⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-12 更新
MoDA: Multi-modal Diffusion Architecture for Talking Head Generation
Authors:Xinyang Li, Gen Li, Zhihui Lin, Yichen Qian, GongXin Yao, Weinan Jia, Aowen Wang, Weihua Chen, Fan Wang
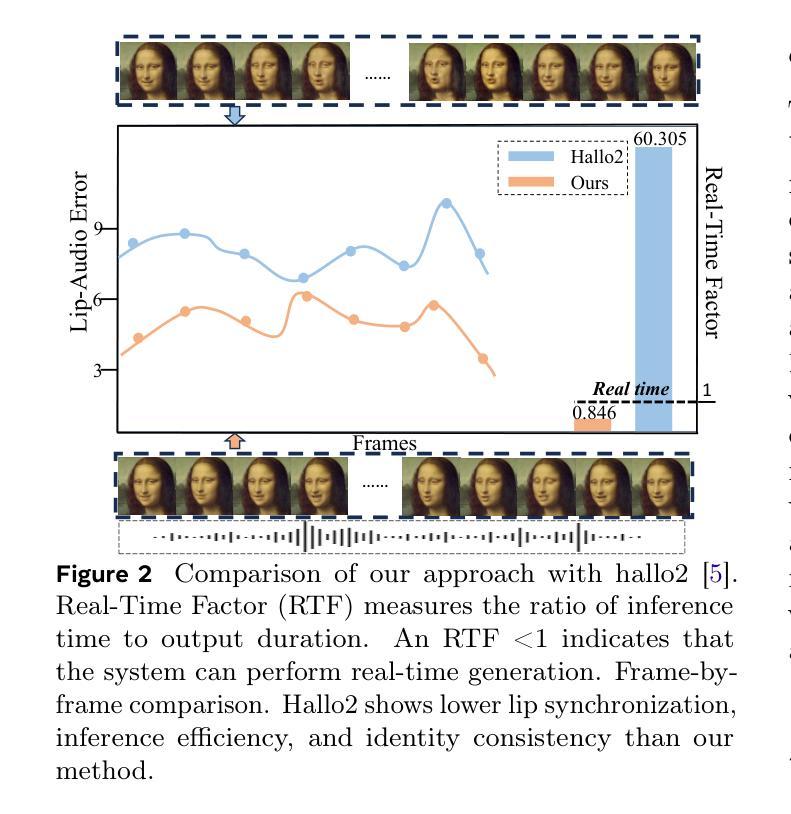
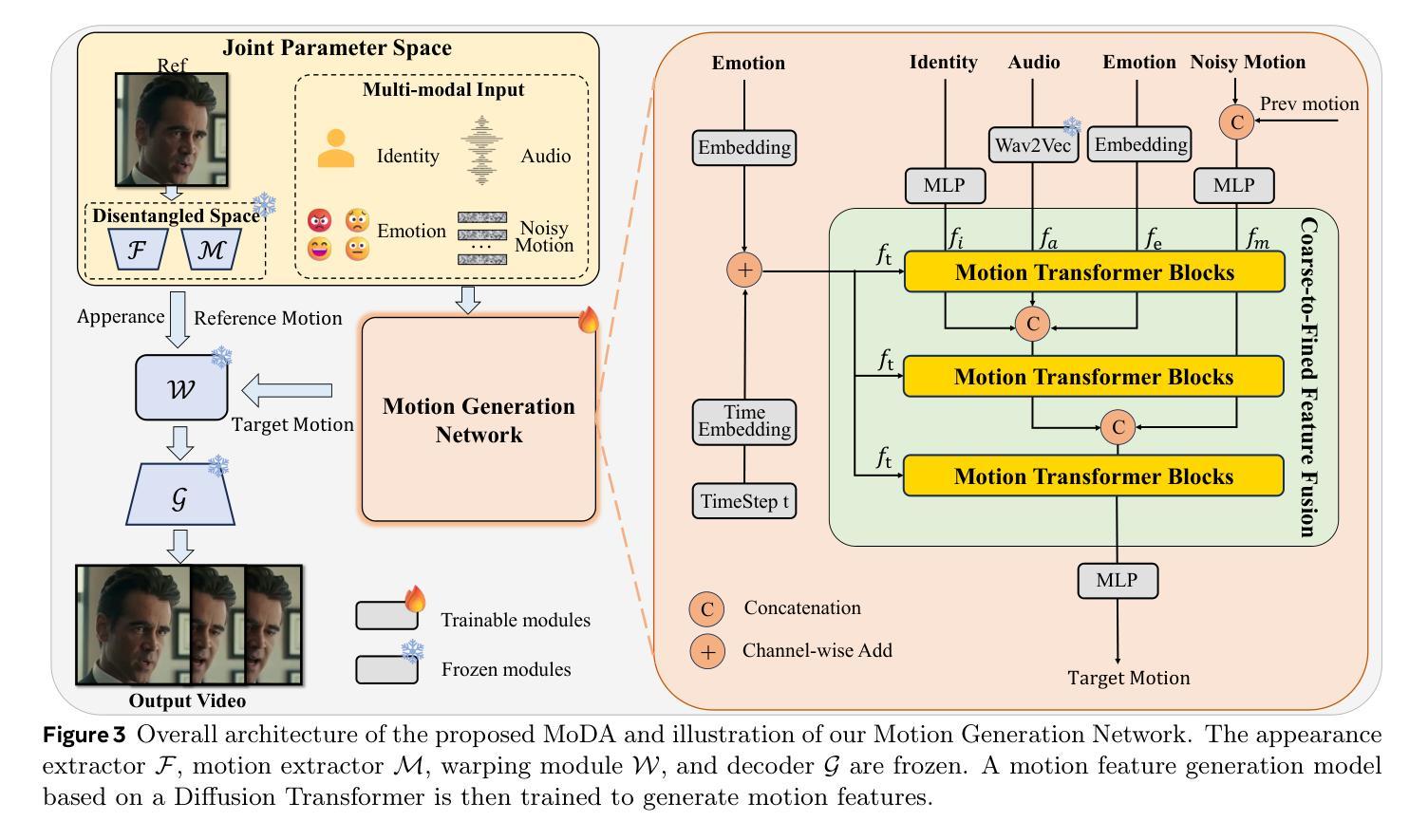
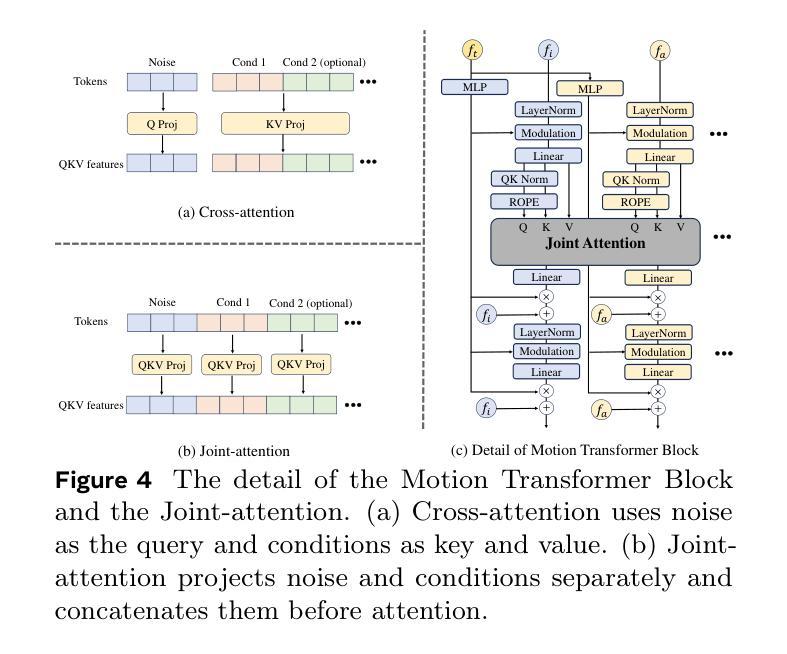
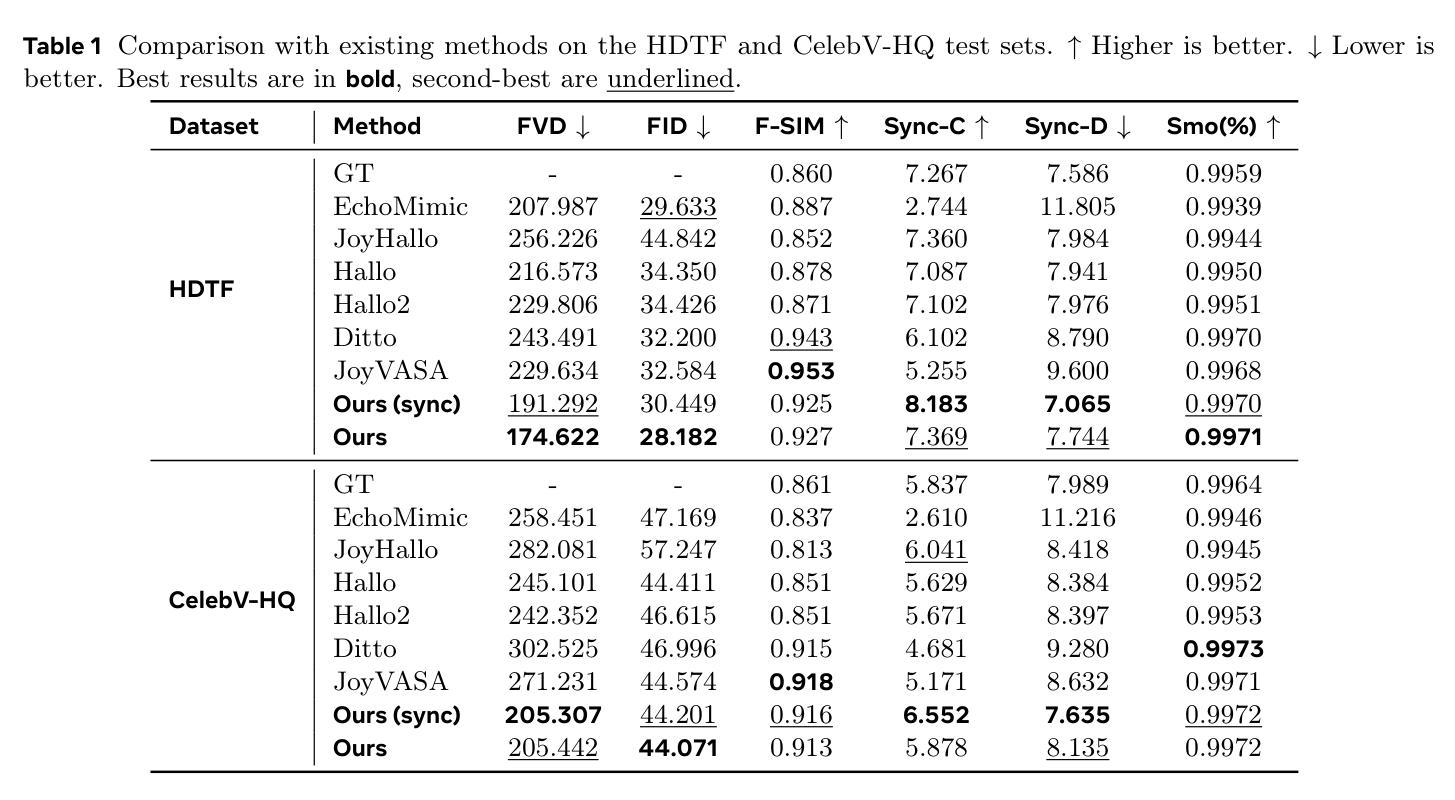
Talking head generation with arbitrary identities and speech audio remains a crucial problem in the realm of the virtual metaverse. Recently, diffusion models have become a popular generative technique in this field with their strong generation capabilities. However, several challenges remain for diffusion-based methods: 1) inefficient inference and visual artifacts caused by the implicit latent space of Variational Auto-Encoders (VAE), which complicates the diffusion process; 2) a lack of authentic facial expressions and head movements due to inadequate multi-modal information fusion. In this paper, MoDA handles these challenges by: 1) defining a joint parameter space that bridges motion generation and neural rendering, and leveraging flow matching to simplify diffusion learning; 2) introducing a multi-modal diffusion architecture to model the interaction among noisy motion, audio, and auxiliary conditions, enhancing overall facial expressiveness. In addition, a coarse-to-fine fusion strategy is employed to progressively integrate different modalities, ensuring effective feature fusion. Experimental results demonstrate that MoDA improves video diversity, realism, and efficiency, making it suitable for real-world applications. Project Page: https://lixinyyang.github.io/MoDA.github.io/
虚拟元宇宙领域中的虚拟人物头部生成与带有任意身份和语音音频的头部生成仍然是一个关键问题。近期,扩散模型凭借其强大的生成能力,已成为该领域的热门生成技术。然而,基于扩散的方法仍存在几个挑战:1)由于变分自编码器(VAE)的隐式潜在空间造成的推理效率低下和视觉伪影,这复杂化了扩散过程;2)由于缺乏多模态信息融合,导致面部表情和头部动作不真实。本文中,MoDA通过以下方法解决了这些挑战:1)定义了一个联合参数空间,该空间桥接了运动生成和神经渲染,并利用流匹配简化了扩散学习;2)引入了多模态扩散架构,以模拟噪声运动、音频和辅助条件之间的交互作用,提高了面部的整体表现力。此外,还采用了由粗到细的融合策略,以逐步融合不同的模态,确保有效的特征融合。实验结果表明,MoDA提高了视频的多样性、真实性和效率,适合用于实际应用。项目页面:https://lixinyyang.github.io/MoDA.github.io/。
论文及项目相关链接
PDF 12 pages, 7 figures
Summary
基于扩散模型的说话人头部生成技术,解决了虚拟元宇宙中的关键难题。面临挑战包括推理效率低下和视觉伪影等。MoDA通过定义联合参数空间和引入多模态扩散架构应对挑战,提高视频多样性和现实感。
Key Takeaways
- 说话人头部生成是虚拟元宇宙的重要问题。
- 扩散模型在此领域成为流行的生成技术,但仍面临挑战。
- MoDA通过定义联合参数空间,简化扩散学习过程。
- MoDA引入多模态扩散架构,建模噪声运动、音频和辅助条件间的交互。
- 粗到细的融合策略确保有效特征融合。
- MoDA提高了视频多样性、现实感和效率,适用于真实应用。
点此查看论文截图