⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-11 更新
CX-Mind: A Pioneering Multimodal Large Language Model for Interleaved Reasoning in Chest X-ray via Curriculum-Guided Reinforcement Learning
Authors:Wenjie Li, Yujie Zhang, Haoran Sun, Yueqi Li, Fanrui Zhang, Mengzhe Xu, Victoria Borja Clausich, Sade Mellin, Renhao Yang, Chenrun Wang, Jethro Zih-Shuo Wang, Shiyi Yao, Gen Li, Yidong Xu, Hanyu Wang, Yilin Huang, Angela Lin Wang, Chen Shi, Yin Zhang, Jianan Guo, Luqi Yang, Renxuan Li, Yang Xu, Jiawei Liu, Yao Zhang, Lei Liu, Carlos Gutiérrez SanRomán, Lei Wang
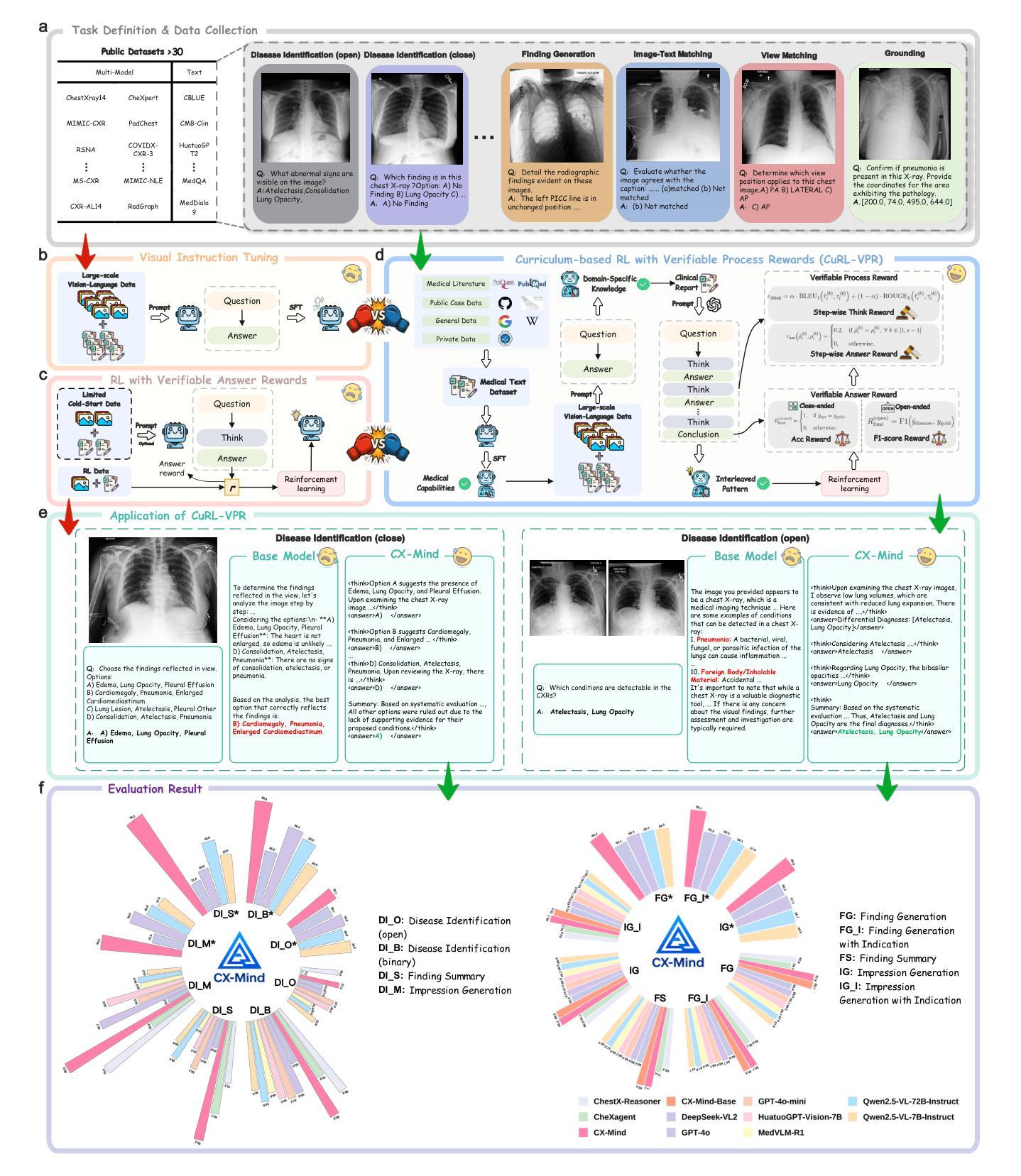
Chest X-ray (CXR) imaging is one of the most widely used diagnostic modalities in clinical practice, encompassing a broad spectrum of diagnostic tasks. Recent advancements have seen the extensive application of reasoning-based multimodal large language models (MLLMs) in medical imaging to enhance diagnostic efficiency and interpretability. However, existing multimodal models predominantly rely on “one-time” diagnostic approaches, lacking verifiable supervision of the reasoning process. This leads to challenges in multi-task CXR diagnosis, including lengthy reasoning, sparse rewards, and frequent hallucinations. To address these issues, we propose CX-Mind, the first generative model to achieve interleaved “think-answer” reasoning for CXR tasks, driven by curriculum-based reinforcement learning and verifiable process rewards (CuRL-VPR). Specifically, we constructed an instruction-tuning dataset, CX-Set, comprising 708,473 images and 2,619,148 samples, and generated 42,828 high-quality interleaved reasoning data points supervised by clinical reports. Optimization was conducted in two stages under the Group Relative Policy Optimization framework: initially stabilizing basic reasoning with closed-domain tasks, followed by transfer to open-domain diagnostics, incorporating rule-based conditional process rewards to bypass the need for pretrained reward models. Extensive experimental results demonstrate that CX-Mind significantly outperforms existing medical and general-domain MLLMs in visual understanding, text generation, and spatiotemporal alignment, achieving an average performance improvement of 25.1% over comparable CXR-specific models. On real-world clinical dataset (Rui-CXR), CX-Mind achieves a mean recall@1 across 14 diseases that substantially surpasses the second-best results, with multi-center expert evaluations further confirming its clinical utility across multiple dimensions.
胸部X光(CXR)成像是在临床实践中最广泛使用的诊断方法之一,涵盖了广泛的诊断任务。最近,基于推理的多模态大型语言模型(MLLMs)在医学成像中的广泛应用提高了诊断效率和解释性。然而,现有的多模态模型主要依赖于“一次性”诊断方法,缺乏推理过程的可验证监督。这带来了包括推理过程冗长、奖励稀疏和频繁出现幻觉等多任务CXR诊断的挑战。为了解决这些问题,我们提出了CX-Mind,这是第一个实现CXR任务的交替“思考-回答”推理的生成模型,由基于课程的强化学习和可验证的过程奖励(CuRL-VPR)驱动。具体来说,我们构建了包含708473张图像和2619148个样本的指令调整数据集CX-Set,以及由临床报告监督的42828个高质量交替推理数据点。在Group Relative Policy Optimization框架下分两个阶段进行优化:首先通过封闭域任务稳定基本推理,然后转移到开放域诊断,采用基于规则的条件过程奖励来绕过对预训练奖励模型的需求。大量的实验结果表明,CX-Mind在视觉理解、文本生成和时空对齐方面显著优于现有的医疗和通用领域MLLMs,在同类CXR特定模型上平均性能提升25.1%。在真实世界临床数据集(Rui-CXR)上,CX-Mind在14种疾病上的平均召回率@1大大超过了第二名,多中心专家评估进一步证实了其在多个维度上的临床实用性。
论文及项目相关链接
Summary
本文主要介绍了CXR成像在临床实践中的广泛应用以及存在的挑战。为应对这些挑战,提出了CX-Mind模型,这是一种实现交互式“思考-回答”推理的生成模型。CX-Mind模型采用基于课程的强化学习和可验证的过程奖励(CuRL-VPR),并通过构建CX-Set数据集进行训练。实验结果表明,CX-Mind在视觉理解、文本生成和时空对齐方面显著优于现有的医疗和通用领域多模态大型语言模型。在真实世界临床数据集上,CX-Mind在多疾病诊断上的表现超过其他模型,得到了多中心专家评估的进一步确认。
Key Takeaways
- CXR成像在临床实践中应用广泛,但存在多任务诊断的挑战,如推理过程冗长、奖励稀疏和频繁出现幻觉。
- CX-Mind模型是一种生成模型,实现了交互式“思考-回答”推理,适用于CXR任务。
- CX-Mind采用基于课程的强化学习和可验证的过程奖励(CuRL-VPR)进行训练。
- CX-Mind在视觉理解、文本生成和时空对齐方面表现优异,相比现有模型平均性能提升25.1%。
- CX-Mind在真实世界临床数据集上的表现超过其他模型,特别是在多疾病诊断方面。
- 多中心专家评估进一步确认了CX-Mind的临床实用性。
- CX-Set数据集是构建CX-Mind模型的关键,包含大量图像和样本,以及由临床报告监督的高质量交互式推理数据点。
点此查看论文截图

LLaDA-MedV: Exploring Large Language Diffusion Models for Biomedical Image Understanding
Authors:Xuanzhao Dong, Wenhui Zhu, Xiwen Chen, Zhipeng Wang, Peijie Qiu, Shao Tang, Xin Li, Yalin Wang
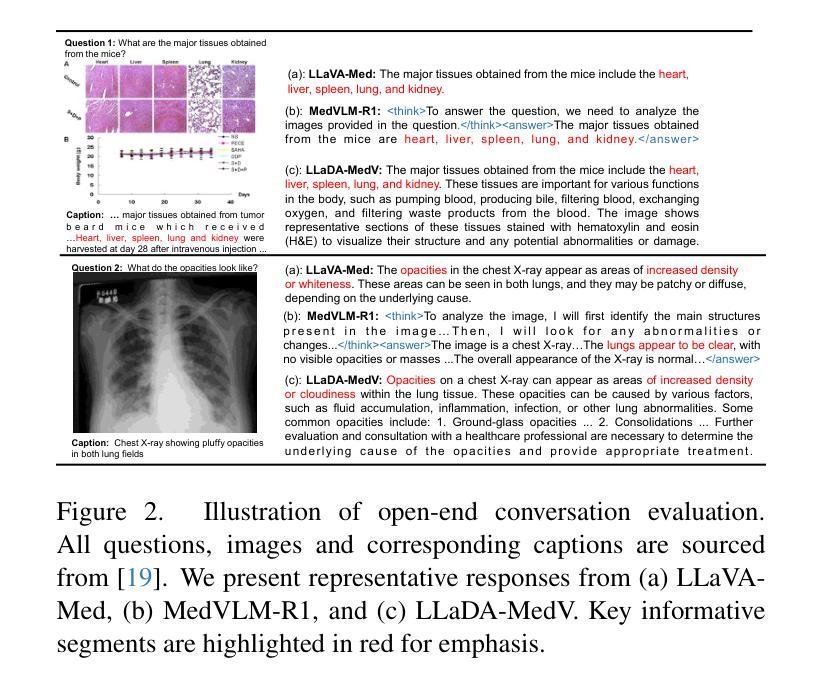
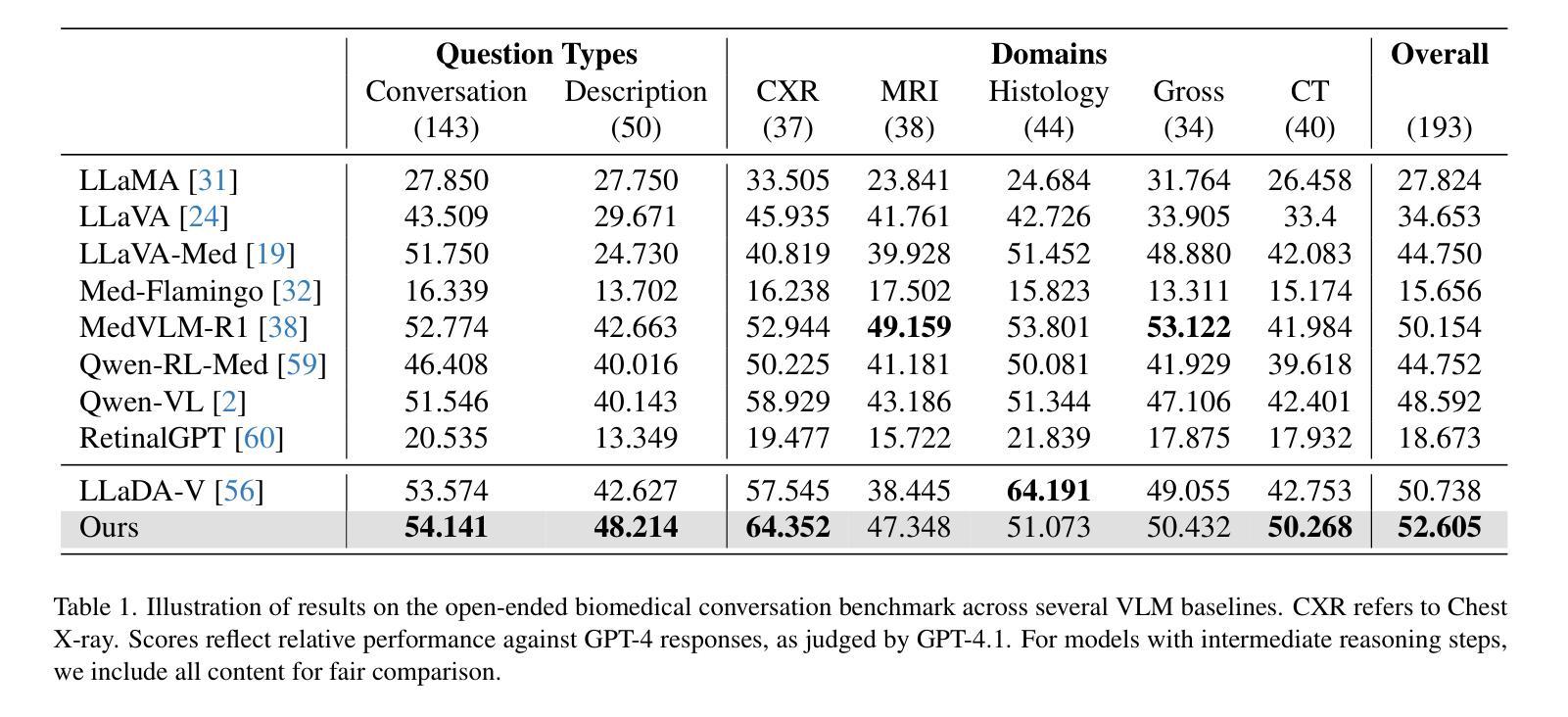
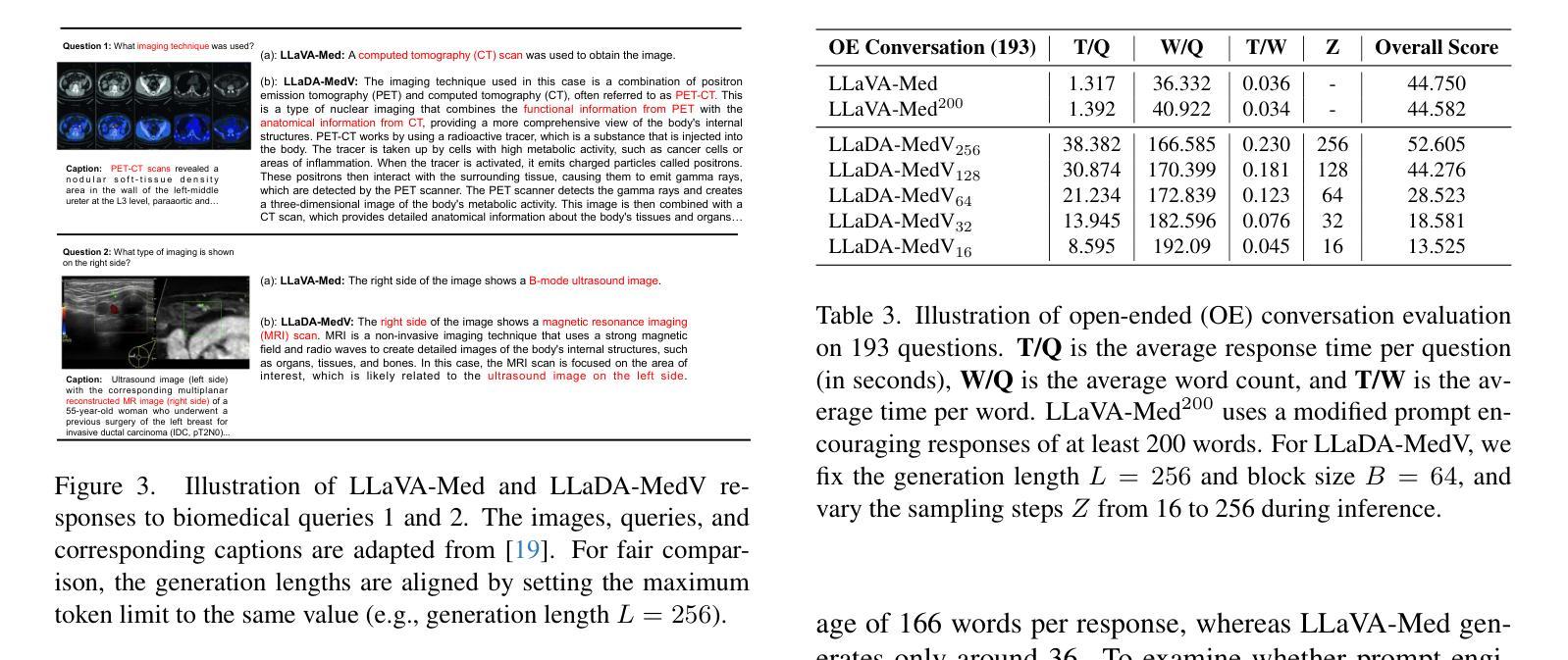
Autoregressive models (ARMs) have long dominated the landscape of biomedical vision-language models (VLMs). Recently, masked diffusion models such as LLaDA have emerged as promising alternatives, yet their application in the biomedical domain remains largely underexplored. To bridge this gap, we introduce \textbf{LLaDA-MedV}, the first large language diffusion model tailored for biomedical image understanding through vision instruction tuning. LLaDA-MedV achieves relative performance gains of 7.855% over LLaVA-Med and 1.867% over LLaDA-V in the open-ended biomedical visual conversation task, and sets new state-of-the-art accuracy on the closed-form subset of three VQA benchmarks: 84.93% on VQA-RAD, 92.31% on SLAKE, and 95.15% on PathVQA. Furthermore, a detailed comparison with LLaVA-Med suggests that LLaDA-MedV is capable of generating reasonably longer responses by explicitly controlling response length, which can lead to more informative outputs. We also conduct an in-depth analysis of both the training and inference stages, highlighting the critical roles of initialization weight selection, fine-tuning strategies, and the interplay between sampling steps and response repetition. The code and model weight is released at https://github.com/LLM-VLM-GSL/LLaDA-MedV.
自回归模型(ARMs)长期以来在生物医学视觉语言模型(VLMs)领域占据主导地位。最近,像LLaDA这样的掩膜扩散模型被证明是一种很有前景的替代方案,但它们在生物医学领域的应用仍鲜有探索。为了弥补这一空白,我们引入了针对生物医学图像理解通过视觉指令调整优化的首个大型语言扩散模型LLaDA-MedV。\LLaDA-MedV在开放式的生物医学视觉对话任务中相对于LLaVA-Med和LLaDA-V分别实现了7.855%和1.867%的性能提升,并在三个VQA基准测试集的闭式子集上达到了最新水平:VQA-RAD的84.93%,SLAKE的92.31%,以及PathVQA的95.15%。此外,与LLaVA-Med的详细比较表明,LLaDA-MedV能够通过明确控制响应长度来生成更长的响应,从而产生更丰富的输出信息。我们还对训练和推理阶段进行了深入分析,重点探讨了初始化权重选择、微调策略以及采样步骤和响应重复之间的相互作用。代码和模型权重已发布在https://github.com/LLM-VLM-GSL/LLaDA-MedV上。
论文及项目相关链接
Summary
LLaDA-MedV是专为生物医学图像理解设计的语言扩散模型,通过视觉指令调整进行优化。相较于其他模型,LLaDA-MedV在开放型生物医学视觉对话任务上取得了相对性能提升,并在三个VQA基准测试集的封闭式子集上达到最新最高准确度。此外,LLaDA-MedV能够生成较长的响应,具有明确的响应长度控制力,提供更多信息。同时,本文还深入探讨了训练和推理阶段的关键要素。
Key Takeaways
- LLaDA-MedV是首个针对生物医学图像理解的扩散模型,通过视觉指令调整进行优化。
- LLaDA-MedV在开放型生物医学视觉对话任务上的性能优于其他模型。
- LLaDA-MedV在三个VQA基准测试集的封闭式子集上达到最新最高准确度。
- LLaDA-MedV能够生成较长的响应,具有明确的响应长度控制能力。
- 与LLaVA-Med相比,LLaDA-MedV在生成响应时表现更优秀。
- 深入探讨了训练和推理阶段的关键要素,包括初始化权重选择、微调策略以及采样步骤和响应重复之间的相互作用。
点此查看论文截图

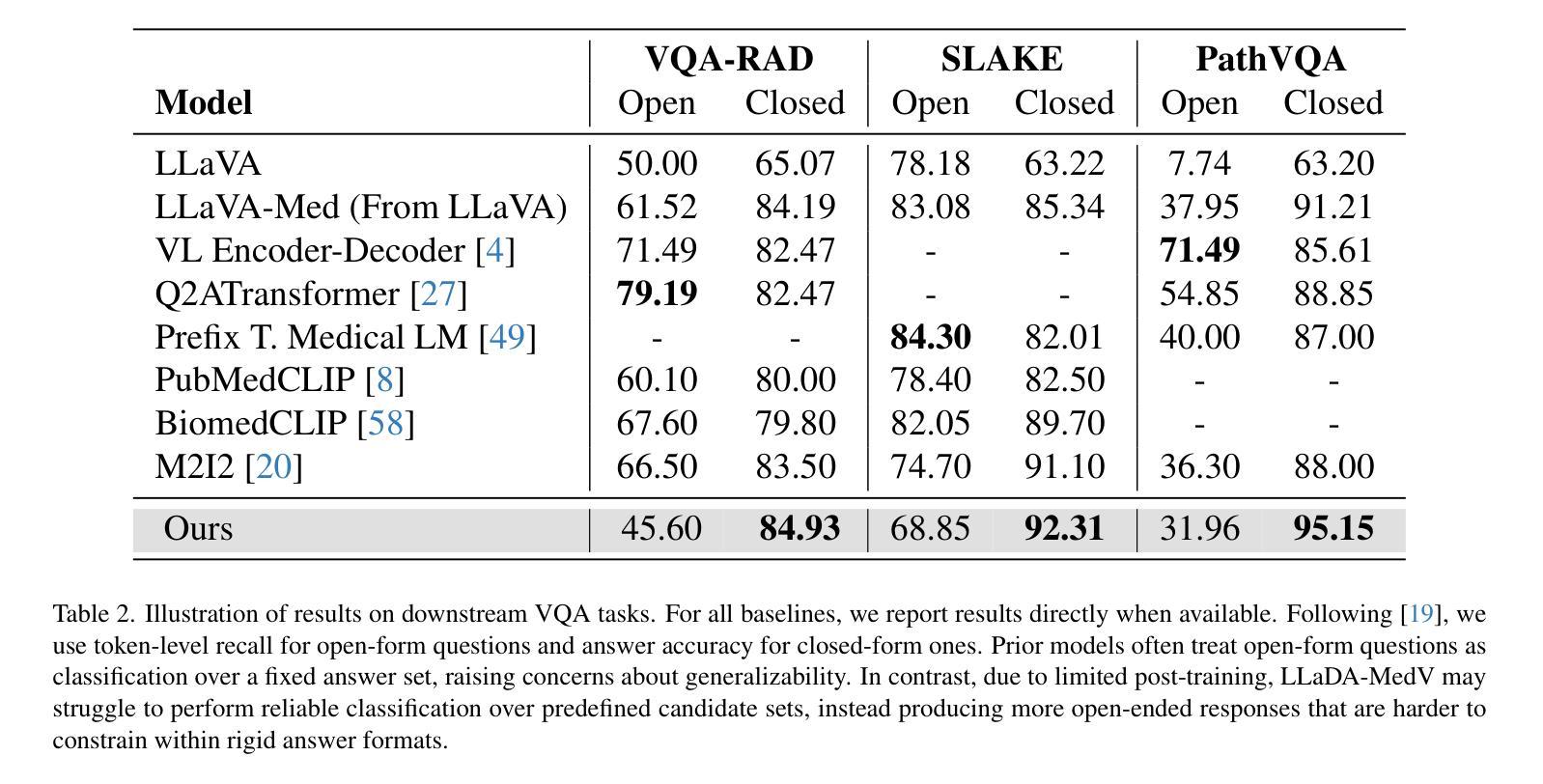
From Query to Logic: Ontology-Driven Multi-Hop Reasoning in LLMs
Authors:Haonan Bian, Yutao Qi, Rui Yang, Yuanxi Che, Jiaqian Wang, Heming Xia, Ranran Zhen
Large Language Models (LLMs), despite their success in question answering, exhibit limitations in complex multi-hop question answering (MQA) tasks that necessitate non-linear, structured reasoning. This limitation stems from their inability to adequately capture deep conceptual relationships between entities. To overcome this challenge, we present ORACLE (Ontology-driven Reasoning And Chain for Logical Eucidation), a training-free framework that combines LLMs’ generative capabilities with the structural benefits of knowledge graphs. Our approach operates through three stages: (1) dynamic construction of question-specific knowledge ontologies using LLMs, (2) transformation of these ontologies into First-Order Logic reasoning chains, and (3) systematic decomposition of the original query into logically coherent sub-questions. Experimental results on several standard MQA benchmarks show that our framework achieves highly competitive performance, rivaling current state-of-the-art models like DeepSeek-R1. Detailed analyses further confirm the effectiveness of each component, while demonstrating that our method generates more logical and interpretable reasoning chains than existing approaches.
尽管大型语言模型(LLM)在问答任务中取得了成功,但在需要非线性、结构化推理的复杂多跳问答(MQA)任务中,它们仍表现出局限性。这一局限性源于它们无法充分捕捉实体之间的深层概念关系。为了应对这一挑战,我们提出了ORACLE(Ontology驱动的Reasoning And Chain用于Logical Eucidation),这是一个无需训练的框架,它结合了LLM的生成能力与知识图谱的结构优势。我们的方法分为三个阶段:一是利用LLM动态构建问题特定的知识本体;二是将这些本体转化为一阶逻辑推理链;三是将原始查询系统地分解为逻辑连贯的子问题。在多个标准MQA基准测试上的实验结果表明,我们的框架取得了极具竞争力的性能,与当前最先进的模型如DeepSeek-R1不相上下。详细的分析进一步证实了每个组件的有效性,同时证明我们的方法生成的逻辑推理链比现有方法更具逻辑性和可解释性。
论文及项目相关链接
Summary
大型语言模型在复杂多跳问答任务中存在局限性,无法充分捕捉实体间的深层概念关系。为此,我们提出了训练免费的框架ORACLE,结合语言模型的生成能力与知识图谱的结构优势,通过构建问题特定知识本体、转换为一阶逻辑推理链和分解原始查询为逻辑连贯的子问题三个阶段进行操作。实验结果表明,该框架在多个标准多跳问答基准测试中表现高度竞争力,与当前最前沿模型如DeepSeek-R1相匹敌。
Key Takeaways
- 大型语言模型在多跳问答任务中存在局限性,无法捕捉实体间的深层概念关系。
- ORACLE框架通过结合语言模型的生成能力和知识图谱的结构优势来克服这一挑战。
- ORACLE框架包括三个阶段:构建问题特定知识本体、转换为逻辑推理链和分解原始查询。
- 实验结果表明,ORACLE框架在多跳问答基准测试中表现优异,具有竞争力。
- ORACLE框架生成的理由链比现有方法更逻辑和可解释。
- 该框架为训练免费提供了一种解决方案,可降低模型训练成本。
点此查看论文截图

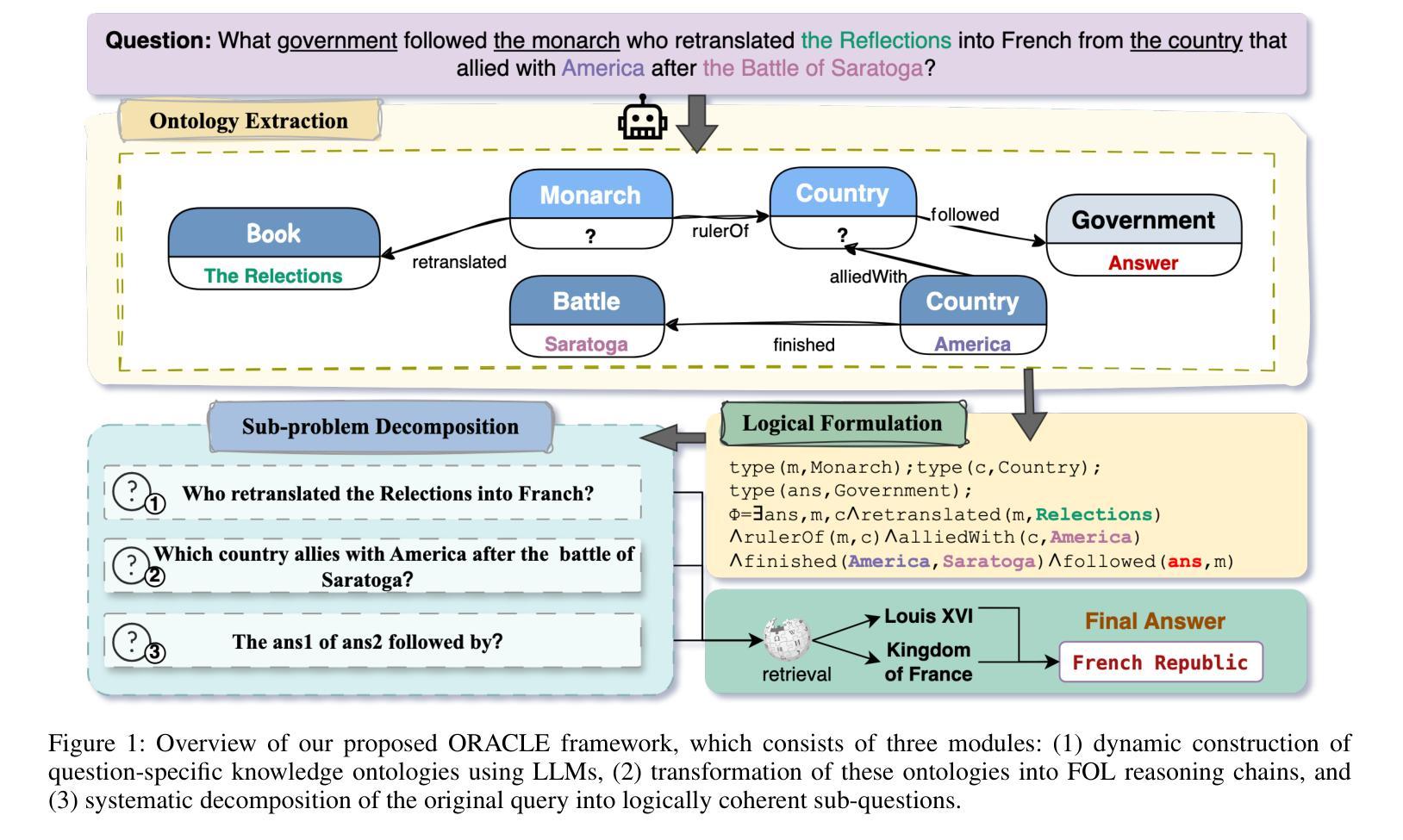

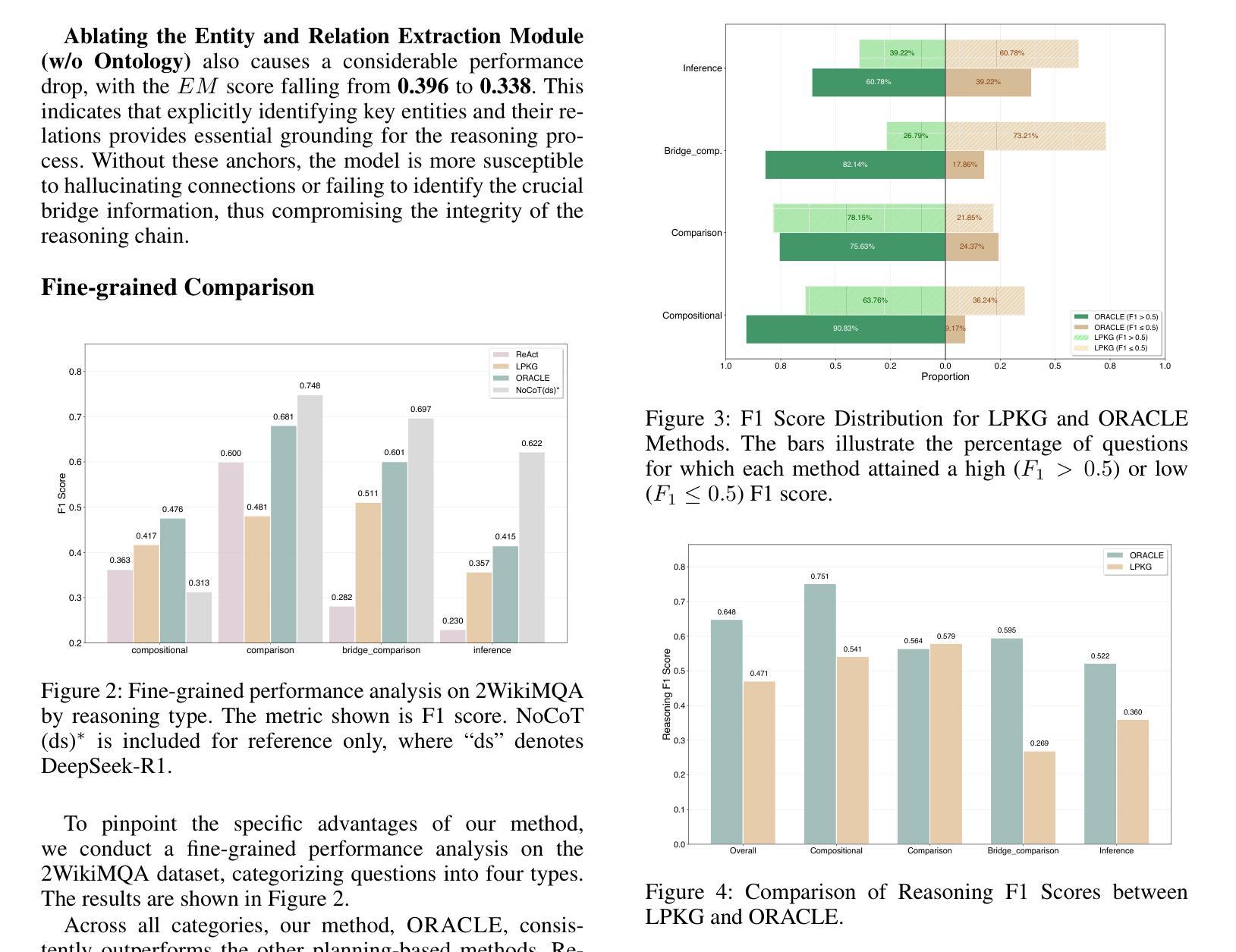
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Authors:Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, Jue Chen, Binhua Li, Zhi Jin, Fei Huang, Yongbin Li, Ge Li
Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its essentially on-policy strategy coupled with LLM’s immense action space and sparse reward. Critically, RLVR can lead to the capability boundary collapse, narrowing the LLM’s problem-solving scope. To address this problem, we propose RL-PLUS, a novel hybrid-policy optimization approach for LLMs that synergizes internal exploitation with external data to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components, i.e., Multiple Importance Sampling to address distributional mismatch from external data, and Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. Compared with existing RLVR methods, RL-PLUS achieves 1) state-of-the-art performance on six math reasoning benchmarks; 2) superior performance on six out-of-distribution reasoning tasks; 3) consistent and significant gains across diverse model families, with average relative improvements up to 69.2%. Moreover, the analysis of Pass@k curves indicates that RL-PLUS effectively resolves the capability boundary collapse problem.
强化学习与可验证奖励(RLVR)已经显著提高了大型语言模型(LLM)的复杂推理能力。然而,由于RLVR本质上是一种基于策略的方法,结合LLM庞大的动作空间和稀疏奖励,使得它在突破LLM的内在能力边界方面遇到困难。关键的是,RLVR可能导致能力边界崩溃,缩小LLM的问题解决范围。为了解决这个问题,我们提出了RL-PLUS,这是一种针对LLM的新型混合策略优化方法,它通过内部利用和外部数据的协同作用,实现更强的推理能力,并超越基础模型的边界。RL-PLUS集成了两个核心组件,即多重重要性采样,以解决外部数据分布不匹配的问题,以及基于探索的优势函数,引导模型走向高价值、未探索的推理路径。我们提供了理论分析和大量实验,以证明我们方法的优越性和通用性。与现有的RLVR方法相比,RL-PLUS在六个数学推理基准测试上达到了最新性能;在六个分布外推理任务上表现优异;在不同模型家族中实现了持续且显著的收益,平均相对改进高达69.2%。此外,Pass@k曲线的分析表明,RL-PLUS有效地解决了能力边界崩溃问题。
论文及项目相关链接
Summary
强化学习与可验证奖励(RLVR)已经显著提高了大型语言模型(LLM)的复杂推理能力。然而,它难以突破基础LLM的内在能力边界,主要是因为其本质上的在策略与LLM的庞大动作空间和稀疏奖励之间的矛盾。为了解决这一问题,我们提出了RL-PLUS,这是一种为LLM设计的新型混合策略优化方法,它通过内部剥削与外部数据的协同,实现了更强的推理能力并超越了基础模型的边界。RL-PLUS包含两个核心组件:多重重要性采样,解决外部数据分布不匹配的问题;基于探索的优势函数,引导模型走向高价值、未探索的推理路径。我们提供了理论分析和大量实验,证明了我们方法的优越性和通用性。与现有的RLVR方法相比,RL-PLUS在六个数学推理基准测试上实现了卓越的性能,在六个非常规推理任务上表现出更好的性能,并在各种模型家族中实现了平均相对改进率高达69.2%。此外,Pass@k曲线的分析表明,RL-PLUS有效地解决了能力边界崩溃问题。
Key Takeaways
- RLVR虽然提升了LLM的推理能力,但存在能力边界问题。
- RL-PLUS是一种新型混合策略优化方法,旨在解决RLVR的问题,提升LLM的推理能力。
- RL-PLUS包含两个核心组件:多重重要性采样和基于探索的优势函数。
- RL-PLUS在多个数学推理和非常规推理任务上表现出卓越性能。
- RL-PLUS具有优越性和通用性,适用于多种模型家族。
- RL-PLUS实现了平均相对改进率高达69.2%。
点此查看论文截图

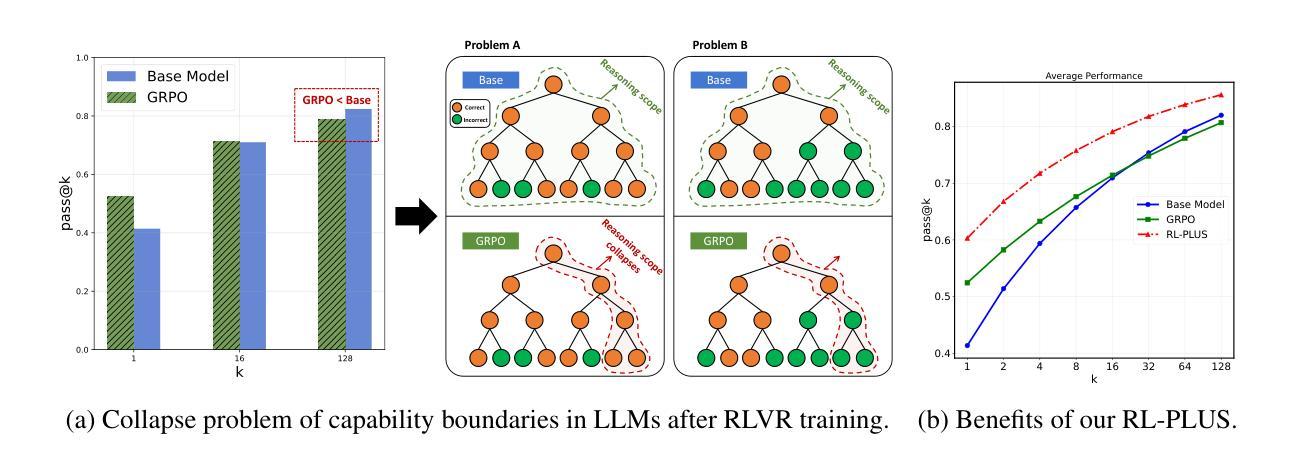
Med-R$^3$: Enhancing Medical Retrieval-Augmented Reasoning of LLMs via Progressive Reinforcement Learning
Authors:Keer Lu, Zheng Liang, Youquan Li, Jiejun Tan, Da Pan, Shusen Zhang, Guosheng Dong, Huang Leng, Bin Cui, Wentao Zhang
In medical scenarios, effectively retrieving external knowledge and leveraging it for rigorous logical reasoning is of significant importance. Despite their potential, existing work has predominantly focused on enhancing either retrieval or reasoning capabilities of the models in isolation, with little attention given to their joint optimization, which leads to limited coordination between the two processes. Additionally, current methods rely heavily on supervised fine-tuning (SFT), which can cause models to memorize existing problem-solving pathways, thereby restricting their generalization ability when confronted with novel problem contexts. Furthermore, while some studies have explored to improve retrieval-augmented reasoning in general domains via reinforcement learning, their reward function designs do not adequately capture the specific demands of the medical domain. To address these challenges, we introduce Med-R$^3$, a Medical Retrieval-augmented Reasoning framework driven by progressive Reinforcement learning. In this framework, we first develop the model’s ability to perform logical reasoning over medical problems. Subsequently, on the basis of this foundation, we adaptively optimize the retrieval capability to better align with the characteristics of knowledge corpus and external information utilization throughout the reasoning process. Finally, we conduct joint optimization of the model’s retrieval and reasoning coordination. Extensive experiments indicate that Med-R$^3$ could achieve state-of-the-art performances, with LLaMA3.1-8B-Instruct + Med-R$^3$ surpassing closed-sourced GPT-4o-mini by 3.93% at a comparable parameter scale, while Qwen2.5-14B augmented with Med-R$^3$ shows a more substantial gain of 13.53%.
在医疗场景中,有效地检索外部知识并利用其进行严谨的逻辑推理具有非常重要的意义。尽管存在潜在的可能性,但目前的工作主要集中在单独增强模型的检索或推理能力上,很少关注它们的联合优化,导致这两个过程之间的协调有限。此外,当前的方法严重依赖于有监督的微调(SFT),这可能导致模型记忆现有的问题解决路径,从而在面对新的问题情境时限制其泛化能力。虽然一些研究已经探索了通过强化学习改进一般领域的检索增强推理,但他们的奖励函数设计并没有充分捕捉到医疗领域的特定需求。为了解决这些挑战,我们引入了Med-R$^3$,这是一个由渐进式强化学习驱动的医疗检索增强推理框架。在这个框架中,我们首先开发模型解决医疗问题的逻辑推理能力。然后,在此基础上,我们自适应地优化检索能力,以更好地适应知识库和外部信息利用的特性,贯穿整个推理过程。最后,我们对模型的检索和推理协调进行联合优化。大量实验表明,**Med-R$^3$**可以达到最先进的性能,LLaMA3.1-8B-Instruct结合Med-R$^3$在可比较的参数规模下超越闭源的GPT-4o-mini 3.93%,而Qwen2.5-14B结合Med-R$^3$则显示出更大的提升幅度,达到13.53%。
论文及项目相关链接
Summary
本文提出一个医疗领域中的检索增强推理框架Med-R³,解决了现有模型在联合优化检索和推理能力方面的不足。该框架通过逐步强化学习来优化模型,首先培养模型解决医疗问题的能力,然后在此基础上自适应优化检索能力,以更好地适应知识库和外部信息的使用特点。最终实现了模型检索和推理的联合优化。实验表明,Med-R³取得了最先进的性能,与闭源GPT-4o-mini相比,LLaMA3.1-8B-Instruct + Med-R³的性能提高了3.93%,而Qwen2.5-14B与Med-R³的结合则显示出更大的增益,提高了13.53%。
Key Takeaways
- Med-R³框架解决了医疗领域中检索和推理的联合优化问题。
- 该框架通过逐步强化学习来优化模型的检索和推理能力。
- Med-R³首先培养模型解决医疗问题的能力,然后优化检索能力,以适应知识库和外部信息的使用特点。
- Med-R³实现了模型检索和推理的联合优化,取得了最先进的性能。
- 与闭源GPT-4o-mini相比,LLaMA3.1-8B-Instruct + Med-R³的性能有所提高。
- Qwen2.5-14B与Med-R³的结合显示出更大的性能提升。
- Med-R³框架具有广泛的应用前景,特别是在医疗领域的知识管理和问题解答方面。
点此查看论文截图

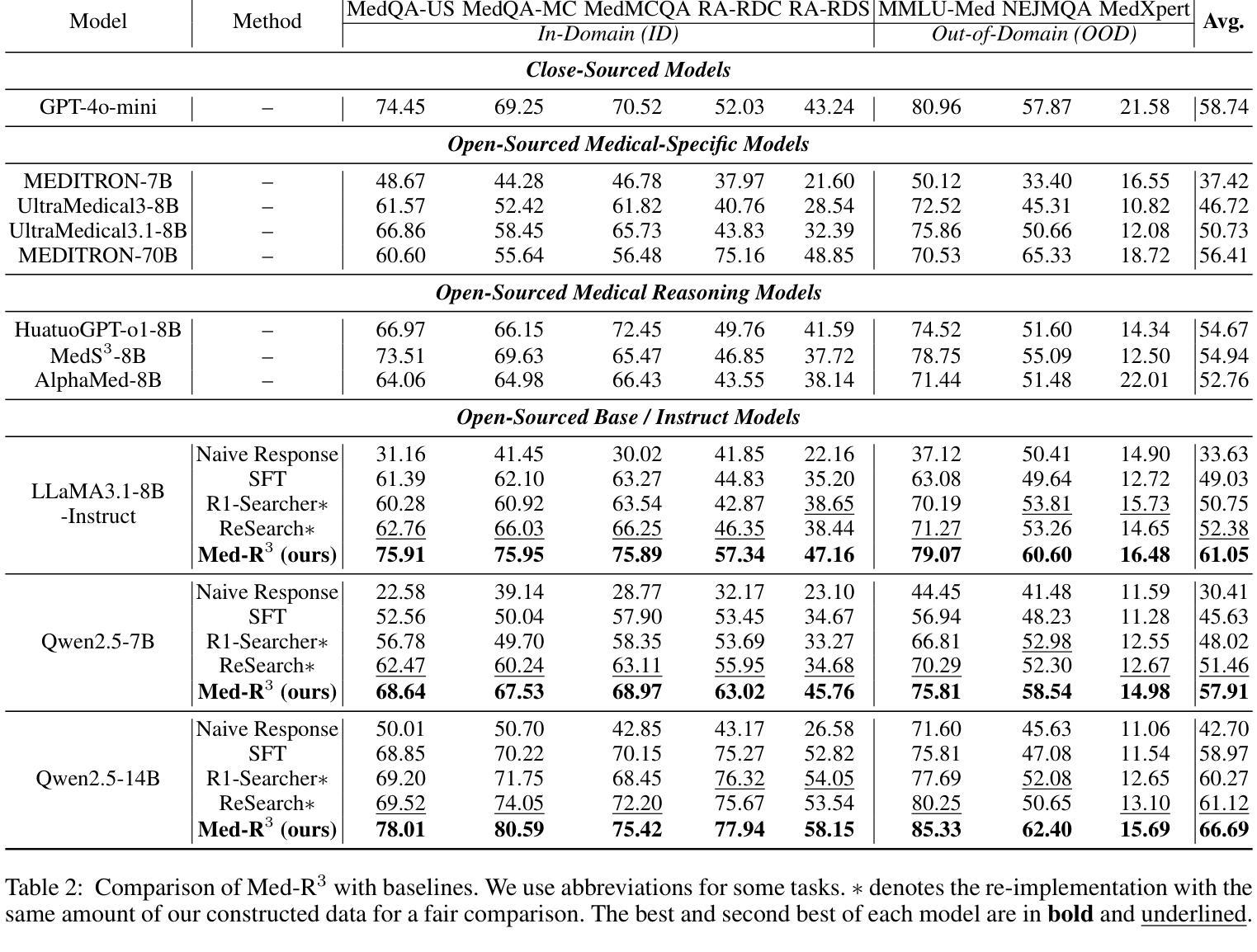
From Sufficiency to Reflection: Reinforcement-Guided Thinking Quality in Retrieval-Augmented Reasoning for LLMs
Authors:Jie He, Victor Gutiérrez-Basulto, Jeff Z. Pan
Reinforcement learning-based retrieval-augmented generation (RAG) methods enhance the reasoning abilities of large language models (LLMs). However, most rely only on final-answer rewards, overlooking intermediate reasoning quality. This paper analyzes existing RAG reasoning models and identifies three main failure patterns: (1) information insufficiency, meaning the model fails to retrieve adequate support; (2) faulty reasoning, where logical or content-level flaws appear despite sufficient information; and (3) answer-reasoning inconsistency, where a valid reasoning chain leads to a mismatched final answer. We propose TIRESRAG-R1, a novel framework using a think-retrieve-reflect process and a multi-dimensional reward system to improve reasoning and stability. TIRESRAG-R1 introduces: (1) a sufficiency reward to encourage thorough retrieval; (2) a reasoning quality reward to assess the rationality and accuracy of the reasoning chain; and (3) a reflection reward to detect and revise errors. It also employs a difficulty-aware reweighting strategy and training sample filtering to boost performance on complex tasks. Experiments on four multi-hop QA datasets show that TIRESRAG-R1 outperforms prior RAG methods and generalizes well to single-hop tasks. The code and data are available at: https://github.com/probe2/TIRESRAG-R1.
基于强化学习的检索增强生成(RAG)方法提高了大型语言模型(LLM)的推理能力。然而,大多数方法仅依赖于最终答案的奖励,忽视了中间推理质量。本文分析了现有的RAG推理模型,并识别出三种主要的失败模式:(1)信息不足,即模型未能检索到足够的支持;(2)推理错误,尽管信息充足,但逻辑或内容层面仍然出现缺陷;(3)答案与推理不一致,即有效的推理链导致不匹配的最终答案。我们提出了TIRESRAG-R1,这是一个使用思考-检索-反思过程和多维奖励系统的新型框架,以提高推理和稳定性。TIRESRAG-R1引入:(1)充足性奖励,以鼓励彻底检索;(2)推理质量奖励,以评估推理链的合理性和准确性;(3)反思奖励,以检测和修正错误。它还采用难度感知重权策略和培训样本过滤,以提高在复杂任务上的性能。在四个多跳问答数据集上的实验表明,TIRESRAG-R1优于先前的RAG方法,并能很好地推广到单跳任务。代码和数据集可在https://github.com/probe2/TIRESRAG-R1获得。
论文及项目相关链接
Summary:基于强化学习的检索增强生成(RAG)方法提高了大型语言模型(LLM)的推理能力。然而,大多数方法仅依赖最终答案奖励,忽视了中间推理质量。本文分析了现有的RAG推理模型,并提出了TIRESRAG-R1框架,采用思考-检索-反思过程和多维奖励系统来改善推理和稳定性。该框架引入充分性奖励、推理质量奖励和反思奖励,并采用难度感知重加权策略和训练样本过滤来提升复杂任务性能。实验表明,TIRESRAG-R1在四个多跳问答数据集上的表现优于先前的RAG方法,并能很好地推广到单跳任务。
Key Takeaways:
- RAG方法增强了LLM的推理能力,但多数仅依赖最终答案奖励,忽视中间推理质量。
- 现有RAG推理模型存在三大失败模式:信息不足、逻辑错误或内容层面缺陷、答案与推理不一致。
- TIRESRAG-R1框架通过思考-检索-反思过程和多维奖励系统改善推理和稳定性。
- TIRESRAG-R1引入充分性奖励、推理质量奖励和反思奖励。
- TIRESRAG-R1采用难度感知重加权策略和训练样本过滤来提升复杂任务性能。
- 实验表明,TIRESRAG-R1在多个多跳问答数据集上表现优异,并能推广至单跳任务。
- TIRESRAG-R1的代码和数据可在https://github.com/probe2/TIRESRAG-R1找到。
点此查看论文截图


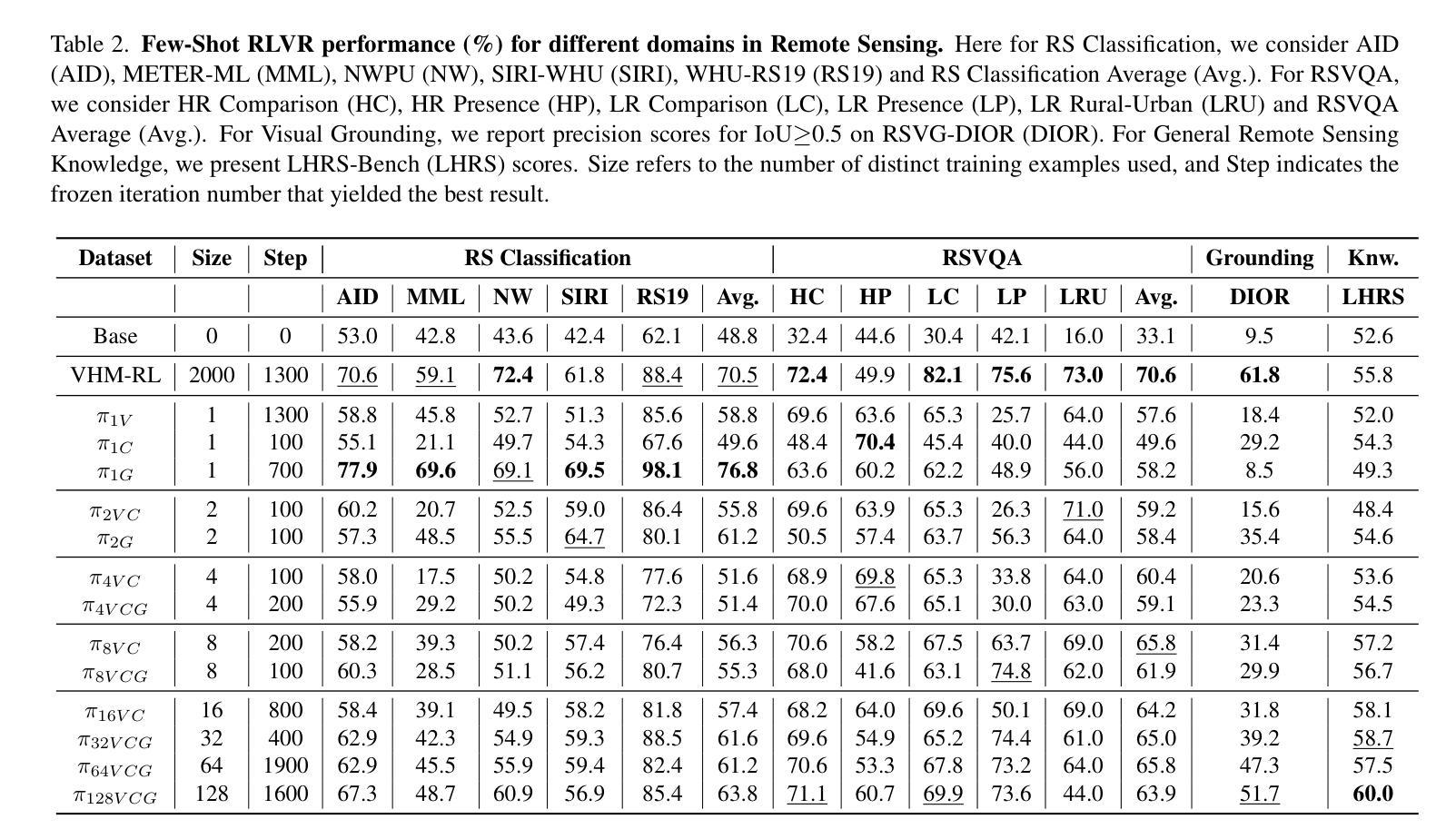
Few-Shot Vision-Language Reasoning for Satellite Imagery via Verifiable Rewards
Authors:Aybora Koksal, A. Aydin Alatan
Recent advances in large language and vision-language models have enabled strong reasoning capabilities, yet they remain impractical for specialized domains like remote sensing, where annotated data is scarce and expensive. We present the first few-shot reinforcement learning with verifiable reward (RLVR) framework for satellite imagery that eliminates the need for caption supervision–relying solely on lightweight, rule-based binary or IoU-based rewards. Adapting the “1-shot RLVR” paradigm from language models to vision-language models, we employ policy-gradient optimization with as few as one curated example to align model outputs for satellite reasoning tasks. Comprehensive experiments across multiple remote sensing benchmarks–including classification, visual question answering, and grounding–show that even a single example yields substantial improvements over the base model. Scaling to 128 examples matches or exceeds models trained on thousands of annotated samples. While the extreme one-shot setting can induce mild, task-specific overfitting, our approach consistently demonstrates robust generalization and efficiency across diverse tasks. Further, we find that prompt design and loss weighting significantly influence training stability and final accuracy. Our method enables cost-effective and data-efficient development of domain-specialist vision-language reasoning models, offering a pragmatic recipe for data-scarce fields: start from a compact VLM, curate a handful of reward-checkable cases, and train via RLVR.
最近的大型语言和视觉语言模型的进步使得强大的推理能力成为可能,然而,在遥感等特定领域,由于标注数据稀缺且昂贵,这些模型仍不实用。我们首次提出了卫星图像领域的少样本强化学习可验证奖励(RLVR)框架,该框架无需字幕监督——仅依赖轻量级、基于规则的二元奖励或基于IoU的奖励。我们将语言模型的“1次射击RLVR”范式适应到视觉语言模型,通过仅一个精选样本进行策略梯度优化,以实现对卫星推理任务的模型输出对齐。在多个遥感基准测试上的综合实验——包括分类、视觉问答和接地——表明,即使是一个例子也能给基础模型带来实质性的改进。扩展到128个例子可与在数千个标注样本上训练的模型相匹配或超越。虽然极端的一次性设置可能会导致特定的任务过拟合,但我们的方法在各种任务中始终表现出稳健的泛化能力和效率。此外,我们发现提示设计和损失权重对训练稳定性和最终精度有重大影响。我们的方法能够实现成本效益和数据效率的领域专业视觉语言推理模型开发,为数据稀缺领域提供了实用方案:从紧凑的VLM开始,精选少数可验证奖励的案例,并通过RLVR进行训练。
论文及项目相关链接
PDF ICCV 2025 Workshop on Curated Data for Efficient Learning (CDEL). 10 pages, 3 figures, 6 tables. Our model, training code and dataset will be at https://github.com/aybora/FewShotReasoning
Summary
近期大型语言和视觉语言模型的进步赋予了强大的推理能力,但在遥感等特定领域仍不适用,因为标注数据稀缺且昂贵。为此,我们提出了首个无需字幕监督的、基于少数案例强化学习与可验证奖励(RLVR)的卫星图像框架。我们采用一种“1次点击RLVR”模式,借助少量精选案例进行策略梯度优化,使模型输出与卫星推理任务对齐。实验表明,即使在单一案例下,该方法相较于基础模型也有显著提升,当扩展到128个案例时,其性能甚至可与在数千个标注样本上训练的模型相媲美。尽管一次性的设置可能会引发特定任务的过度拟合,但我们的方法在各种任务中均展现出稳健的通用性和效率。此外,我们发现提示设计和损失权重对训练稳定性和最终精度有重大影响。
Key Takeaways
- 介绍了大型语言和视觉语言模型在遥感领域的局限性,特别是在数据标注稀缺的问题。
- 提出了基于少数案例强化学习与可验证奖励(RLVR)的卫星图像框架,无需字幕监督。
- 通过策略梯度优化,仅使用少量精选案例即可实现模型输出与卫星推理任务的匹配。
- 实验证明,该方法在多个遥感基准测试中表现优异,包括分类、视觉问答和定位任务。
- 在单一案例下相较于基础模型有显著提升,扩展到更多案例时性能可与大量标注样本训练的模型相媲美。
- 尽管存在任务特定过度拟合的风险,但方法展现出稳健的通用性和效率。
点此查看论文截图

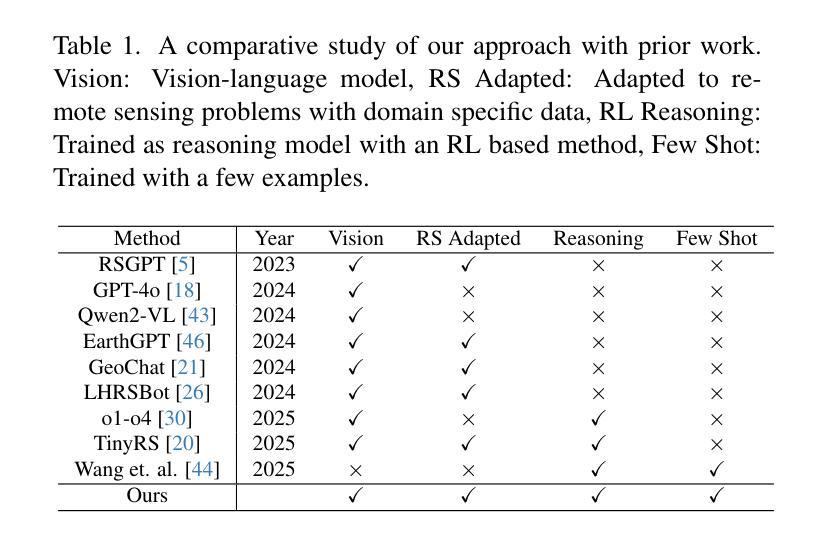
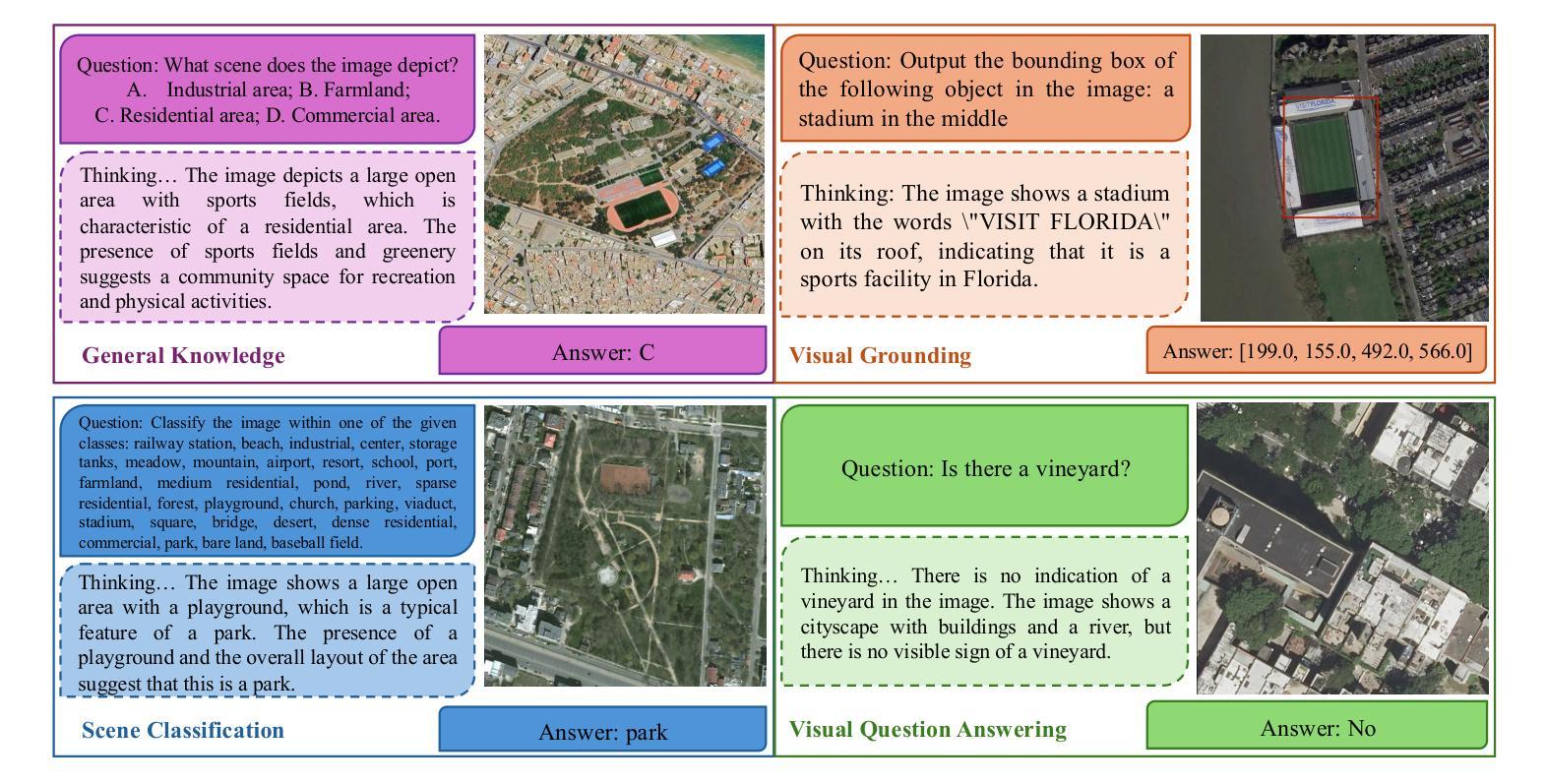
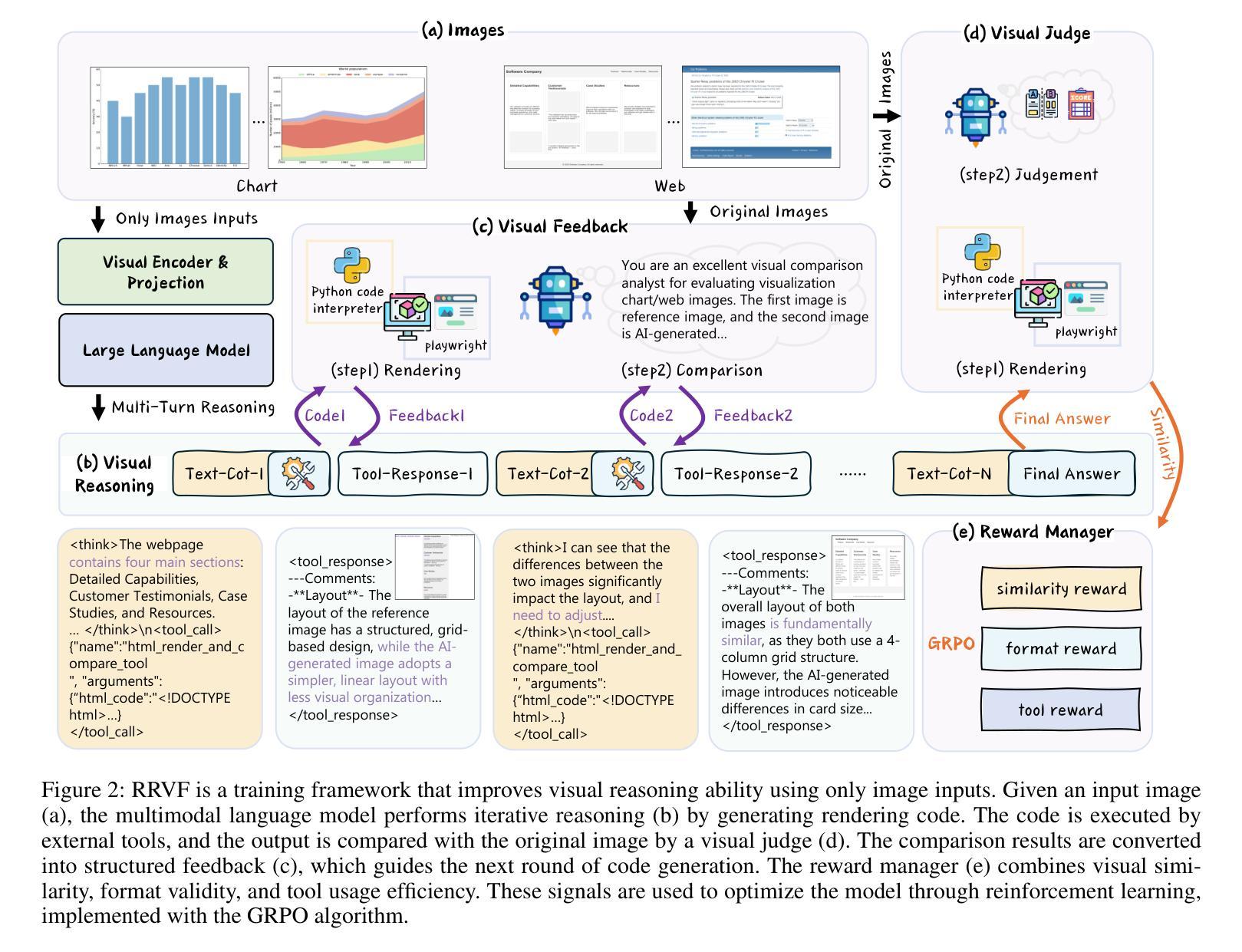
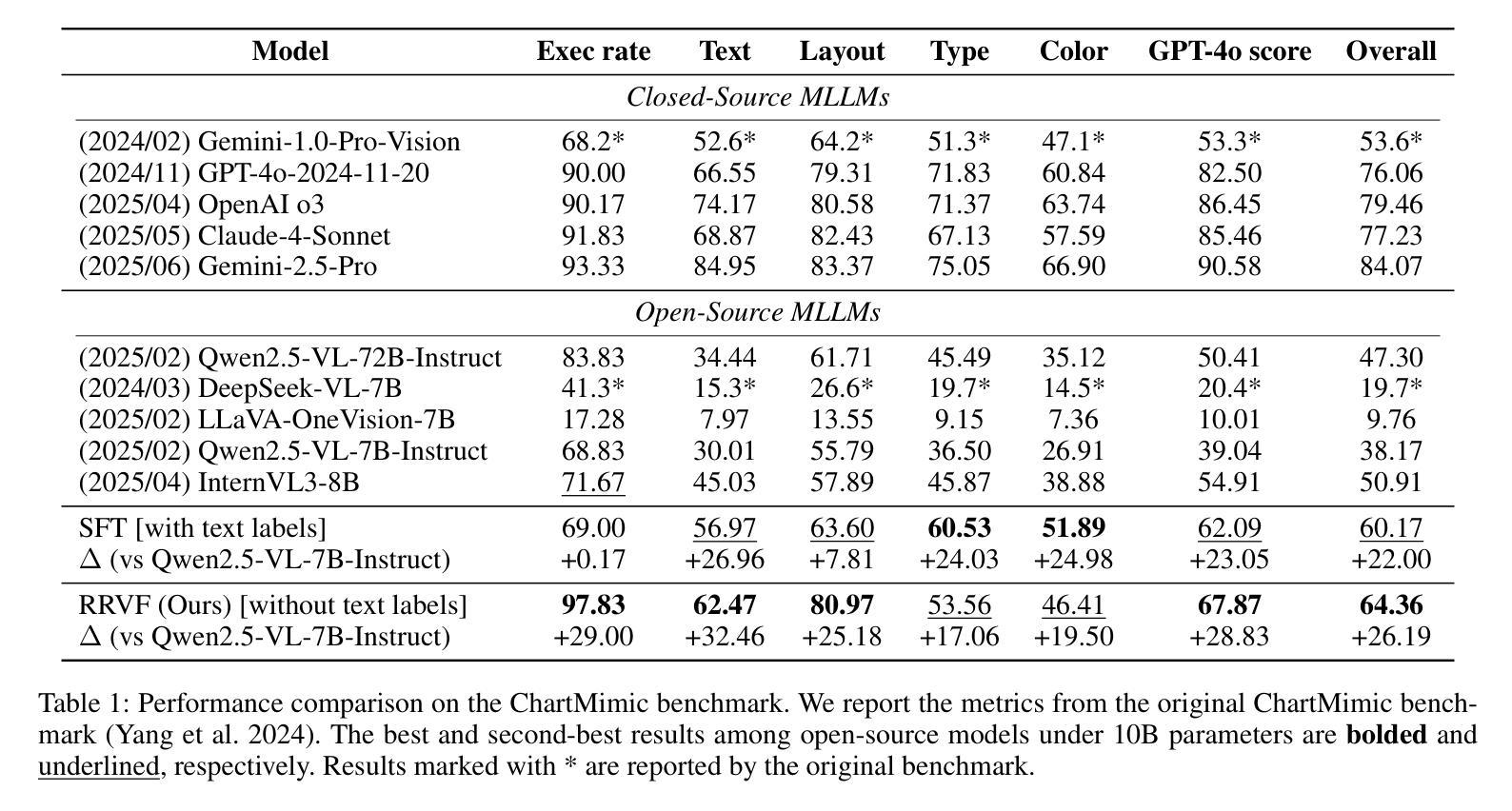
Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Authors:Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, Yu Qiao
Multimodal Large Language Models (MLLMs) exhibit impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework, Reasoning-Rendering-Visual-Feedback'' (RRVF), that enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the Asymmetry of Verification’’ principle, i.e., verifying the rendered output against the source image is substantially easier than performing deep visual reasoning to generate a faithful, structured representation such as code. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL), thereby reducing reliance on image-text supervision. RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform complex reasoning, including self-correction through multi-turn interactions. This process is optimized end-to-end using the GRPO algorithm. Extensive evaluations are conducted on image-to-code generation across two diverse domains: data charts and web interfaces. The RRVF-trained model not only outperforms existing similarly sized open-source MLLMs and supervised fine-tuning baselines but also exhibits superior generalization. Notably, the model outperforms the more advanced MLLM used to generate visual feedback during training. Code is available at https://github.com/L-O-I/RRVF.
多模态大型语言模型(MLLMs)在各种视觉任务中表现出令人印象深刻的效果。随后关于提高其视觉推理能力的调查显著扩大了其性能范围。然而,在推动MLLMs实现深度视觉推理方面,它们对精选的图像文本监督的严重依赖是一个关键的瓶颈。为了解决这个问题,我们引入了一个名为“Reasoning-Rendering-Visual-Feedback”(RRVF)的新型框架,该框架使MLLMs能够从原始图像中学习复杂的视觉推理。该框架建立在“验证不对称性”原理之上,即验证渲染输出与源图像相比,在生成忠实、结构化表示(如代码)时进行深度视觉推理要容易得多。我们证明了这种相对轻松为强化学习(RL)的优化提供了理想的奖励信号,从而减少了图像文本监督的依赖。RRVF实现了涵盖推理、渲染和视觉反馈组件的闭环迭代过程,使模型能够执行包括通过多轮交互进行自我校正的复杂推理。该过程使用GRPO算法进行端到端优化。在数据图表和Web界面两个不同领域的图像到代码生成方面进行了广泛评估。RRVF训练的模型不仅优于现有类似规模的开源MLLMs和监督微调基线,而且表现出卓越的总体化效果。值得注意的是,该模型还超越了训练过程中用于生成视觉反馈的更先进的MLLM。代码可用https://github.com/L-O-I/RRVF。
论文及项目相关链接
Summary
本文介绍了一种名为“Reasoning-Rendering-Visual-Feedback”(RRVF)的新型框架,使多模态大型语言模型(MLLMs)仅从原始图像中学习复杂的视觉推理成为可能。该框架基于“验证不对称性”原理,通过强化学习(RL)优化,实现从图像到代码生成的复杂推理任务。RRVF框架实施了一个涵盖推理、渲染和视觉反馈组件的闭环迭代过程,使模型能够通过多轮交互进行自我校正。在数据图表和网页界面两个不同领域进行的图像到代码生成评估表明,RRVF训练的模型不仅优于同样规模的其他开源MLLMs和监督精细调整基准模型,而且表现出更优秀的泛化能力。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉任务上表现出卓越性能,但在深度视觉推理方面存在依赖图像文本监督的瓶颈。
- 引入了一种新型框架“Reasoning-Rendering-Visual-Feedback”(RRVF),使MLLMs能够从原始图像中学习复杂视觉推理。
- RRVF框架基于“验证不对称性”原理,利用强化学习(RL)提供优化奖励信号。
- RRVF实施了一个涵盖推理、渲染和视觉反馈的闭环迭代过程,实现自我校正和复杂推理。
- 该框架在图像到代码生成任务上进行了广泛评估,涉及数据图表和网页界面两个领域。
- RRVF训练的模型优于其他类似规模的MLLMs和监督精细调整基准模型,并表现出更好的泛化能力。
点此查看论文截图


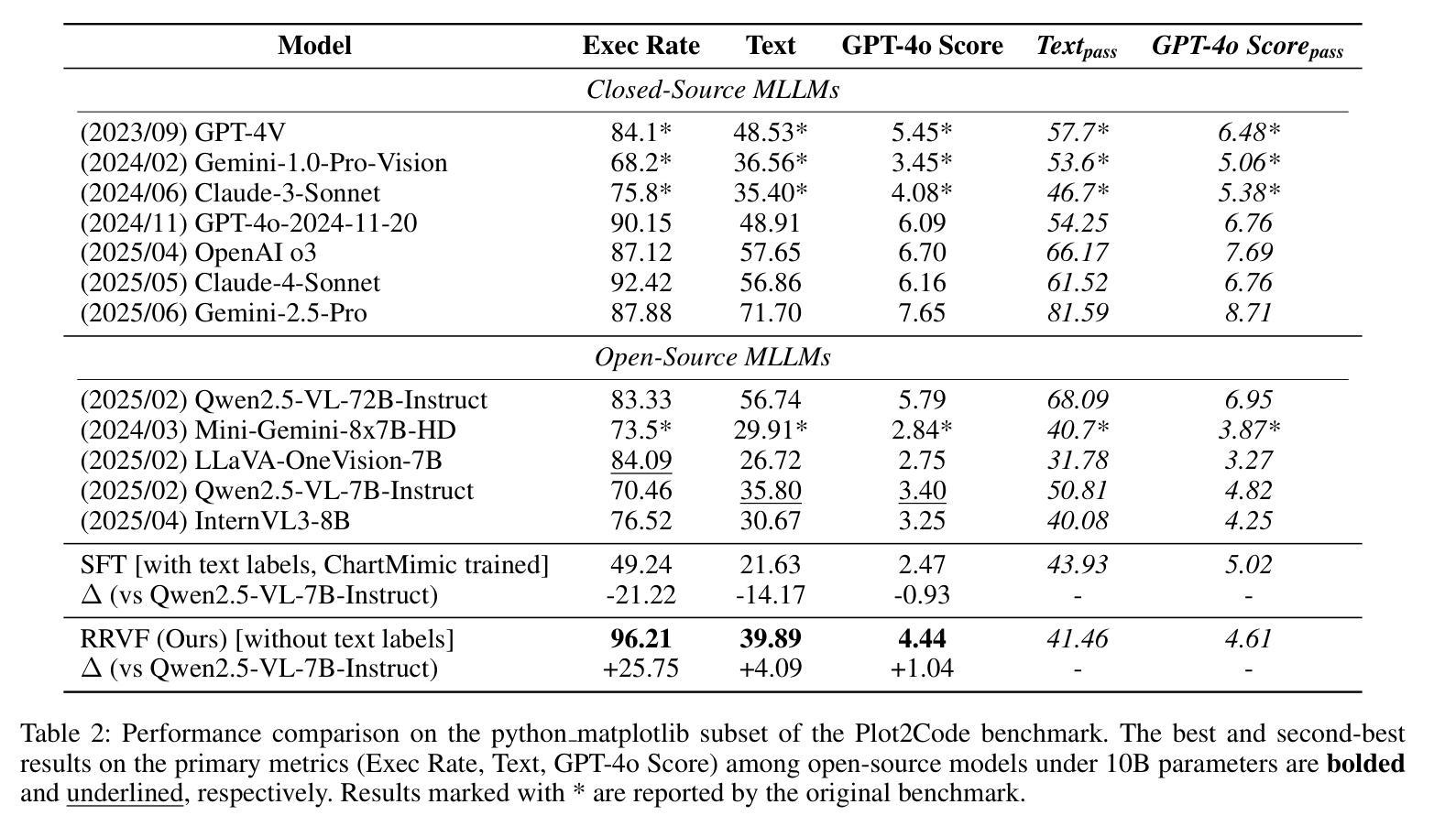
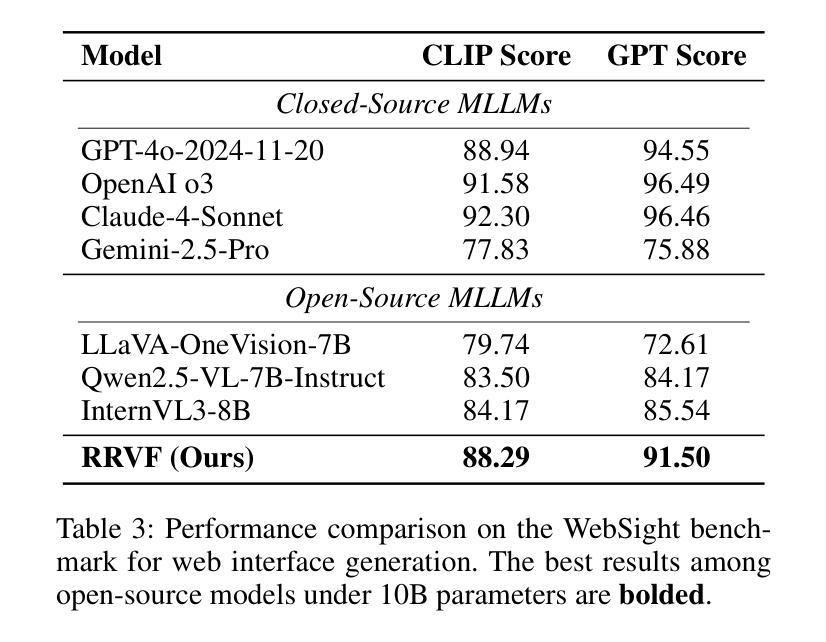
CLARIFID: Improving Radiology Report Generation by Reinforcing Clinically Accurate Impressions and Enforcing Detailed Findings
Authors:Kyeongkyu Lee, Seonghwan Yoon, Hongki Lim
Automatic generation of radiology reports has the potential to alleviate radiologists’ significant workload, yet current methods struggle to deliver clinically reliable conclusions. In particular, most prior approaches focus on producing fluent text without effectively ensuring the factual correctness of the reports and often rely on single-view images, limiting diagnostic comprehensiveness. We propose CLARIFID, a novel framework that directly optimizes diagnostic correctness by mirroring the two-step workflow of experts. Specifically, CLARIFID (1) learns the logical flow from Findings to Impression through section-aware pretraining, (2) is fine-tuned with Proximal Policy Optimization in which the CheXbert F1 score of the Impression section serves as the reward, (3) enforces reasoning-aware decoding that completes “Findings” before synthesizing the “Impression”, and (4) fuses multiple chest X-ray views via a vision-transformer-based multi-view encoder. During inference, we apply a reasoning-aware next-token forcing strategy followed by report-level re-ranking, ensuring that the model first produces a comprehensive Findings section before synthesizing the Impression and thereby preserving coherent clinical reasoning. Experimental results on the MIMIC-CXR dataset demonstrate that our method achieves superior clinical efficacy and outperforms existing baselines on both standard NLG metrics and clinically aware scores.
自动生成的放射学报告具有缓解放射科医生巨大工作量的潜力,但当前的方法在提供临床可靠结论方面遇到了困难。特别是,大多数先前的方法侧重于生成流畅的文字,而没有有效地确保报告的事实正确性,并且通常依赖于单视图图像,这限制了诊断的全面性。我们提出了CLARIFID这一新型框架,它通过镜像专家的两步工作流程来直接优化诊断的正确性。具体来说,CLARIFID(1)通过分段预训练学习从检查结果到印象的逻辑流程,(2)使用近端策略优化进行微调,其中印象部分的CheXbert F1分数作为奖励,(3)强制执行推理感知解码,在完成“检查结果”后合成“印象”,(4)通过基于视觉变换器的多视图编码器融合多个胸部X光片视图。在推理过程中,我们应用了一种推理感知的下一个标记强制策略,然后进行报告级别的重新排序,确保模型首先生成全面的检查结果部分,然后再合成印象,从而保持连贯的临床推理。在MIMIC-CXR数据集上的实验结果表明,我们的方法达到了卓越的临床效果,在标准自然语言生成指标和临床意识评分上都超越了现有基线。
论文及项目相关链接
Summary
本文提出一种名为CLARIFID的新框架,用于自动生成诊断正确的放射学报告。该框架通过模仿专家两步工作流程、学习逻辑流程、精细调整近端策略优化、实施推理感知解码和融合多视角的胸部X光片,提高了报告的准确性和诊断的连贯性。实验结果表明,CLARIFID在MIMIC-CXR数据集上的临床效果显著优于现有方法。
Key Takeaways
- CLARIFID框架旨在解决放射学报告自动生成中诊断正确性的问题。
- 该框架通过模仿专家工作流程来学习逻辑流程,从而提高报告的准确性。
- CLARIFID采用近端策略优化精细调整模型,使用CheXbert F1分数作为奖励。
- 推理感知解码确保报告中的“发现”部分先于“印象”部分完成,保持连贯的临床推理。
- CLARIFID通过融合多视角的胸部X光片来提高报告的全面性。
- 在MIMIC-CXR数据集上的实验表明,CLARIFID在临床效果和性能上优于现有方法。
点此查看论文截图

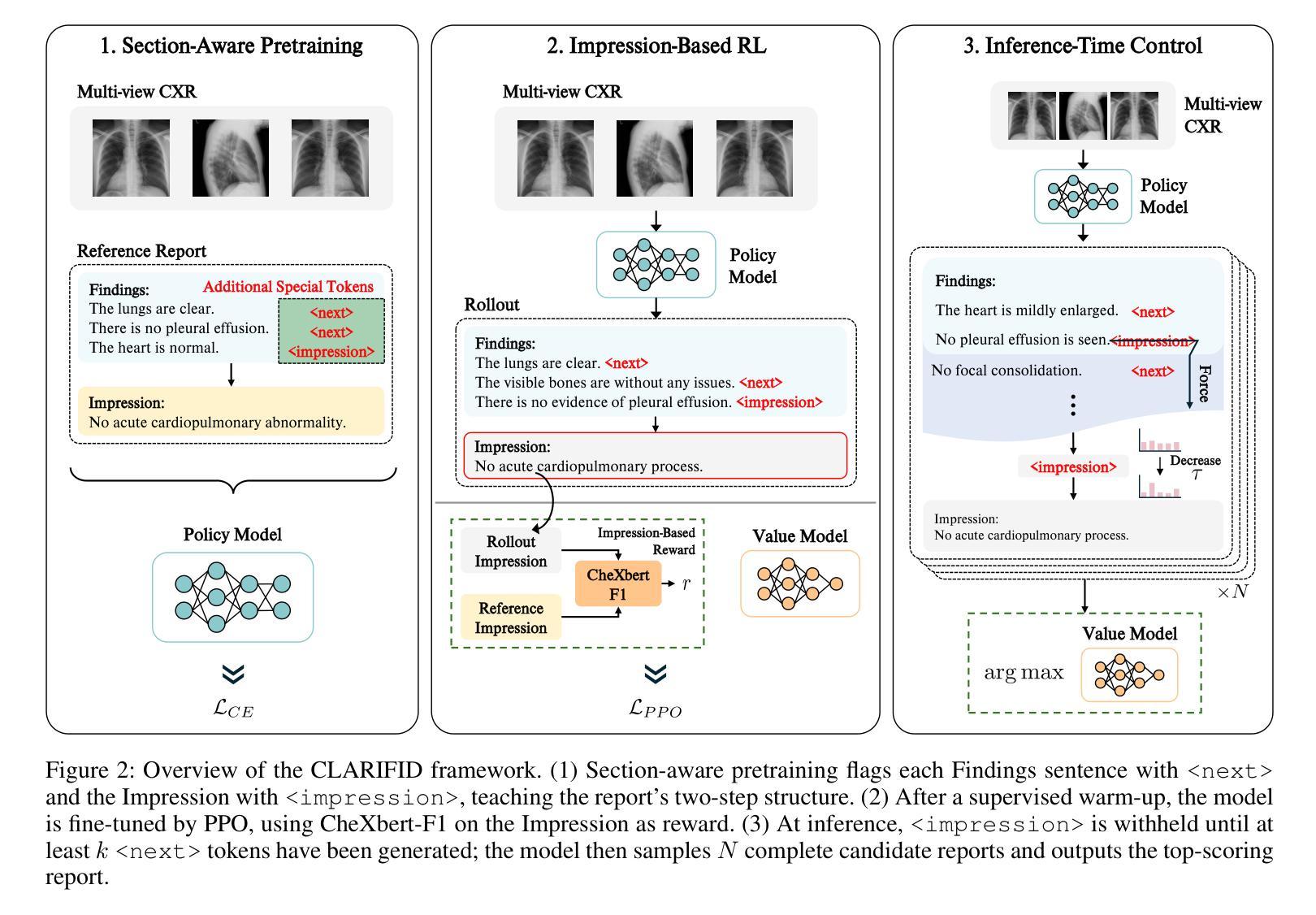

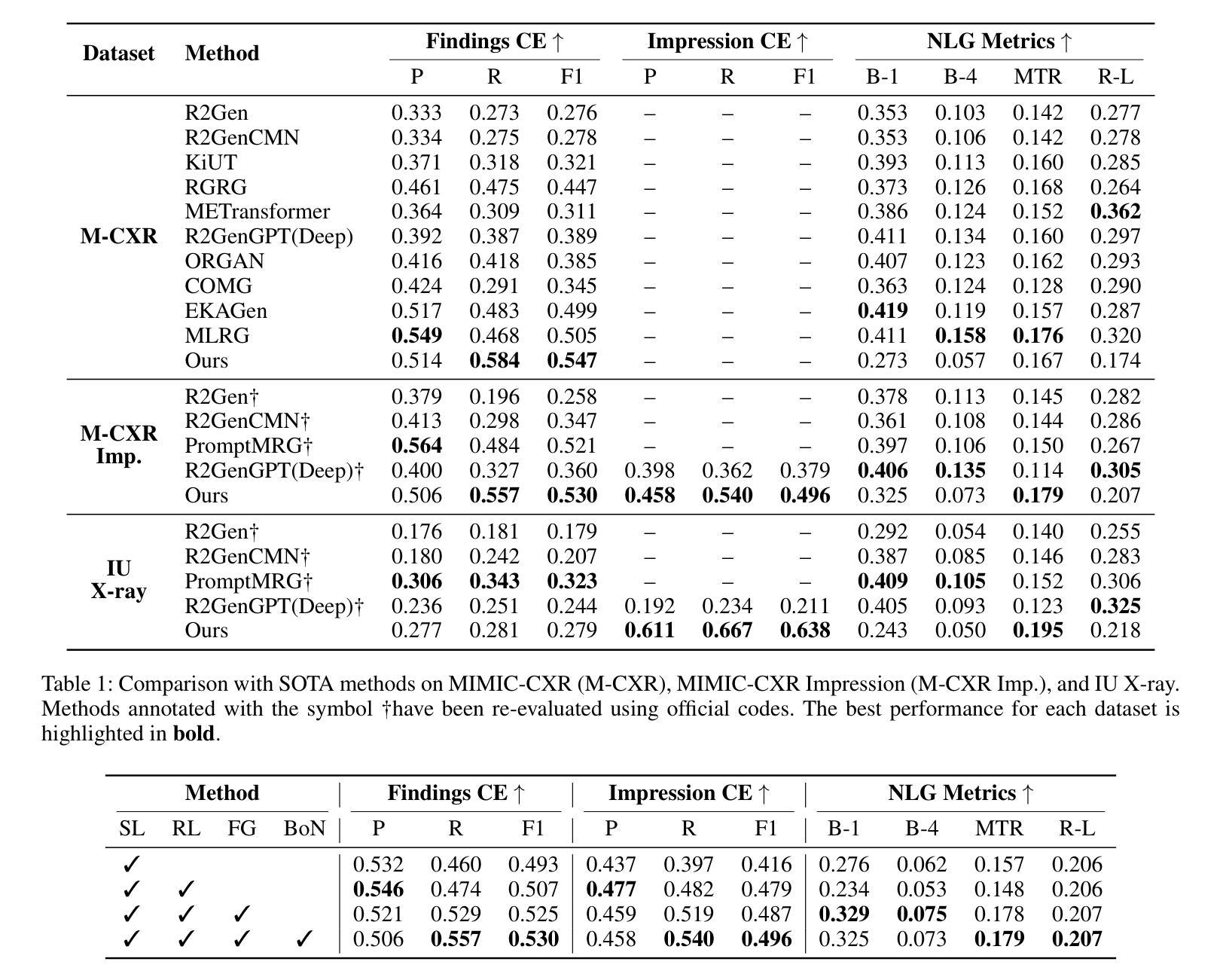
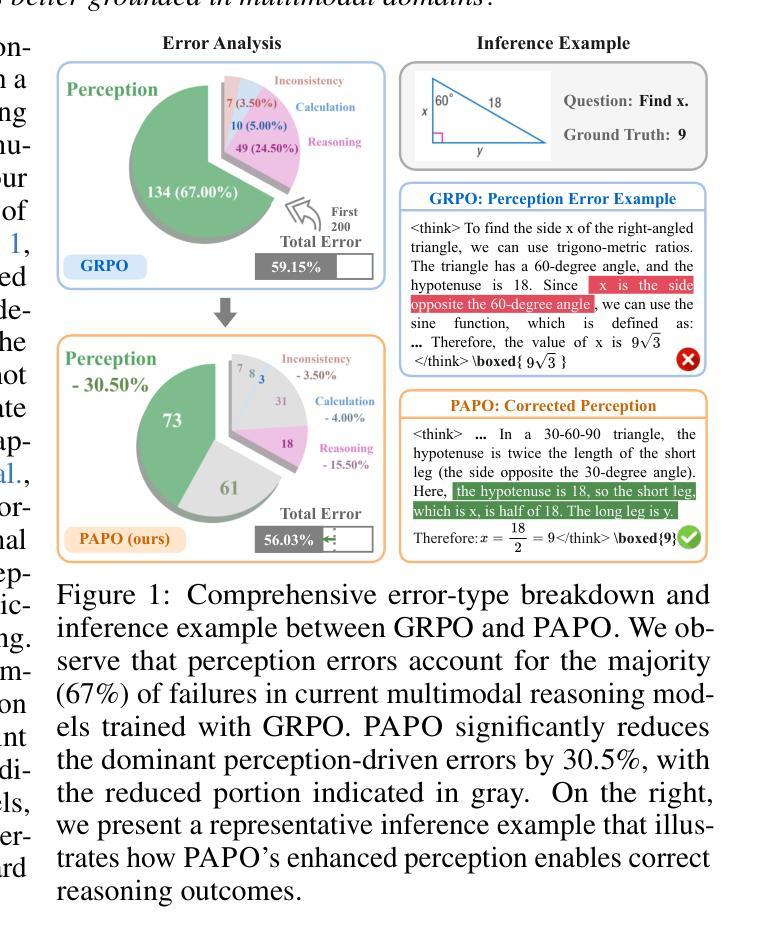
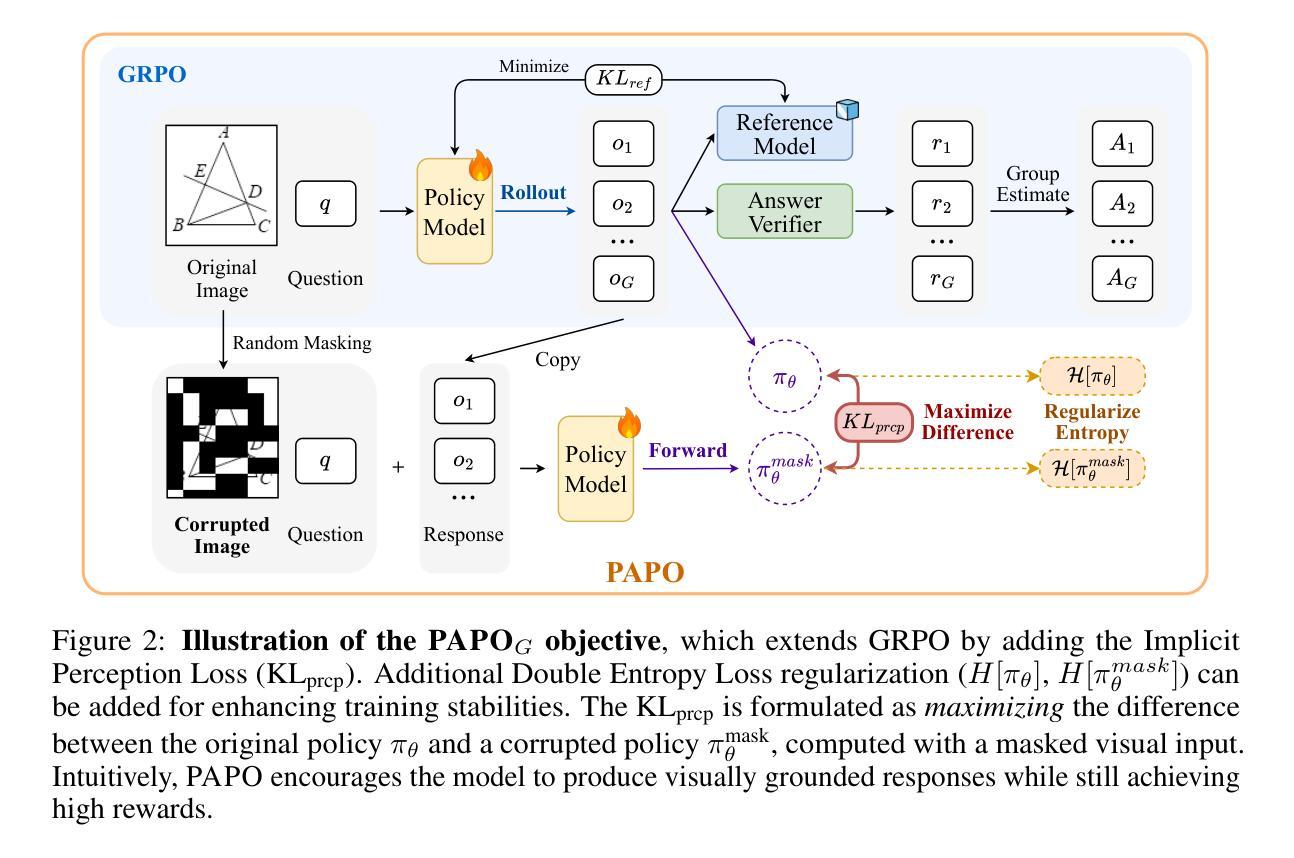
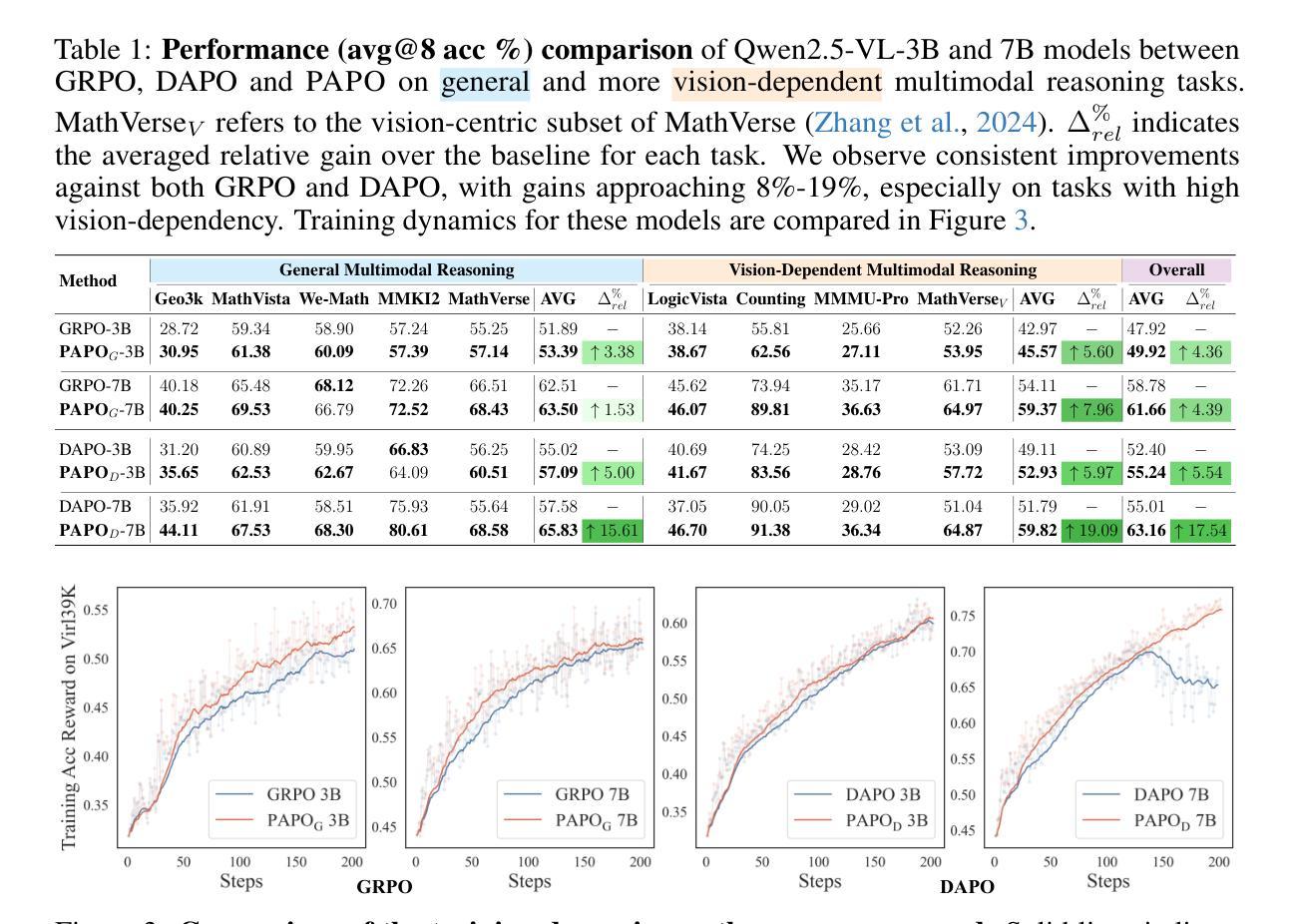
Perception-Aware Policy Optimization for Multimodal Reasoning
Authors:Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, Heng Ji
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose PAPO, a novel policy gradient algorithm that encourages the model to learn to perceive while learning to reason. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term, which can be seamlessly plugged into mainstream RLVR algorithms such as GRPO and DAPO. Notably, PAPO does not rely on additional data curation, reward models, or stronger teacher models. To further enhance the training stability of PAPO, we introduce the Double Entropy Loss, which effectively regularizes the new KL objective without compromising performance. Despite its simplicity, PAPO yields significant overall improvements of 4.4%-17.5% on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%-19.1%, on tasks with high vision dependency. We also observe a substantial reduction of 30.5% in perception errors, indicating improved perceptual capabilities with PAPO. Overall, our work introduces a deeper integration of perception-aware supervision into core learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Code and data will be made publicly available for research purposes. Project page: https://mikewangwzhl.github.io/PAPO.
强化学习与可验证奖励(RLVR)已被证明是赋予大型语言模型(LLM)强大的多步推理能力的一种高效策略。然而,其设计与优化仍针对纯文本领域,在应用于多模态推理任务时表现不佳。我们观察到,当前多模态推理中的误差主要来源于对视觉输入的理解。为了解决这一瓶颈,我们提出了PAPO,这是一种新的策略梯度算法,鼓励模型在学习的过程中学会理解。具体来说,我们以KL散度项的形式引入隐感知损失,它可以无缝地插入到主流RLVR算法中,如GRPO和DAPO。值得注意的是,PAPO不依赖额外的数据整理、奖励模型或更强大的教师模型。为了进一步提高PAPO的训练稳定性,我们引入了双重熵损失,它有效地正则化了新的KL目标,同时不损害性能。尽管其简单性,PAPO在多样化的多模态基准测试中实现了4.4%~17.5%的显著总体改进。在高度依赖视觉的任务中,改进更为显著,达到8.0%~19.1%。我们还观察到感知错误率降低了30.5%,这表明PAPO提高了感知能力。总的来说,我们的工作将感知感知监督更深入地集成到核心学习目标中,并为鼓励视觉化推理的新RL框架奠定了基础。为了研究目的,代码和数据将公开提供。项目页面:https://mikewangwzhl.github.io/PAPO。
论文及项目相关链接
Summary
RLVR策略已证明能够有效赋予大型语言模型多步推理能力,但在多模态推理任务中的表现并不理想,尤其是在视觉输入的感知方面存在主要误差。为解决此瓶颈,提出新型策略PAPO,结合策略梯度算法,鼓励模型在推理中学习感知,引入隐性感知损失(Implicit Perception Loss)以KL散度形式,可无缝插入主流RLVR算法中。PAPO无需额外数据整理、奖励模型或更强大的教师模型,并引入双重熵损失以增强训练稳定性。在多样化多模态基准测试中,PAPO带来4.4%~17.5%的整体改进,高视觉依赖性任务改进更为显著(达8.0%~19.1%),感知错误率降低30.5%。整体而言,PAPO推动感知监督更深入融入核心学习目标,为鼓励视觉推理的新型RL框架奠定基础。
Key Takeaways
- RLVR策略在多模态推理任务中存在视觉感知误差问题。
- PAPO策略是一种新型的政策梯度算法,用于解决RLVR在视觉感知方面的不足。
- PAPO引入隐性感知损失(Implicit Perception Loss),以KL散度形式无缝集成到主流RLVR算法中。
- PAPO改进了多模态基准测试的性能,总体改进范围达到4.4%~17.5%,高视觉依赖性任务的改进更为显著。
- PAPO通过引入双重熵损失增强了训练稳定性。
- PAPO降低了感知错误率30.5%,显示出更好的视觉感知能力。
点此查看论文截图

A Comparative Study of Specialized LLMs as Dense Retrievers
Authors:Hengran Zhang, Keping Bi, Jiafeng Guo
While large language models (LLMs) are increasingly deployed as dense retrievers, the impact of their domain-specific specialization on retrieval effectiveness remains underexplored. This investigation systematically examines how task-specific adaptations in LLMs influence their retrieval capabilities, an essential step toward developing unified retrievers capable of handling text, code, images, and multimodal content. We conduct extensive experiments with eight Qwen2.5 7B LLMs, including base, instruction-tuned, code/math-specialized, long reasoning, and vision-language models across zero-shot retrieval settings and the supervised setting. For the zero-shot retrieval settings, we consider text retrieval from the BEIR benchmark and code retrieval from the CoIR benchmark. Further, to evaluate supervised performance, all LLMs are fine-tuned on the MS MARCO dataset. We find that mathematical specialization and the long reasoning capability cause consistent degradation in three settings, indicating conflicts between mathematical reasoning and semantic matching. The vision-language model and code-specialized LLMs demonstrate superior zero-shot performance compared to other LLMs, even surpassing BM25 on the code retrieval task, and maintain comparable performance to base LLMs in supervised settings. These findings suggest promising directions for the unified retrieval task leveraging cross-domain and cross-modal fusion.
随着大型语言模型(LLM)越来越多地被部署为密集检索器,其特定领域的专业化对检索效果的影响尚未得到充分探索。本研究系统地探讨了LLM的任务特定适应如何影响其检索能力,这是朝着开发能够处理文本、代码、图像和多模态内容的统一检索器迈出的重要一步。我们在八个Qwen2.5 7B LLM上进行了广泛实验,包括基础、指令调优、代码/数学专业化、长推理和视觉语言模型,跨越零射击检索设置和有监督设置。对于零射击检索设置,我们考虑来自BEIR基准测试的文本检索和来自CoIR基准测试的代码检索。此外,为了评估有监督性能,所有LLM都在MS MARCO数据集上进行微调。我们发现数学专业化与长推理能力会在三种设置中造成持续的退化,表明数学推理与语义匹配之间存在冲突。视觉语言模型和代码专业化的LLM在零射击性能上表现出卓越的表现,甚至在代码检索任务上超越了BM25,在有监督环境中与基础LLM保持相当的性能。这些发现表明,利用跨域和跨模态融合的统一检索任务是充满希望的。
论文及项目相关链接
PDF Accepted by CCIR25 and published by Springer LNCS or LNAI
Summary
大型语言模型(LLMs)在密集检索中的应用日益广泛,但其领域特定专业化对检索效果的影响尚未得到充分探索。本研究系统地探讨了LLMs的任务特定适应对其检索能力的影响,这是朝着开发能够处理文本、代码、图像和多模态内容的统一检索器迈出的重要一步。通过对八种Qwen2.5
7B LLMs进行实验,包括基础模型、指令调优、代码/数学专业化、逻辑推理和视觉语言模型在非即席检索和受控监督环境下的表现。结果显示,数学专业化和逻辑推理能力在三种环境中均存在持续退化现象,表明数学推理和语义匹配之间存在冲突。视觉语言模型和代码专用LLMs在零射击任务中表现出卓越性能,甚至在代码检索任务上超越了BM25,并在受控环境中保持了与基础模型相当的性能。这些发现表明,利用跨域和跨模态融合的统一检索任务具有广阔的发展前景。
Key Takeaways
- 大型语言模型(LLMs)在密集检索中的广泛应用,但其领域特定专业化对检索效果的影响尚未充分研究。
- LLMs的任务特定适应对其检索能力有系统性影响,这是开发统一检索器的重要步骤,能够处理文本、代码、图像和多模态内容。
- 数学专业化和逻辑推理能力在LLMs的检索表现中存在冲突,可能导致性能下降。
- 视觉语言模型和代码专用LLMs在零射击任务中表现出卓越性能,甚至超越BM25在代码检索任务上的表现。
- LLMs在受控监督环境下表现稳定,与基础模型性能相当。
- 研究发现跨域和跨模态融合的统一检索任务具有广阔的发展前景。
点此查看论文截图

Scaling LLM Planning: NL2FLOW for Parametric Problem Generation and Rigorous Evaluation
Authors:Jungkoo Kang
Effective agent performance relies on the ability to compose tools and agents into effective workflows. However, progress in Large Language Model (LLM) planning and reasoning is limited by the scarcity of scalable, reliable evaluation data. This study addresses this limitation by identifying a suitable workflow domain for LLM application. I introduce NL2Flow, a fully automated system for parametrically generating planning problems, which are expressed in natural language, a structured intermediate representation, and formal PDDL, and rigorously evaluating the quality of generated plans. NL2Flow generates a dataset of 2296 low-difficulty problems in automated workflow generation and evaluates multiple open-sourced, instruct-tuned LLMs without task-specific optimization or architectural modifications. Results reveal that the highest performing model achieved 86% success in generating valid plans and 69% in generating optimal plans, specifically for problems with feasible plans. Regression analysis shows that the influence of problem characteristics on plan generation is contingent on both model and prompt design. To investigate the potential of LLMs as natural language-to-JSON translators for workflow definition, and to facilitate integration with downstream symbolic computation tools and a symbolic planner, I evaluated the LLM’s translation performance on natural language workflow descriptions. I observed that translating natural language into a JSON representation of a workflow problem yielded a lower success rate than generating a plan directly, suggesting that unnecessary decomposition of the reasoning task may degrade performance and highlighting the benefit of models capable of reasoning directly from natural language to action. As LLM reasoning scales to increasingly complex problems, understanding the shifting bottlenecks and sources of error within these systems will be crucial.
有效的智能体性能依赖于将工具和智能体组合成有效工作流程的能力。然而,由于大型语言模型(LLM)在规划和推理方面缺乏可扩展的、可靠的评价数据,LLM的进展受到限制。本研究通过确定LLM应用的合适工作流程域来解决这一限制。我介绍了NL2Flow,这是一个全自动系统,可以参数化生成规划问题,这些问题以自然语言表示,具有结构化的中间表示形式和正式的PDDL,并对生成计划的质量进行严谨评估。NL2Flow生成了一个包含2296个低难度问题的数据集,在自动工作流程生成中评估了多个开源、经过指令调整的大型语言模型,无需特定任务的优化或架构修改。结果表明,表现最佳模型的生成有效计划成功率为86%,生成最优计划成功率为69%,特别是针对有可行计划的问题。回归分析表明,问题特征对计划生成的影响取决于模型和提示设计。为了研究大型语言模型作为自然语言到JSON翻译器的潜力,用于工作流程定义,并便于与下游符号计算工具和符号规划器集成,我评估了大型语言模型的翻译性能在自然语言工作流描述上。我观察到,将自然语言翻译成工作流问题的JSON表示形式的成功率低于直接生成计划的成功率,这表明不必要的分解推理任务可能会降低性能,并强调直接从自然语言进行推理的模型的好处。随着大型语言模型推理能力在处理越来越复杂的问题时得到提升,了解这些系统内瓶颈和错误源的转变将至关重要。
论文及项目相关链接
PDF 26 pages, 7 figures
摘要
本文研究了大型语言模型(LLM)在生成工作流程计划方面的性能。由于缺少可伸缩、可靠的评估数据,LLM在规划和推理方面的进展受到限制。为此,文章提出了NL2Flow系统,能够自动生成规划问题,并以自然语言、结构化中间表示形式和正式PDDL形式表达,同时严格评估生成计划的质量。实验结果显示,性能最佳模型在生成有效计划方面达到了86%的成功率,在生成最优计划方面达到了69%。回归分析表明,问题特性对计划生成的影响取决于模型和提示设计。此外,文章还探讨了LLM作为自然语言到JSON翻译器的潜力,用于工作流程定义,并便于与下游符号计算工具和符号规划器集成。研究还发现,将自然语言翻译为工作流程问题的JSON表示形式,其成功率低于直接生成计划,这表明将推理任务过度分解可能会降低性能,并强调需要能够直接从自然语言进行推理的模型。随着LLM推理在越来越复杂的问题上的扩展,理解这些系统内部瓶颈和错误来源的转变将至关重要。
关键见解
- LLM在生成工作流程计划方面具有重要应用潜力。
- NL2Flow系统可自动生成规划问题,并严格评估生成计划的质量。
- 最佳模型在生成有效计划方面达到86%的成功率,生成最优计划为69%。
- 回归分析揭示了问题特性、模型和提示设计对计划生成的影响。
- LLM作为自然语言到JSON翻译器的潜力,便于与符号计算工具和规划器集成。
- 直接从自然语言进行推理的模型性能更佳,过度分解推理任务可能降低性能。
- 随着LLM推理处理更复杂问题,理解系统内部转变的瓶颈和错误来源至关重要。
点此查看论文截图

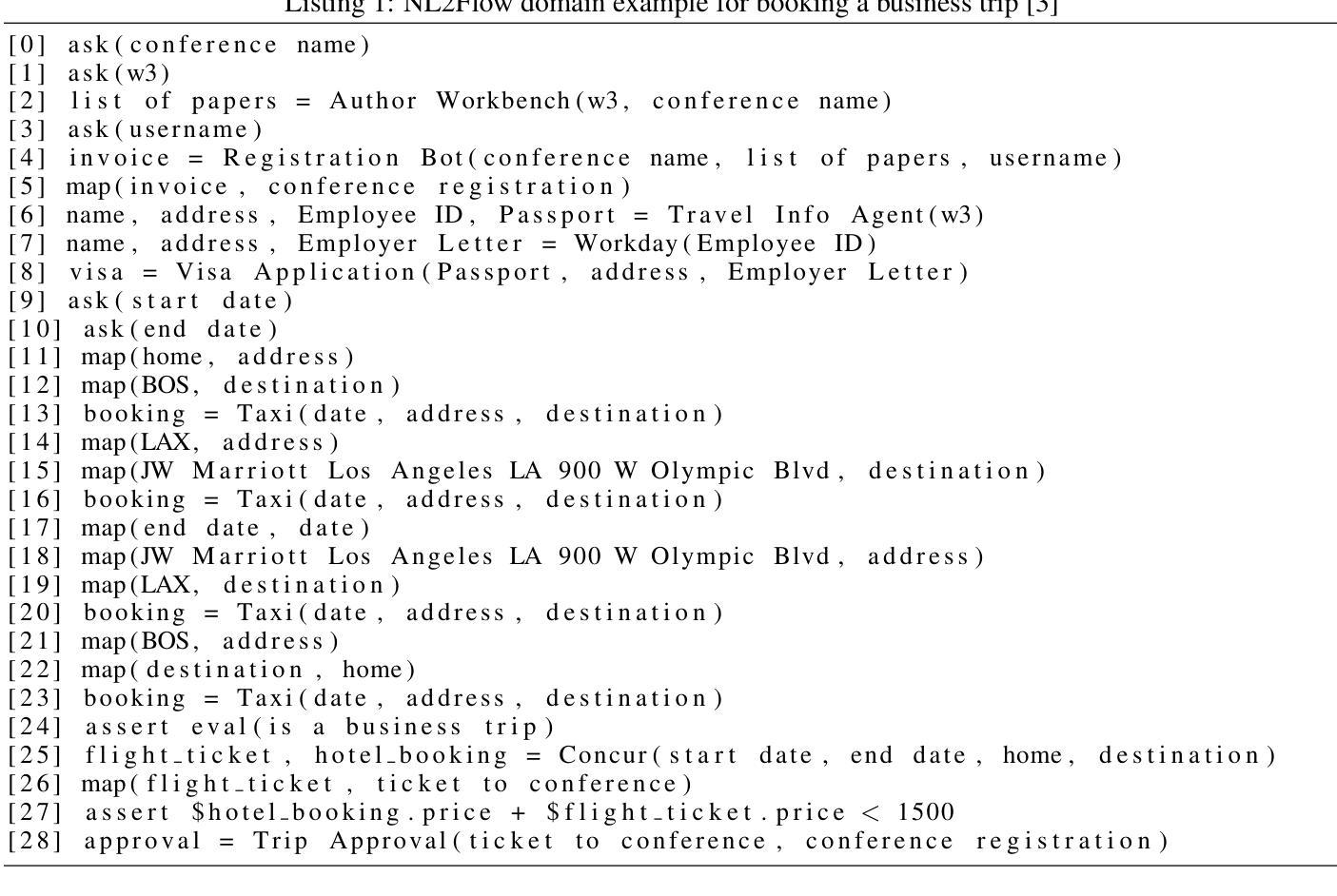

AI4Research: A Survey of Artificial Intelligence for Scientific Research
Authors:Qiguang Chen, Mingda Yang, Libo Qin, Jinhao Liu, Zheng Yan, Jiannan Guan, Dengyun Peng, Yiyan Ji, Hanjing Li, Mengkang Hu, Yimeng Zhang, Yihao Liang, Yuhang Zhou, Jiaqi Wang, Zhi Chen, Wanxiang Che
Recent advancements in artificial intelligence (AI), particularly in large language models (LLMs) such as OpenAI-o1 and DeepSeek-R1, have demonstrated remarkable capabilities in complex domains such as logical reasoning and experimental coding. Motivated by these advancements, numerous studies have explored the application of AI in the innovation process, particularly in the context of scientific research. These AI technologies primarily aim to develop systems that can autonomously conduct research processes across a wide range of scientific disciplines. Despite these significant strides, a comprehensive survey on AI for Research (AI4Research) remains absent, which hampers our understanding and impedes further development in this field. To address this gap, we present a comprehensive survey and offer a unified perspective on AI4Research. Specifically, the main contributions of our work are as follows: (1) Systematic taxonomy: We first introduce a systematic taxonomy to classify five mainstream tasks in AI4Research. (2) New frontiers: Then, we identify key research gaps and highlight promising future directions, focusing on the rigor and scalability of automated experiments, as well as the societal impact. (3) Abundant applications and resources: Finally, we compile a wealth of resources, including relevant multidisciplinary applications, data corpora, and tools. We hope our work will provide the research community with quick access to these resources and stimulate innovative breakthroughs in AI4Research.
近年来,人工智能(AI)的进展,特别是在大型语言模型(如OpenAI-o1和DeepSeek-R1)方面,已在逻辑、推理和实验编码等复杂领域展现出卓越的能力。受到这些进步的推动,许多研究已探索将人工智能应用于创新过程,特别是在科学研究背景下。这些人工智能技术的目标主要是开发能够自主完成广泛科学研究过程的系统。尽管取得了这些重要进展,但关于人工智能用于研究(AI4Research)的全面调查仍然缺失,这阻碍了我们对该领域的理解和进一步发展。为了填补这一空白,我们进行了全面的调查,并为AI4Research提供了统一的视角。具体地,我们工作的主要贡献如下:(1)系统分类学:我们首先引入系统分类学,对AI4Research中的五个主流任务进行分类。(2)新前沿:然后,我们确定了关键的研究空白,并强调了有前景的未来方向,侧重于自动化实验的严谨性和可扩展性,以及社会影响。(3)丰富的应用和资源:最后,我们整理了大量的资源,包括相关的多学科应用、数据集合和工具。我们希望我们的工作能为研究界快速提供这些资源,并刺激AI4Research中的创新突破。
论文及项目相关链接
PDF Preprint, Paper list is available at https://github.com/LightChen233/Awesome-AI4Research
Summary
近期人工智能在大型语言模型方面的进展,如OpenAI-o1和DeepSeek-R1,在逻辑和实验编码等复杂领域表现出卓越的能力。受此启发,人们开始探索人工智能在科学研究中的应用。本文主要对AI在科研领域的应用进行全面调查,并提供了一个统一的视角。主要贡献包括:提出系统分类法,分类了五大主流任务;确定关键研究空白并突出未来有前景的研究方向;编译多学科应用、语料库和工具等资源。
Key Takeaways
- 人工智能在大型语言模型方面的进展为科研领域的应用提供了潜力。
- 目前对于人工智能在科研领域应用的全面调查仍有所欠缺。
- 系统分类法被用来分类五大主流任务在人工智能用于科研中。
- 确定存在的关键研究空白以及未来有前景的研究方向,尤其是自动化实验的严谨性和可扩展性,以及社会影响方面。
- 编译了丰富的资源,包括多学科应用、语料库和工具等。
- 此工作旨在为科研社区提供快速访问资源的途径。
点此查看论文截图

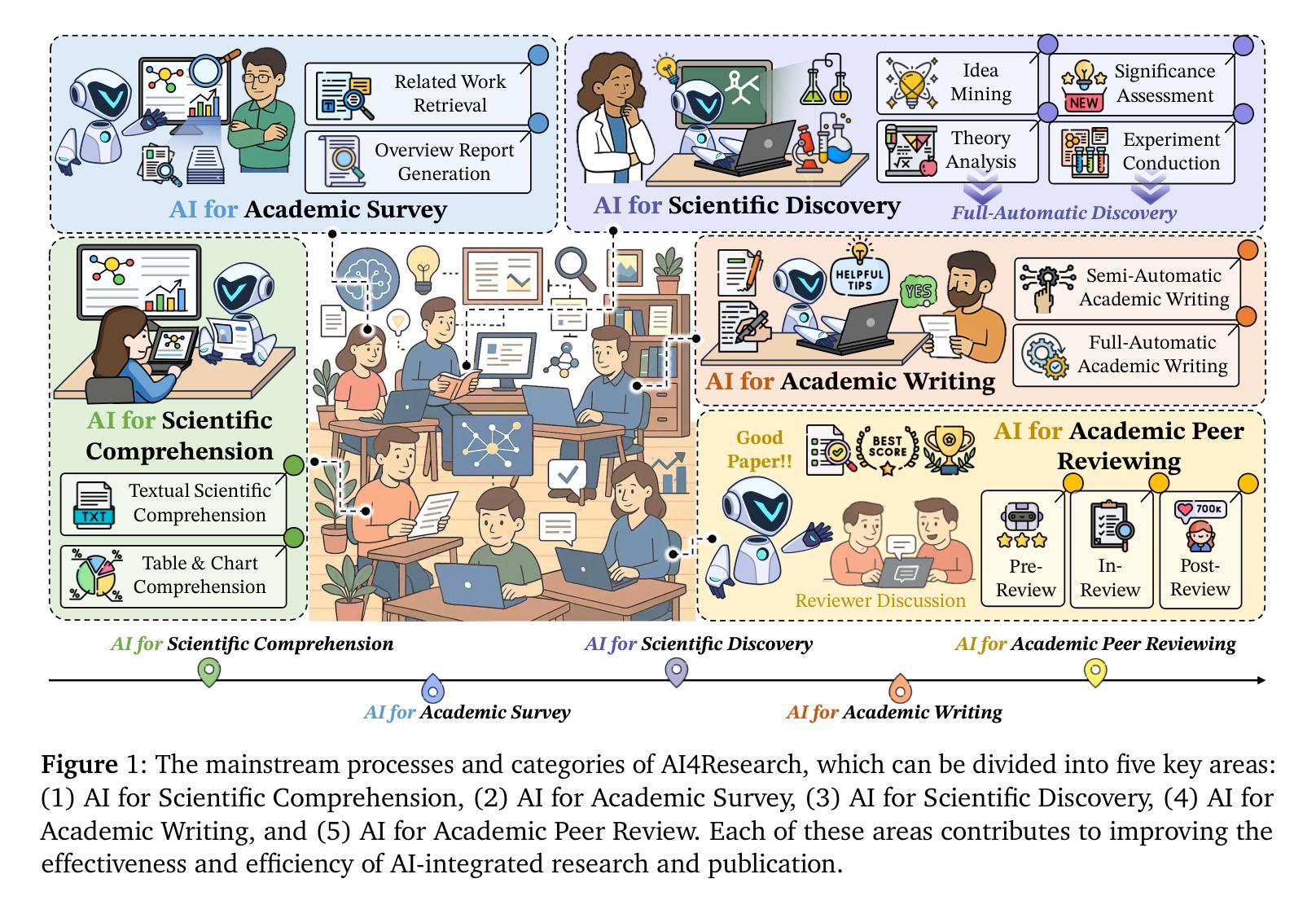
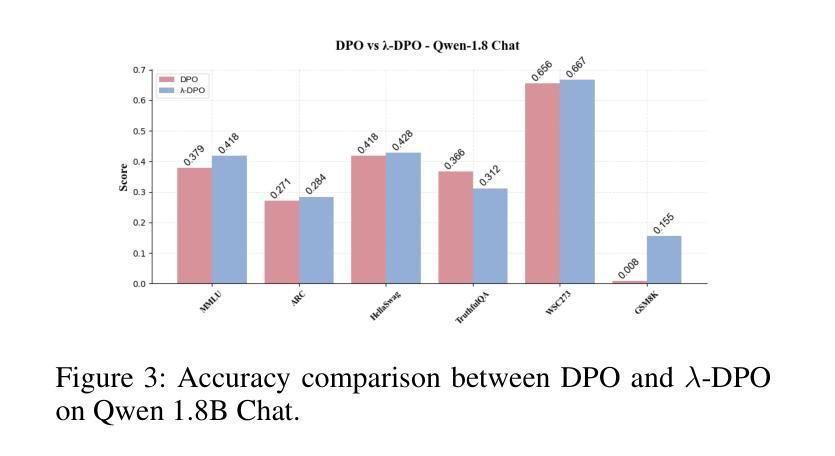
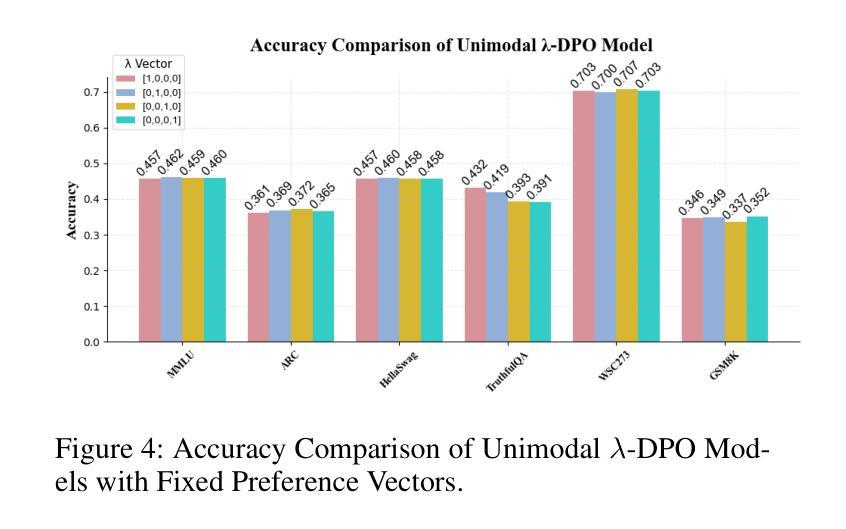
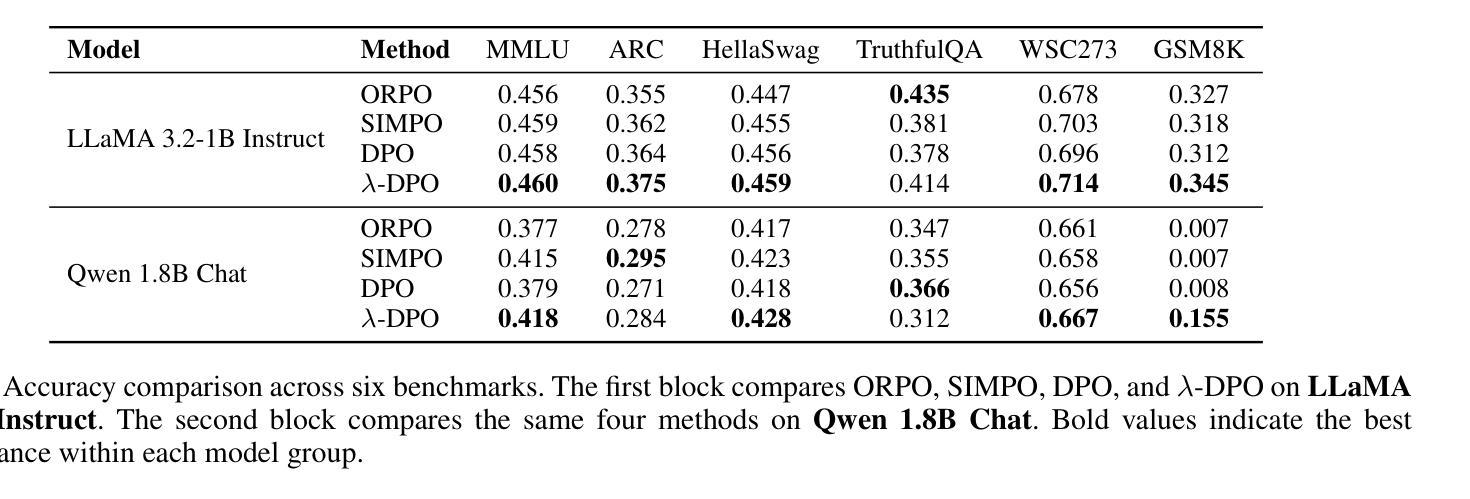
Multi-Preference Lambda-weighted Listwise DPO for Small-Scale Model Alignment
Authors:Yuhui Sun, Xiyao Wang, Zixi Li, Zhenlong Yuan, Jinman Zhao
Large language models (LLMs) demonstrate strong generalization across a wide range of language tasks, but often generate outputs that misalign with human preferences. Reinforcement Learning from Human Feedback (RLHF) addresses this by optimizing models toward human preferences using a learned reward function and reinforcement learning, yielding improved alignment but suffering from high computational cost and instability. Direct Preference Optimization (DPO) simplifies the process by treating alignment as a classification task over binary preference pairs, reducing training overhead while achieving competitive performance. However, it assumes fixed, single-dimensional preferences and only supports pairwise supervision. To address these limitations, we propose Multi-Preference Lambda-weighted Listwise DPO, which allows the model to learn from more detailed human feedback and flexibly balance multiple goals such as helpfulness, honesty, and fluency. Our method models full-ranked preference distributions rather than binary comparisons, enabling more informative learning signals. The lambda vector controls the relative importance of different alignment goals, allowing the model to generalize across diverse human objectives. During inference, lambda can be adjusted without retraining, providing controllable alignment behavior for downstream use. We also introduce a learned scheduler that dynamically samples performant lambda configurations to improve robustness. Notably, our method requires only 20GB of GPU memory for training, making it suitable for compute-constrained settings such as academic labs, educational tools, or on-device assistants. Experiments on 1B-2B scale models show that our method consistently outperforms standard DPO on alignment benchmarks while enabling efficient, controllable, and fine-grained adaptation suitable for real-world deployment.
大型语言模型(LLM)在多种语言任务中展现出强大的泛化能力,但其生成的输出往往与人类偏好不符。强化学习从人类反馈(RLHF)通过使用学习的奖励函数和强化学习来优化模型以符合人类偏好,从而提高对齐程度,但存在计算成本高和不稳定的问题。直接偏好优化(DPO)简化了流程,将对齐视为二元偏好对上的分类任务,降低了训练开销,同时实现了具有竞争力的性能。然而,它假定固定的单维偏好,仅支持成对监督。
论文及项目相关链接
PDF 12 pages, 12 figures, appendix included. To appear in Proceedings of AAAI 2026. Code: https://github.com/yuhui15/Multi-Preference-Lambda-weighted-DPO
摘要
大语言模型具备广泛的跨语言任务泛化能力,但往往产生的输出与人类偏好不符。强化学习从人类反馈(RLHF)通过优化模型向人类偏好靠拢,使用学习奖励函数和强化学习改进对齐,但计算成本高且不稳定。直接偏好优化(DPO)简化了流程,将对齐视为二元偏好对的分类任务,减少了训练开销且表现良好,但它假定固定的单一偏好并且仅支持成对监督。为解决这些局限性,我们提出了多偏好λ加权列表DPO,允许模型从更详细的人类反馈中学习,并灵活平衡多个目标如有用性、诚实性和流畅性。我们的方法模拟完整的偏好分布而不是二元比较,从而获得更多信息的学习信号。λ向量控制不同对齐目标的相对重要性,使模型能够在多种人类目标之间进行泛化。在推理过程中,λ可以无需重新训练而调整,为下游使用提供可控的对齐行为。我们还引入了一个学习调度器,动态采样高性能的λ配置以提高稳健性。值得注意的是,我们的方法仅需要20GB的GPU内存进行训练,适合计算受限的环境如实验室、教育工具或设备助手等。实验表明,我们的方法在基准对齐测试中始终优于标准DPO,同时实现了高效、可控和精细的适应,适合部署到现实世界中。
关键见解
- 大型语言模型(LLMs)在各种语言任务中表现出强大的泛化能力,但输出常与人类偏好不符。
- 强化学习从人类反馈(RLHF)通过优化模型以符合人类偏好,但计算成本高且不稳定。
- 直接偏好优化(DPO)简化了流程,将对齐视为二元偏好对的分类任务,降低训练开销并提高性能。
- 提出了一种新的方法——多偏好λ加权列表DPO,解决了DPO的局限性,允许模型从更详细的人类反馈中学习并灵活平衡多个目标。
- 该方法模拟完整的偏好分布而非二元比较,提供更为信息丰富的学习信号。
- 通过λ向量控制不同对齐目标的相对重要性,提高模型的泛化能力。在推理过程中可调整λ值,为下游应用提供可控的对齐行为。
点此查看论文截图

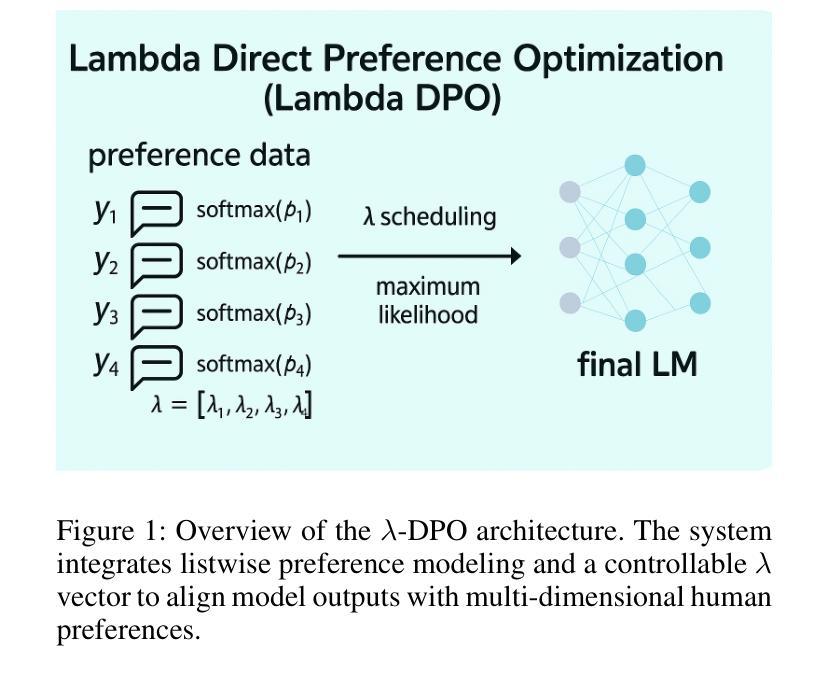
EVINET: Towards Open-World Graph Learning via Evidential Reasoning Network
Authors:Weijie Guan, Haohui Wang, Jian Kang, Lihui Liu, Dawei Zhou
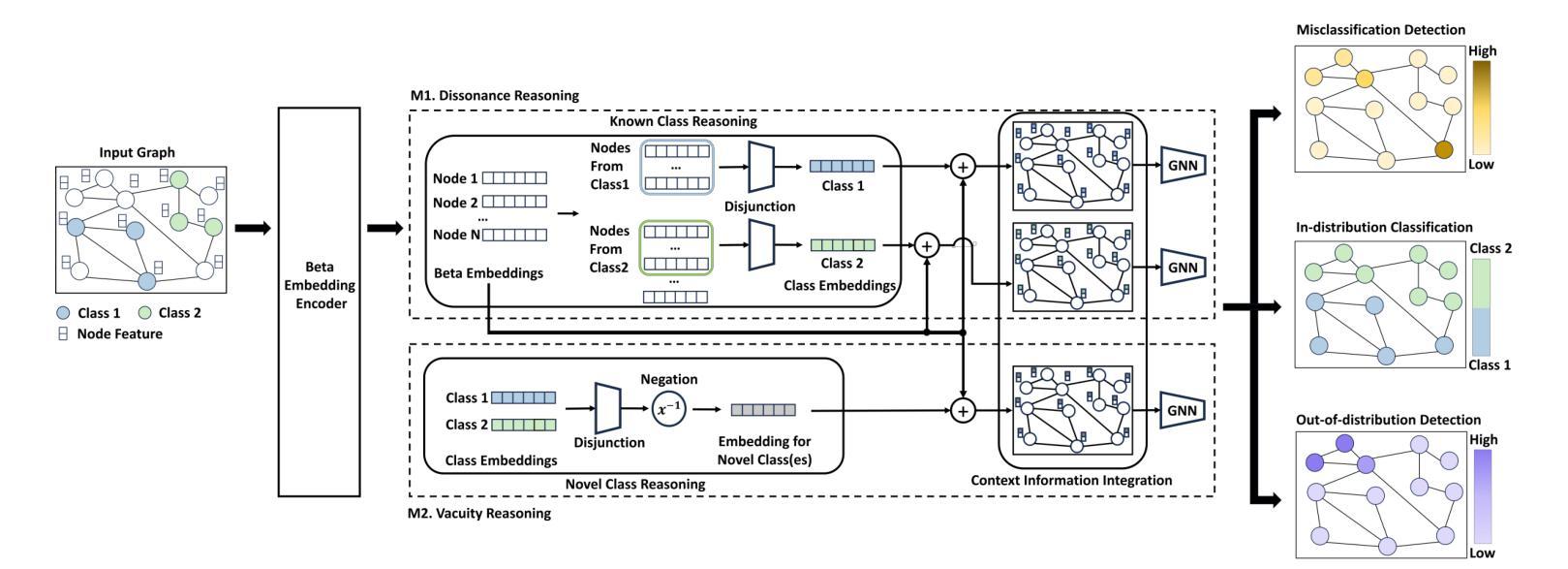
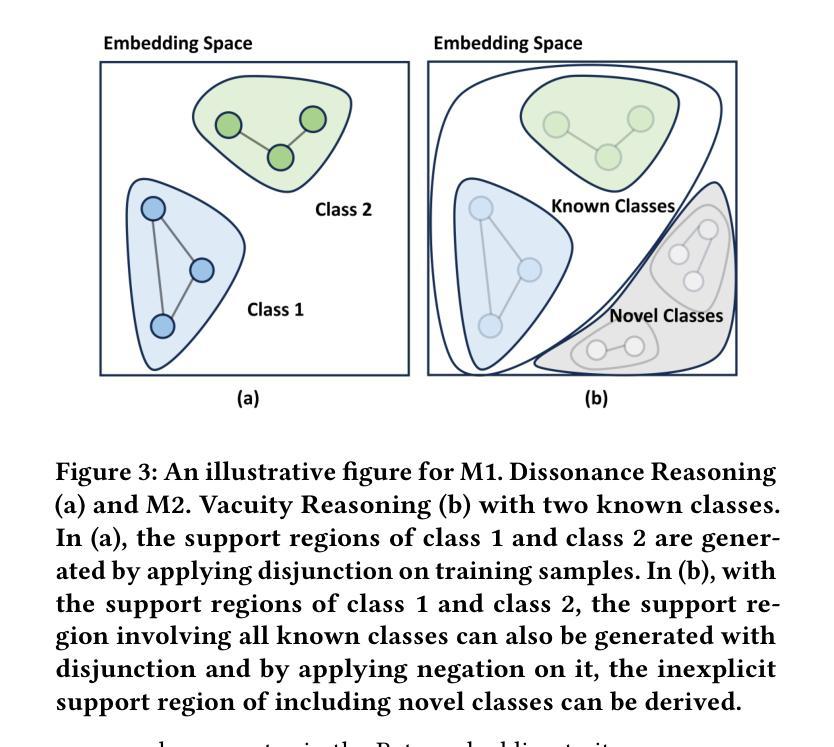
Graph learning has been crucial to many real-world tasks, but they are often studied with a closed-world assumption, with all possible labels of data known a priori. To enable effective graph learning in an open and noisy environment, it is critical to inform the model users when the model makes a wrong prediction to in-distribution data of a known class, i.e., misclassification detection or when the model encounters out-of-distribution from novel classes, i.e., out-of-distribution detection. This paper introduces Evidential Reasoning Network (EVINET), a framework that addresses these two challenges by integrating Beta embedding within a subjective logic framework. EVINET includes two key modules: Dissonance Reasoning for misclassification detection and Vacuity Reasoning for out-of-distribution detection. Extensive experiments demonstrate that EVINET outperforms state-of-the-art methods across multiple metrics in the tasks of in-distribution classification, misclassification detection, and out-of-distribution detection. EVINET demonstrates the necessity of uncertainty estimation and logical reasoning for misclassification detection and out-of-distribution detection and paves the way for open-world graph learning. Our code and data are available at https://github.com/SSSKJ/EviNET.
图学习在多个现实任务中均起到关键作用,但通常在封闭世界假设下进行研究的,事先已知所有数据可能的所有标签。为了在开放且充满噪音的环境中实现有效的图学习,模型用户对模型在已知类别内部数据的预测出错进行反馈是非常关键的,比如错误分类检测或当模型遇到未知类别的数据,即未知分布检测。本文介绍了Evidential Reasoning Network(EVINET),这是一个框架,它通过整合Beta嵌入主观逻辑框架来解决这两个挑战。EVINET包括两个关键模块:用于错误分类检测的Dissonance Reasoning和用于未知分布检测的真空原理(Vacuity Reasoning)。广泛的实验表明,在分布内分类、错误分类检测和未知分布检测的任务中,EVINET在多个指标上的性能均优于现有先进技术。EVINET证明了不确定估计和逻辑推理对于错误分类检测和未知分布检测的重要性,并为开放世界图学习铺平了道路。我们的代码和数据可以在 https://github.com/SSSKJ/EviNET 获得。
论文及项目相关链接
PDF KDD 2025
Summary
本文提出了Evidential Reasoning Network(EVINET)框架,解决了在开放和噪声环境下的图学习所面临的两个挑战:误分类检测和未知类别检测。该框架通过整合Beta嵌入和主观逻辑框架,实现了不和谐推理和真空推理两个关键模块。实验证明,EVINET在多个指标上优于现有技术,并强调了不确定性和逻辑推理对于误分类检测和未知类别检测的重要性,为开放世界图学习奠定了基础。代码和数据集已在GitHub上公开。
Key Takeaways
- Evidential Reasoning Network (EVINET) 是一个解决开放和噪声环境下图学习挑战的新框架。
- EVINET 整合了Beta嵌入和主观逻辑框架,以进行不和谐推理和真空推理。
- 不和谐推理用于误分类检测,而真空推理用于未知类别检测。
- 实验证明,EVINET在多个指标上超越了当前的最先进方法。
- EVINET 强调了不确定性和逻辑推理在误分类检测和未知类别检测中的重要性。
- EVINET 为开放世界图学习开辟了新的道路。
点此查看论文截图