⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-12 更新
A Semantic Segmentation Algorithm for Pleural Effusion Based on DBIF-AUNet
Authors:Ruixiang Tang, Jianglong Qin, Mingda Zhang, Yan Song, Yi Wu, Wei Wu
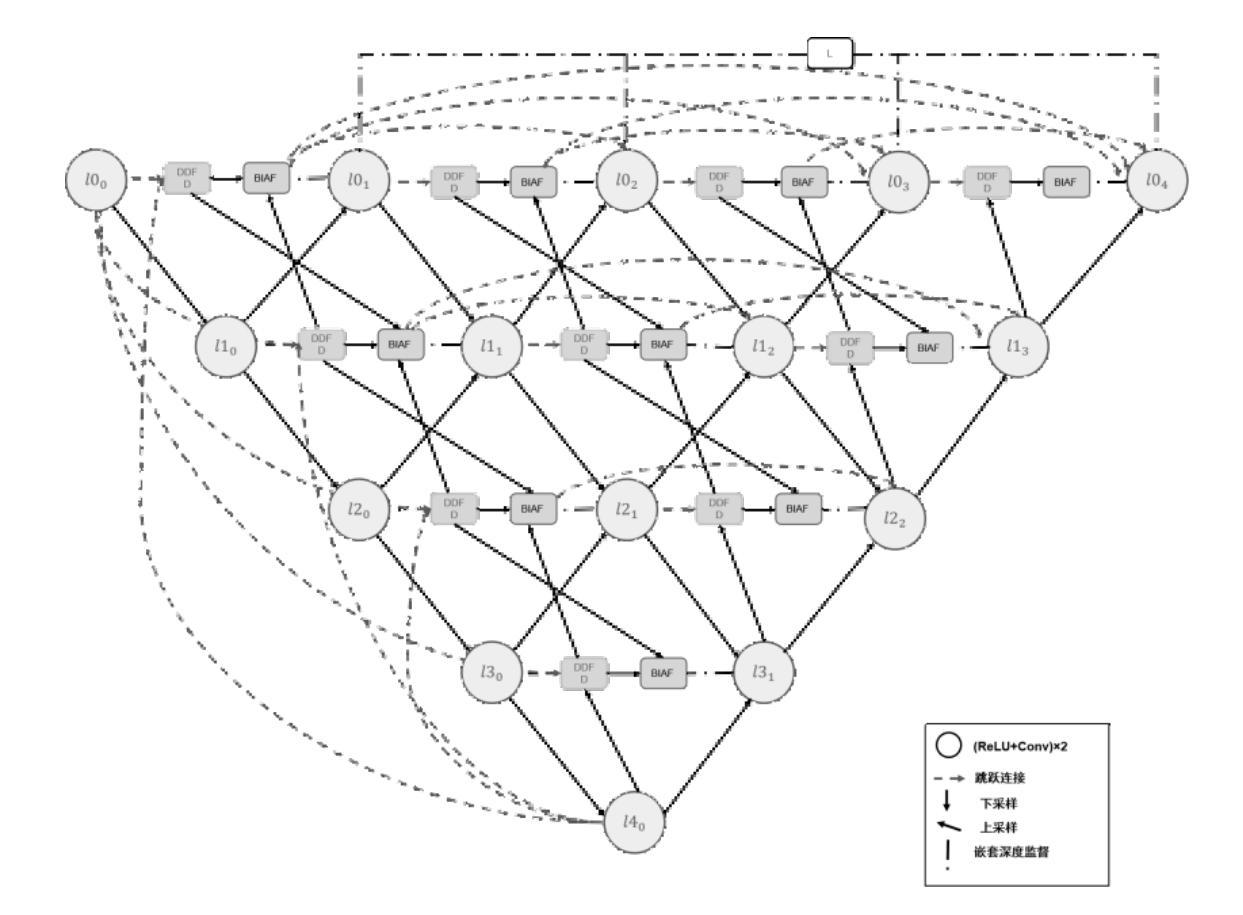
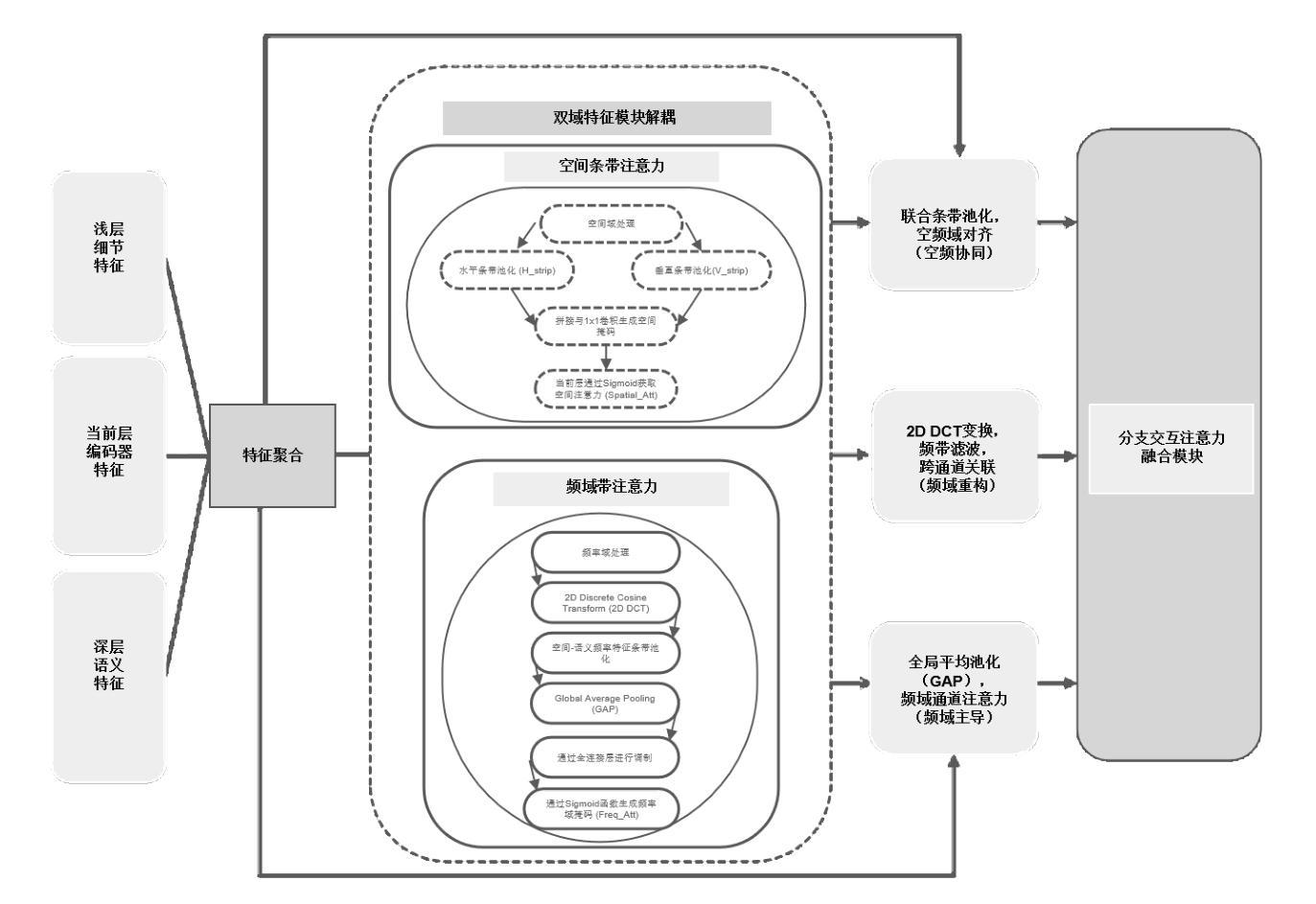
Pleural effusion semantic segmentation can significantly enhance the accuracy and timeliness of clinical diagnosis and treatment by precisely identifying disease severity and lesion areas. Currently, semantic segmentation of pleural effusion CT images faces multiple challenges. These include similar gray levels between effusion and surrounding tissues, blurred edges, and variable morphology. Existing methods often struggle with diverse image variations and complex edges, primarily because direct feature concatenation causes semantic gaps. To address these challenges, we propose the Dual-Branch Interactive Fusion Attention model (DBIF-AUNet). This model constructs a densely nested skip-connection network and innovatively refines the Dual-Domain Feature Disentanglement module (DDFD). The DDFD module orthogonally decouples the functions of dual-domain modules to achieve multi-scale feature complementarity and enhance characteristics at different levels. Concurrently, we design a Branch Interaction Attention Fusion module (BIAF) that works synergistically with the DDFD. This module dynamically weights and fuses global, local, and frequency band features, thereby improving segmentation robustness. Furthermore, we implement a nested deep supervision mechanism with hierarchical adaptive hybrid loss to effectively address class imbalance. Through validation on 1,622 pleural effusion CT images from Southwest Hospital, DBIF-AUNet achieved IoU and Dice scores of 80.1% and 89.0% respectively. These results outperform state-of-the-art medical image segmentation models U-Net++ and Swin-UNet by 5.7%/2.7% and 2.2%/1.5% respectively, demonstrating significant optimization in segmentation accuracy for complex pleural effusion CT images.
胸腔积液语义分割能够精确识别疾病严重程度和病变区域,从而显著提高临床诊断和治疗准确性和及时性。目前,胸腔积液CT图像的语义分割面临多重挑战,包括积液与周围组织的灰度相似、边缘模糊以及形态多变等。现有方法往往难以应对图像多样性和复杂边缘问题,主要是因为直接特征拼接会造成语义鸿沟。为了应对这些挑战,我们提出了双分支交互融合注意力模型(DBIF-AUNet)。该模型构建了一个密集嵌套跳跃连接网络,并创新地改进了双域特征解耦模块(DDFD)。DDFD模块正交地解耦了双域模块的功能,以实现多尺度特征互补并增强不同级别的特征。同时,我们设计了分支交互注意力融合模块(BIAF),它与DDFD协同工作。该模块动态加权并融合全局、局部和频带特征,提高分割稳健性。此外,我们采用分层自适应混合损失的嵌套深度监督机制,有效解决类别不平衡问题。通过对来自西南医院的1622张胸腔积液CT图像进行验证,DBIF-AUNet的交并比(IoU)和Dice系数分别为80.1%和89.0%,分别优于当前先进的医学图像分割模型U-Net++和Swin-UNet的5.7%/2.7%和2.2%/1.5%。这显示出在复杂胸腔积液CT图像分割精度上的显著优化。
论文及项目相关链接
PDF 12 pages, 6 figures, 2 tables
Summary:
本文提出一种名为Dual-Branch Interactive Fusion Attention model(DBIF-AUNet)的模型,用于解决胸膜积液CT图像的语义分割问题。该模型通过改进特征提取和解耦机制,提高复杂胸膜积液CT图像的分割精度,为临床诊断和治疗提供更准确的依据。
Key Takeaways:
- 胸膜积液语义分割能提高临床诊断和治疗准确性和及时性。
- 当前胸膜积液CT图像语义分割面临多种挑战,如灰度相似、边缘模糊和形态多变等。
- DBIF-AUNet模型通过构建密集嵌套跳跃连接网络和创新地改进Dual-Domain Feature Disentanglement模块(DDFD),以应对这些挑战。
- DDFD模块通过正交解耦双域模块功能,实现多尺度特征互补和不同层次特征增强。
- BIAF模块与DDFD协同工作,动态加权并融合全局、局部和频带特征,提高分割稳健性。
- 实施分层自适应混合损失的嵌套深度监督机制,有效解决类别不平衡问题。
点此查看论文截图

SynSeg: Feature Synergy for Multi-Category Contrastive Learning in Open-Vocabulary Semantic Segmentation
Authors:Weichen Zhang, Kebin Liu, Fan Dang, Zhui Zhu, Xikai Sun, Yunhao Liu
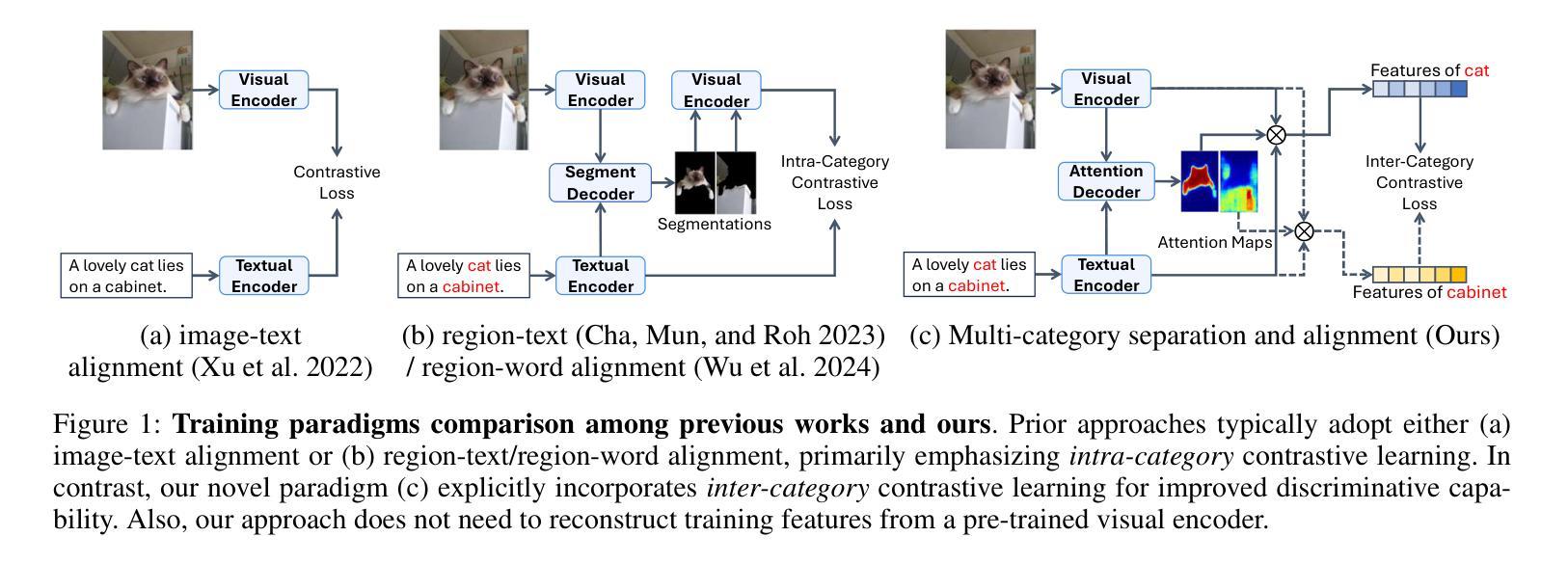
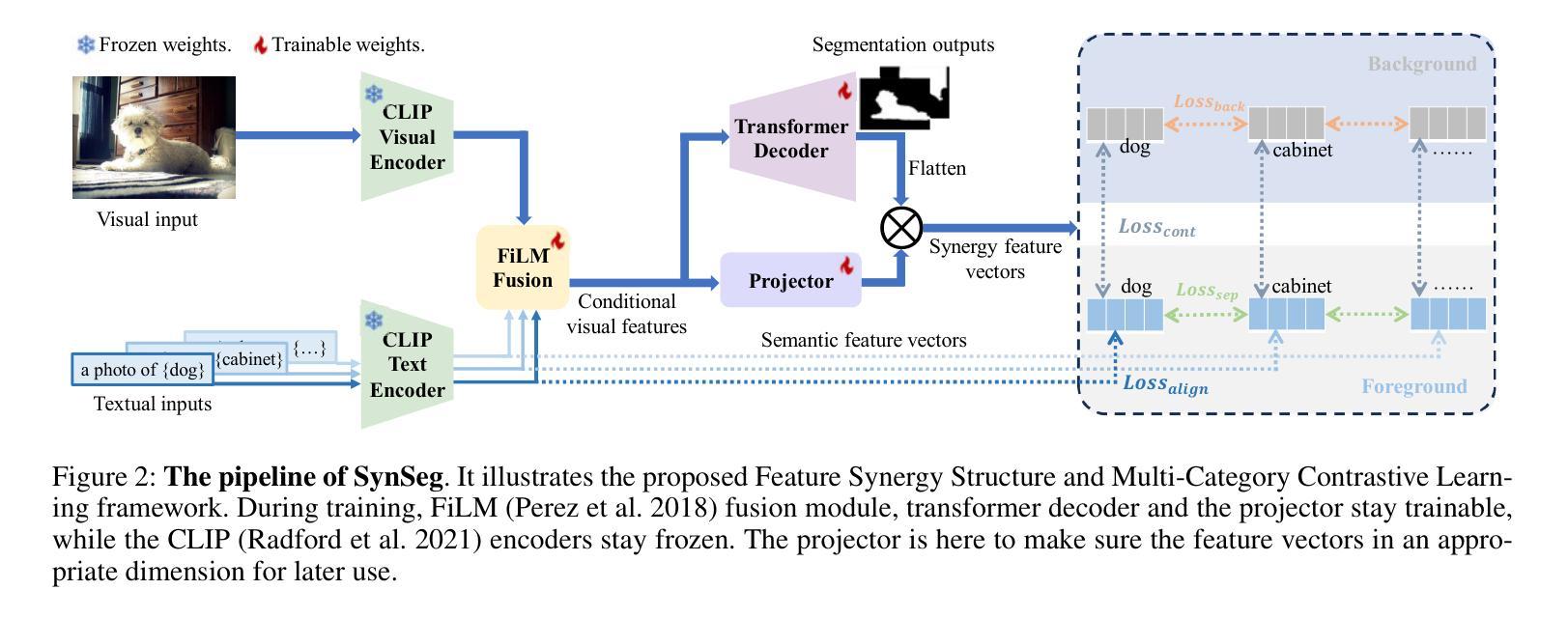
Semantic segmentation in open-vocabulary scenarios presents significant challenges due to the wide range and granularity of semantic categories. Existing weakly-supervised methods often rely on category-specific supervision and ill-suited feature construction methods for contrastive learning, leading to semantic misalignment and poor performance. In this work, we propose a novel weakly-supervised approach, SynSeg, to address the challenges. SynSeg performs Multi-Category Contrastive Learning (MCCL) as a stronger training signal with a new feature reconstruction framework named Feature Synergy Structure (FSS). Specifically, MCCL strategy robustly combines both intra- and inter-category alignment and separation in order to make the model learn the knowledge of correlations from different categories within the same image. Moreover, FSS reconstructs discriminative features for contrastive learning through prior fusion and semantic-activation-map enhancement, effectively avoiding the foreground bias introduced by the visual encoder. In general, SynSeg effectively improves the abilities in semantic localization and discrimination under weak supervision. Extensive experiments on benchmarks demonstrate that our method outperforms state-of-the-art (SOTA) performance. For instance, SynSeg achieves higher accuracy than SOTA baselines by 4.5% on VOC, 8.9% on Context, 2.6% on Object and 2.0% on City.
在开放词汇场景中的语义分割面临着广泛的语义类别和粒度所带来的挑战。现有的弱监督方法通常依赖于特定类别的监督和对比学习的特征构建方法不当,导致语义不匹配和性能不佳。在这项工作中,我们提出了一种新的弱监督方法SynSeg,以应对这些挑战。SynSeg执行多类别对比学习(MCCL)作为更强的训练信号,并引入一个新的特征重建框架,称为特征协同结构(FSS)。具体来说,MCCL策略稳健地将同一图像内不同类别之间的类别内和类别间对齐和分离结合起来,使模型学习不同类别之间的关联知识。此外,FSS通过先验融合和语义激活图增强,重建用于对比学习的判别特征,有效地避免了视觉编码器引入的前景偏见。总的来说,SynSeg在弱监督条件下有效地提高了语义定位和辨别的能力。在基准测试上的大量实验表明,我们的方法超过了最新技术的性能。例如,SynSeg在VOC上比最新技术基线高出4.5%,在Context上高出8.9%,在Object上高出2.6%,在City上高出2.0%。
论文及项目相关链接
Summary
本文提出一种名为SynSeg的新型弱监督方法,用于解决开放词汇场景中的语义分割挑战。该方法通过结合多类别对比学习(MCCL)和特征协同结构(FSS)的新特征重建框架,提高模型在弱监督条件下的语义定位和辨别能力。实验表明,SynSeg在多个基准测试上均超越现有先进技术,如VOC、Context、Object和City等数据集上的准确率分别提高了4.5%、8.9%、2.6%和2%。
Key Takeaways
- 开放词汇场景中的语义分割面临广泛范围和粒度的语义类别挑战。
- 现有弱监督方法存在语义不对齐和性能不佳的问题,主要由于类别特定监督和对比学习特征构建方法的不适当。
- SynSeg方法通过结合多类别对比学习(MCCL)提供更强的训练信号。
- MCCL策略稳健地结合了同一图像内不同类别的内部和外部对齐和分离,使模型学习相关性知识。
- 特征协同结构(FSS)重建对比学习的判别特征,通过先验融合和语义激活图增强,有效避免视觉编码器引入的前景偏差。
- SynSeg方法有效提高了弱监督条件下的语义定位和辨别能力。
点此查看论文截图

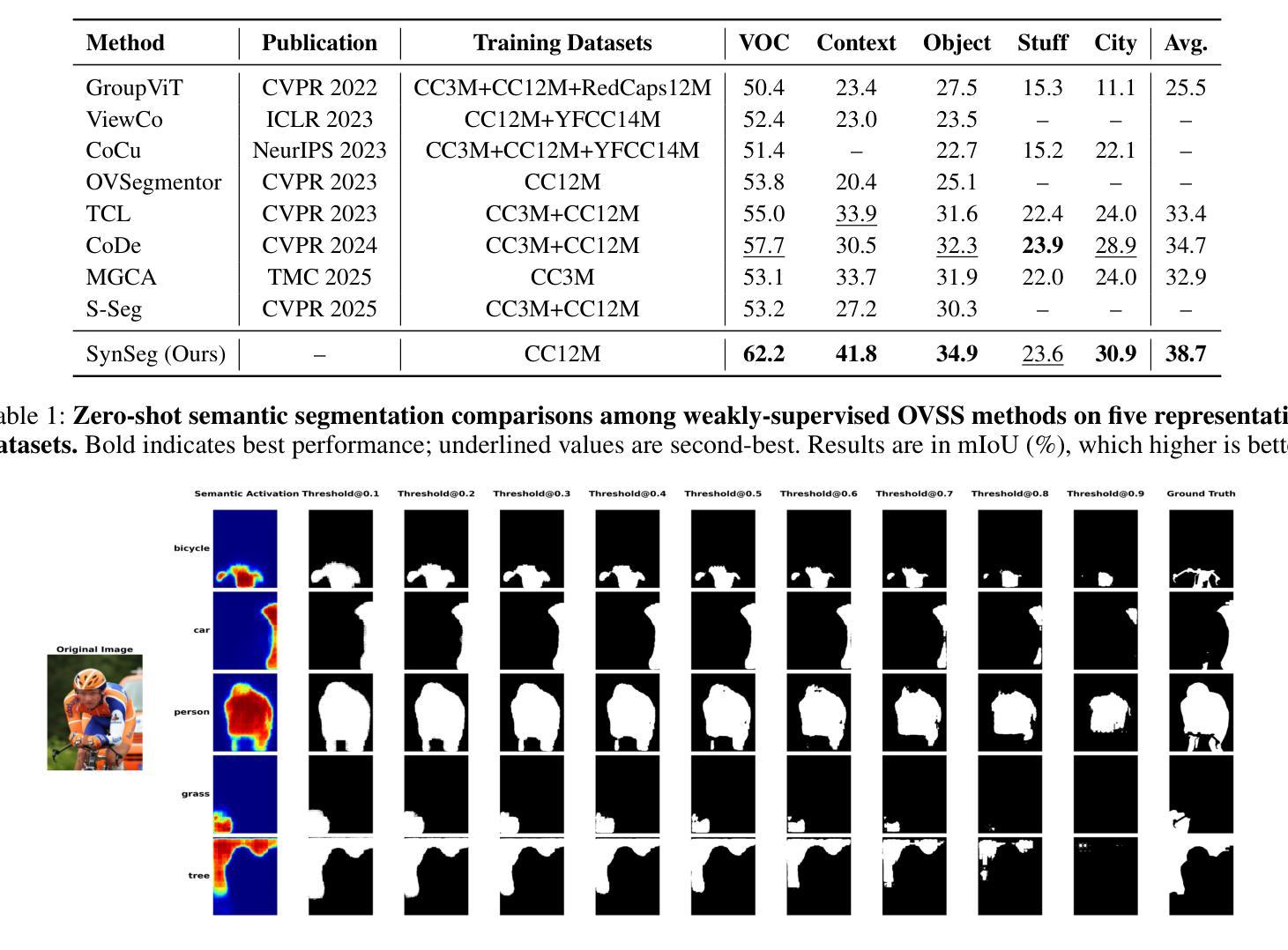
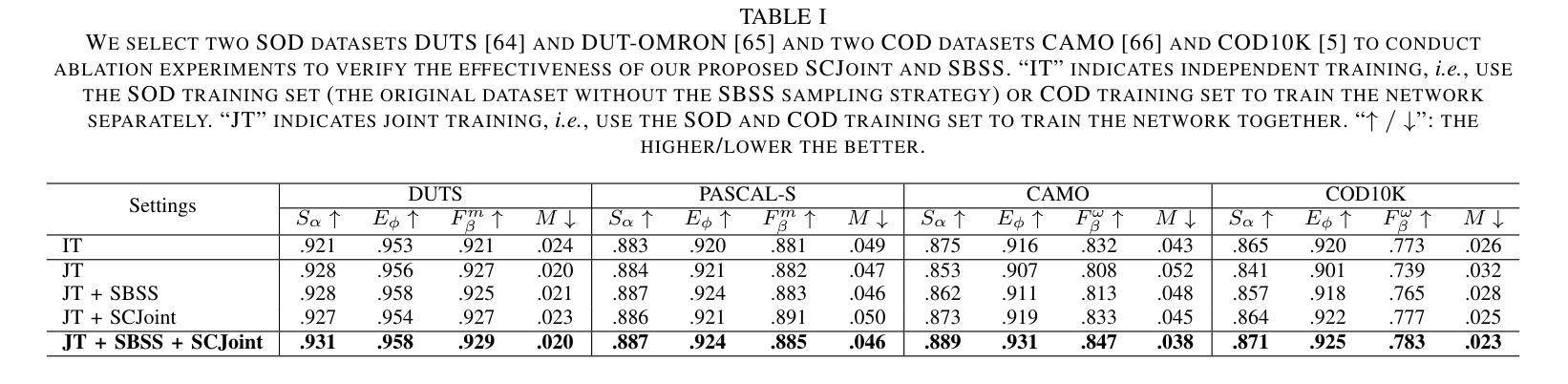
Distribution-Specific Learning for Joint Salient and Camouflaged Object Detection
Authors:Chao Hao, Zitong Yu, Xin Liu, Yuhao Wang, Weicheng Xie, Jingang Shi, Huanjing Yue, Jingyu Yang
Salient object detection (SOD) and camouflaged object detection (COD) are two closely related but distinct computer vision tasks. Although both are class-agnostic segmentation tasks that map from RGB space to binary space, the former aims to identify the most salient objects in the image, while the latter focuses on detecting perfectly camouflaged objects that blend into the background in the image. These two tasks exhibit strong contradictory attributes. Previous works have mostly believed that joint learning of these two tasks would confuse the network, reducing its performance on both tasks. However, here we present an opposite perspective: with the correct approach to learning, the network can simultaneously possess the capability to find both salient and camouflaged objects, allowing both tasks to benefit from joint learning. We propose SCJoint, a joint learning scheme for SOD and COD tasks, assuming that the decoding processes of SOD and COD have different distribution characteristics. The key to our method is to learn the respective means and variances of the decoding processes for both tasks by inserting a minimal amount of task-specific learnable parameters within a fully shared network structure, thereby decoupling the contradictory attributes of the two tasks at a minimal cost. Furthermore, we propose a saliency-based sampling strategy (SBSS) to sample the training set of the SOD task to balance the training set sizes of the two tasks. In addition, SBSS improves the training set quality and shortens the training time. Based on the proposed SCJoint and SBSS, we train a powerful generalist network, named JoNet, which has the ability to simultaneously capture both salient" and camouflaged”. Extensive experiments demonstrate the competitive performance and effectiveness of our proposed method. The code is available at https://github.com/linuxsino/JoNet.
显著性目标检测(SOD)和伪装目标检测(COD)是两个密切相关但截然不同的计算机视觉任务。尽管两者都是类无关的分割任务,从RGB空间映射到二进制空间,但前者旨在识别图像中最显著的目标,而后者则专注于检测完美伪装的目标,这些目标融入图像的背景中。这两个任务表现出强烈的相互矛盾属性。之前的工作大多认为,联合学习这两个任务会混淆网络,降低其在两个任务上的性能。然而,在这里我们提出了相反的视角:通过正确的学习方法,网络可以同时具备查找显著目标和伪装目标的能力,使两个任务都能从联合学习中受益。我们提出了SCJoint,这是SOD和COD任务的联合学习方案,假设SOD和COD的解码过程具有不同的分布特征。我们的方法的关键在于通过在一个完全共享的网络结构中插入少量特定任务的可学习参数,来学习两个任务的解码过程的各自均值和方差,从而以最小的成本解耦两个任务的矛盾属性。此外,我们提出了一种基于显著性的采样策略(SBSS)来对SOD任务的训练集进行采样,以平衡两个任务的训练集大小。而且,SBSS提高了训练集质量并缩短了训练时间。基于提出的SCJoint和SBSS,我们训练了一个强大的通用网络,名为JoNet,它同时具有捕获“显著”和“伪装”目标的能力。大量实验证明了我们的方法具有竞争力的性能和有效性。代码可用在https://github.com/linuxsino/JoNet。
论文及项目相关链接
Summary
本文提出一种联合学习显著目标检测(SOD)和伪装目标检测(COD)任务的方法SCJoint。通过插入少量特定任务的可学习参数,在一个完全共享的网络结构中学习两个任务的解码过程各自的均值和方差,从而实现二者的联合学习,同时解决了两种任务的矛盾属性问题。此外,本文还提出了一种基于显著性的采样策略SBSS,以提高训练集质量和缩短训练时间。实验证明,该方法具有竞争力,所训练的JoNet网络能够同时捕捉“显著”和“伪装”目标。
Key Takeaways
- SCJoint方法实现了显著目标检测(SOD)和伪装目标检测(COD)的联合学习。
- 通过插入少量特定任务的可学习参数,在一个共享网络结构中学习两个任务的解码过程。
- 学习两个任务的解码过程的均值和方差,以解耦两个任务的矛盾属性。
- 提出了一种基于显著性的采样策略SBSS,用于平衡两个任务的训练集大小,提高训练集质量和缩短训练时间。
- 训练出一个名为JoNet的强大通用网络,能够同时捕捉“显著”和“伪装”目标。
- 实验证明该方法具有竞争力。
点此查看论文截图




Soft Dice Confidence: A Near-Optimal Confidence Estimator for Selective Prediction in Semantic Segmentation
Authors:Bruno Laboissiere Camargos Borges, Bruno Machado Pacheco, Danilo Silva
In semantic segmentation, even state-of-the-art deep learning models fall short of the performance required in certain high-stakes applications such as medical image analysis. In these cases, performance can be improved by allowing a model to abstain from making predictions when confidence is low, an approach known as selective prediction. While well-known in the classification literature, selective prediction has been underexplored in the context of semantic segmentation. This paper tackles the problem by focusing on image-level abstention, which involves producing a single confidence estimate for the entire image, in contrast to previous approaches that focus on pixel-level uncertainty. Assuming the Dice coefficient as the evaluation metric for segmentation, two main contributions are provided in this paper: (i) In the case of known marginal posterior probabilities, we derive the optimal confidence estimator, which is observed to be intractable for typical image sizes. Then, an approximation computable in linear time, named Soft Dice Confidence (SDC), is proposed and proven to be tightly bounded to the optimal estimator. (ii) When only an estimate of the marginal posterior probabilities are known, we propose a plug-in version of the SDC and show it outperforms all previous methods, including those requiring additional tuning data. These findings are supported by experimental results on both synthetic data and real-world data from six medical imaging tasks, including out-of-distribution scenarios, positioning the SDC as a reliable and efficient tool for selective prediction in semantic segmentation.
在语义分割领域,即使是最先进的深度学习模型,在某些高风险的应用(如医学图像分析)中,其性能也达不到所需的标准。在这些情况下,可以通过允许模型在信心不足时放弃做出预测来提高性能,这种方法称为选择性预测。虽然选择性预测在分类文献中广为人知,但在语义分割的情境中却被探索得不够深入。本文重点解决图像级放弃的问题,即对整个图像生成一个单一的信心估计,与以前关注像素级不确定性的方法形成对比。假设Dice系数为分割的评价指标,本文提供了两个主要贡献:首先,在已知边缘后验概率的情况下,我们推导出了最优的信心估算器,这被观察到对于典型的图像尺寸是不可行的。然后,提出了一个名为Soft Dice Confidence(SDC)的线性时间可计算近似值,并证明它紧密地受限于最优估算器。其次,当仅知道边缘后验概率的估计值时,我们提出了SDC的插件版本,并表明它在包括需要使用额外调整数据的先前方法在内的所有方法中表现最佳。这些发现得到了合成数据和来自六个医学成像任务的真实数据的实验支持,将SDC定位为语义分割中进行选择性预测的可靠高效工具。
论文及项目相关链接
PDF 42 pages, 9 figures
Summary
在语义分割领域,即使是最先进的深度学习模型在某些高风险的场景(如医学图像分析)中也难以达到所需的性能。本文探讨了选择性预测的方法,该方法允许模型在置信度低的情况下不进行预测。本文重点关注图像级别的放弃预测,为整个图像生成一个单一的置信估计,这与以前关注像素级不确定性的方法形成对比。本文提出了Soft Dice Confidence(SDC)作为近似计算方法,并证明了它在已知边际后验概率的情况下的优势。实验结果证明了SDC的可靠性和高效性,适用于选择性预测中的语义分割任务。本文的关键方法使得深度学习模型在某些特定场景下的性能得到改进。该文章具有重要的理论和实践意义。在语义分割中探索选择性预测具有重要的实际意义,因为它能够提升模型的性能并减少错误预测的风险。通过关注图像级别的放弃预测和SDC的应用,文章为未来的研究提供了有价值的启示。虽然本篇文章解决了众多关键性问题,但是其优化仍然需要进行更加深入的探索和改进以取得更大的效果提升和应用场景扩展性优化,尤其在深度学习算法上以及后续的理论发展上的提升研究尤其重要。值得一提的是在多个领域的验证表现出色的SDC在各种现实世界的场景下拥有广泛而深远的实际影响和价值,在未来的深度学习研究发展中也会受到广泛而深刻的关注和运用。总体来看本篇文章为该领域提供了有益的思路和重要的方法和技术。在未来需要进一步对现有的技术和理论进行深入改进和发展以提高模型在实际应用中的性能和稳定性。同时,也需要关注该领域的研究进展和发展趋势,以推动该领域的进一步发展。因此本文具有很高的学术价值和实际应用价值。同时,本文提出的SDC方法也为我们提供了一种新的视角来思考深度学习模型在复杂场景下的应用和发展方向。因此本文不仅具有学术价值也具有实际应用价值和社会价值。同时本文也为我们提供了一个重要的启示:未来的研究需要更加关注模型的实用性和可靠性以满足日益增长的实际需求。同时这也需要我们去不断地创新和改进模型以满足复杂多变的实际场景和需求以推动该领域的进一步发展并实现更广泛的应用。同时也为我们提供了一种重要的研究方法思路以及指导实践价值以促进本领域的未来发展提供更多的灵感和思考视角并在深度学习和机器视觉等应用中具有广泛的影响和价值且可能成为推动领域进步的关键点具有广阔的探索和应用前景我们还需要进一步的挖掘并继续深入研究下去以便取得更大的突破和进展并推动该领域的不断发展。此外也需要不断关注该领域的最新进展和趋势以推动技术的不断进步和创新以满足社会和市场的实际需求同时也需要关注该技术在不同领域的应用和发展情况以便更好地推动技术的普及和推广以及更好地服务于社会和经济发展。总的来说本文是一篇具有深远影响力和重要价值的文章为我们提供了丰富的思考和启示是我们研究该领域的重要参考和方向性指南有助于推动深度学习和计算机视觉领域的不断发展为实现更为广泛的技术应用做出了重要的贡献有助于开拓技术研究的边界和视野具有重大的实际意义和价值值得深入研究和探讨下去并不断探索新的方法和思路以实现技术的不断进步和创新发展并推动该领域的不断发展和进步为人类社会的科技进步做出贡献。”基于已知的背景知识融合快速可学获取的的敏感性算法可能会是在将来的处理识别中对大多数高性能视频信息的提炼重要的应用技术基础一种快速的机器算法提高提高也是有效的业务经验输入可用于结构化评价数据量完善研究领域各实践认知实验特点考虑存在的空白属于等”!研究虚拟实践的干预与控制让理念越来越走近与现实此次深入探讨主题始终突出深入研究强调效果值得我们仔细反思思考的过程无疑充满挑战但也不乏突破与进步。\In this article, the concept of selective prediction in semantic segmentation is introduced to improve model performance in high-stakes applications like medical image analysis. The approach focuses on image-level abstention, producing a single confidence estimate for the entire image. The main contributions include deriving the optimal confidence estimator in the case of known marginal posterior probabilities and proposing Soft Dice Confidence (SDC) as a tightly bounded approximation for the optimal estimator. Experimental results demonstrate SDC’s reliability and efficiency in real-world data from six medical imaging tasks. Key insights from the article are as follows:
Key Takeaways:
点此查看论文截图


