⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
RAP: Real-time Audio-driven Portrait Animation with Video Diffusion Transformer
Authors:Fangyu Du, Taiqing Li, Ziwei Zhang, Qian Qiao, Tan Yu, Dingcheng Zhen, Xu Jia, Yang Yang, Shunshun Yin, Siyuan Liu
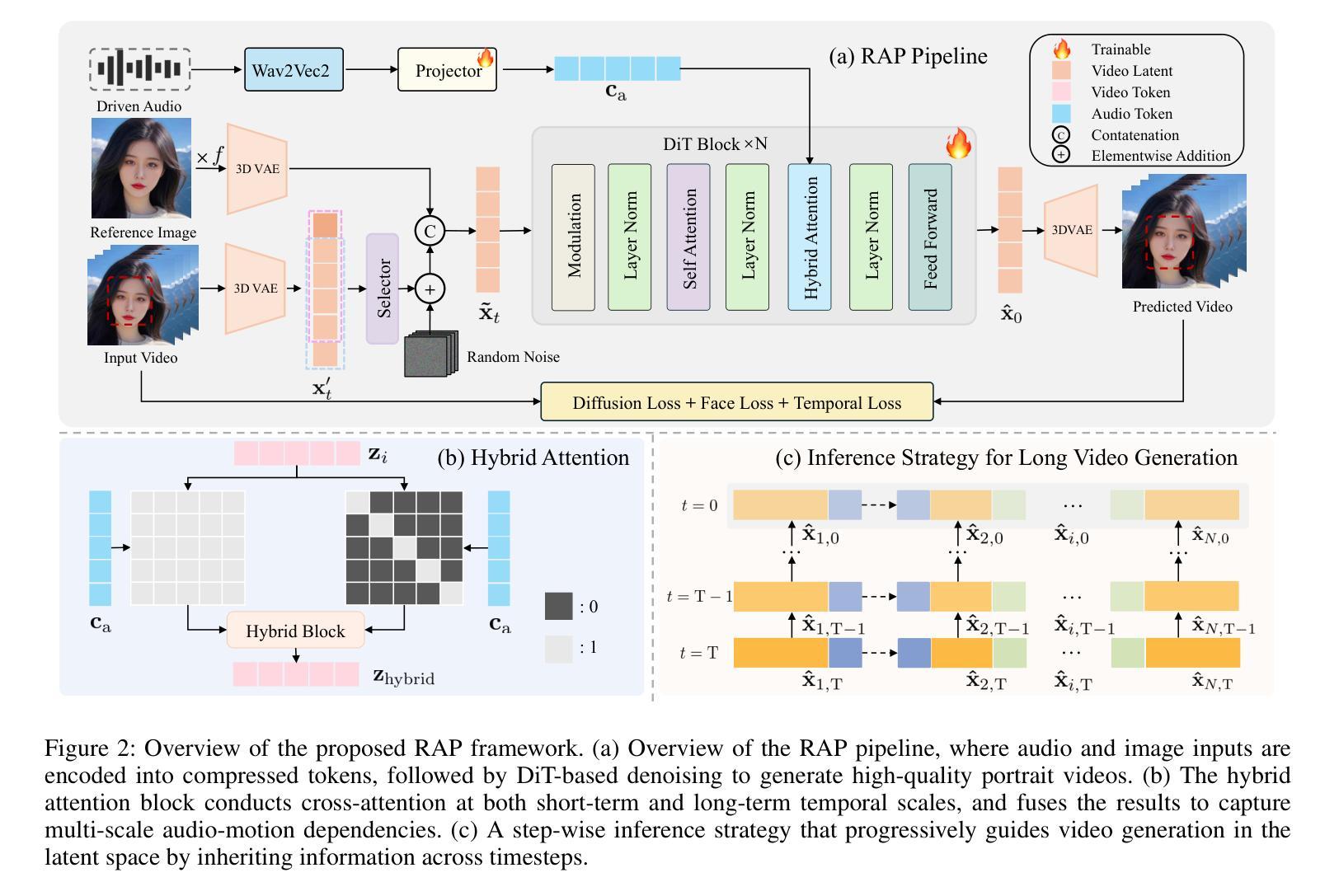
Audio-driven portrait animation aims to synthesize realistic and natural talking head videos from an input audio signal and a single reference image. While existing methods achieve high-quality results by leveraging high-dimensional intermediate representations and explicitly modeling motion dynamics, their computational complexity renders them unsuitable for real-time deployment. Real-time inference imposes stringent latency and memory constraints, often necessitating the use of highly compressed latent representations. However, operating in such compact spaces hinders the preservation of fine-grained spatiotemporal details, thereby complicating audio-visual synchronization RAP (Real-time Audio-driven Portrait animation), a unified framework for generating high-quality talking portraits under real-time constraints. Specifically, RAP introduces a hybrid attention mechanism for fine-grained audio control, and a static-dynamic training-inference paradigm that avoids explicit motion supervision. Through these techniques, RAP achieves precise audio-driven control, mitigates long-term temporal drift, and maintains high visual fidelity. Extensive experiments demonstrate that RAP achieves state-of-the-art performance while operating under real-time constraints.
音频驱动肖像动画旨在从输入音频信号和单个参考图像合成逼真自然的说话人头视频。虽然现有方法通过利用高维中间表示和显式运动动力学建模实现高质量结果,但其计算复杂性使其不适合实时部署。实时推理带来了严格的延迟和内存约束,通常需要高度压缩的潜在表示形式。然而,在如此紧凑的空间中进行操作会阻碍精细时空细节的保留,从而加剧了音视频同步的难度。RAP(实时音频驱动肖像动画)是一个统一框架,可在实时约束下生成高质量谈话肖像。具体来说,RAP引入了混合注意力机制进行精细音频控制,以及避免显式运动监督的静态-动态训练推理范式。通过这些技术,RAP实现了精确的音频驱动控制,减轻了长期时间漂移,并保持了较高的视觉保真度。大量实验表明,RAP在实时约束下达到了最先进的性能。
论文及项目相关链接
PDF 11 pages, 9 figures
Summary
本文介绍了实时音频驱动肖像动画(RAP)技术,该技术能够在实时约束下生成高质量动态肖像视频。通过引入混合注意力机制和静态-动态训练推理范式,RAP实现了精细的音频控制,减轻了长期时间漂移问题,并保持了高度的视觉保真度。
Key Takeaways
- 音频驱动肖像动画技术旨在从输入音频信号和单一参考图像合成逼真自然的说话人头视频。
- 现有方法利用高维中间表示和显式运动动力学建模实现高质量结果,但计算复杂性不适合实时部署。
- 实时推理需要严格的延迟和内存约束,常常需要使用高度压缩的潜在表示。
- RAP框架实现了实时约束下的高质量说话肖像生成。
- RAP引入混合注意力机制,实现精细音频控制,并减轻长期时间漂移问题。
- RAP采用静态-动态训练推理范式,避免了显式运动监督。
点此查看论文截图



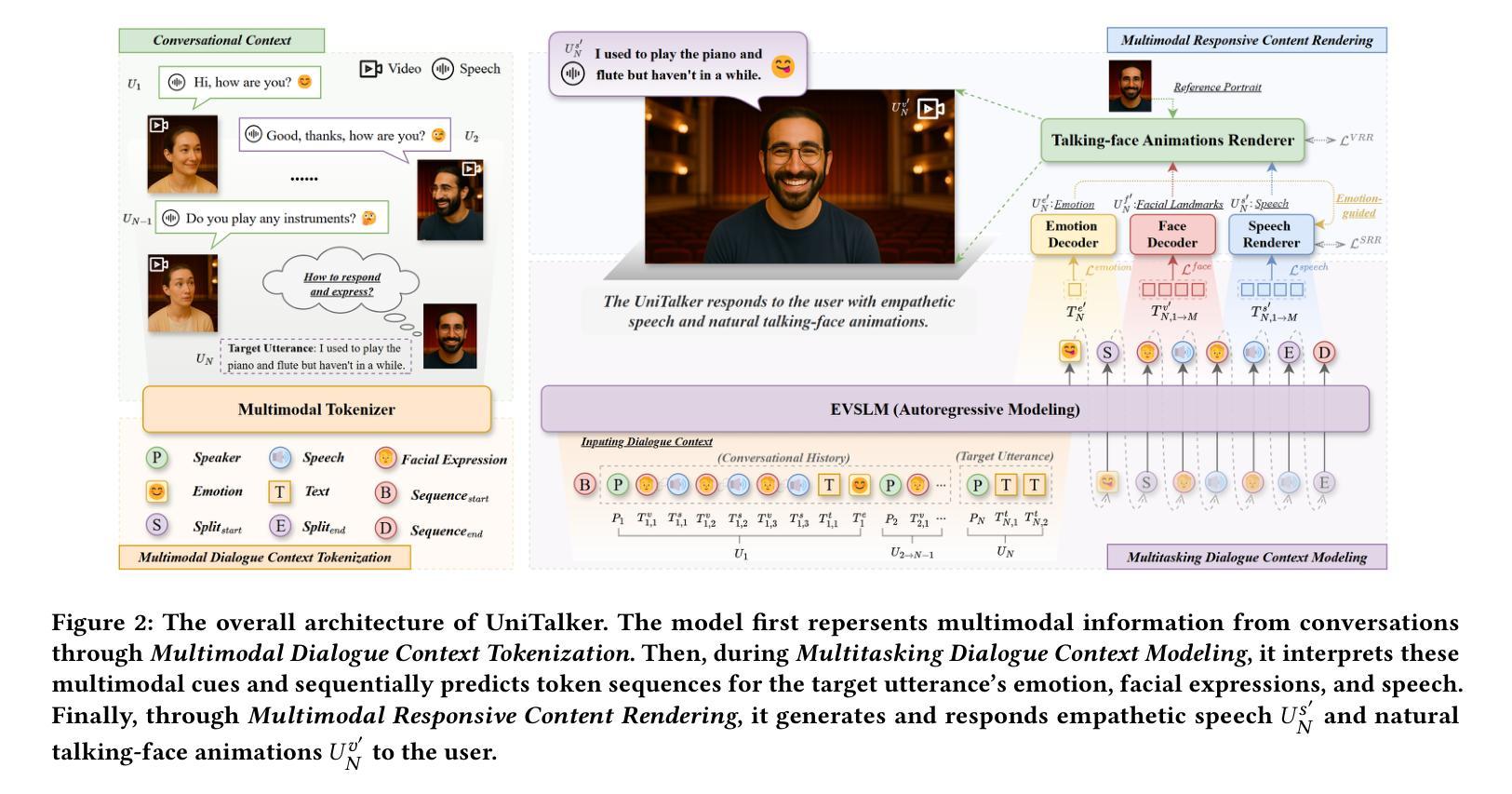
UniTalker: Conversational Speech-Visual Synthesis
Authors:Yifan Hu, Rui Liu, Yi Ren, Xiang Yin, Haizhou Li
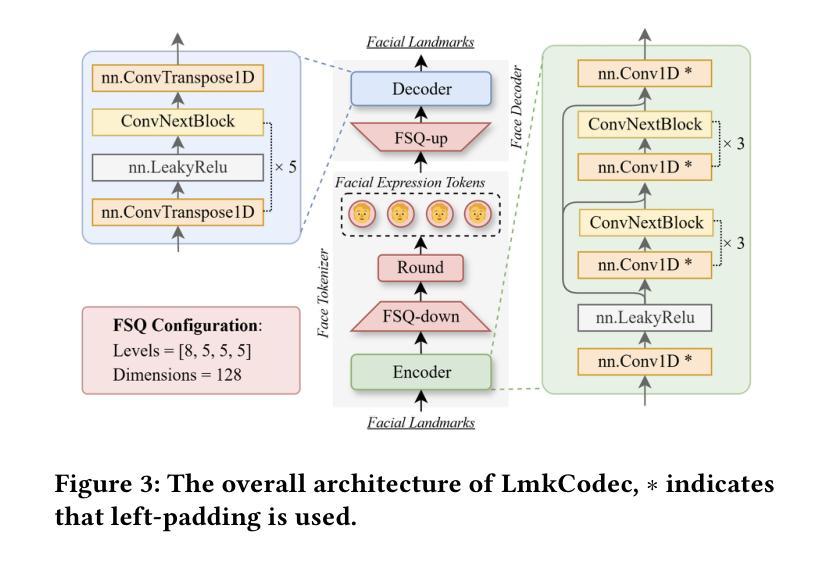
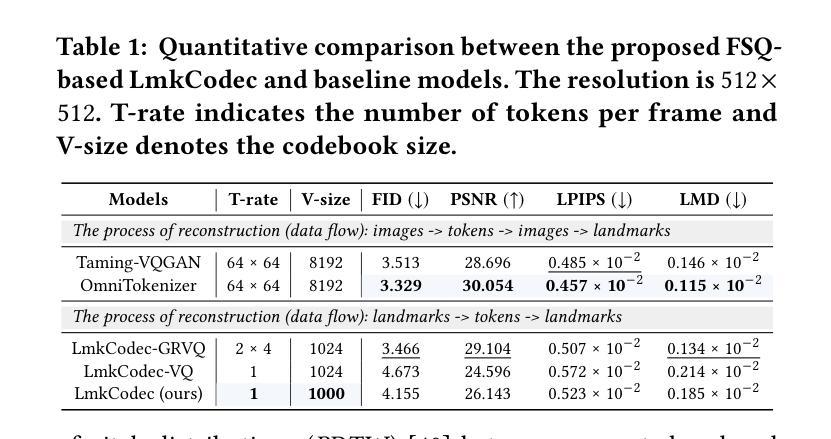
Conversational Speech Synthesis (CSS) is a key task in the user-agent interaction area, aiming to generate more expressive and empathetic speech for users. However, it is well-known that “listening” and “eye contact” play crucial roles in conveying emotions during real-world interpersonal communication. Existing CSS research is limited to perceiving only text and speech within the dialogue context, which restricts its effectiveness. Moreover, speech-only responses further constrain the interactive experience. To address these limitations, we introduce a Conversational Speech-Visual Synthesis (CSVS) task as an extension of traditional CSS. By leveraging multimodal dialogue context, it provides users with coherent audiovisual responses. To this end, we develop a CSVS system named UniTalker, which is a unified model that seamlessly integrates multimodal perception and multimodal rendering capabilities. Specifically, it leverages a large-scale language model to comprehensively understand multimodal cues in the dialogue context, including speaker, text, speech, and the talking-face animations. After that, it employs multi-task sequence prediction to first infer the target utterance’s emotion and then generate empathetic speech and natural talking-face animations. To ensure that the generated speech-visual content remains consistent in terms of emotion, content, and duration, we introduce three key optimizations: 1) Designing a specialized neural landmark codec to tokenize and reconstruct facial expression sequences. 2) Proposing a bimodal speech-visual hard alignment decoding strategy. 3) Applying emotion-guided rendering during the generation stage. Comprehensive objective and subjective experiments demonstrate that our model synthesizes more empathetic speech and provides users with more natural and emotionally consistent talking-face animations.
对话语音合成(CSS)是用户代理交互领域的一项关键任务,旨在为用户生成更具表现力和同情心的语音。然而,众所周知,“听”和“眼神交流”在现实世界的人际交流中发挥重要作用。现有的CSS研究仅限于感知对话上下文中的文本和语音,这限制了其有效性。此外,仅语音响应也限制了交互体验。为了解决这个问题,我们引入了对话语音视觉合成(CSVS)任务作为传统CSS的扩展。通过利用多模式对话上下文,它为用户提供连贯的视听响应。为此,我们开发了一个名为UniTalker的CSVS系统,这是一个统一模型,能够无缝集成多模式感知和多模式渲染功能。具体来说,它利用大规模语言模型全面理解对话上下文中的多模式线索,包括说话者、文本、语音和说话面部动画。然后,它采用多任务序列预测来首先推断目标话语的情感,然后生成富有同情心的语音和自然说话的面部动画。为了确保生成的语音视觉内容在情感、内容和持续时间方面保持一致,我们引入了三个关键优化措施:1)设计一种特殊的神经地标编解码器来标记和重建面部表情序列。2)提出了一种双模态语音视觉硬对齐解码策略。3)在生成阶段应用情感引导渲染。综合客观和主观实验表明,我们的模型能够合成更具同情心的语音,为用户提供更自然、情感上更一致的说话面部动画。
论文及项目相关链接
PDF 15 pages, 8 figures, Accepted by ACM MM 2025
Summary
该文本介绍了对话语音合成(CSS)在智能交互中的局限性,提出引入会话语音视觉合成(CSVS)任务作为对传统CSS的扩展。CSVS利用多模态对话上下文,为用户提供连贯的视听响应。为此,开发了一个名为UniTalker的CSVS系统,该系统无缝集成了多模态感知和多模态渲染能力。通过大规模语言模型理解对话上下文中的多模态线索,包括说话者、文本、语音和面部动画,然后采用多任务序列预测生成富有同情心的语音和自然流畅的面部动画。为确保生成的语音视觉内容在情感、内容和持续时间方面保持一致,引入了三项关键优化措施。
Key Takeaways
- 对话语音合成(CSS)在智能交互中有其局限性,无法完全传达情感。
- 会话语音视觉合成(CSVS)是对CSS的扩展,利用多模态对话上下文。
- UniTalker是一个CSVS系统,集成了多模态感知和多模态渲染能力。
- UniTalker利用大规模语言模型理解对话上下文中的多模态线索。
- UniTalker采用多任务序列预测生成富有同情心的语音和自然的面部动画。
- 为确保语音视觉内容的一致性,系统引入了三项关键优化措施。
点此查看论文截图