⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-13 更新
MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction
Authors:Zijian Dong, Longteng Duan, Jie Song, Michael J. Black, Andreas Geiger
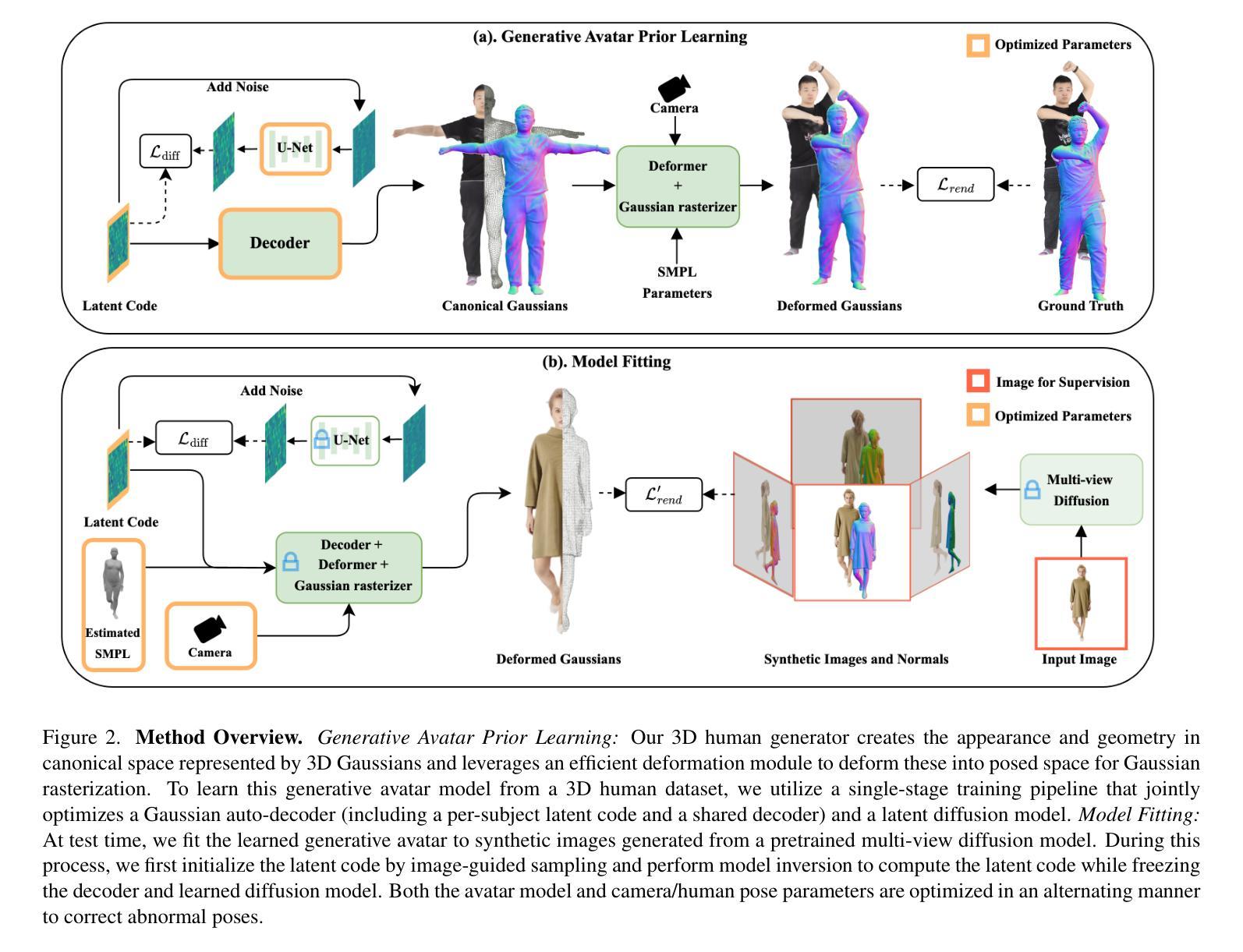
We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to limited 3D training data, such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as model inversion by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides an initialization for model fitting, enforces 3D regularization, and helps in refining pose. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable. For code, see https://zj-dong.github.io/MoGA/.
我们提出了一种新型方法MoGA,能够从单视角图像重建高保真3D高斯化身。主要挑战在于推断出未观察到的外观和几何细节,同时确保3D一致性和逼真性。大多数之前的方法依赖于2D扩散模型来合成未观察到的视图,但这些生成的视图稀疏且不一致,导致3D伪影和模糊的外观。为了解决这些局限性,我们利用生成化身模型,通过从学习的先验分布中采样变形的高斯函数来生成多样的3D化身。由于有限的3D训练数据,仅使用这样的3D模型无法捕获未观察到的身份的所有图像细节。因此,我们将其整合为优先选项,通过将输入图像投影到其潜在空间并施加额外的3D外观和几何约束来确保3D一致性。我们的新颖方法将高斯化身创建公式化为模型反演,通过将生成化身拟合到来自2D扩散模型的合成视图。生成化身提供了模型拟合的初始化,强制执行3D正则化,并有助于优化姿势。实验表明,我们的方法超越了最先进技术,并能很好地推广到现实世界场景。我们的高斯化身本质上是可动画的。有关代码,请参阅https://zj-dong.github.io/MoGA/。
论文及项目相关链接
PDF ICCV 2025 (Highlight), Project Page: https://zj-dong.github.io/MoGA/
Summary
本文介绍了MoGA方法,这是一种从单视角图像重建高保真3D高斯虚拟形象的新技术。该方法主要挑战在于推断出未见的外观和几何细节,同时确保3D的一致性和真实性。为解决现有方法的不足,研究团队结合了生成式虚拟形象模型和采样变形高斯技术,并通过将输入图像投影到潜在空间并加强额外的三维外观和几何约束来确保三维一致性。实验表明,该方法超越了现有技术并在真实场景中具有良好泛化能力。生成的虚拟形象具有内在的可动画性。
Key Takeaways
- MoGA方法能够从单视角图像重建高保真3D高斯虚拟形象。
- 该方法主要挑战在于推断未见的外观和几何细节,并确保三维一致性和真实性。
- 结合生成式虚拟形象模型和采样变形高斯技术解决现有方法的不足。
- 通过将输入图像投影到潜在空间并加强额外的三维外观和几何约束来确保三维一致性。
- MoGA方法超越了现有技术,具有良好的泛化能力。
- 生成的虚拟形象具有内在的可动画性。
点此查看论文截图