⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-13 更新
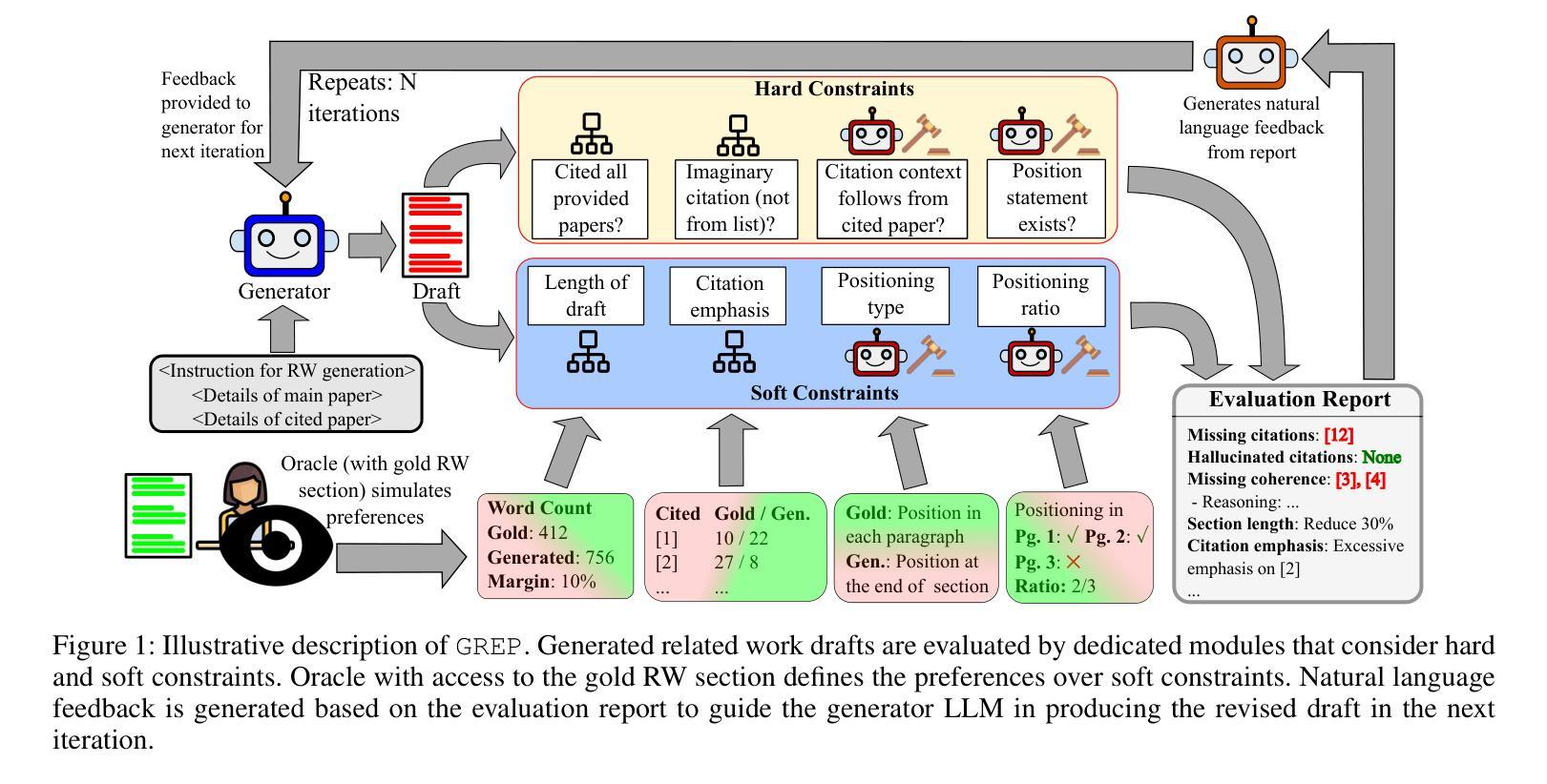
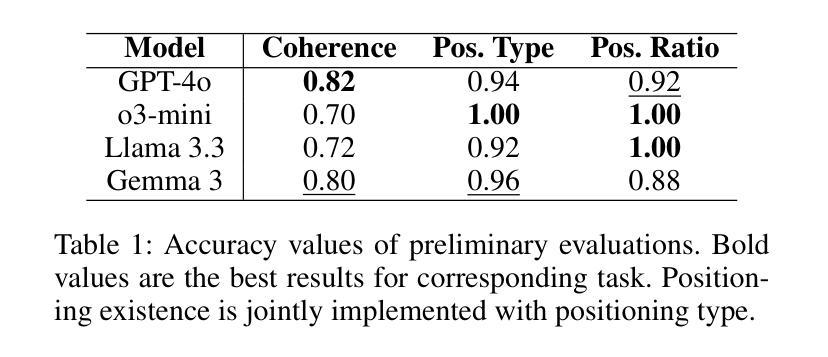
Expert Preference-based Evaluation of Automated Related Work Generation
Authors:Furkan Şahinuç, Subhabrata Dutta, Iryna Gurevych
Expert domain writing, such as scientific writing, typically demands extensive domain knowledge. Recent advances in LLMs show promising potential in reducing the expert workload. However, evaluating the quality of automatically generated scientific writing is a crucial open issue, as it requires knowledge of domain-specific evaluation criteria and the ability to discern expert preferences. Conventional automatic metrics and LLM-as-a-judge systems are insufficient to grasp expert preferences and domain-specific quality standards. To address this gap and support human-AI collaborative writing, we focus on related work generation, one of the most challenging scientific tasks, as an exemplar. We propose GREP, a multi-turn evaluation framework that integrates classical related work evaluation criteria with expert-specific preferences. Instead of assigning a single score, our framework decomposes the evaluation into fine-grained dimensions. This localized evaluation approach is further augmented with contrastive few-shot examples to provide detailed contextual guidance for the evaluation dimensions. The design principles allow our framework to deliver cardinal assessment of quality, which can facilitate better post-training compared to ordinal preference data. For better accessibility, we design two variants of GREP: a more precise variant with proprietary LLMs as evaluators, and a cheaper alternative with open-weight LLMs. Empirical investigation reveals that our framework is able to assess the quality of related work sections in a much more robust manner compared to standard LLM judges, reflects natural scenarios of scientific writing, and bears a strong correlation with the human expert assessment. We also observe that generations from state-of-the-art LLMs struggle to satisfy validation constraints of a suitable related work section. They (mostly) fail to improve based on feedback as well.
专业领域写作,如科学写作,通常需要广泛的专业知识。最近的大型语言模型(LLM)的进步显示出了减少专家工作量的潜力。然而,评估自动生成的科学写作的质量是一个关键的开放性问题,因为它需要了解特定领域的评估标准和辨别专家偏好的能力。传统的自动指标和LLM作为法官的系统不足以把握专家偏好和特定领域的质量标准。为了弥补这一差距并支持人类-人工智能协作写作,我们以相关工作生成这一最具挑战性的科学任务为例。我们提出了GREP,这是一个多轮评估框架,它将经典的相关工作评价标准与专家特定偏好相结合。我们的框架不是分配单一分数,而是将评估分解为精细的维度。这种局部评估方法与对比的少量示例相结合,为评估维度提供了详细的上下文指导。我们的设计原则使我们的框架能够提供质量的基数评估,这有助于更好地进行训练后的比较。为了更方便使用,我们设计了GREP的两个变体:一个更精确的版本使用专属LLM作为评估器,一个更便宜的版本使用开源LLM。经验研究表明,我们的框架能够以更为稳健的方式评估相关工作部分的质量,相比于标准LLM法官,它反映了科学写作的自然场景,并与人类专家评估具有很强的相关性。我们还观察到,来自最新LLM的生成在满足相关工作部分的验证约束方面表现挣扎。他们大多数未能根据反馈进行改进。
论文及项目相关链接
PDF Project page: https://ukplab.github.io/arxiv2025-expert-eval-rw/
Summary
该文本介绍了自然语言处理领域中的一个研究问题,即在科学写作中自动评价的质量问题。为解决该问题,提出了一种名为GREP的多轮评价框架,用于精细评估科学写作的质量。该框架结合了经典的相关工作评价标准与专家特定的偏好,通过局部化的评价方式辅以对比的少量示例来提供详细的上下文指导。此外,为了实际应用,设计了两种GREP变体,一种使用专有大型语言模型作为评估者,另一种则使用开源的大型语言模型作为更经济的选择。经验调查表明,GREP框架能够更稳健地评估相关工作部分的质量,与人类专家评估有较强的相关性。但现有先进技术的大型语言模型在生成满足相关工作部分验证约束的内容方面存在困难,且难以根据反馈进行改进。
Key Takeaways
- LLMs在科学写作中有降低专家工作量的潜力,但自动生成的写作质量评价是一个开放性问题。
- 传统自动指标和LLM作为评委的系统无法把握专家偏好和领域特定质量标准。
- GREP框架被提出以解决此问题,它结合经典的相关工作评价标准与专家特定偏好,进行精细化的评价。
- GREP框架通过局部化的评价和对比的少量示例提供详细的上下文指导。
- GREP有两种变体,一种使用专有LLMs,另一种使用开源LLMs。
- 经验调查表明GREP框架能够更稳健地评估相关工作部分的质量,与人类专家评估有强相关性。
点此查看论文截图

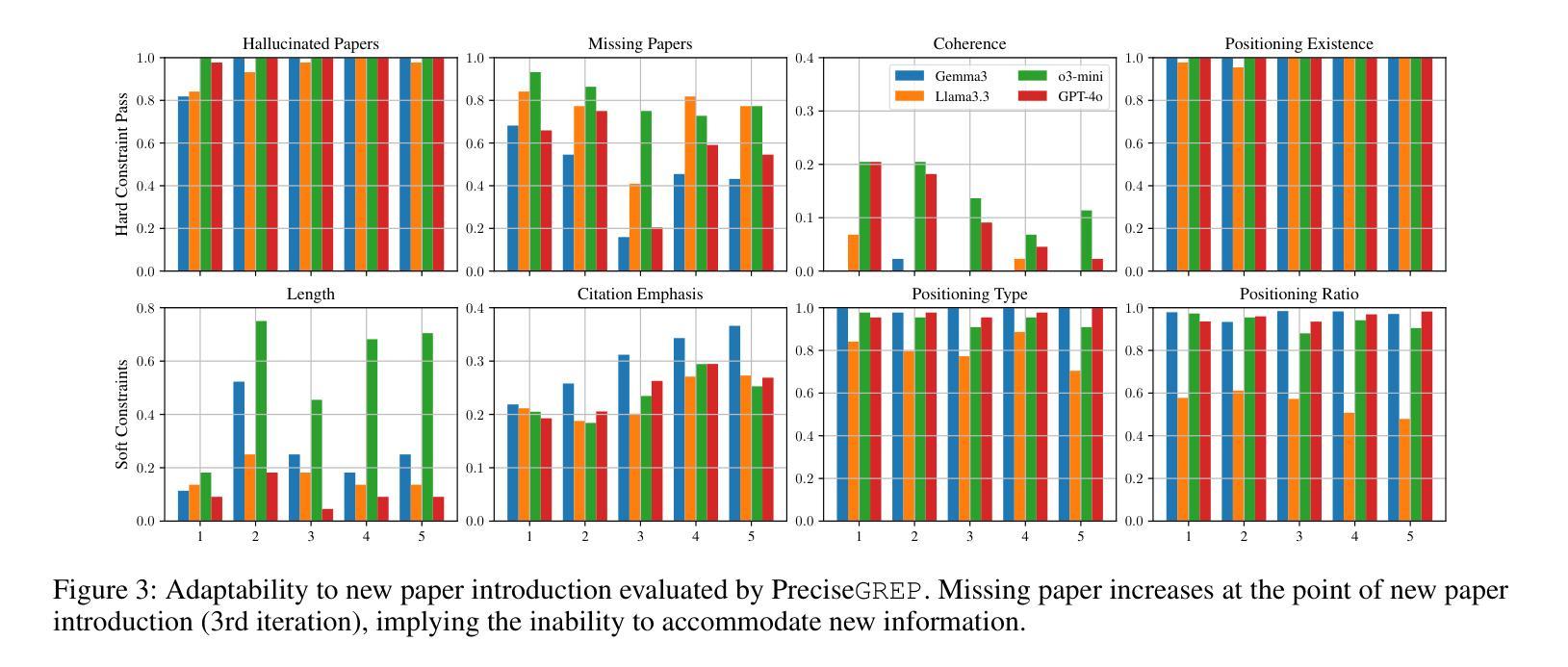
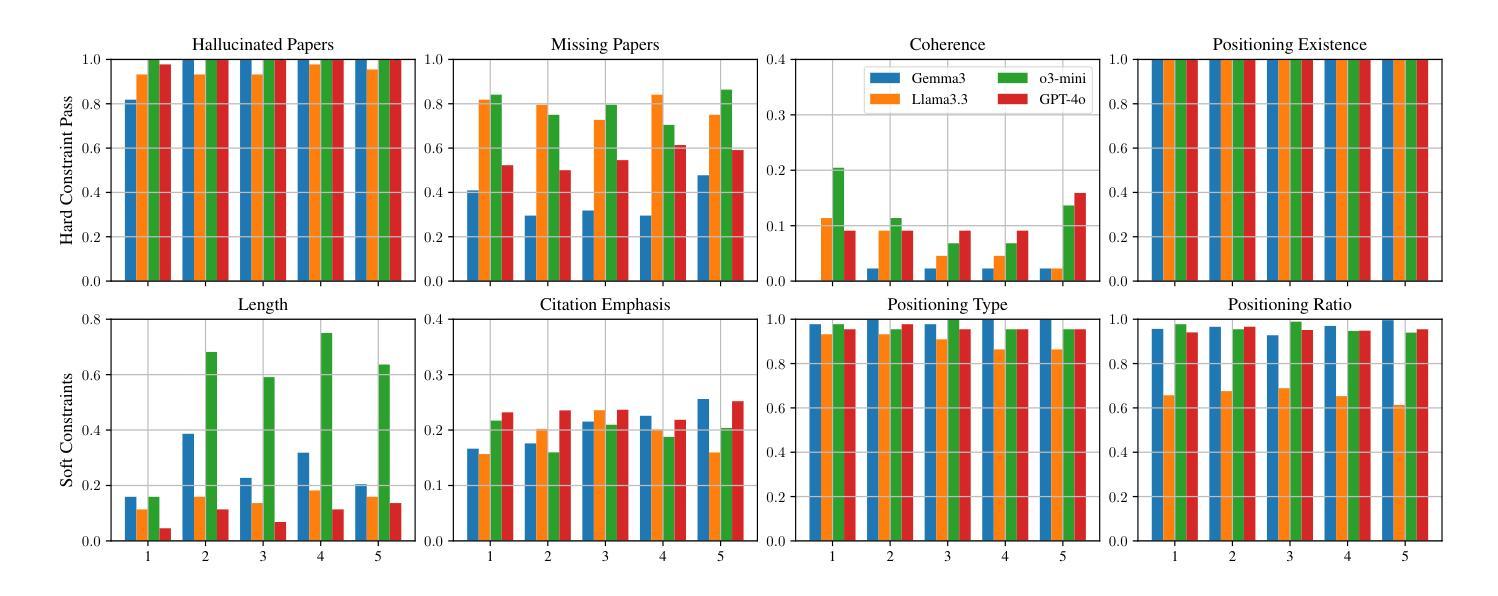
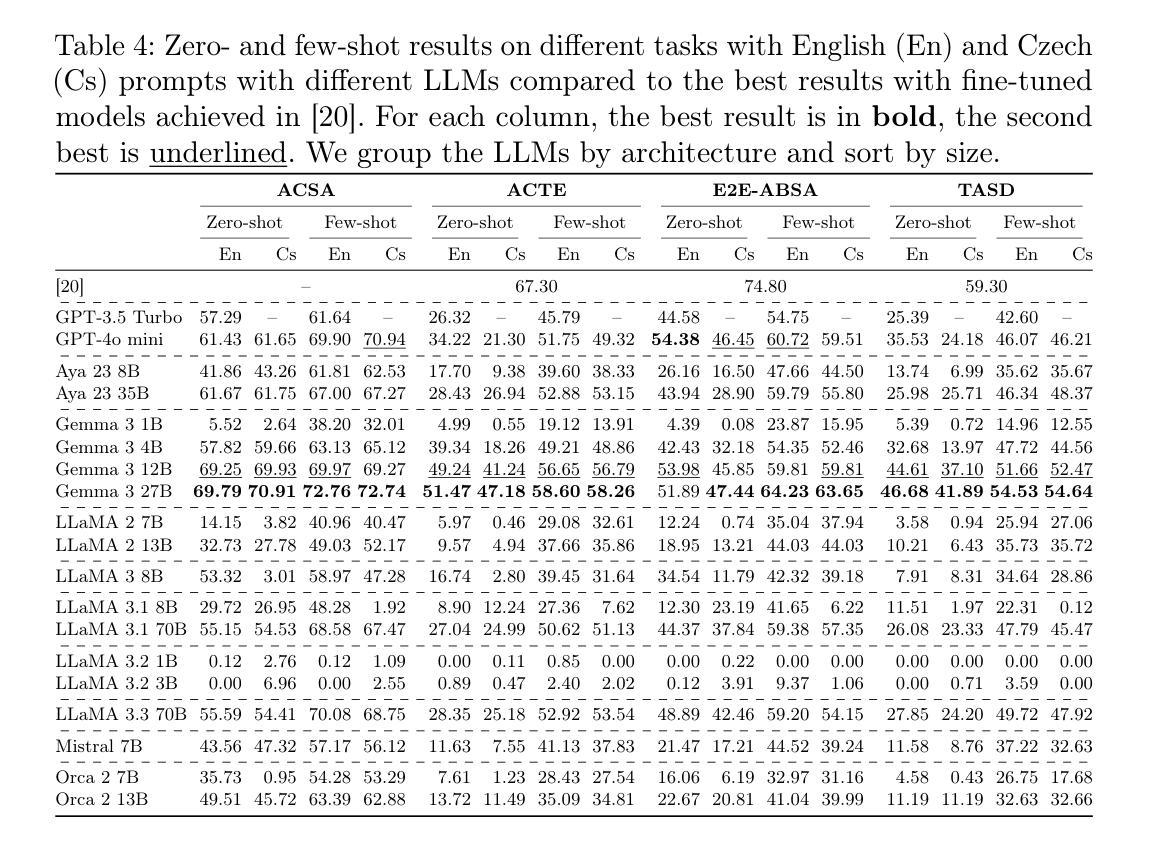
Large Language Models for Czech Aspect-Based Sentiment Analysis
Authors:Jakub Šmíd, Pavel Přibáň, Pavel Král
Aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task that aims to identify sentiment toward specific aspects of an entity. While large language models (LLMs) have shown strong performance in various natural language processing (NLP) tasks, their capabilities for Czech ABSA remain largely unexplored. In this work, we conduct a comprehensive evaluation of 19 LLMs of varying sizes and architectures on Czech ABSA, comparing their performance in zero-shot, few-shot, and fine-tuning scenarios. Our results show that small domain-specific models fine-tuned for ABSA outperform general-purpose LLMs in zero-shot and few-shot settings, while fine-tuned LLMs achieve state-of-the-art results. We analyze how factors such as multilingualism, model size, and recency influence performance and present an error analysis highlighting key challenges, particularly in aspect term prediction. Our findings provide insights into the suitability of LLMs for Czech ABSA and offer guidance for future research in this area.
面向特定方面的情感分析(ABSA)是一种精细粒度的情感分析任务,旨在识别人们对实体的特定方面的情感倾向。尽管大型语言模型(LLM)在各种自然语言处理(NLP)任务中表现出强大的性能,但它们在捷克语ABSA方面的能力尚未得到充分探索。在这项研究中,我们对不同规模和架构的19个LLM在捷克语ABSA方面进行了全面评估,比较了它们在零样本、小样本和微调场景中的性能。我们的结果表明,针对ABSA进行微调的小型领域特定模型在零样本和小样本设置中优于通用LLM,而经过调校的LLM则达到了最先进的水平。我们分析了诸如多语言能力、模型规模和更新频率等因素对性能的影响,并进行了错误分析,突出了面临的挑战,特别是在方面术语预测方面的挑战。我们的研究结果为LLM在捷克语ABSA中的适用性提供了见解,并为该领域的未来研究提供了指导。
论文及项目相关链接
PDF Accepted for presentation at the 28th International Conference on Text, Speech and Dialogue (TSD 2025)
Summary
捷克语方面的基于方面的情感分析(ABSA)旨在识别实体特定方面的情感。大型语言模型(LLM)在各种自然语言处理(NLP)任务中表现出强大的性能,但它们在捷克ABSA方面的能力尚未得到充分探索。本研究对19种不同规模和架构的LLM进行了全面的捷克ABSA评估,比较了它们在零样本、少样本和微调场景中的性能。研究结果显示,针对ABSA进行微调的小型领域特定模型在零样本和少样本设置中优于通用LLM,而经过调校的LLM则取得了最新技术成果。本研究分析了诸如多语言能力、模型规模和时效性等因素对性能的影响,并进行了错误分析,特别强调了术语预测方面的挑战。本研究为LLM在捷克ABSA方面的适用性提供了见解,并为这一领域的未来研究提供了指导。
Key Takeaways
- 大型语言模型(LLMs)在捷克语基于方面的情感分析(ABSA)上的表现尚待探索。
- 在零样本和少样本设置下,针对ABSA进行微调的小型领域特定模型表现较好。
- 经过调校的LLM取得了最新技术成果。
- 多语言能力、模型规模和时效性对LLM在ABSA中的性能有影响。
- 术语预测是ABSA中的一个关键挑战。
- 研究提供了LLMs在捷克ABSA中的适用性见解。
点此查看论文截图



Effortless Vision-Language Model Specialization in Histopathology without Annotation
Authors:Jingna Qiu, Nishanth Jain, Jonas Ammeling, Marc Aubreville, Katharina Breininger
Recent advances in Vision-Language Models (VLMs) in histopathology, such as CONCH and QuiltNet, have demonstrated impressive zero-shot classification capabilities across various tasks. However, their general-purpose design may lead to suboptimal performance in specific downstream applications. While supervised fine-tuning methods address this issue, they require manually labeled samples for adaptation. This paper investigates annotation-free adaptation of VLMs through continued pretraining on domain- and task-relevant image-caption pairs extracted from existing databases. Our experiments on two VLMs, CONCH and QuiltNet, across three downstream tasks reveal that these pairs substantially enhance both zero-shot and few-shot performance. Notably, with larger training sizes, continued pretraining matches the performance of few-shot methods while eliminating manual labeling. Its effectiveness, task-agnostic design, and annotation-free workflow make it a promising pathway for adapting VLMs to new histopathology tasks. Code is available at https://github.com/DeepMicroscopy/Annotation-free-VLM-specialization.
最近,病理组织学的视觉语言模型(VLMs)如CONCH和QuiltNet等取得了显著的进展,在各种任务中展示了令人印象深刻的零样本分类能力。然而,其通用设计可能导致在特定下游应用中的性能不佳。虽然监督微调方法可以解决此问题,但它们需要手动标记的样本进行适应。本文研究了通过继续在现有数据库中提取的与领域和任务相关的图像标题对进行预训练,实现VLMs的无标注适应。我们在CONCH和QuiltNet两种VLMs上进行三项下游任务的实验表明,这些图像标题对显著提高了零样本和少样本的性能。值得注意的是,随着训练规模的扩大,继续预训练的性能与少样本方法相匹配,同时消除了手动标注的需要。其有效性、任务无关的设计和无标注的工作流程使其成为将VLMs适应新病理组织学任务的有前途的途径。代码可在https://github.com/DeepMicroscopy/Annotation-free-VLM-specialization找到。
论文及项目相关链接
Summary
本文探讨了视觉语言模型(VLMs)在组织病理学领域的最新进展,如CONCH和QuiltNet等模型展现出零样本分类能力。然而,对于特定下游应用,通用设计可能导致性能不佳。本文研究通过持续预训练在现有数据库中提取的领域和任务相关的图像标题对来实现无标注适应的VLMs。实验表明这种预训练方法能显著提升零样本和少样本性能,且随着训练集增大,其性能与少样本方法相匹配,同时无需手动标注。这为适应新组织病理学任务的VLMs提供了有前景的路径。
Key Takeaways
- 最新视觉语言模型(VLMs)如CONCH和QuiltNet展现出零样本分类能力。
- VLMs在特定下游应用中性能可能不佳。
- 持续预训练能提高VLMs的零样本和少样本性能。
- 预训练通过使用从现有数据库中提取的领域和任务相关的图像标题对进行。
- 随着训练集增大,无标注预训练的性能与少样本方法相匹配。
- 该方法无需手动标注,为VLMs适应新任务提供了便利。
点此查看论文截图


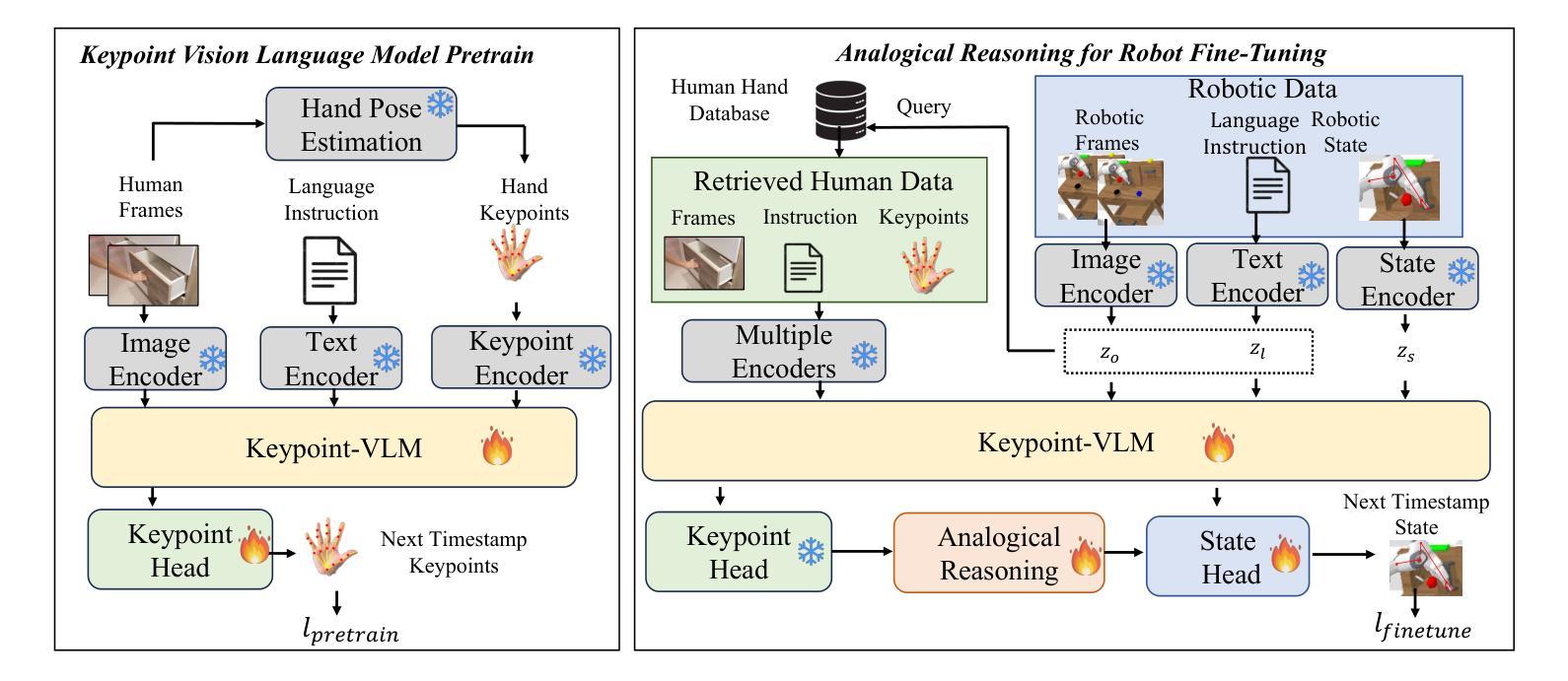
AR-VRM: Imitating Human Motions for Visual Robot Manipulation with Analogical Reasoning
Authors:Dejie Yang, Zijing Zhao, Yang Liu
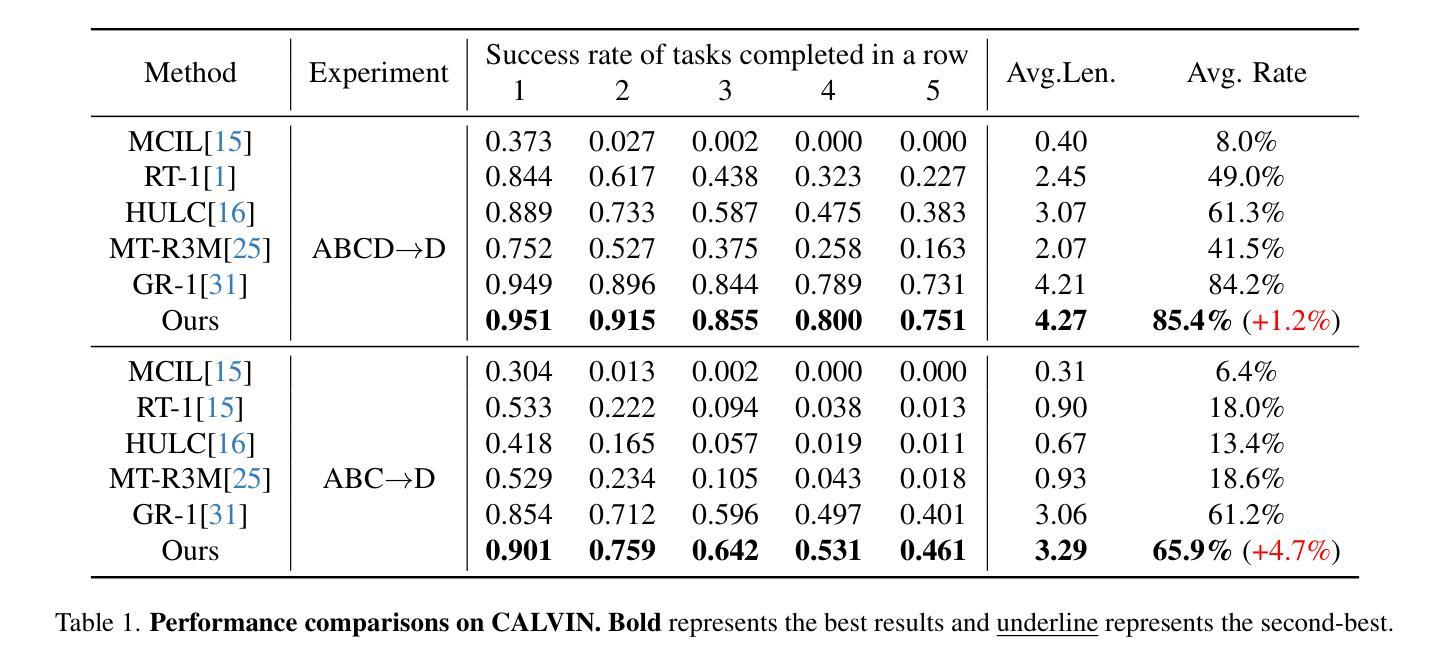
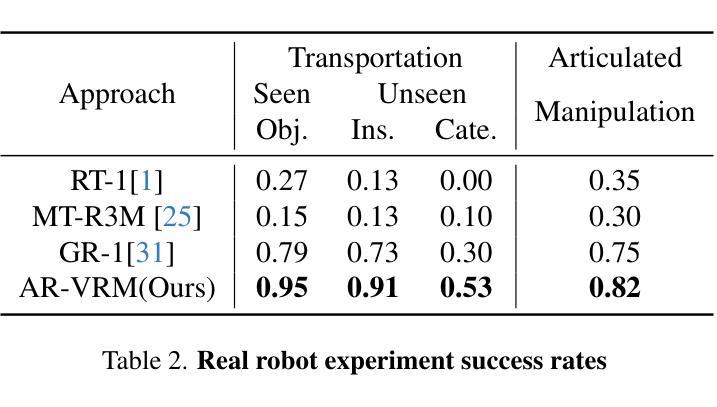
Visual Robot Manipulation (VRM) aims to enable a robot to follow natural language instructions based on robot states and visual observations, and therefore requires costly multi-modal data. To compensate for the deficiency of robot data, existing approaches have employed vision-language pretraining with large-scale data. However, they either utilize web data that differs from robotic tasks, or train the model in an implicit way (e.g., predicting future frames at the pixel level), thus showing limited generalization ability under insufficient robot data. In this paper, we propose to learn from large-scale human action video datasets in an explicit way (i.e., imitating human actions from hand keypoints), introducing Visual Robot Manipulation with Analogical Reasoning (AR-VRM). To acquire action knowledge explicitly from human action videos, we propose a keypoint Vision-Language Model (VLM) pretraining scheme, enabling the VLM to learn human action knowledge and directly predict human hand keypoints. During fine-tuning on robot data, to facilitate the robotic arm in imitating the action patterns of human motions, we first retrieve human action videos that perform similar manipulation tasks and have similar historical observations , and then learn the Analogical Reasoning (AR) map between human hand keypoints and robot components. Taking advantage of focusing on action keypoints instead of irrelevant visual cues, our method achieves leading performance on the CALVIN benchmark {and real-world experiments}. In few-shot scenarios, our AR-VRM outperforms previous methods by large margins , underscoring the effectiveness of explicitly imitating human actions under data scarcity.
视觉机器人操作(VRM)旨在使机器人能够根据机器人状态及视觉观察来执行自然语言指令,因此需要使用昂贵的多模态数据。为了弥补机器人数据的不足,现有的方法已经采用了大规模数据的视觉语言预训练方法。然而,它们要么使用与机器人任务不同的网络数据,要么以隐式方式训练模型(例如,在像素级别预测未来帧),因此在机器人数据不足的情况下,显示出有限的泛化能力。在本文中,我们提出了从大规模人类行为视频数据集中显式学习的方法(即,通过手部关键点模仿人类行为),并引入了具有类比推理(AR-VRM)的视觉机器人操作。为了从人类行为视频中显式地获取动作知识,我们提出了一种关键点视觉语言模型(VLM)预训练方案,使VLM能够学习人类行为知识并直接预测人类手部关键点。在机器人数据进行微调期间,为了促使机械臂模仿人类动作的模式,我们首先检索执行类似操作任务并具有相似历史观察记录的人类行为视频,然后学习人类手部关键点和机器人组件之间的类比推理(AR)映射。通过关注动作关键点而非无关的视觉线索,我们的方法在CALVIN基准测试{和真实世界实验}中取得了领先性能。在少数场景下,我们的AR-VRM大幅超越了以前的方法,突显了在数据稀缺情况下显式模仿人类动作的有效性。
论文及项目相关链接
PDF Accepted by ICCV2025
Summary
本文提出一种基于类比推理的视觉机器人操作(AR-VRM)方法,旨在从大规模的人类行为视频数据集中显式学习动作知识。通过预训练关键点视觉语言模型(VLM),使VLM能够学习人类行为知识并直接预测人手关键点。在机器人数据微调过程中,通过检索执行相似操作任务且具有相似历史观察的人类行为视频,学习人手关键点和机器人组件之间的类比推理映射。该方法关注动作关键点而非无关的视觉线索,在CALVIN基准测试和真实实验环境中表现领先,尤其在数据稀缺的少数拍摄场景中,AR-VRM大幅度优于前序方法,凸显显式模仿人类动作的有效性。
Key Takeaways
- AR-VRM方法通过从大规模人类行为视频数据集中显式学习动作知识,来增强机器人的操作能力。
- 采用预训练的视觉语言模型(VLM)以学习人类行为知识并预测人手关键点。
- 在机器人数据微调过程中,通过检索相似任务及观察的人类行为视频,建立人类手关键点和机器人组件之间的类比推理映射。
- 方法专注于动作关键点,而非无关的视觉线索,以提升机器人操作的准确性。
- 在CALVIN基准测试中,AR-VRM表现出卓越性能。
- 在少数拍摄场景中,AR-VRM显著优于先前的方法,显示出其在数据稀缺情况下的高效性。
点此查看论文截图

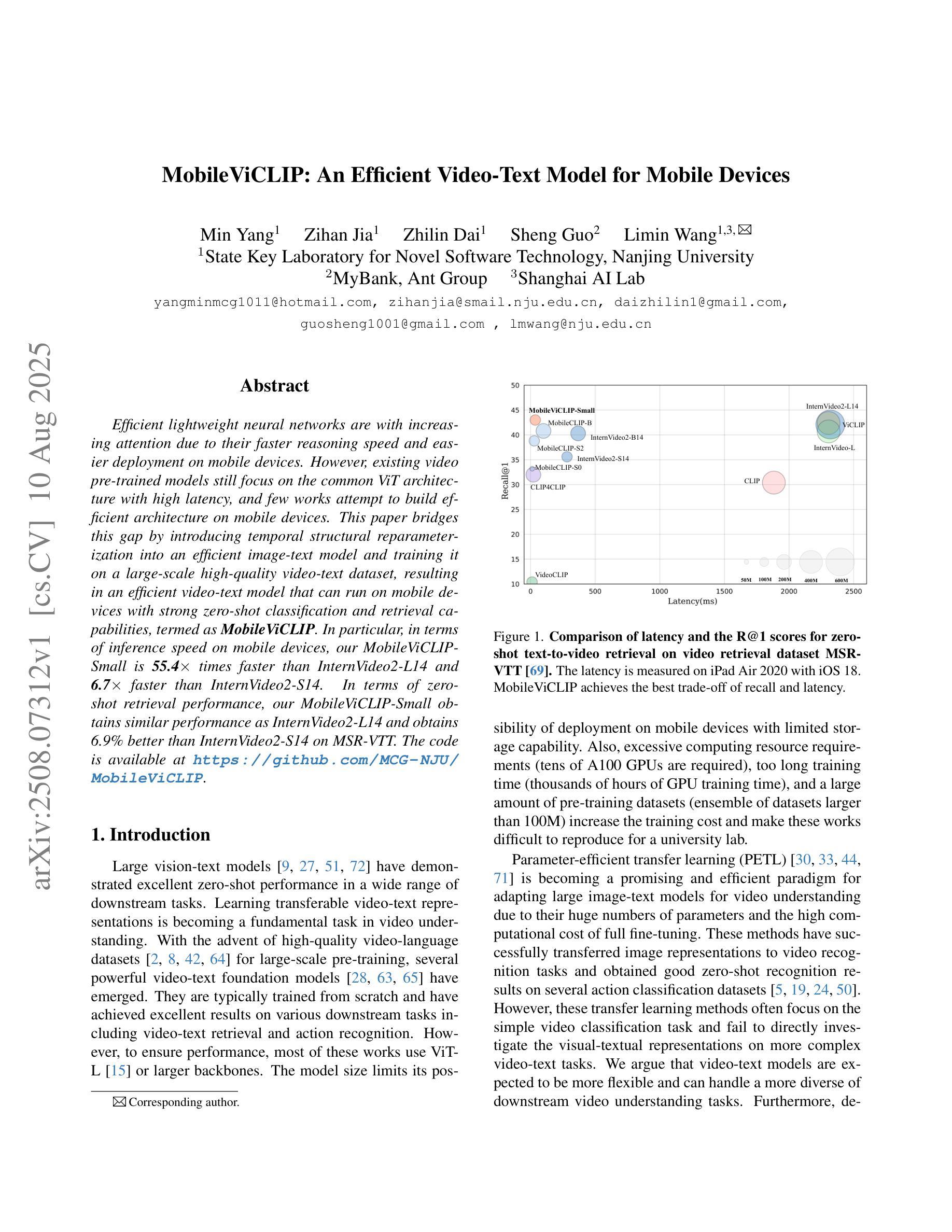
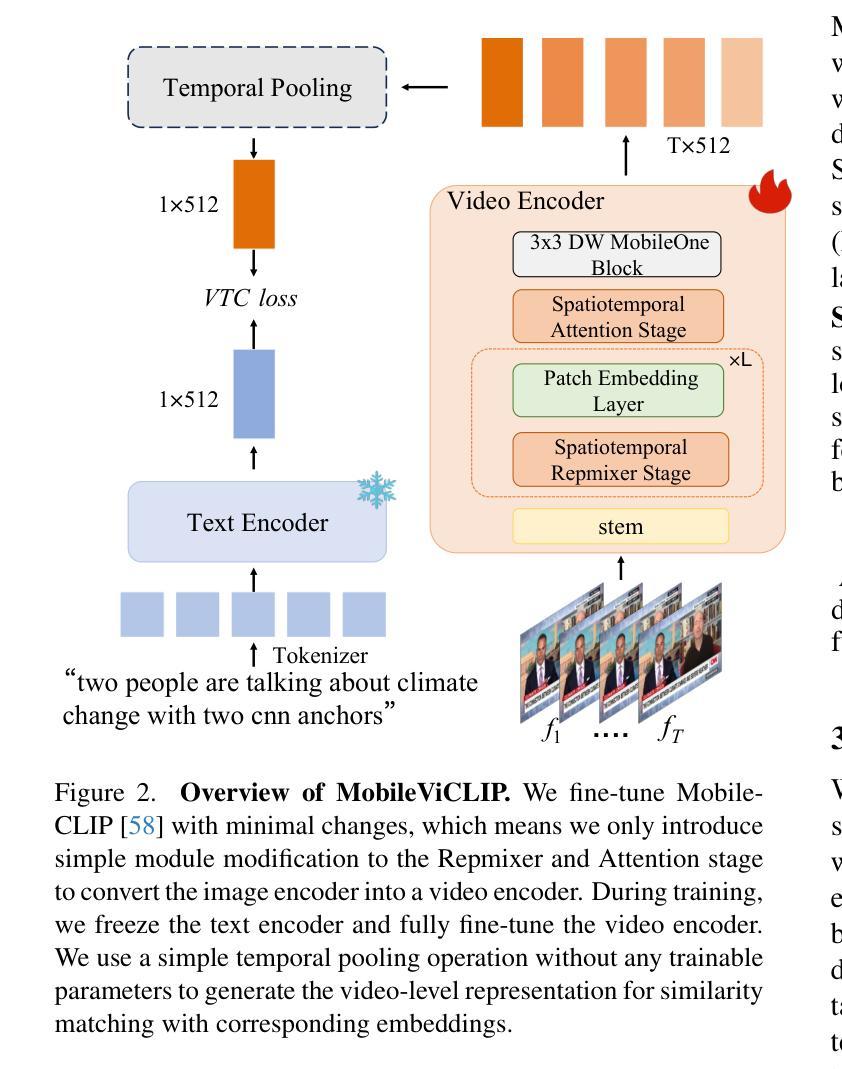
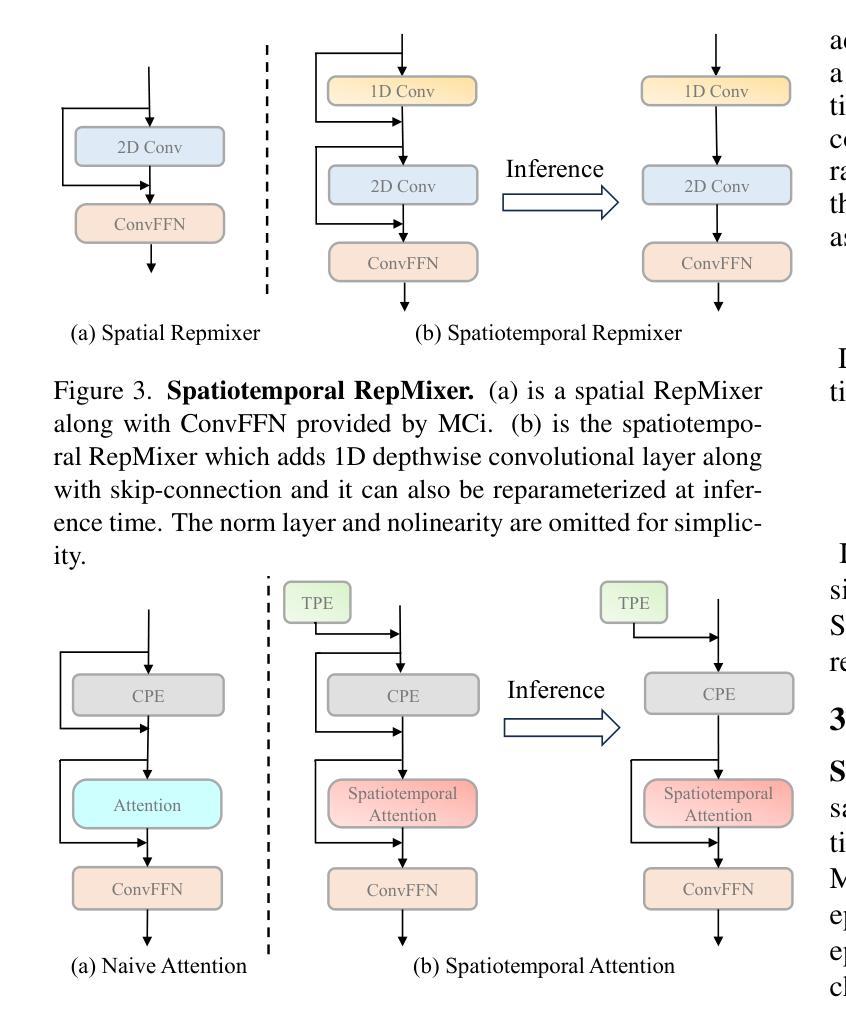
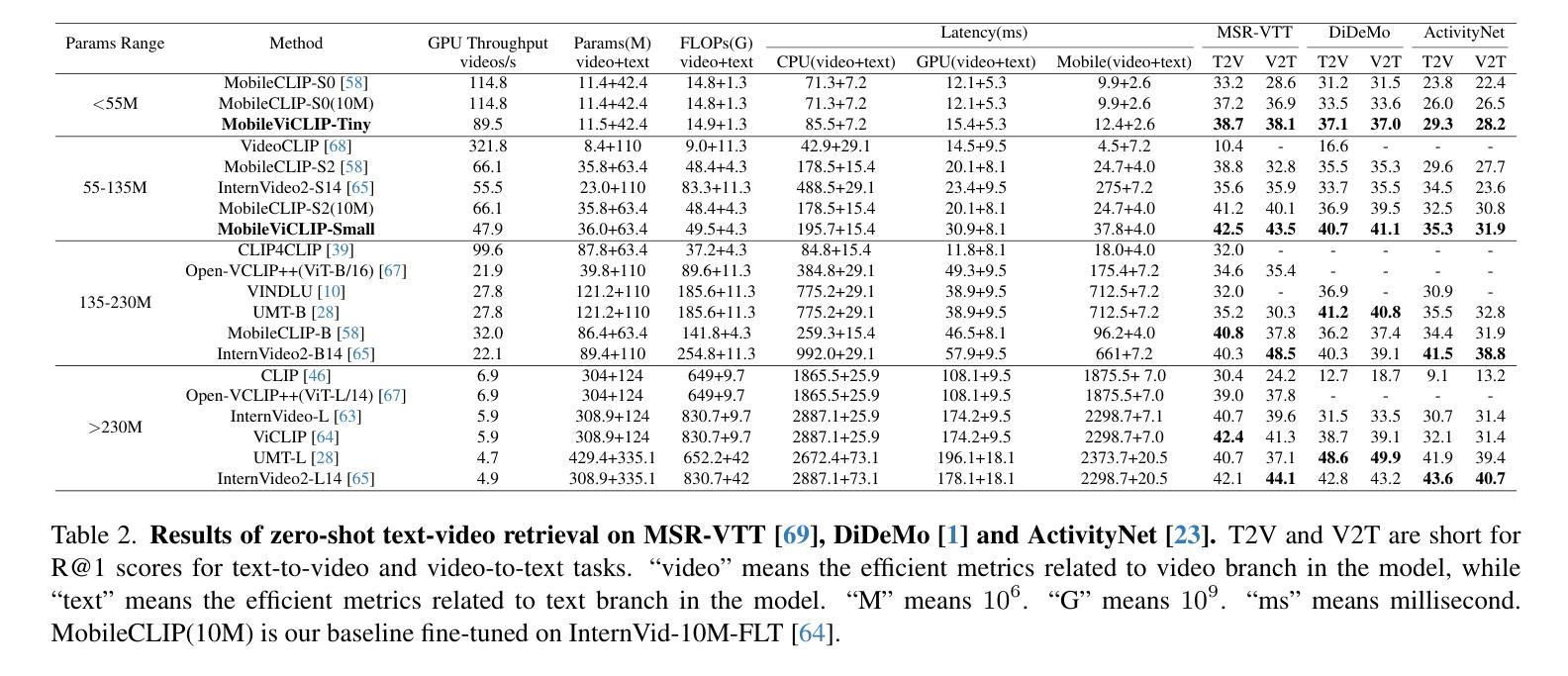
MobileViCLIP: An Efficient Video-Text Model for Mobile Devices
Authors:Min Yang, Zihan Jia, Zhilin Dai, Sheng Guo, Limin Wang
Efficient lightweight neural networks are with increasing attention due to their faster reasoning speed and easier deployment on mobile devices. However, existing video pre-trained models still focus on the common ViT architecture with high latency, and few works attempt to build efficient architecture on mobile devices. This paper bridges this gap by introducing temporal structural reparameterization into an efficient image-text model and training it on a large-scale high-quality video-text dataset, resulting in an efficient video-text model that can run on mobile devices with strong zero-shot classification and retrieval capabilities, termed as MobileViCLIP. In particular, in terms of inference speed on mobile devices, our MobileViCLIP-Small is 55.4x times faster than InternVideo2-L14 and 6.7x faster than InternVideo2-S14. In terms of zero-shot retrieval performance, our MobileViCLIP-Small obtains similar performance as InternVideo2-L14 and obtains 6.9% better than InternVideo2-S14 on MSR-VTT. The code is available at https://github.com/MCG-NJU/MobileViCLIP.
高效轻量级神经网络因其更快的推理速度和在移动设备上的更容易部署而受到越来越多的关注。然而,现有的视频预训练模型仍然主要关注高延迟的通用ViT架构,很少有工作尝试在移动设备上构建高效架构。本文通过引入时间结构重参数化到高效的图像文本模型中,并在大规模高质量的视频文本数据集上进行训练,从而填补了这个空白,得到了一个在移动设备上运行的高效视频文本模型,具有强大的零样本分类和检索能力,被称为MobileViCLIP。特别是,就移动设备上的推理速度而言,我们的MobileViCLIP-Small是InternVideo2-L14的55.4倍,比InternVideo2-S14快6.7倍。在零样本检索性能方面,我们的MobileViCLIP-Small的性能与InternVideo2-L14相似,并在MSR-VTT上比InternVideo2-S14高出6.9%。代码可在https://github.com/MCG-NJU/MobileViCLIP找到。
论文及项目相关链接
PDF Accepted by ICCV2025
Summary
高效轻量级神经网络受到越来越多的关注,因其推理速度快,易于在移动设备上部署。本文引入了一种新的方法,通过时间结构重参数化,在高效图像文本模型上构建视频预训练模型,并在大规模高质量的视频文本数据集上进行训练,得到了可在移动设备上运行的具有强大零样本分类和检索能力的视频文本模型,称为MobileViCLIP。其运行速度非常快,且零样本检索性能优秀。
Key Takeaways
- MobileViCLIP是一个高效轻量级的视频文本模型,能在移动设备上运行并具有强大的零样本分类和检索能力。
- 该模型通过引入时间结构重参数化技术,将图像文本模型扩展到视频领域。
- MobileViCLIP在大型高质量的视频文本数据集上进行训练。
- MobileViCLIP的运行速度显著快于其他同类模型,并且其零样本检索性能也十分优秀。
- 该模型的代码已公开发布在GitHub上。
- MobileViCLIP具有优秀的可扩展性,适用于各种应用场景和资源受限的环境。
点此查看论文截图
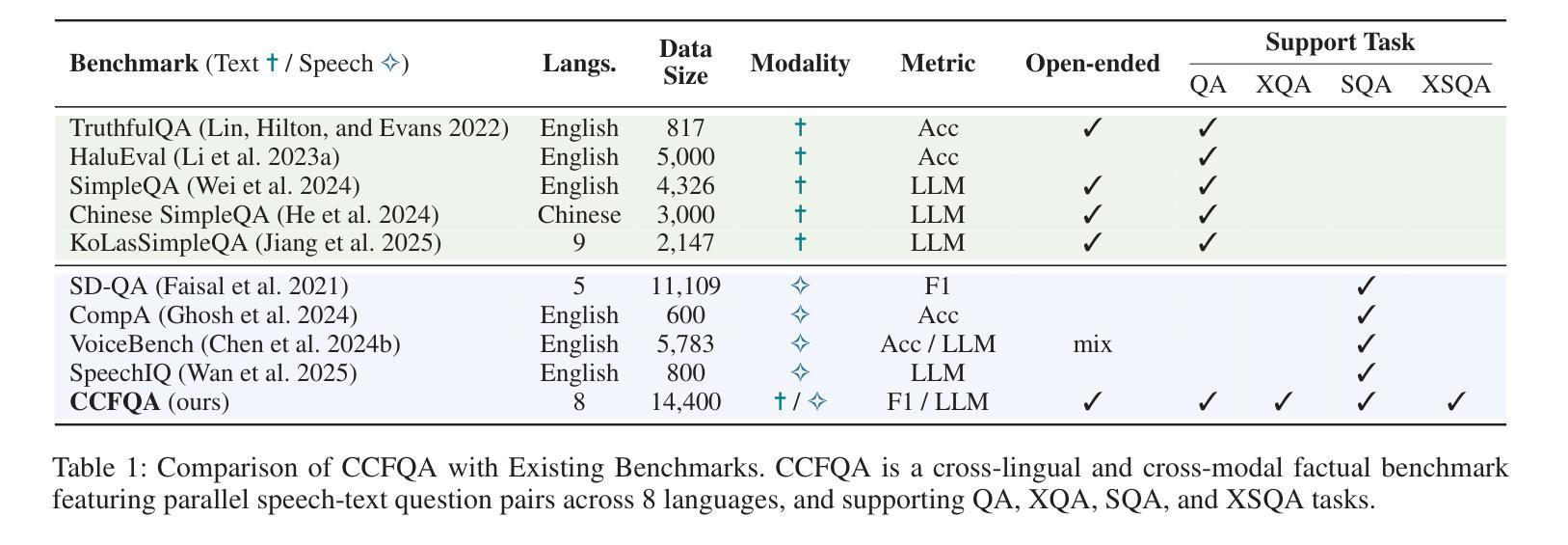
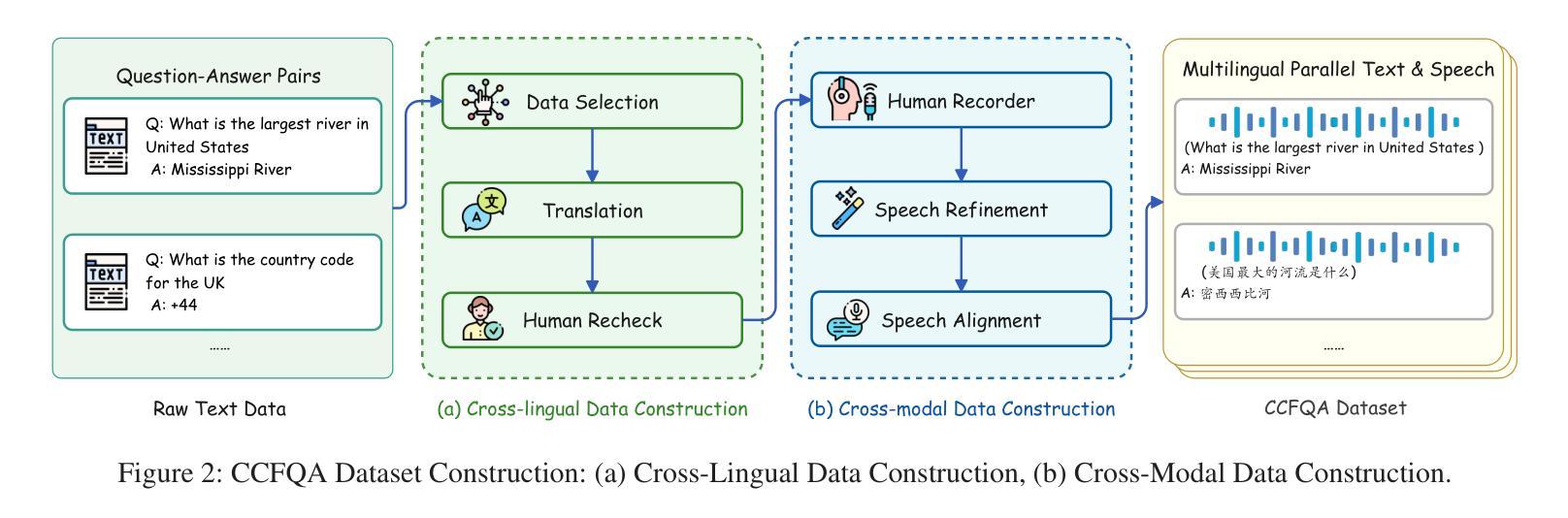
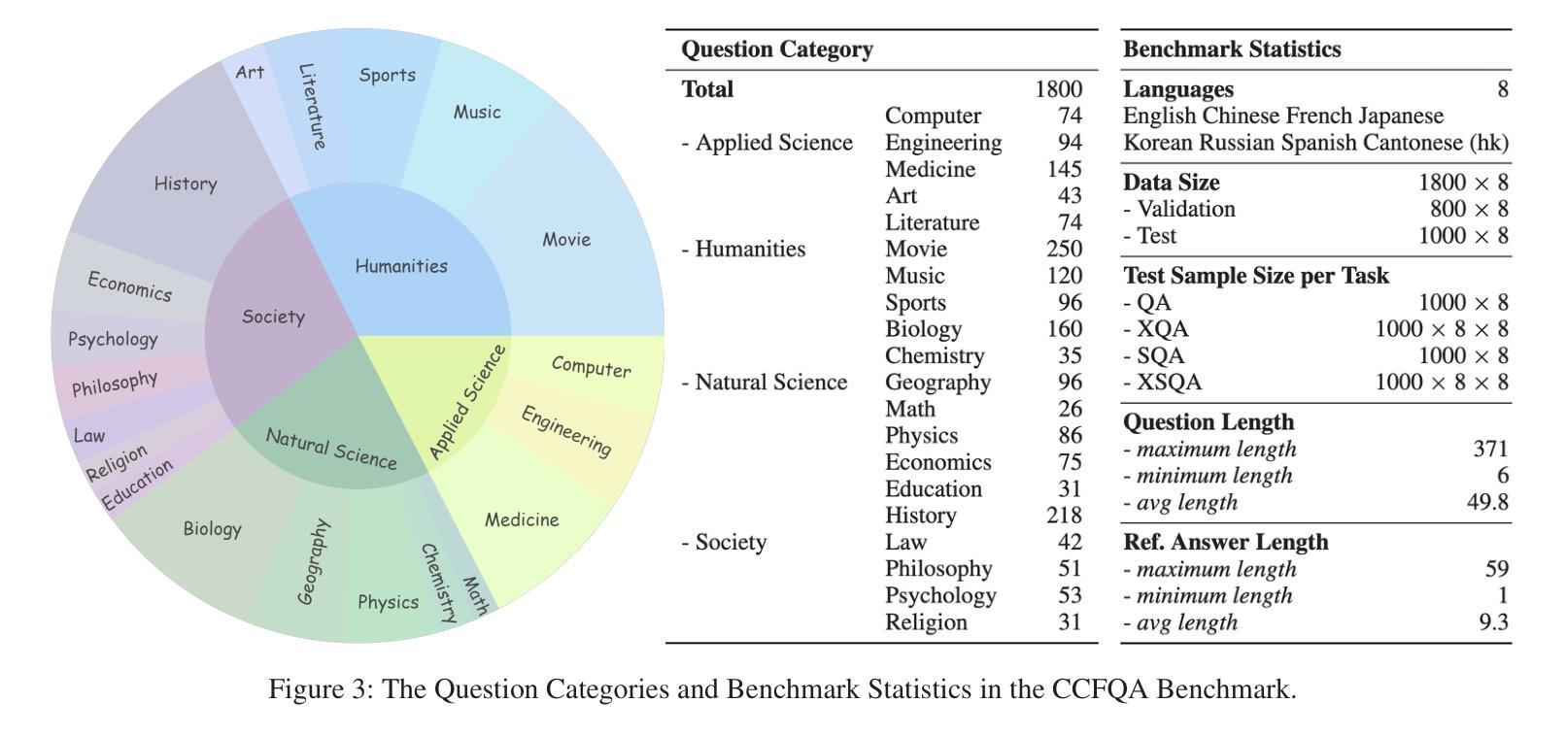
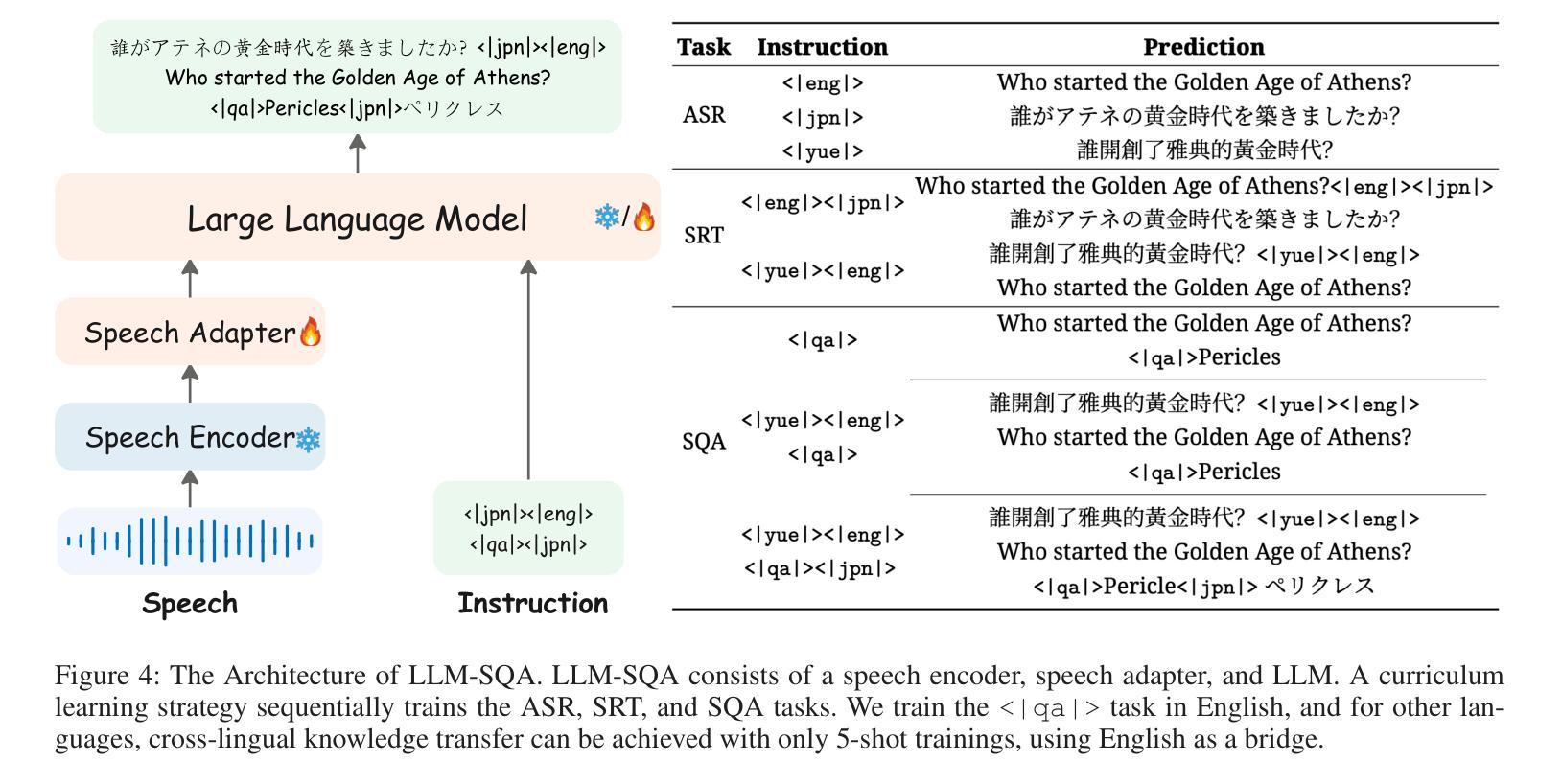
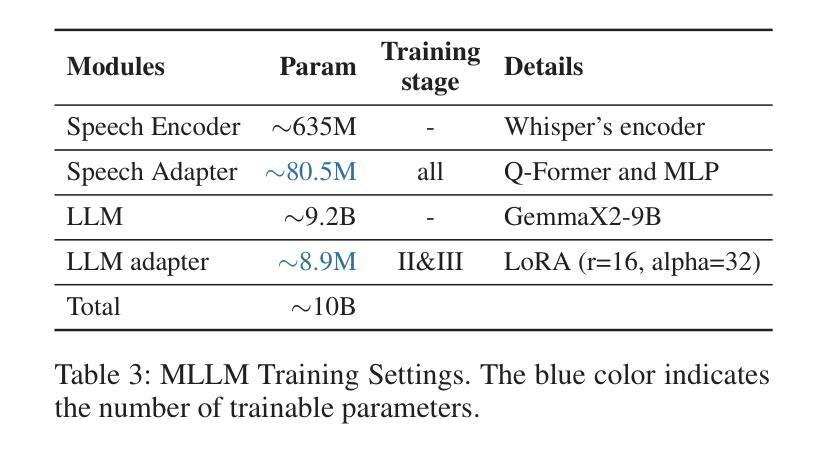
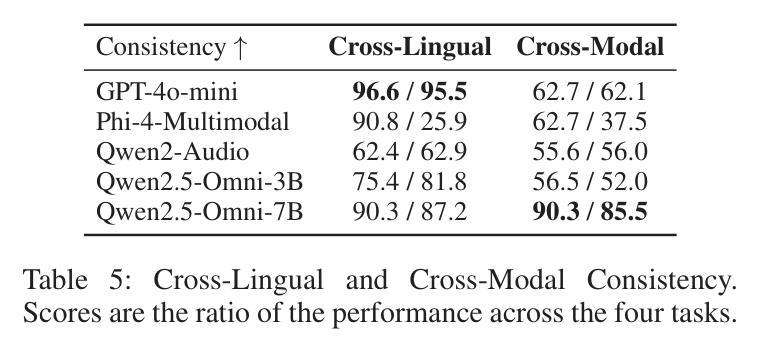
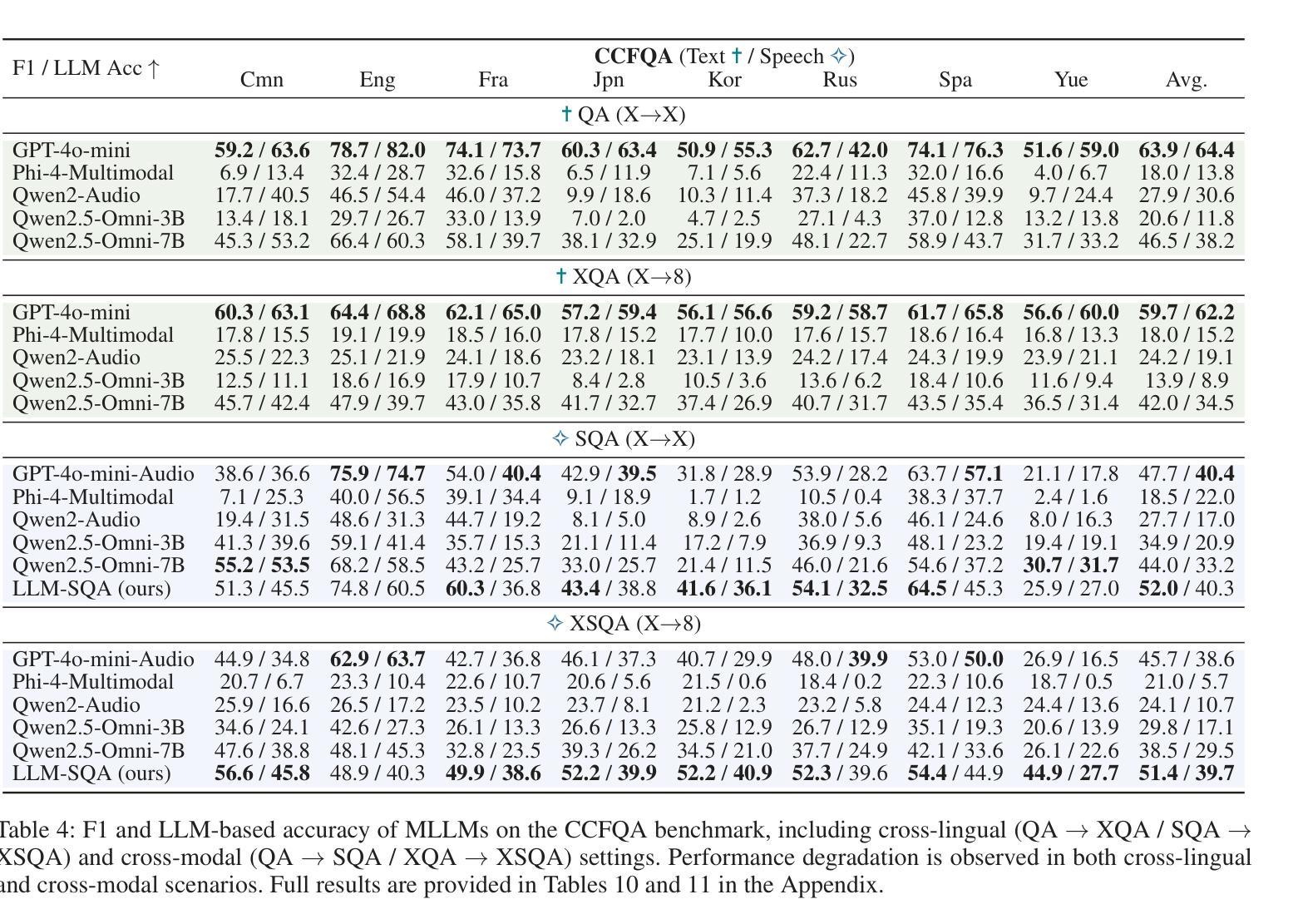
CCFQA: A Benchmark for Cross-Lingual and Cross-Modal Speech and Text Factuality Evaluation
Authors:Yexing Du, Kaiyuan Liu, Youcheng Pan, Zheng Chu, Bo Yang, Xiaocheng Feng, Yang Xiang, Ming Liu
As Large Language Models (LLMs) are increasingly popularized in the multilingual world, ensuring hallucination-free factuality becomes markedly crucial. However, existing benchmarks for evaluating the reliability of Multimodal Large Language Models (MLLMs) predominantly focus on textual or visual modalities with a primary emphasis on English, which creates a gap in evaluation when processing multilingual input, especially in speech. To bridge this gap, we propose a novel \textbf{C}ross-lingual and \textbf{C}ross-modal \textbf{F}actuality benchmark (\textbf{CCFQA}). Specifically, the CCFQA benchmark contains parallel speech-text factual questions across 8 languages, designed to systematically evaluate MLLMs’ cross-lingual and cross-modal factuality capabilities. Our experimental results demonstrate that current MLLMs still face substantial challenges on the CCFQA benchmark. Furthermore, we propose a few-shot transfer learning strategy that effectively transfers the Question Answering (QA) capabilities of LLMs in English to multilingual Spoken Question Answering (SQA) tasks, achieving competitive performance with GPT-4o-mini-Audio using just 5-shot training. We release CCFQA as a foundational research resource to promote the development of MLLMs with more robust and reliable speech understanding capabilities. Our code and dataset are available at https://github.com/yxduir/ccfqa.
随着大型语言模型(LLM)在多语种世界中的日益普及,确保无幻觉的客观性变得至关重要。然而,现有的评估多模态大型语言模型(MLLM)可靠性的基准测试主要侧重于文本或视觉模式,并以英语为主要重点,这在处理多语种输入时,特别是在语音方面,存在评估差距。为了弥补这一差距,我们提出了全新的跨语言跨模态事实基准测试(CCFQA)。具体而言,CCFQA基准测试包含8种语言的语音文本事实问题,旨在系统地评估MLLMs的跨语言和跨模态事实能力。我们的实验结果表明,当前的MLLMs在CCFQA基准测试上面临着巨大的挑战。此外,我们提出了一种小样本迁移学习策略,该策略有效地将英语大型语言模型的问答能力转移到多语种口语问答任务中,仅使用5个小样本的训练就达到了与GPT-4o-mini-Audio相当的性能。我们发布CCFQA作为基础研究资源,以促进开发具有更稳健和可靠语音理解能力的MLLMs。我们的代码和数据集可在https://github.com/yxduir/ccfqa获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在多语种世界中的普及,使得确保无虚构事实的可靠性变得至关重要。然而,现有的多模态大型语言模型(MLLMs)评估基准主要侧重于文本或视觉模态,并以英语为主,这在处理多语种输入时,尤其在语音方面,存在评估空白。为了弥补这一空白,我们提出了跨语言跨模态事实性基准(CCFQA)。CCFQA基准包含8种语言的语音-文本事实问题,旨在系统评估MLLMs的跨语言和跨模态事实性能力。实验结果显明,当前MLLMs在CCFQA基准上仍面临巨大挑战。我们提出了一种有效的少量训练转移学习策略,将英语问答能力转移到多语种口语问答任务上,使用仅5次训练的GPT-4o-mini-Audio取得了具有竞争力的表现。我们发布CCFQA作为研究资源,以促进开发具有更强大和可靠语音理解能力的MLLMs。
Key Takeaways
- 大型语言模型在多语种环境中的普及突出了确保事实无虚构的重要性。
- 现有的评估基准在跨语言和跨模态的事实性评估上存在不足。
- 提出了跨语言跨模态事实性基准(CCFQA)以弥补这一空白。
- CCFQA包含8种语言的语音-文本事实问题,全面评估MLLMs的能力。
- 当前MLLMs在CCFQA上表现仍面临挑战。
- 提出了少量训练转移学习策略,有效转移英语问答能力至多语种口语问答任务。
点此查看论文截图


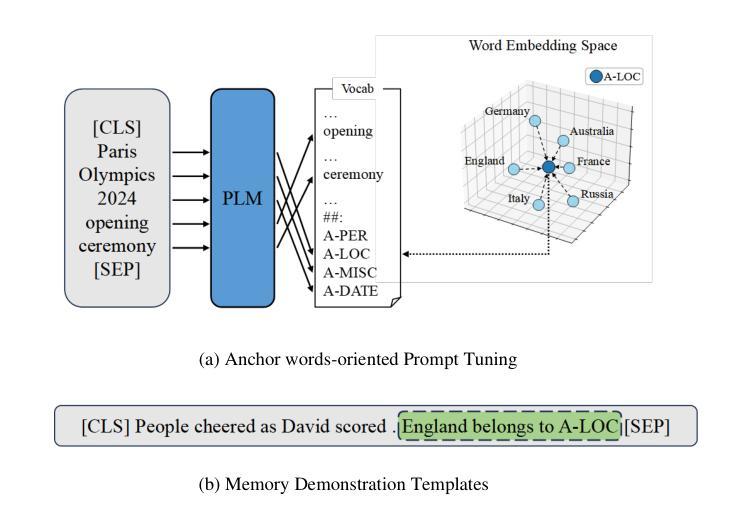
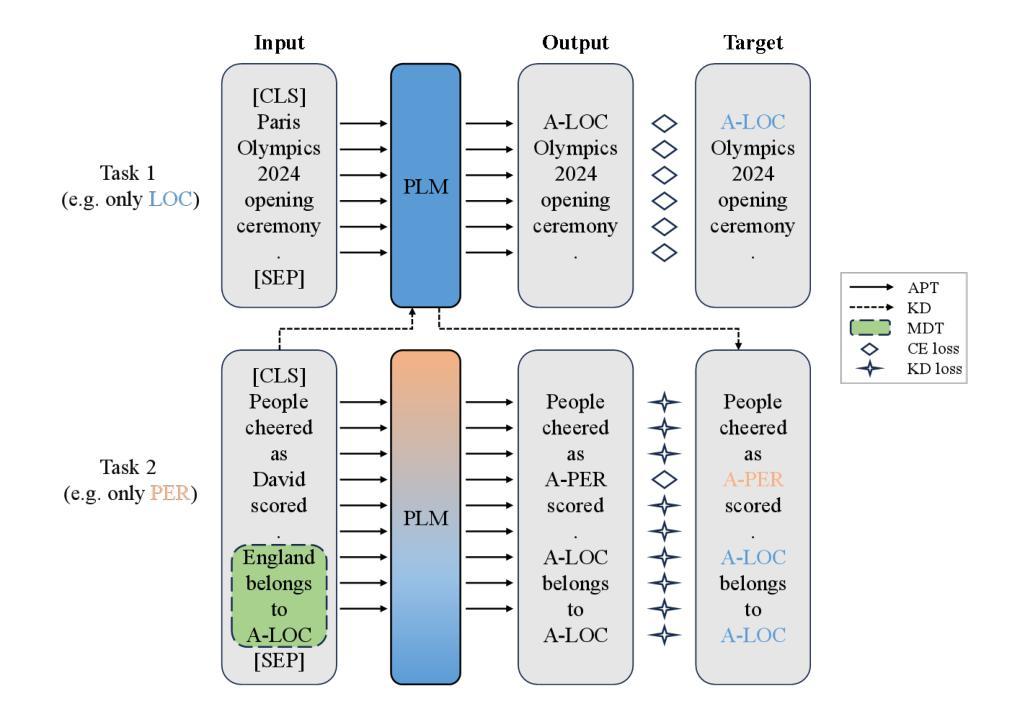
Prompt Tuning for Few-Shot Continual Learning Named Entity Recognition
Authors:Zhe Ren
Knowledge distillation has been successfully applied to Continual Learning Named Entity Recognition (CLNER) tasks, by using a teacher model trained on old-class data to distill old-class entities present in new-class data as a form of regularization, thereby avoiding catastrophic forgetting. However, in Few-Shot CLNER (FS-CLNER) tasks, the scarcity of new-class entities makes it difficult for the trained model to generalize during inference. More critically, the lack of old-class entity information hinders the distillation of old knowledge, causing the model to fall into what we refer to as the Few-Shot Distillation Dilemma. In this work, we address the above challenges through a prompt tuning paradigm and memory demonstration template strategy. Specifically, we designed an expandable Anchor words-oriented Prompt Tuning (APT) paradigm to bridge the gap between pre-training and fine-tuning, thereby enhancing performance in few-shot scenarios. Additionally, we incorporated Memory Demonstration Templates (MDT) into each training instance to provide replay samples from previous tasks, which not only avoids the Few-Shot Distillation Dilemma but also promotes in-context learning. Experiments show that our approach achieves competitive performances on FS-CLNER.
知识蒸馏已成功应用于持续学习命名实体识别(CLNER)任务中,通过使用在旧类数据上训练的教师模型来提炼存在于新类数据中的旧类实体,作为一种正则化方法,从而避免灾难性遗忘。然而,在Few-Shot CLNER(FS-CLNER)任务中,新类实体的稀缺性使得训练模型在推理时难以推广。更为关键的是,缺乏旧类实体信息阻碍了旧知识的提炼,导致模型陷入我们所说的Few-Shot蒸馏困境。在这项工作中,我们通过提示调整范式和记忆演示模板策略来解决上述挑战。具体来说,我们设计了一种可扩展的面向锚点的提示调整(APT)范式,以缩小预训练和微调之间的差距,从而提高少样本场景中的性能。此外,我们将记忆演示模板(MDT)纳入每个训练实例中,提供来自以前任务的回放样本,这不仅避免了Few-Shot蒸馏困境,而且促进了上下文学习。实验表明,我们的方法在FS-CLNER上取得了具有竞争力的表现。
论文及项目相关链接
Summary
知识蒸馏已成功应用于持续学习命名实体识别(CLNER)任务中,利用旧类数据训练的老师模型将旧类实体蒸馏到新类数据中,作为正则化的一种形式,从而避免灾难性遗忘。但在Few-Shot CLNER(FS-CLNER)任务中,新类实体的稀缺性使得模型在推理时难以泛化。更关键的是,缺乏旧类实体信息阻碍了旧知识的蒸馏,导致模型陷入我们称之为的“Few-Shot蒸馏困境”。本研究通过提示调整范式和记忆演示模板策略来解决上述挑战。我们设计了一个可扩展的基于锚点词的提示调整(APT)范式,以缩小预训练和微调之间的差距,从而提高少样本场景中的性能。此外,我们将记忆演示模板(MDT)纳入每个训练实例,提供以往任务的重现样本,这不仅避免了Few-Shot蒸馏困境,还促进了上下文学习。实验表明,我们的方法在FS-CLNER上取得了具有竞争力的表现。
Key Takeaways
- 知识蒸馏已成功应用于CLNER任务中,避免灾难性遗忘。
- 在Few-Shot CLNER(FS-CLNER)任务中面临新类实体稀缺和旧知识蒸馏困难的问题,称为“Few-Shot蒸馏困境”。
- 通过提示调整范式(APT)缩小预训练和微调之间的差距,提高少样本场景性能。
- 记忆演示模板(MDT)纳入训练实例,提供以往任务的重现样本。
- MDT不仅避免了Few-Shot蒸馏困境,还促进了上下文学习。
- 实验显示,该方法在FS-CLNER上表现竞争力。
点此查看论文截图

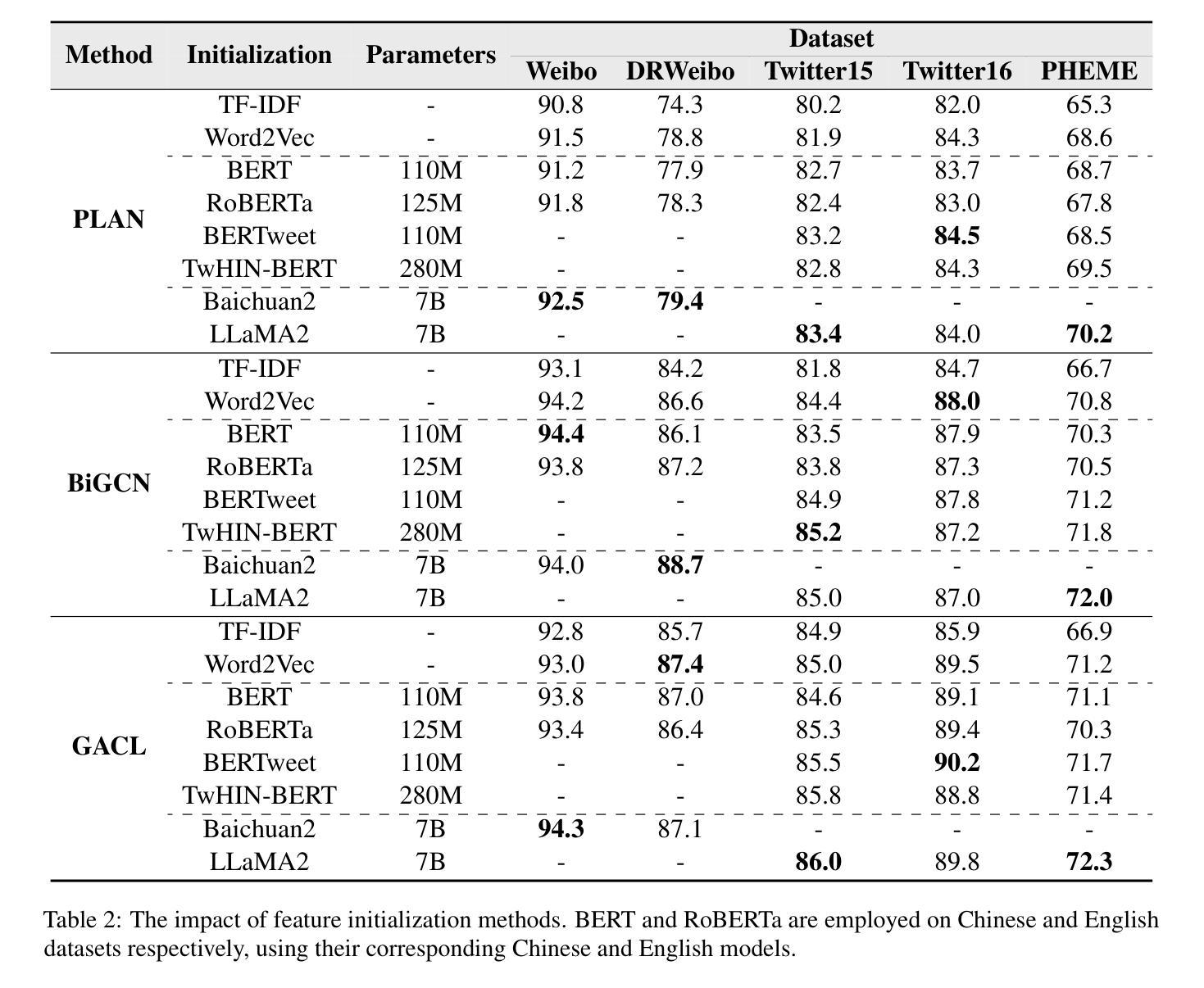
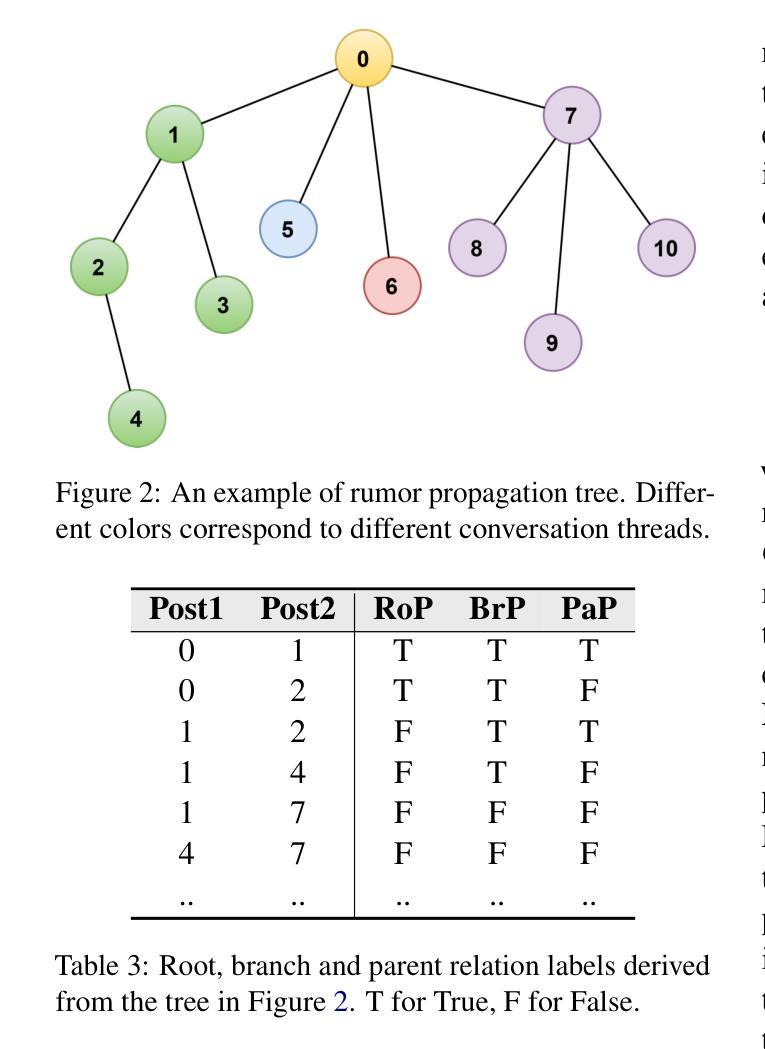
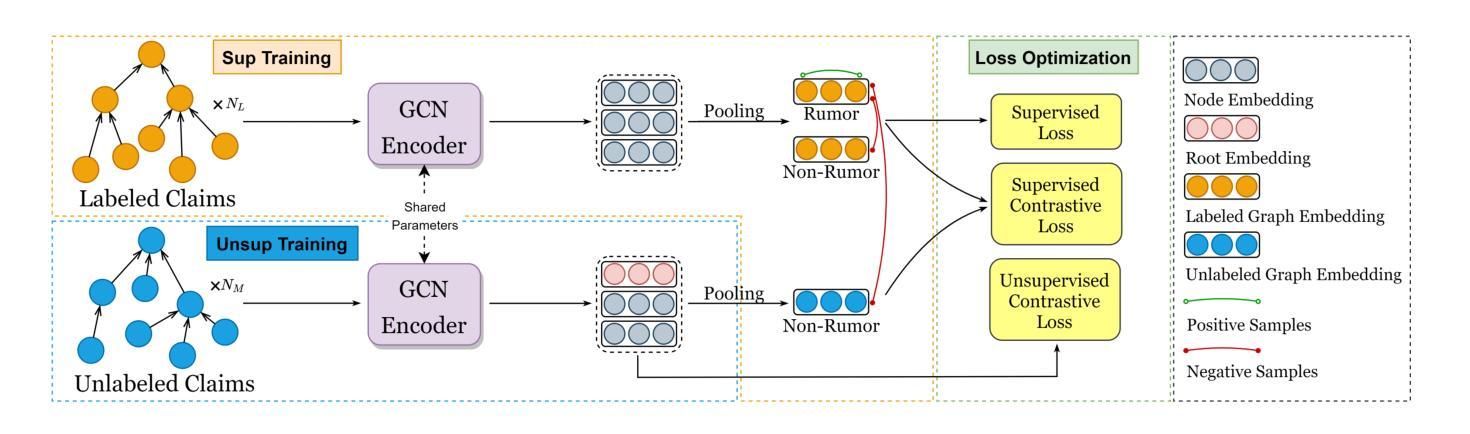
Enhancing Rumor Detection Methods with Propagation Structure Infused Language Model
Authors:Chaoqun Cui, Siyuan Li, Kunkun Ma, Caiyan Jia
Pretrained Language Models (PLMs) have excelled in various Natural Language Processing tasks, benefiting from large-scale pretraining and self-attention mechanism’s ability to capture long-range dependencies. However, their performance on social media application tasks like rumor detection remains suboptimal. We attribute this to mismatches between pretraining corpora and social texts, inadequate handling of unique social symbols, and pretraining tasks ill-suited for modeling user engagements implicit in propagation structures. To address these issues, we propose a continue pretraining strategy called Post Engagement Prediction (PEP) to infuse information from propagation structures into PLMs. PEP makes models to predict root, branch, and parent relations between posts, capturing interactions of stance and sentiment crucial for rumor detection. We also curate and release large-scale Twitter corpus: TwitterCorpus (269GB text), and two unlabeled claim conversation datasets with propagation structures (UTwitter and UWeibo). Utilizing these resources and PEP strategy, we train a Twitter-tailored PLM called SoLM. Extensive experiments demonstrate PEP significantly boosts rumor detection performance across universal and social media PLMs, even in few-shot scenarios. On benchmark datasets, PEP enhances baseline models by 1.0-3.7% accuracy, even enabling it to outperform current state-of-the-art methods on multiple datasets. SoLM alone, without high-level modules, also achieves competitive results, highlighting the strategy’s effectiveness in learning discriminative post interaction features.
预训练语言模型(PLMs)在各种自然语言处理任务中表现出色,这得益于大规模预训练和自注意力机制捕捉长距离依赖的能力。然而,它们在社交媒体应用任务(如谣言检测)上的表现仍然不够理想。我们认为这是由于预训练语料库与社交文本之间的不匹配、对独特社交符号处理不足以及预训练任务不适合建模传播结构中隐含的用户交互造成的。为了解决这些问题,我们提出了一种名为“参与后预测”(PEP)的持续预训练策略,以将传播结构的信息融入PLMs。PEP使模型能够预测帖子之间的根、分支和父子关系,捕获对谣言检测至关重要的立场和情感的交互。我们还整理和发布了大规模的Twitter语料库(TwitterCorpus,包含269GB文本),以及带有传播结构的两个未标记声明对话数据集(UTwitter和UWeibo)。利用这些资源和PEP策略,我们训练了一个适用于Twitter的PLM,称为SoLM。大量实验表明,即使在少量样本的情况下,PEP也能显著提高通用和社交媒体PLMs的谣言检测性能。在基准数据集上,PEP将基线模型的准确率提高1.0-3.7%,甚至能够在多个数据集上超越当前最先进的方法。仅使用SoLM,无需高级模块,也能取得有竞争力的结果,这凸显了该策略在学习区分性帖子交互特征方面的有效性。
论文及项目相关链接
PDF This paper is accepted by COLING2025
Summary
预训练语言模型在自然语言处理任务中表现出色,但在社交媒体应用任务如谣言检测方面的表现尚待提升。为解决这一问题,本文提出一种名为“Post Engagement Prediction”(PEP)的持续预训练策略,旨在将传播结构信息融入预训练语言模型。PEP使模型能够预测帖子之间的根、分支和父关系,从而捕捉对谣言检测至关重要的立场和情感的交互作用。实验表明,PEP策略在通用和社交媒体预训练语言模型上均显著提升了谣言检测性能,即使在少量样本场景下也表现优异。
Key Takeaways
- 预训练语言模型在社交媒体应用任务如谣言检测上的表现有待提高。
- 现有模型面临预训练语料与社交文本不匹配、无法妥善处理独特社交符号以及预训练任务不适合建模用户参与度等问题。
- 提出一种名为PEP的持续预训练策略,旨在将传播结构信息融入预训练语言模型,以改善谣言检测性能。
- PEP策略使模型能够预测帖子间的根、分支和父关系,捕捉关键交互作用。
- 利用Twitter的大型语料库和未标记声明对话数据集进行实证研究,证明PEP策略在提升谣言检测性能方面的有效性。
- PEP策略在多种基准数据集上的表现优于现有最先进的模型,准确率提升范围在1.0%~3.7%。
点此查看论文截图

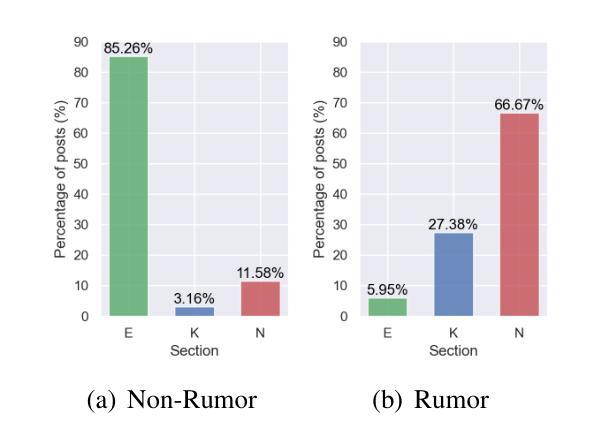
Towards Real-World Rumor Detection: Anomaly Detection Framework with Graph Supervised Contrastive Learning
Authors:Chaoqun Cui, Caiyan Jia
Current rumor detection methods based on propagation structure learning predominately treat rumor detection as a class-balanced classification task on limited labeled data. However, real-world social media data exhibits an imbalanced distribution with a minority of rumors among massive regular posts. To address the data scarcity and imbalance issues, we construct two large-scale conversation datasets from Weibo and Twitter and analyze the domain distributions. We find obvious differences between rumor and non-rumor distributions, with non-rumors mostly in entertainment domains while rumors concentrate in news, indicating the conformity of rumor detection to an anomaly detection paradigm. Correspondingly, we propose the Anomaly Detection framework with Graph Supervised Contrastive Learning (AD-GSCL). It heuristically treats unlabeled data as non-rumors and adapts graph contrastive learning for rumor detection. Extensive experiments demonstrate AD-GSCL’s superiority under class-balanced, imbalanced, and few-shot conditions. Our findings provide valuable insights for real-world rumor detection featuring imbalanced data distributions.
当前基于传播结构学习的谣言检测方法主要是将谣言检测视为在有限标记数据上的类平衡分类任务。然而,现实社交媒体的数据呈现出不平衡的分布,大量的常规帖子中只有一小部分是谣言。为了解决数据稀缺和不平衡问题,我们从微博和推特构建了两个大规模对话数据集并对领域分布进行了分析。我们发现谣言和非谣言分布之间存在明显差异,非谣言主要存在于娱乐领域,而谣言则集中在新闻领域,这表明谣言检测符合异常检测的模式。相应地,我们提出了基于图监督对比学习的异常检测框架(AD-GSCL)。它启发式地将未标记的数据视为非谣言,并适应图对比学习进行谣言检测。大量实验表明,AD-GSCL在类平衡、不平衡和少镜头条件下均表现优越。我们的研究为具有数据分布不平衡特征的实时谣言检测提供了有价值的见解。
论文及项目相关链接
PDF This paper is accepted by COLING2025
Summary
本文介绍了基于传播结构学习的当前谣言检测方法的局限性,这些方法主要作为类平衡分类任务在有限标记数据上进行。针对社交媒体数据的不平衡分布和缺乏数据的问题,研究者在微博和推特上构建了两个大规模对话数据集,并分析了领域分布。研究发现谣言和非谣言的分布存在明显差异,非谣言主要集中在娱乐领域,而谣言则集中在新闻领域,这表明谣言检测符合异常检测模式。据此,研究者提出了基于图监督对比学习的异常检测框架(AD-GSCL),该框架启发式地将未标记数据视为非谣言,并采用图对比学习进行谣言检测。实验表明,AD-GSCL在类平衡、不平衡和少样本条件下均表现出优越性。
Key Takeaways
- 当前谣言检测主要基于有限的标记数据且以类平衡分类任务为主,但社交媒体数据存在不平衡分布问题。
- 研究者通过构建大规模对话数据集发现,非谣言主要集中在娱乐领域,而谣言则集中在新闻领域。
- 谣言检测符合异常检测模式。
- 提出的AD-GSCL框架启发式地将未标记数据视为非谣言,并采用图对比学习进行谣言检测。
- AD-GSCL在多种条件下表现出优越性,包括类平衡、不平衡和少样本条件。
- 研究结果提供了对真实世界谣言检测中不平衡数据分布问题的有价值见解。
点此查看论文截图

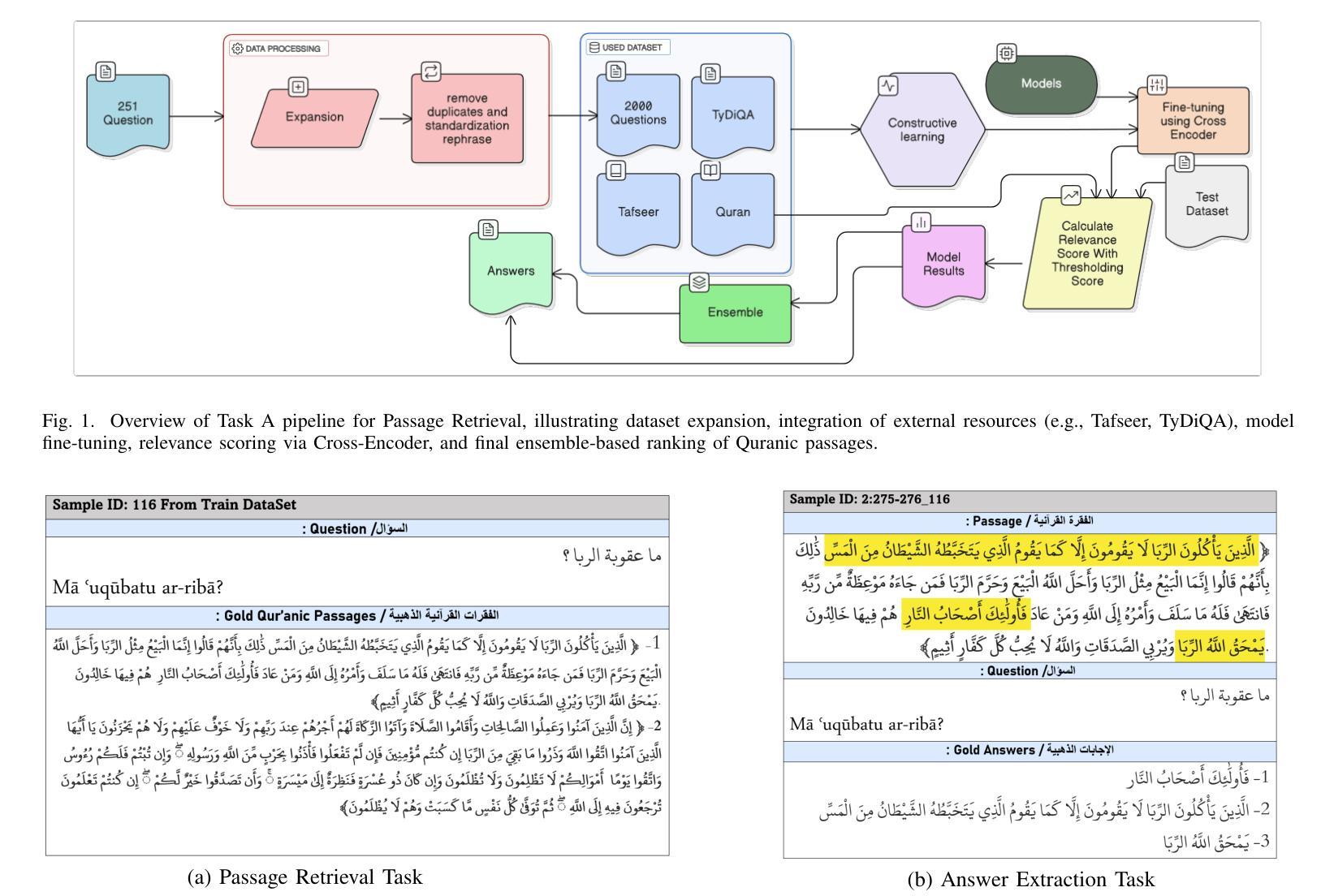
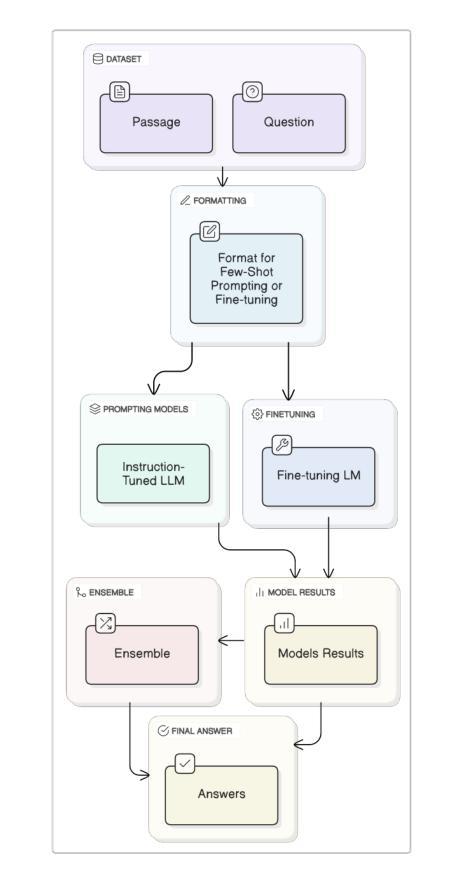
Two-Stage Quranic QA via Ensemble Retrieval and Instruction-Tuned Answer Extraction
Authors:Mohamed Basem, Islam Oshallah, Ali Hamdi, Khaled Shaban, Hozaifa Kassab
Quranic Question Answering presents unique challenges due to the linguistic complexity of Classical Arabic and the semantic richness of religious texts. In this paper, we propose a novel two-stage framework that addresses both passage retrieval and answer extraction. For passage retrieval, we ensemble fine-tuned Arabic language models to achieve superior ranking performance. For answer extraction, we employ instruction-tuned large language models with few-shot prompting to overcome the limitations of fine-tuning on small datasets. Our approach achieves state-of-the-art results on the Quran QA 2023 Shared Task, with a MAP@10 of 0.3128 and MRR@10 of 0.5763 for retrieval, and a pAP@10 of 0.669 for extraction, substantially outperforming previous methods. These results demonstrate that combining model ensembling and instruction-tuned language models effectively addresses the challenges of low-resource question answering in specialized domains.
由于古典阿拉伯语的语言复杂性和宗教文本丰富的语义内涵,伊斯兰问答呈现出独特的挑战。在本文中,我们提出了一种新颖的两阶段框架,该框架同时解决了段落检索和答案提取。对于段落检索,我们将微调阿拉伯语语言模型进行集成,以实现出色的排名性能。对于答案提取,我们采用指令微调的大型语言模型,通过少量提示来克服在小数据集上进行微调时的局限性。我们的方法在伊斯兰问答2023共享任务上取得了最新结果,检索的MAP@10为0.3128,MRR@10为0.5763,提取的pAP@10为0.669,大幅优于以前的方法。这些结果证明了结合模型集成和指令微调的语言模型有效地解决了特定领域低资源问答的挑战。
论文及项目相关链接
PDF 8 pages , 4 figures , Accepted in Aiccsa 2025 , https://conferences.sigappfr.org/aiccsa2025/
Summary
本文提出了一种新颖的两阶段框架,用于解决基于古兰经的问答挑战。首先利用微调阿拉伯语语言模型进行段落检索,实现优质排名性能;然后采用指令微调的大型语言模型进行答案提取,通过少样本提示克服小数据集上的微调限制。该方法在古兰经问答共享任务上取得了最新成果,实现了检索阶段的MAP@10为0.3128和MRR@10为0.5763的高精度排名以及答案提取阶段的pAP@10为0.669的出色表现,显著优于以前的方法。结果表明,结合模型集成和指令微调的语言模型可以有效解决低资源领域的问答挑战。
Key Takeaways
- 面临挑战:古兰经问答面临语言复杂性和宗教文本语义丰富性的挑战。
- 方法创新:提出一种新颖的两阶段框架,包括段落检索和答案提取。
- 段落检索:使用微调阿拉伯语语言模型实现优质排名性能。
- 答案提取:采用指令微调的大型语言模型进行少样本学习以实现高性能提取答案。
- 取得成果:在古兰经问答共享任务上取得最新成果,包括MAP@10、MRR@10和pAP@10等多个维度的提升。
- 超越前法:相比以前的方法,该模型能够更有效地处理低资源领域的问答挑战。
点此查看论文截图

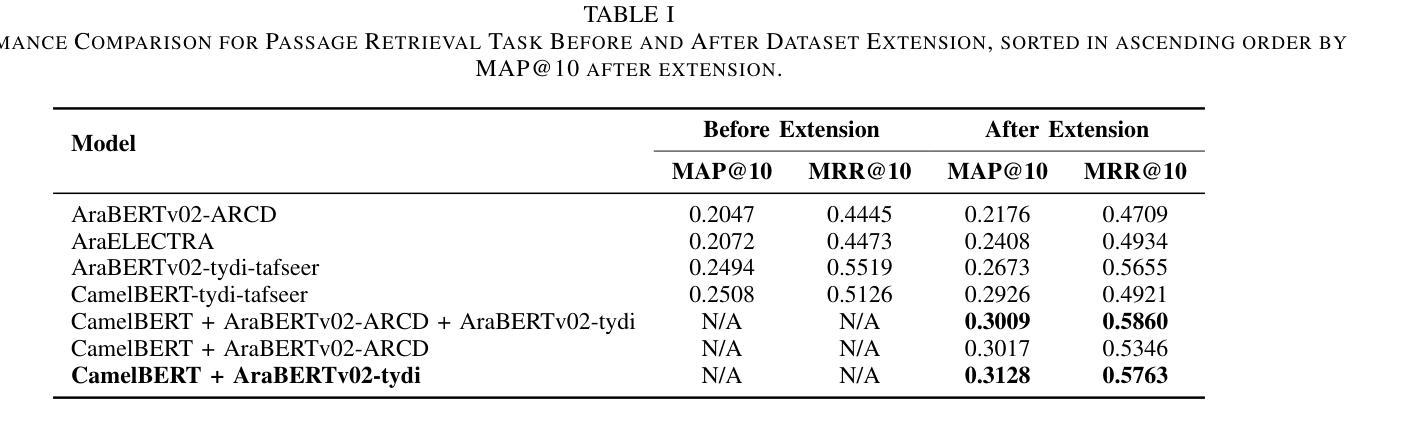
Large Language Models for Oral History Understanding with Text Classification and Sentiment Analysis
Authors:Komala Subramanyam Cherukuri, Pranav Abishai Moses, Aisa Sakata, Jiangping Chen, Haihua Chen
Oral histories are vital records of lived experience, particularly within communities affected by systemic injustice and historical erasure. Effective and efficient analysis of their oral history archives can promote access and understanding of the oral histories. However, Large-scale analysis of these archives remains limited due to their unstructured format, emotional complexity, and high annotation costs. This paper presents a scalable framework to automate semantic and sentiment annotation for Japanese American Incarceration Oral History. Using LLMs, we construct a high-quality dataset, evaluate multiple models, and test prompt engineering strategies in historically sensitive contexts. Our multiphase approach combines expert annotation, prompt design, and LLM evaluation with ChatGPT, Llama, and Qwen. We labeled 558 sentences from 15 narrators for sentiment and semantic classification, then evaluated zero-shot, few-shot, and RAG strategies. For semantic classification, ChatGPT achieved the highest F1 score (88.71%), followed by Llama (84.99%) and Qwen (83.72%). For sentiment analysis, Llama slightly outperformed Qwen (82.66%) and ChatGPT (82.29%), with all models showing comparable results. The best prompt configurations were used to annotate 92,191 sentences from 1,002 interviews in the JAIOH collection. Our findings show that LLMs can effectively perform semantic and sentiment annotation across large oral history collections when guided by well-designed prompts. This study provides a reusable annotation pipeline and practical guidance for applying LLMs in culturally sensitive archival analysis. By bridging archival ethics with scalable NLP techniques, this work lays the groundwork for responsible use of artificial intelligence in digital humanities and preservation of collective memory. GitHub: https://github.com/kc6699c/LLM4OralHistoryAnalysis.
口述历史是生活经历的宝贵记录,特别是在受到系统性不公正和历史抹黑影响的社区中尤为重要。对其口述历史档案的有效和高效分析,可以促进对口述历史的访问和理解。然而,由于口述历史档案的非结构化格式、情感复杂性和高标注成本,这些档案的大规模分析仍然受到限制。本文提出了一个可扩展的框架,用于自动进行日本裔美国人监禁口述历史的语义和情绪注释。我们使用大型语言模型构建了一个高质量的数据集,对多个模型进行了评估,并在历史敏感的上下文中测试了提示工程策略。我们的多阶段方法结合了专家注释、提示设计以及使用ChatGPT、Llama和Qwen对大型语言模型的评估。我们对来自15个叙述者的558个句子进行了情感和语义分类标注,然后评估了零样本、少样本和RAG策略。对于语义分类,ChatGPT的F1分数最高(88.71%),其次是Llama(84.99%)和Qwen(83.72%)。在情感分析中,Llama略优于Qwen(82.66%)和ChatGPT(82.29%),所有模型的性能均相当。使用最佳的提示配置来注释JAIOH收藏中的92,191个句子和来自1,002次访谈的数据。我们的研究结果表明,在引导良好的提示下,大型语言模型可以有效地在大型口述历史集合中进行语义和情绪注释。本研究提供了一个可重复使用的注释管道,为在敏感文化档案分析中应用大型语言模型提供了实际指导。通过架起档案伦理与可扩展的自然语言处理技术之间的桥梁,这项工作为数字人文中人工智能的负责任使用和集体记忆的保存奠定了基础。GitHub地址:https://github.com/kc6699c/LLM4OralHistoryAnalysis。
论文及项目相关链接
摘要
本文关注口述历史档案的分析,特别是受到系统性不公正和历叐性抹杀影响的社群中的口述历史。研究提出了一种可扩展的框架,利用大型语言模型(LLMs)自动进行日本裔美国人关押口述历史的语义和情感注释。研究构建了高质量的数据集,评估了多个模型,并在历史敏感语境中测试了提示工程策略。结果显示,ChatGPT在语义分类上的F1分数最高(88.71%),Llama(84.99%)和Qwen(83.72%)表现略逊。在情感分析中,Llama略胜一筹(82.66%),而ChatGPT(82.29%)与其他模型结果相当。使用最佳的提示配置,成功标注了JAIOH收藏中的92,191句和1,002次访谈。研究表明,在精心设计提示的指导下,大型语言模型可以在大规模口述历史集合中有效执行语义和情感注释。本研究为应用大型语言模型于文化敏感档案分析提供了可重复使用的标注管道和实用指导,为人工智能在数字人文和集体记忆保护中的负责任使用奠定了基础。
关键见解
- 口述历史是记录生活经验的重要资料,特别是在受到系统性不公正和历叐性抹杀的社群中。
- 大型语言模型(LLMs)在口述历史档案的情感和语义自动注释中具有潜力。
- 本研究开发了一个可扩展的框架,用于日本裔美国人关押口述历史的语义和情感注释。
- ChatGPT在语义分类上表现最佳,而Llama在情感分析中稍微占优。
- 利用最佳提示配置,成功标注了大量口述历史句子和访谈。
- 研究结果强调了在文化敏感档案分析中负责任地使用人工智能的重要性。
- 本研究为大型语言模型在数字人文和集体记忆保护中的应用提供了实用指导和可重复使用的标注管道。
点此查看论文截图

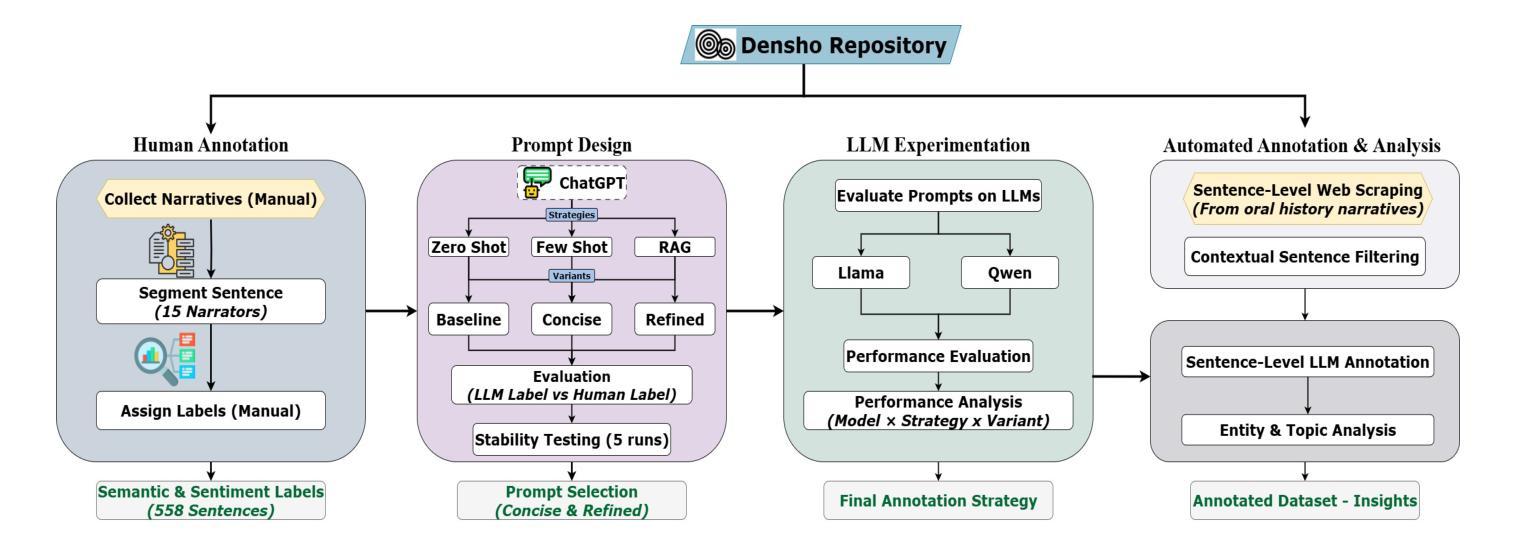
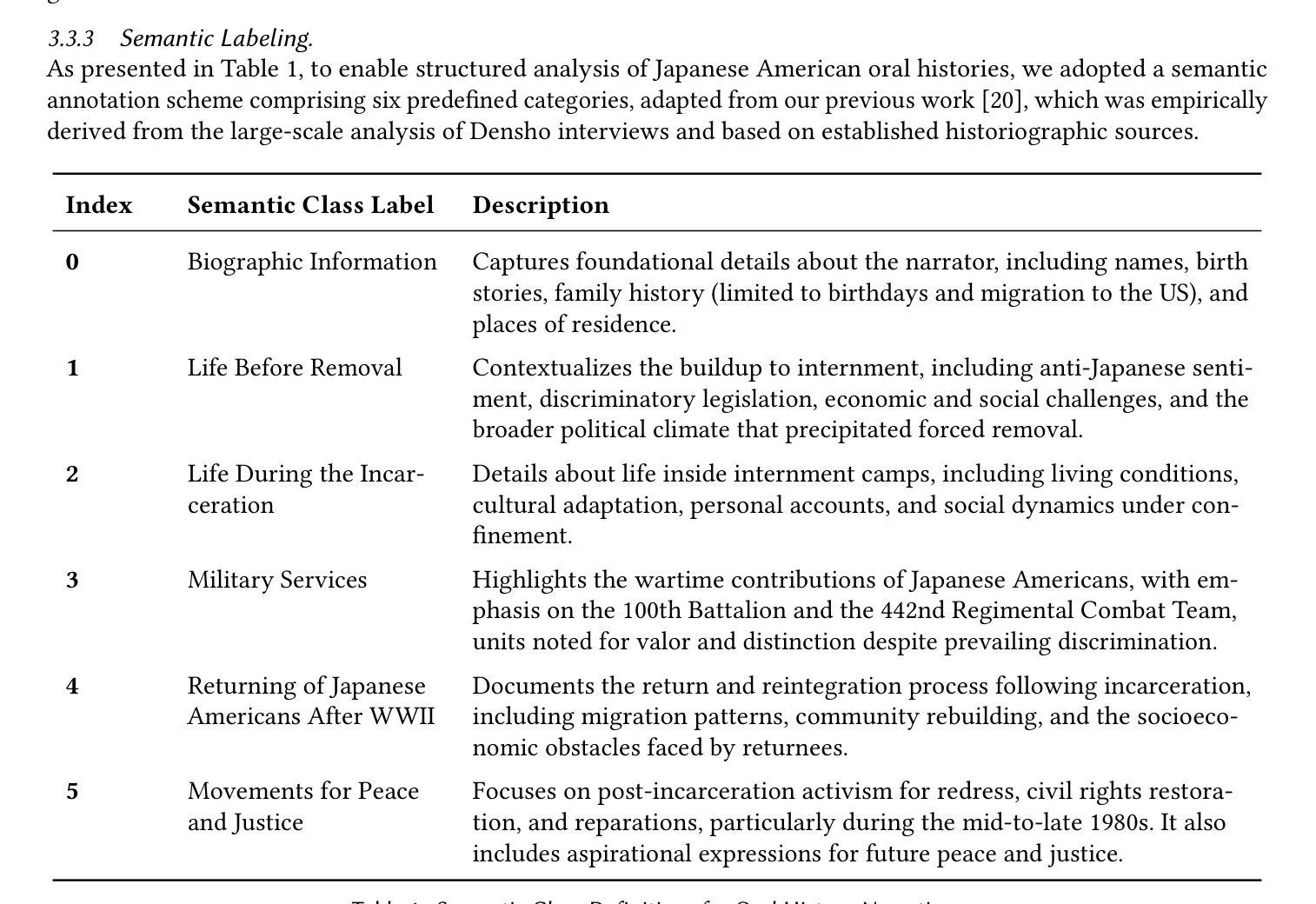
UltraAD: Fine-Grained Ultrasound Anomaly Classification via Few-Shot CLIP Adaptation
Authors:Yue Zhou, Yuan Bi, Wenjuan Tong, Wei Wang, Nassir Navab, Zhongliang Jiang
Precise anomaly detection in medical images is critical for clinical decision-making. While recent unsupervised or semi-supervised anomaly detection methods trained on large-scale normal data show promising results, they lack fine-grained differentiation, such as benign vs. malignant tumors. Additionally, ultrasound (US) imaging is highly sensitive to devices and acquisition parameter variations, creating significant domain gaps in the resulting US images. To address these challenges, we propose UltraAD, a vision-language model (VLM)-based approach that leverages few-shot US examples for generalized anomaly localization and fine-grained classification. To enhance localization performance, the image-level token of query visual prototypes is first fused with learnable text embeddings. This image-informed prompt feature is then further integrated with patch-level tokens, refining local representations for improved accuracy. For fine-grained classification, a memory bank is constructed from few-shot image samples and corresponding text descriptions that capture anatomical and abnormality-specific features. During training, the stored text embeddings remain frozen, while image features are adapted to better align with medical data. UltraAD has been extensively evaluated on three breast US datasets, outperforming state-of-the-art methods in both lesion localization and fine-grained medical classification. The code will be released upon acceptance.
医疗图像中的精确异常检测对于临床决策至关重要。虽然最近基于大规模正常数据的无监督或半监督异常检测方法显示出有希望的结果,但它们缺乏精细的区分,例如良性与恶性肿瘤。此外,超声(US)成像对设备和采集参数的变化高度敏感,导致超声图像中存在明显的领域差距。为了应对这些挑战,我们提出了UltraAD,这是一种基于视觉语言模型(VLM)的方法,它利用少量超声样本进行通用异常定位和精细分类。为了提高定位性能,首先融合查询视觉原型的图像级令牌和可学习的文本嵌入。然后,将图像信息提示特征与补丁级令牌进一步集成,细化局部表示以提高准确性。对于精细分类,从少量图像样本和相应的文本描述中构建了一个内存银行,以捕获解剖结构和异常特定的特征。在训练过程中,存储的文本嵌入保持不变,而图像特征更好地适应医学数据。UltraAD在三个乳腺超声数据集上进行了广泛评估,在病灶定位和精细医学分类方面都优于最新方法。代码将在接受后发布。
论文及项目相关链接
Summary
医学图像中的精确异常检测对临床决策至关重要。针对现有方法缺乏精细粒度区分(如良性与恶性肿瘤)以及超声成像中的设备与采集参数变化带来的领域差距问题,我们提出了UltraAD,一种基于视觉语言模型(VLM)的方法,利用少量超声图像样本进行通用异常定位和精细粒度分类。通过融合查询视觉原型图像级令牌和可学习文本嵌入,增强定位性能。此外,利用少量图像样本及其文本描述构建记忆库,以捕获解剖和异常特定特征,进行精细分类。在三个乳腺超声数据集上的评估表明,UltraAD在病灶定位和精细医学分类方面均优于现有方法。
Key Takeaways
- 医学图像精确异常检测对临床决策至关重要。
- 当前方法缺乏精细粒度区分,如良性与恶性肿瘤的区分。
- UltraAD利用视觉语言模型(VLM)来解决这些问题。
- UltraAD通过融合图像级令牌和文本嵌入来增强异常定位性能。
- 利用少量超声图像样本进行通用异常定位和精细粒度分类。
- 通过构建记忆库来捕获解剖和异常特定特征,进行精细分类。
点此查看论文截图


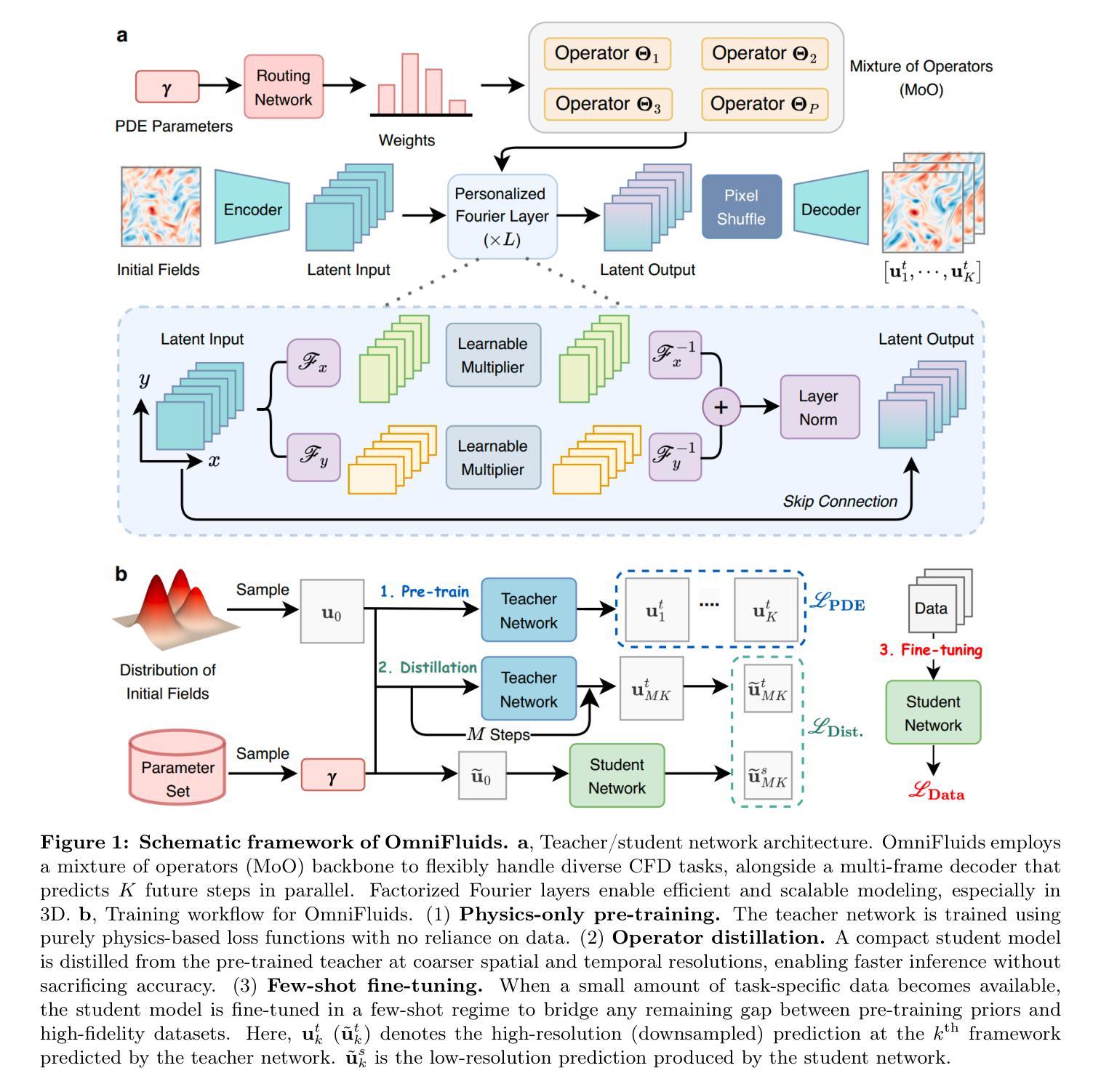
OmniFluids: Physics Pre-trained Modeling of Fluid Dynamics
Authors:Rui Zhang, Qi Meng, Han Wan, Yang Liu, Zhi-Ming Ma, Hao Sun
Computational fluid dynamics (CFD) drives progress in numerous scientific and engineering fields, yet high-fidelity simulations remain computationally prohibitive. While machine learning approaches offer computing acceleration, they typically specialize in single physical systems or require extensive training data, hindering their applicability in highly nonlinear and 3D flow scenarios. To overcome these limitations, we propose OmniFluids, a pure physics pre-trained model that captures fundamental fluid dynamics laws and adapts efficiently to diverse downstream tasks with minimal data. We develop a training framework combining physics-only pre-training, coarse-grid operator distillation, and few-shot fine-tuning. This enables OmniFluids to retain broad physics knowledge while delivering fast and accurate predictions. Architecturally, OmniFluids integrates a mixture of operators, a multi-frame decoder, and factorized Fourier layers, seamlessly incorporating physics-based supervision while allowing efficient and scalable modeling of diverse tasks. Extensive tests on a broad range of 2D and 3D benchmarks show that OmniFluids outperforms state-of-the-art AI-driven methods in terms of flow field prediction and turbulence statistics. It delivers 10–100$\times$ speedups over traditional solvers while maintaining a comparable accuracy and accurately identifies unknown physical parameters from sparse, noisy data. This work demonstrates the potential of training a unified CFD solver exclusively from physics knowledge, offering a new approach for efficient and generalizable modeling across complex fluid systems.
计算流体动力学(CFD)推动了众多科学和工程领域的进步,但高保真模拟在计算能力方面仍然受限。虽然机器学习方法提供了计算加速,但它们通常专门用于单一物理系统或需要大量训练数据,这阻碍了它们在高度非线性和三维流动场景中的应用。为了克服这些限制,我们提出了OmniFluids,这是一个纯物理预训练模型,能够捕捉基本的流体动力学定律,并以高效的方式适应多样化的下游任务,所需数据最少。我们开发了一个训练框架,结合了仅物理预训练、粗网格操作蒸馏和少量样本微调。这使得OmniFluids能够保留广泛的物理知识,同时实现快速和准确的预测。在结构上,OmniFluids融合了多种操作、多帧解码器和因子化傅里叶层,无缝地融入了基于物理的监督,允许对多样化任务进行高效和可扩展的建模。在广泛的二维和三维基准测试上的大量测试表明,OmniFluids在流场预测和湍流统计方面优于最新的AI驱动方法。与传统的求解器相比,它提供了10-100倍的加速,同时保持相当的准确性,并能从稀疏、嘈杂的数据中准确地识别出未知的物理参数。这项工作展示了仅从物理知识训练统一CFD求解器的潜力,为复杂流体系统提供高效和可推广的建模新方法。
论文及项目相关链接
Summary
本文提出一种名为OmniFluids的纯物理预训练模型,该模型能够捕捉基本的流体动力学定律,并能高效适应多种下游任务且所需数据量极小。通过结合物理预训练、粗网格操作蒸馏和少量微调,OmniFluids能够在保留广泛物理知识的同时实现快速准确的预测。在广泛的二维和三维基准测试中,OmniFluids在流场预测和湍流统计方面优于最新的AI驱动方法,并且相对于传统求解器实现了速度和精度的平衡。这项研究展示了仅通过物理知识训练统一CFD求解器的潜力,为复杂流体系统的有效和可推广建模提供了新的途径。
Key Takeaways
- OmniFluids模型结合了物理预训练、粗网格操作蒸馏和少量微调技术,实现了快速准确的预测。
- OmniFluids能够在不同的下游任务中高效适应,所需数据量小。
- OmniFluids在广泛的二维和三维基准测试中表现出优异的性能,特别是在流场预测和湍流统计方面。
- 与传统求解器相比,OmniFluids实现了速度和精度的平衡。
- OmniFluids模型能够准确地识别出稀疏、嘈杂数据中的未知物理参数。
- 该研究展示了仅通过物理知识训练统一CFD求解器的潜力。
点此查看论文截图

GreenMind: A Next-Generation Vietnamese Large Language Model for Structured and Logical Reasoning
Authors:Luu Quy Tung, Hoang Quoc Viet, Pham Bao Loc, Vo Trong Thu
Chain-of-Thought (CoT) is a robust approach for tackling LLM tasks that require intermediate reasoning steps prior to generating a final answer. In this paper, we present GreenMind-Medium-14B-R1, the Vietnamese reasoning model inspired by the finetuning strategy based on Group Relative Policy Optimization. We also leverage a high-quality Vietnamese synthesized reasoning dataset and design two reward functions to tackle the main limitations of this technique: (i) language mixing, where we explicitly detect the presence of biased language characters during the process of sampling tokens, and (ii) we leverage Sentence Transformer-based models to ensure that the generated reasoning content maintains factual correctness and does not distort the final output. Experimental results on the Vietnamese dataset from the VLSP 2023 Challenge demonstrate that our model outperforms prior works and enhances linguistic consistency in its responses. Furthermore, we extend our evaluation to SeaExam-a multilingual multiple-choice dataset, showing the effectiveness of our reasoning method compared to few-shot prompting techniques.
链式思维(CoT)是一种强大的方法,用于解决大型语言模型(LLM)任务,这些任务需要在生成最终答案之前进行中间推理步骤。在本文中,我们介绍了GreenMind-Medium-14B-R1,这是一个受基于组相对策略优化(Group Relative Policy Optimization)微调策略启发的越南语推理模型。我们还利用高质量的越南语合成推理数据集,并设计两个奖励函数来解决这项技术的两个主要局限性:(i)语言混合问题,我们在采样token的过程中显式检测有偏见的语言字符的存在;(ii)我们利用基于句子转换器的模型确保生成的推理内容保持事实正确性,并不歪曲最终输出。在VLSP 2023挑战的越南数据集上的实验结果表明,我们的模型表现优于早期作品,并且在回应中增强了语言一致性。此外,我们将评估扩展到了SeaExam——一个多语种选择题数据集,以展示我们的推理方法与少提示技术相比的有效性。
论文及项目相关链接
Summary
绿心智图-中型-14B-R1是越南推理模型,采用基于组相对策略优化的微调策略。该模型解决了语言混合问题,并利用句子转换器模型确保推理内容的准确性并减少输出扭曲。在越南数据集VLSP 2023挑战中表现优异,并在多语言选择题集SeaExam中验证了其推理方法的有效性。
Key Takeaways
- 介绍了绿心智图-中型-14B-R1模型,它是一个基于越南语言的推理模型。
- 模型采用了微调策略,其基础是组相对策略优化。
- 通过两个奖励函数解决了该技术的两个主要局限性:语言混合和确保生成的推理内容的准确性。
- 通过检测采样令牌过程中存在的偏见语言字符来解决语言混合问题。
- 利用句子转换器模型确保推理内容的准确性并减少输出扭曲。
- 在越南数据集VLSP 2023挑战中,该模型的性能优于以前的工作,并且增强了语言一致性。
点此查看论文截图



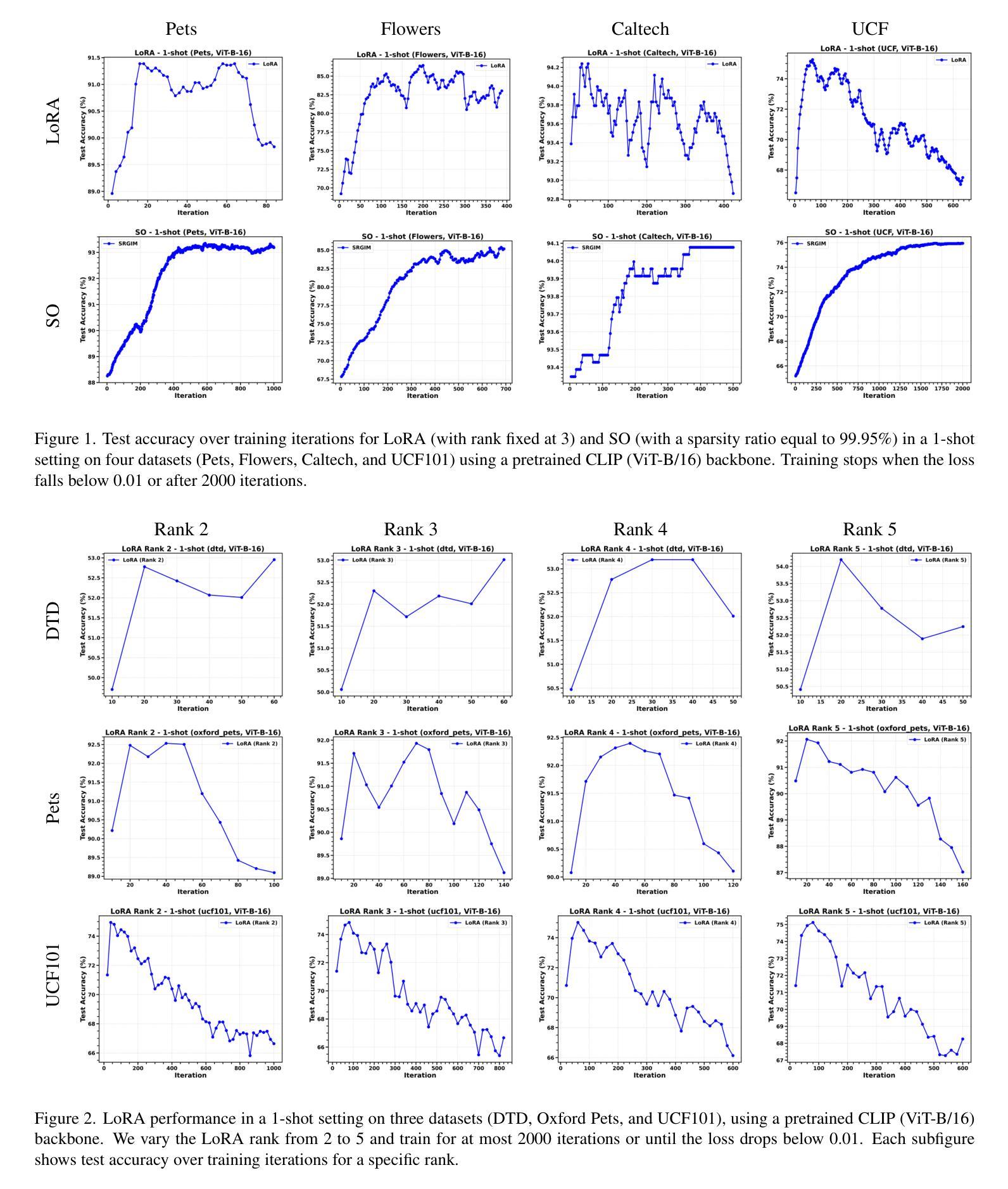
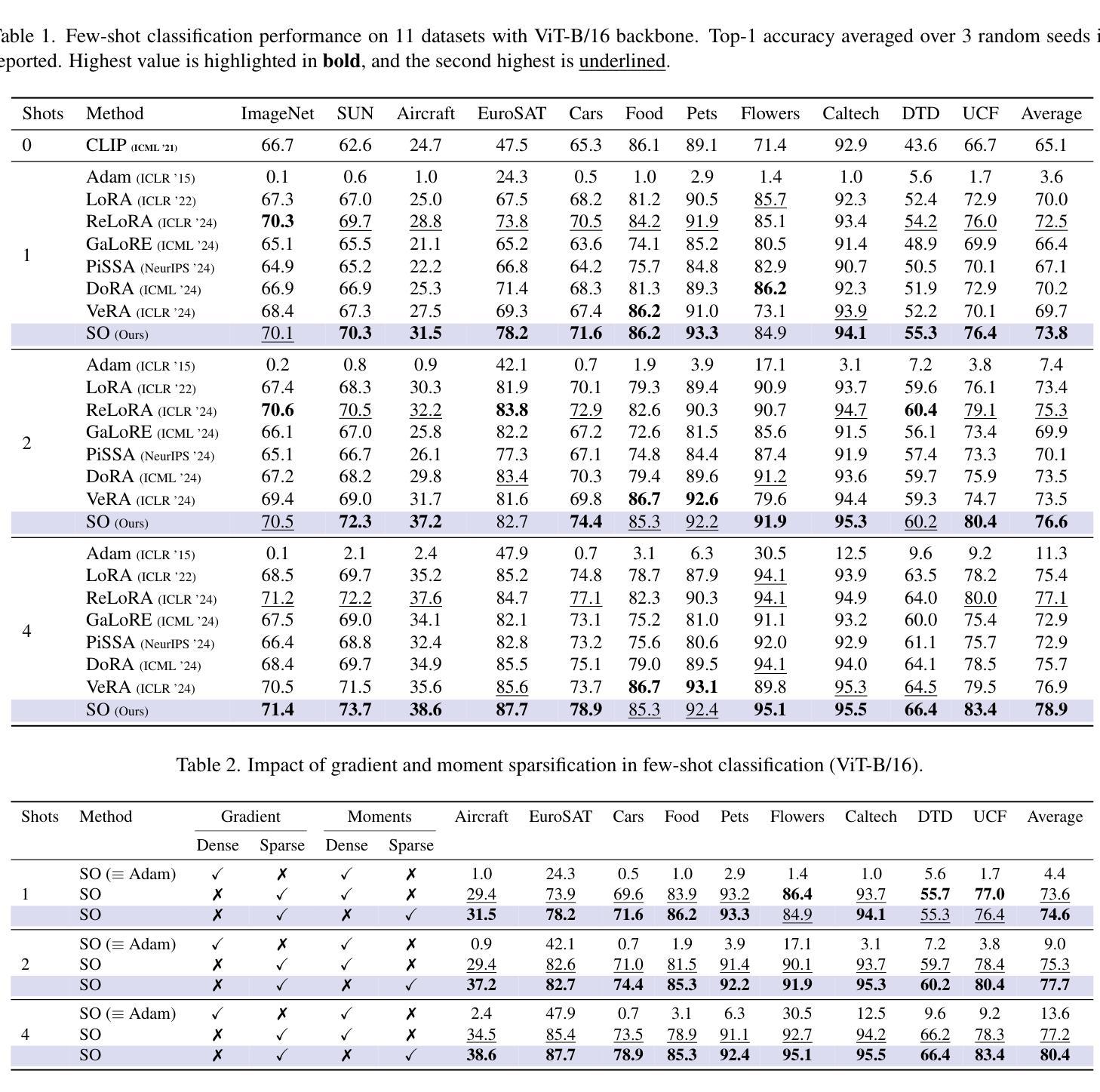
Sparsity Outperforms Low-Rank Projections in Few-Shot Adaptation
Authors:Nairouz Mrabah, Nicolas Richet, Ismail Ben Ayed, Éric Granger
Adapting Vision-Language Models (VLMs) to new domains with few labeled samples remains a significant challenge due to severe overfitting and computational constraints. State-of-the-art solutions, such as low-rank reparameterization, mitigate these issues but often struggle with generalization and require extensive hyperparameter tuning. In this paper, a novel Sparse Optimization (SO) framework is proposed. Unlike low-rank approaches that typically constrain updates to a fixed subspace, our SO method leverages high sparsity to dynamically adjust very few parameters. We introduce two key paradigms. First, we advocate for \textit{local sparsity and global density}, which updates a minimal subset of parameters per iteration while maintaining overall model expressiveness. As a second paradigm, we advocate for \textit{local randomness and global importance}, which sparsifies the gradient using random selection while pruning the first moment based on importance. This combination significantly mitigates overfitting and ensures stable adaptation in low-data regimes. Extensive experiments on 11 diverse datasets show that SO achieves state-of-the-art few-shot adaptation performance while reducing memory overhead.
将视觉语言模型(VLMs)适应具有少量标记样本的新领域仍然是一个巨大的挑战,这主要是由于严重的过度拟合和计算约束。最先进的解决方案,如低秩重参数化,可以缓解这些问题,但它们通常很难推广,并且需要大量调整超参数。本文提出了一种新颖的稀疏优化(SO)框架。与通常将更新限制在固定子空间中的低秩方法不同,我们的SO方法利用高稀疏性来动态调整极少的参数。我们介绍了两种关键范式。首先,我们提倡“局部稀疏性和全局密度”,这可以在每次迭代时更新一小部分参数,同时保持模型的整体表现力。作为第二种范式,我们主张“局部随机性和全局重要性”,使用随机选择来稀疏梯度,并根据重要性进行第一时刻的修剪。这种结合显著减轻了过度拟合问题,并确保在低数据情况下实现稳定的适应。在11个不同数据集上的大量实验表明,SO在少样本适应方面达到了最先进的性能,同时降低了内存开销。
论文及项目相关链接
PDF ICCV2025
摘要
本文提出一种新的优化框架——稀疏优化(SO),用于在具有少量标签样本的新领域中自适应调整视觉语言模型(VLMs)。SO通过局部稀疏性和全局密度相结合的方法动态调整很少的模型参数,以提高在少数样本上的适应性并避免过度拟合。此外,SO还结合了局部随机性和全局重要性的概念,通过随机选择梯度并基于重要性进行修剪来进一步稳定模型在低数据条件下的适应。在多种数据集上的实验表明,SO方法在具有显著减少内存开销的同时实现了先进的少数适应性能。
关键见解
- 稀疏优化(SO)框架被提出用于解决在具有少量标签样本的新领域中自适应调整视觉语言模型(VLMs)的挑战性问题。
- SO框架利用局部稀疏性和全局密度相结合的方法动态调整很少的模型参数,从而提高模型在少数样本上的适应性。
- SO方法结合了局部随机性和全局重要性的概念,通过随机选择梯度并基于重要性进行修剪来进一步稳定模型在低数据条件下的适应。
- 与低秩方法相比,SO框架具有更好的泛化能力和适应性,无需大量的超参数调整。
点此查看论文截图

Hierarchical Relation-augmented Representation Generalization for Few-shot Action Recognition
Authors:Hongyu Qu, Ling Xing, Jiachao Zhang, Rui Yan, Yazhou Yao, Xiangbo Shu
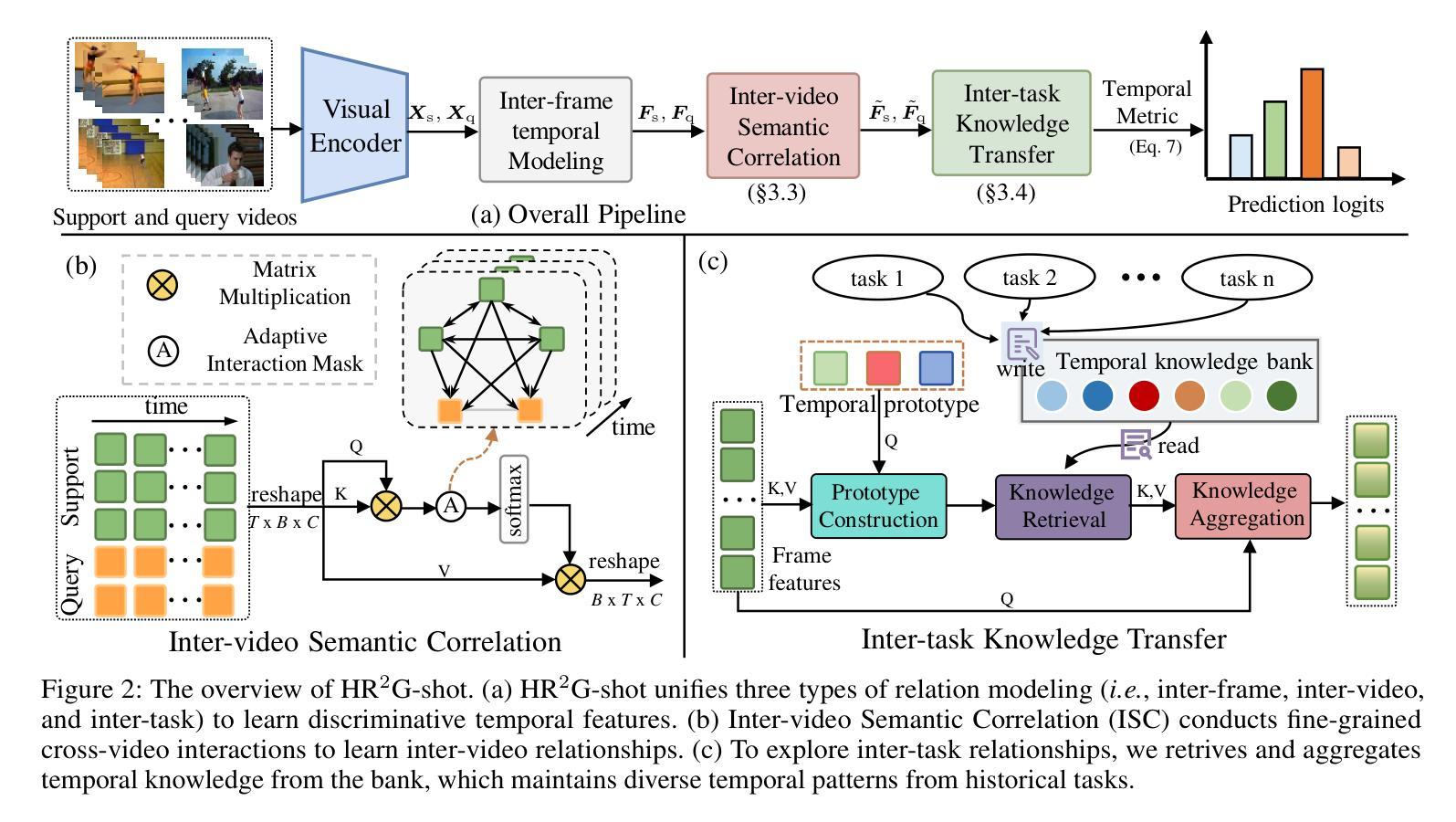
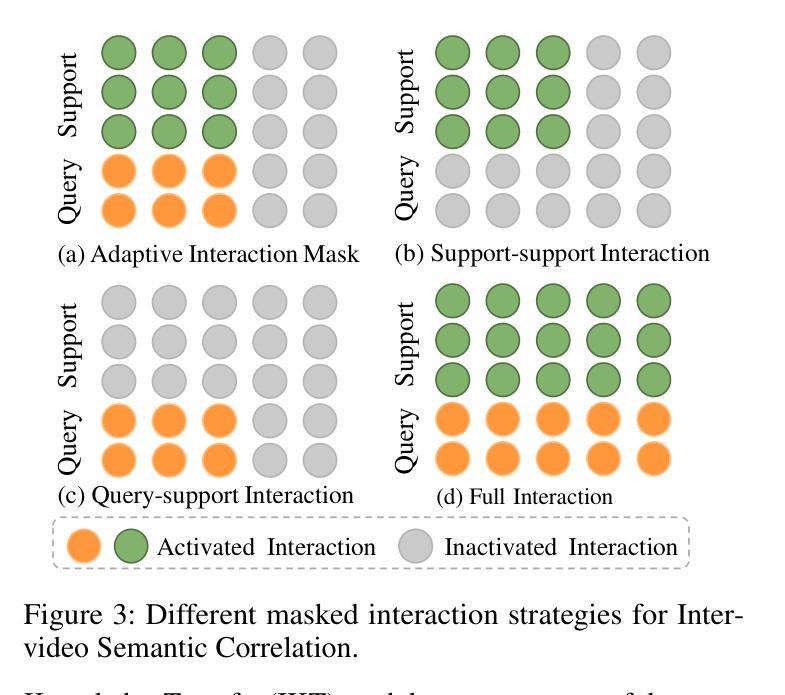
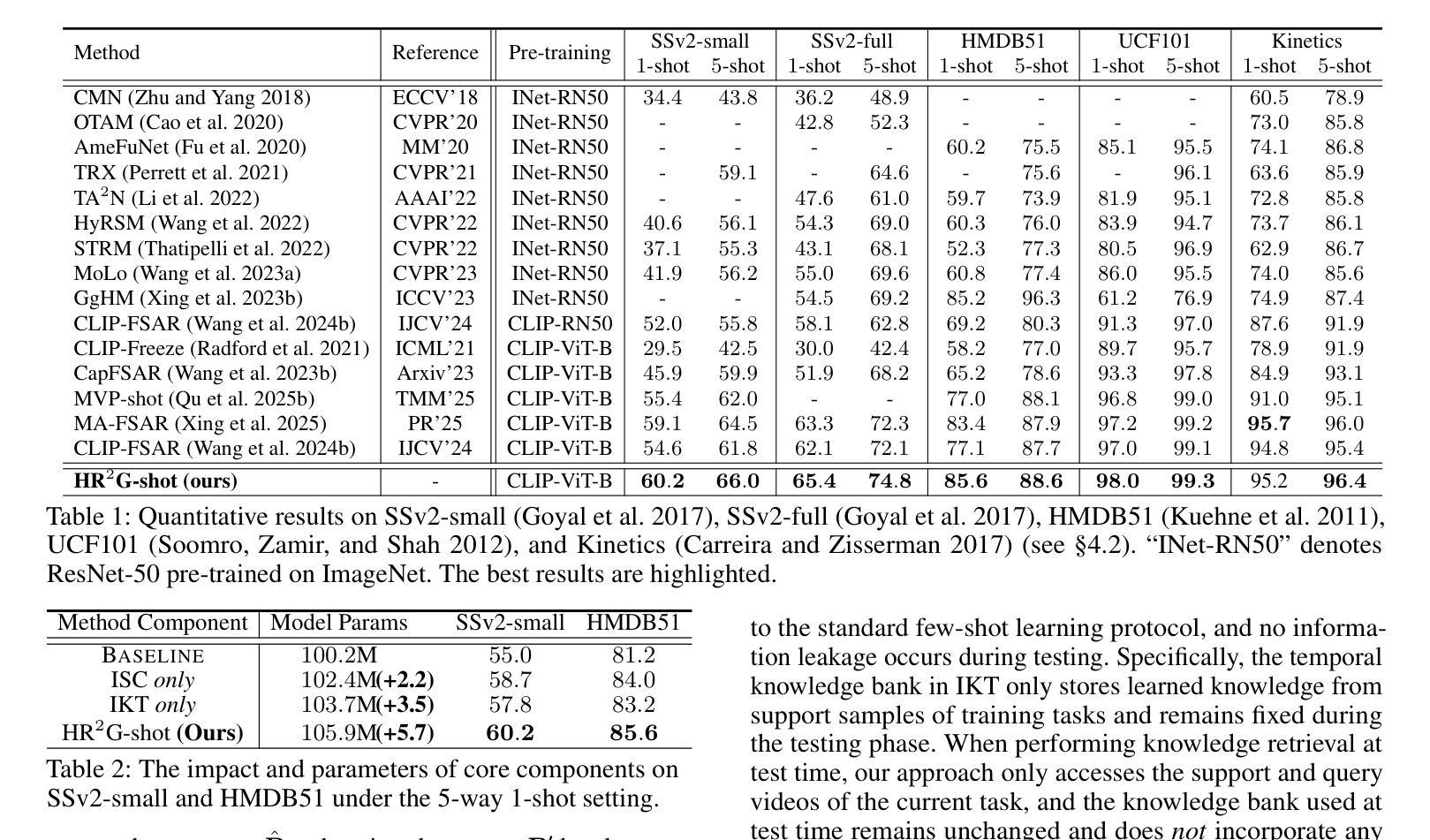
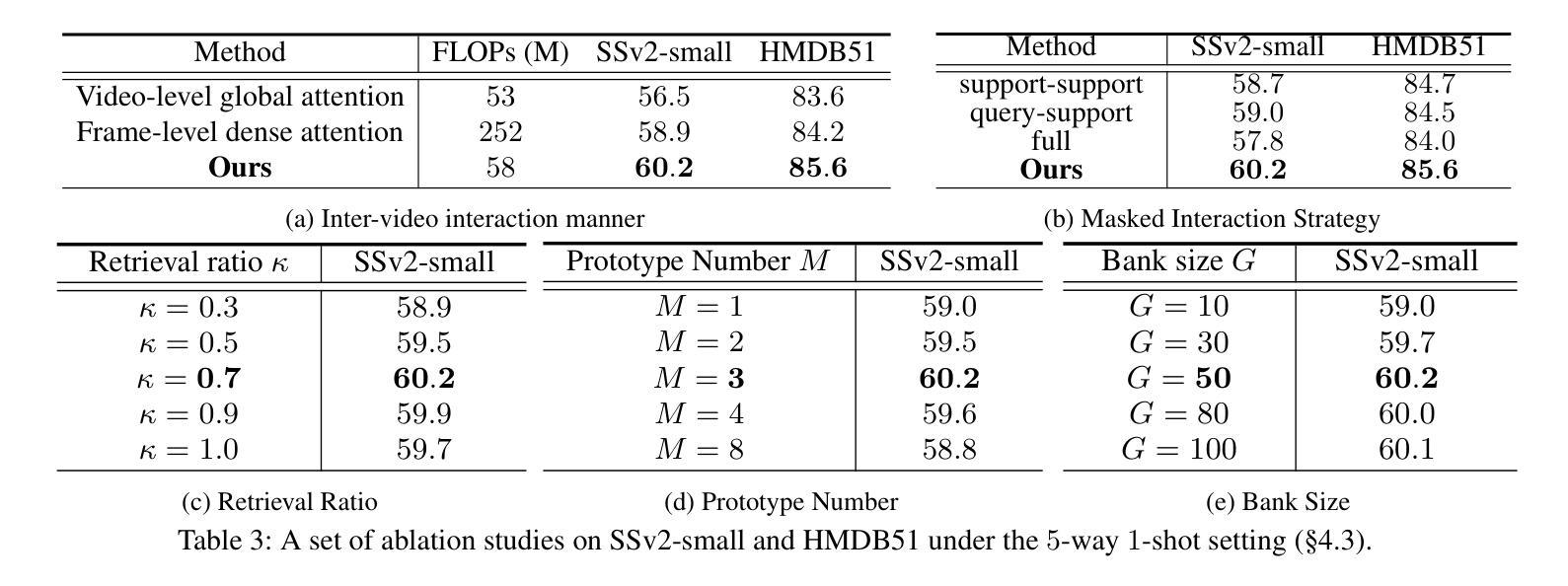
Few-shot action recognition (FSAR) aims to recognize novel action categories with few exemplars. Existing methods typically learn frame-level representations for each video by designing inter-frame temporal modeling strategies or inter-video interaction at the coarse video-level granularity. However, they treat each episode task in isolation and neglect fine-grained temporal relation modeling between videos, thus failing to capture shared fine-grained temporal patterns across videos and reuse temporal knowledge from historical tasks. In light of this, we propose HR2G-shot, a Hierarchical Relation-augmented Representation Generalization framework for FSAR, which unifies three types of relation modeling (inter-frame, inter-video, and inter-task) to learn task-specific temporal patterns from a holistic view. Going beyond conducting inter-frame temporal interactions, we further devise two components to respectively explore inter-video and inter-task relationships: i) Inter-video Semantic Correlation (ISC) performs cross-video frame-level interactions in a fine-grained manner, thereby capturing task-specific query features and enhancing both intra-class consistency and inter-class separability; ii) Inter-task Knowledge Transfer (IKT) retrieves and aggregates relevant temporal knowledge from the bank, which stores diverse temporal patterns from historical episode tasks. Extensive experiments on five benchmarks show that HR2G-shot outperforms current top-leading FSAR methods.
少量样本动作识别(FSAR)旨在使用少量样本识别新型动作类别。现有方法通常通过设计帧间时序建模策略或在粗视频级别粒度上的视频间交互,为每个视频学习帧级表示。然而,它们孤立地处理每个任务片段,忽略了视频之间的精细粒度时序关系建模,因此无法捕获跨视频的共享精细粒度时序模式,也无法从历史任务中重复使用时序知识。鉴于此,我们提出了HR2G-shot,这是一个用于FSAR的分层关系增强表示泛化框架,它统一了三种类型的关系建模(帧间、视频间和任务间),从整体视角学习特定任务的时序模式。除了进行帧间时序交互外,我们还进一步开发了两个组件来分别探索视频间和任务间的关系:一、视频间语义相关性(ISC)以精细粒度的方式执行跨视频帧级交互,从而捕获特定任务的查询特征,增强类内一致性和类间可分离性;二、任务间知识转移(IKT)从知识库中检索和聚合相关的时序知识,该库存储了来自历史任务片段的多种时序模式。在五个基准测试上的广泛实验表明,HR2G-shot的表现优于当前领先的FSAR方法。
论文及项目相关链接
Summary
该文本介绍了Few-shot动作识别(FSAR)的新方法HR2G-shot。该方法旨在通过统一三种关系建模(帧间、视频间和任务间)来学习任务特定的时间模式。它通过探索视频间和任务间的关系,增强了类内一致性和类间可分性,并从历史任务中检索和聚合相关的临时知识。此方法在五个基准测试中表现出色。
Key Takeaways
- Few-shot action recognition (FSAR)的目标是识别少量样本下的新动作类别。
- 现有方法主要关注视频帧级别的表示学习,但忽略了视频间的精细时间关系建模。
- HR2G-shot是一个针对FSAR的层次关系增强表示泛化框架,融合了三种关系建模:帧间、视频间和任务间。
- HR2G-shot通过探索视频间和任务间的关系,增强了模型性能。
- Inter-video Semantic Correlation (ISC)模块以精细粒度的方式执行跨视频帧交互,提高了类内一致性和类间可分性。
- Inter-task Knowledge Transfer (IKT)模块从知识库中检索并聚合来自历史任务的临时知识。
点此查看论文截图

From Limited Labels to Open Domains:An Efficient Learning Method for Drone-view Geo-Localization
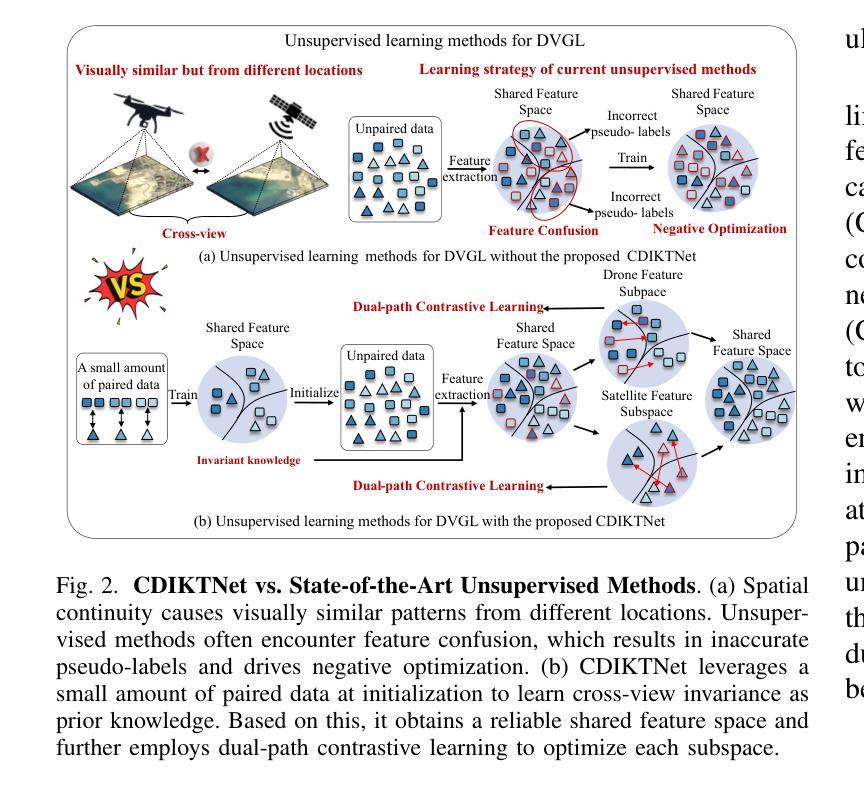
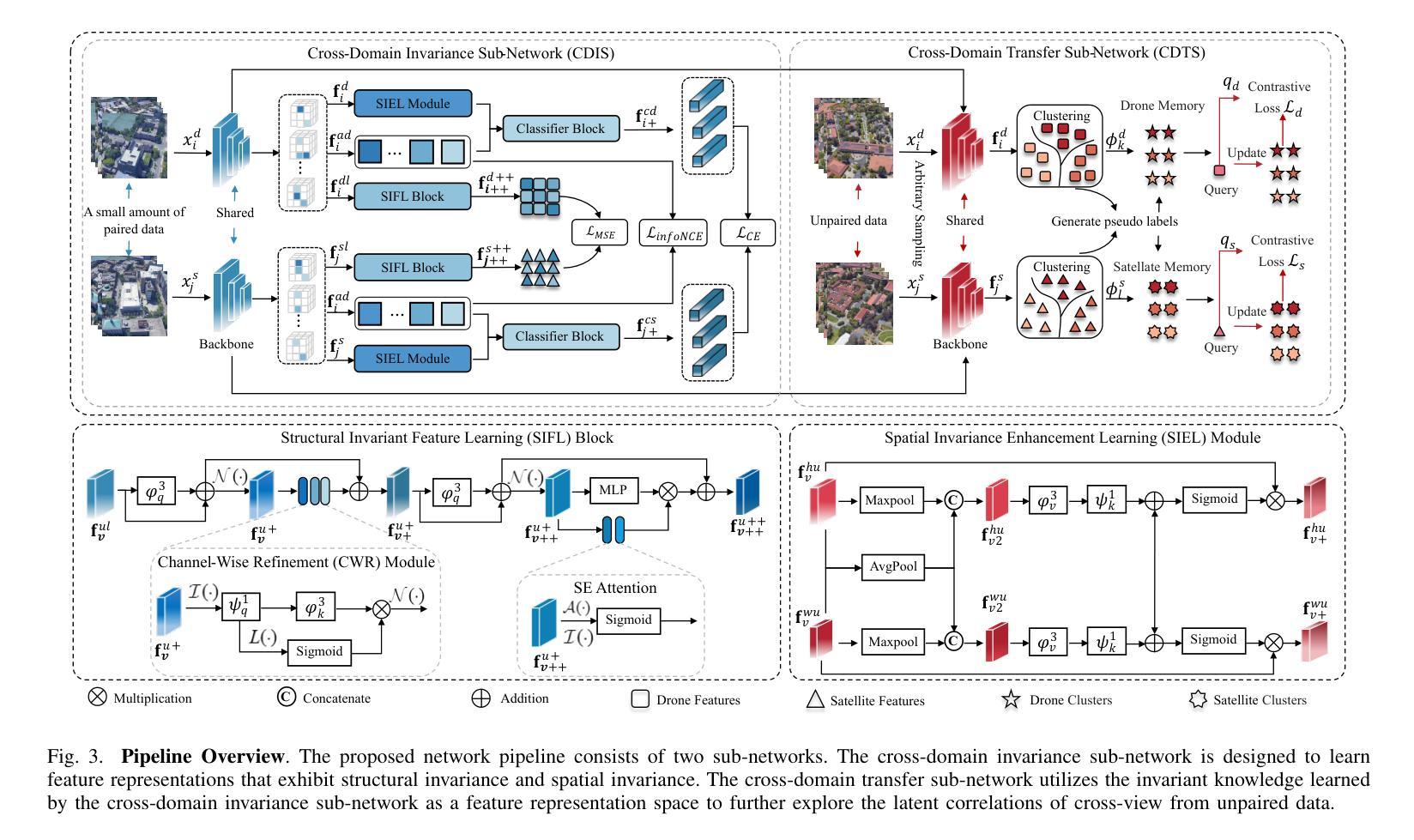
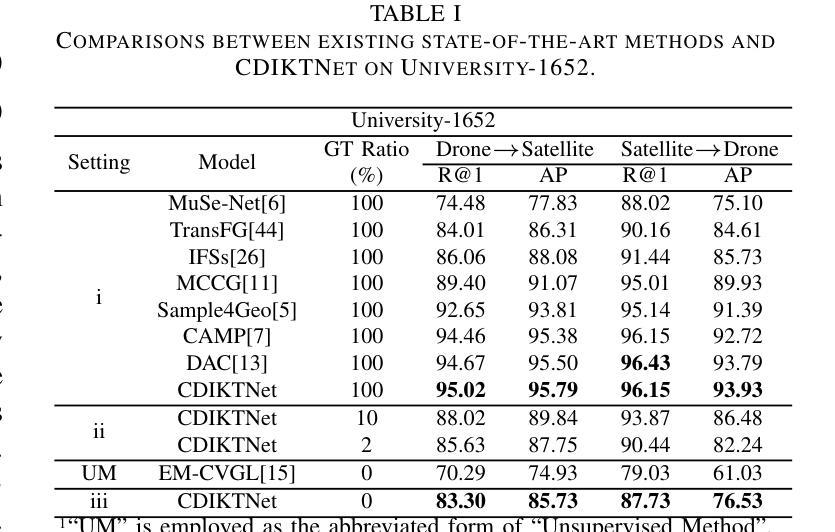
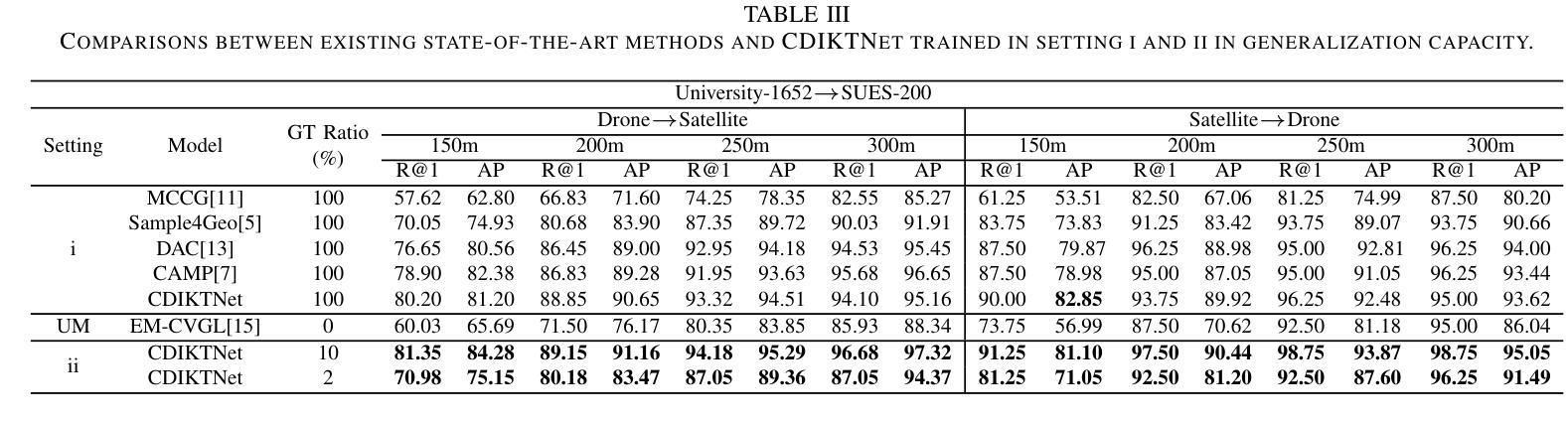
Authors:Zhongwei Chen, Zhao-Xu Yang, Hai-Jun Rong, Jiawei Lang, Guoqi Li
Traditional supervised drone-view geo-localization (DVGL) methods heavily depend on paired training data and encounter difficulties in learning cross-view correlations from unpaired data. Moreover, when deployed in a new domain, these methods require obtaining the new paired data and subsequent retraining for model adaptation, which significantly increases computational overhead. Existing unsupervised methods have enabled to generate pseudo-labels based on cross-view similarity to infer the pairing relationships. However, geographical similarity and spatial continuity often cause visually analogous features at different geographical locations. The feature confusion compromises the reliability of pseudo-label generation, where incorrect pseudo-labels drive negative optimization. Given these challenges inherent in both supervised and unsupervised DVGL methods, we propose a novel cross-domain invariant knowledge transfer network (CDIKTNet) with limited supervision, whose architecture consists of a cross-domain invariance sub-network (CDIS) and a cross-domain transfer sub-network (CDTS). This architecture facilitates a closed-loop framework for invariance feature learning and knowledge transfer. The CDIS is designed to learn cross-view structural and spatial invariance from a small amount of paired data that serves as prior knowledge. It endows the shared feature space of unpaired data with similar implicit cross-view correlations at initialization, which alleviates feature confusion. Based on this, the CDTS employs dual-path contrastive learning to further optimize each subspace while preserving consistency in a shared feature space. Extensive experiments demonstrate that CDIKTNet achieves state-of-the-art performance under full supervision compared with those supervised methods, and further surpasses existing unsupervised methods in both few-shot and cross-domain initialization.
传统监督式的无人机视角地理定位(DVGL)方法严重依赖于配对训练数据,并且在从非配对数据中学习跨视角相关性时遇到困难。此外,当这些方法部署在新领域时,需要获取新的配对数据并进行后续再训练以适应模型,这大大增加了计算开销。现有的无监督方法已经能够基于跨视图相似性生成伪标签来推断配对关系。然而,地理相似性和空间连续性常常导致不同地理位置的视觉类似特征。特征混淆降低了伪标签生成的可靠性,错误的伪标签会导致负面优化。鉴于有监督和无监督DVGL方法固有的这些挑战,我们提出了一种有限监督下的新型跨域不变知识转移网络(CDIKTNet),其架构包括跨域不变性子网络(CDIS)和跨域转移子网络(CDTS)。该架构促进了不变特征学习和知识转移的闭环框架。CDIS旨在从少量配对数据中学习跨视图的结构和空间不变性,作为先验知识。它赋予非配对数据共享特征空间以相似的隐式跨视图相关性进行初始化,从而减轻了特征混淆。基于此,CDTS采用双路径对比学习来进一步优化每个子空间,同时在共享特征空间中保持一致性。大量实验表明,在完全监督下,CDIKTNet相较于其他监督方法达到了最先进的性能,并且在小样本和跨域初始化方面均超越了现有无监督方法。
论文及项目相关链接
Summary
该文本描述了一种新型的跨域不变知识转移网络(CDIKTNet),该网络旨在解决传统监督式无人机视角地理定位(DVGL)方法依赖配对训练数据的问题,并能够在有限的监督下实现跨域不变性。通过引入跨域不变性子网络(CDIS)和跨域转移子网络(CDTS),CDIKTNet能够在未配对数据中隐式地学习跨视角相关性,减少特征混淆,并通过对比学习优化子空间,实现知识转移。此方法在全监督下达到业界领先水平,并在少样本和跨域初始化场景下超越现有无监督方法。
Key Takeaways
- 传统监督式无人机视角地理定位方法依赖配对训练数据,面临跨域学习难题。
- 现有无监督方法通过生成伪标签来推断配对关系,但地理相似性导致的特征混淆影响伪标签可靠性。
- CDIKTNet网络通过引入CDIS和CDTS子网络,实现有限监督下的跨域不变性。
- CDIS从少量配对数据中学习跨视角结构和空间不变性,作为先验知识,缓解未配对数据的特征混淆问题。
- CDTS采用双路径对比学习,优化子空间并保持共享特征空间的一致性。
- CDIKTNet在全监督下表现业界领先,并在少样本和跨域初始化场景下超越现有无监督方法。
点此查看论文截图

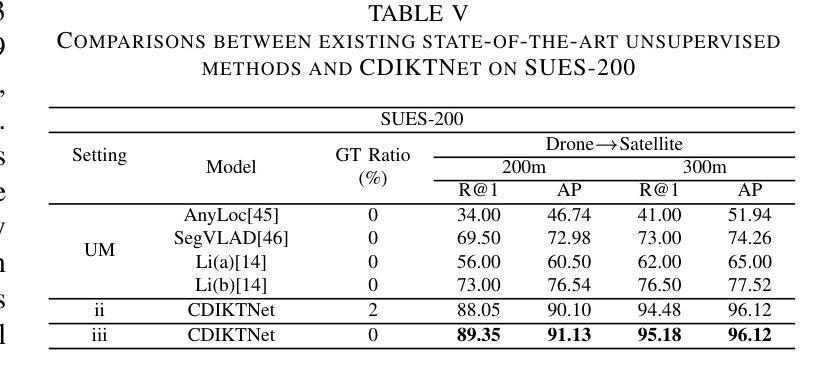
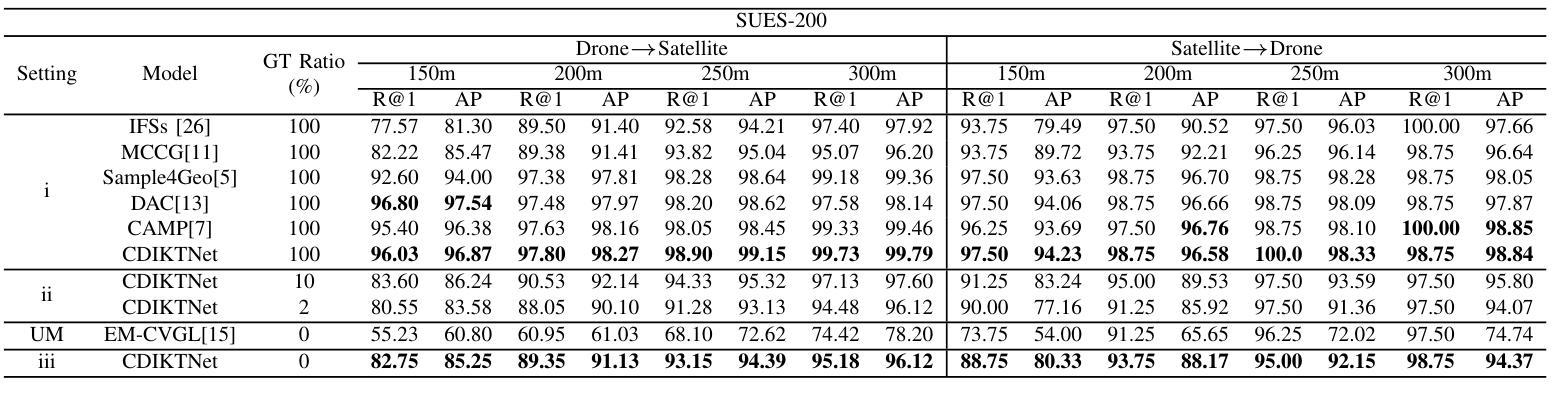
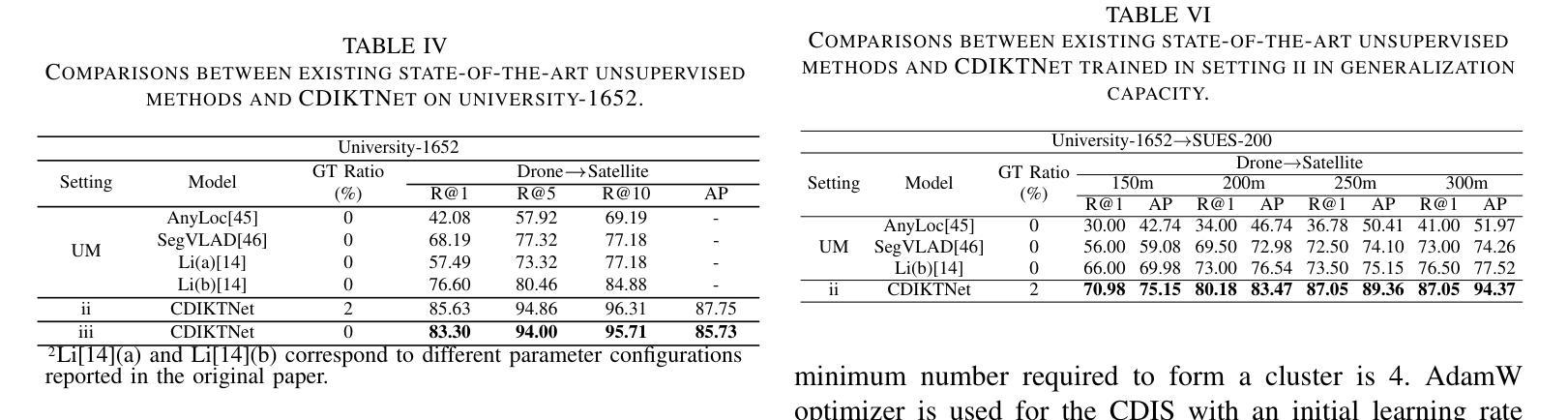
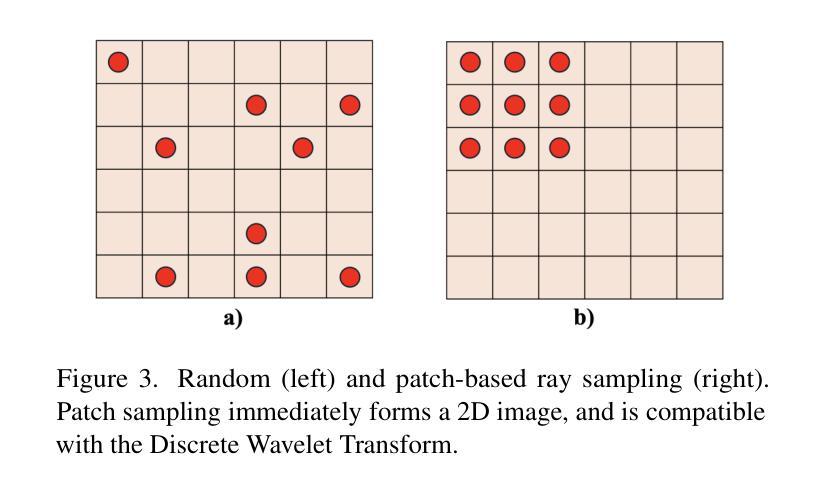
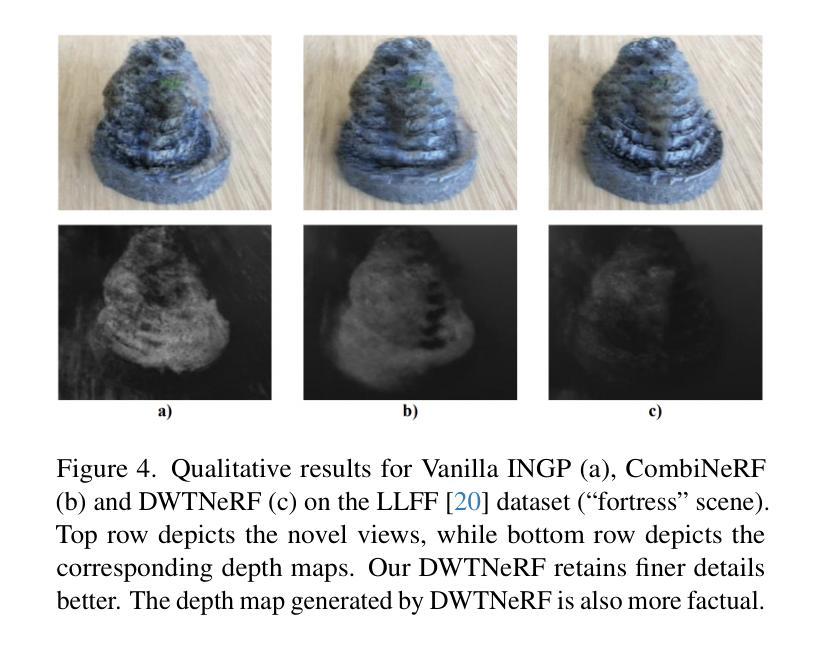
DWTNeRF: Boosting Few-shot Neural Radiance Fields via Discrete Wavelet Transform
Authors:Hung Nguyen, Blark Runfa Li, Truong Nguyen
Neural Radiance Fields (NeRF) has achieved superior performance in novel view synthesis and 3D scene representation, but its practical applications are hindered by slow convergence and reliance on dense training views. To this end, we present DWTNeRF, a unified framework based on Instant-NGP’s fast-training hash encoding. It is coupled with regularization terms designed for few-shot NeRF, which operates on sparse training views. Our DWTNeRF additionally includes a novel Discrete Wavelet loss that allows explicit prioritization of low frequencies directly in the training objective, reducing few-shot NeRF’s overfitting on high frequencies in earlier training stages. We also introduce a model-based approach, based on multi-head attention, that is compatible with INGP, which are sensitive to architectural changes. On the 3-shot LLFF benchmark, DWTNeRF outperforms Vanilla INGP by 15.07% in PSNR, 24.45% in SSIM and 36.30% in LPIPS. Our approach encourages a re-thinking of current few-shot approaches for fast-converging implicit representations like INGP or 3DGS.
神经辐射场(NeRF)在新型视图合成和3D场景表示方面取得了卓越的性能,但其实际应用受到收敛速度慢和依赖密集训练视图的限制。为此,我们提出了DWTNeRF,这是一个基于Instant-NGP快速训练哈希编码的统一框架。它与针对小样本NeRF设计的正则化术语相结合,可在稀疏训练视图上运行。我们的DWTNeRF还包括一种新型离散小波损失,允许在训练目标中直接明确优先处理低频,从而减少小样本NeRF在早期训练阶段对高频的过拟合。我们还介绍了一种基于多头注意力的模型方法,该方法与INGP兼容,对架构更改敏感。在3次拍摄的LLFF基准测试中,DWTNeRF在PSNR上较常规INGP高出15.07%,在SSIM上高出24.45%,在LPIPS上高出36.30%。我们的方法鼓励重新思考当前的快速收敛隐式表示的小样本方法,如INGP或3DGS。
论文及项目相关链接
Summary
基于NeRF的技术在新型视角合成和三维场景表示方面取得了卓越的性能,但其在实际应用中存在收敛速度慢和依赖密集训练视图的问题。为解决这些问题,本文提出了DWTNeRF框架,它结合了Instant-NGP的快速训练哈希编码,并设计了针对少数NeRF的正则化项,可在稀疏训练视图上运行。DWTNeRF还包括一种新型离散小波损失,允许在训练目标中明确优先处理低频信息,从而减少早期训练阶段对高频信息的过度拟合。在3次拍摄的LLFF基准测试中,DWTNeRF相较于普通的INGP在PSNR上提高了15.07%,在SSIM上提高了24.45%,在LPIPS上提高了36.30%。我们的研究鼓励对现有的快速收敛隐式表示方法(如INGP或3DGS)进行新的思考。
Key Takeaways
- DWTNeRF是一个基于NeRF技术的统一框架,旨在解决其在实践中的收敛速度慢和依赖密集训练视图的问题。
- DWTNeRF结合了Instant-NGP的快速训练哈希编码技术,并设计了针对少数NeRF场景的正则化项。
- 提出了新型离散小波损失,能够优先处理低频信息,减少早期训练阶段对高频信息的过度拟合。
- 在3次拍摄的LLFF基准测试中,DWTNeRF相较于普通方法显著提升了性能。
- DWTNeRF提供了一种模型方法,基于多头注意力机制,与敏感的INGP架构变更兼容。
- 研究结果鼓励对当前快速收敛隐式表示方法(如INGP或3DGS)进行新的思考。
点此查看论文截图


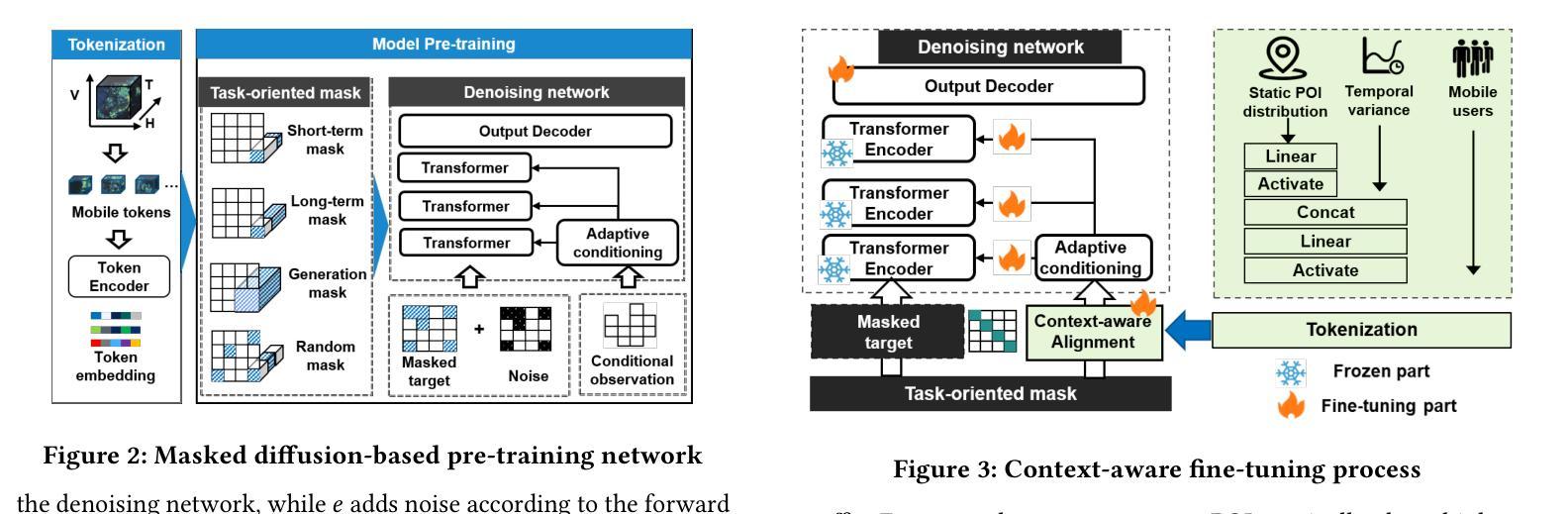
UoMo: A Universal Model of Mobile Traffic Forecasting for Wireless Network Optimization
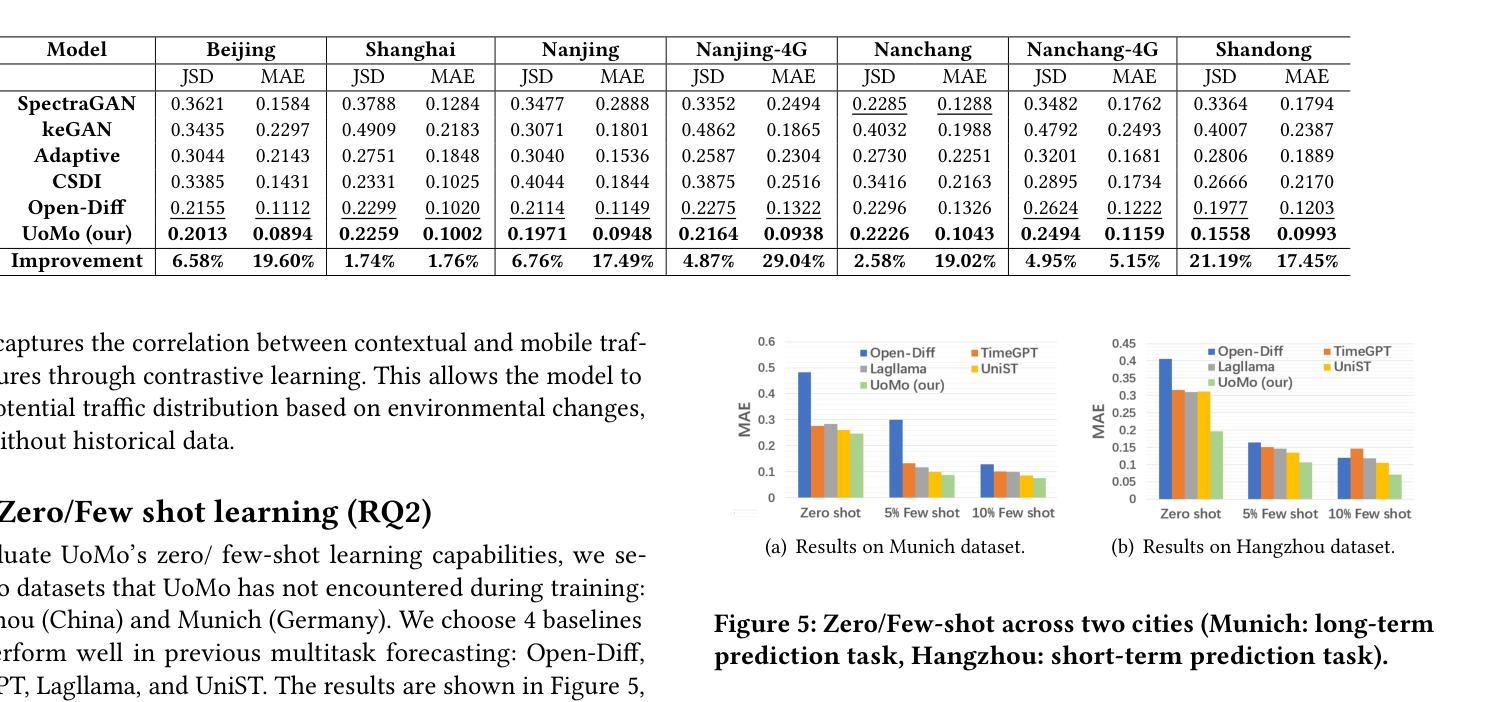
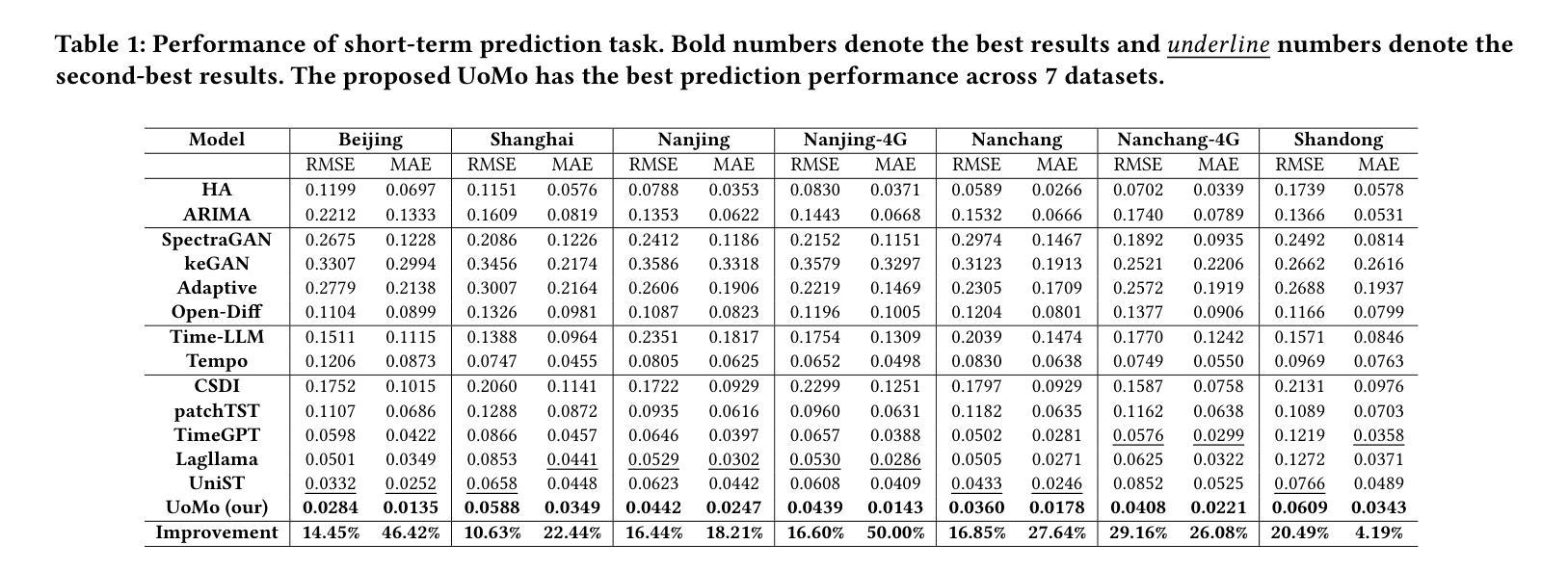
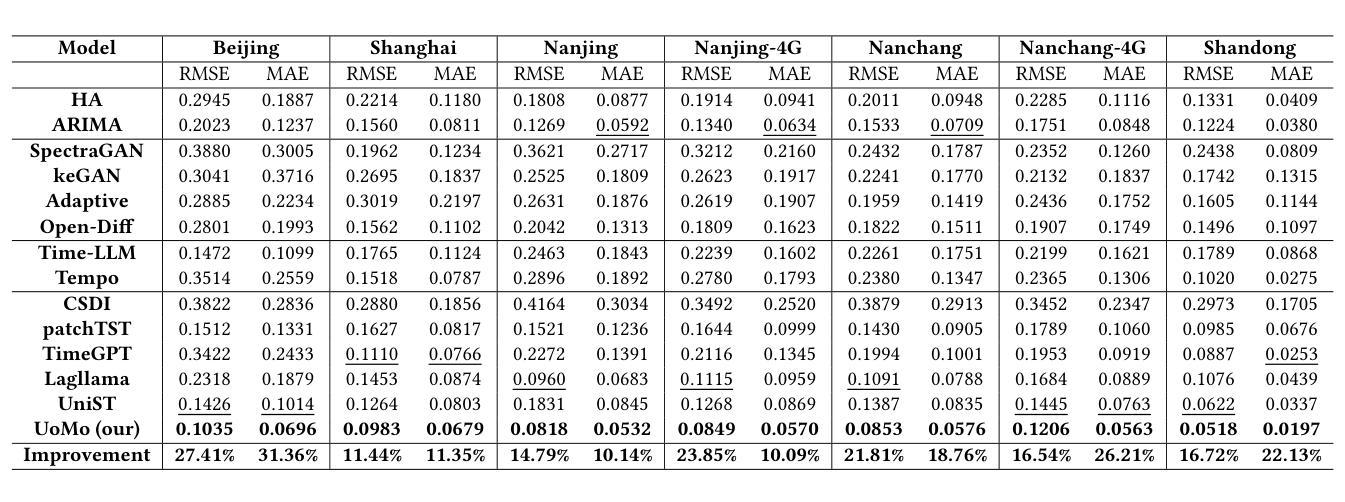
Authors:Haoye Chai, Shiyuan Zhang, Xiaoqian Qi, Baohua Qiu, Yong Li
Mobile traffic forecasting allows operators to anticipate network dynamics and performance in advance, offering substantial potential for enhancing service quality and improving user experience. However, existing models are often task-oriented and are trained with tailored data, which limits their effectiveness in diverse mobile network tasks of Base Station (BS) deployment, resource allocation, energy optimization, etc. and hinders generalization across different urban environments. Foundation models have made remarkable strides across various domains of NLP and CV due to their multi-tasking adaption and zero/few-shot learning capabilities. In this paper, we propose an innovative Foundation model for Mo}bile traffic forecasting (FoMo), aiming to handle diverse forecasting tasks of short/long-term predictions and distribution generation across multiple cities to support network planning and optimization. FoMo combines diffusion models and transformers, where various spatio-temporal masks are proposed to enable FoMo to learn intrinsic features of different tasks, and a contrastive learning strategy is developed to capture the correlations between mobile traffic and urban contexts, thereby improving its transfer learning capability. Extensive experiments on 9 real-world datasets demonstrate that FoMo outperforms current models concerning diverse forecasting tasks and zero/few-shot learning, showcasing a strong universality.
移动流量预测使运营商能够提前预测网络动态和性能,为提高服务质量和改善用户体验提供了巨大潜力。然而,现有模型通常是面向任务的,并且使用定制数据进行训练,这限制了它们在基站部署、资源配置、能源优化等多样化的移动网络任务中的有效性,并阻碍了它们在不同城市环境中的泛化能力。由于其在多任务适应和零/少样本学习能力方面的优势,基础模型在NLP和计算机视觉的各个领域都取得了显著的进步。本文提出了一种创新的移动流量预测基础模型(FoMo),旨在处理短期/长期预测和多城市预测分布生成的多样化预测任务,以支持网络规划和优化。FoMo结合了扩散模型和变压器模型,提出了各种时空掩码,使FoMo能够学习不同任务的内蕴特征,并开发了一种对比学习策略来捕捉移动流量和城市上下文之间的关联,从而提高其迁移学习能力。在9个真实世界数据集上的大量实验表明,FoMo在多样化的预测任务和零/少样本学习方面超越了当前模型,展示了强大的通用性。
论文及项目相关链接
PDF 2025 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2025
Summary
移动流量预测有助于运营商提前预测网络动态和性能,对提高服务质量和用户体验有巨大潜力。然而,现有模型往往是任务导向的,用特定数据进行训练,这在多样化的移动网络任务(如基站部署、资源配置、能源优化等)中限制了其效果,并阻碍了在不同城市环境中的通用化。本文提出一种创新的移动流量预测基础模型(FoMo),旨在处理短期/长期预测和跨多个城市的分布生成等多样化预测任务,以支持网络规划和优化。FoMo结合扩散模型和转换器,通过提出各种时空掩码来学习不同任务的内蕴特征,并开发对比学习策略来捕捉移动流量和城市环境之间的关联,从而提高其迁移学习能力。在9个真实数据集上的广泛实验表明,FoMo在多样预测任务和零/少样本学习能力方面优于当前模型,展现出强大的通用性。
Key Takeaways
- 移动流量预测对运营商而言至关重要,有助于提前预测网络动态和性能。
- 现有模型因任务导向和特定数据训练而具有局限性,难以应对多样化的移动网络任务和不同城市环境的通用化。
- 本文提出的FoMo模型结合了扩散模型和转换器,旨在处理多样化的移动流量预测任务。
- FoMo通过时空掩码学习不同任务的内蕴特征,并应用对比学习策略来捕捉移动流量与城市环境之间的关联。
- FoMo模型在多种预测任务和零/少样本学习能力方面表现出强大的通用性。
- 广泛实验证明FoMo在真实数据集上的效果优于现有模型。
点此查看论文截图


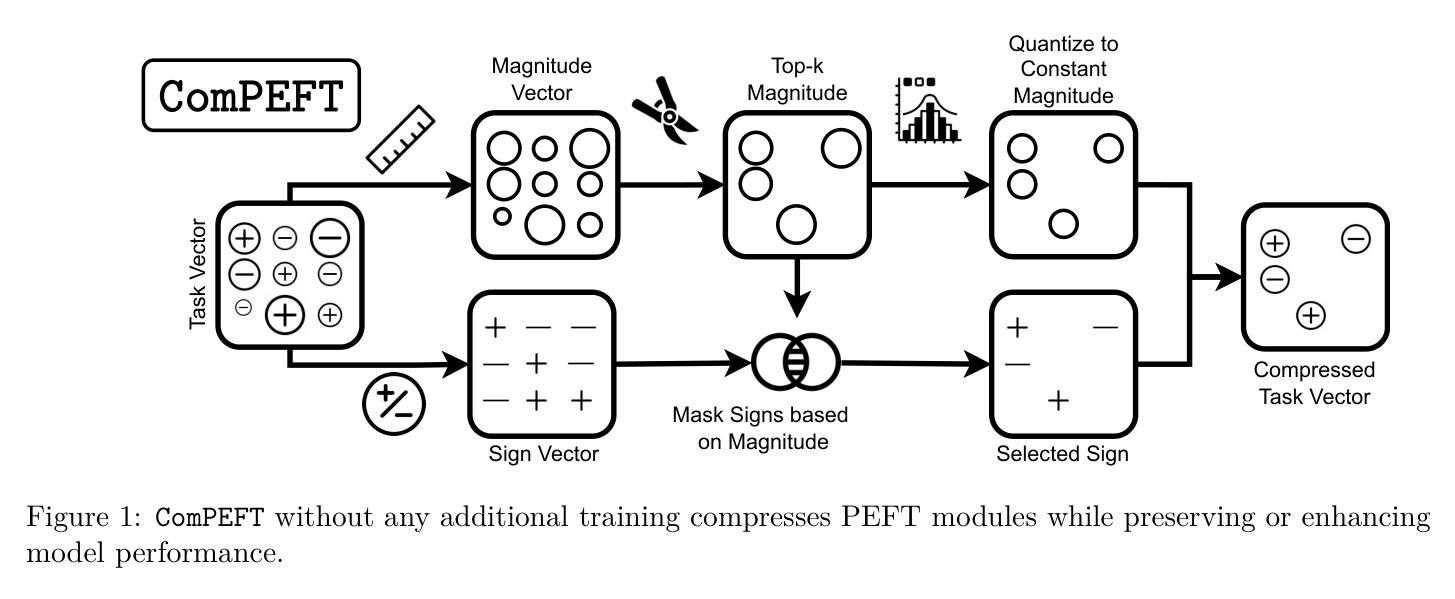
ComPEFT: Compression for Communicating Parameter Efficient Updates via Sparsification and Quantization
Authors:Prateek Yadav, Leshem Choshen, Colin Raffel, Mohit Bansal
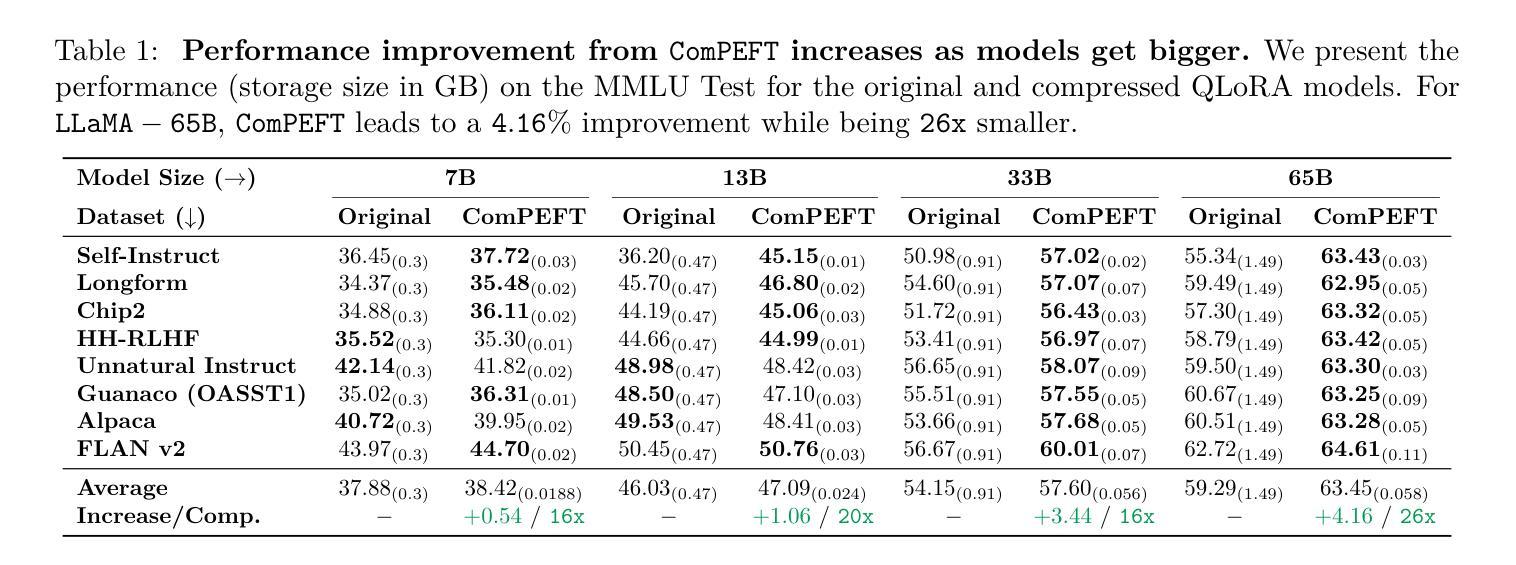
Parameter-efficient fine-tuning (PEFT) techniques make it possible to efficiently adapt a language model to create “expert” models that specialize to new tasks or domains. Recent techniques in model merging and compositional generalization leverage these expert models by dynamically composing modules to improve zero/few-shot generalization. Despite the efficiency of PEFT methods, the size of expert models can make it onerous to retrieve expert models per query over high-latency networks like the Internet or serve multiple experts on a single GPU. To address these issues, we present ComPEFT, a novel method for compressing fine-tuning residuals (task vectors) of PEFT based models. ComPEFT employs sparsification and ternary quantization to reduce the size of the PEFT module without performing any additional retraining while preserving or enhancing model performance. In extensive evaluation across T5, T0, and LLaMA-based models with 200M - 65B parameters, ComPEFT achieves compression ratios of 8x - 50x. In particular, we show that ComPEFT improves with scale - stronger models exhibit higher compressibility and better performance. For example, we show that ComPEFT applied to LLaMA outperforms QLoRA by 4.16% on MMLU with a storage size reduction of up to 26x. In addition, we show that the compressed experts produced by ComPEFT maintain few-shot compositional generalization capabilities, facilitate efficient communication and computation, and exhibit enhanced performance when merged. Lastly, we provide an analysis of different method components, compare it with other PEFT methods, and test ComPEFT’s efficacy for compressing the residual of full-finetuning. Our code is available at https://github.com/prateeky2806/compeft.
参数高效的微调(PEFT)技术使得能够高效地适应语言模型,以创建专门用于新任务或领域的“专家”模型。最近的模型合并和组合泛化技术通过动态组合模块来利用这些专家模型,以提高零/少样本的泛化能力。尽管PEFT方法效率很高,但专家模型的大小可能会在高延迟的网络(如互联网)上针对每个查询检索专家模型变得非常困难,或者在单个GPU上提供多个专家服务时也是如此。为了解决这些问题,我们提出了ComPEFT,这是一种压缩基于PEFT的微调残差(任务向量)的新方法。ComPEFT采用稀疏化和三元量化,在不进行任何额外再训练的情况下减少PEFT模块的大小,同时保留或提高模型性能。在跨越具有2亿至65亿参数的T5、T0和LLaMA模型的大量评估中,ComPEFT实现了高达8倍至50倍的压缩比。特别是,我们表明ComPEFT随着规模的扩大而改进——更强的模型表现出更高的可压缩性和更好的性能。例如,我们在LLaMA上应用的ComPEFT在MMLU上的性能优于QLoRA 4.16%,同时存储空间减少了高达26倍。此外,我们还表明,由ComPEFT产生的压缩专家保持了少样本组合泛化能力,促进了有效的通信和计算,并在合并时表现出增强的性能。最后,我们对不同的方法组件进行了分析,与其他PEFT方法进行了比较,并测试了ComPEFT对全微调残差进行压缩的有效性。我们的代码位于<https://github.com/prateeky280 6/compeft>。
论文及项目相关链接
PDF 25 Pages, 6 Figures, 16 Tables
摘要
参数高效的微调技术使得我们能够有效地适应语言模型来创建专业化的“专家”模型,以应对新任务或领域的需求。近期模型合并和组合泛化技术利用这些专家模型通过动态组合模块提高零次或少次调整情况下的泛化能力。虽然PEFT方法的效率较高,但由于专家模型的大小问题,在诸如互联网的高延迟网络上检索专家模型或对单个GPU上多个专家进行服务可能会变得非常困难。为解决这些问题,我们提出了ComPEFT方法,这是一种压缩PEFT模型微调残差(任务向量)的新方法。ComPEFT采用稀疏化和三元量化技术,无需进行任何额外的再训练即可减小PEFT模块的大小,同时保持或提升模型性能。在跨越T5、T0和LLaMA模型的广泛评估中,参数规模在2亿至数十亿之间,ComPEFT可实现高达8倍至几十倍的压缩比。特别的是,我们发现ComPEFT的表现随着模型规模的扩大而提高——更强大的模型展现出更高的压缩性能和更好的表现。例如,在MMLU上,相较于QLoRA模型,应用ComPEFT的LLaMA模型性能提升了4.16%,同时存储大小减少了高达26倍。此外,我们还证明了ComPEFT生成的压缩专家模型能够保持少次组合泛化能力、促进高效通信和计算,并在合并时展现出增强性能。最后,我们对不同方法进行了比较分析,并测试了ComPEFT在压缩全微调残余方面的有效性。我们的代码可通过链接访问。
关键见解
- PEFT技术允许创建特定任务或领域的专业模型以提高效率。这些模型被称为“专家”模型。这些模型的应用推动了近期的模型合并和组合泛化技术的进步。尽管它们在训练过程中的调整程度较低,但它们的高效性仍然是引人注目的优势。此外,它们在现实世界中任务执行时展示出了惊人的泛化能力。随着研究的深入进行和技术的进步,PEFT的优势在未来会得到更大的挖掘和应用拓展。值得注意的是这类技术的成熟在学界和商业领域产生了广泛关注和使用案例的发展有着更广泛的市场和商业价值值得探索和优化应用在领域应用和影响力方面是极大的对整个社会尤其是机器学习和自然语言处理领域的长远发展都有重大的贡献对于推广领域适应力与技术迭代的未来性有很大的参考价值和对当下行业内激烈的行业发展的重要指引价值是当前乃至未来相关研究领域具有战略意义的一环
接下来我总结了文本中的七个关键见解:
点此查看论文截图