⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-09 更新
Multimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Authors:Xusheng Liang, Lihua Zhou, Nianxin Li, Miao Xu, Ziyang Song, Dong Yi, Jinlin Wu, Hongbin Liu, Jiebo Luo, Zhen Lei
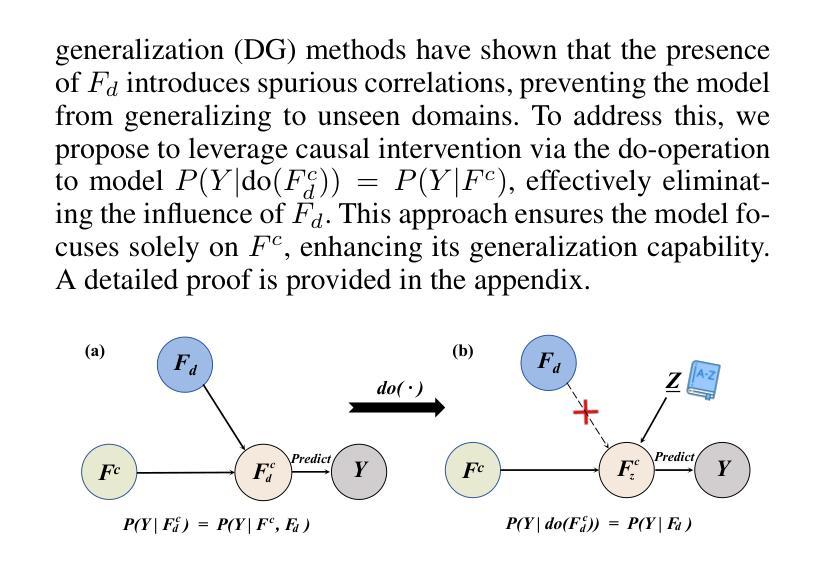
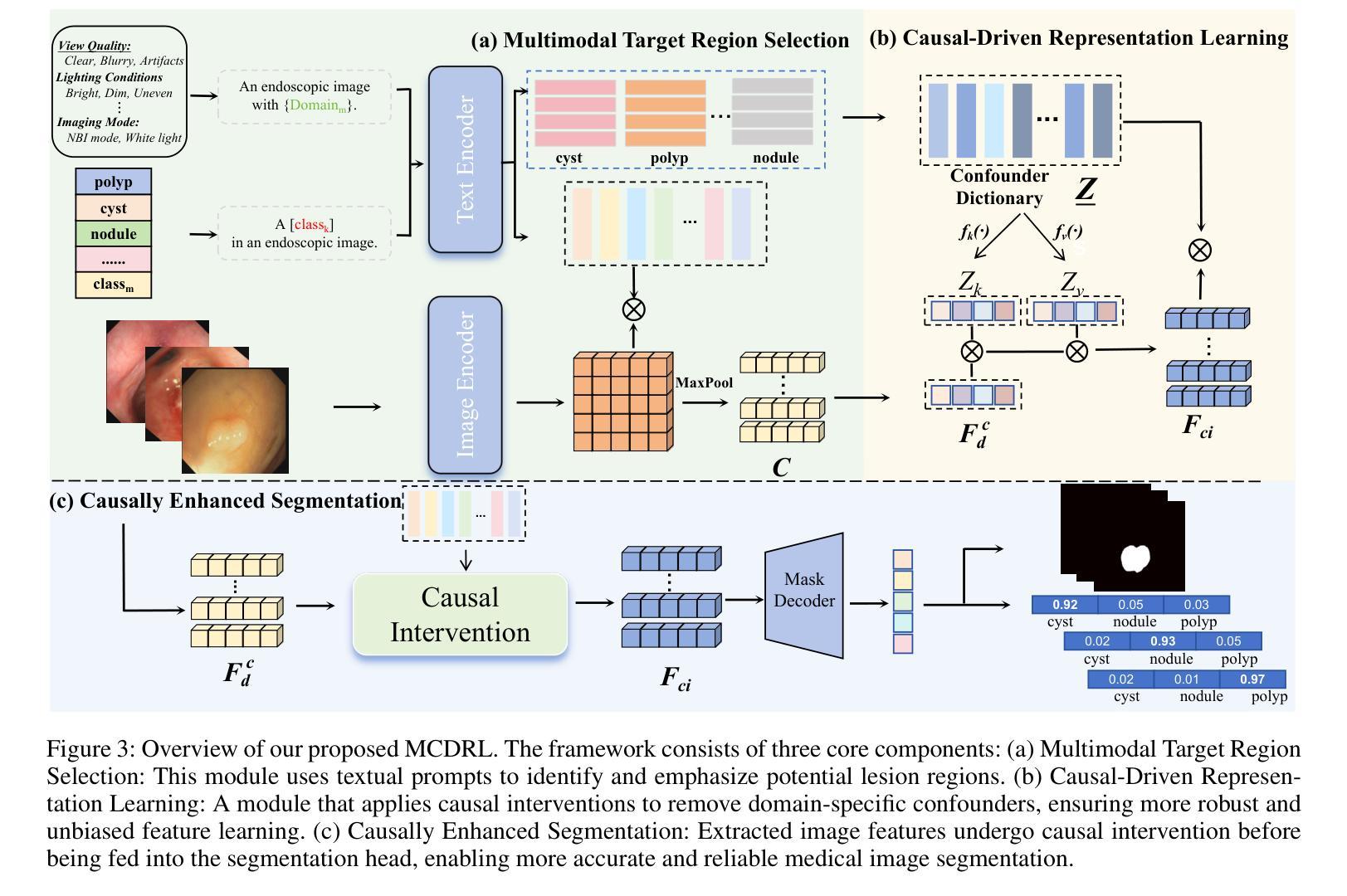
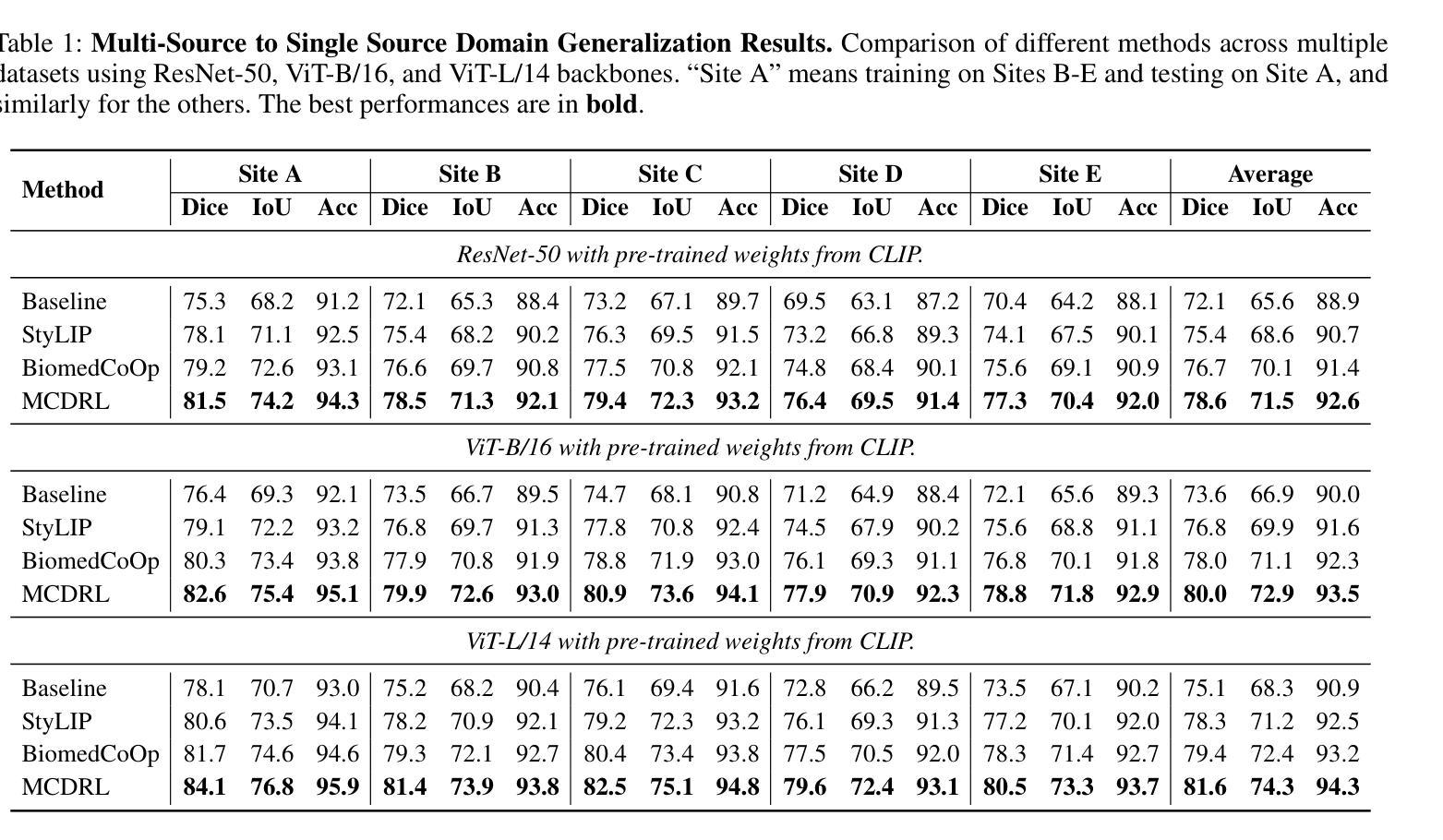
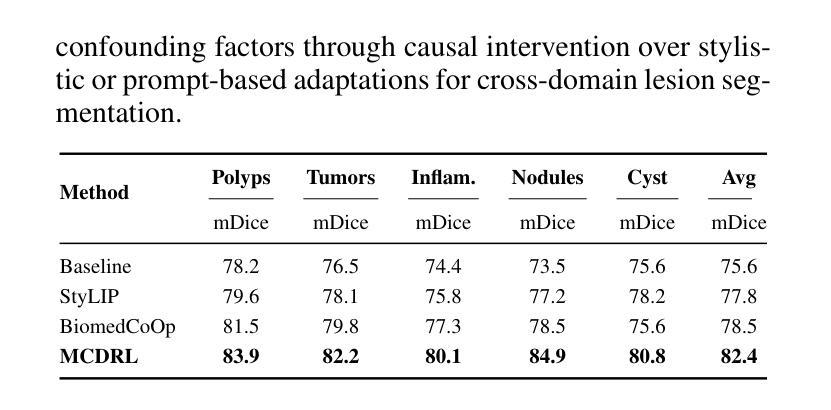
Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP’s cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.
视觉语言模型(VLMs),如CLIP,在各种计算机视觉任务中表现出了出色的零样本能力。然而,由于其应用于医疗影像时面临的高可变性和复杂性,其应用仍然具有挑战性。具体来说,医疗图像通常由于各种混杂因素而导致显著的领域偏移,包括设备差异、程序伪迹和成像模式等。当模型应用于未见领域时,可能导致较差的泛化性能。为了解决这个问题,我们提出了多模态因果驱动表示学习(MCDRL)这一新颖框架,它将因果推理与VLM相结合,解决医疗图像分割中的领域泛化问题。MCDRL的实施分为两步:首先,它利用CLIP的跨模态能力来识别候选病变区域,并通过专门设计的文本提示构建混杂因素词典,以表示领域特定的变化;其次,它训练一个因果干预网络,利用这个词典来识别和消除这些领域特定变化的影响,同时保留对分割任务至关重要的解剖结构信息。大量实验表明,MCDRL始终优于竞争方法,具有更高的分割精度和稳健的泛化能力。
论文及项目相关链接
PDF Under Review
Summary
在医学图像分割领域,由于医学数据的高变性和复杂性,跨领域应用的视觉语言模型(如CLIP)面临挑战。为应对此挑战,我们提出一种结合因果推理的视觉语言模型框架Multimodal Causal-Driven Representation Learning(MCDRL)。MCDRL首先利用CLIP的跨模态能力识别候选病变区域并建立混淆因子词典,然后通过因果干预网络训练,识别并消除领域特定变化的影响,同时保留对分割任务至关重要的解剖结构信息。实验证明,MCDRL在医学图像分割领域表现优异,具有出色的分割精度和稳健的泛化能力。
Key Takeaways
- VLM在医学图像分割中面临挑战:医学数据的高变性和复杂性导致模型在跨领域应用时表现不佳。
- MCDRL框架结合了视觉语言模型和因果推理,旨在解决医学图像分割中的领域泛化问题。
- MCDRL利用CLIP的跨模态能力识别候选病变区域并建立混淆因子词典。
- MCDRL通过因果干预网络训练,旨在消除领域特定变化的影响,同时保留解剖结构信息。
- MCDRL框架在医学图像分割任务中表现出优异的性能,包括分割精度和泛化能力。
- 实验证明MCDRL在多种医学图像分割任务中均表现优异。
点此查看论文截图

CoMAD: A Multiple-Teacher Self-Supervised Distillation Framework
Authors:Sriram Mandalika, Lalitha V
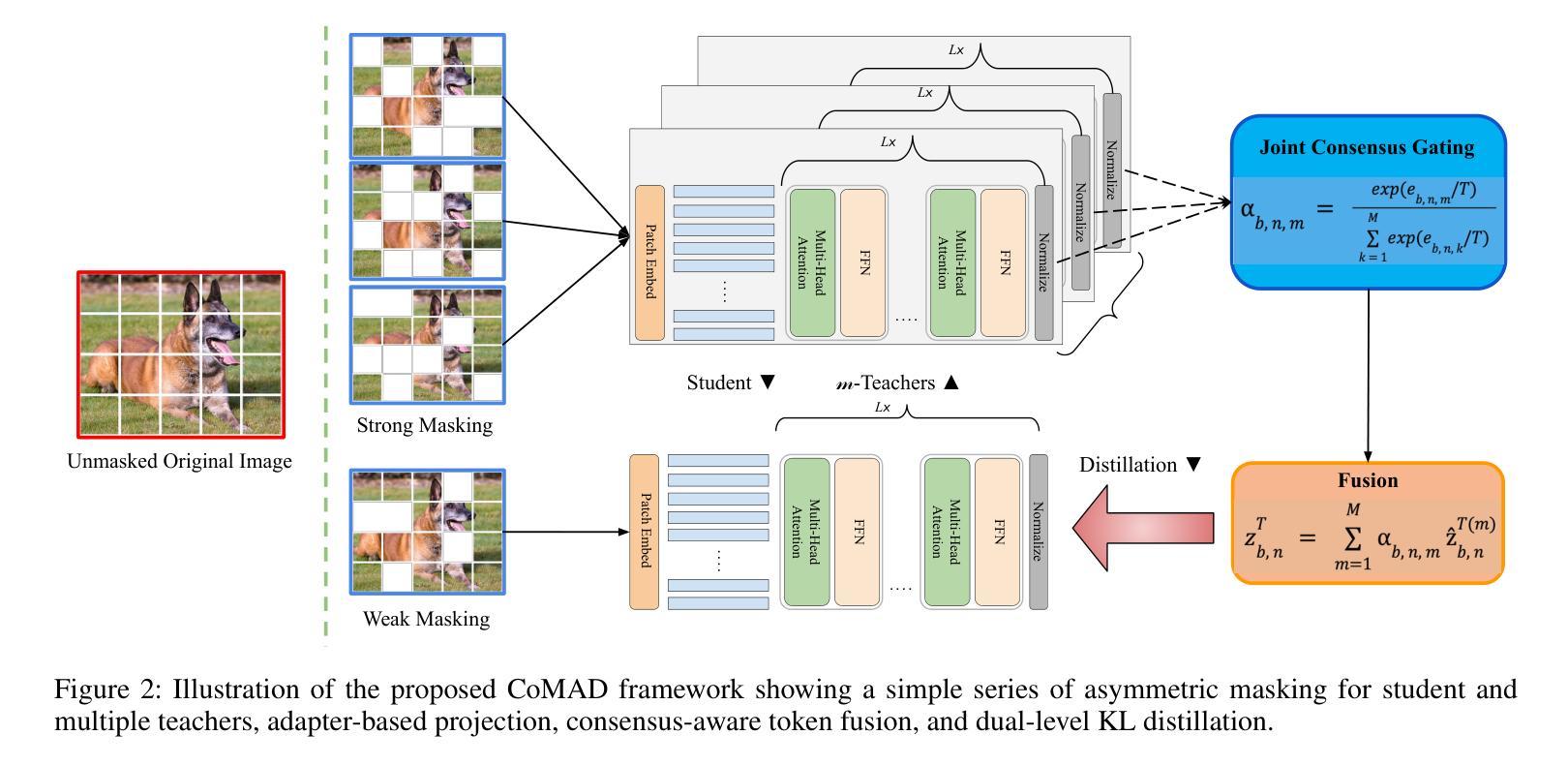
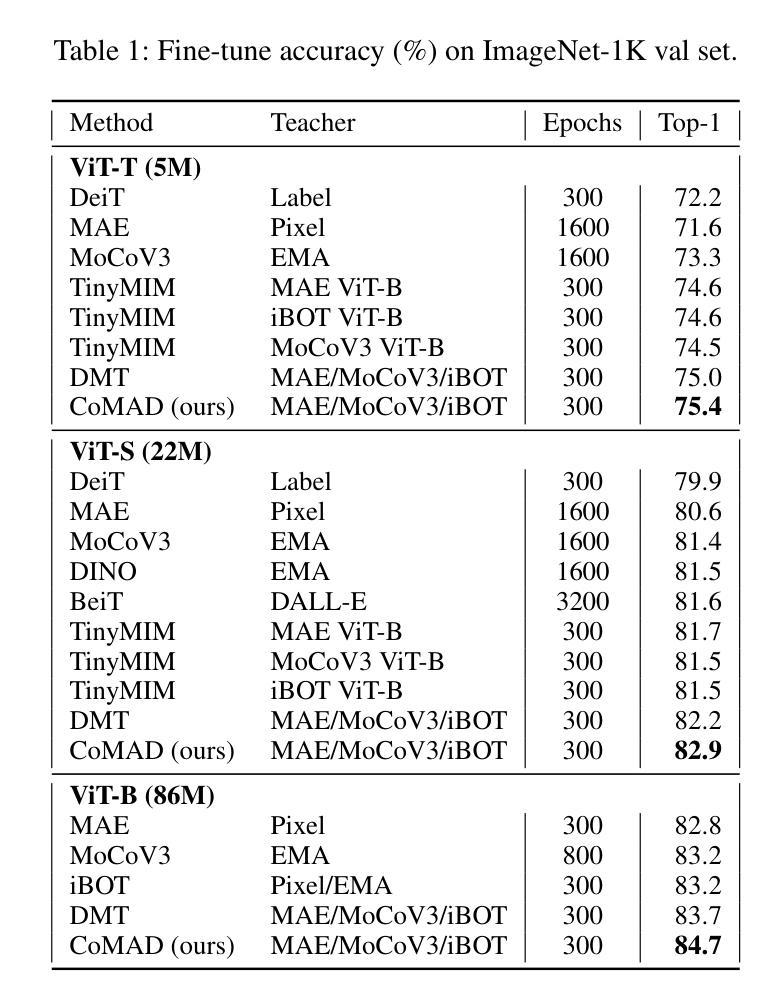
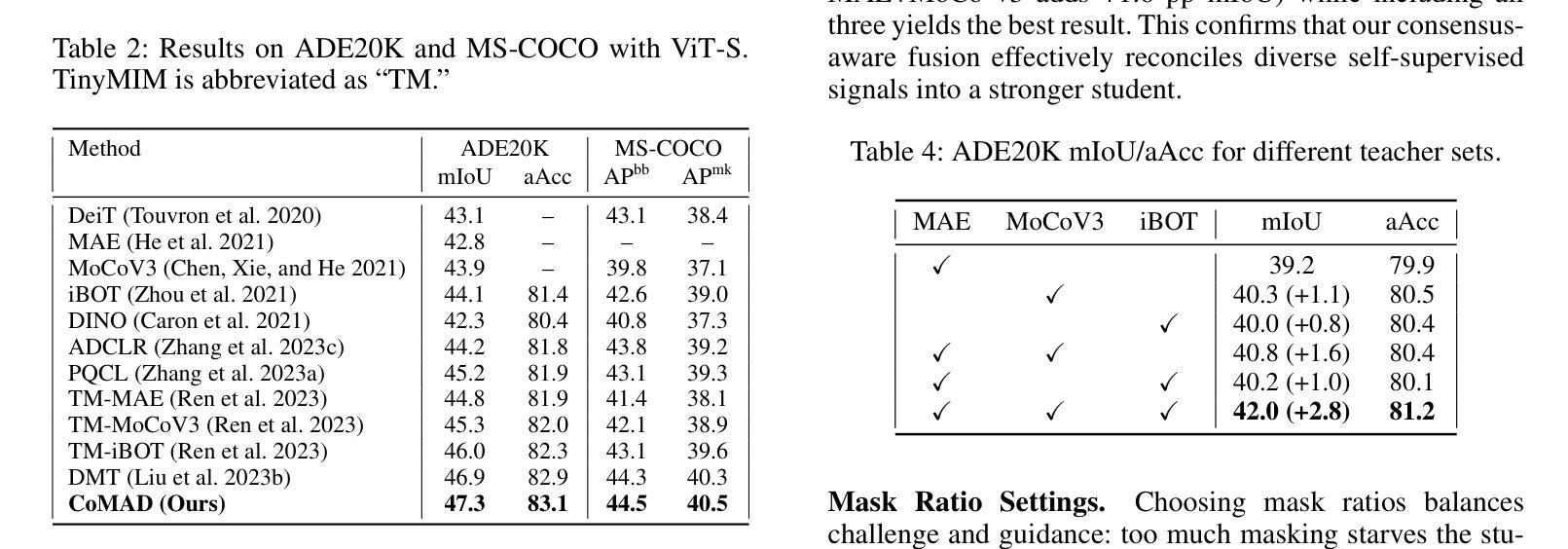
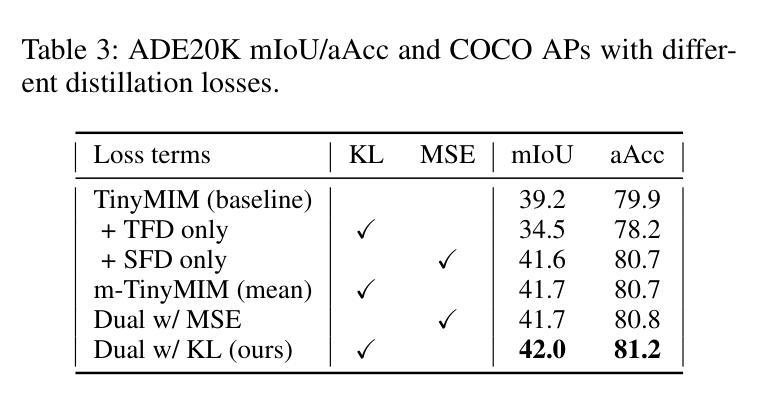
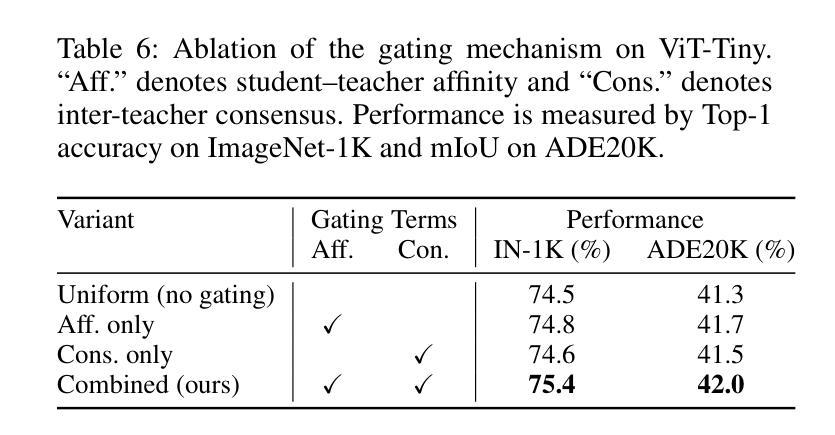
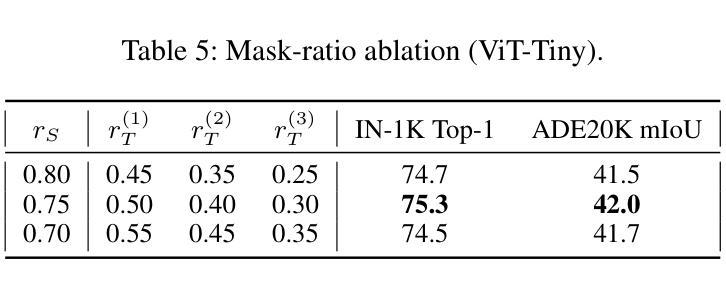
Numerous self-supervised learning paradigms, such as contrastive learning and masked image modeling, learn powerful representations from unlabeled data but are typically pretrained in isolation, overlooking complementary insights and yielding large models that are impractical for resource-constrained deployment. To overcome these challenges, we introduce Consensus-oriented Masked Distillation (CoMAD), a lightweight, parameter-free framework that unifies knowledge from multiple current state-of-the-art self-supervised Vision Transformers into a compact student network. CoMAD distills from three pretrained ViT-Base teachers, MAE, MoCo v3, and iBOT, each offering distinct semantic and contextual priors. Rather than naively averaging teacher outputs, we apply asymmetric masking: the student sees only 25 percent of patches while each teacher receives a progressively lighter, unique mask, forcing the student to interpolate missing features under richer contexts. Teacher embeddings are aligned to the student’s space via a linear adapter and layer normalization, then fused through our joint consensus gating, which weights each token by combining cosine affinity with inter-teacher agreement. The student is trained with dual-level KL divergence on visible tokens and reconstructed feature maps, capturing both local and global structure. On ImageNet-1K, CoMAD’s ViT-Tiny achieves 75.4 percent Top-1, an increment of 0.4 percent over the previous state-of-the-art. In dense-prediction transfers, it attains 47.3 percent mIoU on ADE20K, and 44.5 percent box average precision and 40.5 percent mask average precision on MS-COCO, establishing a new state-of-the-art in compact SSL distillation.
多种自监督学习范式,如对比学习和掩码图像建模,可以从无标签数据中学习强大的表示,但它们通常孤立地进行预训练,忽略了互补的见解,并产生对于资源受限的部署不切实际的庞大模型。为了克服这些挑战,我们引入了面向共识的掩码蒸馏(CoMAD),这是一个轻量级的、无需参数的框架,它将多个当前先进的自监督视觉变压器的知识统一到一个紧凑的学生网络中。CoMAD从三个预训练的ViT-Base教师模型(MAE、MoCo v3和iBOT)中提炼知识,每个模型都提供独特的语义和上下文先验。我们不是简单地平均教师的输出,而是应用不对称掩码:学生只看到25%的补丁,而每个教师则接收到一个越来越轻、独特的掩码,迫使学生在更丰富的上下文环境中推断出缺失的特征。通过线性适配器和层归一化,将教师嵌入与学生空间对齐,然后通过我们的联合共识门控进行融合,该门控通过结合余弦亲和力和教师间协议来为每个令牌加权。学生在可见令牌和重建特征图上使用双重级别的KL散度进行训练,从而捕捉局部和全局结构。在ImageNet-1K上,CoMAD的ViT-Tiny实现了75.4%的Top-1准确率,比之前的最新技术高出0.4个百分点。在密集预测转移方面,它在ADE20K上达到了47.3%的mIoU,在MS-COCO上达到了44.5%的框平均精度和40.5%的掩模平均精度,在紧凑SSL蒸馏领域中创造了新的最先进的水平。
论文及项目相关链接
PDF 8 Pages, 2 Figures
Summary
本文介绍了Consensus-oriented Masked Distillation(CoMAD)框架,该框架能够从多个先进的自监督Vision Transformers中整合知识,训练出一个紧凑的学生网络。CoMAD采用了三种预训练的ViT-Base教师模型(MAE、MoCo v3和iBOT),并利用不对称屏蔽技术对学生进行训练。学生模型能够在更丰富的上下文信息下推断缺失的特征,并从教师模型中融合嵌入信息。CoMAD在ImageNet-1K上的ViT-Tiny模型达到了75.4%的Top-1准确率,并在密集预测转移任务中取得了优异性能。
Key Takeaways
- Consensus-oriented Masked Distillation (CoMAD) 是一个轻量级的、无需参数的框架,能够整合多个自监督Vision Transformers的知识。
- CoMAD利用三种预训练的ViT-Base教师模型:MAE、MoCo v3和iBOT,这些模型提供不同的语义和上下文先验。
- 通过应用不对称屏蔽技术,学生模型能够在更丰富的上下文信息下推断缺失的特征。
- 教师模型的嵌入信息通过线性适配器和层归一化与学生的空间进行对齐,然后通过联合共识门控融合。
- 学生模型使用双重级别的KL散度在可见标记和重建的特征图上进行训练,从而捕捉局部和全局结构。
- 在ImageNet-1K上,CoMAD的ViT-Tiny模型达到了75.4%的Top-1准确率,相比之前的最优性能有所提升。
- 在密集预测转移任务中,CoMAD取得了优异性能,例如在ADE20K上达到了47.3%的mIoU,以及在MS-COCO上取得了较高的box和mask平均精度。
点此查看论文截图