⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-12 更新
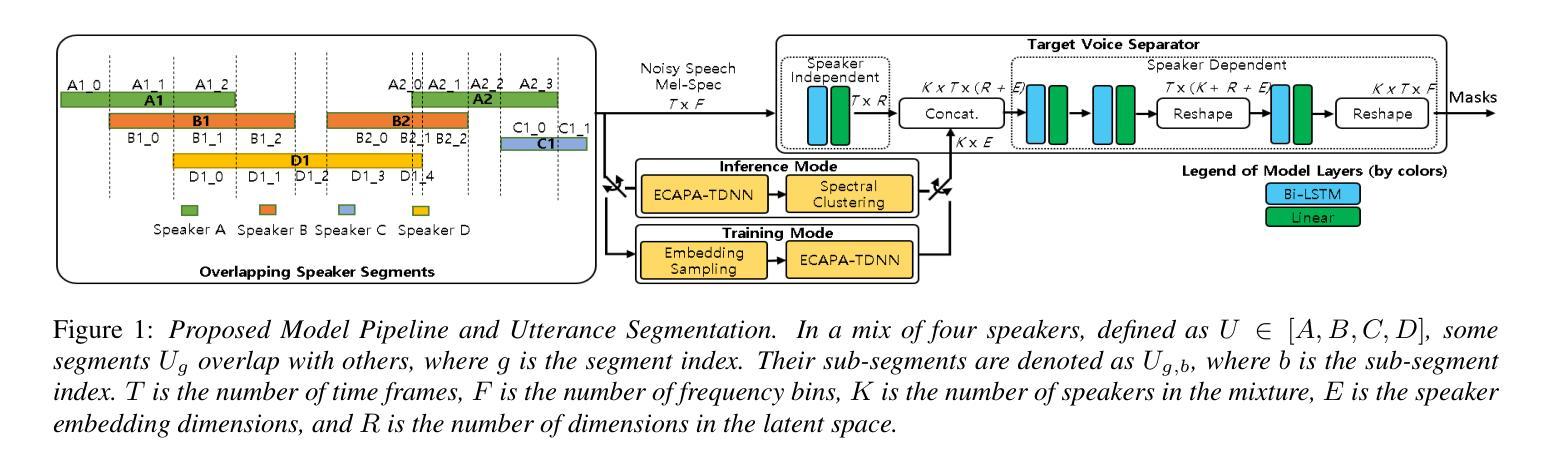
Robust Target Speaker Diarization and Separation via Augmented Speaker Embedding Sampling
Authors:Md Asif Jalal, Luca Remaggi, Vasileios Moschopoulos, Thanasis Kotsiopoulos, Vandana Rajan, Karthikeyan Saravanan, Anastasis Drosou, Junho Heo, Hyuk Oh, Seokyeong Jeong
Traditional speech separation and speaker diarization approaches rely on prior knowledge of target speakers or a predetermined number of participants in audio signals. To address these limitations, recent advances focus on developing enrollment-free methods capable of identifying targets without explicit speaker labeling. This work introduces a new approach to train simultaneous speech separation and diarization using automatic identification of target speaker embeddings, within mixtures. Our proposed model employs a dual-stage training pipeline designed to learn robust speaker representation features that are resilient to background noise interference. Furthermore, we present an overlapping spectral loss function specifically tailored for enhancing diarization accuracy during overlapped speech frames. Experimental results show significant performance gains compared to the current SOTA baseline, achieving 71% relative improvement in DER and 69% in cpWER.
传统的语音分离和说话人身份识别方法依赖于目标说话人的先验知识或音频信号中预先确定的参与者数量。为了解决这些局限性,最近的进展主要集中在开发无需注册的方法,这些方法能够在没有明确的说话人标签的情况下识别目标。这项工作引入了一种新的方法,使用混合自动识别目标说话人嵌入来同时进行语音分离和身份识别。我们提出的模型采用了一个两阶段训练管道,旨在学习对背景噪声干扰具有鲁棒性的说话人表示特征。此外,我们还提出了一种专为提高重叠语音帧中的身份识别准确性而设计的重叠光谱损失函数。实验结果表明,与当前的最佳基线相比,我们的方法取得了显著的性能提升,在DER上实现了相对71%的改进,cpWER上实现了69%的改进。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本文介绍了一种无需注册的新方法,能够自动识别目标说话人的嵌入,用于同时进行语音分离和说话人识别。该方法采用双阶段训练管道,学习稳健的说话人特征表示,并引入针对重叠语音帧的定制重叠光谱损失函数,以提高识别准确性。实验结果表明,与当前最佳基线相比,该方法在DER和cpWER方面取得了显著的相对改进。
Key Takeaways
- 引入了一种无需注册的新方法,能够自动识别目标说话人的嵌入,用于语音分离和说话人识别。
- 采用双阶段训练管道设计,旨在学习稳健的说话人特征表示。
- 定制了重叠光谱损失函数,针对重叠语音帧进行准确性提升。
- 克服了传统方法对目标说话人或预先确定的参与者数量的依赖。
- 取得了显著的相对改进,与当前最佳基线相比在DER和cpWER方面表现优越。
- 训练模型能够适应背景噪音干扰的影响。
点此查看论文截图

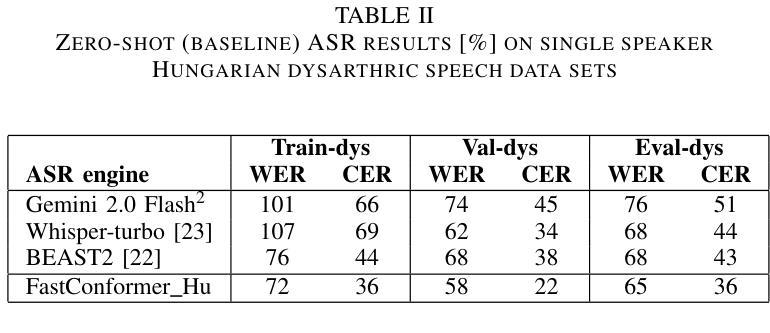
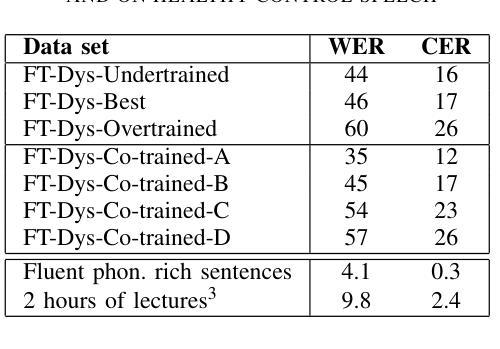
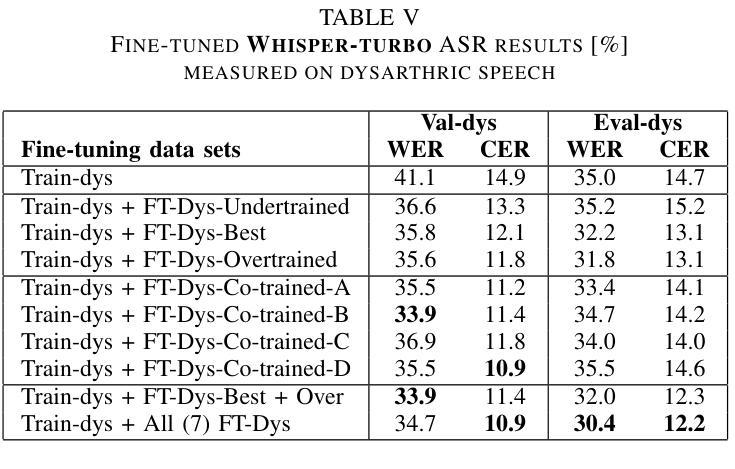
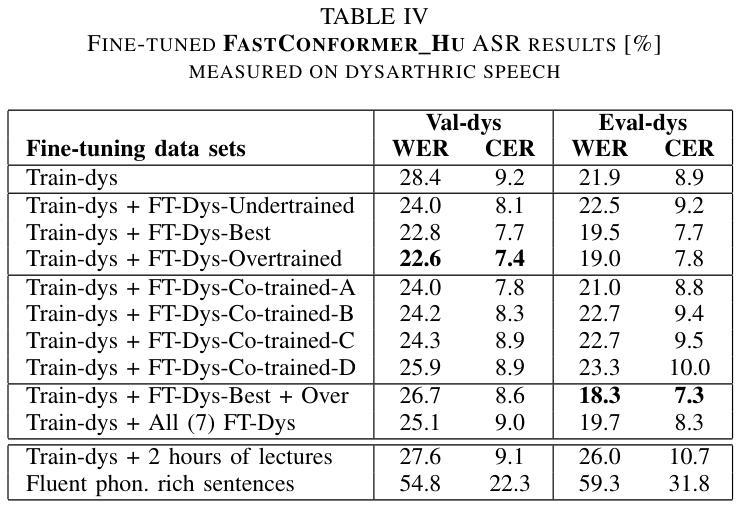
Improved Dysarthric Speech to Text Conversion via TTS Personalization
Authors:Péter Mihajlik, Éva Székely, Piroska Barta, Máté Soma Kádár, Gergely Dobsinszki, László Tóth
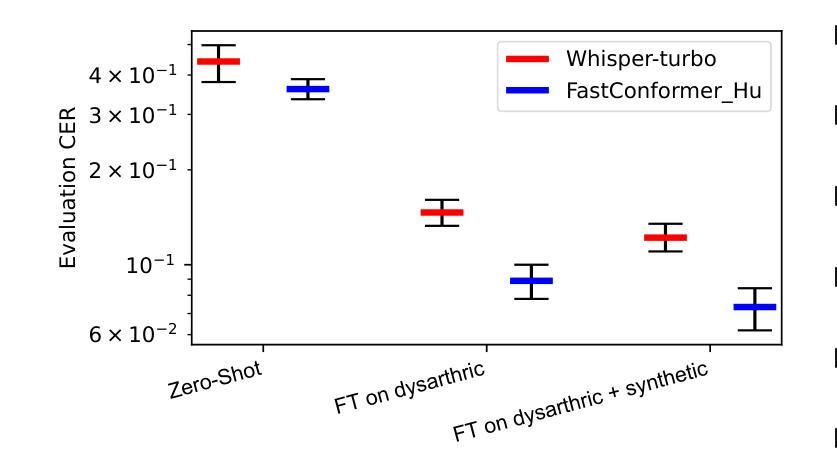
We present a case study on developing a customized speech-to-text system for a Hungarian speaker with severe dysarthria. State-of-the-art automatic speech recognition (ASR) models struggle with zero-shot transcription of dysarthric speech, yielding high error rates. To improve performance with limited real dysarthric data, we fine-tune an ASR model using synthetic speech generated via a personalized text-to-speech (TTS) system. We introduce a method for generating synthetic dysarthric speech with controlled severity by leveraging premorbidity recordings of the given speaker and speaker embedding interpolation, enabling ASR fine-tuning on a continuum of impairments. Fine-tuning on both real and synthetic dysarthric speech reduces the character error rate (CER) from 36-51% (zero-shot) to 7.3%. Our monolingual FastConformer_Hu ASR model significantly outperforms Whisper-turbo when fine-tuned on the same data, and the inclusion of synthetic speech contributes to an 18% relative CER reduction. These results highlight the potential of personalized ASR systems for improving accessibility for individuals with severe speech impairments.
我们针对一位严重缄默症的匈牙利语患者,开发了一个定制化的语音转文本系统,进行了一项案例研究。最先进的自动语音识别(ASR)模型在缄默语音的零样本转录方面存在困难,导致高错误率。为了在使用有限的真实缄默症数据的情况下提高性能,我们通过个性化的文本到语音(TTS)系统生成合成语音来微调ASR模型。我们介绍了一种通过利用给定说话人的发病前录音和说话人嵌入插值来生成具有可控严重程度的合成缄默语音的方法,从而能够在连续的损害程度上对ASR进行微调。对真实和合成缄默语音的微调将字符错误率(CER)从36-51%(零样本)降低到7.3%。我们的匈牙利语单语种FastConformer_Hu ASR模型在相同数据上进行微调时,性能显著优于Whisper-turbo,合成语音的加入导致了相对CER降低了18%。这些结果突显了个性化ASR系统在改善严重言语障碍者的可访问性方面的潜力。
论文及项目相关链接
Summary
该研究针对匈牙利语严重构音障碍者的语音转文本系统进行了个案研究。当前主流的自动语音识别(ASR)模型对于零样本的构音障碍语音转录存在较高误差率。为提高性能并受限于真实的构音障碍数据,该研究使用个性化文本转语音(TTS)系统生成合成语音,对ASR模型进行微调。通过利用患者病前录音和说话人嵌入插值的方法,该研究开发了一种生成具有可控严重程度的合成构音障碍语音的方法,使得ASR模型可以在连续的障碍程度上进行微调。在真实和合成构音障碍语音上的微调将字符错误率(CER)从零样本的36-51%降至7.3%。在同样的数据集上,该研究的匈牙利语FastConformer模型相较于Whisper-turbo表现更优,合成语音的加入带来了相对CER的18%降低。这些结果突显了个性化ASR系统在改善严重语音障碍者的可访问性方面的潜力。
Key Takeaways
- 研究针对匈牙利语严重构音障碍者的语音转文本系统进行了个案研究。
- 当前ASR模型在零样本构音障碍语音转录上存在高误差率。
- 为提高性能,研究使用个性化TTS系统生成合成语音对ASR模型进行微调。
- 通过利用病前录音和说话人嵌入插值,生成具有可控严重程度的合成构音障碍语音。
- 真实和合成构音障碍语音的微调显著降低了字符错误率(CER)。
- 在同样的数据集上,该研究中的FastConformer模型表现优于Whisper-turbo。
点此查看论文截图

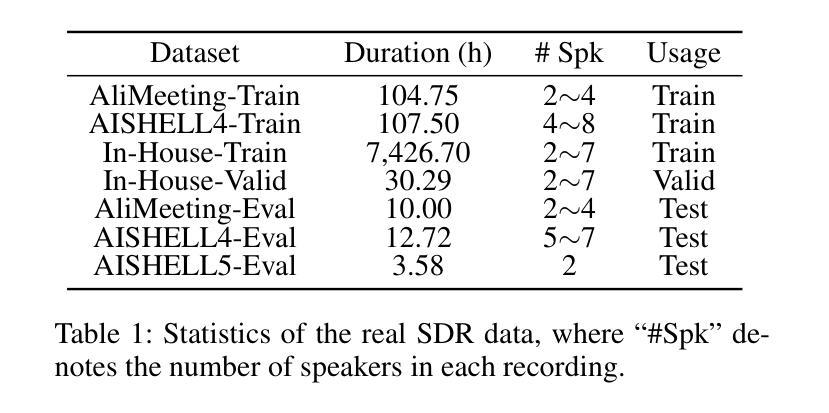
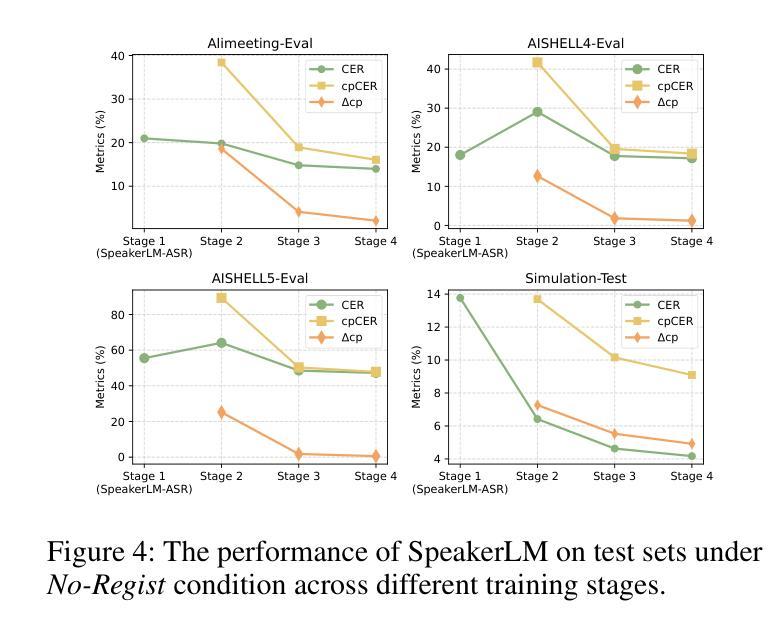
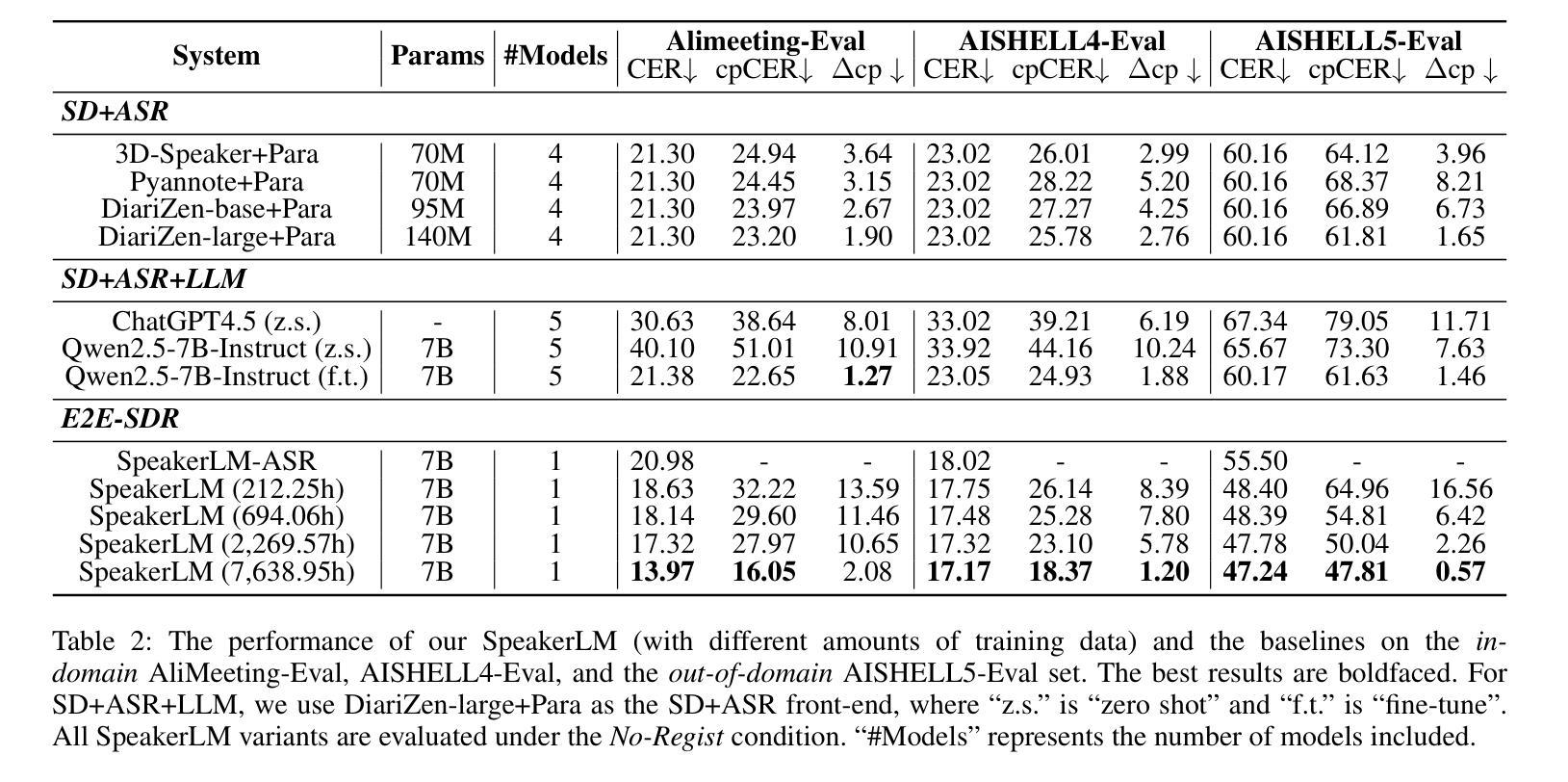
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Authors:Han Yin, Yafeng Chen, Chong Deng, Luyao Cheng, Hui Wang, Chao-Hong Tan, Qian Chen, Wen Wang, Xiangang Li
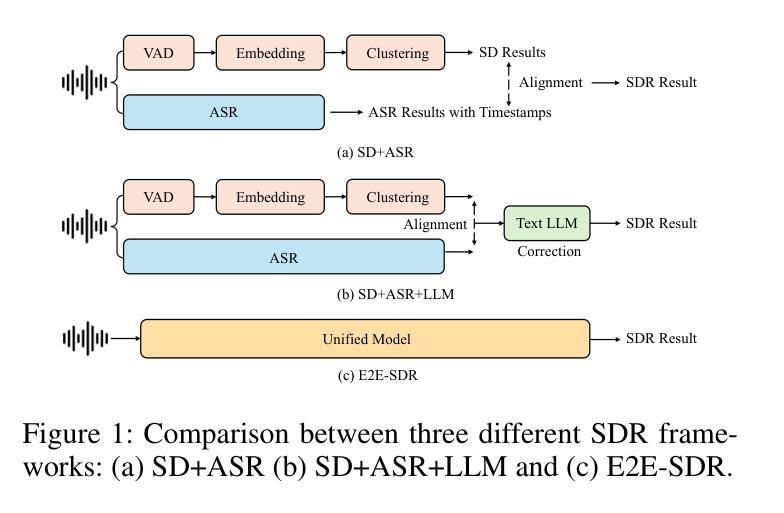
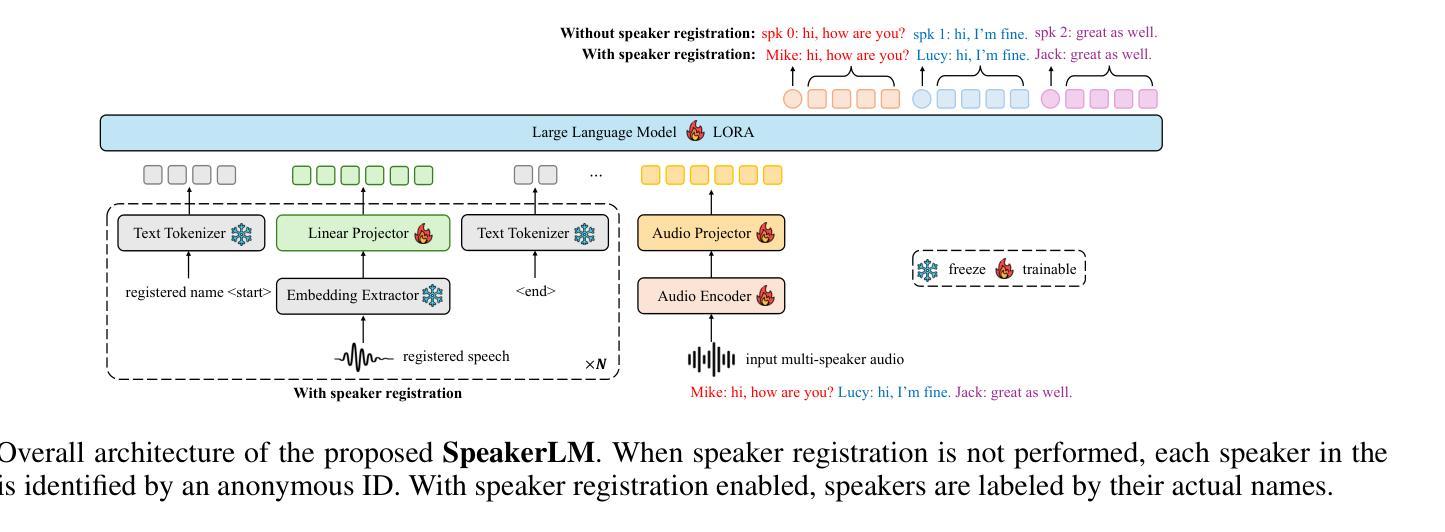
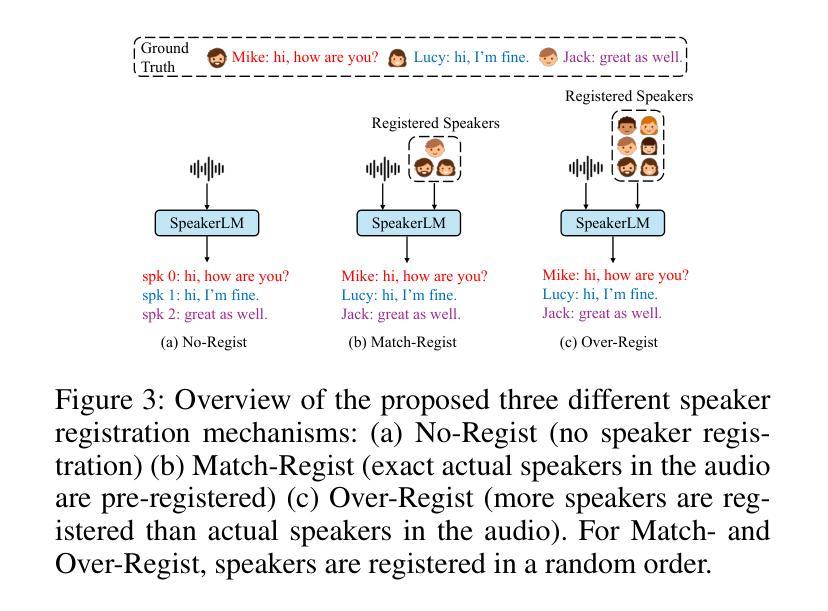
The Speaker Diarization and Recognition (SDR) task aims to predict “who spoke when and what” within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
说话人识别与建模(SDR)任务旨在预测音频剪辑中的“谁何时说了什么”,这在会议转录和对话系统等多说话人现实场景中是一个至关重要的任务。现有的SDR系统通常采用级联框架,结合说话人识别(SD)和自动语音识别(ASR)等多个模块。级联系统存在误差传播、处理重叠语音困难以及缺乏对SD和ASR任务之间协同进行联合优化等局限性。为了解决这些局限性,我们引入了SpeakerLM,一个统一的多媒体语言模型用于SDR,该模型采用端到端方式联合执行SD和ASR。此外,为了适应多样化的现实场景,我们在SpeakerLM中融入灵活的说话人注册机制,实现不同说话人注册设置下的SDR。SpeakerLM通过大规模真实数据的多阶段训练策略逐步开发。大量实验表明,SpeakerLM具有强大的数据扩展能力和泛化能力,与最新的级联基线相比,在域内和域外的公共SDR基准测试中表现均有所超越。此外,实验结果表明,所提出的说话人注册机制可有效确保在不同说话人注册条件和不同注册说话人数量的场景下,SpeakerLM的SDR性能稳健。
论文及项目相关链接
Summary:
本文介绍了针对音频流中的说话人识别和声音识别的任务——说话人追踪与识别(SDR)。现有的SDR系统大多采用级联框架,包含说话人追踪和语音识别等多个模块,但存在误差传递、处理重叠语音困难等缺点。为此,提出了一种端到端的统一多任务语言模型SpeakerLM来解决这一问题。该模型融入了灵活的说话人注册机制,以应对不同说话人注册设置下的实际场景。SpeakerLM在大规模真实数据上采用了多阶段训练策略,具有出色的数据扩展能力和泛化性能,且在公开SDR基准测试中表现出超越现有级联模型的性能。此外,实验结果证实,提出的说话人注册机制能确保在不同注册条件和不同说话人数下的稳健性能。
Key Takeaways:
- Speaker Diarization and Recognition (SDR)任务是预测音频剪辑中“谁何时说了什么”,在多说话人场景如会议转录和对话系统中至关重要。
- 现有SDR系统多采用级联框架,包含说话人追踪和语音识别等模块,存在误差传递和处理重叠语音困难等问题。
- 提出了端到端的统一多任务语言模型SpeakerLM,联合进行说话人追踪和语音识别。
- SpeakerLM融入了灵活的说话人注册机制,以适应不同说话人注册设置下的实际场景。
- SpeakerLM采用多阶段训练策略,在真实大规模数据上表现出卓越的数据扩展能力和泛化性能。
- 在公开SDR基准测试中,SpeakerLM性能超越现有级联模型。
点此查看论文截图

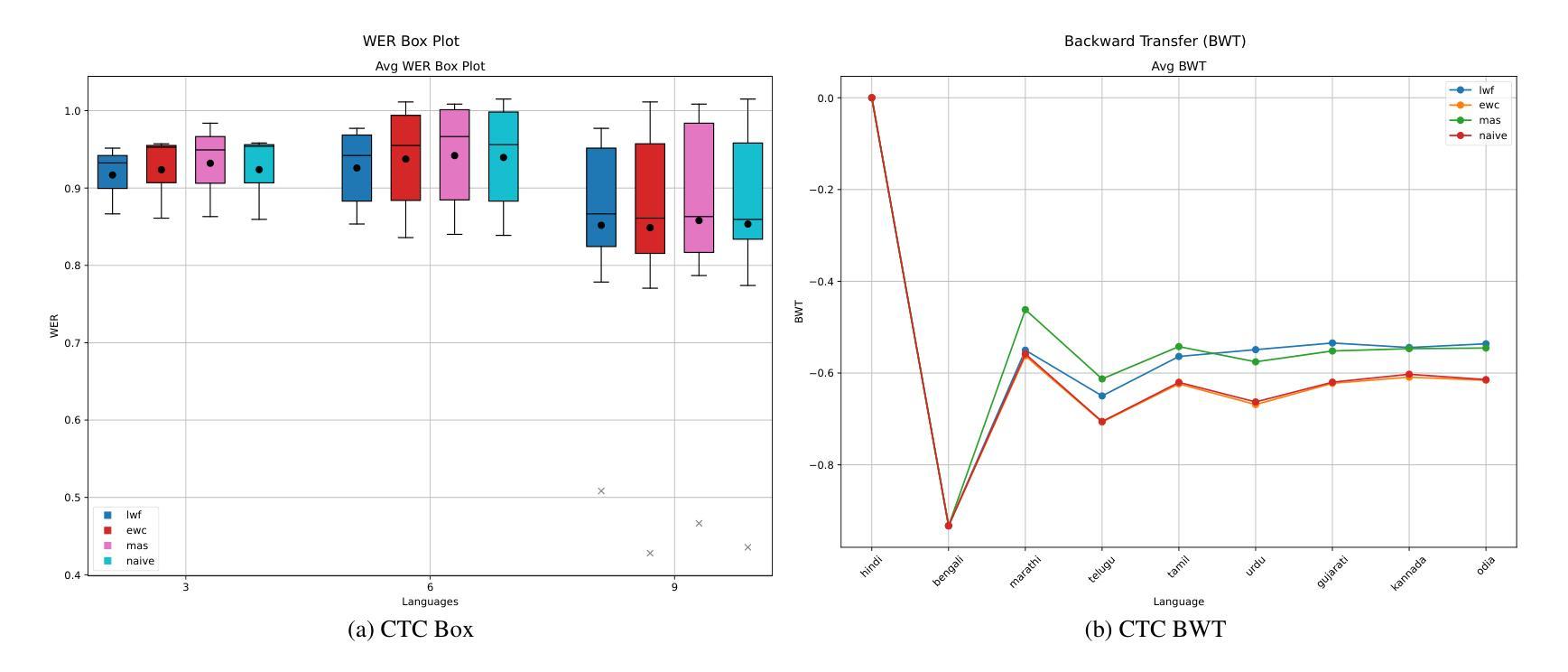
A Study on Regularization-Based Continual Learning Methods for Indic ASR
Authors:Gokul Adethya T, S. Jaya Nirmala
Indias linguistic diversity poses significant challenges for developing inclusive Automatic Speech Recognition (ASR) systems. Traditional multilingual models, which require simultaneous access to all language data, are impractical due to the sequential arrival of data and privacy constraints. Continual Learning (CL) offers a solution by enabling models to learn new languages sequentially without catastrophically forgetting previously learned knowledge. This paper investigates CL for ASR on Indian languages using a subset of the IndicSUPERB benchmark. We employ a Conformer-based hybrid RNN-T/CTC model, initially pretrained on Hindi, which is then incrementally trained on eight additional Indian languages, for a total sequence of nine languages. We evaluate three prominent regularization- and distillation-based CL strategies: Elastic Weight Consolidation (EWC), Memory Aware Synapses (MAS), and Learning without Forgetting (LwF), selected for their suitability in no-replay, privacy-conscious scenarios. Performance is analyzed using Word Error Rate (WER) for both RNN-T and CTC paths on clean and noisy data, as well as knowledge retention via Backward Transfer. We also explore the impact of varying the number of training epochs (1, 2, 5, and 10) per task. Results, compared against naive fine-tuning, demonstrate CLs effectiveness in mitigating forgetting, making it a promising approach for scalable ASR in diverse Indian languages under realistic constraints. The code is available at: https://github.com/FrozenWolf-Cyber/Indic-CL-ASR
印度的语言多样性给开发包容性自动语音识别(ASR)系统带来了重大挑战。由于数据顺序到达和隐私限制,要求同时访问所有语言数据的传统多语言模型并不实用。持续学习(CL)通过使模型能够按顺序学习新语言而不会遗忘之前学到的知识,从而提供了一种解决方案。本文使用IndicSUPERB基准的某个子集,研究CL在印地语ASR上的应用。我们采用基于Conformer的混合RNN-T/CTC模型,该模型最初在印地语上进行预训练,然后顺序地在另外八种印度语言上进行增量训练,总共涉及九种语言序列。我们评估了三种基于正则化和蒸馏的CL策略:弹性权重整合(EWC)、记忆感知突触(MAS)和学习无遗忘(LwF),它们被选中用于无回放、注重隐私的场景。性能分析采用词错误率(WER)评估RNN-T和CTC路径在干净和嘈杂数据上的表现,以及通过反向传输评估知识保留情况。我们还探讨了每个任务训练周期数(1、2、5和10)的不同影响。与简单微调相比,结果证明了CL在减轻遗忘方面的有效性,使其成为在现实约束下实现可扩展的印地语ASR的有前途的方法。代码可从以下网址获取:https://github.com/FrozenWolf-Cyber/Indic-CL-ASR
论文及项目相关链接
Summary
本文探讨了印度语言多样性对开发包容性自动语音识别(ASR)系统的挑战。由于数据序贯到达和隐私限制,传统的同时访问所有语言数据的多语言模型变得不切实际。持续学习(CL)为解决这一问题提供了解决方案,使模型能够顺序学习新语言,而不会遗忘之前的知识。本文研究了基于CL的ASR在印度语言上的应用,采用Conformer混合RNN-T/CTC模型,初始以印地语进行预训练,然后陆续在八种印度语言上进行训练,共涉及九种语言序列。本文评估了三种基于正则化和蒸馏的CL策略:弹性权重整合(EWC)、记忆感知突触(MAS)和学习不会遗忘(LwF),这些策略适用于无回放和隐私意识场景。通过词错误率(WER)评估RNN-T和CTC路径在干净和嘈杂数据上的性能,以及通过向后转移评估知识保留情况。此外,还探讨了每个任务训练周期数(1、2、5和10)的影响。与简单的微调相比,结果证明了CL在缓解遗忘方面的有效性,使其成为在现实约束下可扩展的印度多语言ASR的有前途的方法。
Key Takeaways
- 印度语言多样性对开发包容性自动语音识别(ASR)系统构成挑战。
- 传统多语言模型因数据序贯到达和隐私限制而变得不切实际。
- 持续学习(CL)能使模型顺序学习新语言而不遗忘之前的知识。
- 研究了CL在ASR上的应用在IndicSUPERB基准测试上的表现。
- 采用Conformer混合RNN-T/CTC模型,并陆续在多种印度语言上进行训练。
- 评估了三种基于正则化和蒸馏的CL策略:EWC、MAS和LwF。
点此查看论文截图

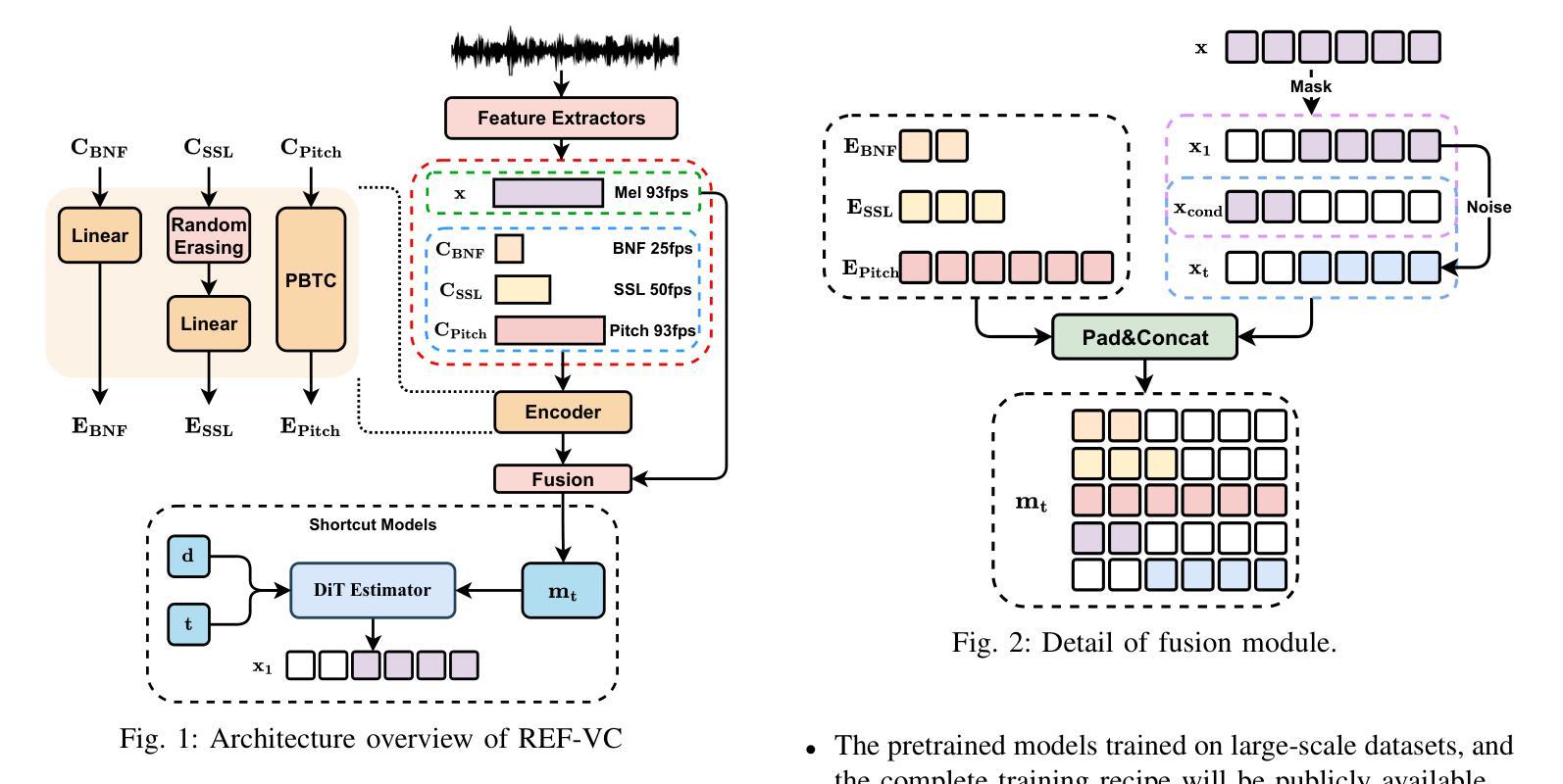
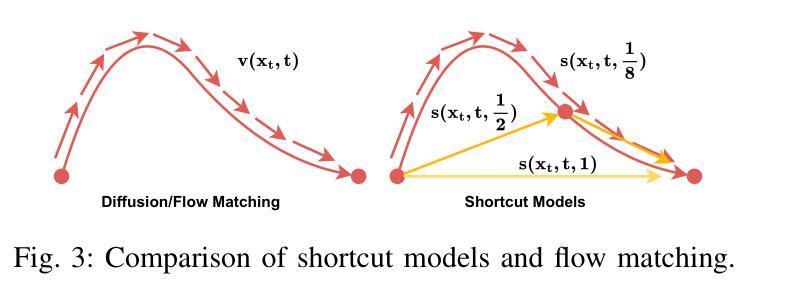
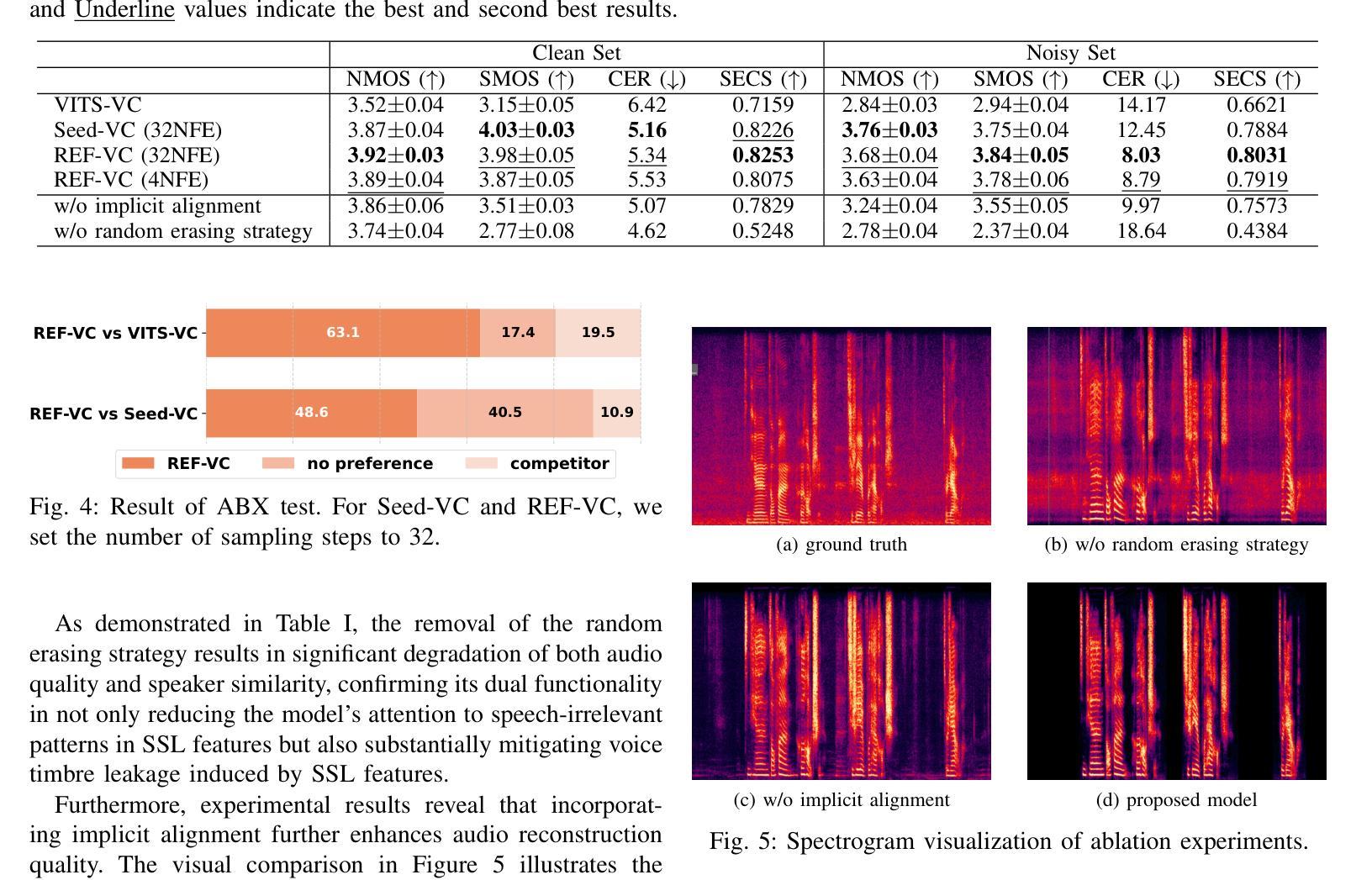
REF-VC: Robust, Expressive and Fast Zero-Shot Voice Conversion with Diffusion Transformers
Authors:Yuepeng Jiang, Ziqian Ning, Shuai Wang, Chengjia Wang, Mengxiao Bi, Pengcheng Zhu, Zhonghua Fu, Lei Xie
In real-world voice conversion applications, environmental noise in source speech and user demands for expressive output pose critical challenges. Traditional ASR-based methods ensure noise robustness but suppress prosody richness, while SSL-based models improve expressiveness but suffer from timbre leakage and noise sensitivity. This paper proposes REF-VC, a noise-robust expressive voice conversion system. Key innovations include: (1) A random erasing strategy to mitigate the information redundancy inherent in SSL features, enhancing noise robustness and expressiveness; (2) Implicit alignment inspired by E2TTS to suppress non-essential feature reconstruction; (3) Integration of Shortcut Models to accelerate flow matching inference, significantly reducing to 4 steps. Experimental results demonstrate that REF-VC outperforms baselines such as Seed-VC in zero-shot scenarios on the noisy set, while also performing comparably to Seed-VC on the clean set. In addition, REF-VC can be compatible with singing voice conversion within one model.
在真实世界的声音转换应用中,源语音中的环境噪声和用户对于表达输出的需求构成了重大挑战。传统的基于自动语音识别(ASR)的方法确保了噪声鲁棒性,但抑制了韵律的丰富性,而基于自监督学习(SSL)的模型提高了表达性,但存在音色泄露和噪声敏感的问题。本文提出了REF-VC,一种噪声鲁棒性强的表达性语音转换系统。主要创新点包括:(1)采用随机擦除策略,减轻SSL特征中的信息冗余,增强噪声鲁棒性和表达性;(2)受E2TTS启发的隐式对齐,抑制非关键特征重建;(3)集成快捷模型,加速流匹配推理,大幅减少至4步。实验结果表明,REF-VC在噪声集上的零样本场景中优于基线方法(如Seed-VC),同时在清洁集上的表现与Seed-VC相当。此外,REF-VC可以在一个模型内兼容歌声转换。
论文及项目相关链接
摘要
本文提出一种稳健且表现力强的语音转换系统REF-VC,解决了真实世界语音转换应用中源语音中的环境噪声和用户对于表现力的需求所带来的挑战。主要创新点包括:采用随机擦除策略减轻SSL特征中的信息冗余,增强噪声鲁棒性和表现力;借鉴E2TTS的隐对齐方式抑制非关键特征重建;集成Shortcut Models加速流匹配推理,减少至4步。实验结果表明,REF-VC在噪声集上的零样本场景表现优于基线方法Seed-VC,同时在清洁集上表现相当。此外,REF-VC可在单一模型内兼容歌声转换。
关键见解
- REF-VC解决了真实世界语音转换中的噪声和表现力需求挑战。
- 采用随机擦除策略减轻SSL特征中的信息冗余。
- 隐对齐方式抑制非关键特征重建。
- 集成Shortcut Models加速流匹配推理。
- REF-VC在噪声集上的零样本场景表现优于Seed-VC。
- REF-VC在清洁集上表现与Seed-VC相当。
- REF-VC可在单一模型内实现歌声转换兼容性。
点此查看论文截图

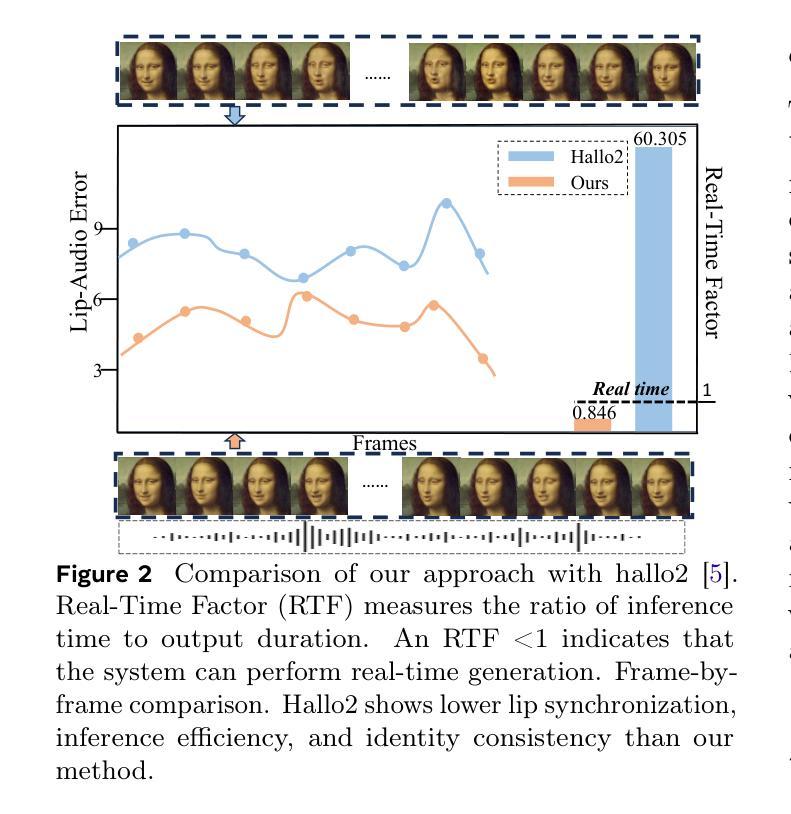
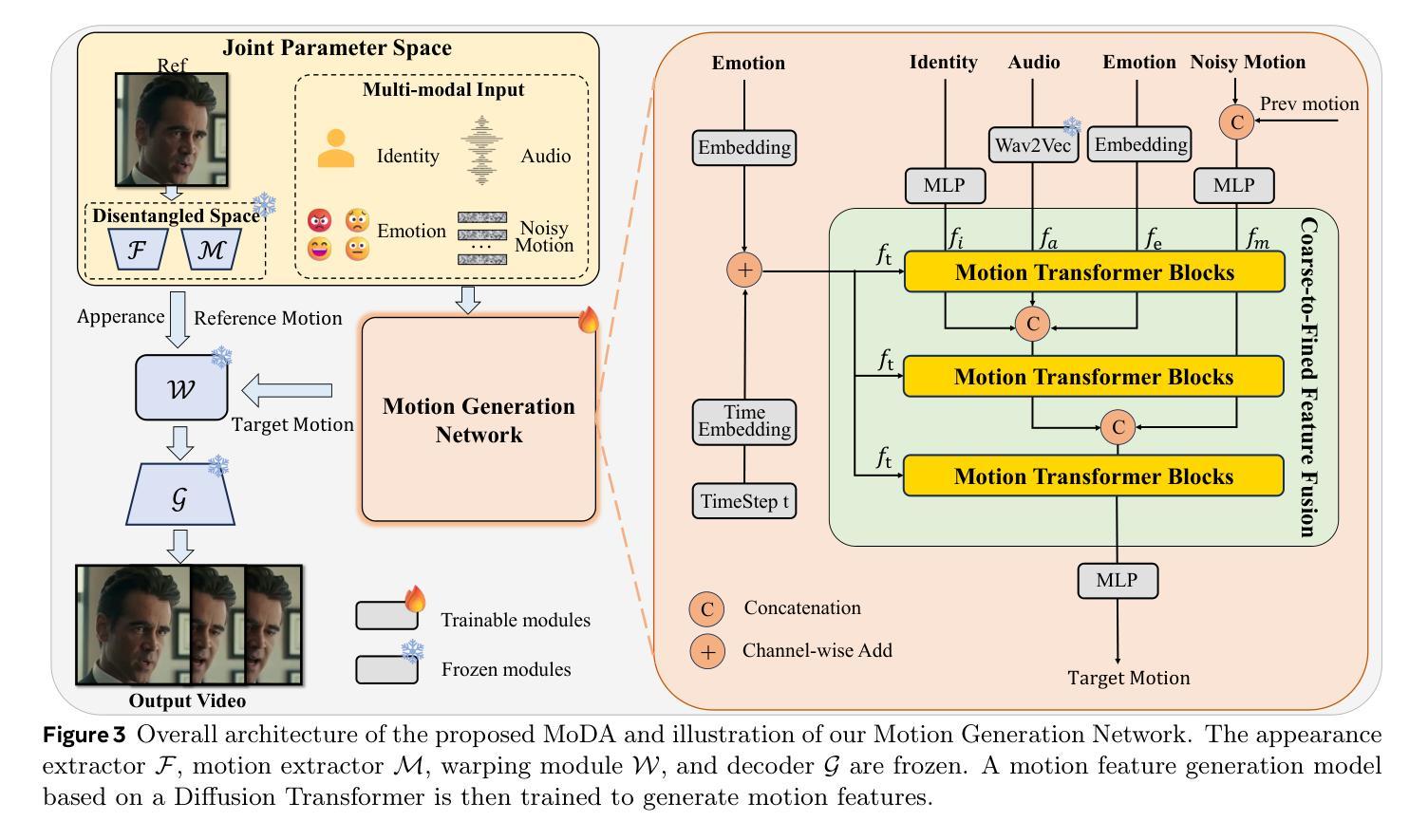
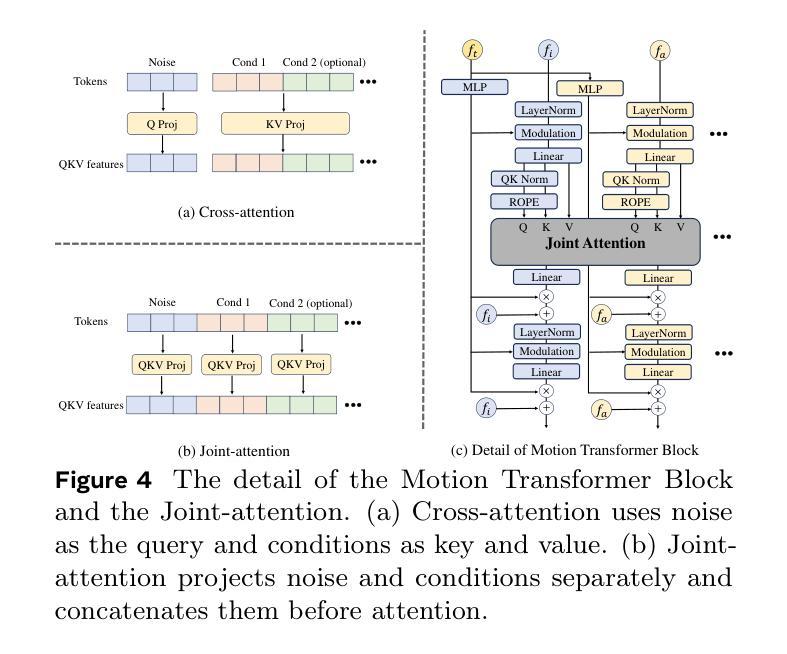
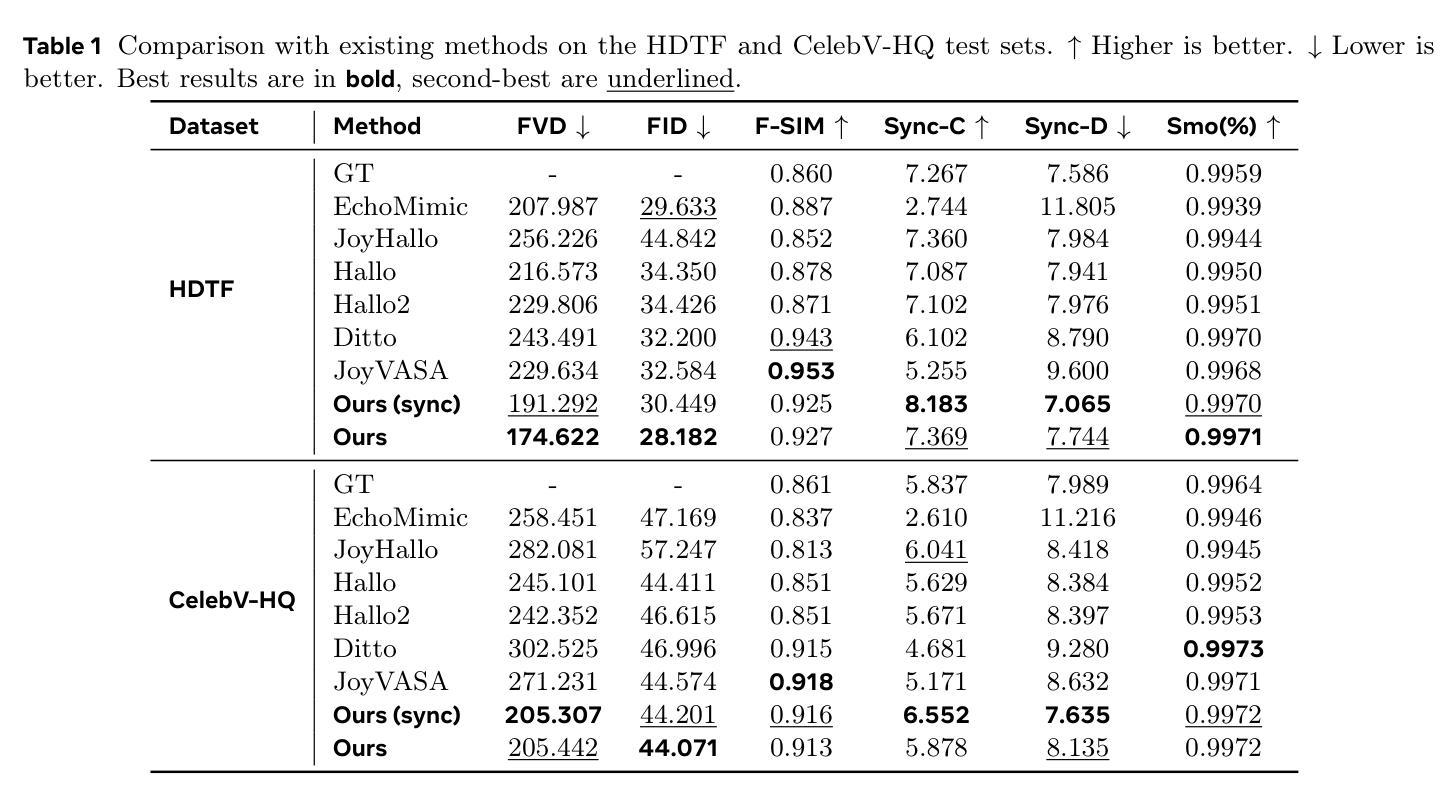
MoDA: Multi-modal Diffusion Architecture for Talking Head Generation
Authors:Xinyang Li, Gen Li, Zhihui Lin, Yichen Qian, GongXin Yao, Weinan Jia, Aowen Wang, Weihua Chen, Fan Wang
Talking head generation with arbitrary identities and speech audio remains a crucial problem in the realm of the virtual metaverse. Recently, diffusion models have become a popular generative technique in this field with their strong generation capabilities. However, several challenges remain for diffusion-based methods: 1) inefficient inference and visual artifacts caused by the implicit latent space of Variational Auto-Encoders (VAE), which complicates the diffusion process; 2) a lack of authentic facial expressions and head movements due to inadequate multi-modal information fusion. In this paper, MoDA handles these challenges by: 1) defining a joint parameter space that bridges motion generation and neural rendering, and leveraging flow matching to simplify diffusion learning; 2) introducing a multi-modal diffusion architecture to model the interaction among noisy motion, audio, and auxiliary conditions, enhancing overall facial expressiveness. In addition, a coarse-to-fine fusion strategy is employed to progressively integrate different modalities, ensuring effective feature fusion. Experimental results demonstrate that MoDA improves video diversity, realism, and efficiency, making it suitable for real-world applications. Project Page: https://lixinyyang.github.io/MoDA.github.io/
在虚拟元宇宙领域,使用任意身份和语音音频生成头部对话仍然是一个关键问题。最近,扩散模型凭借其强大的生成能力,已成为该领域的一种流行的生成技术。然而,基于扩散的方法仍存在几个挑战:1)由于变分自动编码器(VAE)的隐式潜在空间导致的效率低下和视觉伪影,这复杂化了扩散过程;2)由于缺乏多模态信息融合导致面部表达和头部动作不真实。本文中,MoDA通过以下方法应对这些挑战:1)定义了一个联合参数空间,该空间连接运动生成和神经渲染,并利用流匹配简化扩散学习;2)引入多模态扩散架构来模拟噪声运动、音频和辅助条件之间的交互作用,提高面部的整体表现力。此外,采用由粗到细的融合策略来逐步融合不同的模式,确保有效的特征融合。实验结果表明,MoDA提高了视频的多样性、真实性和效率,使其成为适合实际应用的有力工具。项目页面:https://lixinyyang.github.io/MoDA.github.io/。
论文及项目相关链接
PDF 12 pages, 7 figures
摘要
基于扩散模型的虚拟世界中任意身份与语音对话生成仍面临挑战,包括推理效率低、视觉伪影和面部表情缺失等问题。MoDA通过构建联合参数空间简化扩散学习,引入多模态扩散架构提升面部表现力,并采用由粗到细的融合策略确保特征的有效融合。实验证明MoDA提高了视频多样性、真实感和效率,适用于真实场景应用。
关键见解
- 虚拟世界中的对话头生成问题仍然重要,特别是与任意身份和语音音频的结合。
- 扩散模型在该领域因其强大的生成能力而受到欢迎,但存在推理效率低下和视觉伪影等问题。
- MoDA通过定义联合参数空间,简化了运动生成和神经渲染之间的联系。
- MoDA引入了多模态扩散架构,对噪声运动、音频和辅助条件之间的交互进行建模,增强了面部的表现力。
- MoDA采用了由粗到细的融合策略,确保不同模态特征的有效融合。
- 实验证明MoDA提高了视频多样性、真实感和效率。
点此查看论文截图