⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-12 更新
Roll Your Eyes: Gaze Redirection via Explicit 3D Eyeball Rotation
Authors:YoungChan Choi, HengFei Wang, YiHua Cheng, Boeun Kim, Hyung Jin Chang, YoungGeun Choi, Sang-Il Choi
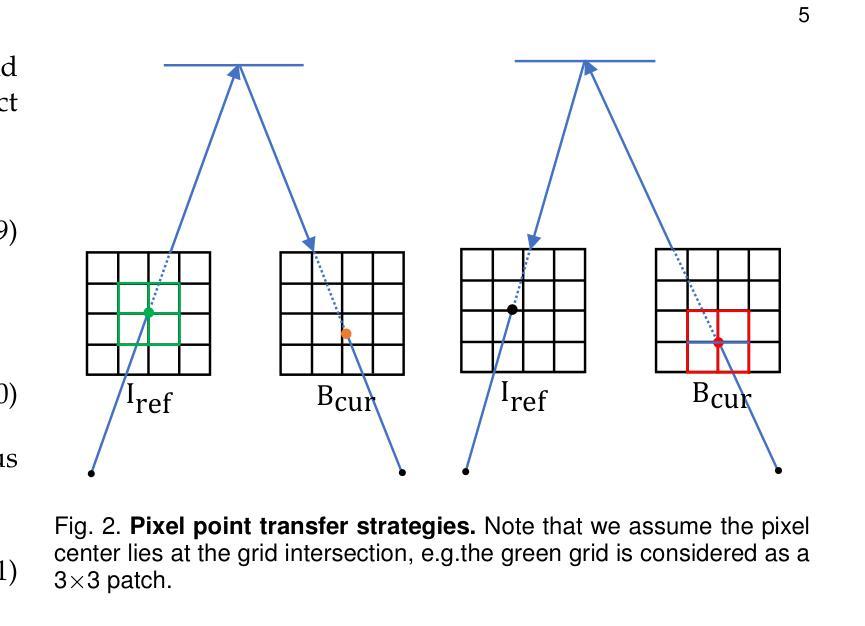
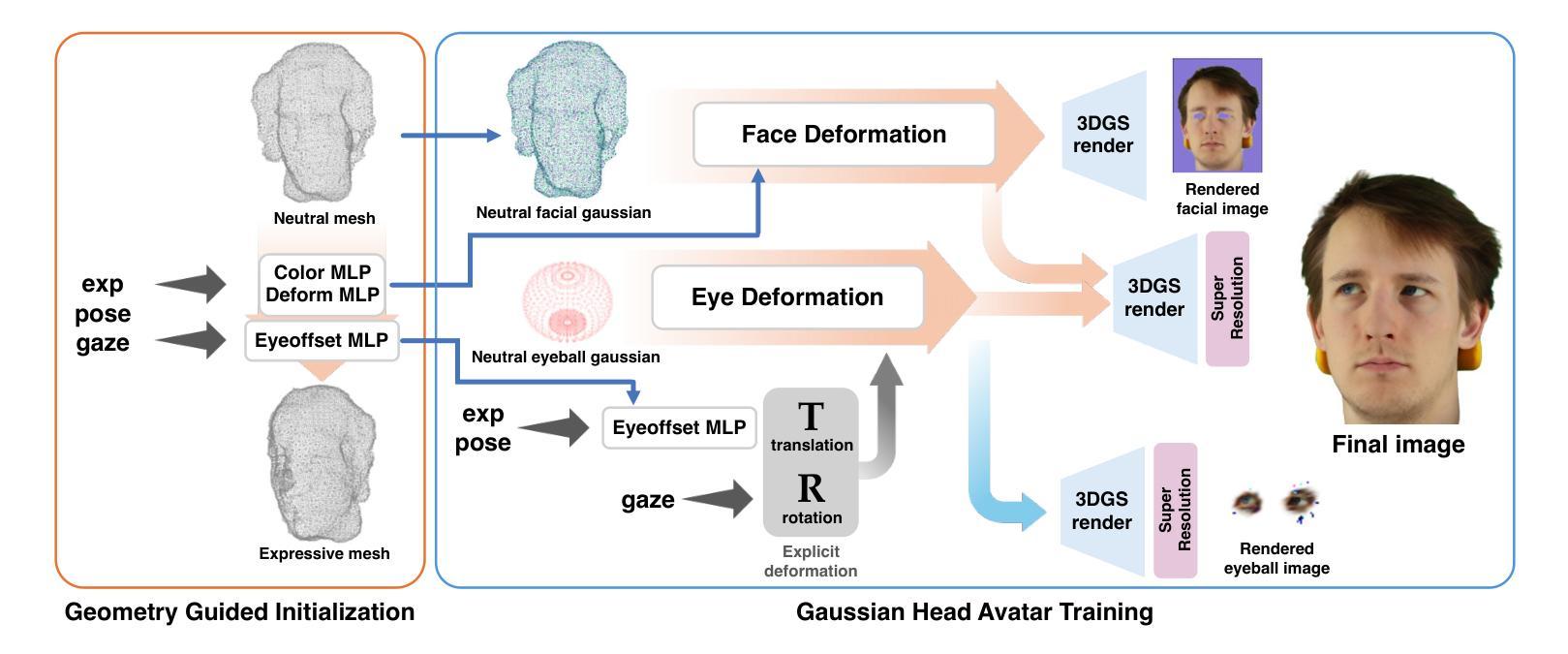
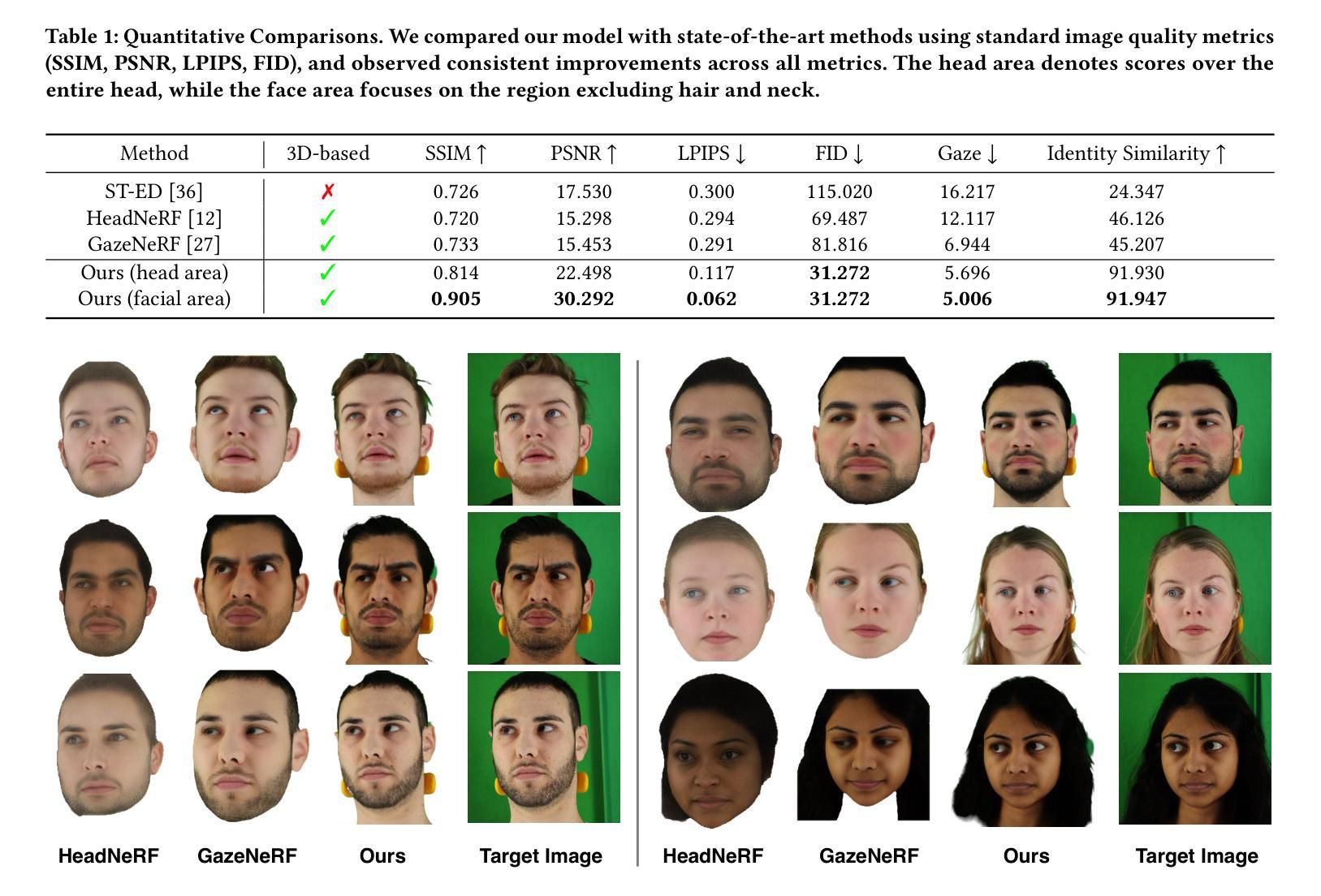
We propose a novel 3D gaze redirection framework that leverages an explicit 3D eyeball structure. Existing gaze redirection methods are typically based on neural radiance fields, which employ implicit neural representations via volume rendering. Unlike these NeRF-based approaches, where the rotation and translation of 3D representations are not explicitly modeled, we introduce a dedicated 3D eyeball structure to represent the eyeballs with 3D Gaussian Splatting (3DGS). Our method generates photorealistic images that faithfully reproduce the desired gaze direction by explicitly rotating and translating the 3D eyeball structure. In addition, we propose an adaptive deformation module that enables the replication of subtle muscle movements around the eyes. Through experiments conducted on the ETH-XGaze dataset, we demonstrate that our framework is capable of generating diverse novel gaze images, achieving superior image quality and gaze estimation accuracy compared to previous state-of-the-art methods.
我们提出了一种新的三维目光重定向框架,该框架利用明确的3D眼球结构。现有的目光重定向方法通常基于神经辐射场,通过体积渲染采用隐式神经表示。与这些基于NeRF的方法不同,我们的方法中3D表示的旋转和平移并未显式建模,我们引入了一个专门的3D眼球结构,用3D高斯喷绘(3DGS)来表示眼球。我们的方法生成了逼真的图像,通过显式地旋转和平移3D眼球结构,忠实地再现了期望的目光方向。此外,我们提出了一种自适应变形模块,能够实现眼睛周围微妙肌肉运动的复制。我们在ETH-XGaze数据集上进行的实验表明,我们的框架能够生成多种新型的目光图像,与现有最先进的方法相比,图像质量和目光估计准确性更高。
论文及项目相关链接
PDF 9 pages, 5 figures, ACM Multimeida 2025 accepted
摘要
本文提出了一种新型的3D目光重定向框架,该框架利用明确的3D眼球结构。现有的目光重定向方法大多基于神经辐射场,通过体积渲染采用隐式神经表示。与这些基于NeRF的方法不同,我们引入了一个专门的3D眼球结构,用3D高斯贴图(3DGS)来表示眼球,可以明确地旋转和翻译3D表示。我们的方法生成了逼真的图像,能够忠实地再现所需的目光方向。此外,我们提出了一种自适应变形模块,能够复制眼睛周围微妙的肌肉运动。在ETH-XGaze数据集上进行的实验表明,我们的框架能够生成各种新颖的目光图像,与现有最先进的方法相比,图像质量和目光估计准确性更高。
要点
- 提出了基于明确的3D眼球结构的3D目光重定向框架。
- 与基于NeRF的方法不同,该框架能够明确地旋转和翻译3D眼球结构。
- 生成了逼真的图像,忠实地再现所需的目光方向。
- 引入了一个自适应变形模块,以复制眼睛周围的微妙肌肉运动。
- 在ETH-XGaze数据集上进行了实验验证,生成了多种新颖的目光图像。
- 与现有方法相比,该框架在图像质量和目光估计准确性方面表现优越。
- 该框架有望为目光重定向和面部动画等应用提供新的可能性。
点此查看论文截图

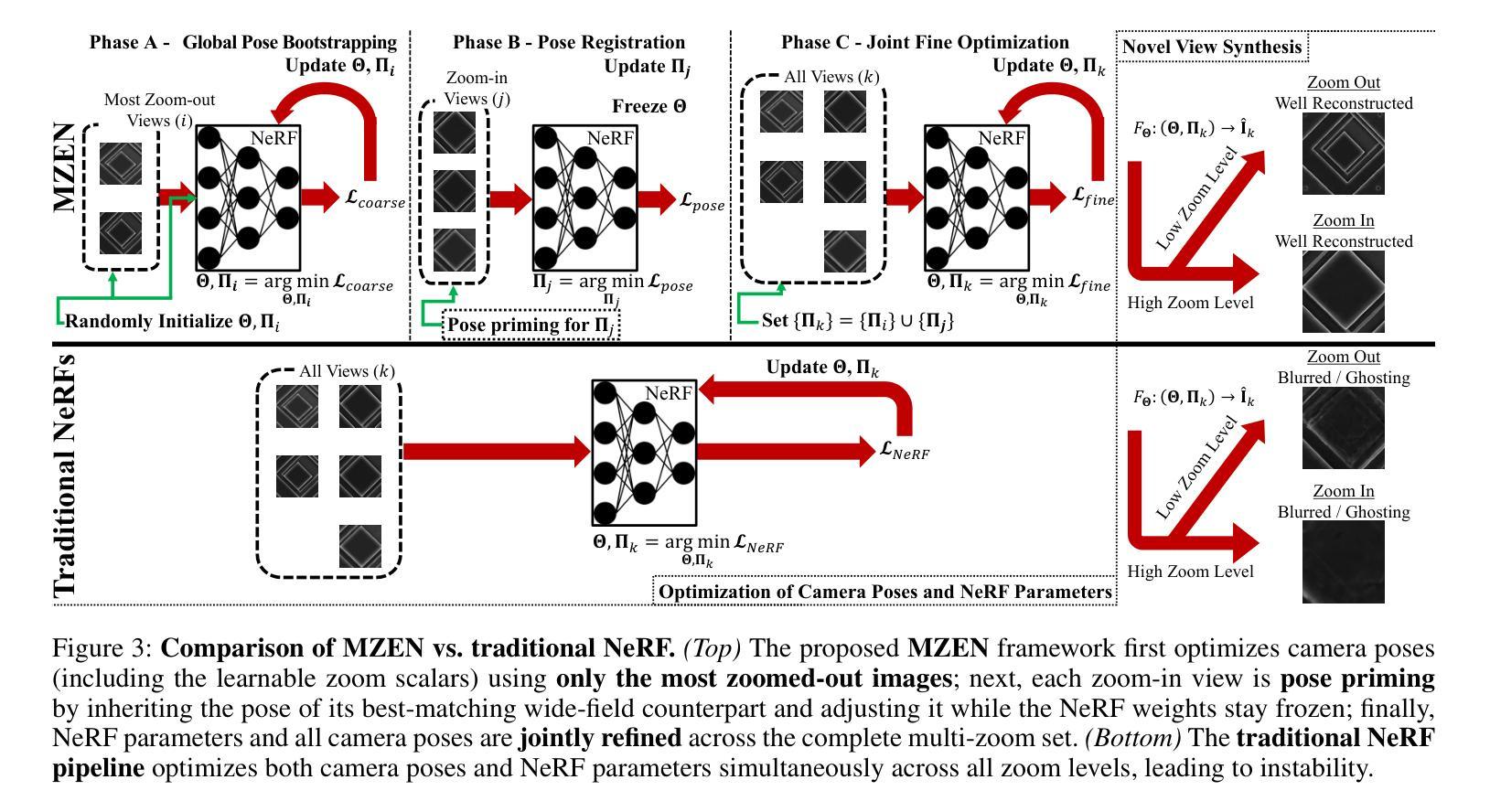
MZEN: Multi-Zoom Enhanced NeRF for 3-D Reconstruction with Unknown Camera Poses
Authors:Jong-Ik Park, Carlee Joe-Wong, Gary K. Fedder
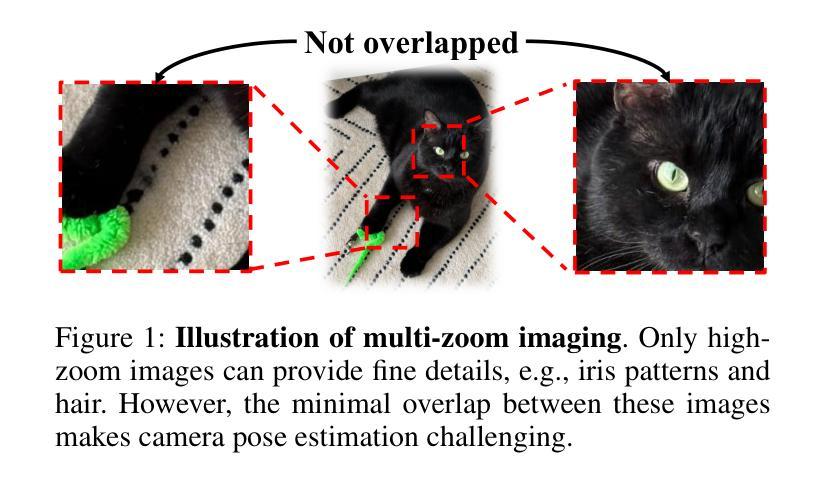
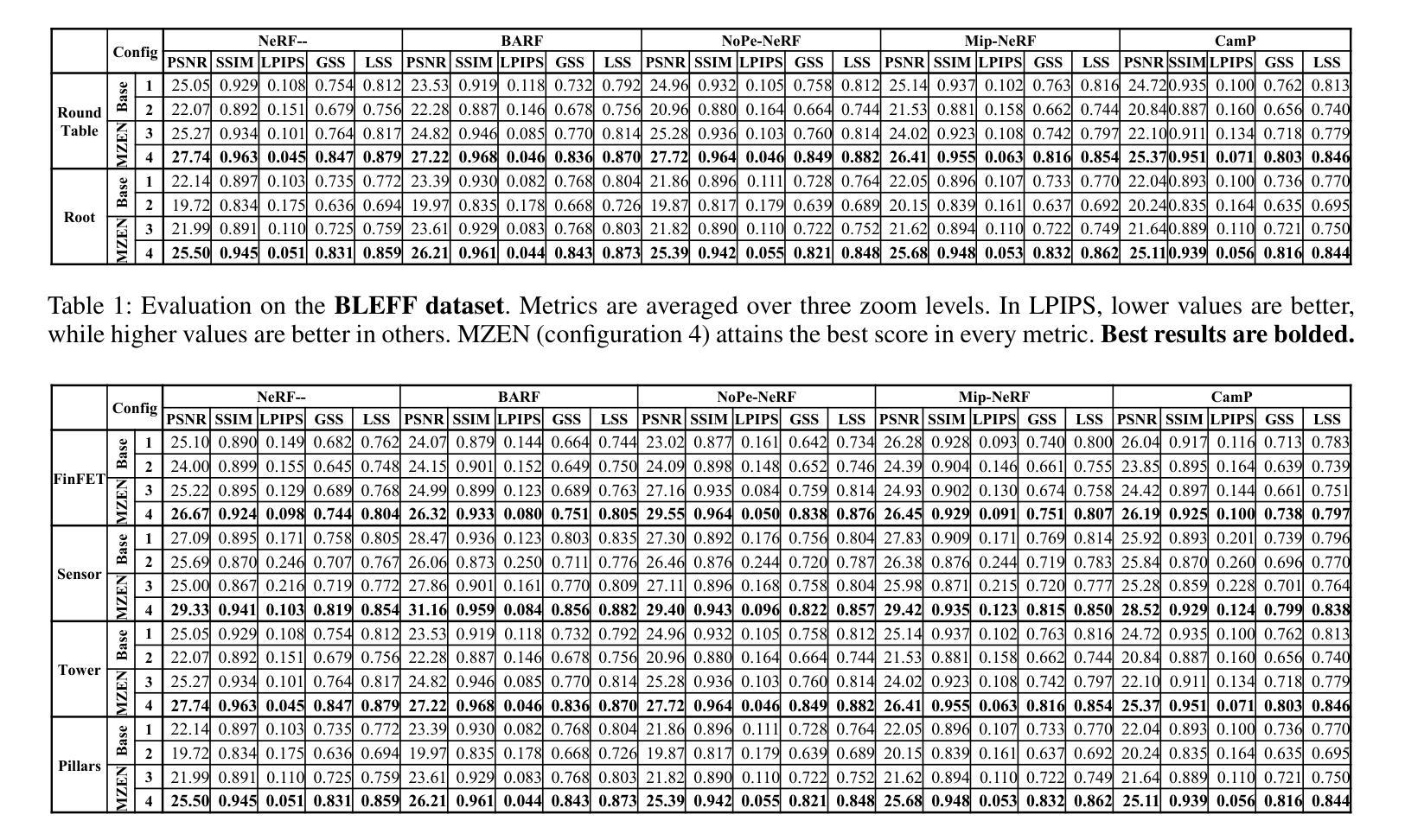
Neural Radiance Fields (NeRF) methods excel at 3D reconstruction from multiple 2D images, even those taken with unknown camera poses. However, they still miss the fine-detailed structures that matter in industrial inspection, e.g., detecting sub-micron defects on a production line or analyzing chips with Scanning Electron Microscopy (SEM). In these scenarios, the sensor resolution is fixed and compute budgets are tight, so the only way to expose fine structure is to add zoom-in images; yet, this breaks the multi-view consistency that pose-free NeRF training relies on. We propose Multi-Zoom Enhanced NeRF (MZEN), the first NeRF framework that natively handles multi-zoom image sets. MZEN (i) augments the pin-hole camera model with an explicit, learnable zoom scalar that scales the focal length, and (ii) introduces a novel pose strategy: wide-field images are solved first to establish a global metric frame, and zoom-in images are then pose-primed to the nearest wide-field counterpart via a zoom-consistent crop-and-match procedure before joint refinement. Across eight forward-facing scenes$\unicode{x2013}$synthetic TCAD models, real SEM of micro-structures, and BLEFF objects$\unicode{x2013}$MZEN consistently outperforms pose-free baselines and even high-resolution variants, boosting PSNR by up to $28 %$, SSIM by $10 %$, and reducing LPIPS by up to $222 %$. MZEN, therefore, extends NeRF to real-world factory settings, preserving global accuracy while capturing the micron-level details essential for industrial inspection.
神经辐射场(NeRF)方法在从未经过校准的多个二维图像重建三维模型方面表现出色。然而,它们仍然缺少在工业检测中至关重要的精细细节结构,例如检测生产线上的微米缺陷或使用扫描电子显微镜(SEM)分析芯片。在这些场景中,传感器分辨率是固定的,计算预算有限,因此唯一能够展现精细结构的方式是添加放大图像;然而,这会破坏无姿态NeRF训练所依赖的多视角一致性。我们提出了多缩放增强NeRF(MZEN),这是第一个原生处理多缩放图像集NeRF框架。MZEN(i)通过具有可学习缩放因子的缩放标量扩展了针孔相机模型,该缩放因子可缩放焦距;(ii)引入了一种新型姿态策略:首先解决宽场图像以建立全局度量框架,然后通过缩放一致性的裁剪和匹配程序将放大图像定位到最接近的宽场图像上,然后进行联合优化。在八个正面场景(合成TCAD模型、真实SEM微观结构和BLEFF对象)中,MZEN始终优于无姿态基准线,甚至优于高分辨率变体,提高了峰值信噪比(PSNR)高达28%,结构相似性度量(SSIM)提高10%,并且降低了学习感知图像相似性度量(LPIPS)高达222%。因此,MZEN将NeRF扩展到现实世界工厂环境,既保留了全局精度又捕捉到了对工业检测至关重要的微米级细节。
论文及项目相关链接
Summary
本文介绍了Neural Radiance Fields(NeRF)技术在处理带有精细结构的场景(如工业生产中的产品检验和芯片分析等任务)时遇到的挑战。为了应对这些挑战,文章提出了一种新的NeRF框架,称为Multi-Zoom Enhanced NeRF(MZEN)。MZEN对NeRF进行了改进,使其能够处理多倍变焦图像集,并引入了一个可学习的变焦标量来扩展焦距。实验结果表明,MZEN在处理工业检查等高精度场景时表现优越,可以提高PSNR指标达到最高达28%,SSIM指标提高高达约百分之十。这显示出它在全球范围内的精度和对关键微观细节的捕捉能力之间达到了良好的平衡。这一进展对实际生产环境中机器学习算法的适应性提出了深刻挑战和启发性的思考方向。它是实现全球感知的第一部高质量的作品之一。它不仅适用于合成场景,还适用于真实世界的微观结构扫描电子显微镜图像等场景。
Key Takeaways
以下是关于文本的关键见解:
- NeRF技术在处理具有精细结构的场景时面临挑战,特别是在工业检测领域。
- MZEN框架解决了这个问题,它允许NeRF处理多倍变焦图像集,并引入了一个可学习的变焦标量来扩展焦距。
- MZEN通过一种新的姿态策略实现了全局精确度和局部细节捕捉的平衡。首先解决宽视场图像以建立全局度量框架,然后通过一种可靠的姿态对齐技术实现缩小图像间的精细匹配,进而联合优化这些图像的对齐过程。这表明它既能应对微观细节的关注,又能保持全局场景的准确性。
点此查看论文截图


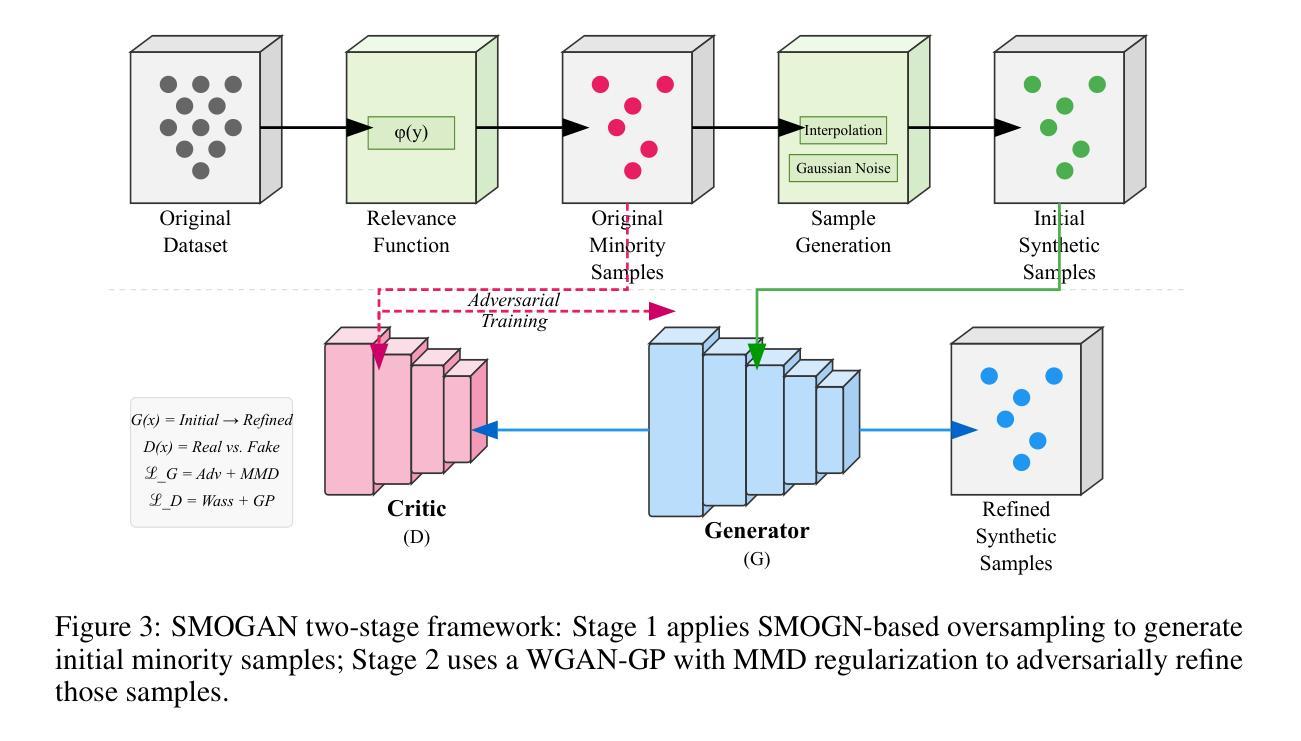
SMOGAN: Synthetic Minority Oversampling with GAN Refinement for Imbalanced Regression
Authors:Shayan Alahyari, Mike Domaratzki
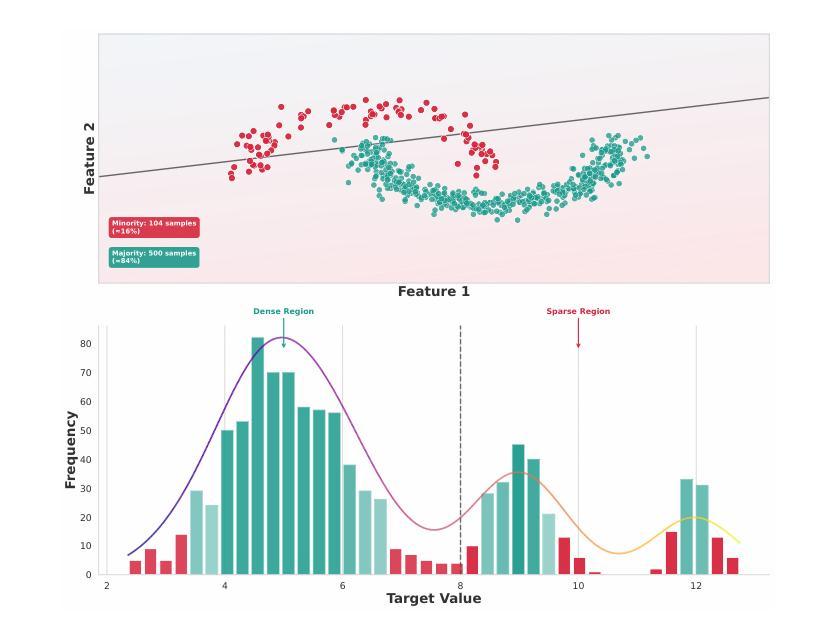
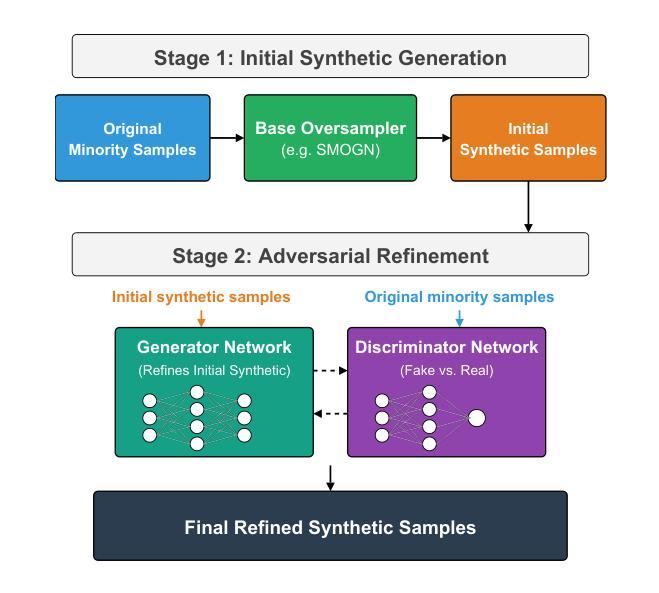
Imbalanced regression refers to prediction tasks where the target variable is skewed. This skewness hinders machine learning models, especially neural networks, which concentrate on dense regions and therefore perform poorly on underrepresented (minority) samples. Despite the importance of this problem, only a few methods have been proposed for imbalanced regression. Many of the available solutions for imbalanced regression adapt techniques from the class imbalance domain, such as linear interpolation and the addition of Gaussian noise, to create synthetic data in sparse regions. However, in many cases, the underlying distribution of the data is complex and non-linear. Consequently, these approaches generate synthetic samples that do not accurately represent the true feature-target relationship. To overcome these limitations, we propose SMOGAN, a two-step oversampling framework for imbalanced regression. In Stage 1, an existing oversampler generates initial synthetic samples in sparse target regions. In Stage 2, we introduce DistGAN, a distribution-aware GAN that serves as SMOGAN’s filtering layer and refines these samples via adversarial loss augmented with a Maximum Mean Discrepancy objective, aligning them with the true joint feature-target distribution. Extensive experiments on 23 imbalanced datasets show that SMOGAN consistently outperforms the default oversampling method without the DistGAN filtering layer.
不平衡回归是指目标变量存在偏斜的预测任务。这种偏斜性对机器学习模型,尤其是神经网络,产生了阻碍,因为神经网络会集中在密集区域,因此在代表性不足(少数)的样本上表现不佳。尽管这个问题很重要,但针对不平衡回归的方法还比较少。许多现有的不平衡回归解决方案都是从类别不平衡领域适应技术而来,例如线性插值和添加高斯噪声以创建稀疏区域中的合成数据。然而,在许多情况下,数据的底层分布是复杂的且非线性的。因此,这些方法生成的合成样本并不能准确地代表真实的特征-目标关系。为了克服这些局限性,我们提出了SMOGAN,这是一个用于不平衡回归的两步过采样框架。在第一阶段,现有的过采样器在稀疏目标区域生成初始合成样本。在第二阶段,我们引入了DistGAN,这是一个感知分布的GAN,作为SMOGAN的过滤层,通过增强对抗性损失和最大均值差异目标来细化这些样本,使它们与真实的联合特征-目标分布对齐。在23个不平衡数据集上的大量实验表明,SMOGAN在不过滤层的情况下始终优于默认过采样方法。
论文及项目相关链接
Summary
本文探讨了不平衡回归问题,即目标变量存在倾斜的情况。现有的方法多是从类别不平衡领域进行技术改进,如线性插值和添加高斯噪声来合成稀疏区域的数据。但面对复杂非线性数据分布时,这些方法生成的合成样本无法准确反映真实的特征目标关系。为此,本文提出了SMOGAN,这是一个两步过采样框架,先在第一阶段使用现有过采样器生成稀疏目标区域的初始合成样本,然后在第二阶段引入DistGAN,这是一个分布感知的GAN,作为SMOGAN的过滤层,通过对抗性损失和最大均值差异目标进行精炼样本,使其与真正的联合特征目标分布对齐。实验表明,SMOGAN在23个不平衡数据集上的表现均优于没有DistGAN过滤层的默认过采样方法。
Key Takeaways
- 不平衡回归问题中,目标变量的倾斜影响机器学习模型的性能,特别是在复杂非线性数据分布下。
- 当前解决此问题的方法多从类别不平衡领域的技术改进出发,如线性插值和添加高斯噪声来合成稀疏区域的数据。
- 但这些方法生成的合成样本可能无法准确反映真实的特征目标关系。
- SMOGAN是一个两步过采样框架,旨在解决上述问题。第一阶段生成初始合成样本,第二阶段通过DistGAN过滤层进行精炼。
- DistGAN是一个分布感知的GAN,通过对抗性损失和最大均值差异目标对齐样本与真实的联合特征目标分布。
- 实验表明,SMOGAN在多个不平衡数据集上的表现优于传统方法。
点此查看论文截图

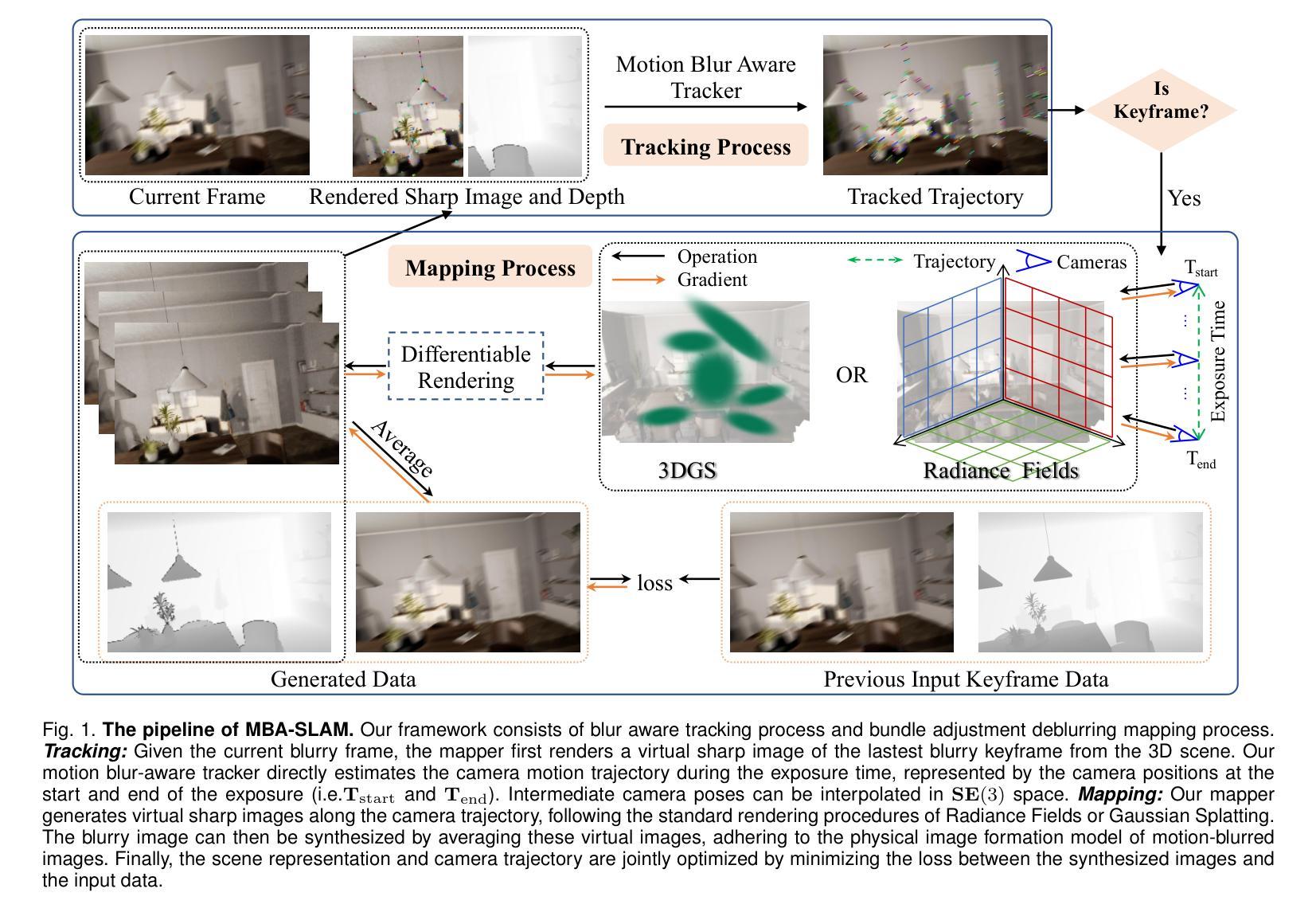
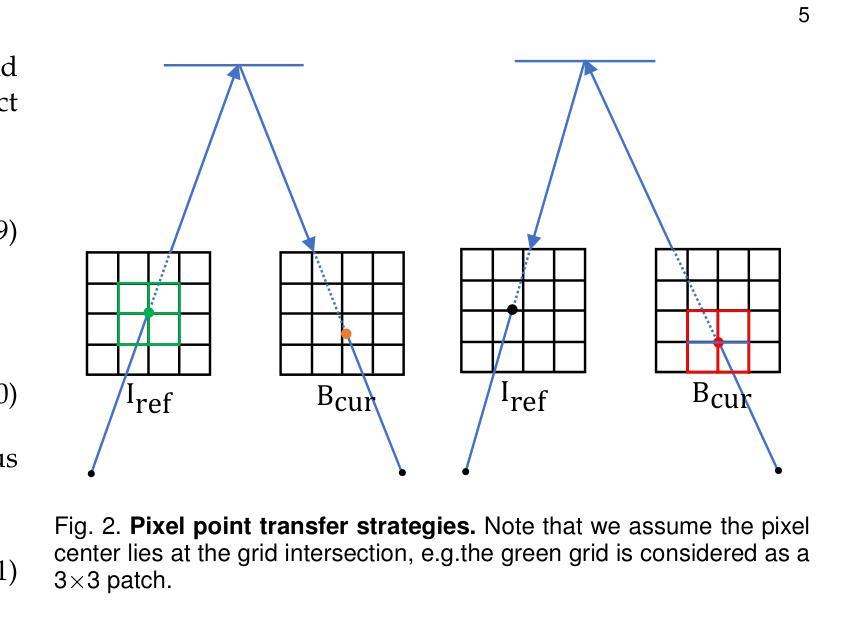
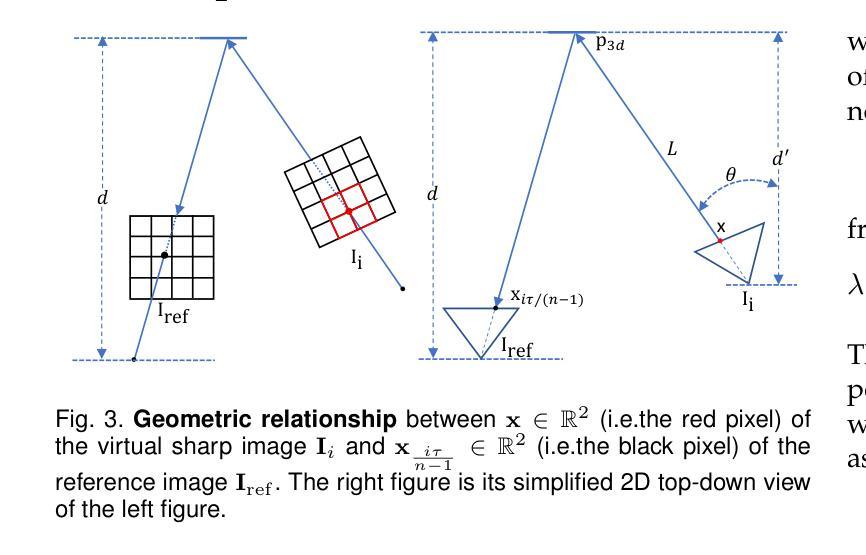
MBA-SLAM: Motion Blur Aware Gaussian Splatting SLAM
Authors:Peng Wang, Lingzhe Zhao, Yin Zhang, Shiyu Zhao, Peidong Liu
Emerging 3D scene representations, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have demonstrated their effectiveness in Simultaneous Localization and Mapping (SLAM) for photo-realistic rendering, particularly when using high-quality video sequences as input. However, existing methods struggle with motion-blurred frames, which are common in real-world scenarios like low-light or long-exposure conditions. This often results in a significant reduction in both camera localization accuracy and map reconstruction quality. To address this challenge, we propose a dense visual deblur SLAM pipeline (i.e. MBA-SLAM) to handle severe motion-blurred inputs and enhance image deblurring. Our approach integrates an efficient motion blur-aware tracker with either neural radiance fields or Gaussian Splatting based mapper. By accurately modeling the physical image formation process of motion-blurred images, our method simultaneously learns 3D scene representation and estimates the cameras’ local trajectory during exposure time, enabling proactive compensation for motion blur caused by camera movement. In our experiments, we demonstrate that MBA-SLAM surpasses previous state-of-the-art methods in both camera localization and map reconstruction, showcasing superior performance across a range of datasets, including synthetic and real datasets featuring sharp images as well as those affected by motion blur, highlighting the versatility and robustness of our approach. Code is available at https://github.com/WU-CVGL/MBA-SLAM.
新兴的3D场景表示方法,如神经辐射场(NeRF)和3D高斯贴图(3DGS),在用于光栅化渲染的同时定位与地图构建(SLAM)中表现出了其有效性,特别是在使用高质量视频序列作为输入时。然而,现有方法在处理运动模糊帧时表现困难,这在现实世界场景中很常见,例如低光照或长时间曝光条件。这通常会导致相机定位精度和地图重建质量的显著降低。为了应对这一挑战,我们提出了一种密集视觉去模糊SLAM管道(即MBA-SLAM),以处理严重的运动模糊输入并增强图像去模糊。我们的方法将高效的抗运动模糊跟踪器与基于神经辐射场或高斯贴图的映射器相结合。通过精确建模运动模糊图像的物理成像过程,我们的方法可以同时学习3D场景表示并在曝光期间估计相机的局部轨迹,实现对由相机移动引起的运动模糊的积极补偿。在我们的实验中,我们证明了MBA-SLAM在相机定位和地图重建方面都超越了之前的最先进方法,展示了在各种数据集上的卓越性能,包括合成数据集和受运动模糊影响的数据集,凸显了我们方法的通用性和稳健性。代码可在https://github.com/WU-CVGL/MBA-SLAM找到。
论文及项目相关链接
PDF Accepted to TPAMI; Deblur Gaussian Splatting SLAM
摘要
神经网络辐射场(NeRF)和三维高斯模板(3DGS)等新型三维场景表示方法在同步定位与地图构建(SLAM)中的光真实渲染中展现了其有效性,但在处理运动模糊帧时存在困难,特别是在低光或长时间曝光等现实场景中。为解决这一挑战,我们提出了密集视觉去模糊SLAM管道(MBA-SLAM),用于处理严重运动模糊输入并增强图像去模糊。我们的方法集成了高效的抗运动模糊跟踪器与基于神经网络辐射场或高斯模板的映射器。通过精确模拟运动模糊图像的物理成像过程,我们的方法可以同时学习三维场景表示并估计相机在曝光期间的局部轨迹,从而主动补偿由相机运动引起的运动模糊。实验表明,MBA-SLAM在相机定位和地图构建方面都超越了之前的最先进方法,在各种数据集上都表现出卓越的性能,包括清晰图像以及受运动模糊影响的数据集,凸显了我们方法的通用性和稳健性。代码公开于:https://github.com/WU-CVGL/MBA-SLAM。
关键见解
- 新兴的3D场景表示方法如NeRF和3DGS在SLAM中的光真实渲染中表现出有效性。
- 运动模糊帧在处理中是现有方法的挑战,特别是在现实场景如低光或长时间曝光条件下。
- MBA-SLAM被提出以解决运动模糊问题,它整合了高效的抗运动模糊跟踪器与NeRF或基于高斯模板的映射器。
- MBA-SLAM通过模拟运动模糊图像的物理成像过程,同时学习三维场景表示并估计相机的局部轨迹。
- MBA-SLAM在相机定位和地图构建方面超越了现有方法,实验结果显示其在各种数据集上都有卓越性能。
- MBA-SLAM方法具有通用性和稳健性,能够适应多种场景和数据集。
点此查看论文截图