⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-11 更新
CRAFT Your Dataset: Task-Specific Synthetic Dataset Generation Through Corpus Retrieval and Augmentation
Authors:Ingo Ziegler, Abdullatif Köksal, Desmond Elliott, Hinrich Schütze
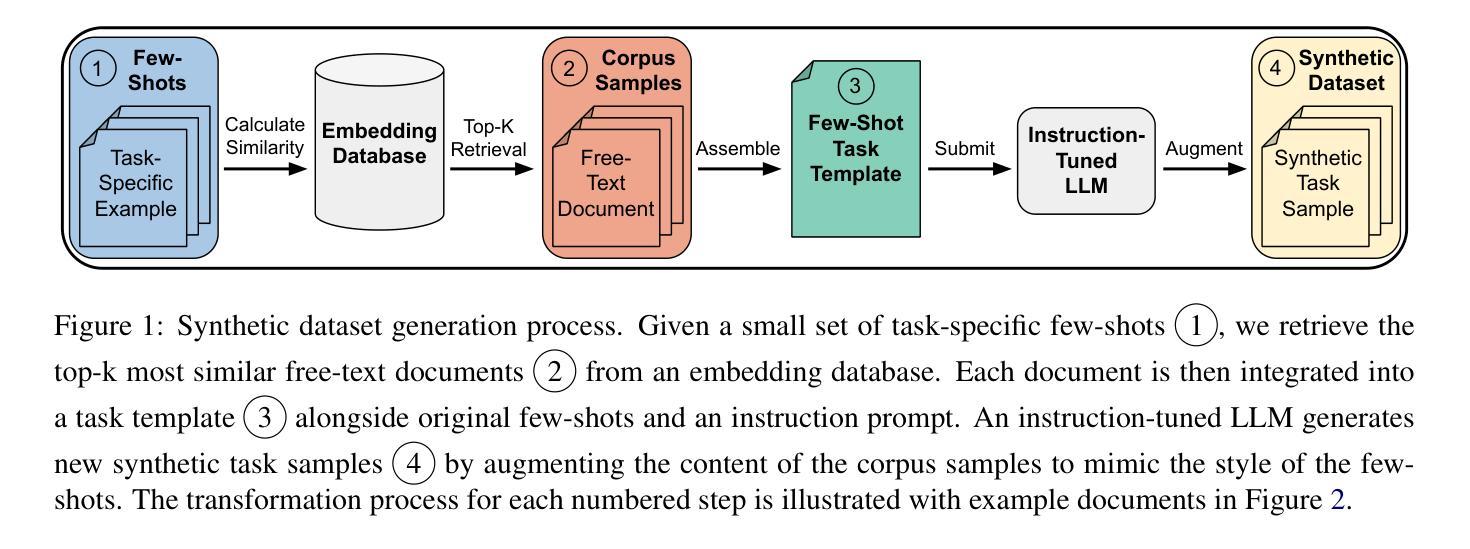
Building high-quality datasets for specialized tasks is a time-consuming and resource-intensive process that often requires specialized domain knowledge. We propose Corpus Retrieval and Augmentation for Fine-Tuning (CRAFT), a method for generating synthetic datasets, given a small number of user-written few-shots that demonstrate the task to be performed. Given these examples, CRAFT uses large-scale public web-crawled corpora and similarity-based document retrieval to find other relevant human-written documents. Lastly, instruction-tuned large language models (LLMs) augment the retrieved documents into custom-formatted task samples, which then can be used for fine-tuning. We demonstrate that CRAFT can efficiently generate large-scale task-specific training datasets for four diverse tasks: biology, medicine, and commonsense question-answering (QA), as well as summarization. Our experiments show that CRAFT-based models outperform or match general LLMs on QA tasks, while exceeding models trained on human-curated summarization data by 46 preference points. CRAFT outperforms other synthetic dataset generation methods such as Self- and Evol-Instruct, and remains robust even when the quality of the initial few-shots varies.
构建针对特定任务的高质量数据集是一个既耗时又需要大量资源的过程,通常需要特定的领域知识。我们提出了基于微调(fine-tuning)的语料库检索和扩充(Corpus Retrieval and Augmentation for Fine-Tuning,简称CRAFT)方法,这是一种生成合成数据集的方法。该方法只需要少量用户编写的演示任务执行情况的简短示例。基于这些示例,CRAFT使用大规模公共网络爬取的语料库和基于相似度的文档检索来找到其他相关的人写文档。最后,通过指令训练的的大型语言模型(LLM)将检索到的文档扩充为自定义格式的任务样本,然后可以用于微调。我们证明了CRAFT可以有效地为四种不同的任务生成大规模的任务特定训练数据集,包括生物学、医学、常识问答(QA)以及摘要。我们的实验表明,基于CRAFT的模型在问答任务上的表现优于或等同于一般的LLM,并且在摘要数据上超过了经过人工整理训练的模型,高出46个偏好点。相较于其他合成数据集生成方法如Self-和Evol-Instruct,CRAFT具有更好的表现,并且在初始简短示例的质量有所变化时仍能保持稳健。
论文及项目相关链接
PDF Accepted at TACL; Pre-MIT Press publication version. Code and dataset available at: https://github.com/ziegler-ingo/CRAFT
Summary
基于少量用户编写的演示任务样本,我们提出了Corpus Retrieval and Augmentation for Fine-Tuning(CRAFT)方法,用于生成合成数据集。该方法利用大规模公共网络爬虫语料库和基于相似度的文档检索,找到其他相关的人写文档。随后,指令微调的大型语言模型(LLM)将检索到的文档扩充为自定义格式的任务样本,可用于微调。实验表明,CRAFT在四个不同任务上表现优异,包括生物学、医学、常识问答和摘要任务。它在问答任务上优于或等于通用LLM,并在摘要任务上超出经过人类策划的训练模型表现达46个偏好点。相较于其他合成数据集生成方法,如Self-和Evol-Instruct,CRAFT更为稳健,即使在初始样本质量参差不齐的情况下仍能保持优良表现。
Key Takeaways
- CRAFT方法是一种用于生成合成数据集的技术,它利用少量用户编写的演示任务样本进行微调训练。
- CRAFT通过大规模公共网络爬虫语料库和基于相似度的文档检索找到相关文档。
- LLM用于扩充检索到的文档为自定义格式的任务样本。
- CRAFT在生物学、医学、常识问答和摘要等多样化任务上表现优异。
- CRAFT在问答任务上的表现优于或等于通用LLM。
- 在摘要任务上,基于CRAFT的模型表现超过使用人类策划数据的模型。
点此查看论文截图