互动变得至关重要。在大多数专注于开发新的AV控制算法(控制器)的研究中,这些算法的性能仅基于如避免碰撞或保持车道效率等性能指标进行评估,而很大程度上忽视了与HDV互动的人性化维度。本文提出了一个结构化的评估框架,通过融入基于人机互动文献的指标来解决这一空白。该框架涵盖了四个关键领域:a)互动效果,b)互动感知,c)互动努力,d)互动能力。这些领域既涵盖了AV的性能,也涵盖了其对周围人类驾驶员的影响。为了证明框架的实用性,我们将其应用于一个案例研究,评估最先进的AV控制器在驾驶模拟器中的合并场景中与人类驾驶员的互动情况。以HDV-HDV互动为基准线,本研究在每个领域都包括了一个代表性的指标:a)感知安全,b)主观评价,特别是参与者如何感知另一辆车的驾驶行为(如侵略性或可预测性),c)驾驶员工作量,d)合并成功。结果表明,在评估AV控制器时融入涵盖所有四个领域的指标可以揭示驾驶员与AV互动时的重要差异。这强调了需要一种更全面的评估方法。我们的框架为研究者、开发者和政策制定者提供了一种系统化方法,以评估AV行为的技术性能之外的情况,促进开发不仅功能强大而且从人类的角度来看也易于理解、可接受和安全的AV。
论文及项目相关链接
Summary
本文提出一个针对自动驾驶车辆(AVs)与人为驾驶车辆(HDVs)交互的评价框架,该框架涵盖了四个关键领域:交互效果、交互感知、交互努力和交互能力。该框架通过应用案例研究展示了其实用性,研究结果表明,在评估自动驾驶车辆控制器时,涵盖这四个领域的指标能够揭示驾驶者在与自动驾驶车辆交互时的关键体验差异。这强调了需要更全面、系统的评估方法。本文有助于研究人员、开发者和政策制定者从人类视角评估自动驾驶车辆的行为,推动自动驾驶车辆不仅在功能上具备能力,而且在人类理解、接受和安全方面也能得到保障。
Key Takeaways
- 自动驾驶车辆(AVs)与人为驾驶车辆(HDVs)的交互评估至关重要。
- 现有研究在评估AV控制算法时,主要基于碰撞避免和车道保持效率等性能指标,忽略了与人类驾驶者交互的人为中心维度。
- 提出的评价框架涵盖了四个关键领域:交互效果、交互感知、交互努力和交互能力,以全面评估AV与HDV的交互。
- 通过案例研究,展示了该框架的实用性,并揭示了仅基于技术性能评估AV控制器时的关键缺陷。
- 涵盖四个领域的指标能够揭示驾驶者在与自动驾驶车辆交互时的体验差异。
- 需要更全面、系统的评估方法来评估自动驾驶车辆的行为,以确保其不仅功能强大,而且从人类视角来看易于理解、接受和安全。
点此查看论文截图

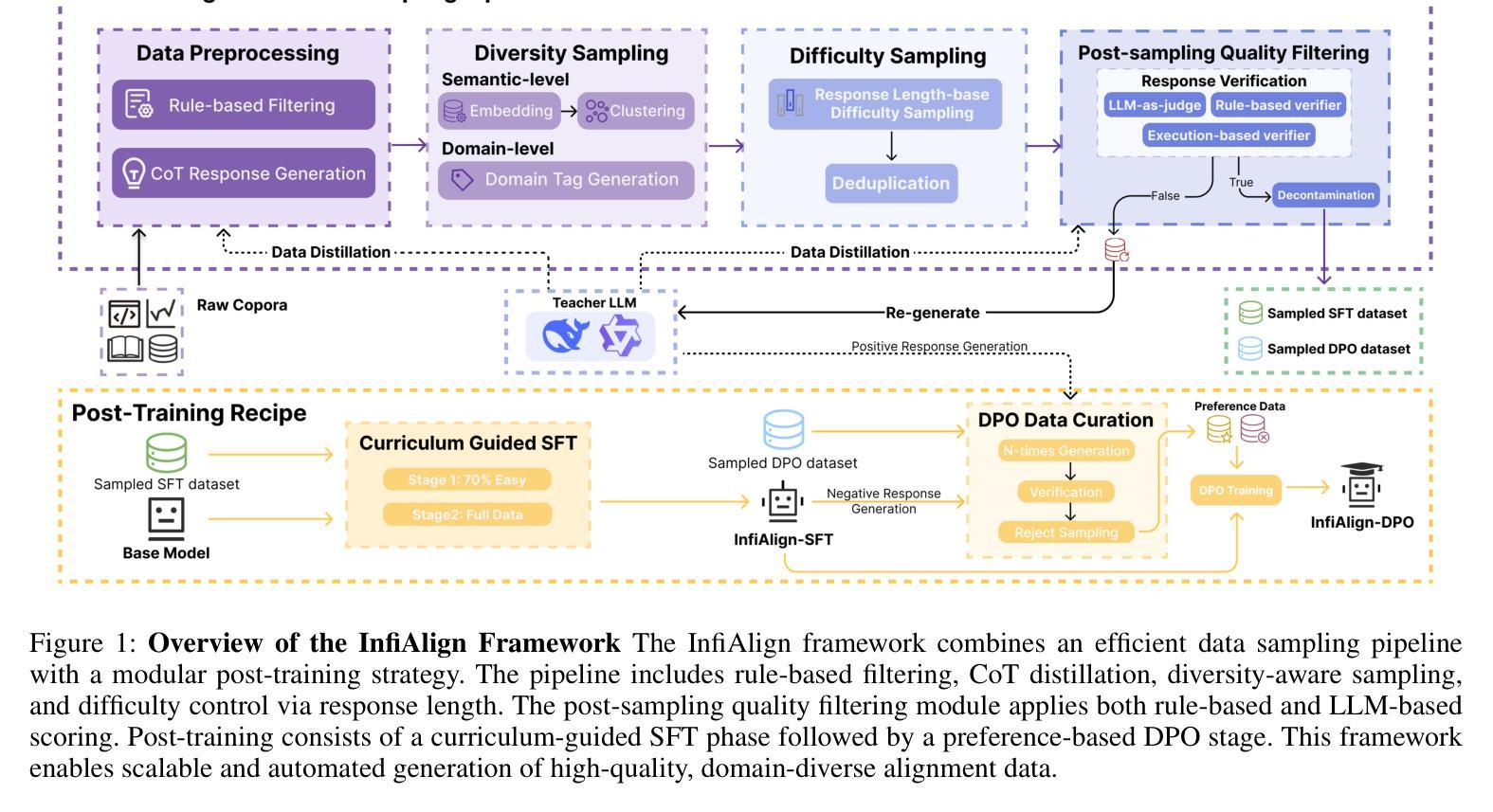
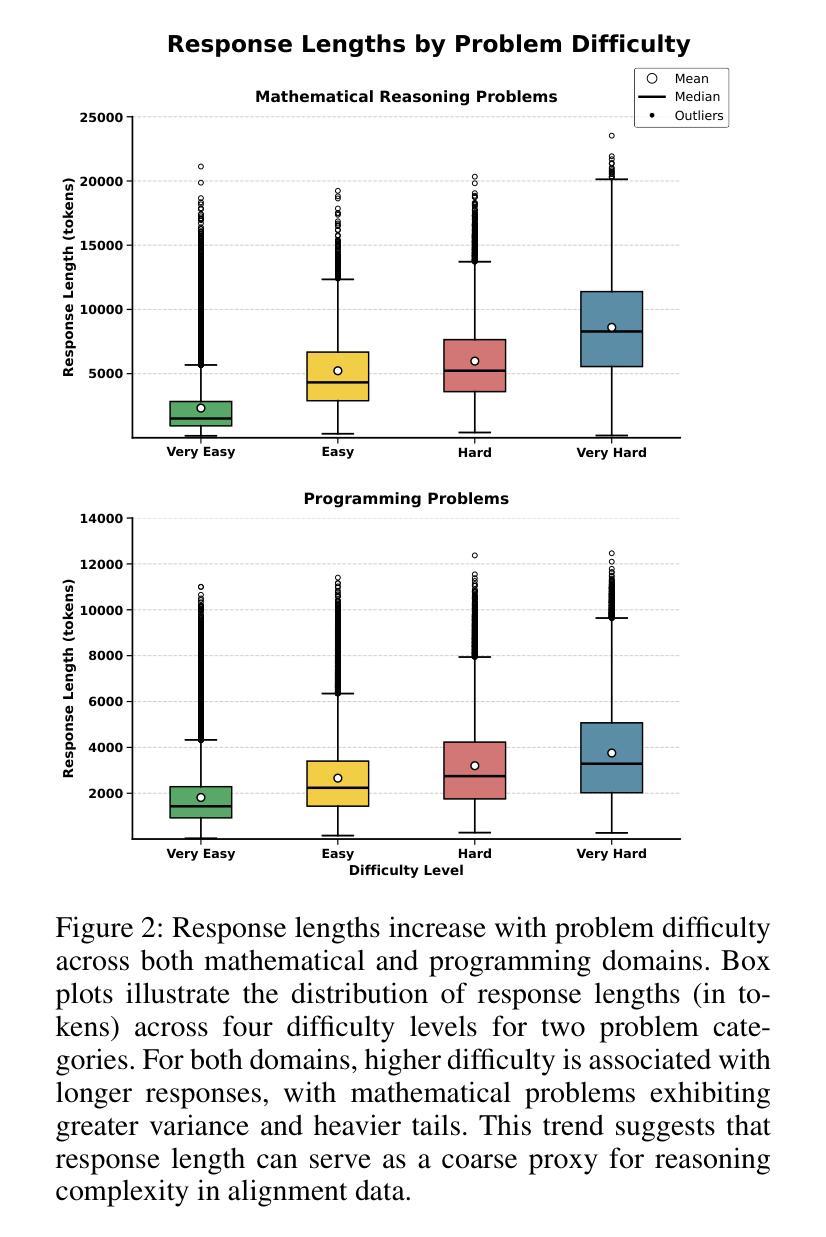
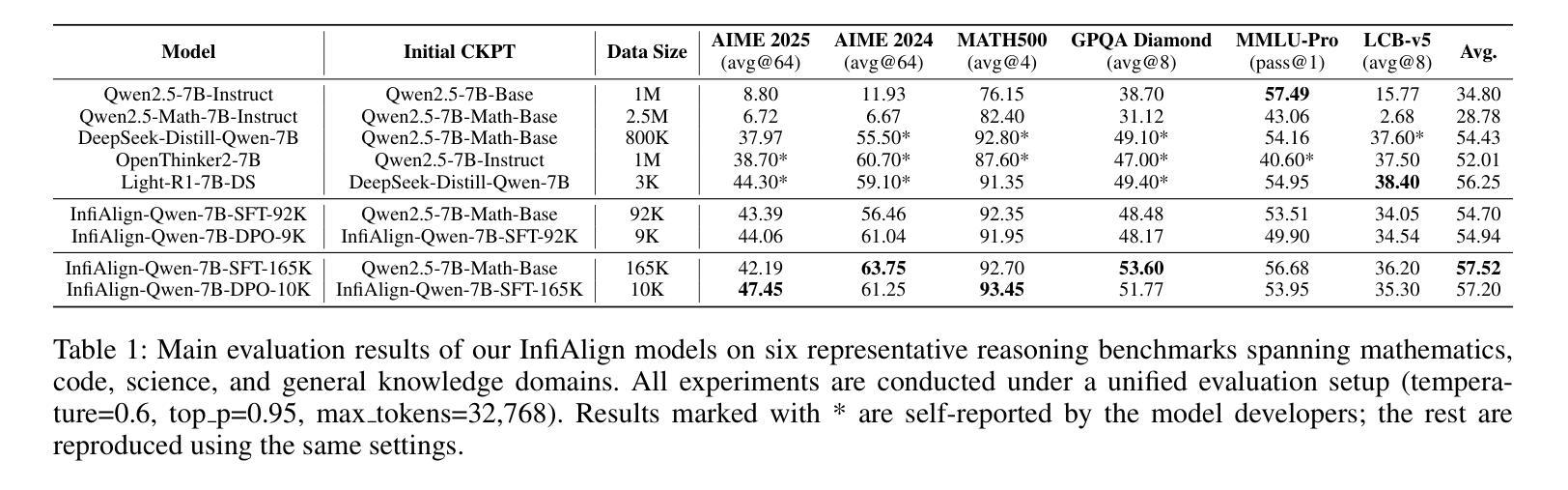
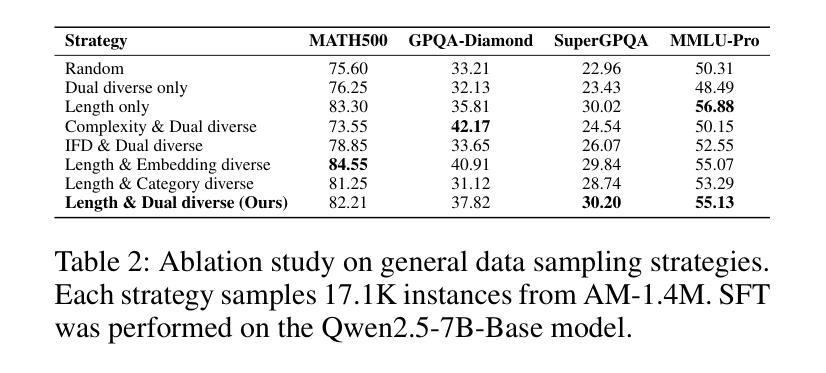
InfiAlign: A Scalable and Sample-Efficient Framework for Aligning LLMs to Enhance Reasoning Capabilities
Authors:Shuo Cai, Su Lu, Qi Zhou, Kejing Yang, Zhijie Sang, Congkai Xie, Hongxia Yang
Large language models (LLMs) have exhibited impressive reasoning abilities on a wide range of complex tasks. However, enhancing these capabilities through post-training remains resource intensive, particularly in terms of data and computational cost. Although recent efforts have sought to improve sample efficiency through selective data curation, existing methods often rely on heuristic or task-specific strategies that hinder scalability. In this work, we introduce InfiAlign, a scalable and sample-efficient post-training framework that integrates supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to align LLMs for enhanced reasoning. At the core of InfiAlign is a robust data selection pipeline that automatically curates high-quality alignment data from open-source reasoning datasets using multidimensional quality metrics. This pipeline enables significant performance gains while drastically reducing data requirements and remains extensible to new data sources. When applied to the Qwen2.5-Math-7B-Base model, our SFT model achieves performance on par with DeepSeek-R1-Distill-Qwen-7B, while using only approximately 12% of the training data, and demonstrates strong generalization across diverse reasoning tasks. Additional improvements are obtained through the application of DPO, with particularly notable gains in mathematical reasoning tasks. The model achieves an average improvement of 3.89% on AIME 24/25 benchmarks. Our results highlight the effectiveness of combining principled data selection with full-stage post-training, offering a practical solution for aligning large reasoning models in a scalable and data-efficient manner. The model checkpoints are available at https://huggingface.co/InfiX-ai/InfiAlign-Qwen-7B-SFT.
大型语言模型(LLM)在广泛的复杂任务中展现出了令人印象深刻的推理能力。然而,通过后期训练增强这些能力仍然是资源密集型的,特别是在数据和计算成本方面。尽管最近的努力试图通过选择性数据收集来提高样本效率,但现有方法通常依赖于启发式或任务特定策略,这阻碍了可扩展性。在这项工作中,我们介绍了InfiAlign,这是一个可扩展且样本效率高的后期训练框架,它将监督微调(SFT)与直接偏好优化(DPO)相结合,以对LLM进行增强推理对齐。InfiAlign的核心是一个稳健的数据选择管道,它使用多维质量指标自动从开源推理数据集中筛选高质量的对齐数据。该管道能够在大幅降低数据需求的同时实现显著的性能提升,并且可扩展到新的数据源。当应用于Qwen2.5-Math-7B-Base模型时,我们的SFT模型在性能上可以与DeepSeek-R1-Distill-Qwen-7B相媲美,同时使用的数据量仅约为12%,并且在各种推理任务中表现出强大的泛化能力。通过应用DPO还获得了额外的改进,特别是在数学推理任务中取得了显著的收益。该模型在AIME 24/25基准测试中平均提高了3.89%的性能。我们的结果强调了原则性数据选择与全阶段后期训练相结合的有效性,为以可扩展和高效数据的方式对齐大型推理模型提供了实用解决方案。该模型检查点位于:https://huggingface.co/InfiX-ai/InfiAlign-Qwen-7B-SFT。
论文及项目相关链接
Summary
大型语言模型(LLM)在广泛复杂任务中展现出强大的推理能力,但其能力增强通过训练后仍然需要大量资源和数据计算成本。近期尽管有所努力改善样本效率通过选择性数据收集,但现有方法经常依赖启发式或任务特定策略阻碍可扩展性。在这项工作中,我们引入InfiAlign,一个可扩展且样本高效的训练后框架,融合了监督微调(SFT)与直接偏好优化(DPO),以提高LLM的推理能力。InfiAlign的核心是一个稳健的数据选择管道,可从开源推理数据集中自动筛选高质量对齐数据,使用多维质量指标。此管道可在大幅降低数据需求的同时实现显著性能提升,且对新数据源具有可扩展性。应用于Qwen2.5-Math-7B-Base模型时,我们的SFT模型性能与DeepSeek-R1-Distill-Qwen-7B相当,仅使用约12%的训练数据,并在各种推理任务中展现出强大的泛化能力。通过应用DPO可获得额外改进,特别是在数学推理任务中。模型在AIME 24/25基准测试中平均提升3.89%。我们的结果强调了结合原则性数据选择与全阶段训练后对齐的有效性和实用性,为大规模和数据高效的方式对齐大型推理模型提供了实际解决方案。
Key Takeaways
- InfiAlign是一个用于增强大型语言模型(LLM)推理能力的训练后框架。
- 它结合了监督微调(SFT)与直接偏好优化(DPO)。
- InfiAlign具有可扩展性和样本效率,通过自动筛选高质量数据降低资源消耗。
- InfiAlign能显著提高模型性能,同时使用较少的训练数据。
- 在Qwen2.5-Math-7B-Base模型上的实验证明了InfiAlign的有效性。
- DPO的应用进一步提高了模型性能,特别是在数学推理任务上。
- 模型在AIME 24/25基准测试中实现了显著的性能提升。
点此查看论文截图

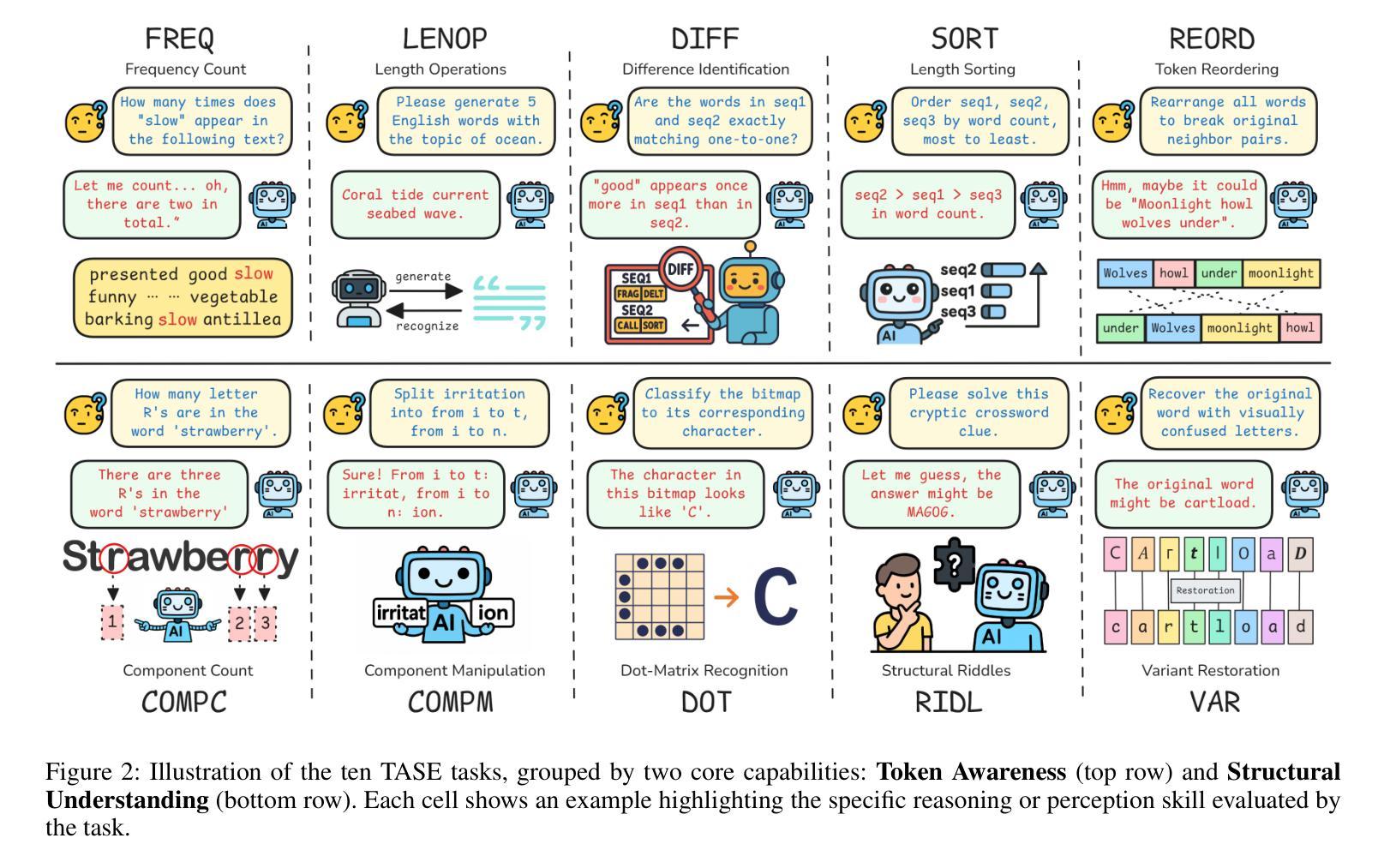
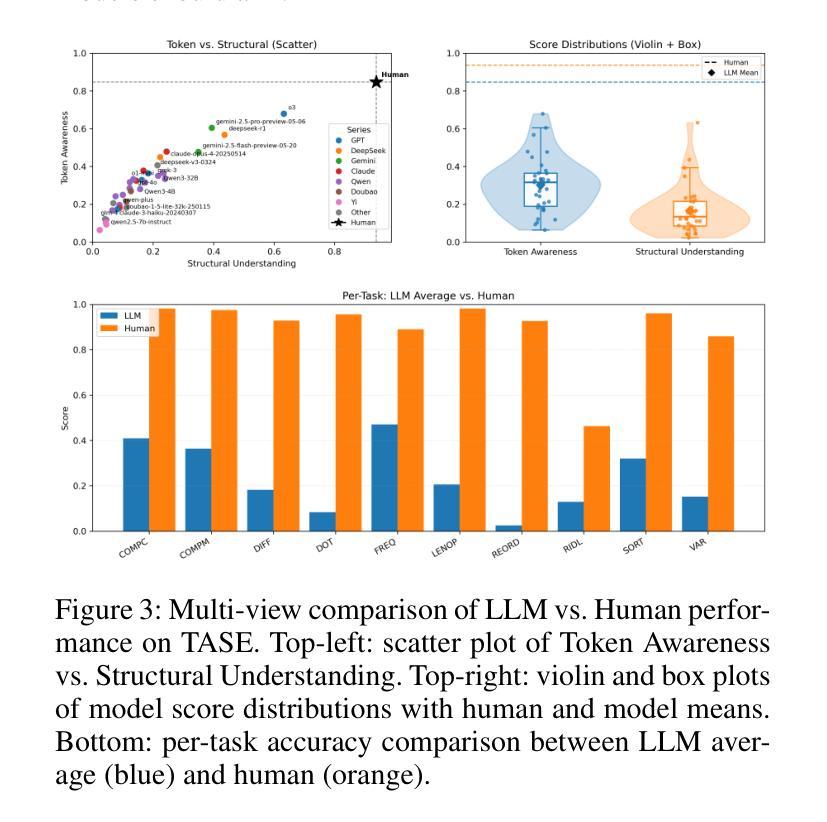
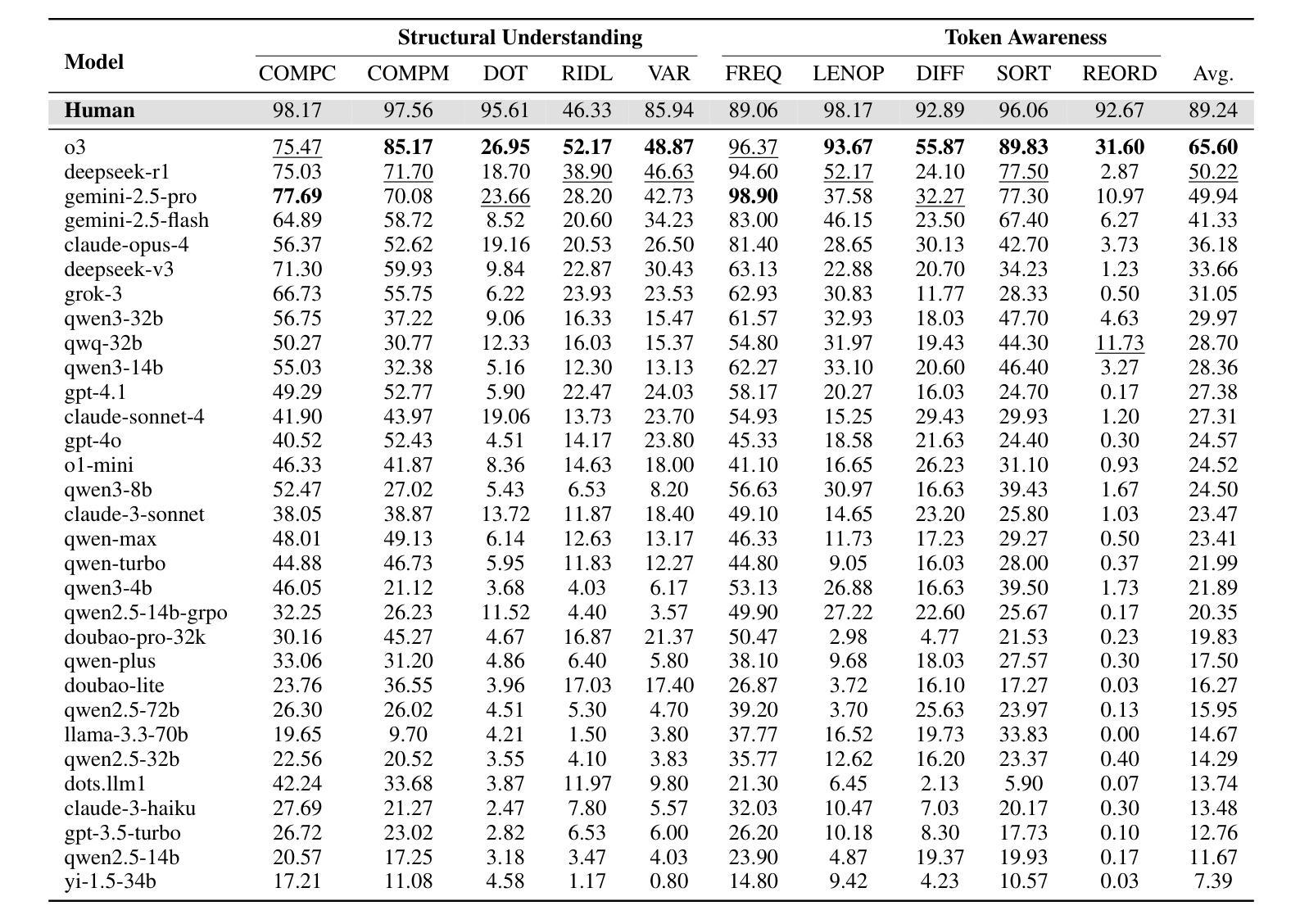
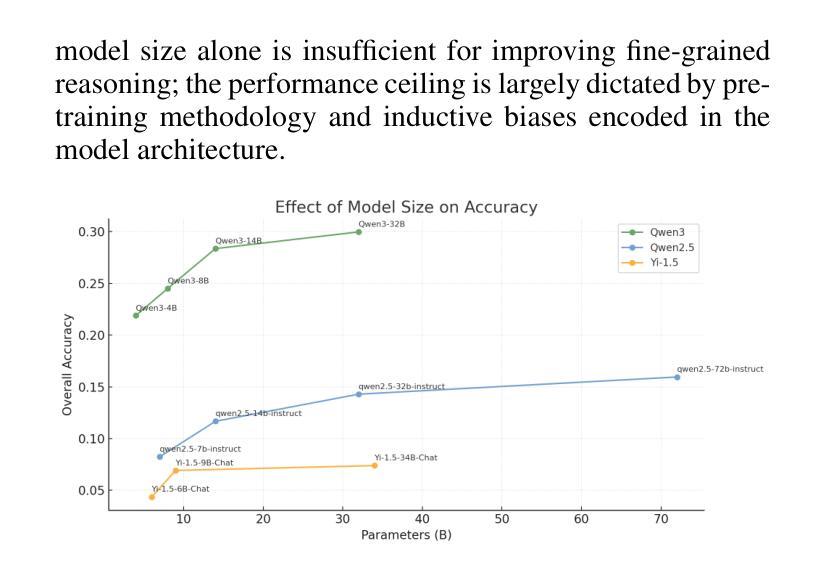
TASE: Token Awareness and Structured Evaluation for Multilingual Language Models
Authors:Chenzhuo Zhao, Xinda Wang, Yue Huang, Junting Lu, Ziqian Liu
While large language models (LLMs) have demonstrated remarkable performance on high-level semantic tasks, they often struggle with fine-grained, token-level understanding and structural reasoning–capabilities that are essential for applications requiring precision and control. We introduce TASE, a comprehensive benchmark designed to evaluate LLMs’ ability to perceive and reason about token-level information across languages. TASE covers 10 tasks under two core categories: token awareness and structural understanding, spanning Chinese, English, and Korean, with a 35,927-instance evaluation set and a scalable synthetic data generation pipeline for training. Tasks include character counting, token alignment, syntactic structure parsing, and length constraint satisfaction. We evaluate over 30 leading commercial and open-source LLMs, including O3, Claude 4, Gemini 2.5 Pro, and DeepSeek-R1, and train a custom Qwen2.5-14B model using the GRPO training method. Results show that human performance significantly outpaces current LLMs, revealing persistent weaknesses in token-level reasoning. TASE sheds light on these limitations and provides a new diagnostic lens for future improvements in low-level language understanding and cross-lingual generalization. Our code and dataset are publicly available at https://github.com/cyzcz/Tase .
虽然大型语言模型(LLM)在高层次语义任务上表现出了出色的性能,但在精细粒度、标记级别的理解和结构性推理方面常常遇到困难——这些能力对于需要精确性和控制的应用来说是必不可少的。我们介绍了TASE,这是一个综合基准测试,旨在评估LLM对跨语言的标记级信息的感知和推理能力。TASE涵盖两个核心类别下的10项任务:标记意识和结构理解,涵盖中文、英文和韩语,评估集包含35927个实例,并具备可扩展的合成数据生成管道用于训练。任务包括字符计数、标记对齐、句法结构解析和长度约束满足等。我们评估了30多个领先的商业和开源LLM,包括O3、Claude 4、Gemini 2.5 Pro和DeepSeek-R1,并使用GRPO训练方法训练了一个定制的Qwen2. 5-14B模型。结果表明,人类性能显著超过当前LLM,揭示了标记级推理的持久性弱点。TASE揭示了这些限制,并为未来在低级别语言理解和跨语言泛化方面的改进提供了新的诊断视角。我们的代码和数据集可在https://github.com/cyzcz/Tase上公开获得。
论文及项目相关链接
Summary:
大型语言模型(LLM)在高层次语义任务上表现突出,但在精细粒度的token级别理解和结构性推理方面存在挑战。为评估LLM对token级别信息的感知和推理能力,我们推出了TASE综合基准测试。TASE涵盖10项任务,分为两个核心类别:token意识和结构理解,涉及中文、英文和韩语。我们评估了30多种领先的商业和开源LLM,并定制了Qwen2.5-14B模型。结果表明,人类性能显著优于当前LLM,揭示了其在token级别推理方面的持续弱点。TASE为未来的低级别语言理解和跨语言泛化改进提供了新的诊断视角。
Key Takeaways:
- 大型语言模型(LLM)在token级别理解和结构性推理方面存在挑战。
- TASE是一个用于评估LLM的基准测试,涵盖token意识和结构理解两个核心类别。
- TASE包含多种语言(中文、英文和韩语),涵盖10项任务。
- 评估了30多种LLM的性能,包括商业和开源模型。
- 定制了Qwen2.5-14B模型并使用GRPO训练方法。
- 人类性能显著优于当前LLM在token级别推理任务上的表现。
- TASE为改进低级别语言理解和跨语言泛化提供了新视角。
点此查看论文截图

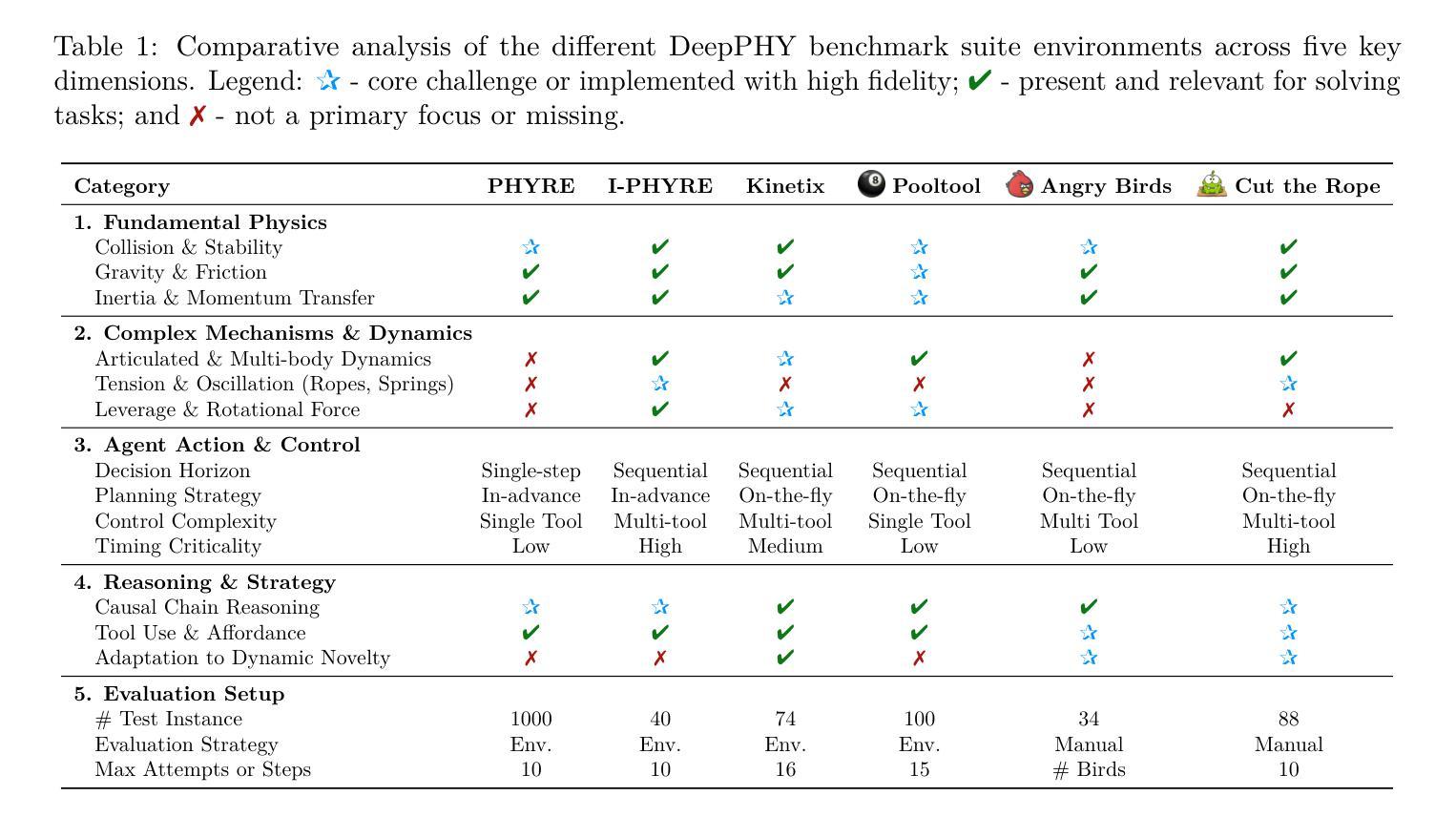
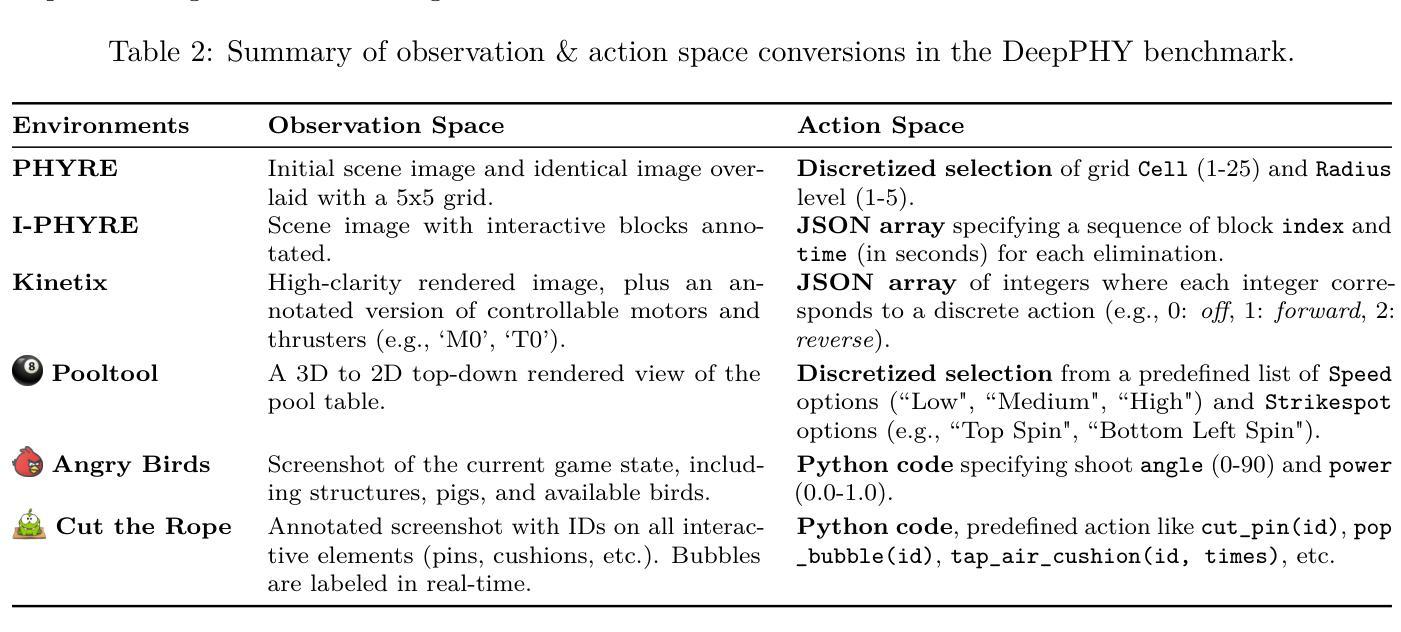
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Authors:Xinrun Xu, Pi Bu, Ye Wang, Börje F. Karlsson, Ziming Wang, Tengtao Song, Qi Zhu, Jun Song, Zhiming Ding, Bo Zheng
Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs’ understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.
尽管视觉语言模型(VLMs)展现出强大的感知能力和令人印象深刻的视觉推理能力,但在复杂的动态环境中,它们在细节关注和精确行动规划方面遇到困难,导致性能不佳。现实世界任务通常需要复杂的交互、高级的空间推理、长期规划和连续的策略改进,通常需要理解目标场景的物理规则。然而,在真实场景中对这些能力进行评估通常成本高昂。为了弥补这一差距,我们引入了DeepPHY,这是一个新型基准框架,旨在通过一系列具有挑战性的模拟环境系统地评估VLMs对基本物理原理的理解和推理能力。DeepPHY整合了不同难度级别的多个物理推理环境,并采用了精细的评估指标。我们的评估发现,即使是最先进的VLMs也难以将描述性的物理知识转化为精确、预测性的控制。
论文及项目相关链接
PDF 48 pages
Summary
在模拟环境中,尽管视觉语言模型(VLMs)展现出强大的感知能力和令人印象深刻的视觉推理能力,但在复杂动态环境中,它们对细节的关注和精确的行动规划能力仍有待提高。真实世界任务通常需要复杂的交互、高级的空间推理、长期规划和连续的策略调整,通常需要理解目标场景的物理规则。为了评估这些能力,我们提出了DeepPHY这一新型基准框架,旨在通过一系列具有挑战性的模拟环境系统地评估VLMs对基本物理原理的理解和推理能力。评估发现,即使是最先进的VLMs也很难将描述性的物理知识转化为精确、预测性的控制力。
Key Takeaways
- VLMs在复杂动态环境中存在细节关注和精确行动规划的挑战。
- 真实世界任务需要复杂的交互、高级的空间推理和连续的策略调整。
- 真实世界任务的完成通常需要理解目标场景的物理规则。
- DeepPHY是一个新型基准框架,旨在评估VLMs对物理原理的理解和推理能力。
- DeepPHY通过模拟环境进行系统化评估,包含不同难度级别的多个物理推理环境。
- 评估发现,VLMs在将描述性物理知识转化为精确、预测性的控制力方面存在困难。
点此查看论文截图

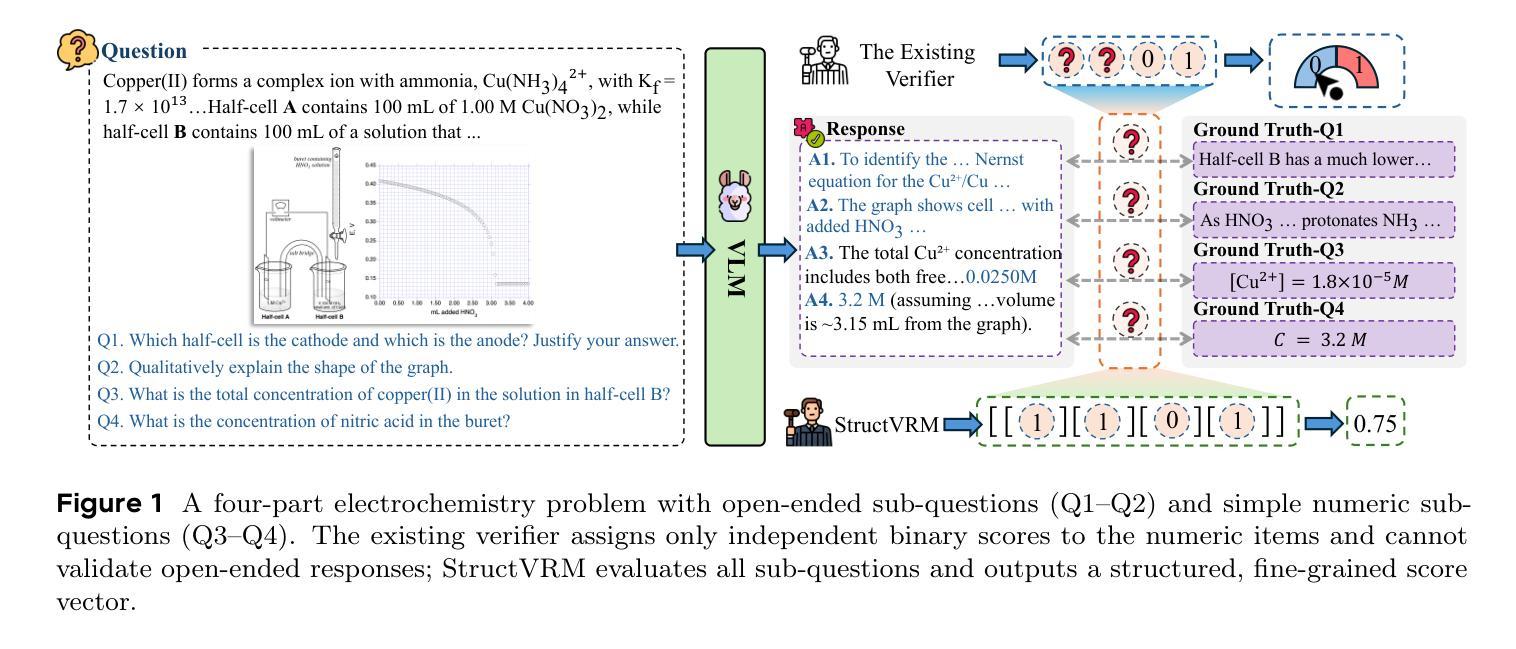
StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Authors:Xiangxiang Zhang, Jingxuan Wei, Donghong Zhong, Qi Chen, Caijun Jia, Cheng Tan, Jinming Gu, Xiaobo Qin, Zhiping Liu, Liang Hu, Tong Sun, Yuchen Wu, Zewei Sun, Chenwei Lou, Hua Zheng, Tianyang Zhan, Changbao Wang, Shuangzhi Wu, Zefa Lin, Chang Guo, Sihang Yuan, Riwei Chen, Shixiong Zhao, Yingping Zhang, Gaowei Wu, Bihui Yu, Jiahui Wu, Zhehui Zhao, Qianqian Liu, Ruofeng Tang, Xingyue Huang, Bing Zhao, Mengyang Zhang, Youqiang Zhou
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
现有的视觉语言模型在处理复杂的多问题推理任务时常常面临挑战,这些任务中的部分正确性对于有效学习至关重要。传统的奖励机制为整个回应提供一个单一的二元分数,这在指导模型解决具有多个子部分的问题时过于粗糙。为了解决这个问题,我们引入了StructVRM方法,它将多模态推理与结构化可验证奖励模型对齐。其核心是一个基于模型的验证器,经过训练可提供精细粒度的子问题级别反馈,评估语义和数学等价性,而不是依赖于僵硬的字符串匹配。这允许在以前难以解决的问题格式中进行微妙的、部分信用评分。大量实验证明了StructVRM的有效性。我们的训练模型Seed-StructVRM在十二个公共多模态基准测试中的六个以及我们新整理的高难度STEM-Bench上达到了最先进的性能。StructVRM的成功验证了使用结构化可验证奖励进行训练是一种在复杂现实世界推理领域提高多模态模型能力的高效方法。
论文及项目相关链接
摘要
在复杂的、涉及多个问题的推理任务中,现有的视觉语言模型常常会遇到困难,部分正确性对于有效学习至关重要。传统的奖励机制为整个响应提供一个单一的二进制分数,这对于指导模型解决具有多个子部分的复杂问题是过于粗略的。为解决此问题,我们提出了StructVRM方法,它将多模态推理与结构化可验证奖励模型对齐。其核心是一个基于模型的验证器,经过训练可提供精细粒度的、子问题级别的反馈,评估语义和数学上的等价性,而非依赖僵硬的字符串匹配。这允许在以前难以解决的问题格式中进行细微的、部分信用的评分。广泛的实验证明了StructVRM的有效性。我们的训练模型Seed-StructVRM在十二个公共多模态基准测试中实现了六个最佳性能,以及我们新整理的高难度STEM-Bench也是如此。StructVRM的成功验证了使用结构化可验证奖励进行培训是一种在复杂的现实世界推理领域推进多模态模型能力的高效方法。
要点掌握
- 现有视觉语言模型在复杂多问题推理任务上表现不足,部分正确性对有效学习至关重要。
- 传统奖励机制过于粗略,无法有效指导模型解决复杂问题。
- StructVRM方法通过结构化可验证奖励模型对齐多模态推理,提供精细粒度的子问题级别反馈。
- StructVRM评估语义和数学上的等价性,而非依赖僵硬的字符串匹配,允许部分信用评分。
- StructVRM方法能够有效提升模型性能,在多个公共多模态基准测试中取得最佳结果。
- Seed-StructVRM模型在多个基准测试上表现优异,验证了结构化可验证奖励方法的有效性。
点此查看论文截图

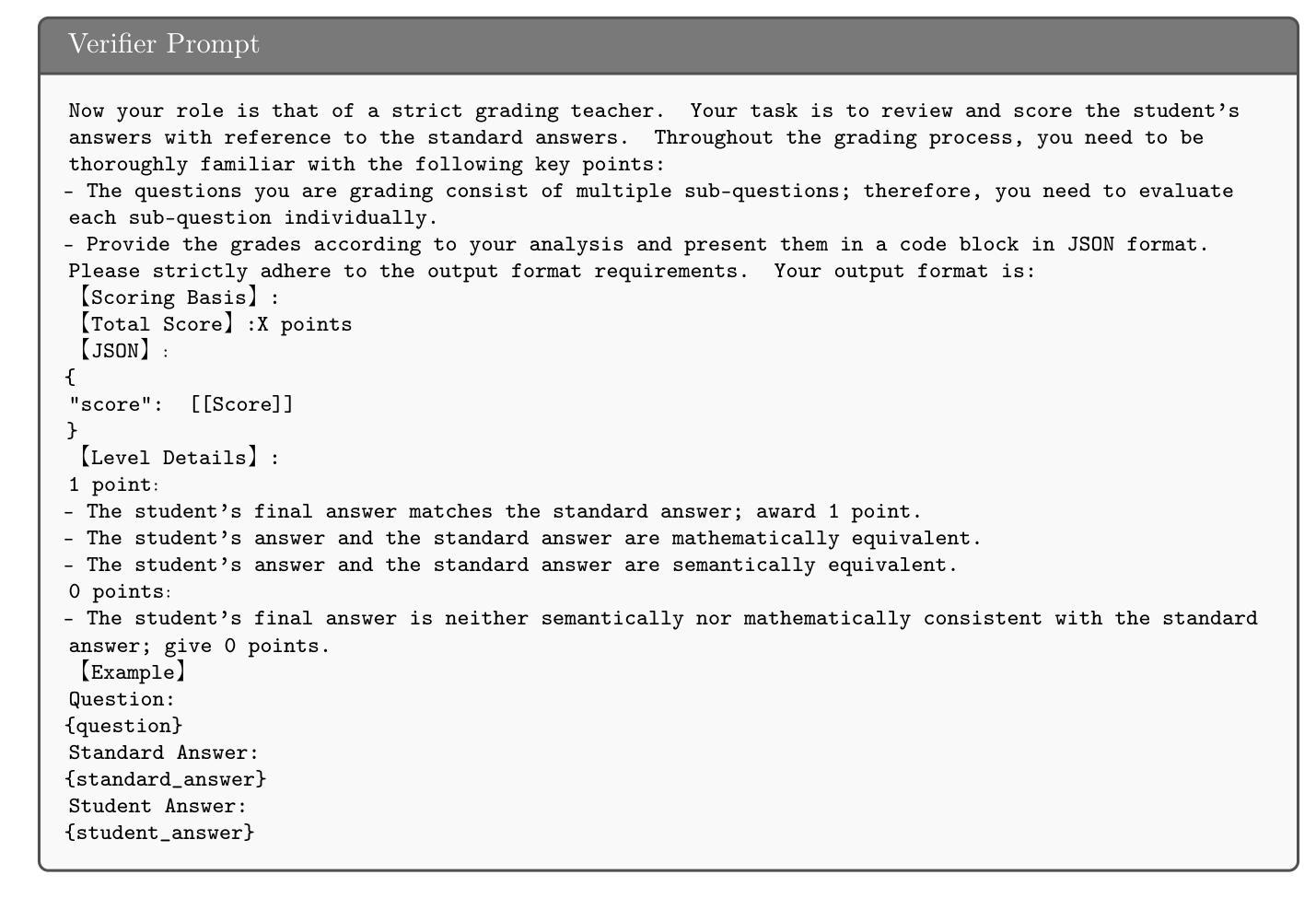
Does Multimodality Improve Recommender Systems as Expected? A Critical Analysis and Future Directions
Authors:Hongyu Zhou, Yinan Zhang, Aixin Sun, Zhiqi Shen
Multimodal recommendation systems are increasingly popular for their potential to improve performance by integrating diverse data types. However, the actual benefits of this integration remain unclear, raising questions about when and how it truly enhances recommendations. In this paper, we propose a structured evaluation framework to systematically assess multimodal recommendations across four dimensions: Comparative Efficiency, Recommendation Tasks, Recommendation Stages, and Multimodal Data Integration. We benchmark a set of reproducible multimodal models against strong traditional baselines and evaluate their performance on different platforms. Our findings show that multimodal data is particularly beneficial in sparse interaction scenarios and during the recall stage of recommendation pipelines. We also observe that the importance of each modality is task-specific, where text features are more useful in e-commerce and visual features are more effective in short-video recommendations. Additionally, we explore different integration strategies and model sizes, finding that Ensemble-Based Learning outperforms Fusion-Based Learning, and that larger models do not necessarily deliver better results. To deepen our understanding, we include case studies and review findings from other recommendation domains. Our work provides practical insights for building efficient and effective multimodal recommendation systems, emphasizing the need for thoughtful modality selection, integration strategies, and model design.
多模态推荐系统因其通过集成多种数据类型提高性能的潜力而越来越受欢迎。然而,这种集成的实际效益仍然不明确,引发了关于何时以及如何真正增强推荐的疑问。在本文中,我们提出了一个结构化评估框架,从四个维度系统地评估多模态推荐:比较效率、推荐任务、推荐阶段和多模态数据集成。我们将一组可复制的多模态模型与强大的传统基线进行基准测试,并在不同的平台上评估它们的性能。我们的研究发现,多模态数据在稀疏交互场景和推荐管道的回溯阶段特别有益。我们还观察到,每种模态的重要性是任务特定的,其中文本特征在电子商务中更有用,而视觉特征在短视频推荐中更有效。此外,我们探索了不同的集成策略和模型大小,发现基于集成学习优于基于融合的学习,而且更大的模型并不一定产生更好的结果。为了深入了解,我们包含了案例研究并回顾了其他推荐领域的发现。我们的工作提供了构建高效且实用的多模态推荐系统的实用见解,强调需要深思熟虑的模态选择、集成策略和模型设计。
论文及项目相关链接
Summary
多模态推荐系统通过整合多种数据类型提高性能,但其实际效益尚不清楚。本文提出一个结构化评估框架,从四个维度系统地评估多模态推荐:比较效率、推荐任务、推荐阶段和多模态数据集成。实验表明,多模态数据在交互场景稀少和推荐管道召回阶段特别有益。不同任务下不同模态的重要性不同,文本特征在电子商务中更有用,视觉特征在短视频推荐中更有效。此外,还发现集成策略和模型大小的影响,如集成学习优于融合学习,大模型不一定效果好。本文深化了我们对多模态推荐系统的理解,为构建高效、实用的多模态推荐系统提供了实际见解。
Key Takeaways
- 多模态推荐系统通过整合多种数据类型提高性能。
- 多模态数据的实际效益尚不清楚,需要系统地评估。
- 多模态数据在交互场景稀少和推荐管道召回阶段特别有益。
- 不同任务下不同模态的重要性不同,文本和视觉特征在不同场景中有不同效果。
- Ensemble-Based Learning在集成策略中表现较好。
- 更大的模型不一定能带来更好的效果。
点此查看论文截图

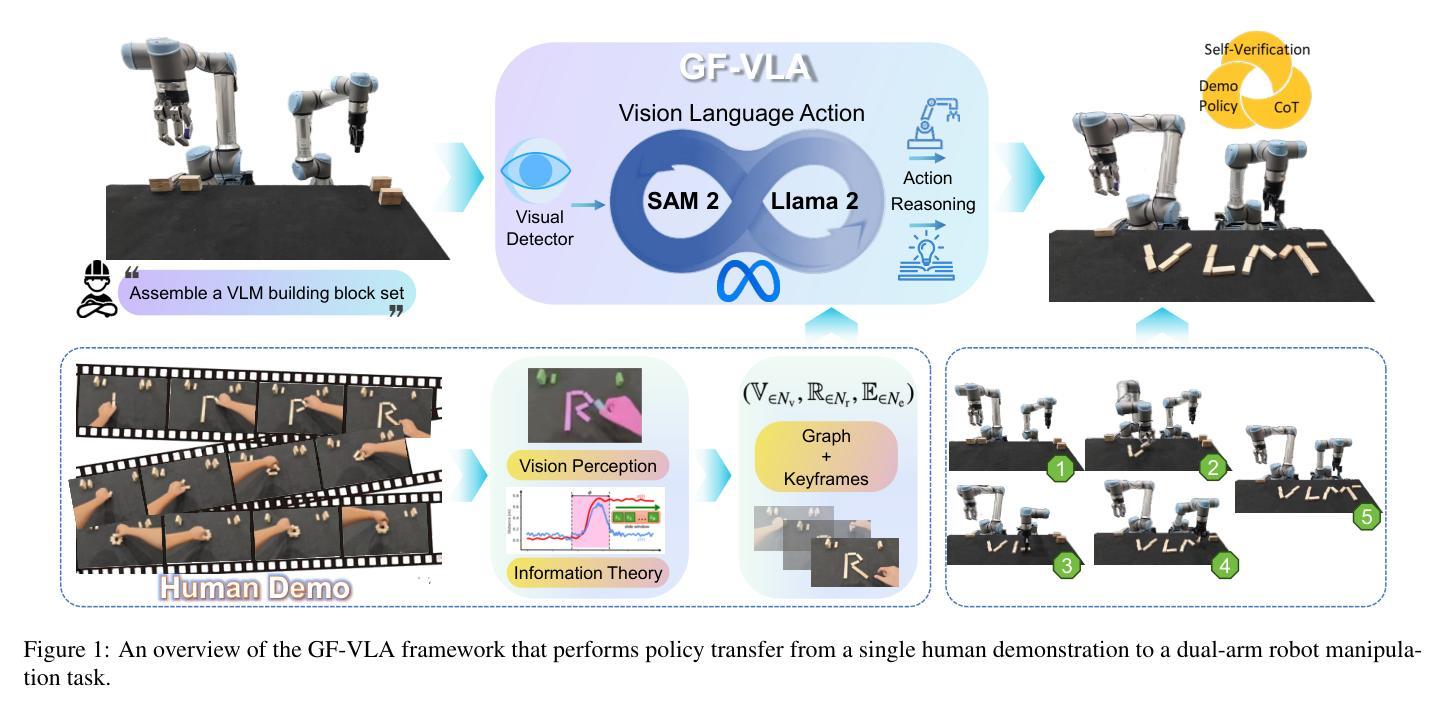
Information-Theoretic Graph Fusion with Vision-Language-Action Model for Policy Reasoning and Dual Robotic Control
Authors:Shunlei Li, Longsen Gao, Jin Wang, Chang Che, Xi Xiao, Jiuwen Cao, Yingbai Hu, Hamid Reza Karimi
Teaching robots dexterous skills from human videos remains challenging due to the reliance on low-level trajectory imitation, which fails to generalize across object types, spatial layouts, and manipulator configurations. We propose Graph-Fused Vision-Language-Action (GF-VLA), a framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB and Depth human demonstrations. GF-VLA first extracts Shannon-information-based cues to identify hands and objects with the highest task relevance, then encodes these cues into temporally ordered scene graphs that capture both hand-object and object-object interactions. These graphs are fused with a language-conditioned transformer that generates hierarchical behavior trees and interpretable Cartesian motion commands. To improve execution efficiency in bimanual settings, we further introduce a cross-hand selection policy that infers optimal gripper assignment without explicit geometric reasoning. We evaluate GF-VLA on four structured dual-arm block assembly tasks involving symbolic shape construction and spatial generalization. Experimental results show that the information-theoretic scene representation achieves over 95 percent graph accuracy and 93 percent subtask segmentation, supporting the LLM planner in generating reliable and human-readable task policies. When executed by the dual-arm robot, these policies yield 94 percent grasp success, 89 percent placement accuracy, and 90 percent overall task success across stacking, letter-building, and geometric reconfiguration scenarios, demonstrating strong generalization and robustness across diverse spatial and semantic variations.
教授机器人从人类视频中掌握灵巧技能仍然具有挑战性,因为这依赖于低层次的轨迹模仿,无法概括各种对象类型、空间布局和操作器配置。我们提出了Graph-Fused Vision-Language-Action(GF-VLA)框架,该框架能够使双臂机器人系统直接从RGB和Depth人类演示中进行任务级别的推理和执行。GF-VLA首先提取基于Shannon信息的线索来识别与任务最相关的手和物体,然后将这些线索编码成按时间顺序排列的场景图,捕捉手与物体以及物体与物体之间的交互。这些图与受语言控制的大型模型进行融合,生成层次化的行为树和可解释的笛卡尔运动命令。为了提高双臂环境中的执行效率,我们进一步引入了跨手选择策略,该策略通过无明确几何推理的方式推断最佳的夹持器分配。我们在涉及符号形状构造和空间泛化的四个结构化双臂积木组装任务上评估了GF-VLA。实验结果表明,基于信息论的场景表示在图中实现了超过95%的准确性和高达93%的子任务分割率,支持大型语言模型规划器生成可靠且人类可读的策略。当双臂机器人执行这些策略时,它们的抓握成功率达到了高达94%,放置准确性为高达89%,并且在堆叠、字母构造和几何重构场景中整体任务成功率为高达90%,这显示了在不同空间和语义变化中的强大泛化和稳健性。
论文及项目相关链接
PDF Journal under review
Summary:
机器人从人类视频中学习灵巧技能具有挑战性,因为依赖于低级别的轨迹模仿,无法概括不同类型的对象、空间布局和操作配置。为此,我们提出了Graph-Fused Vision-Language-Action(GF-VLA)框架,该框架使双臂机器人系统能够从RGB和深度的人类演示中直接进行任务级别的推理和执行。GF-VLA通过提取基于香农信息的线索来识别最具任务相关性的手和物体,然后将这些线索编码成捕获手与物体之间以及物体与物体之间互动的时空场景图。这些图与语言条件下的变压器相融合,生成层次化的行为树和可解释的笛卡尔运动命令。为提高双臂环境中的执行效率,我们进一步引入了跨手选择策略,该策略能够在无需显式几何推理的情况下推断最佳夹持器分配。我们在涉及符号形状构建和空间泛化的四个结构化双臂块组装任务上评估了GF-VLA。实验结果表明,信息理论场景表示法实现了超过95%的图准确性和93%的子任务分割,支持LLM规划器生成可靠且易于理解的任务策略。当由双臂机器人执行时,这些策略在堆叠、字母构建和几何重构场景中分别实现了94%的抓取成功率、89%的定位精度和90%的总体任务成功率,显示出强大的泛化能力和对各种空间语义变化的稳健性。
Key Takeaways:
- 机器人从人类视频中学习技能存在挑战,因为基于低级别轨迹模仿的方法无法适应不同情境。
- 提出了Graph-Fused Vision-Language-Action(GF-VLA)框架,使机器人能从RGB和深度演示中直接进行任务级别的学习和执行。
- GF-VLA利用香农信息理论来识别任务相关的手和物体,并编码成场景图,捕获手与物体间的互动。
- 融合语言条件下的变压器生成行为树和运动命令,提高机器人的任务执行能力。
- 引入跨手选择策略,优化双臂机器人在复杂任务中的执行效率。
- 在四个双臂块组装任务上的实验验证了GF-VLA框架的有效性,表现出高准确率和泛化能力。
点此查看论文截图

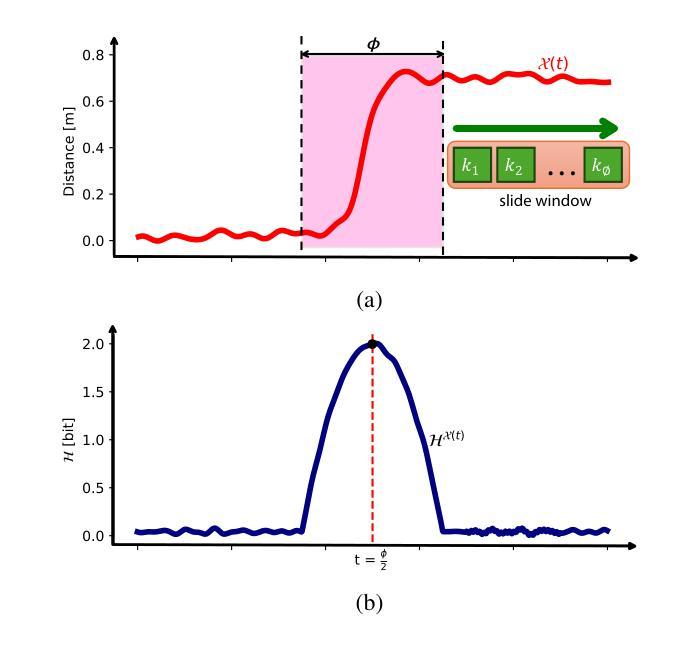
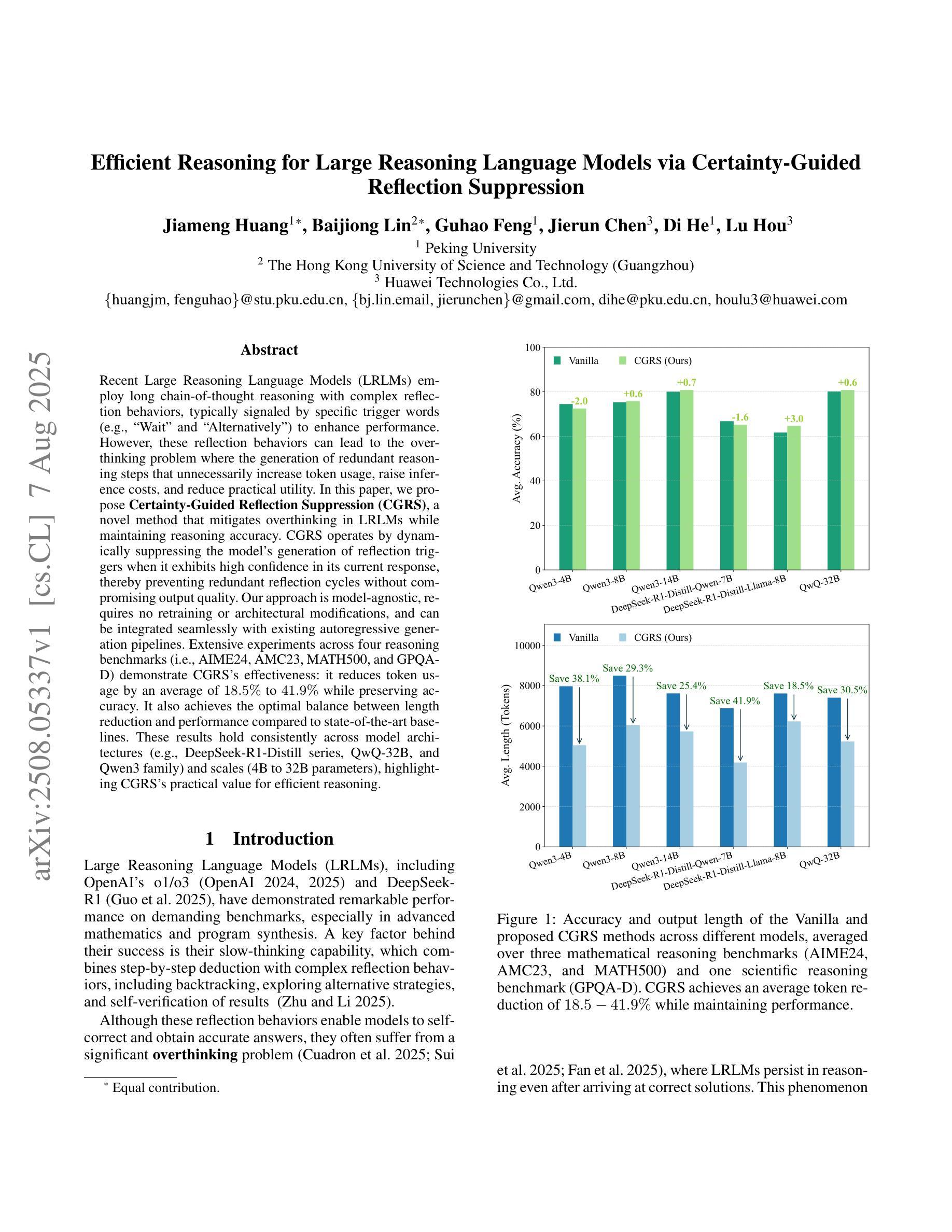
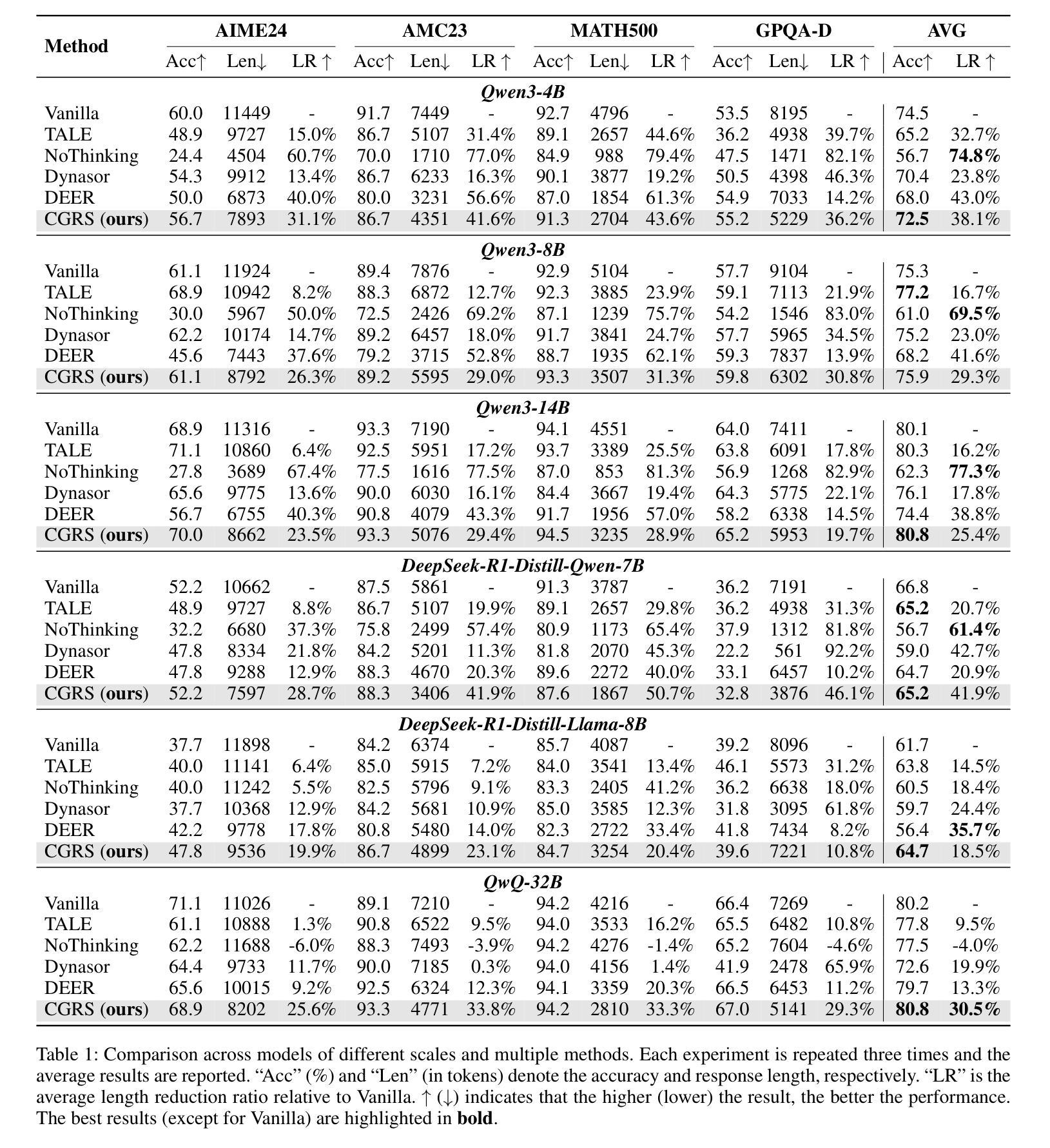
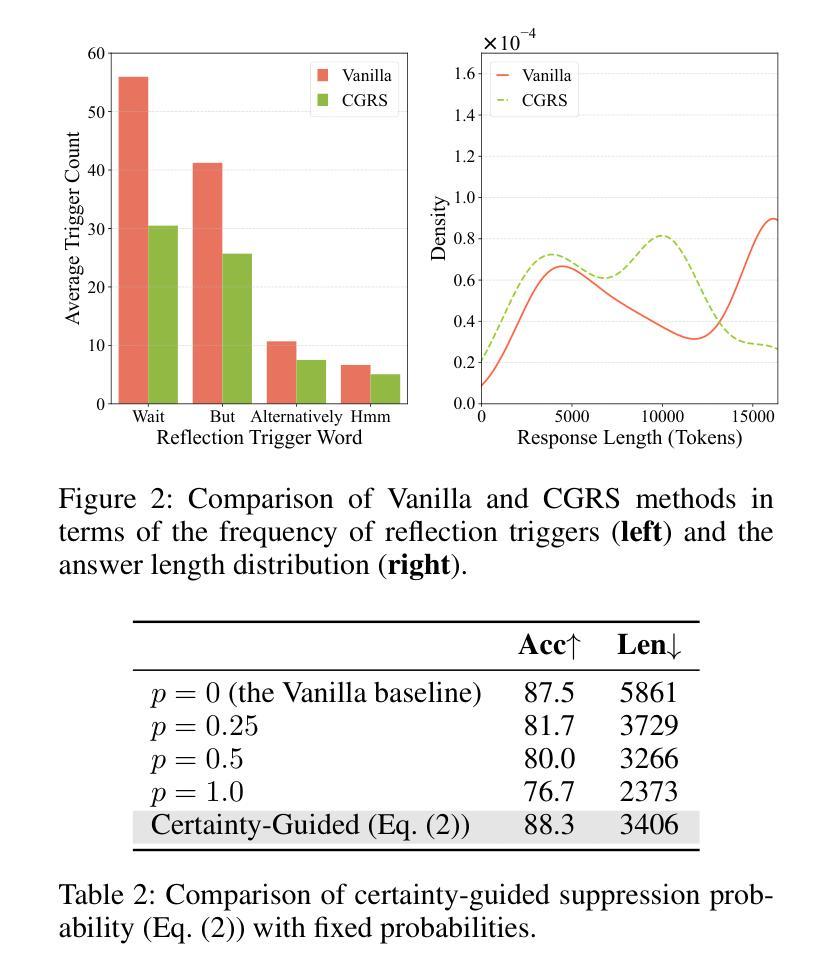
Efficient Reasoning for Large Reasoning Language Models via Certainty-Guided Reflection Suppression
Authors:Jiameng Huang, Baijiong Lin, Guhao Feng, Jierun Chen, Di He, Lu Hou
Recent Large Reasoning Language Models (LRLMs) employ long chain-of-thought reasoning with complex reflection behaviors, typically signaled by specific trigger words (e.g., “Wait” and “Alternatively”) to enhance performance. However, these reflection behaviors can lead to the overthinking problem where the generation of redundant reasoning steps that unnecessarily increase token usage, raise inference costs, and reduce practical utility. In this paper, we propose Certainty-Guided Reflection Suppression (CGRS), a novel method that mitigates overthinking in LRLMs while maintaining reasoning accuracy. CGRS operates by dynamically suppressing the model’s generation of reflection triggers when it exhibits high confidence in its current response, thereby preventing redundant reflection cycles without compromising output quality. Our approach is model-agnostic, requires no retraining or architectural modifications, and can be integrated seamlessly with existing autoregressive generation pipelines. Extensive experiments across four reasoning benchmarks (i.e., AIME24, AMC23, MATH500, and GPQA-D) demonstrate CGRS’s effectiveness: it reduces token usage by an average of 18.5% to 41.9% while preserving accuracy. It also achieves the optimal balance between length reduction and performance compared to state-of-the-art baselines. These results hold consistently across model architectures (e.g., DeepSeek-R1-Distill series, QwQ-32B, and Qwen3 family) and scales (4B to 32B parameters), highlighting CGRS’s practical value for efficient reasoning.
近期的大型推理语言模型(LRLM)采用长链思维推理,伴随复杂的反思行为,通常通过特定的触发词(例如“等等”和“或者”)来增强性能。然而,这些反思行为可能导致过度思考的问题,产生冗余的推理步骤,不必要地增加令牌使用量,提高推理成本,并降低实用性。在本文中,我们提出了确定性引导反思抑制(CGRS),这是一种减轻LRLM中过度思考的新方法,同时保持推理准确性。CGRS通过动态抑制模型在对其当前响应表现出高信心时生成反思触发,从而防止冗余的反思循环而不损害输出质量。我们的方法是模型无关的,不需要重新训练或架构修改,并且可以无缝集成到现有的自回归生成管道中。在四个推理基准测试(即AIME24、AMC23、MATH500和GPQA-D)上的广泛实验证明了CGRS的有效性:它在保持准确性的同时,平均减少令牌使用18.5%至41.9%。与最新基线相比,它在长度减少和性能之间达到了最佳平衡。这些结果在不同的模型架构(例如DeepSeek-R1-Distill系列、QwQ-32B和Qwen3系列)和规模(4B至32B参数)上持续存在,这突出了CGRS在高效推理中的实用价值。
论文及项目相关链接
PDF Technical Report
Summary
本文提出一种名为Certainty-Guided Reflection Suppression(CGRS)的方法,用于缓解大型推理语言模型(LRLMs)中的过度思考问题。该方法通过动态抑制模型生成反思触发词来减少冗余推理步骤,从而提高模型的实用性和效率。CGRS方法具有模型无关性,无需重新训练或修改架构,可无缝集成到现有的自回归生成管道中。实验结果表明,CGRS在四个推理基准测试上有效减少了令牌使用,同时保持准确性。
Key Takeaways
- 大型推理语言模型(LRLMs)使用长链式思维进行复杂推理,但可能导致过度思考问题。
- 过度思考表现为生成冗余推理步骤,增加令牌使用、提高推理成本并降低实用性。
- Certainty-Guided Reflection Suppression(CGRS)方法旨在缓解过度思考问题,通过动态抑制模型生成反思触发词来实现。
- CGRS方法具有模型无关性,无需重新训练或修改架构。
- CGRS可无缝集成到现有的自回归生成管道中,实验结果表明其有效性。
- CGRS在四个推理基准测试上减少了令牌使用,降低了18.5%至41.9%,同时保持准确性。
点此查看论文截图
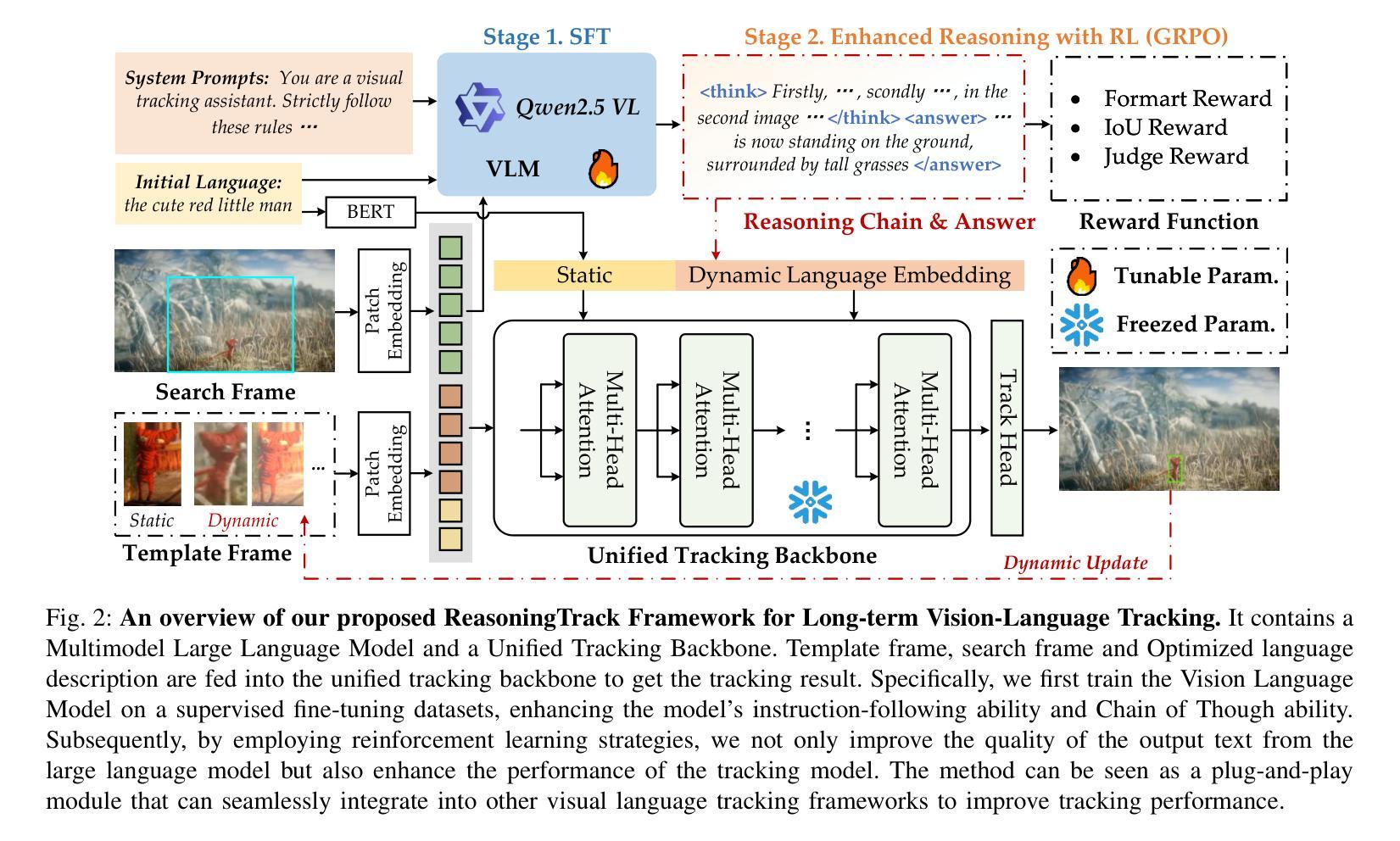
ReasoningTrack: Chain-of-Thought Reasoning for Long-term Vision-Language Tracking
Authors:Xiao Wang, Liye Jin, Xufeng Lou, Shiao Wang, Lan Chen, Bo Jiang, Zhipeng Zhang
Vision-language tracking has received increasing attention in recent years, as textual information can effectively address the inflexibility and inaccuracy associated with specifying the target object to be tracked. Existing works either directly fuse the fixed language with vision features or simply modify using attention, however, their performance is still limited. Recently, some researchers have explored using text generation to adapt to the variations in the target during tracking, however, these works fail to provide insights into the model’s reasoning process and do not fully leverage the advantages of large models, which further limits their overall performance. To address the aforementioned issues, this paper proposes a novel reasoning-based vision-language tracking framework, named ReasoningTrack, based on a pre-trained vision-language model Qwen2.5-VL. Both SFT (Supervised Fine-Tuning) and reinforcement learning GRPO are used for the optimization of reasoning and language generation. We embed the updated language descriptions and feed them into a unified tracking backbone network together with vision features. Then, we adopt a tracking head to predict the specific location of the target object. In addition, we propose a large-scale long-term vision-language tracking benchmark dataset, termed TNLLT, which contains 200 video sequences. 20 baseline visual trackers are re-trained and evaluated on this dataset, which builds a solid foundation for the vision-language visual tracking task. Extensive experiments on multiple vision-language tracking benchmark datasets fully validated the effectiveness of our proposed reasoning-based natural language generation strategy. The source code of this paper will be released on https://github.com/Event-AHU/Open_VLTrack
视觉语言跟踪近年来得到了越来越多的关注,因为文本信息可以有效地解决指定要跟踪的目标对象时的不灵活性和准确性问题。现有的工作要么直接将固定语言与视觉特征融合,要么简单地使用注意力进行修改,然而,它们的性能仍然有限。最近,一些研究人员探索了使用文本生成来适应跟踪过程中目标的变化,然而,这些工作未能深入揭示模型的推理过程,并且没有充分利用大型模型的优点,这进一步限制了其整体性能。为了解决上述问题,本文提出了一种基于推理的视觉语言跟踪新框架,名为ReasoningTrack,该框架基于预训练的视觉语言模型Qwen2.5-VL。我们采用有监督微调(SFT)和强化学习GRPO对推理和语言生成进行优化。我们将更新的语言描述嵌入其中,并与视觉特征一起输入到统一的跟踪主干网络中。然后,我们采用跟踪头来预测目标对象的特定位置。此外,我们提出了一个大规模长期视觉语言跟踪基准数据集TNLLT,它包含200个视频序列。我们在该数据集上对20个基准视觉跟踪器进行了重新训练和评估,为视觉语言视觉跟踪任务奠定了坚实的基础。在多个视觉语言跟踪基准数据集上的大量实验充分验证了我们提出的基于推理的自然语言生成策略的有效性。本文的源代码将发布在https://github.com/Event-AHU/Open_VLTrack上。
论文及项目相关链接
Summary
本文提出一种基于预训练视觉语言模型Qwen2.5-VL的推理型视觉语言跟踪框架ReasoningTrack。该框架结合监督微调(SFT)和强化学习GRPO进行优化,嵌入更新的语言描述并将其与视觉特征一起输入到统一的跟踪主干网络中。采用跟踪头预测目标对象的具体位置。此外,本文还提出大规模长期视觉语言跟踪基准数据集TNLLT,并在此数据集上重新训练和评估了20个基准视觉跟踪器,为视觉语言跟踪任务奠定了坚实基础。实验证明,基于推理的自然语言生成策略有效。
Key Takeaways
- 视觉语言跟踪结合了文本信息,以解决目标对象指定中的不灵活性和不准确性问题。
- 现有方法包括直接融合语言与视觉特征或使用注意力机制进行修改,但性能有限。
- 论文提出一种新型推理型视觉语言跟踪框架ReasoningTrack,基于预训练视觉语言模型Qwen2.5-VL。
- 使用监督微调(SFT)和强化学习GRPO优化推理和语言生成。
- 嵌入更新后的语言描述与视觉特征一起输入到跟踪主干网络中。
- 提出大规模长期视觉语言跟踪基准数据集TNLLT,包含200个视频序列。
点此查看论文截图


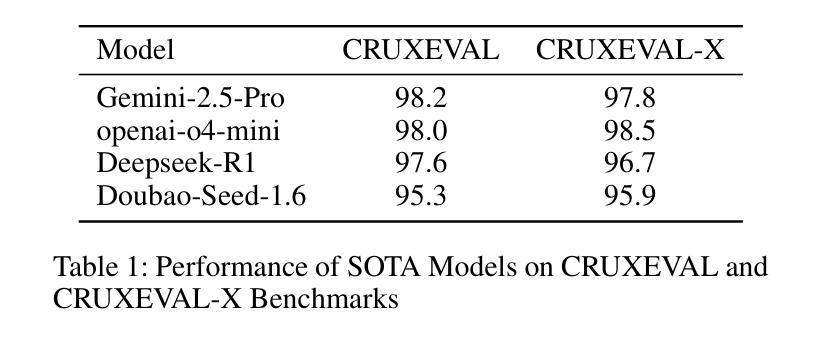
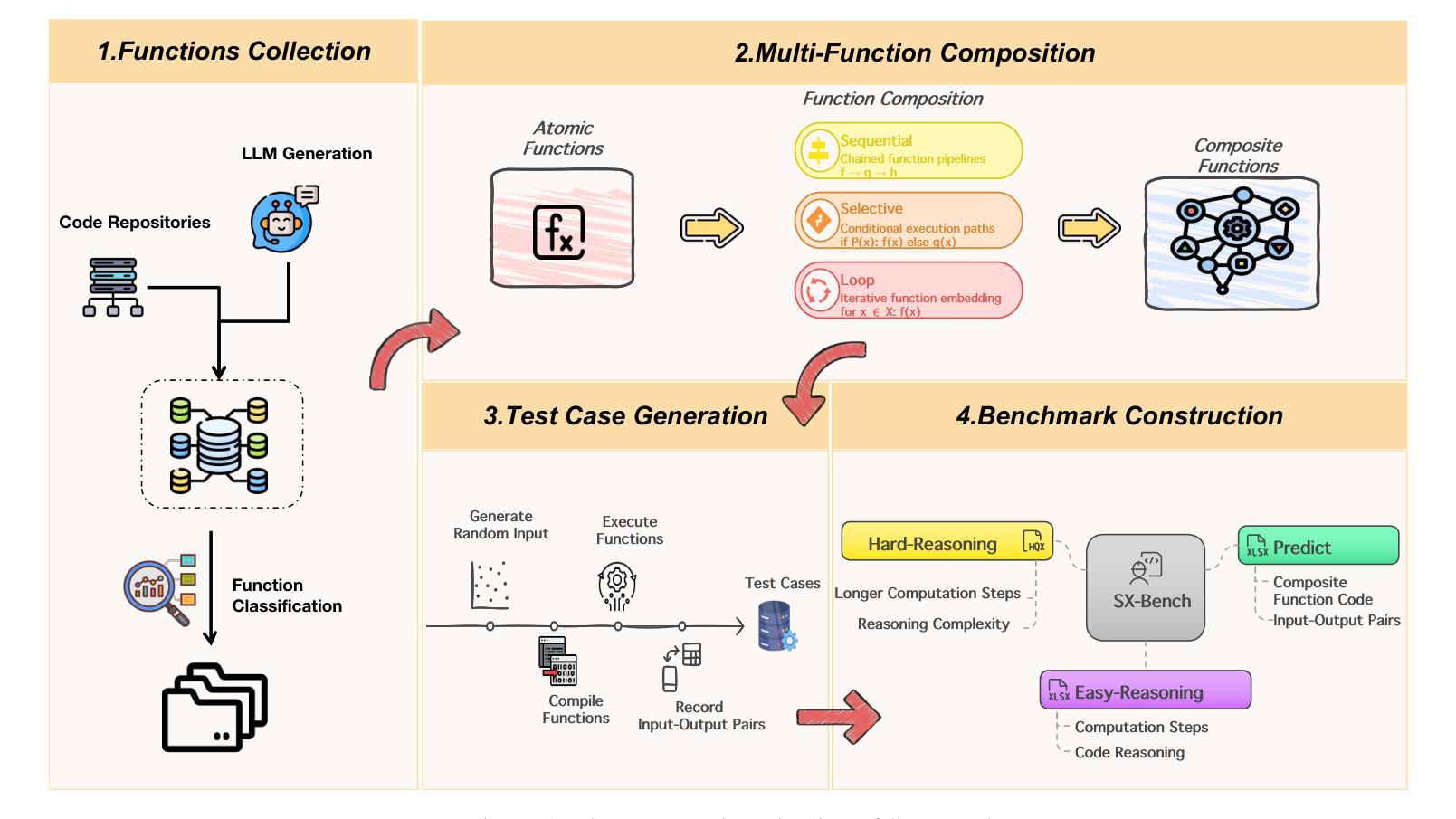
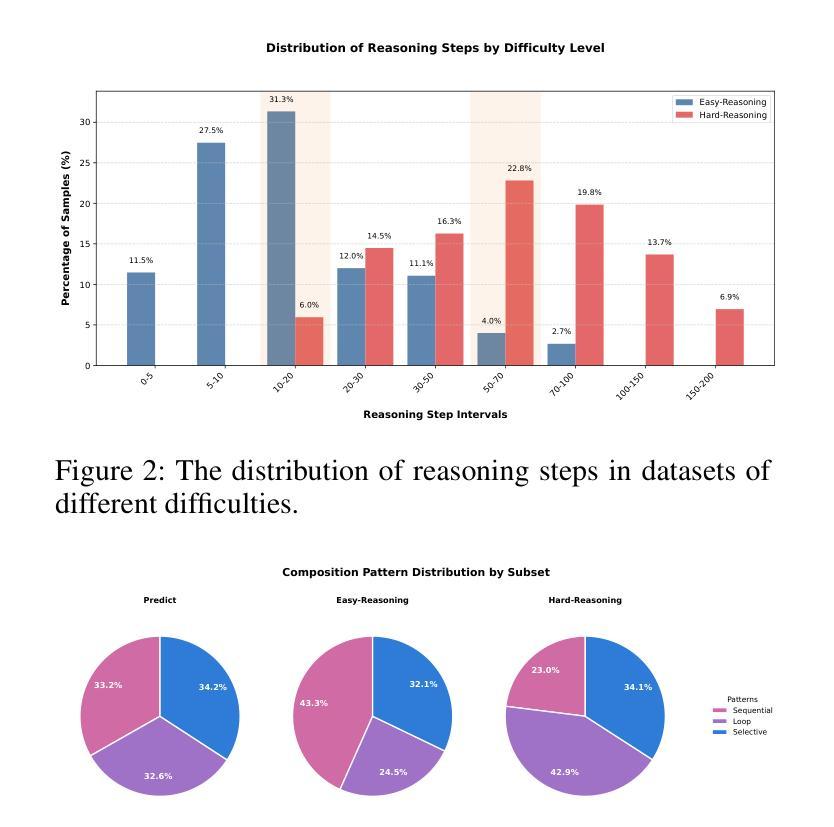
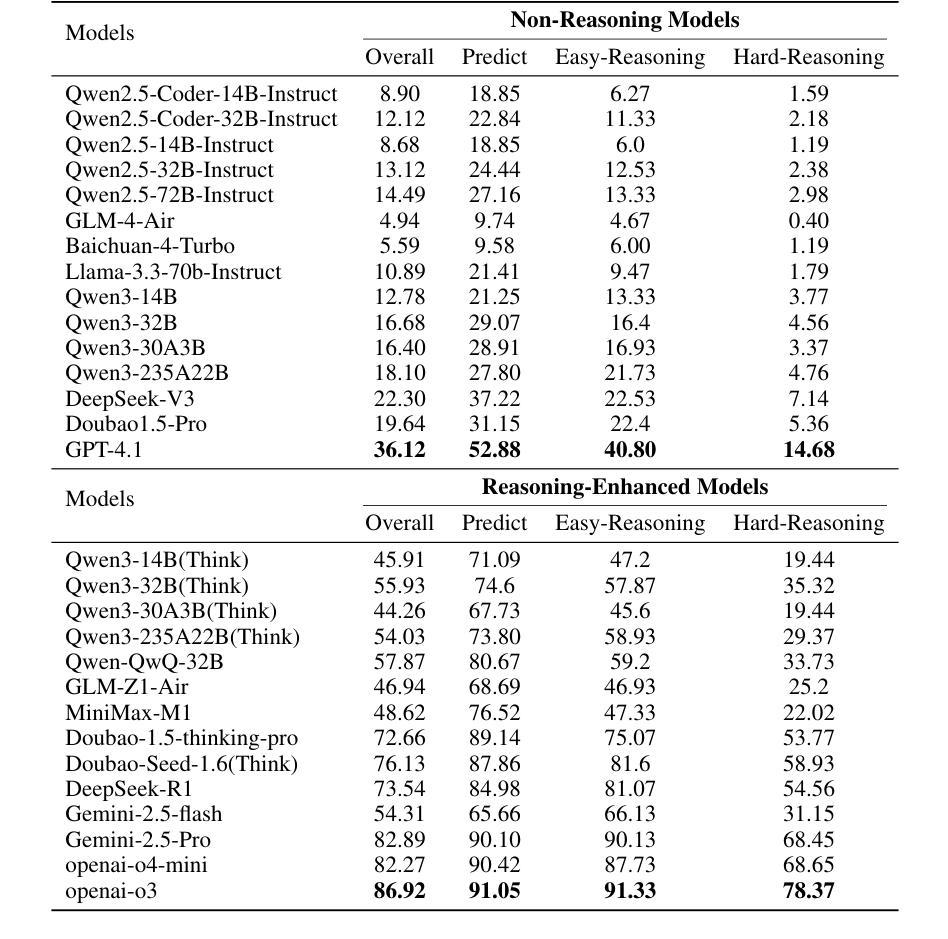
STEPWISE-CODEX-Bench: Evaluating Complex Multi-Function Comprehension and Fine-Grained Execution Reasoning
Authors:Kaiwen Yan, Yuhang Chang, Zirui Guo, Yaling Mou, Jiang Ming, Jingwei Sun
In recent years, large language models (LLMs) have made significant progress in code intelligence, yet systematically evaluating their code understanding and reasoning abilities remains challenging. Mainstream benchmarks such as HumanEval and MBPP primarily assess functional correctness, while reasoning benchmarks like CRUXEVAL are limited to single-function, low-complexity scenarios. As a result, advanced models achieve nearly saturated scores, limiting their discriminative power. To address this, we present STEPWISE-CODEX-Bench (SX-Bench), a novel benchmark designed for complex multi-function understanding and fine-grained execution reasoning. SX-Bench features tasks involving collaboration among multiple sub-functions (e.g., chained calls, nested loops), shifting evaluation towards overall control and data flow modeling. It defines “computation steps” as the minimal execution unit and requires models to predict the total number of steps in reasoning tasks, thereby assessing a model’s in-depth understanding of dynamic execution beyond simple I/O matching. Evaluation on over 20 mainstream models (including 14 reasoning-enhanced models) demonstrates that SX-Bench is highly discriminative: even the state-of-the-art OpenAI-O3 achieves only 78.37 percent accuracy on Hard-Reasoning tasks, much lower than its saturated scores on previous benchmarks, thereby revealing bottlenecks in complex and fine-grained reasoning. We also release an automated pipeline combining program synthesis, symbolic execution, and LLM-aided validation for efficient benchmark generation and quality assurance. SX-Bench advances code evaluation from “single-function verification” to “multi-function dynamic reasoning,” providing a key tool for the in-depth assessment of advanced code intelligence models.
近年来,大型语言模型(LLM)在代码智能方面取得了显著进展,但系统地评估其代码理解和推理能力仍然具有挑战性。主流基准测试如HumanEval和MBPP主要评估功能正确性,而推理基准测试如CRUXEVAL仅限于单一功能、低复杂度的场景。因此,先进模型在基准测试中获得近乎饱和的分数,这限制了它们的辨别力。为了解决这个问题,我们提出了STEPWISE-CODEX-Bench(SX-Bench),这是一个专为复杂多功能理解和精细执行推理设计的新型基准测试。SX-Bench涉及多个子功能之间的协作任务,如链式调用、嵌套循环等,将评估转向整体控制和数据流建模。它定义了“计算步骤”作为最小的执行单元,并要求模型预测推理任务中的总步骤数,从而评估模型对动态执行的深入理解,而不仅仅是简单的输入输出匹配。对超过20个主流模型的评估(包括14个增强推理模型)表明,SX-Bench具有很强的辨别力:即使是最新一代的OpenAI-O3在硬推理任务上的准确率也只有78.37%,远低于其在以前基准测试中的饱和分数,从而揭示了其在复杂和精细推理方面的瓶颈。我们还发布了一个自动化管道,结合程序合成、符号执行和LLM辅助验证,以提高基准测试生成和质量控制效率。SX-Bench推动代码评估从“单功能验证”转向“多功能动态推理”,为高级代码智能模型的深入评估提供了关键工具。
论文及项目相关链接
Summary
大语言模型(LLMs)在代码智能方面取得了显著进展,但在系统评估其代码理解和推理能力方面仍然面临挑战。当前主流基准测试主要评估功能正确性,而推理基准测试仅限于单一功能、低复杂度的场景。因此,我们提出了STEPWISE-CODEX-Bench(SX-Bench),这是一种用于复杂多函数理解和精细执行推理的新型基准测试。SX-Bench的任务涉及多个子函数之间的协作,要求模型预测推理任务中的总步骤数,从而评估模型对动态执行的深入理解。评估结果显示SX-Bench具有高度辨别力,即使是最先进的OpenAI-O3在硬推理任务上的准确率也只有78.37%,远低于其在先前基准测试上的饱和分数。SX-Bench的推出,标志着代码评估从“单功能验证”跃进到“多功能动态推理”,为高级代码智能模型的深入评估提供了关键工具。
Key Takeaways
- 大语言模型(LLMs)在代码智能方面取得显著进展,但评估其代码理解和推理能力仍具挑战。
- 现有基准测试主要关注功能正确性,缺乏对于复杂、精细推理能力的评估。
- STEPWISE-CODEX-Bench(SX-Bench)是一种新型基准测试,旨在评估多函数理解和执行推理能力。
- SX-Bench任务涉及多子函数协作,要求模型预测推理步骤数,以评估其对动态执行的深入理解。
- SX-Bench具有高度辨别力,能够揭示模型在复杂和精细推理方面的瓶颈。
- 先进模型在SX-Bench上的表现远低于其在先前基准测试上的饱和分数。
点此查看论文截图



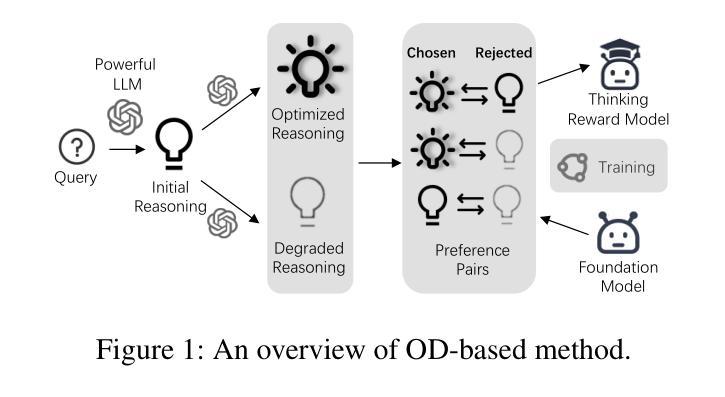
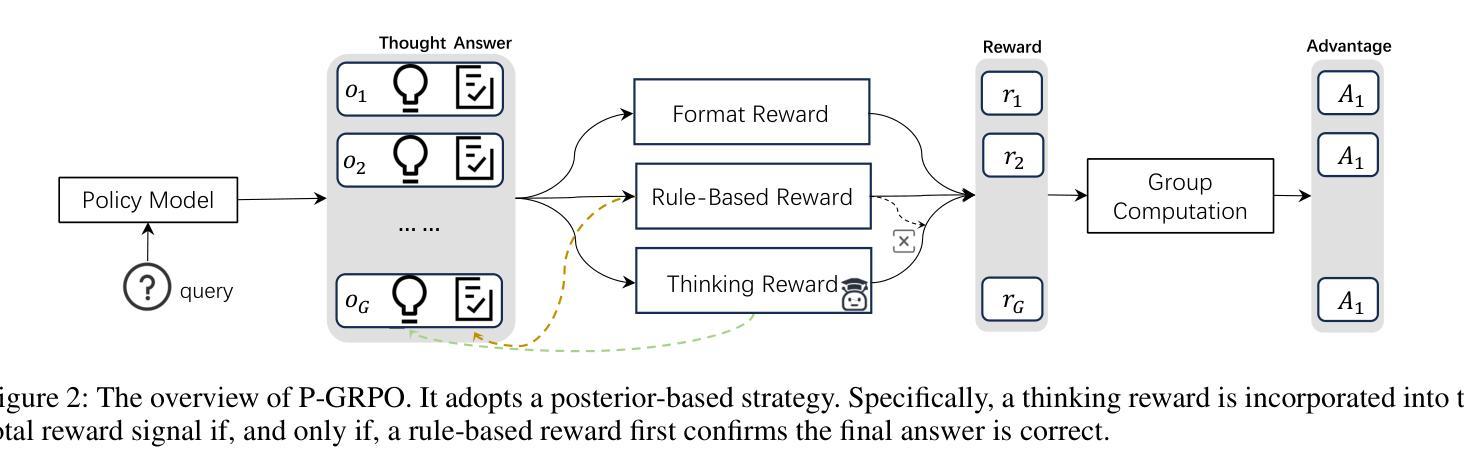
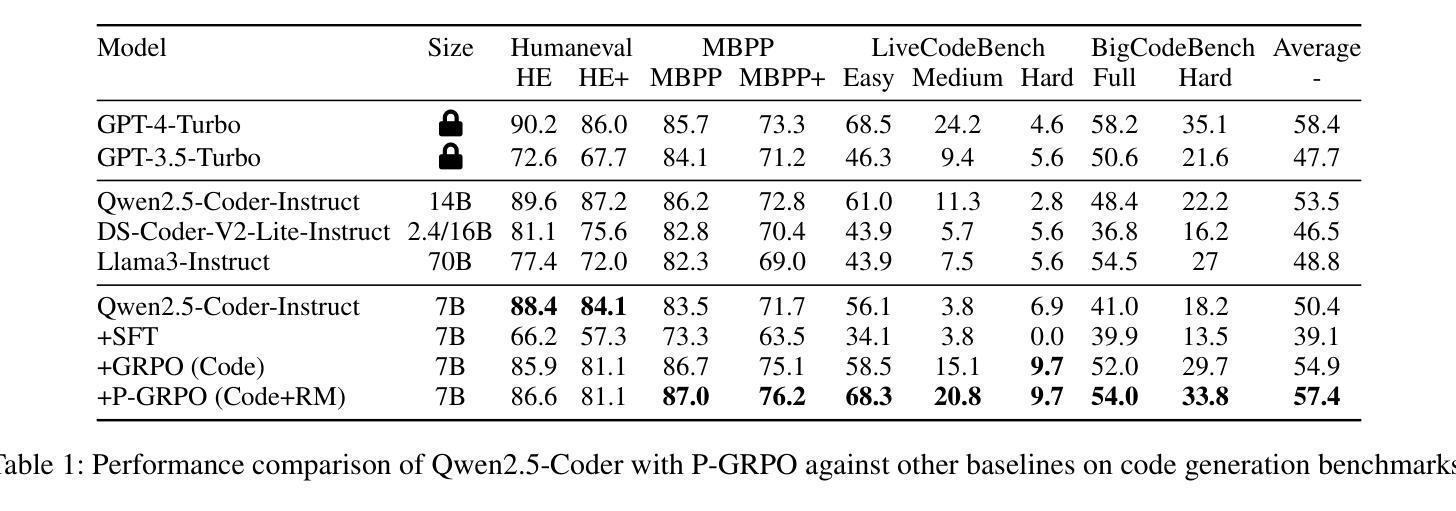
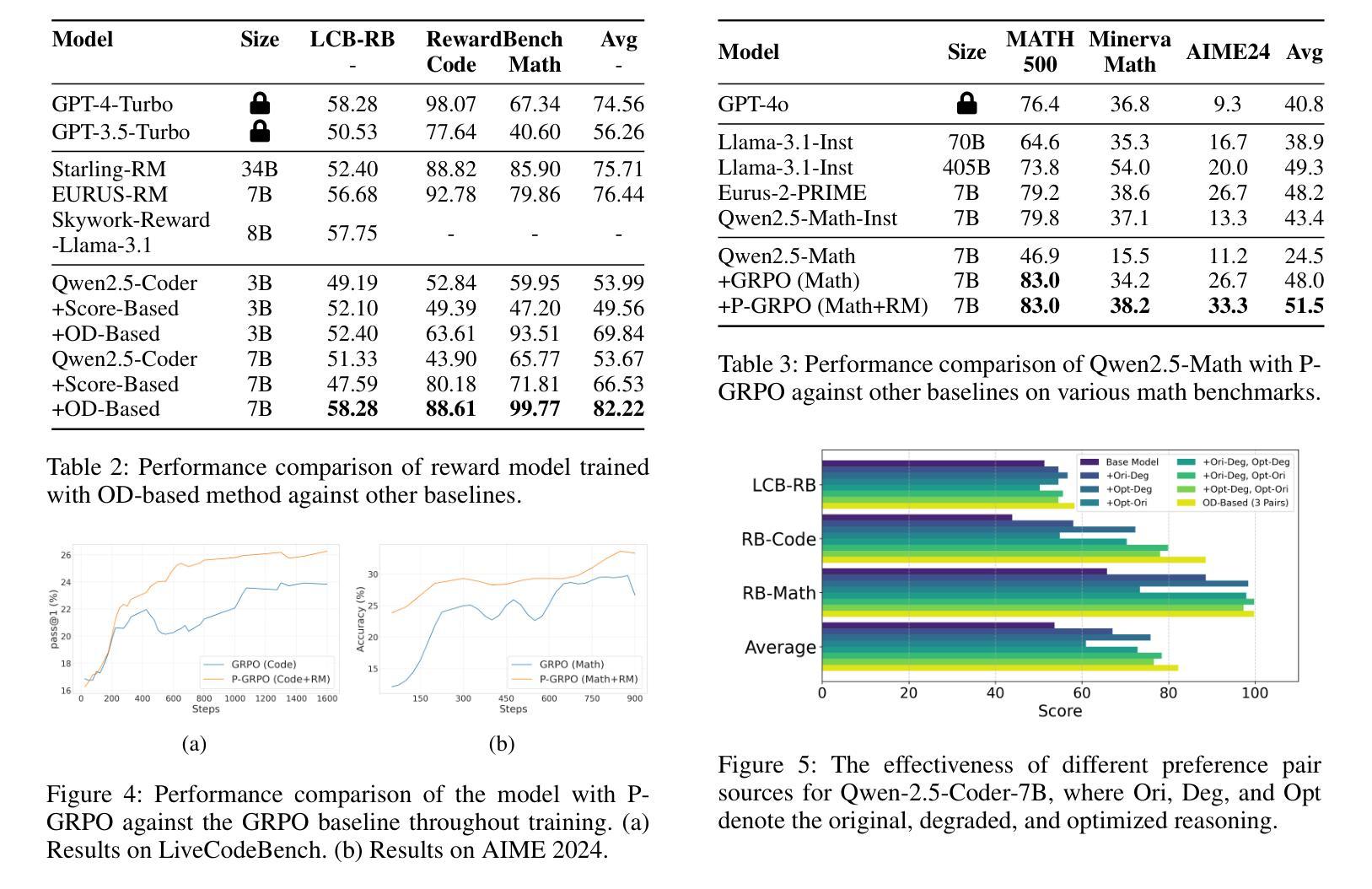
Posterior-GRPO: Rewarding Reasoning Processes in Code Generation
Authors:Lishui Fan, Yu Zhang, Mouxiang Chen, Zhongxin Liu
Reinforcement learning (RL) has significantly advanced code generation for large language models (LLMs). However, current paradigms rely on outcome-based rewards from test cases, neglecting the quality of the intermediate reasoning process. While supervising the reasoning process directly is a promising direction, it is highly susceptible to reward hacking, where the policy model learns to exploit the reasoning reward signal without improving final outcomes. To address this, we introduce a unified framework that can effectively incorporate the quality of the reasoning process during RL. First, to enable reasoning evaluation, we develop LCB-RB, a benchmark comprising preference pairs of superior and inferior reasoning processes. Second, to accurately score reasoning quality, we introduce an Optimized-Degraded based (OD-based) method for reward model training. This method generates high-quality preference pairs by systematically optimizing and degrading initial reasoning paths along curated dimensions of reasoning quality, such as factual accuracy, logical rigor, and coherence. A 7B parameter reward model with this method achieves state-of-the-art (SOTA) performance on LCB-RB and generalizes well to other benchmarks. Finally, we introduce Posterior-GRPO (P-GRPO), a novel RL method that conditions process-based rewards on task success. By selectively applying rewards to the reasoning processes of only successful outcomes, P-GRPO effectively mitigates reward hacking and aligns the model’s internal reasoning with final code correctness. A 7B parameter model with P-GRPO achieves superior performance across diverse code generation tasks, outperforming outcome-only baselines by 4.5%, achieving comparable performance to GPT-4-Turbo. We further demonstrate the generalizability of our approach by extending it to mathematical tasks. Our models, dataset, and code are publicly available.
强化学习(RL)在大型语言模型(LLM)的代码生成方面取得了重大进展。然而,当前的模式依赖于测试用例的结果导向奖励,忽视了中间推理过程的质量。虽然直接监督推理过程是一个有前景的方向,但它非常容易受到奖励破解的影响,即策略模型学会利用推理奖励信号而不提高最终的结果。为了解决这个问题,我们引入了一个统一的框架,可以有效地在RL中融入推理过程的质量。首先,为了进行推理评估,我们开发了LCB-RB基准测试,它包括优质和劣质推理过程的偏好对。其次,为了准确地评分推理质量,我们引入了基于优化退化(OD)的方法来进行奖励模型训练。该方法通过系统地优化和退化初始推理路径,沿着推理质量的精选维度(如事实准确性、逻辑严谨性和连贯性)生成高质量的偏好对。使用这种方法的70亿参数奖励模型在LCB-RB上取得了最先进的性能,并能够很好地推广到其他基准测试。最后,我们介绍了后置GRPO(P-GRPO),这是一种新型的RL方法,它根据任务成功来制定基于过程的奖励。通过有选择地对成功结果的推理过程施加奖励,P-GRPO有效地减轻了奖励破解问题,并使模型的内部推理与最终的代码正确性相符。使用P-GRPO的70亿参数模型在多种代码生成任务中表现优越,比仅基于结果的基线高出4.5%,其性能与GPT-4 Turbo相当。我们还通过将其扩展到数学任务来展示我们方法的一般性。我们的模型、数据集和代码都是公开可用的。
论文及项目相关链接
Summary
强化学习在大型语言模型(LLM)的代码生成中取得了显著进展,但现有方法主要依赖测试案例的结果奖励,忽视了中间推理过程的质量。本研究引入了一个统一框架,该框架可以有效地将推理过程的质量纳入强化学习考量。研究首先开发了LCB-RB基准测试集,包含优质与劣质推理过程的偏好对,用于评估推理质量。接着,提出了基于优化与降级(OD-based)的奖励模型训练方法,通过系统地优化和降级初始推理路径,生成高质量偏好对。使用此方法,7B参数的奖励模型在LCB-RB上达到最新水平并良好地推广到其他基准测试。最后,研究引入了基于过程奖励的后验GRPO(P-GRPO)强化学习方法,该方法对成功的任务结果应用选择性奖励,有效防止奖励被滥用。P-GRPO模型在多样化的代码生成任务中表现出卓越性能,比仅依赖结果基线提高了4.5%,并可与GPT-4 Turbo相提并论。此外,研究还将方法扩展到数学任务中展示了其通用性。
Key Takeaways
- 强化学习在大型语言模型的代码生成中取得了进展,但忽视了推理过程的质量。
- 引入LCB-RB基准测试集来评估推理质量,包含优质与劣质推理过程的偏好对。
- 提出基于优化与降级的奖励模型训练方法,生成高质量偏好对并提升模型性能。
- 引入P-GRPO强化学习方法,通过选择性应用奖励来防止奖励被滥用,提高模型性能。
- P-GRPO模型在多样化的代码生成任务中表现出卓越性能,并在数学任务中展示了通用性。
- 7B参数奖励模型在基准测试中表现最佳,且方法具有良好的推广性。
点此查看论文截图


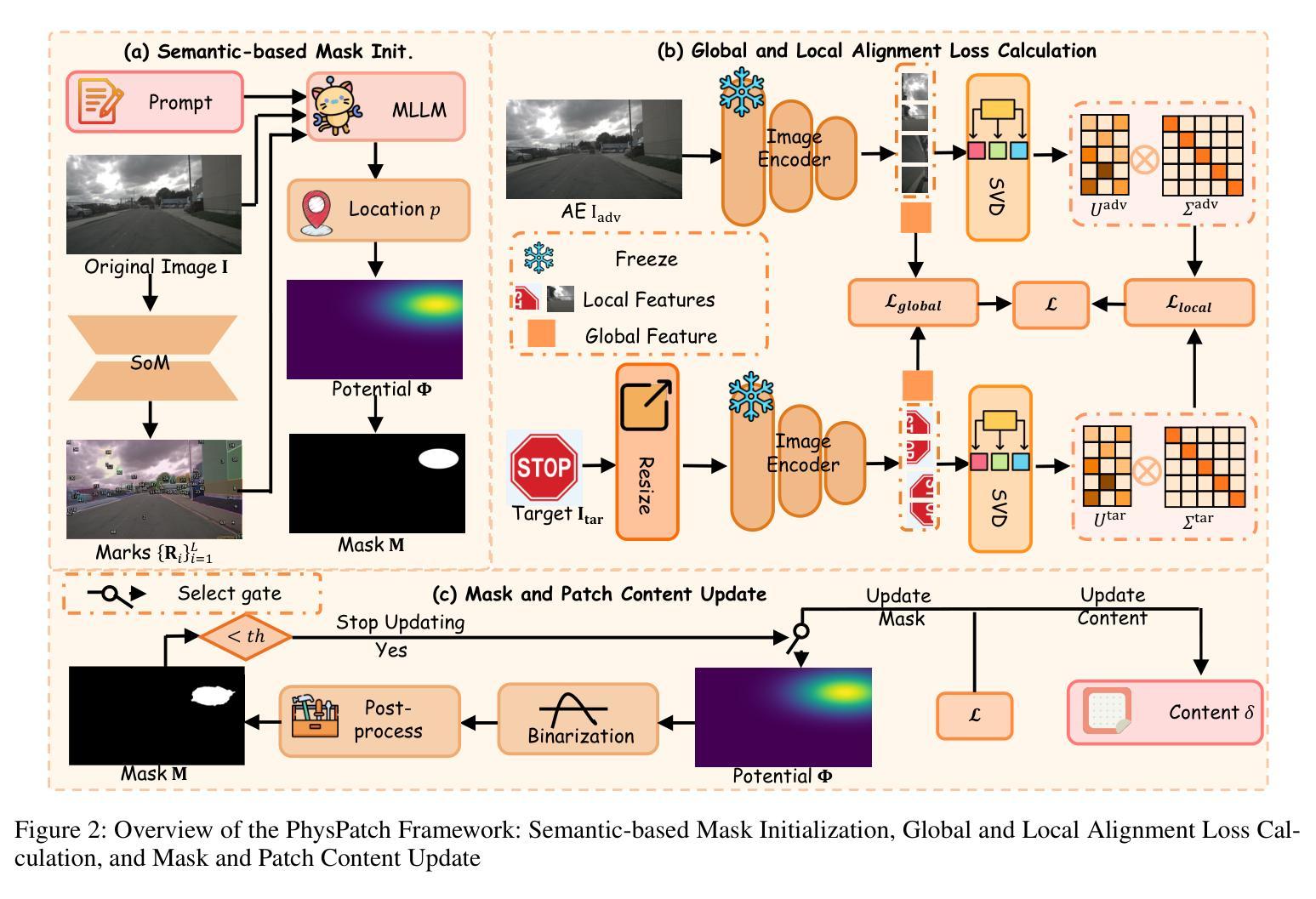
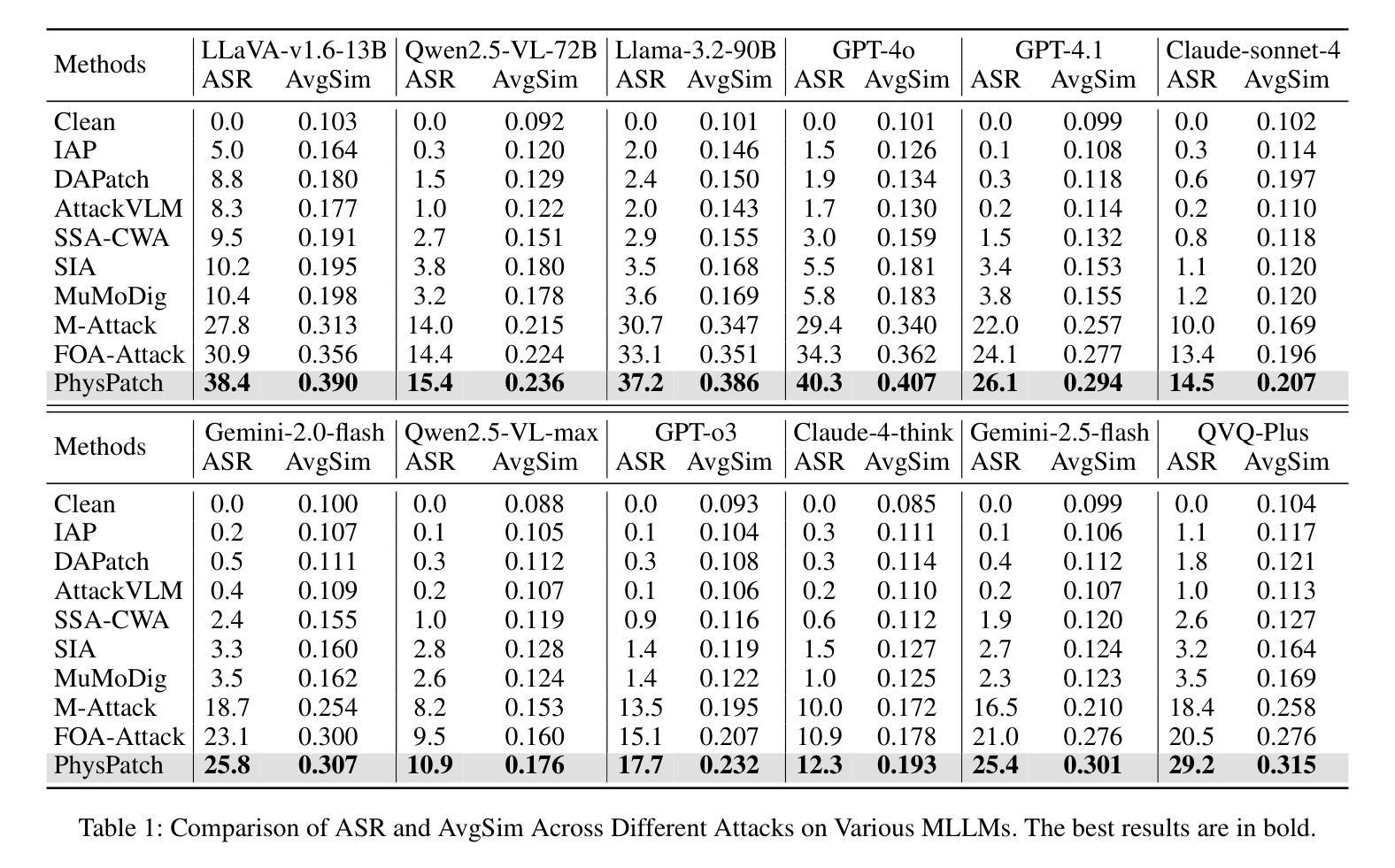
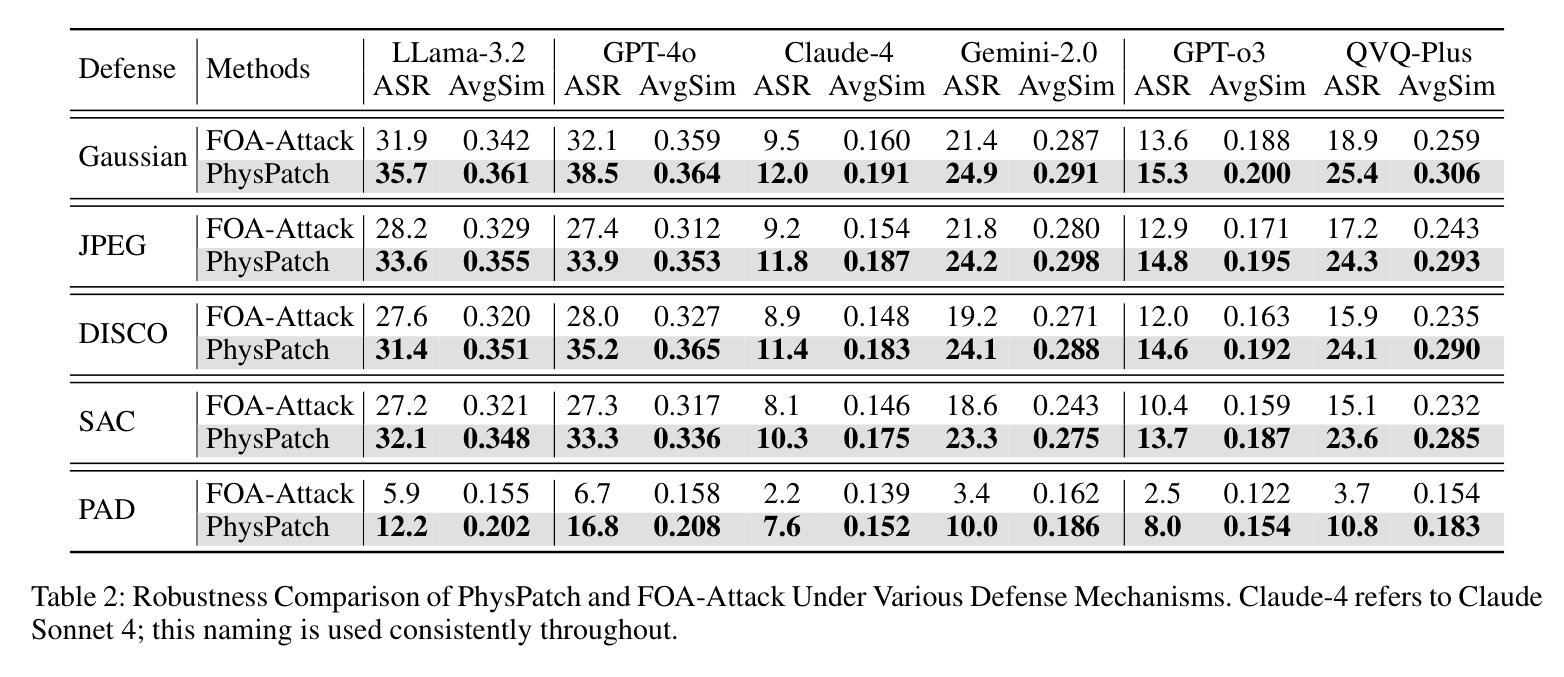
PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack for Multimodal Large Language Models-based Autonomous Driving Systems
Authors:Qi Guo, Xiaojun Jia, Shanmin Pang, Simeng Qin, Lin Wang, Ju Jia, Yang Liu, Qing Guo
Multimodal Large Language Models (MLLMs) are becoming integral to autonomous driving (AD) systems due to their strong vision-language reasoning capabilities. However, MLLMs are vulnerable to adversarial attacks, particularly adversarial patch attacks, which can pose serious threats in real-world scenarios. Existing patch-based attack methods are primarily designed for object detection models and perform poorly when transferred to MLLM-based systems due to the latter’s complex architectures and reasoning abilities. To address these limitations, we propose PhysPatch, a physically realizable and transferable adversarial patch framework tailored for MLLM-based AD systems. PhysPatch jointly optimizes patch location, shape, and content to enhance attack effectiveness and real-world applicability. It introduces a semantic-based mask initialization strategy for realistic placement, an SVD-based local alignment loss with patch-guided crop-resize to improve transferability, and a potential field-based mask refinement method. Extensive experiments across open-source, commercial, and reasoning-capable MLLMs demonstrate that PhysPatch significantly outperforms prior methods in steering MLLM-based AD systems toward target-aligned perception and planning outputs. Moreover, PhysPatch consistently places adversarial patches in physically feasible regions of AD scenes, ensuring strong real-world applicability and deployability.
多模态大型语言模型(MLLMs)由于其强大的视觉语言推理能力,已成为自动驾驶(AD)系统的不可或缺的部分。然而,MLLMs容易受到对抗性攻击的影响,特别是对抗性补丁攻击,这在现实场景中可能构成严重威胁。现有的基于补丁的攻击方法主要是为对象检测模型设计的,当转移到基于MLLM的系统时,由于后者的复杂架构和推理能力,其表现较差。为了解决这些局限性,我们提出了PhysPatch,这是一个针对基于MLLM的AD系统的物理可实现和可转移的对抗性补丁框架。PhysPatch联合优化补丁的位置、形状和内容,以提高攻击的有效性和现实世界的适用性。它引入了一种基于语义的掩模初始化策略,用于实现真实的放置位置,一种基于SVD的局部对齐损失,结合补丁引导的裁剪和缩放,以提高可转移性,以及一种基于势场的掩模细化方法。在开源、商业和具有推理能力的MLLMs上的广泛实验表明,PhysPatch在引导基于MLLM的AD系统实现目标对齐的感知和规划输出方面显著优于先前的方法。此外,PhysPatch始终在AD场景的物理可行区域中放置对抗性补丁,确保强大的现实世界适用性和可部署性。
论文及项目相关链接
Summary:
多模态大型语言模型(MLLMs)在自动驾驶(AD)系统中扮演着日益重要的角色,得益于其强大的视觉-语言推理能力。然而,MLLM易受对抗性攻击威胁,尤其是对抗性补丁攻击,在真实场景中可能带来严重威胁。针对现有补丁攻击方法针对对象检测模型的局限性,以及MLLM系统的复杂架构和推理能力而效果不佳的问题,我们提出了PhysPatch框架。PhysPatch联合优化补丁的位置、形状和内容,以提高攻击效果和真实世界适用性。它通过基于语义的掩模初始化策略实现逼真的补丁放置,使用SVD的局部对齐损失和补丁引导的裁剪调整策略以提高传输性,以及基于势场的掩模优化方法。大量实验表明,PhysPatch在目标对齐感知和规划输出方面显著优于现有方法,能成功引导MLLM为基础的AD系统。此外,PhysPatch确保对抗性补丁在AD场景的合理区域放置,保证其在真实世界的强大适用性和部署能力。
Key Takeaways:
一、MLLMs在自动驾驶系统中发挥重要作用,但易受对抗性攻击威胁。尤其是对抗性补丁攻击在实际场景中可能造成严重威胁。
二、现有补丁攻击方法主要针对对象检测模型设计,无法有效应用于MLLMs。因为它们无法适应MLLMs的复杂架构和强大的推理能力。
三、为了克服这些局限,我们提出了PhysPatch框架。它针对MLLMs的AD系统进行优化设计,通过联合优化补丁的位置、形状和内容来提高攻击效果和真实世界适用性。
四、PhysPatch引入基于语义的掩模初始化策略实现逼真的补丁放置,并通过SVD的局部对齐损失和补丁引导的裁剪调整策略提高传输性能。
五、通过大量实验验证,PhysPatch显著提高了攻击效果,并能成功引导MLLM为基础的AD系统产生目标对齐的感知和规划输出。
点此查看论文截图


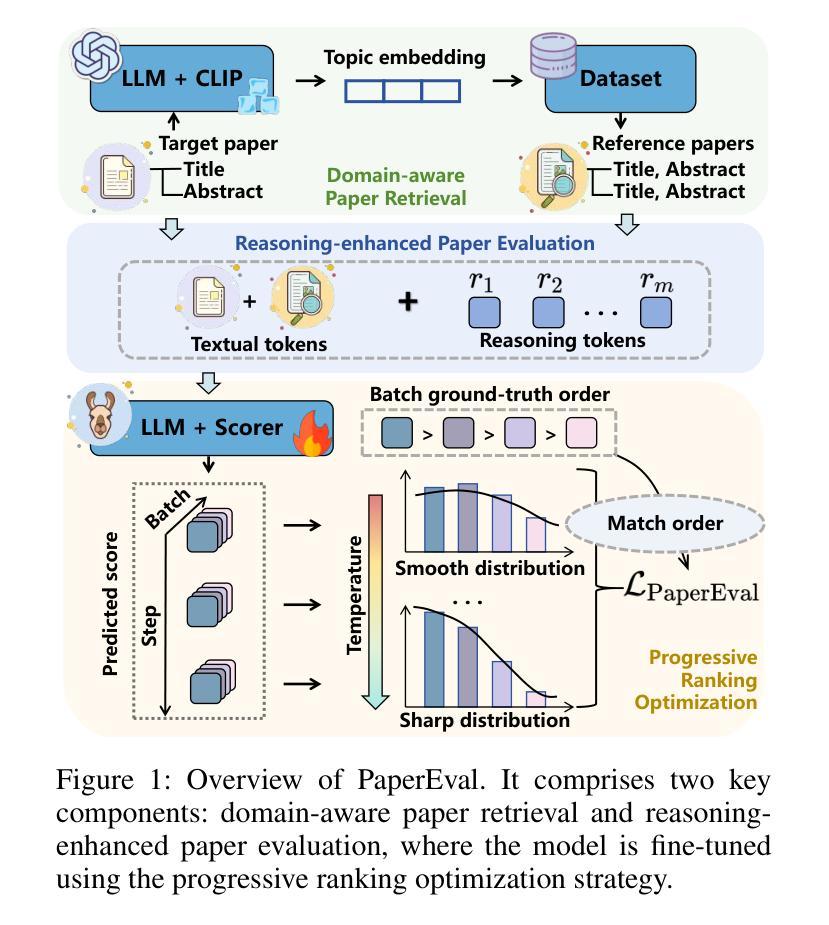
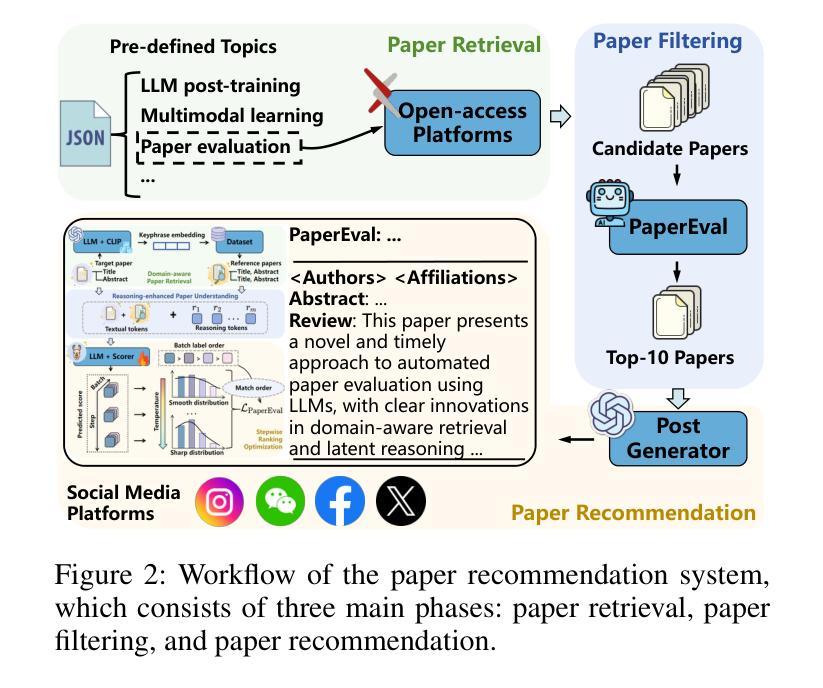
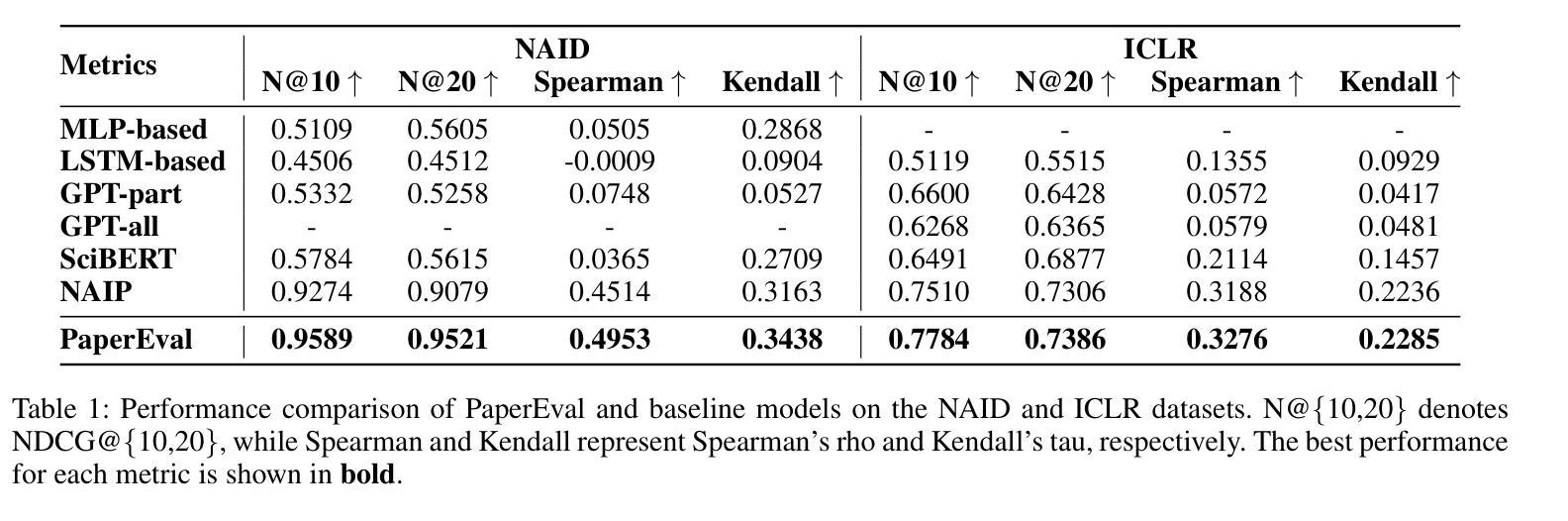
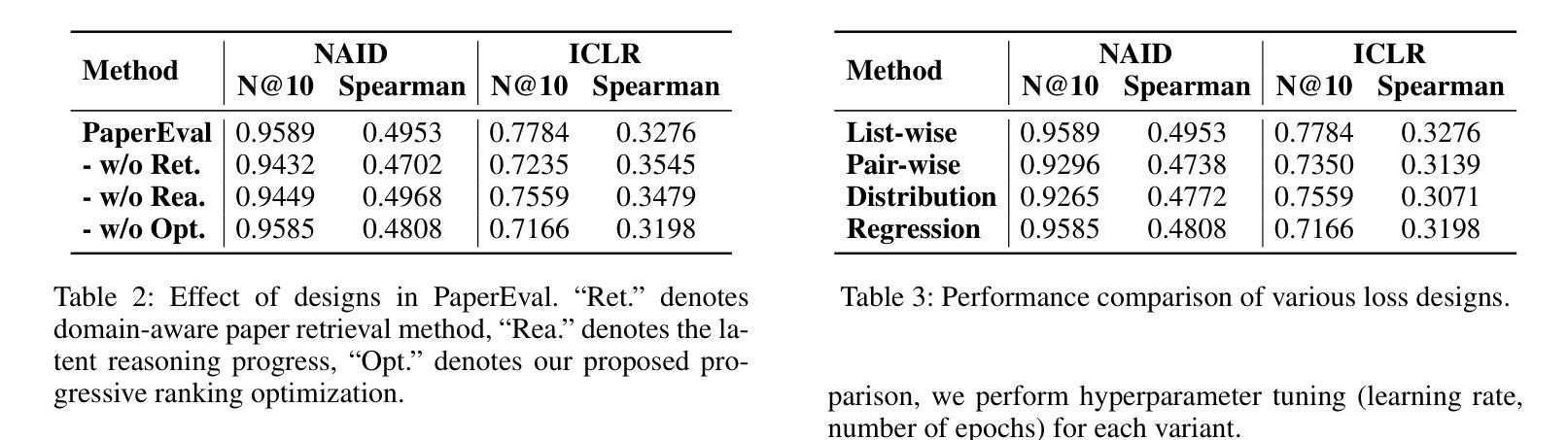
Navigating Through Paper Flood: Advancing LLM-based Paper Evaluation through Domain-Aware Retrieval and Latent Reasoning
Authors:Wuqiang Zheng, Yiyan Xu, Xinyu Lin, Chongming Gao, Wenjie Wang, Fuli Feng
With the rapid and continuous increase in academic publications, identifying high-quality research has become an increasingly pressing challenge. While recent methods leveraging Large Language Models (LLMs) for automated paper evaluation have shown great promise, they are often constrained by outdated domain knowledge and limited reasoning capabilities. In this work, we present PaperEval, a novel LLM-based framework for automated paper evaluation that addresses these limitations through two key components: 1) a domain-aware paper retrieval module that retrieves relevant concurrent work to support contextualized assessments of novelty and contributions, and 2) a latent reasoning mechanism that enables deep understanding of complex motivations and methodologies, along with comprehensive comparison against concurrently related work, to support more accurate and reliable evaluation. To guide the reasoning process, we introduce a progressive ranking optimization strategy that encourages the LLM to iteratively refine its predictions with an emphasis on relative comparison. Experiments on two datasets demonstrate that PaperEval consistently outperforms existing methods in both academic impact and paper quality evaluation. In addition, we deploy PaperEval in a real-world paper recommendation system for filtering high-quality papers, which has gained strong engagement on social media – amassing over 8,000 subscribers and attracting over 10,000 views for many filtered high-quality papers – demonstrating the practical effectiveness of PaperEval.
随着学术出版物的快速和持续增长,识别高质量研究成为了一个日益紧迫的挑战。虽然最近利用大型语言模型(LLM)进行自动化论文评估的方法显示出巨大的潜力,但它们通常受到过时的领域知识和有限的推理能力的限制。在这项工作中,我们提出了PaperEval,这是一个基于LLM的自动化论文评估新颖框架,它通过两个关键组件解决这些限制:1)一个领域感知的论文检索模块,检索相关的并行工作以支持对新颖性和贡献的上下文评估;2)一种潜在推理机制,实现对复杂动机和方法论的深入理解,以及与支持更精确和可靠的评估的并行相关工作的全面比较。为了引导推理过程,我们引入了一种渐进式排名优化策略,鼓励LLM通过相对比较来迭代优化其预测。在两个数据集上的实验表明,PaperEval在学术影响力和论文质量评估方面始终优于现有方法。此外,我们将PaperEval部署在现实世界中的论文推荐系统中,以筛选高质量论文,它在社交媒体上获得了强烈的关注度——积累了超过8,000名订阅者和超过1万名浏览量筛选出的高质量论文的视图——证明了PaperEval的实际有效性。
论文及项目相关链接
Summary
本文介绍了一种基于大型语言模型(LLM)的自动化论文评价框架——PaperEval。该框架通过两个关键组件解决了现有方法的局限性:一是领域感知的论文检索模块,支持对新颖性和贡献的上下文评估;二是潜在推理机制,支持对复杂动机和方法的深入理解,以及与相关论文的全面比较,从而实现更准确可靠的评价。实验证明,PaperEval在学术影响力和论文质量评价方面均优于现有方法。此外,将其部署于实际论文推荐系统中,可有效筛选高质量论文,在社会媒体上获得强烈反响。
Key Takeaways
- 论文数量激增导致高质量研究识别成为挑战。
- PaperEval框架利用LLM进行自动化论文评价。
- PaperEval具备领域感知的论文检索和潜在推理机制两个关键组件。
- 检索模块支持上下文评估,推理机制支持对论文的深入理解和全面比较。
- PaperEval在学术影响力和论文质量评价方面表现优异。
- PaperEval已成功部署于实际论文推荐系统,获得社会媒体上的强烈反响。
点此查看论文截图