⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-12 更新
CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignment
Authors:Shengzhu Yang, Jiawei Du, Shuai Lu, Weihang Zhang, Ningli Wang, Huiqi Li
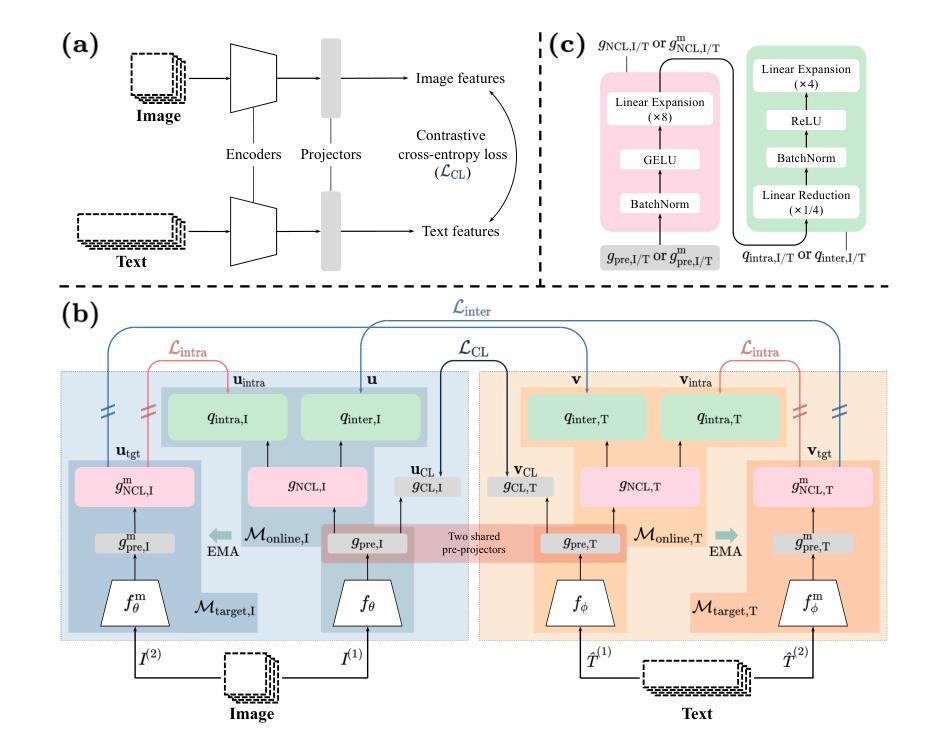
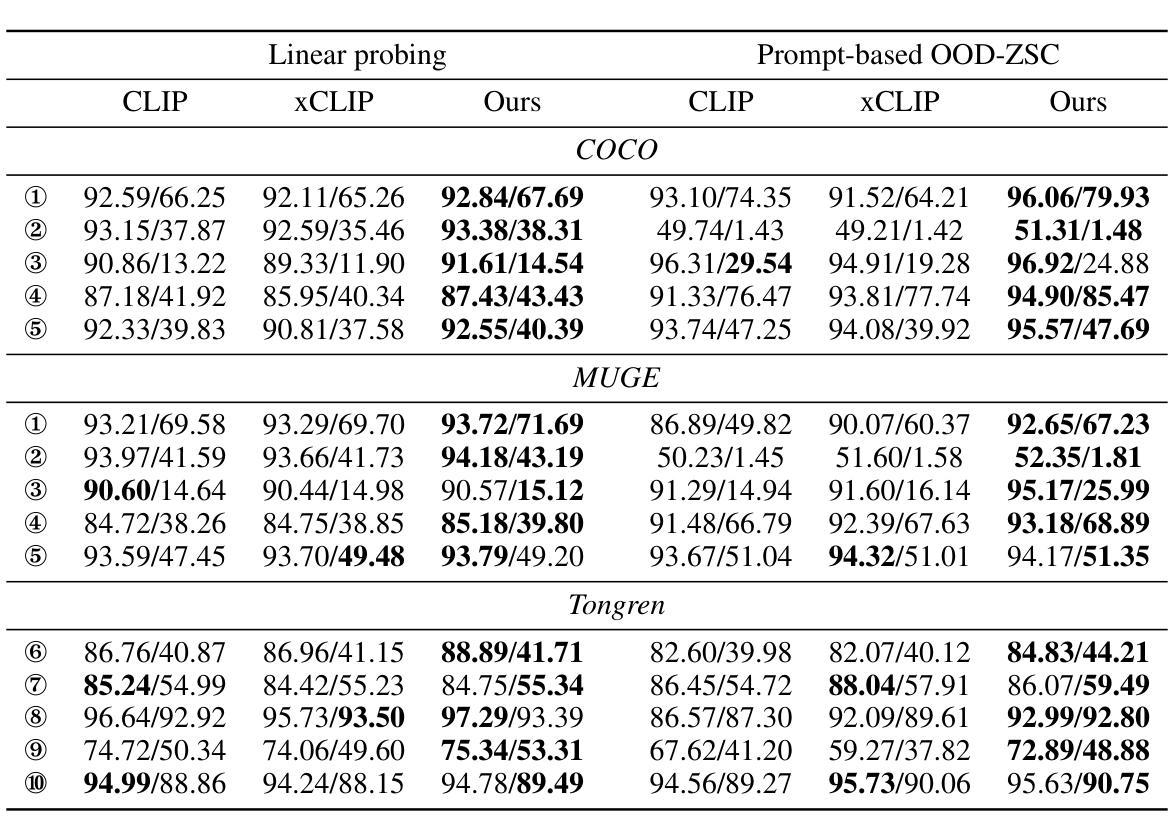
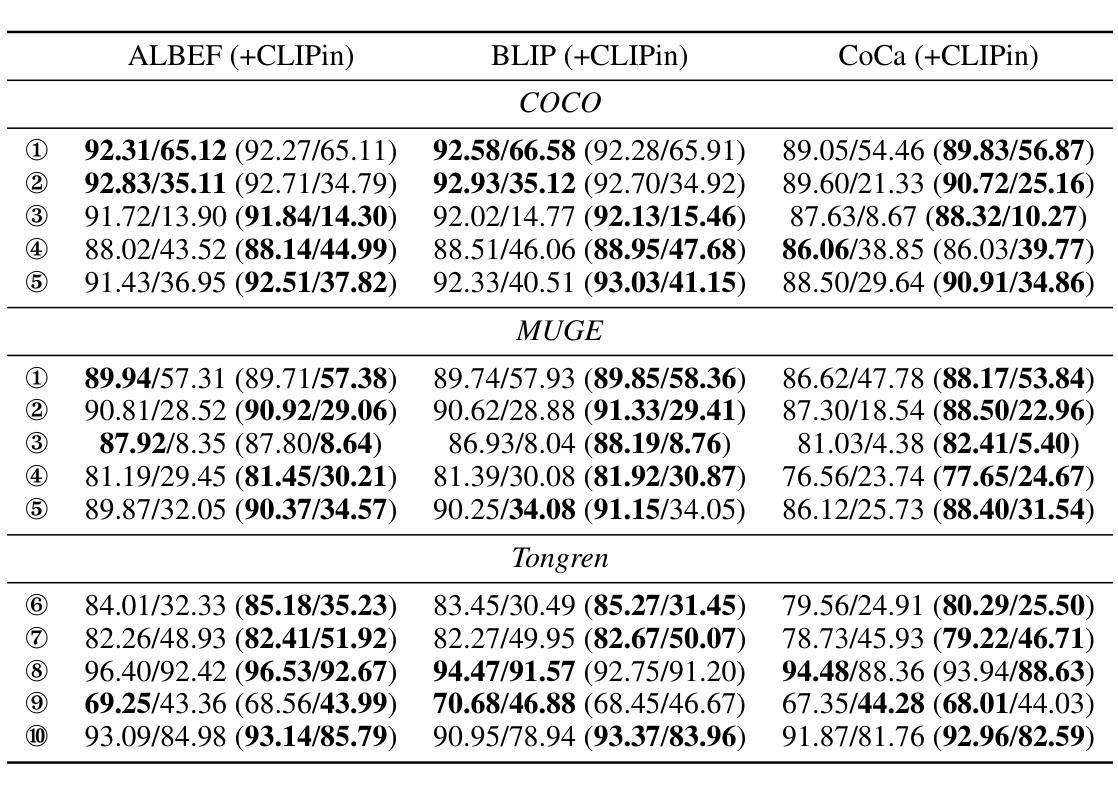
Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model’s ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
大规模的自然图像文本数据集,尤其是那些从网上自动收集的数据集,由于弱监督而往往存在语义对齐不紧密的问题,而医疗数据集则往往具有高度的跨模态关联但内容多样性较低。这些特性给对比语言图像预训练(CLIP)带来了共同挑战:它们阻碍了模型学习稳健和可泛化表示的能力。在这项工作中,我们提出了CLIPin,这是一种统一的非对比式插件,可以无缝集成到CLIP风格的架构中,以改善多模态语义对齐,提供更强的监督,增强对齐稳健性。此外,还为图像和文本模态设计了两个共享预投影仪,以在参数折衷的方式下促进对比学习和非对比学习的集成。在多种下游任务上的广泛实验证明了CLIPin作为与各种对比框架兼容的即插即用组件的有效性和通用性。代码可在https://github.com/T6Yang/CLIPin找到。
论文及项目相关链接
Summary
本文提出了CLIPin,一个统一的非对比式插件,旨在改进多模态语义对齐,提高模型的鲁棒性和泛化能力。通过采用共享预处理器和项目器的方式,增强了图像和文本模态的融合,同时也融合了对比和非对比学习的优点。实验证明,CLIPin作为一种插件,在各种对比框架中具有有效性和通用性。
Key Takeaways
- CLIPin是一种针对对比语言图像预训练(CLIP)的非对比式插件,用于改进多模态语义对齐。
- CLIPin提高了模型的鲁棒性和泛化能力,尤其在大型自然图像文本数据集上表现优异。
- 通过共享预处理器和项目器的方式,CLIPin增强了图像和文本模态的融合。
- CLIPin融合了对比和非对比学习的优点,提高了模型的性能。
- CLIPin兼容各种对比框架,具有广泛的适用性。
- CLIPin在多种下游任务上的实验证明了其有效性。
点此查看论文截图

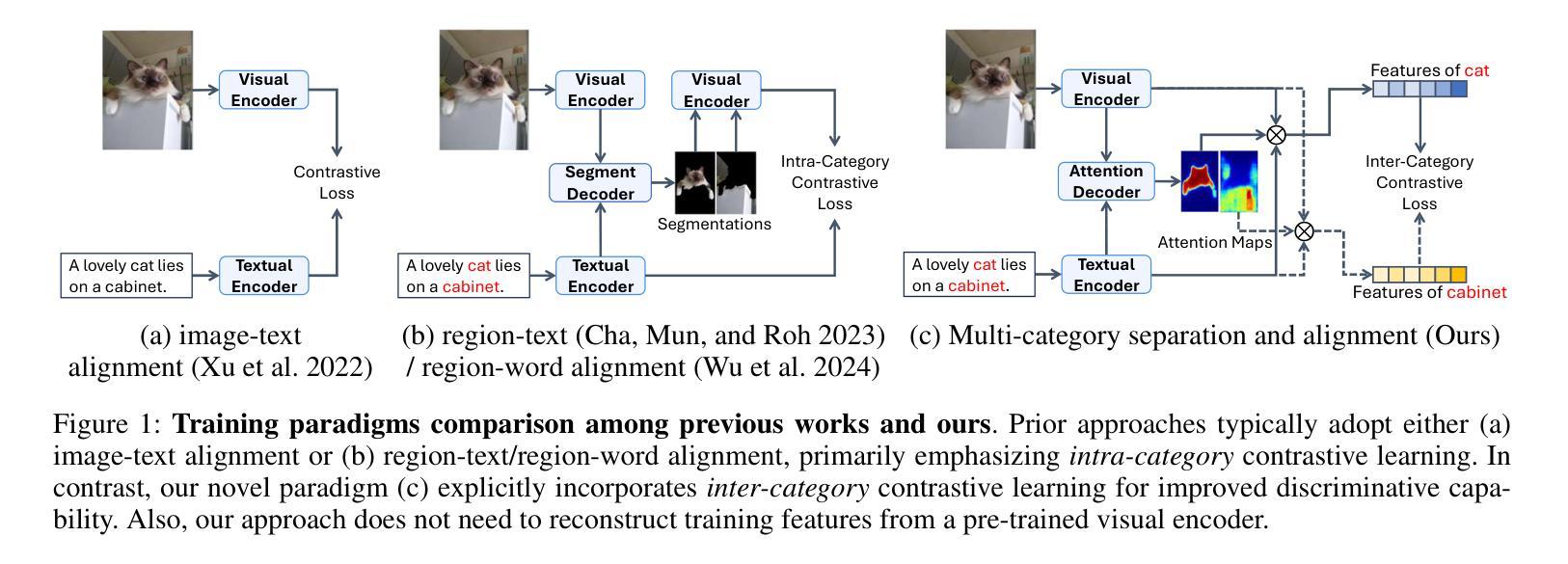
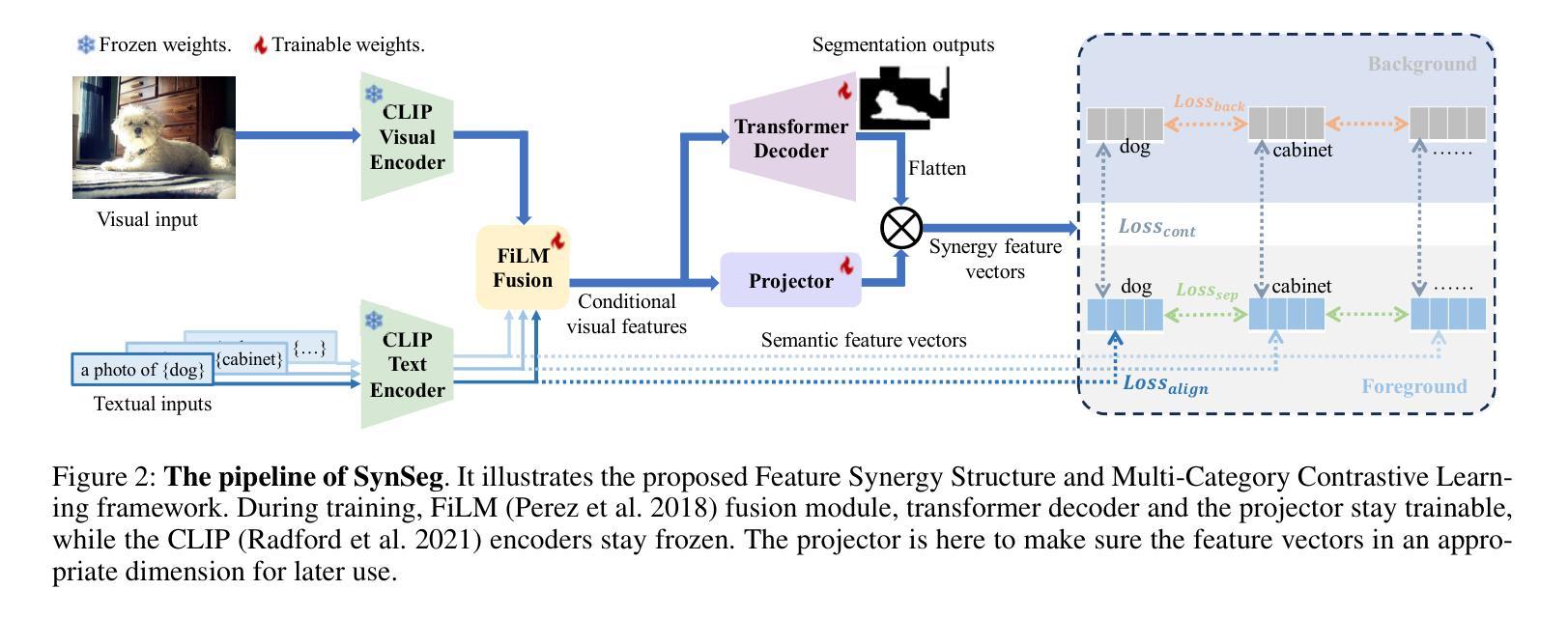
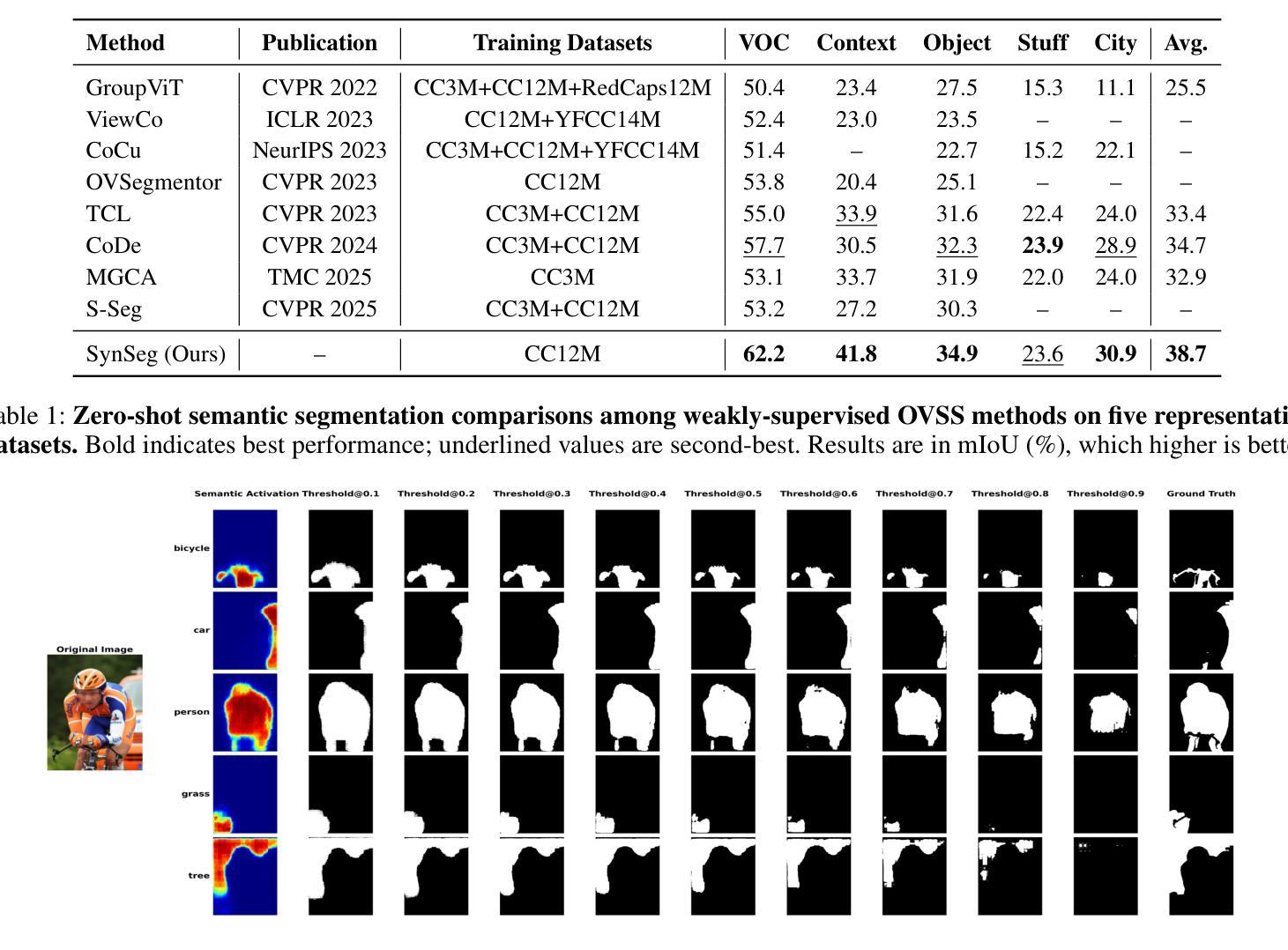
SynSeg: Feature Synergy for Multi-Category Contrastive Learning in Open-Vocabulary Semantic Segmentation
Authors:Weichen Zhang, Kebin Liu, Fan Dang, Zhui Zhu, Xikai Sun, Yunhao Liu
Semantic segmentation in open-vocabulary scenarios presents significant challenges due to the wide range and granularity of semantic categories. Existing weakly-supervised methods often rely on category-specific supervision and ill-suited feature construction methods for contrastive learning, leading to semantic misalignment and poor performance. In this work, we propose a novel weakly-supervised approach, SynSeg, to address the challenges. SynSeg performs Multi-Category Contrastive Learning (MCCL) as a stronger training signal with a new feature reconstruction framework named Feature Synergy Structure (FSS). Specifically, MCCL strategy robustly combines both intra- and inter-category alignment and separation in order to make the model learn the knowledge of correlations from different categories within the same image. Moreover, FSS reconstructs discriminative features for contrastive learning through prior fusion and semantic-activation-map enhancement, effectively avoiding the foreground bias introduced by the visual encoder. In general, SynSeg effectively improves the abilities in semantic localization and discrimination under weak supervision. Extensive experiments on benchmarks demonstrate that our method outperforms state-of-the-art (SOTA) performance. For instance, SynSeg achieves higher accuracy than SOTA baselines by 4.5% on VOC, 8.9% on Context, 2.6% on Object and 2.0% on City.
在开放词汇场景下的语义分割面临着广泛的语义类别范围和粒度所带来的挑战。现有的弱监督方法通常依赖于特定类别的监督和对比学习的特征构建方法不当,导致语义不对齐和性能不佳。在这项工作中,我们提出了一种新的弱监督方法SynSeg,以应对这些挑战。SynSeg执行多类别对比学习(MCCL)作为更强的训练信号,并引入一个新的特征重建框架,称为特征协同结构(FSS)。具体来说,MCCL策略稳健地将同一图像内不同类别之间的类别内和类别间对齐和分离结合起来,使模型能够学习不同类别之间的关联知识。此外,FSS通过先验融合和语义激活图增强来重建用于对比学习的判别特征,有效地避免了视觉编码器带来的前景偏差。总的来说,SynSeg在弱监督条件下有效地提高了语义定位和鉴别的能力。在基准测试上的大量实验表明,我们的方法优于最新技术(SOTA)的表现。例如,SynSeg在VOC上比最新技术基线高出4.5%,在Context上高出8.9%,在Object上高出2.6%,在City上高出2.0%。
论文及项目相关链接
Summary
本文提出一种名为SynSeg的弱监督语义分割方法,通过多类别对比学习(MCCL)和特征协同结构(FSS)框架解决开放词汇场景下的语义分割挑战。MCCL策略使模型在同一图像内学习不同类别的相关性,FSS框架重建对比学习的判别特征,避免视觉编码器引入的前景偏差。在基准测试上的实验表明,SynSeg在弱监督下提高了语义定位和判别能力,且性能优于现有最佳方法。
Key Takeaways
- 开放词汇场景下的语义分割面临广泛范围和粒度的语义类别挑战。
- 现有弱监督方法依赖类别特定的监督和对比学习的特征构建方法不当,导致语义不匹配和性能不佳。
- 本文提出一种名为SynSeg的弱监督方法,通过多类别对比学习(MCCL)和特征协同结构(FSS)框架来解决这些挑战。
- MCCL策略结合了类别内的对齐和分离,使模型学习同一图像内不同类别的相关性。
- FSS框架通过先验融合和语义激活图增强来重建对比学习的判别特征。
- SynSeg有效提高了弱监督下的语义定位和判别能力。
点此查看论文截图

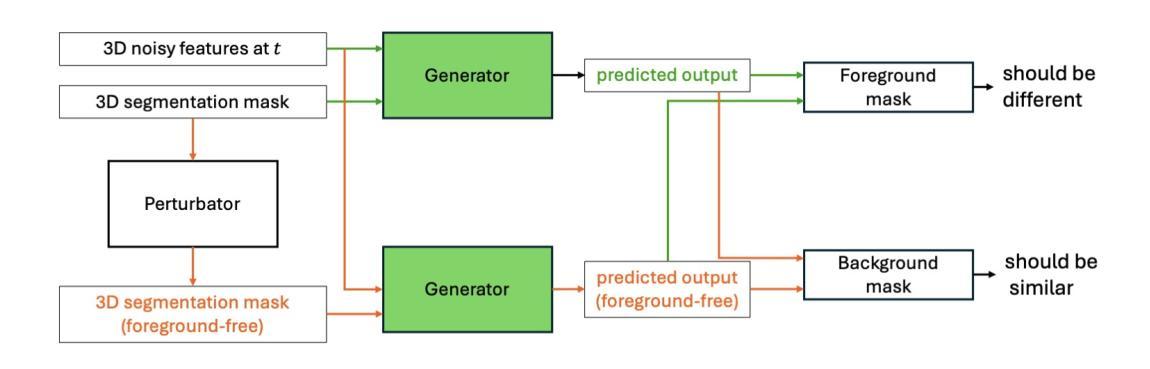
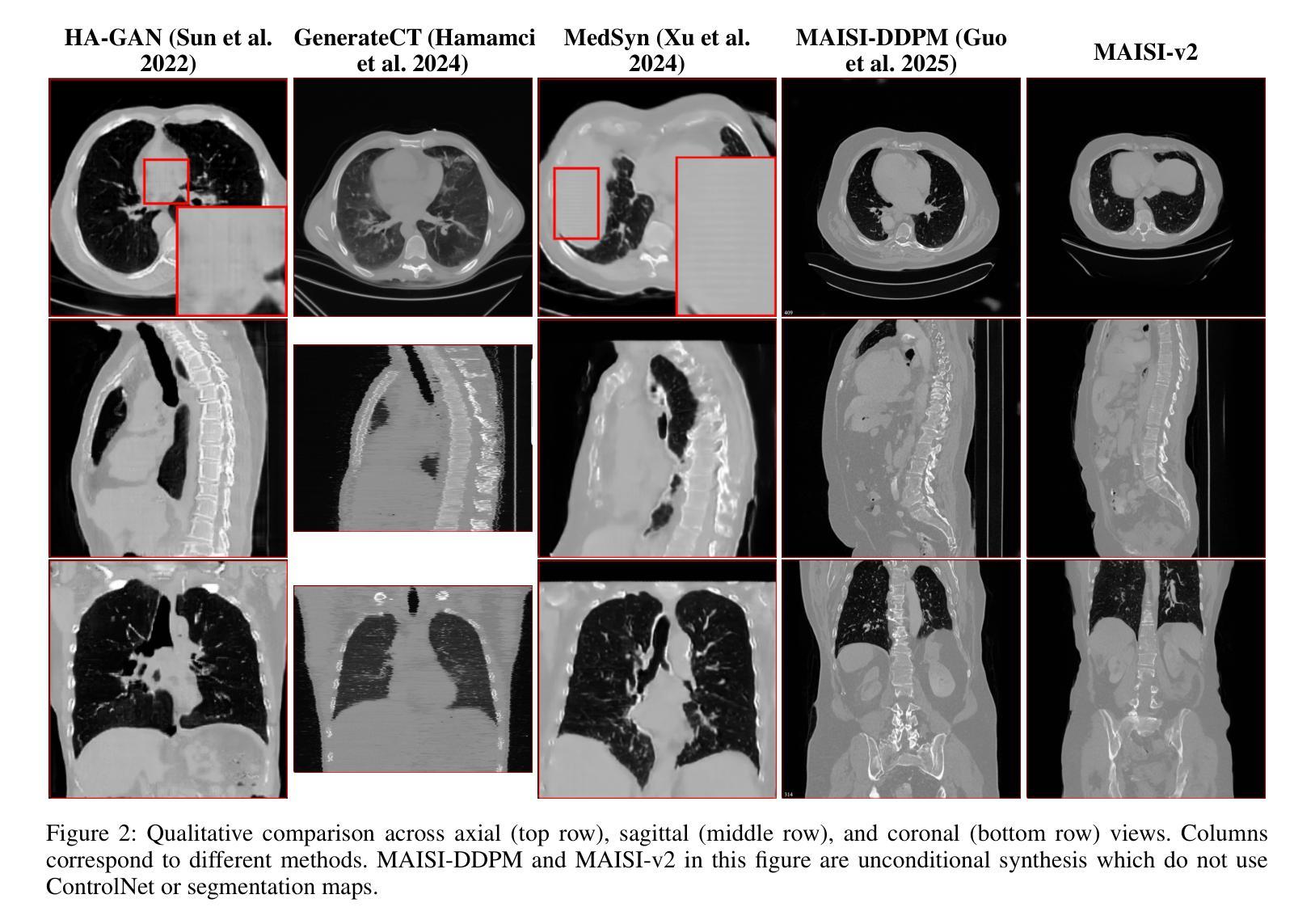
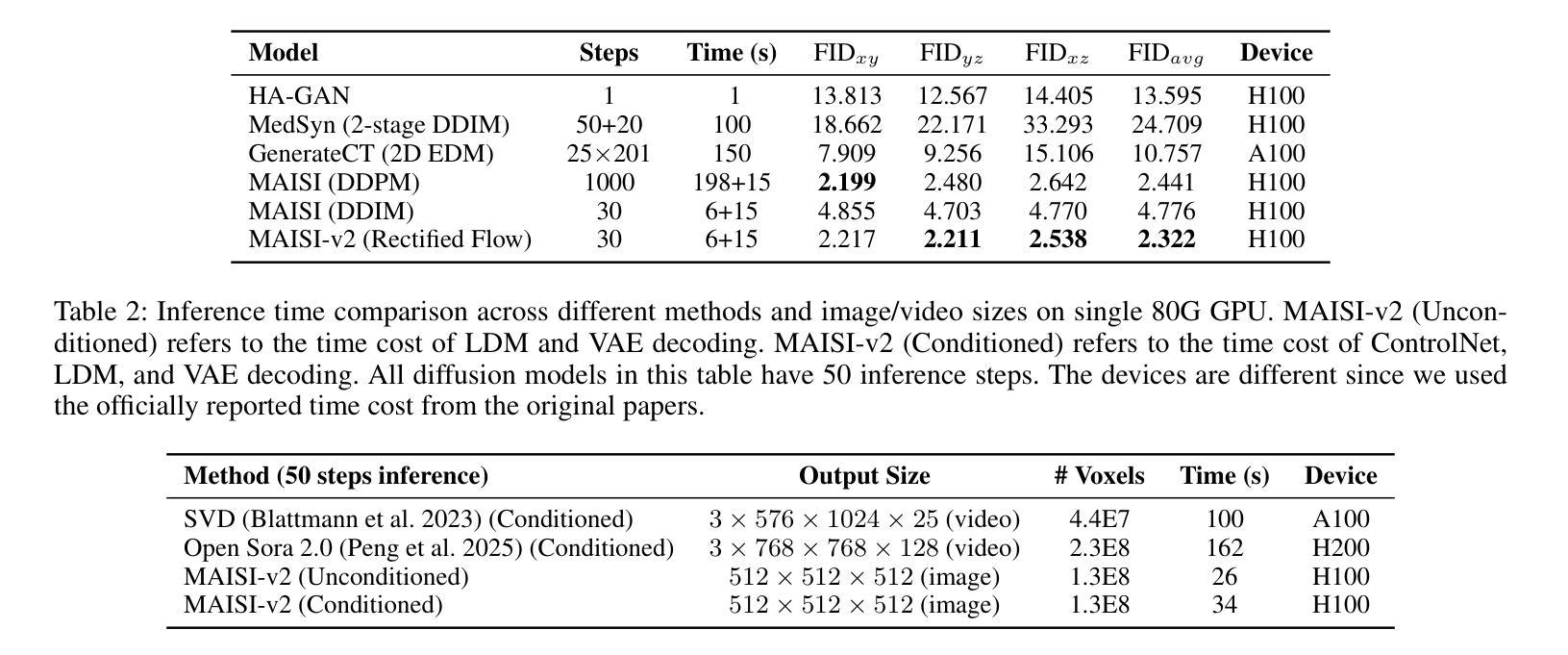
MAISI-v2: Accelerated 3D High-Resolution Medical Image Synthesis with Rectified Flow and Region-specific Contrastive Loss
Authors:Can Zhao, Pengfei Guo, Dong Yang, Yucheng Tang, Yufan He, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, Daguang Xu
Medical image synthesis is an important topic for both clinical and research applications. Recently, diffusion models have become a leading approach in this area. Despite their strengths, many existing methods struggle with (1) limited generalizability that only work for specific body regions or voxel spacings, (2) slow inference, which is a common issue for diffusion models, and (3) weak alignment with input conditions, which is a critical issue for medical imaging. MAISI, a previously proposed framework, addresses generalizability issues but still suffers from slow inference and limited condition consistency. In this work, we present MAISI-v2, the first accelerated 3D medical image synthesis framework that integrates rectified flow to enable fast and high quality generation. To further enhance condition fidelity, we introduce a novel region-specific contrastive loss to enhance the sensitivity to region of interest. Our experiments show that MAISI-v2 can achieve SOTA image quality with $33 \times$ acceleration for latent diffusion model. We also conducted a downstream segmentation experiment to show that the synthetic images can be used for data augmentation. We release our code, training details, model weights, and a GUI demo to facilitate reproducibility and promote further development within the community.
医学图像合成是临床和研究应用中的一个重要主题。最近,扩散模型已成为该领域的主流方法。尽管它们具有优势,但许多现有方法仍然面临(1)通用性有限,仅适用于特定部位或体素间距,(2)推理速度慢,这是扩散模型的常见问题,(3)与输入条件的对齐性差,这对医学影像来说是关键问题。MAISI是一个先前提出的框架,解决了通用性问题,但仍然面临推理速度慢和条件一致性有限的问题。在这项工作中,我们推出了MAISI-v2,这是第一个加速的3D医学图像合成框架,通过整合校正流来实现快速和高质量的生成。为了进一步提高条件保真度,我们引入了一种新型的区域特异性对比损失,以提高对感兴趣区域的敏感性。我们的实验表明,MAISI-v2可以在潜在扩散模型上实现最先进的图像质量,并实现了高达$33 \times$的加速效果。我们还进行了下游分割实验,以证明合成图像可用于数据增强。我们发布了我们的代码、训练细节、模型权重和GUI演示,以促进可重复性并推动社区内的进一步发展。
论文及项目相关链接
摘要
本文介绍了医学图像合成领域中的一项新研究。针对现有方法存在的问题,如通用性有限、推理速度慢和输入条件对齐不佳等,本文提出了MAISI-v2框架。该框架是首个加速的3D医学图像合成框架,通过整合修正流实现快速且高质量的生成。为提高条件保真度,引入了一种新的区域特异性对比损失,以提高对感兴趣区域的敏感性。实验表明,MAISI-v2可在潜在扩散模型上实现33倍的加速,同时达到最先进的图像质量。此外,还进行了下游分割实验,以展示合成图像可用于数据增强。本文公开了代码、训练细节、模型权重和GUI演示,以促进社区内的可重复性和进一步发展。
关键见解
- 医学图像合成在临床和研究应用中的重要性以及扩散模型在该领域的领先地位。
- 现有医学图像合成方法存在的局限性,如通用性、推理速度和输入条件对齐问题。
- MAISI-v2框架的提出,解决了这些问题,实现了快速且高质量的医学图像合成。
- MAISI-v2通过整合修正流技术实现高效的图像生成。
- 为提高条件保真度,引入了新的区域特异性对比损失。
- 实验结果表明MAISI-v2在潜在扩散模型上实现了显著的加速,并达到了最先进的图像质量。
点此查看论文截图