⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-12 更新
MOR-VIT: Efficient Vision Transformer with Mixture-of-Recursions
Authors:YiZhou Li
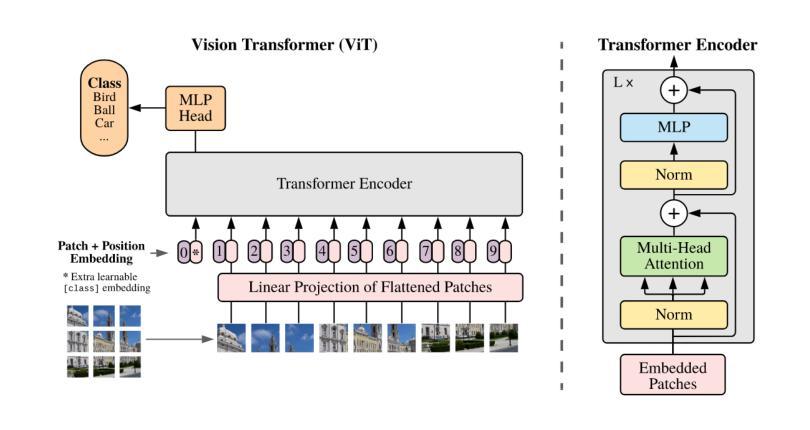
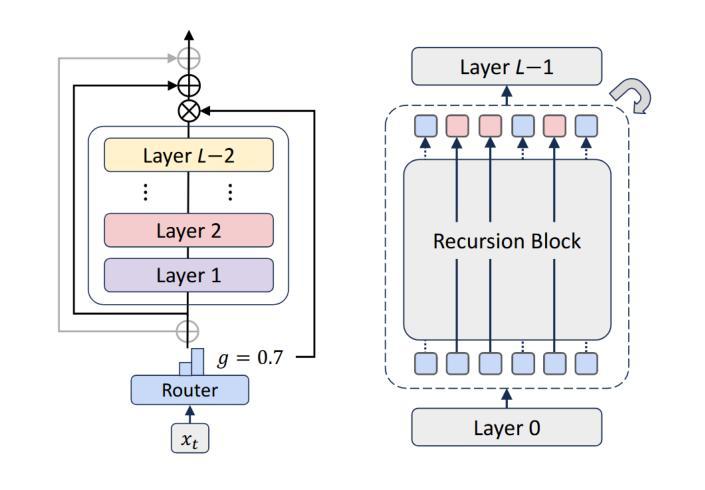
Vision Transformers (ViTs) have achieved remarkable success in image recognition, yet standard ViT architectures are hampered by substantial parameter redundancy and high computational cost, limiting their practical deployment. While recent efforts on efficient ViTs primarily focus on static model compression or token-level sparsification, they remain constrained by fixed computational depth for all tokens. In this work, we present MoR-ViT, a novel vision transformer framework that, for the first time, incorporates a token-level dynamic recursion mechanism inspired by the Mixture-of-Recursions (MoR) paradigm. This approach enables each token to adaptively determine its processing depth, yielding a flexible and input-dependent allocation of computational resources. Extensive experiments on ImageNet-1K and transfer benchmarks demonstrate that MoR-ViT not only achieves state-of-the-art accuracy with up to 70% parameter reduction and 2.5x inference acceleration, but also outperforms leading efficient ViT baselines such as DynamicViT and TinyViT under comparable conditions. These results establish dynamic recursion as an effective strategy for efficient vision transformers and open new avenues for scalable and deployable deep learning models in real-world scenarios.
视觉Transformer(ViT)在图像识别方面取得了显著的成功,但标准的ViT架构存在大量的参数冗余和较高的计算成本,限制了其实际应用部署。尽管最近在高效ViT方面的努力主要集中在静态模型压缩或token级别的稀疏化上,但它们仍然受到所有token固定计算深度的限制。在这项工作中,我们提出了MoR-ViT,这是一个新的视觉transformer框架,它首次结合了受递归混合(MoR)范式启发的token级别动态递归机制。这种方法允许每个token自适应地确定其处理深度,从而实现计算资源的灵活和输入依赖分配。在ImageNet-1K和迁移基准测试的大量实验表明,MoR-ViT不仅实现了最先进的准确性,同时减少了高达70%的参数和2.5倍的推理加速,而且在相同条件下优于领先的高效ViT基准测试,如DynamicViT和TinyViT。这些结果证明了动态递归是高效视觉transformer的有效策略,并为现实世界场景中可伸缩和可部署的深度学习模型打开了新途径。
论文及项目相关链接
PDF 20 pages,9 figuers
Summary
本文提出了MoR-ViT,一种新型视觉转换器框架,首次采用基于混合递归(MoR)范式的令牌级动态递归机制。该方法使每个令牌能够自适应地确定其处理深度,实现了计算资源的灵活和输入依赖分配。在ImageNet-1K和传输基准测试上的实验表明,MoR-ViT不仅实现了最先进的准确性,同时在参数减少70%和推理加速2.5倍的情况下,还在比较条件下超越了领先的EfficientViT和TinyViT。这证明了动态递归是有效的策略,为实际场景中可伸缩和可部署的深度学习模型打开了新的途径。
Key Takeaways
- MoR-ViT是一种新型的视觉转换器框架,结合了混合递归(MoR)范式的动态递归机制。
- 该方法使每个令牌能够自适应地确定其处理深度,实现了计算资源的灵活分配。
- MoR-ViT实现了参数减少70%和推理加速2.5倍的效果。
- MoR-ViT在ImageNet-1K和传输基准测试上实现了最先进的准确性。
- MoR-ViT相比其他领先的EfficientViT和TinyViT模型具有更好的性能。
- 动态递归策略被证明是有效的,为实际场景中可伸缩和可部署的深度学习模型提供了新的途径。
点此查看论文截图